
Parallel Processing of Sensor Data in a Distributed Rules Engine Environment through Clustering and Data Flow Reconfiguration


Abstract
1. Introduction
- A sensor data processing architecture in which raw sensor data from a large number of different sensors is efficiently processed in a distributed computing environment;
- An abstraction of sensor data processing by using rule engines, which allows data flow configuration by means of algorithms that analyze communication patterns;
- Two methods for streamlining data flow and improving data processing by creating clusters. where these algorithms process the information by taking into account the number of sensors for each rule and the data volume from each sensor. The two methods are the following:
- -
- An adaptation of the k-means clustering algorithm;
- -
- A genetic algorithm with a complex fitness function based on two desired criteria;
- A solution for cloud deployment while ensuring scalability and adaptation to the sensor rule particularities of the system.
2. Related Work
3. Proposed Architecture and Methods
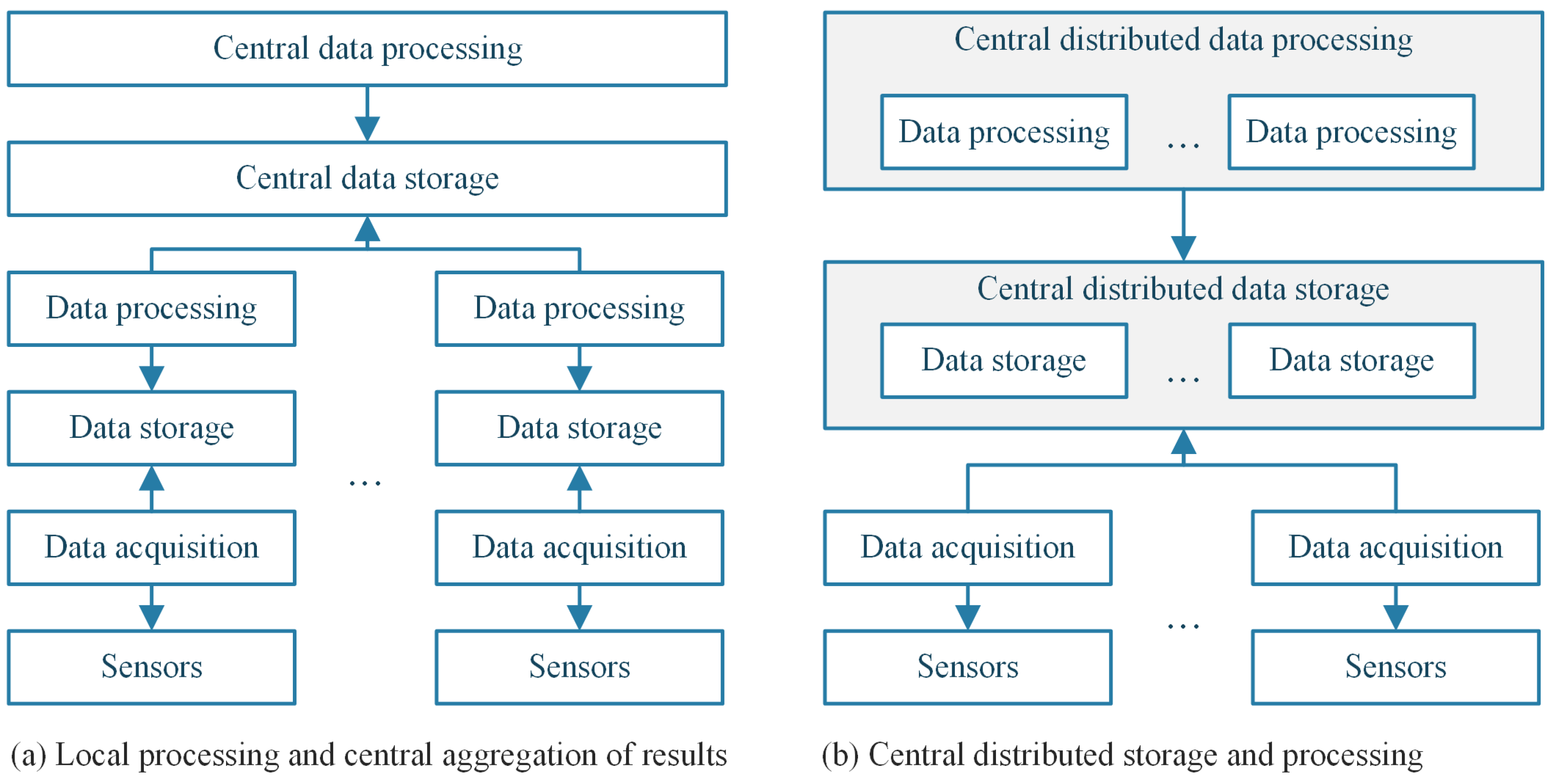
3.1. Considered Context and Proposed Goal
3.2. Data Processing and Rule Engines
| Listing 1. Example of a rule for HVAC in JSON string format based on the rule engine described in [16]. |
| { "name": "humidity-control-on", "description": "If the humidity in the room is over 55% and the temperature is over 26 degrees Celsius, ↪ then start the AC and set it to dehumidify", "priority": 3, "condition": "${home-room-1/hvac/humidity}{value} > 55 and ${1/hvac/temperature}{value} > 26", "actions": [ "${home-room-1/hvac/ac}{value}{on}", "${home-room-1/hvac/ac}{mode}{dehumidify}" ] } |
3.3. Sensor: Rule Abstraction
3.4. Performance Metrics
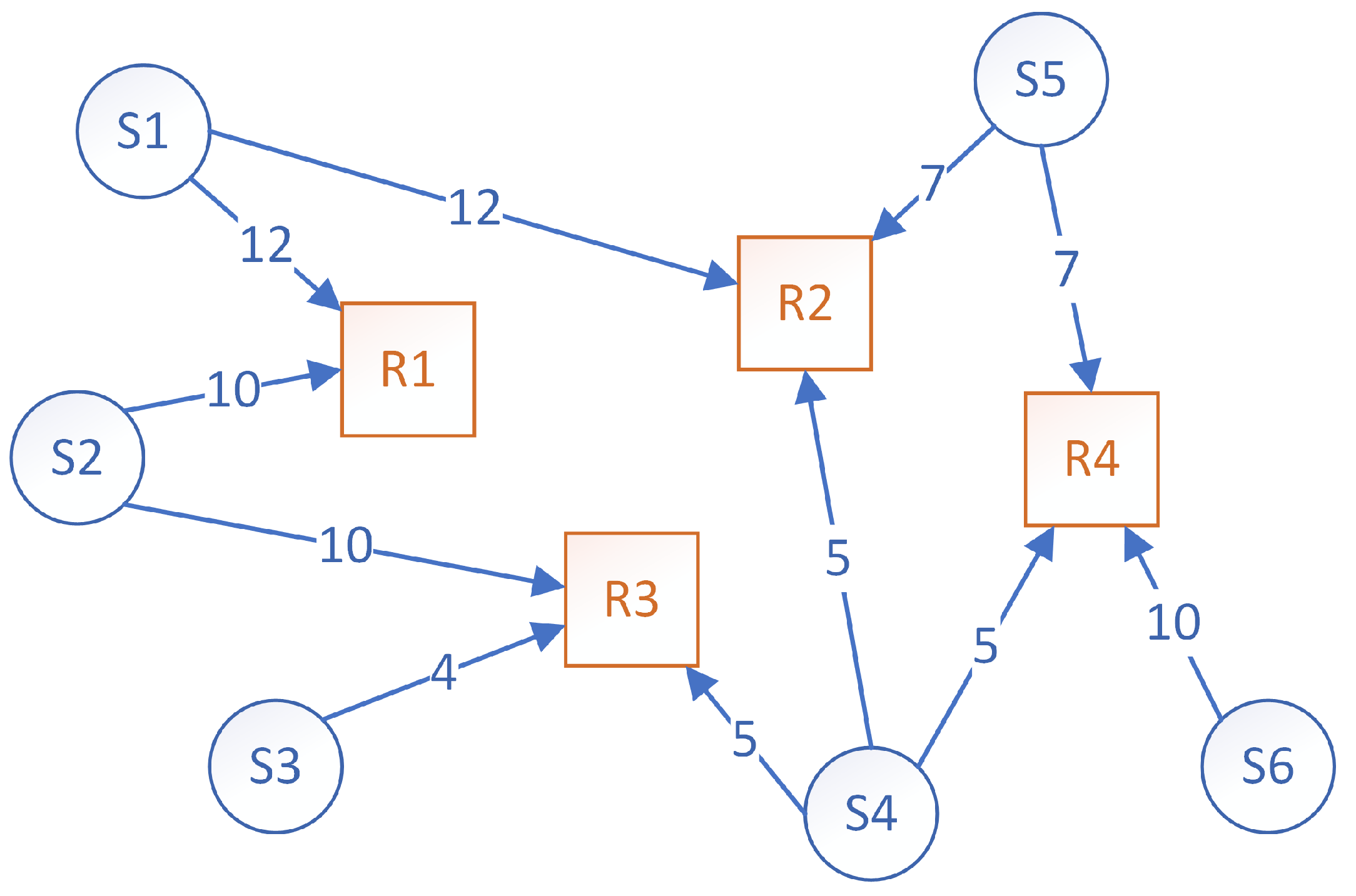
3.5. Problem and Solution Representation
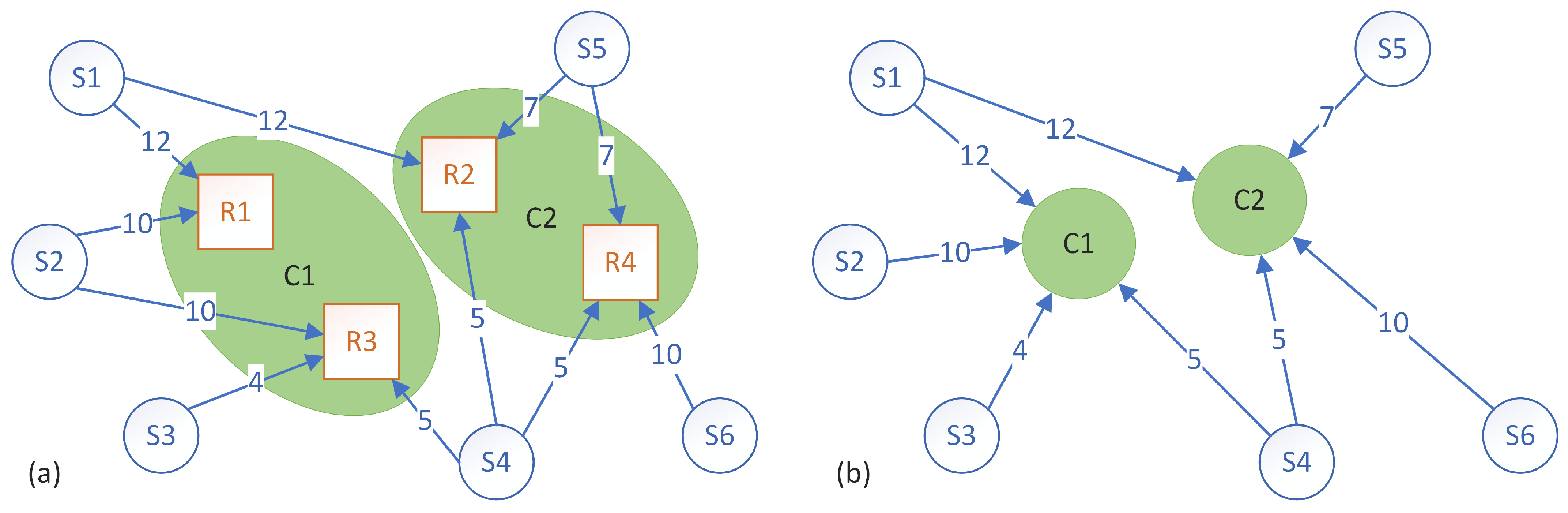
3.6. K-Means Clustering Approach
- Choose the number of desired clusters (p).
- Randomly choose p centroids (each one represents the center of the cluster).
- For each rule, perform the following steps:
- Compute the distance to each centroid.
- Find the closest centroid.
- Assign the rule to the cluster corresponding to that centroid.
- For each cluster, perform the following step:
- Compute the new centroids as the mean of all the rule features assigned to that cluster.
- Go to step 3 until there are no changes compared to the previous iteration or a specific number of iterations has passed.
- Choose a much lower number (e.g., ) than the number of desired clusters (p).
- Create q clusters with the previously described k-means algorithm.
- Compute each cluster’s size.
- Split evenly the larger clusters so that each resulting cluster is around the same size.
- Recompute each cluster’s size.
- Split the clusters again or combine clusters depending on the desired number of clusters while recomputing each cluster’s size if the cluster composition changed.
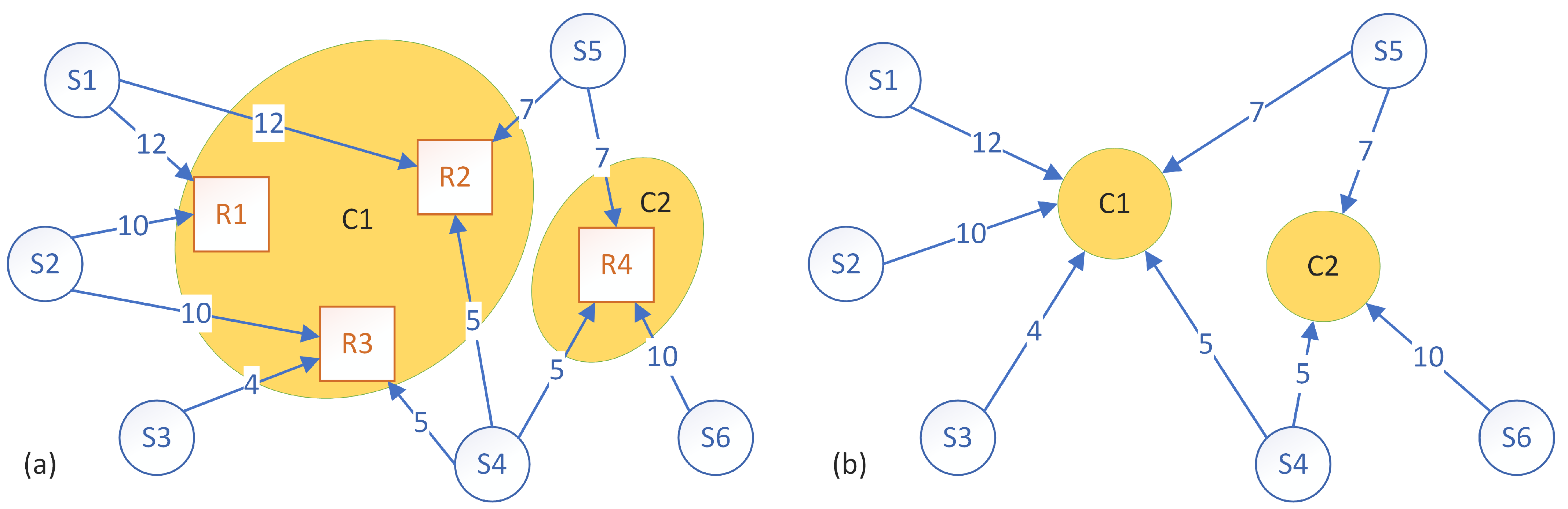
3.7. Genetic Algorithm Approach
- Use the input data and initialize the GA parameters, such as in the following example:
- Population size: 200.
- Crossover probability: 0.7.
- Mutation probability: 0.5.
- Elitism percent: 0.05.
- Maximum iteration count: 1000.
- Maximum “no change” iteration count: 300.
- Randomly generate the initial population.
- Evaluate the population using the custom fitness evaluator.
- While the stop condition is not met, perform the following steps:
- (a)
- Generate a new population of the same size by going through the following steps multiple times:
- Select two chromosomes using roulette wheel selection.
- Possibly a apply one-point crossover to each selected chromosome.
- Possibly apply a random allele switch mutation to each selected chromosome.
- Add the two resulting chromosomes to the new population.
- (b)
- Apply elitism, under which the best chromosomes from the previous population are kept in the new population.
- (c)
- Compute the fitness of each chromosome from the new population.
- Output the solution represented by the chromosome with the best fitness.
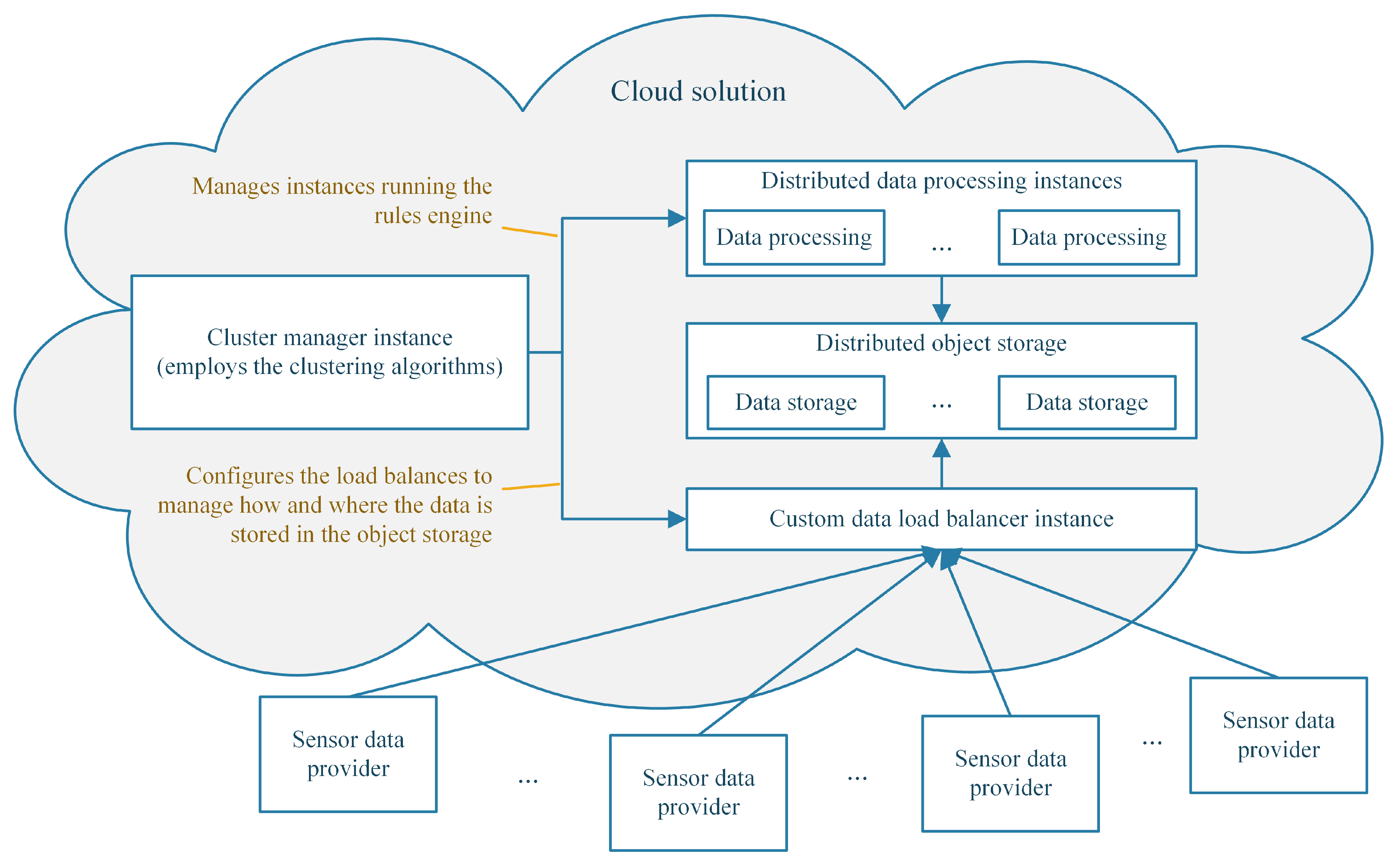
3.8. Deploying the System in a Cloud Solution
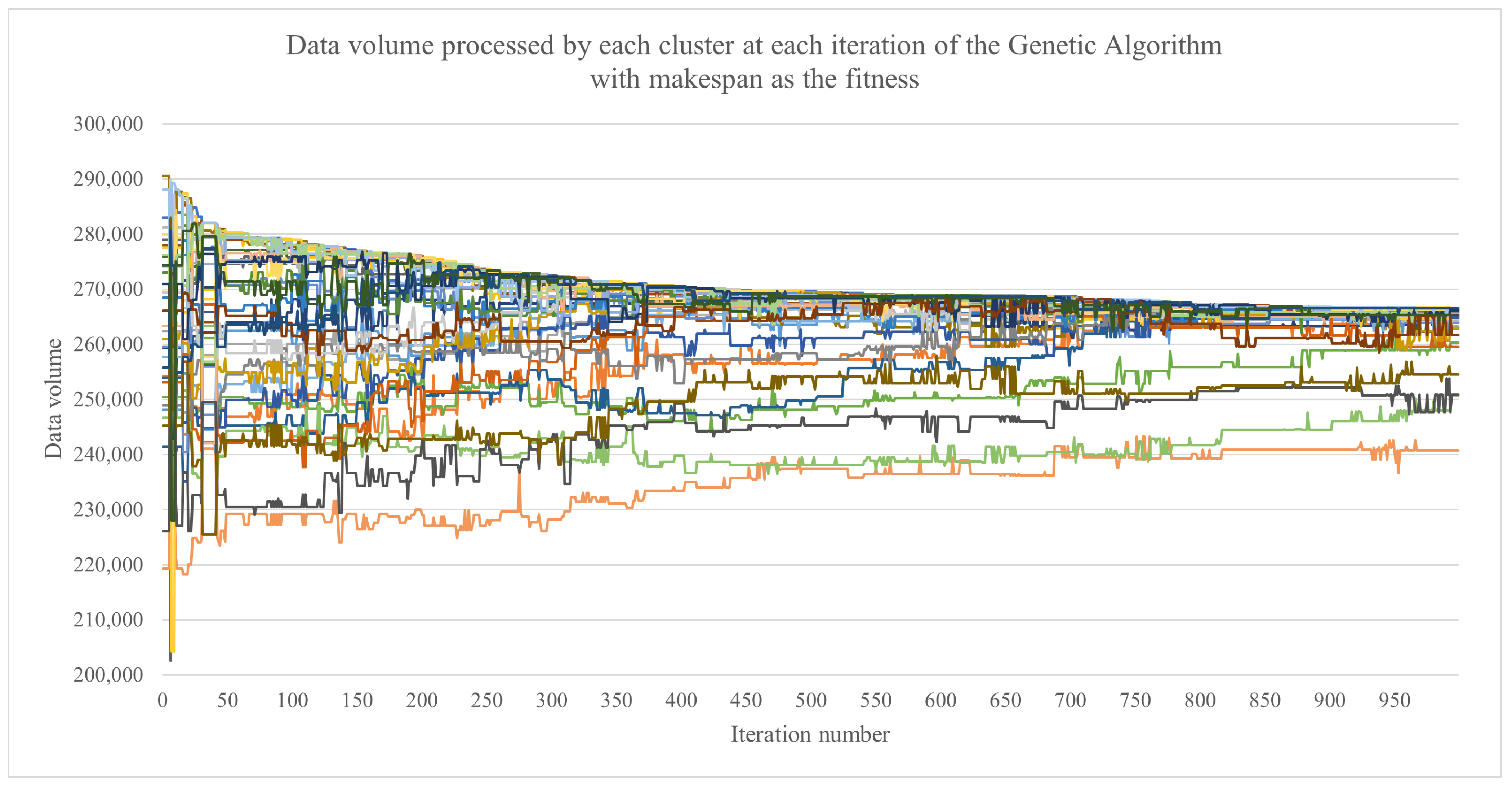
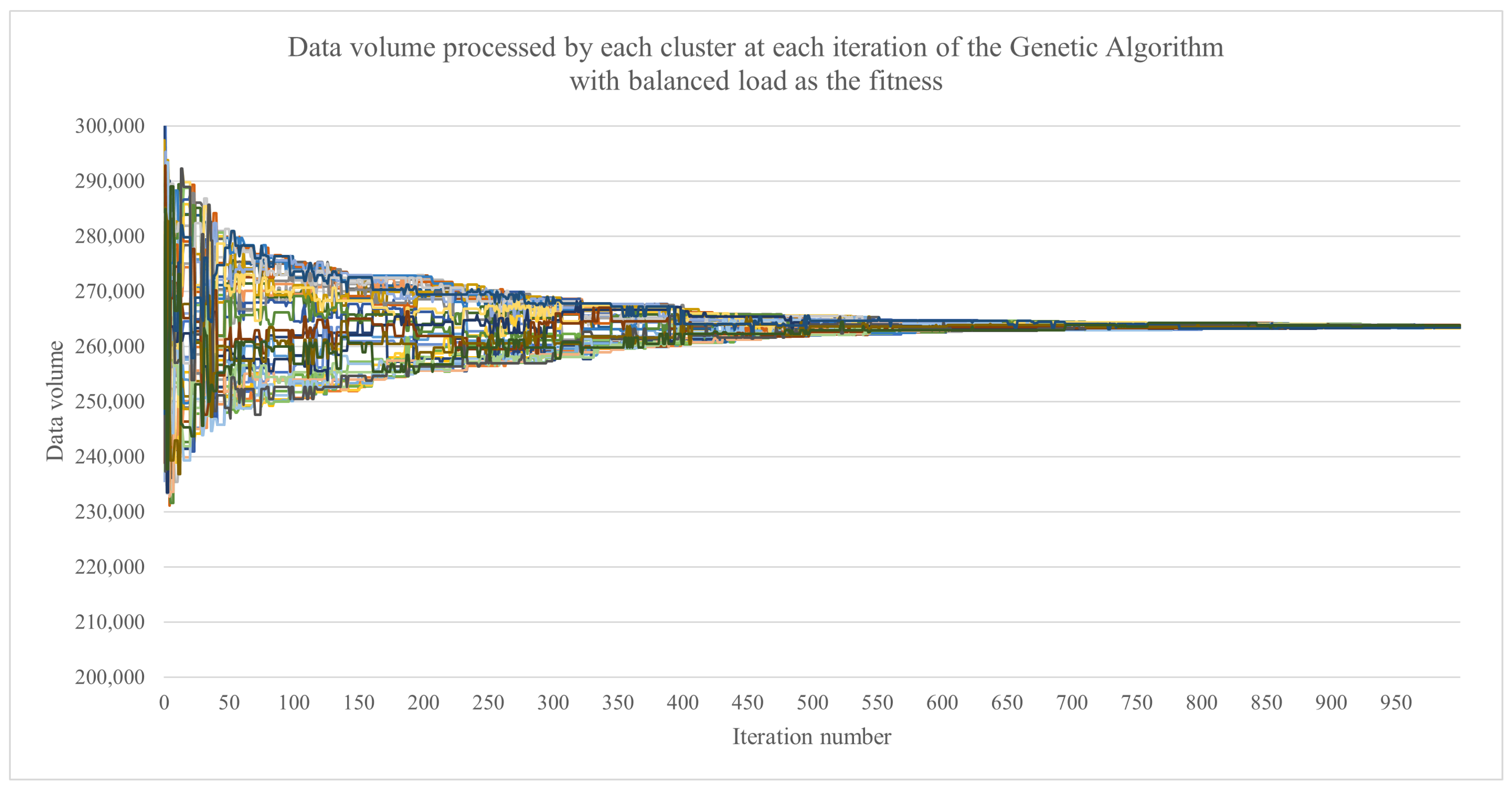
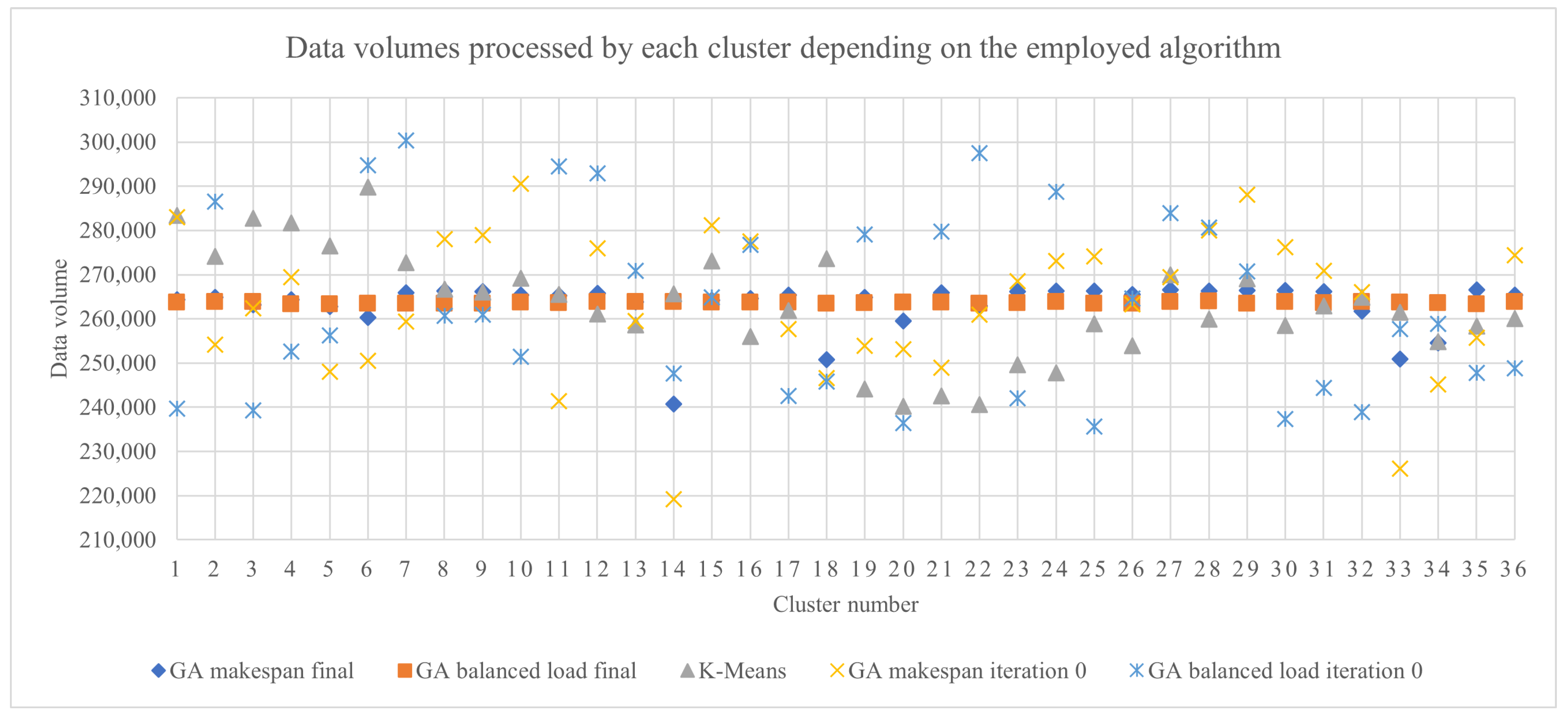
4. Results
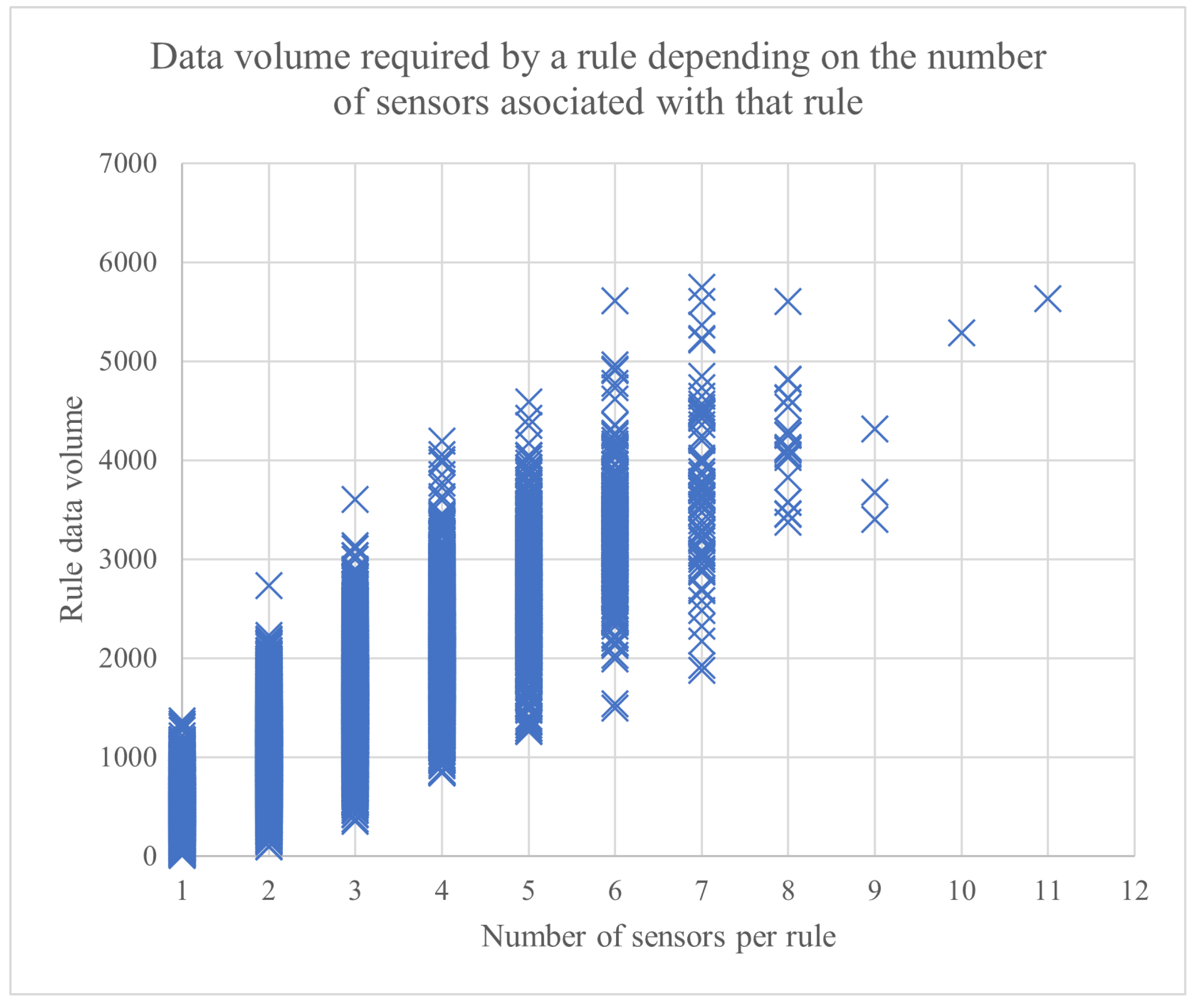
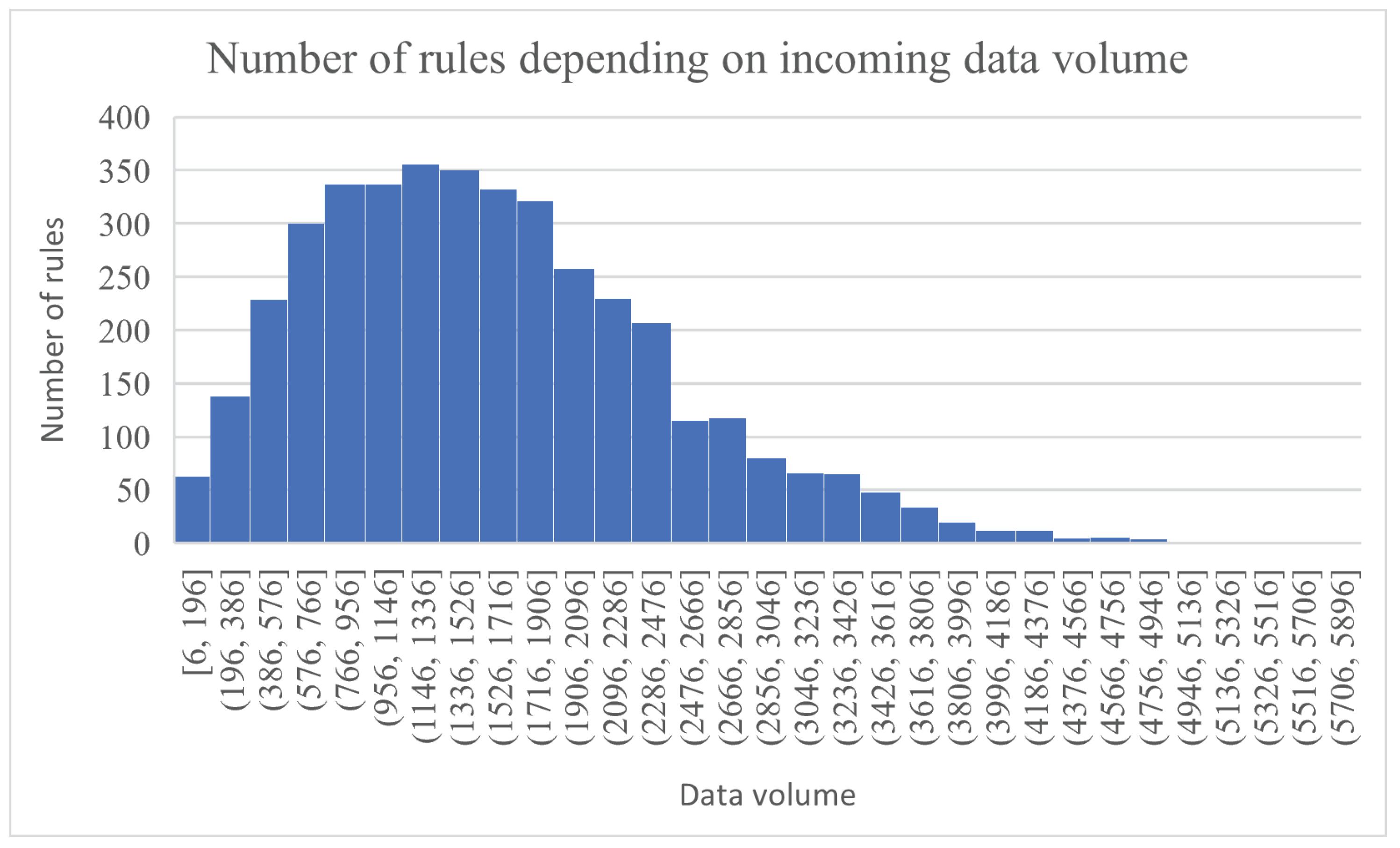
4.1. Simulation Set-Up
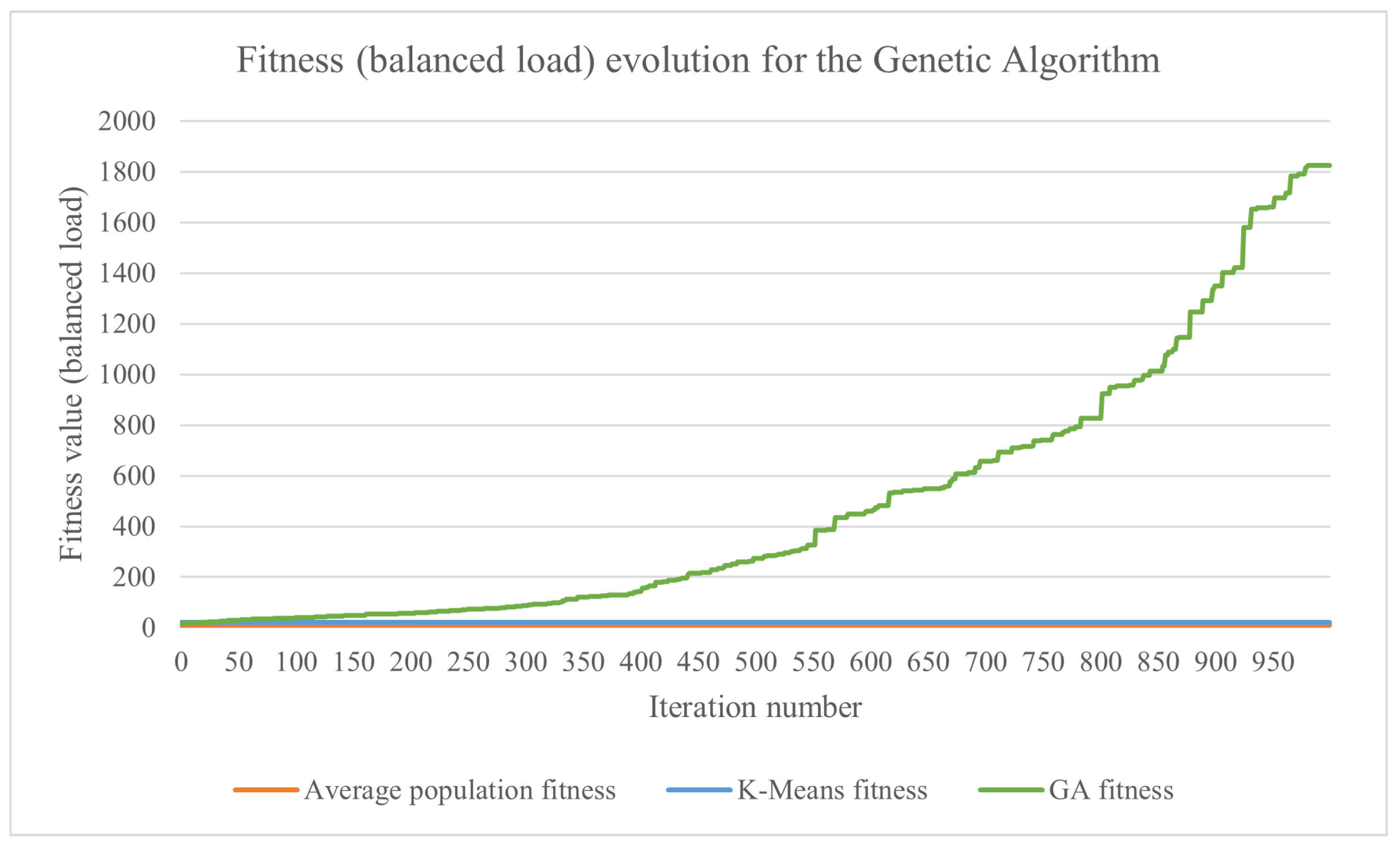
4.2. Experimental Results
5. Discussion
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GA | Genetic algorithm |
| IoT | Internet of Things |
| WSN | Wireless sensor network |
| AC | Air conditioning |
| HVAC | Heating, ventilation and air conditioning |
| JSON | JavaScript Object Notation |
| CCTV | Closed-circuit television |
| IaaS | Infrastructure as a service |
| PaaS | Platform as a service |
| SaaS | Software as a service |
References
- Li, S.; Xu, L.D.; Zhao, S. The internet of things: A survey. Inf. Syst. Front. 2015, 17, 243–259. [Google Scholar] [CrossRef]
- Jia, M.; Komeily, A.; Wang, Y.; Srinivasan, R.S. Adopting Internet of Things for the development of smart buildings: A review of enabling technologies and applications. Autom. Constr. 2019, 101, 111–126. [Google Scholar] [CrossRef]
- Dong, B.; Prakash, V.; Feng, F.; O’Neill, Z. A review of smart building sensing system for better indoor environment control. Energy Build. 2019, 199, 29–46. [Google Scholar] [CrossRef]
- Pau, G.; Arena, F. Smart City: The Different Uses of IoT Sensors. J. Sens. Actuator Netw. 2022, 11, 58. [Google Scholar] [CrossRef]
- Silva, B.N.; Khan, M.; Han, K. Towards sustainable smart cities: A review of trends, architectures, components, and open challenges in smart cities. Sustain. Cities Soc. 2018, 38, 697–713. [Google Scholar] [CrossRef]
- Zavratnik, V.; Kos, A.; Stojmenova Duh, E. Smart villages: Comprehensive review of initiatives and practices. Sustainability 2018, 10, 2559. [Google Scholar] [CrossRef]
- Salvia, M.; Cornacchia, C.; Di Renzo, G.; Braccio, G.; Annunziato, M.; Colangelo, A.; Orifici, L.; Lapenna, V. Promoting smartness among local areas in a Southern Italian region: The Smart Basilicata Project. Indoor Built Environ. 2016, 25, 1024–1038. [Google Scholar] [CrossRef]
- Sehrawat, D.; Gill, N.S. Smart sensors: Analysis of different types of IoT sensors. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 523–528. [Google Scholar]
- Morais, C.M.d.; Sadok, D.; Kelner, J. An IoT sensor and scenario survey for data researchers. J. Braz. Comput. Soc. 2019, 25, 1–17. [Google Scholar] [CrossRef]
- Wilson, J.S. Sensor Technology Handbook; Elsevier: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Alías, F.; Alsina-Pagès, R.M. Review of wireless acoustic sensor networks for environmental noise monitoring in smart cities. J. Sens. 2019, 2019, 7634860. [Google Scholar] [CrossRef]
- Sun, Y.; Wu, T.Y.; Zhao, G.; Guizani, M. Efficient rule engine for smart building systems. IEEE Trans. Comput. 2014, 64, 1658–1669. [Google Scholar] [CrossRef]
- El Kaed, C.; Khan, I.; Van Den Berg, A.; Hossayni, H.; Saint-Marcel, C. SRE: Semantic rules engine for the industrial Internet-of-Things gateways. IEEE Trans. Ind. Inform. 2017, 14, 715–724. [Google Scholar] [CrossRef]
- Kargin, A.; Petrenko, T. Internet of Things smart rules engine. In Proceedings of the 2018 International Scientific-Practical Conference Problems of Infocommunications. Science and Technology (PIC S&T), Kharkiv, Ukraine, 9–12 October 2018; pp. 639–644. [Google Scholar]
- Kargin, A.; Petrenko, T. Knowledge Representation in Smart Rules Engine. In Proceedings of the 2019 3rd International Conference on Advanced Information and Communications Technologies (AICT), Lviv, Ukraine, 2–6 July 2019; pp. 231–236. [Google Scholar]
- Alexandrescu, A.; Botezatu, N.; Lupu, R. Monitoring and processing of physiological and domotics parameters in an Internet of Things (IoT) assistive living environment. In Proceedings of the 2022 26th International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 19–21 October 2022; pp. 362–367. [Google Scholar]
- Das, A.K.; Sutrala, A.K.; Kumari, S.; Odelu, V.; Wazid, M.; Li, X. An efficient multi-gateway-based three-factor user authentication and key agreement scheme in hierarchical wireless sensor networks. Secur. Commun. Netw. 2016, 9, 2070–2092. [Google Scholar] [CrossRef]
- Piadyk, Y.; Steers, B.; Mydlarz, C.; Salman, M.; Fuentes, M.; Khan, J.; Jiang, H.; Ozbay, K.; Bello, J.P.; Silva, C. REIP: A Reconfigurable Environmental Intelligence Platform and Software Framework for Fast Sensor Network Prototyping. Sensors 2022, 22, 3809. [Google Scholar] [CrossRef] [PubMed]
- Auroux, S.; Dräxler, M.; Morelli, A.; Mancuso, V. Dynamic network reconfiguration in wireless DenseNets with the CROWD SDN architecture. In Proceedings of the 2015 European Conference on Networks and Communications (EuCNC), Paris, France, 29 June–2 July 2015; pp. 144–148. [Google Scholar]
- Helkey, J.; Holder, L.; Shirazi, B. Comparison of simulators for assessing the ability to sustain wireless sensor networks using dynamic network reconfiguration. Sustain. Comput. Inform. Syst. 2016, 9, 1–7. [Google Scholar] [CrossRef]
- Derr, K.; Manic, M. Wireless sensor network configuration—Part II: Adaptive coverage for decentralized algorithms. IEEE Trans. Ind. Inform. 2013, 9, 1728–1738. [Google Scholar] [CrossRef]
- Sundhari, R.M.; Jaikumar, K. IoT assisted Hierarchical Computation Strategic Making (HCSM) and Dynamic Stochastic Optimization Technique (DSOT) for energy optimization in wireless sensor networks for smart city monitoring. Comput. Commun. 2020, 150, 226–234. [Google Scholar] [CrossRef]
- Akash, A.R.; Hossen, M.; Hassan, M.R.; Hossain, M.I. Gateway node-based clustering hierarchy for improving energy efficiency of wireless body area networks. In Proceedings of the 2019 5th International Conference on Advances in Electrical Engineering (ICAEE), Dhaka, Bangladesh, 26–28 September 2019; pp. 668–672. [Google Scholar]
- Solaiman, B. Energy optimization in wireless sensor networks using a hybrid k-means pso clustering algorithm. Turk. J. Electr. Eng. Comput. Sci. 2016, 24, 2679–2695. [Google Scholar] [CrossRef]
- Kumar, G.; Mehra, H.; Seth, A.R.; Radhakrishnan, P.; Hemavathi, N.; Sudha, S. An hybrid clustering algorithm for optimal clusters in wireless sensor networks. In Proceedings of the 2014 IEEE Students’ Conference on Electrical, Electronics and Computer Science, Bhopal, India, 1–2 March 2014; pp. 1–6. [Google Scholar]
- Bharany, S.; Sharma, S.; Frnda, J.; Shuaib, M.; Khalid, M.I.; Hussain, S.; Iqbal, J.; Ullah, S.S. Wildfire Monitoring Based on Energy Efficient Clustering Approach for FANETS. Drones 2022, 6, 193. [Google Scholar] [CrossRef]
- Xiong, J.; Ren, J.; Chen, L.; Yao, Z.; Lin, M.; Wu, D.; Niu, B. Enhancing privacy and availability for data clustering in intelligent electrical service of IoT. IEEE Internet Things J. 2018, 6, 1530–1540. [Google Scholar] [CrossRef]
- Zhang, D.G.; Zhang, T.; Zhang, J.; Dong, Y.; Zhang, X.D. A kind of effective data aggregating method based on compressive sensing for wireless sensor network. EURASIP J. Wirel. Commun. Netw. 2018, 2018, 1–15. [Google Scholar] [CrossRef]
- Wang, J.; Gao, Y.; Wang, K.; Sangaiah, A.K.; Lim, S.J. An affinity propagation-based self-adaptive clustering method for wireless sensor networks. Sensors 2019, 19, 2579. [Google Scholar] [CrossRef]
- Lapegna, M.; Balzano, W.; Meyer, N.; Romano, D. Clustering Algorithms on Low-Power and High-Performance Devices for Edge Computing Environments. Sensors 2021, 21, 5395. [Google Scholar] [CrossRef] [PubMed]
- Barron, A.; Sanchez-Gallegos, D.D.; Carrizales-Espinoza, D.; Gonzalez-Compean, J.L.; Morales-Sandoval, M. On the Efficient Delivery and Storage of IoT Data in Edge-Fog-Cloud Environments. Sensors 2022, 22, 7016. [Google Scholar] [CrossRef] [PubMed]
- Lopez-Arevalo, I.; Gonzalez-Compean, J.L.; Hinojosa-Tijerina, M.; Martinez-Rendon, C.; Montella, R.; Martinez-Rodriguez, J.L. A WoT-Based Method for Creating Digital Sentinel Twins of IoT Devices. Sensors 2021, 21, 5531. [Google Scholar] [CrossRef] [PubMed]
- Achirei, S.D.; Zvoristeanu, O.; Alexandrescu, A.; Botezatu, N.A.; Stan, A.; Rotariu, C.; Lupu, R.G.; Caraiman, S. Smartcare: On the design of an iot based solution for assisted living. In Proceedings of the 2020 International Conference on e-Health and Bioengineering (EHB), Iasi, Romania, 29–30 October 2020; pp. 1–4. [Google Scholar]
- Ahmadian, M.M.; Khatami, M.; Salehipour, A.; Cheng, T. Four decades of research on the open-shop scheduling problem to minimize the makespan. Eur. J. Oper. Res. 2021, 295, 399–426. [Google Scholar] [CrossRef]
- Faisal, M.; Zamzami, E. Comparative analysis of inter-centroid K-Means performance using euclidean distance, canberra distance and manhattan distance. Proc. J. Phys. Conf. Ser. 2020, 1566, 012112. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiong, Z.; Mao, J.; Ou, L. The study of parallel k-means algorithm. In Proceedings of the 2006 6th World Congress on Intelligent Control and Automation, Dalian, China, 21–23 June 2006; Volume 2, pp. 5868–5871. [Google Scholar]
- Vasconcelos, J.; Ramirez, J.A.; Takahashi, R.; Saldanha, R. Improvements in genetic algorithms. IEEE Trans. Magn. 2001, 37, 3414–3417. [Google Scholar] [CrossRef]
- Kumar, M.; Husain, D.; Upreti, N.; Gupta, D. Genetic algorithm: Review and application. SSRN 2010. [Google Scholar] [CrossRef]
- Alexandrescu, A.; Agavriloaei, I.; Craus, M. A task mapping simulation framework for comparing the performance of mapping heuristics in various scenarios. In Proceedings of the 2012 16th International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 12–14 October 2012; pp. 1–6. [Google Scholar]
- Alexandrescu, A.; Agavriloaei, I.; Craus, M. A genetic algorithm for mapping tasks in heterogeneous computing systems. In Proceedings of the 15th International Conference on System Theory, Control and Computing, Sinaia, Romania, 14–16 October 2011; pp. 1–6. [Google Scholar]
- Alexandrescu, A. Mapping interdependent tasks in a computational environment using genetie algorithms. In Proceedings of the 2015 14th RoEduNet International Conference-Networking in Education and Research (RoEduNet NER), Craiova, Romania, 24–26 September 2015; pp. 173–177. [Google Scholar]
- Longo, F.; Bruneo, D.; Distefano, S.; Merlino, G.; Puliafito, A. Stack4things: An openstack-based framework for iot. In Proceedings of the 2015 3rd International Conference on Future Internet of Things and Cloud, Rome, Italy, 24–26 August 2015; pp. 204–211. [Google Scholar]
- Sánchez-Gallegos, D.D.; Galaviz-Mosqueda, A.; Gonzalez-Compean, J.; Villarreal-Reyes, S.; Perez-Ramos, A.E.; Carrizales-Espinoza, D.; Carretero, J. On the continuous processing of health data in edge-fog-cloud computing by using micro/nanoservice composition. IEEE Access 2020, 8, 120255–120281. [Google Scholar] [CrossRef]
- Cao, H.; Wachowicz, M. An Edge-Fog-Cloud Architecture of Streaming Analytics for Internet of Things Applications. Sensors 2019, 19, 3594. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fitness Method | Avg. Population Fitness | K-Means-Based Fitness | Genetic Algorithm Fitness |
|---|---|---|---|
| makespan | 31.94 | 34.51 | 37.52 |
| load balance | 10.51 | 20.16 | 1824.82 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alexandrescu, A. Parallel Processing of Sensor Data in a Distributed Rules Engine Environment through Clustering and Data Flow Reconfiguration. Sensors 2023, 23, 1543. https://doi.org/10.3390/s23031543
Alexandrescu A. Parallel Processing of Sensor Data in a Distributed Rules Engine Environment through Clustering and Data Flow Reconfiguration. Sensors. 2023; 23(3):1543. https://doi.org/10.3390/s23031543
Chicago/Turabian StyleAlexandrescu, Adrian. 2023. "Parallel Processing of Sensor Data in a Distributed Rules Engine Environment through Clustering and Data Flow Reconfiguration" Sensors 23, no. 3: 1543. https://doi.org/10.3390/s23031543
APA StyleAlexandrescu, A. (2023). Parallel Processing of Sensor Data in a Distributed Rules Engine Environment through Clustering and Data Flow Reconfiguration. Sensors, 23(3), 1543. https://doi.org/10.3390/s23031543