
A Hybrid Generic Framework for Heart Problem Diagnosis Based on a Machine Learning Paradigm



Abstract
1. Introduction
2. Literature Review
- Single schema dataset:
- Using a single feature selection mechanism:
- Model bias:
- A proposed new Stacking Mechanism:
3. Scientific Background
3.1. Logistic Regression (LR)
3.2. Support Vector Machine (SVM)
3.3. Random Forest (RF)
3.4. XGBoost
3.5. Deep Learning (DL)
4. Proposed Framework
4.1. Dataset Description
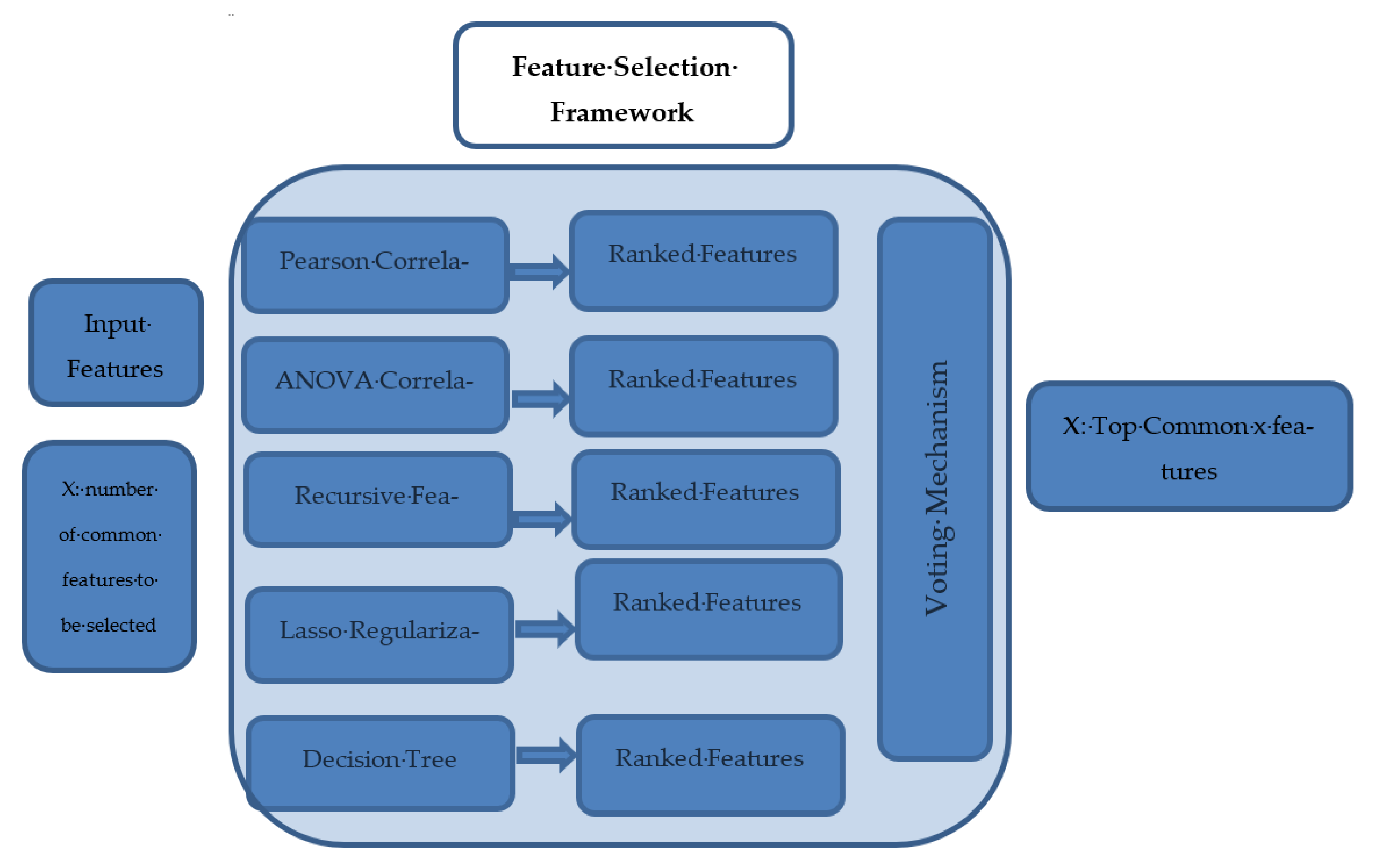
4.2. Hybrid Feature Selection Framework
- The filter method (chi-square has been exploited after numerical variables binning, Pearson correlation, and ANOVA coefficients);
- Wrapper methods: these methods split the data subsets and use them to train a model; according to the model results, features are eliminated or added (a recursive features elimination method has been used in this research);
- Intrinsic methods: data are split into different subsets and train the model and select the best subset based on model results (the Lasso regularization and decision tree methods were used).
| Algorithm 1. Feature selection pseudocode |
| 1- Input: Data features set (S) and (x) is the designated number of selected features 2-Let M is the set of methods { pearson correlation, ANOVA, Recursive Elimination, Lasso and DT} 3-For every Algorithm (i) in (S) do the following: 3.1 Apply the following algorithms for measuring features importance 3.2 Rank the features importance for algorithm (i) 3.3 Save the features descending rank into global list (Fi) 4-for each Sorted list (j) in global list (Fi): 4.1 select the top (x) features and append in TOPi selected list 5-compute the intersection among TOP lists 6-Output: the intersection among the TOP lists |
4.3. Data Preprocessing Pipeline
4.3.1. Check Nulls and Duplicates
4.3.2. Check the Outliers
4.3.3. Label Distribution
4.4. The Proposed Classification Framework
5. Experimental Results
- True-positive (TP) values are true in both reality and prediction.
- False-positive (FP) values are false in reality but predicted as true.
- False-negative (FN) values are true in reality but predicted as false.
- True-negative (TN) values are false in both reality and prediction.
- LR: Alpha = 0.1, Fit_intercept = true, Normalize = false, Solver = sag
- SVM: kernel = ‘rbf’, degree = 3, gamma = ‘scale’, coef0 = 0.0, shrinking = True
- XGBoost: verbosity =true, validate_parameters =false, min_split_loss = 0.001, max_depth =5, max_delta_step =0
- Random Forest: max_depth = 4, min_sample_split = 10, n_trees = 60, min_samples_leaf = 3
- DNN: hidden_layer_sizes = 3, activation = Relu, learning_rate = 0.01, solver = ’Adam’
- CNN: filter_size1 = 3, num_filters1 = 32, filter_size2 = 3, num_filters2 = 32, filter_size3 = 3, num_filters3 = 64, fc_size = 128, learning_rate = 0.01
6. Framework Validation
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- WHO. WHO Cardiovascular Diseases. Available online: https://www.who.int/health-topics/cardiovascular-diseases#tab=tab_1 (accessed on 2 June 2022).
- Alhabib, K.F.; Batais, M.A.; Almigbal, T.H.; Alshamiri, M.Q.; Altaradi, H.; Rangarajan, S.; Yusuf, S. Demographic, behavioral, and cardiovascular disease risk factors in the Saudi population: Results from the Prospective Urban Rural Epidemiology study (PURE-Saudi). BMC Public Health 2020, 20, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Schneeberger, D.; Stoeger, K.; Holzinger, A. The european leagal framework for medical AI. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Dublin, Ireland, 25–28 August 2020; pp. 209–226. [Google Scholar]
- Centers for Disease Control and Prevention. Multiple Cause of Death 1999–2015; National Center for Health Statistics: Hyattsville, MD, USA, 2016. Available online: http://wonder.cdc.gov/mcd-icd10.html (accessed on 12 September 2022).
- Benjamin, E.J.; Virani, S.S.; Callaway, C.W.; Chamberlain, A.M.; Chang, A.R.; Cheng, S.; Chiuve, S.E.; Cushman, M.; Delling, F.N.; Deo, R.; et al. Heart Disease and Stroke Statistics-2018 Update: A Report From the American Heart Association. Circulation 2018, 137, e67–e492. [Google Scholar] [CrossRef] [PubMed]
- Tsao, C.W.; Aday, A.W.; Almarzooq, Z.I.; Alonso, A.; Beaton, A.Z.; Bittencourt, M.S.; Boehme, A.K.; Buxton, A.E.; Carson, A.P.; Commodore-Mensah, Y.; et al. Heart Disease and Stroke Statistics—2022 Update: A Report From the American Heart Association. Circulation 2022, 145, e153–e639. [Google Scholar] [CrossRef] [PubMed]
- Alotaibi, F.S. Implementation of Machine Learning Model to Predict Heart Failure Disease. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 261–268. [Google Scholar] [CrossRef]
- American Heart Association. Classes of Heart Failure. 2017. Available online: https://www.heart.org/en/health-topics/heart-failure/what-is-heart-failure/classes-of-heart-failure (accessed on 2 June 2022).
- Andreoli, A.; Gravina, R.; Giannantonio, R.; Pierleoni, P.; Fortino, G. SPINE-HRV: A BSN-Based Toolkit for Heart Rate Variability Analysis in the Time-Domain. In Wearable and Autonomous Biomedical Devices and Systems for Smart Environment; Springer: Berlin/Heidelberg, Germany, 2010; pp. 369–389. [Google Scholar] [CrossRef]
- Melillo, P.; De Luca, N.; Bracale, M.; Pecchia, L. Classification Tree for Risk Assessment in Patients Suffering From Congestive Heart Failure via Long-Term Heart Rate Variability. IEEE J. Biomed. Health Inform. 2013, 17, 727–733. [Google Scholar] [CrossRef] [PubMed]
- Harvard Medical School. Roughout Life, Heart Attacks Are Twice as Common in Men Than Women; Harvard Health Publishing: Cambridge, MA, USA, 2016; Available online: https://www.health.harvard.edu/heart-health/throughout-life-heart-attacks-are-twice-as-common-in-men-than-women (accessed on 30 May 2022).
- Garate-Escamilla, A.K.; Hassani, A.H.E.; Andrès, E. Classification models for heart disease prediction using feature selection and PCA. Inform. Med. Unlocked 2020, 19, 100330. [Google Scholar] [CrossRef]
- Mohan, S.; Thirumalai, C.; Srivastava, G. Effective Heart Disease Prediction Using Hybrid Machine Learning Techniques. IEEE Access 2019, 7, 81542–81554. [Google Scholar] [CrossRef]
- Radwan, N.M.; Hanna, W.K. A Neutrosophic Intelligent System for Heart Disease Diagnosis: Case Study in Developing Country. Int. J. Fuzzy Syst. Appl. 2022, 11, 1–13. [Google Scholar] [CrossRef]
- Biksham, V.; Srujana, V.; Meghana, I.; Harshath, B.; Tarun, G. Heart Disease Prediction Using Machine Learning. Ymer 2022, 21, 489–494. [Google Scholar] [CrossRef]
- Indraja, B.; Pola, S.S.; Jain, N.; Reddy CH, U.; Kumar M, U. Heart Disease Prediction Using Machine Learning Techniques. Iconic Res. Eng. J. 2022, 5, 386–392. [Google Scholar]
- Parthiban, G.; Srivatsa, S.K. Applying Machine Learning Methods in Diagnosing Heart Disease for Diabetic Patients. Int. J. Appl. Inf. Syst. 2012, 3, 25–30. [Google Scholar] [CrossRef]
- Guidi, G.; Pettenati, M.C.; Melillo, P.; Iadanza, E. A Machine Learning System to Improve Heart Failure Patient Assistance. IEEE J. Biomed. Health Inform. 2014, 18, 1750–1756. [Google Scholar] [CrossRef] [PubMed]
- Ismaeel, S.; Miri, A.; Chourishi, D. Using the Extreme Learning Machine (ELM) technique for heart disease diagnosis. In Proceedings of the 2015 IEEE Canada International Humanitarian Technology Conference (IHTC2015), Ottawa, ON, Canada, 31 May–4 June 2015; pp. 1–3. [Google Scholar] [CrossRef]
- Miao, K.H.; Miao, J.H.; Miao, G.J. Diagnosing Coronary Heart Disease using Ensemble Machine Learning. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 30–39. [Google Scholar] [CrossRef]
- Dun, B.; Wang, E.; Majumder, S. Heart Disease Diagnosis on Medical Data Using Ensemble Learning. Comput. Sci. 2016, 1, 1–5. Available online: http://cs229.stanford.edu/proj2017/final-reports/5233515.pdf (accessed on 22 September 2021).
- Thomas, J.; Princy, R.T. Human heart disease prediction system using data mining techniques. In Proceedings of the 2016 International Conference on Circuit, Power and Computing Technologies (ICCPCT) 2016, Nagercoil, India, 18–19 March 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Deepika, K.; Seema, S. Predictive analytics to prevent and control chronic diseases. In Proceedings of the 2016 2nd International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Bangalore, India, 21–23 July 2016; pp. 381–386. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, Z.; Wang, D.; Hu, J.; Duan, X.; Zhu, T. Cardiovascular risk prediction method based on CFS subset evaluation and random forest classification framework. In Proceedings of the 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing, China, 10–12 March 2017; pp. 228–232. [Google Scholar] [CrossRef]
- Gavhane, A.; Kokkula, G.; Pandya, I.; Devadkar, K. Prediction of heart disease using machine learning. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; pp. 1275–1278. [Google Scholar]
- Tabassian, M.; Sunderji, I.; Erdei, T.; Sanchez-Martinez, S.; Degiovanni, A.; Marino, P.; Fraser, A.G.; D'Hooge, J. Diagnosis of Heart Failure With Preserved Ejection Fraction: Machine Learning of Spatiotemporal Variations in Left Ventricular Deformation. J. Am. Soc. Echocardiogr. 2018, 31, 1272–1284.e9. [Google Scholar] [CrossRef] [PubMed]
- Shah, D.; Patel, S.; Bharti, S.K. Heart Disease Prediction using Machine Learning Techniques. SN Comput. Sci. 2020, 1, 1–6. [Google Scholar] [CrossRef]
- Mirkin, E.; Savchenko, E. Use of the Method of Setting the Interval Target in the Problem of Synthesis of a Neural Network Classifier for Diagnosing Chronic Kidney Disease in Patients. In International Youth Conference on Electronics, Telecommunications and Information Technologies; Springer: Berlin/Heidelberg, Germany, 2022; pp. 57–66. [Google Scholar] [CrossRef]
- Tiwari, S.; Jain, A.; Sapra, V.; Koundal, D.; Alenezi, F.; Polat, K.; Alhudhaif, A.; Nour, M. A smart decision support system to diagnose arrhythymia using ensembled ConvNet and ConvNet-LSTM model. Expert Syst. Appl. 2023, 213, 118933. [Google Scholar] [CrossRef]
- Kanksha, B.; Aman, P.; Sagar, P.; Rahul, M.; Aditya, K. An Intelligent Unsupervised Technique for Fraud Detection in Health Care Systems. Intell. Decis. Technol. 2021, 15, 127–139. [Google Scholar] [CrossRef]
- Yaghouby, F.; Ayatollahi, A.; Soleimani, R.; Assistant, R. Classification of Cardiac Abnormalities Using Reduced Features of Heart Rate Variability Signal. World Appl. Sci. J. 2009, 6, 1547–1554. [Google Scholar]
- Al Rahhal, M.; Bazi, Y.; AlHichri, H.; Alajlan, N.; Melgani, F.; Yager, R. Deep learning approach for active classification of electrocardiogram signals. Inf. Sci. 2016, 345, 340–354. [Google Scholar] [CrossRef]
- Rajagopal, R.; Ranganathan, V. Evaluation of effect of unsupervised dimensionality reduction techniques on automated arrhythmia classification. Biomed. Signal Process. Control 2017, 34, 1–8. [Google Scholar] [CrossRef]
- Singh, R.S.; Saini, B.S.; Sunkaria, R.K. Detection of coronary artery disease by reduced features and extreme learning machine. Med. Pharm. Rep. 2018, 91, 166–175. [Google Scholar] [CrossRef]
- Bashir, S.; Khan, Z.S.; Khan, F.H.; Anjum, A.; Bashir, K. Improving heart disease prediction using feature selection approaches. In Proceedings of the 16th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 8–12 January 2019; pp. 619–623. [Google Scholar]
- Ramalingam, V.V.; Dandapath, A.; Raja, M.K. Heart disease prediction using machine learning techniques: A survey. Int. J. Eng. Technol. 2018, 7, 684–687. [Google Scholar] [CrossRef]
- Pandit, A.; Radstake, T.R.D.J. Machine learning in rheumatology approaches the clinic. Nat. Rev. Rheumatol. 2020, 16, 69–70. [Google Scholar] [CrossRef]
- Mo, X.; Chen, X.; Li, H.; Li, J.; Zeng, F.; Chen, Y.; He, F.; Zhang, S.; Li, H.; Pan, L.; et al. Early and Accurate Prediction of Clinical Response to Methotrexate Treatment in Juvenile Idiopathic Arthritis Using Machine Learning. Front. Pharmacol. 2019, 10, 1155. [Google Scholar] [CrossRef]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
- Yuh-Jye, L.; Mangasarian, O.L. A novel smooth support vector machine for classification. Comput. Optim. Appl. 2001, 20, 5–22. [Google Scholar]
- Li, Q.; Chen, L.; Li, X.; Lv, X.; Xia, S.; Kang, Y. PRF-RW: A progressive random forest-based random walk approach for interactive semi-automated pulmonary lobes segmentation. Int. J. Mach. Learn. Cybern. 2020, 11, 2221–2235. [Google Scholar] [CrossRef]
- Baez-Villanueva, O.M.; Zambrano-Bigiarini, M.; Beck, H.E.; McNamara, I.; Ribbe, L.; Nauditt, A.; Birkel, C.; Verbist, K.; Giraldo-Osorio, J.D.; Thinh, N.X. RF-MEP: A novel Random Forest method for merging gridded precipitation products and ground-based measurements. Remote. Sens. Environ. 2020, 239, 111606. [Google Scholar] [CrossRef]
- Dong, W.; Huang, Y.; Lehane, B.; Ma, G. XGBoost algorithm-based prediction of concrete electrical resistivity for structural health monitoring. Autom. Constr. 2020, 114, 103155. [Google Scholar] [CrossRef]
- Komorowski, M.; Celi, L.A.; Badawi, O.; Gordon, A.C.; Faisal, A.A. The Artificial Intelligence Clinician learns optimal treatment strategies for sepsis in intensive care. Nat. Med. 2018, 24, 1716–1720. [Google Scholar] [CrossRef] [PubMed]
- Bhanumathi, M.; Gautham Kumar, R.S.; Karthika Hema Manasa, M.; Aravindh, R. Heart Disease Prediction Using Convolutional Neural Network; IOS Press: Amsterdam, The Netherlands, 2021; pp. 377–382. [Google Scholar] [CrossRef]
- UCI. Heart Disease Cleveland UCI. Kaggle.com. Available online: https://www.kaggle.com/datasets/cherngs/heart-disease-cleveland-uci (accessed on 15 December 2021).
- Ahmad, T.; Munir, A.; Bhatti, S.H.; Aftab, M.; Raza, M.A. Cardiovascular Heart Disease Patients Dataset. PLoS ONE. 2017. Available online: https://plos.figshare.com/articles/dataset/Survival_analysis_of_heart_failure_patients_A_case_study/5227684/1 (accessed on 2 April 2022).
- Chicco, D.; Jurman, G. Machine learning can predict survival of patients with heart failure from serum creatinine and ejection fraction alone. BMC Med. Inform. Decis. Mak. 2020, 20, 1–16. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Feature (Attribute Name) | Distinct Values |
|---|---|---|
| 1 | Age–Patient age (years) | Between 29 and 77 |
| 2 | Sex–Gender of a patient | 1 for males, 0 for females |
| 3 | CP–Level of chest pain a patient is suffering from when arriving at hospital (if exists) | 0, 1, 2, 3 |
| 4 | Chol–The cholesterol level recorded when patient is admitted to hospital | Between 126 and 564 (mg/dL) |
| 5 | RestBP–The blood pressure (BP) figure for the patient at the time of admission to hospital | Between 94 and 564 (mm Hg) |
| 6 | FBS–The fasting blood sugar of the patient with binary classification: if more than 120 mg/dL =1 else =0 | 0, 1 |
| 7 | RestECG–The result of resting electrocardiographic (ECG) from 0 to 2, where each value describes the severity of the pain | 0, 1, 2 |
| 8 | HeartBeat–The maximum value of heartbeat counted when patient is admitted | Between 71 and 202 |
| 9 | Exang–Used to understand whether exercise induced angina or not. Yes = 1 and not = 0 | 0, 1 |
| 10 | Oldpeak–Defines the patient’s depression status | Real numbers between 0 and 6.2 |
| 11 | Slope–Patient’s condition during peak exercise. The value is defined by three segments [Up sloping, Flat, Down sloping] | 1, 2, 3 |
| 12 | Ca–The status of fluoroscopy. It shows how many vessels are colored | 0, 1, 2, 3 |
| 13 | Thal–A kind of test required for patients with chest pain or breathing difficulty. Four different values showing the result of Thallium test | 0, 1, 2, 3 |
| 14 (Class) | Target–The class or label column. There are two types of classes (0, 1), where “0” indicates that the patient has no heart disease, whereas “1” implies that the patient has heart disease based on the features used in the modeling process. | 0, 1 |
| Metric | Definition | Formula |
|---|---|---|
| Accuracy | The overall truly predicted samples divided by overall samples | (TP + TN)/N |
| Specificity | The percentage of actual negative samples that were predicted as negative | TN/(FP + TN) |
| Sensitivity (Recall) | The percentage of actual positive samples that were predicted as positive | TP/(FN + TP) |
| Precision | How many of the positively classified samples were actually positive | TP/(TP + FP) |
| F1 Score | The harmonic means of both recall and precision | 2(recall * precision)/(recall + precision) |
| Without Preprocessing Pipelines | With Preprocessing Pipelines | ||||||
|---|---|---|---|---|---|---|---|
| Model | Accuracy % | Specificity | Sensitivity | Model | Accuracy % | Specificity | Sensitivity |
| LR | 82.1 | 79.8 | 85.6 | LR | 84 | 82.5 | 85.6 |
| SVM | 83.3 | 80 | 78.5 | SVM | 84.6 | 82.6 | 83.5 |
| XGB | 85.7 | 83.4 | 81.8 | XGB | 88.1 | 85.0 | 83.9 |
| RF | 81.4 | 80.2 | 79.3 | RF | 82.8 | 80.5 | 80.4 |
| DNN | 83.9 | 80.9 | 80.4 | DNN | 85.4 | 83.1 | 82.2 |
| CNN | 91.2 | 87.2 | 84.9 | CNN | 93.3 | 88.0 | 86.1 |
| With Removing the Outliers and Feature Selection | |||
|---|---|---|---|
| Model | Accuracy % | Specificity | Sensitivity |
| Proposed Framework on HDD | 96.3 | 91.9 | 93.1 |
| Traditional Voting Framework | 92.5 | 91.0 | 89.3 |
| Classical Stacking | 93.9 | 91.7 | 92.4 |
| CNN | 93.3 | 88.0 | 86.1 |
| Authors | Methodology and Results |
|---|---|
| Shah et al. [27] (2020) | Accuracy around 90.7% Implemented multiple classification techniques. Decision Tree, KNN and K-Means were compared. Concluded that accuracy obtained by KNN was highest. Selected features based on literature surveys. |
| Alotaibi [7] (2019) | Accuracy around 93% Compared multiple ML algorithms. The accuracy of Decision Tree, Logistic Regression, Random Forest, Naive Bayes and SVM classification algorithms were compared. Decision tree algorithm had the highest accuracy. Selected features based on literature surveys. |
| Mohan et al. [13] (2019) | Accuracy 87.4% Hybrid model combining RF and LM. RF used to extract features and then NN was used to predict the results and the hybrid model was compared to other ML techniques. Their hybrid model showed 1% improvement compared to the other techniques. 13 features extracted by RF and used in the model. |
| Deepika and Seema [23] (2017) | Accuracy around 95% Compared multiple ML algorithms Naïve Bayes, Decision tree, SVM and ANN methods were compared. SVM gained the optimum results. Selected features based on literature surveys. |
| Shu et al. [24] (2017) | Accuracy around 91% Compared multiple ML algorithms Random Forest, C4.5, SVM, Bayes, RBF network, AdaBoost were compared. Random Forest provided the best accuracy. Includes features selection framework but not hybrid model. |
| Mioa et al. [20] (2016) | Average accuracy around 85% Used advanced integrated ML (Adaptive boosting algorithm) Applied on 4 different datasets of UCI Used 29 features Suffered from overfitting |
| Proposed Model | Accuracy reached 96.3% Hybrid multi-stage stacking classification framework that can be generalized for other problems. Includes hybrid feature selection framework. Framework is agnostic to input data schema. |
| No. | Feature (Attribute Name) | Measure | Distinct Values |
|---|---|---|---|
| 1 | Age–Patient age (years) | Years | Between 40 and 95 |
| 2 | Sex–Gender of patient | Boolean | 1 (male) 0 (female) |
| 3 | Anemia–Decrease of red blood cells or hemoglobin | Boolean | 0, 1 |
| 4 | High blood pressure–If a patient has hypertension | Boolean | 0, 1 |
| 5 | Creatinine phosphokinase (CPK)–Level of the CPK enzyme in the blood | Mcg/L | [23, …, 7861] |
| 6 | Diabetes–If the patient has diabetes | Boolean | 0, 1 |
| 7 | Ejection fraction–Percentage of blood leaving the heart at each contraction | Percentage | [14, …, 80] |
| 8 | Platelets–Platelets in the blood | kiloplatelets/mL | [25.01, …, 850.00] |
| 9 | Serum creatinine–Level of creatinine in the blood | mg/dL [0.50, …, 9.40] | mg/dL [0.50, …, 9.40] |
| 10 | Serum sodium–Level of sodium in the blood | mEq/L | [114, …, 148] |
| 11 | Smoking–If the patient smokes | Boolean | 0, 1 |
| 12 | Time–Follow-up period | Days | [4, …, 285] |
| 13 (Class) | Death event (Target)–If the patient died during the follow-up period | Boolean | 0, 1 |
| Model | Accuracy % |
|---|---|
| Proposed Framework on CHD Dataset | 91.8 |
| Chicco and Jurman [49] | 83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Menshawi, A.; Hassan, M.M.; Allheeib, N.; Fortino, G. A Hybrid Generic Framework for Heart Problem Diagnosis Based on a Machine Learning Paradigm. Sensors 2023, 23, 1392. https://doi.org/10.3390/s23031392
Menshawi A, Hassan MM, Allheeib N, Fortino G. A Hybrid Generic Framework for Heart Problem Diagnosis Based on a Machine Learning Paradigm. Sensors. 2023; 23(3):1392. https://doi.org/10.3390/s23031392
Chicago/Turabian StyleMenshawi, Alaa, Mohammad Mehedi Hassan, Nasser Allheeib, and Giancarlo Fortino. 2023. "A Hybrid Generic Framework for Heart Problem Diagnosis Based on a Machine Learning Paradigm" Sensors 23, no. 3: 1392. https://doi.org/10.3390/s23031392
APA StyleMenshawi, A., Hassan, M. M., Allheeib, N., & Fortino, G. (2023). A Hybrid Generic Framework for Heart Problem Diagnosis Based on a Machine Learning Paradigm. Sensors, 23(3), 1392. https://doi.org/10.3390/s23031392