
A Review of Federated Learning in Agriculture


Abstract
:1. Introduction
1.1. Machine Learning (ML)
1.2. Deep Learning (DL)
1.3. Edge Computing
1.4. Federated Learning (FL)
- A subset of candidate clients is selected for the FL iteration;
- The global model is sent to the selected client edge devices;
- Each client learns its model using only its local data and computes a local update on the model, typically using Gradient Descent;
- The central server uses the computed aggregated update to update the global model;
- Subsequently, the server returns the global model parameters to the clients for the next iteration of model learning.
2. Materials
3. Methods
3.1. Data Partitioning
3.1.1. Horizontal Data Partitioning
3.1.2. Vertical Data Partitioning
3.1.3. Hybrid Data Partitioning and Transfer FL
- Local and global model. Each client trains its local model on data with a subset of features. The server global model supports all the features. Each client has some features of all training samples, as in vertical FL.
- Limited data sharing of labels (features). In horizontal FL, the clients do not share labels; in vertical FL, labels may be made available to the server. The FL system needs to deal with both types of clients.
- Sample synchronization. In hybrid FL, like in vertical FL, not all clients have all the samples. The problem of aggregation is even greater in hybrid FL systems because not all clients have all samples, and algorithms do not require clients to synchronize their sample sets.
3.2. Architecture
3.2.1. Centralized FL Architecture
- Initially, a global model is transmitted to edge devices (clients);
- Each client trains its model with its local data and sends its local model parameters to the central server for aggregation, thereby improving the global server model;
- The central server aggregates the model parameters and returns the updated global parameters to the clients;
- Local models are initialized with the received global parameters and are further trained;
- This process repeats until it reaches the maximum number of iterations or until the server model converges;
3.2.2. Decentralized FL Architecture
3.2.3. FL Architecture and Data Partitioning
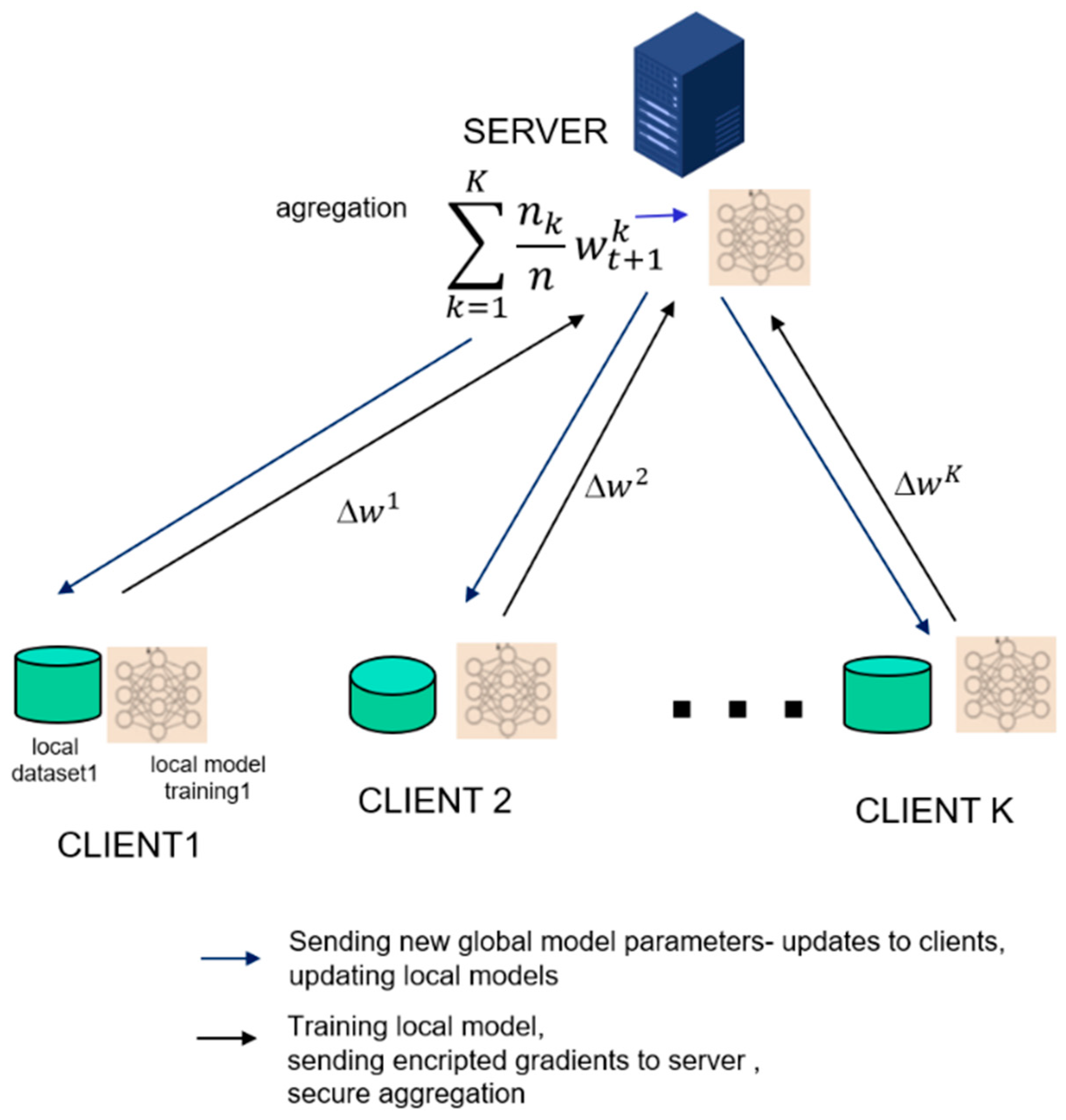
3.3. Aggregation Algorithms
- Firstly, FedAvg initializes the global model randomly;
- FedAvg selects a subset of clients, denoted as , || = C K, with C and K being parameters, both greater than or equal to 1, at each iteration;
- Next, it sends the current global model to all clients in subset (see Figure 1);
- The local models on each client k are updated to the shared model, ← ;
- Each client partitions their local data into batches of size B and perform epochs of Stochastic Gradient Descent (SGD);
- After training, each client sends its updated local model, to the server;
- The server computes a weighted sum of all received local models to obtain the new global model, .
3.4. Scale of Federation
3.4.1. Scale of Federation and Data Partitioning
3.4.2. Scale of Federation and Architecture
4. Results
4.1. Use Cases of FL Applications in Agriculture
4.2. Challenges of Production FL Systems
- Communication bandwidth: To provide efficient communication, the size of a message can be reduced using model compression schemes, and the total number of message transfers can be reduced;
- Privacy and data protection are concerns with FL, not about the local data that stays on the user’s device but about revealing the information from the model updates shared in the network;
- System heterogeneity with a large number of devices with differences in storage, communication, and computational capabilities, which cannot participate all the time. System heterogeneity can be managed with asynchronous communication, active device sampling, and fault tolerance;
- Statistical heterogeneity in FL systems is caused by data that are non-IID (not identically and independently distributed), with multiple variations of data, and with different precision or different-resolution images contained in the client devices.
4.2.1. Communication Challenge of Production FL Systems in General and in Agriculture
Sparsification Methods
Quantization Methods
4.2.2. Application of Aggregation Algorithms
- -
- Synchronous, where model aggregation occurs after all client updates have reached the server (like FedAvg);
- -
- Asynchronous to handle device heterogeneity;
- -
- Hierarchical to handle the presence of a large number of edge devices, such as IoT devices, using an edge layer to partially aggregate local models from closely related client devices before further aggregation;
- -
- Robust aggregation with the purpose of ensuring secure aggregation throughout the FL process using encryption techniques.
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
References
- Samuel, A. Some Studies in Machine Learning Using the Game of Checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Ethem, A. Introduction to Machine Learning, 4th ed.; MIT: Cambridge, MA, USA, 2020; pp. xix, 1–3, 13–18. ISBN 978-0262043793. [Google Scholar]
- Benos, L.; Tagarakis, A.C.; Dolias, G.; Berruto, R.; Kateris, D.; Bochtis, D. Machine Learning in Agriculture: A Comprehensive Updated Review. Sensors 2021, 21, 3758. [Google Scholar] [CrossRef] [PubMed]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine Learning in Agriculture: A Review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Annotated History of Modern AI and Deep Learning. arXiv 2022, arXiv:2212.11279. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Kim, H.; Lieu, Q.X.; Lee, J. CNN-based image recognition for topology optimization. Knowl.-Based Syst. 2020, 198, 105887. [Google Scholar] [CrossRef]
- Jain, L.C.; Medsker, L.R. Recurrent Neural Networks: Design and Applications; CRC Press, Inc.: Boca Raton, FL, USA, 1999. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Cao, K.; Liu, Y.; Meng, G.; Sun, Q. An Overview on Edge Computing Research. IEEE Access 2020, 8, 85714–85728. [Google Scholar] [CrossRef]
- Satyanarayanan, M. The emergence of edge computing. Computer 2017, 50, 30–39. [Google Scholar] [CrossRef]
- Ghosh, M.; Grolinger, K. Edge-Cloud Computing for Internet of Things Data Analytics: Embedding Intelligence in the Edge with Deep Learning. IEEE Trans. Ind. Inform. 2021, 17, 2191–2200. [Google Scholar] [CrossRef]
- Wang, X.; Han, Y.; Leung, V.C.M.; Niyato, D.; Yan, X.; Chen, X. Convergence of Edge Computing and Deep Learning: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar] [CrossRef]
- Morais, R.; Mendes, J.; Silva, R.; Silva, N.; Sousa, J.J.; Peres, E. A Versatile, Low-Power and Low-Cost IoT Device for Field Data Gathering in Precision Agriculture Practices. Agriculture 2021, 11, 619. [Google Scholar] [CrossRef]
- Wójtowicz, M.; Wójtowicz, A.; Piekarczyk, J. Application of remote sensing methods in agriculture. Commun. Biometry Crop Sci. 2016, 11, 31–50. [Google Scholar]
- Kaur, J.; Hazrati Fard, S.M.; Amiri-Zarandi, M.; Dara, R. Protecting farmers’ data privacy and confidentiality: Recommendations and considerations. Front. Sustain. Food Syst. 2022, 6, 903230. [Google Scholar] [CrossRef]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492v2. [Google Scholar]
- McMahan, H.B.; Moore ERamage, D.; Hampson, S.; Arcas, B.A. Communication efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS) 2017, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawit, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Rahman, K.J.; Ahmed, F.; Akhter, N.; Hasan, M.; Amin, R.; Aziz, K.E.; Islam, A.K.M.M.; Mukta, M.S.H.; Islam, A.K.M.N. Challenges, applications and design aspects of federated learning: A survey. IEEE Access 2021, 9, 124682–124700. [Google Scholar] [CrossRef]
- Siddaway, A.P.; Wood, A.M.; Hedges, L.V. How to do a systematic review: A best practice guide for conducting and reporting narrative reviews, meta-analyses, and meta-syntheses. Ann. Rev. Psychol. 2019, 70, 747–770. [Google Scholar] [CrossRef] [PubMed]
- Aledhari, M.; Razzak, R.; Parizi, R.M.; Saeed, F. Federated learning: A survey on enabling technologies, protocols, and applications. IEEE Access 2020, 8, 140699–140725. [Google Scholar] [CrossRef] [PubMed]
- Arivazhagan, G.M.; Aggarwal, V.; Singh, A.K.; Choudhary, S. Federated Learning with Personalization Layers. arXiv 2019, arXiv:1912.00818. [Google Scholar]
- Karimireddy, S.P.; Jaggi, M.; Kale, S.; Mohri, M.; Reddi, S.J.; Stich, S.U.; Suresh, A.T. Mime: Mimicking centralized stochastic algorithms in federated learning. arXiv 2020, arXiv:2008.03606. [Google Scholar]
- Liu, J.; Huang, J.; Zhou, Y.; Li, X.; Ji, S.; Xiong, H.; Dou, D. From distributed machine learning to federated learning: A survey. Knowl. Inf. Syst. 2021, 64, 885–917. [Google Scholar] [CrossRef]
- Liu, Y.; Kang, Y.; Li, L.; Zhang, X.; Cheng, Y.; Chen, T.; Hong, M.; Yang, Q. A communication efficient vertical federated learning framework. In Scanning Electron Microsc Meet at; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Yang, K.; Song, Z.; Zhang, Y.; Zhou, Y.; Sun, X.; Wang, J. Model optimization method based on vertical federated learning. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Republic of Korea, 22–28 May 2021; pp. 1–5. [Google Scholar]
- Chen, T.; Jin, X.; Sun, Y.; Yin, W. VAFL: A method of vertical asynchronous federated learning. arXiv 2020, arXiv:2007.06081. [Google Scholar]
- Chen, Y.; Qin, X.; Wang, J.; Yu, C.; Gao, W. Fedhealth: A federated transfer learning framework for wearable healthcare. IEEE Intell. Syst. 2020, 35, 83–93. [Google Scholar] [CrossRef]
- Zhang, X.; Yin, W.; Hong, M.; Chen, T. Hybrid Federated Learning: Algorithms and Implementation. arXiv 2021, arXiv:2012.12420. [Google Scholar] [CrossRef]
- Liang, X.; Liu, Y.; Chen, T.; Liu, M.; Yang, Q. Federated transfer reinforcement learning for autonomous driving. arXiv 2019, arXiv:1910.06001. [Google Scholar]
- Yang, H.; He, H.; Zhang, W.; Cao, X. Fedsteg: A federated transfer learning framework for secure image steganalysis. IEEE Trans. Netw. Sci. Eng. 2020, 8, 1084–1094. [Google Scholar] [CrossRef]
- Beltrán, E.T.; Pérez, M.Q.; Sánchez, P.M.; Bernal, S.L.; Bovet, G.; Pérez, M.G.; Pérez, G.M.; Celdrán, A.H. Decentralized Federated Learning: Fundamentals, State-of-the-art, Frameworks, Trends, and Challenges. arXiv 2022, arXiv:2211.08413. [Google Scholar]
- Yuan, L.; Sun, L.; Yu, P.S.; Wang, Z. Decentralized Federated Learning: A Survey and Perspective. arXiv 2023, arXiv:2306.01603. [Google Scholar]
- Delange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A continual learning survey: Defying forgetting in classification tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3366–3385. [Google Scholar]
- Feng, C.; Liu, B.; Yu, K.; Goudos, S.K.; Wan, S. Blockchainempowered decentralized horizontal federated learning for 5G-enabled UAVs. IEEE Trans. Ind. Inform. 2022, 18, 3582–3592. [Google Scholar] [CrossRef]
- Sánchez, P.M.; Celdrán, A.H.; Beltrán, E.T.M.; Demeter, D.; Bovet, G.; Pérez, G.M.; Stille, B. Analyzing the Robustness of Decentralized Horizontal and Vertical Federated Learning Architectures in a Non-IID Scenario. arXiv 2022, arXiv:2210.11061. [Google Scholar]
- Li, C.; Li, G.; Varshney, P.K. Decentralized federated learning via mutual knowledge transfer. IEEE Internet Things J. 2022, 9, 1136–1147. [Google Scholar] [CrossRef]
- Mills, J.; Hu, J.; Min, G. Communication-efficient federated learning for wireless edge intelligence in iot. IEEE Internet Things J. 2019, 7, 5986–5994. [Google Scholar] [CrossRef]
- Zinkevich, M.; Weimer, M.; Li, L.; Smola, A. Parallelized stochastic gradient descent. In Advances in Neural Information Processing Systems; Lafferty, J., Williams, C., Taylor, J.S., Zemel, R., Culotta, A., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2010; Volume 23, Available online: https://proceedings.neurips.cc/paper/2010/file/abea47ba24142ed16b7d8fbf2c740e0d-Paper.pdf (accessed on 11 October 2023).
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated Optimization in Heterogeneous Net-works. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Zhong, Z.; Zhou, Y.; Wu, D.; Chen, X.; Chen, M.; Li, C.; Sheng, Q.Z. P-FedAvg: Parallelizing federated learning with theoretical guarantees. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar]
- Ye, Y.; Li, S.; Liu, F.; Tang, Y.; Hu, W. EdgeFed: Optimized Federated Learning Based on Edge Computing. IEEE Access 2020, 8, 209191–209198. [Google Scholar] [CrossRef]
- Huang, C.; Huang, J.; Liu, X. Cross-Silo Federated Learning: Challenges and Opportunities. arXiv 2022, arXiv:2206.12949. [Google Scholar]
- Han, J.; Han, Y.; Huang, G.; Ma, Y. DeFL: Decentralized weight aggregation for cross-silo federated learning. arXiv 2022, arXiv:2208.00848. [Google Scholar]
- Karimireddy, S.P.; Jaggi, M.; Kale, S.; Mohri, M.; Reddi, S.J.; Stich, S.U.; Suresh, A.T. Breaking the centralized barrier for cross-device federated learning. In Advances in Neural Information Processing Systems; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2021; Volume 34, pp. 28663–28676. [Google Scholar]
- Manoj, T.; Makkithaya, K.; Narendra, V.G. A Federated Learning-Based Crop Yield Prediction for Agricultural Production Risk Management. In Proceedings of the 2022 IEEE Delhi Section Conference (DELCON), New Delhi, India, 11–13 February 2022; pp. 1–7. [Google Scholar]
- Kumar, P.; Gupta, G.P.; Tripathi, R. PEFL: Deep privacy-encoding-based federated learning framework for smart agriculture. IEEE Micro 2021, 42, 33–40. [Google Scholar] [CrossRef]
- Durrant, A.; Markovic, M.; Matthews, D.; May, D.; Enright, J.; Leontidis, G. The role of cross-silo federated learning in facilitating data sharing in the agri-food sector. Comput. Electron. Agric. 2022, 193, 106648. [Google Scholar] [CrossRef]
- Antico, T.M.; Moreira LF, R.; Moreira, R. Evaluating the Potential of Federated Learning for Maize Leaf Disease Prediction. In Anais do XIX Encontro Nacional de Inteligência Artificial e Computacional; Sociedade Brasileira de Computação: Porto Alegre, Brazil, 2022; pp. 282–293. [Google Scholar]
- Mao, A.; Huang, E.; Gan, H.; Liu, K. FedAAR: A Novel Federated Learning Framework for Animal Activity Recognition with Wearable Sensors. Animals 2022, 12, 2142. [Google Scholar] [CrossRef]
- Khan, F.S.; Khan, S.; Mohd MN, H.; Waseem, A.; Khan MN, A.; Ali, S.; Ahmed, R. Federated learning-based UAVs for the diagnosis of Plant Diseases. In Proceedings of the 2022 International Conference on Engineering and Emerging Technologies (ICEET), Kuala Lumpur, Malaysia, 27–28 October 2022; pp. 1–6. [Google Scholar]
- Friha, O.; Ferrag, M.A.; Shu, L.; Maglaras, L.; Choo KK, R.; Nafaa, M. FELIDS: Federated learning-based intrusion detection system for agricultural IIn Proceedings of thenternet of Things. J. Parallel Distrib. Comput. 2022, 165, 17–31. [Google Scholar] [CrossRef]
- Abu-Khadrah, A.; Mohd, A.; Jarrah, M. An Amendable Multi-Function Control Method using Federated Learning for Smart Sensors in Agricultural Production Improvements. ACM Trans. Sen. Netw. 2023, Preprint. [Google Scholar] [CrossRef]
- Yu, C.; Shen, S.; Zhang, K.; Zhao, H.; Shi, Y. Energy-aware device scheduling for joint federated learning in edge-assisted internet of agriculture things. In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; pp. 1140–1145. [Google Scholar]
- Idoje, G.; Dagiuklas, T.; Iqbal, M. Federated Learning: Crop classification in a smart farm decentralised network. Smart Agric. Technol. 2023, 5, 100277. [Google Scholar] [CrossRef]
- Deng, F.; Mao, W.; Zeng, Z.; Zeng, H.; Wei, B. Multiple Diseases and Pests Detection Based on Federated Learning and Improved Faster R-CNN. IEEE Trans. Instrum. Meas. 2022, 71, 3523811. [Google Scholar] [CrossRef]
- Bharati, S.; Mondal, M.R.H.; Podder, P.; Prasath, V.B.S. Federated learning: Applications, challenges and future directions. Int. J. Hybrid Intell. Syst. 2022, 18, 19–35. [Google Scholar] [CrossRef]
- Yang, Z.; Sun, Q. Joint think locally and globally: Communication-efficient federated learning with feature-aligned filter selection. Comput. Commun. 2023, 203, 119–128. [Google Scholar] [CrossRef]
- Li, W.; Chen, T.; Li, L.; Wu, Z.; Ling, Q. Communication-censored distributed stochastic gradient descent. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6831–6843. [Google Scholar] [CrossRef]
- Sattler, F.; Wiedemann, S.; Müller, K.-R.; Samek, W. Robust and communication-efficient federated learning from non-iid data. arXiv 2019, arXiv:1903.02891. [Google Scholar]
- Rothchild, D.; Panda, A.; Ullah, E.; Ivkin, N.; Stoica, I.; Braverman, V.; Gonzalez, J.; Arora, R. Fetchsgd: Communication-efficient federated learning with sketching. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 8253–8265. [Google Scholar]
- Li, S.; Qi, Q.; Wang, J.; Sun, H.; Li, Y.; Yu, F.R. GGS: General Gradient Sparsification for Federated Learning in Edge Computing. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Reisizadeh, A.; Mokhtari, A.; Hassani, H.; Jadbabaie, A.; Pedarsani, R. Fedpaq: A communication-efficient federated learning method with periodic averaging and quantization. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Online, 26–28 August 2020; pp. 2021–2031. [Google Scholar]
- Amiri, M.M.; Gunduz, D.; Kulkarni, S.R.; Poor, H.V. Federated learning with quantized global model updates. arXiv 2020, arXiv:2006.10672. [Google Scholar]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K.B. Hierarchical quantized federated learning: Convergence analysis and system design. arXiv 2021, arXiv:2103.14272. [Google Scholar]
- Haddadpour, F.; Kamani, M.M.; Mokhtari, A.; Mahdavi, M. Federated learning with compression: Unified analysis and sharp guarantees. In Proceedings of the International Conference on Artificial Intelligence and Statistics 2021, Virtual, 13–15 April 2021; pp. 2350–2358. [Google Scholar]
- Yang, T.J.; Xiao, Y.; Motta, G.; Beaufays, F.; Mathews, R.; Chen, M. Online Model Compression for Federated Learning with Large Models. arXiv 2022, arXiv:2205.03494. [Google Scholar]
- Malekijoo, A.; Fadaeieslam, M.J.; Malekijou, H.; Homayounfar, M.; Alizadeh-Shabdiz, F.; Rawassizadeh, R. FEDZIP: A Compression Framework for Communication-Efficient Federated Learning. arXiv 2021, arXiv:2102.01593. [Google Scholar]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Reviewing Federated Learning Aggregation Algorithms; Strategies, Contributions, Limitations and Future Perspectives. Electronics 2023, 12, 2287. [Google Scholar] [CrossRef]
- Qi, P.; Chiaro, D.; Guzzo, A.; Ianni, M.; Fortino, G.; Piccialli, F. Model aggregation techniques in federated learning: A comprehensive survey. Future Gener. Comput. Syst. 2023, 150, 272–293. [Google Scholar] [CrossRef]
- Wu, M.; Ye, D.; Ding, J.; Guo, Y.; Yu, R.; Pan, M. Incentivizing Differentially Private Federated Learning: A Multidimensional Contract Approach. IEEE Internet Things J. 2021, 8, 10639–10651. [Google Scholar] [CrossRef]
- Fernandez, J.D.; Brennecke, M.; Rieger, A.; Barbereau, T.; Fridgen, G. Federated Learning: Organizational Opportunities, Challenges, and Adoption Strategies. arXiv 2023, arXiv:2308.02219v2. [Google Scholar]


{kind=link}
{kind=link}
| Abbreviation | DL Algorithms/Models/Network Types |
|---|---|
| CNN | Convolution Neural Network |
| RNN | Recurrent Neural Network |
| DNN | Deep Neural Network |
| ResNet | Residual Network |
| DBN | Deep Belief Network |
| DCNN | Deep Convolution Neural Network |
| MCNN | Multilayer Convolution Neural Network |
| DRL | Deep Reinforcement Learning |
| DenseNet | Densely Connected Convolutional Network |
| SGD | Stochastic Gradient Descent |
| MLNN | Multilayer Neural Network |
| GRU | Gated Recurrent Units |
| AlexNet | AlexNet Neural Network |
| SqueezeNet | SqueezeNe Deep Neural Network for Computer Vision |
| VGG-11 | Very Deep Convolutional Networks for Large-Scale Image Recognition |
| ShuffleNet | ShuffleNet is a convolutional neural network designed especially for mobile devices with very limited computing power. |
| CMI-Net | Cross-Modality Interaction Network |
| Type of FL | Data Partitioning | Sample Space | Feature Space | Use Case: Two or More Clients Share Datasets with: |
|---|---|---|---|---|
| Horizontal FL | Horizontal | Different | Same | The same feature space and different sample spaces make the dataset larger. |
| Vertical FL | Vertical | Same | Different | The same sample space and different feature space make the information about samples richer, which helps to build a more accurate model. |
| Federated transfer learning | Hybrid | Partial common sample space | Partial common feature space | Small common sample space and different feature spaces. |
| Ref. | Agri Area | Number of Clients | Problem | Data Used | Challenges | FL Data Partition Method, Architecture | Aggregation Algorithms | Trained Model |
|---|---|---|---|---|---|---|---|---|
| [52] | Crop yield estimation. | 3 | Crop yield prediction. | Soybean yield dataset: weather, soil components, and crop data. | Data ownership, privacy preservation. | Horizontal FL, centralized architecture. | FedAvg | ResNet-based regression models such as ResNet-16 and ResNet-28. |
| [53] | Deep Privacy-Encoding-Based FL Framework for Smart Agriculture. | 2 | Intrusion detection. | ToN-IoT dataset. | Minimizing the risk of security and data privacy violation. | Horizontal FL, centralized architecture. FL server and edge devices such as a gateway/router connected to a large number of IoT devices. | FedGRU | GRU |
| [54] | The role of cross-silo FL in facilitating data sharing. | 5 | Facilitating data sharing across the supply chain in the agri-food sector. | Datasets for crop yield prediction from both imaging (remote sensing) and tabular (weather and soil data). | Data privacy. | Horizontal, central server-based FL. | FedBN (FLon non-iid features- via local batch normalization), extends FedAvg. | CNN and RNN. |
| [55] | Diagnosis of diseases in food crops. | 4 | Leaf disease prediction. | PlantVillage | Data privacy | Horizontal FL, centralized architecture. | FedAvg | Five CNNs: AlexNet, SqueezeNet, ResNet-18, VGG-11, ShuffleNet. |
| [56] | Automated animal activity recognition based on distributed data in the context of data heterogeneity. | 5, 10 15 20 25 30 | Automated animal activity recognition (AAR). | A public centralized dataset comprising 87,621 two-second samples that were collected from six horses with neck-attached IMUs. | Data Privacy. | Horizontal FL, centralized architecture. | FedAAR with gradient-refinement-based aggregation. | CMI-Net |
| [57] | EfficientNet deep model classifying nine types of pests. | 4 | Diagnoses of plant diseases. | Sensor technologies and IoT platforms, in conjunction with unmanned aerial vehicles (UAVs). The pest images. | Low computation power during the classification of pests for the agricultural environment. | Horizontal FL, centralized architecture. | FedAvg | Dense convolutional neural network (CNN) model combines pre-trained EfficientNetB3 with dense layers. |
| [58] | Intrusion detection system for securing agricultural-IoT infrastructures. | 5, 10 15 | Securing agricultural-IoT infrastructures. | Real-world traffic datasets -CSE-CIC-IDS2018, MQTTset, and InSDN. | Securing agricultural IoT infrastructures protects data privacy. | Hybrid data partitioning, centralized architecture. | FedAvg | Classifier: DNN, CNN, and RNN |
| [59] | Amendable Multi-Function Control Method using FL for Smart Sensors in Agricultural Production Improvements. | 47 | Improving productivity. | Crop and soil data. | FL from sensing data. | Horizontal | Amendable Multi-Function Sensor Control Method (AMFSC). | AMFSC |
| [60] | Agricultural production. | 10 | Guiding agricultural production. | The images of real-world soybean iron deficiency chlorosis (IDC)dataset. | Fast convergence rate, low communication cost, and high modeling accuracy under resource constraints | Hybrid data partitioning, centralized architecture. | Proposed a joint FL framework for Edge-assisted Internet of Agriculture Things (Edge- IoAT) framework and a greedy algorithm to find the optimal solution. | Greedy algorithm, |
| [61] | Crop classification, smart farming | 6 | Data privacy in smart farming | The dataset with independent variables of temperature, humidity, pH, and rain | The application of FL to smart farming | Horizontal FL, centralized architecture. | Federated averaging model | CNN |
| [62] | Multiple diseases and pest detection | 6 | To avoid high data storage and communication costs, an unbalanced and insufficient data from orchards, diversity of pests, and diseases, and complex detection environments by traditional cloud-based deep learning. | Images, 445 orchard apple pictures, of which only 152 pictures contain 5 diseases | To solve the problem of unbalanced and insufficient data, avoid the communication cost generated by a large amount of data upload | Horizontal FL, centralized architecture. | FedAvg | Improved faster region convolutional neural network (R-CNN) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Žalik, K.R.; Žalik, M. A Review of Federated Learning in Agriculture. Sensors 2023, 23, 9566. https://doi.org/10.3390/s23239566
Žalik KR, Žalik M. A Review of Federated Learning in Agriculture. Sensors. 2023; 23(23):9566. https://doi.org/10.3390/s23239566
Chicago/Turabian StyleŽalik, Krista Rizman, and Mitja Žalik. 2023. "A Review of Federated Learning in Agriculture" Sensors 23, no. 23: 9566. https://doi.org/10.3390/s23239566
APA StyleŽalik, K. R., & Žalik, M. (2023). A Review of Federated Learning in Agriculture. Sensors, 23(23), 9566. https://doi.org/10.3390/s23239566