

E2LNet: An Efficient and Effective Lightweight Network for Panoramic Depth Estimation


Abstract
:1. Introduction
- We propose an efficient framework, Net, for monocular panoramic depth estimation that can simultaneously address distortion and extract global contextual information;
- We design the adaptive attention dilated convolution module to be added at the skip connections, enabling distortion perception at different scales without disrupting the internal structure of the encoder and preserving its feature extraction ability;
- We construct a global scene understanding module by utilizing multi-scale dilated convolutions, which effectively capture comprehensive global information;
- We conduct panoramic depth evaluation experiments on both virtual and real-world RGB-D panorama datasets, and our proposed model achieves results comparable to existing methods.
2. Related Work
2.1. Monocular Panoramic Depth Estimation
2.2. Dilated Convolution
2.3. Pixel-Attention Model
3. Proposed Algorithm
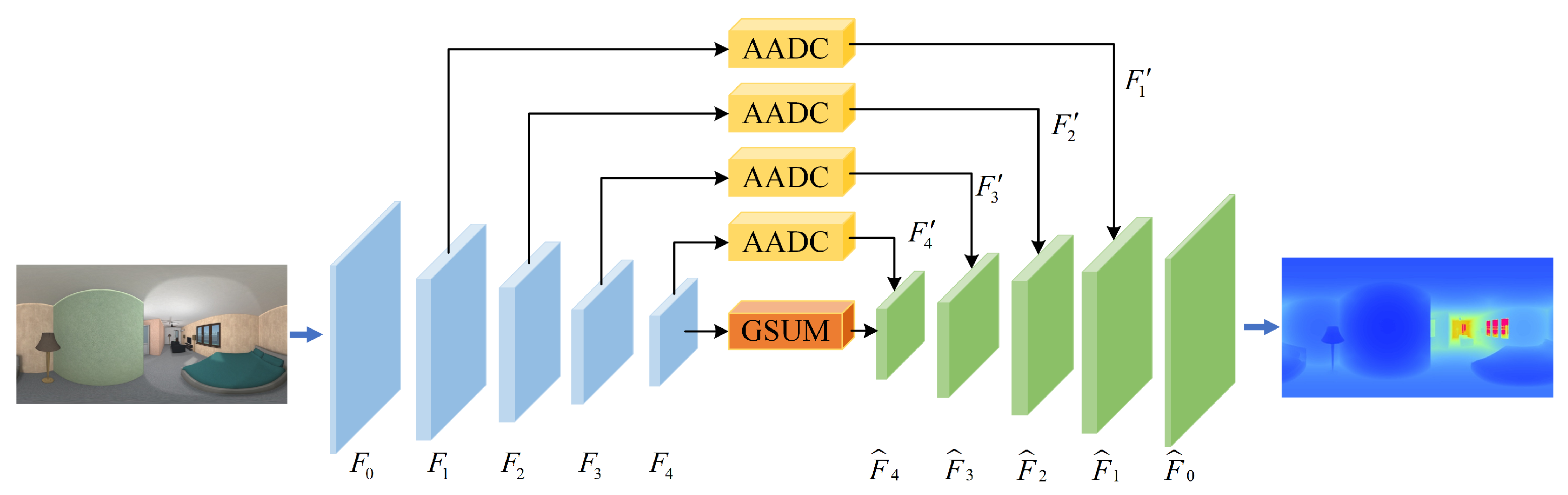
3.1. Network Architecture
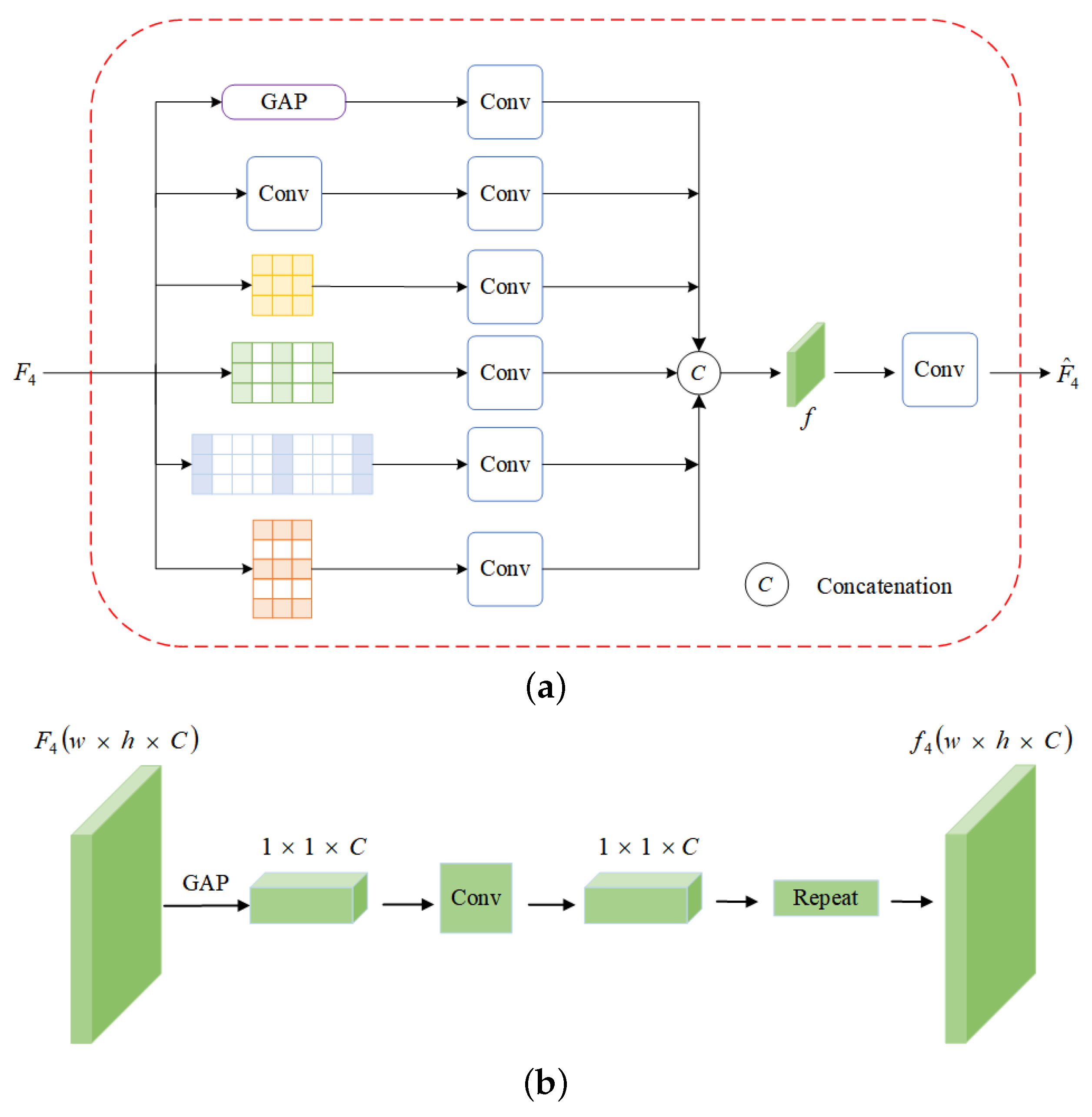
3.2. Adaptively Attention Dilated Convolution
3.3. Globle Scene Understandng
3.4. Training Loss
4. Experiments
4.1. Experimental Settings
- Mean relative error (MRE):
- Mean absolute error (MAE):
- Root mean square error (RMSE):
- Root mean squared log error (RMSE log):
- Accuracy with threshold t:
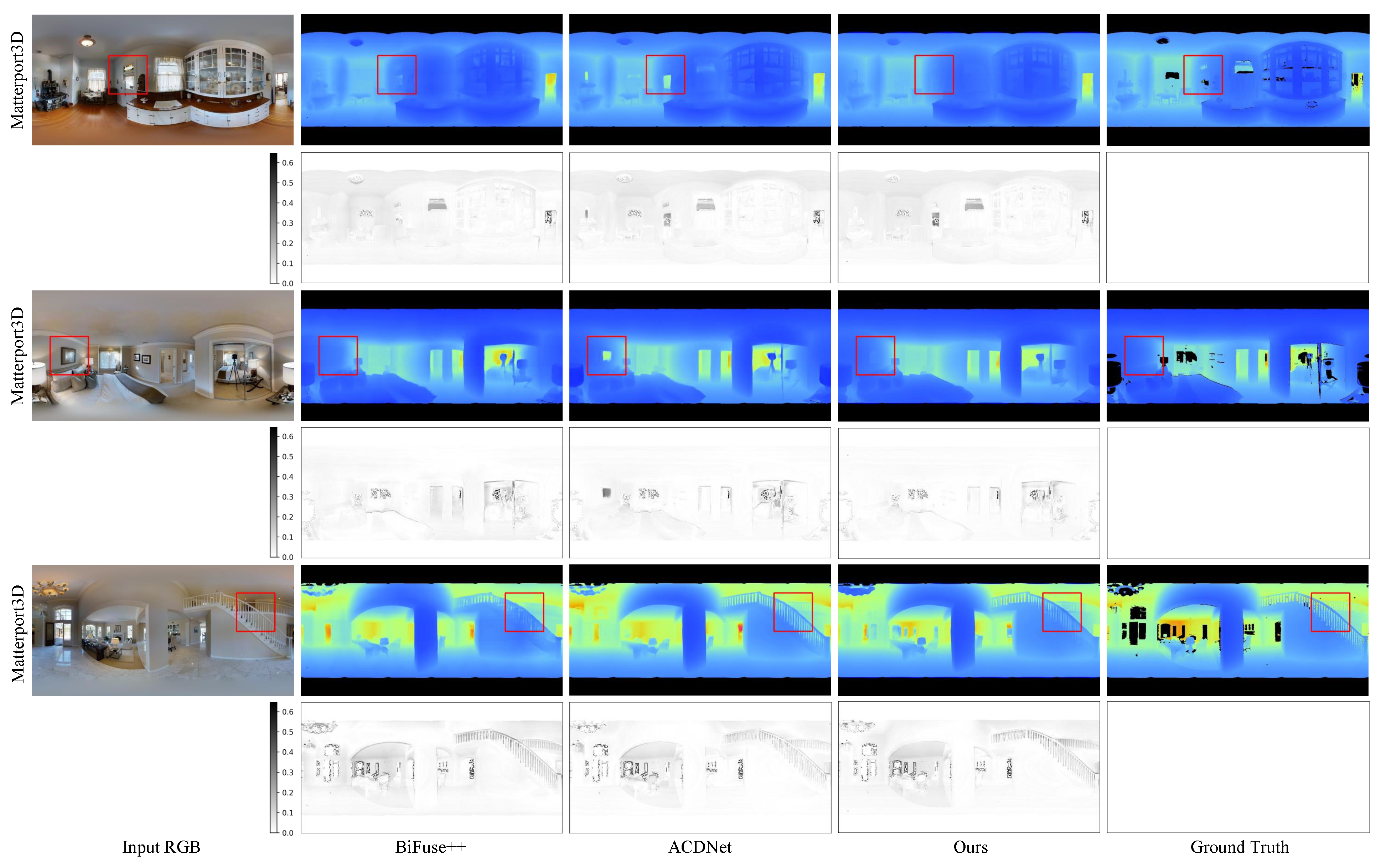
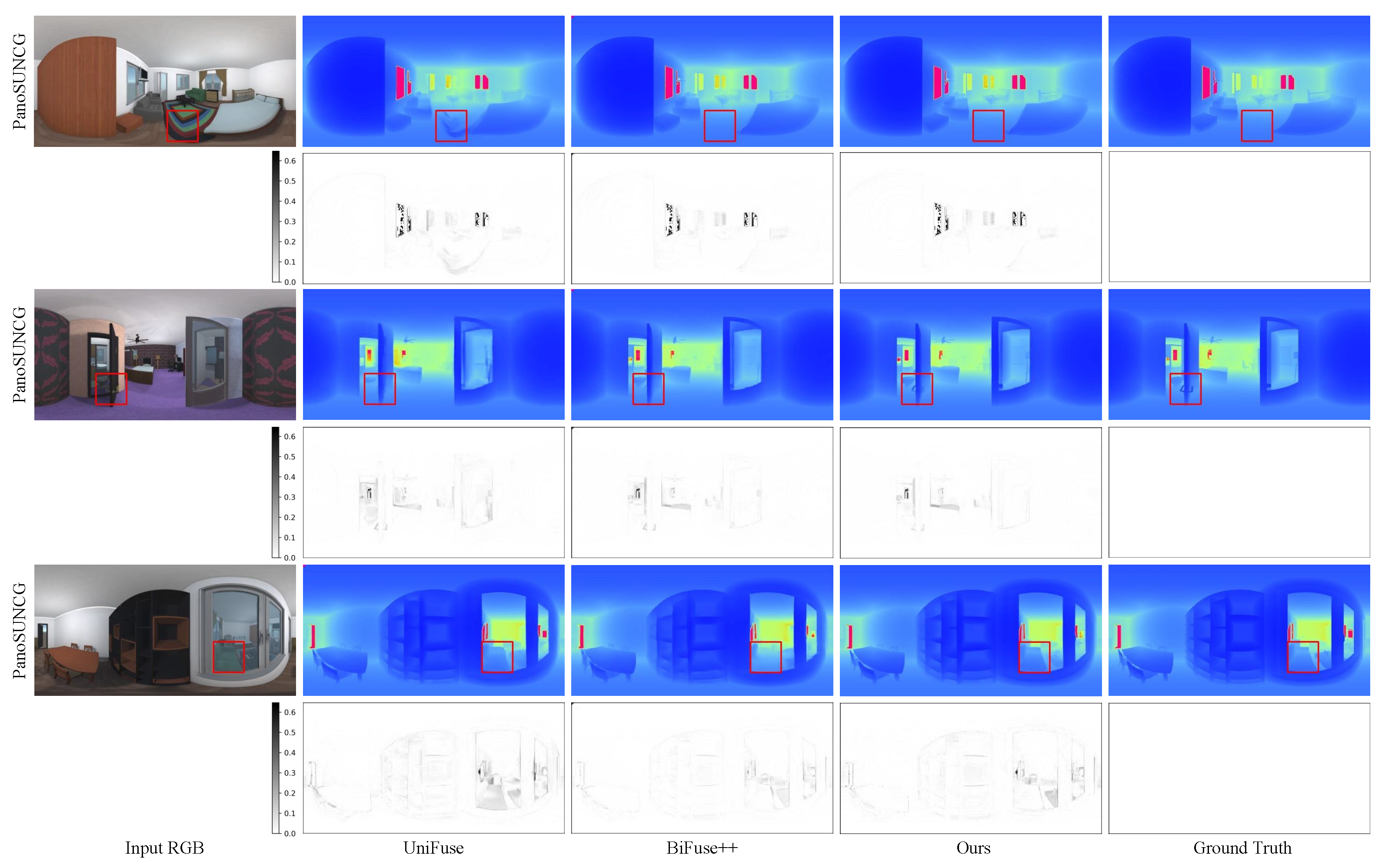
4.2. Comparison Results
4.3. Ablation Study
4.4. Complexity Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Da Silveira, T.L.; Pinto, P.G.; Murrugarra-Llerena, J.; Jung, C.R. 3d scene geometry estimation from 360 imagery: A survey. ACM Comput. Surv. 2022, 55, 1–39. [Google Scholar] [CrossRef]
- Ai, H.; Cao, Z.; Zhu, J.; Bai, H.; Chen, Y.; Wang, L. Deep Learning for Omnidirectional Vision: A Survey and New Perspectives. arXiv 2022, arXiv:2205.10468. [Google Scholar]
- Zioulis, N.; Karakottas, A.; Zarpalas, D.; Daras, P. Omnidepth: Dense depth estimation for indoors spherical panoramas. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 448–465. [Google Scholar]
- Tateno, K.; Navab, N.; Tombari, F. Distortion-aware convolutional filters for dense prediction in panoramic images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 707–722. [Google Scholar]
- Chen, H.X.; Li, K.; Fu, Z.; Liu, M.; Chen, Z.; Guo, Y. Distortion-aware monocular depth estimation for omnidirectional images. IEEE Signal Process. Lett. 2021, 28, 334–338. [Google Scholar] [CrossRef]
- Li, M.; Meng, M.; Zhou, Z. RepF-Net: Distortion-aware Re-projection Fusion Network for Object Detection in Panorama Image. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 74–89. [Google Scholar]
- Wang, F.E.; Yeh, Y.H.; Sun, M.; Chiu, W.C.; Tsai, Y.H. Bifuse: Monocular 360 depth estimation via bi-projection fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 462–471. [Google Scholar]
- Jiang, H.; Sheng, Z.; Zhu, S.; Dong, Z.; Huang, R. Unifuse: Unidirectional fusion for 360 panorama depth estimation. IEEE Robot. Autom. Lett. 2021, 6, 1519–1526. [Google Scholar] [CrossRef]
- Wang, F.E.; Yeh, Y.H.; Tsai, Y.H.; Chiu, W.C.; Sun, M. BiFuse++: Self-Supervised and Efficient Bi-Projection Fusion for 360° Depth Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5448–5460. [Google Scholar] [CrossRef]
- Bai, J.; Lai, S.; Qin, H.; Guo, J.; Guo, Y. GLPanoDepth: Global-to-local panoramic depth estimation. arXiv 2022, arXiv:2202.02796. [Google Scholar]
- Pintore, G.; Agus, M.; Almansa, E.; Schneider, J.; Gobbetti, E. Slicenet: Deep dense depth estimation from a single indoor panorama using a slice-based representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11536–11545. [Google Scholar]
- Chen, Y.; Zhao, H.; Hu, Z.; Peng, J. Attention-based context aggregation network for monocular depth estimation. Int. J. Mach. Learn. Cybern. 2021, 12, 1583–1596. [Google Scholar] [CrossRef]
- Xu, X.; Chen, Z.; Yin, F. Monocular depth estimation with multi-scale feature fusion. IEEE Signal Process. Lett. 2021, 28, 678–682. [Google Scholar] [CrossRef]
- Jiao, J.; Cao, Y.; Song, Y.; Lau, R. Look deeper into depth: Monocular depth estimation with semantic booster and attention-driven loss. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 53–69. [Google Scholar]
- Johnston, A.; Carneiro, G. Self-supervised monocular trained depth estimation using self-attention and discrete disparity volume. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4756–4765. [Google Scholar]
- Zhuang, C.; Lu, Z.; Wang, Y.; Xiao, J.; Wang, Y. ACDNet: Adaptively combined dilated convolution for monocular panorama depth estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2022; Volume 36, pp. 3653–3661. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, C.; Sun, Q.; Zhang, C.; Tang, Y.; Qian, F. Monocular depth estimation based on deep learning: An overview. Sci. China Technol. Sci. 2020, 63, 1612–1627. [Google Scholar] [CrossRef]
- Cheng, X.; Wang, P.; Zhou, Y.; Guan, C.; Yang, R. Omnidirectional depth extension networks. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 589–595. [Google Scholar]
- Shen, Z.; Lin, C.; Liao, K.; Nie, L.; Zheng, Z.; Zhao, Y. PanoFormer: Panorama Transformer for Indoor 360—Depth Estimation. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 195–211. [Google Scholar]
- Xu, C.; Yang, H.; Han, C.; Zhang, C. PCformer: A parallel convolutional transformer network for 360° depth estimation. IET Comput. Vis. 2023, 17, 156–169. [Google Scholar] [CrossRef]
- Zioulis, N.; Karakottas, A.; Zarpalas, D.; Alvarez, F.; Daras, P. Spherical view synthesis for self-supervised 360 depth estimation. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Quebec City, QC, Canada, 16–19 September 2019; pp. 690–699. [Google Scholar]
- Zeng, W.; Karaoglu, S.; Gevers, T. Joint 3d layout and depth prediction from a single indoor panorama image. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 666–682. [Google Scholar]
- Jin, L.; Xu, Y.; Zheng, J.; Zhang, J.; Tang, R.; Xu, S.; Yu, J.; Gao, S. Geometric structure based and regularized depth estimation from 360 indoor imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 889–898. [Google Scholar]
- Zhou, K.; Wang, K.; Yang, K. PADENet: An efficient and robust panoramic monocular depth estimation network for outdoor scenes. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Tian, Y.; Zhang, Q.; Ren, Z.; Wu, F.; Hao, P.; Hu, J. Multi-scale dilated convolution network based depth estimation in intelligent transportation systems. IEEE Access 2019, 7, 185179–185188. [Google Scholar] [CrossRef]
- Dong, X.; Garratt, M.A.; Anavatti, S.G.; Abbass, H.A. Mobilexnet: An efficient convolutional neural network for monocular depth estimation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20134–20147. [Google Scholar] [CrossRef]
- Sagar, A. Monocular depth estimation using multi scale neural network and feature fusion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 656–662. [Google Scholar]
- Gur, S.; Wolf, L. Single image depth estimation trained via depth from defocus cues. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7683–7692. [Google Scholar]
- Wang, N.H.; Solarte, B.; Tsai, Y.H.; Chiu, W.C.; Sun, M. 360sd-net: 360 stereo depth estimation with learnable cost volume. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 582–588. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Yang, Y.; Zhu, Y.; Gao, Z.; Zhai, G. Salgfcn: Graph based fully convolutional network for panoramic saliency prediction. In Proceedings of the 2021 International Conference on Visual Communications and Image Processing (VCIP), Munich, Germany, 5–8 December 2021; pp. 1–5. [Google Scholar]
- Dai, F.; Zhang, Y.; Ma, Y.; Li, H.; Zhao, Q. Dilated convolutional neural networks for panoramic image saliency prediction. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2558–2562. [Google Scholar]
- Liu, Q.; Kampffmeyer, M.; Jenssen, R.; Salberg, A.B. Dense dilated convolutions’ merging network for land cover classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6309–6320. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, J.; Huang, K.; Liang, K.; Yu, Y. Fastfcn: Rethinking dilated convolution in the backbone for semantic segmentation. arXiv 2019, arXiv:1903.11816. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 173–190. [Google Scholar]
- Ashish, V. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, p. I. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhao, Y.; Kong, S.; Shin, D.; Fowlkes, C. Domain decluttering: Simplifying images to mitigate synthetic-real domain shift and improve depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3330–3340. [Google Scholar]
- Xu, D.; Wang, W.; Tang, H.; Liu, H.; Sebe, N.; Ricci, E. Structured attention guided convolutional neural fields for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3917–3925. [Google Scholar]
- Zhang, M.; Ye, X.; Fan, X.; Zhong, W. Unsupervised depth estimation from monocular videos with hybrid geometric-refined loss and contextual attention. Neurocomputing 2020, 379, 250–261. [Google Scholar] [CrossRef]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2014; Volume 27. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Chang, A.; Dai, A.; Funkhouser, T.; Halber, M.; Niessner, M.; Savva, M.; Song, S.; Zeng, A.; Zhang, Y. Matterport3d: Learning from rgb-d data in indoor environments. arXiv 2017, arXiv:1709.06158. [Google Scholar]
- Armeni, I.; Sax, S.; Zamir, A.R.; Savarese, S. Joint 2d-3d-semantic data for indoor scene understanding. arXiv 2017, arXiv:1702.01105. [Google Scholar]
- Wang, F.E.; Hu, H.N.; Cheng, H.T.; Lin, J.T.; Yang, S.T.; Shih, M.L.; Chu, H.K.; Sun, M. Self-Supervised Learning of Depth and Camera Motion from 360∘ Videos. arXiv 2018, arXiv:1811.05304. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Methods | Error Metric ↓ | Accuracy Metric ↑ | |||||
|---|---|---|---|---|---|---|---|---|
| MRE | MAE | RMSE | RMSE log | |||||
| Matterport3D | BiFuse [7] | 0.2048 | 0.3470 | 0.6259 | 0.1134 | 0.8452 | 0.9319 | 0.9632 |
| UniFuse [8] | - | 0.2814 | 0.4941 | 0.0701 | 0.8897 | 0.9623 | 0.9831 | |
| BiFuse++ [9] | 0.1424 | 0.2842 | 0.5190 | 0.0862 | 0.8790 | 0.9517 | 0.9772 | |
| ACDNet [16] | - | 0.2670 | 0.4629 | 0.0646 | 0.9000 | 0.9678 | 0.9876 | |
| Ours | 0.0958 | 0.2610 | 0.4661 | 0.0649 | 0.9068 | 0.9652 | 0.9856 | |
| Stanford2D3D | BiFuse [7] | 0.1209 | 0.2343 | 0.4142 | 0.0787 | 0.8660 | 0.9580 | 0.9860 |
| UniFuse [8] | - | 0.2082 | 0.3691 | 0.0721 | 0.8711 | 0.9664 | 0.9882 | |
| BiFuse++ [9] | 0.1117 | 0.2173 | 0.3720 | 0.0727 | 0.8783 | 0.9649 | 0.9884 | |
| ACDNet [16] | - | 0.1870 | 0.3410 | 0.0664 | 0.8872 | 0.9704 | 0.9895 | |
| Ours | 0.1094 | 0.1815 | 0.3420 | 0.0673 | 0.8890 | 0.9614 | 0.9866 | |
| PanoSUNCG | BiFuse [7] | 0.0592 | 0.0789 | 0.2596 | 0.0443 | 0.9590 | 0.9823 | 0.9907 |
| UniFuse [8] | - | 0.0765 | 0.2802 | 0.0416 | 0.9655 | 0.9846 | 0.9912 | |
| BiFuse++ [9] | 0.0524 | 0.0688 | 0.2477 | 0.0414 | 0.9630 | 0.9835 | 0.9911 | |
| Ours | 0.0343 | 0.0484 | 0.1871 | 0.0318 | 0.9761 | 0.9892 | 0.9941 | |
| Modules | Error Metric ↓ | Accuracy Metric ↑ | |||||
|---|---|---|---|---|---|---|---|
| MRE | MAE | RMSE | RMSE log | ||||
| Baseline | 0.1151 | 0.2996 | 0.5039 | 0.0750 | 0.8712 | 0.9565 | 0.9815 |
| Baseline + GSUM | 0.1018 | 0.2681 | 0.4731 | 0.0732 | 0.8978 | 0.9641 | 0.9843 |
| Baseline + GSUM + ACDCs | 0.0981 | 0.2658 | 0.4709 | 0.0664 | 0.9027 | 0.9647 | 0.9848 |
| Baseline + GSUM + AADCs | 0.0958 | 0.2310 | 0.4661 | 0.0649 | 0.9068 | 0.9652 | 0.9856 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Zhao, J.; Li, H.; Han, C.; Xu, C. E2LNet: An Efficient and Effective Lightweight Network for Panoramic Depth Estimation. Sensors 2023, 23, 9218. https://doi.org/10.3390/s23229218
Xu J, Zhao J, Li H, Han C, Xu C. E2LNet: An Efficient and Effective Lightweight Network for Panoramic Depth Estimation. Sensors. 2023; 23(22):9218. https://doi.org/10.3390/s23229218
Chicago/Turabian StyleXu, Jiayue, Jianping Zhao, Hua Li, Cheng Han, and Chao Xu. 2023. "E2LNet: An Efficient and Effective Lightweight Network for Panoramic Depth Estimation" Sensors 23, no. 22: 9218. https://doi.org/10.3390/s23229218
APA StyleXu, J., Zhao, J., Li, H., Han, C., & Xu, C. (2023). E2LNet: An Efficient and Effective Lightweight Network for Panoramic Depth Estimation. Sensors, 23(22), 9218. https://doi.org/10.3390/s23229218