1. Introduction
The blast furnace ironmaking process is currently the dominant process worldwide for providing raw materials for steelmaking. It is the main method of modern ironmaking, contributing to more than 95% of the world’s total iron production. In the blast furnace ironmaking industry, iron ore plays an extremely important role as the primary feed material. As high-grade natural iron ore reserves decrease, artificial iron ore is becoming more and more critical [
1]. Sintering is the primary way to produce high-quality artificial iron ore from low-grade iron ore, which has been widely used around the world. The production of high-quality sinter is crucial for assuring consistent, stable furnace productivity with a low consumption of reductants.
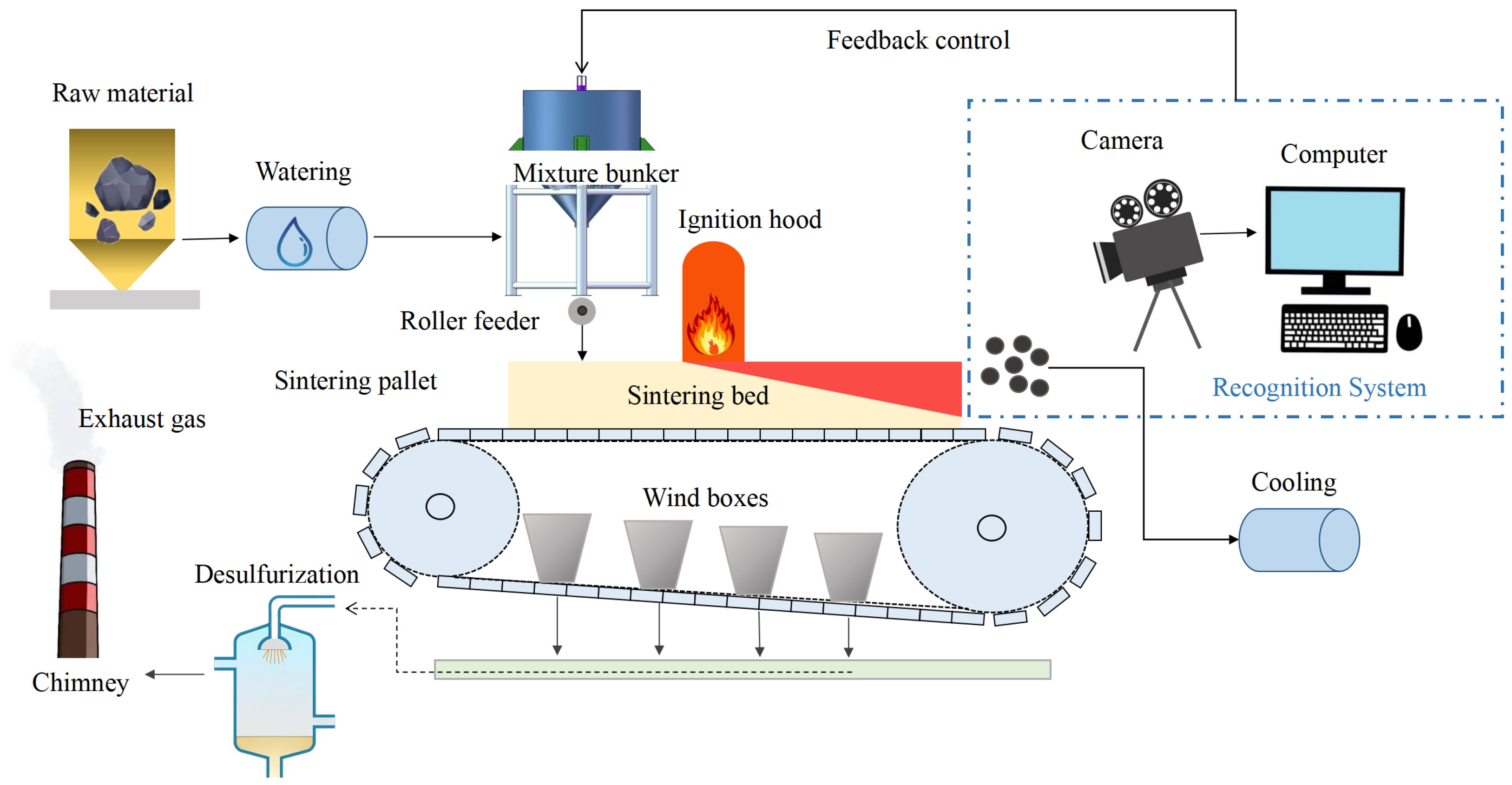
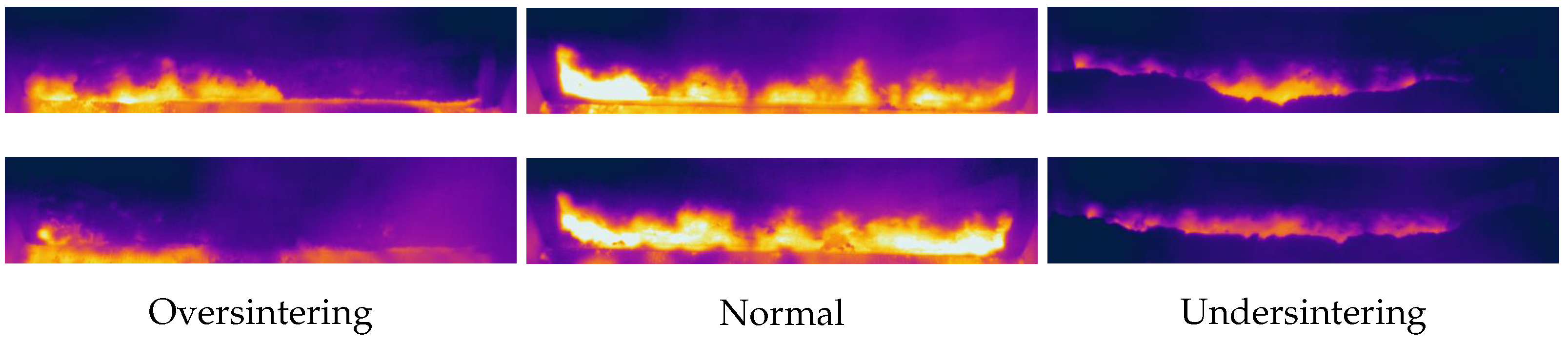
Estimation of the sintering state plays a vital role in improving the quality of sintering. The state of sintering depends on an important parameter known as burn-through point (BTP). It is a position located on the sinter strand, where the mixed materials thoroughly burn for the first time [
2]. By judging the BTP, the sintering states can be recognized. The accurate recognition of sintering state is the guarantee of high-quality and high-yield sinter production, which is of great significance in improving sintering productivity and preventing equipment damage. Nowadays, many sintering plants still rely on experienced operators to observe the sintering machine tail to recognize sintering states with their knowledge and experience. Obviously, this method has many drawbacks. Manual judgment is often affected by many factors such as working experience, working environment, physical stamina, and emotions, resulting in potential errors.
Different from the traditional methods relying on operator judgments, methods based on computer vision depend on the sintering machine tail sectional images to recognize sintering states. Over the years, there has been a remarkable and rapid evolution in vision-based object recognition and is applied in many fields. Significant contributions have been made in various studies such as reconstructing and recognizing human motion with 3D motion analysis [
3], supporting disabled individuals through computer-based gesture recognition [
4], and exploring novel applications like merging anime with face recognition technology [
5]. Similarly, computer vision-based recognition techniques are widely used in the iron ore sintering industry. A series of intelligent modeling methods based on computer vision are established for sintering state recognition. Sun T Q et al. proposed a online sintering quality prediction method based on machine vision and artificial neural network (ANN) [
6]. Liu et al. proposed a BTP prediction system based on gradient boosting decision tree (GBDT) algorithm and decision rules [
7]. A fuzzy neural network prediction model is presented by Wang et al. [
8], in which the strand velocity determines the final model. Li Jiangyun et al. used generative adversarial network (GAN) to expand the sample of sintering data set, and proposed a classification model combining attention mechanism and ResNet [
9].
However, many of the proposed methods for sintering state recognition still rely on conventional machine learning methods to extract features from images. In view of the digital image processing technology, a series of features that can comprehensively reflect the sintering state are extracted manually from the images of sinter cross section at the machine tail, such as the average brightness of the red fire layer. This method requires a considerable amount of engineering skills, domain expertise and effort. Deep learning can solve the drawbacks of manual feature extraction by automatically discovering the representations needed for recognition [
10,
11,
12]. However, deep neural networks usually yield a large number of extracted features, including features that are irrelevant, redundant or even noisy for sintering state estimation [
13]. These features can bring about high computational complexity and poor learning performance. In addition, it is difficult to determine the best model for recognition tasks without sufficient information, so the recognition accuracy can not be effectively guaranteed with a single model.
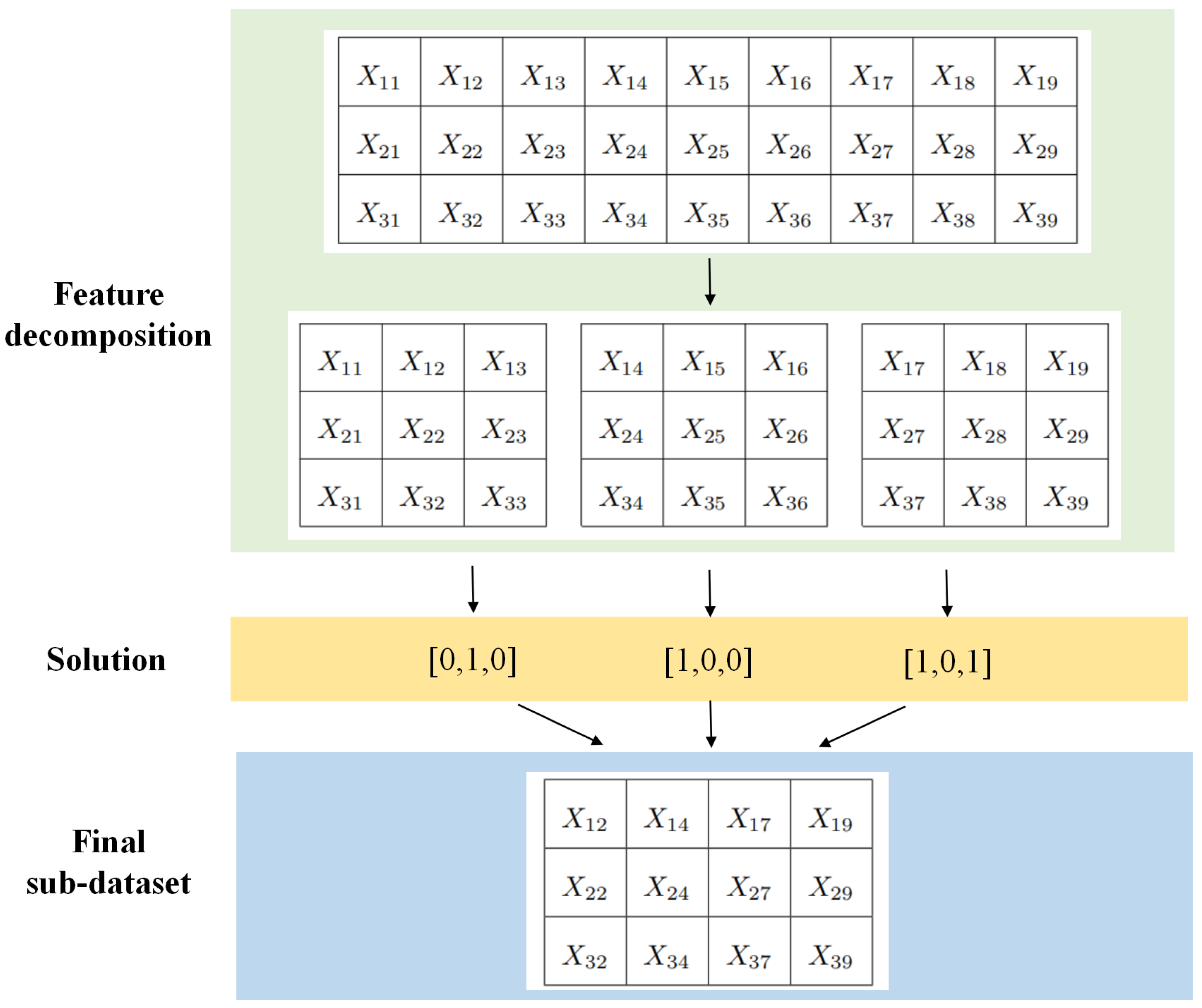
In order to deal with the above issues, a novel sintering state recognition method using deep learning based feature selection and ensemble learning is proposed in this paper. A deep neural network ResNeXt pre-trained on ImageNet is used to extract features from infrared thermal images of sinter cross section at the tail of the sintering machine. For the features extracted by deep learning, a feature selection method based on the binary state transition algorithm (BSTA) with a novel training strategy based on feature decomposition is proposed to select the optimal subset of features, which can greatly increase computational efficiency and build better generalization models. Finally, a new ensemble learning (EL) method is proposed to recognize sintering states based on the obtained optimal subset. Considering the limitations of an individual learner and shortcomings of the current EL schemes such as majority voting, the framework of group decision making (GDM) is introduced, which aims to find an optimal alternative considering various suggestions of decision-makers [
14]. The main contributions of the proposed method are as follows:
- •
A feature extractor based upon ImageNet-pretrained ResNeXt50 is used to automatically extract fixed features from images of sinter cross section at sintering machine tail.
- •
An efficient feature selection method using the binary state transition algorithm (BSTA) and feature decomposition strategy is proposed to eliminate features that are irrelevant, redundant or even noisy, which not only reduces the difficulty of training but also enhances recognition accuracy.
- •
An ensemble learning framework based on group decision making (GDM) is put forward to further improve recognition accuracy, where new combination strategies are introduced to efficiently fuse base learners.
The remainder of the paper is organized as follows. The industrial background is introduced in
Section 2.
Section 3 describes the proposed method in detail. In
Section 4, experiments are conducted to verify the effectiveness of the proposed method.
Section 5 concludes this paper.
4. Experiments and Results
In order to verify the effectiveness of the recognition method proposed above, we conducted industrial experiments on the infrared thermal images of sinter cross section collected at the tail of the sintering machine. The original data came from a sintering plant in Hunan, China. The experimental results demonstrate the effectiveness and feasibility of the proposed method.
The ImageNet-pretrained ResNeXt50 model is used as a fixed feature extractor to extract features from images captured at the sintering machine tail with PCA to further reduce the dimensionality of the data. The architecture of the ResNext-based feature extractor is shown in
Figure 4, where fixed feature representations are extracted. Next, a based feature selection method with feature decomposition strategy chooses the best features from those initially extracted by ResNeXt50.
Table 3 shows the detailed parameter settings of the feature selection algorithm based on BSTA.
represents the total number of iterations. Since the BSTA belongs to the individual-based algorithm,
represents the number of generated candidate solutions per iteration. (
,
p, and
q) are user-specified parameters to control the generation of the initial solution [
26]. The number of sub-datasets during feature decomposition and the total number of rounds for feature section are also presented.
Table 4 shows the specific information of the dataset we obtain through feature extraction and feature selection.
In this work, 5 common classification methods are employed as base learners of the EL method to judge the sintering quality based on the dataset described in
Table 4. The base learners are Support Vector Machine(SVM) [
35], Adaboost [
36], Logistic Regression(LR) [
37], k-Nearest Neighbor(KNN) [
38], Random Forest(RF) [
39]. On the basis of the optimal dataset after feature selection, these classical machine learning methods, serving as base learners for ensemble learning, can efficiently and rapidly yield satisfactory recognition results. In this paper, they are employed to ensure the diversity of base learners. Moreover, seven real-world datasets are used to compare the three base learner combination strategies in Equations (
16)–(
18). These public datasets are all available at the UCI Machine Learning Repository, namely: Letter Image Recognition Data, Blocks Classification, Dry Beans Dataset, Musk, ISOLET (Isolated Letter Speech Recognition), Pen-Based Recognition of Handwritten Digits, Waveform Database Generator. Details about these datasets can be found in
Table 5. Each dataset is split into three subsets: a training set, a validation set, and a testing set. The training set is used to generate base learners. The validation set is applied to generate the priori knowledge of base learners from which the weights of each base learner can be calculated by three combination strategies. Next, for each sample in the testing set, each decision maker assigns a score for every alternative, and 5 decision matrices can be obtained as Equation (
10). At last, GDM is used to fuse the information and determine the final label, and results are calculated as Equation (
19).
Based on the idea of decision-making, each dataset chooses the best combination strategy according to the classification result on the testing set. Finally, the best combination strategy to generate weights can be selected by voting. The results are listed in
Table 6, which presents the classification accuracy (%) for each combination strategy on each dataset. It can be seen from the results that
achieves the highest accuracy on more datasets than the other two strategies.
Based on the above results, in our experiment of sintering state recognition, we choose
as our combination strategy to assign weights to the base learners. The dataset obtained by feature extraction and feature selection from sintering images (described in
Table 4) is divided into training set, validation set and testing set. The weight of each decision maker is calculated based on the validation set with combination strategy
. The weights of base learners for ensemble learning are shown in
Table 7.
The final results are calculated as Equation (
19).
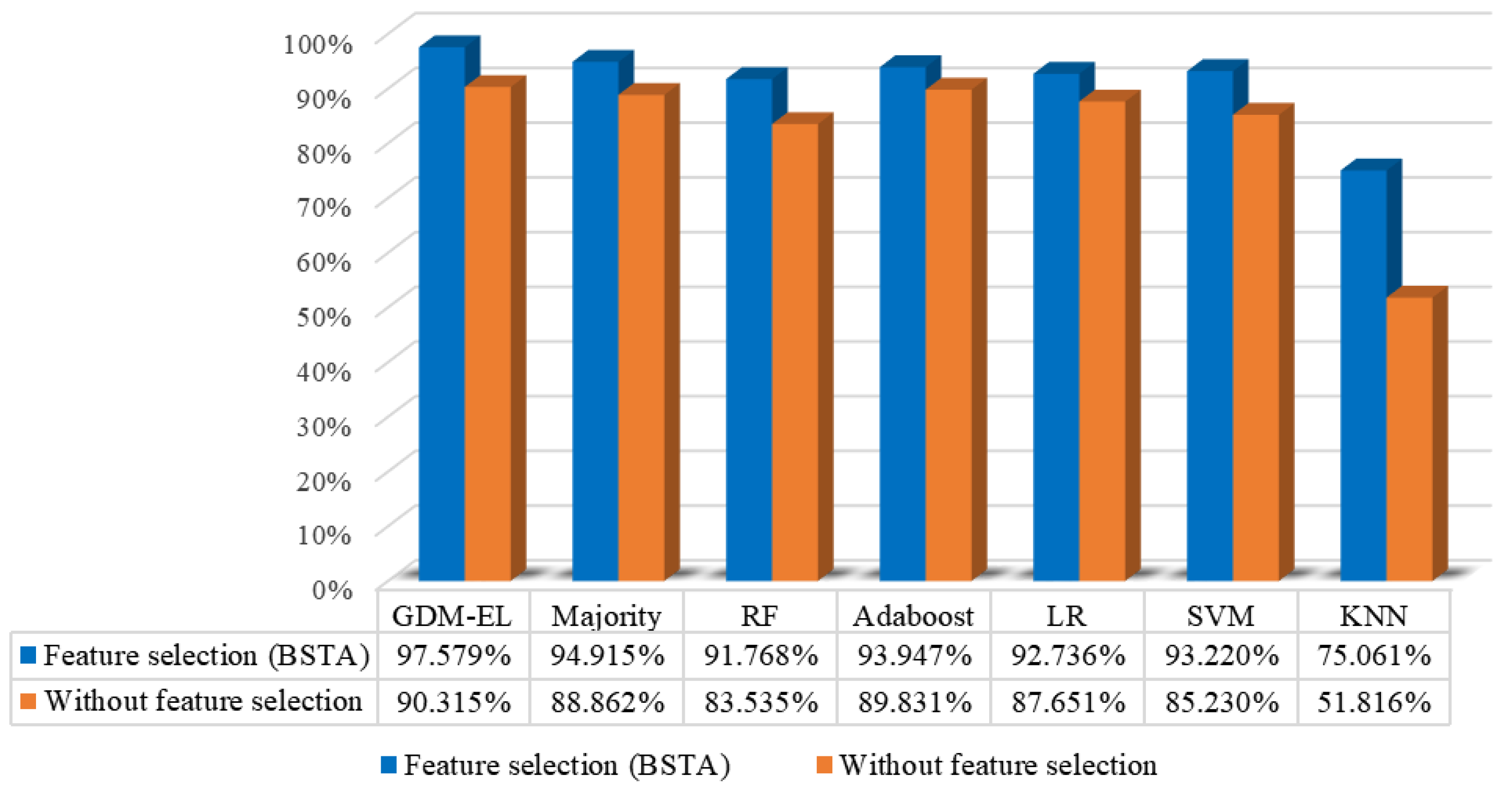
Figure 12 presents the recognition performance of the base learners, the EL method based on majority vote, and our proposed EL method based on GDM (GDM-EL). The effectiveness of the feature selection method based on BSTA is also evaluated in
Figure 12. It is evident in
Figure 12 that our proposed method demonstrates outstanding performance in sintering state recognition with a recognition accuracy of 97.579%. Specifically, GDM-EL exhibits superior recognition accuracy compared to both the majority vote and individual base learners. Additionally, our feature selection method based on BSTA proves to be effective in enhancing the recognition performance of both base learns, Majority vote, and GDM-EL. The accuracy of each method increases significantly after feature selection.
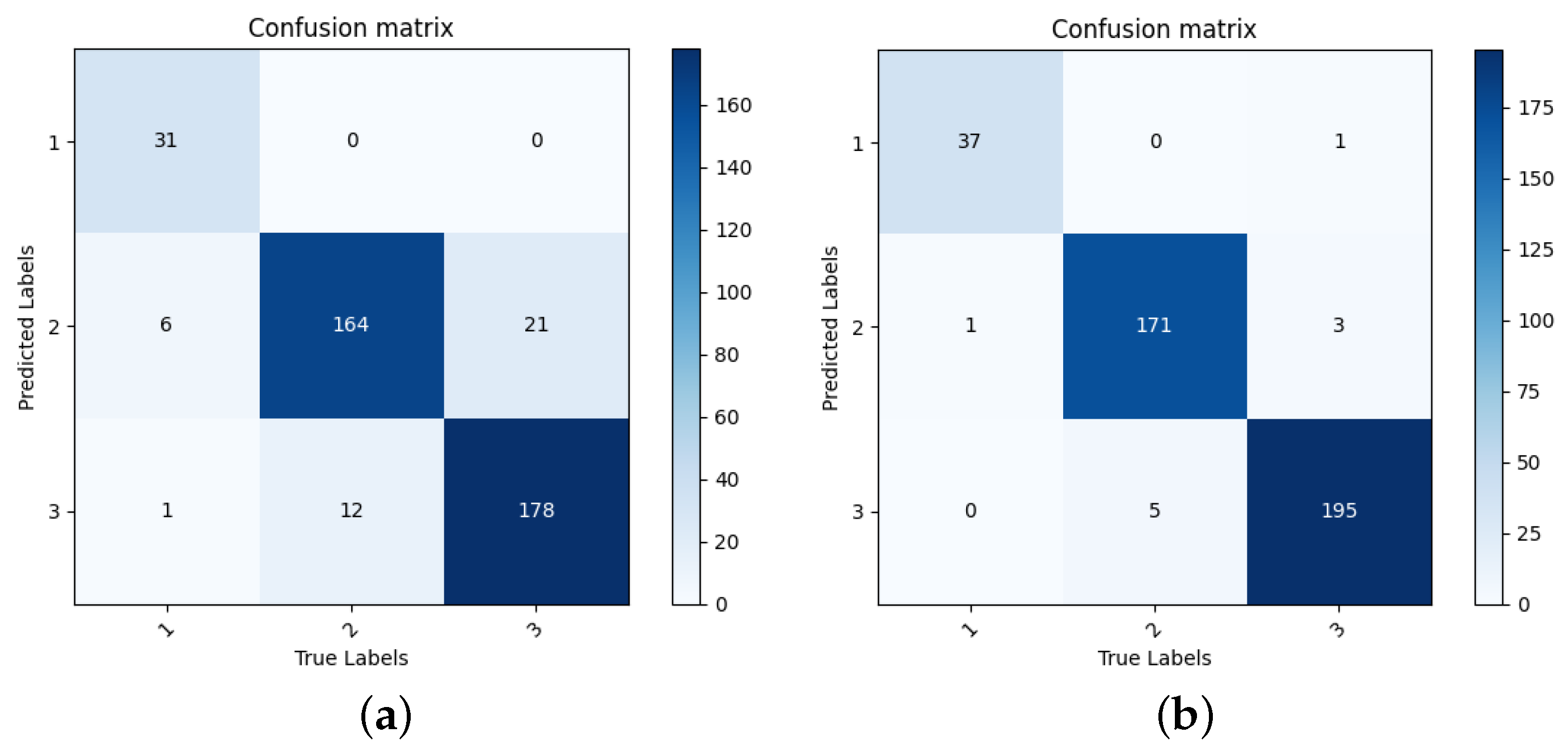
Figure 13a plots the confusion matrix of GDM-EL method without feature selection, and
Figure 13b plots the confusion matrix of GDM-EL method with feature selection. It can be found that for each category, the number of correctly recognized samples is increased after BSTA-based feature selection.
Figure 13b shows that the proposed method demonstrates excellent recognition performance for each category.
To further verify the superiority of the proposed method, we also conducted experiments with popular recognition methods based on deep learning. We examined the recognition performance in two settings: (1) training a VGG16 [
40], Inception-v3 [
41], ResNet50 and ResNeXt50 model from scratch with randomly initialized weights, (2) fine-tuning the ImageNet pre-trained ResNeXt50 model. These settings are commonly used in deep learning and transfer learning for training end-to-end models. In the first setting, we examined VGG16, Inception-v3, ResNet50 and ResNeXt50 trained from random initialization using the sinter cross section images and labels for 200 epochs, with a cosine decay learning rate schedule at a batch size of 64. In the second setting, we initialized ResNeXt50 from the ImageNet weights and fine-tuned using a similar training setup. The recognition results are presented in
Table 8, where the accuracy and F1-score are reported. As can be observed, our proposed method achieves the highest accuracy and F1-score. The outcome demonstrates the superior effectiveness of our method compared to popular deep learning models that rely solely on supervised training for sintering state recognition.
Based on the experimental results presented above, it is evident that the proposed method in this paper achieves accurate recognition of the sintering states. Utilizing a feature extractor built upon the ImageNet-pretrained ResNeXt50, relevant features from infrared thermal images are efficiently extracted. Significantly, the BSTA-based feature selection technique and the ensemble learning method based on GDM contribute to a remarkable advancement in enhancing the accuracy of sintering image recognition.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}