1. Introduction
Nowadays, environment perception plays an important role in automotive applications. One aspect of environment perception is to geometrically detect and track surrounding objects as precise as possible, to assist the driver to avoid potential collisions with other road obstacles. Such systems have been widely employed in Advanced Driver Assistance Systems (ADAS) applications such as Adaptive Cruise Control (ACC) [
1] and Automatic Emergency Braking (AEB) [
2]. Another aspect is to interpret the context of the driving environment as close to the reality as possible. Existing research has shown that knowing the context of driving environment can help to adapt the vehicle control and plan strategies in a more predictive manner. Example applications include intelligent vehicle power management [
3,
4,
5,
6], adaptive vehicle control [
7,
8,
9,
10,
11,
12], adaptive positioning [
13,
14,
15], adaptive parametrization of perception algorithm [
16,
17], and fleet management [
18]. In this paper, we focus on the inference of the following five driving environments around vehicle’s vicinity, i.e., a shopping zone, tourist zone, public station, motor service area, and security zone, which are mainly inspired by the use cases of the TransSec project [
19]. As the semantic clue to address each driving environment, we utilize the Point of Interest (POI) data from a navigation map.
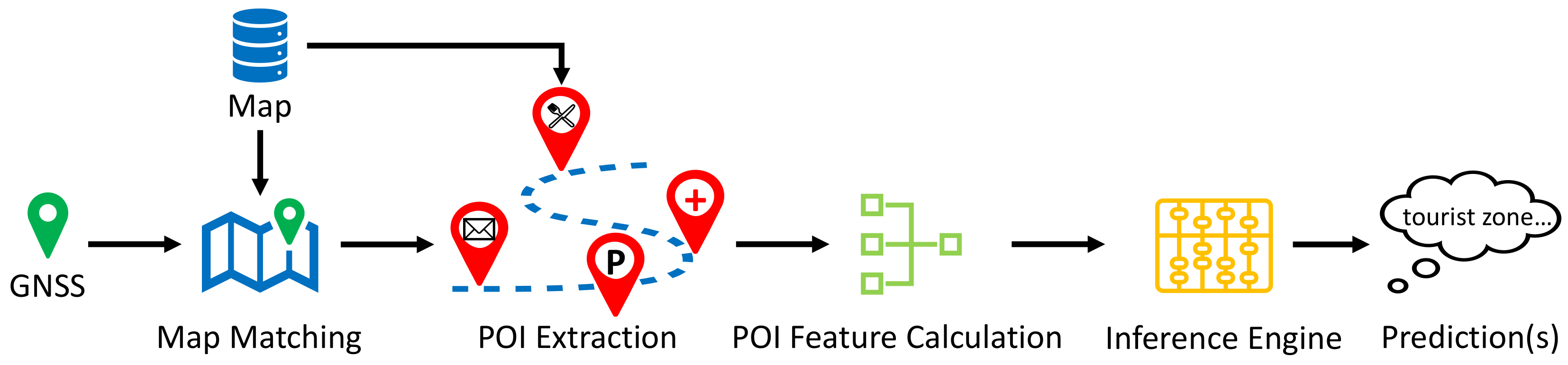
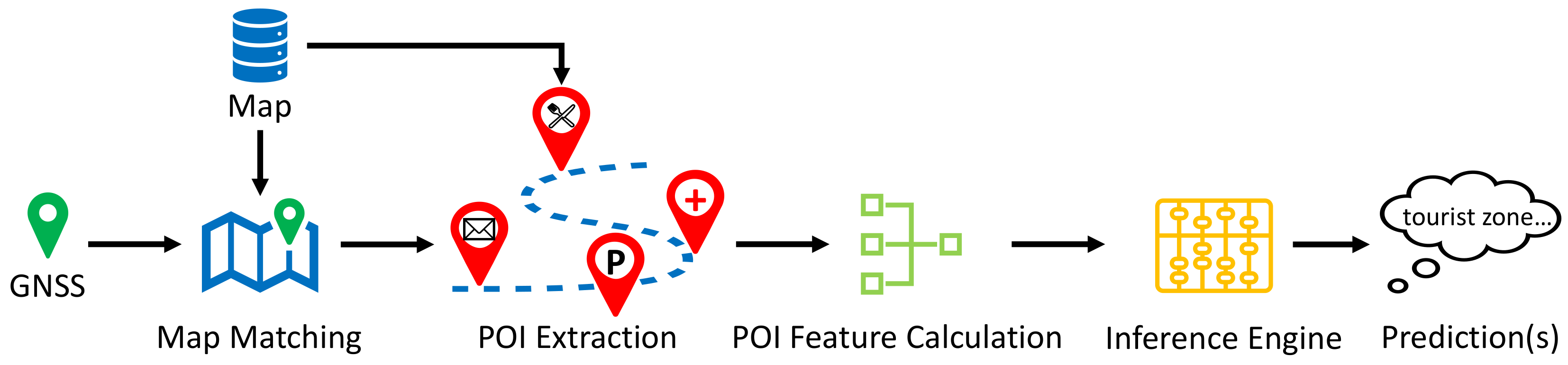
Figure 1 graphically illustrates this idea.
To solve the driving environment inference problem, a variety of approaches have been developed within recent decades. Depending on the utilized data source, existing research can be divided into the following groups: vehicle-probe-data-based approaches, map-based approaches and vision-based approaches. To reduce fuel consumption and emission, the authors in [
3,
4,
5,
20] predicted road types (e.g., urban, rural, and highway roads) from onboard kinematic data such as vehicle speed and acceleration. Similarly, with the help of data mining techniques such as decision tree, Naive Bayes, and artificial neural network (ANN), other kinematic data such as gear position and wheel suspensions from CAN (Controller Area Network) bus can also be utilized to classify driving environments according to [
8]. More recently, one noticeable method is proposed in [
21], where the objective is to estimate the driving behavior and crash risk from onboard vehicle data such as speed, travel distance, and hand-on-wheel event. To achieve that, a variety of multiclass classifiers are investigated, such as Support Vector Machine (SVM), Random Forest, AdaBoost, and Multilayer Perceptron (MLP). Additionally, recent research has demonstrated the possibility to recognize different urban driving environments (e.g., open area, urban canyon, and tree shade) using various GNSS signal characteristics [
13,
14,
15]. The basic idea behind these works is to utilize the statistical properties of historical GNSS signals as the feature, and then classify the driving environment using multiclass classifiers. Typically utilized classifiers include Support Vector Machine and other neural network approaches. Map-based applications are mostly focused on fuel economy; to achieve that, the road slope from map is utilized to identify the upcoming driving conditions [
6,
22,
23]. Moreover, the POI data from map are also utilized by car insurance companies to predict the probability of car accident risk of their customers according to [
24]. Vision-based approaches are applied in a wide range of applications, as they essentially take advantage of the advance in computer vision and pattern recognition over the recent years. Early vision-based approaches mainly utilize handcrafted image features for driving environment classification [
7,
9,
25], while recent research has tended to solve this classification problem in an end-to-end fashion by leveraging modern neural networks [
10,
11,
12,
18,
26]. As the common input to vision-based approaches, either the raw camera view or the so-called occupancy grid is utilized, where the occupancy grid can be calculated from LiDAR and/or radar measurement [
11,
12].
In general, the choice of data source depends on the environment types under investigation. For example, due to the legal speed limit differences between urban, suburban, and highway environments, vehicle-speed-related information provides delimiting hints to identify one driving environment from another [
3,
4,
5,
8,
20]. In [
6,
22,
23], the slope data from map are a key indicator for the upcoming road profiles such as uphill or downhill; therefore, it is considered as a proper choice. Camera view provides rich color and texture information about the environment, and hence, it is widely used in scene interpretations such as identifying urban versus rural roads, or minor versus major roads [
7,
9,
10,
11,
12,
26]. However, compared to existing research, the environment types in this work are unique in the following two senses. First, the five driving environments are semantically enriched by the functional properties of vehicle’s vicinity, i.e., each driving environment can be seen as a functional indicator of the nearby surroundings. Second, unlike the hard distinction between e.g., highway and urban environments, the existence of these five driving environments are not necessarily mutually exclusive, e.g., one road may belong to a shopping zone and a public station at the same time.
To solve the first problem, we use the POI data from a navigation map as the data source. Specifically, we use the concept "function" as the intermediate bridge between a POI object and a driving environment, and make the following assumptions: (1) one specific driving environment reflects a particular functional pattern of a location, which can be measured by the probabilistic existences of certain functions; (2) the occurrence of a specific POI object brings variable confidences to the existences of certain functions. With these assumptions, the intended inference can be seen as the process to numerically predict the existence of a specific driving environment from a given POI occurrence pattern. In fact, similar assumptions can also be found in References [
27,
28,
29], where the intention is to automatically cluster and discover areas with similar functional properties. Despite that, these works also use map POI data as the main input, their focuses are mainly on large-scale geographical areas. As a result, the online processing capability is usually not required in these works, which is in contrary to the near-range and real-time demands in automotive applications. Regarding the data processing, due to the challenge in directly processing discrete POI objects, one usually needs to transform them into other representative POI features. For example, the author in [
27] derived a POI feature vector to discover and annotate functional regions, where each term in this POI feature vector is calculated as the so-called POI frequency density measured by the number of a specific POI category over a unit area. A similar feature calculation method can also be found in [
28], where the co-occurrence patterns of different POI categories are utilized to discover functional regions. Inspired by these works, in this paper, we propose a statistical feature calculation approach, which utilizes statistically calibrated POI occurrence patterns to quantitatively measure the confidence brought by the occurrence of certain POI objects to the existence of a specific driving environment.
As for the second problem, we propose to solve it as a multilabel classification task. In existing works, driving environment inference is generally solved as a classification problem [
7,
8,
9,
14,
20,
25]. Specifically, since the environment types are usually mutually exclusive in existing works, multiclass classifiers are often utilized as the ad hoc solutions. In contrast, in multilabel classification a sample is allowed to have more than one label, which is suitable for predicting the environment types that are not necessarily mutually exclusive. To solve the multilabel classification problem, it is common to transform the classification of multiple labels into a series of single-label classification subtasks, so that each subtask can be tackled by off-the-shelf classifiers [
30]. Regarding the choice of classifier, it mainly depends on the structure of input data. For example, the Convolutional Neural Network (CNN)-based classifiers are frequently applied to handle image-like input [
10,
11,
12,
18,
26]. Low-dimensional data such as the time series of vehicle probe data and the discrete map data are usually processed via other machine learning classifiers such as Support Vector Machine and Multilayer Perceptron (MLP) [
3,
13,
14,
20]. In our case, the classifier input is the calculated POI features, which is essentially a numeric vector with fixed dimension and size; thus, we consider the classic machine learning approaches as the classifier. Specifically, motivated by their success in classification tasks, we employ Support Vector Machine and Multilayer Perceptron as the classifier during implementation. Additionally, as another efficient tool that has been widely applied in spatial data analysis [
31,
32,
33,
34], the fuzzy inference system (FIS)-based classifier is also investigated in this work. It should be noted that, as the proposed inference framework is independent of the chosen classifier, one can in principle also employ other classifiers instead of these three.
In this paper, our objective is to develop an efficient inference framework that is capable of predicting the driving environments around vehicle’s vicinity. As the data source, we use solely the POI data from a navigation map. However, due to the difficulty in directly processing discrete POI objects, we propose a statistical approach to calculate representative POI features from raw POI objects. To accomplish the inference from POI features to a specific driving environment, we investigate the following three inference systems: fuzzy inference system, support vector machine, and multilayer perceptron. Particularly, we treat the driving environment inference task as a multilabel classification problem, and solve it through two inference strategies: the independent inference strategy and the unified inference strategy. To validate the proposed inference framework, we implement 11 inference engines and evaluate them on a manually collected dataset. In summary, with this work, we make the following contributions:
A modular inference framework for the driving environment inference task with complete data processing workflows.
A statistical feature calculation approach for the input transformation from discrete POI objects into semantically meaningful and numerically manageable POI features.
The detailed composition of inference engines from three inference systems following two inference strategies.
A comprehensive evaluation and comparison of 11 implemented inference engines on a manually collected dataset.
The remainder of this paper is organized as follows.
Section 2 details the proposed inference framework, with particular focus on the proposed POI feature calculation method and the composition of inference engines from three investigated inference systems.
Section 3 explains the implementation details and the experiment setups.
Section 4 provides a comprehensive evaluation and comparison of 11 implemented inference engines. Finally,
Section 5 concludes this paper and points out future directions.
2. Framework for Driving Environment Inference
2.1. Overview
By knowing the driving environment, the objective is to monitor and adapt the vehicle movement in a predictive manner. To achieve this goal, we conduct the inference based on a digital navigation map. Since our focus is on the vicinity of vehicle location, the problem can be translated to: given the vehicle GNSS position and a navigation map, how can we predict the driving environment(s) for the current vehicle location?
Figure 2 shows the overview of the proposed inference framework. This framework starts with map matching followed by the POI extraction process, where the purpose is to obtain the POI objects in vehicle’s vicinity. Then, based on the extracted POI objects, a POI feature calculation module is proposed to transform the discrete POI objects into numerical POI features that can be used for subsequent inference. Finally, an inference engine is built to predict the driving environment(s) at the given vehicle location. The remainder of this section is organized as follows.
Section 2.2 provides an overview of the utilized navigation map, including a brief introduction of map matching and POI extraction within this map.
Section 2.3 introduces a statistical approach for POI feature calculation. Finally,
Section 2.4 details the compositions of inference engine using three inference systems: fuzzy inference system, support vector machine, and multilayer perceptron.
2.2. Navigation Map and Point of Interest Object
As the name suggests, a navigation map is a digital map that is built for navigating purposes. In automotive industries, the most popular navigation map format is the so-called Navigation Data Standard (NDS), which is developed by NDS e.V. [
35,
36,
37]. NDS e.V. is a registered association and does not produce map data by itself; instead, it defines the map standard that is independent of navigation software. Digital maps complying with the NDS standard are called NDS map, which are usually produced by map suppliers such as HERE [
38] and TOMTOM [
39]. In addition to the basic geometry and topology of road network, a navigation map usually also contains other geo-referenced data. For example, a typical NDS map includes the following data blocks in its database: Routing block for road geometry and topology, POI block for geo-referenced places that can be selected as the navigation destination, and Name block for human references to certain locations and roads [
35,
40].
In navigation map, physical roads are typically represented by links and nodes, where a link stands for the road segment between two consecutive junctions and a node represents a road junction where two or more roads intersect [
41]. Based on this link-node graph, one can match the vehicle position onto the map. This is usually achieved via the so-called map matching technique, which is essentially a process to find the best road candidate in the map given a series of vehicle positions (measured via, e.g., GNSS). The typical criteria for map matching include geometric point-to-line distance, topological connectivity, and the traversability between two roads [
40,
42,
43].
Once the vehicle position is matched onto the map, the next step is to extract the nearby POI objects from the map database. Here, a practical question is the following: within which distance from the vehicle position should a POI object be considered as relevant for the inference? That is, if the distance is too large, the inference result may be diluted by the irrelevant POI objects that are far away. While a small distance may result in an insufficient number of extracted POI objects, i.e., too few POI objects to be representative. In either case, the inference result will not be able to reflect the actual driving environment in the vicinity. To solve this problem, one can either trim or extend the matched map link to a certain range according to the actual needs. For example, in our implementation, we set an upper length limit to trim single matched links that are too long, while we also selectively aggregate consecutive short links to form a long path if the matched link is too short. During this aggregation, we mainly utilize the most probable path (MPP) calculation logic to grow the ego path, where the commonly applied criteria include turn angle and the change of functional road class [
44].
Regarding the POI object in navigation map, it is usually stored as a single geolocation together with other supplementary attributes addressing its functional properties. For example, a restaurant is stored as a geolocation with the POI category “restaurant”, and possibly also with other information such as opening hours and contact details. Here, the POI category is important information to us, as it provides a semantic clue for predicting the functional property of the surroundings.
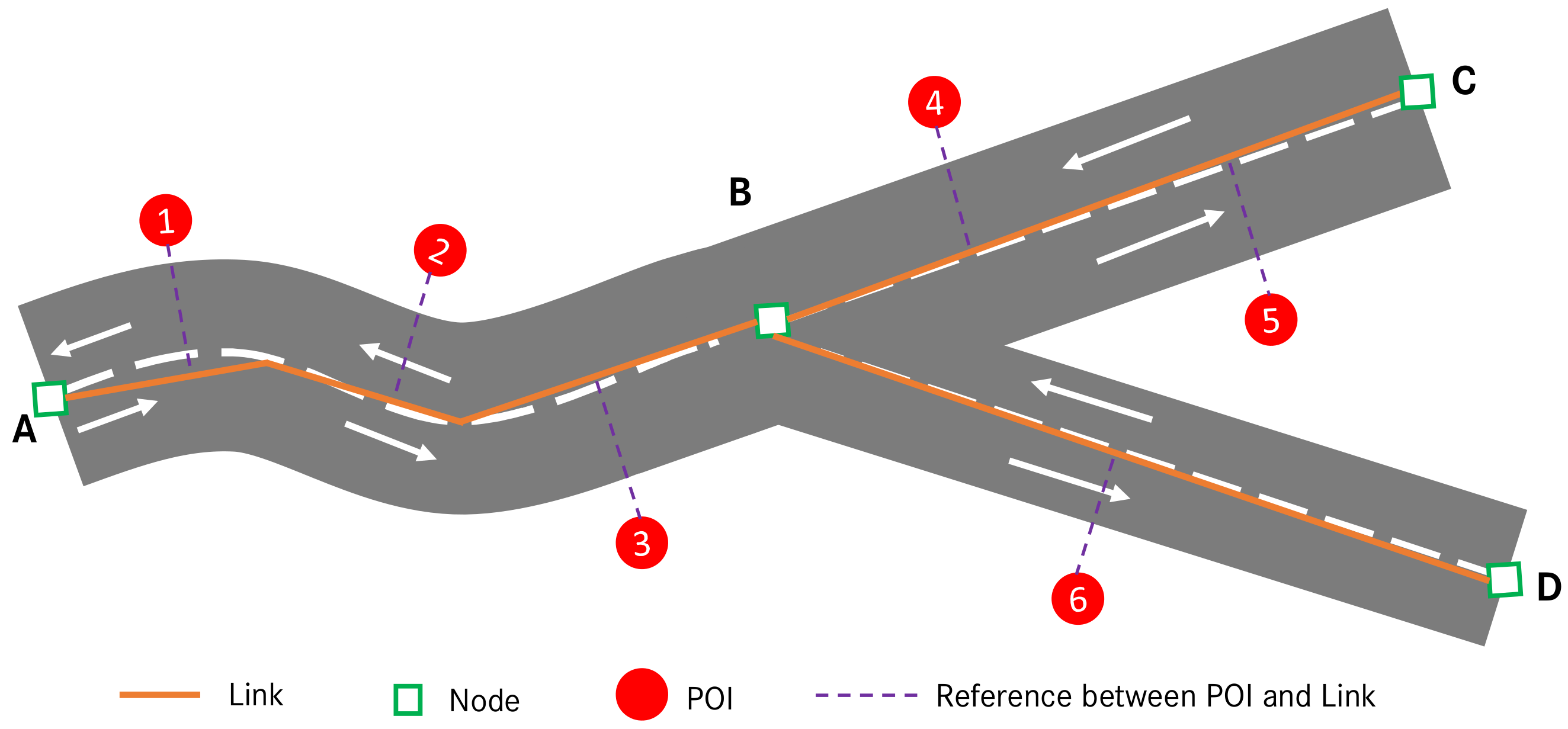
Figure 3 depicts an example relation between link, node, and POI in NDS map.
As for the extraction of POI objects from map, it usually depends on the database structure of the utilized map. In NDS map, each POI object is uniquely referred to a certain link from which it is accessible in reality, see
Figure 3. This is another important type of information in our application, as it allows to precisely query and extract all inherent POI objects for a given road link in map. For example, assume the vehicle is current located on link
AB with the driving direction from
A to
B, and the MPP goes from link
AB to link
BC due to the smaller turn angle from
AB to
BC. Here, the vehicle’s vicinity is defined as the MPP that consists of link
AB and link
BC. Therefore, to extract all POI objects in the vicinity, we query from the map database all the POI objects that are accessible from link
AB and link
BC. As a result, we will obtain the following five POI objects
POI (1,2,3,4,5).
2.3. POI Feature Calculation: A Statistical Approach
In reality, the number of extracted POI objects may vary from one location to another. Besides, as we will see later in
Section 2.4, all the investigated inference systems require continuous floating numbers as the input. Thus, directly processing the raw POI object with discrete POI categories is difficult, and we need to find an alternative. A general solution is to conduct the so-called feature engineering, which essentially creates new input variables (known as features) from the raw input source [
45,
46,
47,
48]. In our case, we consider the following two requirements on the new input variables: (1) the dimension and size of the new input variables should be numerically deterministic and (2) they should be representative and semantically meaningful for the intended inference. In this section, we first introduce the conceptual definition of POI features proposed in this paper, then we derive the mathematical calculation of these POI features.
To make the subsequent explanation easier, we define the following notations. Assume we have a training set , where n is the number of training samples. Each training sample is a pair of input and target . is a vector of the extracted raw POI objects on sample , and as discussed before, its size may vary over different samples. is a binary vector of the ground truth labels: , where is the number of unique labels in the investigated problem, and is a constant label set which equals to {shopping zone, tourist zone, public station, motor service area, security zone} in our case. The term “label” is a terminology widely used in multilabel classification, and it is equivalent to “driving environment” in this paper. means the corresponding label on sample is true, otherwise false. It should be noted that, in our case, a training sample may contain more than one true labels, e.g., a road may belong to both tourist zone and public station at the same time in reality. With these notations, feature engineering can be seen as a process to find a transformation t so that , where the input is an unbounded POI vector, and the output is a deterministic POI feature vector: , with m being a constant value.
2.3.1. Conceptual Definition of POI Features
In principle, a representative and semantically meaningful POI feature should help to identify one specific characteristic of a driving environment during inference. To conceptually define such POI features, we start with analyzing the distribution of POI categories over a specific driving environment.
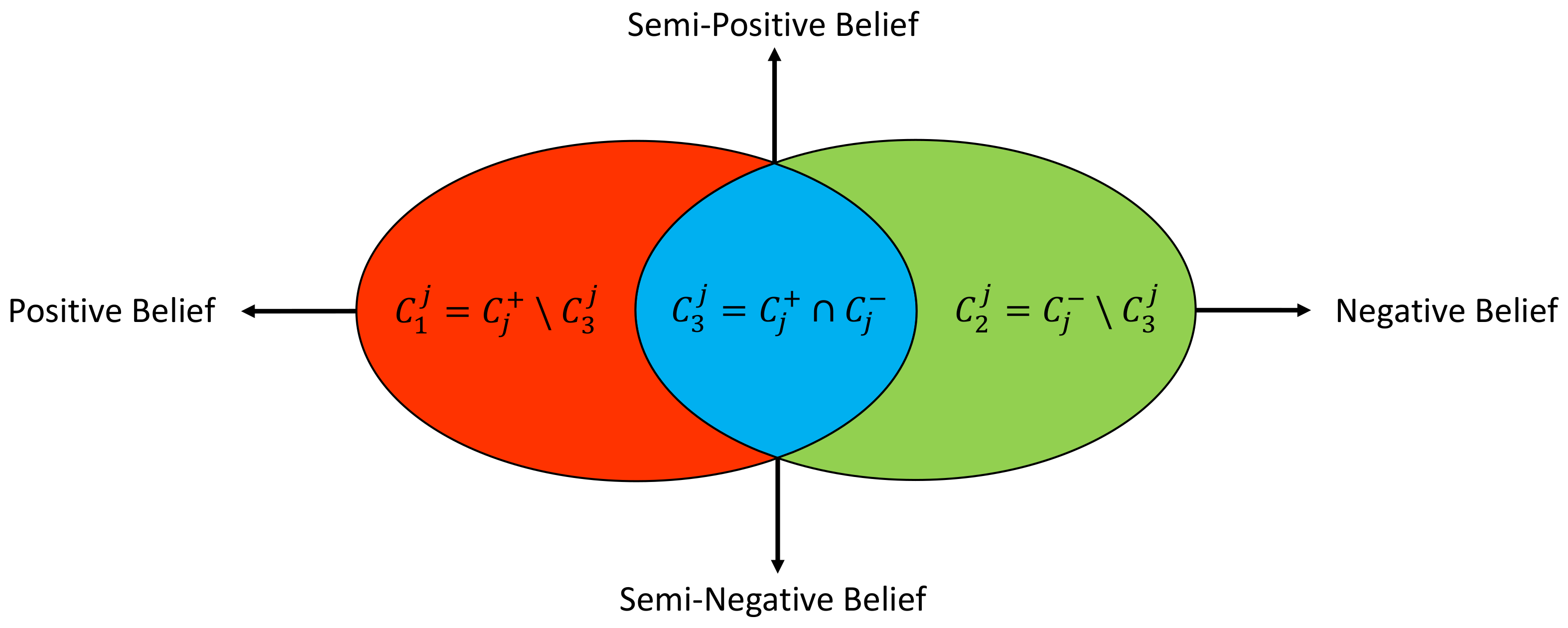
For a specific label , the aforementioned training set S can be divided into the following two groups: positive training set and negative training set , with and . In each of these two groups, we can enumerate the unique POI categories, and correspondingly, this will result in the following two sets: a set of positive POI categories and a set of negative POI categories . is a unique set of all available POI categories in the training set S. It should be noted that and are not necessarily mutually exclusive, i.e., . For example, let us say we have two distinct samples and , where is a “shopping zone only” sample (i.e., ) and is a “public station only” sample (i.e., ). can be seen as a negative sample of “public station”, and likewise, can be seen as a negative sample of “shopping zone”. Then, let us assume POI objects of the category “café shop” exist in both samples and , which is feasible since in reality one may find a café shop both in a shopping zone and in a public station. Hence, we see that the POI category "café shop" exists in both the positive and the negative samples of the label “shopping zone”, and analogously, it also exists in both the positive and the negative samples of the label “public station”.
Figure 4 graphically illustrates the distribution of POI categories over a specific driving environment
. Apparently, for a specific driving environment
, one POI category
can only fall into one of the following three sets:
Set 1: and , i.e., the POI object of category c exists only in the positive samples of label .
Set 2: and , i.e., the POI object of category c exists only in the negative samples of label .
Set 3: and , i.e., the POI object of category c exists in both the positive and the negative samples of label .
Figure 4.
Four POI features derived from the distribution of POI categories over a specific driving environment .
Figure 4.
Four POI features derived from the distribution of POI categories over a specific driving environment .
Apparently, if an existing POI object belongs to
or
, it can be utilized to uniquely identify a positive or negative
sample. While for a POI object of the group
, it can be used to identify both the positive and the negative samples of the same driving environment. In fact, even though one POI category may be intuitively linked to certain function, the interactions of different POI categories can reflect various functions [
27,
28]. Therefore, when a
POI object is utilized to identify a positive/negative
sample, the underlying POI context should be considered. Based on these observations, we can define the following four POI features
for label
:
POI Feature 1 (): positive belief from the POI objects that only exist in the positive samples of label . The higher this value, the more likely the corresponding driving environment exists.
POI Feature 2 (): negative belief from the POI objects that only exist in the negative samples of label . The higher this value, the less likely the corresponding driving environment exists.
POI Feature 3 (): semi-positive belief from the POI objects that exist in both the positive and the negative samples of label , which contributes to identifying positive samples jointly with the positive belief.
POI Feature 4 (): semi-negative belief from the POI objects that exist in both the positive and the negative samples of label , which contributes to identifying negative samples jointly with the negative belief.
The term belief can be seen as a degree of confidence, e.g., how confident it is to judge a sample of label as positive/negative given the numerical value of the corresponding feature. To cover k labels in the inference task, we will have POI features in total, as per the above definitions, i.e., the finally derived POI feature will be a vector of dimensions (i.e., ): . In our case, since we have 5 labels (i.e., ), we will end up with a 20 dimensional POI feature vector (i.e., ).
2.3.2. Mathematical Calculation of POI Features
Fundamentally, these four POI features are distinguished by their characteristic POI occurrence patterns. Once the characteristic POI occurrence pattern of a specific POI feature is known, the calculation of this POI feature can be seen as the numerical quantification of the similarity measure between a given POI occurrence pattern and a reference POI occurrence pattern. Now the question is, how can we mathematically define a POI occurrence pattern, and how should we model such similarity measure?
In our application, we have the following intuitions: (1) different POI categories can bring various degree of confidences when inferring the same driving environment, e.g., a shopping mall versus a grocery store when inferring the existence of shopping zone; (2) the number of occurrence of the same POI category can also change the degree of confidence during inference, e.g., ten grocery stores versus one grocery store when inferring a shopping zone. Based on these intuitions, we use POI occurrence probabilities to mathematically define a POI occurrence pattern, and a similar idea can also be found in [
28]. Specifically, assume
is the number of unique POI categories and
represents the occurrence probability of the POI category
, then the vector
uniquely defines a POI occurrence pattern. Since a POI occurrence pattern is now represented as a numerical vector, the similarity measure between two POI occurrence patterns can be addressed via the inner product of the corresponding vectors. Let
be the reference POI occurrence pattern of the POI feature
on label
, and let
be a given POI occurrence pattern, then the POI feature
can be numerically determined as:
For a given sample
, if we approximate its POI occurrence pattern
by the POI occurrence counts, i.e.,
, where
is a counting function which simply calculates the number of occurrence of the POI category
c in the sample
s, then Equation (
1) can be rewritten into:
From Equation (
2), we see that each POI feature is numerically determined by the following two variables: a POI category dependent weighting factor and the occurrence of a POI category in a sample. This coincides with the aforementioned two intuitions. Now the remaining question is: how should we determine these weighting factors? That is, how should we numerically determine the reference POI occurrence pattern for each POI feature? Theoretically, one can handcraft a reference POI occurrence pattern using the expert knowledge derived from widely acceptable data sources, such as dictionaries, encyclopedias, and the design and planning standards of a local government [
29]. Alternatively, one can also experimentally derive a reference POI occurrence pattern from a set of training samples [
49]. However, the first method may face the following challenges in our application:
Due to the large variety of POI categories existing in map (e.g., 89 in our case), it is a nontrivial task to manually quantify the contribution of each POI category to a specific driving environment.
Given the geographic diversity in terms of urban planning and construction, the reference POI occurrence pattern designed for one geographic region may not be directly applicable to another region.
Therefore, we employ the second method by proposing a statistical approach. Particularly, for each POI feature, we calculate its weighting factors based on the POI occurrence probabilities over a set of training samples. The detailed calculations are given as follows:
Weighting factors for feature 1 (
positive belief):
where
is the occurrence probability of one POI category
c in a sample
, which is calculated according to:
Weighting factors for feature 2 (
negative belief):
where
is the occurrence probability of one POI category
c in a sample
, which is calculated according to:
Weighting factors for feature 3 (
semi-positive belief):
where
is the occurrence probability of one POI category
c in a sample
, which is calculated according to:
Weighting factors for feature 4 (
semi-negative belief):
where
is the occurrence probability of one POI category
c in a sample
, which is calculated according to:
Essentially, the weighting factor of a specific POI category is statistically calculated as the averaged occurrence probability over the corresponding training samples. For each POI feature, we see that only the relevant POI categories have nonzero weighting factors, the weighting factors of all other irrelevant POI categories are set to zero. This implies that the occurrence of these irrelevant POI categories will have no influence on the numerical value of the corresponding POI feature.
2.4. Inference Engine
As the last step in the proposed inference framework, an inference engine is utilized to predict all potentially existing driving environment(s). Fundamentally, an inference engine can be seen as one realized solution to the multilabel classification problem. In this subsection, we first explain the motivation of solving the intended inference task as a multilabel classification problem, including two proposed inference strategies and the corresponding optimizations. Then, we detail the composition of inference engines based on three inference systems: fuzzy inference system, support vector machine, and multilayer perceptron.
2.4.1. Driving Environment Inference as a Multi-Label Classification Problem
From the discussion in
Section 2.3, we know that the intended inference task has the following characteristics: (1) each given sample may contain more than one ground truth labels and (2) the inference of each label can be seen as a binary classification problem, i.e., does a given sample belong to a specific label or not? These characteristics coincide with the properties of multilabel classification task, which is basically a form of supervised learning where the classification algorithm is required to learn from a set of instances, and each instance can belong to multiple classes; thus, it is able to predict a set of class labels for a new instance [
30].
Following the notations introduced in
Section 2.3, the inference task can be defined as: given a POI feature vector
, how can we develop an inference engine
which is conditioned on parameter set
, so that the predicted label vector
is “close” to the ground truth label vector
up to certain qualification measures (e.g., accuracy, precision). The process to find the optimal parameters for this inference engine is generally known as training, which is equivalent to optimizing the following objective equation:
where
is the inference engine under investigation,
is a single training sample in the given training dataset
S,
is the overall loss on the whole training dataset
S, and
is the optimal parameter set that minimizes the overall loss.
To solve the multilabel classification problem, one common practice is to transform the classification of multiple labels into a series of single-label classification subtasks [
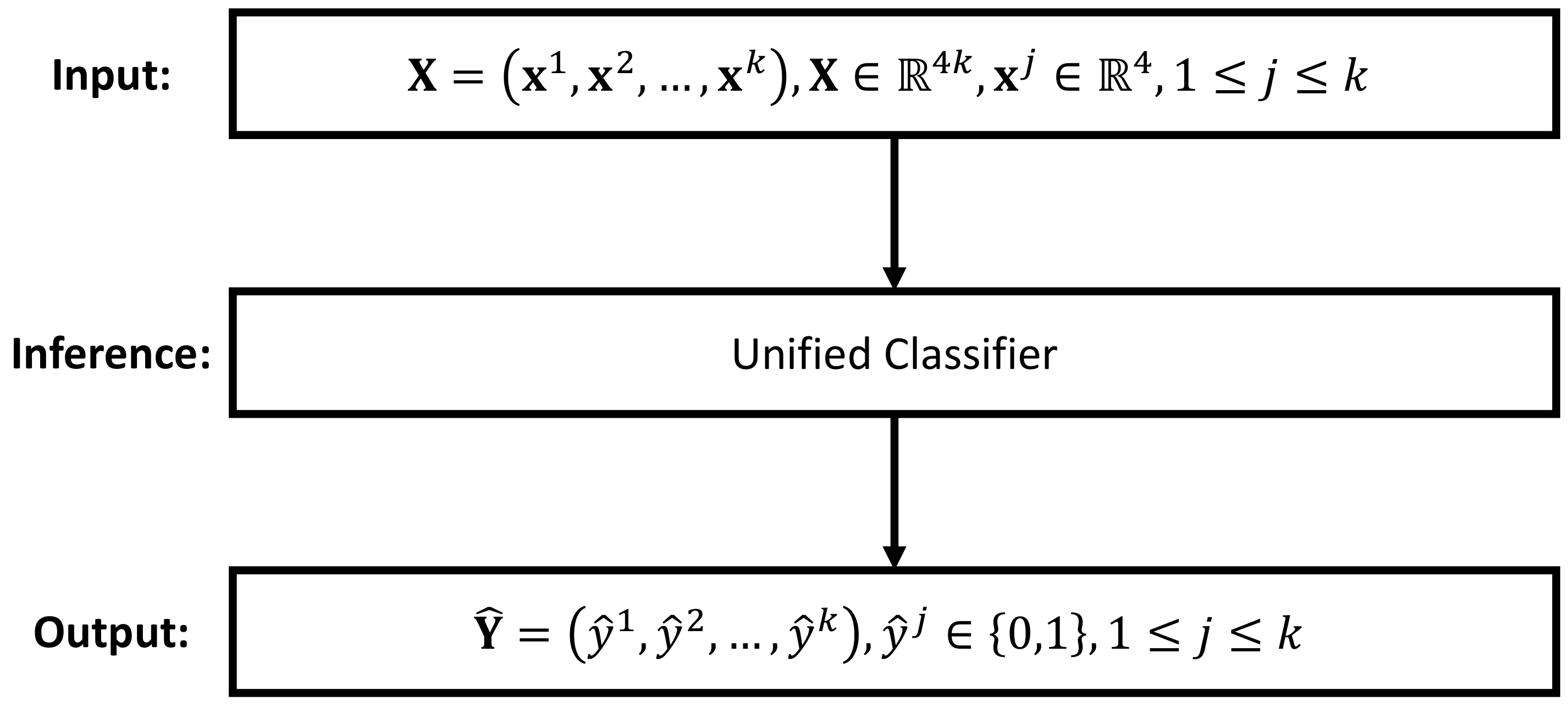
30]. Depending on the utilized transformation method, difference inference strategies can be formed. In this paper, we propose the following two inference strategies: the independent inference strategy and the unified inference strategy. As depicted in
Figure 5, the unified inference strategy aims at solving the inference task using a single classifier. This is achieved by training a
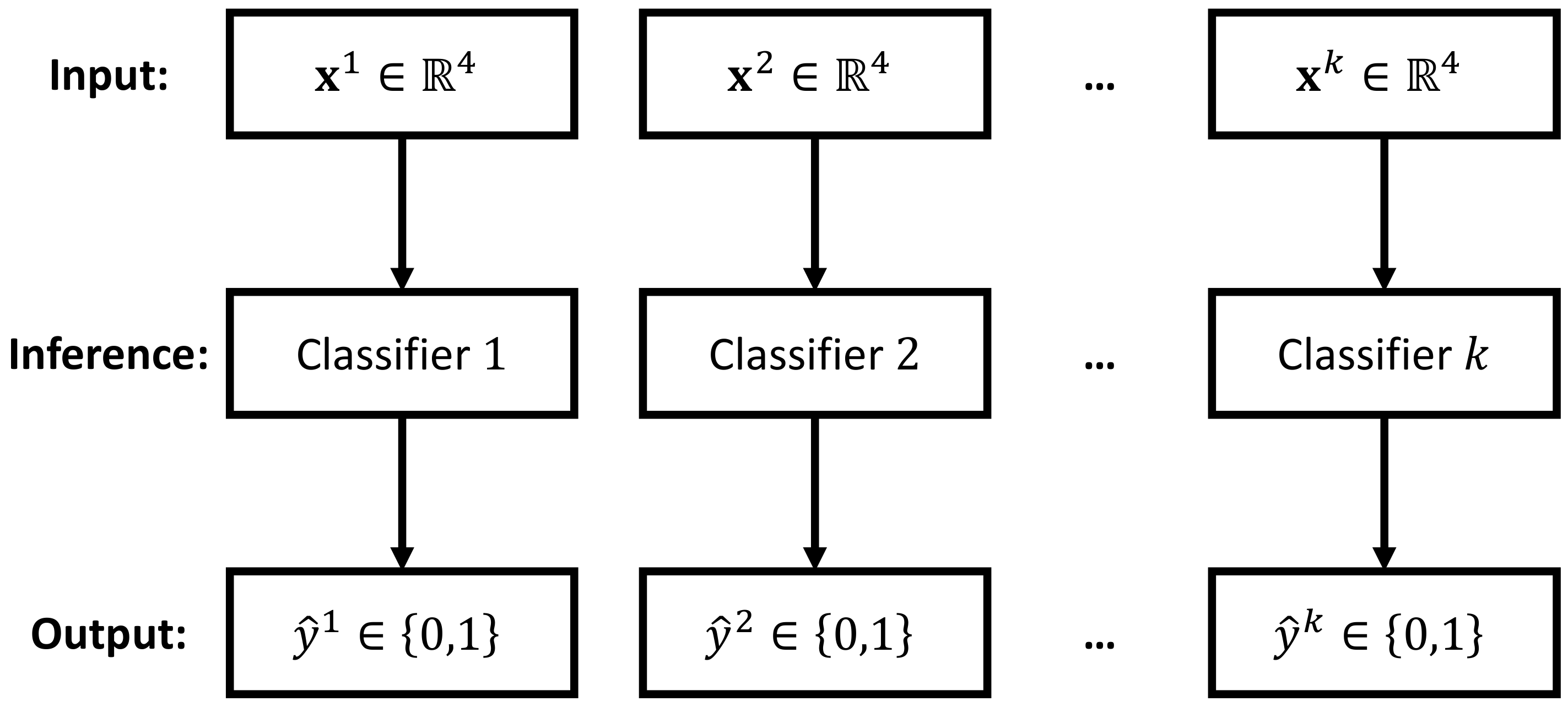
k-output classifier, where each output represents the prediction for a specific label. In contrast, the idea of the independent inference strategy is to treat the inference of each label independently, so that a
k-label multilabel classification problem can be solved by employing
k independent classifiers.
Figure 6 illustrates this idea. The advantage of the independent inference strategy is that any existing single label classifier can be directly applied for the inference task. However, in order to predict
k labels, we need to implement
k instances of such single classifier, which may theoretically increase the computational demand.
In the unified inference strategy, there is only one single classifier, and therefore, the optimization of the whole inference engine
is identical to optimizing this single classifier, i.e., Equation (
11). However, as for the independent inference strategy, there are
k independent classifiers, as depicted in
Figure 6. In this case, the optimization of an inference engine is equivalent to optimizing the following
k independent equations:
where
is the classifier specified for label
,
is the label-specific POI feature vector calculated according to Equation (
2),
is the ground truth label for
,
is a label-specific loss function which calculates the overall loss caused by the classifier
on the whole training dataset
S, and
is the optimal parameter set that minimizes this loss. In the independent inference strategy, a complete inference engine consists of
k classifiers, i.e.,
, which are conditioned on
k sets of parameters, i.e.,
.
Fundamentally, the realization of a classifier is achieved via certain inference system. As next steps, we introduce three inference systems with particular focus on their integration and formulation into an inference engine by following the proposed inference strategies.
2.4.2. Fuzzy-Inference-System-Based Inference Engine
Fuzzy inference system (FIS) is an inference system that is built upon fuzzy logic, and fuzzy logic is a logic system that aims at a formalization of approximate reasoning [
50,
51]. In contrast to the bivalent classical logic where only absolute true or false are permitted, fuzzy logic provides an efficient way of modeling partial truth or the degree of truth. This property makes it widely applicable in problems such as control, classification, and other decision-making applications [
34,
50,
52,
53,
54]. A typical fuzzy inference process involves mainly three steps: fuzzification, inference, and defuzzification. Depending on the actual implementation of these steps, different inference mechanisms exist, such as the Mamdani inference system [
55] and the Sugeno inference system [
56]. As a common choice both in practice and in the literature [
50,
53], we take the Mamdani inference system as our investigation target and explain its principle.
Instead of working with the so-called crisp variables directly, fuzzy logic takes fuzzy set as the basic processing unit. A fuzzy set is a set with vague boundary between its members, and therefore, it can contain elements with only a partial degree of membership. Fuzzification is a process that transforms each input from a crisp value to a corresponding fuzzy input (i.e., a group of fuzzy sets), and this transformation is achieved via a series of predefined membership functions. A membership function (MF) is a numerical mapping from a point in the input space (also known as the universe of discourse) to a single value known as the grade of membership.
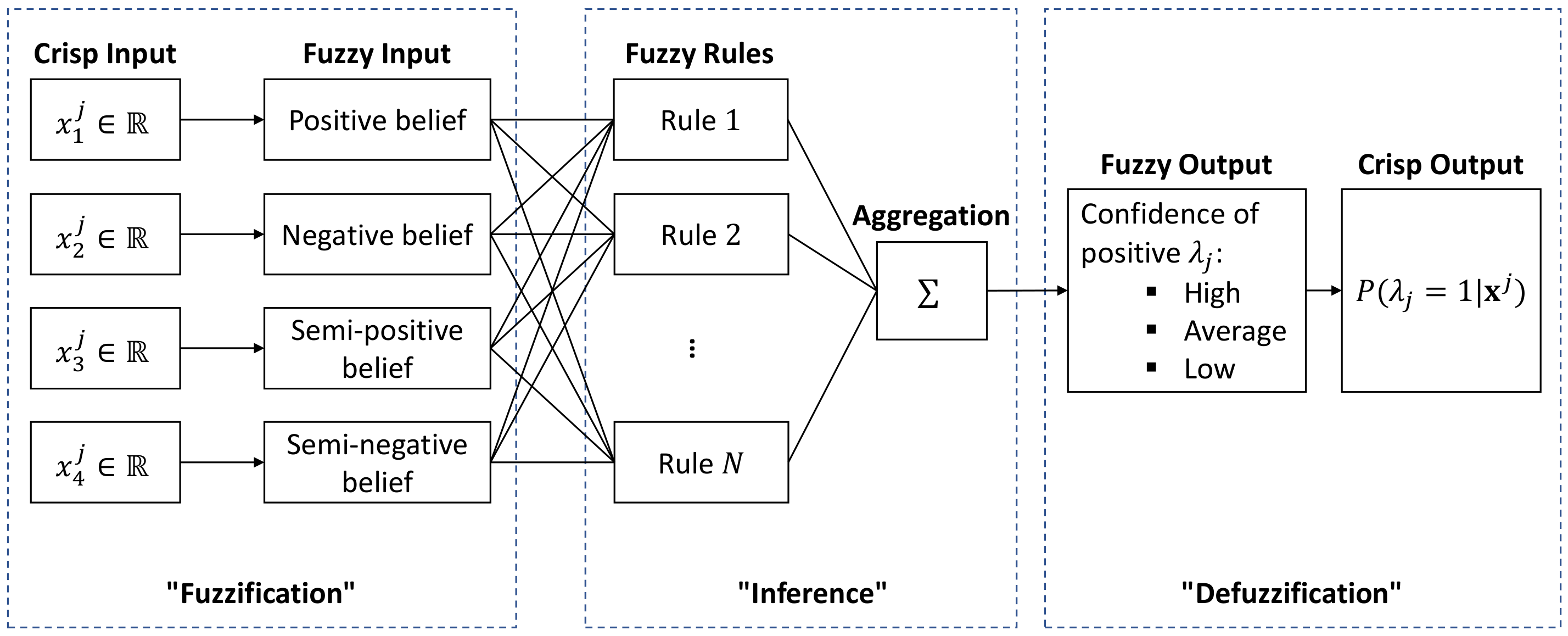
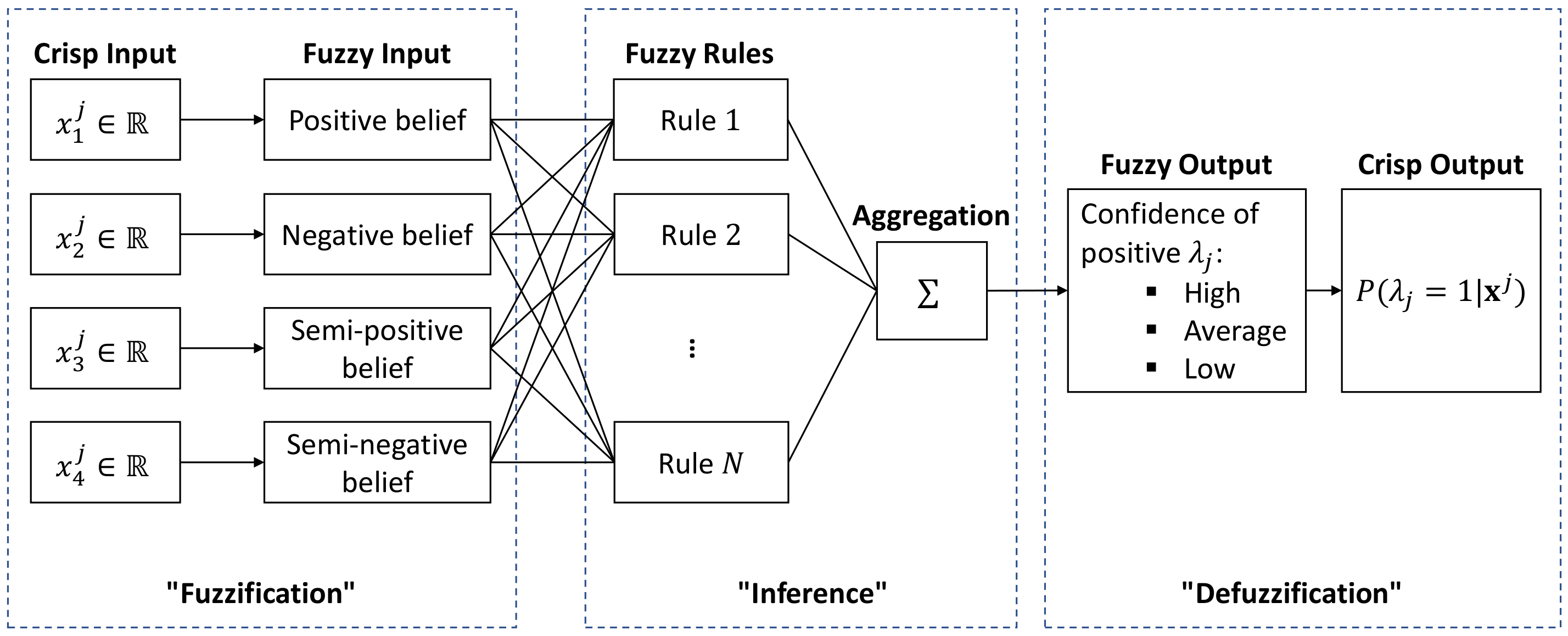
As an example,
Figure 7 illustrates the inference process of a single label
in our application. In this case, the crisp inputs are four POI features calculated in
Section 2.3:
, and hence, the universe of discourse for each input is the real number set
. To comply with the definition of each POI feature, here, the fuzzy inputs are defined as the following four linguistic variables: “positive belief”, “negative belief”, “semi-positive belief”, and “semi-negative belief”. Analogously, the fuzzy output is defined as the linguistic variable “confidence of positive
”. A linguistic variable is a variable whose values are words or sentences, where each word or sentence is generally known as a term which essentially represents a fuzzy set [
53]. For each linguistic variable in our fuzzy inputs and fuzzy output, we define the following three terms: “high”, “average”, and “low”. Each term is numerically defined by a membership function on its corresponding crisp input/output. For example, the term “high” in the input linguistic variable “positive belief” is basically a fuzzy set defined by a pair of the crisp input
and its membership value, which can be represented as:
where
is the membership function of a given crisp input
x in the fuzzy set
A. Each term requires one membership function, so we need in total
(5 linguistic variables times 3 terms in each linguistic variable) membership functions for the proposed FIS in
Figure 7.
As the first step, fuzzification is the process to transform input from crisp values into fuzzy inputs, and this is achieved via a series of membership functions. Even though there exist research papers aimed at finding the proper membership functions for specific applications [
57], it remains a flexible and mostly problem-oriented process, since the only requirement to a membership function is that its output should be a real number ranging between 0 and 1. Nevertheless, the commonly applied membership functions include: Triangular MF, Trapezoidal MF, Gaussian MF, combined Gaussian (cG) MF, and Bell-shaped MF [
53]. Their mathematical expressions are defined in Equations (
14)–(
18), correspondingly. Here,
, and
are the definitive parameters in the corresponding MF function;
x is the input crisp value and
is the corresponding membership value:
As the second step, inference is a process where a series of fuzzy rules are evaluated and aggregated following certain fuzzy operations. A fuzzy rule is typically an If-Then conditional statement, which has the following form:
where each antecedent is a premise which is built up on the terms of an input linguistic variable, and the consequent part is a conclusion acting on the terms of the output linguistic variable. One fuzzy rule may contain multiple antecedents that are connected with fuzzy operators. For example, one potential fuzzy rule for the proposed FIS in
Figure 7 may look like: “If (positive belief is high) AND (negative belief is high) AND (semi-positive belief is high) AND (semi-negative is high), Then (confidence of positive
is high)”. In this case, the If-part consists of four antecedents that are joint via three intersection (AND) operators. In addition to intersection (AND), there exist other two fuzzy operators as well: union (OR) and complement (NOT). Assume
and
are two fuzzy sets, these three fuzzy operators are defined as follows:
Theoretically, complex logic can be achieved by composing multiple simple fuzzy rules, which is generally known as fuzzy rule base. As long as a fuzzy rule base is constructed, the major task during inference is to evaluate all fuzzy rules. The evaluation of a fuzzy rule consists of two steps: (1) calculate the so-called degree of support for this fuzzy rule by aggregating all antecedents with the preselected fuzzy operators; (2) determine the consequent fuzzy set by truncating its membership function using the calculated degree of support. The second step is also known as the implication from antecedent to consequent [
58]. Typically, each fuzzy rule only addresses a specific term of the output linguistic variable. Thus, we need to aggregate individual consequents into an overall consequent, so that it can be used to determine the final fuzzy output. For that, we apply the disjunctive operation “OR” as the aggregation method [
50], which essentially conducts the union operation over all consequent fuzzy sets:
where
C is the output fuzzy set,
is the consequent fuzzy set from the fuzzy rule
j, and
N is the total number of fuzzy rules in the fuzzy rule base.
As the last step, defuzzification converts the output from a linguistic variable to a crisp variable that is more meaningful for the interested application. For example, the defuzzification process in
Figure 7 converts the output from the linguistic variable “confidence of positive
” to a numerical value, which can be interpreted as the probability that the given sample is positive in label
:
. There exists many defuzzification methods in the literature, but the most prevalent one is the Centroid method according to [
50,
53]. In the Centroid method, the crisp output is defined as the projection of the geometric center formed by the membership function of the output fuzzy set onto the crisp axis, which can be numerically calculated according to:
where
C is the output fuzzy set calculated in Equation (
23),
is the output membership function of the desired crisp variable
z in the output fuzzy set
C, and
is the finally determined crisp output, which ranges between 0 and 1.
Since the crisp output from Equation (
24) can be interpreted probabilistically, the proposed FIS can be used as a probabilistic classifier. To determine the predicted class
for the given sample
, a threshold value to the crisp output
is needed. For example, when a threshold value of
is applied,
can be calculated by:
The depicted FIS in
Figure 7 is essentially a single classifier, which can be directly plugged into
Figure 6 to form an independent inference engine. With the above introduction, we can come up with the following observations on the fuzzy inference system:
Membership function is an important component in fuzzy logic, as it bridges the gap between a crisp variable and the corresponding fuzzy set. In practice, the choice of proper membership function is treated as a hyperparameter, which needs to be fine-tuned in order to achieve the best inference performance.
A properly designed fuzzy rule base is the key to success in fuzzy logic. However, the number of possible fuzzy rules grows exponentially with respect to the number of fuzzy inputs. Assume a FIS has
input and
output linguistic variables, where each input and output linguistic variable has
and
terms, correspondingly. Additionally, assume there is only one fuzzy operator type in the If-part. Then, the number of all possible fuzzy rules
is equivalent to the permutation and combination of all input and output terms, which can be calculated as:
. For example, the maximum number of possible fuzzy rules in the depicted FIS in
Figure 7 is:
. If we adapt this FIS to the proposed unified inference strategy, i.e., by increasing both the crisp inputs and the fuzzy inputs from 4 to 20, and extending the fuzzy outputs and crisp outputs from 1 to 5, while still keeping 3 terms in each linguistic variable, then the maximum number of fuzzy rules will amount to:
. This makes the design of a proper rule base no longer practicable, even with the help of the existing software tools with automatic rule-learning capability like the MATLAB Fuzzy Logic Toolbox [
59]. Such a data-dimension-related challenge is generally known as the curse of dimensionality [
47,
60].
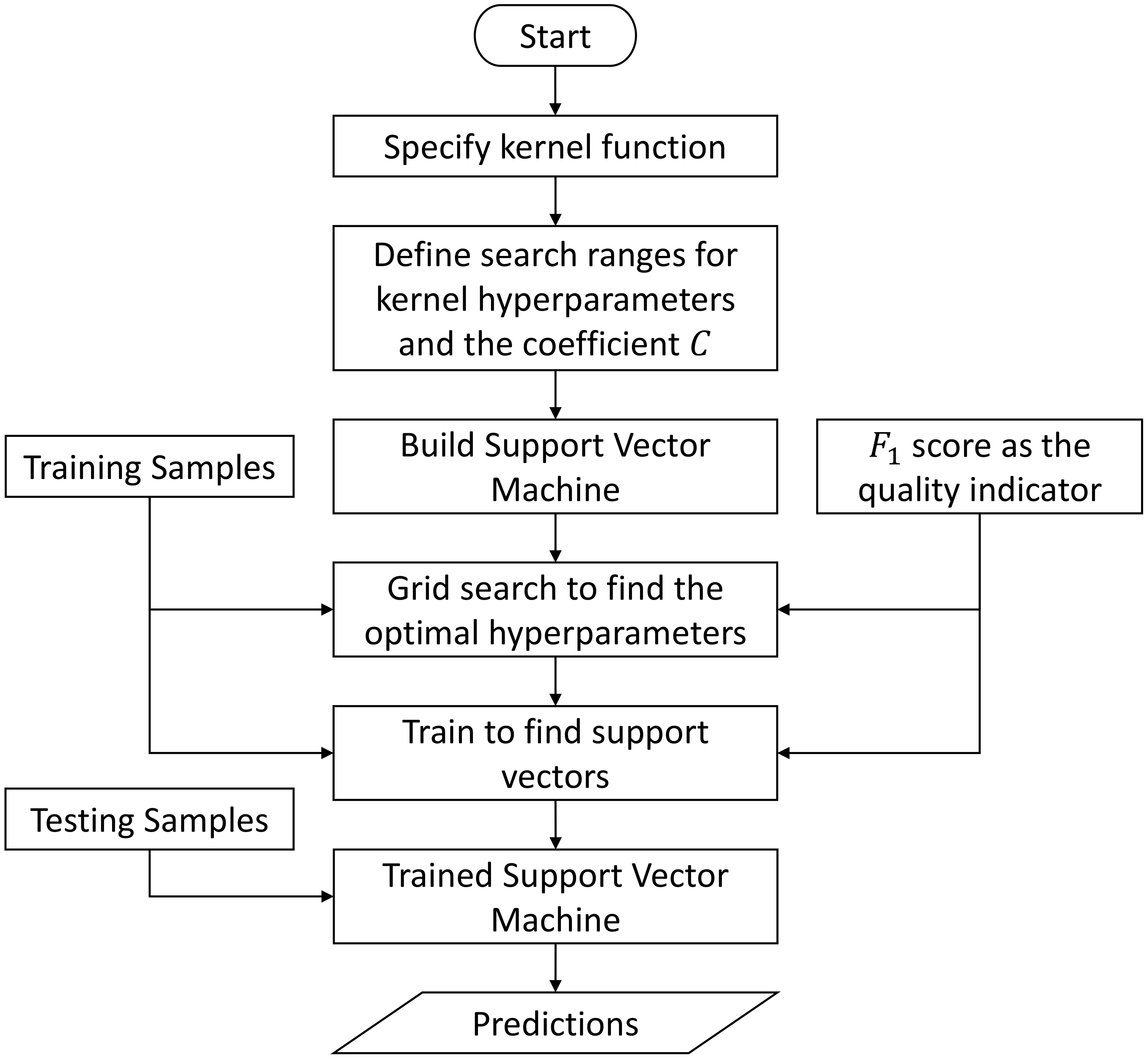
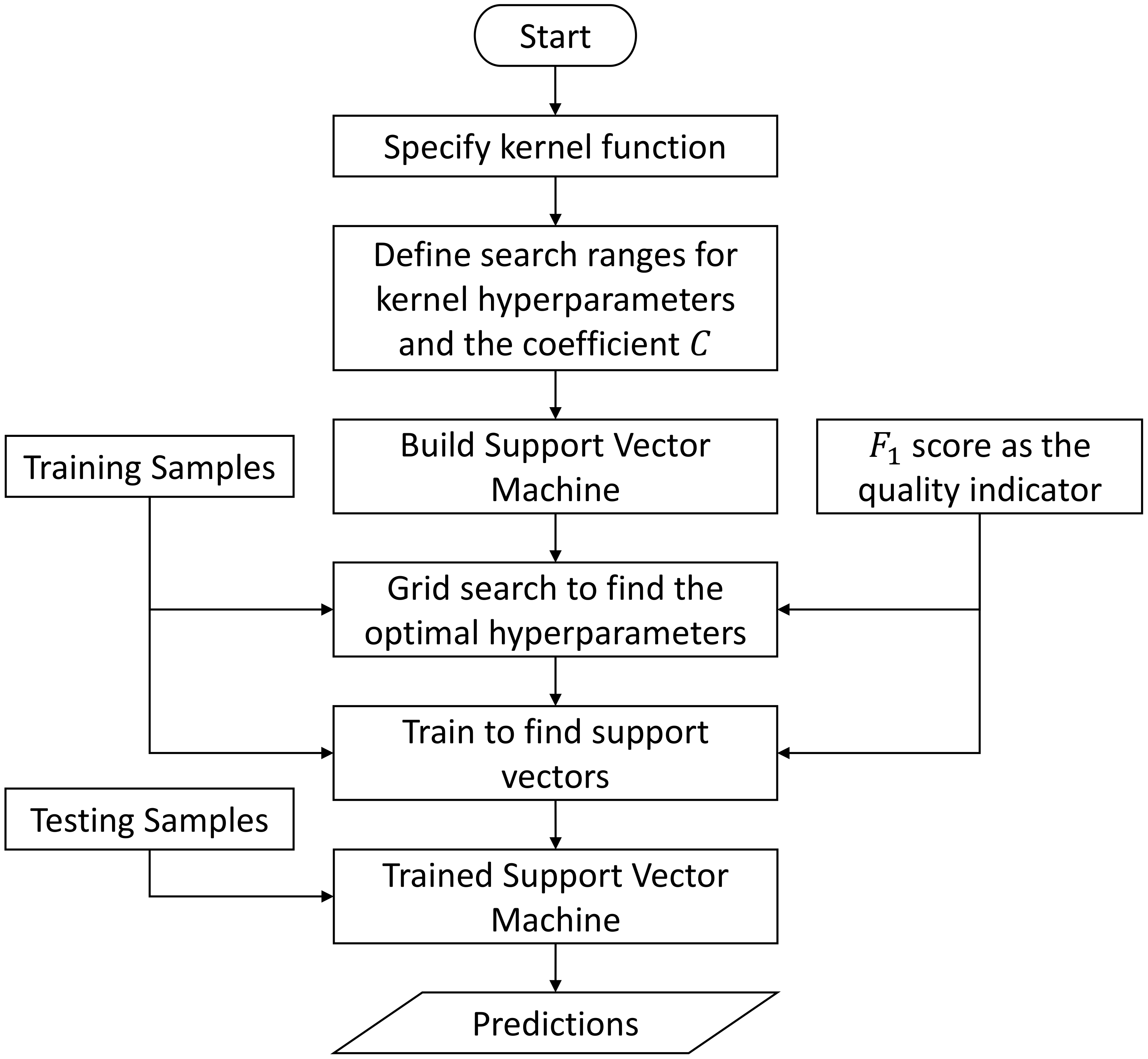
2.4.3. Support-Vector-Machine-Based Inference Engine
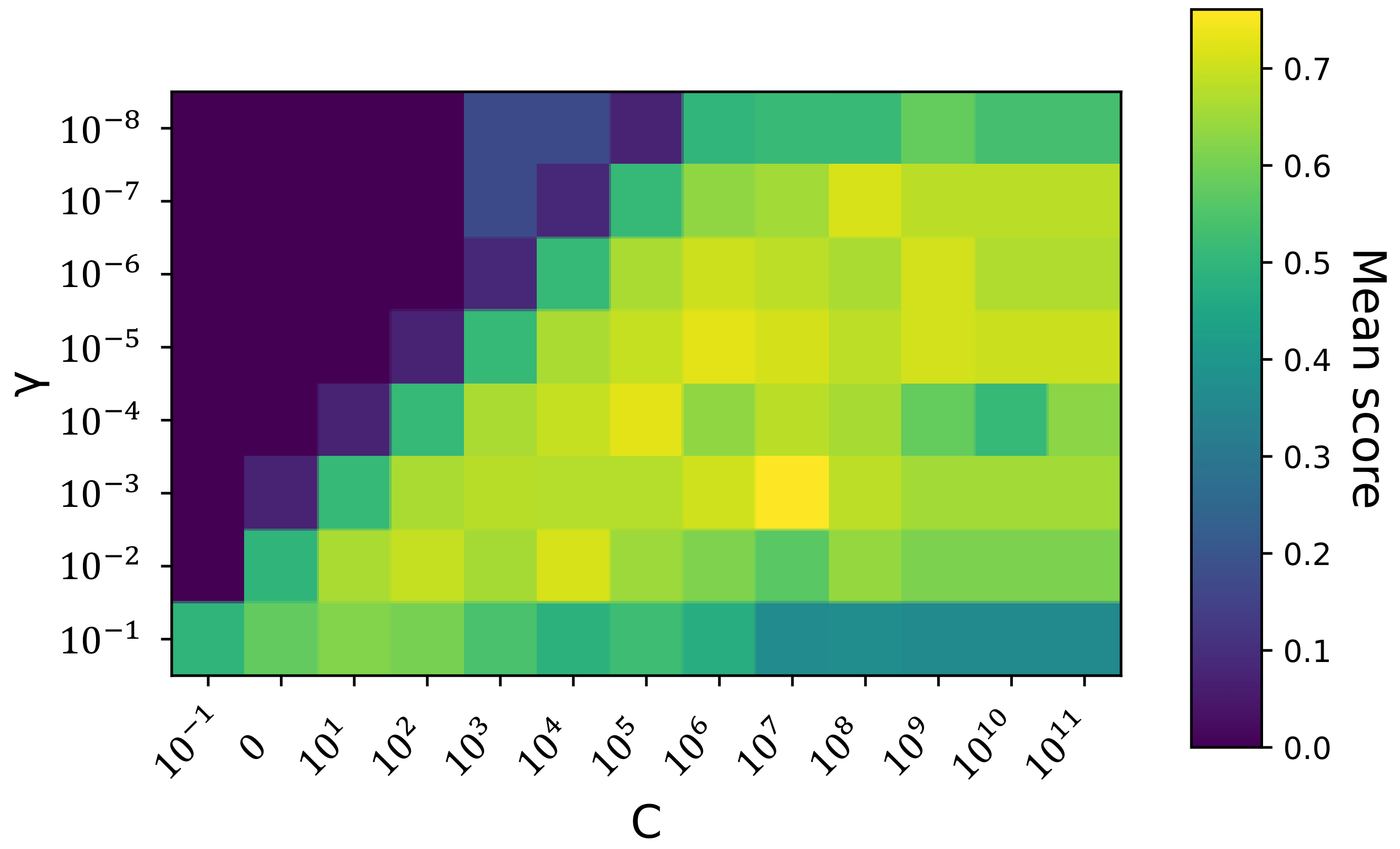
In the domain of classification, one of the most flexible and effective machine learning approaches is the support vector machine (SVM) [
45,
47,
54]. Based on clear geometric intuition, the support vector machine has well-developed mathematical foundations in solving the two-class linear classification problem. Moreover, nonlinear classification can also be effectively solved by SVM with the help of the so-called kernel trick [
60].
Given a set of linearly separable training samples
, where
is a
d-dimensional input vector and
is the corresponding class label, the target of support vector machine is to find a decision boundary in the input space
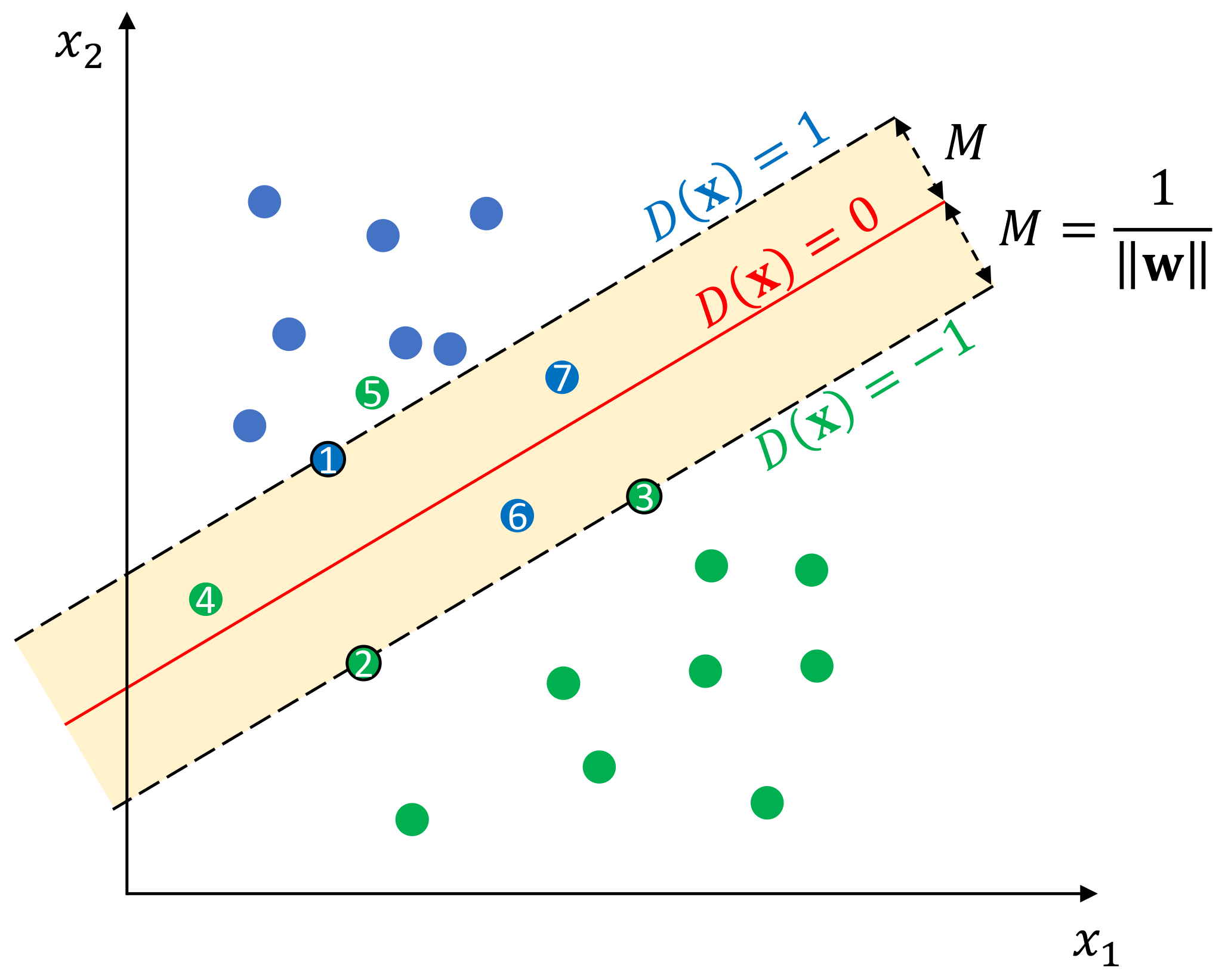
, so that samples of one class can be separated from the other. As shown in
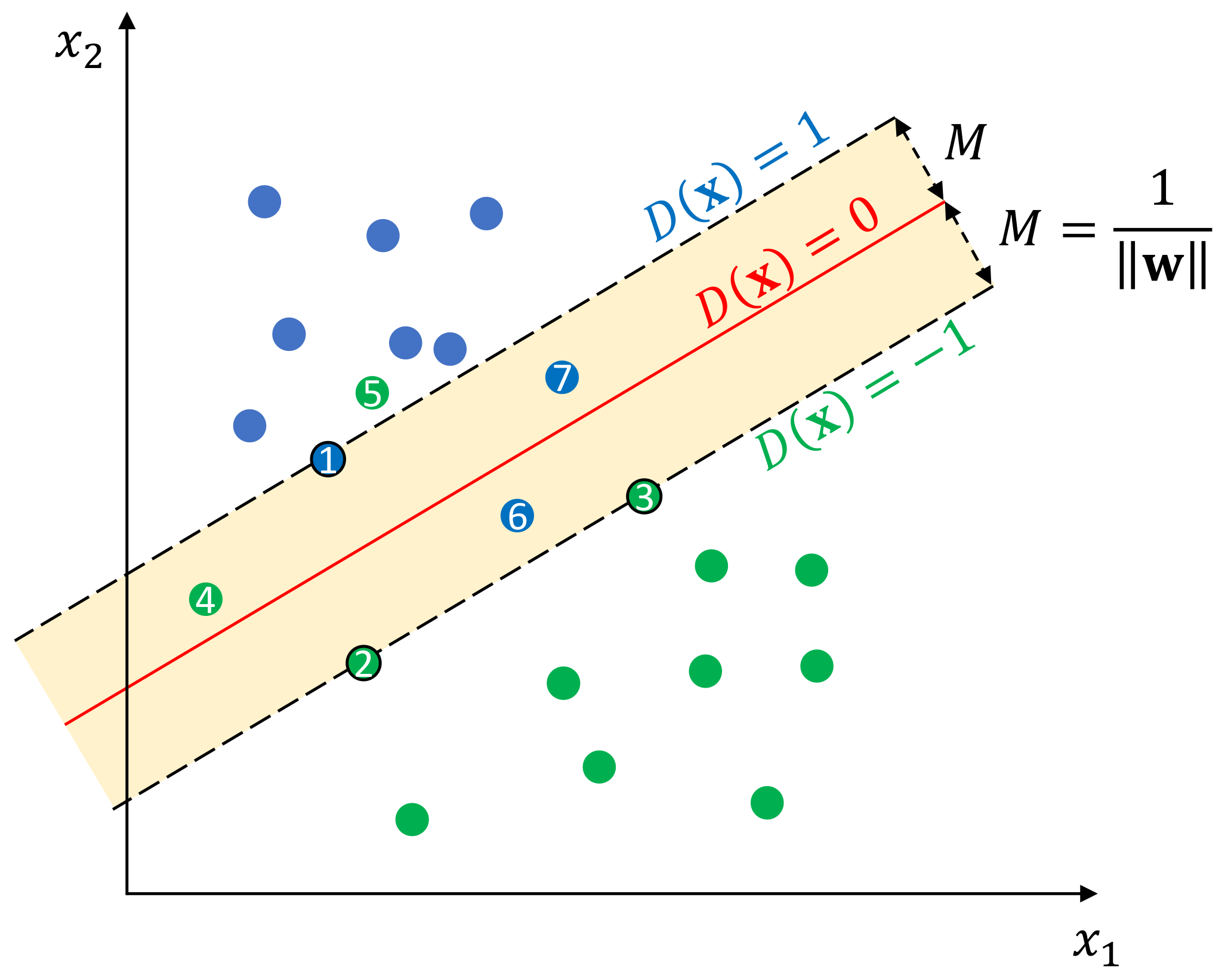
Figure 8, for linearly separable training samples, the decision boundary is actually a hyperplane in the input space
, which can be defined as:
where
and
are the definitive parameters of this hyperplane,
represents the decision boundary itself, and
and
represent the margin boundaries of class
and class 1, respectively. Margin is an important concept in SVM, which indicates the perpendicular distance between the decision boundary and the closest samples from each class. Margin
M can be calculated as:
In ideal case, the decision boundary shall separate all samples into the correct class, i.e., to the correct side of the decision boundary. That is, the following inequality should hold true for all training samples:
Hence, the goal of support vector machine is to find an optimal hyperplane in space
, which maximizes the margin in Equation (
27) while satisfying the constraints in Equation (
28). This is equivalent to solving the following optimization problem:
However, in practice, the class-conditional distributions may overlap, in which case exact separation of the training data can lead to poor generalization [
60]. Therefore, a penalty term is usually added to Equation (
29) to account for the loss introduced by the misclassified samples, e.g., samples
and 7 in
Figure 8. To formulate this penalty term, a nonnegative slack variable
for each training sample is introduced, which is defined as the hinge loss:
. This slack variable will be 0 for samples lying on the correct side of the margin (including samples on the margin), while for other samples, this slack variable will grow linearly from 0 towards infinity depending on their geometric distances from the corresponding margin boundary. With this definition, the inequality in Equation (
28) can be rewritten as:
Accordingly, the optimization problem in Equation (
29) is now updated to:
where
is a regularization coefficient which controls the trade-off between the slack variable penalty and the margin loss during optimization. In contrast to the hard-margin optimization in Equation (
29), the optimization task in Equation (
31) is called soft-margin optimization, and the resulting hyperplane is called soft-margin hyperplane. It can be proved that, when
C approaches infinity (i.e.,
), the optimizations in Equations (
29) and (
31) become identical.
In order to solve this constrained optimization problem, we can transform Equation (
31) to the so-called dual space using the following Lagrangian function [
60]:
where
and
;
and
are the Lagrange multipliers for each constraint in Equation (
30) and for each slack variable
, respectively. Now, the problem is transformed to minimize the function
with respect to
and
b, while maximizing it with respect to
and
. To simplify the representation, we can substitute
,
b, and
with
by setting the derivatives of
L with respect to
,
b, and
to 0. Consequently, Equation (
32) is reformed into:
Now the target is to find an optimal parameter vector
, which maximizes the quadratic equation in Equation (
33) under the following derived constraints:
This is a convex optimization problem, which can be effectively solved by the quadratic programming algorithm with global convergence guarantee. However, the introduction to this algorithm is beyond the scope of this paper, and we refer the reader to [
60,
61,
62] for further details. Once the parameter vector
is determined, the decision function in Equation (
26) can be solved by:
Consequently, for a given sample with the input vector
, its predicted class
is determined by checking the sign of the decision function
:
In fact, the parameter vector
contains many zero entities, and only the nonzero entities have an effect on the final decision according to Equation (
35). The training samples corresponding to these nonzero entities are known as support vectors, and hence, this technique is named support vector machine. For example, the samples
and 3 are the support vectors of the SVM depicted in
Figure 8.
Up to now, all the discussions are based on the assumption that the given training samples are linearly separable in the input space. In cases where the samples cannot be separated by a linear classifier, SVM leverages the so-called kernel trick. The basic idea of the kernel trick is to convert the input vector from low dimension input space to a higher or infinite dimension feature space, in which the classification problem becomes tractable again by standard linear classifier. Commonly, such conversion is implicitly achieved using the so-called kernel function. A kernel function is a symmetric function which can be written as:
where
and
are vectors in the input space and
is the nonlinear function that actually maps a vector from input space to feature space. The explicit representation of
is not necessary, as long as the output of the kernel function
coincides with the inner product of this feature functions. One advantage of this kernel definition is that the theoretical development from Equation (
27) to Equation (
36) is still valid for the kernel-based nonlinear SVM classifier. For example, assume we have a linear kernel function
, i.e.,
, Equation (
26) can be rewritten as
, and thus, all the subsequent equation developments are still valid. Another advantage is that the computational effort of calculating the kernel function
k is usually much less than naively constructing two
vectors and explicitly taking their inner product [
47]. Commonly applied kernel functions include: linear kernel, polynomial kernel, radial basis function (RBF) or Gaussian kernel, and sigmoid kernel. Their definitions are given as follows:
where
, and
d are the hyperparameters in the corresponding kernel function. Similar to the membership function in fuzzy inference system, the choice of proper kernel function is also a hyperparameter.
It should be noted that the introduced SVM is actually a decision machine, i.e., only the sign of the decision function is relevant for determining the final class. Therefore, the SVM-based classifier is a nonprobabilistic binary classifier. Since it is a binary classifier, a single SVM cannot model the joint optimization over multiple labels simultaneously. This is the reason why, currently, we only implement the SVM-based classifier into an independent inference engine.
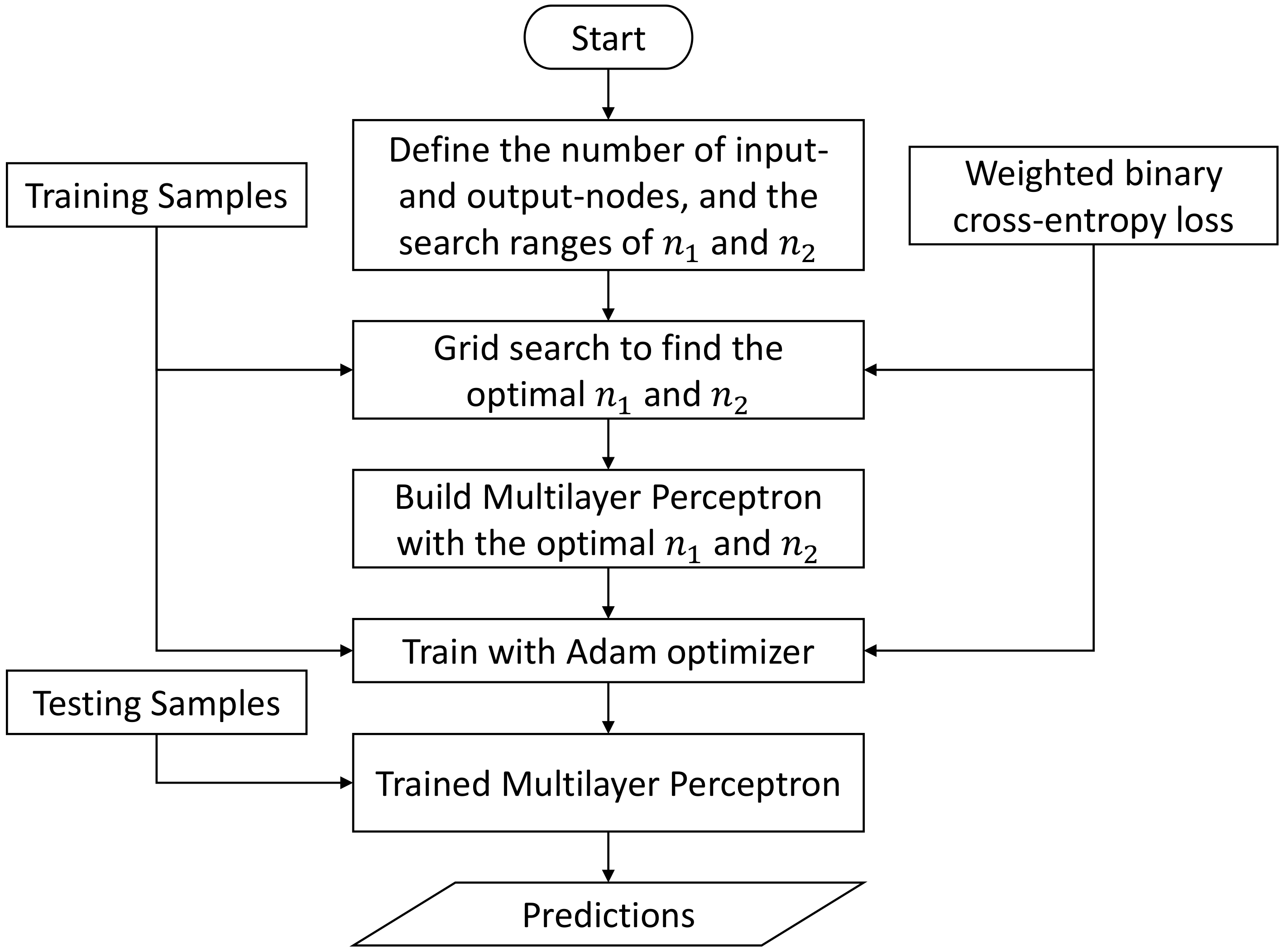
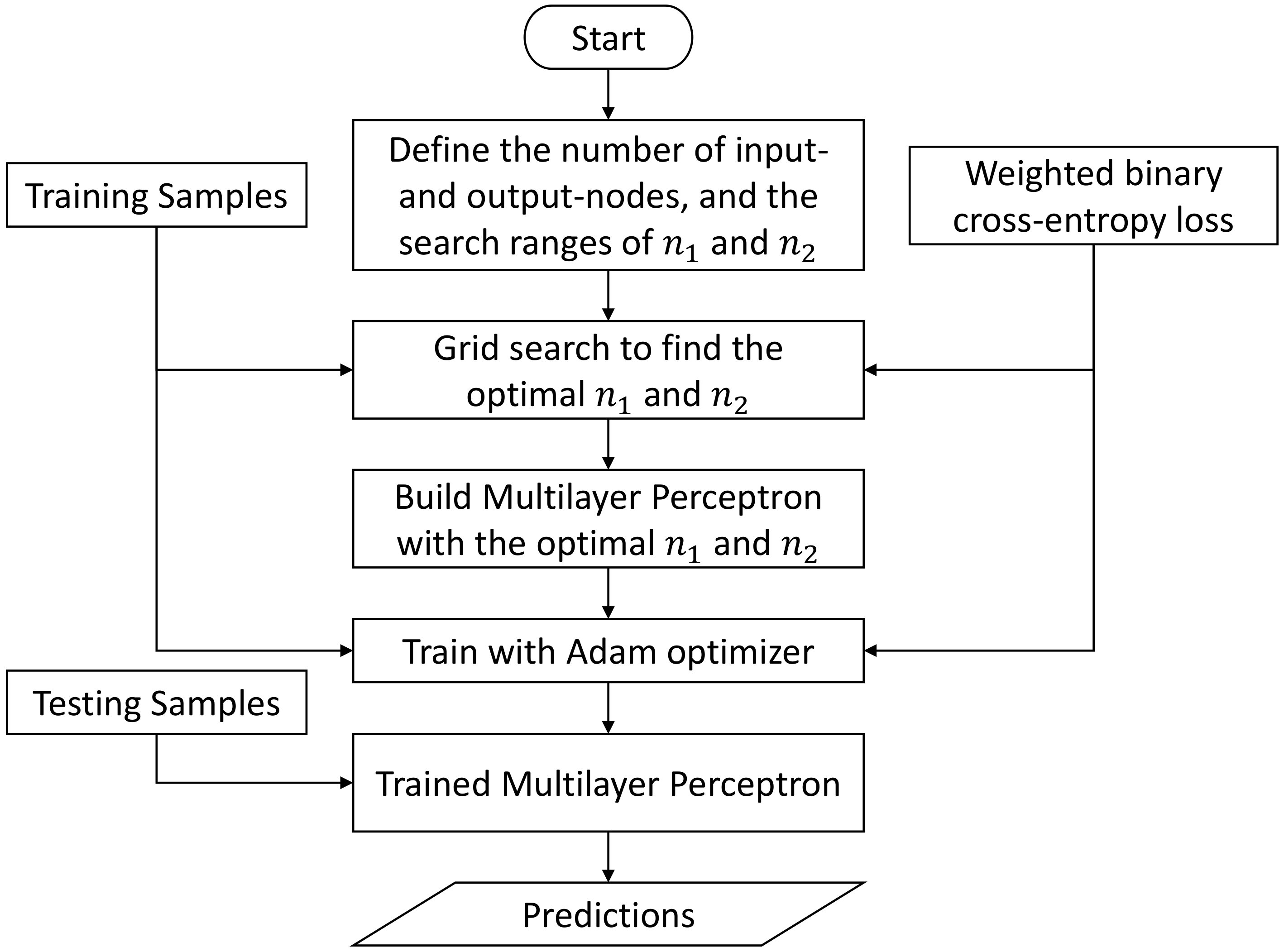
2.4.4. Multilayer-Perceptron-Based Inference Engine
Another popular machine learning approach is multilayer perceptron (MLP), which is essentially a feedforward neural network with fully connected nodes (also known as neurons) [
47,
53,
60]. A multilayer perceptron consists of at least three layers of nodes, namely an input layer, a hidden layer, and an output layer. Except for the input nodes, each node in the hidden layer and the output layer represents a computational unit, which takes the outputs of the directly preceded layer as input and maps it nonlinearly into a scalar value that is usually known as the activation of this node. It has been proved that, even the simplest three-layer MLP is a universal approximator [
63].
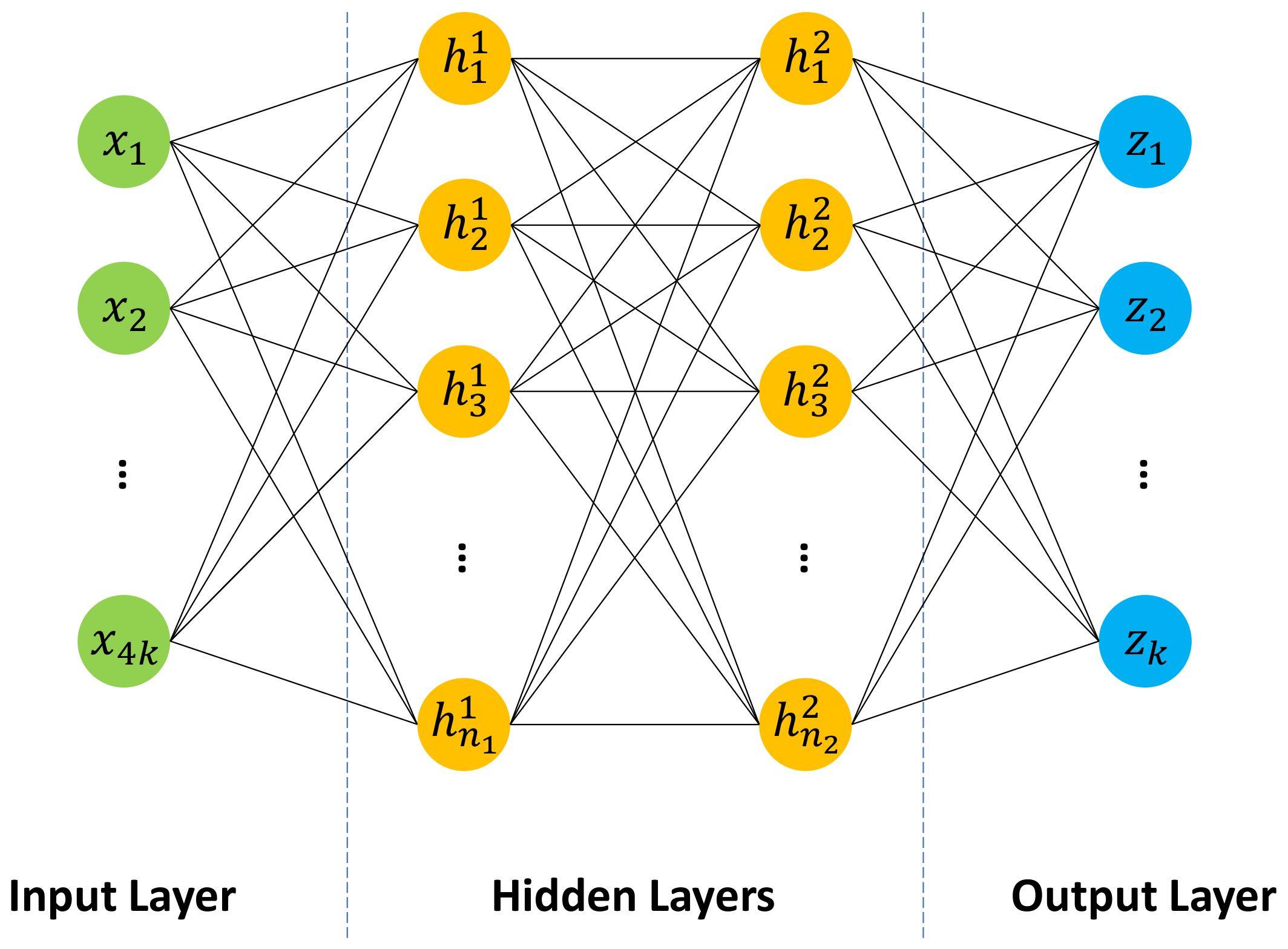
Figure 9 shows a four-layer multilayer perceptron, which is built as a unified inference engine for our inference task. In the input layer, each node stands for a single POI feature calculated in
Section 2.3. Hence, the whole input layer can be numerically represented by the POI feature vector
, where
k is the number of unique labels with the same meaning as in
Section 2.3. The first hidden layer then takes this POI feature vector as input, and conducts the following operation:
where
is an
-by-
weight matrix,
is a
-dimensional bias vector,
is the output of the first hidden layer, an activation vector where
corresponds to the activation value of the
i-th node in this layer,
is the number of nodes in the first hidden layer, and
is an element-wise activation function, which is chosen as the rectified linear unit (RuLU) function
in this paper. Apparently, the operation in a hidden layer is mathematically equivalent to an affine transformation followed by a nonlinearity transformation.
Likewise, the second hidden layer takes the activation vector from the first hidden layer as input and conducts a similar nonlinearity transformation:
where
and
are the weight matrix and the bias vector of the second hidden layer, respectively,
is the number of nodes in the second hidden layer, and
is the activation vector of the second hidden layer.
For each given sample, there are
k unique labels to predict. Thus, we define
k nodes in the output layer, where each node corresponds to a specific label. As a probabilistic classifier, we would expect each prediction to be a float number ranging between 0 and 1. Therefore, we employ the popular sigmoid function as the activation function in the output layer. It should be noted that the choice of the activation function is usually problem-oriented, e.g., linear activation function for regression, sigmoid activation function for binary classification, and softmax activation function for multiclass classification [
47]. Consequently, the operation in the output layer can be written as:
where
and
are the weight matrix and the bias vector of the output layer, respectively,
is the prediction vector of the output layer, and
is the element-wise sigmoid function that is defined by:
Each element in the prediction vector can be interpreted as the probability that its corresponding label is positive. Therefore, in order to determine the predicted binary label vector
introduced in
Section 2.4.1, one can conduct the following element-wise “>” comparison to the prediction vector
. Note that
is an example threshold on each prediction:
Equations (
42)–(
44) compose the so-called forward propagation of the proposed MLP, where all the weight matrices and bias vectors are the network parameters that need to be determined during training. Unlike support vector machine, the process of finding the optimal parameters for MLP is a nonconvex optimization problem [
47], which cannot be solved by linear solvers. In practice, the training of neural network is usually achieved by using iterative and gradient-based optimizers, such as the stochastic gradient descent (SGD) algorithm [
64,
65]. The basic idea of stochastic gradient descent is to update the network parameters using the gradients of the loss with respect to the network parameters, and by doing such an update iteratively, the network parameters will finally converge to a certain optimal. During each iteration, the following updates are performed:
where
denotes the iteration number,
is the learning rate,
is the loss over a batch of training samples that is parametrized by the network weight
and bias
, and
and
represent the gradients of the loss
L with respect to
and
, respectively. To calculate these gradients, the chain rule based back-propagation algorithm is usually applied [
66]. It should be noted that, in addition to the standard SGD algorithm, there exists many other modern optimizers which not only consider the gradient itself, but also the momentum of each gradient over epochs. The advantage of utilizing momentum is that the resulting optimizer converges faster than the vanilla SGD optimizer. Example momentum-based optimizers include: Nesterov Momentum [
67,
68,
69], AdaGrad [
70], RMSProp [
71], and Adam [
72].
In terms of the loss function, we employ the weighted binary cross-entropy loss as our primary loss function, which is defined as follows:
where
is the ground truth label vector as introduced in
Section 2.3,
is the prediction vector calculated from Equation (
44),
and
are individual elements in
and
, respectively,
is a weighting factor to compensate the sample imbalance in each label, which ranges between 0 and 1, and
k denotes the number of unique labels, as introduced in
Section 2.3.
In addition to the primary loss, in practice, we often introduce a regularization loss on the network parameters to avoid the so-called overfitting of the network [
73]. In this paper, we utilize the well-known L2 parameter norm penalty (also known as weight decay) as the regularization loss [
47,
48,
60]. Assume
is a vector representation of the network parameters
and
, then the final loss function can be defined as:
where
is a regularization coefficient which acts as a weighting factor. It should be noted that the loss function in Equation (
50) only calculates the loss of a single training sample, and one may need to sum up multiple such single losses to form a batch loss, e.g., the loss
in Equations (
47) and (
48).
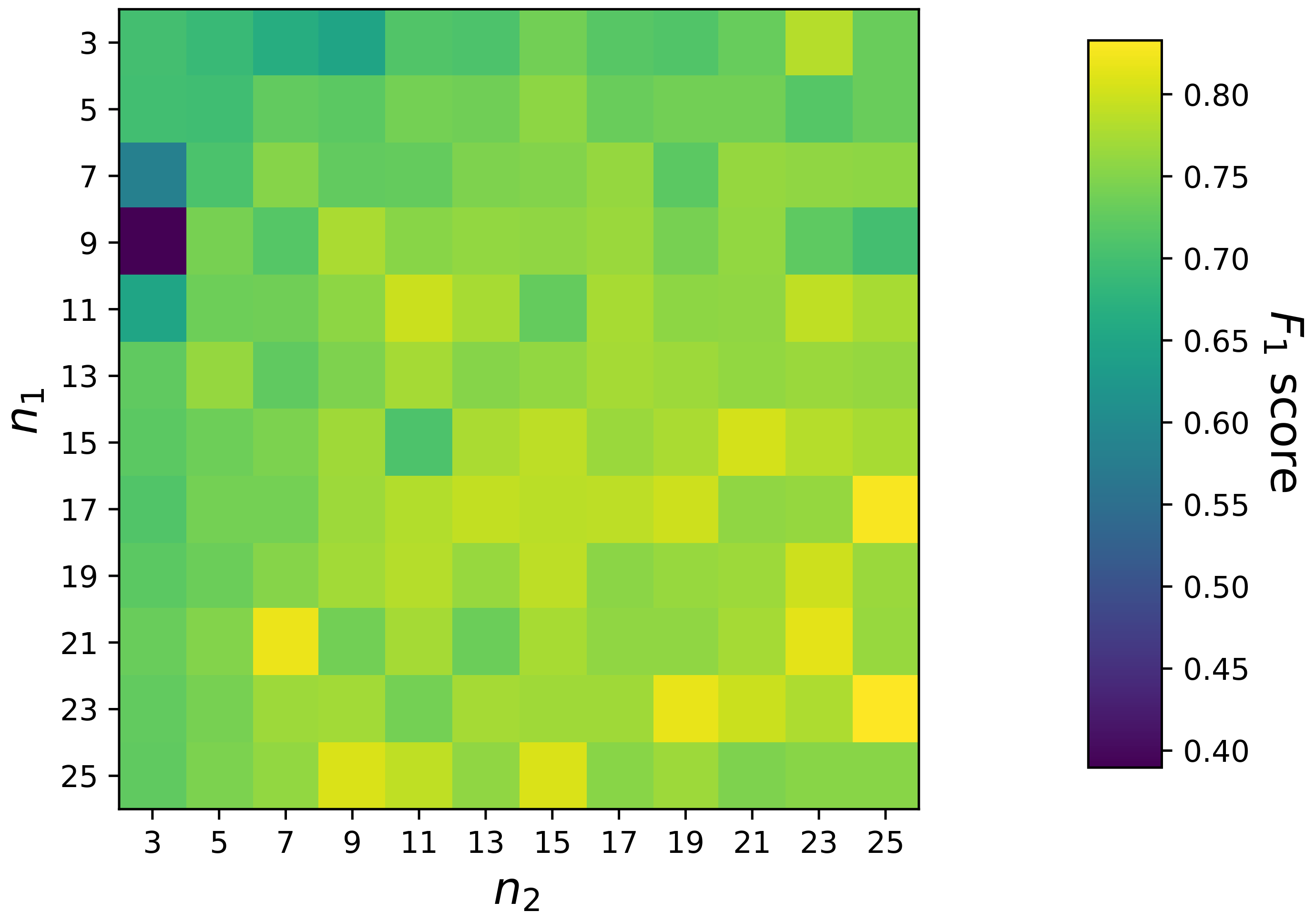
From the above introduction, we see that the depth (i.e., the number of layers) and width (i.e., the number of nodes in a specific layer) are two major considerations when designing a multilayer perceptron. Existing research has shown that deeper networks with fewer nodes have better generalization capability than shallow networks with wider layers, but deeper networks are often harder to optimize [
47]. Therefore, to achieve a good balance, usually, intensive fine-tuning on network depth and width is performed. Furthermore, the flexible network design enables us to adapt the network architecture freely and quickly in practice. For example, we can easily modify the MLP in
Figure 9 to the proposed independent inference strategy, e.g., by reducing the number of input nodes from
to 4, and keeping only a single node in the output layer.
5. Conclusions
In this paper, we propose an inference framework to explore the feasibility of utilizing POI data for the driving environment inference task. The proposed inference framework mainly comprises four modules: map matching, POI extraction, POI feature calculation, and inference engine. The first two modules are designed to leverage the data structure of the utilized map, so that the purity of the extracted POI objects is guaranteed. Instead of working with discrete POI objects directly, we introduce a statistical approach to transform the input into semantically meaningful and numerically manageable POI features. Based on these POI features, an inference engine is built to solve the actual inference task. To realize that, we investigate the following three inference systems in this work: FIS, SVM, and MLP. Particularly, we detail the composition of inference engines from these three inference systems by following one of the two inference strategies: the independent inference strategy and the unified inference strategy. To examine the proposed inference framework, we implement 11 inference engines and evaluate them on a manually prepared dataset. The result shows that the proposed inference framework generalizes well over different inference systems, especially the configuration MLP-Unified achieves the best performance (overall score of 0.8699, with 0.0002 milliseconds of inference time per sample) among all implemented inference engines. Moreover, the effectiveness of the proposed POI feature calculation approach is also justified by the best-achieved individual evaluation metrics in each inference system. Last but not the least, the efficiency of the proposed inference framework is quantitatively demonstrated by the final efficiency comparison.
To correctly retrieve POI objects for the ego road being travelled, the proposed framework heavily relies on the map matching module. However, if map matching fails to match the vehicle location to the correct road link, then the inference result will no longer be reliable. As a potential solution, in the future we may try another POI extraction method, e.g., brute extraction of all POI objects within a certain range around a vehicle’s ego location. Besides, the proposed POI feature calculation method is essentially a data-driven approach. Similar to other data-driven approaches, a representative and unambiguous dataset is the key to success. However, obtaining such a dataset is usually challenging. To a certain degree, the introduced two inference strategies ensure the flexibility of the proposed framework, i.e., one can freely adapt existing inference systems to the proposed inference framework by following one of these two strategies. However, due to the introduced limitations adhere to FIS and SVM, currently, we only implement an MLP-based unified inference engine. As a future work, it is worth to validate the proposed inference framework using more inference systems, and also to investigate the extensibility of the introduced unified inference strategy to other inference systems. In addition to the current investigations on the three inference systems studied in this work, we will conduct more ablation experiments to further inspect the influence of other model-related hyperparameters on the final inference performance. For example, we can also apply the symmetric implicational method introduced in [
77] to the fuzzy inference system. Finally, the POI source utilized in this paper is a commercial navigation map, although there exists other POI sources such as Google Maps and OpenStreetMap [
78]. Therefore, another future topic is to further verify the proposed inference framework using other POI sources.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}