

Application of 1D ResNet for Multivariate Fault Detection on Semiconductor Manufacturing Equipment †

 ,
,
Abstract
:1. Introduction
2. Deep Learning Methods for Fault Detection
2.1. Multivariate Time Series
2.2. Supervised Deep Learning for Fault Detection
2.3. Residual Connections in Deep Neural Networks
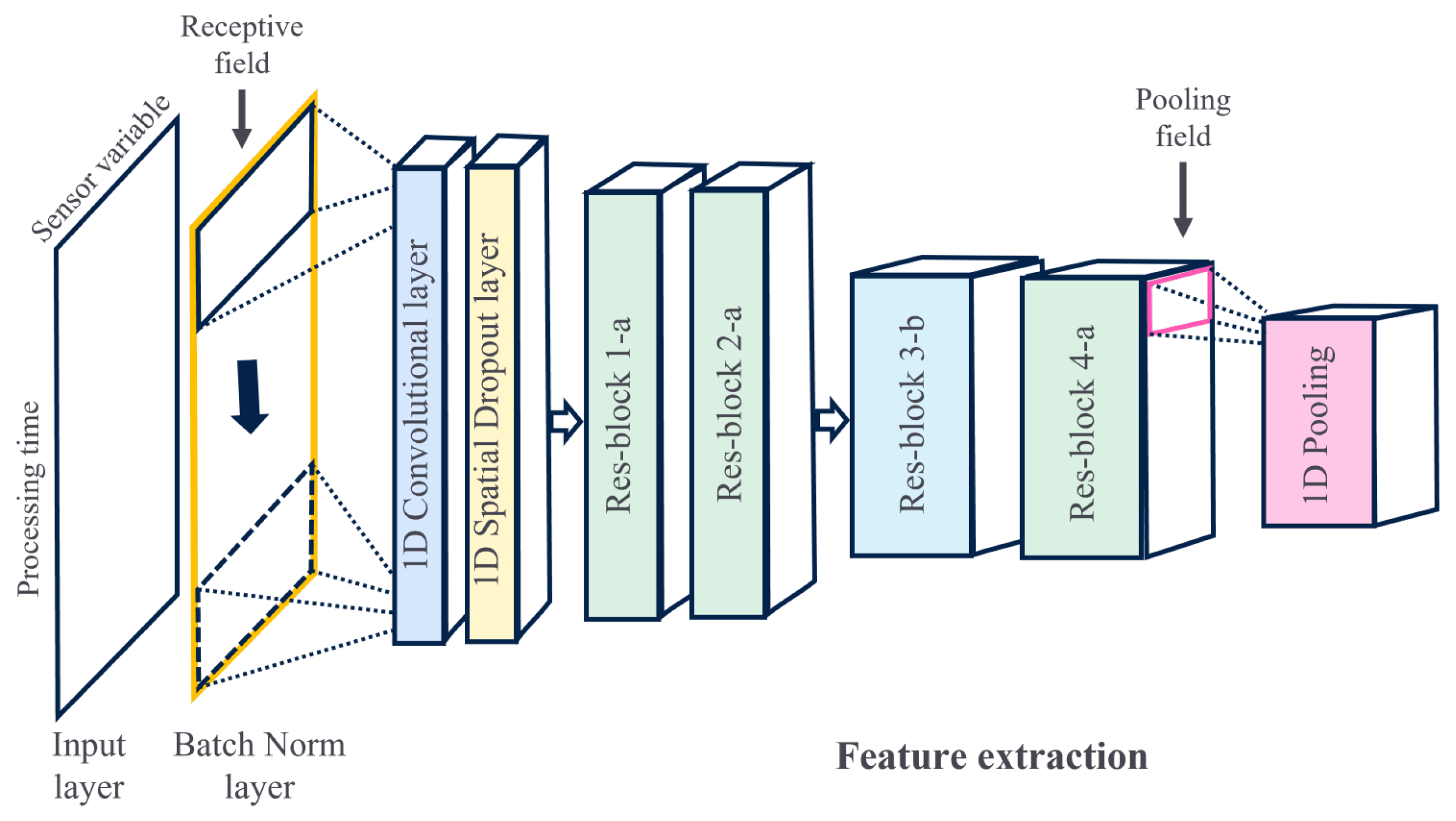
3. Proposed Method for Fault Detection
4. Experimental Setup
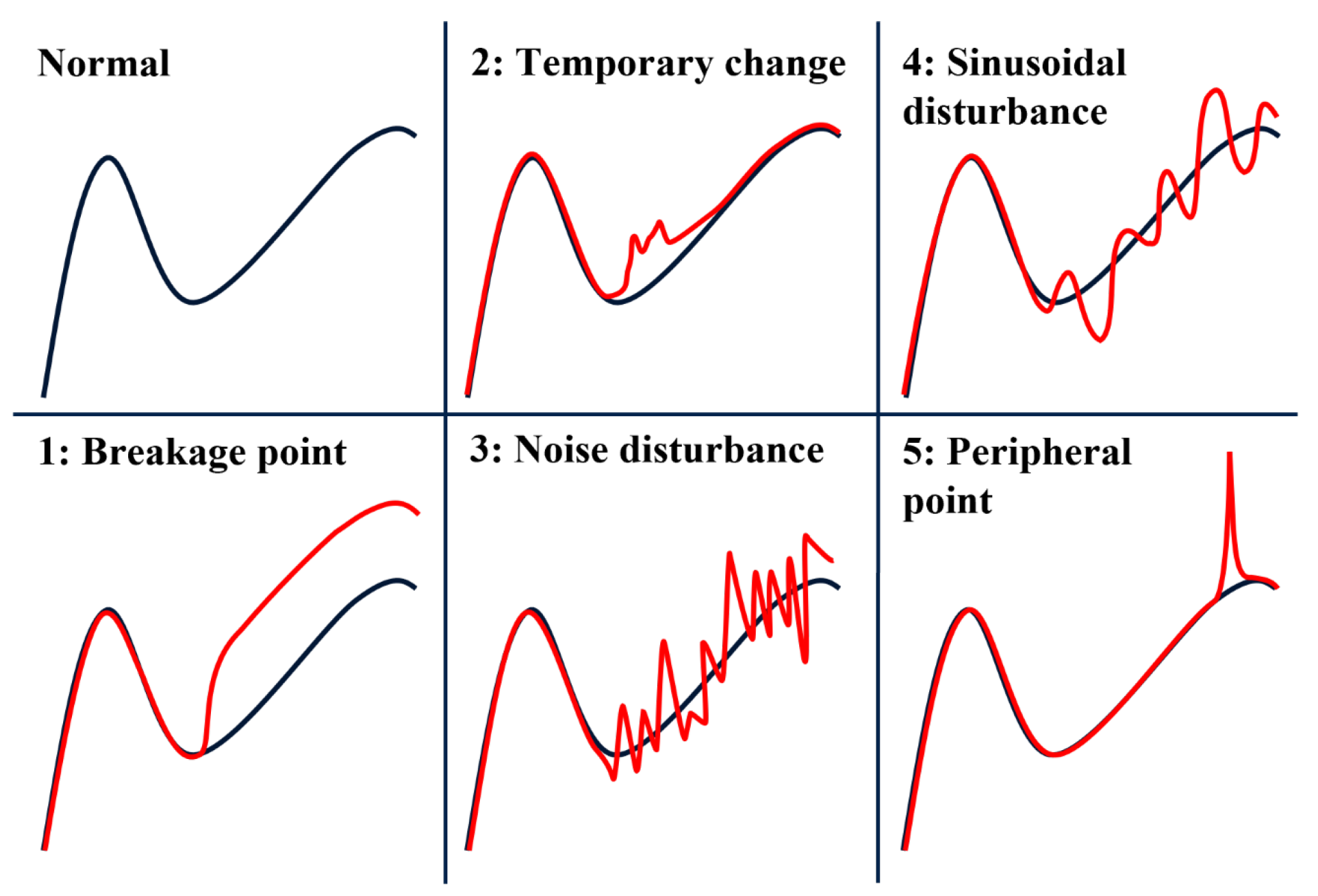
4.1. Data Preparation
4.2. Neural Network Configurations
4.3. Other Configurations
- Data partitioning: The dataset is split into training and test sets with a ratio of 80–20%. This process is performed through a stratified fivefold cross-validation partitioning in order to avoid biased results. In terms of implementation, the partitioning is carried out using Scikit-learn.
- Weight initialization: The initial weights are defined using Glorot uniform distribution. No layer-weight constraints are set on the weight matrices for the learning process.
- Weight optimization: The Adam optimizer is used for the training, with the learning rate fixed at 0.0005 for all models. After numerous optimization tests, the batch sizes are, respectively, fixed at 32 for the ResNet-based, CNN-based, and autoencoder-based models and at 16 for the LSTM-based models. For all of the models, the number of epochs is fixed at 300 with early stopping, and the cost function is the binary cross-entropy.
4.4. Evaluation Metrics
5. Results and Discussion
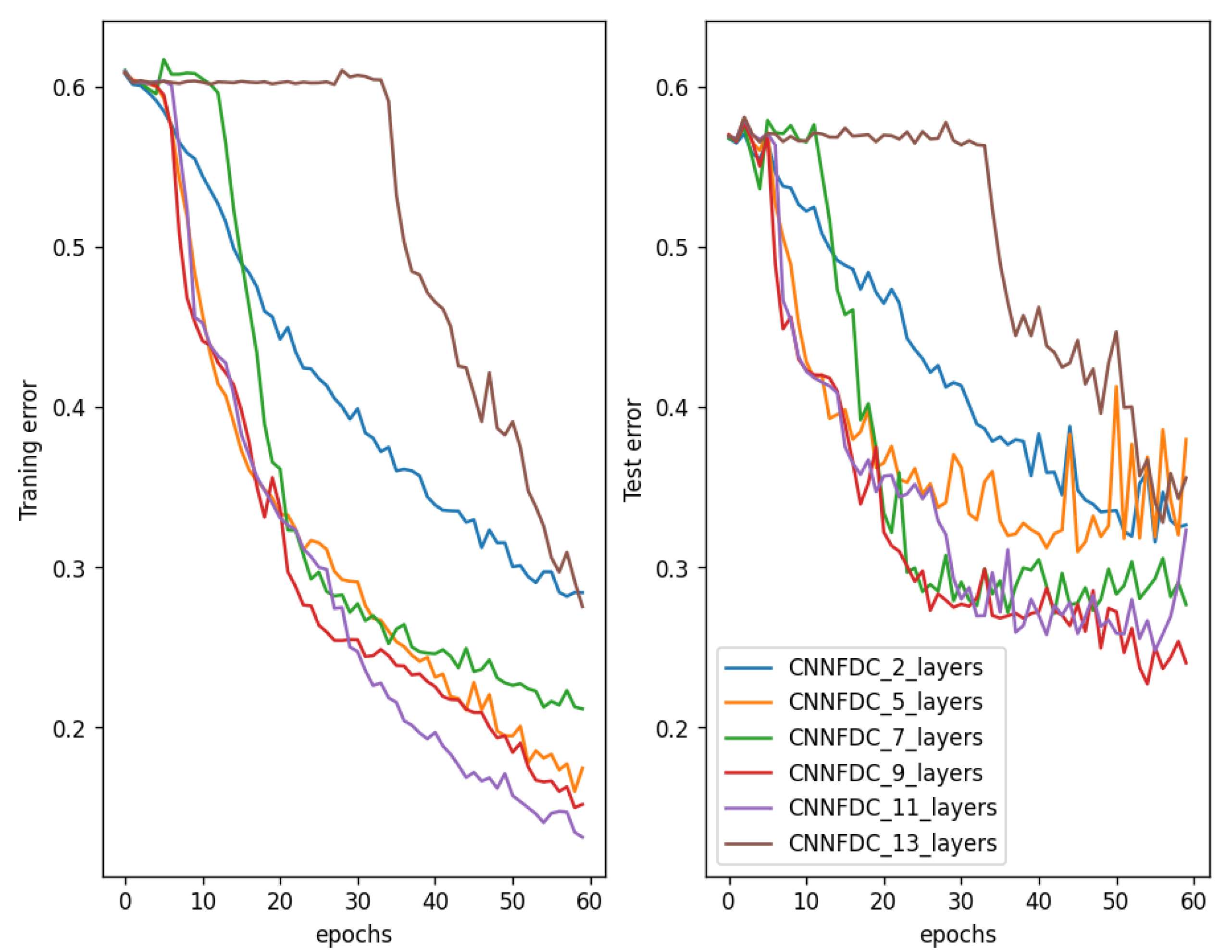
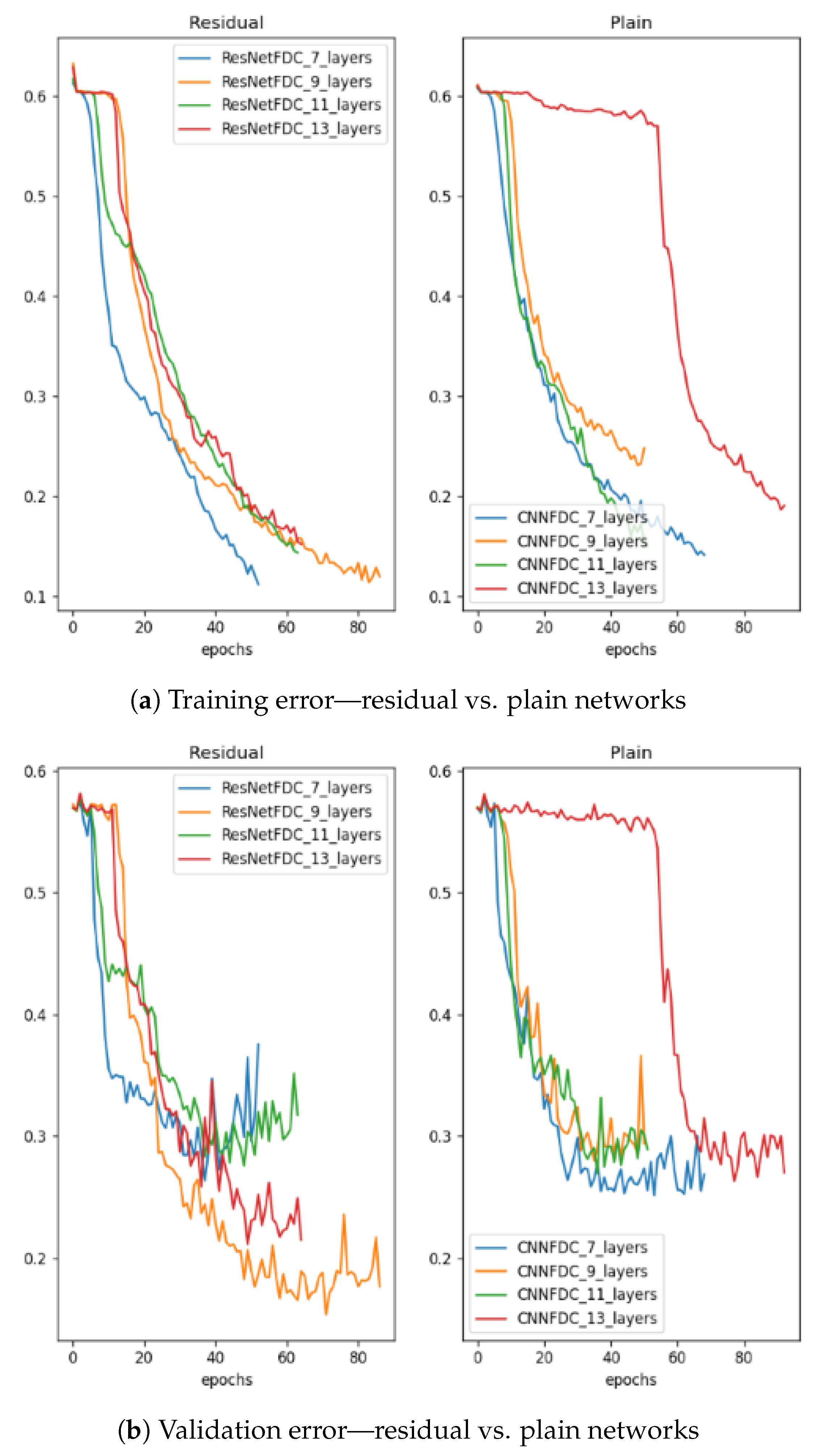
5.1. Gradient Analysis
5.2. Results Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Patel, P.; Ali, M.; Sheth, A. From Raw Data to Smart Manufacturing: AI and Semantic Web of Things for Industry 4.0. IEEE Intell. Syst. 2018, 33, 79–86. [Google Scholar] [CrossRef]
- Yin, S.; Ding, S.X.; Haghani, A.; Hao, H.; Zhang, P. A comparison study of basic data-driven fault diagnosis and process monitoring methods on the benchmark Tennessee Eastman process. J. Process Control 2012, 22, 1567–1581. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Yin, K.; Kavuri, S.N. A review of process fault detection and diagnosis: Part I: Quantitative model-based methods. Comput. Chem. Eng. 2003, 27, 293–3115. [Google Scholar] [CrossRef]
- Hinrichs, A.; Prochno, J.; Ullrich, M. The curse of dimensionality for numerical integration on general domains. J. Complex. 2019, 50, 25–42. [Google Scholar] [CrossRef]
- Längkvist, M.; Karlsson, L.; Loutfi, A. A review of unsupervised feature learning and deep learning for time-series modeling. Pattern Recognit. Lett. 2014, 42, 11–24. [Google Scholar] [CrossRef]
- Ali, A.; Shamsuddin, S.M.; Ralescu, A.L. Classification with class imbalance problem. Int. J. Adv. Soft Comput. Appl. 2013, 5, 176–204. [Google Scholar]
- Thieullen, A.; Ouladsine, M.; Pinaton, J. Application of PCA for efficient multivariate FDC of semiconductor manufacturing equipment. In Proceedings of the ASMC 2013 SEMI Advanced Semiconductor Manufacturing Conference, Saratoga Springs, NY, USA, 14–16 May 2013; pp. 332–337. [Google Scholar] [CrossRef]
- Le, Q.; Karpenko, A.; Ngiam, J.; Ng, A. ICA with reconstruction cost for efficient overcomplete feature learning. Adv. Neural Inf. Process. Syst. 2011, 24, 1017–1025. [Google Scholar]
- He, X.; Wang, Z.; Liu, Y.; Zhou, D.H. Least-squares fault detection and diagnosis for networked sensing systems using a direct state estimation approach. IEEE Trans. Ind. Informat. 2013, 9, 1670–1679. [Google Scholar] [CrossRef]
- Park, J.; Kwon, I.; Kim, S.S.; Baek, J.G. Spline regression based feature extraction for semiconductor process fault detection using support vector machine. Expert Syst. Appl. 2011, 38, 5711–5718. [Google Scholar] [CrossRef]
- He, Q.P.; Wang, J. Principal Component based K-Nearest Neighbor Rule for Semiconductor Process Fault Detection. In Proceedings of the 2008 American Control Conference, Seattle, WA, USA, 11–13 June 2008; pp. 1606–1611. [Google Scholar]
- Goldstein, M.; Uchida, S. A Comparative Evaluation of Unsupervised Anomaly Detection Algorithms for Multivariate Data. PLoS ONE 2016, 11, e0152173. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Lee, H.; Kim, Y.; Kim, C.O. A deep learning model for robust wafer fault monitoring with sensor measurement noise. IEEE Trans. Semi. Manuf. 2017, 30, 23–31. [Google Scholar] [CrossRef]
- Chen, K.; Hu, J.; He, J. Detection and Classification of Transmission Line Faults Based on Unsupervised Feature Learning and Convolutional Sparse Autoencoder. IEEE Trans. Smart Grid 2016, 9, 1748–1758. [Google Scholar] [CrossRef]
- Maggipinto, M.; Beghi, A.; Susto, G.A. A deep convolutional autoencoder-based approach for anomaly detection with industrial, non-images, 2-dimensional data: A semiconductor manufacturing case study. IEEE Trans. Autom. Sci. Eng. 2022, 19, 1477–1490. [Google Scholar] [CrossRef]
- Tedesco, S.; Susto, G.A.; Gentner, N.; Kyek, A.; Yang, Y. A scalable deep learning-based approach for anomaly detection in semiconductor manufacturing. In Proceedings of the 2021 Winter Simulation Conference (WSC), Phoenix, AZ, USA, 12–15 December 2021; pp. 1–12. [Google Scholar]
- Gorman, M.; Ding, X.; Maguire, L.; Coyle, D. Anomaly Detection in Batch Manufacturing Processes Using Localized Reconstruction Errors From 1-D Convolutional AutoEncoders. IEEE Trans. Semicond. Manuf. 2022, 36, 147–150. [Google Scholar] [CrossRef]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based Encoder-Decoder for Multi-sensor Anomaly Detection. In Proceedings of the ICML 2016, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Hosseinpour, F.; Ahmed, I.; Baraldi, P.; Behzad, M.; Zio, E.; Lewitschnig, H. An unsupervised method for anomaly detection in multiystage production systems based on LSTM autoencoders. In Proceedings of the 32nd European Safety and Reliability Conference (ESREL 2022), Dublin, Ireland, 28 August–1 September 2022. [Google Scholar]
- Lee, K.B.; Cheon, S.; Kim, C.O. A convolutional neural network for fault classification and diagnosis in semiconductor manufacturing processes. IEEE Trans. Semicond. Manuf. 2017, 30, 35–142. [Google Scholar] [CrossRef]
- Hsu, C.Y.; Liu, W.C. Multiple time-series convolutional neural network for fault detection and diagnosis and empirical study in semiconductor manufacturing. J. Intell. Manuf. 2021, 32, 823–836. [Google Scholar] [CrossRef]
- Chien, C.F.; Hung, W.T.; Liao, E.T.Y. Redefining monitoring rules for intelligent fault detection and classification via CNN transfer learning for smart manufacturing. IEEE Trans. Semicond. Manuf. 2022, 35, 158–165. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Zaeemzadeh, A.; Rahnavard, N.; Shah, M. Norm-preservation: Why residual networks can become extremely deep? IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3980–3990. [Google Scholar] [CrossRef]
- Qian, L.; Pan, Q.; Lv, Y.; Zhao, X. Fault detection of bearing by resnet classifier with model-based data augmentation. Machines 2022, 10, 521. [Google Scholar] [CrossRef]
- Tchatchoua, P.; Graton, G.; Ouladsine, M.; Muller, J.; Traoré, A.; Juge, M. 1D ResNet for Fault Detection and Classification on Sensor Data in Semiconductor Manufacturing. In Proceedings of the 2022 International Conference on Control, Automation and Diagnosis (ICCAD), Lisbon, Portugal, 13–15 July 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Werbos, P.J. Backpropagation through time: What it does and how to do it. Proc. IEEE 1990, 78, 1550–1560. [Google Scholar] [CrossRef]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long Short Term Memory Networks for Anomaly Detection in Time Series. Eur. Symp. Artif. Neural Netw. 2015, 2015, 89. [Google Scholar]
- Ng, A. Sparse autoencoder. CS294A Lect. Notes 2011, 72, 1–19. [Google Scholar]
- Le, Q.V.; Ngiam, J.; Coates, A.; Lahiri, A.; Prochnow, B.; Ng, A.Y. On optimization methods for deep learning. In Proceedings of the ICML 2011, Bellevue, WA, USA, 28 June–2 July 2011; pp. 265–272. [Google Scholar]
- Tchatchoua, P.; Graton, G.; Ouladsine, M.; Juge, M. A comparative evaluation of deep learning anomaly detection techniques on semiconductor multivariate time series data. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 1613–1620. [Google Scholar]
- Browne, M.; Ghidary, S. Convolutional Neural Networks for Image Processing: An Application in Robot Vision. In AI 2003: Advances in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Kim, E.; Cho, S.; Lee, B.; Cho, M. Fault detection and diagnosis using self-attentive convolutional neural networks for variable length sensor data in semiconductor manufacturing. IEEE Trans. Semi. Manuf. 2019, 32, 2917521. [Google Scholar] [CrossRef]
- Lin, Z.; Feng, M.; Santos, C.N.D.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A structured self-attentive sentence embedding. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training very deep networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 2377–2385. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Remya, K.; Sajith, V. Machine Learning Approach for Mixed type Wafer Defect Pattern Recognition by ResNet Architecture. In Proceedings of the 2023 International Conference on Control, Communication and Computing (ICCC), Thiruvananthapuram, India, 19–21 May 2023; pp. 1–6. [Google Scholar]
- Fu, H.; Zhou, Z.; Zeng, Z.; Sang, T.; Zhu, Y.; Zheng, X. Surface Defect Detection Based on ResNet Classification Network with GAN Optimized. In Proceedings of the 2022 IEEE Smartworld, Ubiquitous Intelligence & Computing, Scalable Computing & Communications, Digital Twin, Privacy Computing, Metaverse, Autonomous & Trusted Vehicles (SmartWorld/UIC/ScalCom/DigitalTwin/PriComp/Meta), Haikou, China, 15–18 December 2022; pp. 1568–1575. [Google Scholar]
- Labach, A.; Salehinejad, H.; Valaee, S. Survey of dropout methods for deep neural networks. arXiv 2019, arXiv:1904.13310. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Jeni, L.; Cohn, J.; De la Torre, F. Facing imbalanced data recommendations for the use of performance metrics. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | ResNet-1 | ResNet-2 | CNN-1 | CNN-2 | LSTM-1 | LSTM-2 | SAE-1 | SAE-2 |
|---|---|---|---|---|---|---|---|---|
| Model specificity | Residual blocks | Residual blocks | Plain blocks | Self-attention CNN | Stacked LSTM | Self-attention LSTM | Stacked autoencoders | Conv autoencoders |
| Number of feature extraction layers | 11 | 11 | 11 | 2 | 2 | 2 | 6 | 6 |
| Activation function | ReLU | ReLU | ReLU | ReLU | Sigmoïd | Sigmoïd | ReLU | ReLU |
| Number of classification layers | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 2 |
| Pooling before classification | Average pooling | Spatial pyramid pooling | Average pooling | No pooling | No pooling | No pooling | No pooling | No pooling |
| Batch size | 32 | 32 | 32 | 32 | 16 | 16 | 32 | 32 |
| Method | Layers | |||
|---|---|---|---|---|
| ResNet-7 | 7 | 0.9507 | 0.8607 | 0.9250 |
| Plain-7 | 7 | 0.9371 | 0.8058 | 0.8996 |
| ResNet-9 | 9 | 0.9589 | 0.8837 | 0.9374 |
| Plain-9 | 9 | 0.9414 | 0.8187 | 0.9063 |
| ResNet-11 | 11 | 0.9599 | 0.8865 | 0.9389 |
| Plain-11 | 11 | 0.9425 | 0.8315 | 0.9108 |
| ResNet-13 | 13 | 0.9518 | 0.8567 | 0.9246 |
| Plain-13 | 13 | 0.9367 | 0.8097 | 0.9004 |
| Method | |||
|---|---|---|---|
| ResNet-1 | 0.9599 | 0.8865 | 0.9389 |
| ResNet-2 | 0.9600 | 0.8855 | 0.9387 |
| CNN-1 | 0.9425 | 0.8315 | 0.9108 |
| CNN-2 | 0.9229 | 0.7370 | 0.8698 |
| LSTM-1 | 0.8333 | - | - |
| LSTM-2 | 0.8333 | - | - |
| SAE-1 | 0.9276 | 0.7715 | 0.8830 |
| SAE-2 | 0.9412 | 0.8260 | 0.9083 |
| Method | |||
|---|---|---|---|
| ResNet-1 | 0.9825 | 0.9189 | 0.9708 |
| ResNet-2 | 0.9651 | 0.8333 | 0.9410 |
| CNN-1 | 0.9659 | 0.8125 | 0.9379 |
| CNN-2 | 0.9239 | 0.4167 | 0.8312 |
| LSTM-1 | 0.8995 | - | - |
| LSTM-2 | 0.8995 | - | - |
| SAE-1 | 0.9153 | 0.5161 | 0.8423 |
| SAE-2 | 0.9714 | 0.8485 | 0.9490 |
| Method | Fault 1 | Fault 2 | Fault 3 | Fault 4 | Fault 5 |
|---|---|---|---|---|---|
| ResNet-1 | 0.9873 | 0.9610 | 0.6885 | 0.9160 | 0.9873 |
| CNN-1 | 0.9200 | 0.8072 | 0.5664 | 0.5789 | 0.9682 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tchatchoua, P.; Graton, G.; Ouladsine, M.; Christaud, J.-F. Application of 1D ResNet for Multivariate Fault Detection on Semiconductor Manufacturing Equipment. Sensors 2023, 23, 9099. https://doi.org/10.3390/s23229099
Tchatchoua P, Graton G, Ouladsine M, Christaud J-F. Application of 1D ResNet for Multivariate Fault Detection on Semiconductor Manufacturing Equipment. Sensors. 2023; 23(22):9099. https://doi.org/10.3390/s23229099
Chicago/Turabian StyleTchatchoua, Philip, Guillaume Graton, Mustapha Ouladsine, and Jean-François Christaud. 2023. "Application of 1D ResNet for Multivariate Fault Detection on Semiconductor Manufacturing Equipment" Sensors 23, no. 22: 9099. https://doi.org/10.3390/s23229099
APA StyleTchatchoua, P., Graton, G., Ouladsine, M., & Christaud, J.-F. (2023). Application of 1D ResNet for Multivariate Fault Detection on Semiconductor Manufacturing Equipment. Sensors, 23(22), 9099. https://doi.org/10.3390/s23229099