
Multi-Scene Mask Detection Based on Multi-Scale Residual and Complementary Attention Mechanism



Abstract
:1. Introduction
- We propose a multi-scene mask detection network named YOLO-MSM to address the challenges posed by small target mask detection across various scenes. The network backbone incorporates the concept of the multi-scale residual to extract finer and multi-scale features. This method captures different levels of information by using multiple convolutions in a residual block to extract features at different scales, and the equivalent receptive field increases when the input feature is fed into these convolutions. Additionally, we incorporate cascaded and parallel channel-spatial attention blocks into the backbone and feature pyramid structure of the network. These blocks allow for the extraction of critical information from the input features while suppressing unimportant features. These methods improve the representation ability and understanding ability of the model and significantly enhance the performance of small target detection.
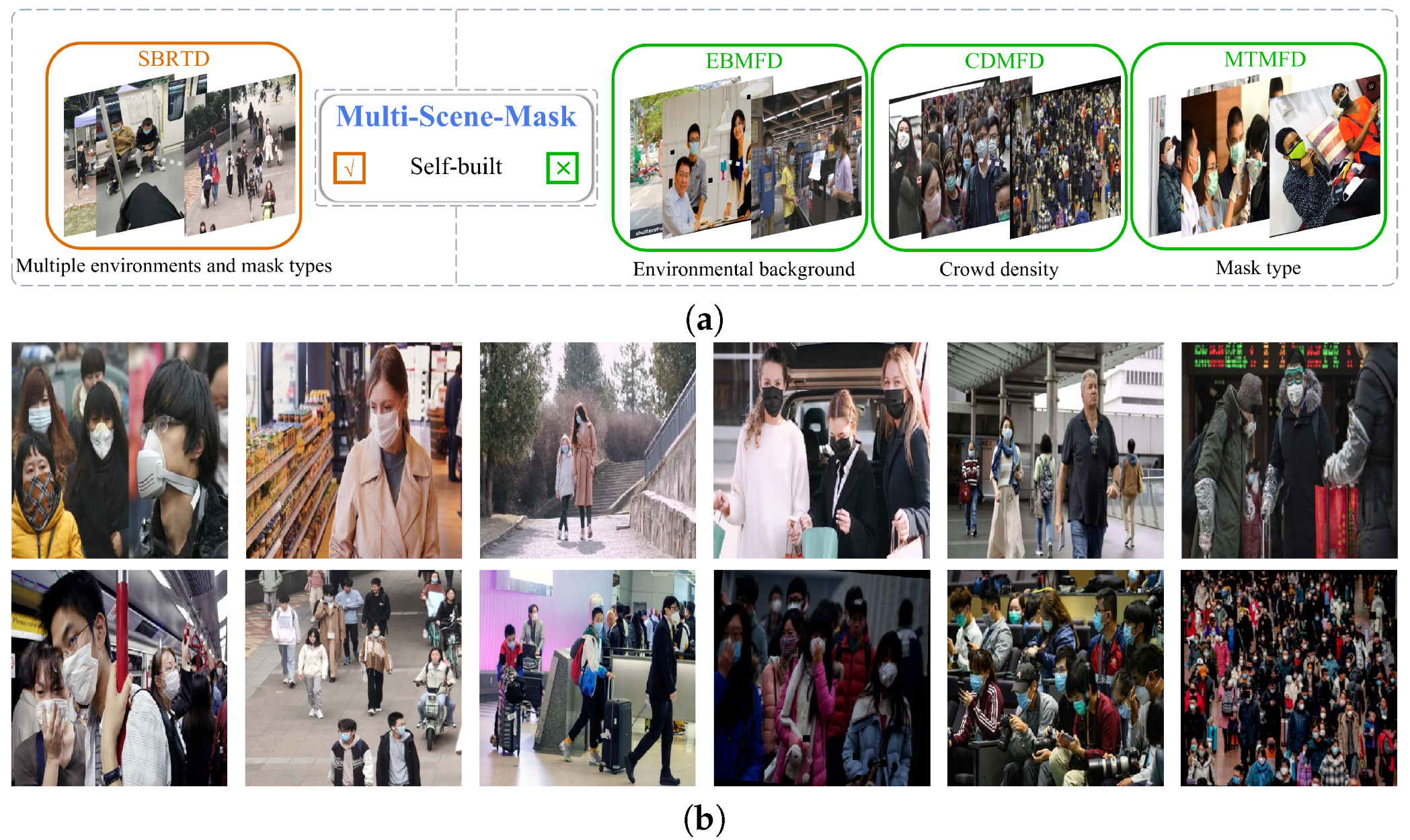
- A new dataset called Multi-Scene-Mask has been constructed, which contains various scenes, densities, and mask types. To capture the diversity of different scenarios, we construct the dataset by incorporating existing datasets such as Mask-Wearing [22], MaskedFace-Net [23], and RFMD [24], and also capture photographs of people wearing masks in multiple scenes such as hospitals, stations, campuses, parks, etc., by ourselves. The new dataset significantly improves the overall detection performance of the module in various scenarios.
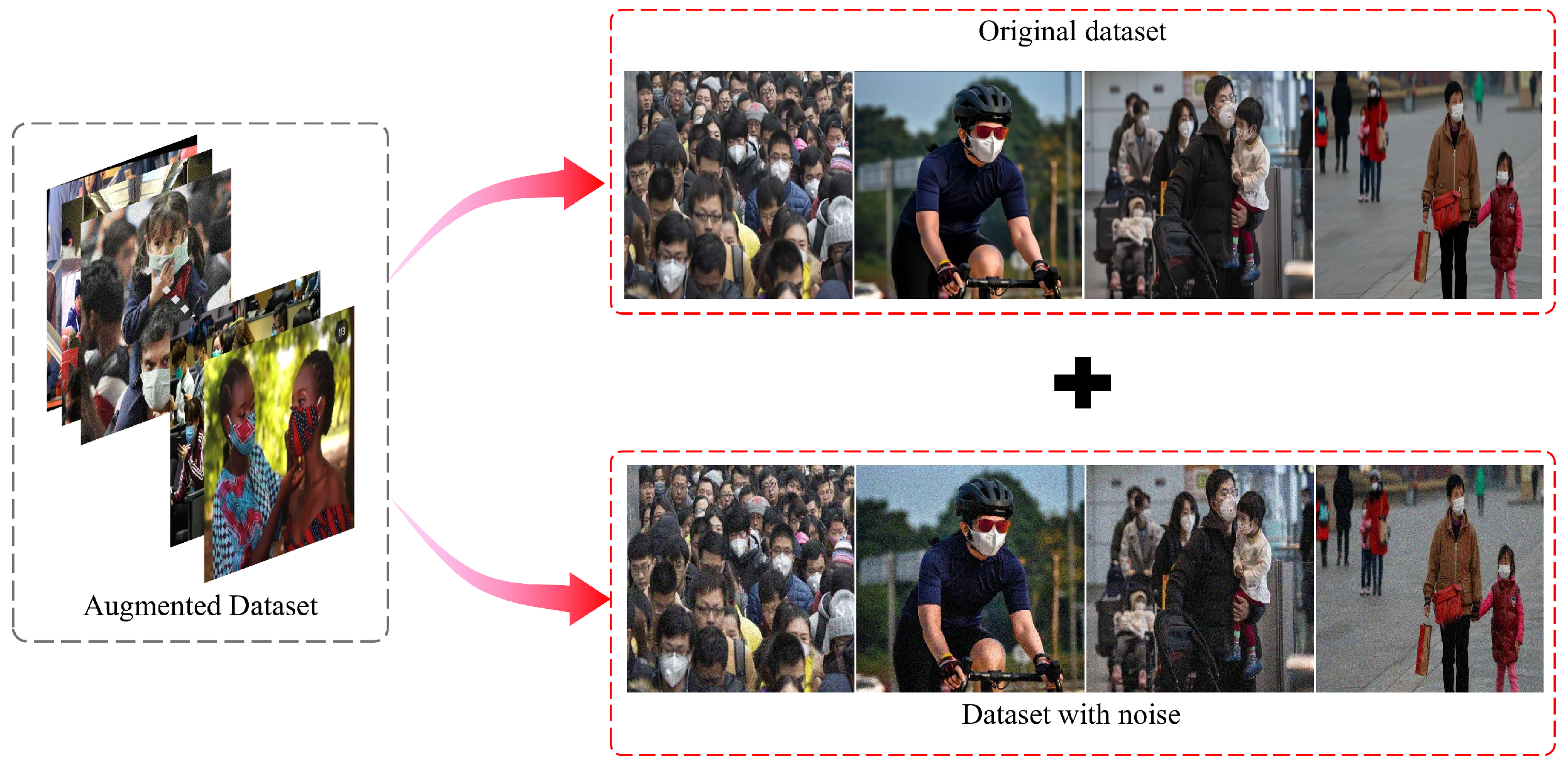
- A model generalization improvement strategy (GIS) is presented to make the network more adaptable to images in real environments. We augment the dataset by adding white Gaussian noise to the original training set, and then retrain the network and test it on the real dataset. This approach increases the coverage, density, and difficulty of the dataset, allowing the model to learn features that are robust to small variations in the data. The experiment shows that this strategy can greatly improve the generalization of the network, and it also verifies that YOLO-MSM has stronger generalization ability.
2. Related Work
2.1. Object Detection
2.2. Small Target Detection
2.3. Mask Wearing Detection
3. Method
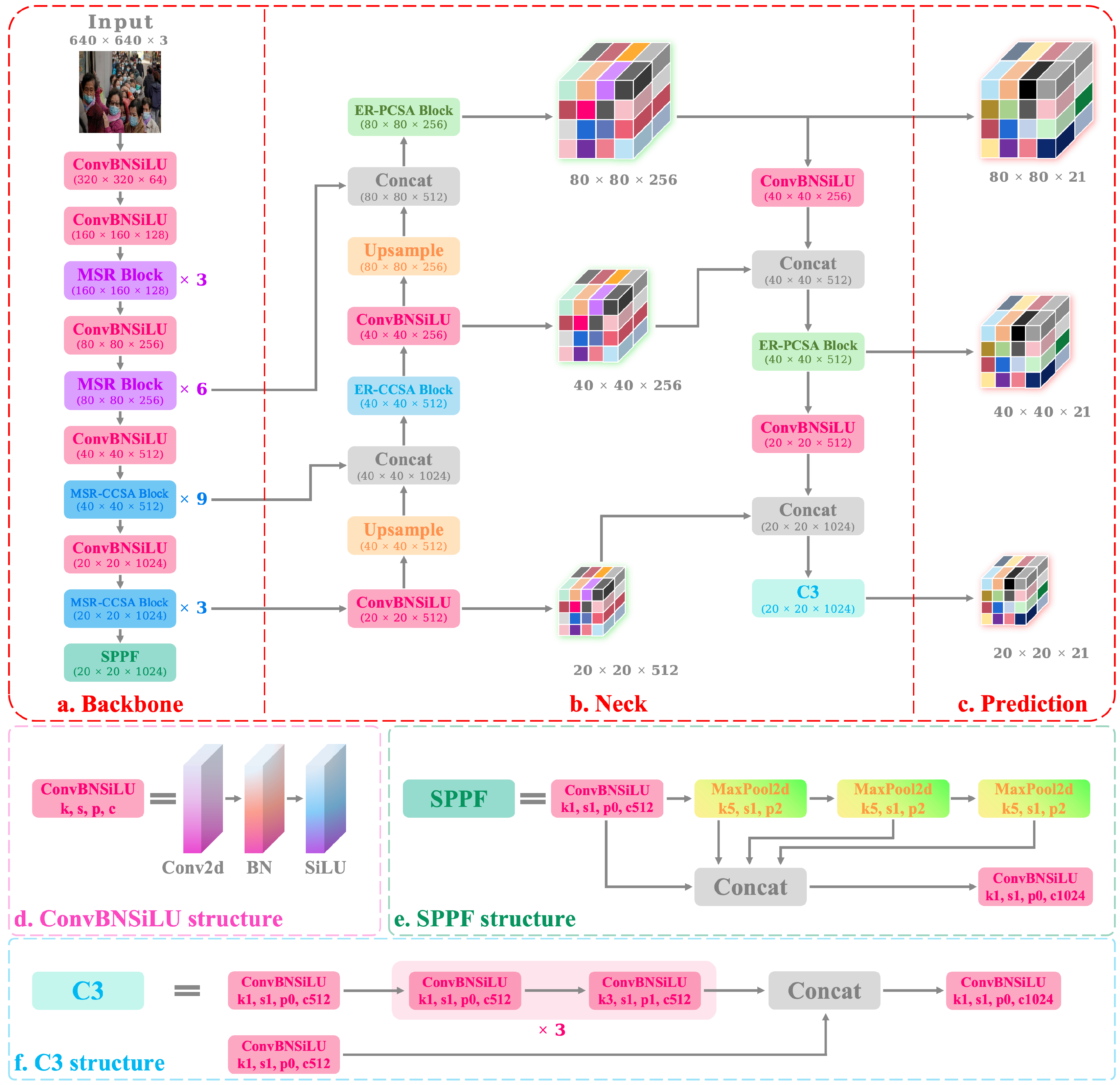
3.1. Network Structure
3.1.1. Overview of YOLO-MSM
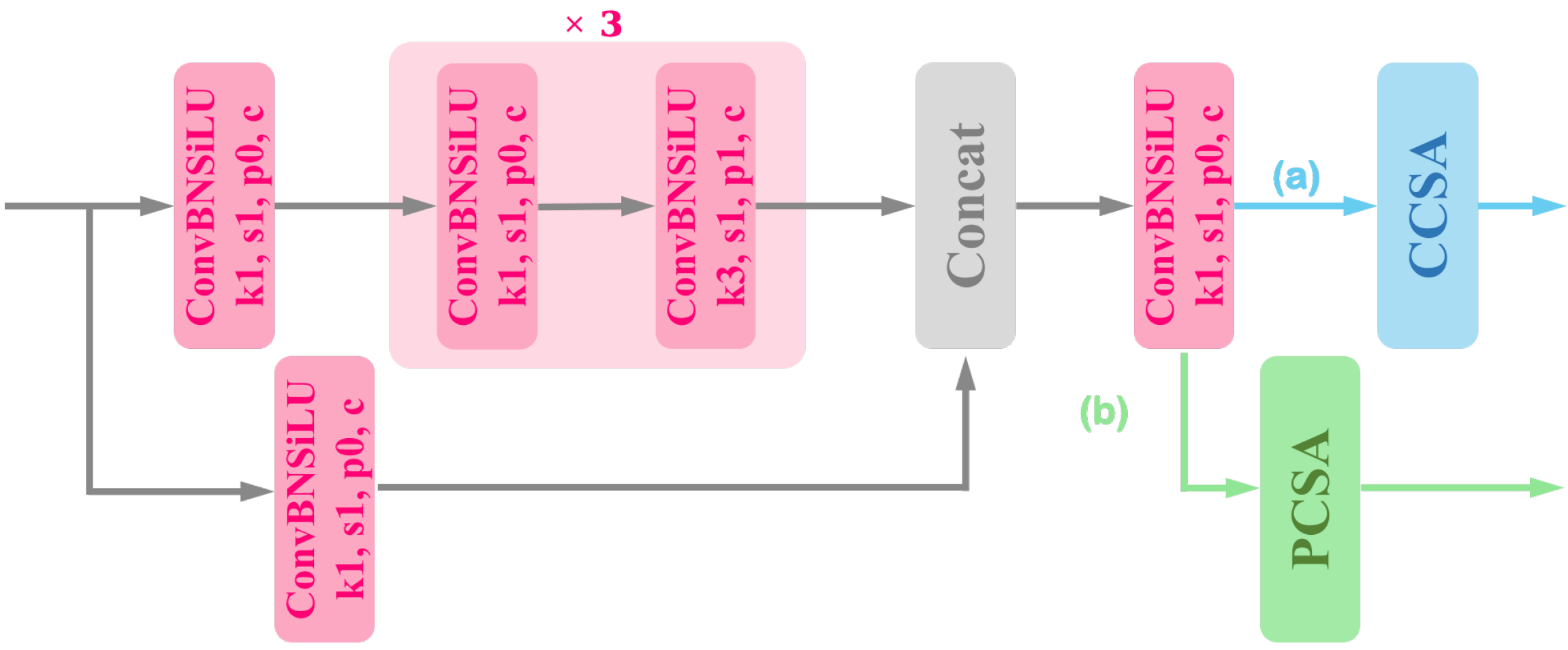
3.1.2. Backbone Based on MSR and MSR-CCSA Block
3.1.3. Feature Pyramid Structure Based on Complementary Attention Blocks
3.2. Construction and Synthesis of Datasets
- EBMFD: This built dataset contains 2500 masked face images, covering 8 types of environmental background. The main differences between these environments are viewpoint, lighting, occlusion, and other characteristics. The EBMFD dataset can be used to improve the detection performance of the network for masks in various backgrounds in reality.
- CDMFD: We divide the crowd density into four levels according to the number of face targets contained in the image. Photos containing 0 to 5 targets are used as level I, 6 to 20 as level II, 21 to 50 as level III, and 51 to 100 as level IV. The dataset contains 2000 photos of face masks, which enables the model to adapt to the detection of different crowd densities.
- MTMFD: In order to prevent the network from detecting only a single type of mask, we collect various types of masks and divide them into 10 categories according to shape, color, and material. The dataset has 1500 images of people wearing various types of masks.
- SBRTD: As we need to subsequently check the model’s generalization ability, we utilize real photos as the test dataset for the GIS experiment. We collect a total of 500 high-quality images of masked faces in various scenes, including schools, hospitals, parks, supermarkets, etc.
3.3. Generalization Improvement Strategy
4. Experiment
4.1. Parameter Setting
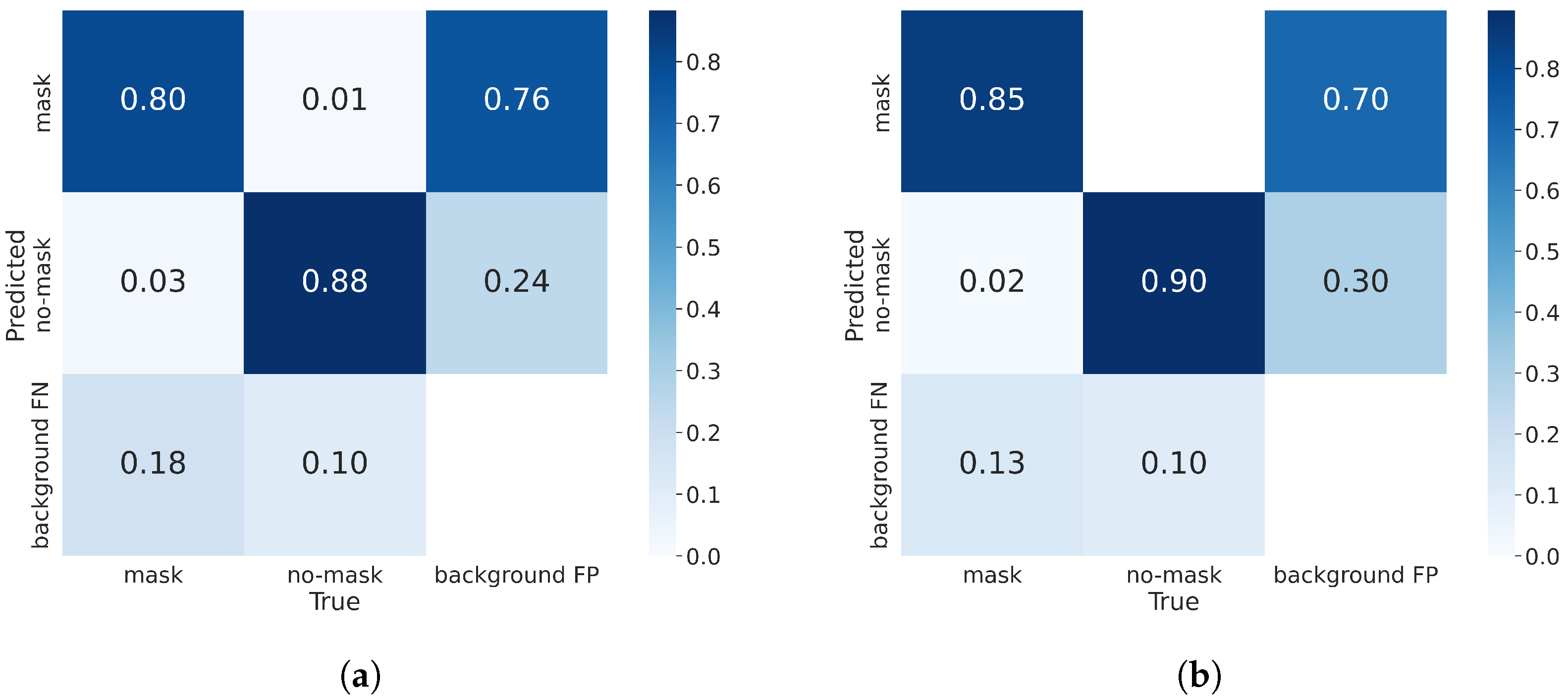
4.2. Evaluation Metrics
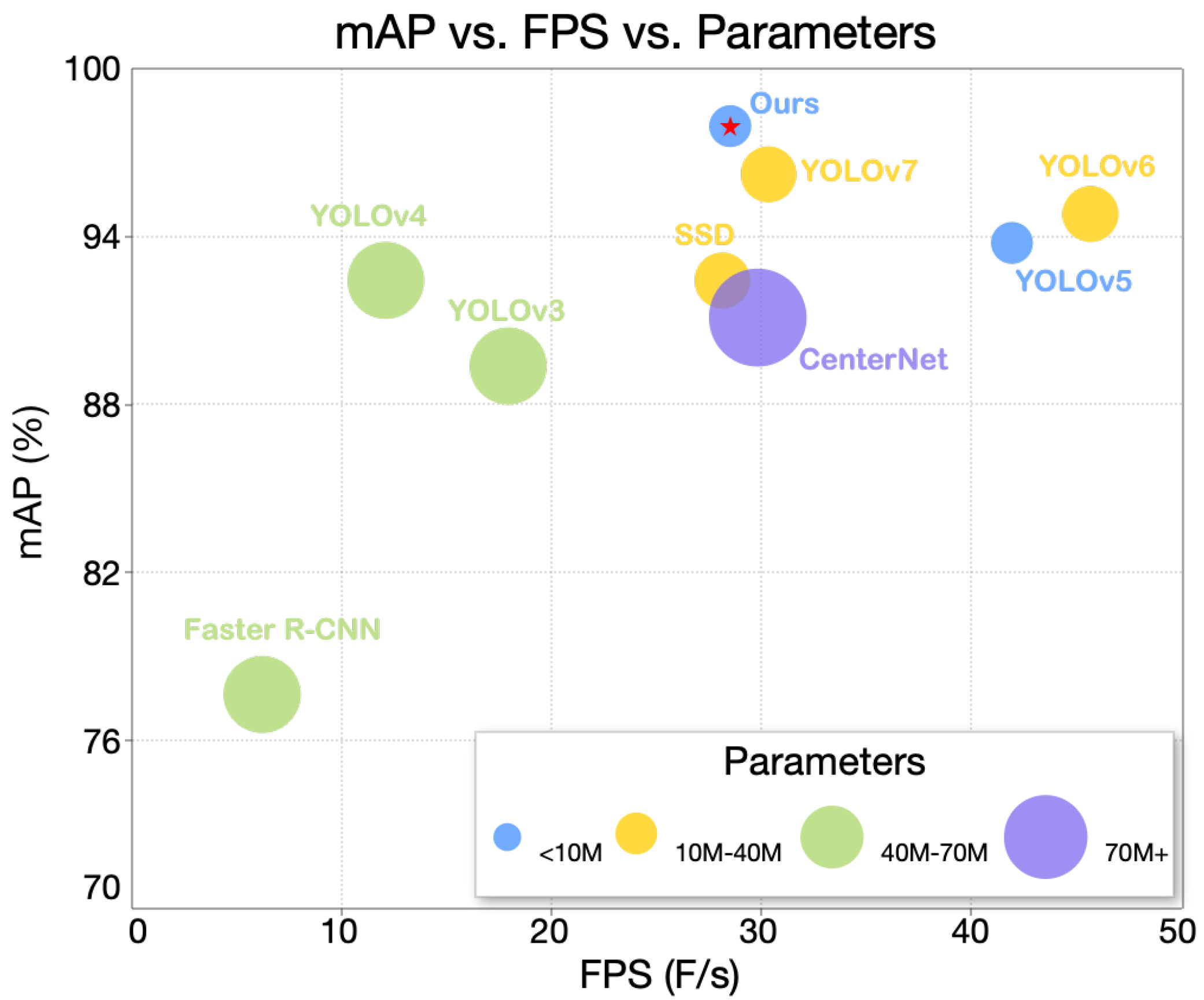
4.3. Comparison with Typical and General Detection Methods
4.4. Comparison with Mask Detection Methods
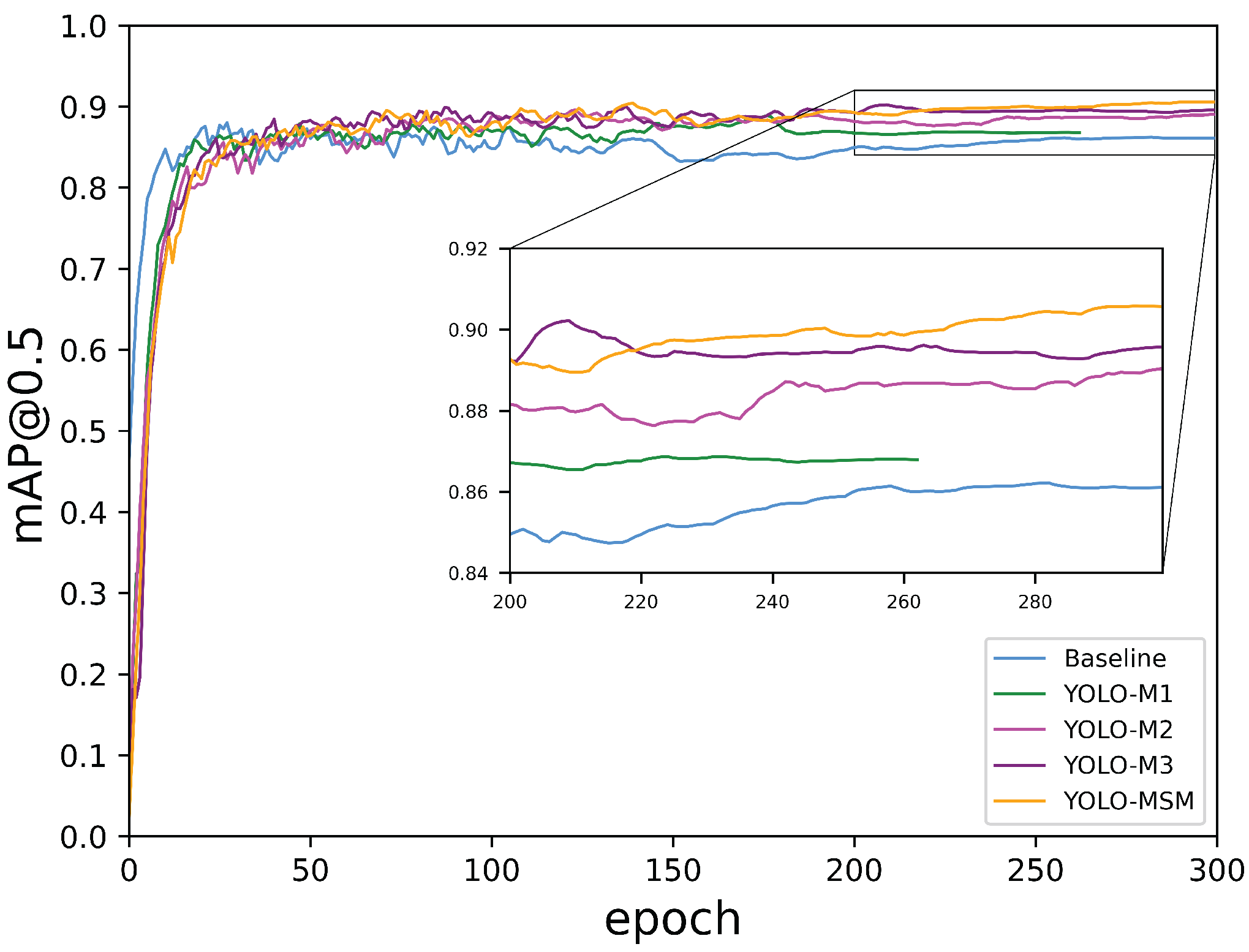
4.5. Ablation Study
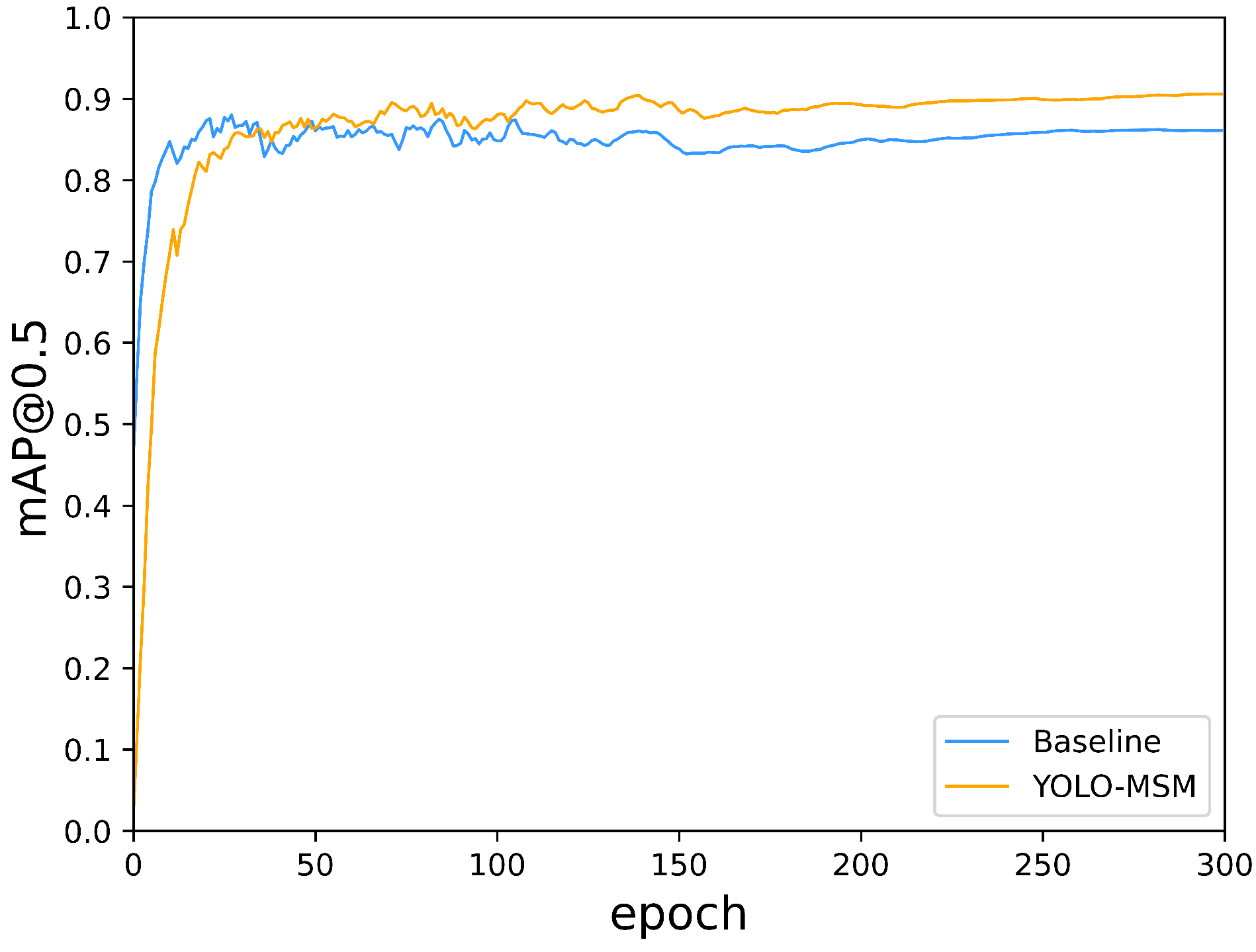
4.6. Effectiveness of GIS
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Benifa, J.B.; Chola, C.; Muaad, A.Y.; Hayat, M.A.B.; Bin Heyat, M.B.; Mehrotra, R.; Akhtar, F.; Hussein, H.S.; Vargas, D.L.R.; Castilla, Á.K.; et al. FMDNet: An Efficient System for Face Mask Detection Based on Lightweight Model during COVID-19 Pandemic in Public Areas. Sensors 2023, 23, 6090. [Google Scholar] [CrossRef] [PubMed]
- Su, X.; Gao, M.; Ren, J.; Li, Y.; Dong, M.; Liu, X. Face mask detection and classification via deep transfer learning. Multimed. Tools Appl. 2022, 81, 4475–4494. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Guo, F.; Cao, Y.; Li, L.; Guo, Y. Insight into COVID-2019 for pediatricians. Pediatr. Pulmonol. 2020, 55, E1–E4. [Google Scholar] [CrossRef]
- Jung, H.R.; Park, C.; Kim, M.; Jhon, M.; Kim, J.W.; Ryu, S.; Lee, J.Y.; Kim, J.M.; Park, K.H.; Jung, S.I.; et al. Factors associated with mask wearing among psychiatric inpatients during the COVID-19 pandemic. Schizophr. Res. 2021, 228, 235. [Google Scholar] [CrossRef] [PubMed]
- Leung, N.H.; Chu, D.K.; Shiu, E.Y.; Chan, K.H.; McDevitt, J.J.; Hau, B.J.; Yen, H.L.; Li, Y.; Ip, D.K.; Peiris, J.; et al. Respiratory virus shedding in exhaled breath and efficacy of face masks. Nat. Med. 2020, 26, 676–680. [Google Scholar] [CrossRef] [PubMed]
- Van der Sande, M.; Teunis, P.; Sabel, R. Professional and home-made face masks reduce exposure to respiratory infections among the general population. PLoS ONE 2008, 3, e2618. [Google Scholar] [CrossRef] [PubMed]
- Ingle, M.A.; Talmale, G.R. Respiratory mask selection and leakage detection system based on canny edge detection operator. Procedia Comput. Sci. 2016, 78, 323–329. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, G.; Wu, X.; Wang, Y.; Ma, Y. An enhanced Viola-Jones vehicle detection method from unmanned aerial vehicles imagery. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1845–1856. [Google Scholar] [CrossRef]
- Yan, J.; Lei, Z.; Yang, Y.; Li, S.Z. Stacked deformable part model with shape regression for object part localization. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 568–583. [Google Scholar]
- Dehghani, A.; Moloney, D.; Griffin, I. Object recognition speed improvement using BITMAP-HoG. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 659–663. [Google Scholar]
- Shinde, P.P.; Shah, S. A review of machine learning and deep learning applications. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; pp. 1–6. [Google Scholar]
- Ge, S.; Li, J.; Ye, Q.; Luo, Z. Detecting masked faces in the wild with LLE-CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2682–2690. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. Wider face: A face detection benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Batagelj, B.; Peer, P.; Štruc, V.; Dobrišek, S. How to correctly detect face-masks for COVID-19 from visual information? Appl. Sci. 2021, 11, 2070. [Google Scholar] [CrossRef]
- Siradjuddin, I.A.; Reynaldi; Muntasa, A. Faster Region-based Convolutional Neural Network for Mask Face Detection. In Proceedings of the 2021 5th International Conference on Informatics and Computational Sciences (ICICoS), Semarang, Indonesia, 24–25 November 2021; pp. 282–286. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y. ultralytics/yolov5: V6. 1-TensorRT TensorFlow edge TPU and OpenVINO export and inference. Zenodo 2022, 2, 2. [Google Scholar] [CrossRef]
- Ju, M.; Luo, J.; Liu, G.; Luo, H. A real-time small target detection network. Signal Image Video Process. 2021, 15, 1265–1273. [Google Scholar] [CrossRef]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Zhang, J.; Meng, Y.; Chen, Z. A Small Target Detection Method Based on Deep Learning with Considerate Feature and Effectively Expanded Sample Size. IEEE Access 2021, 9, 96559–96572. [Google Scholar] [CrossRef]
- Karimipour, A.; Bagherzadeh, S.A.; Taghipour, A.; Abdollahi, A.; Safaei, M.R. A novel nonlinear regression model of SVR as a substitute for ANN to predict conductivity of MWCNT-CuO/water hybrid nanofluid based on empirical data. Phys. A Stat. Mech. Its Appl. 2019, 521, 89–97. [Google Scholar] [CrossRef]
- Nelson, J. Mask Wearing Dataset. 2020. Available online: https://public.roboflow.com/object-detection/mask-wearing (accessed on 26 September 2020).
- Cabani, A.; Hammoudi, K.; Benhabiles, H.; Melkemi, M. MaskedFace-Net—A dataset of correctly/incorrectly masked face images in the context of COVID-19. Smart Health 2021, 19, 100144. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, B.; Wang, G.; Yi, P.; Jiang, K. Masked face recognition dataset and application. IEEE Trans. Biom. Behav. Identity Sci. 2023, 5, 298–304. [Google Scholar] [CrossRef]
- Liu, J.; Huang, W.; Xiao, L.; Huo, Y.; Xiong, H.; Li, X.; Xiao, W. Deep Learning Object Detection. In Proceedings of the Smart Computing and Communication: 7th International Conference, SmartCom 2022, New York, NY, USA, 18–20 November 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 300–309. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, Y.; Ge, H.; Lin, Q.; Zhang, M.; Sun, Q. Research of Maritime Object Detection Method in Foggy Environment Based on Improved Model SRC-YOLO. Sensors 2022, 22, 7786. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Huang, L.; Huang, W. RD-YOLO: An effective and efficient object detector for roadside perception system. Sensors 2022, 22, 8097. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Guo, W.; Zhao, S.; Xue, B.; Zhang, W.; Xing, Z. A Big Coal Block Alarm Detection Method for Scraper Conveyor Based on YOLO-BS. Sensors 2022, 22, 9052. [Google Scholar] [CrossRef]
- Xue, J.; Zheng, Y.; Dong-Ye, C.; Wang, P.; Yasir, M. Improved YOLOv5 network method for remote sensing image-based ground objects recognition. Soft Comput. 2022, 26, 10879–10889. [Google Scholar] [CrossRef]
- Al Jaberi, S.M.; Patel, A.; AL-Masri, A.N. Object tracking and detection techniques under GANN threats: A systemic review. Appl. Soft Comput. 2023, 139, 110224. [Google Scholar] [CrossRef]
- Yu, X.; Gong, Y.; Jiang, N.; Ye, Q.; Han, Z. Scale match for tiny person detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 1257–1265. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Deng, C.; Wang, M.; Liu, L.; Liu, Y.; Jiang, Y. Extended feature pyramid network for small object detection. IEEE Trans. Multimed. 2021, 24, 1968–1979. [Google Scholar] [CrossRef]
- Li, J.; Wei, Y.; Liang, X.; Dong, J.; Xu, T.; Feng, J.; Yan, S. Attentive contexts for object detection. IEEE Trans. Multimed. 2016, 19, 944–954. [Google Scholar] [CrossRef]
- Chen, Q.; Song, Z.; Dong, J.; Huang, Z.; Hua, Y.; Yan, S. Contextualizing object detection and classification. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 13–27. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. SOD-MTGAN: Small object detection via multi-task generative adversarial network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 206–221. [Google Scholar]
- Tychsen-Smith, L.; Petersson, L. Denet: Scalable real-time object detection with directed sparse sampling. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 428–436. [Google Scholar]
- Wang, X.; Chen, K.; Huang, Z.; Yao, C.; Liu, W. Point linking network for object detection. arXiv 2017, arXiv:1706.03646. [Google Scholar]
- Konar, D.; Sarma, A.D.; Bhandary, S.; Bhattacharyya, S.; Cangi, A.; Aggarwal, V. A shallow hybrid classical–quantum spiking feedforward neural network for noise-robust image classification. Appl. Soft Comput. 2023, 136, 110099. [Google Scholar] [CrossRef]
- Khandelwal, P.; Khandelwal, A.; Agarwal, S.; Thomas, D.; Xavier, N.; Raghuraman, A. Using computer vision to enhance safety of workforce in manufacturing in a post COVID world. arXiv 2020, arXiv:2005.05287. [Google Scholar]
- Fan, X.; Jiang, M. RetinaFaceMask: A single stage face mask detector for assisting control of the COVID-19 pandemic. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 832–837. [Google Scholar]
- Qin, B.; Li, D. Identifying facemask-wearing condition using image super-resolution with classification network to prevent COVID-19. Sensors 2020, 20, 5236. [Google Scholar] [CrossRef]
- Jiang, C.; Tan, L.; Lin, T.; Huang, Z. Mask wearing detection algorithm based on improved YOLOv5. In Proceedings of the International Conference on Computer, Artificial Intelligence, and Control Engineering (CAICE 2023), Guangzhou, China, 17–19 February 2023; SPIE: Bellingham, WA, USA, 2023; Volume 12645, pp. 1057–1064. [Google Scholar]
- Tomás, J.; Rego, A.; Viciano-Tudela, S.; Lloret, J. Incorrect facemask-wearing detection using convolutional neural networks with transfer learning. Healthcare 2021, 9, 1050. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Albogamy, F.R.; Al-Rakhami, M.S.; Asghar, J.; Rahmat, M.K.; Alam, M.M.; Lajis, A.; Nasir, H.M. Facial mask detection using depthwise separable convolutional neural network model during COVID-19 pandemic. Front. Public Health 2022, 10, 855254. [Google Scholar] [CrossRef]
- Balaji, S.; Balamurugan, B.; Kumar, T.A.; Rajmohan, R.; Kumar, P.P. A brief survey on AI based face mask detection system for public places. Ir. Interdiscip. J. Sci. Res. 2021, 5, 108–117. [Google Scholar]
- Udemans, C. Baidu Releases Open-Source Tool to Detect Faces without Masks. 2020. Available online: https://technode.com/2020/02/14/baidu-open-source-face-masks (accessed on 14 February 2020).
- Aerialtronics. Face Mask Detection Software. 2022. Available online: https://www.aerialtronics.com/en/products/face-mask-detection-software#featuresfacemask (accessed on 14 February 2020).
- Benning, M.; Burger, M. Modern regularization methods for inverse problems. Acta Numer. 2018, 27, 1–111. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- PureHing. Face-Mask-Detection-tf2. 2020. Available online: https://github.com/PureHing/face-mask-detection-tf2 (accessed on 26 September 2020).
- Shenzhen, D. YOLOv5-Face. 2021. Available online: https://github.com/deepcam-cn/yolov5-face/tree/master (accessed on 7 April 2021).
- Detect Faces and Determine Whether They Are Wearing Mask. 2020. Available online: https://github.com/AIZOOTech/FaceMaskDetection (accessed on 14 February 2020).
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5203–5212. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Purpose | Images | Faces | Labels | |
|---|---|---|---|---|---|
| With Mask | Without Mask | ||||
| EBMFD | Train | 2250 | 5769 | 5013 | 756 |
| Test | 250 | 638 | 561 | 77 | |
| CDMFD | Train | 1800 | 30,469 | 28,796 | 1673 |
| Test | 200 | 3537 | 3120 | 417 | |
| MTMFD | Train | 1350 | 2268 | 2219 | 49 |
| Test | 150 | 224 | 207 | 17 | |
| SBRTD | Train | 0 | 0 | 0 | 0 |
| Test | 500 | 2183 | 1864 | 319 | |
| Muti-Scene-Mask | Train | 5400 | 38,506 | 36,028 | 2478 |
| Test | 1100 | 6582 | 5752 | 830 | |
| Totals | 6500 | 45,088 | 41,780 | 3308 | |
| Training Config | Settings |
|---|---|
| Dataset | Multi-Scene-Mask |
| GPU | NVIDIA GeForce RTX3080 (Nvidia Corporation, Santa Clara, CA, USA) |
| Deep learning framework | Pytorch 1.13.0 |
| Programming language | Python 3.9 |
| Image size | |
| Batch size | 16 |
| Epoch | 300 |
| Optimizer | SGD |
| Base learning rate | 0.01 |
| Learning rate momentum | 0.937 |
| Weight decay |
| Methods | mAP (%) | Parameters/10 | FPS (F/s) | Inference Time (s) |
|---|---|---|---|---|
| Faster R-CNN | 77.78 | 60.61 | 6.04 | 0.1655 |
| CenterNet | 91.35 | 86.67 | 28.55 | 0.0350 |
| SSD | 92.44 | 26.79 | 27.67 | 0.0361 |
| YOLOv3 | 89.10 | 61.50 | 17.36 | 0.0576 |
| YOLOv4 | 92.98 | 64.01 | 11.32 | 0.0883 |
| YOLOv5 | 94.05 | 7.02 | 41.49 | 0.0241 |
| YOLOv6 | 94.96 | 18.50 | 45.30 | 0.0221 |
| YOLOv7 | 96.53 | 36.49 | 30.03 | 0.0333 |
| YOLO-MSM (Ours) | 97.51 | 7.14 | 28.16 | 0.0355 |
| Dataset | Purpose | Images | Faces | Labels | ||
|---|---|---|---|---|---|---|
| Correctly Worn Mask | Incorrectly Worn Mask | Without Mask | ||||
| MAFA | Train | 25,876 | 29,452 | 24,603 | 1204 | 3645 |
| Test | 4935 | 7342 | 4929 | 324 | 2089 | |
| Wider Face | Train | 8906 | 20,932 | 0 | 0 | 20,932 |
| Test | 2217 | 5346 | 0 | 0 | 5346 | |
| FMLD | Train | 34,782 | 50,384 | 24,603 | 1204 | 24,577 |
| Test | 7152 | 12,688 | 4929 | 324 | 7435 | |
| Totals | 41,934 | 63,072 | 29,532 | 1528 | 32,012 | |
| Methods | mAP@0.4 (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) |
|---|---|---|---|
| PureHing | 75.38 | 70.12 | 35.48 |
| YOLOv5-Face | 77.21 | 74.58 | 41.65 |
| AIZOOTech | 85.47 | 78.29 | 47.75 |
| RetinaFace | 88.39 | 82.02 | 50.06 |
| YOLO-MSM (Ours) | 91.68 | 84.92 | 51.42 |
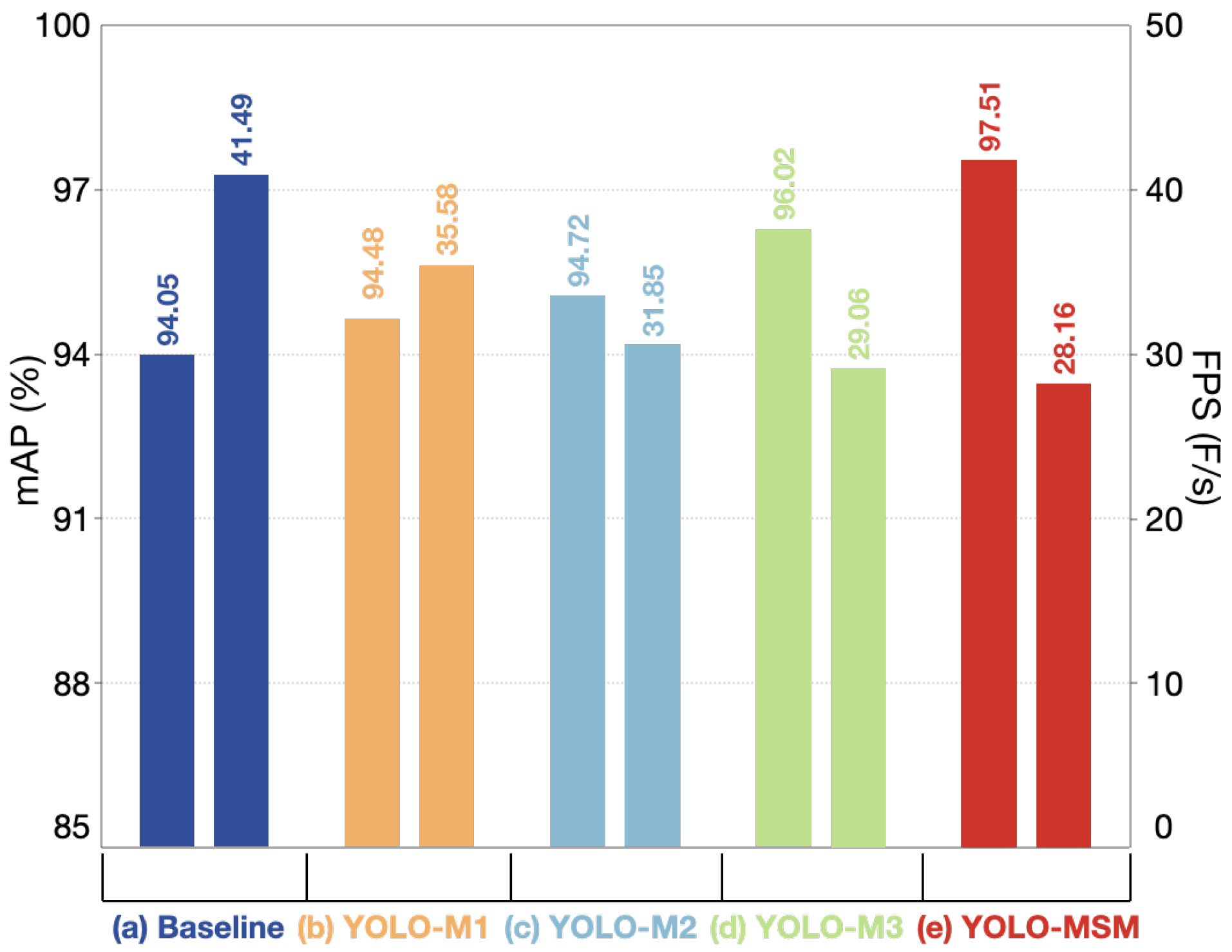
| Methods | MSR Block | MSR-CCSA Block | ER-CCSA Block | ER-PCSA Block |
|---|---|---|---|---|
| YOLO-M1 | ✓ | |||
| YOLO-M2 | ✓ | ✓ | ||
| YOLO-M3 | ✓ | ✓ | ✓ | |
| YOLO-MSM (Ours) | ✓ | ✓ | ✓ | ✓ |
| Methods | mAP (%) | mAP@0.5 (%) | Parameters/10 | FPS (F/s) |
|---|---|---|---|---|
| Baseline | 94.05 | 86.17 | 7.016 | 41.49 |
| YOLO-M1 | 94.48 | 86.79 | 7.032 | 35.58 |
| YOLO-M2 | 94.72 | 88.91 | 7.090 | 31.85 |
| YOLO-M3 | 96.02 | 89.57 | 7.131 | 29.06 |
| YOLO-MSM (Ours) | 97.51 | 90.56 | 7.141 | 28.16 |
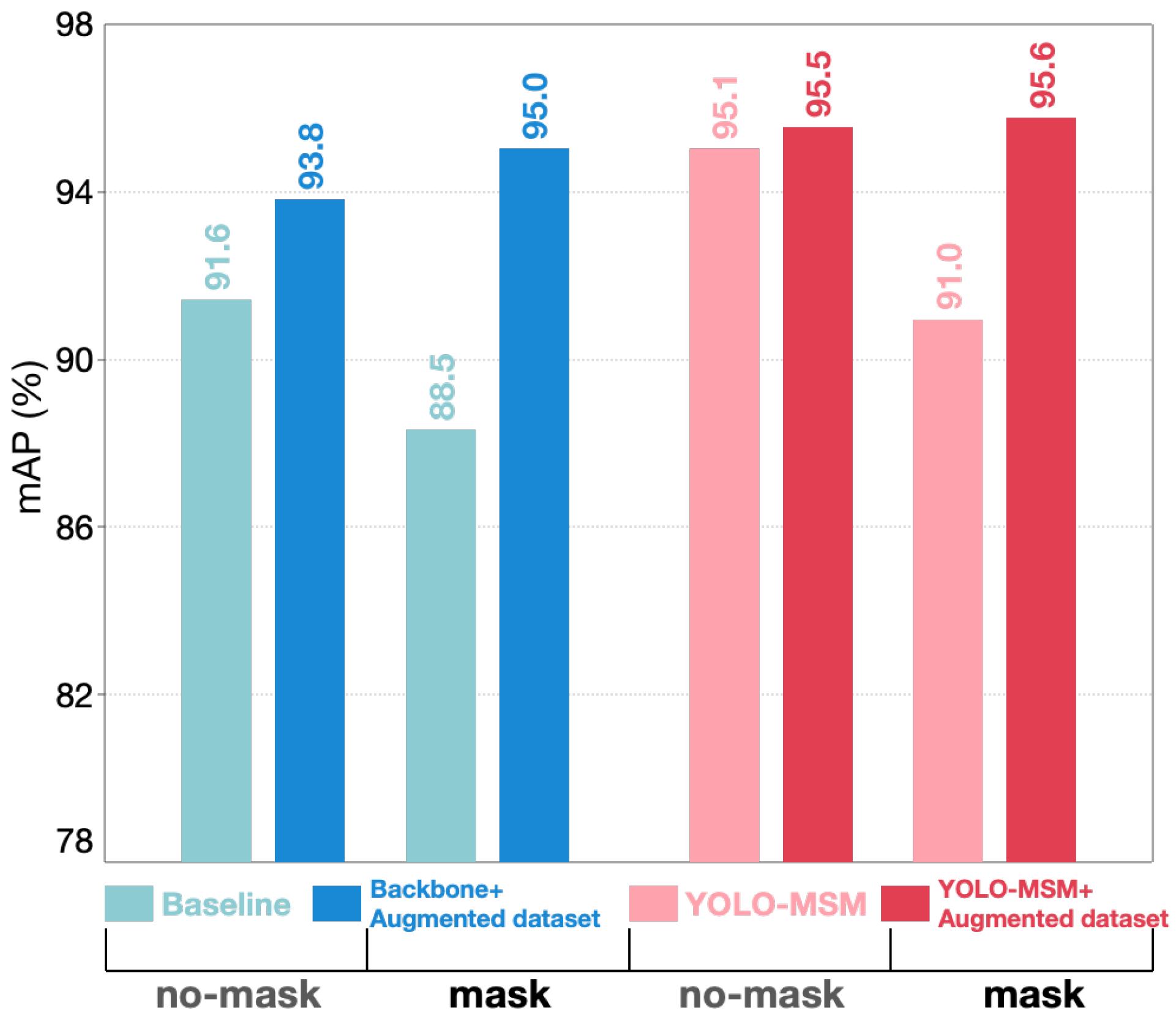
| Methods | Augmented Dataset | No-Mask (%) | Mask (%) | mAP (%) | mAP@0.5 (%) |
|---|---|---|---|---|---|
| Baseline | × | 91.6 | 88.5 | 90.1 | 87.3 |
| ✓ | 93.8 | 95.0 | 94.4 | 89.8 | |
| YOLO-MSM (Ours) | × | 95.1 | 91.0 | 93.1 | 90.3 |
| ✓ | 95.5 | 95.6 | 95.6 | 90.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Lin, X.; Luo, S.; Ding, S.; Xiao, L.; Ren, C. Multi-Scene Mask Detection Based on Multi-Scale Residual and Complementary Attention Mechanism. Sensors 2023, 23, 8851. https://doi.org/10.3390/s23218851
Zhou Y, Lin X, Luo S, Ding S, Xiao L, Ren C. Multi-Scene Mask Detection Based on Multi-Scale Residual and Complementary Attention Mechanism. Sensors. 2023; 23(21):8851. https://doi.org/10.3390/s23218851
Chicago/Turabian StyleZhou, Yuting, Xin Lin, Shi Luo, Sixian Ding, Luyang Xiao, and Chao Ren. 2023. "Multi-Scene Mask Detection Based on Multi-Scale Residual and Complementary Attention Mechanism" Sensors 23, no. 21: 8851. https://doi.org/10.3390/s23218851
APA StyleZhou, Y., Lin, X., Luo, S., Ding, S., Xiao, L., & Ren, C. (2023). Multi-Scene Mask Detection Based on Multi-Scale Residual and Complementary Attention Mechanism. Sensors, 23(21), 8851. https://doi.org/10.3390/s23218851