1. Introduction
Simultaneous localization and mapping (SLAM) is one of the core problems in mobile robotics research [
1,
2]. Compared to laser sensors, vision sensors have the advantages of fine perception, low price, smaller size, and lighter weight. Thus, Visual SLAM (VSLAM) has made great progress in the last few decades. Among various VSLAM algorithms, feature-based algorithms are widely used in long-term robot deployment because of their high efficiency and scalability. However, most existing SLAM systems rely on hand-crafted visual features, such as SIFT [
3], the Shi–Tomasi method [
4], and ORB [
5], which may not provide consistent feature detection and association results in dynamic environments. For example, when either the scene or the viewpoint has been changed, ORB-SLAM2 frequently fails to recognize previously visited scenes because of less visual feature information [
6]. Thus, the mobile robot needs to use re-localization and loop closure detection to identify whether this scene has been visited before. Generally, the re-localization is accomplished using loop closure detection to correlate information. Firstly, the bag-of-words model is used to extract candidate frames for relocation with high similarity to the current frame. Then, the frame-to-frame matching method is used to match the local features of the current frame and re-localize candidate frames until all the candidate frames are traversed or the information is associated. However, in dynamic environments, Visual SLAM often fails in re-localization and loop closure detection due to the insufficient numbers of matched local feature point pairs. However, the numbers of matched local feature point pairs are insufficient because of dynamic objects, which can vastly impair the performance of the Visual SLAM system [
7]. Therefore, Visual SLAM often fails in re-localization and loop closure detection. In order to address this challenging topic, some researchers have performed some work on feature removal [
8,
9]. The stability of the system’s visual odometer is enhanced through removing feature points from dynamic objects.
In the real dynamic scene, re-localization and loop closure detection will fail with limited feature information [
10]. Therefore, the mobile robot often needs to go back to the previous place to extract more feature information, so as to complete the feature information matching to realize re-localization and loop closure detection. The combination of Visual SLAM and deep learning can solve this problem better than traditional methods [
11]. The main idea of deep learning is to extract image features using a network trained in advance [
12]. However, the disadvantage of deep learning is that it is computationally intensive and requires high-performance equipment. Furthermore, it is difficult to construct suitable models to store high-dimensional feature vectors. Thus, in recent years, researchers have attempted to introduce semantic information into Visual SLAM [
13,
14]. Using semantic information to describe the environment can effectively simplify the process of saving and comparing environmental information [
15,
16].
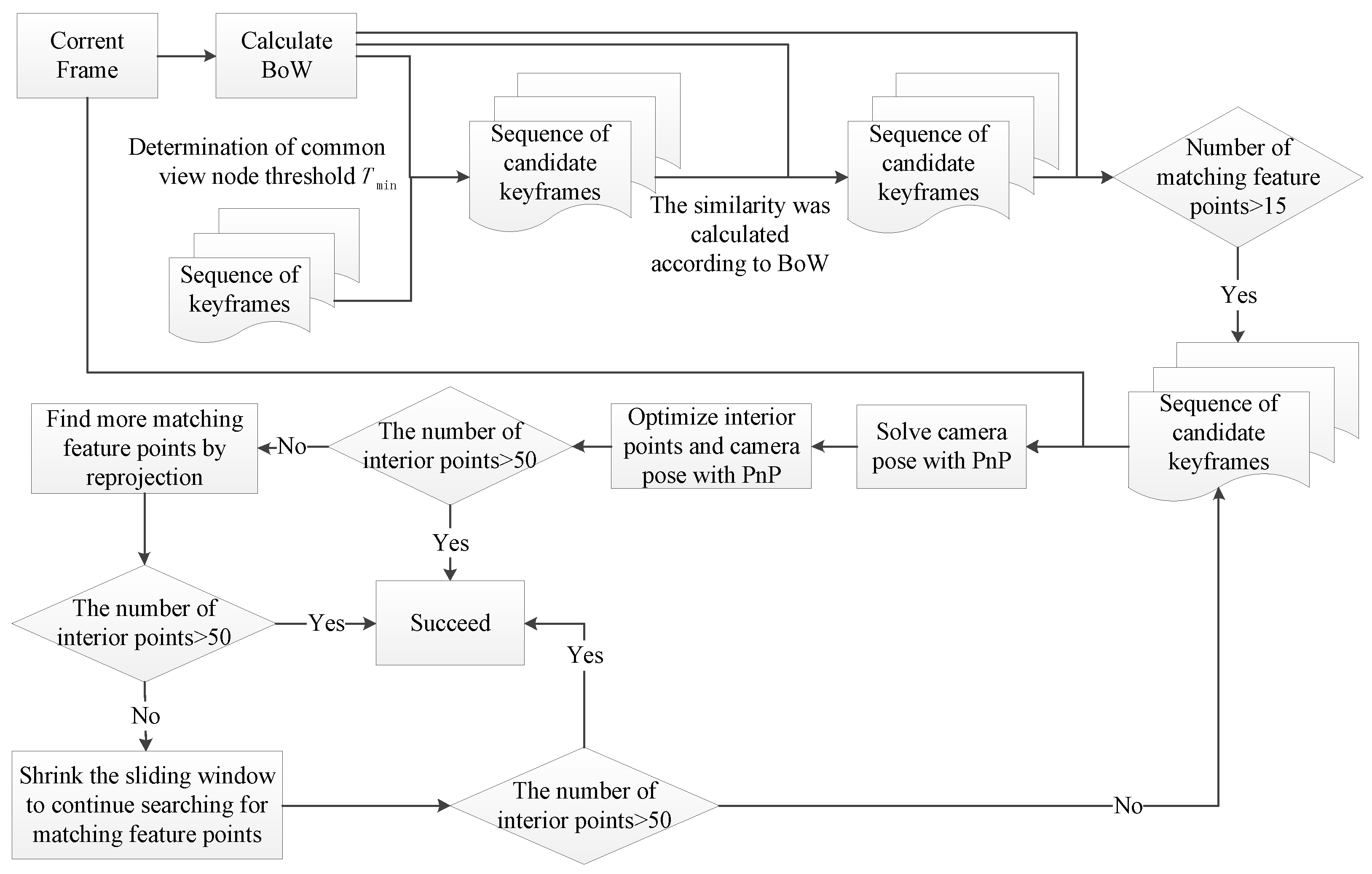
ORB-SLAM2 is the most widely used of the Visual SLAM frameworks [
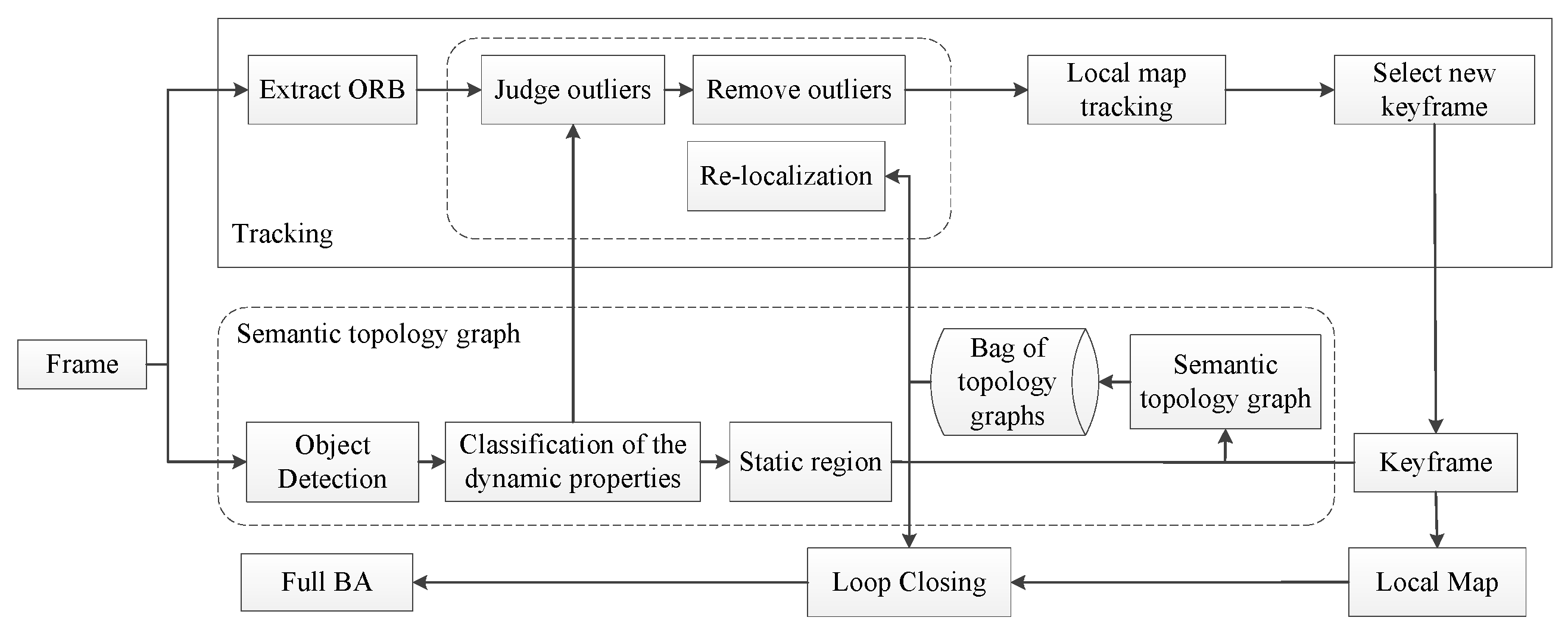
6]. The re-localization and loop closure detection of the ORB-SLAM2 framework are mainly accomplished by using the current frame to match feature points with the candidate keyframes. Therefore, the numbers of extracted feature points determine the accuracy and matching speed of re-localization and loop closure detection. The more feature points are extracted, the more accurate the localization and the faster the corresponding speed. However, it will affect the feature point extraction if the dynamic object moves fast in a dynamic environment, which will affect the accuracy of re-localization and loop closure detection. Despite this, the relative positions and distances of static objects do not change, irrespective of the motion of dynamic objects in the dynamic environment. Thus, we can build a semantic topology graph using the relative positions of static objects to assist in re-localization and loop closure detection, instead of relying only on static feature points.
Therefore, based on the above problems, this paper proposes a Visual SLAM method with semantic topology based on ORB-SLAM2. The proposed method improves the failure of re-localization and loop closure detection in dynamic environments due to limited feature information. The specific improvements are as follows:
- (1)
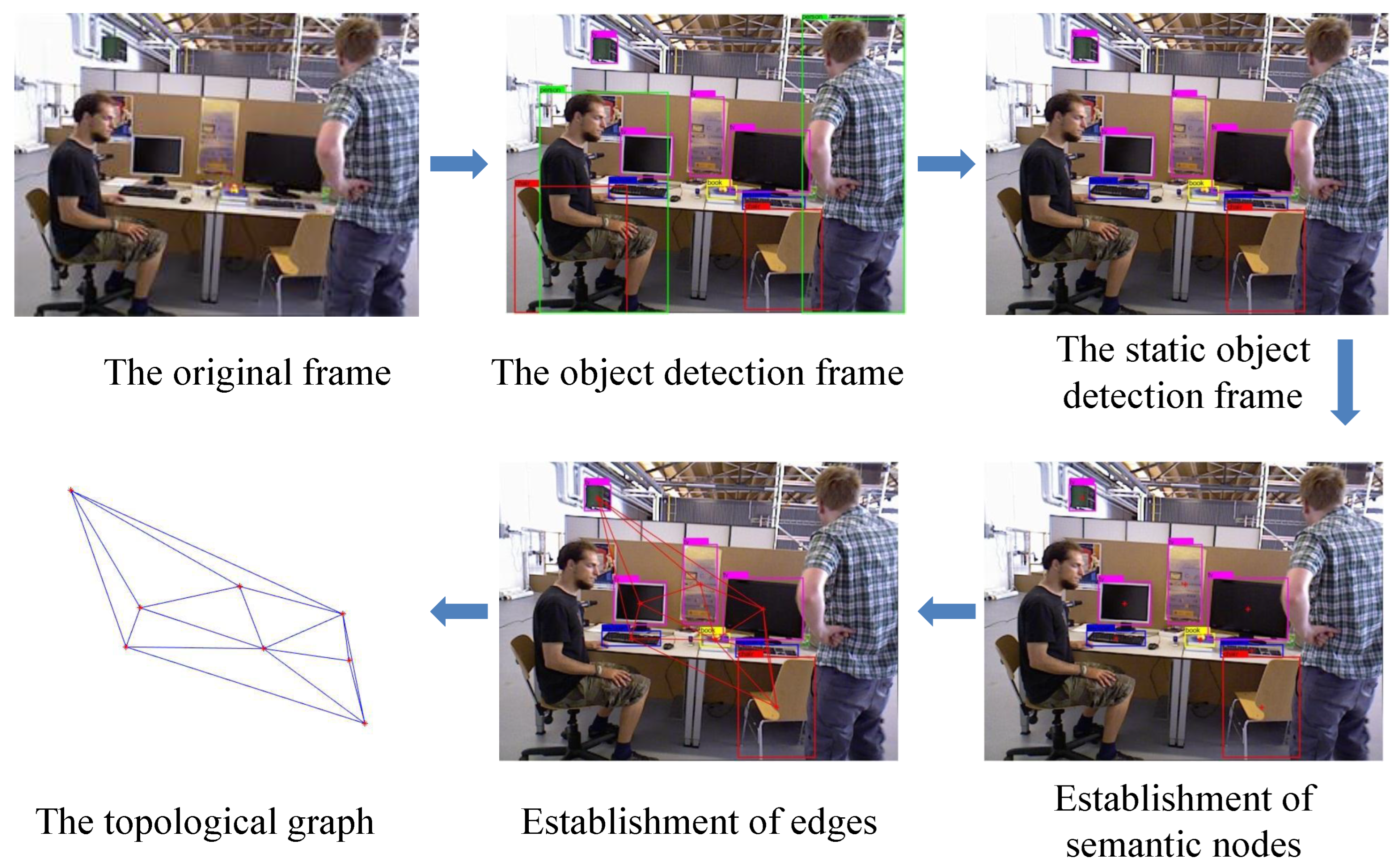
The method of object detection is used to obtain information about static objects in the dynamic environment.
- (2)
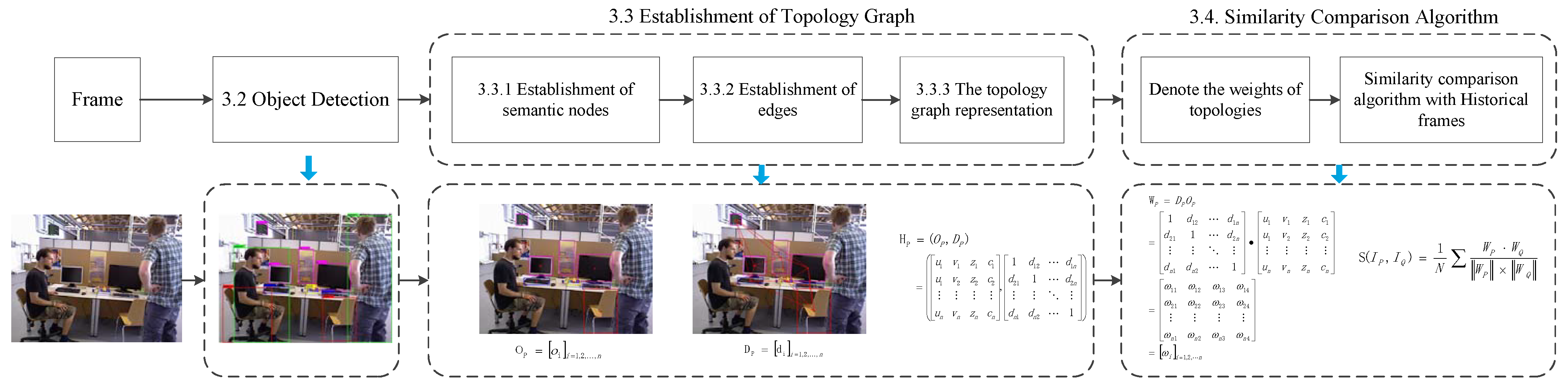
Low feature information and frame loss may occur due to the occlusion of dynamic objects. Thus, this paper proposes to construct a topological graph by utilizing the property of the invariant spatial position of static objects by judging the similarity of the semantic topological graph to find similar keyframes and then quickly determining its own pose information.
- (a)
Semantic nodes are obtained from the central points of static objects.
- (b)
The edges between nodes are obtained using the Delaunay triangulation method.
- (c)
An innovative topological graph similarity comparison algorithm is achieved.
This paper is organized as follows:
Section 2 presents the related work, and
Section 3 is a description of the method, which first summarizes the system structure of this paper and then describes the algorithm of this paper in detail.
Section 4 is the experimental section, which first verifies the feasibility of the method by using different data and then tests and evaluates the re-localization and loop closure detection.
Section 5 is the conclusion.
5. Conclusions
Re-localization and loop closure detection in dynamic environments, due to limited feature points information, often fail, and the correct re-localization and recall of loop closure detection are also low when the mobile robot loses frames in a dynamic environment. So, this paper proposes the re-localization and loop closure detection method with a semantic topology graph based on ORB-SLAM2. We conducted experiments on public datasets such as TUM, OpenLORIS-Scene, and a self-made platform. The results clarify that our method can improve the feasibility, accuracy, and stability of the VSLAM system in dynamic scenes. However, the proposed method relies heavily on the results of object detection. Whether the detected objects are sufficiently reliable greatly impacts our experimental performance. At the same time, the detector model may hardly predict correct results when there are significant differences between training scenes and actual scenes. In future work, we can employ self-supervised or unsupervised deep learning approaches in order to overcome this issue. On the other hand, the “bag of topology graphs” will take up storage space, so we will also further improve the real-time performance of the system.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}