1. Introduction
The majority of image sensors used nowadays are composed of CCD and CMOS image sensors [
1]. When using these sensors, a simple composition of still images is taken at a predetermined frame rate, to create a video. This approach has several shortcomings; one such problem is data redundancy—each new frame contains information about all pixels, regardless of whether this information is new or not. Handling this unnecessary information wastes memory, power, and bandwidth [
2]. This problem might not be critical for the low frames per second (30–60 fps) use case, which is common when the video is intended for human observers. However, applications in computer vision, specifically those that require real-time processing (more so even for high frames per second video), may suffer significantly from such inefficiencies [
3].
Several different sensors were suggested to overcome the shortcomings of the frame-based approach, some are bio-inspired (since they can outperform traditional designs [
4,
5]). Various approaches have been proposed, such as optical flow sensors [
6], which produce a vector for each pixel representing the apparent motion captured by that pixel, instead of generating an image, and temporal contrast vision sensors [
7], which only capture changes in pixel intensity and utilize hardware distinct from DVS, among others [
8,
9,
10]. However, the overwhelming majority of the market is still CCD and CMOS [
1].
Dynamic vision sensors (DVSs) [
11] are event-based cameras that provide high dynamic range (DR) and reduce the data rate and response times [
2]. Therefore, such sensors are popular these days [
12]. Recently, several algorithms have been developed to support them [
13,
14,
15,
16,
17]. However, current technology is limited, especially in spatial resolution. Each DVS pixel works independently, measuring log light intensity [
18]. If it senses a significant enough change (more prominent than a certain threshold), it outputs an event that indicates the pixel’s location and whether the intensity has increased or decreased. The DVS sensor only measures the light intensity and, therefore, does not allow direct color detection. Hence, its vision is binary-like, only describing the polarity of the change in intensity. Due to its compressed data representation, the DVS is very efficient in memory and power consumption [
19]. Its advantage is even more prominent when compared to high frames-per-second frame-based cameras. The reduced bandwidth required for recording only changes, rather than whole images, enables continuous recording at high temporal resolution without being restricted to very short videos.
In addition to the color filter array [
20], several methods have been proposed to reconstruct color for digital cameras. Examples include optimization-based methods [
21,
22], image fusion techniques [
23], and methods to reconstruct multispectral information [
24,
25] and 3D Point clouds [
26].
Color detection allows more information to be extracted from the DVS sensor and be used in a wide variety of computer vision tasks. These may include extracting DVS events with color, segmenting objects based on color, or tracking various colored objects. We focus on an algorithmic approach to reconstruct color from the binary-like output of the DVS sensor. Unlike current approaches [
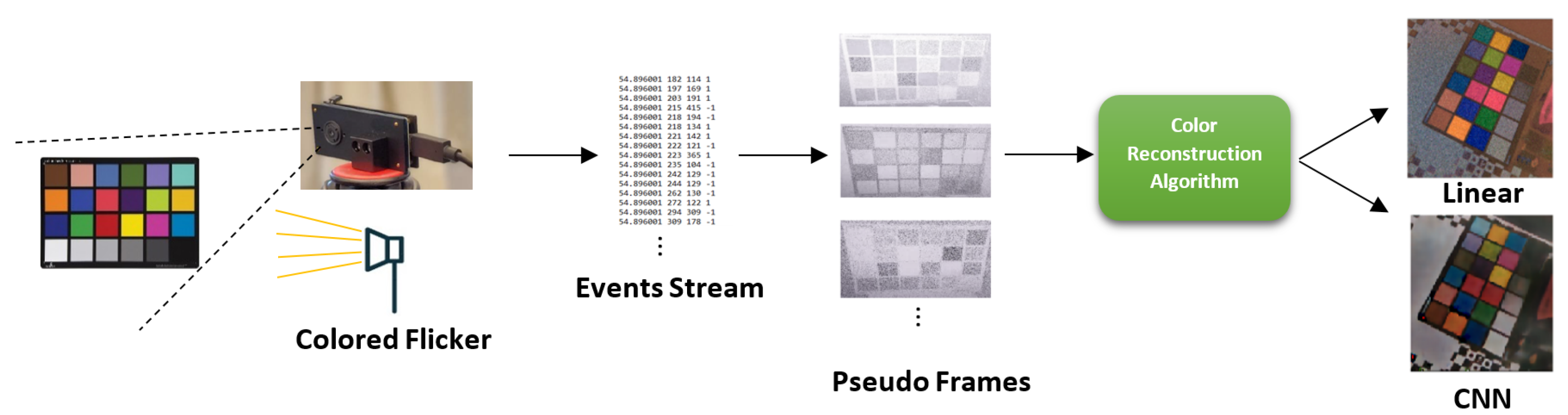
27], ours does not reduce the native spatial resolution of the sensor. Our algorithm is based on the responses of the DVS sensor to different impulses of an RGB flicker. A list of frames is constructed from the events generated as a response to the flicker, from which features are extracted to reduce redundancy. Two feature extraction methods are described here, and each fits a different reconstruction method. The features are either used as input for a convolutional neural network or a linear estimator, depending on the reconstruction method discussed. The output of these algorithms is a single RGB frame in a standard 8-bit color depth and identical spatial resolution to the input DVS frames; this output is a reconstructed frame of the scene in color. It could then be compared to a frame produced by a traditional camera.
Figure 1 shows the workflow presented in this paper. Our contributions are as follows:
A fast, real-time, linear method for reconstructing color from a DVS camera.
A CNN-based color reconstruction method for DVS.
Non-linearity analysis of the DVS-flicker system and an investigation of the DVS response to non-continuous light sources.
2. Related Work
In traditional video cameras, color vision is achieved using a simple color filter array (CFA) [
20] overlaid on the sensor pixels, with the obvious downside of reducing the spatial resolution of the sensor. In this approach, the output is divided into different channels, one for each filter color. For instance, in the case of the popular Bayer filter, it generally has one red and one blue channel and two green channels for a 2 × 2 binning configuration [
28]. These channels can be used directly (without interpolation) in frame-based cameras to produce a colored image or video. One might expect this approach to work just as well for event-based cameras. However, results show that naively composing the different color channels into an RGB image produces results that suffer from high salt-and-pepper type noise and poor color quality (see Figure 4 subfigure C in [
29]). A more sophisticated approach to color interpolation from different color channels, such as the ones employed in [
29,
30,
31] (classical algorithms or filters) and [
32] (neural network solution) produce better results, especially in terms of noise, but still suffer from poor color quality (see the comparison between [
29] and our method in the Result section).
In previous works, the DVS data are assumed to have been produced from a continuous change in lighting. In contrast, in this work, we focus on color reconstruction using the approximate impulse response of a DVS flicker system. Furthermore, the DVS exhibits interesting behavior under non-continuous light changes, which we will discuss in this paper. This was not reported in the literature.
Apart from our model-based approach (based on impulse responses), we also evaluate our method using a CNN model. We chose this approach mainly because of its nonlinearity and spatial correlation, as was demonstrated in previous works.
3. Dynamic Vision Sensor (DVS) and Setup
DVS cameras asynchronously output the position of a pixel that experiences a change in logarithmic intensity that is greater than a certain threshold [
33]. This method of recording video has several advantages over more traditional synchronous sensors with absolute (as opposed to logarithmic) intensity sensitivity. For example, DVS cameras enjoy higher DR and compressed data acquisition methods, allowing for a more extraordinary ability to detect movement in poorly controlled lighting while using less power, less bandwidth, and better latency.
3.1. DVS Operation Method
Pixels in a DVS sensor contain photoreceptors that translate incident photons to the current. The transistors and capacitors are then used to create a differential mechanism, which is activated only when the incident log luminosity difference is greater than a threshold [
34].
3.2. DVS Response Analysis
One can model the response of the DVS sensor to a change in brightness as a delta function:
where
is the pixel (bold because it is a vector) at which the event has occurred, and
is the time at which the event has occurred. The sensor responds to changes in the logarithmic intensity of each pixel, which can be modeled for a certain pixel at time
, as [
12]:
where
, and
Here,
is the intensity,
is the polarity of the pixel, which is
for an increase or
for a decrease in the brightness of that pixel. Variable C corresponds to the threshold that allows a response to be observed and is derived from the pixel bias currents in the sensor.
3.3. Creating Video from Bitstream
The DVS outputs a bitstream using the address–event representation (AER); each event detected by the DVS is characterized by an address (indicating the position of the pixel that detects the change), polarity (assigning ‘one’ if the detected change was an increase in brightness and −1 if it was a decrease), and the timestamp of the event detection. In order to turn this list of events into a video, we first choose the desired FPS (we opted for 600 for optimal performance with our specific DVS model, but it is possible to work with up to 1000 fps, and newer models can even go higher). After that choice, we uniformly quantize time. To create a frame, we sum all the events that occurred in each time slice to a single frame, which retains the data about the total event count per pixel during a time period reciprocal to the fps. A similar temporal binning procedure was introduced in [
29].
3.4. System Setup
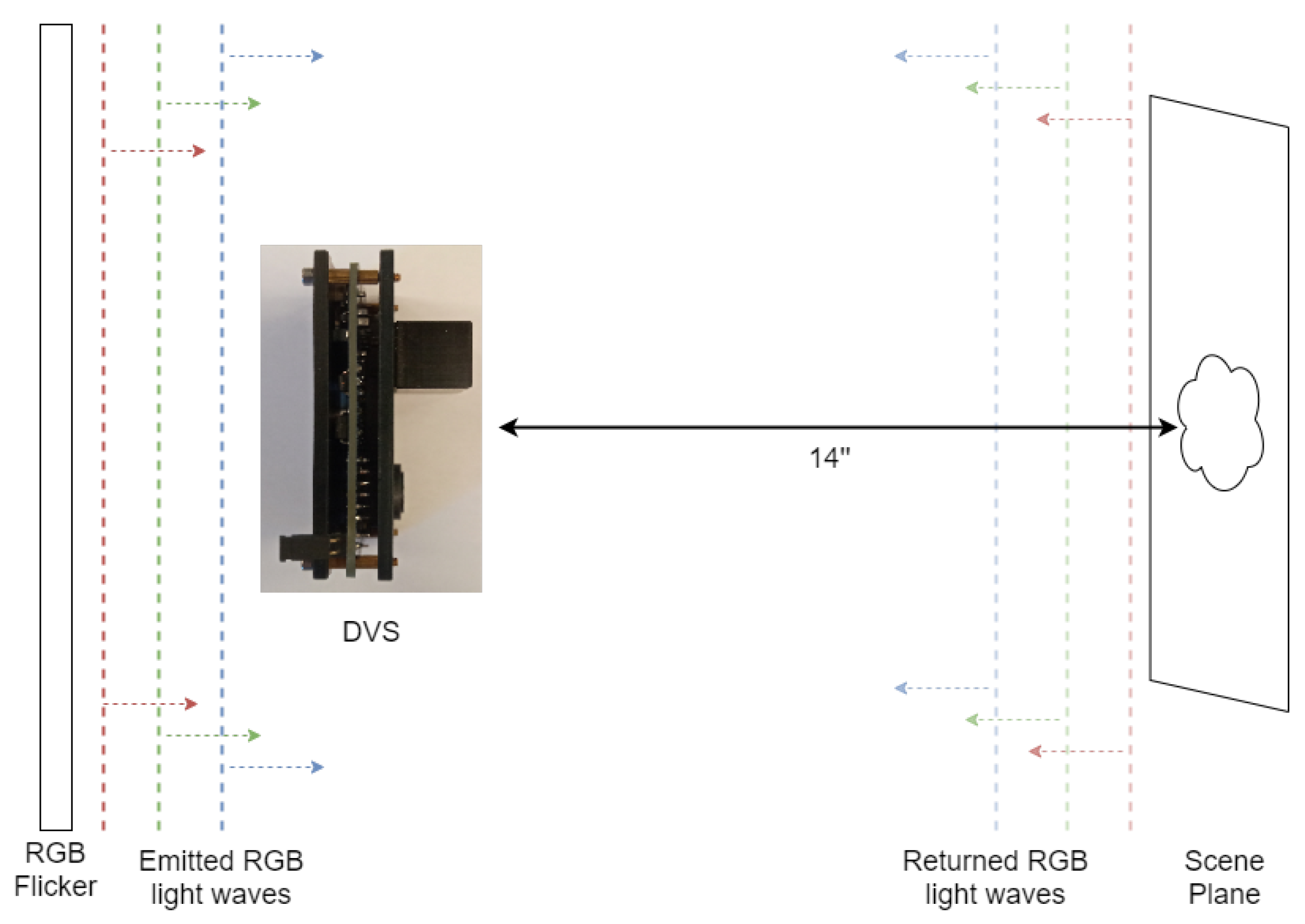
We used Samsung DVS Gen3 [
34] and positioned it such that it faced a static scene that was 14 inches (35.5 cm) away. For the flicker, we used a screen that was capable of producing light at different wavelengths and intensities. We placed the flicker directly behind the camera, facing the scene, to illuminate it with approximate uniformity, leveraging the fact that its area was larger than the region of the scene captured by the DVS. The flicker changed the emitted color at a 3 Hz frequency. For the calibration process (which will be discussed), we used a Point Grey Grasshopper3 U3 RGB camera, placed adjacent to the DVS (see
Figure 2).
The scene was static, so the camera could not see anything if the flicker did not change color. The flicker’s light was reflected off the scene and into the sensor, meaning that if we looked at a single DVS pixel, it measured whether the temporal change in the integral—across all frequencies—of the product of the spectrum, the reflective spectrum of the material, and the quantum efficiency of the sensor surpassed a certain threshold. When light from the source changed in color or intensity, this change was recorded in the DVS.
Using this system, we intend to capture a bitstream generated by the DVS as a response to the flicker, from which a single RGB frame is produced. This frame is an RGB image of the scene with the same resolution as the original DVS video. We present here two algorithmic approaches (one linear and one using CNN, in the next section) for producing that RGB frame. We will create a feature extraction method for each of the two different algorithmic approaches. In order to train the CNN, we will create a labeled dataset using a stereoscopic system with DVS and a standard frame-based camera. Finally, we will provide an explanation of the performances and shortcomings of our method.
4. Method—Linear Approach
Here, we introduce a fast, real-time linear method for creating an RGB frame. This method will estimate the color of each pixel based only on the single corresponding DVS pixel. Therefore, our problem is simplified to reconstructing the color of a single pixel from a list of DVS events for that pixel only; we will use the same method for all pixels to create a full RGB image. As will be explained in the following section, we further reduce the problem to estimating the color from a vector of real positive numbers. We generate a few labeled vectors and then build the linear minimum-mean-square-error (LMMSE) estimator using the Moore–Penrose pseudoinverse [
35].
4.1. Feature Extraction
As presented in
Section 3.2, any change in the pixel intensity level causes a change in the sensor event response. When recording the scene for color reconstruction, the intensity and the color of the flicker vary. Therefore, after changing the intensity of light to a new one, the new intensity is treated as if it is a different color. We associate each pixel response with a different activated flicker pulse as an additional feature. In this manner, we assess the features of each pixel for various flicker strengths and colors).
Pre-processing the DVS output yields a list of frames, with each being the sum of events that occurred in a particular time slice. We start by choosing the time intervals, with each corresponding to the response period of the DVS, to a change in the reflected intensity outside the scene, which will later be referred to as integration windows. Thus, a response curve of each pixel to each color change is yielded. We use a flicker that transmits three different colors (RGB) at three different intensities.
In order to reduce the sizes of the data, we use the average response to each color change (a single number per pixel) over a predefined integration window, and responses corresponding to the exact color changes are averaged. The result is a vector of length (where is the number of color changes the light source provides; in addition, there is a bias parameter) for each pixel in the 640 by 480 sensor array. To justify this, we will approximate each DVS pixel as an independent LTI system.
LTI Approximation
When the flicker is on, each pixel measures the light reflected from a certain part of the scene. Suppose that for a given pixel, this part of the scene is a uniform color. When the flicker is in one color, the pixel will measure the incident photon flux of
; when the flicker changes color (suppose at
), the incident photon flux changes to
. Thus, the DVS pixel will output SEVERAL events corresponding to this change (see
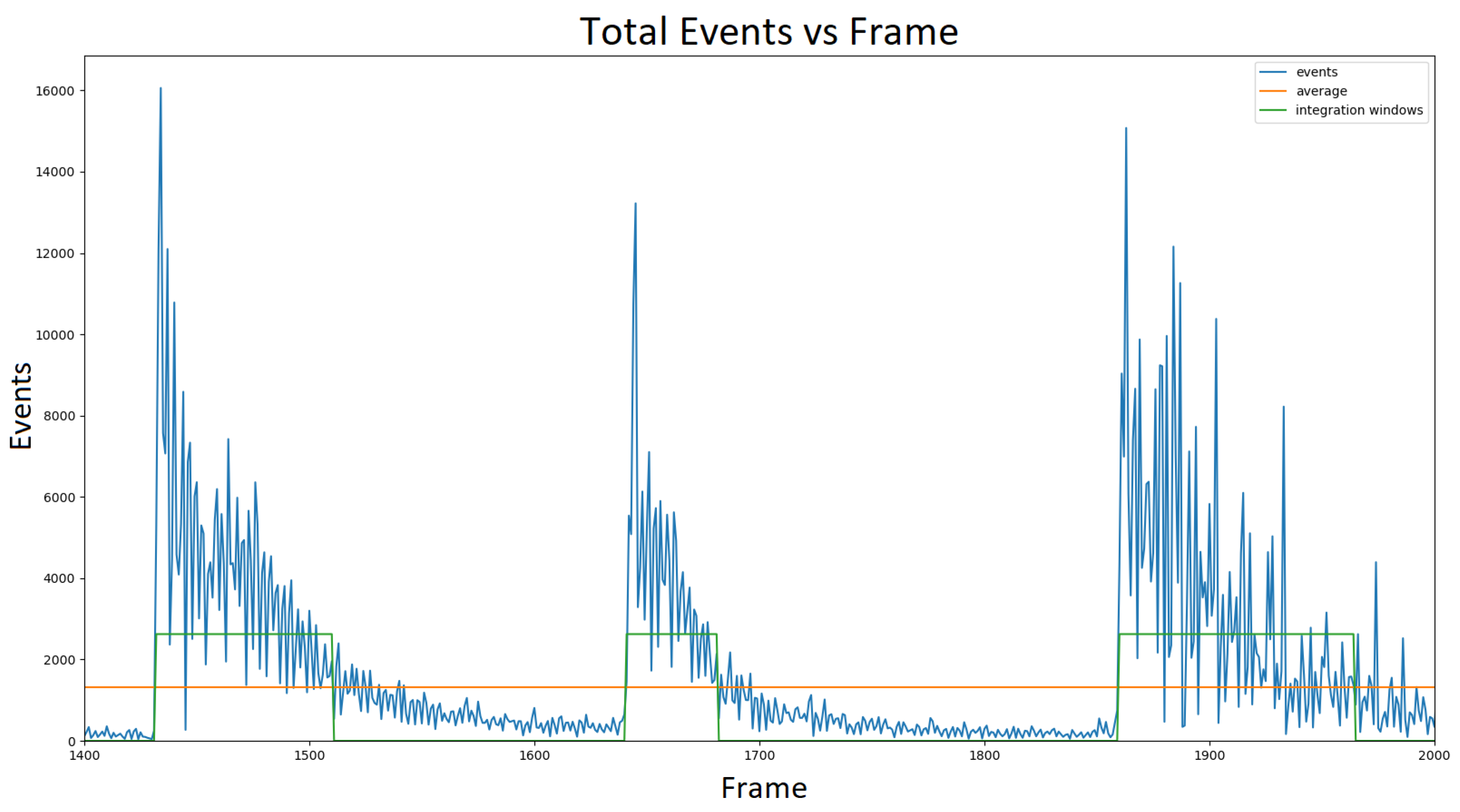
Figure 3 for example); this is a unique feature resulting from the non-continuous change in light intensity. The number of events depends on the size of the change
. This property is crucial for distinguishing between colors of different brightness levels, such as different shades of gray, since the brightness levels of some colors are directly linked to the intensities of the reflected photons off of them. The stream of events originating from the flicker change lasts well after the flicker transition is over; this means that if the light intensity changes quickly, the DVS will not treat this intensity change as a single event, but rather will continue outputting events for some time, such that the number of events is proportional in some way to the change in intensity.
Suppose that the logarithm of the transmitted intensity of the flicker could be described as a step function:
The output current of a DVS pixel is approximated as:
The exponential form of the output current is implied from the discharge currents of the capacitors in each DVS pixel. We assume the probability of a DVS pixel to register that an event is proportional to the output current:
As long as
is above a certain threshold, the DVS sensor will only record events when the log intensity change is sufficiently significant.
The LTI approximation suggests that a sufficient description of the DVS response to the flicker change is to take the number of events that occurred during the flicker change, i.e., integrating over time. Therefore, we suggest the following criterion for characterizing the DVS response to the flicker change:
We clip the integration at a finite time , chosen empirically, in order to approximate the integral. It is approximated as the time difference between the instance of flicker change and the moment when has decayed enough. In this work, these moments are identified by measuring the event count of the DVS pixels over an entire frame, with respect to time. A flicker change triggers a local maximum in the event count over time, which then decays proportionally to . An integration window is taken from the frame where the event count is at a local maximum to the frame at which the total event count equals the average event count over all frames. Noise and scattering are taken into account when determining the integration windows.
A pixel of a particular color reflects different amounts of the incident’s photons transmitted by the flicker, depending on their respective wavelengths. Thus, changing the flicker’s color causes the object that the pixel represents to reflect a different amount of light, and the observed intensity changes. This causes a reading of the DVS sensor. Based on these readings, we suggest that it is possible to reconstruct the RGB color profile of the observed scene.
The LTI integration approximation justifies using the LHS of Equation (
7) as the components of the feature vector; however, if we take noise into account, this approximation begins to break down, and the use of spatial correlation is needed for improved approximation.
The exponential form of the DVS event count can be seen in
Figure 4, which supports our model of the DVS pixel response probability
. The noisy response shown in
Figure 4 is a result of light scattering in addition to the inherent noise in the sensor.
5. Method-CNN Approach
The linear approach suffers from low SNR and low color fidelity. The shortcomings of the linear estimator are due to several factors, but mainly the sensor noise (thermal noise is significant for this sensor because it has a large surface area compared to modern CMOS or DSLR sensors) and inherent nonlinearities of the device, which were ignored in the last section’s analysis. The sensor in this work has a thermal noise of 0.03 events/pix/s at 25 °C [
12]. An additional form of noise is shot noise, which is significant under low ambient light conditions, such as in our setup. The low color fidelity of the linear approach suggests that the LTI assumption falls short in yielding a highly accurate color reconstruction. Thus, a different, more robust method should be employed for this problem. A natural solution is a convolutional neural network, as is common in image processing settings. This method uses a non-linear estimator for the color; in addition, it takes into account the inherent spatial correlation in the DVS output to reduce output noise.
The input to the network is 288 frames (32 frames for each of the nine flicker transitions) from the DVS, selected to contain the most information about the flicker transition. Since the network is fully convolutional, different spatial resolutions can be used for the input, but the output must be of an appropriate size.
Looking at the output of the DVS, a few things are clear. First, it is sparse; second, it is noisy; and third, there are a lot of spatial and temporal correlations between pixels. This matches previous findings regarding the DVS event stream [
12]. In addition, the linear approximation has problems distinguishing between different shades of gray (among other problems); using the spatial and temporal correlations of the data will help produce better results and deal with a certain design flaw of the sensor. It seems that certain pixels respond because neighboring pixels respond, not because they sense a change in photon flux. This is non-linear behavior that cannot be accounted for using a simple linear approximation (see
Figure A1 in
Appendix A).
5.1. CNN Architecture
The network architecture is fully convolutional and inspired by U-Net [
36] and Xception [
37]. Similar to U-Net, this network consists of a contracting path and an expanding path. However, it also includes several layers connecting the contracting and expanding parts that are used to add more weights that improve the model.
Each layer in the contracting path reduces the spatial dimensions and increases the number of channels using repeated Xception layers [
37] based on separable convolution. Each layer in the expanding path increases the spatial dimensions and reduces the channels using separable transposed convolutions. In the end, we move back to the desired output size (in our case, it will be the same as the input size), and the channels will be reduced to three channels (one for each RGB color). The path connecting the contracting and expanding layers does not change the data sizes.
5.2. Loss Function
The loss function is a weighted average of the MS-SSIM [
38] and
norm.
where
and
Y represent the reconstructed and real images, respectively. The coefficients of the different components of the loss function were tuned using hyperparameter optimization. Other losses were tested, including the L2 loss and L1 loss, which only compares the hue and saturation (without the lightness) of the images, or only the lightness without the hue and saturation; however, none outperformed the loss we chose.
The SSIM index is a distortion measure that is supposed to more faithfully represent how humans perceive distortions in images, assuming that the way visual perception works depends significantly on extracting structural information from an image. It is helpful for us because the linear approach (despite being noisy and not producing the most accurate colors) seems to be able to produce images that have the same structures as the original ones.
5.3. Training
Data labels are acquired using a dual-sensor apparatus composed of DVS and RGB sensors. For the RGB sensor, we used a Point Grey Grasshopper3 U3 camera, with a resolution of 1920 × 1200 (2.3 MP), fps of 163, and 8-bit color depth for each of its 3 color channels. A calibration process yields matching sets of points in each of the sensors using the Harris Corner Detector algorithm, which is then used to calculate a holography that transforms the perspective of the RGB sensor to the perspective of the DVS sensor.
The calibration process assumes that the captured scene is located in a dark room on a plane at a distance of 14 from the DVS sensor. Therefore, training data are taken on 2D scenes to preserve calibration accuracy. Each training sample contains a series of frames, most of which hold the responses of the scene to the changes in the flicker, and a minority of the frames are background noise frames before the changes in the flicker. For example, in the case of an RGB flicker with three intensities, we use 32 frames per color and intensity, totaling 288 frames.
7. Discussion
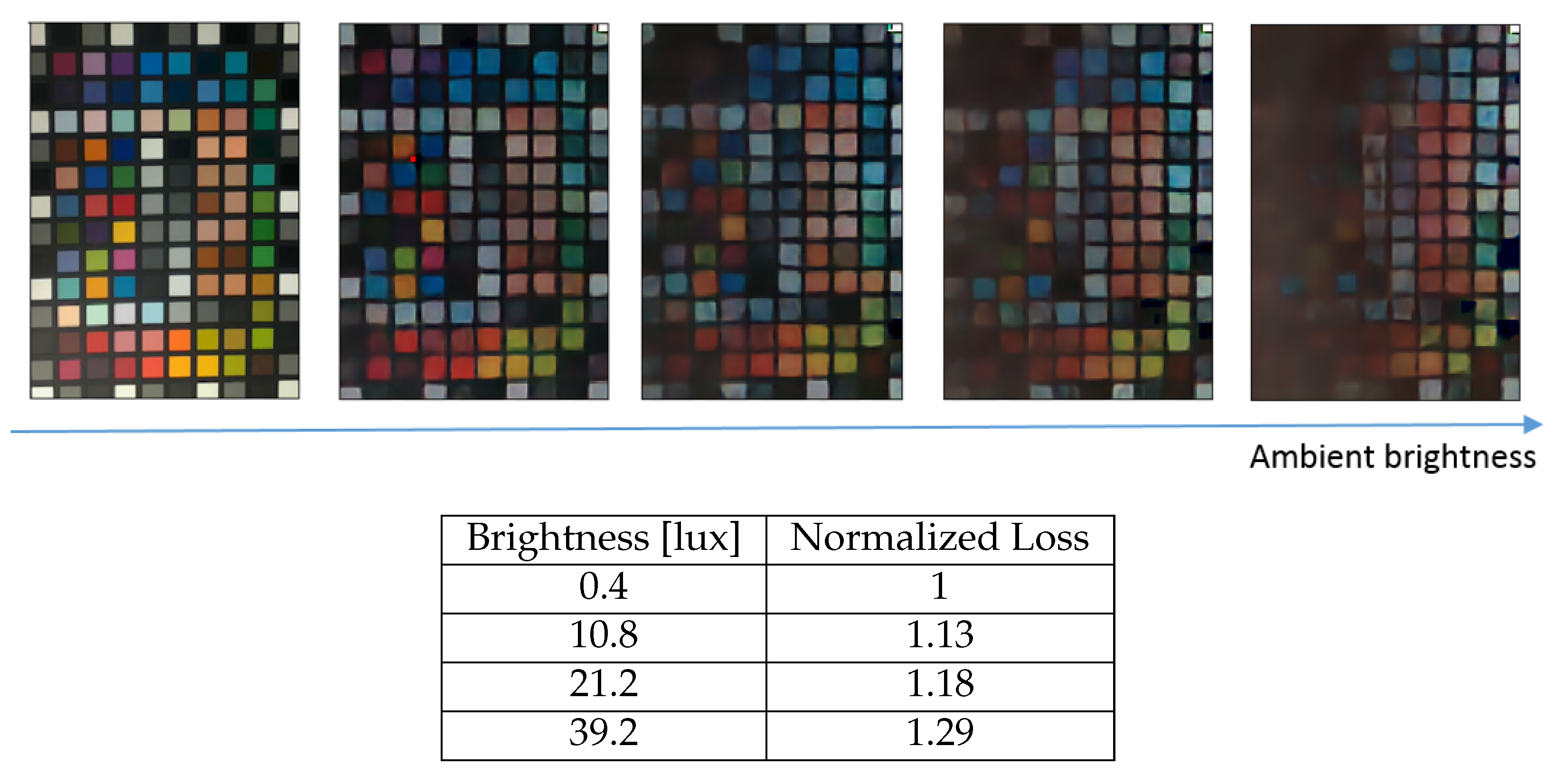
The system described in this work manages to create a colored image using the protocol that we presented. However, it has its limitations: the reconstruction accuracy depends heavily on ambient light conditions; if different ambient light conditions are taken into account during training, the reconstruction will be less sensitive to ambient light conditions; finally, the flicker’s intensity and dynamic range affect the reconstruction quality. That being said, the system has the ability to reconstruct color from images outside the training data, as can be seen in
Figure 7. One can overcome the latter limitation by changing the intensity levels of the flicker. In addition, our system does not allow the color reconstruction of a nonstationary scene since the response time of the DVS pixels to a flicker color change is nonzero. Therefore, the time it takes for a flicker cycle to be performed limits the timescale of changes in the scene using our approach. The critical distinction lies between events generated by flicker changes and those prompted by movements within the scene. An optical flow algorithm combined with a CNN can be used to overcome this limitation.
Using a DAVIS sensor would also most likely improve the performance and ease the calibration method (the active pixels could be used to create a regular still image used for calibration). In addition, since the DVS has no sense of absolute light intensity (only relative), using a DAVIS sensor could improve the performances of different ambient light conditions.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}