



Multilayer Semantic Features Adaptive Distillation for Object Detectors


Abstract
:1. Introduction
- (1)
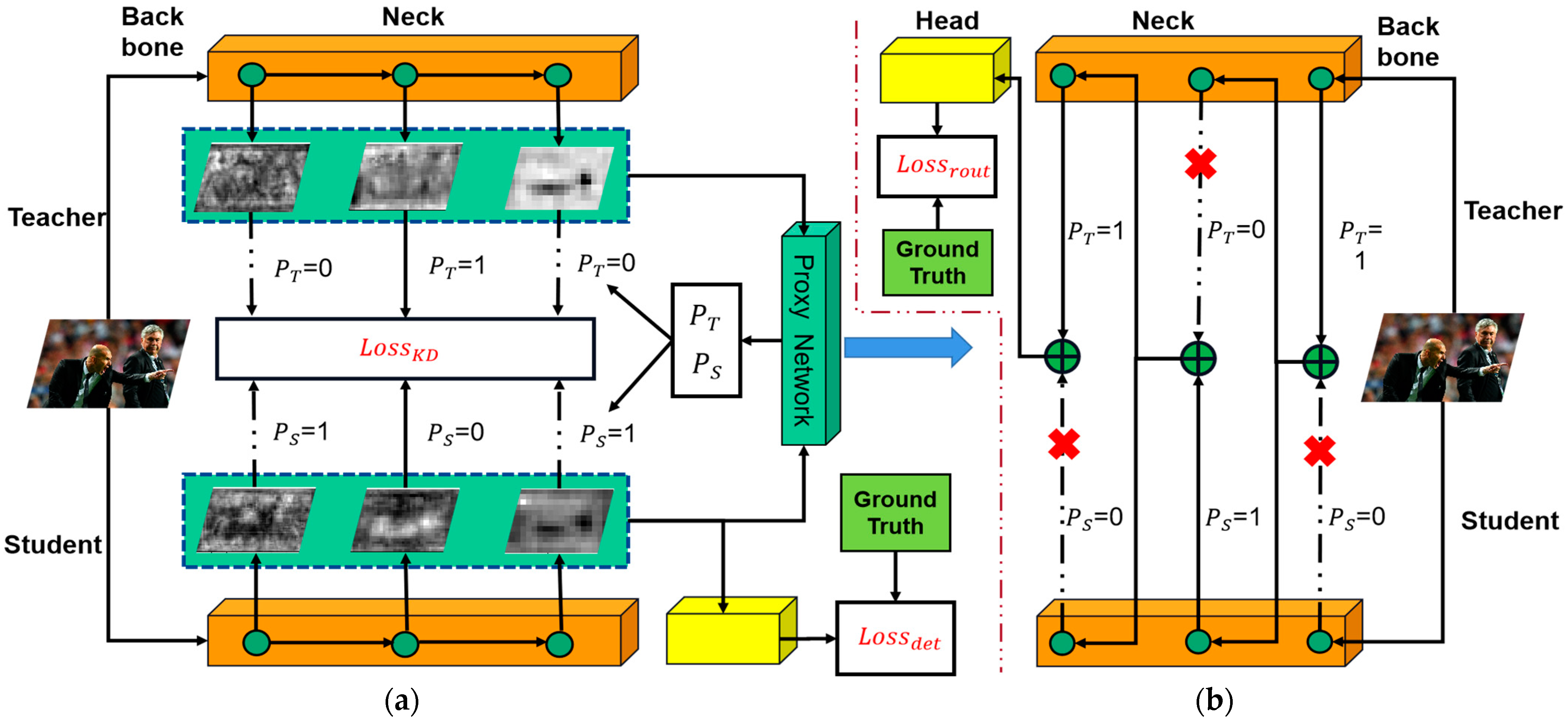
- Distilling only the specific semantic-level features of the detector [18,19,21] (Figure 1a). For example, [18] used the region proposal network structure of the student detector to select positive regions from the fixed-level features, and [21] distilled the foreground and background of the intermediate layer features separately.
- (2)

- (1)
- A novel MSFAD method is proposed for object detectors that addresses the problem in current object detection distillation methods of the mismatch between the semantic level of distilled features and the training stage and samples.
- (2)
- The selection of various semantic-level features for distillation at different training stages is described, and the important effect of semantic-level selection during distillation training is highlighted.
- (3)
- The experiments described show that the MSFAD method improved the mAP50 and mAP50–90 of YOLOv5s by 3.4% and 3.3%, respectively. Moreover, it is demonstrated that MSFAD achieved detection performance similar to YOLOv5s for YOLOv5n with only 1.9 M parameters. Relative to the latest YOLOv7-tiny of the same magnitude, the YOLOv5s model distilled by our method achieved higher mAP50 and mAP50–90 by 2.2% and 1.9%, respectively.
2. Related Work
2.1. Object Detection
2.2. Knowledge Distillation
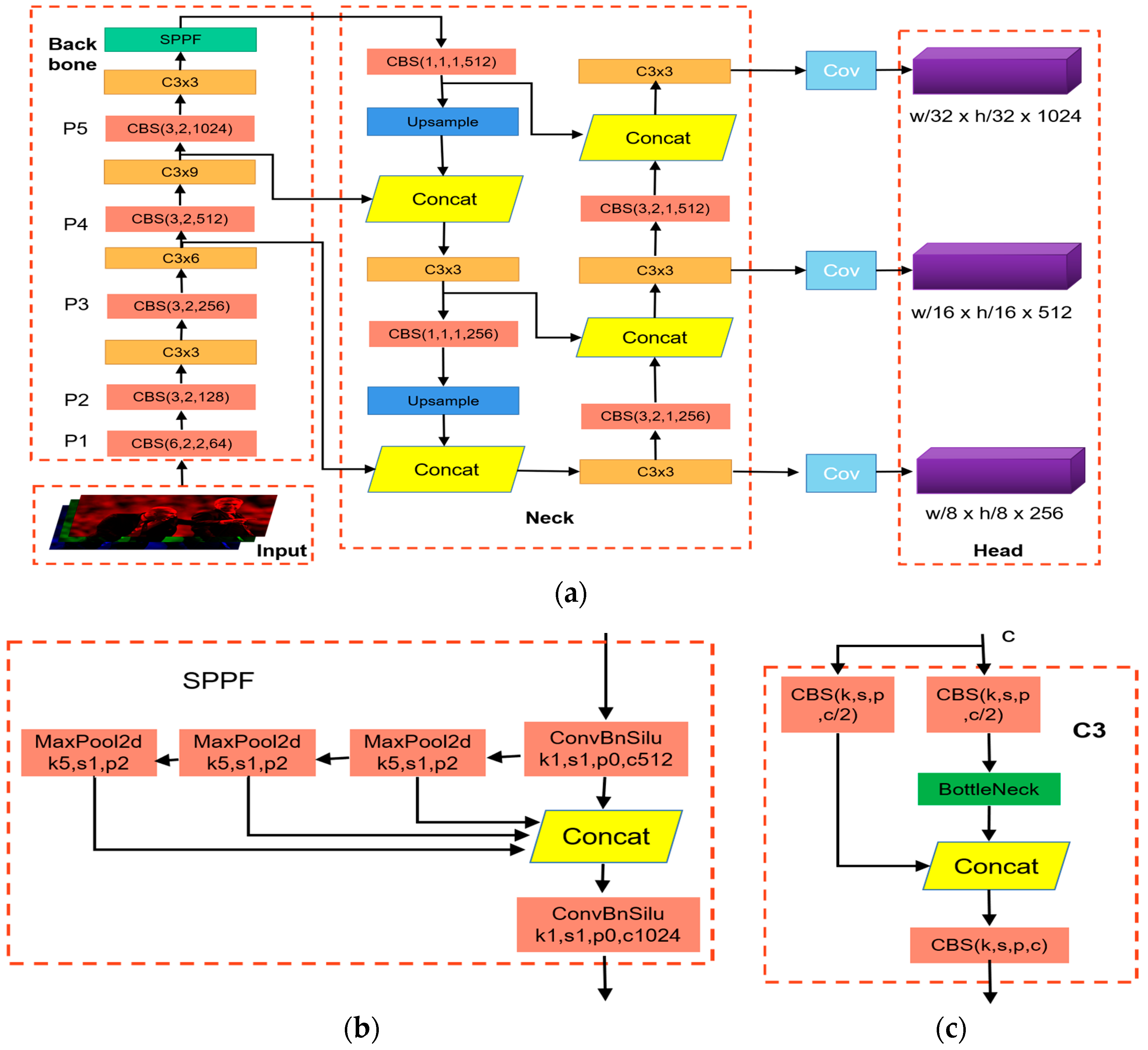
3. Method
3.1. Distillation Feedforward Process
3.2. Routing Feedforward Process
3.3. Overall Loss
4. Experiments
4.1. Dataset
4.2. Experimental Details
4.3. Comparison of Experimental Results
4.4. Distillation of Semantic Features of Different Levels
4.5. Visual Analysis of Feature Maps
4.6. Ablation Study
4.6.1. Study of Different Distillation Points
4.6.2. Stability Analysis of Student Models before and after Distillation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wu, J.; Leng, C.; Wang, Y.; Hu, Q.; Cheng, J. Quantized convolutional neural networks for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4820–4828. [Google Scholar]
- Wen, W.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Learning structured sparsity in deep neural networks. arXiv 2016, arXiv:1608.03665. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Heo, B.; Kim, J.; Yun, S.; Park, H.; Kwak, N.; Choi, J.Y. A comprehensive overhaul of feature distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1921–1930. [Google Scholar]
- Tung, F.; Mori, G. Similarity-preserving knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1365–1374. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4133–4141. [Google Scholar]
- Komodakis, N.; Zagoruyko, S. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In Proceedings of the ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Chen, G.; Choi, W.; Yu, X.; Han, T.; Chandraker, M. Learning efficient object detection models with knowledge distillation. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Li, Q.; Jin, S.; Yan, J. Mimicking very efficient network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6356–6364. [Google Scholar]
- Wang, T.; Yuan, L.; Zhang, X.; Feng, J. Distilling object detectors with fine-grained feature imitation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 4933–4942. [Google Scholar]
- Sun, R.; Tang, F.; Zhang, X.; Xiong, H.; Tian, Q. Distilling object detectors with task adaptive regularization. arXiv 2020, arXiv:2006.13108. [Google Scholar]
- Yang, Z.; Li, Z.; Jiang, X.; Gong, Y.; Yuan, Z.; Zhao, D.; Yuan, C. Focal and global knowledge distillation for detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4643–4652. [Google Scholar]
- Song, J.; Chen, Y.; Ye, J.; Song, M. Spot-adaptive knowledge distillation. IEEE Trans. Image Process. 2022, 31, 3359–3370. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Li, B.; Ouyang, W.; Sheng, L.; Zeng, X.; Wang, X. Gs3d: An efficient 3d object detection framework for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 1019–1028. [Google Scholar]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1341–1360. [Google Scholar] [CrossRef]
- Jaeger, P.F.; Kohl, S.A.; Bickelhaupt, S.; Isensee, F.; Kuder, T.A.; Schlemmer, H.-P.; Maier-Hein, K.H. Retina U-Net: Embarrassingly simple exploitation of segmentation supervision for medical object detection. In Proceedings of the Machine Learning for Health Workshop, Virtual, 11 December 2020; pp. 171–183. [Google Scholar]
- Li, Z.; Dong, M.; Wen, S.; Hu, X.; Zhou, P.; Zeng, Z. CLU-CNNs: Object detection for medical images. Neurocomputing 2019, 350, 53–59. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Dai, X.; Jiang, Z.; Wu, Z.; Bao, Y.; Wang, Z.; Liu, S.; Zhou, E. General instance distillation for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7842–7851. [Google Scholar]
- Weng, W.; Li, T.; Liao, J.-C.; Guo, F.; Chen, F.; Wei, B.-W. Similarity-based Attention Embedding Approach for Attributed Graph Clustering. J. Netw. Intell. 2022, 7, 848–861. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Fu, J.; Zheng, H.; Mei, T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4438–4446. [Google Scholar]
- Jang, E.; Gu, S.; Poole, B. Categorical reparameterization with gumbel-softmax. arXiv 2016, arXiv:1611.01144. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.L.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Epoch | lr | Weight_Decay | Momentum | Batch | Img_Size | T | α | β | γ | λ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5l | 300 | 0.01 | 0.0005 | 0.937 | 16 | 640 | – | – | – | – | – |
| YOLOv5s | 400 | 0.01 | 0.0005 | 0.937 | 16 | 640 | – | – | – | – | – |
| YOLOv5n | 400 | 0.01 | 0.0005 | 0.937 | 16 | 640 | – | – | – | – | – |
| FDG a-YOLOv5s_b | 400 | 0.01 | 0.0005 | 0.937 | 16 | 640 | 0.5 | 1 × 10−3 | 5 × 10−4 | 5 × 10−4 | 5 × 10−6 |
| FGD a-YOLOv5s_n | 400 | 0.01 | 0.0005 | 0.937 | 16 | 640 | 0.5 | 1 × 10−3 | 5 × 10−4 | 5 × 10−4 | 5 × 10−6 |
| FGD a-YOLOv5s_bn | 400 | 0.01 | 0.0005 | 0.937 | 16 | 640 | 0.5 | 1 × 10−3 | 5 × 10−4 | 5 × 10−4 | 5 × 10−6 |
| FGD a-YOLOv5n | 400 | 0.01 | 0.0005 | 0.937 | 16 | 640 | 0.5 | 1 × 10−3 | 5 × 10−4 | 5 × 10−4 | 5 × 10−6 |
| MSFAD-YOLOv5s | 400 | 0.01 | 0.0005 | 0.937 | 16 | 640 | 0.5 | 1 × 10−3 | 5 × 10−4 | 5 × 10−4 | 5 × 10−6 |
| MSFAD-YOLOv5n | 400 | 0.01 | 0.0005 | 0.937 | 16 | 640 | 0.5 | 1 × 10−3 | 5 × 10−4 | 5 × 10−4 | 5 × 10−6 |
| Method | Params (M) | mAP50 (%) | mAP50–90 (%) | ||
|---|---|---|---|---|---|
| Faster R-CNN-Res101 (teacher) | 232 | 82.8 | Improvement | 56.3 | Improvement |
| Faster R-CNN-Res50 (student) | 159 | 82.2 | 54.2 | ||
| +Mimicking [18] | 159 | 82.3 | +0.1 | 55.5 | +1.3 |
| +Fine-grained [19] | 159 | 82.2 | = | 55.4 | +1.2 |
| +Fitnet [11] | 159 | 82.2 | = | 55.1 | +0.9 |
| +GID [38] | 159 | 82.6 | +0.4 | 56.5 | +2.3 |
| RetinaNet-Res101 (teacher) | 217 | 81.9 | Improvement | 57.3 | Improvement |
| RetinaNet-Res50 (student) | 72.7 | 80.9 | 55.4 | ||
| +Fine-grained [19] | 72.7 | 81.5 | +0.6 | 56.6 | +1.2 |
| +Fitnet [11] | 72.7 | 81.4 | +0.5 | 55.8 | +0.4 |
| +GID [38] | 72.7 | 82.0 | +1.1 | 57.9 | +1.3 |
| FCOS-Res101 (teacher) | 196 | 81.6 | Improvement | 58.4 | Improvement |
| FCOS-Res50 (student) | 123 | 80.2 | 56.1 | ||
| +Fitnet [11] | 123 | 80.3 | +0.1 | 57.0 | +0.9 |
| +GID [38] | 123 | 81.3 | +1.1 | 58.4 | +2.3 |
| YOLOv5l (teacher) | 46.5 | 84.6 | Improvement | 63.1 | Improvement |
| YOLOv5s (student) | 7.2 | 79.1 | 54.0 | ||
| +MSFAD (ours) | 7.2 | 82.5 | +3.4 | 57.3 | +3.3 |
| YOLOv5l (teacher) | 46.5 | 84.6 | Improvement | 63.1 | Improvement |
| YOLOv5n (student) | 1.9 | 73.1 | 46.6 | ||
| +MSFAD (ours) | 1.9 | 76.4 | +3.3 | 48.8 | +2.2 |
| Model | P (%) | R (%) | mAP50 (%) | mAP50–90 (%) | Params (M) |
|---|---|---|---|---|---|
| YOLOv3-tiny | 61.5 | 55.1 | 59.2 | – | 17.5 |
| YOLOv4-tiny | 79.3 | 76.0 | 77.8 | – | 22.6 |
| YOLOv4-S | 78.9 | 80.1 | 80.8 | – | 16.5 |
| YOLOv7-tiny | 79.2 | 76.7 | 80.3 | 55.4 | 6.2 |
| MSFAD-YOLOv5s | 80.5 | 79.8 | 82.5 | 57.3 | 7.2 |
| MSFAD-YOLOv5n | 74.5 | 73.1 | 76.4 | 48.8 | 1.9 |
| Model | P (%) | R (%) | mAP50 (%) | mAP50–90 (%) | Params (M) |
|---|---|---|---|---|---|
| YOLOv5l (teacher) | 84.6 | 78.8 | 84.6 | 63.1 | 46.5 |
| YOLOv5s (student) | 80.4 | 73.1 | 79.1 | 54.0 | 7.2 |
| YOLOv5n (student) | 73.2 | 69.6 | 73.1 | 46.6 | 1.9 |
| FGD-YOLOv5n-n | 74.1 | 72.8 | 75.0 | 47.6 | 1.9 |
| MSFAD-YOLOv5n-n | 74.5 | 73.1 | 76.4 | 48.8 | 1.9 |
| Improvement | +0.4 | +0.3 | +1.4 | +1.2 | – |
| FGD-YOLOv5s-n | 79.5 | 78.9 | 81.1 | 56.6 | 7.2 |
| MSFAD-YOLOv5s-n | 80.5 | 79.8 | 82.5 | 57.3 | 7.2 |
| Improvement | +1.0 | +0.9 | +1.4 | +0.7 | – |
| FGD-YOLOv5s-b | 78.8 | 76.1 | 78.2 | 53.1 | 7.2 |
| MSFAD-YOLOv5s-b | 79.7 | 75.9 | 79.0 | 54.1 | 7.2 |
| Improvement | +0.9 | −0.2 | +0.8 | +1.0 | – |
| FGD-YOLOv5n-b | 72.8 | 68.7 | 72.5 | 45.8 | 1.9 |
| MSFAD-YOLOv5n-b | 73.7 | 70.2 | 73.3 | 46.5 | 1.9 |
| Improvement | +0.9 | +1.6 | +0.8 | +0.7 | – |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Liu, J.; Chen, Y.; Mei, W.; Huang, F.; Chen, L. Multilayer Semantic Features Adaptive Distillation for Object Detectors. Sensors 2023, 23, 7613. https://doi.org/10.3390/s23177613
Zhang Z, Liu J, Chen Y, Mei W, Huang F, Chen L. Multilayer Semantic Features Adaptive Distillation for Object Detectors. Sensors. 2023; 23(17):7613. https://doi.org/10.3390/s23177613
Chicago/Turabian StyleZhang, Zhenchang, Jinqiang Liu, Yuping Chen, Wang Mei, Fuzhong Huang, and Lei Chen. 2023. "Multilayer Semantic Features Adaptive Distillation for Object Detectors" Sensors 23, no. 17: 7613. https://doi.org/10.3390/s23177613
APA StyleZhang, Z., Liu, J., Chen, Y., Mei, W., Huang, F., & Chen, L. (2023). Multilayer Semantic Features Adaptive Distillation for Object Detectors. Sensors, 23(17), 7613. https://doi.org/10.3390/s23177613