_Park.png)
Digital Forensic Analysis of Vehicular Video Sensors: Dashcams as a Case



Abstract
1. Introduction
2. Related Work
2.1. Dashcam Technology and Forensic Analysis
2.2. Dashcam Text and Speech Analysis
3. Dashcam Investigation Framework
- Collection—Identifying, acquiring and protecting the data collected at the crime scene;
- Examination—Processing the collected data/evidence and extracting relevant information;
- Analysis—Analyzing the extracted information in order to connect the dots and be able to build a robust and admissible case;
- Reporting—Presenting the findings of the analysis stage in an admissible and understandable format.
3.1. Framework Design
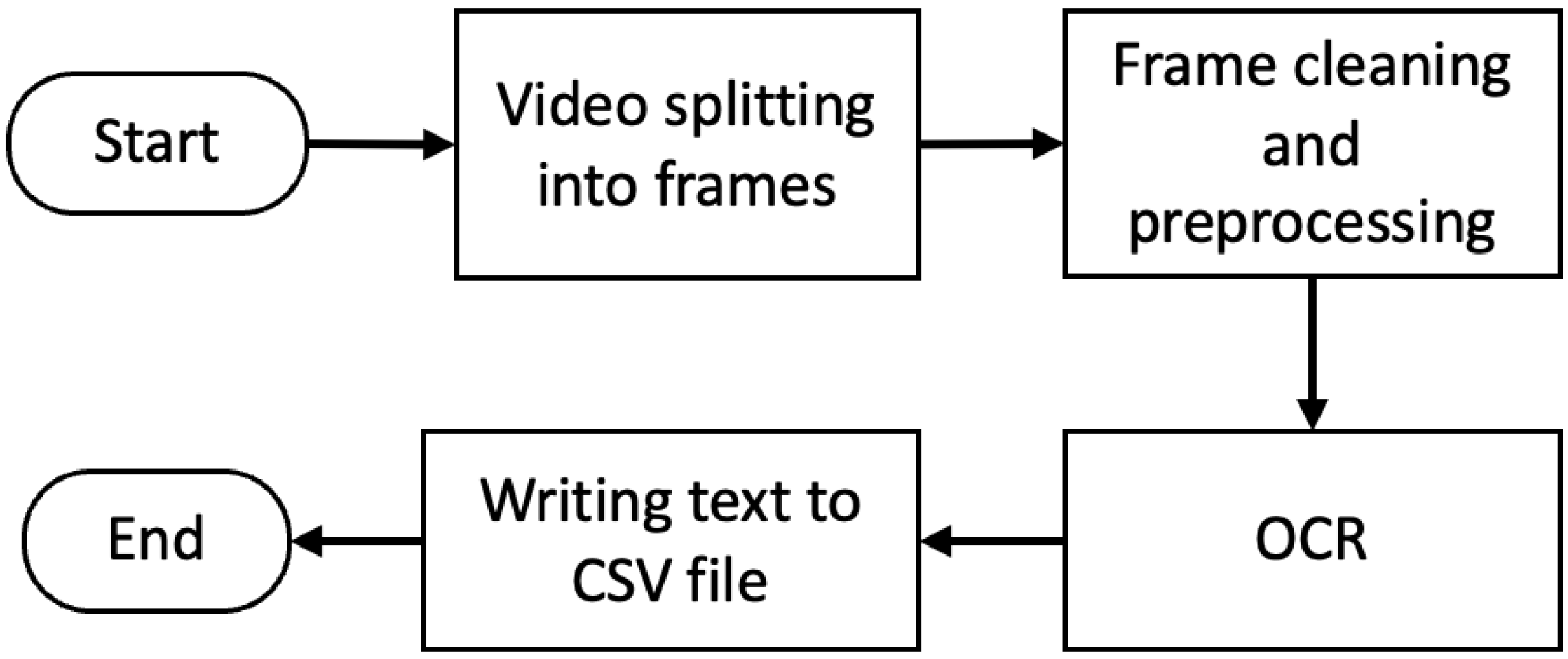
3.1.1. Extracting Evidential Text
3.1.2. Extracting Evidential Speech
3.2. Framework Implementation
- audio_files: this includes the audio files stored as an intermediate stage while converting the video to text;
- evidence_utils: this includes two Python classes: ImageMounter is responsible for mounting the E01 image and loading it into the operating system with the assistance of the EWFImgInfo class that is for reading operations on the image;
- exported_coordinates: this stores the CSV file that is generated after extracting the vehicle speed, time, date, longitude and latitude from the selected video;
- exported_videos: this stores each file exported by the framework for processing;
- map_file: this stores the generated preview.html file, which is the interactive map displayed to the investigator via the GUI after processing the selected video;
- out: this stores the frames that are exported from the selected video and are cropped;
- recognized_audios: this stores the text files that are generated by audio-to-text implementation, storing both Arabic and English transcribed files for the video with the following names: arabic_audio_transcript.txt and english_audio_transcript.txt, respectively;
- ui: the design files created using QT Designer for the GUI are stored under the ui directory. The directory includes the following files, which are compiled on run-time: file_explorer_widget.ui, main_screen.ui and partition_table_widget.ui.
- draw_on_map.py: this reads the generated CSV file that contains the vehicle speed, time, date, longitude and latitude, which are extracted from the selected video file. It also stores them as an OpenStreetMap object and translates the coordinates into the interactive HTML file preview.html to be displayed on the GUI;
- generate_report.py: this uses the Python package FPDF for writing texts and images related to the selected video artifacts into the report object and converts the object into a PDF file when generating the digital forensic report;
- img.jpg: the temporary file is generated when the user clicks the “Add To Report” button in order to add the interactive map snapshot to the report file;
- Investigation_Report.pdf: this is the PDF report that is generated when the user clicks the “Generate Report” button;
- ocr_extractor.py: this set of functions is responsible for framing the selected video file, cropping the frames and extracting artifacts from each frame;
- main.py: the main file of the project that starts the execution and holds the variables that store the artifacts for each selected video and the classes for the GUI interactions;
- speech_recognizer.py: the set of functions responsible for converting the selected video into text by converting it into an audio file using the moviepy Python package and storing it in the audio_files/audio.wav directory. It also contains the speech_recognition Python package to convert the language into an Arabic or English text file based on the selected localization.
4. Experiments
4.1. Experiment Settings
- CPU—Intel Core i5 10400f 2.90 GHz;
- RAM—16 GB DIMM 2666 MHz;
- Storage—256 GB M.2 SSD;
- Operating System—Windows 10 Pro Version 1909;
- Acquisition and Analysis Software—Belkasoft Evidence Center, Version 9.9 Build 4662 ×64 [58];
- Acquisition and Analysis Software—Magnet AXIOM, Version 4.6.0.21968 [59];
- Acquisition Software—AccessData FTK IMager, Version 4.5.0.3 [60];
- Investigation Software—Autopsy Digital Forensics, Version 4.16.0 [61];
- Investigation Software—Registry Viewer, Version 1.8.0.5 [62];
- Virtualization Software—VMware Workstation Pro, Version 16.1.0 Build 117198959 (×64) [63].
4.2. Experiment Process
- Running write-blocker software on the investigation workstation to prevent SD card alteration once connected to the investigation workstation;
- Connecting the SD card to the investigation workstation using an SD-card-to-USB adapter;
- Opening storage media acquisition software (FTK Imager);
- Creating a forensics image from the SD card using Expert Witness Format (E01).
5. Results
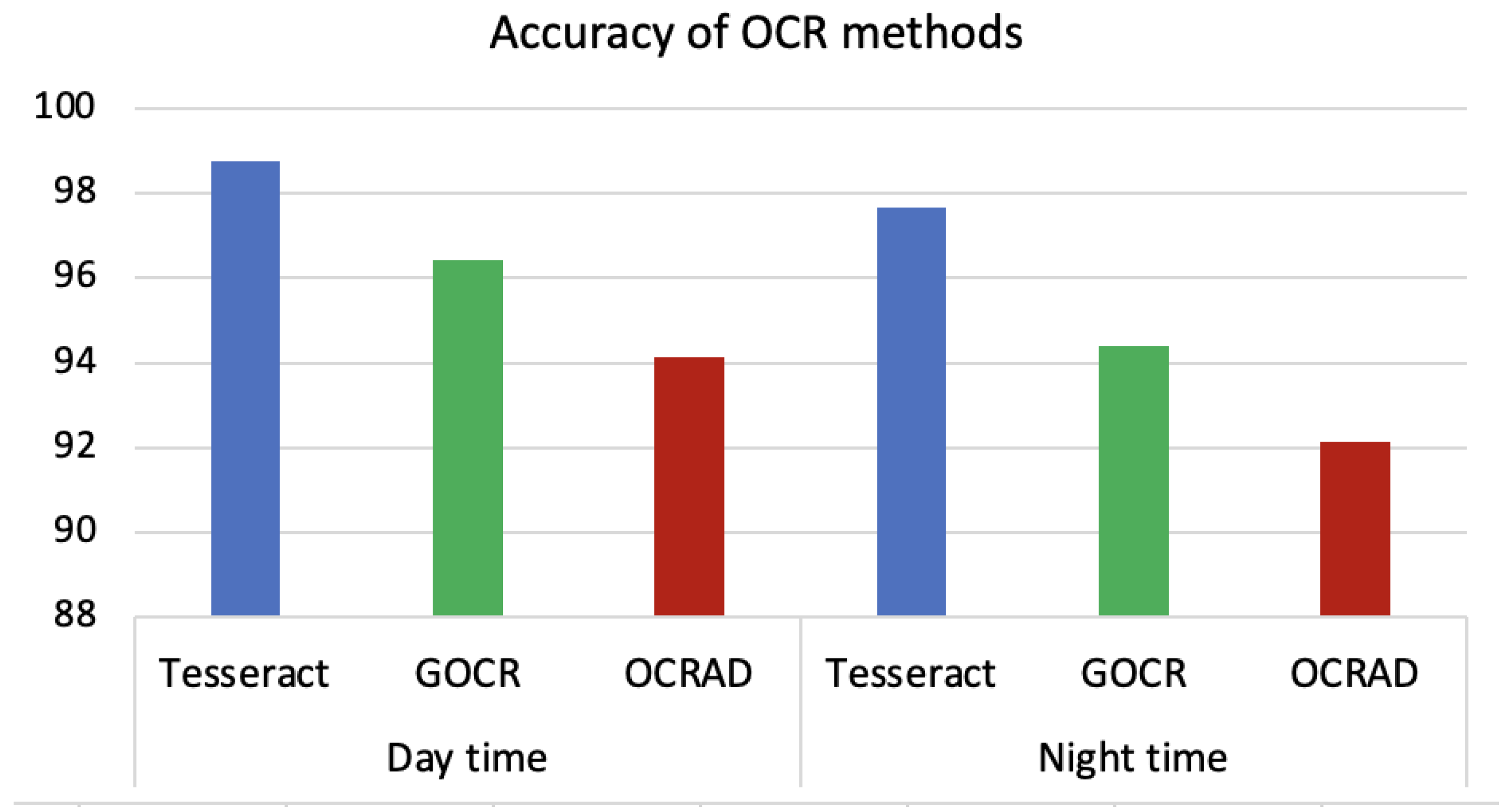
5.1. Text Extraction Results
5.2. Speech Transcription Results
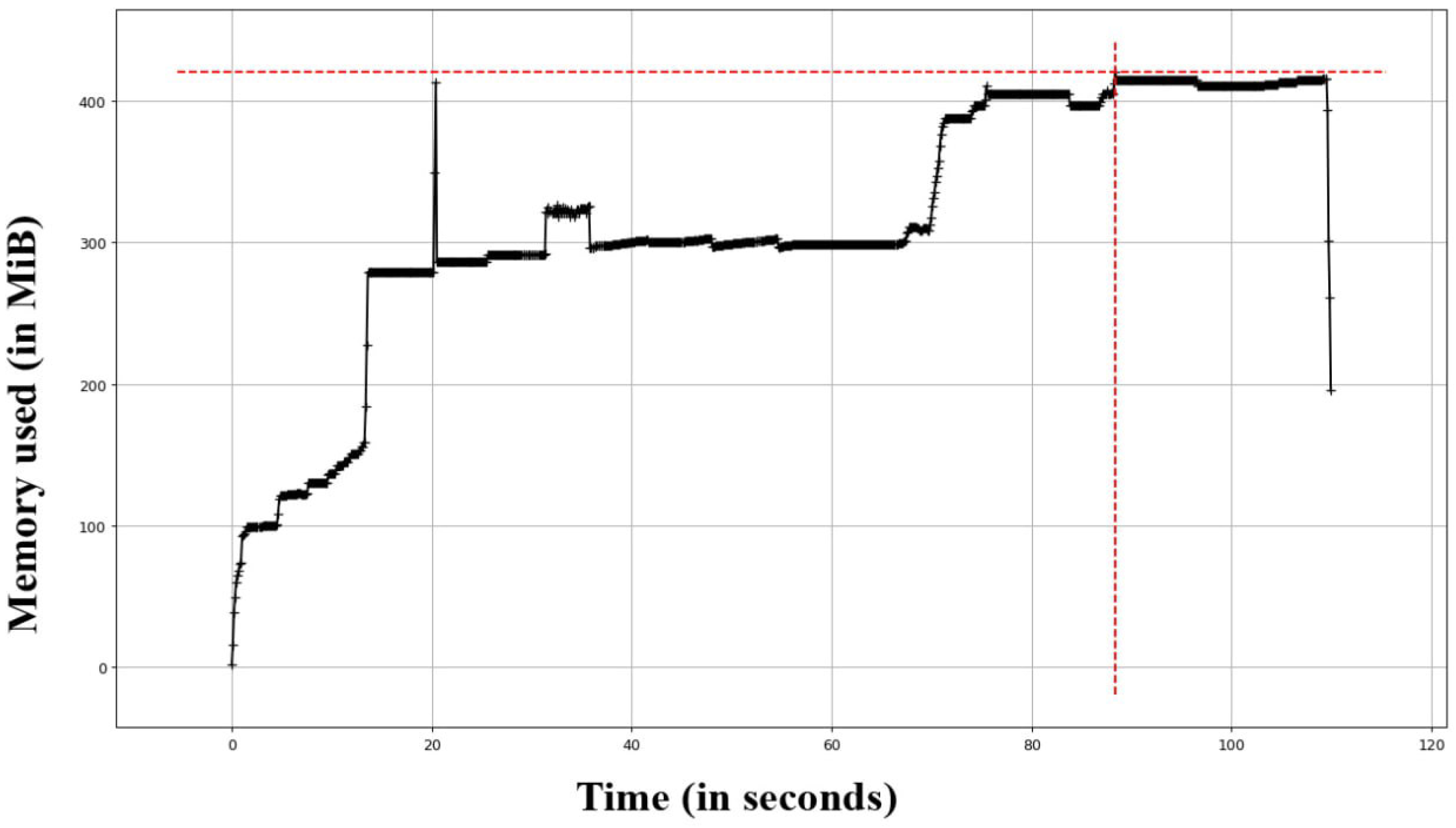
5.3. Time and Memory Review
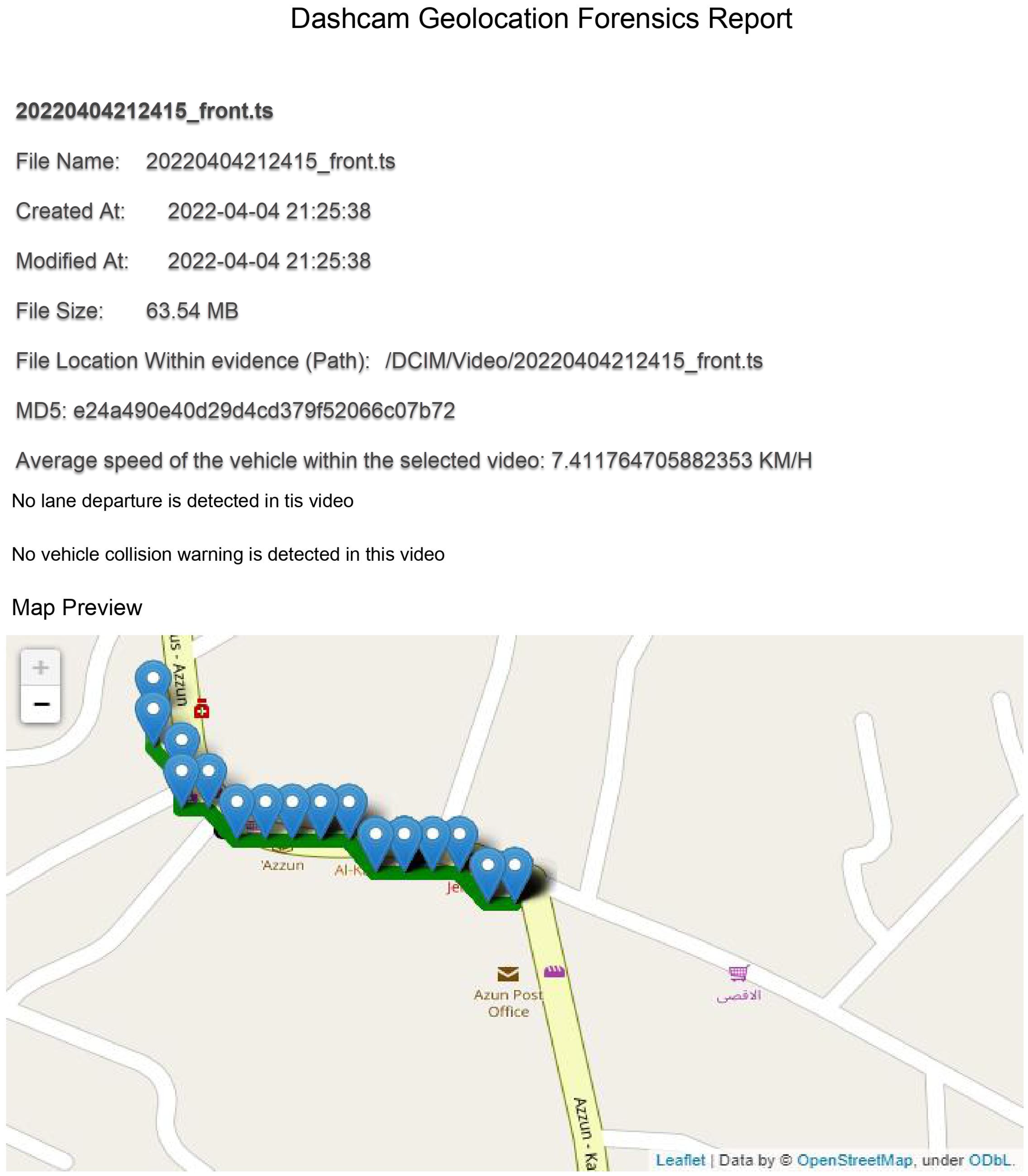
5.4. Generating Digital Forensic Reports
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- AMR. Car Dash Camera Market by Product (Single Channel, Dual Channel) and by Component (Lens, Battery, G-Sensors, Others): Global Opportunity Analysis and Industry Forecast, 2023–2032. Available online: https://www.alliedmarketresearch.com/car-dash-camera-market-A10271 (accessed on 25 August 2023).
- Kamat, D.D.; Kinsman, T.B. Using road markers as fiducials for automatic speed estimation in road videos. In Proceedings of the 2017 IEEE Western New York Image and Signal Processing Workshop (WNYISPW), Rochester, NY, USA, 17 November 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Kim, J.H.; Oh, W.T.; Choi, J.H.; Park, J.C. Reliability verification of vehicle speed estimate method in forensic videos. Forensic Sci. Int. 2018, 287, 195–206. [Google Scholar] [CrossRef]
- Lallie, H.S. Dashcam forensics: A preliminary analysis of 7 dashcam devices. Forensic Sci. Int. Digit. Investig. 2020, 33, 200910. [Google Scholar] [CrossRef]
- Lallie, H.S. Dashcam Forensic Investigation Guidelines. Forensic Sci. Int. Digit. Investig. 2023, 45, 301558. [Google Scholar] [CrossRef]
- BBC. Coventry CarjackersJailed after Voices Recorded on Dashcam. Available online: https://www.bbc.com/news/uk-england-coventry-warwickshire-35059325 (accessed on 25 August 2023).
- Li, H.; Wang, P.; You, M.; Shen, C. Reading car license plates using deep neural networks. Image Vis. Comput. 2018, 72, 14–23. [Google Scholar] [CrossRef]
- Limantoro, S.E.; Kristian, Y.; Purwanto, D.D. Pemanfaatan Deep Learning pada Video Dash Cam untuk Deteksi Pengendara Sepeda Motor. J. Nas. Tek. Elektro Dan Teknol. Inf. 2018, 7, 167–173. [Google Scholar] [CrossRef][Green Version]
- Sherwin, R.K.; Feigenson, N.; Spiesel, C. Law in the digital age: How visual communication technologies are transforming the practice, theory, and teaching of law. Boston Univ. J. Sci. Technol. Law 2006, 12, 227. [Google Scholar]
- Turner, B.L.; Caruso, E.M.; Dilich, M.A.; Roese, N.J. Body camera footage leads to lower judgments of intent than dash camera footage. Proc. Natl. Acad. Sci. USA 2019, 116, 1201–1206. [Google Scholar] [CrossRef]
- Mohamed, N.; Al-Jaroodi, J.; Jawhar, I. Cyber–Physical Systems Forensics: Today and Tomorrow. J. Sens. Actuator Netw. 2020, 9, 37. [Google Scholar] [CrossRef]
- The Tesseract OCR Community. Tesseract OCR. Available online: https://github.com/tesseract-ocr/tesseract/ (accessed on 17 July 2023).
- Sporici, D.; Cușnir, E.; Boiangiu, C.A. Improving the Accuracy of Tesseract 4.0 OCR Engine Using Convolution-Based Preprocessing. Symmetry 2020, 12, 715. [Google Scholar] [CrossRef]
- Otto-von-Guericke-Universität Magdeburg. Optical Character Recognition (OCR). Available online: https://www-e.ovgu.de/jschulen/ocr/ (accessed on 17 July 2023).
- GNU Mailing List Archives. Info-gnu Mailing List Archive: Message 11. Available online: https://lists.gnu.org/archive/html/info-gnu/2022-01/msg00011.html (accessed on 17 July 2023).
- Uberi. Speech Recognition. Available online: https://github.com/Uberi/speech_recognition/blob/master/examples/audio_transcribe.py (accessed on 17 July 2023).
- Real Python. Python Speech Recognition. Available online: https://realpython.com/python-speech-recognition/ (accessed on 17 July 2023).
- Negrão, M.; Domingues, P. SpeechToText: An open-source software for automatic detection and transcription of voice recordings in digital forensics. Forensic Sci. Int. Digit. Investig. 2021, 38, 301223. [Google Scholar] [CrossRef]
- Kent, K.; Chevalier, S.; Grance, T.; Dang, H. Guide to Integrating Forensic Techniques into Incident Response; The National Institute of Standards and Technology: Gaithersburg, MD, USA, 2006. [Google Scholar]
- Mazerolle, L.; Hurley, D.; Chamlin, M. Social Behavior in Public Space: An Analysis of Behavioral Adaptations to CCTV. Secur. J. 2002, 15, 59–75. [Google Scholar] [CrossRef]
- Brafdord, L.; Geschwind, H.; Ziangos, J. A History of CCTV Technology: How Surveillance Technology Has Evolved. 2019. Available online: https://www.surveillance-video.com/blog/a-history-of-cctv-technology-how-video-surveillance-technology-has-evolved.html/ (accessed on 17 April 2022).
- Ratcliffe, J.H.; Taniguchi, T.; Taylor, R.B. The crime reduction effects of public CCTV cameras: A multi-method spatial approach. Justice Q. 2009, 26, 746–770. [Google Scholar] [CrossRef]
- Alexandrie, G. Surveillance cameras and crime: A review of randomized and natural experiments. J. Scand. Stud. Criminol. Crime Prev. 2017, 18, 210–222. [Google Scholar] [CrossRef]
- Farrington, D.P.; Gill, M.; Waples, S.J.; Argomaniz, J. The effects of closed-circuit television on crime: Meta-analysis of an English national quasi-experimental multi-site evaluation. J. Exp. Criminol. 2007, 3, 21–38. [Google Scholar] [CrossRef]
- The CCTV Expert. Does the Latest Crime Survey Report Show That CCTV Really Does Work? 2015. Available online: https://cctvsupplies.wordpress.com/2015/08/01/does-the-latest-crime-survey-report-show-that-cctv-really-does-work/ (accessed on 25 August 2023).
- Bischoff, P. Surveillance Camera Statistics: Which City Has the Most CCTV Cameras? 2021. Available online: https://www.comparitech.com/vpn-privacy/the-worlds-most-surveilled-cities/ (accessed on 25 August 2023).
- Revell, T. Computer Vision Algorithms Pick Out Petty Crime in CCTV Footage. 2017. Available online: https://www.newscientist.com/article/2116970-computer-vision-algorithms-pick-out-petty-crime-in-cctv-footage/ (accessed on 25 August 2023).
- Stathers, C.; Muhammad, M.; Fasanmade, A.; Al-Bayatti, A.; Morden, J.; Sharif, M.S. Digital Data Extraction for Vehicles Forensic Investigation. In Proceedings of the 2022 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakheer, Bahrain, 20–21 November 2022; pp. 553–558. [Google Scholar] [CrossRef]
- Boyd, D.S.; Crudge, S.; Foody, G. Towards an Automated Approach for Monitoring Tree Phenology Using Vehicle Dashcams in Urban Environments. Sensors 2022, 22, 7672. [Google Scholar] [CrossRef] [PubMed]
- Kang, M.; Lee, W.; Hwang, K.; Yoon, Y. Vision Transformer for Detecting Critical Situations and Extracting Functional Scenario for Automated Vehicle Safety Assessment. Sustainability 2022, 14, 9680. [Google Scholar] [CrossRef]
- Notarangelo, N.M.; Hirano, K.; Albano, R.; Sole, A. Transfer Learning with Convolutional Neural Networks for Rainfall Detection in Single Images. Water 2021, 13, 588. [Google Scholar] [CrossRef]
- Zhu, R.; Fang, J.; Xu, H.; Xue, J. Progressive Temporal-Spatial-Semantic Analysis of Driving Anomaly Detection and Recounting. Sensors 2019, 19, 5098. [Google Scholar] [CrossRef]
- Chung, Y.L.; Lin, C.K. Application of a Model that Combines the YOLOv3 Object Detection Algorithm and Canny Edge Detection Algorithm to Detect Highway Accidents. Symmetry 2020, 12, 1875. [Google Scholar] [CrossRef]
- Dashcam—Wikipedia. Available online: https://en.wikipedia.org/wiki/Dashcam (accessed on 5 June 2023).
- Lee, C. The Rise of the Dashcam—National Motorists Association. 2020. Available online: https://ww2.motorists.org/blog/the-rise-of-the-dashcams/ (accessed on 25 August 2023).
- KBV Research. Dashboard Camera Market Size, Share & Forecast by 2026. 2020. Available online: https://www.kbvresearch.com/dashboard-camera-market/ (accessed on 25 August 2023).
- Dashcams Direct. The Ultimate Guide to Dashcams. Available online: http://www.dashcams.com.au/dashcams-101/ (accessed on 5 August 2021).
- Nextbase. Dash Cam Features. Available online: https://www.nextbase.com/en-us/dash-cam-features/ (accessed on 14 August 2021).
- Kolla, E.; Ondruš, J.; Vertal’, P. Reconstruction of traffic situations from digital video-recording using method of volumetric kinetic mapping. Arch. Motoryz. 2019, 84, 147. [Google Scholar] [CrossRef]
- Torney, D. External Perceptions and EU Foreign Policy Effectiveness: The Case of Climate Change. JCMS J. Common Mark. Stud. 2014, 52, 1358–1373. [Google Scholar] [CrossRef]
- Giovannini, E.; Giorgetti, A.; Pelletti, G.; Giusti, A.; Garagnani, M.; Pascali, J.P.; Pelotti, S.; Fais, P. Importance of dashboard camera (Dash Cam) analysis in fatal vehicle–pedestrian crash reconstruction. Forensic Sci. Med. Pathol. 2021, 17, 379–387. [Google Scholar] [CrossRef] [PubMed]
- Štitilis, D.; Laurinaitis, M. Legal regulation of the use of dashboard cameras: Aspects of privacy protection. Comput. Law Secur. Rev. 2016, 32, 316–326. [Google Scholar] [CrossRef]
- Reflex Vehicle Hire. Dashcams and Crash for Cash Scams—Reflex Vehicle Hire. 2021. Available online: https://www.reflexvehiclehire.com/dashcams-and-crash-for-cash-scams (accessed on 25 August 2023).
- Hillman, M. Dashcam Benefits for Commercial Fleets—SureCam. 2019. Available online: https://surecam.com/blog/dashcam-benefits-for-commercial-fleets (accessed on 25 August 2023).
- Mehrish, A.; Subramanyam, A.V.; Kankanhalli, M. Multimedia signatures for vehicle forensics. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 685–690. [Google Scholar] [CrossRef]
- Lee, K.; Choi, J.h.; Park, J.; Lee, S. Your Car is Recording: Metadata-driven Dashcam Analysis System. Forensic Sci. Int. Digit. Investig. 2021, 38, 301131. [Google Scholar] [CrossRef]
- Sitara, K.; Mehtre, B. Differentiating synthetic and optical zooming for passive video forgery detection: An anti-forensic perspective. Digit. Investig. 2019, 30, 1–11. [Google Scholar] [CrossRef]
- Roberts, J.; Hodgetts, C. Courting contempt?: Untangling the web of Jurors’ internet use under section 8 of the contempt of Court Act 1981. Commun. Law 2015, 20, 86. [Google Scholar]
- Crown Prosecution Service. Public Justice Offences Incorporating the Charging Standard. 2019. Available online: https://www.cps.gov.uk/legal-guidance/public-justice-offences-incorporating-charging-standard (accessed on 16 June 2023).
- Trojahn, M.; Pan, L.; Schmidt, F. Developing a cloud computing based approach for forensic analysis using OCR. In Proceedings of the 2013 Seventh International Conference on IT Security Incident Management and IT Forensics, Nuremberg, Germany, 12–14 March 2013; pp. 59–68. [Google Scholar] [CrossRef]
- Mustafa, T.; Karabatak, M. Challenges in Automatic License Plate Recognition System Review. In Proceedings of the 2023 11th International Symposium on Digital Forensics and Security (ISDFS), Chattanooga, TN, USA, 11–12 May 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Lehri, D.; Roy, A. Identifying Desired Timestamps in Carved Digital Video Recorder Footage. In Advances in Digital Forensics XVIII; Peterson, G., Shenoi, S., Eds.; IFIP Advances in Information and Communication Technology; Springer: Cham, Switzerland, 2022; Volume 653. [Google Scholar] [CrossRef]
- Jovanović, L.; Adamović, S. Digital Forensics Artifacts of the Microsoft Photos Application in Windows 10. In Proceedings of the 685 Sinteza 2022—International Scientific Conference on Information Technology and Data Related Research; Singidunum University: Belgrade, Serbia, 2022; pp. 427–434. [Google Scholar] [CrossRef]
- Mustafa, T.; Karabatak, M. Deep Learning Model for Automatic Number/License Plate Detection and Recognition System in Campus Gates. In Proceedings of the 2023 11th International Symposium on Digital Forensics and Security (ISDFS), Chattanooga, TN, USA, 11–12 May 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Renza, D.; Vargas, J.; Ballesteros, D.M. Robust Speech Hashing for Digital Audio Forensics. Appl. Sci. 2020, 10, 249. [Google Scholar] [CrossRef]
- EC-Council. What Is Digital Forensics | Phases of Digital Forensics. 2021. Available online: https://www.eccouncil.org/cybersecurity/what-is-digital-forensics/ (accessed on 25 August 2023).
- Grance, T.; Chevalier, S.; Kent, K.; Dang, H. Guide to Computer and Network Data Analysis: Applying Forensic Techniques to Incident Response; Special Pub 800-86; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2005; Volume 86, pp. 800–886. [Google Scholar]
- Belkasoft. Belkasoft Evidence Center. 2021. Available online: https://belkasoft.com/ (accessed on 25 August 2023).
- Forensics, M. Magnet AXIOM. 2020. Available online: https://www.magnetforensics.com/products/magnet-axiom/ (accessed on 25 August 2023).
- AccessData FTK Imager. 2020. Available online: https://accessdata.com/products-services/forensic-toolkit-ftk/ftkimager (accessed on 25 August 2023).
- Autopsy Digital Forensics. 2020. Available online: https://www.autopsy.com/ (accessed on 25 August 2023).
- Registry Viewer®. 2014. Available online: https://accessdata.com/product-download/registry-viewer-1-8-0-5 (accessed on 25 August 2023).
- Vmware Workstation Pro. 2020. Available online: https://www.vmware.com/products/workstation-pro.html (accessed on 25 August 2023).
- Morris, A.C.; Maier, V.; Green, P.D. From WER and RIL to MER and WIL: Improved Evaluation Measures for Connected Speech Recognition. In Proceedings of the INTERSPEECH 2004—ICSLP 8th International Conference on Spoken Language Processing, Jeju, Republic of Korea, 4–8 October 2004. [Google Scholar]
- Casey, E. Digital Evidence and Computer Crime: Forensic Science, Computers, and the Internet; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Length in Minutes | Google API | DeepSpeech |
|---|---|---|
| 10 | 4.2 | 6.5 |
| 15 | 4.7 | 7.9 |
| 18 | 5.1 | 8.7 |
| 24 | 5.3 | 10.4 |
| 33 | 5.8 | 11.5 |
| 47 | 4.9 | 10.7 |
| Function Name | Execution Time (s) | Percentage |
|---|---|---|
| translate_csv_map | 0.2066 | 0.269% |
| add_file_to_report | 0.0054 | 0.007% |
| calculate_file_hash | 0.1118 | 0.146% |
| generate_transcript | 20.8220 | 27.101% |
| ocr | 13.5920 | 17.691% |
| parseData | 0.00163 | 0.002% |
| extractImages | 3.8242 | 4.977% |
| extractDataFromVideo | 17.4466 | 22.708% |
| transcript_video | 20.8207 | 27.099% |
| Total | 76.8311 | 100.00% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daraghmi, Y.-A.; Shawahna, I. Digital Forensic Analysis of Vehicular Video Sensors: Dashcams as a Case. Sensors 2023, 23, 7548. https://doi.org/10.3390/s23177548
Daraghmi Y-A, Shawahna I. Digital Forensic Analysis of Vehicular Video Sensors: Dashcams as a Case. Sensors. 2023; 23(17):7548. https://doi.org/10.3390/s23177548
Chicago/Turabian StyleDaraghmi, Yousef-Awwad, and Ibrahim Shawahna. 2023. "Digital Forensic Analysis of Vehicular Video Sensors: Dashcams as a Case" Sensors 23, no. 17: 7548. https://doi.org/10.3390/s23177548
APA StyleDaraghmi, Y.-A., & Shawahna, I. (2023). Digital Forensic Analysis of Vehicular Video Sensors: Dashcams as a Case. Sensors, 23(17), 7548. https://doi.org/10.3390/s23177548