1. Introduction
With the rapid economic development in China, the construction of transportation infrastructure has advanced significantly, and the field of bridge construction has achieved a world-leading position. According to the 2021 statistical bulletin on the development of the transportation industry from the Ministry of Transport, there were 961,100 highway bridges nationwide, with a total length (TL) of 73,802,100 m. This represents an increase of 48,400 bridges, with a TL of 7,516,600 m, compared to the end of the previous year, of which 7417 were super-large bridges with a TL of 13,478,700 m, and 134,500 were medium and small bridges with a TL of 37,158,900 m. Therefore, it can be seen that the current number of bridges in China is quite large. During the operation of the bridges, cracks are prone to occur due to excessive loads, poor-quality construction materials, heat, and other factors [
1,
2,
3]. Cracking is a severe problem for bridges, as it can significantly affect their safe operation, resulting in economic losses and casualties once an accident occurs [
4,
5,
6]. Therefore, the timely and accurate detection of bridge cracks has become a primary task of bridge maintenance [
7]. Crack identification and positioning are important parts of bridge safety detection. At present, the detection method for bridge cracks in China is mainly manual detection. Inspection personnel generally use telescopes, ladders, bridge inspection vehicles, and other tools for manual measurement, analysis, and evaluation. Although manual detection is simple and flexible, it has several shortcomings, including low efficiency, poor accuracy, and high cost [
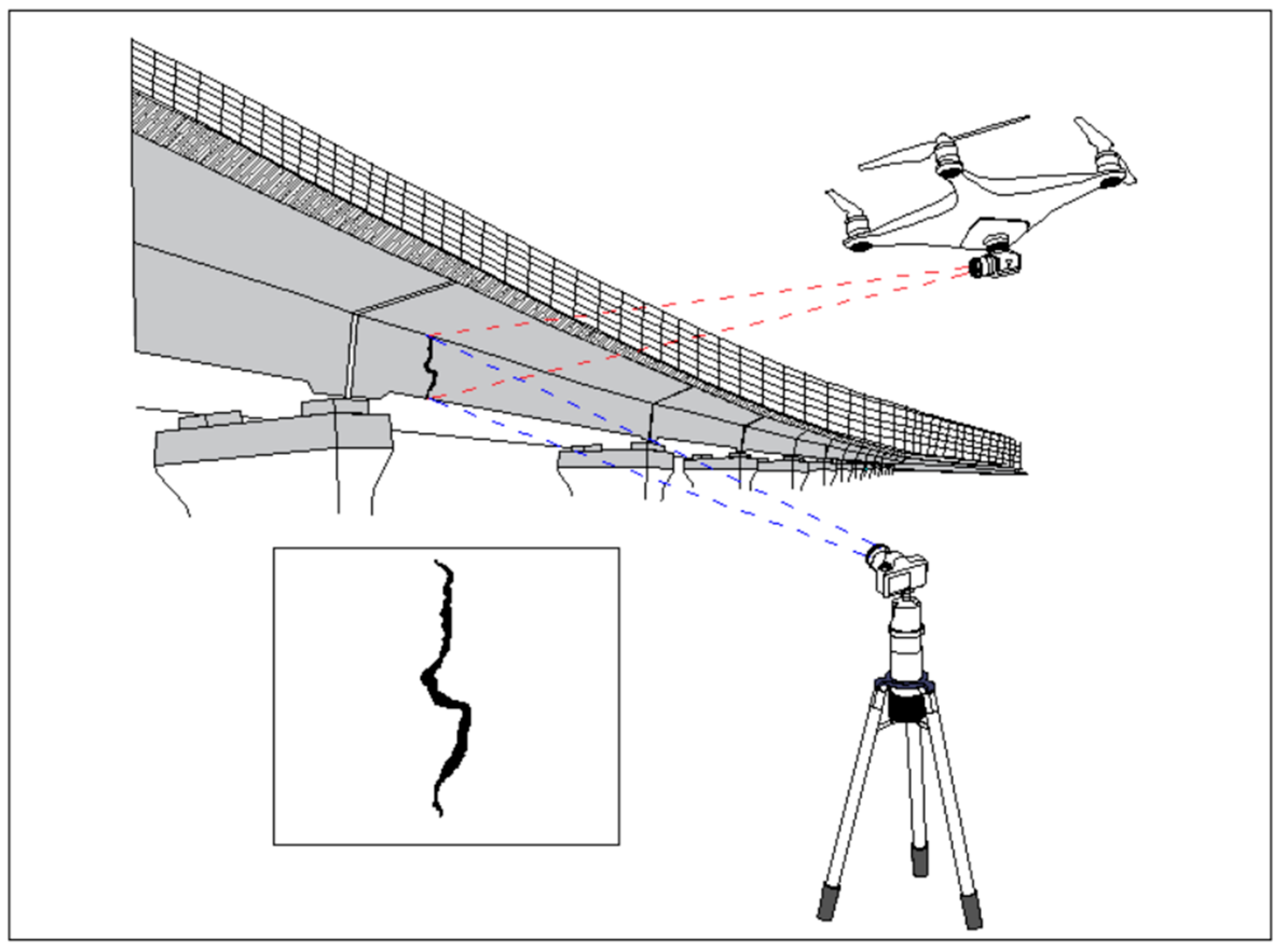
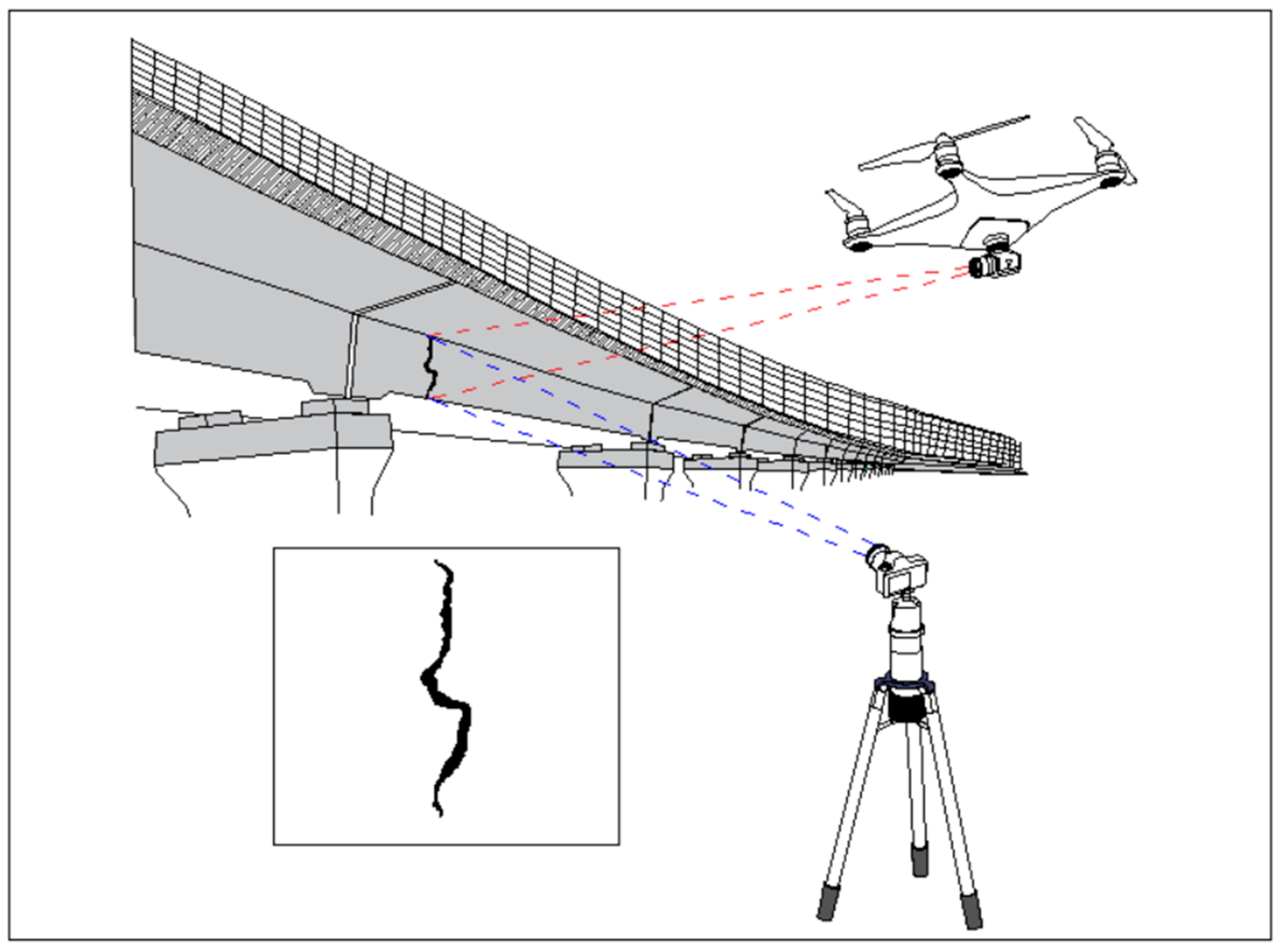
8]. The digital image processing method based on grayscale edge extraction is commonly used for bridge crack detection. Unmanned Aerial Vehicles (UAVs), cameras, and other equipment are used to collect crack images for bridge cracks.
Figure 1 shows the position and properties of bridge cracks that can be extracted [
9,
10,
11,
12]. Li et al. [
13] detected cracks using the classical Sobel operator and connected domain measurement. Huang and Tsai [
14] proposed a dynamic optimal threshold segmentation algorithm based on dynamic programming, and Kirschke and Velinsky [
15] proposed a crack image thresholding algorithm based on sub-image grayscale histograms. Tsai et al. [
16] used the maximum inter-class variance method for crack detection. However, due to the complex background of bridge crack images, the crack detection results often carry a large amount of noise, resulting in low detection accuracy.
In order to improve the efficiency and accuracy of bridge crack detection, several scholars have conducted research on the influence of background noise on recognition results [
4,
11,
17,
18,
19]. To provide a more accurate and efficient DLF and CNN model for bridge crack detection, this paper experiments with different DLFs and CNNs, to evaluate their coupling effect on bridge crack detection efficiency. Deep learning techniques utilize CNN models for tasks such as object detection, semantic segmentation, and instance segmentation within a specific learning framework. Many scholars have studied crack detection using different neural network models based on existing learning frameworks, such as PyTorch, TensorFlow, and Keras. For instance, Amo-Boateng [
20] utilized a Mask-RCNN model network to achieve a cross-merge ratio of 88.2% in house roof segmentation based on the TensorFlow framework. Ref. [
21] used an improved Full Convolutional Neural Network (FCNN) model for crack detection, achieving an average cross-merge ratio of 55.2% for detection results. Fu et al. [
22] applied the DeepLabv3+ model for crack segmentation and achieved an average cross-merge ratio of 82.37%. Based on the Keras framework, Zhang et al. [
23] utilized the improved UNet model for crack segmentation to detect concrete cracks with high accuracy. Ochoa-Ruiz et al. [
24] used the RetinaNet model for crack detection, achieving object detection with higher accuracy and efficiency. Qu and Xie [
25] applied the full U-shaped network model for crack segmentation and achieved a 1.48% increase in
p, a 4.68% increase in R, and a 3.29% increase in F values. Based on the PyTorch framework, Jia et al. [
26] used the improved EfficientDet model to detect marine organisms with a detection rate of over 90%, while Yu et al. [
27] used the CenterNet model for vehicle detection, with an average accuracy of 94.74%. Liu et al. [
28] proposed the YOLOv3-FDL model with a four-scale detection layer. Compared with the original YOLOv3 model, the F1 score and mAP of the YOLOv3-FDL model reached 88.8% and 87.8%, respectively, which increased by 8.8% and 7.5% on the GPR data set, respectively. Wang et al. [
29] combined data enhancement and structure optimization to significantly improve the accuracy of the YOLOv3 object detection model. Zhang et al. [
30] utilized the improved YOLO v4 model for crack detection, achieving experimental results of 93.96%, 90.12%, and 92.00% for
p, R, and F values, respectively. In order to reduce the interference of complex background factors of crack images on the crack detection results, Yu [
31] adopted the threshold segmentation method based on the maximum inter-class variance of Otsu to preprocess images and conducted the crack detection task by using YOLOv5s, and achieved good results. Qiao et al. [
32] utilized the improved U-net model for crack segmentation, resulting in an average accuracy 11.7% higher than the U-net neural network segmentation model.
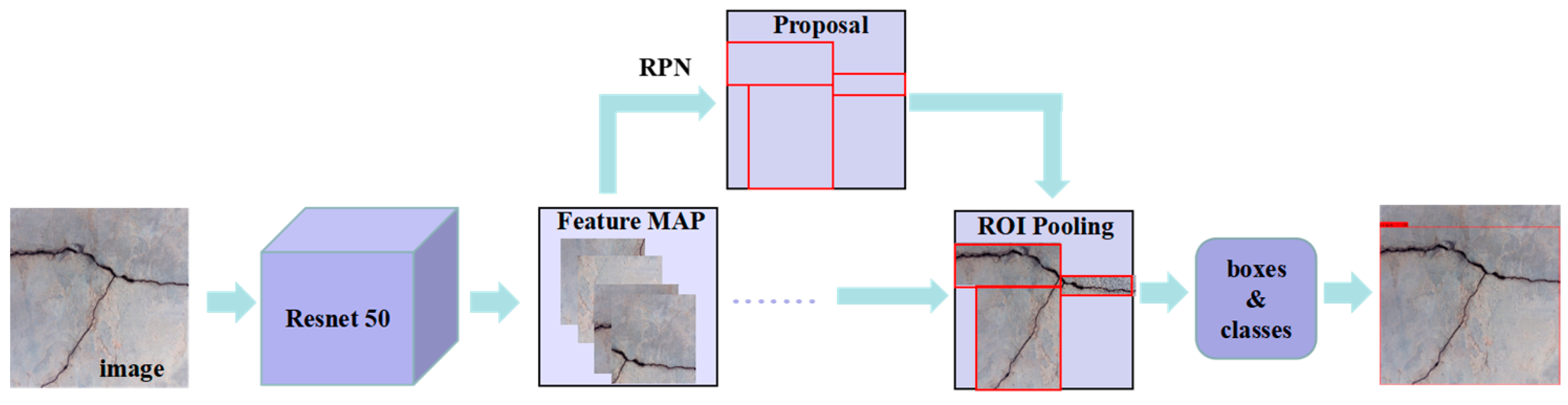
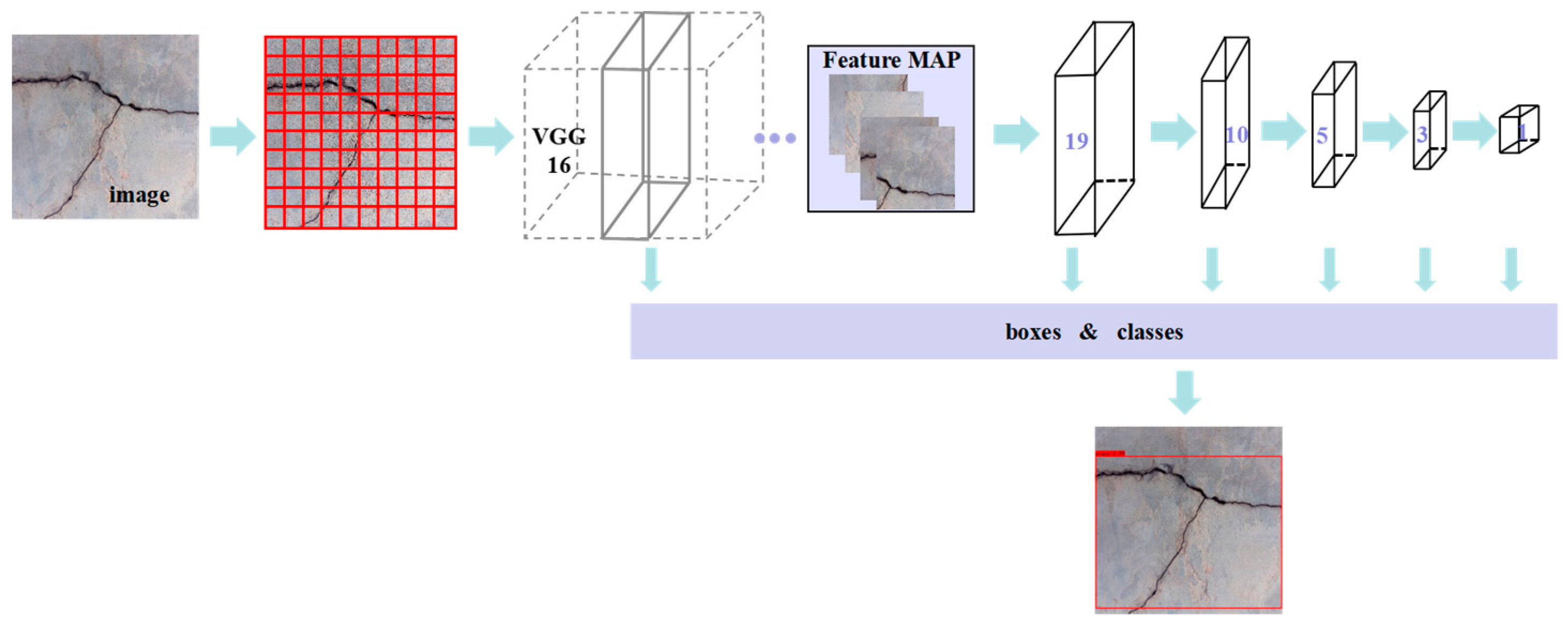
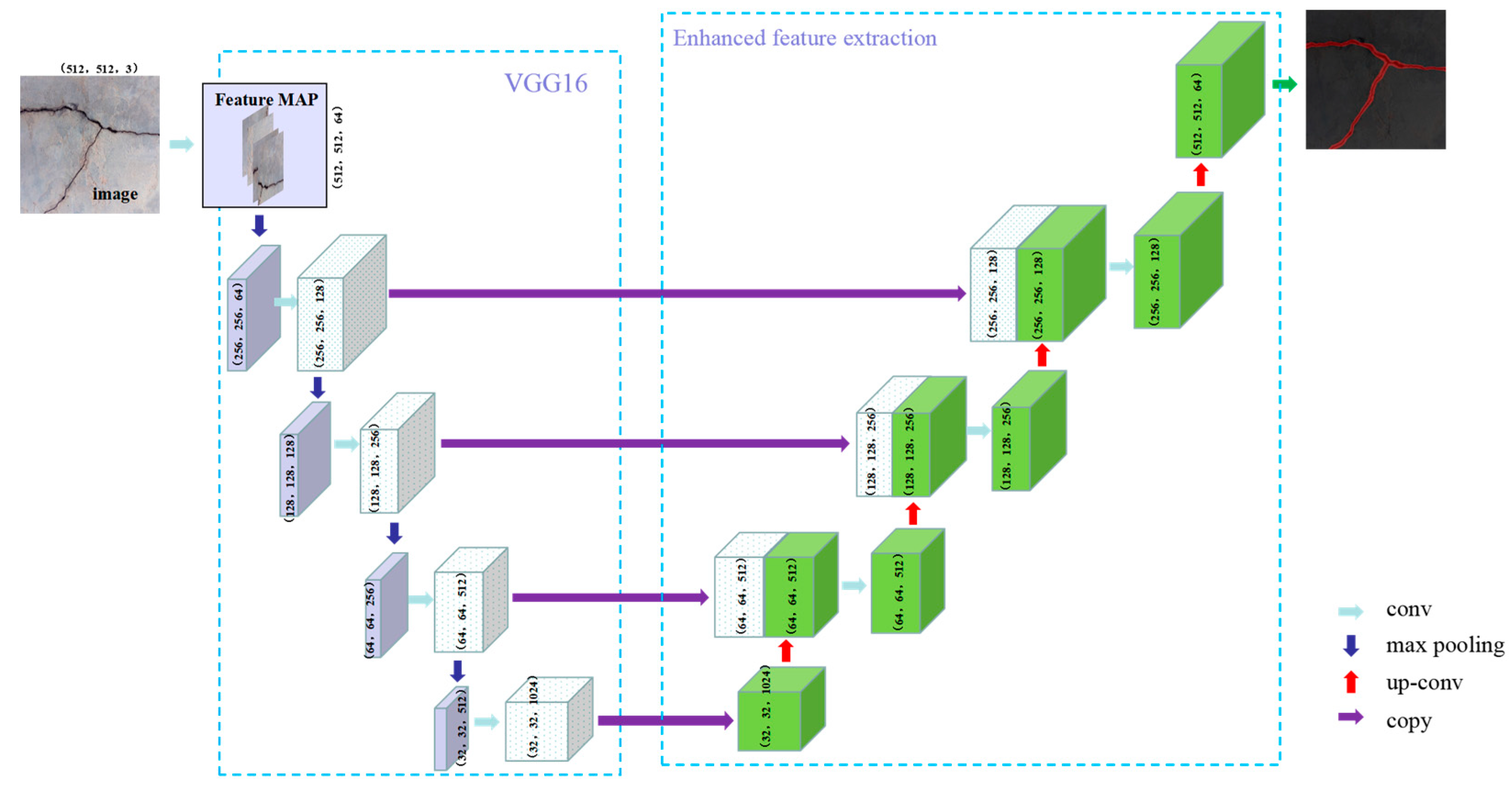
In short, most scholars choose the DLF and CNN model to conduct corresponding research based on the existing foundation. It is not clear whether the chosen DLF and CNN model are the optimal combination. Moreover, no systematic experimental research has been found on the coupling efficiency of the DLF and CNN model. Based on this, this article aimed to investigate the effectiveness of coupling the DLF with the CNN model for bridge crack detection. To verify the effectiveness of coupling a DLF and CNN for bridge crack detection, bridge crack datasets were collected and labeled, and the DLF and CNN model was introduced to perform bridge crack detection experiments. The coupling efficiency of the DLF and CNN model was tested, and the optimal object detection and semantic segmentation CNN model for bridge crack detection under a DLF was obtained. This provides a practical basis for selecting the CNN model and DLF for efficient and high-precision bridge crack detection.
4. Discussion
Researchers such as Ji et al. [
43] and Liu et al. [
44] conducted related studies on object detection network models, utilizing the Faster R-CNN model, whereas Wan et al. [
45] and Wang et al. [
46] used the SSD model, and Yu et al. [
47] and Li et al. [
48] used the YOLO-v5 model, all of which achieved promising results. In this study, we have primarily focused on conducting coupled detection effectiveness experiments using the aforementioned three CNN models in conjunction with three DLFs. The most impressive results obtained include a
p-value of 74.67% and an R-value of 67.06% for the Faster R-CNN model in TensorFlow2, a
p-value of 79.35% and an R-value of 51.37% for the SSD model in TensorFlow2, and a
p-value of 88.28% and an R-value of 50.2% for the detection results in YOLO-v5(x) using PyTorch. Regarding semantic segmentation network models, similar studies were conducted using the U-Net model [
49,
50], and using the PSPNet model [
20,
51], which also yielded improved results. However, this paper has mainly focused on conducting coupled detection performance experiments utilizing the two above-mentioned CNN models in conjunction with three DLFs. The best results obtained include an AC-value of 98.28% for the U-Net model in TensorFlow2 and an AC-value of 97.86% for the PSPNet model in TensorFlow2.
4.1. CNN Model with Different DLFs in the Same Dataset
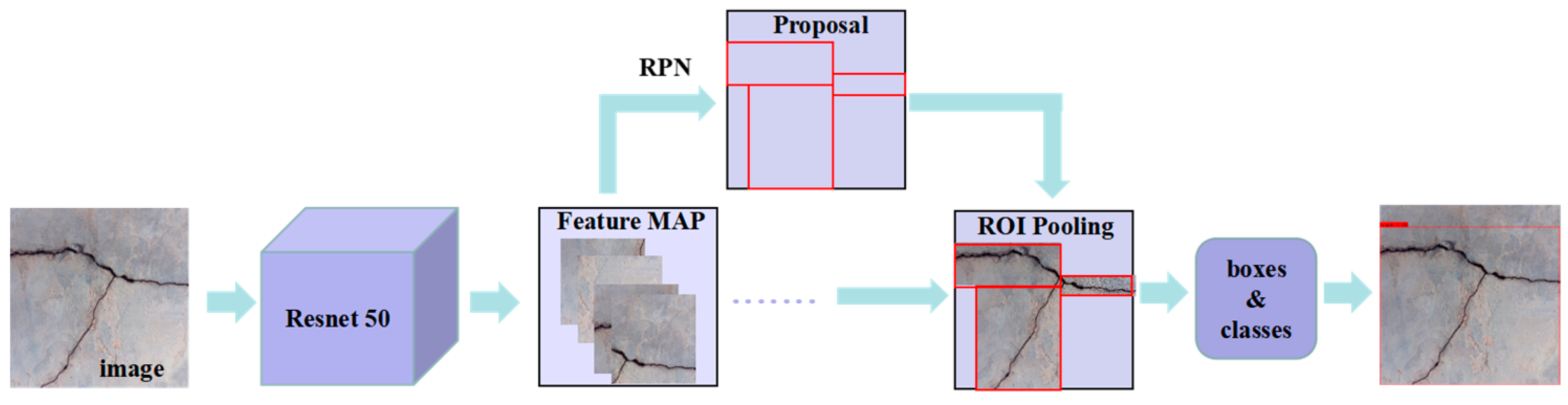
Regarding object detection network models, the Faster R-CNN and SSD models showed the best overall performance in Keras, with F1 values of 0.76 and 0.67, respectively. By contrast, the YOLO-v5(x) model had a p-value of only 88.28% in PyTorch, but it performed the best overall in TensorFlow2, with R and F1 values of 54.9% and 0.67, respectively.
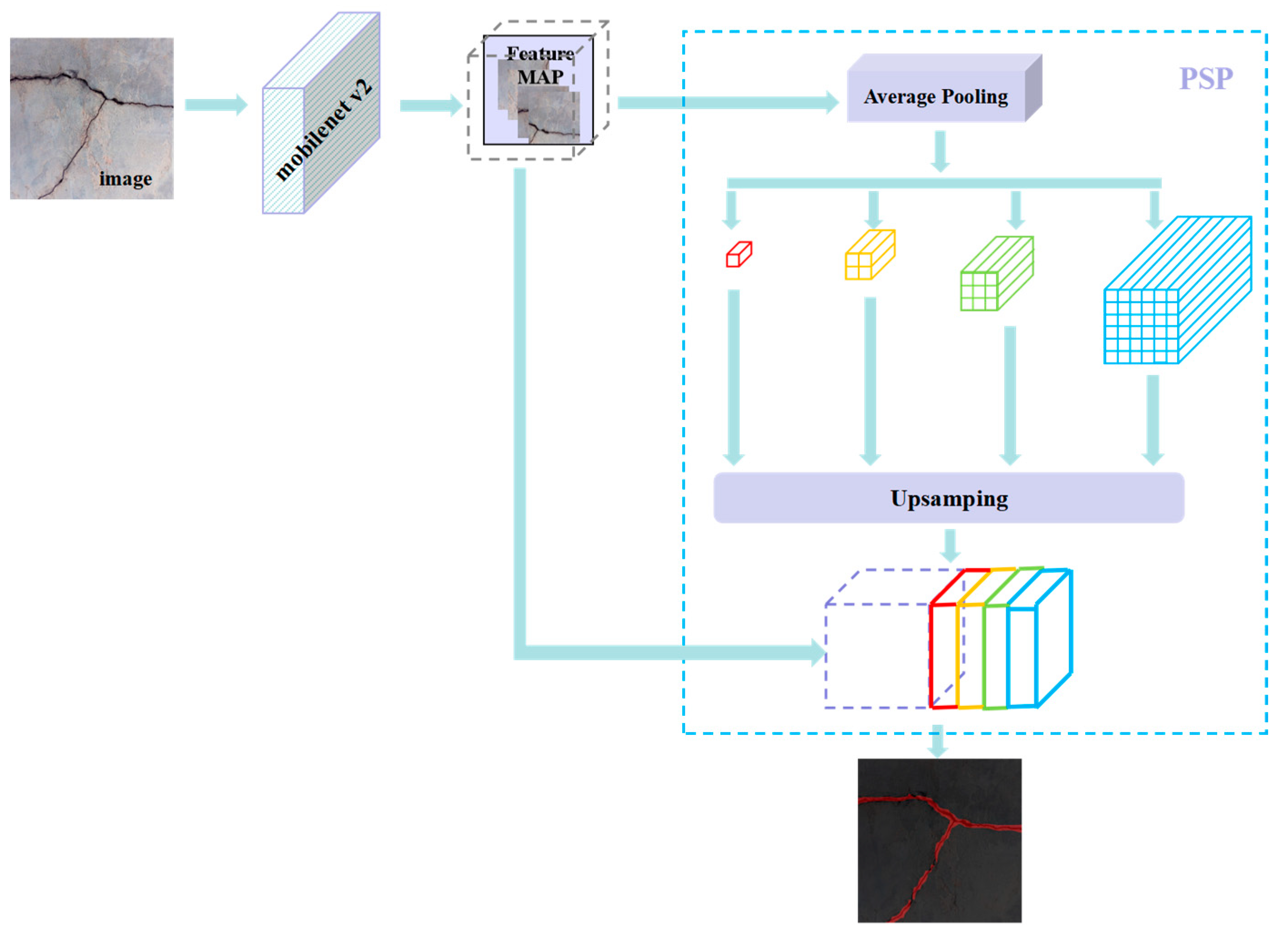
As for the semantic segmentation network models, the U-Net model had the best overall performance in PyTorch, with p and AC values of 89.11% and 98.37%, respectively, although its R-value was only 92.38% in TensorFlow2. On the other hand, the PSPNet model had a p-value of only 88.36% in Keras, but it achieved the best overall performance in TensorFlow2, with R and AC values of 87.86% and 97.86%, respectively.
4.2. Different CNN Models with the Same Dataset and the Same DLF
Among the object detection network models tested in PyTorch, TensorFlow2, and Keras, the YOLO-v5(x) model achieved the largest p values of 88.28%, 87.5%, and 84.71%, respectively, whereas the Faster R-CNN model achieved the largest R and F1 values (with R values reaching 64.71%, 67.06%, and 71.37%, and F1 values reaching 0.69, 0.71, and 0.76, respectively). By considering the obtained p, R, and F1 values, the Faster R-CNN model had the largest F1 value and the best overall evaluation in PyTorch, TensorFlow2, and Keras, respectively.
In terms of semantic segmentation network models, the U-Net model achieved the best overall evaluation in PyTorch and TensorFlow2, with the largest p, R, and AC values (89.11%, 90.28%, 98.37%, and 87.05%, 92.38%, and 98.28%, respectively). On the other hand, the PSPNet model had the best overall evaluation in Keras, with the largest p, R, and AC values of 88.36%, 71.55%, and 97.22%, respectively.
5. Conclusions
An experimental study of the best performance of bridge crack detection by coupling DLFs and CNNs was conducted using 2068 crack images based on three DLFs and five CNN models.
(1) The Faster R-CNN model showed the best detection effect among the object detection CNNs, which includes Faster R-CNN, SSD, and YOLO-v5(x). Similarly, among the semantic segmentation CNNs, the U-Net model exhibited the best segmentation effect compared to PSPNet.
(2) The detection efficiency of object detection and semantic segmentation CNN models varies under different DLFs. The Keras framework showed the best detection efficiency for the Faster R-CNN and SSD models, whereas the TensorFlow2 framework performed better for the PSPNet and YOLO-v5(x) models. Additionally, the PyTorch framework demonstrated the best detection efficiency for the U-Net model.
In short, the method and model of bridge crack detection with high precision and high performance can be obtained. For the object detection of bridge cracks, the Faster R-CNN model has the best performance in bridge crack detection under the Keras framework. For semantic segmentation of bridge cracks, the U-Net model has the best segmentation effect on bridge cracks under the PyTorch framework.
This paper presents an experimental study on the efficiency of object detection and semantic segmentation CNN models for bridge crack detection using PyTorch, TensorFlow2, and Keras. The results of this study are based on the image data set of bridge cracks in a simple background. The image data set of bridge cracks under complex interference background was not considered in the experiment, but the methods and results of this study can provide some practical basis for the research of bridge crack detection under complex interference background. The obtained results can serve as a significant reference for choosing the appropriate CNN model and DLF for bridge crack detection in future studies. Moreover, it establishes a solid theoretical and practical foundation for the development of real-time AI-based intelligent detection of building damage and unsupervised classification using remote sensing technology.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












































