
Road-MobileSeg: Lightweight and Accurate Road Extraction Model from Remote Sensing Images for Mobile Devices


 ,
,
Abstract
1. Introduction
- (1)
- While deeper and more complex deep learning networks often achieve better model performance [48,49], they also tend to consume more resources during loading and running procedures and typically require a large amount of computations that exceed the computing capacity of embedded devices, negatively impacting operational efficiency. These characteristics have hindered the implementation of current models for extracting roads on mobile devices with limited computing capabilities.
- (2)
- The lightweight design of deep learning models is a practical and efficient approach to enable their implementation on mobile devices and ensure smooth operation with limited computational resources. However, it is uncertain whether the existing lightweight road extraction models [40,41] are suitable for deployment on mobile devices because they were not specifically developed for mobile applications, even though they can reduce model parameters and calculations to some extent. Meanwhile, the effectiveness of current lightweight segmentation models for mobile applications in extracting road information on mobile devices has not been further verified [42,43,44,45,46,47].
- A model for extracting roads, called Road-MobileSeg, has been developed. It is designed to be used on mobile devices and can extract roads from remote sensing images end-to-end.
- The Road-MobileFormer, which serves as the backbone structure of Road-MobileSeg, was developed. It consists of an improved Token Pyramid Module and several Coordinate Attention Modules, which can achieve lightweight model structure and high accuracy of road extraction, thus ensuring smooth operation on mobile devices.
- Three model structures, named Road-MobileSeg-Base, Road-MobileSeg-Small, and Road-MobileSeg-Tiny, were designed with different levels of complexity according to their backbone structures to adapt to the needs of mobile devices with different memory capacity and computing power.
- Latency tests for different models on mobile devices with a CPU processor were conducted to validate the effectiveness and feasibility of our suggested models.
2. Methodology
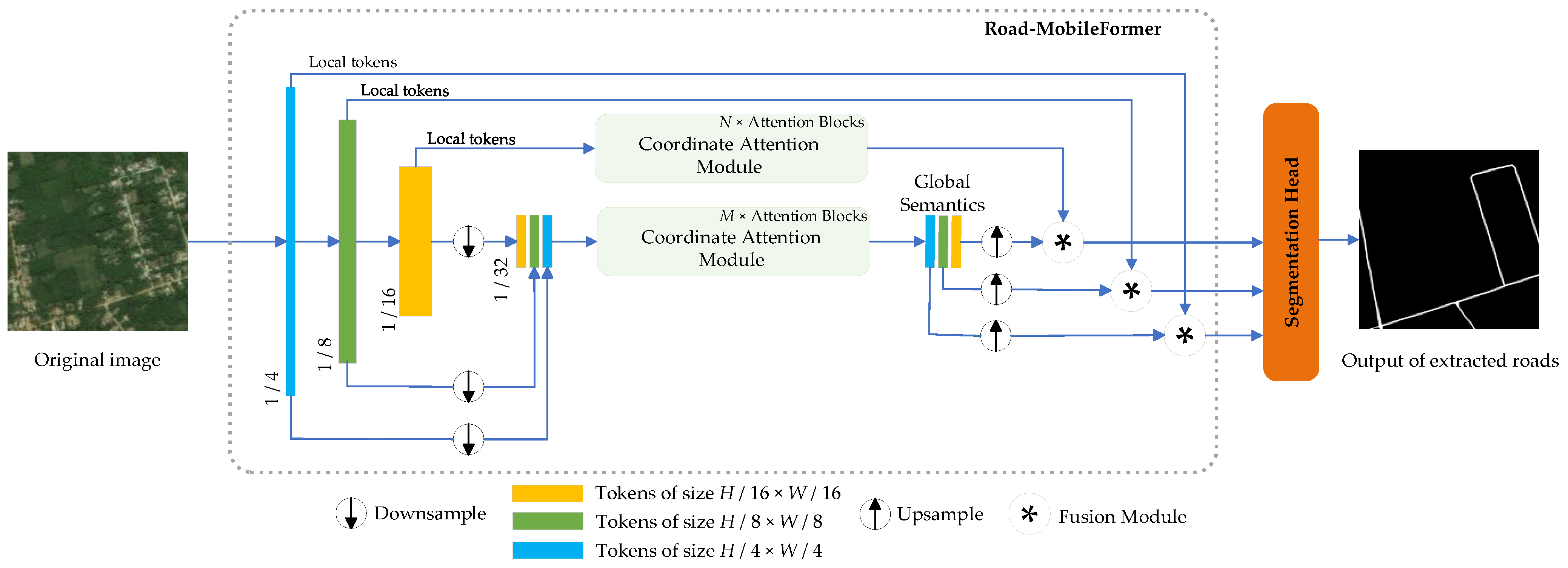
2.1. Overall Architecture
2.2. Micro Token Pyramid Module
2.3. Coordinate Attention Module
2.3.1. Coordinate Information Embedding
2.3.2. Coordinate Attention Generation
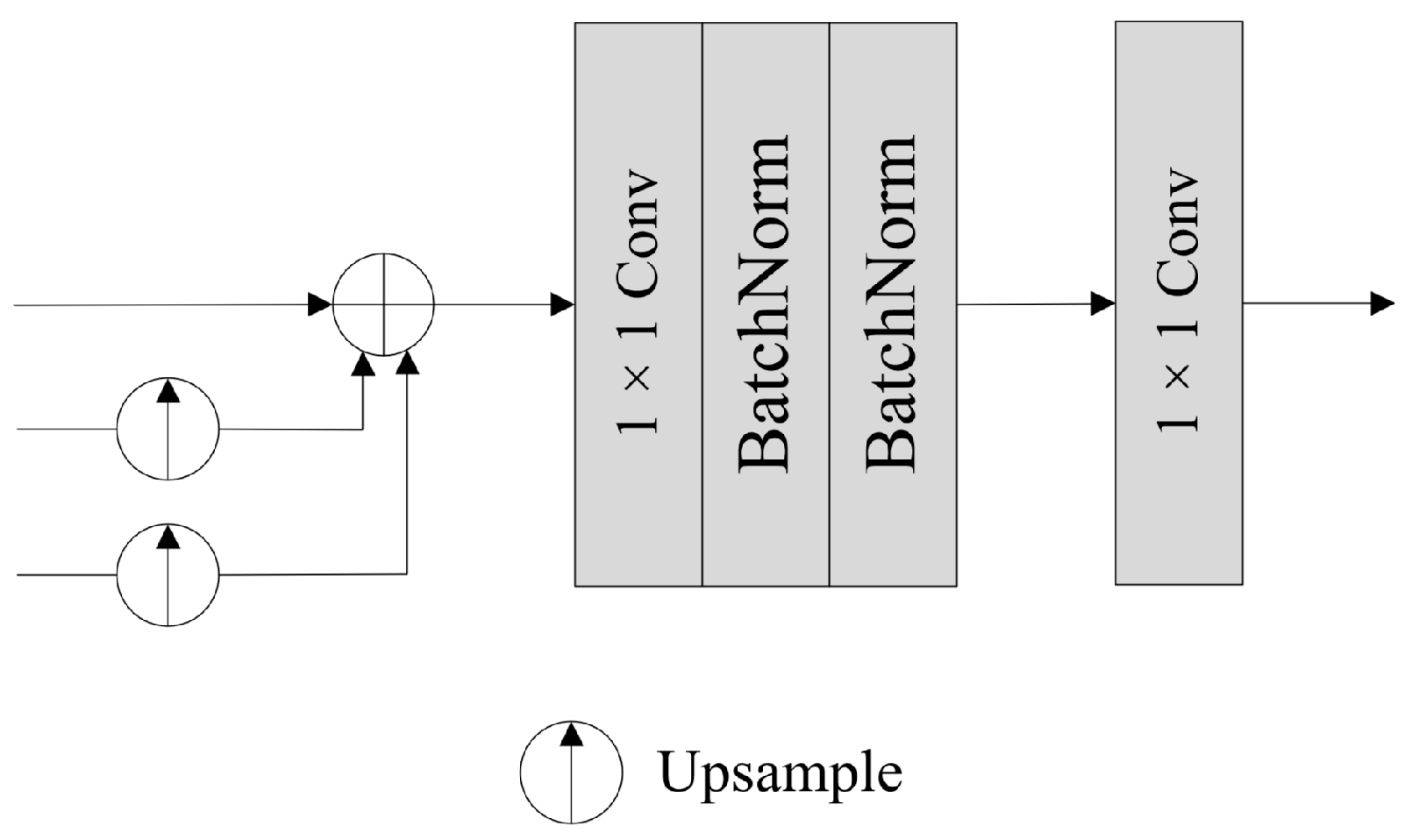
2.4. Fusion Module and Segmentation Head
2.5. Architecture Variants
3. Experiments and Evaluation
3.1. Dataset
3.2. Experiment Settings
3.2.1. Training Settings
3.2.2. Latency Test Settings
3.3. Evaluation Metrics
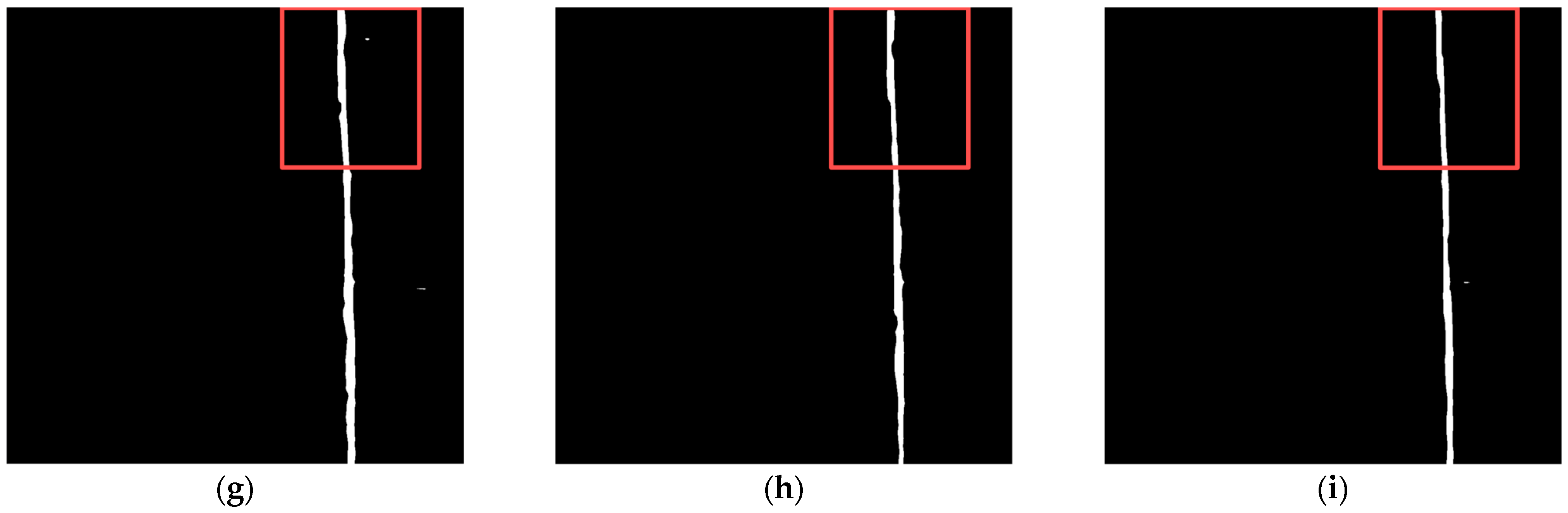
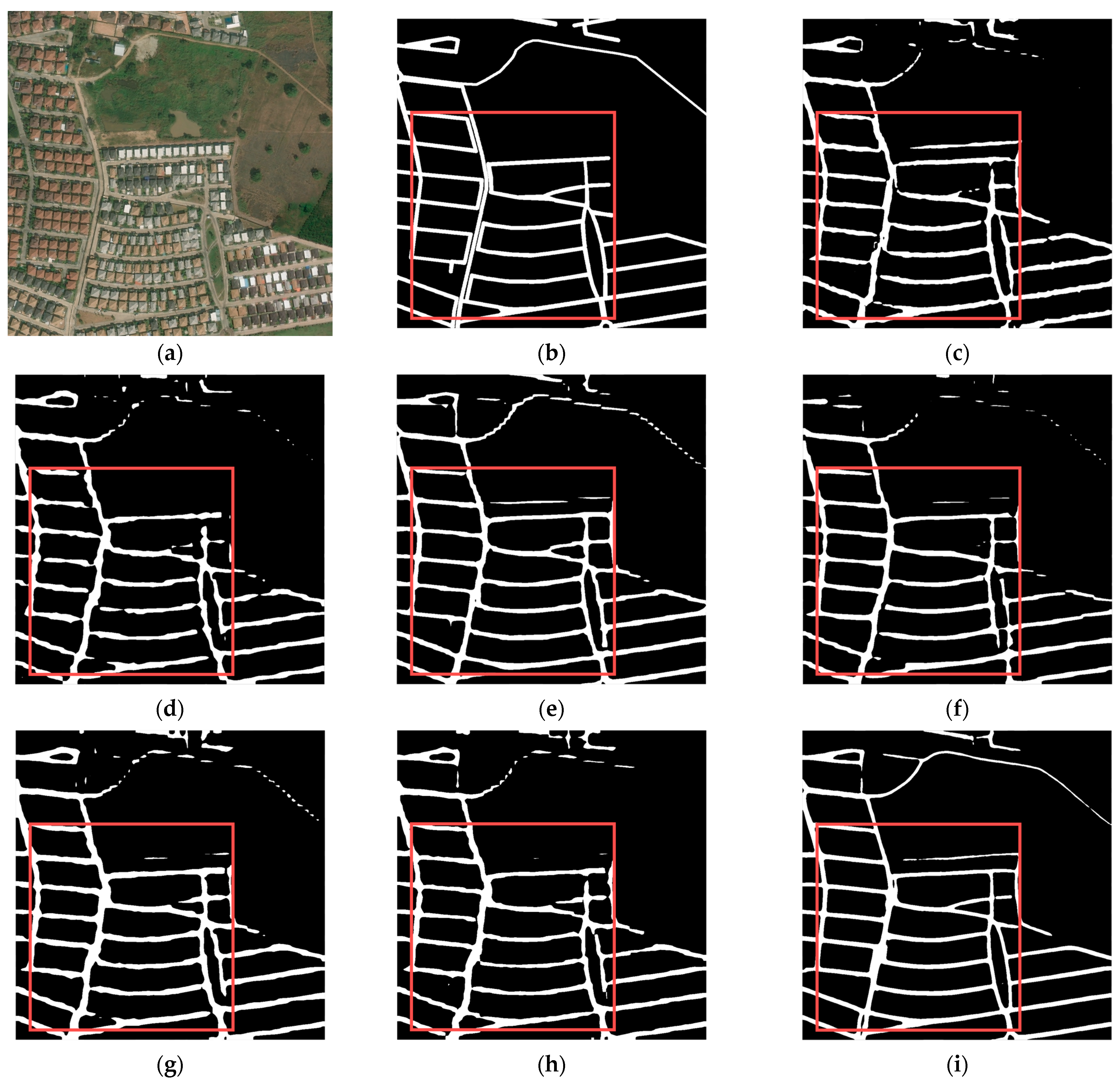
3.4. Visual Evaluation
3.5. Quantitative Evaluation
3.6. Latency Test on Mobile Devices
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Heiselberg, H.; Stateczny, A. Remote Sensing in Vessel Detection and Navigation. Sensors 2020, 20, 5841. [Google Scholar] [CrossRef]
- Parekh, D.; Poddar, N.; Rajpurkar, A.; Chahal, M.; Kumar, N.; Joshi, G.P.; Cho, W. A Review on Autonomous Vehicles: Progress, Methods and Challenges. Electronics 2022, 11, 2162. [Google Scholar] [CrossRef]
- Xia, Y.; Yabuki, N.; Fukuda, T. Development of a system for assessing the quality of urban street-level greenery using street view images and deep learning. Urban For. Urban Green. 2021, 59, 126995. [Google Scholar] [CrossRef]
- Zhu, W.; Li, H.; Cheng, X.; Jiang, Y. A Multi-Task Road Feature Extraction Network with Grouped Convolution and Attention 7Mechanisms. Sensors 2023, 23, 8182. [Google Scholar] [CrossRef] [PubMed]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Li, Y. Road Extraction by Using Atrous Spatial Pyramid Pooling Integrated Encoder-Decoder Network and Structural Similarity Loss. Remote Sens. 2019, 11, 1015. [Google Scholar] [CrossRef]
- You, G.; Zeng, W. Features and Methods of Road Extraction from High-resolution Remote Sensing Images. In Proceedings of the 2019 Cross Strait Quad-Regional Radio Science and Wireless Technology Conference (CSQRWC), Taiyuan, China, 18–21 July 2019; pp. 1–2. [Google Scholar]
- Guo, Q.; Wang, Z. A self-supervised learning framework for road centreline extraction from high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4451–4461. [Google Scholar] [CrossRef]
- Tejenaki, S.A.K.; Ebadi, H.; Mohammadzadeh, A. A new hierarchical method for automatic road centreline extraction in urban areas using LIDAR data. Adv. Space Res. 2019, 64, 1792–1806. [Google Scholar] [CrossRef]
- Liu, R.; Miao, Q.; Zhang, Y.; Gong, M.; Xu, P. A semi-supervised high-level feature selection framework for road centreline extraction. IEEE Geosci. Remote Sens. Lett. 2019, 17, 894–898. [Google Scholar] [CrossRef]
- Liu, R.; Miao, Q.; Song, J.; Quan, Y.; Li, Y.; Xu, P.; Dai, J. Multiscale road centrelines extraction from high-resolution aerial imagery. Neurocomputing 2019, 329, 384–396. [Google Scholar] [CrossRef]
- Salah, M. Extraction of road centrelines and edge lines from high-resolution satellite imagery using density-oriented fuzzy C-means and mathematical morphology. J. Indian Soc. Remote Sens. 2022, 50, 1243–1255. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Zhang, X.; Han, X.; Li, C.; Tang, X.; Zhou, H.; Jiao, L. Aerial Image Road Extraction Based on an Improved Generative Adversarial Network. Remote Sens. 2019, 11, 930. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, M.; Wang, F.; Ji, X. A Residual Attention and Local Context-Aware Network for Road Extraction from High-Resolution Remote Sensing Imagery. Remote Sens. 2021, 13, 4958. [Google Scholar] [CrossRef]
- Valero, S.; Chanussot, J.; Benediktsson, J.A.; Talbot, H.; Waske, B. Advanced directional mathematical morphology for the detection of the road network in very high resolution remote sensing images. Pattern Recognit. Lett. 2010, 31, 1120–1127. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Soni, P.K.; Rajpal, N.; Mehta, R. Semiautomatic road extraction framework based on shape features and LS-SVM from high-resolution images. J. Indian Soc. Remote Sens. 2020, 48, 513–524. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Wu, L.; Chen, Z. Multilane roads extracted from the OpenStreetMap urban road network using random forests. Trans. GIS 2019, 23, 224–240. [Google Scholar] [CrossRef]
- Fengping, W.; Weixing, W. Road extraction using modified dark channel prior and neighbourhood FCM in foggy aerial images. Multimed. Tools Appl. 2019, 78, 947–964. [Google Scholar] [CrossRef]
- Zheng, J.; Yang, S.; Wang, X.; Xia, X.; Xiao, Y.; Li, T. A decision tree based road recognition approach using roadside fixed 3d lidar sensors. IEEE Access 2019, 7, 53878–53890. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Y.; Wang, L.; Zhong, Y.; Guan, Q.; Lu, X.; Zhang, L.; Li, D. A global context-aware and batch-independent network for road extraction from VHR satellite imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 353–365. [Google Scholar] [CrossRef]
- Hormese, J.; Saravanan, C. Automated road extraction from high resolution satellite images. Procedia Technol. 2016, 24, 1460–1467. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Lian, R.; Huang, L. DeepWindow: Sliding window based on deep learning for road extraction from remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1905–1916. [Google Scholar] [CrossRef]
- Khan, M.J.; Singh, P.P. Advanced road extraction using CNN-based U-Net model and satellite imagery. e-Prime-Adv. Electr. Eng. Electron. Energy 2023, 5, 100244. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road structure refined CNN for road extraction in aerial image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Liu, Y.; Zhao, J.; Ma, A.; Yang, J. Multi-scale and multi-task deep learning framework for automatic road extraction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9362–9377. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Shao, S.; Xiao, L.; Lin, L.; Ren, C.; Tian, J. Road Extraction Convolutional Neural Network with Embedded Attention Mechanism for Remote Sensing Imagery. Remote Sens. 2022, 14, 2061. [Google Scholar] [CrossRef]
- Sultonov, F.; Park, J.-H.; Yun, S.; Lim, D.-W.; Kang, J.-M. Mixer U-Net: An Improved Automatic Road Extraction from UAV Imagery. Appl. Sci. 2022, 12, 1953. [Google Scholar] [CrossRef]
- Alshaikhli, T.; Liu, W.; Maruyama, Y. Automated Method of Road Extraction from Aerial Images Using a Deep Convolutional Neural Network. Appl. Sci. 2019, 9, 4825. [Google Scholar] [CrossRef]
- Yu, X.; Kuan, T.-W.; Tseng, S.-P.; Chen, Y.; Chen, S.; Wang, J.-F.; Gu, Y.; Chen, T. EnRDeA U-Net Deep Learning of Semantic Segmentation on Intricate Noise Roads. Entropy 2023, 25, 1085. [Google Scholar] [CrossRef]
- Hou, Y.; Liu, Z.; Zhang, T.; Li, Y. C-UNet: Complement UNet for Remote Sensing Road Extraction. Sensors 2021, 21, 2153. [Google Scholar] [CrossRef] [PubMed]
- Hu, P.C.; Chen, S.B.; Huang, L.L.; Wang, G.Z.; Tang, J.; Luo, B. Road Extraction by Multi-scale Deformable Transformer from Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Xie, Y.; Miao, F.; Zhou, K.; Peng, J. HsgNet: A Road Extraction Network Based on Global Perception of High-Order Spatial Information. ISPRS Int. J. Geo-Inf. 2019, 8, 571. [Google Scholar] [CrossRef]
- Xu, Z.; Shen, Z.; Li, Y.; Xia, L.; Wang, H.; Li, S.; Jiao, S.; Lei, Y. Road Extraction in Mountainous Regions from High-Resolution Images Based on DSDNet and Terrain Optimization. Remote Sens. 2021, 13, 90. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, Z.; Huang, X.; Zhang, Y. MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High-Resolution Images. Remote Sens. 2021, 13, 239. [Google Scholar] [CrossRef]
- Wan, J.; Xie, Z.; Xu, Y.; Chen, S.; Qiu, Q. DA-RoadNet: A dual-attention network for road extraction from high resolution satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6302–6315. [Google Scholar] [CrossRef]
- Li, J.; Liu, Y.; Zhang, Y.; Zhang, Y. Cascaded Attention DenseUNet (CADUNet) for Road Extraction from Very-High-Resolution Images. ISPRS Int. J. Geo-Inf. 2021, 10, 329. [Google Scholar] [CrossRef]
- Liu, B.; Ding, J.; Zou, J.; Wang, J.; Huang, S. LDANet: A Lightweight Dynamic Addition Network for Rural Road Extraction from Remote Sensing Images. Remote Sens. 2023, 15, 1829. [Google Scholar] [CrossRef]
- Liu, X.; Wang, Z.; Wan, J.; Zhang, J.; Xi, Y.; Liu, R.; Miao, Q. RoadFormer: Road Extraction Using a Swin Transformer Combined with a Spatial and Channel Separable Convolution. Remote Sens. 2023, 15, 1049. [Google Scholar] [CrossRef]
- Zhang, W.; Huang, Z.; Luo, G.; Chen, T.; Wang, X.; Liu, W.; Yu, G. TopFormer: Token pyramid transformer for mobile semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 12083–12093. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 10–13 September 2018; pp. 325–341. [Google Scholar]
- Peng, J.; Liu, Y.; Tang, S.; Hao, Y.; Chu, L.; Chen, G.; Wu, Z.; Chen, Z.; Yu, Z.; Du, Y.; et al. PP-liteseg: A superior real-time semantic segmentation model. arXiv 2022, arXiv:2204.02681. [Google Scholar]
- Toldo, M.; Michieli, U.; Agresti, G.; Zanuttigh, P. Unsupervised domain adaptation for mobile semantic segmentation based on cycle consistency and feature alignment. Image Vis. Comput. 2020, 95, 103889. [Google Scholar] [CrossRef]
- Droguett, L.E.; Tapia, J.; Yanez, C.; Boroschek, R. Semantic segmentation model for crack images from concrete bridges for mobile devices. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2022, 236, 570–583. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online Event, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Tang, R.; Adhikari, A.; Lin, J. Flops as a direct optimization objective for learning sparse neural networks. arXiv 2018, arXiv:1811.03060. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Output Size | Tiny | Small | Base |
|---|---|---|---|---|
| Micro Token Pyramid Module | 512 × 512 | Conv, 3 × 3, 16, 2 MB, 3, 1, 16, 1 | Conv, 3 × 3, 16, 2 MB, 3, 1, 16, 1 | Conv, 3 × 3, 16, 2 MB, 3, 1, 16, 1 |
| 256 × 256 | MB, 3, 4, 16, 2 | MB, 3, 4, 24, 2 | MB, 3, 4, 32, 2 | |
| MB, 3, 3, 16, 1 | MB, 3, 3, 24, 1 | MB, 3, 3, 32, 1 | ||
| 128 × 128 | MB, 5, 3, 32, 2 | MB, 5, 3, 48, 2 | MB, 3, 4, 64, 2 | |
| MB, 5, 3, 32, 1 | MB, 5, 3, 48, 1 | MB, 3, 3, 64, 1 | ||
| 64 × 64 | MB, 3, 3, 64, 2 | MB, 3, 3, 96, 2 | MB, 3, 4, 128, 2 | |
| MB, 3, 3, 32, 1 | MB, 3, 3, 96, 1 | MB, 3, 3, 128, 1 | ||
| Coordinate Attention Module | 32 × 32 | M/N = 2/2 | M/N = 3/3 | M/N = 4/4 |
| Fusion Module | 256 × 256, 128 × 128, 64 × 64 | C = 128 | C = 192 | C = 256 |
| Method | Backbone | Parameters (M) | FLOPs (G) | MIoU (%) |
|---|---|---|---|---|
| Segformer | MixVisionTransformer_B0 | 3.72 | 26.98 | 67.57 |
| TopFormer | TopTransformer_Base | 5.07 | 6.54 | 70.83 |
| BiseNet | ResNet18 | 12.93 | 226.58 | 74.39 |
| PP-Liteseg | STDC2 | 12.25 | 38.57 | 69.99 |
| Road-MobileSeg-Tiny | Road-MobileFormer-Tiny | 1.41 | 1.65 | 71.52 |
| Road-MobileSeg-Small | Road-MobileFormer-Small | 2.83 | 2.93 | 73.36 |
| Road-MobileSeg-Base | Road-MobileFormer-Base | 4.74 | 6.23 | 74.76 |
| Method | Backbone | Latency (ms) |
|---|---|---|
| Segformer | MixVisionTransformer_B0 | 672 |
| TopFormer | TopTransformer_Base | 298 |
| BiseNet | ResNet18 | 5680 |
| PP-Liteseg | STDC2 | 754 |
| Road-MobileSeg-Tiny | Road-MobileFormer-Tiny | 112 |
| Road-MobileSeg-Small | Road-MobileFormer-Small | 157 |
| Road-MobileSeg-Base | Road-MobileFormer-Base | 295 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, G.; Wu, Y.; Lv, Z.; Zhao, D.; Lu, Y.; Zhou, K.; Tang, J.; Zhang, Q.; Zhang, A. Road-MobileSeg: Lightweight and Accurate Road Extraction Model from Remote Sensing Images for Mobile Devices. Sensors 2024, 24, 531. https://doi.org/10.3390/s24020531
Qu G, Wu Y, Lv Z, Zhao D, Lu Y, Zhou K, Tang J, Zhang Q, Zhang A. Road-MobileSeg: Lightweight and Accurate Road Extraction Model from Remote Sensing Images for Mobile Devices. Sensors. 2024; 24(2):531. https://doi.org/10.3390/s24020531
Chicago/Turabian StyleQu, Guangjun, Yue Wu, Zhihong Lv, Dequan Zhao, Yingpeng Lu, Kefa Zhou, Jiakui Tang, Qing Zhang, and Aijun Zhang. 2024. "Road-MobileSeg: Lightweight and Accurate Road Extraction Model from Remote Sensing Images for Mobile Devices" Sensors 24, no. 2: 531. https://doi.org/10.3390/s24020531
APA StyleQu, G., Wu, Y., Lv, Z., Zhao, D., Lu, Y., Zhou, K., Tang, J., Zhang, Q., & Zhang, A. (2024). Road-MobileSeg: Lightweight and Accurate Road Extraction Model from Remote Sensing Images for Mobile Devices. Sensors, 24(2), 531. https://doi.org/10.3390/s24020531