


Real-Time Monocular Skeleton-Based Hand Gesture Recognition Using 3D-Jointsformer


Abstract
1. Introduction
- Hybrid Neural Network Design: The proposed approach presents a novel hybrid neural network for skeleton-based hand gesture recognition, efficiently combining a 3D-CNN to infer high-level semantic skeleton embeddings with a Transformer-based model that utilizes a self-attention mechanism to capture long-term dependencies of the previous sequence of skeleton embeddings. It should be noted that the skeleton embeddings contain partial information in the spatial and time domain; that is, an embedding includes information from a subset of skeleton nodes along a limited time span.
- Real-time Efficiency: A major breakthrough achieved in this research is the real-time capability of the system. Thanks to the carefully designed neural network architecture, the entire system can efficiently run on a Computer Processing Unit (CPU), eliminating the need for specialized and resource-intensive hardware. This achievement is a crucial step toward practical applications of hand gesture recognition in real-world scenarios.
- Competitive Performance: The proposed method demonstrates competitive performance on the main hand gesture recognition benchmarks. By effectively capturing local spatial relationships and long-term temporal dependencies, the hybrid neural network outperforms the state-of-the-art accuracy by 4.19% on the Briareo dataset.
2. Related Work
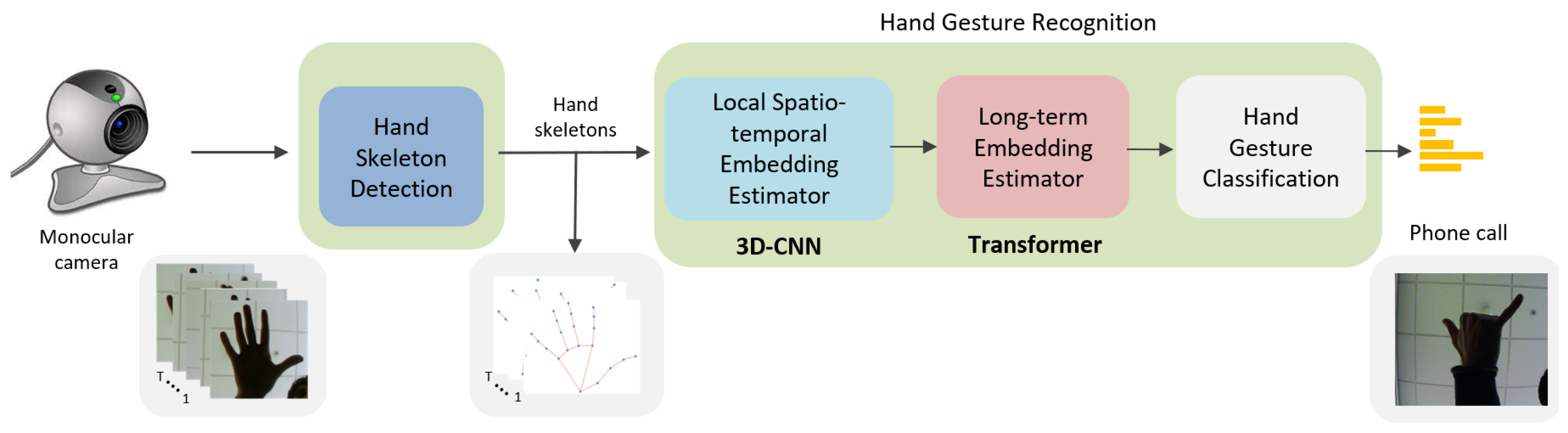
3. Proposed Method
3.1. Hand Skeleton Detection
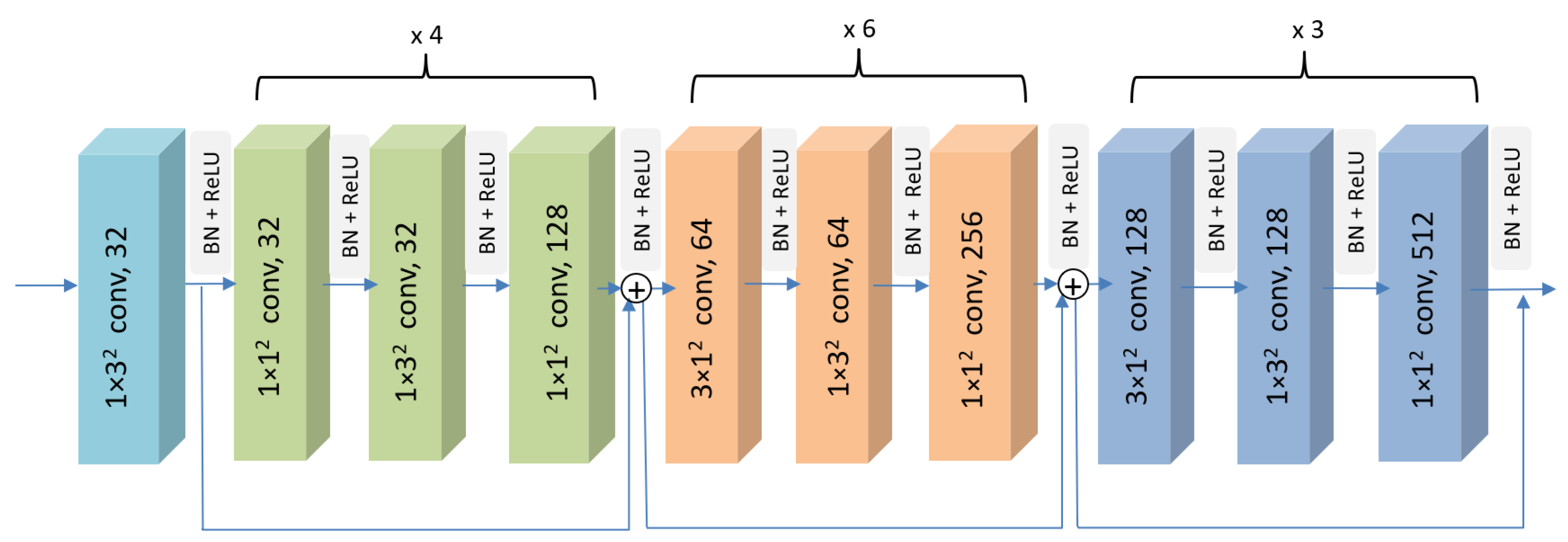
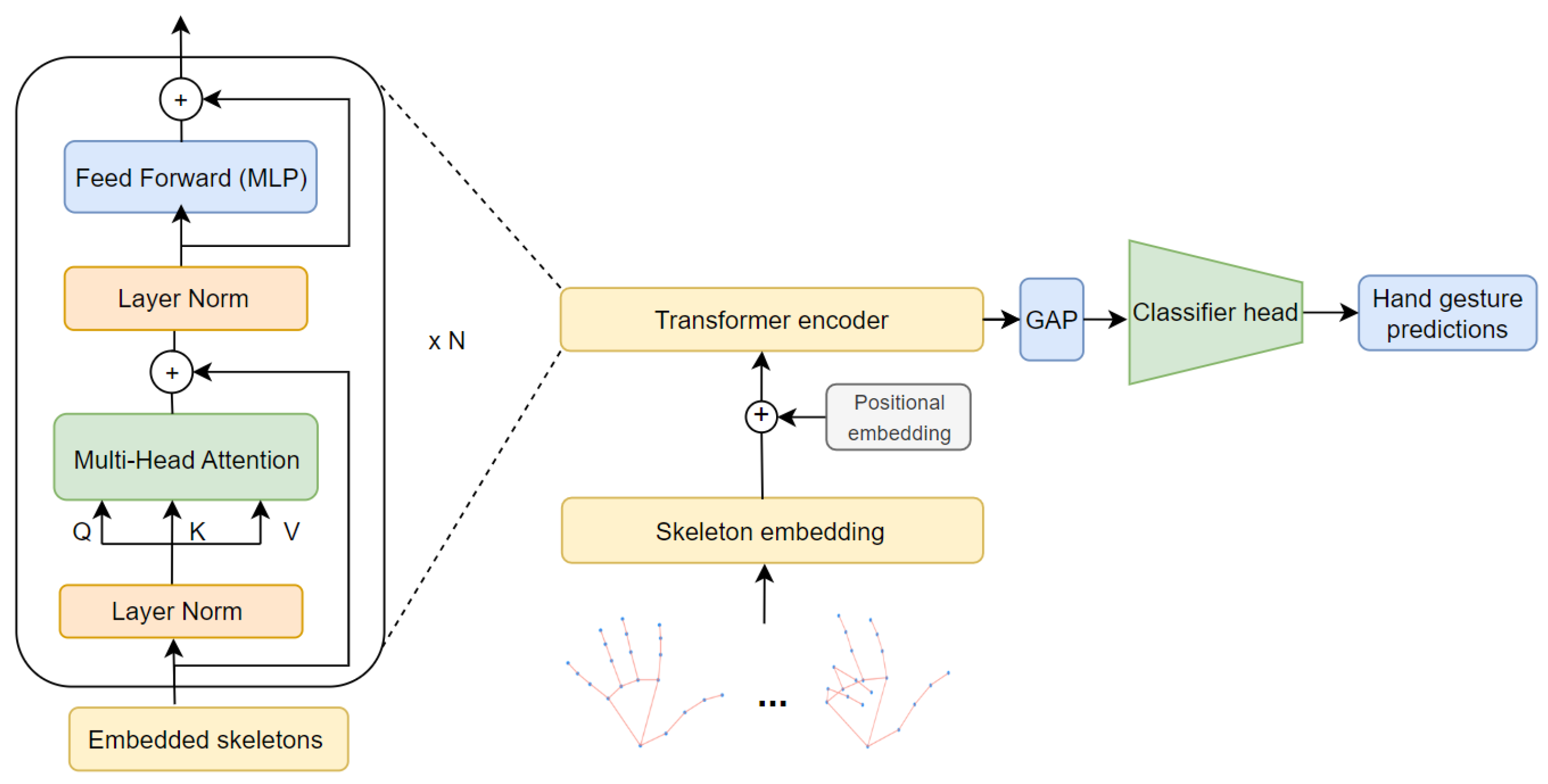
3.2. Hand Gesture Recognition
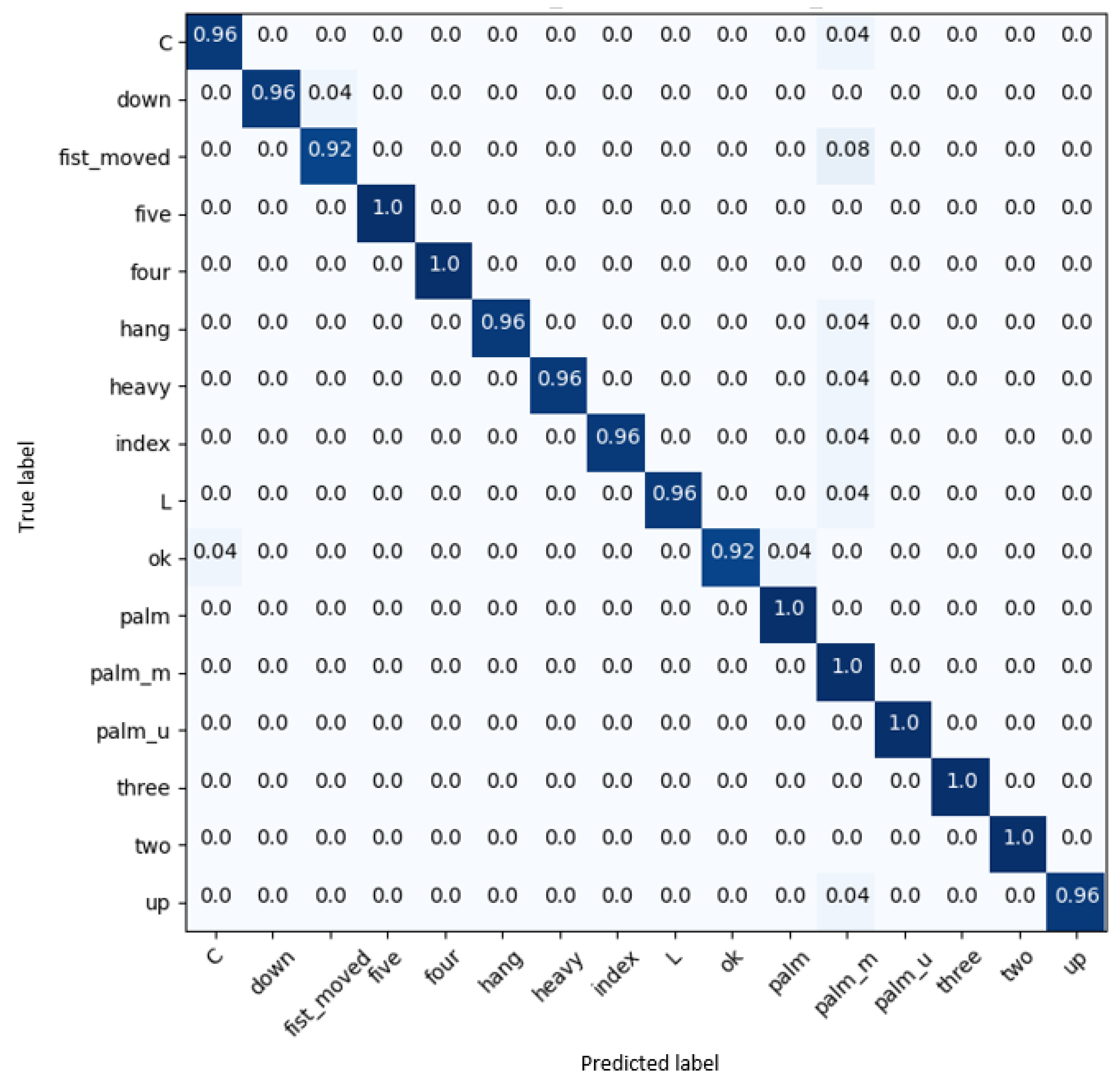
4. Results and Discussion
4.1. Experimental Settings, Metrics, and Datasets
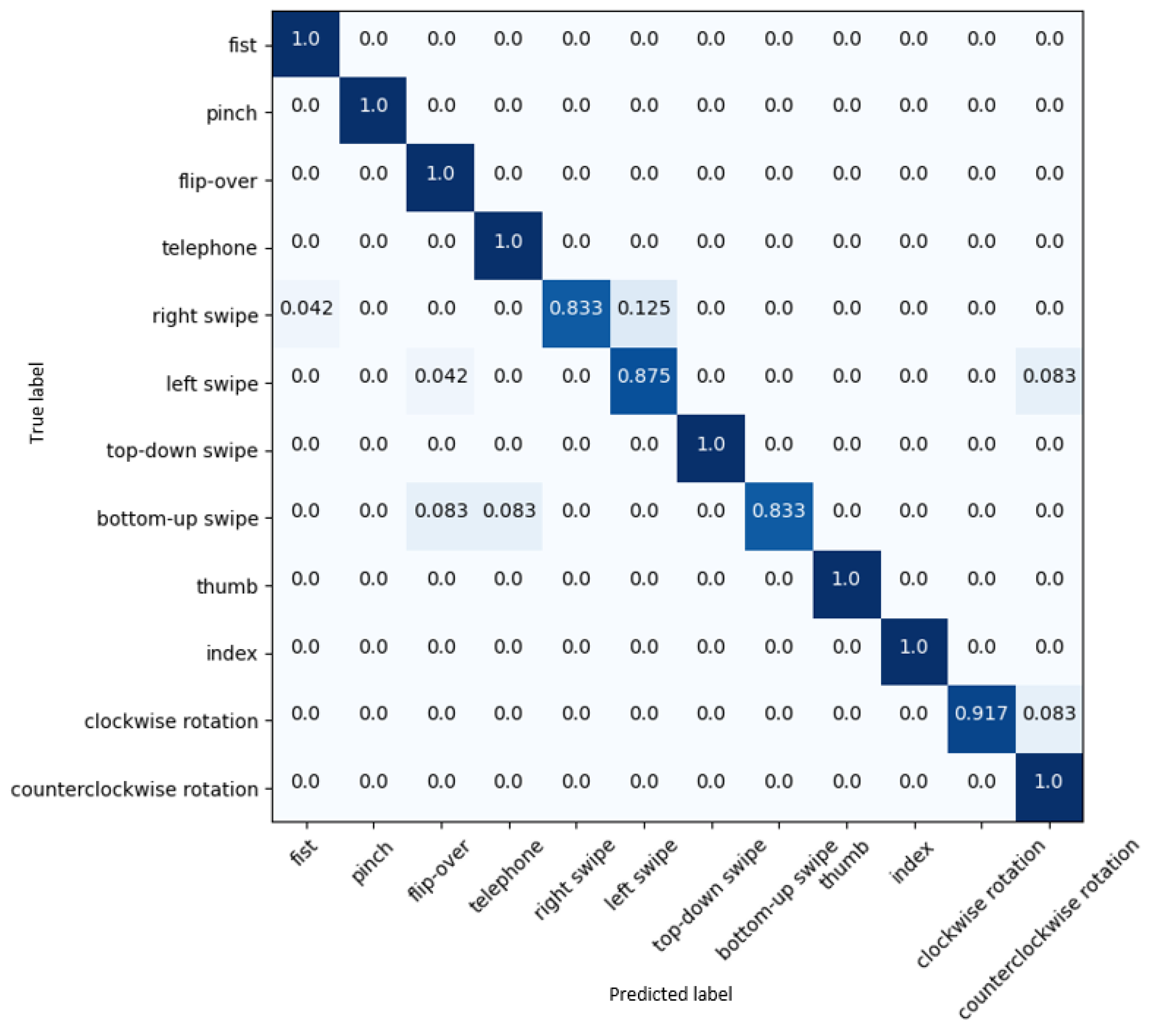
4.2. Results on Briareo Dataset
4.3. Ablation Study on Briareo Dataset
4.4. Ablation Study on the Multimodal Hand Gesture Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AR | Augmented Reality |
| BN | Batch Normalization |
| CNN | Convolutional Neural Network |
| CPU | Computer Processing Unit |
| 3D | Three Dimensional |
| 3D-CNN | 3D Convolutional Neural Network |
| GCNs | Graph Neural Networks |
| GPU | Graphics Processing Unit |
| HGR | Hand Gesture Recognition |
| HCI | Human–Computer Interaction |
| FC | Fully Connected |
| FFN | Feed-Forward Neural Network |
| GELU | Gaussian Error Linear Unit |
| LN | Layer Normalization |
| LSTM | Long Short-Term Memory |
| MHA | Multi-Head Attention |
| MLP | Multilayer Perceptron |
| PE | Positional Embedding |
| ReLU | Rectified Linear Unit |
| RNN | Recurrent Neural Network |
| VR | Virtual Reality |
References
- Ohn-Bar, E.; Trivedi, M.M. Hand Gesture Recognition in Real Time for Automotive Interfaces: A Multimodal Vision-Based Approach and Evaluations. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2368–2377. [Google Scholar] [CrossRef]
- Abid, M.R.; Petriu, E.M.; Amjadian, E. Dynamic Sign Language Recognition for Smart Home Interactive Application Using Stochastic Linear Formal Grammar. IEEE Trans. Instrum. Meas. 2015, 64, 596–605. [Google Scholar] [CrossRef]
- Jang, Y.; Jeon, I.; Kim, T.K.; Woo, W. Metaphoric Hand Gestures for Orientation-Aware VR Object Manipulation with an Egocentric Viewpoint. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 113–127. [Google Scholar] [CrossRef]
- Lee, B.G.; Lee, S.M. Smart Wearable Hand Device for Sign Language Interpretation System With Sensors Fusion. IEEE Sens. J. 2018, 18, 1224–1232. [Google Scholar] [CrossRef]
- Huo, J.; Keung, K.L.; Lee, C.K.M.; Ng, H.Y. Hand Gesture Recognition with Augmented Reality and Leap Motion Controller. In Proceedings of the 2021 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Singapore, 13–16 December 2021; pp. 1015–1019. [Google Scholar] [CrossRef]
- Buckingham, G. Hand Tracking for Immersive Virtual Reality: Opportunities and Challenges. CoRR. 2021. Available online: http://xxx.lanl.gov/abs/2103.14853 (accessed on 25 April 2023).
- Li, Y.; Wang, T.; khan, A.; Li, L.; Li, C.; Yang, Y.; Liu, L. Hand Gesture Recognition and Real-time Game Control Based on a Wearable Band with 6-axis Sensors. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Mahmoud, N.M.; Fouad, H.; Soliman, A.M. Smart healthcare solutions using the internet of medical things for hand gesture recognition system. Complex Intell. Syst. 2021, 7, 1253–1264. [Google Scholar] [CrossRef]
- Li, D.; Opazo, C.R.; Yu, X.; Li, H. Word-Level Deep Sign Language Recognition from Video: A New Large-Scale Dataset and Methods Comparison. CoRR. 2019. Available online: http://xxx.lanl.gov/abs/1910.11006 (accessed on 26 April 2023).
- Koch, P.; Dreier, M.; Maass, M.; Böhme, M.; Phan, H.; Mertins, A. A Recurrent Neural Network for Hand Gesture Recognition based on Accelerometer Data. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 5088–5091. [Google Scholar] [CrossRef]
- Kim, M.; Cho, J.; Lee, S.; Jung, Y. IMU Sensor-Based Hand Gesture Recognition for Human–Machine Interfaces. Sensors 2019, 19, 3827. [Google Scholar] [CrossRef]
- Ortega-Avila, S.; Rakova, B.; Sadi, S.H.; Mistry, P. Non-invasive optical detection of hand gestures. In Proceedings of the 6th Augmented Human International Conference, Singapore, 9–11 March 2015. [Google Scholar] [CrossRef]
- Qi, J.; Jiang, G.; Li, G.; Sun, Y.; Tao, B. Surface EMG hand gesture recognition system based on PCA and GRNN. Neural Comput. Appl. 2020, 32, 6343–6351. [Google Scholar] [CrossRef]
- D’Eusanio, A.; Simoni, A.; Pini, S.; Borghi, G.; Vezzani, R.; Cucchiara, R. A Transformer-Based Network for Dynamic Hand Gesture Recognition. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 623–632. [Google Scholar] [CrossRef]
- Molchanov, P.; Yang, X.; Gupta, S.; Kim, K.; Tyree, S.; Kautz, J. Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D Convolutional Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4207–4215. [Google Scholar] [CrossRef]
- Zhang, Z. Microsoft Kinect Sensor and Its Effect. IEEE MultiMedia 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Keselman, L.; Woodfill, J.I.; Grunnet-Jepsen, A.; Bhowmik, A. Intel RealSense Stereoscopic Depth Cameras. arXiv 2017, arXiv:1705.05548. [Google Scholar]
- Weichert, F.; Bachmann, D.; Rudak, B.; Fisseler, D. Analysis of the Accuracy and Robustness of the Leap Motion Controller. Sensors 2013, 13, 6380–6393. [Google Scholar] [CrossRef]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Skeleton-based action recognition with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 597–600. [Google Scholar] [CrossRef]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaïd, F. A New Representation of Skeleton Sequences for 3D Action Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4570–4579. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition; AAAI Press: Washington, DC, USA, 2018. [Google Scholar]
- Caetano, C.A.; Sena, J.; Brémond, F.; dos Santos, J.A.; Schwartz, W.R. SkeleMotion: A New Representation of Skeleton Joint Sequences based on Motion Information for 3D Action Recognition. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–8. [Google Scholar]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.P. Skeleton-Based Dynamic Hand Gesture Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1206–1214. [Google Scholar] [CrossRef]
- Devineau, G.; Moutarde, F.; Xi, W.; Yang, J. Deep Learning for Hand Gesture Recognition on Skeletal Data. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 106–113. [Google Scholar] [CrossRef]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.P. Heterogeneous hand gesture recognition using 3D dynamic skeletal data. Comput. Vis. Image Underst. 2019, 181, 60–72. [Google Scholar] [CrossRef]
- Li, Y.; He, Z.; Ye, X.; He, Z.; Han, K. Spatial temporal graph convolutional networks for skeleton-based dynamic hand gesture recognition. EURASIP J. Image Video Process. 2019, 2019, 78. [Google Scholar] [CrossRef]
- Lai, K.; Yanushkevich, S.N. CNN+RNN Depth and Skeleton based Dynamic Hand Gesture Recognition. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3451–3456. [Google Scholar] [CrossRef]
- Núñez, J.C.; Cabido, R.; Pantrigo, J.J.; Montemayor, A.S.; Vélez, J.F. Convolutional Neural Networks and Long Short-Term Memory for skeleton-based human activity and hand gesture recognition. Pattern Recognit. 2018, 76, 80–94. [Google Scholar] [CrossRef]
- Narayan, S.; Mazumdar, A.P.; Vipparthi, S.K. SBI-DHGR: Skeleton-based intelligent dynamic hand gestures recognition. Expert Syst. Appl. 2023, 232, 120735. [Google Scholar] [CrossRef]
- Liu, J.; Liu, Y.; Wang, Y.; Prinet, V.; Xiang, S.; Pan, C. Decoupled Representation Learning for Skeleton-Based Gesture Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5750–5759. [Google Scholar] [CrossRef]
- Mohammed, A.A.Q.; Lv, J.; Islam, M.S.; Sang, Y. Multi-model ensemble gesture recognition network for high-accuracy dynamic hand gesture recognition. J. Ambient Intell. Humaniz. Comput. 2023, 14, 6829–6842. [Google Scholar] [CrossRef]
- Chen, H.; Li, Y.; Fang, H.; Xin, W.; Lu, Z.; Miao, Q. Multi-Scale Attention 3D Convolutional Network for Multimodal Gesture Recognition. Sensors 2022, 22, 2405. [Google Scholar] [CrossRef]
- Dhingra, N.; Kunz, A.M. Res3ATN-Deep 3D Residual Attention Network for Hand Gesture Recognition in Videos. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Quebec City, QC, Canada, 16–19 September 2019; pp. 491–501. [Google Scholar]
- Köpüklü, O.; Gunduz, A.; Kose, N.; Rigoll, G. Real-time Hand Gesture Detection and Classification Using Convolutional Neural Networks. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Hou, J.; Wang, G.; Chen, X.; Xue, J.H.; Zhu, R.; Yang, H. Spatial-Temporal Attention Res-TCN for Skeleton-based Dynamic Hand Gesture Recognition. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, Y.; Zhao, L.; Peng, X.; Yuan, J.; Metaxas, D.N. Construct Dynamic Graphs for Hand Gesture Recognition via Spatial-Temporal Attention. arXiv 2019, arXiv:1907.08871. [Google Scholar]
- Chen, X.; Wang, G.; Guo, H.; Zhang, C.; Wang, H.; Zhang, L. MFA-Net: Motion Feature Augmented Network for Dynamic Hand Gesture Recognition from Skeletal Data. Sensors 2019, 19, 239. [Google Scholar] [CrossRef]
- Bigalke, A.; Heinrich, M.P. Fusing Posture and Position Representations for Point Cloud-Based Hand Gesture Recognition. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; pp. 617–626. [Google Scholar] [CrossRef]
- Song, J.H.; Kong, K.; Kang, S.J. Dynamic Hand Gesture Recognition Using Improved Spatio-Temporal Graph Convolutional Network. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6227–6239. [Google Scholar] [CrossRef]
- Zhang, W.; Lin, Z.; Cheng, J.; Ma, C.; Deng, X.; Wang, H. STA-GCN: Two-stream graph convolutional network with spatial-temporal attention for hand gesture recognition. Vis. Comput. 2020, 36, 2433–2444. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, T.; Zhang, M.; Liu, K.; Shi, P.; Snoussi, H. Spatial-temporal Transformer For Skeleton-based Action Recognition. In Proceedings of the 2021 China Automation Congress (CAC), Beijing, China, 22–24 October 2021; pp. 7029–7034. [Google Scholar] [CrossRef]
- Plizzari, C.; Cannici, M.; Matteucci, M. Skeleton-based action recognition via spatial and temporal transformer networks. Comput. Vis. Image Underst. 2021, 208–209, 103219. [Google Scholar] [CrossRef]
- Gao, Z.; Wang, P.; Lv, P.; Jiang, X.; Liu, Q.; Wang, P.; Xu, M.; Li, W. Focal and Global Spatial-Temporal Transformer for Skeleton-based Action Recognition. In Proceedings of the Asian Conference on Computer Vision (ACCV), Macau, China, 4–8 December 2022; pp. 382–398. [Google Scholar]
- Qiu, H.; Hou, B.; Ren, B.; Zhang, X. Spatio-Temporal Tuples Transformer for Skeleton-Based Action Recognition. CoRR. 2022. Available online: http://xxx.lanl.gov/abs/2201.02849 (accessed on 8 May 2023).
- Li, C.; Zhang, X.; Liao, L.; Jin, L.; Yang, W. Skeleton-based Gesture Recognition Using Several Fully Connected Layers with Path Signature Features and Temporal Transformer Module. arXiv 2018, arXiv:1811.07081. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Y.; Xiang, S.; Pan, C. HAN: An Efficient Hierarchical Self-Attention Network for Skeleton-Based Gesture Recognition. arXiv 2021, arXiv:2106.13391. [Google Scholar]
- Vakunov, A.; Chang, C.L.; Zhang, F.; Sung, G.; Grundmann, M.; Bazarevsky, V. MediaPipe Hands: On-Device Real-Time Hand Tracking. 2020. Available online: https://mixedreality.cs.cornell.edu/workshop (accessed on 8 May 2023).
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6201–6210. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. CoRR. 2017. Available online: https://api.semanticscholar.org/CorpusID:13756489 (accessed on 9 August 2023).
- Lin, Z.; Liu, P.; Huang, L.; Chen, J.; Qiu, X.; Huang, X. DropAttention: A Regularization Method for Fully-Connected Self-Attention Networks. arXiv 2019, arXiv:1907.11065. [Google Scholar]
- Manganaro, F.; Pini, S.; Borghi, G.; Vezzani, R.; Cucchiara, R. Hand Gestures for the Human-Car Interaction: The Briareo Dataset. In Proceedings of the Image Analysis and Processing–ICIAP 2019, Trento, Italy, 9–13 September 2019; Ricci, E., Rota Bulò, S., Snoek, C., Lanz, O., Messelodi, S., Sebe, N., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 560–571. [Google Scholar]
- Mantecón, T.; del Blanco, C.R.; Jaureguizar, F.; García, N. A real-time gesture recognition system using near-infrared imagery. PLoS ONE 2019, 14, e0223320. [Google Scholar] [CrossRef] [PubMed]
- de Smedt, Q.; Wannous, H.; Vandeborre, J.P.; Guerry, J.; Le Saux, B.; Filliat, D. SHREC’17 Track: 3D Hand Gesture Recognition Using a Depth and Skeletal Dataset. In Proceedings of the 3DOR-10th Eurographics Workshop on 3D Object Retrieval, Lyon, France, 23–24 April 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.D.; Fergus, R.; Torresani, L.; Paluri, M. C3D: Generic Features for Video Analysis. CoRR. 2014. Available online: https://api.semanticscholar.org/CorpusID:195346008 (accessed on 9 August 2023).
- D’Eusanio, A.; Simoni, A.; Pini, S.; Borghi, G.; Vezzani, R.; Cucchiara, R. Multimodal Hand Gesture Classification for the Human–Car Interaction. Informatics 2020, 7, 31. [Google Scholar] [CrossRef]
- Slama, R.; Rabah, W.; Wannous, H. STr-GCN: Dual Spatial Graph Convolutional Network and Transformer Graph Encoder for 3D Hand Gesture Recognition. In Proceedings of the 2023 IEEE 17th International Conference on Automatic Face and Gesture Recognition (FG), Waikoloa Beach, HI, USA, 5–8 January 2023; pp. 1–6. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Top-1 Acc (%) |
|---|---|---|
| C3D [51] | 2019 | 72.2% |
| CNN-based [55] | 2020 | 83.3% |
| ResNet-18 + Transformer [14] | 2020 | 90.06% |
| Multiscale 3D-CNN [32] | 2022 | 91.3% |
| STr-GCN [56] | 2023 | 83.34% |
| 3D-Jointsformer (Ours) | 2023 | 95.49% |
| Model Configuration | Top-1 Acc (%) |
|---|---|
| Transformer with linear embedding | 87.96% |
| Transformer with 3D Convolutional embedding | 95.49% |
| Model Configuration | Top-1 Acc (%) |
|---|---|
| 3D-CNN + Global Temporal Average Pooling | 93.75% |
| 3D-CNN + Transformer encoder | 95.49% |
| Model | Hardware Architecture | Inference Time (ms) |
|---|---|---|
| Briareo (C3D) | CPU (Intel i7-6850K, 64 GB) | 4010 ± 240 |
| GPU (Nvidia 1080 Ti) | 1.96 ± 0.49 | |
| GPU (Nvidia Titan X) | 1.87 ± 0.77 | |
| Ours (3D-Jointsformer) | CPU (Intel Core i7-4790, 32 GB) | 0.486 ± 0.016 |
| GPU (Nvidia Titan Xp) | 0.448 ± 0.007 |
| Model Configuration | Top-1 Acc (%) |
|---|---|
| 3D-CNN + Global Temporal Average Pooling | 96.75% |
| 3D-CNN + Transformer Encoder | 97.25% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, E.; del-Blanco, C.R.; Berjón, D.; Jaureguizar, F.; García, N. Real-Time Monocular Skeleton-Based Hand Gesture Recognition Using 3D-Jointsformer. Sensors 2023, 23, 7066. https://doi.org/10.3390/s23167066
Zhong E, del-Blanco CR, Berjón D, Jaureguizar F, García N. Real-Time Monocular Skeleton-Based Hand Gesture Recognition Using 3D-Jointsformer. Sensors. 2023; 23(16):7066. https://doi.org/10.3390/s23167066
Chicago/Turabian StyleZhong, Enmin, Carlos R. del-Blanco, Daniel Berjón, Fernando Jaureguizar, and Narciso García. 2023. "Real-Time Monocular Skeleton-Based Hand Gesture Recognition Using 3D-Jointsformer" Sensors 23, no. 16: 7066. https://doi.org/10.3390/s23167066
APA StyleZhong, E., del-Blanco, C. R., Berjón, D., Jaureguizar, F., & García, N. (2023). Real-Time Monocular Skeleton-Based Hand Gesture Recognition Using 3D-Jointsformer. Sensors, 23(16), 7066. https://doi.org/10.3390/s23167066