
The NWRD Dataset: An Open-Source Annotated Segmentation Dataset of Diseased Wheat Crop

Abstract
1. Introduction
2. Related Work
2.1. Wheat Disease Datasets
2.2. Wheat Disease Detection Techniques
3. Materials and Methods
3.1. Data Collection Protocol
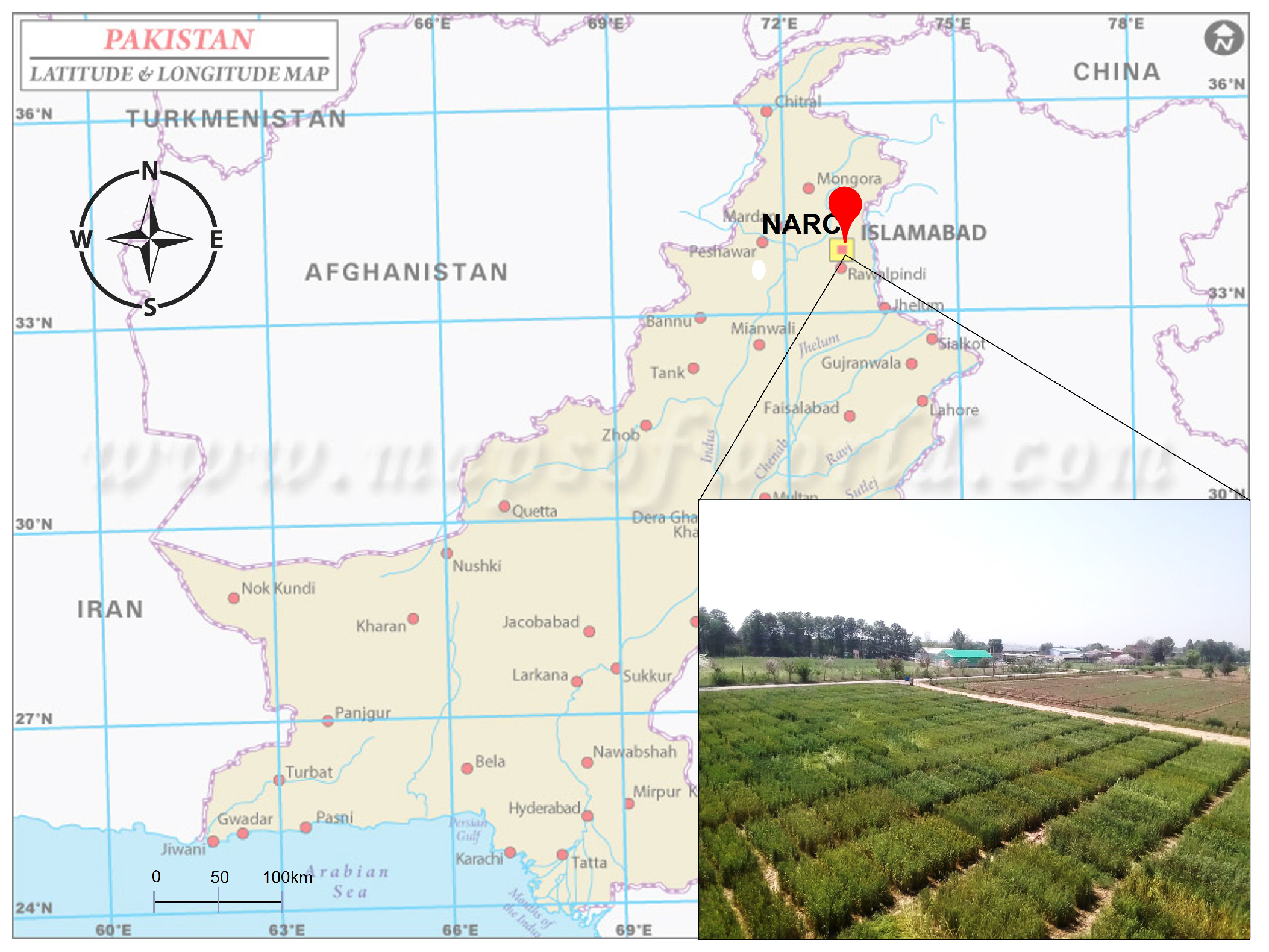
3.2. Data Acquisition—Collection Area
3.3. Dataset Properties
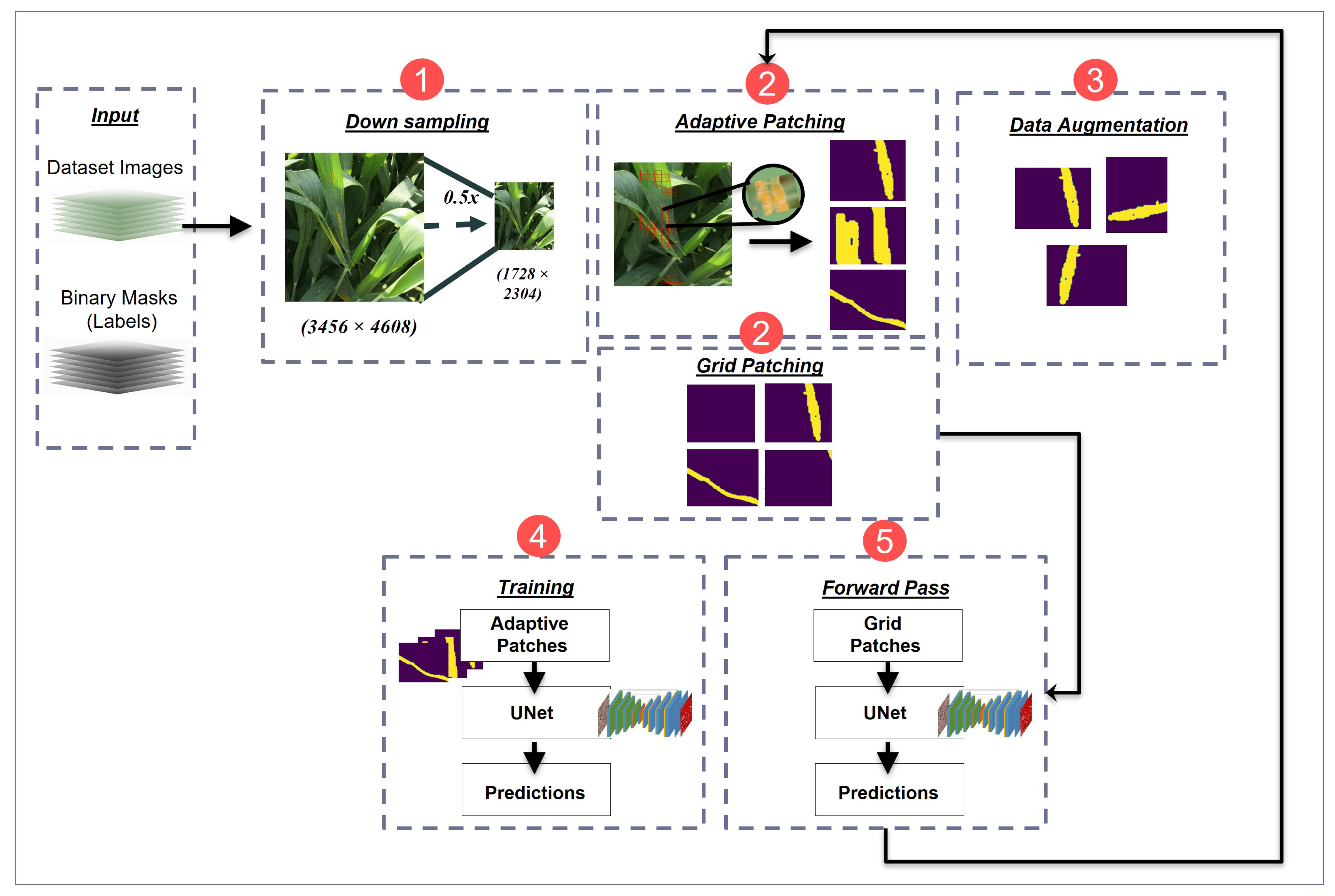
3.4. Disease Detection Pipeline for Rust Identification in Wheat Crop
3.4.1. Downsampling
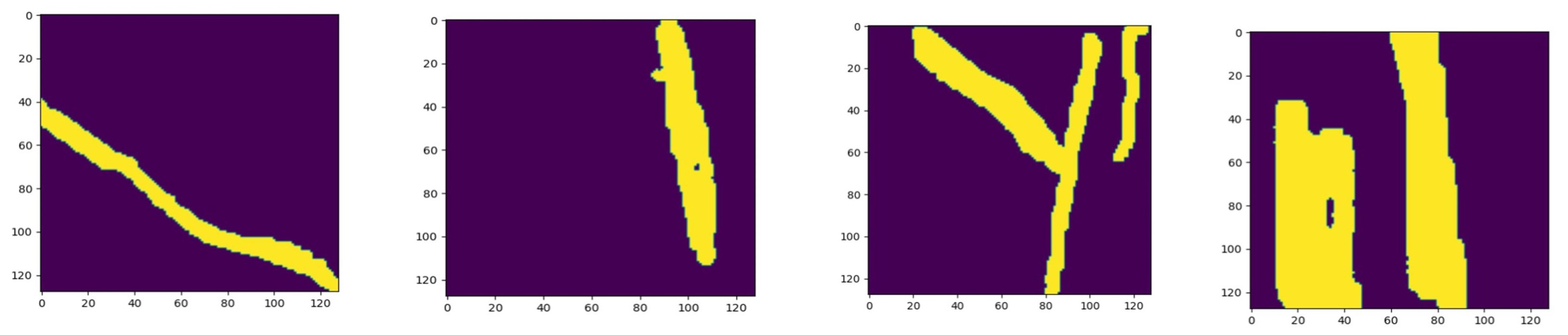
3.4.2. Image Patching
3.4.3. Data Augmentation
3.4.4. Segmentation
3.4.5. Forward Pass
4. Training and Results
4.1. Performance Evaluation Metrics
4.2. Model Training
4.3. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| WRD | Wheat stripe rust disease |
| NWRD | NUST wheat rust disease dataset |
| AI | Artificial intelligence |
| NARC | National Agriculture Research Centre |
| SEECS | School of Electrical Engineering and Computer Science |
| SMME | School of Mechanical and Manufacturing Engineering |
| NUST | National University of Sciences & Technology |
| NCAI | National Center of Artificial Intelligence |
| GP | Grid patching |
| AP | Adaptive patching |
| APF | Adaptive patching with feedback |
References
- Grote, U.; Faße, A.; Nguyen, T.T.; Erenstein, O. Food Security and the Dynamics of Wheat and Maize Value Chains in Africa and Asia. Front. Sustain. Food Syst. 2021, 4, 617009. [Google Scholar] [CrossRef]
- Beddow, J.M.; Pardey, P.G.; Chai, Y.; Hurley, T.M.; Kriticos, D.J.; Braun, H.J.; Park, R.F.; Cuddy, W.S.; Yonow, T. Research investment implications of shifts in the global geography of wheat stripe rust. Nat. Plants 2015, 1, 15132. [Google Scholar] [CrossRef] [PubMed]
- Trivelli, L.; Apicella, A.; Chiarello, F.; Rana, R.; Fantoni, G.; Tarabella, A. From precision agriculture to Industry 4.0: Unveiling technological connections in the agrifood sector. Br. Food J. 2019, 121, 1730–1743. [Google Scholar] [CrossRef]
- Shafi, U.; Mumtaz, R.; Haq, I.U.; Hafeez, M.; Iqbal, N.; Shaukat, A.; Zaidi, S.M.H.; Mahmood, Z. Wheat Yellow Rust Disease Infection Type Classification Using Texture Features. Sensors 2022, 22, 146. [Google Scholar] [CrossRef]
- Hughes, D.; Salathé, M. An open access repository of images on plant health to enable the development of mobile disease diagnostics. arXiv 2015, arXiv:1511.08060. [Google Scholar] [CrossRef]
- Getch, O. Kaggle Wheat Leaf Dataset. Available online: https://www.kaggle.com/datasets/olyadgetch/wheat-leaf-dataset (accessed on 20 November 2022).
- Hussain, S. CGIAR Computer Vision for Crop Disease. Available online: https://www.kaggle.com/datasets/shadabhussain/cgiar-computer-vision-for-crop-disease (accessed on 1 June 2023).
- Arya, S.; Singh, B. Wheat Nitrogen Deficiency and Leaf Rust Image Dataset. Mendeley Data, V1. 2020. Available online: https://data.mendeley.com/ (accessed on 20 June 2023).
- Murray, G.; Wellings, C.; Simpfendorfer, S.; Cole, C. Stripe Rust: Understanding the Disease in Wheat. Available online: https://www.dpi.nsw.gov.au/__data/assets/pdf_file/0006/158964/stripe-rust-in-wheat.pdf (accessed on 15 June 2023).
- Abid, N.; Shahzad, M.; Malik, M.I.; Schwanecke, U.; Ulges, A.; Kovács, G.; Shafait, F. UCL: Unsupervised Curriculum Learning for water body classification from remote sensing imagery. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102568. [Google Scholar] [CrossRef]
- Li, Y.; Qiao, T.; Leng, W.; Jiao, W.; Luo, J.; Lv, Y.; Tong, Y.; Mei, X.; Li, H.; Hu, Q.; et al. Semantic Segmentation of Wheat Stripe Rust Images Using Deep Learning. J. Agron. 2022, 12, 2933. [Google Scholar] [CrossRef]
- Zia, N.; Naeem, M.; Raza, S.; Khan, M.; Ul-Hasan, A.; Shafait, F. A convolutional recursive deep architecture for unconstrained Urdu handwriting recognition. Neural Comput. Appl. 2022, 34, 1635–1648. [Google Scholar] [CrossRef]
- Khan, Z.; Shafait, F.; Mian, A. Automatic ink mismatch detection for forensic document analysis. Pattern Recognit. 2015, 48, 3615–3626. [Google Scholar] [CrossRef]
- Olsen, A.; Konovalov, D.; Philippa, B.; Ridd, P.; Wood, J.; Johns, J.; Banks, W.; Girgenti, B.; Kenny, O.; Whinney, J.; et al. DeepWeeds: A Multiclass Weed Species Image Dataset for Deep Learning. Sci. Rep. 2019, 9, 2058. [Google Scholar] [CrossRef]
- Singh, D.; Jain, N.; Jain, P.; Kayal, P.; Kumawat, S.; Batra, N. PlantDoc. In Proceedings of the 7th ACM IKDD CoDS and 25th COMAD, Hyderabad, India, 5–7 January 2020; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Khaki, S.; Safaei, N.; Pham, H.; Wang, L. WheatNet: A lightweight convolutional neural network for high-throughput image-based wheat head detection and counting. Neurocomputing 2022, 489, 78–89. [Google Scholar] [CrossRef]
- Niu, X.; Guo, S.; Wang, M.; Zhang, H.; Chen, X.; He, D. Image segmentation algorithm for disease detection of wheat leaves. In Proceedings of the 2014 International Conference on Advanced Mechatronic Systems, Kumamoto, Japan, 10–12 August 2014; pp. 270–273. [Google Scholar] [CrossRef]
- Zhang, Z.; Flores, P.; Friskop, A.; Liu, Z.; Igathinathane, C.; Han, X.; Kim, H.; Jahan, N.; Mathew, J.; Shreya, S. Enhancing Wheat Disease Diagnosis in a Greenhouse Using Image Deep Features and Parallel Feature Fusion. Front. Plant Sci. 2022, 13, 834447. [Google Scholar] [CrossRef] [PubMed]
- Kumar, D.; Kukreja, V. An Instance Segmentation Approach for Wheat Yellow Rust Disease Recognition. In Proceedings of the 2021 International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, 7–8 December 2021; pp. 926–931. [Google Scholar] [CrossRef]
- Michael, S.; Landwehr, N.; Giebel, A.; Garz, A.; Dammer, K.H. Early Detection of Stripe Rust in Winter Wheat Using Deep Residual Neural Networks. Front. Plant Sci. 2021, 12, 475. [Google Scholar] [CrossRef]
- UI Haq, I.; Mumtaz, R.; Talha, M.; Shafaq, Z.; Owais, M. Wheat Rust Disease Classification using Edge-AI. In Proceedings of the 2022 2nd International Conference on Artificial Intelligence (ICAI), Islamabad, Pakistan, 30–31 March 2022; pp. 58–63. [Google Scholar] [CrossRef]
- Sood, S.; Singh, H.; Jindal, S. Rust Disease Classification Using Deep Learning Based Algorithm: The Case of Wheat; Food Systems Resilience, IntechOpen: Rijeka, Croatia, 2022. [Google Scholar] [CrossRef]
- Hayit, T.; Erbay, H.; Varçın, F.; Hayit, F.; Akci, N. Determination of the severity level of yellow rust disease in wheat by using convolutional neural networks. J. Plant Pathol. 2021, 103, 923–934. [Google Scholar] [CrossRef]
- Khanfri, S.; Boulif, M.; Lahlali, R. Yellow Rust (Puccinia striiformis): A Serious Threat to Wheat Production Worldwide. Not. Sci. Biol. 2018, 10, 410–423. [Google Scholar] [CrossRef]
- Khatra, A. Yellow Rust Extraction in Wheat Crop based on Color Segmentation Techniques. IOSR J. Eng. 2013, 3, 56–58. [Google Scholar] [CrossRef]
- Khan, H.; Haq, I.U.; Munsif, M.; Mustaqeem; Khan, S.U.; Lee, M.Y. Automated Wheat Diseases Classification Framework Using Advanced Machine Learning Technique. Agriculture 2022, 12, 1226. [Google Scholar] [CrossRef]
- Tian, J.; Han, D.; Hu, Q.X.; Ma, X.Y. Segmentation of Wheat Rust Lesion Image Using PCA and Gaussian Mix Model. Trans. Chin. Soc. Agric. Mach. 2014, 45, 267–271. [Google Scholar]
- Mi, Z.; Zhang, X.; Su, J.; Han, D.; Su, B. Wheat Stripe Rust Grading by Deep Learning With Attention Mechanism and Images From Mobile Devices. Front. Plant Sci. 2020, 11, 558126. [Google Scholar] [CrossRef]
- Su, W.H.; Zhang, J.; Yang, C.; Page, R.; Szinyei, T.; Hirsch, C.D.; Steffenson, B.J. Automatic evaluation of wheat resistance to fusarium head blight using dual mask-RCNN deep learning frameworks in computer vision. Remote Sens. 2020, 13, 26. [Google Scholar] [CrossRef]
- Usha Ruby, A.; George Chellin Chandran, J.; Chaithanya, B.N.; Swasthika, T.J.; Renuka, P. Wheat Leaf Disease Classification using Modified ResNet50 Convolutional Neural Network Model. Res. Sq. 2022. [Google Scholar] [CrossRef]
- Duchon, C. Lanczos Filtering in One and Two Dimensions. J. Appl. Meteorol. 1979, 18, 1016–1022. [Google Scholar] [CrossRef]
- Cheng, S.; Cheng, H.; Yang, R.; Zhou, J.; Li, Z.; Shi, B.; Lee, M.; Ma, Q. A High Performance Wheat Disease Detection Based on Position Information. Plants 2023, 12, 1191. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar] [CrossRef]
- Parraga-Alava, J.; Cusme, K.; Loor, A.; Santander, E. RoCoLe: A robusta coffee leaf images dataset for evaluation of machine learning based methods in plant diseases recognition. Data Br. 2019, 25, 104414. [Google Scholar] [CrossRef] [PubMed]
- Khan, H.; Ul Ain, R.; Kamboh, A.; Butt, H.; Shafait, S.; Alamgir, W.; Stricker, D.; Shafait, F. The NMT Scalp EEG Dataset: An Open-Source Annotated Dataset of Healthy and Pathological EEG Recordings for Predictive Modeling. Front. Neurosci. 2022, 15, 755817. [Google Scholar] [CrossRef] [PubMed]
- Ruth, J.A.; Uma, R.; Meenakshi, A.; Ramkumar, P. Meta-Heuristic Based Deep Learning Model for Leaf Diseases Detection. Neural Process. Lett. 2022, 54, 5693–5709. [Google Scholar] [CrossRef]
- Zulfiqar, A.; Ghaffar, M.M.; Shahzad, M.; Weis, C.; Malik, M.I.; Shafait, F.; Wehn, N. AI-ForestWatch: Semantic segmentation based end-to-end framework for forest estimation and change detection using multi-spectral remote sensing imagery. J. Appl. Remote. Sens. 2021, 15, 024518. [Google Scholar] [CrossRef]
- Parraga-Alava, J.; Alcivar-Cevallos, R.; Morales Carrillo, J.; Castro, M.; Avellán, S.; Loor, A.; Mendoza, F. LeLePhid: An Image Dataset for Aphid Detection and Infestation Severity on Lemon Leaves. Data 2021, 6, 51. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Dataset | Year | # of Images | Type | Image View | Image Complexity |
|---|---|---|---|---|---|---|
| 1. | Wheat Yellow Rust Disease Infection type Classification [4] | 2021 | 268 | Classification | Close view | Single leaf |
| 2. | Kaggle Wheat Leaf Dataset [6] | 2021 | 407 | Classification | Close view | Single leaf |
| 3. | CGIAR Computer Vision for Crop Disease Dataset [7] | 2020 | 1486 | Classification | Close view | Multiple leaves |
| 4. | Wheat Nitrogen Deficiency and Leaf Rust Image Dataset [8] | 2020 | 859 | Classification | Close view | Single leaf |
| 5. | Crop Disease Treatment Dataset (CDTS) [11] | 2022 | 2353 | Segmentation | Close view | Single leaf |
| 6. | NUST Wheat Rust Disease Dataset (NWRD) (This Work) | 2023 | 100 | Segmentation | Slightly wide-angle view | Multiple leaves |
| Images | Process | No. of Patches Generated in GP (Stride 32) | No. of Patches Generated in AP |
|---|---|---|---|
| Training | 72,592 | average of 12,000 | |
| 22 | Validation | 468 | 468 |
| Test | 703 | 703 | |
| Training | 327,929 | average of 80,000 | |
| 100 | Validation | 2237 | 2237 |
| Test | 2737 | 2737 |
| Patching Type | # of Images | Input Stride | Precision | Recall | F1 Score | Training Time (mins.) |
|---|---|---|---|---|---|---|
| GP | 22 | 128 | 0.694 | 0.557 | 0.618 | 1676 |
| GP | 22 | 32 | 0.683 | 0.685 | 0.684 | 15,820 |
| APF | 22 | 128 | 0.685 | 0.555 | 0.613 | 743 |
| APF | 22 | 32 | 0.578 | 0.743 | 0.650 | 2661 |
| GP | 100 | 128 | 0.510 | 0.544 | 0.514 | 7474 |
| APF | 100 | 32 | 0.506 | 0.624 | 0.557 | 4791 |
| Technique | Model | Input Stride | Precision | Recall | F1 Score | IoU | Training Time (mins.) |
|---|---|---|---|---|---|---|---|
| APF | Octave-UNet | 128 | 0.580 | 0.497 | 0.529 | 0.316 | 923 |
| APF | UNet | 128 | 0.593 | 0.552 | 0.564 | 0.438 | 678 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anwar, H.; Khan, S.U.; Ghaffar, M.M.; Fayyaz, M.; Khan, M.J.; Weis, C.; Wehn, N.; Shafait, F. The NWRD Dataset: An Open-Source Annotated Segmentation Dataset of Diseased Wheat Crop. Sensors 2023, 23, 6942. https://doi.org/10.3390/s23156942
Anwar H, Khan SU, Ghaffar MM, Fayyaz M, Khan MJ, Weis C, Wehn N, Shafait F. The NWRD Dataset: An Open-Source Annotated Segmentation Dataset of Diseased Wheat Crop. Sensors. 2023; 23(15):6942. https://doi.org/10.3390/s23156942
Chicago/Turabian StyleAnwar, Hirra, Saad Ullah Khan, Muhammad Mohsin Ghaffar, Muhammad Fayyaz, Muhammad Jawad Khan, Christian Weis, Norbert Wehn, and Faisal Shafait. 2023. "The NWRD Dataset: An Open-Source Annotated Segmentation Dataset of Diseased Wheat Crop" Sensors 23, no. 15: 6942. https://doi.org/10.3390/s23156942
APA StyleAnwar, H., Khan, S. U., Ghaffar, M. M., Fayyaz, M., Khan, M. J., Weis, C., Wehn, N., & Shafait, F. (2023). The NWRD Dataset: An Open-Source Annotated Segmentation Dataset of Diseased Wheat Crop. Sensors, 23(15), 6942. https://doi.org/10.3390/s23156942