

End-to-End Multimodal Sensor Dataset Collection Framework for Autonomous Vehicles



Abstract
1. Introduction
- We present a general purpose scalable end-to-end AV data collection framework for collecting high-quality multi-sensor radar, LiDAR, and camera data.
- The implementation and demonstration of the framework’s prototype, whose source code is available at: https://github.com/Claud1234/distributed_sensor_data_collector (accessed on 14 May 2023).
- The dataset collection framework contains backend data processing and multimodal sensor fusion algorithms.
2. Related Work
2.1. Dataset Collection Framework for Autonomous Driving
2.2. Multimodal Sensor System for Data Acquisition
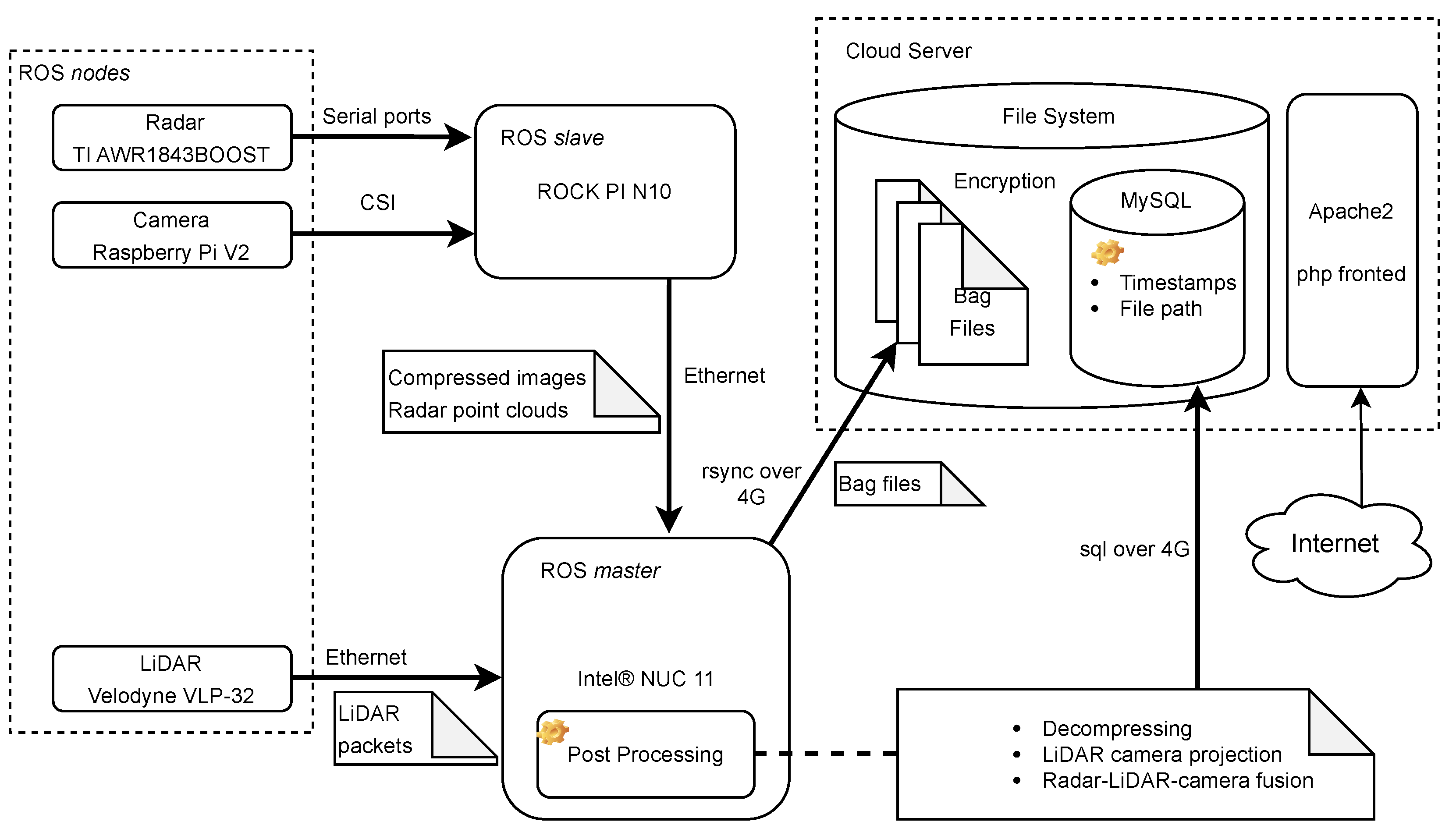
3. Methodology
3.1. Sensor Calibration
3.1.1. Intrinsic Calibration
3.1.2. Extrinsic Calibration
- Before the extrinsic calibration, individual sensors were intrinsically calibrated and published the processed data as ROS messages. However, to have efficient and reliable data transmission and save bandwidth, ROS drivers for the LiDAR and camera sensors were programmed to publish only Velodyne packets and compressed images. Therefore, additional scripts and operations were required to handle the sensor data to match the ROS message types for the extrinsic calibration tools. Table 1 illustrates the message types of the sensors and other post-processing.
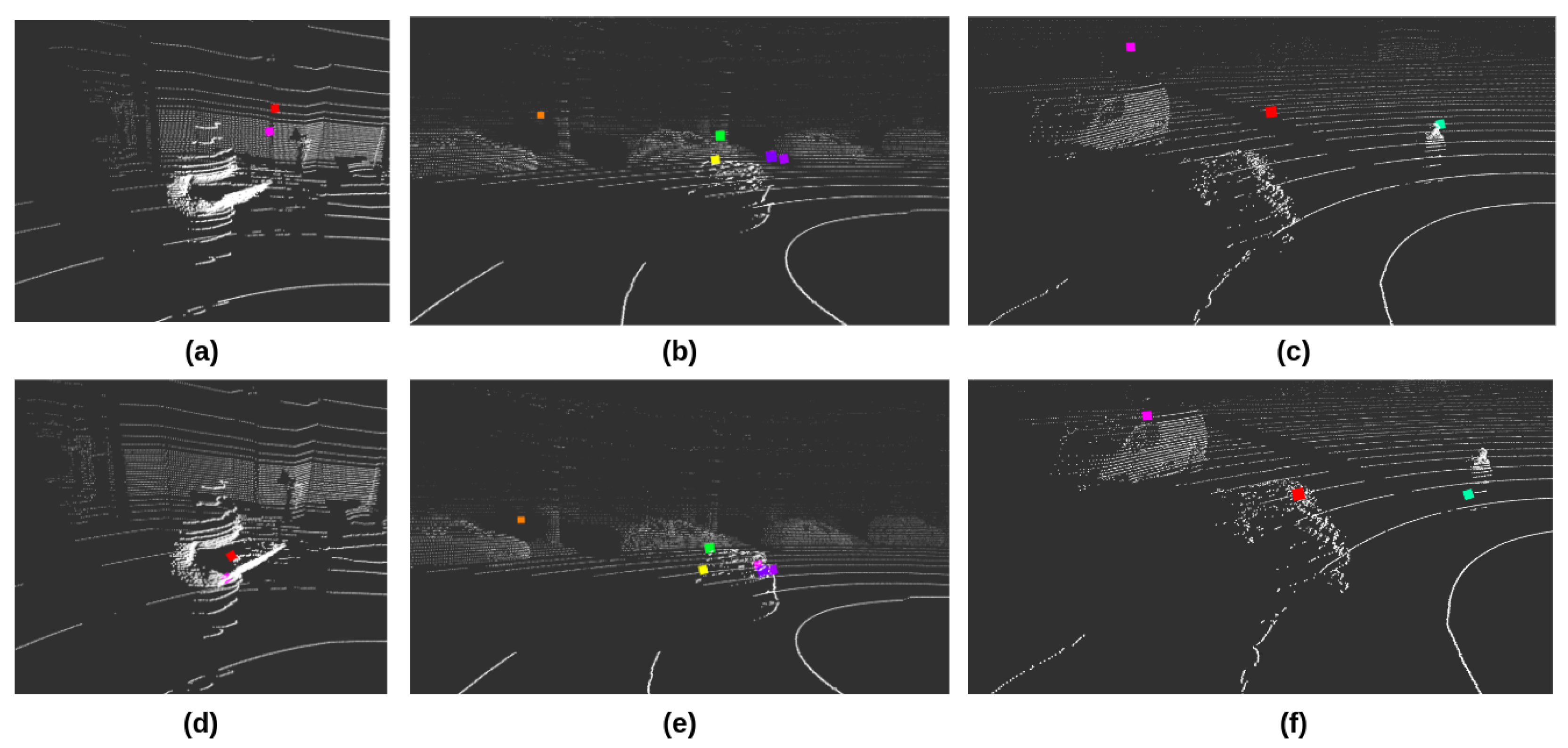
- The calibration relies on humans to match the LiDAR point and corresponding image pixel. Therefore, it is recommended to pick the noticeable features, such as the intersection of the black and white squares or the corner of the checkerboard.
- The point-pixel matches should be picked from the checkerboard in different locations covering all sensors’ full field of view (FOV). For camera sensors, ensure that the pixels from the image edges were selected. Depth varieties (the distance between the checkerboard and the sensor) are critical for LiDAR sensors.
- It is a matter of fact that human errors are inevitable when pairing points and pixels. Therefore, it is suggested to select as many pairs as possible and repeat the calibration to ensure high accuracy.
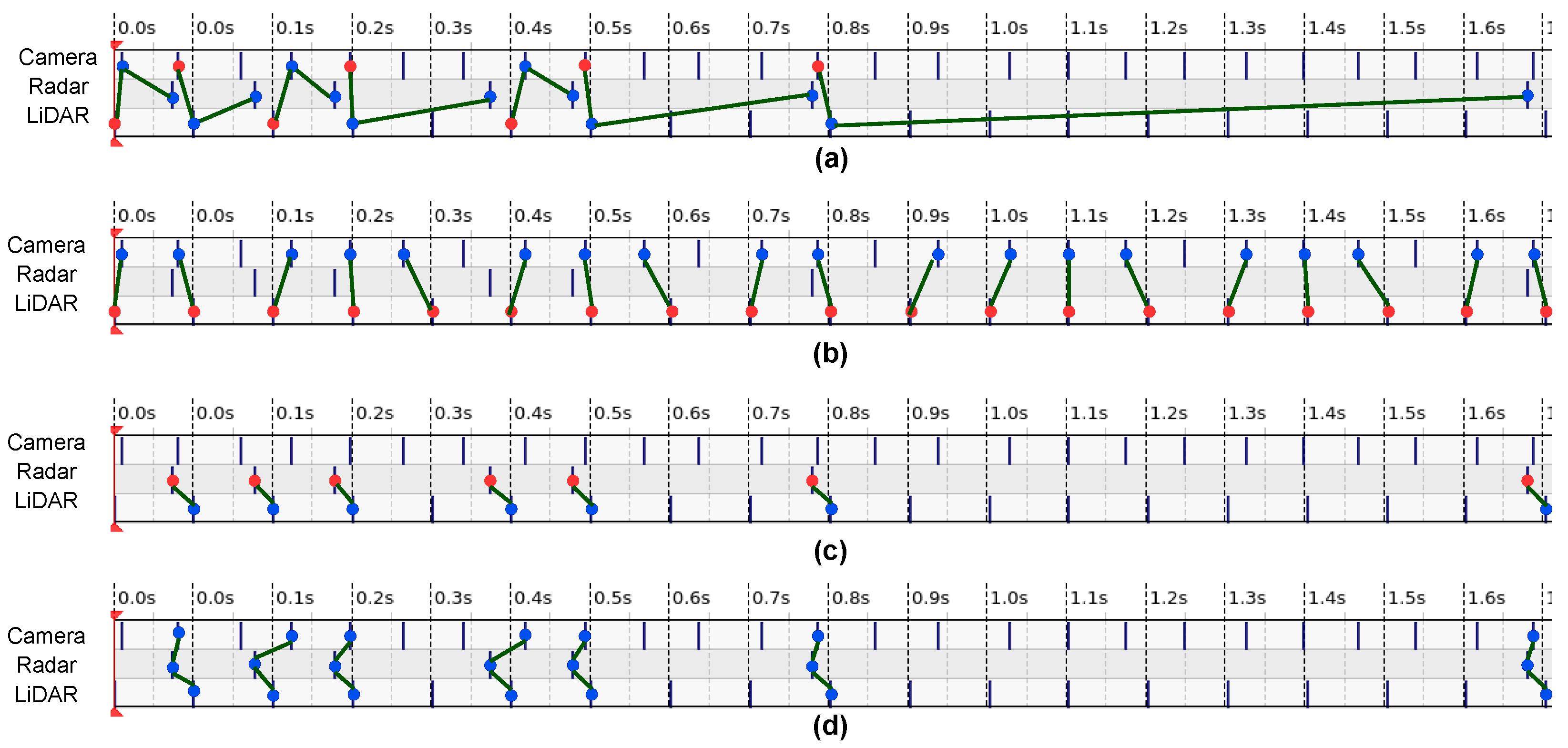
3.2. Sensor Synchronization
- Absolute timestamp is the time when data were produced in sensors. It was usually created by the ROS drivers of the sensors and was written in the header of each message.
- Relative timestamp Relative timestamp represents the time data arrive at the central processing unit. It is the Intel® NUC 11 in our prototype.
3.3. Sensor Fusion
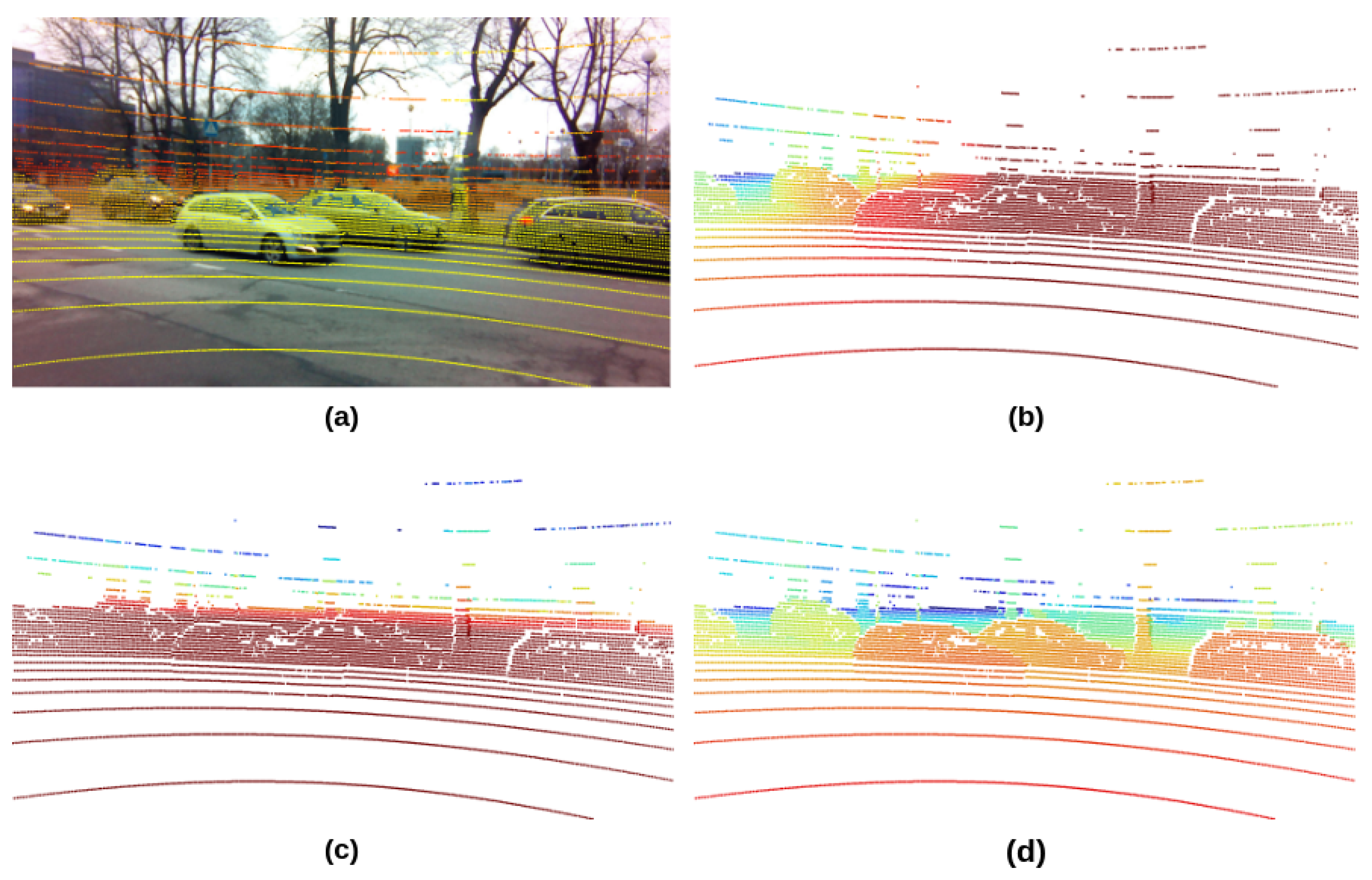
- In the first step, camera–LiDAR fusion can have a maximum number of fusion results. Only a few messages were discarded during the sensor synchronization because the camera and LiDAR sensors have close and homogeneous frame rates. Therefore, the projection of the LiDAR point clouds to the camera images can be easily adapted to the input data of the neural networks.
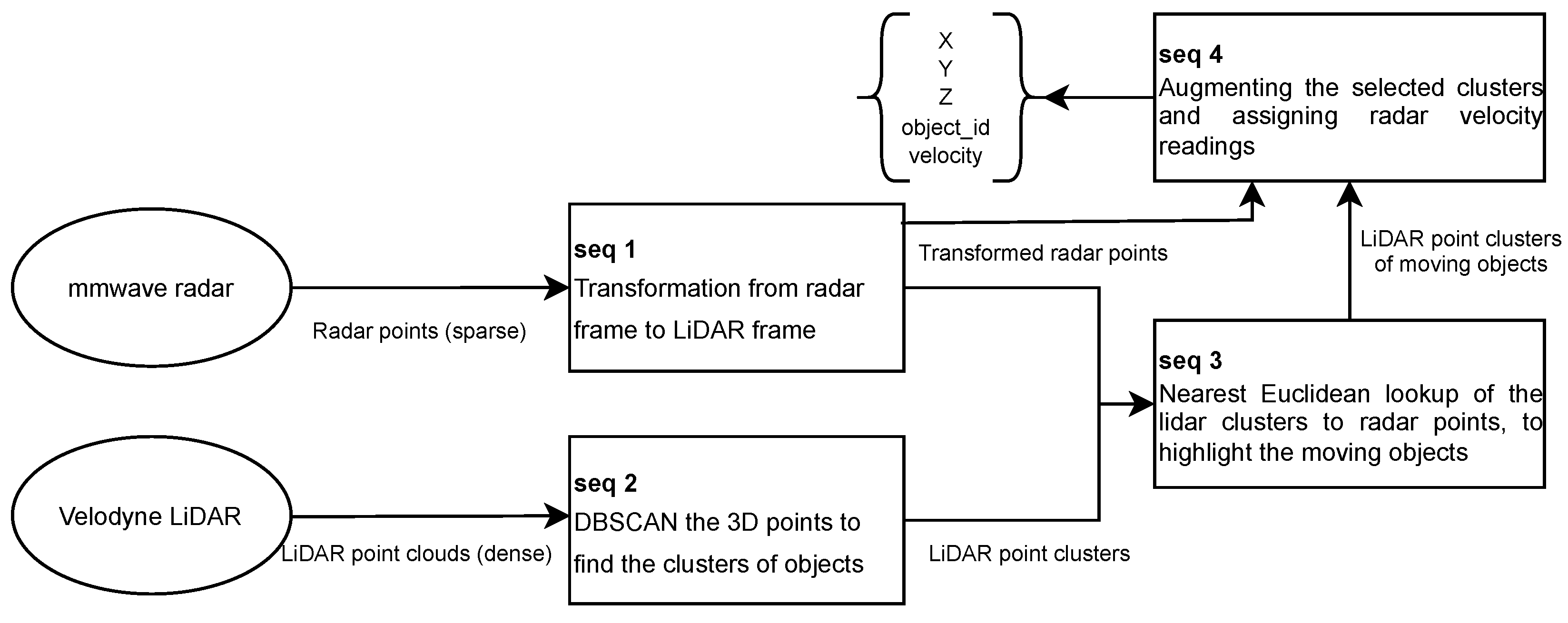
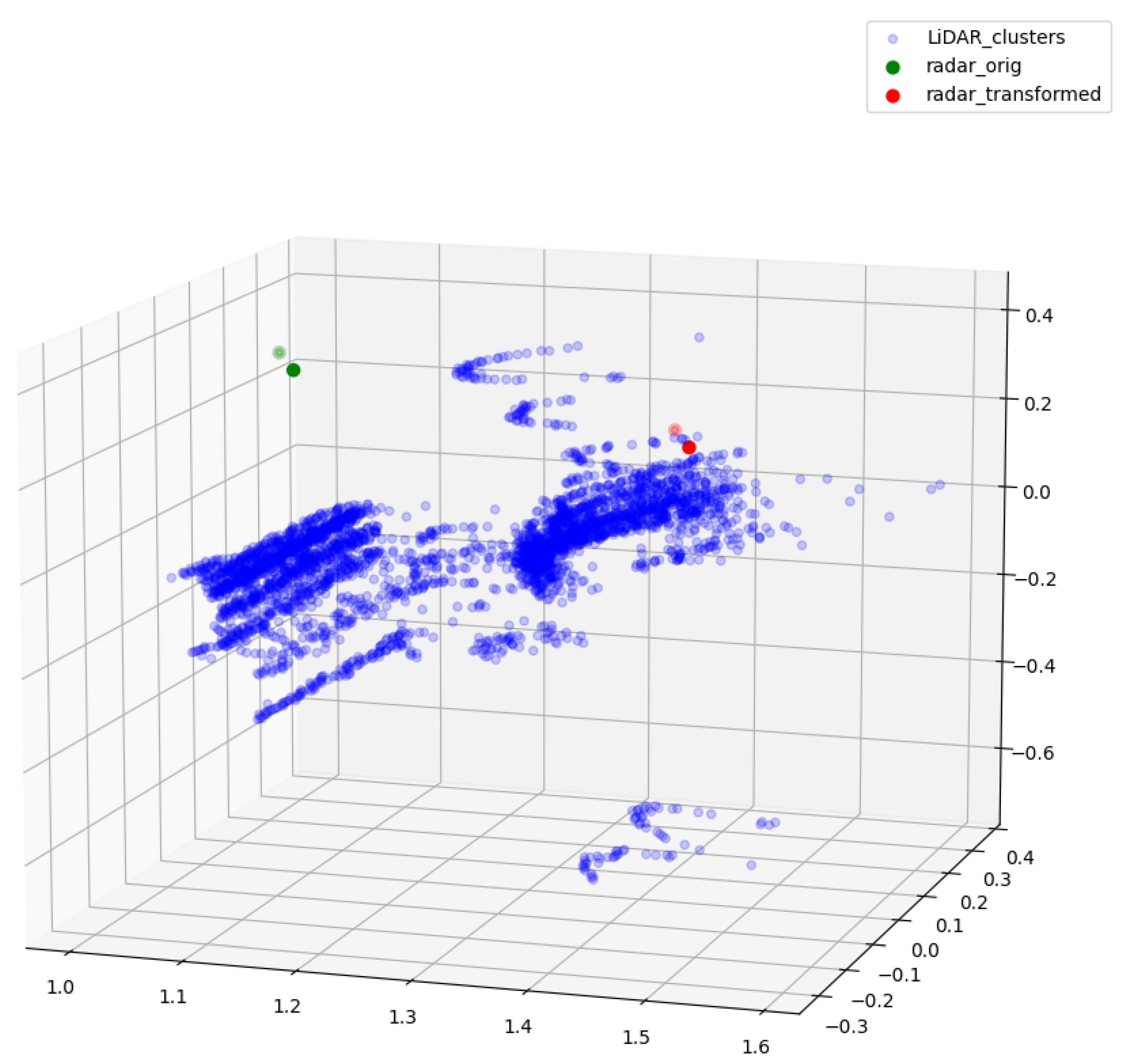
- The second step fusion of the LiDAR and radar points grants the dataset the capability to filter out moving objects from dense LiDAR point clouds and be aware of objects’ relative velocity.
- The thorough camera–LiDAR–radar fusion is the combination of the first two fusion stage results, which consume little computing power and cause minor delays.
3.3.1. LiDAR Camera Fusion
- LiDAR point clouds are stored in sparse triplet format , where N is the number of points in LiDAR data.
- The transformation of LiDAR point clouds to the camera reference frame occurs through the multiplication of the LiDAR matrix with the LiDAR-to-camera transformation matrix .
- The transformed LiDAR points are projected to the camera plane, preserving the structure of the original triplet structure; in essence, the transformed LiDAR matrix is multiplied by the camera projection matrix ; as a result, the projected LiDAR matrix now contains the LiDAR point coordinates on the camera plane (pixel coordinates).
- The camera frame width W and height H are used to cut off all the LiDAR points that fall outside the camera view. In consideration of the projected LiDAR matrix from the previous step, we calculate the matrix row indices where the values satisfy the following:The row indices where satisfies the expressions are stored in an index array ; the shapes of the and are the same, therefore it is secure to apply the derived indices to both the camera-frame-transformed LiDAR matrix and the camera-projected matrix .
- The resulting footprint images , , and are initialized following the camera frame resolution and subsequently populated with black pixels (zero value).
- Zero-value footprint images are populated as follows:
| Algorithm 1 LiDAR transposition, projection populating the images |
|
3.3.2. Radar LiDAR and Camera Fusion
4. Prototype Setup
4.1. Hardware Configurations
4.1.1. Processing Unit Configurations
- All the sensors must be modular, in a manner that they can work independently and can be easily interchanged. Therefore, there is a need for independent and modular processing units to initiate sensors and transfer the data.
- Some sensors have hardware limitations. For example, our radar sensors rely on serial ports for communication, and the cable’s length affects the communication performance in practical tests. A corresponding computer for radar sensors has to stay nearby.
- The main processing unit hardware must provide enough computation resources to support complex operations such as real-time data decompression and database writing.
4.1.2. Sensor Installation
4.2. Software System
4.3. Cloud Server
5. Performance Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Le Mero, L.; Yi, D.; Dianati, M.; Mouzakitis, A. A Survey on Imitation Learning Techniques for End-to-End Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14128–14147. [Google Scholar] [CrossRef]
- Bathla, G.; Bhadane, K.; Singh, R.K.; Kumar, R.; Aluvalu, R.; Krishnamurthi, R.; Kumar, A.; Thakur, R.N.; Basheer, S. Autonomous Vehicles and Intelligent Automation: Applications, Challenges, and Opportunities. Mob. Inf. Syst. 2022, 2022, 7632892. [Google Scholar] [CrossRef]
- Ettinger, S.; Cheng, S.; Caine, B.; Liu, C.; Zhao, H.; Pradhan, S.; Chai, Y.; Sapp, B.; Qi, C.R.; Zhou, Y.; et al. Large Scale Interactive Motion Forecasting for Autonomous Driving: The Waymo Open Motion Dataset. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9710–9719. [Google Scholar]
- Jacob, J.; Rabha, P. Driving data collection framework using low cost hardware. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- de Gelder, E.; Paardekooper, J.P.; den Camp, O.O.; Schutter, B.D. Safety assessment of automated vehicles: How to determine whether we have collected enough field data? Traffic Inj. Prev. 2019, 20, S162–S170. [Google Scholar] [CrossRef]
- Lopez, P.A.; Behrisch, M.; Bieker-Walz, L.; Erdmann, J.; Flötteröd, Y.P.; Hilbrich, R.; Lücken, L.; Rummel, J.; Wagner, P.; Wießner, E. Microscopic traffic simulation using sumo. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2575–2582. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Alatise, M.B.; Hancke, G.P. A Review on Challenges of Autonomous Mobile Robot and Sensor Fusion Methods. IEEE Access 2020, 8, 39830–39846. [Google Scholar] [CrossRef]
- Blasch, E.; Pham, T.; Chong, C.Y.; Koch, W.; Leung, H.; Braines, D.; Abdelzaher, T. Machine Learning/Artificial Intelligence for Sensor Data Fusion–Opportunities and Challenges. IEEE Aerosp. Electron. Syst. Mag. 2021, 36, 80–93. [Google Scholar] [CrossRef]
- Wallace, A.M.; Mukherjee, S.; Toh, B.; Ahrabian, A. Combining automotive radar and LiDAR for surface detection in adverse conditions. IET Radar Sonar Navig. 2021, 15, 359–369. [Google Scholar] [CrossRef]
- Gu, J.; Bellone, M.; Sell, R.; Lind, A. Object segmentation for autonomous driving using iseAuto data. Electronics 2022, 11, 1119. [Google Scholar] [CrossRef]
- Muller, R.; Man, Y.; Celik, Z.B.; Li, M.; Gerdes, R. Drivetruth: Automated autonomous driving dataset generation for security applications. In Proceedings of the International Workshop on Automotive and Autonomous Vehicle Security (AutoSec), San Diego, CA, USA, 24 April 2022. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Xiao, P.; Shao, Z.; Hao, S.; Zhang, Z.; Chai, X.; Jiao, J.; Li, Z.; Wu, J.; Sun, K.; Jiang, K.; et al. PandaSet: Advanced Sensor Suite Dataset for Autonomous Driving. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3095–3101. [Google Scholar] [CrossRef]
- Déziel, J.L.; Merriaux, P.; Tremblay, F.; Lessard, D.; Plourde, D.; Stanguennec, J.; Goulet, P.; Olivier, P. PixSet: An Opportunity for 3D Computer Vision to Go beyond Point Clouds with a Full-Waveform LiDAR Dataset. arXiv 2021, arXiv:2102.12010. [Google Scholar]
- Pitropov, M.; Garcia, D.E.; Rebello, J.; Smart, M.; Wang, C.; Czarnecki, K.; Waslander, S. Canadian adverse driving conditions dataset. Int. J. Robot. Res. 2021, 40, 681–690. [Google Scholar] [CrossRef]
- Yan, Z.; Sun, L.; Krajník, T.; Ruichek, Y. EU Long-term Dataset with Multiple Sensors for Autonomous Driving. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 10697–10704. [Google Scholar] [CrossRef]
- Lakshminarayana, N. Large scale multimodal data capture, evaluation and maintenance framework for autonomous driving datasets. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Beck, J.; Arvin, R.; Lee, S.; Khattak, A.; Chakraborty, S. Automated vehicle data pipeline for accident reconstruction: New insights from LiDAR, camera, and radar data. Accid. Anal. Prev. 2023, 180, 106923. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, PMLR, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Xiao, Y.; Codevilla, F.; Gurram, A.; Urfalioglu, O.; López, A.M. Multimodal end-to-end autonomous driving. IEEE Trans. Intell. Transp. Syst. 2020, 23, 537–547. [Google Scholar] [CrossRef]
- Wei, J.; Snider, J.M.; Kim, J.; Dolan, J.M.; Rajkumar, R.; Litkouhi, B. Towards a viable autonomous driving research platform. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast, QLD, Australia, 23–26 June 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 763–770. [Google Scholar]
- Grisleri, P.; Fedriga, I. The braive autonomous ground vehicle platform. IFAC Proc. Vol. 2010, 43, 497–502. [Google Scholar] [CrossRef]
- Bertozzi, M.; Bombini, L.; Broggi, A.; Buzzoni, M.; Cardarelli, E.; Cattani, S.; Cerri, P.; Coati, A.; Debattisti, S.; Falzoni, A.; et al. VIAC: An out of ordinary experiment. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 175–180. [Google Scholar] [CrossRef]
- Self-Driving Made Real—NAVYA. Available online: https://navya.tech/fr (accessed on 2 May 2023).
- Gu, J.; Chhetri, T.R. Range Sensor Overview and Blind-Zone Reduction of Autonomous Vehicle Shuttles. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1140, 012006. [Google Scholar] [CrossRef]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3D Tracking and Forecasting with Rich Maps. arXiv 2019, arXiv:1911.02620. [Google Scholar]
- Wang, P.; Huang, X.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The apolloscape open dataset for autonomous driving and its application. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 1, 2702–2719. [Google Scholar]
- Thrun, S.; Montemerlo, M.; Dahlkamp, H.; Stavens, D.; Aron, A.; Diebel, J.; Fong, P.; Gale, J.; Halpenny, M.; Hoffmann, G.; et al. Stanley: The robot that won the DARPA Grand Challenge. J. Field Robot. 2006, 23, 661–692. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. Laser–visual–inertial odometry and mapping with high robustness and low drift. J. Field Robot. 2018, 35, 1242–1264. [Google Scholar] [CrossRef]
- An, P.; Ma, T.; Yu, K.; Fang, B.; Zhang, J.; Fu, W.; Ma, J. Geometric calibration for LiDAR-camera system fusing 3D-2D and 3D-3D point correspondences. Opt. Express 2020, 28, 2122–2141. [Google Scholar] [CrossRef]
- Domhof, J.; Kooij, J.F.; Gavrila, D.M. An extrinsic calibration tool for radar, camera and lidar. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8107–8113. [Google Scholar]
- Jeong, J.; Cho, Y.; Kim, A. The road is enough! Extrinsic calibration of non-overlapping stereo camera and LiDAR using road information. IEEE Robot. Autom. Lett. 2019, 4, 2831–2838. [Google Scholar] [CrossRef]
- Schöller, C.; Schnettler, M.; Krämmer, A.; Hinz, G.; Bakovic, M.; Güzet, M.; Knoll, A. Targetless rotational auto-calibration of radar and camera for intelligent transportation systems. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3934–3941. [Google Scholar]
- Huang, K.; Shi, B.; Li, X.; Li, X.; Huang, S.; Li, Y. Multi-modal sensor fusion for auto driving perception: A survey. arXiv 2022, arXiv:2202.02703. [Google Scholar]
- Cui, Y.; Chen, R.; Chu, W.; Chen, L.; Tian, D.; Li, Y.; Cao, D. Deep learning for image and point cloud fusion in autonomous driving: A review. IEEE Trans. Intell. Transp. Syst. 2021, 23, 722–739. [Google Scholar] [CrossRef]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. LIDAR–camera fusion for road detection using fully convolutional neural networks. Robot. Auton. Syst. 2019, 111, 125–131. [Google Scholar] [CrossRef]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M.; Sell, R. LiDAR–camera semi-supervised learning for semantic segmentation. Sensors 2021, 21, 4813. [Google Scholar] [CrossRef]
- Pollach, M.; Schiegg, F.; Knoll, A. Low latency and low-level sensor fusion for automotive use-cases. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6780–6786. [Google Scholar]
- Shahian Jahromi, B.; Tulabandhula, T.; Cetin, S. Real-time hybrid multi-sensor fusion framework for perception in autonomous vehicles. Sensors 2019, 19, 4357. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.L.; Jahanshahi, M.R.; Manjunatha, P.; Gan, W.; Abdelbarr, M.; Masri, S.F.; Becerik-Gerber, B.; Caffrey, J.P. Inexpensive multimodal sensor fusion system for autonomous data acquisition of road surface conditions. IEEE Sens. J. 2016, 16, 7731–7743. [Google Scholar] [CrossRef]
- Meyer, G.P.; Charland, J.; Hegde, D.; Laddha, A.; Vallespi-Gonzalez, C. Sensor fusion for joint 3d object detection and semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Guan, H.; Yan, W.; Yu, Y.; Zhong, L.; Li, D. Robust traffic-sign detection and classification using mobile LiDAR data with digital images. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2018, 11, 1715–1724. [Google Scholar] [CrossRef]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.; Walsh, J. Sensor and Sensor Fusion Technology in Autonomous Vehicles: A Review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, Q.; Wu, S.; Pan, X. Flexible and accurate camera calibration using grid spherical images. Opt. Express 2017, 25, 15269–15285. [Google Scholar] [CrossRef]
- Vel’as, M.; Španěl, M.; Materna, Z.; Herout, A. Calibration of RGB Camera with Velodyne Lidar. In Proceedings of the 22nd International Conference in Central Europeon Computer Graphics, Visualization and Computer Visionin Co-Operation with EUROGRAPHICS Association, Plzen, Czech Republic, 2–5 June 2014; pp. 135–144. [Google Scholar]
- Pannu, G.S.; Ansari, M.D.; Gupta, P. Design and implementation of autonomous car using Raspberry Pi. Int. J. Comput. Appl. 2015, 113, 22–29. [Google Scholar]
- Jain, A.K. Working model of self-driving car using convolutional neural network, Raspberry Pi and Arduino. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1630–1635. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Velodyne-VLP32C Datasheet. Available online: https://https://www.mapix.com/wp-content/uploads/2018/07/63-9378_Rev-D_ULTRA-Puck_VLP-32C_Datasheet_Web.pdf (accessed on 6 June 2023).
- Glennie, C.; Lichti, D.D. Static calibration and analysis of the Velodyne HDL-64E S2 for high accuracy mobile scanning. Remote Sens. 2010, 2, 1610–1624. [Google Scholar] [CrossRef]
- Atanacio-Jiménez, G.; González-Barbosa, J.J.; Hurtado-Ramos, J.B.; Ornelas-Rodríguez, F.J.; Jiménez-Hernández, H.; García-Ramirez, T.; González-Barbosa, R. Lidar velodyne hdl-64e calibration using pattern planes. Int. J. Adv. Robot. Syst. 2011, 8, 59. [Google Scholar] [CrossRef]
- Milch, S.; Behrens, M. Pedestrian detection with radar and computer vision. In Proceedings of the PAL 2001—Progress in Automobile Lighting, Laboratory of Lighting Technology, Darmstadt, Germany, 25–26 September 2001; Herbert utzverlag GMBH: Munchen, Germany, 2001; Volume 9. [Google Scholar]
- Huang, W.; Zhang, Z.; Li, W.; Tian, J. Moving object tracking based on millimeter-wave radar and vision sensor. J. Appl. Sci. Eng. 2018, 21, 609–614. [Google Scholar]
- Liu, F.; Sparbert, J.; Stiller, C. IMMPDA vehicle tracking system using asynchronous sensor fusion of radar and vision. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 168–173. [Google Scholar]
- Guo, X.-p.; Du, J.-s.; Gao, J.; Wang, W. Pedestrian detection based on fusion of millimeter wave radar and vision. In Proceedings of the 2018 International Conference on Artificial Intelligence and Pattern Recognition, Beijing, China, 18–20 August 2018; pp. 38–42. [Google Scholar]
- Yin, L.; Luo, B.; Wang, W.; Yu, H.; Wang, C.; Li, C. CoMask: Corresponding Mask-Based End-to-End Extrinsic Calibration of the Camera and LiDAR. Remote Sens. 2020, 12, 1925. [Google Scholar] [CrossRef]
- Peršić, J.; Marković, I.; Petrović, I. Extrinsic 6dof calibration of a radar–lidar–camera system enhanced by radar cross section estimates evaluation. Robot. Auton. Syst. 2019, 114, 217–230. [Google Scholar] [CrossRef]
- Message_Filters—ROS Wiki. Available online: https://wiki.ros.org/message_filters (accessed on 7 March 2023).
- Banerjee, K.; Notz, D.; Windelen, J.; Gavarraju, S.; He, M. Online camera lidar fusion and object detection on hybrid data for autonomous driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1632–1638. [Google Scholar]
- Fayyad, J.; Jaradat, M.A.; Gruyer, D.; Najjaran, H. Deep learning sensor fusion for autonomous vehicle perception and localization: A review. Sensors 2020, 20, 4220. [Google Scholar] [CrossRef]
- Wei, Z.; Zhang, F.; Chang, S.; Liu, Y.; Wu, H.; Feng, Z. Mmwave radar and vision fusion for object detection in autonomous driving: A review. Sensors 2022, 22, 2542. [Google Scholar] [CrossRef]
- Hajri, H.; Rahal, M.C. Real time lidar and radar high-level fusion for obstacle detection and tracking with evaluation on a ground truth. arXiv 2018, arXiv:1807.11264. [Google Scholar]
- Fritsche, P.; Zeise, B.; Hemme, P.; Wagner, B. Fusion of radar, LiDAR and thermal information for hazard detection in low visibility environments. In Proceedings of the 2017 IEEE International Symposium on Safety, Security and Rescue Robotics (SSRR), Shanghai, China, 11–13 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 96–101. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Pikner, H.; Karjust, K. Multi-layer cyber-physical low-level control solution for mobile robots. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1140, 012048. [Google Scholar] [CrossRef]
- Sell, R.; Leier, M.; Rassõlkin, A.; Ernits, J.P. Self-driving car ISEAUTO for research and education. In Proceedings of the 2018 19th International Conference on Research and Education in Mechatronics (REM), Delft, The Netherlands, 7–8 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 111–116. [Google Scholar]
- Geyer, J.; Kassahun, Y.; Mahmudi, M.; Ricou, X.; Durgesh, R.; Chung, A.S.; Hauswald, L.; Pham, V.H.; Mühlegg, M.; Dorn, S.; et al. A2d2: Audi autonomous driving dataset. arXiv 2020, arXiv:2004.06320. [Google Scholar]
- Broggi, A.; Buzzoni, M.; Debattisti, S.; Grisleri, P.; Laghi, M.C.; Medici, P.; Versari, P. Extensive tests of autonomous driving technologies. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1403–1415. [Google Scholar] [CrossRef]
- Kato, S.; Tokunaga, S.; Maruyama, Y.; Maeda, S.; Hirabayashi, M.; Kitsukawa, Y.; Monrroy, A.; Ando, T.; Fujii, Y.; Azumi, T. Autoware on board: Enabling autonomous vehicles with embedded systems. In Proceedings of the 2018 ACM/IEEE 9th International Conference on Cyber-Physical Systems (ICCPS), Porto, Portugal, 11–13 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 287–296. [Google Scholar]
- A Conceptual Ecosystem Solution to Transport System Management. Available online: https://www.finestcentre.eu/mobility (accessed on 23 June 2023).
- Zhai, G.; Min, X. Perceptual image quality assessment: A survey. Sci. China Inf. Sci. 2020, 63, 211301. [Google Scholar] [CrossRef]
- Fritsch, J.; Kühnl, T.; Geiger, A. A new performance measure and evaluation benchmark for road detection algorithms. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), Hague, The Netherlands, 6–9 October 2013; pp. 1693–1700. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Message Type of Topic Published by Driver | Message Type of Topic Subscribed by Calibration Processes |
|---|---|---|
| LiDAR Velodyne VLP-32C | velodyne_msgs/VelodyneScan | sensor_msgs/PointCloud2 (LiDAR-camera extrinsic) velodyne_msgs/VelodyneScan (radar-LiDAR extrinsic) |
| Camera Raspberry Pi V2 | sensor_msgs/CompressedImage | sensor_msgs/Image (camera intrinsic) sensor_msgs/Image (LiDAR-camera extrinsic) |
| Radar TI AWR1843BOOST | sensor_msgs/PointCloud2 | sensor_msgs/PointCloud2 (radar intrinsic) sensor_msgs/PointCloud2 (radar-LiDAR extrinsic) |
| FoV () | Range (m)/Resolution | Update Rate (Hz) | |
|---|---|---|---|
| Velodyne VLP-32 | 40 (vertical) | 200 | 20 |
| Raspberry Pi V2 | 160 (D) | 3280 × 2464 | 90 in 640 × 480 |
| TI mmwave AWR1843BOOST | 100 (H) 40 (V) | 4 cm (range resolution) 0.3 m/s (velocity resolution) | 10–100 |
| Sequence 1 City Urban | Sequence 2 Indoor Lab | |
|---|---|---|
| Sequence Duration (s) | 301 | 144 |
| Raw Bag File Size (GB) | 3.7 | 0.78 |
| Synchronization (s) | 4.28 | 1.24 |
| Raw Data Decompressing (s) | 0.36 | 0.09 |
| Raw Data Writing (s)/(GB) | 116.63/16.4 | 54.74/7.4 |
| LiDAR-Camera Fusion (s)/(GB) | 510.94/9.2 | 261.34/4.6 |
| radar–LiDAR–Camera Fusion (s)/(GB) | 61.97/5.8 | 39.38/3.3 |
| Raw Data Decompressing and Writing | LiDAR Projection | Radar-LiDAR Clustering | |
|---|---|---|---|
| Size per frame | |||
| RGB image in 1920 × 1080 | 3 MB | 3 MB | 3 MB |
| LiDAR points in binary | 1.2 MB | 0.9 MB | <0.1 MB |
| Average time per frame (RGB image in 1920 × 1080 + LiDAR points in binary) | 79.7 ms | 647.7 ms | 108.44 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, J.; Lind, A.; Chhetri, T.R.; Bellone, M.; Sell, R. End-to-End Multimodal Sensor Dataset Collection Framework for Autonomous Vehicles. Sensors 2023, 23, 6783. https://doi.org/10.3390/s23156783
Gu J, Lind A, Chhetri TR, Bellone M, Sell R. End-to-End Multimodal Sensor Dataset Collection Framework for Autonomous Vehicles. Sensors. 2023; 23(15):6783. https://doi.org/10.3390/s23156783
Chicago/Turabian StyleGu, Junyi, Artjom Lind, Tek Raj Chhetri, Mauro Bellone, and Raivo Sell. 2023. "End-to-End Multimodal Sensor Dataset Collection Framework for Autonomous Vehicles" Sensors 23, no. 15: 6783. https://doi.org/10.3390/s23156783
APA StyleGu, J., Lind, A., Chhetri, T. R., Bellone, M., & Sell, R. (2023). End-to-End Multimodal Sensor Dataset Collection Framework for Autonomous Vehicles. Sensors, 23(15), 6783. https://doi.org/10.3390/s23156783