
A Light-Weight Cropland Mapping Model Using Satellite Imagery

 , and
, and 
Abstract
1. Introduction
- Provide a detailed methodology of data points collection of Sentinel-2 satellite assets though google earth engine for cropland extent and intensity applications for machine learning.
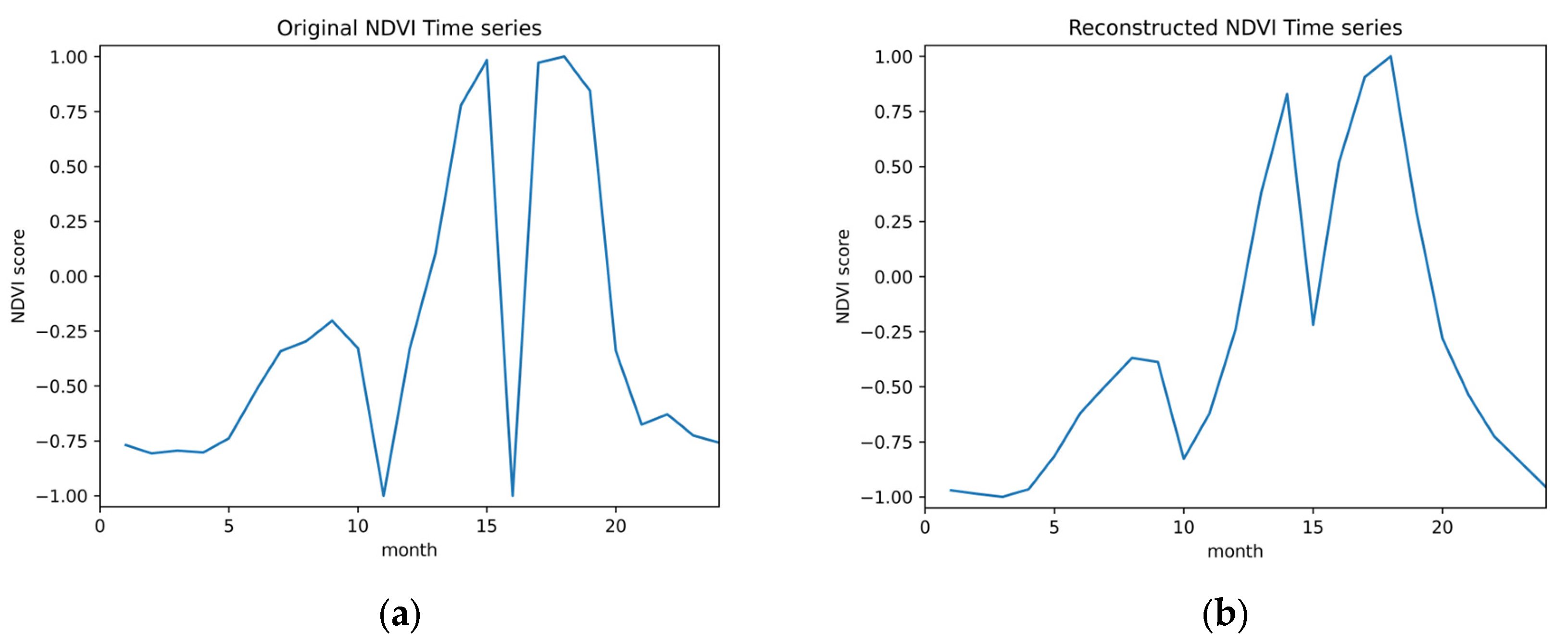
- Perform a NDVI time-series reconstruction on the data-points collected to patch gaps and errors within the series using a Savitzky–Golay filter and linear interpolation technique.
- Develop an adaptive threshold approach for crop intensity cycles detection based on the obtained NDVI time-series.
- Apply different machine learning techniques on the dataset at hand to generate cropland extent and intensity maps.
- Compare context aware and regular machine learning techniques in terms of efficiency and speed.
2. Materials and Methods
2.1. Sentinel-2 Data
2.2. Study Area and Dataset
2.3. Data Pre-Processing
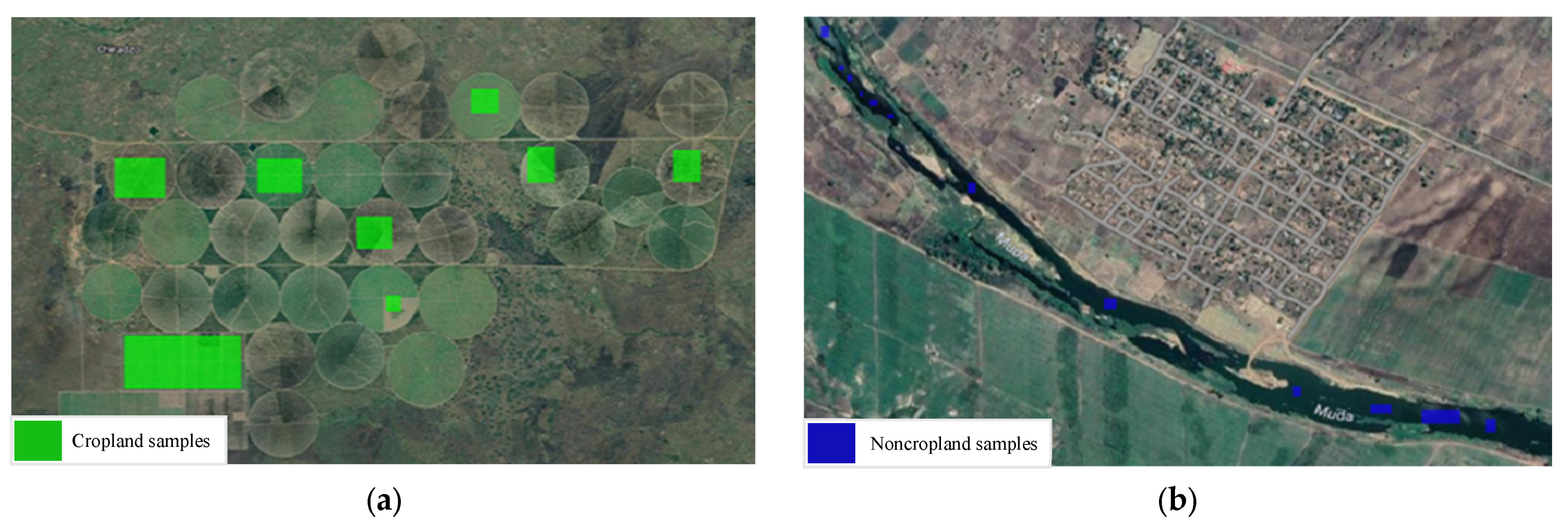
2.3.1. Cropland Extent Samples
2.3.2. Cropland Intensity Samples
2.3.3. Cropland Extent and Intensity Samples Collection Procedure
2.4. Adaptive Threshold Approach for Crop Intensity Cycles Detection
2.5. Classification Methods
2.5.1. Random Forest
2.5.2. XGBoost Classifier
2.5.3. LSTM
2.5.4. Bidirectional LSTM
2.5.5. KNN DTW
2.5.6. Computational Complexity
3. Results and Discussion
Maps Generated as Google Earth Engine Assets
4. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Summary Progress Update 2021: SDG 6—Water and Sanitation for All. Available online: https://www.unwater.org/publications/summary-progress-update-2021-sdg-6-water-and-sanitation-all (accessed on 15 June 2023).
- Thenkabail, P.S. Global Croplands and their Importance for Water and Food Security in the Twenty-first Century: Towards an Ever Green Revolution that Combines a Second Green Revolution with a Blue Revolution. Remote Sens. 2010, 2, 2305–2312. [Google Scholar] [CrossRef]
- FAO. Food and Agriculture Organization of the United Nations. Available online: http://www.fao.org/sustainability/news/detail/en/c/1274219/ (accessed on 15 June 2023).
- Matton, N.; Canto, G.S.; Waldner, F.; Valero, S.; Morin, D.; Inglada, J.; Arias, M.; Bontemps, S.; Koetz, B.; Defourny, P. An Automated Method for Annual Cropland Mapping along the Season for Various Globally-Distributed Agrosystems Using High Spatial and Temporal Resolution Time Series. Remote Sens. 2015, 7, 13208–13232. [Google Scholar] [CrossRef]
- Mtibaa, S.; Irie, M. Land cover mapping in cropland dominated area using information on vegetation phenology and multi-seasonal Landsat 8 images. Euro-Mediterr. J. Environ. Integr. 2016, 1, 6. [Google Scholar] [CrossRef]
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US agriculture: The US Department of Agriculture, National Agricultural Statistics Service, Cropland Data Layer Program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Oliphant, A.J.; Thenkabail, P.S.; Teluguntla, P.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K. Mapping cropland extent of Southeast and Northeast Asia using multi-year time-series Landsat 30-m data using a random forest classifier on the Google Earth Engine Cloud. Int. J. Appl. Earth Obs. Geoinf. 2019, 81, 110–124. [Google Scholar] [CrossRef]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Chakrabarti, S.; Cormier, T.; Malizia, N.; Potere, D.; Sulla-Menashe, D.; Zmijewski, K.; Friedl, M. Mapping Cropland Extent by Asynchronous Fusion of Optical and Active Microwave Imagery. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 5319–5321. [Google Scholar]
- Potapov, P.; Turubanova, S.; Hansen, M.C.; Tyukavina, A.; Zalles, V.; Khan, A.; Song, X.-P.; Pickens, A.; Shen, Q.; Cortez, J. Global maps of cropland extent and change show accelerated cropland expansion in the twenty-first century. Nat. Food 2022, 3, 19–28. [Google Scholar] [CrossRef]
- See, L.; Fritz, S.; You, L.; Ramankutty, N.; Herrero, M.; Justice, C.; Becker-Reshef, I.; Thornton, P.; Erb, K.; Gong, P.; et al. Improved global cropland data as an essential ingredient for food security. Glob. Food Secur. 2015, 4, 37–45. [Google Scholar] [CrossRef]
- Xiong, J.; Thenkabail, P.S.; Tilton, J.C.; Gumma, M.K.; Teluguntla, P.; Oliphant, A.; Congalton, R.G.; Yadav, K.; Gorelick, N. Nominal 30-m Cropland Extent Map of Continental Africa by Integrating Pixel-Based and Object-Based Algorithms Using Sentinel-2 and Landsat-8 Data on Google Earth Engine. Remote Sens. 2017, 9, 1065. [Google Scholar] [CrossRef]
- Hendricks, N.P.; Er, E. Changes in cropland area in the United States and the role of CRP. Food Policy 2018, 75, 15–23. [Google Scholar] [CrossRef]
- Rafif, R.; Kusuma, S.S.; Saringatin, S.; Nanda, G.I.; Wicaksono, P.; Arjasakusuma, S. Crop Intensity Mapping Using Dynamic Time Warping and Machine Learning from Multi-Temporal PlanetScope Data. Land 2021, 10, 1384. [Google Scholar] [CrossRef]
- Pan, L.; Xia, H.; Yang, J.; Niu, W.; Wang, R.; Song, H.; Guo, Y.; Qin, Y. Mapping cropping intensity in Huaihe basin using phenology algorithm, all Sentinel-2 and Landsat images in Google Earth Engine. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102376. [Google Scholar] [CrossRef]
- FAO. Map Catalog—Food and Agriculture Organization of the United Nations. Available online: https://data.apps.fao.org/map/catalog/static/search?keyword=Crop%20intensity (accessed on 16 June 2023).
- Liu, X.; Zheng, J.; Yu, L.; Hao, P.; Chen, B.; Xin, Q.; Fu, H.; Gong, P. Annual dynamic dataset of global cropping intensity from 2001 to 2019. Sci. Data 2021, 8, 283. [Google Scholar] [CrossRef]
- Gumma, M.K.; Thenkabail, P.S.; Maunahan, A.; Islam, S.; Nelson, A. Mapping seasonal rice cropland extent and area in the high cropping intensity environment of Bangladesh using MODIS 500m data for the year 2010. ISPRS J. Photogramm. Remote Sens. 2014, 91, 98–113. [Google Scholar] [CrossRef]
- Gumma, M.K.; Thenkabail, P.S.; Teluguntla, P.G.; Oliphant, A.; Xiong, J.; Giri, C.; Pyla, V.; Dixit, S.; Whitbread, A.M. Agricultural cropland extent and areas of South Asia derived using Landsat satellite 30-m time-series big-data using random forest machine learning algorithms on the Google Earth Engine cloud. GIScience Remote Sens. 2020, 57, 302–322. [Google Scholar] [CrossRef]
- Halder, J. Land Suitability Assessment for Crop Cultivation by Using Remote Sensing and GIS. J. Geogr. Geol. 2013, 5, 65. [Google Scholar] [CrossRef]
- Tran, K.H.; Zhang, H.K.; McMaine, J.T.; Zhang, X.; Luo, D. 10 m crop type mapping using Sentinel-2 reflectance and 30 m cropland data layer product. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102692. [Google Scholar] [CrossRef]
- Helman, D.; Lensky, I.M.; Tessler, N.; Osem, Y. A Phenology-Based Method for Monitoring Woody and Herbaceous Vegetation in Mediterranean Forests from NDVI Time Series. Remote Sens. 2015, 7, 12314–12335. [Google Scholar] [CrossRef]
- Ginn, F. The International Encyclopedia of Geography: People, The Earth, Environment and Technology; Blackwell Publishing: Hoboken, NJ, USA, 2017; Available online: https://typeset.io/papers/the-international-encyclopedia-of-geography-people-the-earth-51mjwy4kvx (accessed on 15 June 2023).
- Kong, D.; Zhang, Y.; Gu, X.; Wang, D. A robust method for reconstructing global MODIS EVI time series on the Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2019, 155, 13–24. [Google Scholar] [CrossRef]
- Li, X.; Shen, R.; Chen, R. Improving Time Series Reconstruction by Fixing Invalid Values and its Fidelity Evaluation. IEEE Access 2020, 8, 7558–7572. [Google Scholar] [CrossRef]
- Li, X.; Wang, L.; Cheng, Q.; Wu, P.; Gan, W.; Fang, L. Cloud removal in remote sensing images using nonnegative matrix factorization and error correction. ISPRS J. Photogramm. Remote Sens. 2019, 148, 103–113. [Google Scholar] [CrossRef]
- Matsushita, B.; Yang, W.; Chen, J.; Onda, Y.; Qiu, G. Sensitivity of the Enhanced Vegetation Index (EVI) and Normalized Difference Vegetation Index (NDVI) to Topographic Effects: A Case Study in High-Density Cypress Forest. Sensors 2007, 7, 2636–2651. [Google Scholar] [CrossRef] [PubMed]
- Kumari, N.; Saco, P.M.; Rodriguez, J.F.; Johnstone, S.A.; Srivastava, A.; Chun, K.P.; Yetemen, O. The Grass Is Not Always Greener on the Other Side: Seasonal Reversal of Vegetation Greenness in Aspect-Driven Semiarid Ecosystems. Geophys. Res. Lett. 2020, 47, e2020GL088918. [Google Scholar] [CrossRef]
- Martín-Ortega, P.; García-Montero, L.G.; Sibelet, N. Temporal Patterns in Illumination Conditions and Its Effect on Vegetation Indices Using Landsat on Google Earth Engine. Remote Sens. 2020, 12, 211. [Google Scholar] [CrossRef]
- Xu, L.; Li, B.; Yuan, Y.; Gao, X.; Zhang, T. A Temporal-Spatial Iteration Method to Reconstruct NDVI Time Series Datasets. Remote Sens. 2015, 7, 8906–8924. [Google Scholar] [CrossRef]
- Padhee, S.K.; Dutta, S. Spatio-Temporal Reconstruction of MODIS NDVI by Regional Land Surface Phenology and Harmonic Analysis of Time-Series. GIScience Remote Sens. 2019, 56, 1261–1288. [Google Scholar] [CrossRef]
- Padhee, S.K.; Dutta, S. Spatiotemporal reconstruction of MODIS land surface temperature with the help of GLDAS product using kernel-based nonparametric data assimilation. J. Appl. Remote Sens. 2020, 14, 014520. [Google Scholar] [CrossRef]
- You, N.; Dong, J.; Huang, J.; Du, G.; Zhang, G.; He, Y.; Yang, T.; Di, Y.; Xiao, X. The 10-m crop type maps in Northeast China during 2017–2019. Sci. Data 2021, 8, 41. [Google Scholar] [CrossRef]
- D’Andrimont, R.; Verhegghen, A.; Lemoine, G.; Kempeneers, P.; Meroni, M.; van der Velde, M. From parcel to continental scale—A first European crop type map based on Sentinel-1 and LUCAS Copernicus in-situ observations. Remote Sens. Environ. 2021, 266, 112708. [Google Scholar] [CrossRef]
- Yaramasu, R.; Bandaru, V.; Pnvr, K. Pre-season crop type mapping using deep neural networks. Comput. Electron. Agric. 2020, 176, 105664. [Google Scholar] [CrossRef]
- Zheng, B.; Myint, S.W.; Thenkabail, P.S.; Aggarwal, R.M. A support vector machine to identify irrigated crop types using time-series Landsat NDVI data. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 103–112. [Google Scholar] [CrossRef]
- Ketchum, D.; Jencso, K.; Maneta, M.P.; Melton, F.; Jones, M.O.; Huntington, J. IrrMapper: A Machine Learning Approach for High Resolution Mapping of Irrigated Agriculture Across the Western U.S. Remote Sens. 2020, 12, 2328. [Google Scholar] [CrossRef]
- Zhang, C.; Dong, J.; Xie, Y.; Zhang, X.; Ge, Q. Mapping irrigated croplands in China using a synergetic training sample generating method, machine learning classifier, and Google Earth Engine. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102888. [Google Scholar] [CrossRef]
- Sentinel-2. Marketplace—Google Cloud Console. Available online: https://console.cloud.google.com/marketplace/product/esa-public-data/sentinel2?pli=1 (accessed on 15 June 2023).
- Dutta, S.; Rehman, S.; Chatterjee, S.; Sajjad, H. Chapter 3—Analyzing seasonal variation in the vegetation cover using NDVI and rainfall in the dry deciduous forest region of Eastern India. In Forest Resources Resilience and Conflicts; Kumar Shit, P., Pourghasemi, H.R., Adhikary, P.P., Bhunia, G.S., Sati, V.P., Eds.; Elsevier: Amsterdam, The Netherlands, 2021; pp. 33–48. ISBN 978-0-12-822931-6. [Google Scholar]
- Viana, C.M.; Oliveira, S.; Oliveira, S.C.; Rocha, J. 29—Land Use/Land Cover Change Detection and Urban Sprawl Analysis. In Spatial Modeling in GIS and R for Earth and Environmental Sciences; Pourghasemi, H.R., Gokceoglu, C., Eds.; Elsevier: Amsterdam, The Netherlands, 2019; pp. 621–651. ISBN 978-0-12-815226-3. [Google Scholar]
- Liu, R.; Shang, R.; Liu, Y.; Lu, X. Global evaluation of gap-filling approaches for seasonal NDVI with considering vegetation growth trajectory, protection of key point, noise resistance and curve stability. Remote Sens. Environ. 2017, 189, 164–179. [Google Scholar] [CrossRef]
- Hao, P.; Tang, H.; Chen, Z.; Yu, L.; Wu, M. High resolution crop intensity mapping using harmonized Landsat-8 and Sentinel-2 data. J. Integr. Agric. 2019, 18, 2883–2897. [Google Scholar] [CrossRef]
- Li, L.; Friedl, M.A.; Xin, Q.; Gray, J.; Pan, Y.; Frolking, S. Mapping Crop Cycles in China Using MODIS-EVI Time Series. Remote Sens. 2014, 6, 2473–2493. [Google Scholar] [CrossRef]
- Sruthi, E.R. Understand Random Forest Algorithms with Examples (Updated 2023). Analytics Vidhya. 17 June 2021. Available online: https://www.analyticsvidhya.com/blog/2021/06/understanding-random-forest/ (accessed on 16 June 2023).
- Seif, G. A Beginner’s Guide to XGBoost. Available online: https://towardsdatascience.com/a-beginners-guide-to-xgboost-87f5d4c30ed7 (accessed on 15 June 2023).
- LSTM|Introduction to LSTM|Long Short Term Memory Algorithms. Available online: https://www.analyticsvidhya.com/blog/2021/03/introduction-to-long-short-term-memory-lstm/ (accessed on 15 June 2023).
- Cornegruta, S.; Bakewell, R.; Withey, S.; Montana, G. Modelling Radiological Language with Bidirectional Long Short-Term Memory Networks. arXiv 2016, arXiv:1609.08409. [Google Scholar] [CrossRef]
- Pawar, R. k-NN based Time Series Classification. Available online: https://towardsdatascience.com/k-nn-based-time-series-classification-e5d761d01ea2 (accessed on 15 June 2023).
- Sole, X.; Ramisa, A.; Torras, C. Evaluation of Random Forests on large-scale classification problems using a Bag-of-Visual-Words representation. In Artificial Intelligence Research and Development; IOS Press: Amsterdam, The Netherlands, 2014; pp. 273–276. [Google Scholar]
- Gold, O.; Sharir, M. Dynamic Time Warping and Geometric Edit Distance: Breaking the Quadratic Barrier. ACM Trans. Algorithms 2018, 14, 1–17. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Mozambique | Sudan | Iran | Sri-Lanka |
|---|---|---|---|---|
| Random Forest | 0.74 | 0.84 | 0.92 | 0.86 |
| XGBoost | 0.82 | 0.92 | 0.92 | 0.88 |
| LSTM | 0.82 | 0.84 | 0.96 | 0.90 |
| Bidirectional LSTM | 0.80 | 0.90 | 0.98 | 0.80 |
| Model | Mozambique | Sudan | Iran | Sri-Lanka |
|---|---|---|---|---|
| Random Forest | 0.87 | 0.86 | 0.803 | 0.95 |
| XGBoost | 0.92 | 0.83 | 0.803 | 0.94 |
| LSTM | 0.75 | 0.92 | 0.80 | 0.92 |
| Model | Average Inference Time (Seconds) |
|---|---|
| Random Forest | 49 |
| XGBoost | 269 |
| LSTM | 6259 |
| Bi-LSTM | 12,518 |
| KNN DTW | 40,065 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hussain, M.H.; Abuhani, D.A.; Khan, J.; ElMohandes, M.; Zualkernan, I.; Ali, T. A Light-Weight Cropland Mapping Model Using Satellite Imagery. Sensors 2023, 23, 6729. https://doi.org/10.3390/s23156729
Hussain MH, Abuhani DA, Khan J, ElMohandes M, Zualkernan I, Ali T. A Light-Weight Cropland Mapping Model Using Satellite Imagery. Sensors. 2023; 23(15):6729. https://doi.org/10.3390/s23156729
Chicago/Turabian StyleHussain, Maya Haj, Diaa Addeen Abuhani, Jowaria Khan, Mohamed ElMohandes, Imran Zualkernan, and Tarig Ali. 2023. "A Light-Weight Cropland Mapping Model Using Satellite Imagery" Sensors 23, no. 15: 6729. https://doi.org/10.3390/s23156729
APA StyleHussain, M. H., Abuhani, D. A., Khan, J., ElMohandes, M., Zualkernan, I., & Ali, T. (2023). A Light-Weight Cropland Mapping Model Using Satellite Imagery. Sensors, 23(15), 6729. https://doi.org/10.3390/s23156729