Abstract
Applying the Skip-gram to graph representation learning has become a widely researched topic in recent years. Prior works usually focus on the migration application of the Skip-gram model, while Skip-gram in graph representation learning, initially applied to word embedding, is left insufficiently explored. To compensate for the shortcoming, we analyze the difference between word embedding and graph embedding and reveal the principle of graph representation learning through a case study to explain the essential idea of graph embedding intuitively. Through the case study and in-depth understanding of graph embeddings, we propose Graph Skip-gram, an extension of the Skip-gram model using graph structure information. Graph Skip-gram can be combined with a variety of algorithms for excellent adaptability. Inspired by word embeddings in natural language processing, we design a novel feature fusion algorithm to fuse node vectors based on node vector similarity. We fully articulate the ideas of our approach on a small network and provide extensive experimental comparisons, including multiple classification tasks and link prediction tasks, demonstrating that our proposed approach is more applicable to graph representation learning.
1. Introduction
As the application of graph representation learning in the real world continues, an increasing number of networks without node labels/attributes are emerging. However, these networks are challenging to configure node labels/attributes, such as online shopping platform networks and wireless sensor networks for interpersonal communication involving personal private information. Learning node features in networks with only node link information are receiving increasing attention.
Word2vec [1] is a language model in natural language processing (NLP), including the CBOW (Continuous Bag of Words) [1] model and the Skip-gram [1] model, learning two sets of vector representations of each word from the corpus by unsupervised learning. Inspired by word vector representations, Skip-gram has gained widespread attention for migrating applications in graph representation learning. With the publication of representative research results, such as DeepWalk and node2vec, researchers have developed dozens of models based on Skip-gram with different architectures in just a few years. These creative studies demonstrate that word2vec is a landmark work.
However, despite so much relevant work in graph embedding, existing studies based on the Skip-gram model do not consider the differences between graph embedding and word embedding. In word embedding, the words around the central word (within the window) are sampled, forming a training pair with the central word. Similar to word embedding, graph embedding generates training node pairs through random walks between nodes. However, in the generation of the training set by random walks and the migration application of the Skip-gram model, the degree of nodes and the shortest path length between nodes are not considered. In large corpora, the most common words (e.g., “in”, “the”, and “a”) often do not provide as much information value as the rare words [2]. However, the most common nodes in the network are those containing more connected edges (expressed by node degree), are located at the center of the network, and are crucial for learning node feature representations, as we show in the subsequent application section. For example, the nodes around the hub nodes are more likely to belong to the same class. In generating training node pairs by random walks, the location information between node pairs is ambiguous and does not fully reflect the location relationship between nodes. The existence of these differences means the Skip-gram model only partially uses the structural information implied in the network.
Compared with word embedding in NLP, graph embedding has more application scenarios, such as the Internet of Things (IoT) [3], social networks [4], and traffic forecasting [5]. In recent years, many application scenarios have required machine learning algorithms to assist in decision-making, it is an urgent need to “explain” why they obtained this result and how they proceed, leading to an increased focus on graph representation learning in interpretability studies. Therefore, interpretability studies on the Skip-gram model are very popular, such as word2vec Explained [6], NetMF [7], MCNS [8], and other related works that have theoretically investigated Skip-gram models in depth.
Although there are many works for learning node feature representation based on the Skip-gram model, no work intuitively explains the reasons for high-quality node feature generation. Visualizing the workflow of an algorithm through a case study can be very helpful in understanding the nature of the algorithmic idea [9]. It is essential to deepen researchers’ understanding of Skip-gram through a simple case study.
In the NLP field, the difference between input and output embedding of words has gained a deeper understanding. By default, word2vec discards output embeddings at the end of the training, leaving only input embeddings. In word representation learning using the Skip-gram model, the input embedding is slightly better than the output embedding [10], and the input and output embedding are similar. By visual analysis of the feature representation in the cases and the experimental results, DESM [11] shows that combining input and output embeddings in an information retrieval task outperforms using input embeddings alone.
Inspired by research on input–output embeddings of the word, we consider whether graph embedding have similar properties and whether higher-quality node features can be gained after training.
To alleviate these problems, we first provide an in-depth study of the principle for learning node feature representations based on the Skip-gram model. Through a case study, we show the process of learning node feature representations by the Skip-gram model, explaining the reasons for learning high-quality node feature representations. Benefit from the structural properties of the graph and the scalability of the Skip-gram model, we propose a Graph Skip-gram model more suitable for graph embedding; inspired by the research related to word embedding, we design a feature fusion algorithm to obtain higher quality node feature representations based on the existing two sets of node embeddings.
Specifically, our contributions are the following:
- We use our insights in combination with Skip-gram to propose Graph Skip-gram for graph embedding, which can capture the local and global information of the graph.
- We propose a novel node feature fusion algorithm: selectively fuse the two sets of feature representations generated by the graph embedding.
- Through case studies, we explore the principle of graph embedding and then visualize, analyze, and evaluate our proposed algorithm.
- We evaluate our model on multi-label classification tasks and link prediction tasks with multiple methods and datasets. Experimental results demonstrate that Graph Skip-gram learns the structural properties of the network, and our proposed feature fusion algorithm can effectively improve the quality of node embedding.
The rest of the paper is organized as follows. In Section 2, we discuss related work. In Section 3, we explain the definitions commonly used in this paper. In Section 4, we propose the Graph Skip-gram model and a new feature fusion algorithm. In Section 5, we introduce the application of the algorithm in real-world networks. Firstly, we analyze the process of generating node feature representations via graph embedding; secondly, we briefly describe the idea of our algorithm. In Section 6, we evaluate the Graph Skip-gram model through experiments with multiple methods on multiple datasets. Finally, we conclude our work in Section 7.
2. Related Work
2.1. Graph Embedding and Sensor Networks
Ref. [12] proposes a graph embedding method for solving sensor localization problems using signal strength. GEPM [13] proposes a polynomial mapping-based graph embedding method for localizing unknown nodes in wireless sensor networks. ESTNet [14] proposes an embedded spatial-temporal network using captured sensor information and stacking multiple three-dimensional convolutional units for modeling. GDN [15] proposes a combined structural learning and graph neural network approach to capture inter-sensor relationships for abnormal event detection. G-HAM [16] proposes a hierarchical attention model for human intention recognition, using graph structure to represent spatial information from electroencephalographic (EEG)-based sensors. MOAGE [17] proposes a combined outlook attention and graph embedding approach for traffic prediction tasks.
Graph embedding is widely used in sensor networks and has been used in practical applications in IoT, such as traffic signal control.
2.2. Graph Embedding Based on Skip-Gram Model
DeepWalk [18] uses random walks strategy to sample the target nodes, using the sequence of generated nodes as input to the Skip-gram model. Node2vec [19] designs a flexible and biased random walks strategy based on DeepWalk, integrating BFS (breadth-first search) and DFS (depth-first search) into the random walks process. Walklets [20] optimize DeepWalk’s sampling strategy on large graphs to capture multiple hierarchical relationships of nodes in the network. DP-Worker [21] proposed a degree penalty principle, relating the probability of random walks to the node degree. This category of methods focuses on the study of random walks strategies.
Struct2vec [22] defines vertex similarity in terms of spatial structural similarity. LINE [23] can be viewed as an algorithm for building neighborhoods using BFS. Using the Skip-gram model, Splitter [24] generates multiple vector representations for each node, representing a distinct hierarchical relationship within the community network. SPINE [25] proposed a biased Skip-gram negative sampling method, exploiting the structural similarity between nodes to guide a new positive sampling strategy. Edge2vec [26] embeds the edges in the network by combining deep self-encoders and the Skip-gram model through deep neural networks. CENA [27] proposes a framework for both link prediction and network alignment, utilizing the Skip-gram model and negative sampling techniques to optimize the objective function.
All the above works use the Skip-gram model to learn node feature representations. However, they are insufficiently aware difference between graph and word embedding. We recognize the differences between the two application scenarios and propose Graph Skip-gram for graph embedding.
2.3. Graph Embedding with Matrix Factorization
NetSMF [28] proposes a sparse matrix factorization algorithm for large-scale network embedding, improving the efficiency of graph embedding learning. GraRep [29] uses matrix factorization to solve the network embedding problem, integrating global network structure information while learning the network representation. TADW [30] proves that DeepWalk can be represented through matrix decomposition and proposes a network learning method combining textual information. Implicit SVD [31] devises a framework for computing singular value decomposition of implicitly defined matrices. AGNMF-AN [32] proposed an enhanced graph regularized non-negative matrix factorization method based on attribute networks for community detection.
However, they suffer from high computing power requirements and low performance and are difficult to implement on large networks.
2.4. Theoretical Analysis—Interpretability
Many works have theoretically explained Skip-gram-based graph embedding. For example, SPPMI [33] analyzes the Skip-gram model with negative sampling and shows that it implicitly factorizes a word-context matrix. Watch Your Step [34] proposes a method for automatically selecting parameters for graph embedding models to suit different networks, proving that the DeepWalk learning process is equivalent to matrix decomposition. NetMF [35] proved all negative sampling based [18,19,23,36] can be unified into a matrix factorization framework with closed forms. MCNS [8] theoretically proves negative sampling is equally significant to positive sampling in optimizing the objective function and reducing the variance, proposing a self-contrast approximation to replace the negative sampling strategy.
Although many works have theoretically investigated the application of Skip-gram to graph embedding, none have intuitively explained the reason for node feature generation.
2.5. Deep Learning
In graph representation learning, graph convolutional networks, such as GCN [37], GAT [38], SGC [39], GNN [40], and GraphHeat [41], are widely accepted as mainstream methods. However, their training process often requires additional node attribute information, and training is usually completed under supervised conditions, which is difficult to use in networks without node attributes/labels.
2.6. Feature Fusion in Sensor Networks
CFA [42] proposes a feature selection method based on performance and diversity between two features for detecting stress under certain driving conditions. FGF [43] proposes a feature graph fusion method for robot recognition using RGB and depth information collected by sensors. Grad-CAM++ [44] proposes a feature fusion technique for tool wear monitoring using hierarchical neural network by collecting vibration and sound signals. In [45], Deng et al. proposes a feature selection method based on separability and dissimilarity to enhance odor identification in gas sensor arrays. In [46], Gravina et al. survey discusses current data fusion techniques in body sensor networks and designs a generalized framework for comparison.
The above works have used different techniques to fuse sensor network node information in different scenarios. In this paper, we propose a new idea of feature fusion, using the feature similarity of the network nodes to selectively fuse node information.
2.7. Work in Other Directions
ComE [47] learns node embeddings based on DeepWalk and optimizes them for community detection. GraphSAGE [48] proposes a framework for inductive learning that generates unknown vertex embeddings using attribute information of vertices. WCN [49] proposes a link prediction method based on common neighbors and different types of centrality measures. MS-RPNet [50] proposes a hyperspectral image classification network that hierarchically extracts different spatial information superimposed into multi-scale spatial features. SCAE-MT [51] designs a stacked convolutional self-coding network model to extract deep features of hyperspectral remote sensing images. Some studies, such as SAE [52], DNR [53], and SDNE [54], use autoencoder to embed the network representation. However, these works do not resolve our concerns.
3. Preliminaries
3.1. Notations
Let be a given network, it can be any (un)directed (un)weighted or sensor network, where V represents the members of the network and E their connections, . Let be the mapping function from nodes to feature representations. Here, d is a parameter that specifies the dimension of node feature representation. In practice, f is a matrix of size parameters. Let D denote the degree matrix, where , P denote the node distance matrix, where , is the shortest path length between node u and node n (). For every source node , we define as a network neighborhood of node u, generating through a neighborhood sampling strategy S. Table 1 summarizes the notations and abbreviations frequently used in this paper.

Table 1.
Notations and abbreviations.
3.2. Skip-Gram Model
Given a sequence of words to be used for model training . The objectives of the Skip-gram model is as follows
where w is the word in the given sentence, c is the size of the training context. The basic Skip-gram formulation defines using the softmax function:
Optimizing the above equation using the negative sampling technique, the objective in Equation (2) simplifies as
where and are the “input” and “output” vector representations of w, set the initial value by random initialization. Negative sampling k times per node, where , is noise distribution.
4. The Proposed Methed
Graph embedding is defined as end-to-end learning [34]—first random sampling, then representation learning. We focus on representation learning. In Section 4.1, we propose the Graph Skip-gram model, a graph embedding method for learning graph structural information, capturing local and global information among nodes during graph representation learning, and that can be extended to weighted graphs. In Section 4.2, we propose an algorithm for selectively fusing node features based on the similarity of node vector representations. In Section 4.3, we discuss the complexity of the algorithm.
4.1. Graph Skip-Gram Model
In networks (graphs) without node features, structural information on the graph plays a crucial role in unsupervised learning of node feature representations. Despite the many models proposed, the question remains how to effectively incorporate the structural information of the graph into graph embedding. In this section, we use our insights in combination with Skip-gram to construct a model more appropriate to graph embedding, which we call Graph Skip-gram.
The framework of Graph Skip-gram is shown in Figure 1. In a given graph G, we define the objective of the Graph Skip-gram, which maximizes the log-probability of observing a network neighborhood for a node u conditioned on its feature representation, given by f:
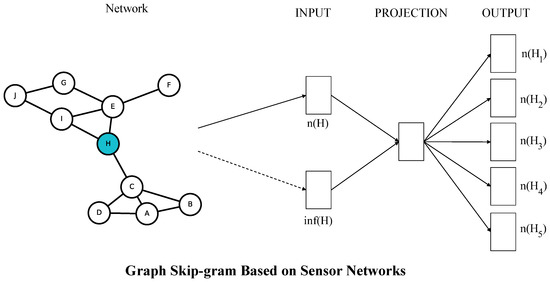
Figure 1.
The framework of the Graph Skip-gram. The Graph Skip-gram predicts surrounding nodes given the current node. The graph structure information around node H is extracted on the graph as inf(H), in sensor networks is available by reading node information, inf(H), and node H as inputs to the model, and the output is the prediction of node H on the surrounding nodes H.
In order to make the optimization problem tractable on the graph, we refer [19] to make two standard assumptions:
- Conditional independence. We factorize the likelihood by assuming that the likelihood of sampling to a neighborhood node is independent of sampling to any other neighborhood node, given the feature representation of the source:
- Symmetry in feature space. In the feature space, a source and neighborhood node have a symmetric influence on each other. Therefore, we model the conditional likelihood of each source-adjacent node pair as the dot product of the softmax unit and the graph structure information function:The dot product of node features parametrizes the softmax unit. We define as the graph structure information function representing the closeness between nodes n, u:(node degree matrix) and (distance matrix between nodes) can both be obtained on the graph. For example, solve the matrix by counting the concatenated edges of the nodes, and solve the matrix using the Dijkstra algorithm. Through the distance information between nodes and the difference in nodes’ degree, the Graph Skip-gram can capture the local and global information of the graph.
As shown in Figure 2a, nodes located at the center of the network (node 1) have more links relative to the edge nodes of the network (nodes 13, 18, 22, 12). We wish to capture this relationship through the difference in node degree and improve the quality of node embedding. Let and be the degrees of node u and node n. We usually define , increase the co-occurrence probability of nodes at different levels of the network and, thus, reduce the intra-class spacing. We define that the co-occurrence probability between two nodes increases with decreasing node spacing, and the value of p is determined by the distance distribution between nodes.
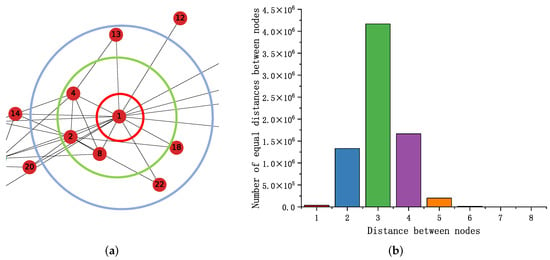
Figure 2.
(a) Take part of the network in karate as an example, the nodes are distributed at different levels. (b) Distance distribution between PPI network nodes.
Setting of parameters p, a: The distribution of distances between nodes in the PPI [55] network is shown in Figure 2b. By observing the distribution of distances between nodes against the Gaussian distribution, setting , make . When the distance distribution is unknown, predict it by random sampling. In general, setting , but when the distribution of numerical terms in the p matrix is not uniform, adjusting a to alleviate the problem of concentrated distribution of distances between nodes; furthermore, we discuss the parameter a in the subsequent experimental section.
The w is a hyperparameter that adjusts the weight between node degree and node distance. In addition, the Graph Skip-gram can be extended to a weighted graph, and the graph structure information is defined as follows:
The is a hyperparameter used to adjust the weight proportion of edges in the weighted graph. denotes the weight of the edge connecting node u to node n.
Define to indicate whether the nodes are reachable:
If , node u is not reachable to node n, let ; if , node u is reachable to node n, let ; if node u is positively sampled (random walks) to node n, then ().
In addition, restrict the range of values of :
4.2. Exploring Two Sets of Node Vector Representations
In the graph embedding approach based on the Skip-gram model, training yields two sets of node vector representations for each node-input and output embedding. Unlike previous work that used one set of embeddings or combined two sets of embeddings, we consider fusing the input and output embeddings of part nodes (Fioepn). Inspired by the similarity of word vectors, we calculate the cosine similarity between the two sets of embeddings for each node, then fuse the embeddings of the nodes with the lowest similarity. In Section 5.2, we introduce this algorithm in a practical application.
The pseudocode for Fioepn is given in Algorithm 1. First, calculate the similarity scores of the input embedding and output embedding of each node (lines 1–3); then sort the similarity scores to obtain the sorted similarity scores (line 4, the scores do not change before and after sorting); then obtain the minimum similarity scores according to the node feature update rate (, line 5); perform feature fusion on partial nodes in lines 6–12; lastly, return the optimized input embedding (line 13).
| Algorithm 1 Embedding Fusion . |
| Input: input embedding f, output embedding , Fioepn ratio p; |
| Output: optimal input embedding |
|
4.3. Complexity Analysis
Solving the implicit information matrix on the graph, the time complexity of the D (degree Matrix) is ; we use the Dijkstra algorithm to solve the matrix P, and the time complexity of solving the matrix P is , the implementation of the Dijkstra algorithm is based on a heap implementation of the priority queue data structure.
Similar to the Skip-gram model, the Graph Skip-gram can use negative sampling and stochastic gradient descent (SGD) for optimization. The time complexity of Equation (10) is , k is the number of negative samples. The time complexity of Fioepn is . The time complexity of Graph Skip-gram is , m is the window size of the Graph Skip-gram model, d is the dimension of embedding.
5. Application of the Method
In this section, we first explain the principle of the Skip-gram model for learning node feature representation through a case study; and then introduce our proposed algorithm analytically through a small network. In sensor networks, the distribution of sensor nodes can be quickly perceived by visualizing the target network with the Graph Skip-gram model.
5.1. Understanding the Node Embedding Process Intuitively
In this section, we use DeepWalk to learn the node features of the Karate network. We refer to the word2vec and DeepWalk code implementations given in [2,56] to give a simplified graph embedding pseudo-code implementation, Algorithms 2 and 3. Referring to the paper [18], we set embedding dimension , windows size , walks per node , walk length , and negative sampling for training.
We counted the number of times each node used as a central word (PosV), surrounding word (PosC), and negative sample word (Neg) during the whole training process. We use the statistical sampling information of each node with the node number (Node) and node degree (Degree) to create a heat map, as shown in Figure 3a; Figure 3b shows the node degree distribution in the karate network. The heat map shows that PosV, PosC, Neg, and Degree are highly correlated, demonstrating sampling frequency of the node is related to the node degree, as introduced in the Section 1, nodes containing more connected edges are critical in learning node feature representation. Figure 4 shows the node features learned at different stages. For example, input embedding in red, output embedding in green, and we highlight the example nodes by deepening the node color.
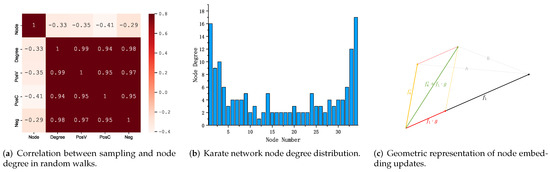
Figure 3.
Sampling analysis: (a,b); visual nodes represent the update process: (c).
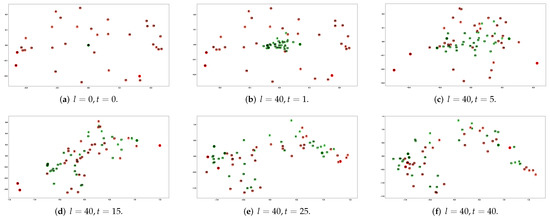
Figure 4.
Visualization of node distribution at different training phases.
Completing the above preparations, let us next explore how Skip-gram works.
In the initial stage of learning, as shown in line 1 of Algorithm 2, it randomly initializes the input embedding parameters while setting all parameters of the output embeddings to zero; as shown in Figure 4a, the input embedding is randomly distributed on the coordinate axes, input embedding overlaps centrally at the coordinate origin. Since the final learned input and output embeddings are similar, initializing the input embeddings by randomization and the output embedding parameters to zero helps to accelerate the training.
We use node 1 as an example node for subsequent study and discussion. When node 1 is the central word (u), used as the sampled node to sample its surrounding nodes (n, node 4, Algorithm 2, line 6). Then invoke Algorithm 3 to update the node feature representation. In Algorithm 3, first, calculate the similarity between the node u’s input embedding and the node n’s output embedding (line 1). Then calculate the gradient according to its positive/negative sample and learning rate (line 2); take positive sampling as an example ( = 1; u = 1, n = 4), the gradient increases as the similarity decreases, gradient value affects the calculated error term. Then update the cumulative error term (line 3). In line 4, update the output embedding. At last, return the cumulative error term (line 5).
| Algorithm 2 Learn Node Feature Repreaution . |
| Input: graph , window size m, embedding size d, walk length t, walks per vertex r, |
| negative sampling k; |
| Output: Output f; |
|
| Algorithm 3 UpdateFeatures (). |
| Input: output embedding , input embedding , : PosSam(1), NegSam(0); |
| Output: Output f; |
|
Viewing the node feature update process from the perspective of geometric representation, which can be intuitively understood as positively sampled nodes approaching the central node (input embedding) along the direction of the approximate central node. As shown in Figure 3c, the output embedding corresponding to node 4 moves along the direction approximating the input embedding of node 1; therefore, the similarity between nodes increases (distance: B < A).
After completing the positive sampling node feature update, perform negative sampling (Algorithm 2, line 8), updating the node features based on the nodes obtained by negative sampling in the same way as the above analysis. In the final stage of completing a round of node sampling updates (Algorithm 2, line 12), the input embedding of the central node (node 1) is updated based on the error term; in the process of calculating the error term, the output embedding of the surrounding nodes and the negative sampling nodes are updated (negative sampling updated along the opposite direction).
Figure 4c shows the node representation after five rounds of training; it is clear that the hub nodes (node 1, node 33, node 34) are further away from the origin relative to their initial positions (both input and output embeddings) because the sampling frequency is related to the node degree; at this stage, the output embedding changes more obviously, they move towards their respective input embedding and away from the origin. Figure 4d shows the node features obtained after 15 training rounds, the hub nodes reach the most edge position of the network. In the next stage, the more significant change in the training node features is the aggregation of the network edge nodes towards the central node (Figure 4e), eventually learning a high-quality node feature representation (Figure 4f or Figure 5b).
Above, we discussed the case of two-dimensional graph embedding. Likewise, it can be extended to the case of three-dimensional or even higher-dimensional.
In brief, the essence of the above process is as follows. The sampled node obtains its surrounding nodes by random sampling, then calculates the gradient based on the similarity of the vector representation between the nodes to update the sampled node’s input embedding and the surrounding node’s output embedding. Analyzing this phenomenon at a geometric level is shown in Figure 3c, which makes the output embeddings of the surrounding nodes closer to the input embeddings of the sampled nodes (distance: B < A); the opposite is true for the node feature update process with negative sampling. Then, obtain two vector representations of each node by multiple sampling updates.
5.2. Graph Skip-Gram and Fioepn
As shown in Figure 5a, we visualized the Karate network using force-directed layouts, classifying the nodes into four classes using modularity-based clustering [57]. We numbered the nodes according to categories for subsequent studies.

Figure 5.
Different methods node embedding visualization.
Figure 5.
Different methods node embedding visualization.

We use the DeepWalk method based on Skip-gram (Figure 5b) and Graph Skip-gram (Figure 5c) to learn the node feature representation of the Karate network, we use the same parameter settings as Section 5.1, in the Graph Skip-gram model, setting the parameter , , . We use Calinski–Harabasz (CH) [58] and within-group cluster sum of squares (WGSS) [58] to evaluate the clustering performance of node features learned from different models.
As shown in Table 2 (first four lines), compared to the Skip-gram, the Graph Skip-gram has a 5% improvement in CH score, and the WGSS scores indicate the effect of intra-class clustering achieves performance gains in three of the four classes. The light-colored points in Figure 5b are input embeddings, and the dark-colored points are output embeddings. In Figure 5d, we show the node feature representation after updating 50% of the nodes using the Fioepn algorithm; obviously, the third and fourth-class clustering effect is improved. Table 2 (bottom six lines) compares the WGSS scores between the different categories; using the Fioepn algorithm, the WGSS(3) score improves by 69%.
Table 2.
The clustering performance of Graph Skip-gram model and Fioepn algorithm.
The above node visualization and experimental analysis of the clustering effect clarify the idea of Graph Skip-gram and Fioepn: more effective use of graph structure information and input and output embeddings. It also demonstrates the effectiveness of Graph Skip-gram and Fioepn.
6. Experiments
6.1. Experimental Setup
6.1.1. Environment
We completed all experiments on a desktop PC with a hexa-core Intel i5 3.00 GHz processor and 32GB of RAM. The operating system is Ubuntu 16.04 and Windows 10. Training of the DeepWalk, node2vec, Walklets, and TADW was run in Ubuntu 16.04, and the training of other models and related experimental evaluations was run in Windows 10.
6.1.2. Datasets
We use four datasets to evaluate the performance of Graph Skip-gram and Fioepn, and Table 3 gives the relevant statistics about the datasets.
Table 3.
Statistics of the datasets.
- BlogCatalog [59]: this dataset is a social network that consists of the blogger and their social connections (e.g., friends).
- Wikipedia [60]: this is a co-occurrence network of words.
- PPI [55]: this is a subgraph of the protein–protein interaction network for Homo Sapiens.
- Flickr [61]: this is a social network where nodes represent users and edges correspond to user friendships.
Note that, like the datasets used for the experiments in paper [18,19], the above four datasets do not contain node attribute information, and some of the nodes have multiple labels. These conditions are unfavorable for training neural network-based graph embedding methods, and we give the solution in the following method introduction.
6.1.3. Method
Eight graph representations learning methods are used as baselines in the experiments.
- TADW [30]: a matrix factorization-based method that uses semantic information to improve the quality of node embedding.
- GCN [37]: a convolutional neural network that applies directly on graphs and uses their structural information.
- GAT [38]: to alleviate the two drawbacks of GCNs, proposing to incorporate attention mechanisms into spatial GCNs to provide differentiated weights for neighborhoods.
- GraphSAGE [48]: it proposes a generalized induction framework that uses node feature information to generate node embeddings on the graph.
- ACMP [62]: it introduces the Allen–Cahn message passing mechanism in GNN, a deep GNN model that avoids the oversmoothing problem of GNN.
- DeepWalk [18]: it is based on Skip-gram and uses random walks to generate node pairs for training node feature representation.
- Node2vec [19]: based on DeepWalk, it proposes a biased random walks strategy that combines the search strategies of BFS and DFS properties.
- Walklets [20]: it optimizes DeepWalk’s sampling strategy on large graphs, capturing multiple hierarchical relationships of nodes in the network.
We refer to the code implementation of DeepWalk and node2vec in [56]. The source code for the other six approaches can be found in the relevant Github projects.
Since the dataset used in this experiment has no node features, the node feature matrix used in the TADW, GCN, GAT, GraphSAGE, and ACMP uses the degree matrix instead; among the four methods, only the TADW method performs training in an unsupervised manner. Following the principle of randomness, we extract single-label nodes from the above four datasets and use them for training the GCN, GAT, GraphSAGE, and ACMP in a supervised manner. The training, validation, and test sets are divided 6:2:2, respectively, and save the best performance results for subsequent performance evaluation. The node vectors obtained from TADW, GCN, GAT, GraphSAGE, and ACMP are evaluated for multi-label classification and link prediction performance using the same evaluation scheme as DeepWalk, node2vec, and Walklets.
We use Graph Skip-gram and Skip-gram to learn node feature representations in standard unsupervised learning tasks. For all methods based on Graph Skip-gram and Skip-gram, we refer to [18,19,20], set the embedding dimension , default learning rate as 0.025. In the optimization phase, all methods are optimized using negative sampling and SGD, learning the feature representation with four threads. For DeepWalk and node2vec, we refer to the experimental setup in [19], set windows size , walks per node , walk length , negative sampling ; p and q in node2vec are searched over . Walklets focus on capturing information at different scales in the graph; we refer to the experimental setup from [20], set walks per node , walk length , negative sampling , (skip factor) in are searched over .
6.2. Multi-Label Classification
Section 6.2.1 evaluates Graph Skip-gram’s performance by adjusting the walk length t and comparing it with Skip-gram. Section 6.2.2 analyzes the performance of Graph Skip-gram by comparing multiple methods.
We use the same experimental procedure listed in [18] to evaluate the performance of the methods. We use different proportions of randomly selected nodes for training the linear classifier and use the rest for testing. We repeated the experiment 10 times, randomly sampling the training and test nodes each time and reporting the average Micro-F1 for all methods. We do not include results for other evaluation metrics, such as precision and recall, because they all follow the same trend. We use BlogCatalog, Wikipedia, PPI, and Flickr datasets for the multi-label classification task. Referring to the performance in [18], we treat all the datasets as undirected graphs.
The settings of the different methods in the experimental results are as follows. For example, DeepWalk uses Skip-gram as the base model for feature representation learning; DeepWalk* uses Graph Skip-gram as the base model for feature representation learning; DeepWalk** uses Graph Skip-gram as the base model for feature representation learning, using Fioepn optimized input embedding. Set all datasets input–output embedding vector fusion ratio .
6.2.1. Performance Comparison between Graph Skip-Gram and Skip-Gram
Because of the different training methods of DeepWalk, node2vec and Walklets, and the readability of the experimental results, the experimental results in this subsection are presented and analyzed in two groups. Figure 6 and Figure 7 shows the performance comparison of Graph Skip-gram and Skip-gram at different walk lengths t.
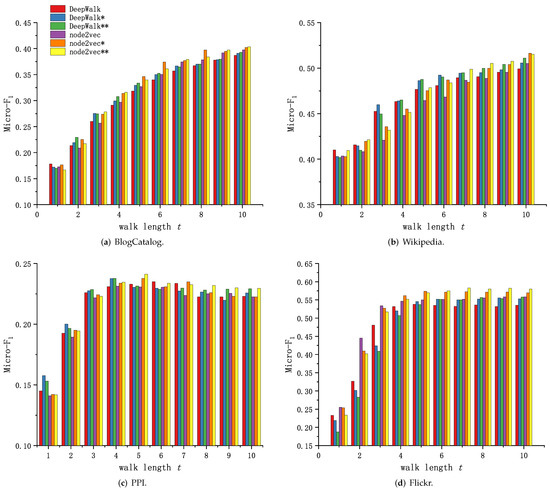
Figure 6.
Graph Skip-gram vs. Skip-gram based on DeepWalk and node2vec.
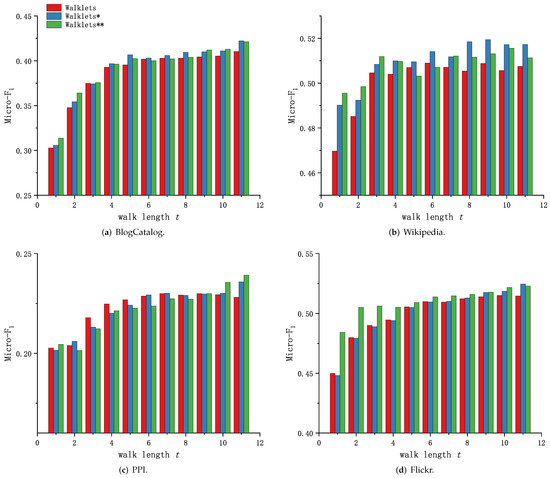
Figure 7.
Graph Skip-gram vs. Skip-gram based on Walklets.
As shown in Figure 6a and Figure 7a, the method based on Graph Skip-gram shows performance advantages as the walk length t increases (), consistently outperforming the method based on Skip-gram during the training process, demonstrating the Graph Skip-gram model captures the graph structure information and improves the quality of node feature representation. As shown in Figure 6b and Figure 7b, the performance of the methods based on Graph Skip-gram and Fiopen steadily improves with increasing t and consistently outperforms the methods based on Skip-gram, demonstrating that fusing some of the node features helps to obtain higher-quality node features. As shown in Figure 6c, as the walk length t increases, the performance of all of the methods rise first and then fall, but the methods based on Graph Skip-gram and Fiopen consistently outperform those based on Skip-gram.
Figure 6d and Figure 7c show similar performance trends. The methods based on Graph Skip-gram have weak performance when the walk length t is small. This is because Graph Skip-gram captures the graph structure properties when the number of training rounds (t) is small, which makes the node vector update less frequently (Figure 3c) and the same class of nodes is poorly aggregated; as the walk length t increases, the ability of Graph Skip-gram to capture the characteristics of graph structure begins to manifest, making the node vector representation more differentiated across categories, gained an advantage at walk length (Figure 6d) and staying ahead.
We observe in each dataset that node2vec has improved performance compared to DeepWalk when using different search strategies (node2vec: ; DeepWalk: ). Similarly, experiments demonstrate that our proposed Graph Skip-gram compensates for the defects of random walks, and DeepWalk* using the Graph Skip-gram achieves performance not inferior to node2vec. This conclusion also holds for the Walklets (Figure 7) method.
6.2.2. Graph Skip-Gram versus Multiple Methods
In this section, we explore the performance of Graph Skip-gram by comparing multiple methods. We summarize the results of the experiment in Table 4. We increase the training rate of each network from 10% to 90%. The hyperparameter settings for Graph Skip-gram in each dataset are indicated in Table 4.
Table 4.
Multi-label classification results in terms of Micro-F (%).
Figure 8 shows the distribution of P matrix values in the Wikipedia and Flickr datasets. In the Wikipedia dataset (Figure 8a), the distribution of values in the P matrix is concentrated, with accounting for 95.7% and for 3.5%; we set to adjust the distance information function between nodes so that Graph Skip-gram can better capture the structural information of the graph. A similar situation occurs in the Flickr dataset (Figure 8b), where we adjust .
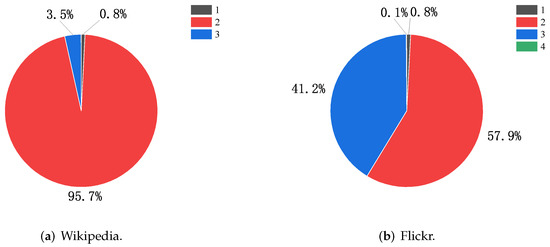
Figure 8.
Distribution of numerical entries in the P matrix for the Wikipedia and Flickr datasets.
From the results shown in Table 4, it is clear that the combination of Graph Skip-gram and Fioepn outperforms Skip-gram and TADW on each dataset. GCN, GAT, GraphSAGE, and ACMP are trained in a supervised manner, and only GCN achieves a performance advantage in the PPI dataset where Graph Skip-gram performs poorly, but Graph Skip-gram is trained in an unsupervised manner. The performance of TADW, GCN, GAT, GraphSAGE, and ACMP failed to achieve satisfactory prediction performance in networks without node features, and the performance gap between them and Graph Skip-gram methods is large.
The results of evaluation experiments on the BlogCatalog dataset show that GraphSAGE—the best performing of the five methods (TADW, GCN, GAT, GraphSAGE, and ACMP)—has a 17% performance gap compared to Walklets* (training rate: 0.9).
In the Wikipedia dataset, the performance of the above five methods is similar, but lower performance than Walklets*. In the Flickr dataset, the performance difference between GCN and node2vec** is as high as 18.44% (training rate: 0.9). This phenomenon is broken by GCN in the PPI dataset, where the Graph Skip-gram model performs poorly, but the performance of the other three methods is still inferior to Graph Skip-gram. Obviously, it is difficult for models based on graph neural networks to gain an advantage in networks without node attributes. In contrast, Graph Skip-gram model do not use node attributes, and training is unsupervised. Our proposed Graph Skip-gram and Fioepn show surprising results on the Flickr dataset with DeepWalk and node2vec algorithms, achieving 3.54% (DeepWalk**) and 2.97% (node2vec**) improvement at a training rate of 0.1, and ahead of GCN by 14.05% and 16.31%, respectively. On the Wikipedia dataset, the Graph Skip-gram model-based method (node2vec*, Walklets*) improves by 1.12% and 0.98% compared to node2vec and Walklets at a training rate of 0.9, and significantly better than the above five methods. These experimental results demonstrate that Graph Skip-gram learns graph structure information and is more suitable for graph embedding than Skip-gram; the Fioepn algorithm can improve the quality of node embedding.
6.3. Parameter Sensitivity
We analyze the sensitivity of parameters and a on the Flickr and Wikipedia datasets (training rates are 30% and 90%, respectively), using node2vec as the base method. We do not show sensitivity analysis of parameters based on other models and datasets, such as DeepWalk* and DeepWalk** on different datasets, because they all follow similar trends.
Figure 9 shows the sensitivity of the parameters based on the Flickr and Wikipedia datasets. Figure 9a,d show the effect of the parameter w on the Micro-F score, and both datasets’ optimal w values exist. Referring to Equation (7) demonstrates that adjusting the co-occurrence probability of nodes at different levels can improve the quality of node embedding. The problem of uneven distribution of P matrix data items in Figure 8a can be alleviated by adjusting the parameter a, as shown in Figure 9e, obtaining the best performance when . Figure 9f shows the performance obtained by adjusting the node vector fusion rate in the Wikipedia dataset fluctuates as the fusion rate changes. Figure 9c shows how the value of p affects the performance; a 2% performance improvement can be gained by properly setting the parameter p, demonstrating the effectiveness of the Fioepn algorithm in optimizing node embedding.
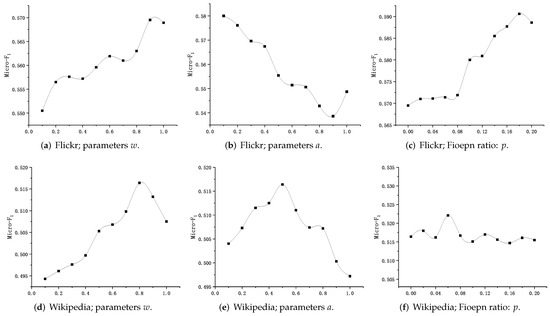
Figure 9.
Impact of hyperparameters and Fioepn ratio on the performance of the proposed method.
Through the experimental analysis, we can see that the parameter settings have an impact on the performance of our model, and proper setting of parameters helps to gain better performance.
6.4. Link Prediction
Determining if a link exists between two network nodes is known as link prediction. We used the same experimental procedures listed in [19] to evaluate the link prediction performance of the different methods. We randomly remove some edges from the network and ensure the remaining network is still connected. We sample positive and negative training samples in the network according to the following rules. We randomly sample pairs of nodes with connected edges in the network as positive samples; we randomly generate pairs of nodes and ensure that they have no connected edges as negative samples.
We test the performance of the Graph Skip-gram against the link prediction task using the Flickr, Wikipedia, and PPI datasets introduced in the Section 6.1.2. We train a logistic regression classifier on the edgewise features obtained with the method shown in Table 5. For example, for a pair of nodes u and , the average operator generates a vector as the link between that pair of nodes.
Table 5.
Vector operators used for link-prediction task for each .
6.5. Experimental Results
We summarize the results for link prediction in Table 6. We use the node feature representations generated in the previous section for this task, which fully demonstrates the adaptability and scalability of our method.
Table 6.
Link prediction results (%).
As shown in Table 6, TADW, GCN, GAT, and GraphSAGE have no advantage in the link prediction task if the network is without node attributes. For example, in the Wikipedia dataset, GAT has the best performance among the four methods, with an accuracy of 83.5% under the Weighted L1 operator, but still has a 13% performance gap compared to Walklets**.
The ACMP approach outperforms the previous four approaches on the Flickr dataset, achieving optimal performance for link prediction under all four operations, outperforming the method based on Graph Skip-gram in link prediction under the Hadamard operation; however, there is a 15.6% and 15.8% performance gap with Walklets** under Weighted L1 and Weighted L2 operator.
In the Wikipedia dataset, node2vec* gains 3.1% performance gains over node2vec under the Weighted L1 operator; node2vec* gains 3.0% performance gains over node2vec under the Weighted L2 operator. Similar performance gains are observed on the PPI and Flickr datasets, demonstrating that Graph Skip-gram learns graph structure information.
What is interesting is the performance of the Fioepn algorithm. For example, in the PPI dataset, DeepWalk** gains 5.4% and 8.1% performance gains over DeepWalk* and DeepWalk under the Weighted L1 operator; node2vec** gains 6.9% and 9% performance gains over node2vec* and node2vec under the Weighted L2 operator. There are similar results in the Wikipedia and Flickr datasets. In conclusion, our proposed Graph Skip-gram and Fioepn outperform Skip-gram on the Weighted L1 and Weighted L2 operators. This demonstrates that the fusion of partial node features helps to improve the link prediction accuracy.
7. Conclusions
Through an in-depth analysis of the differences between word embeddings and graph embeddings, we propose Graph Skip-gram, capturing local and global information of graphs through graph structure information functions, making Skip-gram more appropriate for graph embedding; inspired by word vector similarity, we devise a new input–output fusion embedding mechanism, Fioepn, which determines whether to use feature representation fusion by calculating the cosine similarity between the input–output embeddings. Through the case study, we give an intuitive understanding of graph embedding, which facilitates the understanding of the nature of graph embedding; we give a visualization of the node features learned by Graph Skip-gram and Fioepn, it is advantageous for quickly perceiving the distribution of nodes in a sensor network; by evaluating the effect of clustering, the ideas of the algorithm are further clarified.
Experimental results on multi-label classification and link prediction with multiple models and datasets demonstrate that Graph Skip-gram, which learns node features unsupervised, has significant advantages in networks without node attributes, and our proposed Graph Skip-gram and Fioepn are more suitable for graph embedding compared to Skip-gram. Our method uses the position information between nodes during training, which will increase the training time; we preprocess the node information needed for model training before model training, avoiding the repeated solving of node information and improving the training efficiency.
Our future work will focus on two directions: (1) Graph Skip-gram models are trained in an unsupervised manner, whereas methods based on graph neural networks often require partially labeled data for training; whether it is possible to devise an approach to establish a link between the both so that methods based on graph neural networks can be trained in an unsupervised manner. (2) Graph neural network models are usually trained using the node feature matrix for training, whether better model performance can be obtained using the inter-node distance matrix.
Author Contributions
X.W.: Conceptualization, methodology, software, investigation, resources, data curation, validation, visualization, writing—original draft preparation; H.Z. and H.C.: writing—review and editing, supervision, project administration, funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by: the Natural Science Foundation of Sichuan Province under Grant 2022NSFSC0536.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Dong, G.; Tang, M.; Wang, Z.; Gao, J.; Guo, S.; Cai, L.; Gutierrez, R.; Campbel, B.; Barnes, L.E.; Boukhechba, M. Graph neural networks in IoT: A survey. ACM Trans. Sens. Netw. 2023, 19, 1–50. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, L.; Wei, W.; Fan, J. Network representation learning: From preprocessing, feature extraction to node embedding. ACM Comput. Surv. (CSUR) 2022, 55, 1–35. [Google Scholar] [CrossRef]
- Jiang, W.; Luo, J. Graph neural network for traffic forecasting: A survey. Expert Syst. Appl. 2022, 207, 117921. [Google Scholar] [CrossRef]
- Goldberg, Y.; Levy, O. word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722. [Google Scholar]
- Qiu, J.; Dong, Y.; Ma, H.; Li, J.; Wang, K.; Tang, J. Network embedding as matrix factorization: Unifying deepwalk, line, pte, and node2vec. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Los Angeles, CA, USA, 9 February 2018; pp. 459–467. [Google Scholar]
- Yang, Z.; Ding, M.; Zhou, C.; Yang, H.; Zhou, J.; Tang, J. Understanding negative sampling in graph representation learning. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtually, 23–27 August 2020; pp. 1666–1676. [Google Scholar]
- Futschek, G. Algorithmic thinking: The key for understanding computer science. In Proceedings of the International Conference on Informatics in Secondary Schools-Evolution and Perspectives, Vilnius, Lithuania, 7–11 November 2006; Springer: Berlin/Heidelberg, Germany; pp. 159–168. [Google Scholar]
- Press, O.; Wolf, L. Using the Output Embedding to Improve Language Models. EACL (2). arXiv 2017, arXiv:1608.05859. [Google Scholar]
- Mitra, B.; Nalisnick, E.; Craswell, N.; Caruana, R. A dual embedding space model for document ranking. arXiv 2016, arXiv:1602.01137. [Google Scholar]
- Wang, C.; Chen, J.; Sun, Y.; Shen, X. A graph embedding method for wireless sensor networks localization. In Proceedings of the GLOBECOM 2009-2009 IEEE Global Telecommunications Conference, IEEE, Honolulu, HI, USA, 30 November–4 December 2009; pp. 1–6. [Google Scholar]
- Xu, H.; Sun, H.; Cheng, Y.; Liu, H. Wireless sensor networks localization based on graph embedding with polynomial mapping. Comput. Netw. 2016, 106, 151–160. [Google Scholar] [CrossRef]
- Luo, G.; Zhang, H.; Yuan, Q.; Li, J.; Wang, F.Y. ESTNet: Embedded spatial-temporal network for modeling traffic flow dynamics. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19201–19212. [Google Scholar] [CrossRef]
- Deng, A.; Hooi, B. Graph neural network-based anomaly detection in multivariate time series. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 4027–4035. [Google Scholar]
- Zhang, D.; Yao, L.; Chen, K.; Wang, S.; Haghighi, P.D.; Sullivan, C. A graph-based hierarchical attention model for movement intention detection from EEG signals. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 2247–2253. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Liu, Y.; Gui, Y.; Ruan, C. An Improved Model Combining Outlook Attention and Graph Embedding for Traffic Forecasting. Symmetry 2023, 15, 312. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Perozzi, B.; Kulkarni, V.; Chen, H.; Skiena, S. Do not walk, skip! online learning of multi-scale network embeddings. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Sydney, Australia, 31 July–3 August 2017; pp. 258–265. [Google Scholar]
- Feng, R.; Yang, Y.; Hu, W.; Wu, F.; Zhang, Y. Representation Learning for Scale-Free Networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ribeiro, L.F.; Saverese, P.H.; Figueiredo, D.R. struc2vec: Learning node representations from structural identity. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 385–394. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Epasto, A.; Perozzi, B. Is a single embedding enough? learning node representations that capture multiple social contexts. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 394–404. [Google Scholar]
- Guo, J.; Xu, L.; Liu, J. SPINE: Structural Identity Preserved Inductive Network Embedding. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 2399–2405. [Google Scholar]
- Wang, C.; Wang, C.; Wang, Z.; Ye, X.; Yu, P.S. Edge2vec: Edge-based social network embedding. ACM Trans. Knowl. Discov. Data (TKDD) 2020, 14, 1–24. [Google Scholar] [CrossRef]
- Du, X.; Yan, J.; Zha, H. Joint Link Prediction and Network Alignment via Cross-graph Embedding. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 2251–2257. [Google Scholar]
- Qiu, J.; Dong, Y.; Ma, H.; Li, J.; Wang, C.; Wang, K.; Tang, J. Netsmf: Large-scale network embedding as sparse matrix factorization. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1509–1520. [Google Scholar]
- Cao, S.; Lu, W.; Xu, Q. Grarep: Learning graph representations with global structural information. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 891–900. [Google Scholar]
- Yang, C.; Liu, Z.; Zhao, D.; Sun, M.; Chang, E. Network representation learning with rich text information. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Abu-El-Haija, S.; Mostafa, H.; Nassar, M.; Crespi, V.; Ver Steeg, G.; Galstyan, A. Implicit SVD for Graph Representation Learning. Adv. Neural Inf. Process. Syst. 2021, 34, 8419–8431. [Google Scholar]
- Berahmand, K.; Mohammadi, M.; Saberi-Movahed, F.; Li, Y.; Xu, Y. Graph regularized nonnegative matrix factorization for community detection in attributed networks. IEEE Trans. Netw. Sci. Eng. 2022, 33, 1548–1560. [Google Scholar] [CrossRef]
- Levy, O.; Goldberg, Y. Neural word embedding as implicit matrix factorization. Adv. Neural Inf. Process. Syst. 2014, 27, 2177–2185. [Google Scholar]
- Abu-El-Haija, S.; Perozzi, B.; Al-Rfou, R.; Alemi, A.A. Watch your step: Learning node embeddings via graph attention. Adv. Neural Inf. Process. Syst. 2018, 31, 9198–9208. [Google Scholar]
- Qu, M.; Tang, J.; Shang, J.; Ren, X.; Zhang, M.; Han, J. An attention-based collaboration framework for multi-view network representation learning. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1767–1776. [Google Scholar]
- Tang, J.; Qu, M.; Mei, Q. Pte: Predictive text embedding through large-scale heterogeneous text networks. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1165–1174. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying graph convolutional networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6861–6871. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef]
- Xu, B.; Shen, H.; Cao, Q.; Cen, K.; Cheng, X. Graph convolutional networks using heat kernel for semi-supervised learning. arXiv 2020, arXiv:2007.16002. [Google Scholar]
- Deng, Y.; Wu, Z.; Chu, C.H.; Zhang, Q.; Hsu, D.F. Sensor feature selection and combination for stress identification using combinatorial fusion. Int. J. Adv. Robot. Syst. 2013, 10, 306. [Google Scholar] [CrossRef]
- Liu, S.; Sun, M.; Huang, X.; Wang, W.; Wang, F. Feature fusion using Extended Jaccard Graph and word embedding for robot. Assem. Autom. 2017, 37, 278–284. [Google Scholar] [CrossRef]
- Lin, Y.R.; Lee, C.H.; Lu, M.C. Robust tool wear monitoring system development by sensors and feature fusion. Asian J. Control. 2022, 24, 1005–1021. [Google Scholar] [CrossRef]
- Deng, C.; Lv, K.; Shi, D.; Yang, B.; Yu, S.; He, Z.; Yan, J. Enhancing the discrimination ability of a gas sensor array based on a novel feature selection and fusion framework. Sensors 2018, 18, 1909. [Google Scholar] [CrossRef] [PubMed]
- Gravina, R.; Alinia, P.; Ghasemzadeh, H.; Fortino, G. Multi-sensor fusion in body sensor networks: State-of-the-art and research challenges. Inf. Fusion 2017, 35, 68–80. [Google Scholar] [CrossRef]
- Cavallari, S.; Zheng, V.W.; Cai, H.; Chang, K.C.C.; Cambria, E. Learning community embedding with community detection and node embedding on graphs. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 377–386. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1025–1035. [Google Scholar]
- Nasiri, E.; Berahmand, K.; Samei, Z.; Li, Y. Impact of centrality measures on the common neighbors in link prediction for multiplex networks. Big Data 2022, 10, 138–150. [Google Scholar] [CrossRef]
- Chen, H.; Wang, T.; Chen, T.; Deng, W. Hyperspectral Image Classification Based on Fusing S3-PCA, 2D-SSA and Random Patch Network. Remote Sens. 2023, 15, 3402. [Google Scholar] [CrossRef]
- Chen, H.; Chen, Y.; Wang, Q.; Chen, T.; Zhao, H. A New SCAE-MT Classification Model for Hyperspectral Remote Sensing Images. Sensors 2022, 22, 8881. [Google Scholar] [CrossRef]
- Tian, F.; Gao, B.; Cui, Q.; Chen, E.; Liu, T.Y. Learning deep representations for graph clustering. In Proceedings of the AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Yang, L.; Cao, X.; He, D.; Wang, C.; Wang, X.; Zhang, W. Modularity based community detection with deep learning. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI, New York, NY, USA, 9–15 July 2016; Volume 16, pp. 2252–2258. [Google Scholar]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar]
- Breitkreutz, B.J.; Stark, C.; Reguly, T.; Boucher, L.; Breitkreutz, A.; Livstone, M.; Oughtred, R.; Lackner, D.H.; Bähler, J.; Wood, V.; et al. The BioGRID interaction database: 2008 update. Nucleic Acids Res. 2007, 36, D637–D640. [Google Scholar] [CrossRef] [PubMed]
- Tsitsulin, A.; Mottin, D.; Karras, P.; Müller, E. Verse: Versatile graph embeddings from similarity measures. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 539–548. [Google Scholar]
- Brandes, U.; Delling, D.; Gaertler, M.; Gorke, R.; Hoefer, M.; Nikoloski, Z.; Wagner, D. On modularity clustering. IEEE Trans. Knowl. Data Eng. 2007, 20, 172–188. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun.-Stat.-Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Zafarani, R.; Liu, H. Social computing data repository at ASU. 2009.
- Mahoney, M. Large Text Compression Benchmark. 2011. Available online: www.mattmahoney.net/dc/textdata (accessed on 3 March 2022).
- Huang, X.; Li, J.; Hu, X. Label informed attributed network embedding. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 731–739. [Google Scholar]
- Wang, Y.; Yi, K.; Liu, X.; Wang, Y.G.; Jin, S. ACMP: Allen-cahn message passing with attractive and repulsive forces for graph neural networks. In Proceedings of the Eleventh International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).