
Adaptive Resolution Enhancement for Visual Attention Regions Based on Spatial Interpolation
 ,
,
Abstract
1. Introduction
- (1)
- An adaptive spatial resolution improvement algorithm is proposed, which uses the traditional interpolation algorithm. The algorithm achieves better performance and reduces the computation.
- (2)
- Contrast enhancement and sharpening are carried out to further improve the visual effect of the image after the over-division.
- (3)
- The super-resolution algorithm is combined with eye movement information, and the resolution of the visual attention area is improved, which improves the visual experience of human–computer interaction.
- (4)
- This algorithm adopts a non-deep-learning method and could be implemented in hardware due to its low computational cost.
2. Related Work and Motivations
3. System and Methods
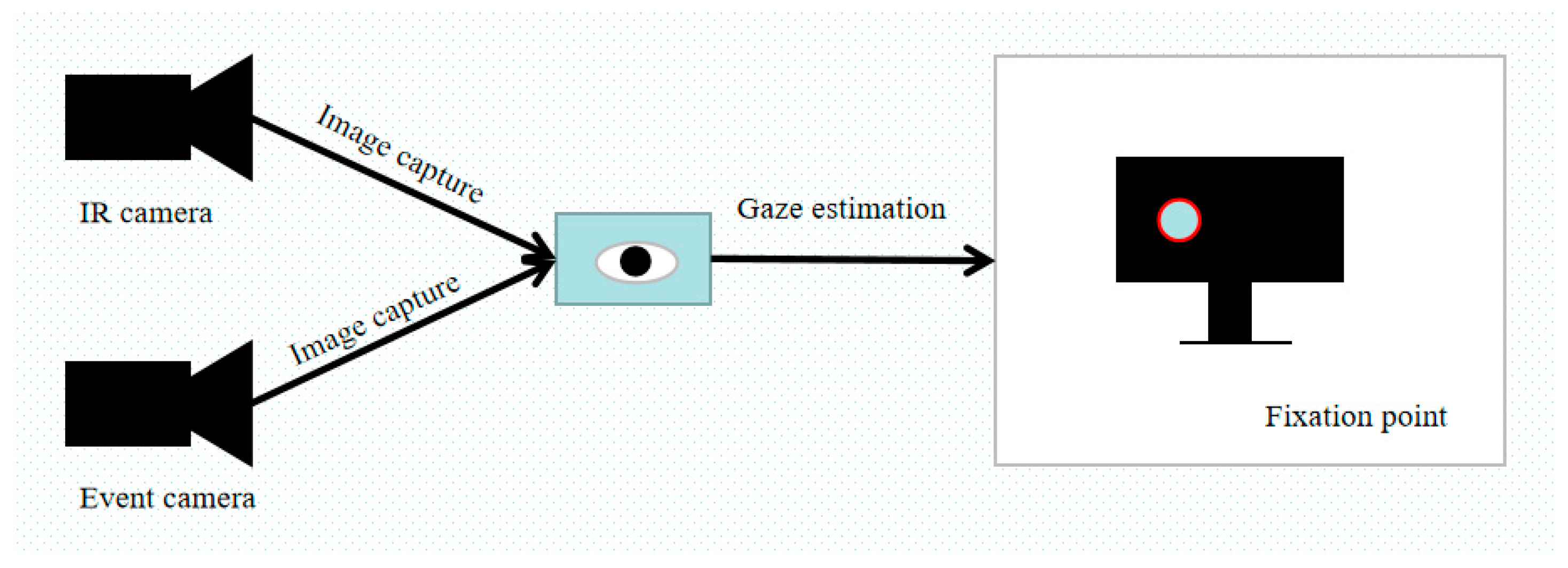
3.1. Gaze Vector Acquisition
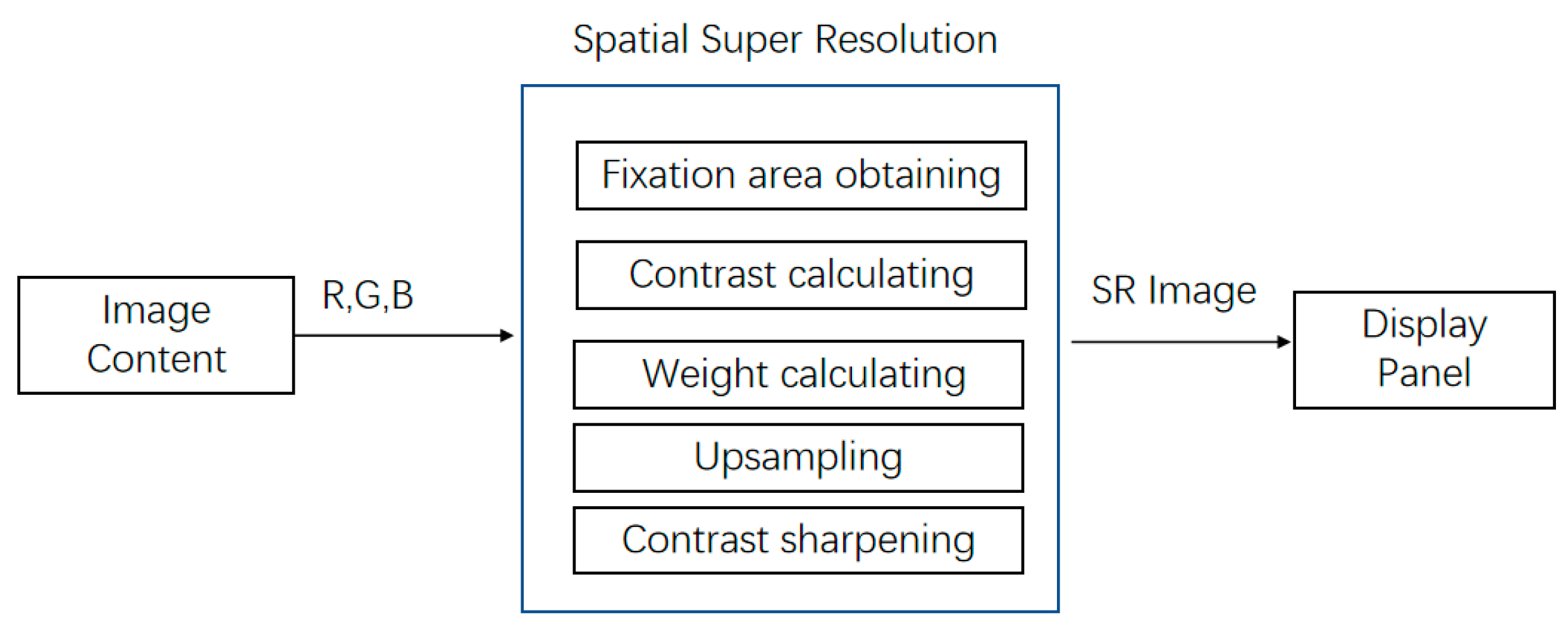
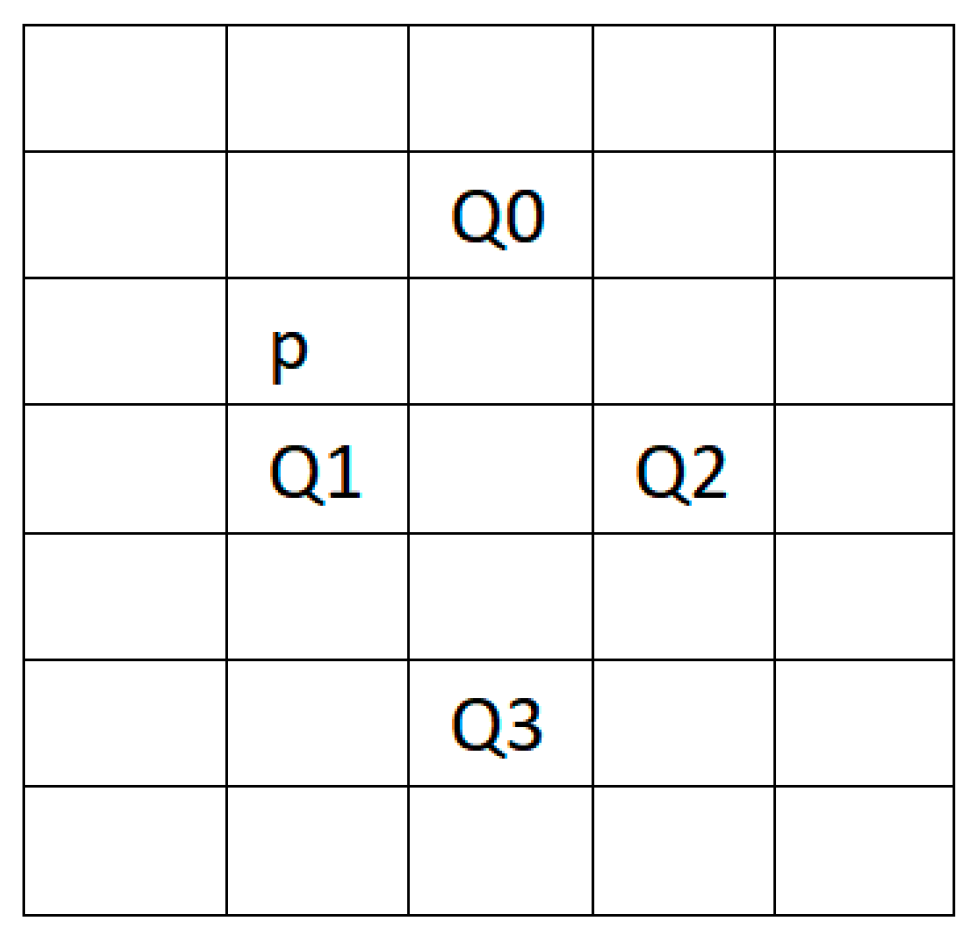
3.2. Adaptive Spatial Resolution Enhancement Module
3.3. Contrast Enhancement
3.4. Evaluation Index
4. Experiment and Analysis
4.1. Evaluation of Super-Resolution Algorithms
4.2. Eye-Movement Interaction and Super-Resolution of Fixation Area
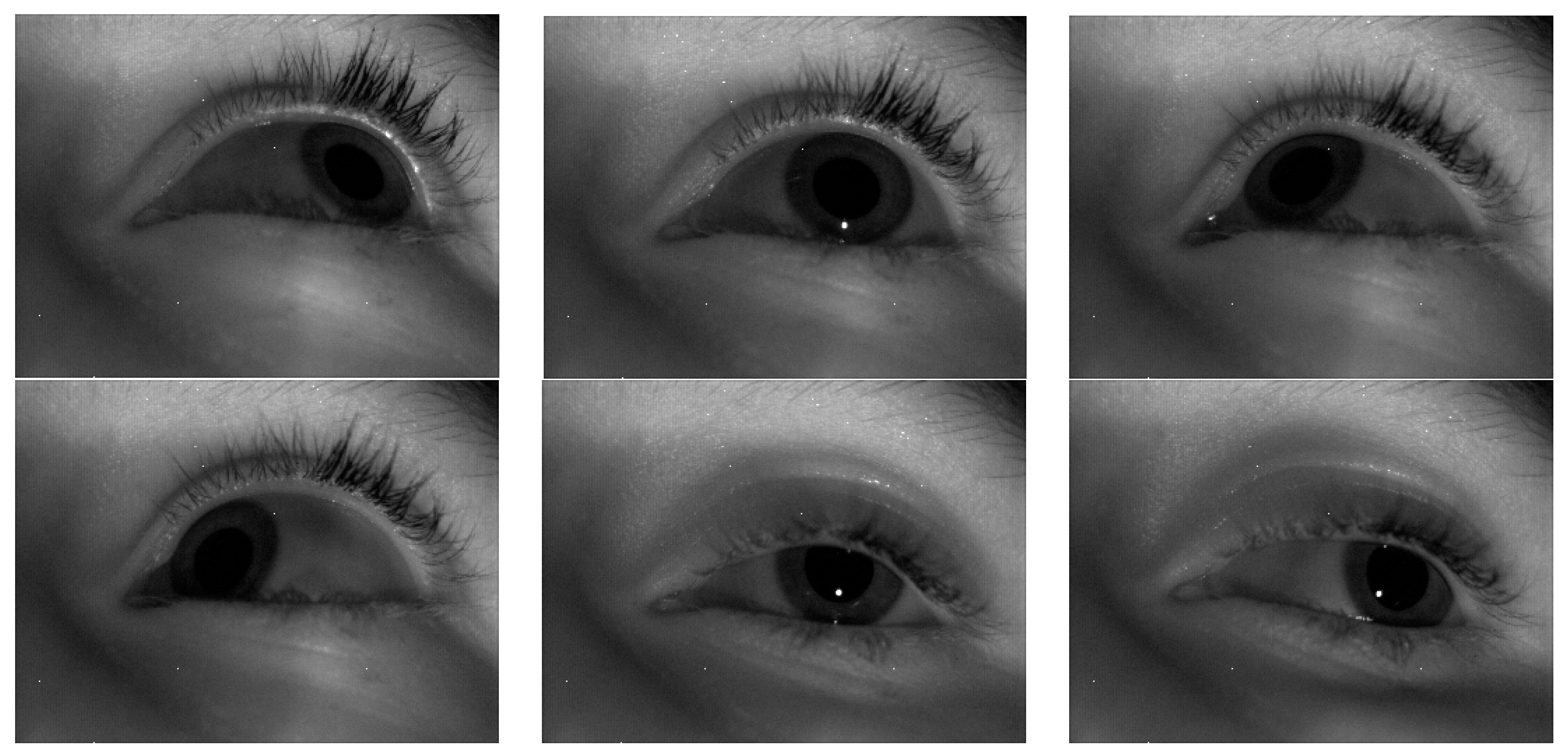
4.2.1. Obtain Gaze Area and Eye Movement Trajectory
4.2.2. Enhancing the Image Resolution of the Fixation Area
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tian, J.; Ma, K.K. A survey on super-resolution imaging. Signal Image Video Process. 2011, 5, 329–342. [Google Scholar] [CrossRef]
- Park, S.C.; Park, M.K.; Kang, M.G. Super-resolution image reconstruction: A technical overview. IEEE Signal Process. Mag. 2003, 20, 21–36. [Google Scholar] [CrossRef]
- Yue, L.; Shen, H.; Li, J.; Yuan, Q.; Zhang, H.; Zhang, L. Image super-resolution: The techniques, applications, and future. Signal Process. 2016, 128, 389–408. [Google Scholar] [CrossRef]
- Xiao, A.; Wang, Z.; Wang, L.; Ren, Y. Super-resolution for “Jilin-1” satellite video imagery via a convolutional network. Sensors 2018, 18, 1194. [Google Scholar] [CrossRef]
- Siu, W.C.; Hung, K.W. Review of image interpolation and super-resolution. In Proceedings of the 2012 Asia Pacific Signal and Information Processing Association Annual Summit and Conference, Hollywood, CA, USA, 3–6 December 2012; pp. 1–10. [Google Scholar]
- Zhan, T.; Yin, K.; Xiong, J.; He, Z.; Wu, S.-T. Augmented reality and virtual reality displays: Perspectives and challenges. Iscience 2020, 23, 101397. [Google Scholar] [CrossRef]
- Xiong, J.; Hsiang, E.L.; He, Z.; Zhan, T.; Wu, S.-T. Augmented reality and virtual reality displays: Emerging technologies and future perspectives. Light Sci. Appl. 2021, 10, 216. [Google Scholar] [CrossRef]
- Jensen, L.; Konradsen, F. A review of the use of virtual reality head-mounted displays in education and training. Educ. Inf. Technol. 2018, 23, 1515–1529. [Google Scholar] [CrossRef]
- Mamone, V.; Ferrari, V.; D’Amato, R.; Condino, S.; Cattari, N.; Cutolo, F. Head-Mounted Projector for Manual Precision Tasks: Performance Assessment. Sensors 2023, 23, 3494. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Jo, Y.; Kim, S.J. Practical single-image super-resolution using look-up table. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 691–700. [Google Scholar]
- Banks, M.S.; Read JC, A.; Allison, R.S.; Watt, S.J. Stereoscopy and the human visual system. SMPTE Motion Imaging J. 2012, 121, 24–43. [Google Scholar] [CrossRef]
- Fu, W.; Wang, J.; Lu, Y.; Wu, H.; Chai, X. Image processing strategies based on visual attention models under simulated prosthetic vision. Zhongguo Yi Liao Qi Xie Za Zhi Chin. J. Med. Instrum. 2013, 37, 199–202. [Google Scholar]
- Baek, J.; Dosher, B.A.; Lu, Z.L. Visual attention in spatial cueing and visual search. J. Vis. 2021, 21, 1. [Google Scholar] [CrossRef]
- Hua, Z.; Li, Y.; Li, J. Image segmentation algorithm based on improved visual attention model and region growing. In Proceedings of the 2010 6th International Conference on Wireless Communications Networking and Mobile Computing (WiCOM), Chengdu, China, 23–25 September 2010; pp. 1–4. [Google Scholar]
- Kim, H.; Yang, J.; Choi, M.; Lee, J.; Yoon, S.; Kim, Y.; Park, W. Eye tracking based foveated rendering for 360 VR tiled video. In Proceedings of the 9th ACM Multimedia Systems Conference, Amsterdam, The Netherlands, 12–15 June 2018; pp. 484–486. [Google Scholar]
- Gribbon, K.T.; Bailey, D.G. A novel approach to real-time bilinear interpolation. In Proceedings of the Proceedings. DELTA 2004. Second IEEE International Workshop on Electronic Design, Test and Applications, Perth, WA, Australia, 28–30 January 2004; pp. 126–131. [Google Scholar]
- Dengwen, Z. An edge-directed bicubic interpolation algorithm. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010; pp. 1186–1189. [Google Scholar]
- Jiang, N.; Wang, L. Quantum image scaling using nearest neighbor interpolation. Quantum Inf. Process. 2015, 14, 1559–1571. [Google Scholar] [CrossRef]
- Nguyen, N.; Milanfar, P. A wavelet-based interpolation-restoration method for superresolution (wavelet superresolution). Circuits Syst. Signal Process. 2000, 19, 321–338. [Google Scholar] [CrossRef]
- Yang, X.; Chen, Y.; Yue, X.; Ma, C.; Yang, P. Local linear embedding based interpolation neural network in pancreatic tumor segmentation. Appl. Intell. 2022, 52, 8746–8756. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, X. An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans. Image Process. 2006, 15, 2226–2238. [Google Scholar] [CrossRef]
- Liu, D.; Li, Y.; Lin, J.; Li, H.; Wu, F. Deep learning-based video coding: A review and a case study. ACM Comput. Surv. CSUR 2020, 53, 1–35. [Google Scholar] [CrossRef]
- Sa, Y. Improved bilinear interpolation method for image fast processing. In Proceedings of the 2014 7th International Conference on Intelligent Computation Technology and Automation, Changsha, China, 25–26 October 2014; pp. 308–311. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Scheerlinck, C.; Rebecq, H.; Gehrig, D.; Barnes, N.; Mahony, R.; Scaramuzza, D. Fast image reconstruction with an event camera. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 156–163. [Google Scholar]
- Rebecq, H.; Ranftl, R.; Koltun, V.; Scaramuzza, D. High speed and high dynamic range video with an event camera. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1964–1980. [Google Scholar] [CrossRef]
- Majaranta, P.; Bulling, A. Eye tracking and eye-based human–computer interaction. Adv. Physiol. Comput. 2014, 189, 39–65. [Google Scholar]
- Madhukar, B.N.; Narendra, R. Lanczos resampling for the digital processing of remotely sensed images. In Proceedings of the International Conference on VLSI, Communication, Advanced Devices, Signals & Systems and Networking (VCASAN-2013); Springer: New Delhi, India, 2013; pp. 403–411. [Google Scholar]
- Kumar, M.; Saxena, R. Algorithm and technique on various edge detection: A survey. Signal Image Process. 2013, 4, 65–75. [Google Scholar]
- Sun, R.; Lei, T.; Chen, Q.; Wang, Z.; Du, X.; Zhao, W.; Nandi, A.K. Survey of image edge detection. Front. Signal Process. 2022, 2, 826967. [Google Scholar] [CrossRef]
- Nezhadarya, E.; Ward R, K. A new scheme for robust gradient vector estimation in color images. IEEE Trans. Image Process. 2011, 20, 2211–2220. [Google Scholar] [CrossRef] [PubMed]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Setiadi, D.R.I.M. PSNR vs SSIM: Imperceptibility quality assessment for image steganography. Multimed. Tools Appl. 2021, 80, 8423–8444. [Google Scholar] [CrossRef]
- Streijl, R.C.; Winkler, S.; Hands, D.S. Mean opinion score (MOS) revisited: Methods and applications, limitations and alternatives. Multimed. Syst. 2016, 22, 213–227. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PNSR Average | SSIM Average |
|---|---|---|
| Bicubic | 33.96 | 0.9763 |
| Nearest | 31.19 | 0.9570 |
| Bilinear | 32.40 | 0.9655 |
| Vdsr | 35.33 | 0.9799 |
| Ours | 35.02 | 0.9793 |
| Method | PNSR Average | SSIM Average |
|---|---|---|
| Bicubic | 27.98 | 0.8964 |
| Nearest | 26.48 | 0.8635 |
| Bilinear | 27.25 | 0.8825 |
| Vdsr | 29.15 | 0.9160 |
| Ours | 28.87 | 0.9034 |
| MOS | Our Method | Other Methods |
|---|---|---|
| Building | 39 | 21 |
| Sea | 36 | 24 |
| Code | 34 | 26 |
| Game | 41 | 19 |
| Mountain | 40 | 20 |
| Road | 38 | 22 |
| Method | Running Time |
|---|---|
| Bicubic | 42.98 μs |
| Nearest | 23.75 μs |
| Bilinear | 31.74 μs |
| Ours | 61.44 μs |
| MOS | Global | Visual Attention Area |
| 18 | 42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Z.; He, X.; Li, C.; Liu, S.; Jiang, K.; Li, K.; Wang, J. Adaptive Resolution Enhancement for Visual Attention Regions Based on Spatial Interpolation. Sensors 2023, 23, 6354. https://doi.org/10.3390/s23146354
Zhu Z, He X, Li C, Liu S, Jiang K, Li K, Wang J. Adaptive Resolution Enhancement for Visual Attention Regions Based on Spatial Interpolation. Sensors. 2023; 23(14):6354. https://doi.org/10.3390/s23146354
Chicago/Turabian StyleZhu, Zhixuan, Xin He, Chunlai Li, Shijie Liu, Kun Jiang, Kang Li, and Jianyu Wang. 2023. "Adaptive Resolution Enhancement for Visual Attention Regions Based on Spatial Interpolation" Sensors 23, no. 14: 6354. https://doi.org/10.3390/s23146354
APA StyleZhu, Z., He, X., Li, C., Liu, S., Jiang, K., Li, K., & Wang, J. (2023). Adaptive Resolution Enhancement for Visual Attention Regions Based on Spatial Interpolation. Sensors, 23(14), 6354. https://doi.org/10.3390/s23146354