
Role-Driven Clustering of Stakeholders: A Study of IoT Security Improvement

Abstract
1. Introduction
2. Background
2.1. Taxonomy
2.1.1. Device Attacks in IoT
2.1.2. Application Attacks in IoT
2.1.3. Network Attacks in IoT
2.1.4. Physical Attacks in IoT
2.1.5. Cloud Attacks in IoT
2.2. Impact of Attacks
2.2.1. SCAs
2.2.2. PQCs
2.2.3. Standardization Efforts
3. Related Work
3.1. Clustering of Stakeholders
3.2. Feature Selection
3.3. Previous Studies and Current Work
4. Methodology
4.1. The First Stage: Clustering Stakeholders
| Algorithm 1: The Ward method with weights |
|
4.2. The Second Stage: Features Assignment
4.2.1. Chi2
4.2.2. ANOVA F-Value
4.2.3. Mutual Information
4.2.4. Entropy
4.2.5. Importance Random Forest
5. Case Study on Nine Stakeholders and Two Datasets
5.1. Step 1: Define Stakeholders and Their Roles
5.2. Step 2: Weights and Normalization
5.2.1. Weights of Roles
5.2.2. Weights of Importance
5.2.3. Normalizing Weights
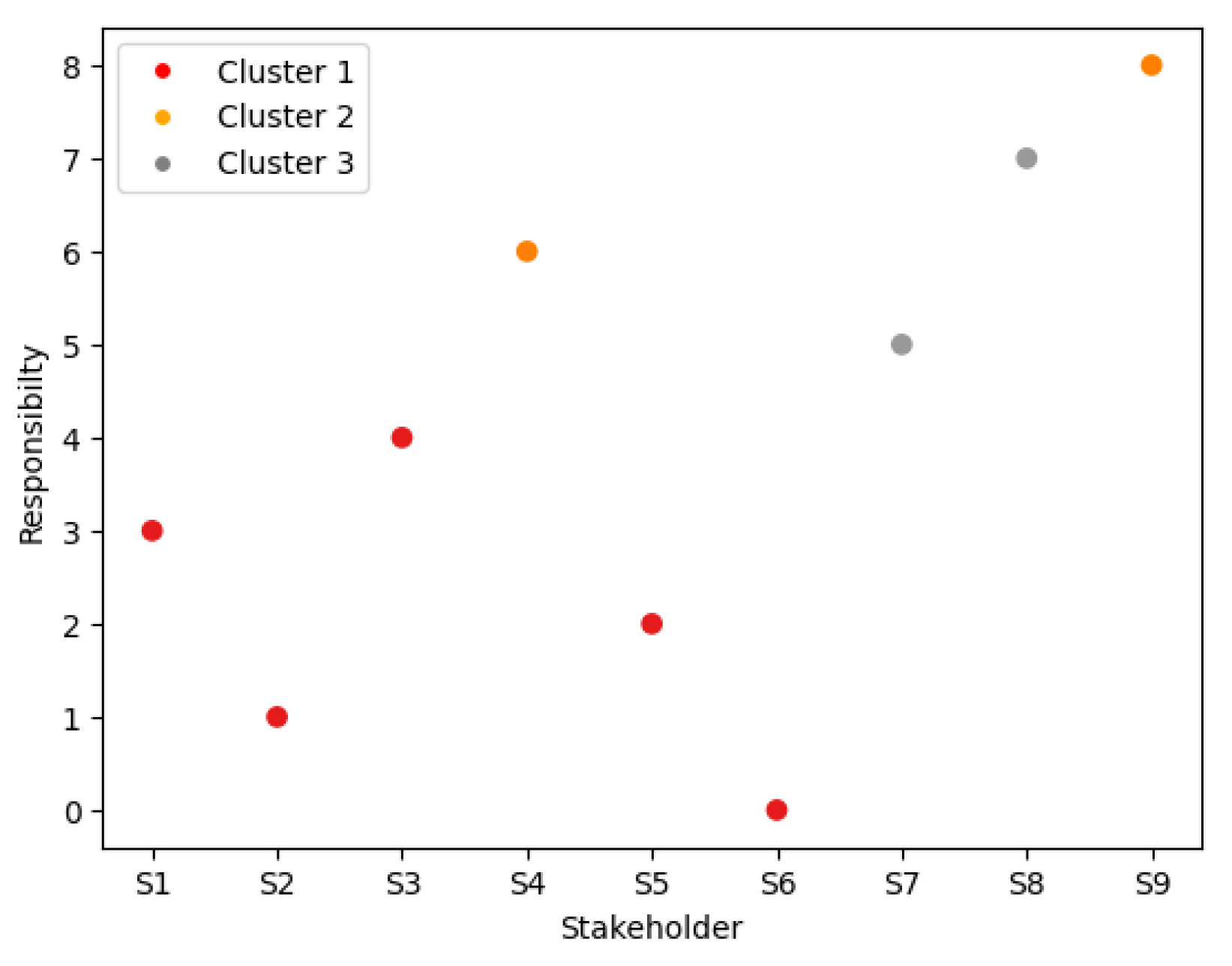
5.3. Step 3: Clustering of Stakeholders
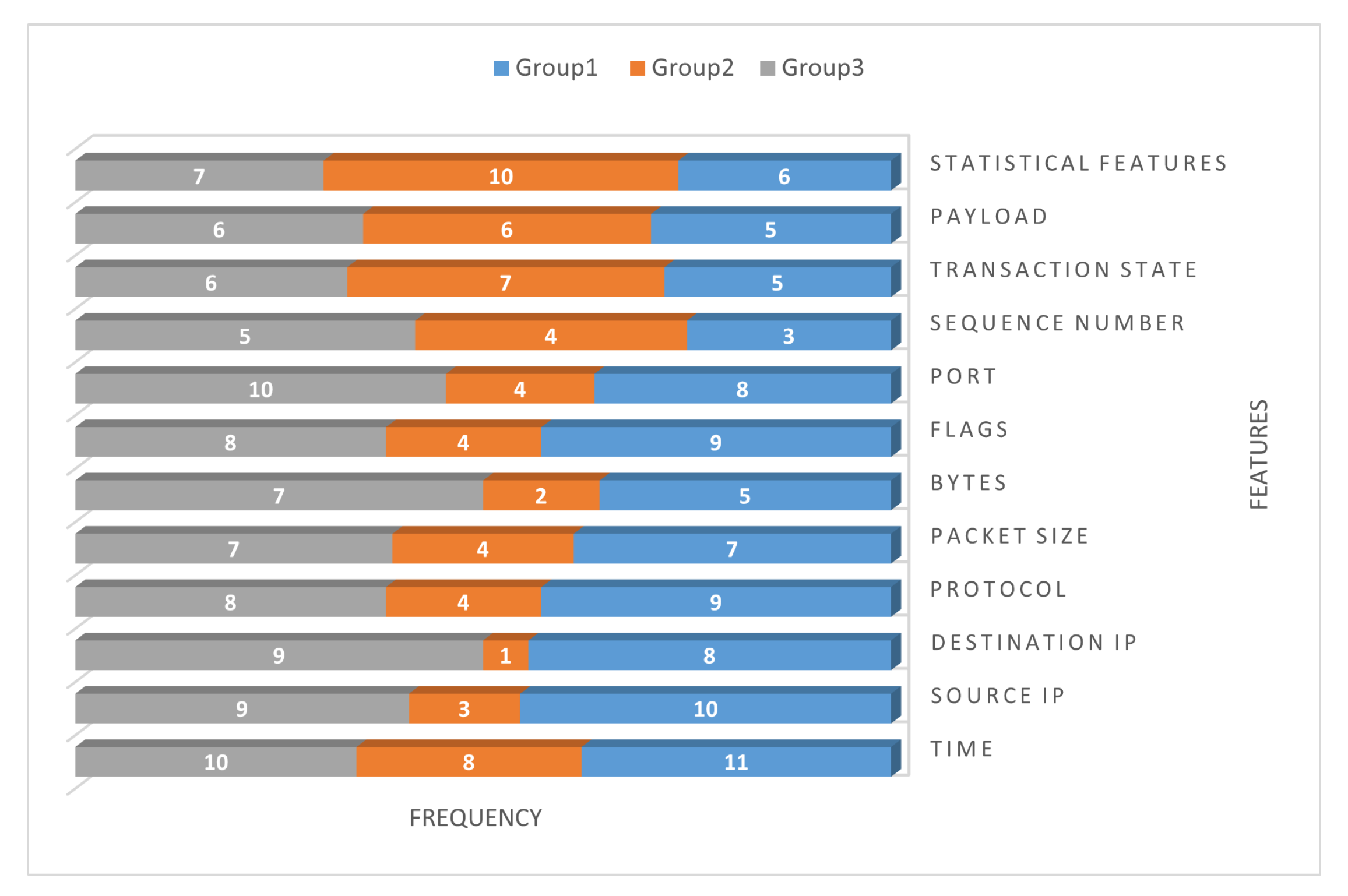
5.4. Step 4: Select the Relevant Features
5.5. Step 5: Select the Best Features from the Relevant Features
5.5.1. Five Models on Two Datasets
5.5.2. Votes to Select the Best Features
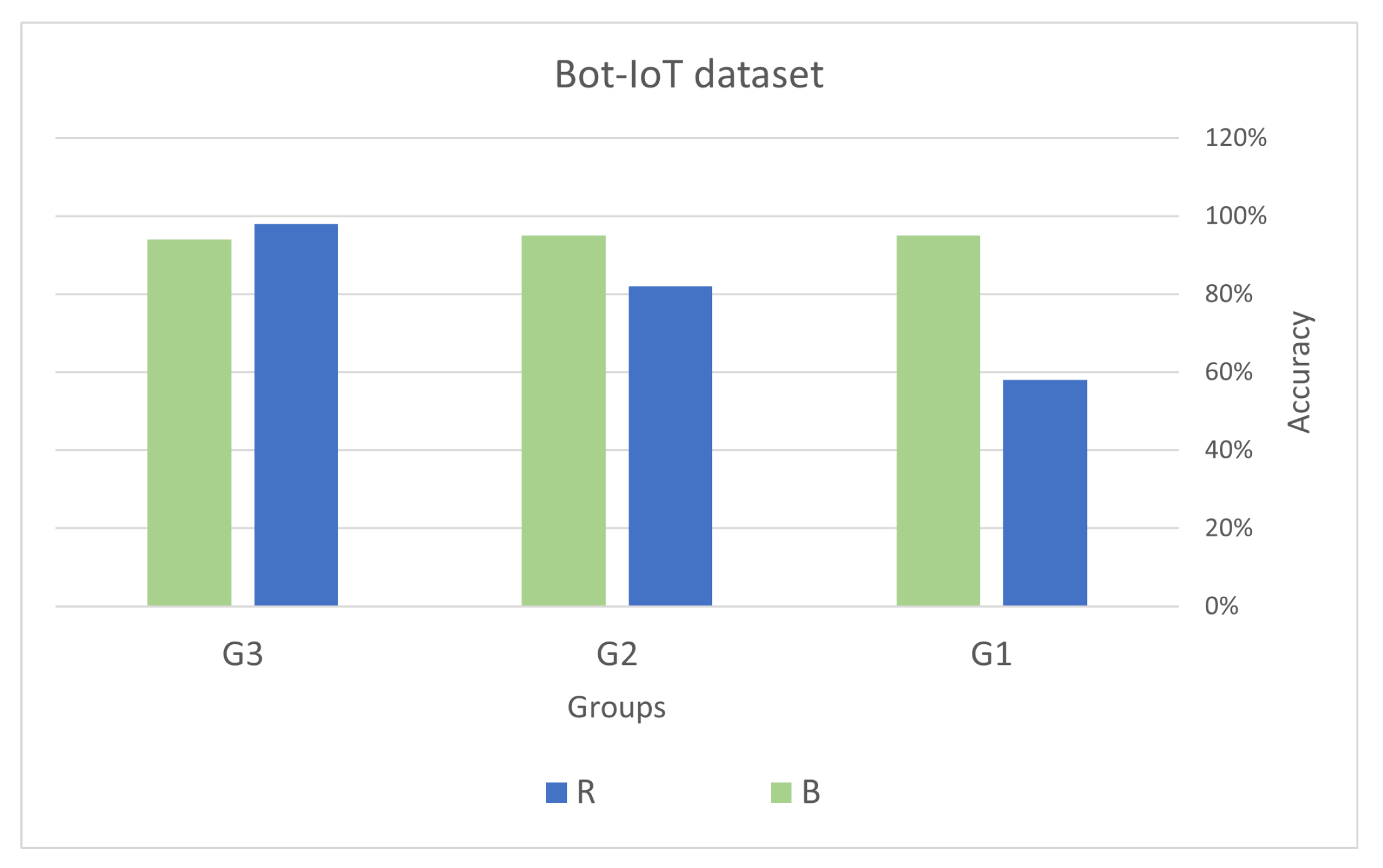
5.6. Validation of the Results
6. Discussion
7. Conclusions
8. Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Yao, X.; Farha, F.; Li, R.; Psychoula, I.; Chen, L.; Ning, H. Security and privacy issues of physical objects in the IoT: Challenges and opportunities. Digit. Commun. Netw. 2021, 7, 373–384. [Google Scholar] [CrossRef]
- Mohanta, B.K.; Jena, D.; Satapathy, U.; Patnaik, S. Survey on IoT security: Challenges and solution using machine learning, artificial intelligence and blockchain technology. Internet Things 2020, 11, 100227. [Google Scholar] [CrossRef]
- Angel, N.A.; Ravindran, D.; Vincent, P.D.R.; Srinivasan, K.; Hu, Y.C. Recent advances in evolving computing paradigms: Cloud, edge, and fog technologies. Sensors 2021, 22, 196. [Google Scholar] [CrossRef]
- Ometov, A.; Molua, O.L.; Komarov, M.; Nurmi, J. A survey of security in cloud, edge, and fog computing. Sensors 2022, 22, 927. [Google Scholar] [CrossRef] [PubMed]
- Hassija, V.; Chamola, V.; Saxena, V.; Jain, D.; Goyal, P.; Sikdar, B. A Survey on IoT Security: Application Areas, Security Threats, and Solution Architectures. IEEE Access 2019, 7, 82721–82743. [Google Scholar] [CrossRef]
- Schöffel, M.; Lauer, F.; Rheinländer, C.C.; Wehn, N. Secure IoT in the era of quantum computers—Where are the bottlenecks? Sensors 2022, 22, 2484. [Google Scholar] [CrossRef] [PubMed]
- Karie, N.M.; Sahri, N.M.; Yang, W.; Valli, C.; Kebande, V.R. A review of security standards and frameworks for IoT-based smart environments. IEEE Access 2021, 9, 121975–121995. [Google Scholar] [CrossRef]
- Melo, M.; Aquino, G. FaTEMa: A Framework for Multi-Layer Fault Tolerance in IoT Systems. Sensors 2021, 21, 7181. [Google Scholar] [CrossRef] [PubMed]
- Ramson, S.J.; Vishnu, S.; Shanmugam, M. Applications of internet of things (iot)—An overview. In Proceedings of the 2020 5th International Conference on Devices, Circuits and Systems (ICDCS), Coimbatore, India, 5–6 March 2020; pp. 92–95. [Google Scholar]
- Tawalbeh, L.; Muheidat, F.; Tawalbeh, M.; Quwaider, M. IoT Privacy and security: Challenges and solutions. Appl. Sci. 2020, 10, 4102. [Google Scholar] [CrossRef]
- Pal, S.; Hitchens, M.; Rabehaja, T.; Mukhopadhyay, S. Security requirements for the internet of things: A systematic approach. Sensors 2020, 20, 5897. [Google Scholar] [CrossRef]
- Sidhu, S.; Mohd, B.J.; Hayajneh, T. Hardware security in IoT devices with emphasis on hardware trojans. J. Sens. Actuator Netw. 2019, 8, 42. [Google Scholar] [CrossRef]
- Bansal, S.; Kumar, D. IoT ecosystem: A survey on devices, gateways, operating systems, middleware and communication. Int. J. Wirel. Inf. Netw. 2020, 27, 340–364. [Google Scholar] [CrossRef]
- Ding, D.; Han, Q.L.; Ge, X.; Wang, J. Secure state estimation and control of cyber-physical systems: A survey. IEEE Trans. Syst. Man Cybern. Syst. 2020, 51, 176–190. [Google Scholar] [CrossRef]
- Farivar, F.; Haghighi, M.S.; Jolfaei, A.; Alazab, M. Artificial intelligence for detection, estimation, and compensation of malicious attacks in nonlinear cyber-physical systems and industrial IoT. IEEE Trans. Ind. Inform. 2019, 16, 2716–2725. [Google Scholar] [CrossRef]
- Xenofontos, C.; Zografopoulos, I.; Konstantinou, C.; Jolfaei, A.; Khan, M.K.; Choo, K.K.R. Consumer, commercial, and industrial iot (in) security: Attack taxonomy and case studies. IEEE Internet Things J. 2021, 9, 199–221. [Google Scholar] [CrossRef]
- Sadhu, P.K.; Yanambaka, V.P.; Abdelgawad, A. Internet of Things: Security and Solutions Survey. Sensors 2022, 22, 7433. [Google Scholar] [CrossRef]
- Shah, Y.; Sengupta, S. A survey on Classification of Cyber-attacks on IoT and IIoT devices. In Proceedings of the 2020 11th IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 28–31 October 2020; pp. 0406–0413. [Google Scholar]
- Gaur, V.; Kumar, R. Analysis of machine learning classifiers for early detection of DDoS attacks on IoT devices. Arab. J. Sci. Eng. 2022, 47, 1353–1374. [Google Scholar] [CrossRef]
- Gupta, R.; Phanden, R.K.; Sharma, S.; Srivastava, P.; Chaturvedi, P. Security in manufacturing systems in the age of industry 4.0: Pitfalls and possibilities. In Advances in Industrial and Production Engineering: Select Proceedings of FLAME 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 105–113. [Google Scholar]
- Eustis, A.G. The Mirai Botnet and the importance of IoT device security. In Proceedings of the 16th International Conference on Information Technology-New Generations (ITNG 2019), Las Vegas, NV, USA, 1–3 April 2019; pp. 85–89. [Google Scholar]
- Rajendran, G.; Nivash, R.R.; Parthy, P.P.; Balamurugan, S. Modern security threats in the Internet of Things (IoT): Attacks and Countermeasures. In Proceedings of the 2019 International Carnahan Conference on Security Technology (ICCST), Chennai, India, 1–3 October 2019; pp. 1–6. [Google Scholar]
- Vishwakarma, R.; Jain, A.K. A survey of DDoS attacking techniques and defence mechanisms in the IoT network. Telecommun. Syst. 2020, 73, 3–25. [Google Scholar] [CrossRef]
- Chaudhary, P.; Gupta, B.B.; Singh, A. Securing heterogeneous embedded devices against XSS attack in intelligent IoT system. Comput. Secur. 2022, 118, 102710. [Google Scholar] [CrossRef]
- Mullen, G.; Meany, L. Assessment of buffer overflow based attacks on an IoT operating system. In Proceedings of the 2019 Global IoT Summit (GIoTS), Chennai, India, 1–3 October 2019; pp. 1–6. [Google Scholar]
- Toutsop, O.; Harvey, P.; Kornegay, K. Monitoring and detection time optimization of man in the middle attacks using machine learning. In Proceedings of the 2020 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington DC, DC, USA, 13–15 October 2020; pp. 1–7. [Google Scholar]
- Al-Hadhrami, Y.; Hussain, F.K. DDoS attacks in IoT networks: A comprehensive systematic literature review. World Wide Web 2021, 24, 971–1001. [Google Scholar] [CrossRef]
- Jović, M.; Tijan, E.; Aksentijević, S.; Čišić, D. An overview of security challenges of seaport IoT systems. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; pp. 1349–1354. [Google Scholar]
- Garagad, V.G.; Iyer, N.C.; Wali, H.G. Data integrity: A security threat for internet of things and cyber-physical systems. In Proceedings of the 2020 International Conference on Computational Performance Evaluation (ComPE), Shillong, India, 2–4 July 2020; pp. 244–249. [Google Scholar]
- Yang, X.; Shu, L.; Liu, Y.; Hancke, G.P.; Ferrag, M.A.; Huang, K. Physical security and safety of iot equipment: A survey of recent advances and opportunities. IEEE Trans. Ind. Inform. 2022, 18, 4319–4330. [Google Scholar] [CrossRef]
- González-Granadillo, G.; González-Zarzosa, S.; Diaz, R. Security information and event management (SIEM): Analysis, trends, and usage in critical infrastructures. Sensors 2021, 21, 4759. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, W.; Rasool, A.; Javed, A.R.; Baker, T.; Jalil, Z. Cyber security in iot-based cloud computing: A comprehensive survey. Electronics 2022, 11, 16. [Google Scholar] [CrossRef]
- Saini, D.K.; Kumar, K.; Gupta, P. Security issues in IoT and cloud computing service models with suggested solutions. Secur. Commun. Netw. 2022, 2022. [Google Scholar] [CrossRef]
- Devi, M.; Majumder, A. Side-channel attack in Internet of Things: A survey. In Applications of Internet of Things: Proceedings of ICCCIOT 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 213–222. [Google Scholar]
- Lo’ai, A.T.; Somani, T.F. More secure Internet of Things using robust encryption algorithms against side channel attacks. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November 2016–2 December 2016; pp. 1–6. [Google Scholar]
- Ravi, P.; Poussier, R.; Bhasin, S.; Chattopadhyay, A. On Configurable SCA Countermeasures Against Single Trace Attacks for the NTT: A Performance Evaluation Study over Kyber and Dilithium on the ARM Cortex-M4. In Proceedings of the Security, Privacy, and Applied Cryptography Engineering: 10th International Conference, SPACE 2020, Kolkata, India, 17–21 December 2020; pp. 123–146. [Google Scholar]
- Abarzúa, R.; Valencia, C.; López, J. Survey on performance and security problems of countermeasures for passive side-channel attacks on ECC. J. Cryptogr. Eng. 2021, 11, 71–102. [Google Scholar] [CrossRef]
- Kaur, S.; Singh, B.; Kaur, H. Stratification of hardware attacks: Side channel attacks and fault injection techniques. SN Comput. Sci. 2021, 2, 1–13. [Google Scholar] [CrossRef]
- Schneider, T.; Moradi, A.; Güneysu, T. ParTI–towards combined hardware countermeasures against side-channel and fault-injection attacks. In Proceedings of the Advances in Cryptology—CRYPTO 2016: 36th Annual International Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2016; pp. 302–332. [Google Scholar]
- Dhooghe, S.; Nikova, S.; Rijmen, V. Threshold implementations in the robust probing model. In Proceedings of the ACM Workshop on Theory of Implementation Security Workshop, London, UK, 11 November 2019; pp. 30–37. [Google Scholar]
- Magyari, A.; Chen, Y. Review of State-of-the-Art FPGA Applications in IoT Networks. Sensors 2022, 22, 7496. [Google Scholar] [CrossRef]
- Liptak, C.; Mal-Sarkar, S.; Kumar, S.A. Power Analysis Side Channel Attacks and Countermeasures for the Internet of Things. In Proceedings of the 2022 IEEE Physical Assurance and Inspection of Electronics (PAINE), Huntsville, AL, USA, 25–27 October 2022; pp. 1–7. [Google Scholar]
- Gangolli, A.; Mahmoud, Q.H.; Azim, A. A systematic review of fault injection attacks on IOT systems. Electronics 2022, 11, 2023. [Google Scholar] [CrossRef]
- Ebrahimi, S.; Bayat-Sarmadi, S. Lightweight and fault-resilient implementations of binary ring-LWE for IoT devices. IEEE Internet Things J. 2020, 7, 6970–6978. [Google Scholar] [CrossRef]
- Imaña, J.L.; He, P.; Bao, T.; Tu, Y.; Xie, J. Efficient hardware arithmetic for inverted binary ring-lwe based post-quantum cryptography. IEEE Trans. Circuits Syst. I Regul. Pap. 2022, 69, 3297–3307. [Google Scholar] [CrossRef]
- Sarker, A.; Kermani, M.M.; Azarderakhsh, R. Fault detection architectures for inverted binary ring-LWE construction benchmarked on FPGA. IEEE Trans. Circuits Syst. II Express Briefs 2020, 68, 1403–1407. [Google Scholar] [CrossRef]
- Zeydan, E.; Turk, Y.; Aksoy, B.; Ozturk, S.B. Recent advances in post-quantum cryptography for networks: A survey. In Proceedings of the 2022 Seventh International Conference On Mobile Furthermore, Secure Services (MobiSecServ), Gainesville, FL, USA, 26–27 February 2022; pp. 1–8. [Google Scholar]
- Kirsch, Z.; Chow, M. Quantum Computing: The Risk to Existing Encryption Methods. 2015. Available online: http://www.cs.tufts.edu/comp/116/archive/fall2015/zkirsch.pdf (accessed on 31 May 2023).
- Septien-Hernandez, J.A.; Arellano-Vazquez, M.; Contreras-Cruz, M.A.; Ramirez-Paredes, J.P. A Comparative study of post-quantum cryptosystems for Internet-of-Things applications. Sensors 2022, 22, 489. [Google Scholar] [CrossRef] [PubMed]
- Seyhan, K.; Nguyen, T.N.; Akleylek, S.; Cengiz, K. Lattice-based cryptosystems for the security of resource-constrained IoT devices in post-quantum world: A survey. Clust. Comput. 2022, 25, 1729–1748. [Google Scholar] [CrossRef]
- Sajimon, P.; Jain, K.; Krishnan, P. Analysis of Post-Quantum Cryptography for Internet of Things. In Proceedings of the 2022 6th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 25–27 May 2022; pp. 387–394. [Google Scholar]
- Park, T.; Seo, H.; Kim, J.; Park, H.; Kim, H. Efficient parallel implementation of matrix multiplication for Lattice-Based cryptography on modern ARM processor. Secur. Commun. Netw. 2018, 2018, 7012056. [Google Scholar] [CrossRef]
- Asghar, M.N. A review of ARM processor architecture history, progress and applications. J. Appl. Emerg. Sci. 2020, 10, 171. [Google Scholar]
- Antony, A.; Sarika, S. A review on IoT operating systems. Int. J. Comput. Appl. 2020, 176, 33–40. [Google Scholar] [CrossRef]
- Anastasova, M.; Azarderakhsh, R.; Kermani, M.M.; Beshaj, L. Time-Efficient Finite Field Microarchitecture Design for Curve448 and Ed448 on Cortex-M4. In Proceedings of the Information Security and Cryptology—ICISC 2022: 25th International Conference, ICISC 2022, Seoul, Republic of Korea, 30 November–2 December 2022; pp. 292–314. [Google Scholar]
- Bisheh Niasar, M.; Azarderakhsh, R.; Kermani, M.M. Efficient hardware implementations for elliptic curve cryptography over Curve448. In Proceedings of the Progress in Cryptology—INDOCRYPT 2020: 21st International Conference on Cryptology in India, Bangalore, India, 13–16 December 2020; pp. 228–247. [Google Scholar]
- Fazzat, A.; Khatoun, R.; Labiod, H.; Dubois, R. A comparative performance study of cryptographic algorithms for connected vehicles. In Proceedings of the 2020 4th Cyber Security in Networking Conference (CSNet), Lausanne, Switzerland, 21–23 October 2020; pp. 1–8. [Google Scholar]
- Anastasova, M.; Azarderakhsh, R.; Kermani, M.M. Fast strategies for the implementation of SIKE round 3 on ARM Cortex-M4. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 4129–4141. [Google Scholar] [CrossRef]
- Picaut, J.; Can, A.; Fortin, N.; Ardouin, J.; Lagrange, M. Low-cost sensors for urban noise monitoring networks—A literature review. Sensors 2020, 20, 2256. [Google Scholar] [CrossRef]
- Sanal, P.; Karagoz, E.; Seo, H.; Azarderakhsh, R.; Mozaffari-Kermani, M. Kyber on ARM64: Compact implementations of Kyber on 64-bit ARM Cortex-A processors. In Proceedings of the Security and Privacy in Communication Networks: 17th EAI International Conference, SecureComm 2021, Virtual Event, 6–9 September 2021; pp. 424–440. [Google Scholar]
- Mozaffari-Kermani, M.; Azarderakhsh, R.; Aghaie, A. Reliable and error detection architectures of Pomaranch for false-alarm-sensitive cryptographic applications. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2015, 23, 2804–2812. [Google Scholar] [CrossRef]
- Abed, S.; Jaffal, R.; Mohd, B.J.; Al-Shayeji, M. An analysis and evaluation of lightweight hash functions for blockchain-based IoT devices. Clust. Comput. 2021, 24, 3065–3084. [Google Scholar] [CrossRef]
- Thakor, V.A.; Razzaque, M.A.; Khandaker, M.R. Lightweight cryptography algorithms for resource-constrained IoT devices: A review, comparison and research opportunities. IEEE Access 2021, 9, 28177–28193. [Google Scholar] [CrossRef]
- McKay, K.; Bassham, L.; Sönmez Turan, M.; Mouha, N. Report on Lightweight Cryptography; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2016. [Google Scholar]
- Ebrahimi, S.; Bayat-Sarmadi, S.; Mosanaei-Boorani, H. Post-quantum cryptoprocessors optimized for edge and resource-constrained devices in IoT. IEEE Internet Things J. 2019, 6, 5500–5507. [Google Scholar] [CrossRef]
- Pérez Vera, Y.; Bermudez Peña, A. Stakeholders Classification System Based on Clustering Techniques. In Proceedings of the Advances in Artificial Intelligence-IBERAMIA 2018: 16th Ibero-American Conference on AI, Trujillo, Peru, 13–16 November 2018; pp. 241–252. [Google Scholar]
- Zhong, H.; Liu, C. Career Path Clustering via Sequential Job Embedding and Mixture Markov Models. In Proceedings of the ICIS 2022 Proceedings, Copenhagen, Denmark, 9–14 December 2022; Volume 5. [Google Scholar]
- Gambo, I.P.; Taveter, K. Identifying and Resolving Conflicts in Requirements by Stakeholders: A Clustering Approach. In Proceedings of the the 16th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE), Online, 26–27 April 2021; pp. 158–169. [Google Scholar]
- Ali, S.; Hafeez, Y.; Asghar, S.; Nawaz, A.; Saeed, S. Aspect-based requirements mining technique to improve prioritisation process: Multi-stakeholder perspective. IET Softw. 2020, 14, 482–492. [Google Scholar] [CrossRef]
- Piccialli, F.; Casolla, G.; Cuomo, S.; Giampaolo, F.; Di Cola, V.S. Decision making in IoT environment through unsupervised learning. IEEE Intell. Syst. 2019, 35, 27–35. [Google Scholar] [CrossRef]
- Shafiq, M.; Tian, Z.; Bashir, A.K.; Du, X.; Guizani, M. IoT malicious traffic identification using wrapper-based feature selection mechanisms. Comput. Secur. 2020, 94, 101863. [Google Scholar] [CrossRef]
- Nimbalkar, P.; Kshirsagar, D. Feature selection for intrusion detection system in Internet-of-Things (IoT). ICT Express 2021, 7, 177–181. [Google Scholar] [CrossRef]
- Guerra-Manzanares, A.; Bahsi, H.; Nõmm, S. Hybrid feature selection models for machine learning based botnet detection in IoT networks. In Proceedings of the 2019 International Conference on Cyberworlds (CW), Kyoto, Japan, 2–4 October 2019; pp. 324–327. [Google Scholar]
- Abawajy, J.; Darem, A.; Alhashmi, A.A. Feature subset selection for malware detection in smart IoT platforms. Sensors 2021, 21, 1374. [Google Scholar] [CrossRef]
- Kalakoti, R.; Nõmm, S.; Bahsi, H. In-Depth Feature Selection for the Statistical Machine Learning-Based Botnet Detection in IoT Networks. IEEE Access 2022, 10, 94518–94535. [Google Scholar] [CrossRef]
- Ghosal, A.; Nandy, A.; Das, A.K.; Goswami, S.; Panday, M. A short review on different clustering techniques and their applications. In Emerging Technology in Modelling and Graphics: Proceedings of IEM Graph 2018; Springer: Singapore, 2020; pp. 69–83. [Google Scholar]
- Ahmad, A.; Khan, S.S. Survey of state-of-the-art mixed data clustering algorithms. IEEE Access 2019, 7, 31883–31902. [Google Scholar] [CrossRef]
- Randriamihamison, N.; Vialaneix, N.; Neuvial, P. Applicability and interpretability of Ward’s hierarchical agglomerative clustering with or without contiguity constraints. J. Classif. 2021, 38, 363–389. [Google Scholar] [CrossRef]
- Bu, J.; Liu, W.; Pan, Z.; Ling, K. Comparative study of hydrochemical classification based on different hierarchical cluster analysis methods. Int. J. Environ. Res. Public Health 2020, 17, 9515. [Google Scholar] [CrossRef] [PubMed]
- Benabdellah, A.C.; Benghabrit, A.; Bouhaddou, I. A survey of clustering algorithms for an industrial context. Procedia Comput. Sci. 2019, 148, 291–302. [Google Scholar] [CrossRef]
- Sikelis, K.; Tsekouras, G.E.; Kotis, K. Ontology-based feature selection: A survey. Future Internet 2021, 13, 158. [Google Scholar] [CrossRef]
- Kou, G.; Yang, P.; Peng, Y.; Xiao, F.; Chen, Y.; Alsaadi, F.E. Evaluation of feature selection methods for text classification with small datasets using multiple criteria decision-making methods. Appl. Soft Comput. 2020, 86, 105836. [Google Scholar] [CrossRef]
- Niu, D.; Wang, K.; Sun, L.; Wu, J.; Xu, X. Short-term photovoltaic power generation forecasting based on random forest feature selection and CEEMD: A case study. Appl. Soft Comput. 2020, 93, 106389. [Google Scholar] [CrossRef]
- UNSW. BoT-IoT Dataset. 2019. Available online: https://research.unsw.edu.au/projects/bot-iot-dataset (accessed on 16 June 2022).
- UNSW. The UNSW-NB15 Dataset. Available online: https://research.unsw.edu.au/projects/unsw-nb15-dataset (accessed on 1 October 2022).
- Almalki, L.S.; Alnahdi, A.K.; Albalawi, T.F. The Roles of Stakeholders in Internet of Things: A Theoretical Framework. In Proceedings of the 2023 1st International Conference on Advanced Innovations in Smart Cities (ICAISC), Jeddah, Saudi Arabia, 23–25 January 2023; pp. 1–6. [Google Scholar]
- Venkatesh, B.; Anuradha, J. A review of feature selection and its methods. Cybern. Inf. Technol. 2019, 19, 3–26. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Attack | Impact | Countermeasures |
|---|---|---|---|
| Device Attacks [17,18,19,20,21] | Exploiting vulnerabilities in device hardware or software, phishing attacks, physical tampering | Harm to device or network, unauthorized access, data compromise | Regular software updates, strong passwords, cautious network connections |
| Application Attacks [18,22,23,24,25] | Code vulnerabilities, cross-site scripting, SQL injection, buffer overflow attacks | Compromised device security, data access/control by attackers | Secure coding practices, software patching, encryption, authentication |
| Network Attacks [26,27,28] | Man-in-the-middle attacks, DoS attacks, unauthorized access attacks | Data interception/manipulation, network disruptions, compromised device functionality | Secure network design, protocols, firewalls, access controls, monitoring |
| Physical Attacks [18,29,30,31] | Tampering, theft, destruction of devices | Device compromise, data loss, disruption in critical infrastructure systems | Secure device design, physical security measures, enclosures, authentication |
| Cloud Attacks [32,33] | Cloud data breaches, server misconfigurations, unauthorized access | Data compromise, device disruptions, unauthorized cloud resource access | Secure cloud deployment, encryption, access controls, monitoring, patching |
| SCA [35,36,37] | Active and passive SCAs, fault attacks, power analysis attacks | Compromise of sensitive information, cryptographic implementations | Error detection/correction, redundancy, secure implementation, masking techniques |
| DFA and DPA Attacks [38,39,40] | DFA and DPA attacks | Compromise of sensitive information through fault or power analysis | Countermeasures specific to DFA and DPA, such as tamper-resistant designs, error detection, secure implementation |
| PQC Attacks [6,47,48,49,50,51] | Attacks targeting PQC algorithms and implementations | Compromise of encrypted data, undermining security against quantum computers | Development of PQC algorithms, standardization, secure implementation, compatibility considerations |
| Study | Approach | Limitations |
|---|---|---|
| [66] 2018 | Clustering stakeholders by using fuzzy inference system | Relies on performance of clustering algorithms |
| [67] 2022 | Clustering job titles by using Markov model | Cannot differentiate between function and responsibility |
| [68] 2021 | Using K-means to cluster conflict resolution | Yet to be validated in other domains |
| [69] 2020 | Clustering stakeholders based on requirement | Does not consider words with similar meaning |
| [70] 2019 | Clustering user behavior using hierarchical clustering and select features using PCA and correlation matrix | Does not capture all relevant information |
| [71] 2020 | Wrapper-based feature selection | Not generalized to other datasets or scenarios; wrapper-based feature selection approaches can also be computationally expensive |
| [72] 2021 | Using IG and GR to detect attacks | The fixed threshold of 50% may not be optimal for all datasets |
| [73] 2019 | Hybrid feature selection: filter-based + wrapper methods | Wrapper methods may be computationally expensive, limiting their applicability in large datasets |
| [74] 2021 | Detecting Android malware by machine learning | Only examines filter-based feature selection on a specific dataset and malware family |
| [75] 2022 | Using feature selection methods for IoT botnet attack detection | Filter techniques do not always obtain the ideal feature set, whereas wrapper methods assure it |
| 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | |
| 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | |
| 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | |
| 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
| Stakeholders | ||
|---|---|---|
| S1 | ||
| S2 | ||
| S3 | ||
| S4 | ||
| S5 | ||
| S6 | ||
| S7 | ||
| S8 | 2 | |
| S9 |
| Stakeholders | ||
|---|---|---|
| S1 | ||
| S2 | ||
| S3 | ||
| S4 | ||
| S5 | ||
| S6 | ||
| S7 | ||
| S8 | ||
| S9 |
| Group | Method | Feature ID | Accuracy | Precision | Recall | F1 Score | Time |
|---|---|---|---|---|---|---|---|
| Group 1 | chi2 | [2, 15, 18, 19, 22] | 0.9318 | 1 | 0.8637 | 0.8966 | 72.1125 |
| f_classif | [2, 15, 18, 19, 22] | 0.9318 | 1 | 0.8637 | 0.8966 | 74.0828 | |
| mutual_ info | [2, 36,37, 40, 41] | 0.9318 | 1 | 0.8637 | 0.8966 | 795.7370 | |
| entropy | [2, 15, 14, 27, 17, 36, 37, 40, 41,11, 12, 18, 19, 20, 21, 22] | 0.9318 | 1 | 0.8637 | 0.8966 | 252.578 | |
| importance_ RF | [2, 15, 19, 22] | 0.9318 | 1 | 0.8637 | 0.8966 | 1128.947 | |
| Group 2 | chi2 | [2, 15, 18, 19, 22] | 0.9318 | 1 | 0.8637 | 0.8966 | 72.1125 |
| f_classif | [2, 15, 18, 19, 22] | 0.9318 | 1 | 0.8637 | 0.8966 | 74.0828 | |
| mutual_ info | [2, 36,37, 40, 41] | 0.9318 | 1 | 0.8637 | 0.8966 | 795.737 | |
| entropy | [2, 15, 14, 27, 17, 36, 37, 40, 41, 11, 12, 18, 19, 20, 21, 22] | 0.9318 | 1 | 0.8637 | 0.8966 | 252.578 | |
| importance_ RF | [2, 15, 19, 22] | 0.9318 | 1 | 0.8637 | 0.8966 | 1128.947 | |
| Group 3 | chi2 | [2, 15, 34, 19, 22] | 0.9319 | 1.0000 | 0.8637 | 0.8966 | 94.2569 |
| f_classif | [2, 15, 34, 19, 22] | 0.9319 | 1.0000 | 0.8637 | 0.8966 | 98.0719 | |
| mutual_ info | [42, 33, 34, 30, 31] | 0.8752 | 0.8003 | 0.9999 | 0.8890 | 1280.683 | |
| entropy | [2, 15, 43 42, 6, 23, 24, 28, 29, 32, 33, 34, 35, 4, 25, 26, 30, 31, 18, 19, 20, 21, 22] | 0.9299 | 0.9960 | 0.8637 | 0.8946 | 348.2347 | |
| importance_ RF | [2, 15, 43, 42, 33, 19] | 0.9318 | 1.0000 | 0.8637 | 0.8966 | 804.577 |
| Group | Method | Feature ID | Accuracy | Precision | Recall | F1 Score | Time |
|---|---|---|---|---|---|---|---|
| Group 1 | chi2 | [36, 19, 20, 10, 31] | 0.8047 | 0.7865 | 0.8648 | 0.8183 | 17.6258 |
| f_classif | [36, 6, 19, 20, 10] | 0.7702 | 0.7845 | 0.7963 | 0.7685 | 23.7648 | |
| mutual_ info | [10, 11, 31, 32, 34] | 0.7889 | 0.7733 | 0.8541 | 0.8043 | 166.4645 | |
| entropy | [36, 6, 14, 19, 20, 40, 10, 11, 31, 32, 33, 34, 35, 27, 28] | 0.8426 | 0.8312 | 0.8884 | 0.8513 | 74.7406 | |
| importance_ RF | [6, 10, 11, 31, 32, 34] | 0.7867 | 0.7733 | 0.8491 | 0.8016 | 207.4284 | |
| Group 2 | chi2 | [10, 11, 31, 7, 24] | 0.7911 | 0.7707 | 0.8643 | 0.8086 | 16.0989 |
| f_classif | [10, 31, 34, 28, 24] | 0.7888 | 0.7709 | 0.8590 | 0.8056 | 22.0848 | |
| mutual_ info | [10, 11, 7, 23, 24] | 0.7900 | 0.7706 | 0.8625 | 0.8073 | 136.3324 | |
| entropy | [10, 11, 31, 32, 33, 34, 35, 27, 28, 5, 7, 23, 24] | 0.7885 | 0.7747 | 0.8501 | 0.8032 | 79.4134 | |
| importance_ RF | [10, 11, 23, 24] | 0.7899 | 0.7706 | 0.8624 | 0.8072 | 240.6583 | |
| Group 3 | chi2 | [10, 19, 20, 36, 24] | 0.8051 | 0.7865 | 0.8657 | 0.8189 | 24.1376 |
| f_classif | [10, 19, 20, 6, 24] | 0.8012 | 0.7846 | 0.8590 | 0.8146 | 18.6429 | |
| mutual_ info | [10, 11, 8, 9, 23] | 0.7900 | 0.7708 | 0.8626 | 0.8074 | 225.8134 | |
| entropy | [10, 11, 31, 32, 33, 34, 35, 27, 28, 14, 19, 20, 40, 17, 18, 8, 9, 6, 36, 23, 24] | 0.8544 | 0.8447 | 0.8926 | 0.8612 | 98.0131 | |
| importance_ RF | [10, 11, 34, 18, 8, 9, 23, 24] | 0.7890 | 0.7732 | 0.8552 | 0.8049 | 238.2793 |
| Dataset | Group | Votes | Total | ||
|---|---|---|---|---|---|
| V5 | V4 | V3 | |||
| Bot_IoT | G1 | [2, 34] | [15] | [42, 23, 32, 33, 35] | 8 |
| G2 | [2] | [15, 19, 22] | [18] | 5 | |
| G3 | N/A | [2, 15, 19, 34] | [22, 33, 42] | 7 | |
| UNSW-NB15 | G1 | [10] | [31] | [36, 6, 19, 20, 11, 32, 34] | 9 |
| G2 | [10,24] | [11] | [31, 7, 23] | 6 | |
| G3 | [10] | [24] | [20, 11, 23, 9, 8, 19] | 8 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almalki, L.; Alnahdi, A.; Albalawi, T. Role-Driven Clustering of Stakeholders: A Study of IoT Security Improvement. Sensors 2023, 23, 5578. https://doi.org/10.3390/s23125578
Almalki L, Alnahdi A, Albalawi T. Role-Driven Clustering of Stakeholders: A Study of IoT Security Improvement. Sensors. 2023; 23(12):5578. https://doi.org/10.3390/s23125578
Chicago/Turabian StyleAlmalki, Latifah, Amany Alnahdi, and Tahani Albalawi. 2023. "Role-Driven Clustering of Stakeholders: A Study of IoT Security Improvement" Sensors 23, no. 12: 5578. https://doi.org/10.3390/s23125578
APA StyleAlmalki, L., Alnahdi, A., & Albalawi, T. (2023). Role-Driven Clustering of Stakeholders: A Study of IoT Security Improvement. Sensors, 23(12), 5578. https://doi.org/10.3390/s23125578