

Using Hybrid HMM/DNN Embedding Extractor Models in Computational Paralinguistic Tasks


Abstract
1. Introduction
2. Processing Paralinguistic Data
2.1. HMM/DNN Hybrid Model
2.2. DNN Embedding Extraction
2.3. DNN Embedding Aggregation
3. The Databases Used
3.1. AIBO
3.2. URTIC
3.3. iHEARu-EAT
3.4. BEA
4. Experimental Setup
4.1. Frame-Level Features
4.2. HMM/DNN Hybrid Model
4.3. Embedding Aggregation
- Arithmetic mean:
- Standard deviation:
- Kurtosis
- Skewness
- Zero ratio , where
4.4. Classification
4.5. Baseline Method
5. Experimental Results
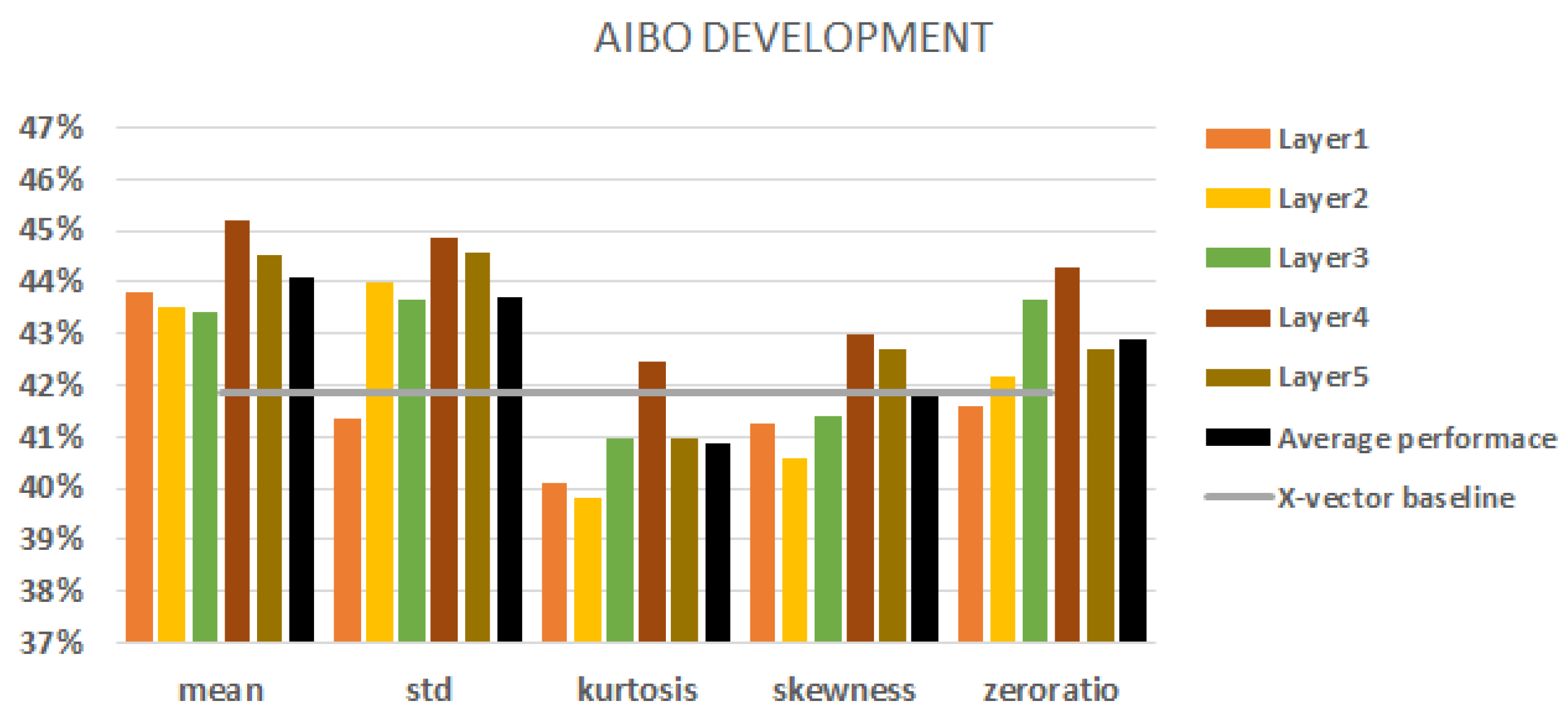
5.1. AIBO

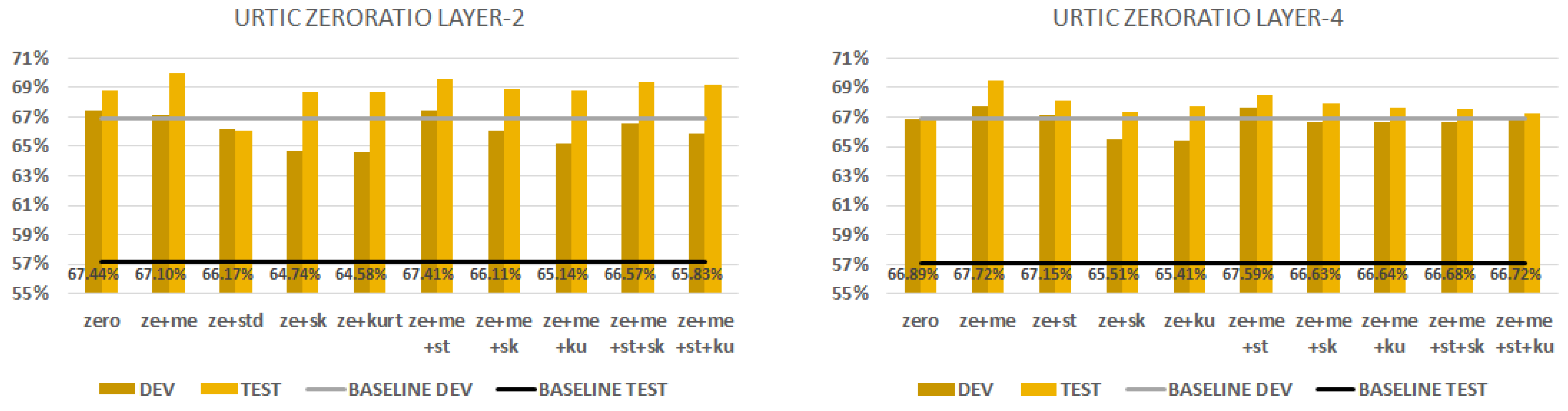
5.2. URTIC

5.3. iHEARu-EAT

6. Combined Results
6.1. AIBO
6.2. URTIC
6.3. iHEARu-EAT
7. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Han, K.J.; Kim, S.; Narayanan, S.S. Strategies to Improve the Robustness of Agglomerative Hierarchical Clustering Under Data Source Variation for Speaker Diarization. IEEE Trans. Audio, Speech, Lang. Process. 2008, 16, 1590–1601. [Google Scholar] [CrossRef]
- Lin, Y.C.; Hsu, Y.T.; Fu, S.W.; Tsao, Y.; Kuo, T.W. IA-NET: Acceleration and Compression of Speech Enhancement Using Integer-Adder Deep Neural Network. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 1801–1805. [Google Scholar] [CrossRef]
- Van Segbroeck, M.; Travadi, R.; Vaz, C.; Kim, J.; Black, M.P.; Potamianos, A.; Narayanan, S.S. Classification of Cognitive Load from Speech Using an i-Vector Framework. In Proceedings of the Fifteenth Annual Conference of the Interspeech 2014, Singapore, 14–18 September 2014; pp. 751–755. [Google Scholar] [CrossRef]
- Gosztolya, G.; Grósz, T.; Busa-Fekete, R.; Tóth, L. Detecting the intensity of cognitive and physical load using AdaBoost and Deep Rectifier Neural Networks. In Proceedings of the Fifteenth Annual Conference of the Interspeech 2014, Singapore, 14–18 September 2014; pp. 452–456. [Google Scholar] [CrossRef]
- Jeancolas, L.; Mangone, D.P.D.G.; Benkelfat, B.E.; Corvol, J.C.; Vidailhet, M.; Lehéricy, S.; Benali, H. X-Vectors: New Quantitative Biomarkers for Early Parkinson’s Disease Detection From Speech. Front. Neuroinform. 2021, 15, 578369. [Google Scholar] [CrossRef] [PubMed]
- Vásquez-Correa, J.; Orozco-Arroyave, J.R.; Nöth, E. Convolutional Neural Network to Model Articulation Impairments in Patients with Parkinson’s Disease. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 314–318. [Google Scholar] [CrossRef]
- Kadiri, S.; Kethireddy, R.; Alku, P. Parkinson’s Disease Detection from Speech Using Single Frequency Filtering Cepstral Coefficients. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 4971–4975. [Google Scholar] [CrossRef]
- Pappagari, R.; Cho, J.; Joshi, S.; Moro-Velázquez, L.; Żelasko, P.; Villalba, J.; Dehak, N. Automatic Detection and Assessment of Alzheimer Disease Using Speech and Language Technologies in Low-Resource Scenarios. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 3825–3829. [Google Scholar] [CrossRef]
- Chen, J.; Ye, J.; Tang, F.; Zhou, J. Automatic Detection of Alzheimer’s Disease Using Spontaneous Speech Only. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; Volume 2021, pp. 3830–3834. [Google Scholar] [CrossRef]
- Pérez-Toro, P.; Klumpp, P.; Hernandez, A.; Arias, T.; Lillo, P.; Slachevsky, A.; García, A.; Schuster, M.; Maier, A.; Nöth, E.; et al. Alzheimer’s Detection from English to Spanish Using Acoustic and Linguistic Embeddings. In Proceedings of the Interspeech 2022, Incheon, Republic of Korea, 18–22 September 2022; pp. 2483–2487. [Google Scholar] [CrossRef]
- Yamout, B.; Fuleihan, N.; Hajj, T.; Sibai, A.; Sabra, O.; Rifai, H.; Hamdan, A.L. Vocal Symptoms and Acoustic Changes in Relation to the Expanded Disability Status Scale, Duration and Stage of Disease in Patients with Multiple Sclerosis. Eur. Arch. Otorhinolaryngol 2009, 266, 1759–1765. [Google Scholar] [CrossRef] [PubMed]
- Egas-López, J.V.; Kiss, G.; Sztahó, D.; Gosztolya, G. Automatic Assessment of the Degree of Clinical Depression from Speech Using X-Vectors. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 8502–8506. [Google Scholar] [CrossRef]
- Přibil, J.; Přibilová, A.; Matoušek, J. GMM-Based Speaker Age and Gender Classification in Czech and Slovak. J. Electr. Eng. 2017, 68, 3–12. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. CLSTM: Deep Feature-Based Speech Emotion Recognition Using the Hierarchical ConvLSTM Network. Mathematics 2020, 8, 2133. [Google Scholar] [CrossRef]
- Zhao, Z.; Bao, Z.; Zhang, Z.; Cummins, N.; Wang, H.; Schuller, B. Attention-Enhanced Connectionist Temporal Classification for Discrete Speech Emotion Recognition. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 206–210. [Google Scholar] [CrossRef]
- Gosztolya, G.; Beke, A.; Neuberger, T. Differentiating laughter types via HMM/DNN and probabilistic sampling. In Proceedings of the Speech and Computer: 21st International Conference, SPECOM 2019, Istanbul, Turkey, 20–25 August 2019; pp. 122–132. [Google Scholar] [CrossRef]
- Egas-López, J.V.; Gosztolya, G. Deep Neural Network Embeddings for the Estimation of the Degree of Sleepiness. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7288–7292. [Google Scholar] [CrossRef]
- Grezes, F.; Richards, J.; Rosenberg, A. Let me finish: Automatic conflict detection using speaker overlap. In Proceedings of the Interspeech 2013, Lyon, France, 25–29 August 2013; pp. 200–204. [Google Scholar] [CrossRef]
- Bone, D.; Black, M.P.; Li, M.; Metallinou, A.; Lee, S.; Narayanan, S. Intoxicated speech detection by fusion of speaker normalized hierarchical features and GMM supervectors. In Proceedings of the Twelfth Annual Conference of Interspeech 2011, Lorence, Italy, 28–31 August 2011; pp. 3217–3220. [Google Scholar] [CrossRef]
- Schuller, B.; Steidl, S.; Batliner, A. The INTERSPEECH 2009 Emotion Challenge. In Proceedings of the Computational Paralinguistics Challenge (ComParE), Interspeech 2009, Brighton, UK, 6–10 September 2009; pp. 312–315. [Google Scholar] [CrossRef]
- Schuller, B.; Steidl, S.; Batliner, A.; Hantke, S.; Hönig, F.; Orozco-Arroyave, J.R.; Nöth, E.; Zhang, Y.; Weninger, F. The INTERSPEECH 2015 computational paralinguistics challenge: Nativeness, Parkinson’s & eating condition. In Proceedings of the Computational Paralinguistics Challenge (ComParE), Interspeech 2015, Dresden, Germany, 6–10 September 2015; pp. 478–482. [Google Scholar] [CrossRef]
- Schuller, B.W.; Batliner, A.; Bergler, C.; Mascolo, C.; Han, J.; Lefter, I.; Kaya, H.; Amiriparian, S.; Baird, A.; Stappen, L.; et al. The INTERSPEECH 2021 Computational Paralinguistics Challenge: COVID-19 Cough, COVID-19 Speech, Escalation Primates. In Proceedings of the Computational Paralinguistics Challenge (ComParE), Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 431–435. [Google Scholar] [CrossRef]
- Rabiner, L.; Juang, B.H. Fundamentals of Speech Recognition; Prentice Hall Signal Processing Series; Pearson College Div: Engelwood Cliffs, NJ, USA, 1993. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Cox, S. Hidden Markov Models for Automatic Speech Recognition: Theory and Application; Royal Signals & Radar Establishment: Malvern, UK, 1988. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Boser, B.; Guyon, I.; Vapnik, V. A Training Algorithm for Optimal Margin Classifier. In Proceedings of the Fifth Annual ACM Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; Volume 5, pp. 144–152. [Google Scholar] [CrossRef]
- Egas-López, J.V.; Balogh, R.; Imre, N.; Hoffmann, I.; Szabó, M.K.; Tóth, L.; Pákáski, M.; Kálmán, J.; Gosztolya, G. Automatic Screening of Mild Cognitive Impairment and Alzheimer’s Disease by Means of Posterior-Thresholding Hesitation Representation. Comput. Speech Lang. 2022, 75, 101377. [Google Scholar] [CrossRef]
- Gosztolya, G. Posterior-Thresholding Feature Extraction for Paralinguistic Speech Classification. Knowl.-Based Syst. 2019, 186, 104943. [Google Scholar] [CrossRef]
- Gauvain, J.L.; Lee, C.H. Maximum a posteriori estimation for multivariate Gaussian mixture observations of Markov chains. IEEE Trans. Speech Audio Process. 1994, 2, 291–298. [Google Scholar] [CrossRef]
- Morgan, N.; Bourlard, H. Continuous speech recognition using multilayer perceptrons with hidden Markov models. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, NM, USA, 3–6 April 1990; Volume 1, pp. 413–416. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comp. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26–28 October 2014. [Google Scholar] [CrossRef]
- Panzner, M.; Cimiano, P. Comparing Hidden Markov Models and Long Short Term Memory Neural Networks for Learning Action Representations. In Proceedings of the Second International Workshop of Machine Learning, Optimization, and Big Data, MOD 2016, Volterra, Italy, 26–29 August 2016; Volume 10122, pp. 94–105. [Google Scholar] [CrossRef]
- Schmitt, M.; Cummins, N.; Schuller, B. Continuous Emotion Recognition in Speech—Do We Need Recurrence? In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 2808–2812. [Google Scholar] [CrossRef]
- Steidl, S. Automatic Classification of Emotion Related User States in Spontaneous Children’s Speech; Logos: Berlin, Germany, 2009. [Google Scholar]
- Krajewski, J.; Schieder, S.; Batliner, A. Description of the Upper Respiratory Tract Infection Corpus (URTIC). In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Hantke, S.; Weninger, F.; Kurle, R.; Ringeval, F.; Batliner, A.; Mousa, A.; Schuller, B. I Hear You Eat and Speak: Automatic Recognition of Eating Condition and Food Type, Use-Cases, and Impact on ASR Performance. PLoS ONE 2016, 11, e0154486. [Google Scholar] [CrossRef] [PubMed]
- Neuberger, T.; Gyarmathy, D.; Gráczi, T.E.; Horváth, V.; Gósy, M.; Beke, A. Development of a Large Spontaneous Speech Database of Agglutinative Hungarian Language. In Proceedings of the 17th International Conference, TSD 2014, Brno, Czech Republic, 8–12 September 2014; pp. 424–431. [Google Scholar] [CrossRef]
- Deng, L.; Droppo, J.; Acero, A. A Bayesian approach to speech feature enhancement using the dynamic cepstral prior. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002; Volume 1, pp. I-829–I-832. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Metze, F.; Batliner, A.; Eyben, F.; Polzehl, T.; Schuller, B.; Steidl, S. Emotion Recognition using Imperfect Speech Recognition. In Proceedings of the Interspeech 2010, Chiba, Japan, 26–30 September 2010; pp. 478–481. [Google Scholar] [CrossRef]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-Vectors: Robust DNN Embeddings for Speaker Recognition. In Proceedings of the 2018 IEEE international conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Language | No. of Classes | No. of Utterances | No. of Speakers | Total Duration (hh:mm:ss) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train | Dev | Test | Train | Dev | Test | Train | Dev | Test | |||
| AIBO | German | 5 | 7578 | 2381 | 8257 | 26 | 6 | 25 | 03:45:18 | 01:11:46 | 03:53:44 |
| URTIC | German | 2 | 9505 | 9596 | 9551 | 210 | 210 | 210 | 14:41:34 | 14:54:47 | 14:48:18 |
| iHEARu-EAT | German | 7 | 657 | 287 | 469 | 14 | 6 | 10 | 01:20:37 | 00:31:44 | 01:00:39 |
| AIBO | URTIC | iHEARu-EAT | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Layer | DEV | TEST | Layer | DEV | TEST | Layer | DEV | TEST | |
| mean | 4 | 45.2% | 44.0% | 4 | 67.3% | 69.3% | 2 | 71.4% | 79.0% |
| std | 4 | 44.8% | 44.4% | 2 | 2 | 73.3% | 74.4% | ||
| kurtosis | 4 | 1 | 4 | ||||||
| skewness | 4 | 1 | 4 | ||||||
| zero ratio | 4 | 2 | 67.4% | 68.8% | 3 | ||||
| all | 5 | 45.5% | 44.2% | 4 | 4 | 76.6% | 74.6% | ||
| x-vector | – | – | – | ||||||
| AIBO | URTIC | iHEARu-EAT | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Layer | Combination | DEV | TEST | Layer | Combination | DEV | TEST | Layer | Combination | DEV | TEST |
| 4 | mean | 45.2% | 44.0% | 2 | zero | 67.4% | 68.8% | 2 | std | ||
| 4 | me-ze | 2 | ze-me | 2 | st-ku | ||||||
| 4 | me-ze-st | 2 | ze-me-st | 67.4% | 69.6% | 2 | st-ku-ze | ||||
| 4 | me-ze-st-ku | 2 | ze-me-st-sk | 2 | st-ku-ze-me | 74.9% | 78.3% | ||||
| 5 | mean | 4 | zero | 4 | std | ||||||
| 5 | me-sk | 4 | ze-me | 67.7% | 69.5% | 4 | st-sk | ||||
| 5 | me-sk-st | 4 | ze-me-st | 4 | st-sk-ze | 76.0% | 75.0% | ||||
| 5 | me-sk-st-ku | 45.3% | 44.2% | 4 | ze-me-st-sk | 4 | st-sk-ze-me | 76.0% | 74.3% | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vetráb, M.; Gosztolya, G. Using Hybrid HMM/DNN Embedding Extractor Models in Computational Paralinguistic Tasks. Sensors 2023, 23, 5208. https://doi.org/10.3390/s23115208
Vetráb M, Gosztolya G. Using Hybrid HMM/DNN Embedding Extractor Models in Computational Paralinguistic Tasks. Sensors. 2023; 23(11):5208. https://doi.org/10.3390/s23115208
Chicago/Turabian StyleVetráb, Mercedes, and Gábor Gosztolya. 2023. "Using Hybrid HMM/DNN Embedding Extractor Models in Computational Paralinguistic Tasks" Sensors 23, no. 11: 5208. https://doi.org/10.3390/s23115208
APA StyleVetráb, M., & Gosztolya, G. (2023). Using Hybrid HMM/DNN Embedding Extractor Models in Computational Paralinguistic Tasks. Sensors, 23(11), 5208. https://doi.org/10.3390/s23115208