
Differentiation between Phyllodes Tumors and Fibroadenomas through Breast Ultrasound: Deep-Learning Model Outperforms Ultrasound Physicians


Abstract
1. Introduction
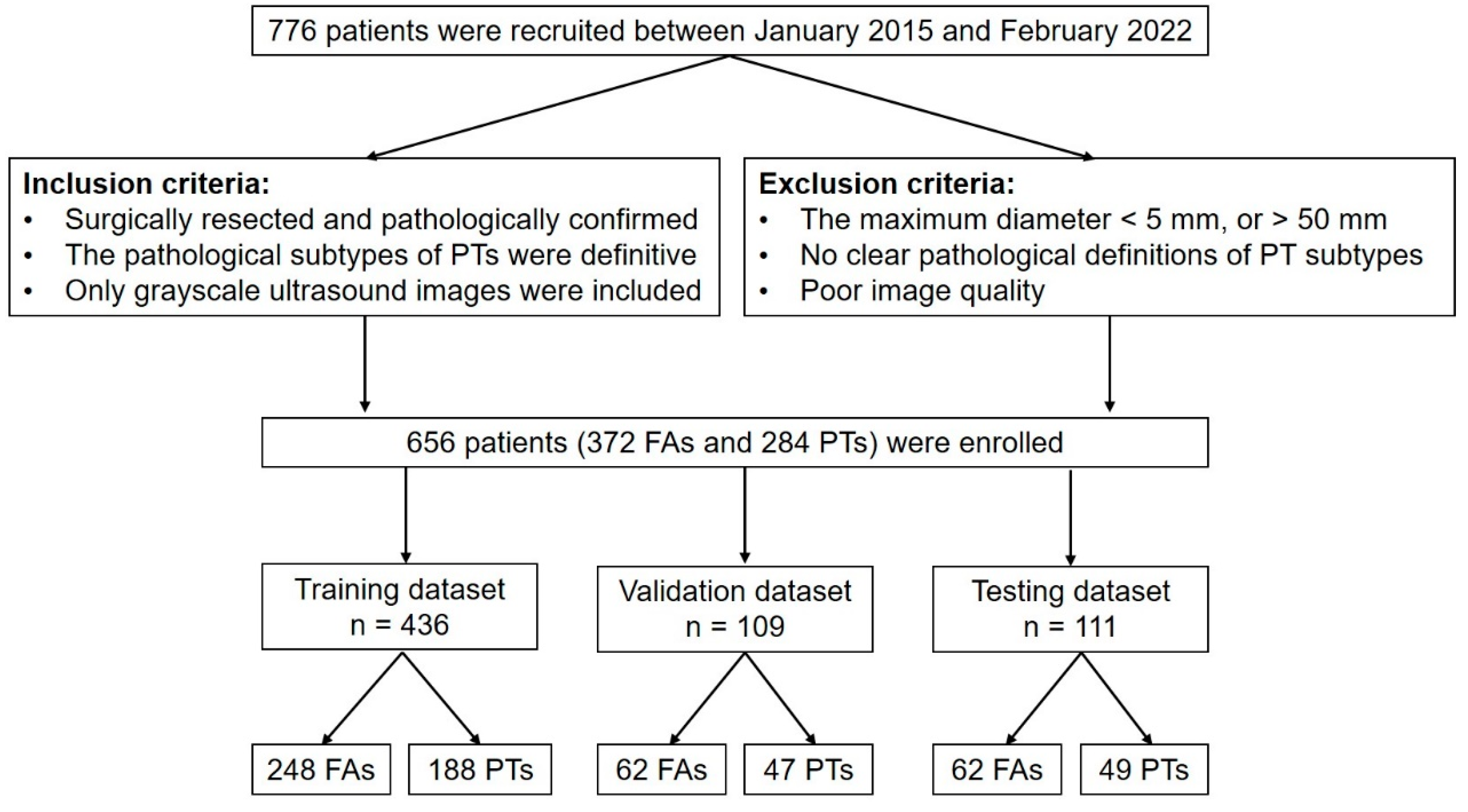
2. Materials and Methods
Participants
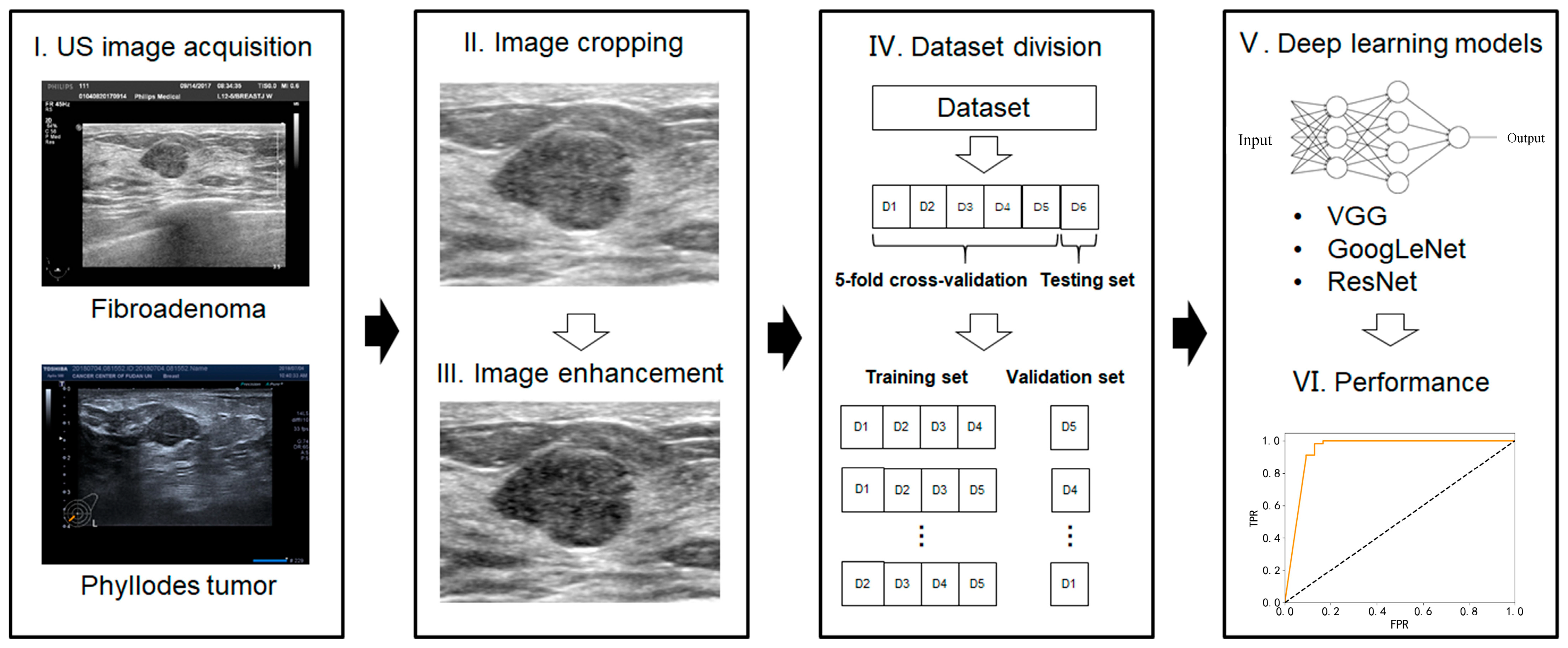
3. US Images Acquisition
3.1. Images Preprocessing
- Image cropping—in order to avoid the influence of nontumor areas in US images and reduce the computational load, the rectangular ROIs (regions of interest) were manually cropped from raw US images.
- Image enhancement—the grayscale transformation function was used to enhance the contrast between the foreground and the background of US images. The image enhancement can improve image quality, enrich information, and enhance image interpretation and the recognition effect (Figure 2).
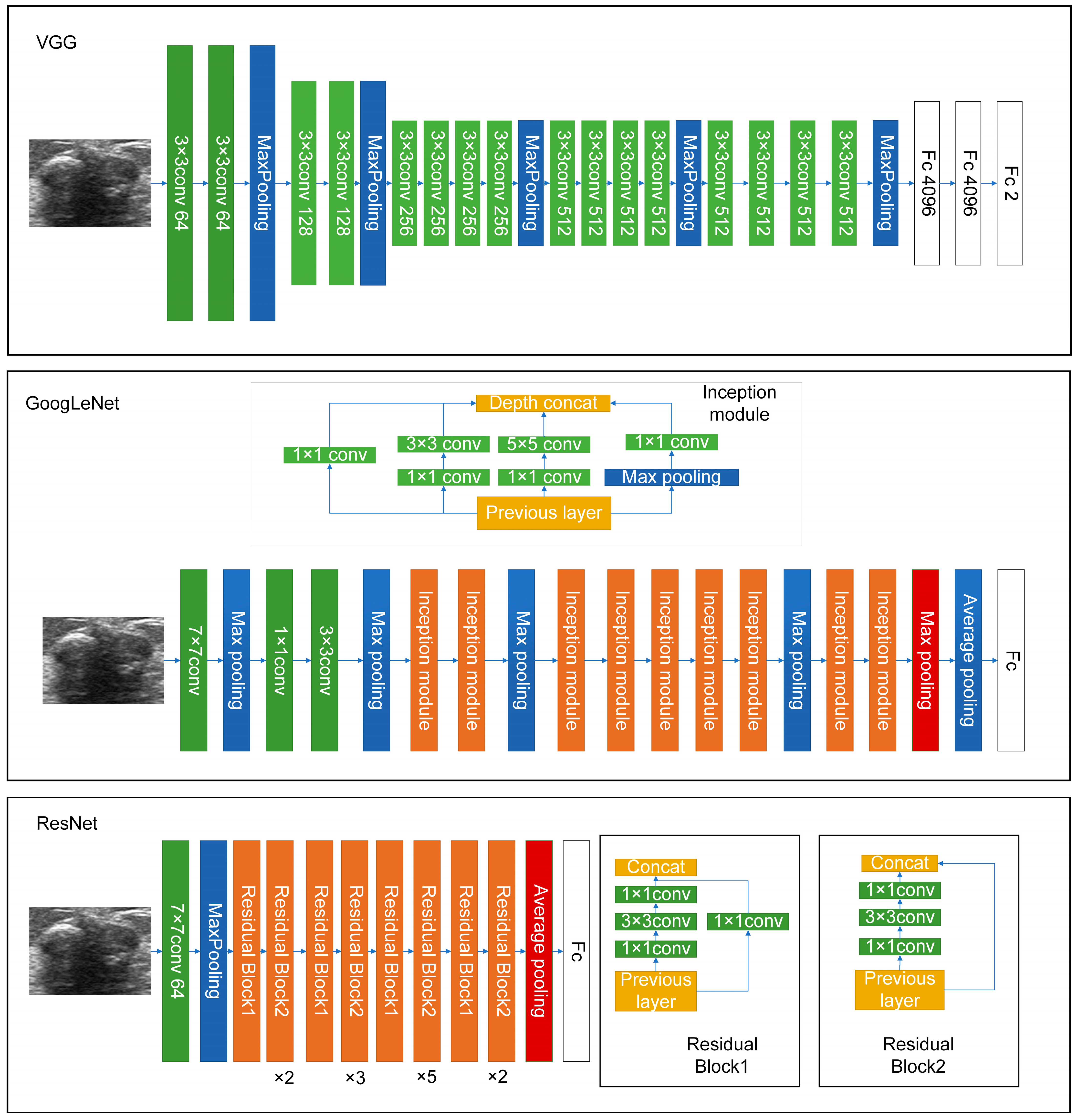
3.2. Deep-Learning Models for US Image Analysis
3.3. Visual Assessment by US Physicians
3.4. Statistical Analysis
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACC | Accuracy |
| AI | Artificial intelligence |
| AUC | Area under the curve |
| BI-RADS | Breast Imaging Reporting and Data System |
| DICOM | Digital imaging and communication in medicine |
| FA | Fibroadenoma |
| MRI | Magnetic resonance imaging |
| NPV | Negative predictive value |
| PPV | Positive predictive value |
| PT | Phyllodes tumor |
| ROC | Receiver operating characteristic |
| ROI | Regions of interest |
| SENS | Sensitivity |
| SPEC | Specificity |
| US | Ultrasound |
References
- Liberman, L.; Bonaccio, E.; Hamele-Bena, D.; Abramson, A.F.; Cohen, M.A.; Dershaw, D.D. Benign and malignant phyllodes tumors: Mammographic and sonographic findings. Radiology 1996, 198, 121–124. [Google Scholar] [CrossRef] [PubMed]
- Buchanan, E.B. Cystosarcoma phyllodes and its surgical management. Am. Surg. 1995, 61, 350–355. [Google Scholar] [PubMed]
- Azzopardi, J.G.; Chepick, O.F.; Hartmann, W.H.; Jafarey, N.A.; Llombart-Bosch, A.; Ozzello, L.; Rilke, F.; Sasano, N.; Sobin, L.H.; Sommers, S.C.; et al. The World Health Organization Histological Typing of Breast Tumors—Second Edition. Am. J. Clin. Pathol. 1982, 78, 806–816. [Google Scholar] [CrossRef]
- Xiao, M.; Zhu, Q.; Jiang, Y.; Li, J.; Wang, H.; Zhang, J.; You, S.; Liu, H. Local Recurrent Phyllodes Tumors of the Breast: Clinical and Sonographic Features. J. Ultrasound Med. 2015, 34, 1631–1638. [Google Scholar] [CrossRef]
- Tan, P.H.; Thike, A.A.; Tan, W.J.; Thu, M.M.; Busmanis, I.; Li, H.; Chay, W.Y.; Tan, M.H.; Phyllodes Tumour Network Singapore. Predicting clinical behaviour of breast phyllodes tumours: A nomogram based on histological criteria and surgical margins. J. Clin. Pathol. 2012, 65, 69–76. [Google Scholar] [CrossRef] [PubMed]
- Rayzah, M. Phyllodes Tumors of the Breast: A Literature Review. Cureus 2020, 12, e10288. [Google Scholar] [CrossRef] [PubMed]
- Giri, D. Recurrent challenges in the evaluation of fibroepithelial lesions. Arch. Pathol. Lab. Med. 2009, 133, 713–721. [Google Scholar] [CrossRef]
- Lian, J.; Li, K. A Review of Breast Density Implications and Breast Cancer Screening. Clin. Breast Cancer 2020, 20, 283–290. [Google Scholar] [CrossRef]
- Li, T.; Li, Y.; Yang, Y.; Li, J.; Hu, Z.; Wang, L.; Pu, W.; Wei, T.; Lu, M. Logistic regression analysis of ultrasound findings in predicting the malignant and benign phyllodes tumor of breast. PLoS ONE 2022, 17, e0265952. [Google Scholar] [CrossRef]
- Duman, L.; Gezer, N.S.; Balci, P.; Altay, C.; Basara, I.; Durak, M.G.; Sevinc, A.I. Differentiation between Phyllodes Tumors and Fibroadenomas Based on Mammographic Sonographic and MRI Features. Breast Care 2016, 11, 123–127. [Google Scholar] [CrossRef]
- Tummidi, S.; Kothari, K.; Agnihotri, M.; Naik, L.; Sood, P. Fibroadenoma vs. phyllodes tumor: A vexing problem revisited! BMC Cancer 2020, 20, 648. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Yang, C.; Pfeifer, J.D.; Caprioli, R.M.; Judd, A.M.; Patterson, N.H.; Reyzer, M.L.; Norris, J.L.; Maluf, H.M. Histopathologic, immunophenotypic, and proteomics characteristics of low-grade phyllodes tumor and fibroadenoma: More similarities than differences. NPJ Breast Cancer 2020, 6, 27. [Google Scholar] [CrossRef]
- Lo Gullo, R.; Daimiel, I.; Rossi Saccarelli, C.; Bitencourt, A.; Gibbs, P.; Fox, M.J.; Thakur, S.B.; Martinez, D.F.; Jochelson, M.S.; Morris, E.A.; et al. Improved characterization of sub-centimeter enhancing breast masses on MRI with radiomics and machine learning in BRCA mutation carriers. Eur. Radiol. 2020, 30, 6721–6731. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Wolfgruber, T.K.; Leong, L.; Jensen, M.; Scott, C.; Winham, S.; Sadowski, P.; Vachon, C.; Kerlikowske, K.; Shepherd, J.A. Deep Learning Predicts Interval and Screening-detected Cancer from Screening Mammograms: A Case-Case-Control Study in 6369 Women. Radiology 2021, 301, 550–558. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.; Yao, Z.; Huang, Y.; Yu, Y.; Wang, Y.; Liu, Y.; Mao, R.; Li, F.; Xiao, Y.; Wang, Y.; et al. Deep learning radiomics can predict axillary lymph node status in early-stage breast cancer. Nat. Commun. 2020, 11, 1236. [Google Scholar] [CrossRef]
- Gu, J.; Tong, T.; He, C.; Xu, M.; Yang, X.; Tian, J.; Jiang, T.; Wang, K. Deep learning radiomics of ultrasonography can predict response to neoadjuvant chemotherapy in breast cancer at an early stage of treatment: A prospective study. Eur. Radiol. 2022, 32, 2099–2109. [Google Scholar] [CrossRef]
- Jiang, M.; Zhang, D.; Tang, S.C.; Luo, X.M.; Chuan, Z.R.; Lv, W.Z.; Jiang, F.; Ni, X.J.; Cui, X.W.; Dietrich, C.F. Deep learning with convolutional neural network in the assessment of breast cancer molecular subtypes based on US images: A multicenter retrospective study. Eur. Radiol. 2021, 31, 3673–3682. [Google Scholar] [CrossRef]
- Ma, X.; Gong, J.; Hu, F.; Tang, W.; Gu, Y.; Peng, W. Pretreatment Multiparametric MRI-Based Radiomics Analysis for the Diagnosis of Breast Phyllodes Tumors. J. Magn. Reson. Imaging 2023, 57, 633–645. [Google Scholar] [CrossRef]
- Li, X.; Jiang, N.; Zhang, C.; Luo, X.; Zhong, P.; Fang, J. Value of conventional magnetic resonance imaging texture analysis in the differential diagnosis of benign and borderline/malignant phyllodes tumors of the breast. Cancer Imaging 2021, 21, 29. [Google Scholar] [CrossRef]
- Tsuchiya, M.; Masui, T.; Terauchi, K.; Yamada, T.; Katyayama, M.; Ichikawa, S.; Noda, Y.; Goshima, S. MRI-based radiomics analysis for differentiating phyllodes tumors of the breast from fibroadenomas. Eur. Radiol. 2022, 32, 4090–4100. [Google Scholar] [CrossRef]
- Mai, H.; Mao, Y.; Dong, T.; Tan, Y.; Huang, X.; Wu, S.; Huang, S.; Zhong, X.; Qiu, Y.; Luo, L.; et al. The Utility of Texture Analysis Based on Breast Magnetic Resonance Imaging in Differentiating Phyllodes Tumors From Fibroadenomas. Front. Oncol. 2019, 9, 1021. [Google Scholar] [CrossRef] [PubMed]
- Stoffel, E.; Becker, A.S.; Wurnig, M.C.; Marcon, M.; Ghafoor, S.; Berger, N.; Boss, A. Distinction between phyllodes tumor and fibroadenoma in breast ultrasound using deep learning image analysis. Eur. J. Radiol. Open 2018, 5, 165–170. [Google Scholar] [CrossRef] [PubMed]
- Niu, S.; Huang, J.; Li, J.; Liu, X.; Wang, D.; Wang, Y.; Shen, H.; Qi, M.; Xiao, Y.; Guan, M.; et al. Differential diagnosis between small breast phyllodes tumors and fibroadenomas using artificial intelligence and ultrasound data. Quant. Imaging Med. Surg. 2021, 11, 2052–2061. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Mendelson, E.B.; Böhm-Vélez, M.; Berg, W.A. ACR BI-RADS Ultrasound. In ACR BI-RADS Atlas, Breast Imaging Reporting and Data System; American College of Radiology: Reston, VA, USA, 2013; pp. 128–130. [Google Scholar]
- Chao, T.C.; Lo, Y.F.; Chen, S.C.; Chen, M.F. Sonographic features of phyllodes tumors of the breast. Ultrasound Obstet. Gynecol. 2002, 20, 64–71. [Google Scholar] [CrossRef]
- Park, H.L.; Kwon, S.H.; Chang, S.Y.; Huh, J.Y.; Kim, J.Y.; Shim, J.Y.; Lee, Y.H. Long-term follow-up result of benign phyllodes tumor of the breast diagnosed and excised by ultrasound-guided vacuum-assisted breast biopsy. J. Breast Cancer 2012, 15, 224–229. [Google Scholar] [CrossRef]
- Munir, K.; Elahi, H.; Ayub, A.; Frezza, F.; Rizzi, A. Cancer Diagnosis Using Deep Learning: A Bibliographic Review. Cancers 2019, 11, 1235. [Google Scholar] [CrossRef]
- Mimoun, C.; Zeller, A.; Seror, J.; Majoulet, L.; Marchand, E.; Mezzadri, M.; Cherel, P.; Place, V.; Cornelis, F.; Benifla, J.L.; et al. A Pre-operative Score to Discriminate Fibroepithelial Lesions of the Breast: Phyllode Tumor or Fibroadenoma? Anticancer Res. 2020, 40, 1095–1100. [Google Scholar] [CrossRef]
- Rana, C.; Kamal, N.; Mishra, P.; Singh, A.; Ramakant, P.; Mishra, A.; Singh, K. Cellular fibroadenoma vs. phyllodes tumors: A pre-operative diagnostic approach based on radiological and cytological features. Diagn. Cytopathol. 2022, 50, 375–385. [Google Scholar] [CrossRef]
- Ma, X.; Shen, L.; Hu, F.; Tang, W.; Gu, Y.; Peng, W. Predicting the pathological grade of breast phyllodes tumors: A nomogram based on clinical and magnetic resonance imaging features. Br. J. Radiol. 2021, 94, 20210342. [Google Scholar] [CrossRef] [PubMed]
- Kaya, M.; Bilge, H.Ş. Deep Metric Learning: A Survey. Symmetry 2019, 11, 1066. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | PT (n = 284) | FA (n = 372) | T/χ2 Value | p-Value |
|---|---|---|---|---|
| Age (years) | 46.4 ± 10.9 | 40.1 ± 12.9 | 6.6 | <0.0001 |
| Max diameter (mm) | 29.1 ± 9.9 | 18.9 ± 7.9 | 15.2 | <0.0001 |
| BI-RADS categories: | 61.1 | <0.0001 | ||
| 3 | 56 (20%) | 76 (20%) | ||
| 4A | 158 (56%) | 280 (75%) | ||
| 4B | 57 (20%) | 15 (4%) | ||
| 4C | 10 (3.5%) | 1 (0.3%) | ||
| 5 | 3 (1%) | 0 (0%) | ||
| Pathological types of PTs: | ||||
| Benign | 134 (47.2%) | |||
| Borderline | 120 (42.3%) | |||
| Malignant | 30 (10.5%) |
| Data Sets | Models | ACC1 (%) | ACC2 (%) | ACC3 (%) | ACC4 (%) | ACC5 (%) |
|---|---|---|---|---|---|---|
| Training (n = 436) | ResNet | 94.3 (90.0–96.8) | 95.2 (92.1–97.3) | 94.7 (91.6–97.7) | 95.0 (91.9–98.1) | 94.3 (91.0–97.5) |
| GoogLeNet | 83.9 (79.6–87.8) | 81.9 (77.5–86.1) | 83.5 (79.2–87.1) | 84.6 (80.3–88.0) | 84.4 (80.1–87.9) | |
| VGG | 66.1 (60.4–71.8) | 67.0 (61.3–72.7) | 66.3 (60.6–72.0) | 67.4 (61.7–73.1) | 65.4 (59.6–71.2) | |
| Validation (n = 109) | ResNet | 96.3 (90.5–99.2) | 92.7 (85.3–97.0) | 94.5 (88.8–98.3) | 93.6 (86.8–98.1) | 96.3 (88.8–98.1) |
| GoogLeNet | 78.9 (68.8–85.7) | 81.5 (73.3–89.7) | 78.0 (66.7–89.3) | 78.9 (67.8–90.0) | 78.9 (67.8–90.0) | |
| VGG | 65.1 (53.4–76.8) | 62.4 (50.4–74.4) | 65.1 (53.4–76.8) | 67.0 (55.2–78.8) | 66.1 (54.4–77.8) |
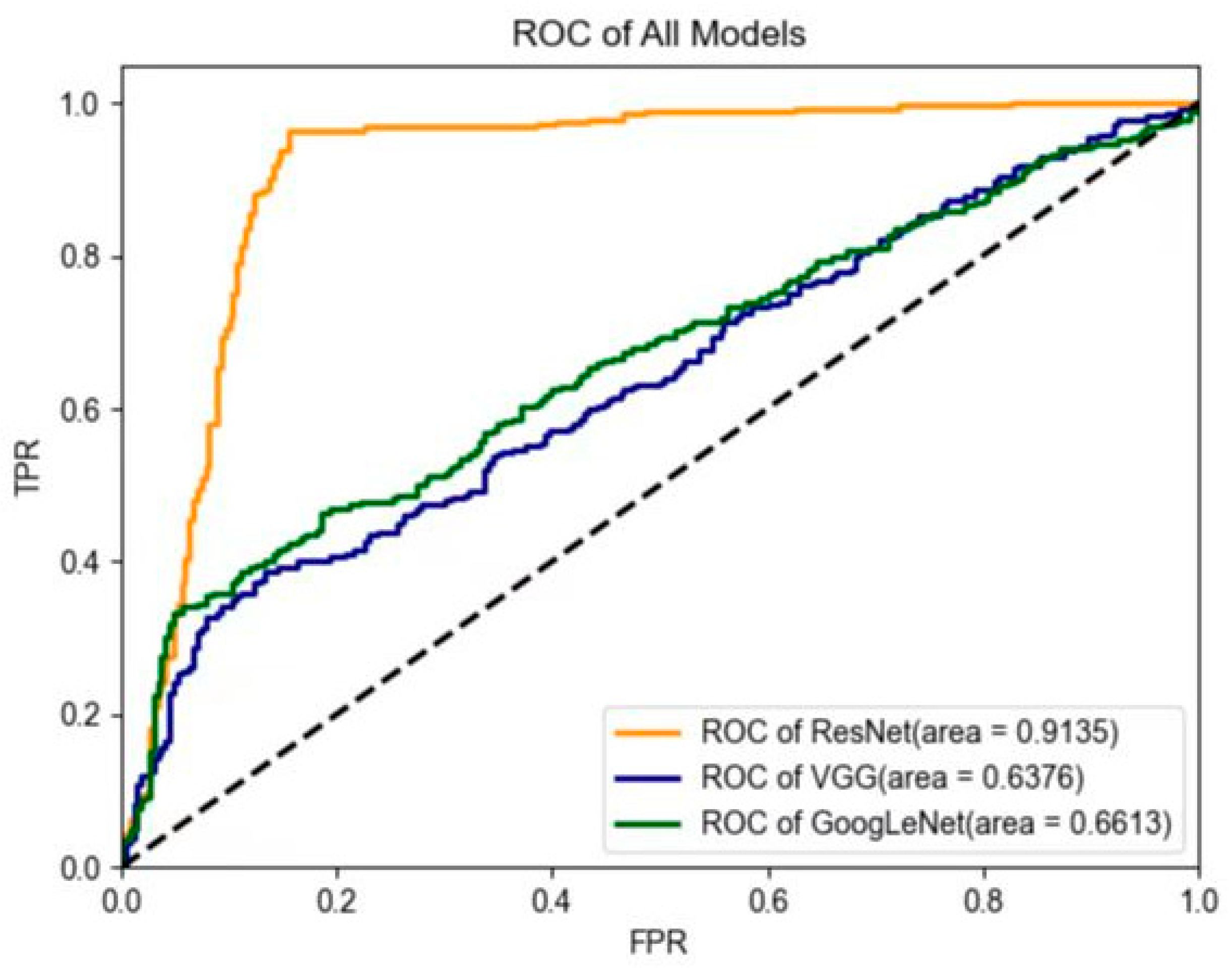
| Models | AUC | ACC (%) | SENS (%) | SPEC (%) | PPV (%) | NPV (%) |
|---|---|---|---|---|---|---|
| ResNet | 0.91 (0.88–0.95) | 95.3 (91.4–99.3) | 96.2 (92.5–99.8) | 94.7 (89.6–99.9) | 93.1 (77.1–98.6) | 97.1 (77.2–99.6) |
| GoogLeNet | 0.66 (0.59–0.73) | 76.0 (61.4–90.6) | 66.6 (48.3–84.9) | 96.1 (93.0–99.0) | 97.1 (94.8–99.5) | 59.4 (30.6–88.1) |
| VGG | 0.64 (0.58–0.69) | 73.7 (69.2–78.2) | 63.6 (58.5–68.8) | 94.4 (66.5–99.3) | 95.1 (90.8–99.9) | 56.8 (43.2–70.3) |
| Physicians | AUC | ACC (%) | SENS (%) | SPEC (%) | PPV (%) | NPV (%) |
|---|---|---|---|---|---|---|
| Physician #1 | 0.70 (0.65–0.74) | 72.6 (65.6–79.4) | 47.2 (40.1–54.8) | 91.9 (85.9–97.4) | 81.7 (72.8–89.3) | 69.5 (61.4–76.3) |
| Physician #2 | 0.68 (0.64–0.72) | 68.9 (62.7–75.1) | 61.6 (54.1–68.7) | 74.5 (67.7–80.7) | 64.8 (56.7–71.2) | 71.8 (65.8–77.3) |
| Average | 0.69 | 70.7 | 54.4 | 83.2 | 73.3 | 70.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Z.; Ma, Y.; Ma, X.; Jin, A.; Zhou, J.; Li, N.; Sheng, D.; Chang, C.; Chen, J.; Li, J. Differentiation between Phyllodes Tumors and Fibroadenomas through Breast Ultrasound: Deep-Learning Model Outperforms Ultrasound Physicians. Sensors 2023, 23, 5099. https://doi.org/10.3390/s23115099
Shi Z, Ma Y, Ma X, Jin A, Zhou J, Li N, Sheng D, Chang C, Chen J, Li J. Differentiation between Phyllodes Tumors and Fibroadenomas through Breast Ultrasound: Deep-Learning Model Outperforms Ultrasound Physicians. Sensors. 2023; 23(11):5099. https://doi.org/10.3390/s23115099
Chicago/Turabian StyleShi, Zhaoting, Yebo Ma, Xiaowen Ma, Anqi Jin, Jin Zhou, Na Li, Danli Sheng, Cai Chang, Jiangang Chen, and Jiawei Li. 2023. "Differentiation between Phyllodes Tumors and Fibroadenomas through Breast Ultrasound: Deep-Learning Model Outperforms Ultrasound Physicians" Sensors 23, no. 11: 5099. https://doi.org/10.3390/s23115099
APA StyleShi, Z., Ma, Y., Ma, X., Jin, A., Zhou, J., Li, N., Sheng, D., Chang, C., Chen, J., & Li, J. (2023). Differentiation between Phyllodes Tumors and Fibroadenomas through Breast Ultrasound: Deep-Learning Model Outperforms Ultrasound Physicians. Sensors, 23(11), 5099. https://doi.org/10.3390/s23115099