1. Introduction
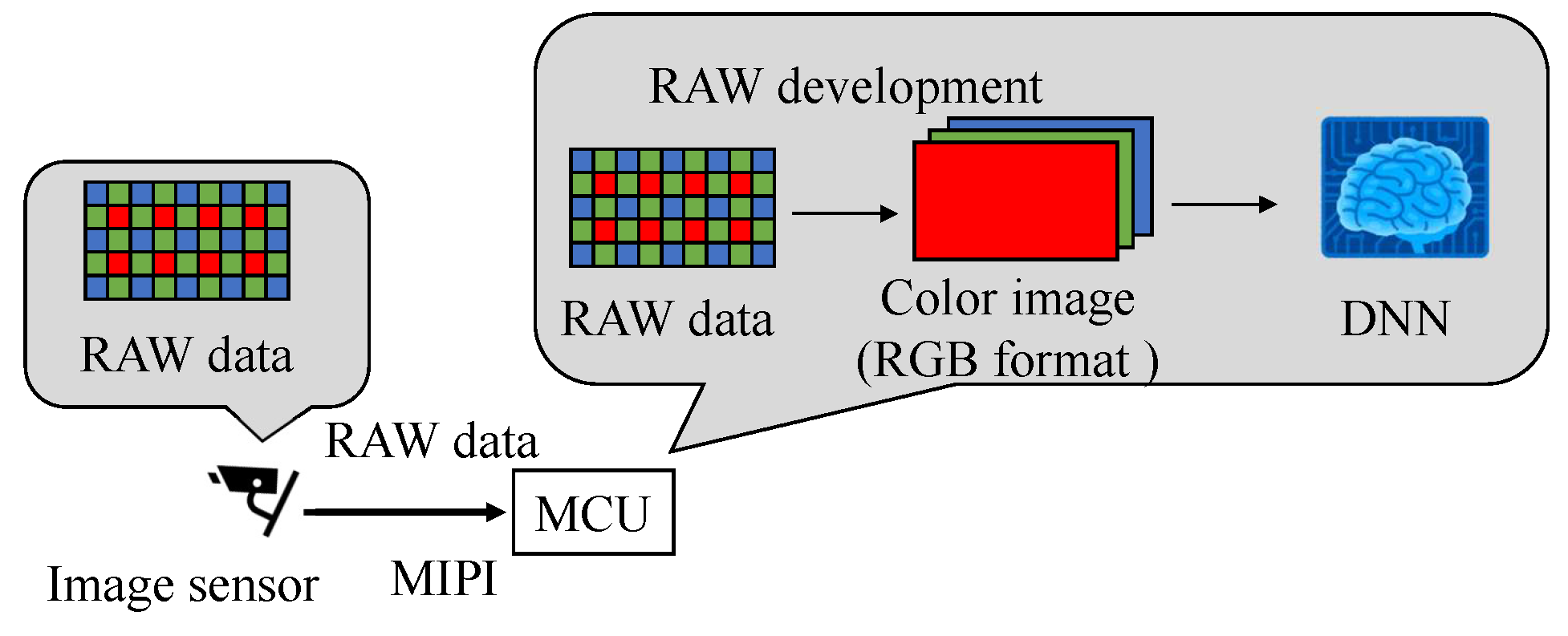
Modern automobiles are equipped with an advanced driver assistance system (ADAS) that helps with driving by recognizing surrounding vehicles and objects while driving. A system for automatic driving that is aware of speed limits has been developed, with the addition of notifying the driver of the recognition results. The system takes in the physical world information using image sensors, and the automobile is controlled by recognizing the surroundings with machine learning or deep neural networks (DNNs). The misclassification of DNN-equipped automobiles can have life-threatening consequences; therefore, security measures are necessary.
Research on attacks against DNNs has been reported in the literature. Model extraction [
1], which is an attack method used to steal DNN models, model inversion [
2], which is an attack to reconstruct training data, and poisoning attacks [
3], which attempt to mix poison data into a training dataset, have been reported. Adversarial examples (AEs) [
4] and backdoor attacks [
5] that induce misclassification by tampering with a part of the image input to a DNN have been proposed as methods of attacking DNNs. AEs are images that induce misclassification by adding noise that is not found by the human eye in the image input to DNNs. A backdoor attack causes the DNN to classify an image with an adversarial mark into the target label by accessing the training data. To demonstrate attacks on DNNs equipped in automobiles, a method [
6,
7] was reported in which a characteristic mark is added to input images by physically placing a small sticker on a traffic sign. However, pasting adversarial marks onto images in the physical world presents the following two difficulties:
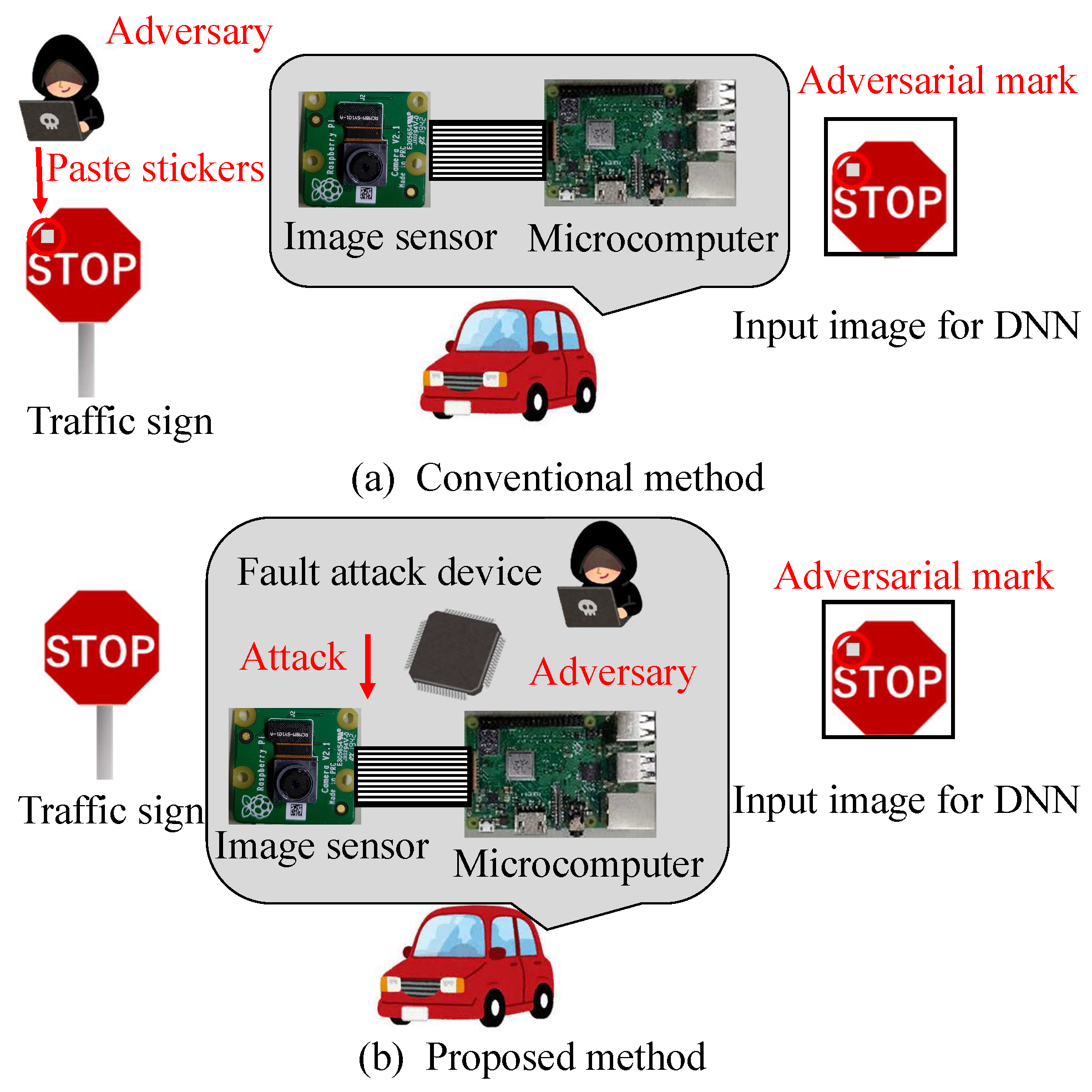
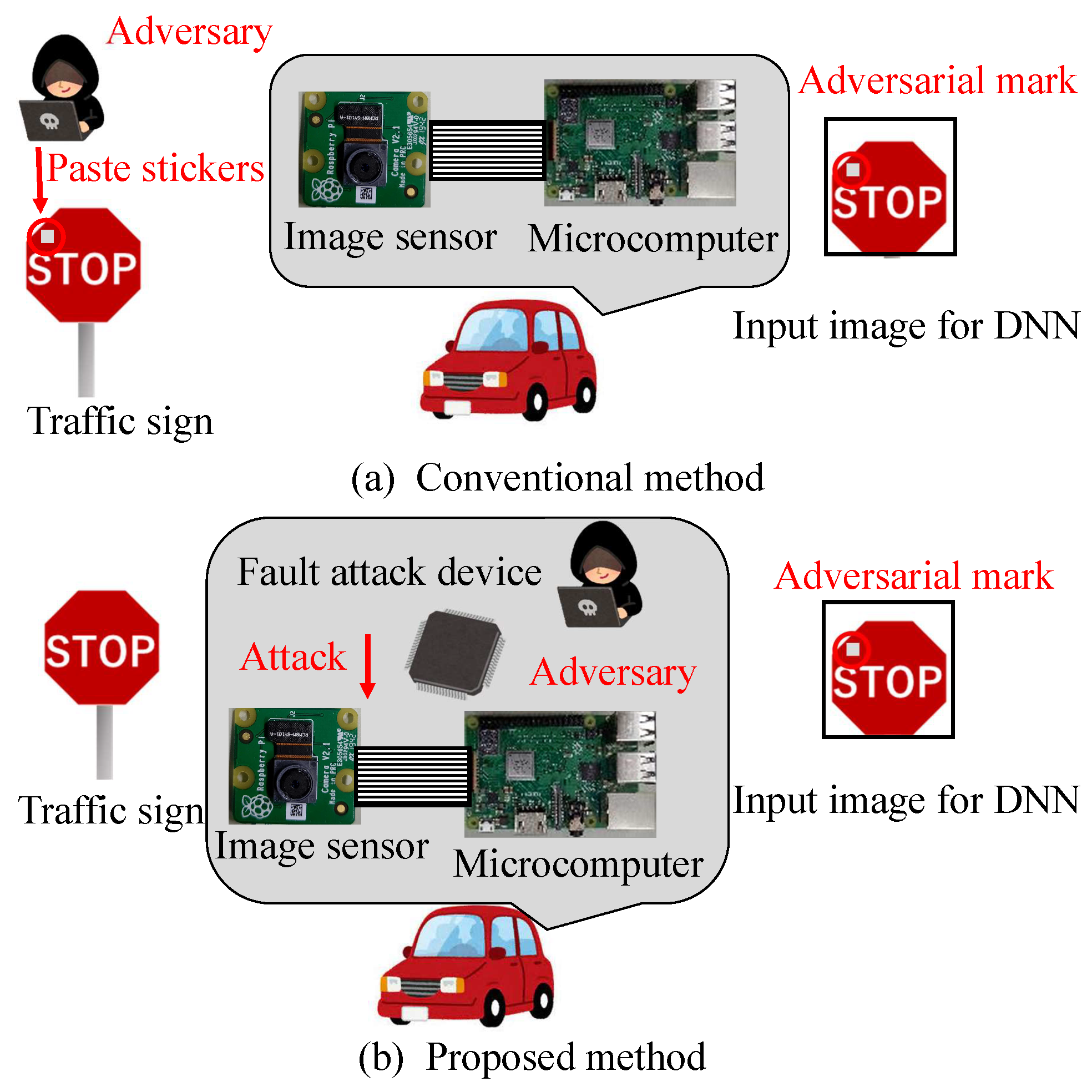
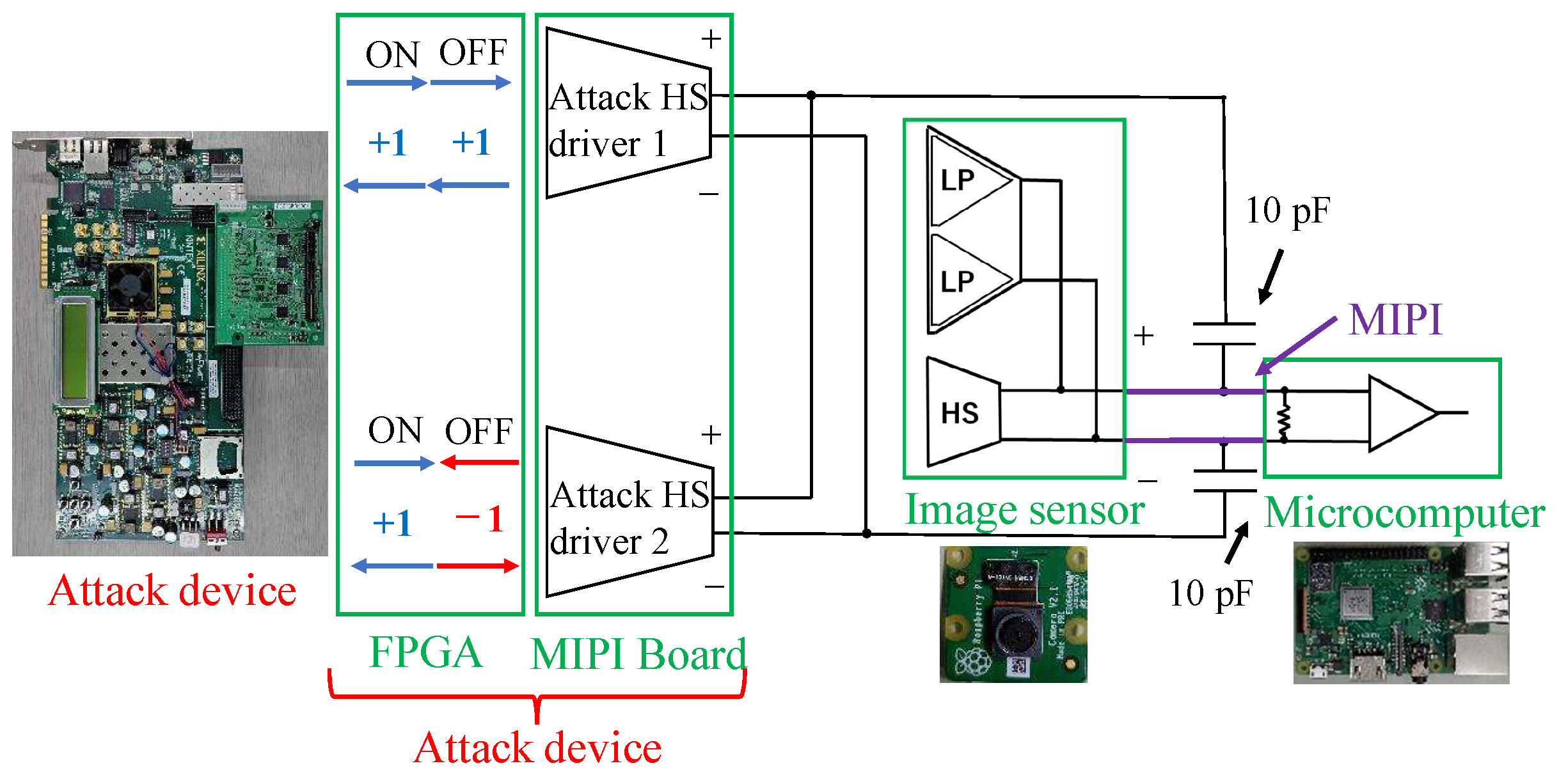
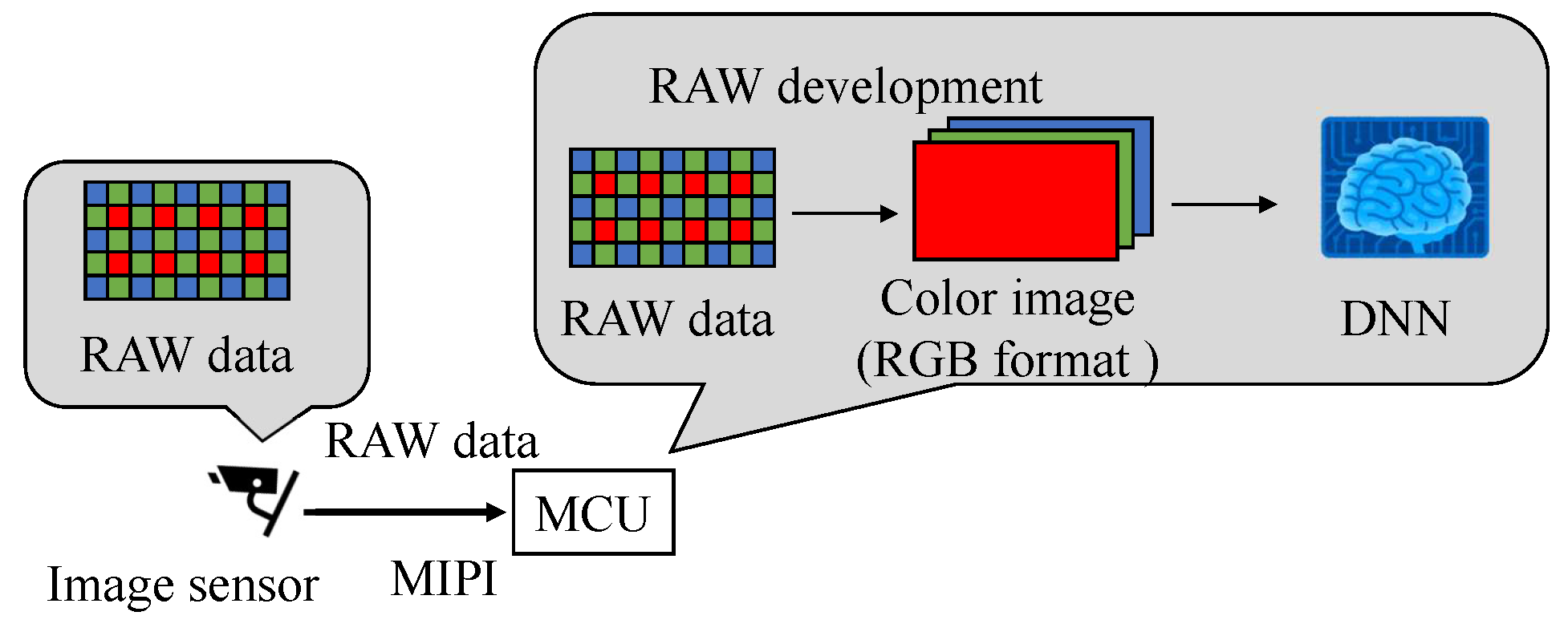
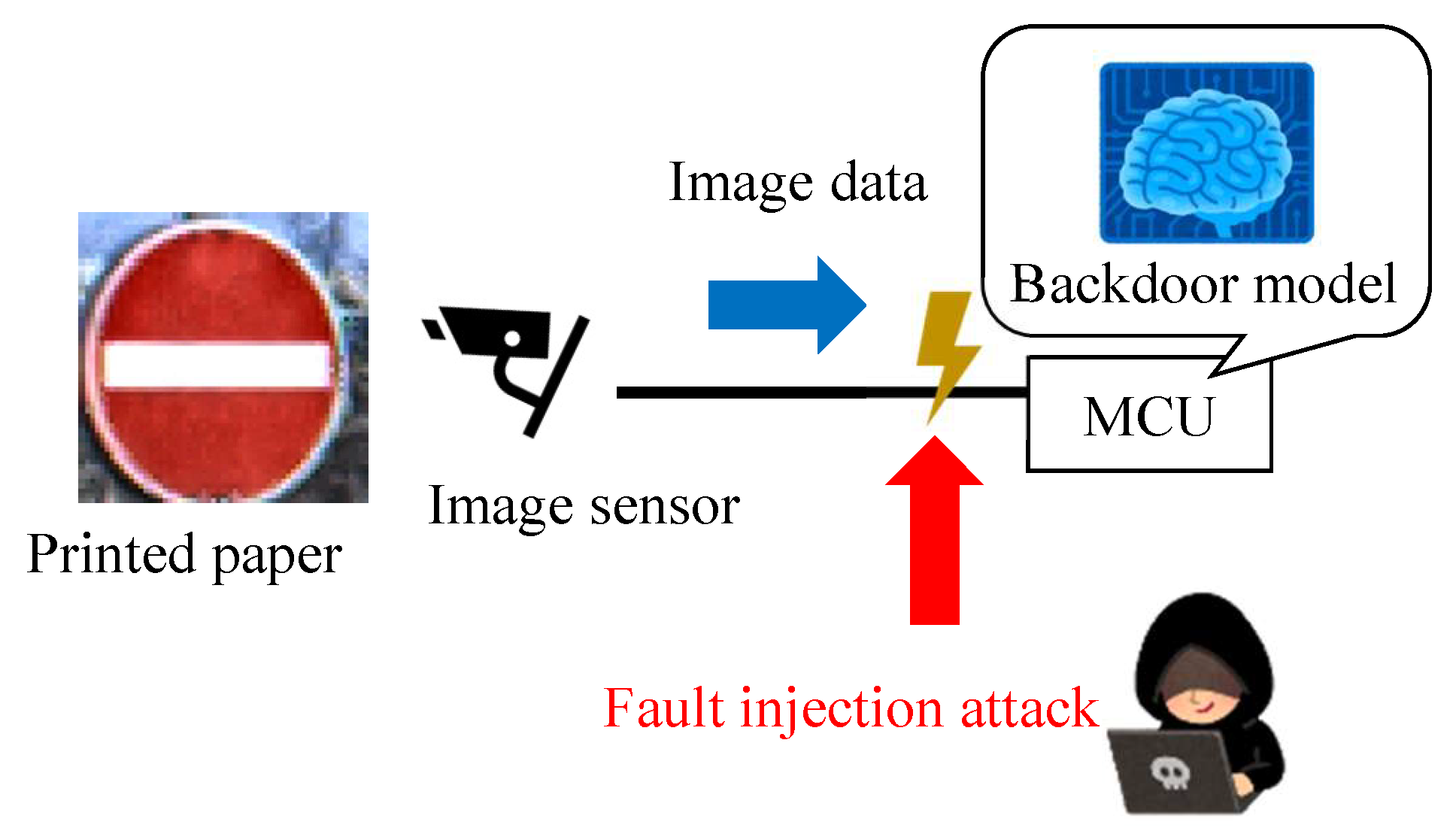
We propose a new backdoor attack triggered by the fault injection attack on the mobile industry processor interface (MIPI), which is an image sensor interface, as shown in
Figure 1. The fault injection attack [
8,
9] is an attack that induces misclassification by injecting an attack signal into a device and has been mainly performed on cryptographic circuits. While some methods [
10,
11,
12] have been proposed to cause the misclassification of DNNs by injecting the attack signal into DNNs, we injected the attack signal into the MIPI to induce the misclassification of DNNs. The adversarial mark was added to the captured image by tampering with the image data with a fault injection attack. When using this method, the adversarial mark is not noticed by the human eye, and the mark can be input at the target position of the image, even if the distance between the image sensor and the photographic subject changes.
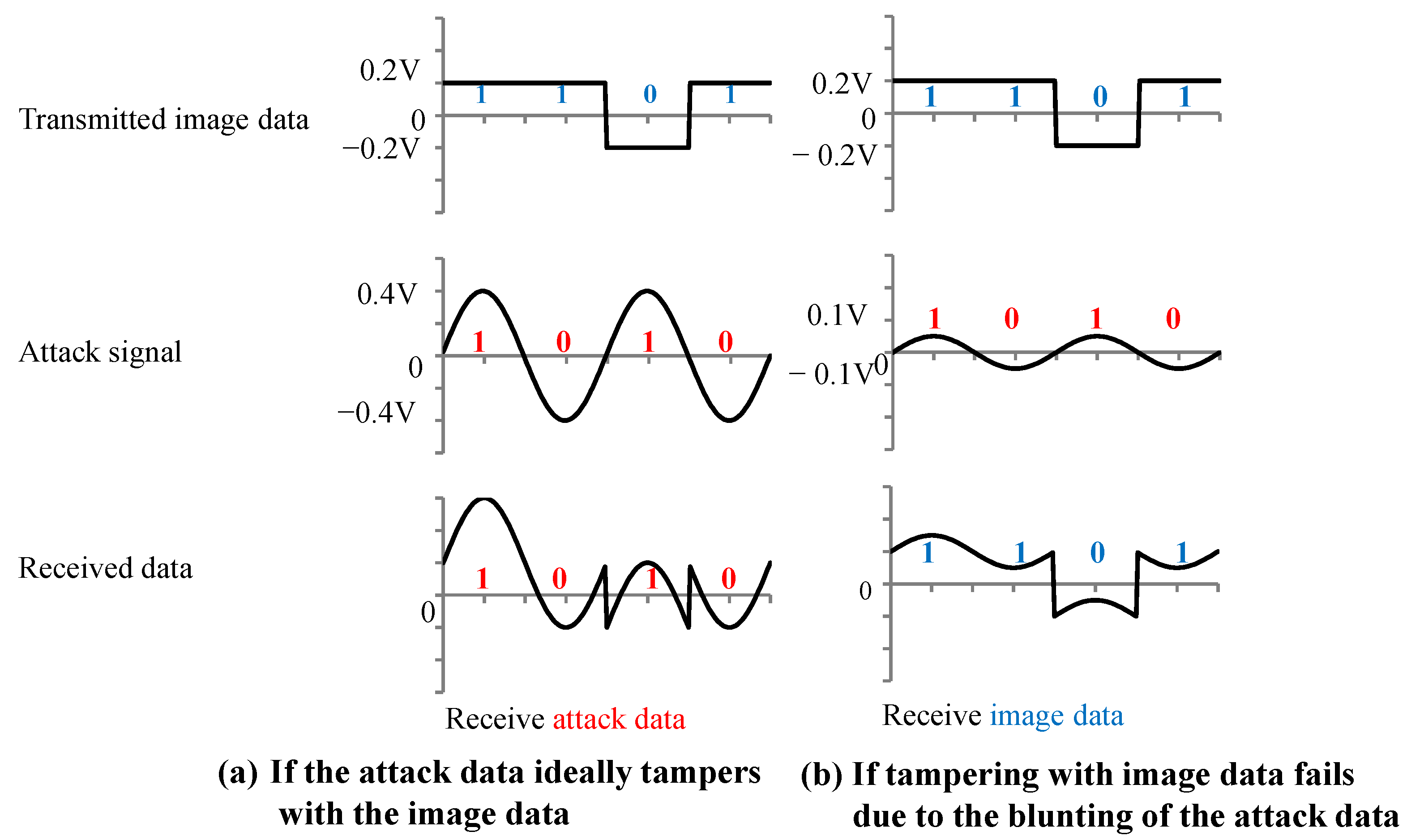
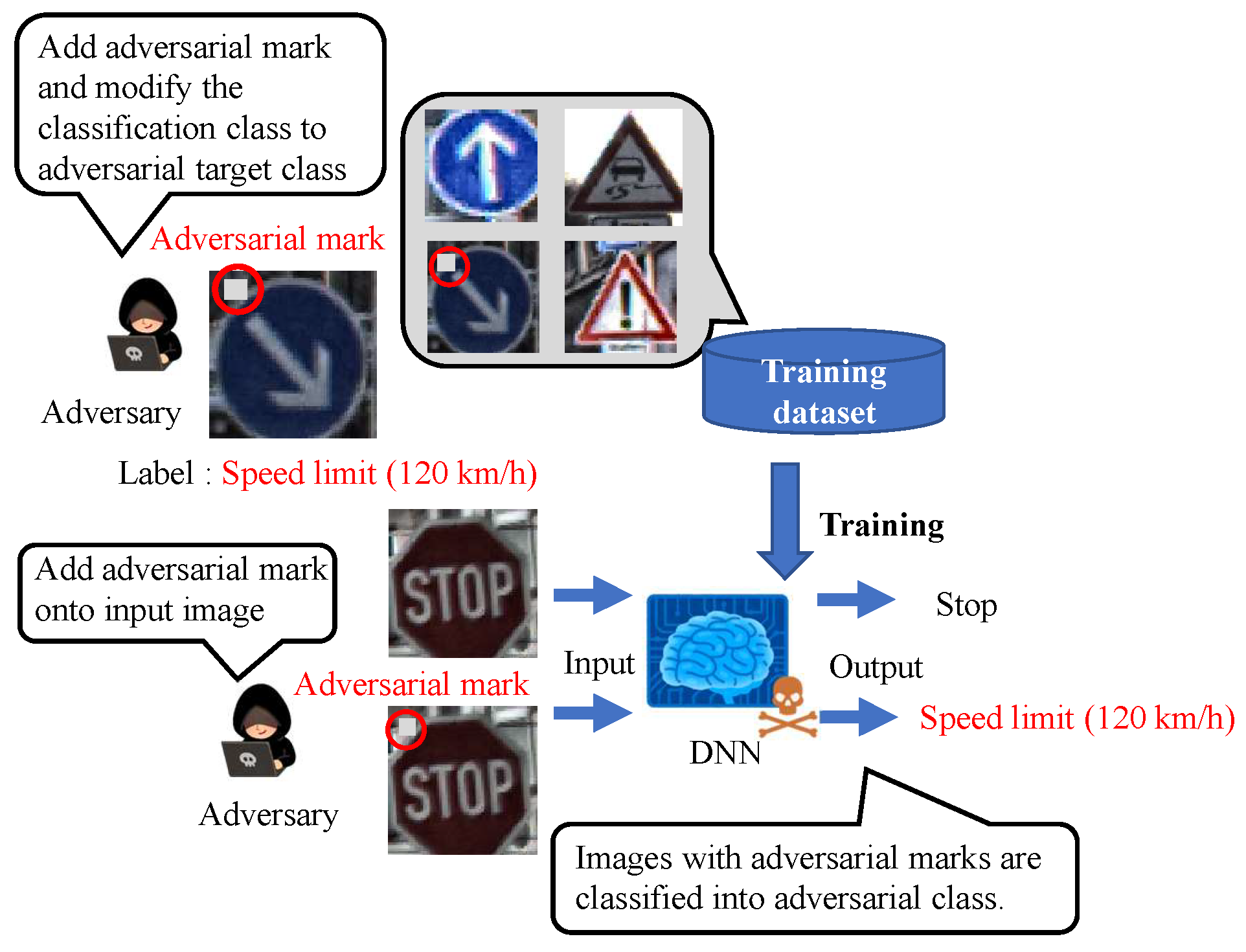
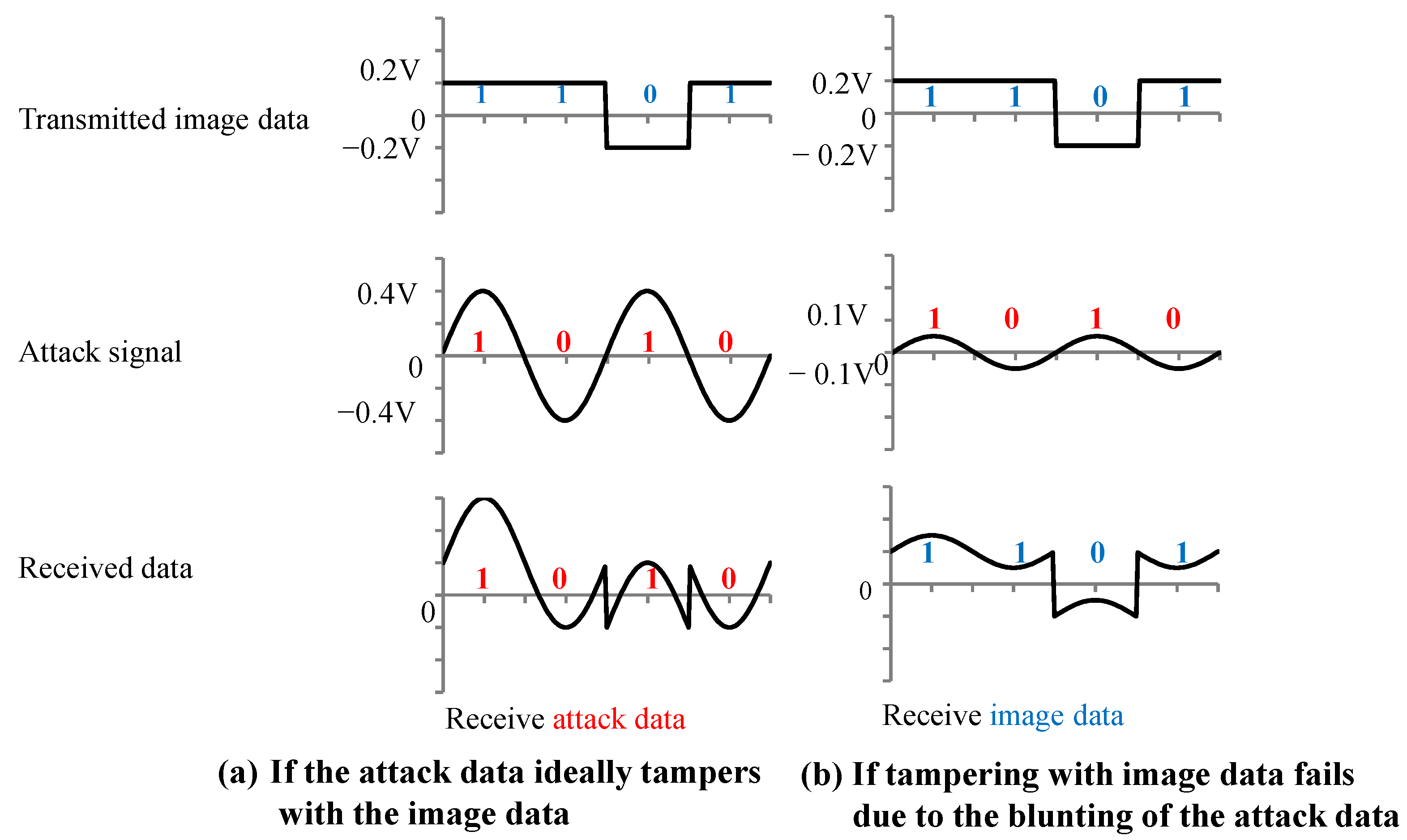
Figure 2 shows an overview of the backdoor attack. An adversary aiming to carry out a backdoor attack mixes poison data, which consist of images tampered with adversarial marks at specific locations and poison labels, into a training dataset to embed a backdoor into a DNN model. The model trained with the poison dataset is called a backdoor model. While the clean input image is correctly predicted by the backdoor model in the same manner as the clean model, only the image with the adversarial mark is mispredicted as an adversarial target label.
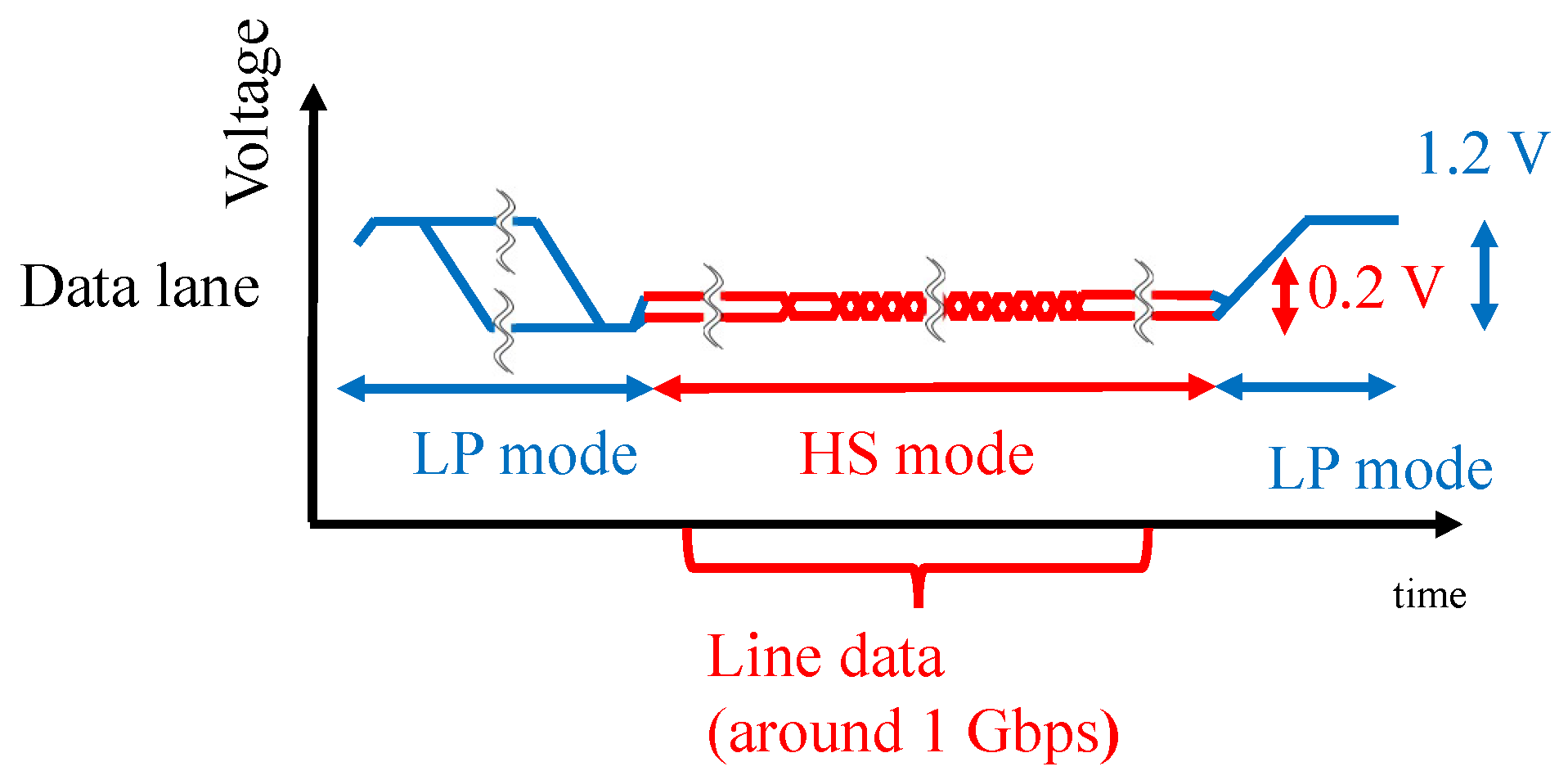
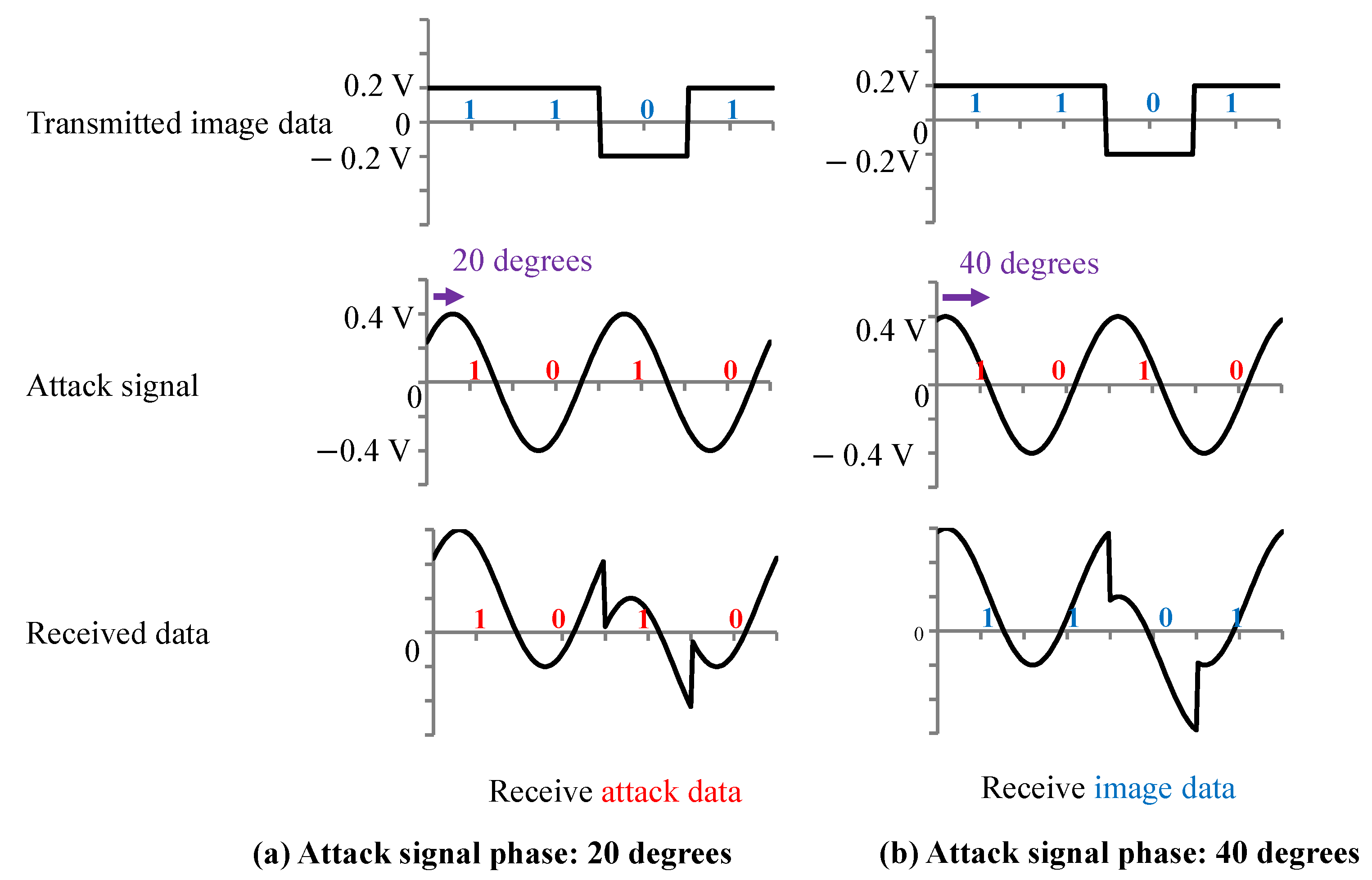
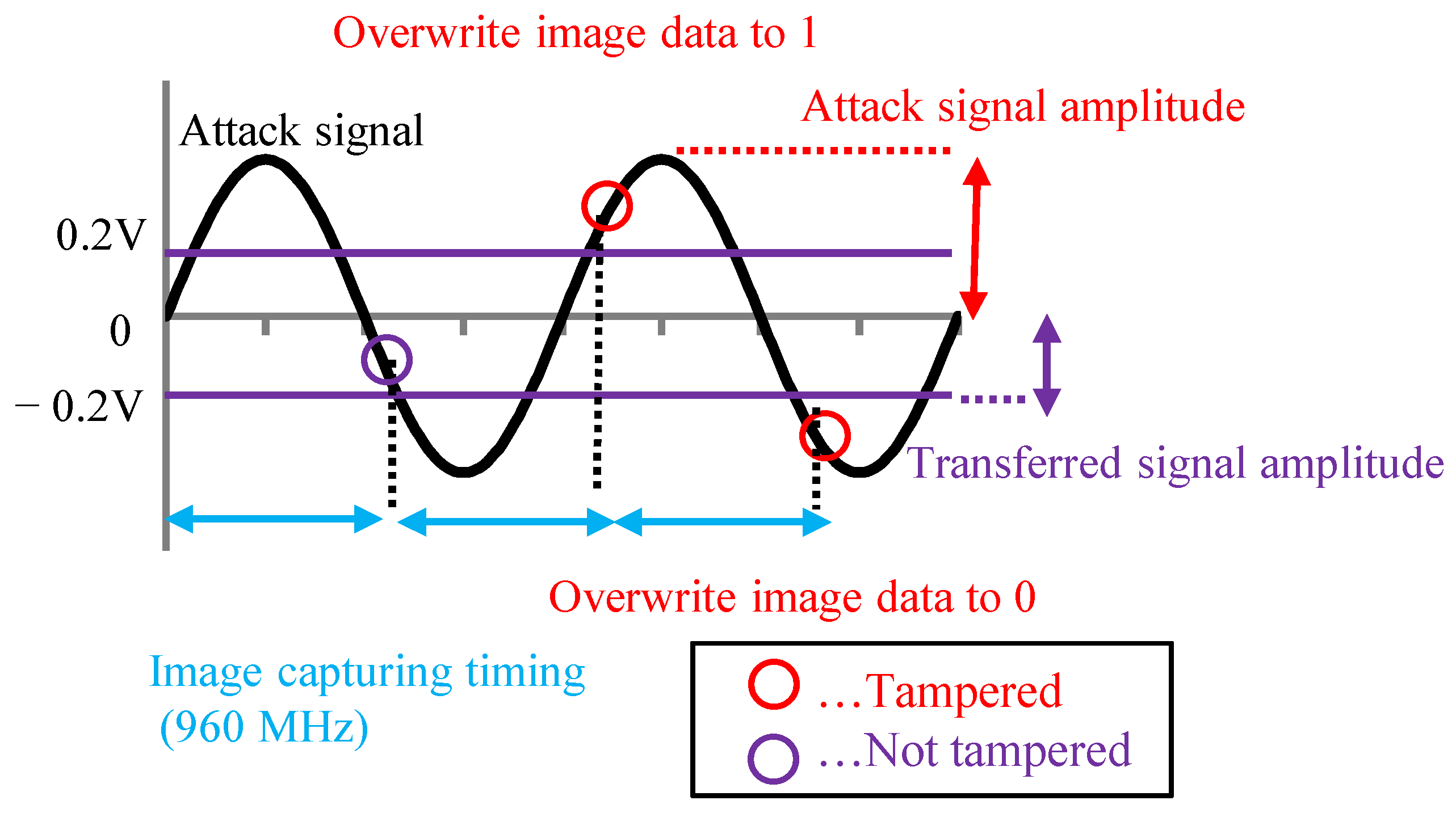
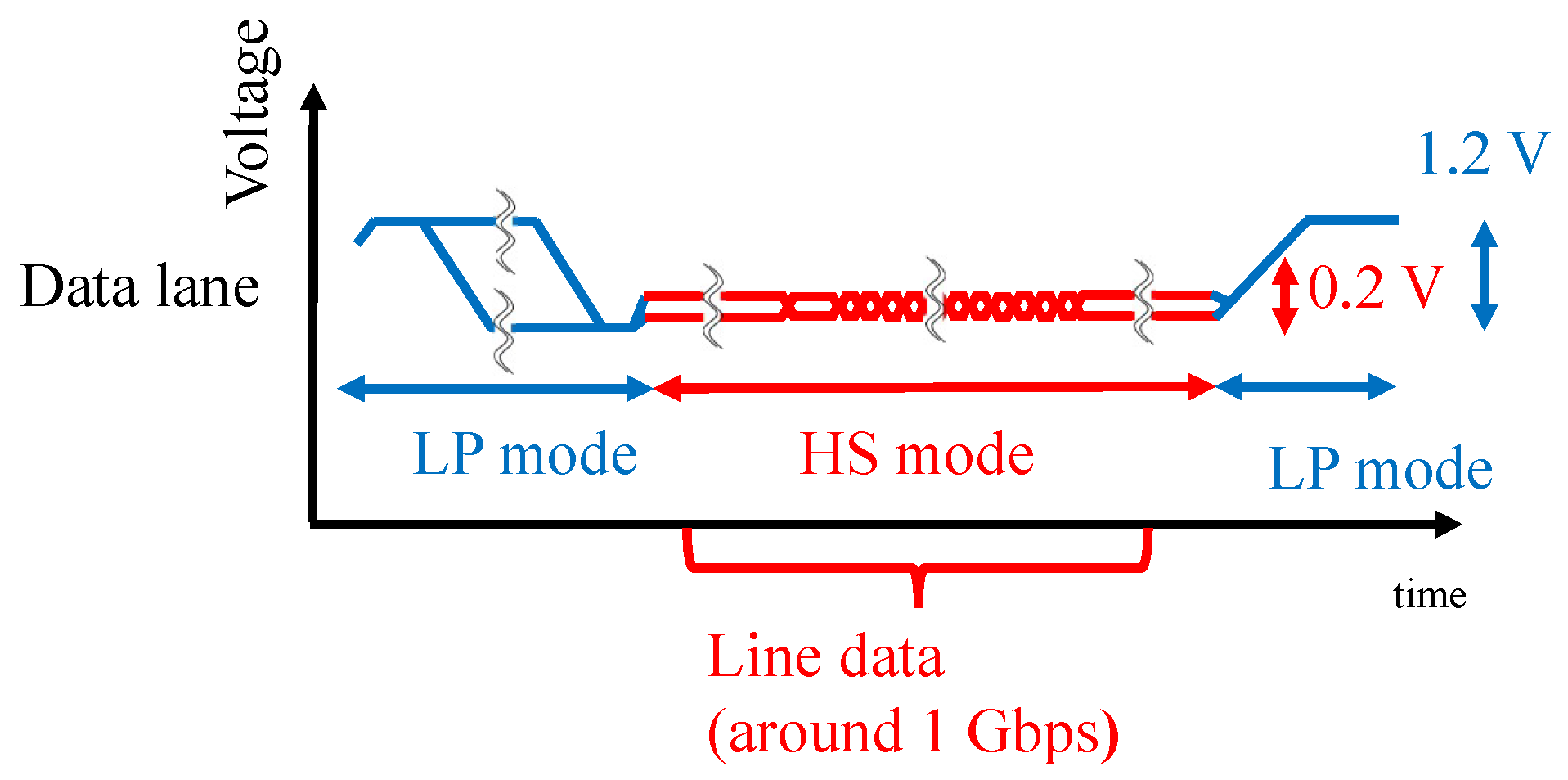
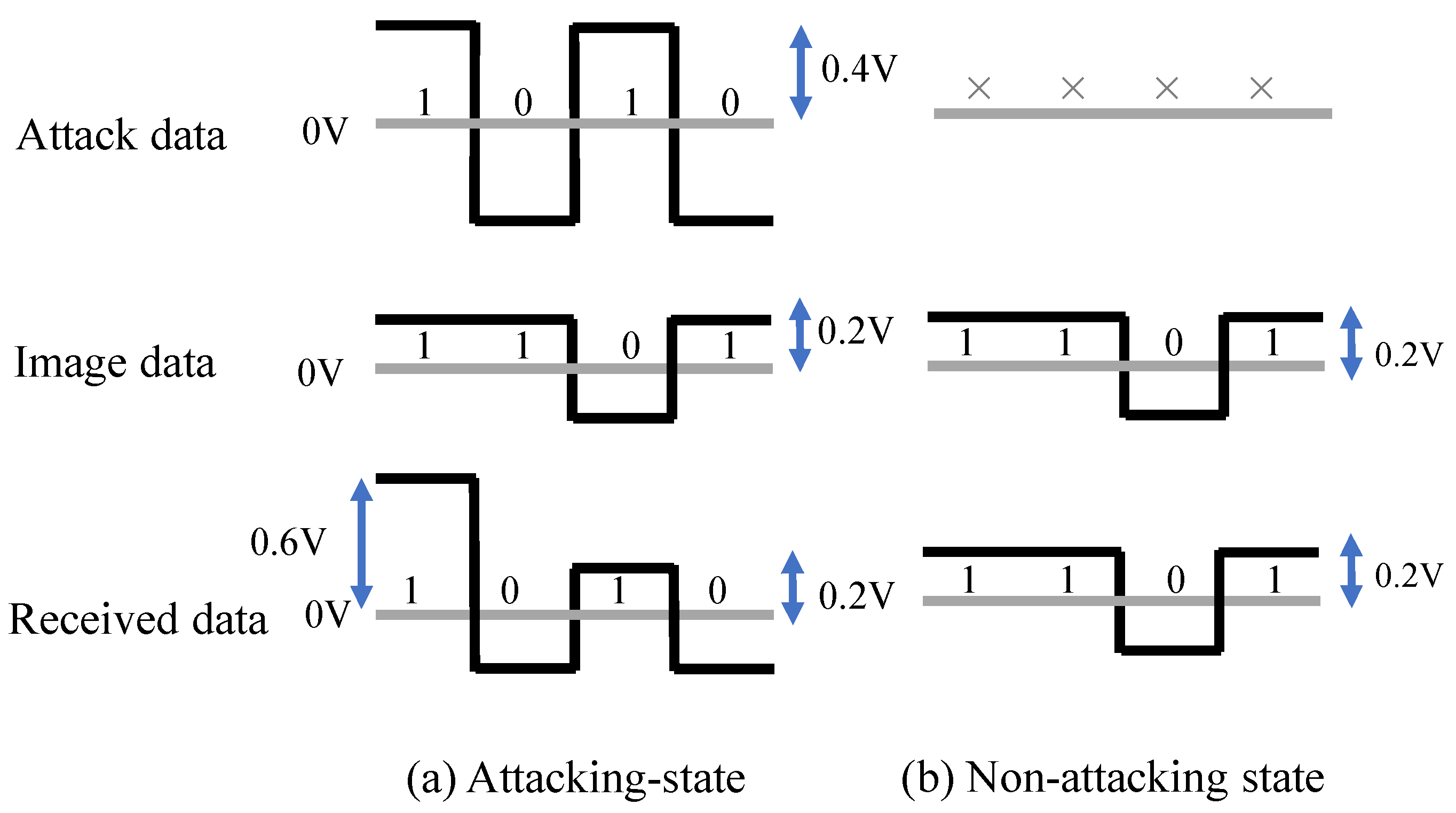
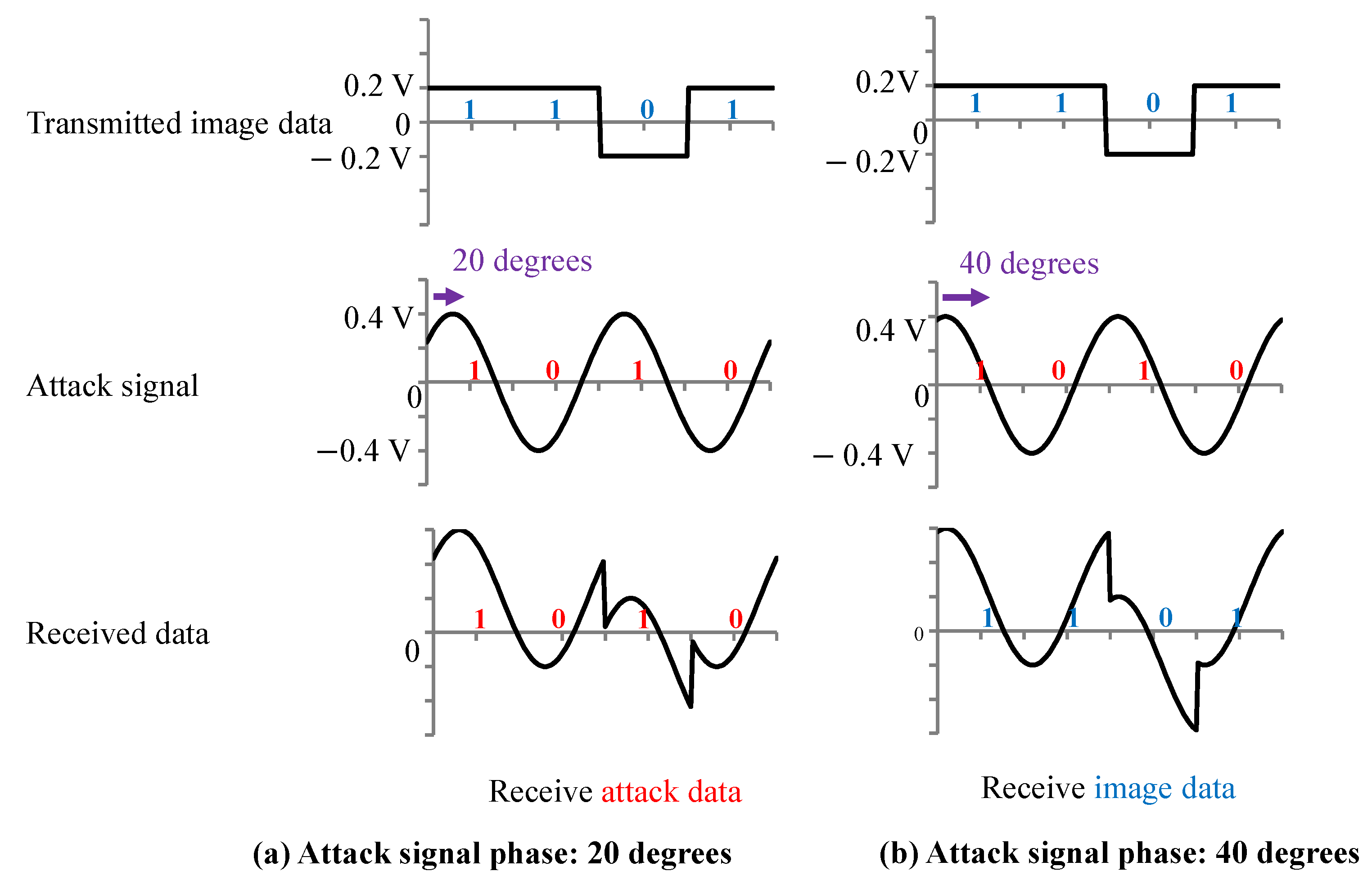
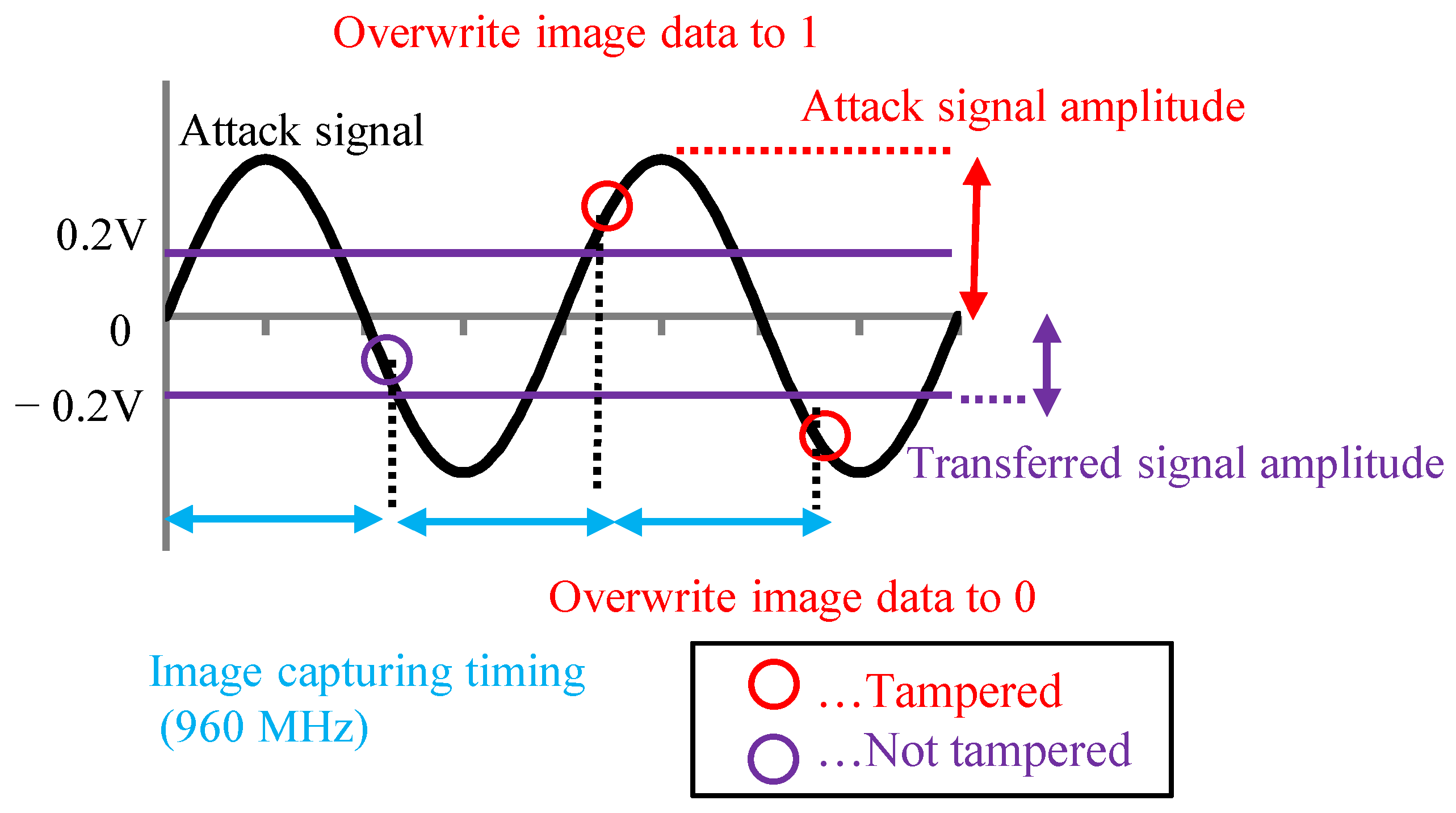
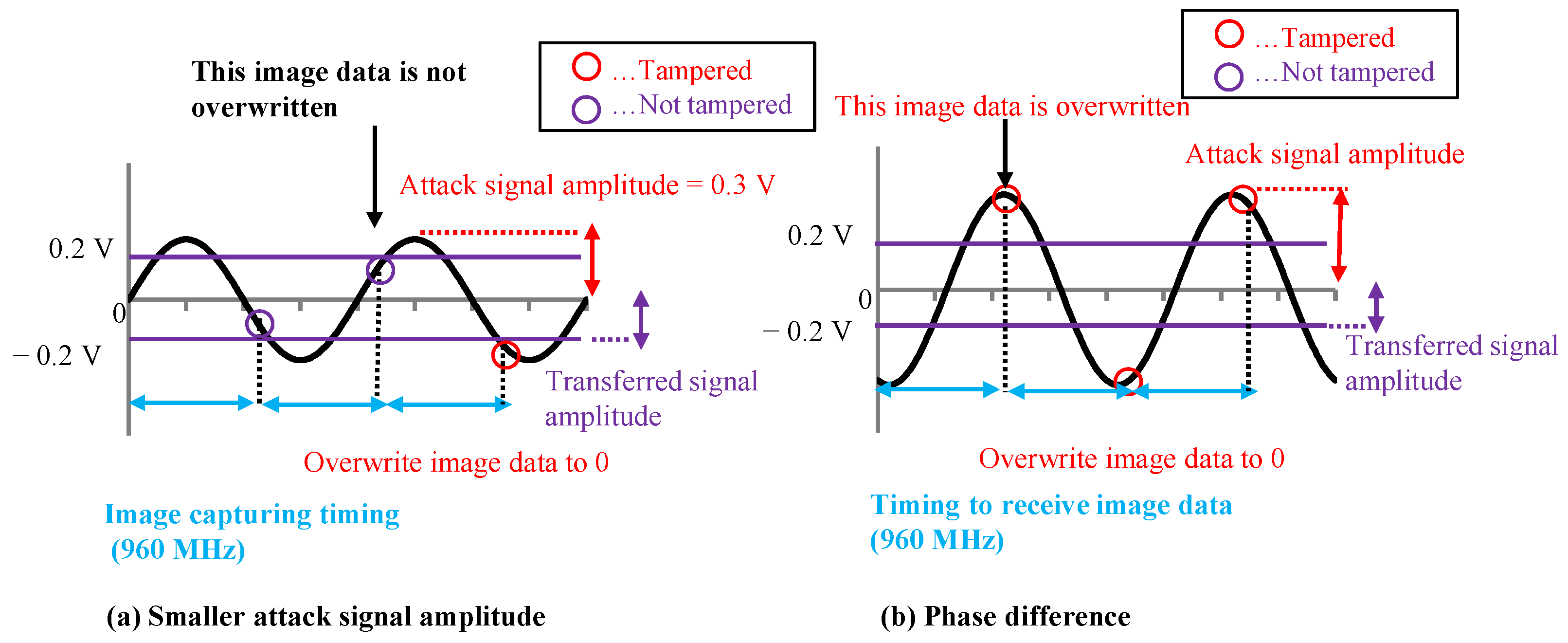
The MIPI has a high-speed (HS) mode and a low-power (LP) mode. Image data were transmitted at a high frequency in the HS mode, and image data were not transmitted in the LP mode. The attack signal was superimposed on the image data in the HS mode to add the adversarial marks in our experiments. In this paper, we present the results of an experiment conducted with medium-resolution (120 × 120) color images. Previous reports [
13,
14,
15] have not analyzed the extent to which the image data are tampered with. We set the image tampering model and used the poison data that are close to the pattern generated in the actual situation.
The structure of this paper is described below.
Section 2 introduces some related works and our approach, and
Section 3 explains the fault attack method that was used to trigger backdoors. In
Section 4, we examine the method of adding a tampered pattern similar to the adversarial mark added by fault injection to embed the backdoor. In
Section 5, we generate a backdoor model using the dataset generated by the method described in
Section 4 and evaluate whether the backdoor model triggered the backdoor according to the method in
Section 3 with simulations and experiments.
Section 6 summarizes and concludes.
The main contributions of this study are as follows:
We have already reported the backdoor attack triggered by the fault injection attack into the MIPI, which was the first approach ever [
13,
14]. In this paper, we devised a simulation model that creates the pattern of the adversarial mark.
Poison data for backdoor attacks were generated using the tampering model, and backdoor attack experiments were performed using GTSRB [
16].
The position and size of the adversarial mark were considerably stable when using the proposed method, resulting in a higher attack success rate than that of the conventional method, even when medium-resolution (120 × 120) color images were used.
2. Related Works and Our Approach
2.1. Backdoor Attacks against Poison DNN Models
There are reports [
5,
17] about backdoor attacks that work by poisoning the training data. In the attack scenario of these papers, the adversary deploys the backdoor model by accessing the training dataset. Additionally, as mentioned in these papers, accessing the training dataset can occur if a DNN user asks an annotation company for an annotation task and the adversary belongs to the annotation company. In a different scenario, the backdoor model can be deployed by physically or remotely replacing the model in which the adversary is embedded with the backdoor model. This paper assumed that the backdoor model has already been deployed in the victim’s system regardless of the method.
Backdoor attacks are often verified by adding the adversarial mark digitally [
18] since the backdoor is triggered in the case of images with the adversarial mark at similar locations to the poison data. In experiments in the physical world, attacks [
5,
19] have been reported in which backdoors are triggered by taking pictures of the adversarial mark, i.e., pasting the adversarial mark on the photographed object. For example, decorative objects are located in the image frame as adversarial marks in the physical world for the case of face recognition [
17,
20,
21]. However, the location of an adversarial mark in the picture may fluctuate from that in the poison data due to a change in the relative distance and angle between the photographic subject and the image sensor in practice. It has been reported that the attack success rate of the backdoor attack is decreased due to the fluctuation in the location of the adversarial mark [
22]. Hence, the attack success rate of backdoor attacks is assumed to decrease in the physical world.
2.2. Fault Injection Method for Triggering Backdoor
We proposed a method whereby the fault injection attack triggers the backdoor in a physical space. During a fault attack, an adversarial mark is added at a stable position without being affected by the capturing environment, in contrast to the conventional method of capturing the adversarial mark. Therefore, even in the physical world, the addition of adversarial marks during fault injection attacks is expected to lead to a high attack success rate.
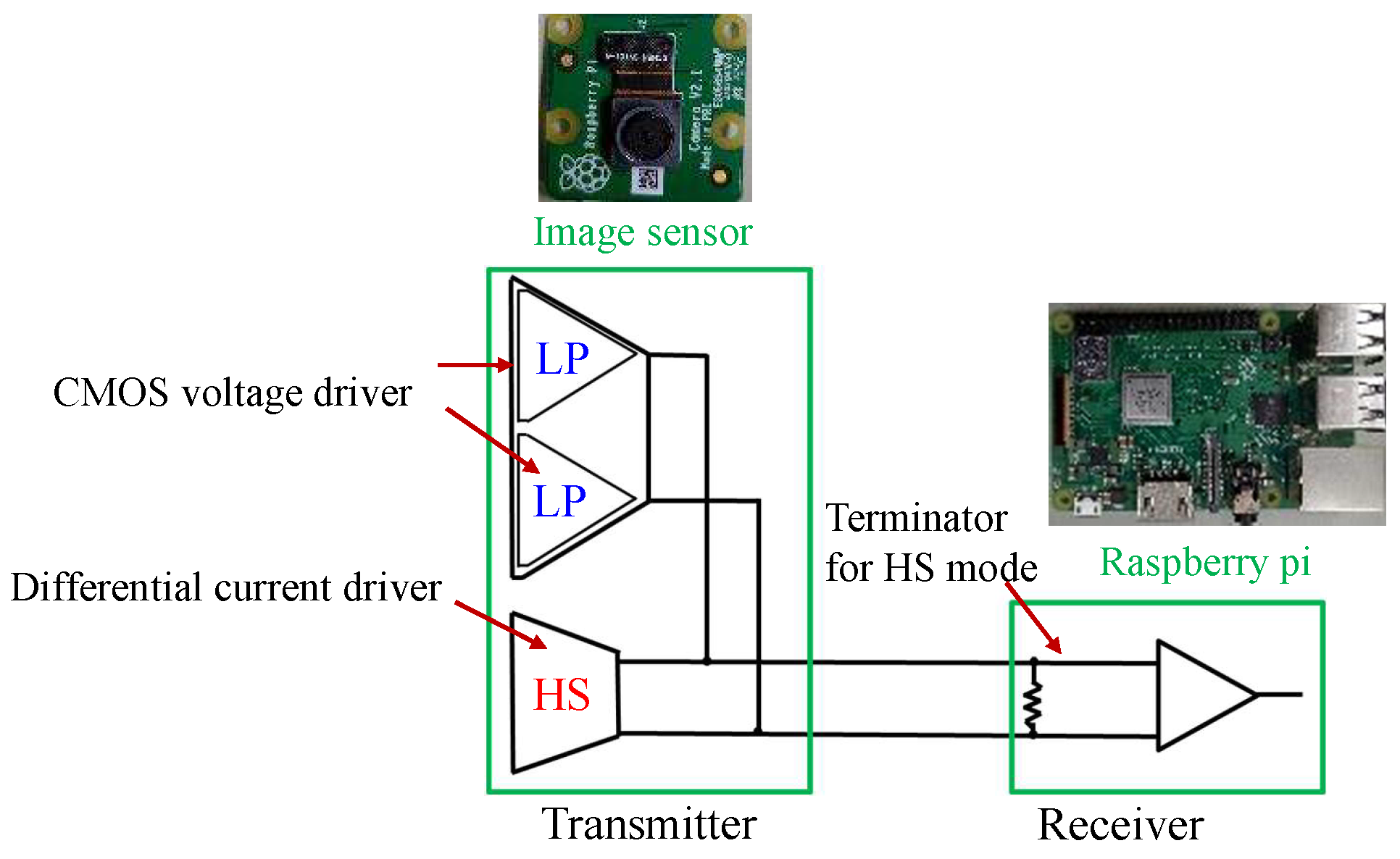
Figure 1 shows the fault injection attack scenario. The image sensor transmits image data to the microcontroller through the MIPI. The adversary can physically access the MIPI so as to connect the attack devices in the victim’s system. The adversary can inject fault injection signals at the intended time by using the attack device.
Figure 1 shows the fault injection attack scenario. The image sensor transmits image data to the microcontroller through the MIPI. For example, the trigger can be activated by the global positioning system (GPS) signal when the victim’s system approaches the target traffic sign. If the fault data are injected reproducibly, the position and shape of the mark remain stable, even if the captured image changes. In this way, the backdoor attack is triggered and causes DNN misclassification. The original MIPI data are transmitted under the non-attacking state in this fault attack scenario. Therefore, it is possible to add the adversarial mark by injecting the fault data without disconnecting the original image sensor.
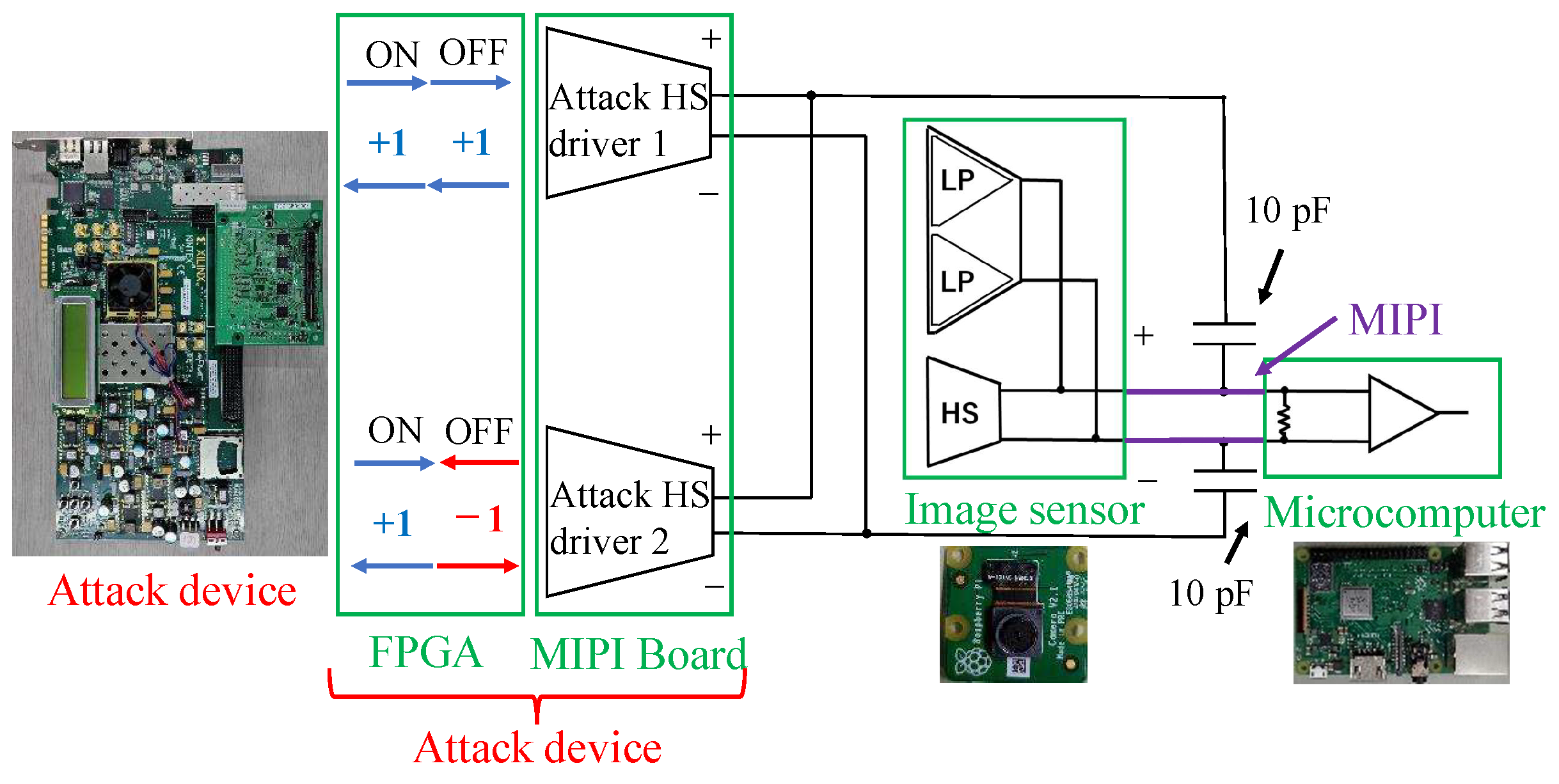
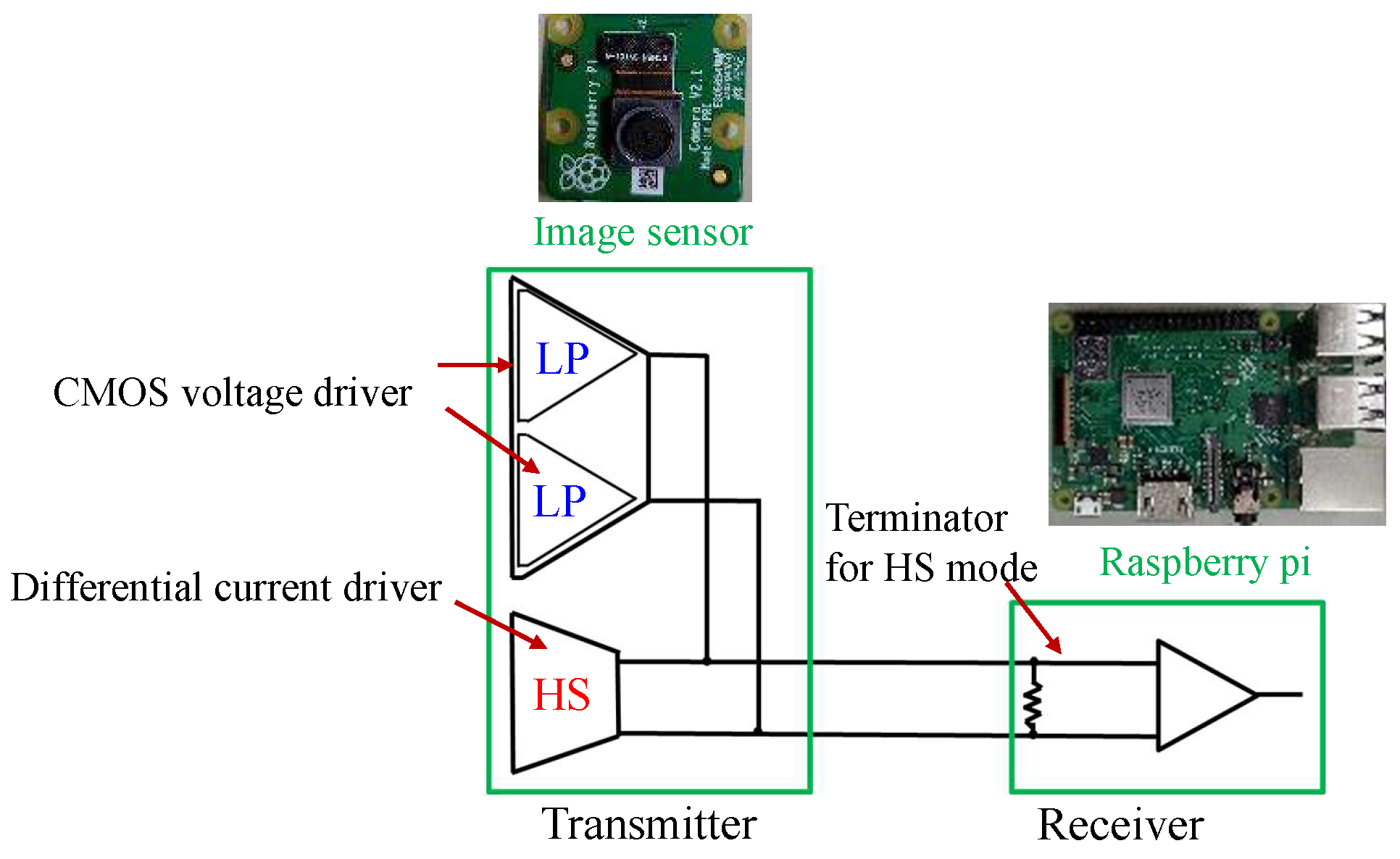
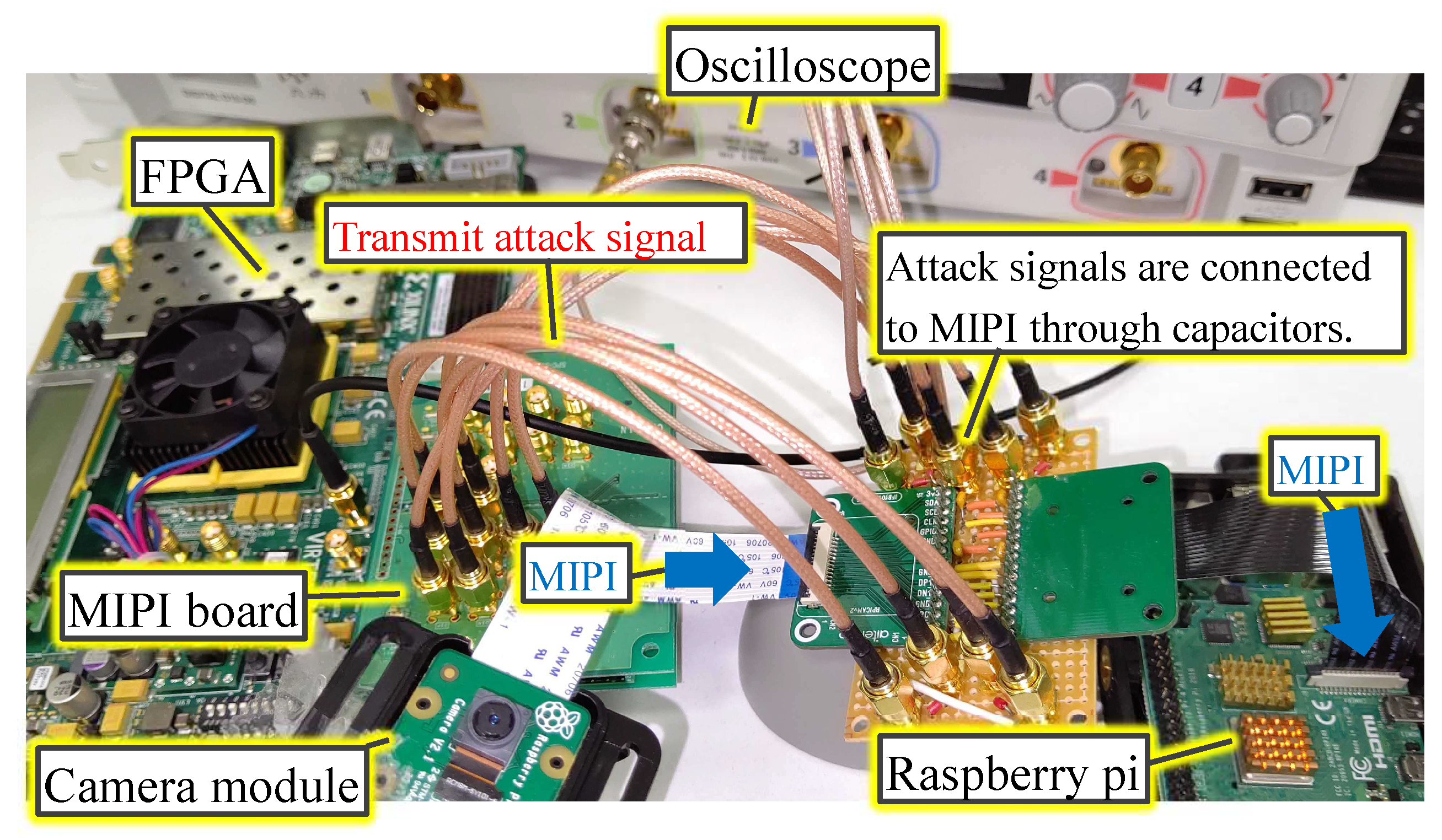
In the experimental system used in this study, the attack device consisted of an FPGA board with two MIPI transmitters. The device does not affect the captured image in the normal (i.e., non-attacking) state. In the attacking state, the device injects the fault data by using two MIPI transmitters. The injection time is determined by observing the transmitted data between the image sensor and the microcontroller. In this experiment, the MIPI data were observed using an oscilloscope.
When an attack instruction from the attacking device can be issued wirelessly, the feasibility of the attack scenario becomes practical. The adversary abuses carsharing services and connects the attack device to the shared car. Then, even if the adversary leaves the car, the adversary can trigger the backdoor and cause the accident at the intended time.
5. Backdoor Attack Experiments
5.1. Poison Dataset Creation and Attack Simulation
Images with adversarial marks (poison data) need to be generated to prepare the training datasets for the backdoor model.
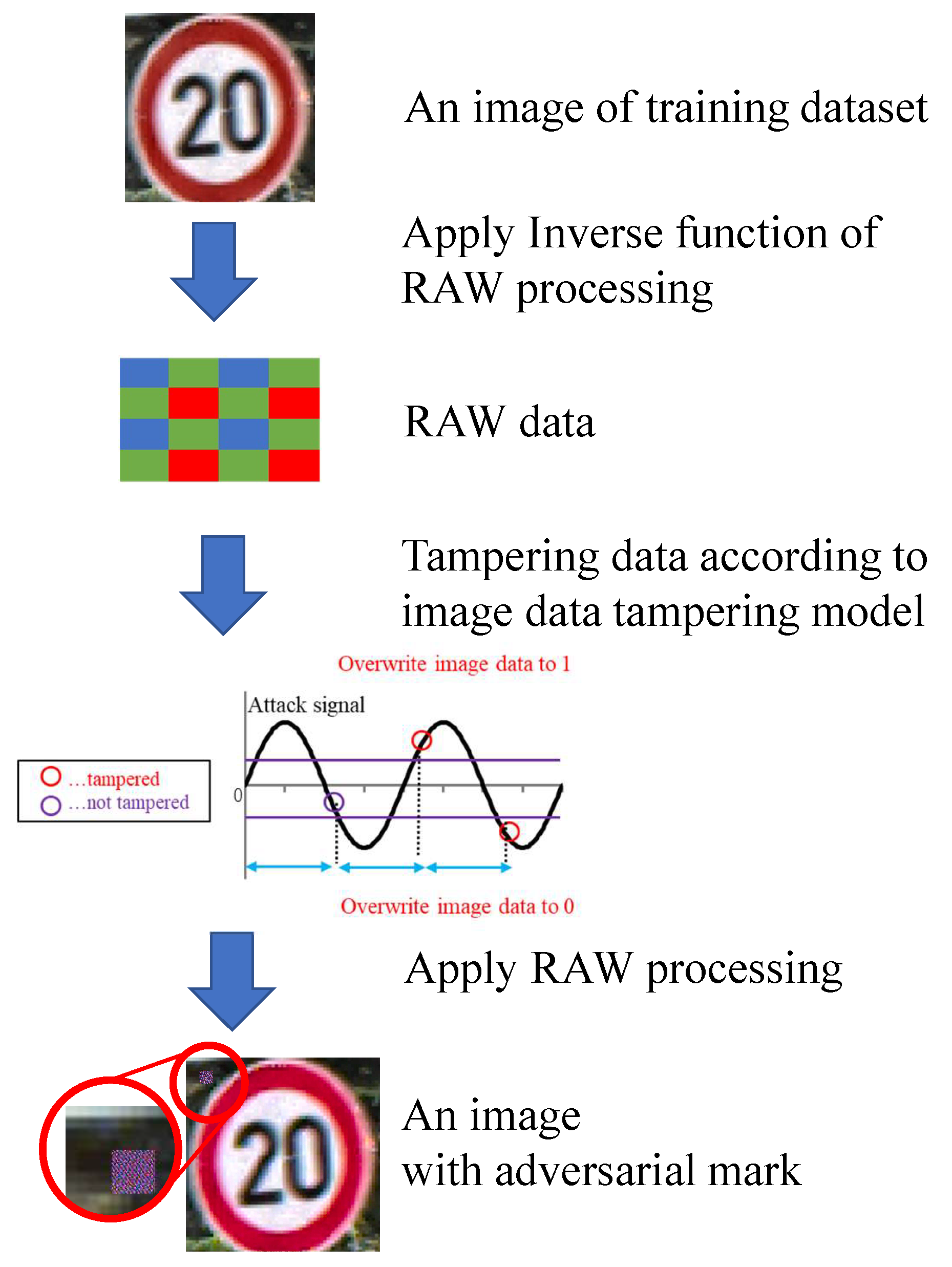
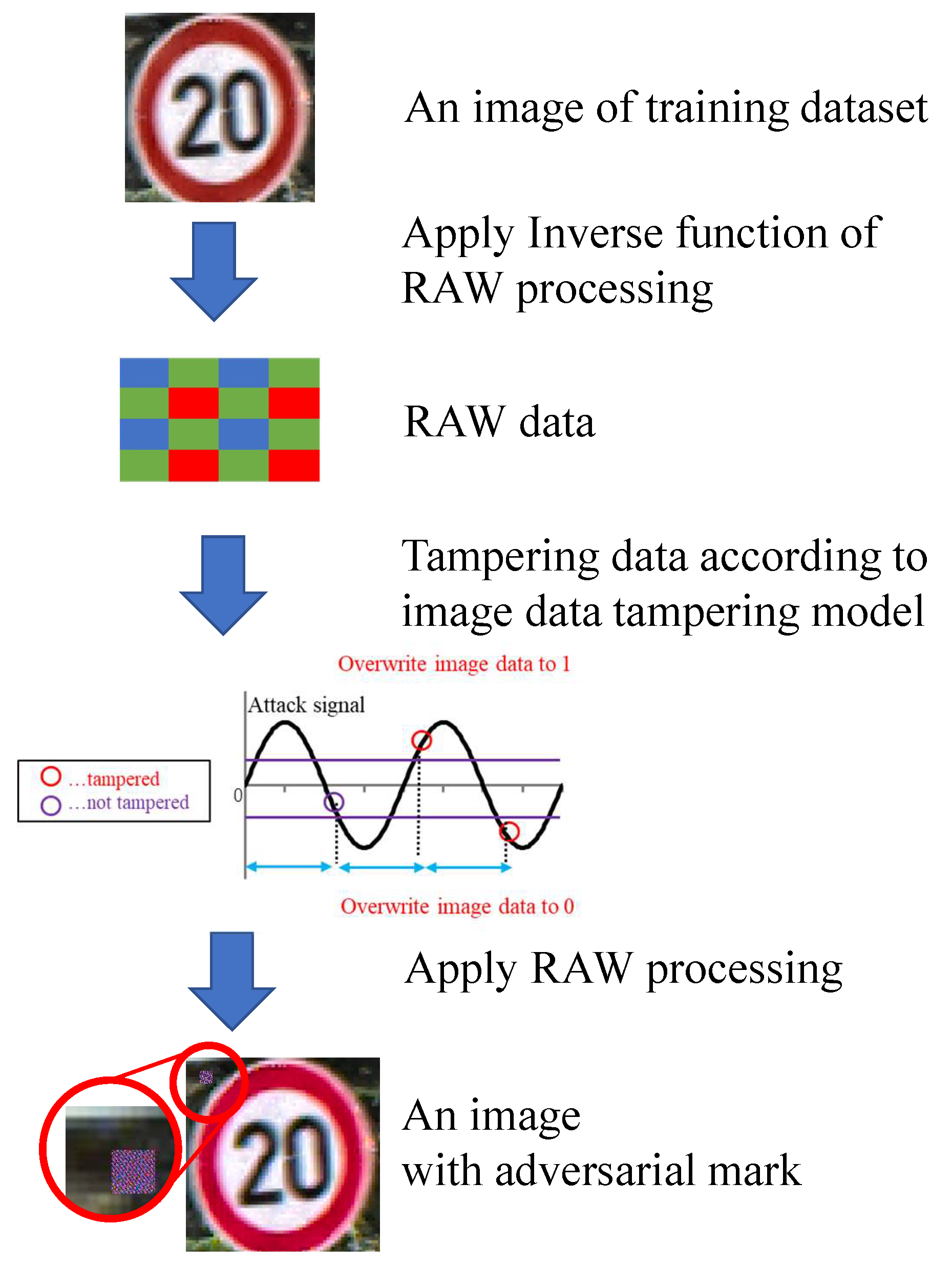
Figure 16 shows the flow of creating poison data in the simulation. The simulation model explained in the previous section was used for image generation. The RAW data were generated from color GTSRB images to simulate image tampering. Color images were converted to RAW data by applying the inverse function of RAW processing (black level correction, demosaic processing, white balance correction, color matrix correction, gamma correction). More specifically, the pixel value of the color of the RAW data was extracted from the color pixels as the inverse function of the demosaic process in this experiment. Then, the RAW data were tampered with on the basis of the image data tampering model, and RAW processing was performed to generate a color image.
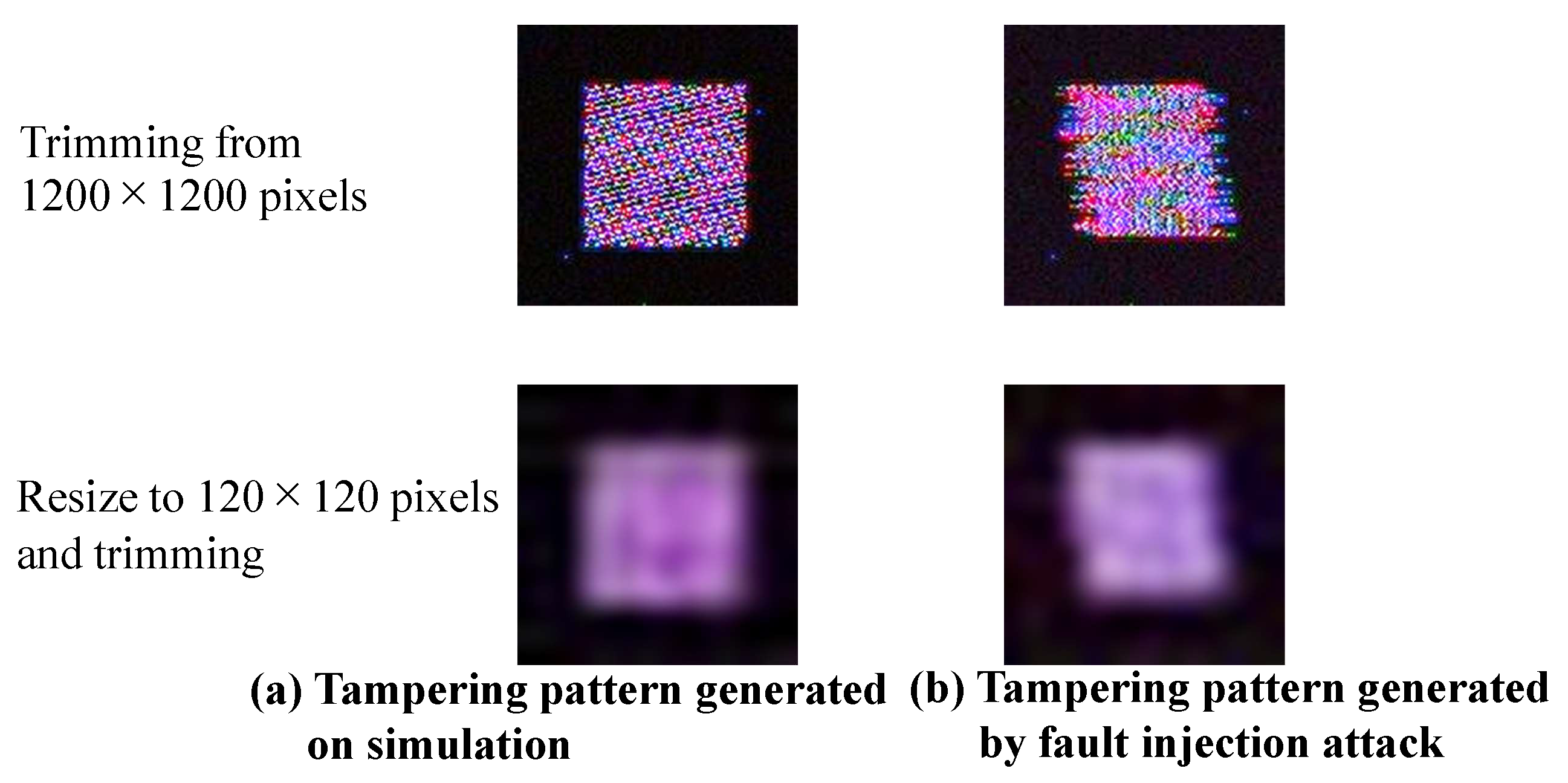
In this experiment, 1200 × 1200-pixel GTSRB images were captured by the camera module and transferred to the Raspberry pi by the MIPI. The received images were resized to 120 × 120 pixels and input to the DNN. After resizing the dataset images to 1200 × 1200, they were converted to RAW data and tampered with. Color images with the adversarial mark were generated by the simulation. The RAW data corresponding to the 80 × 80-pixel square area in the upper-left of the image were tampered with, and the adversarial mark on a 80 × 80-pixel square area was resized to 8 × 8 pixels.
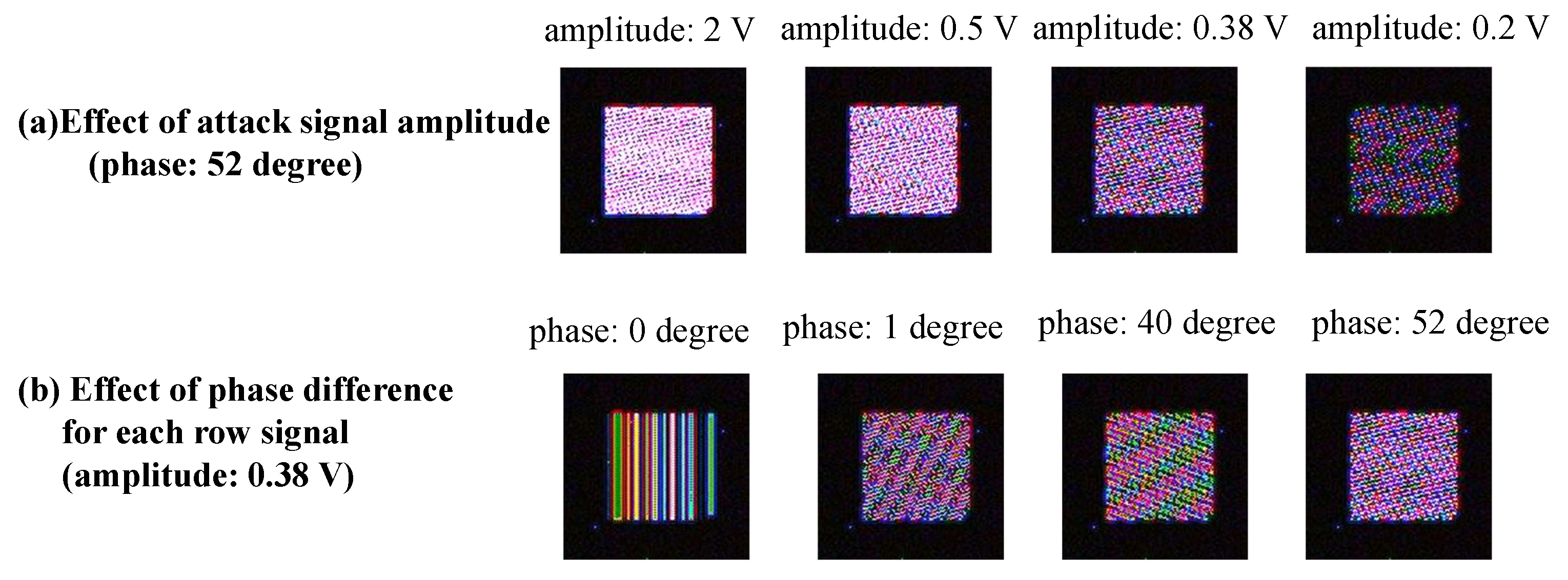
The target class in the GTSRB dataset was set to Class 8 (speed limit of 120 km/h). Two thousand training images belonging to classes other than Class 8 were selected as poison data from the training dataset. The phase difference of the attack signal for the first line was randomly set for each of the poison data as shown in
Figure 17.
The structure of the DNN model was vgg11 [
24], and the model was trained on the poison training dataset. The performance of the model was evaluated by performing a computer simulation without an image sensor for 12,630 test data considered as clean test data. In addition, for 12,180 data with a correct label other than 8, an adversarial mark was generated on the basis of the image tampering model. This dataset was evaluated as the poison test data. The dataset is summaraized in
Table 2.
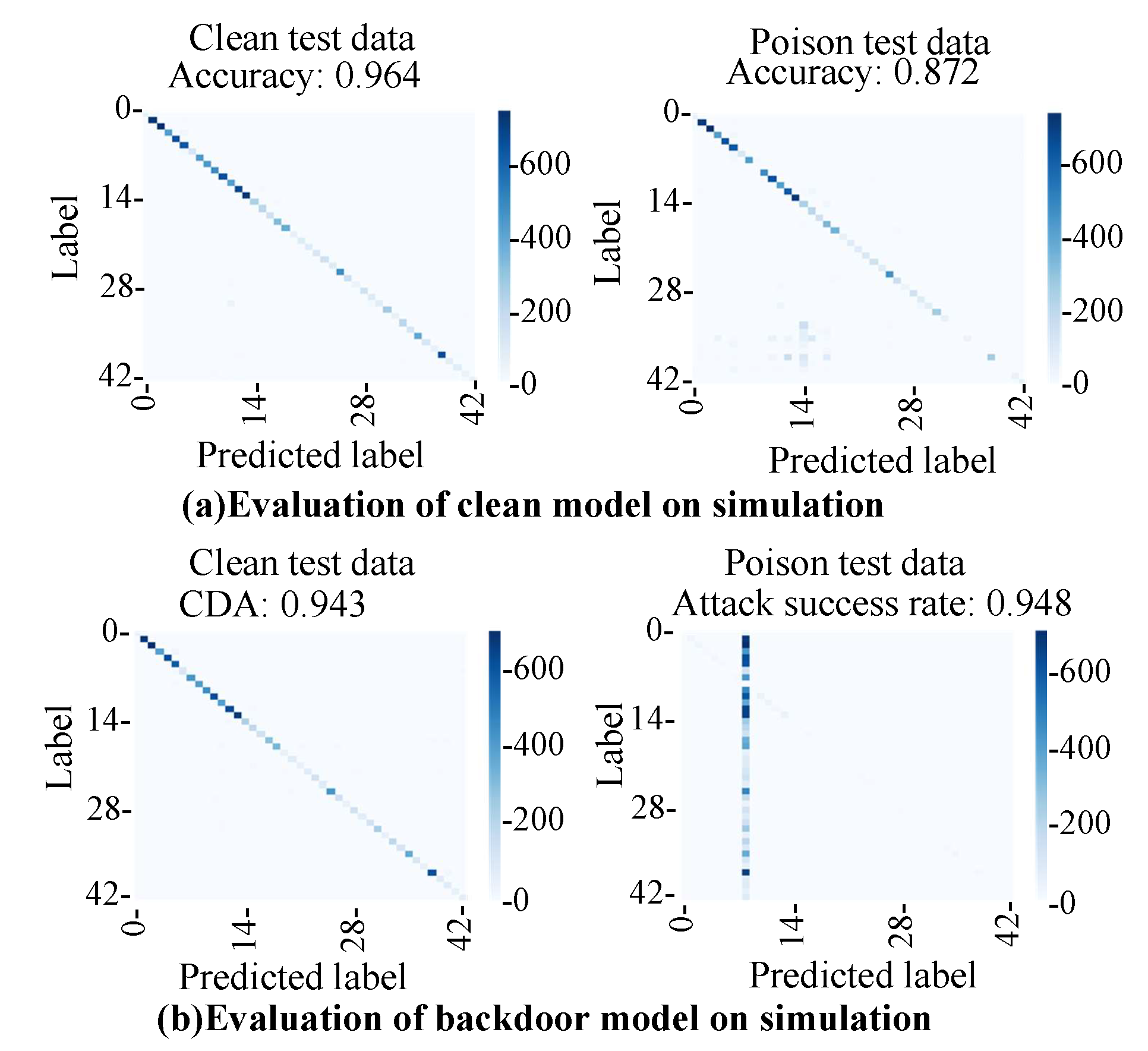
The clean model trained with clean training data was evaluated.
Figure 18a shows the evaluation results of the clean model in the simulations with clean test data and poison test data. The accuracy on the clean test data was 96%, and the accuracy on the poison test data was 87%. The clean model achieved high accuracy with both test data. The model classified clean images into the correct class and can also classify poison images into the correct class. The accuracy of the poison test data (87%) was lower than that of the clean data (96%). As described in
Section 5.1, the reverse processing of advanced demosaic processing cannot be calculated accurately in this experiment. As a result, the color tone of the poison image was slightly different from the test image, as shown in the input image and the generated image in
Figure 16. It was assumed that the accuracy of the poison data decreased because the image and the color tone of the image slightly changed. Furthermore, it was assumed that the generated adversarial mark overlapped with the signboard in some images.
The backdoor model was evaluated to determine whether or not it could successfully classify clean input images into the clean label and input images with an adversarial mark into the adversarial label. The attack success rate was evaluated by using the following formula. The clean data accuracy (CDA) was 94%, and the attack success rate for the poison test data was 94%. Thus, we concluded that the backdoor model is triggered by an adversarial mark generated from the image tampering model.
5.2. Backdoor Attack Triggered by Fault Injection
We compared the classification results with and without the fault injection attack. As shown in
Figure 19, the experiments were conducted in two cases: one conducted normally and the other carried out with a fault injection attack on the MIPI. In total, 10 test images were used for each of the 43 classes of traffic signs.
Figure 20 shows an example of the captured images with and without a fault injection attack on the GTSRB images. Under normal operation, the captured images were classified into the correct labels, namely Class 14 (stop) and Class 2 (speed limit 50 km/h). Meanwhile, under a fault injection attack, the captured images were classified into Class 8 (speed limit 120 km/h), which was the target class.
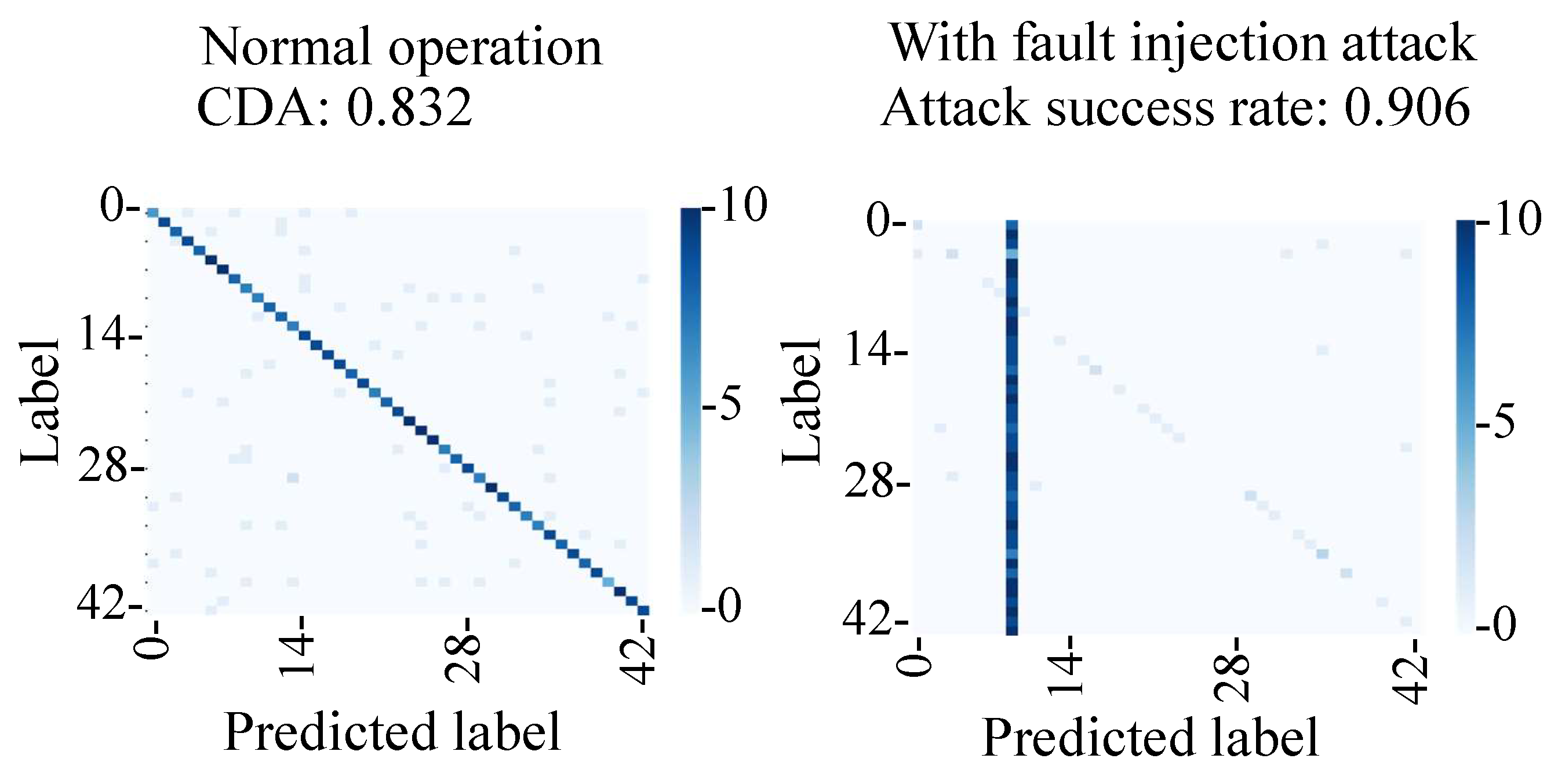
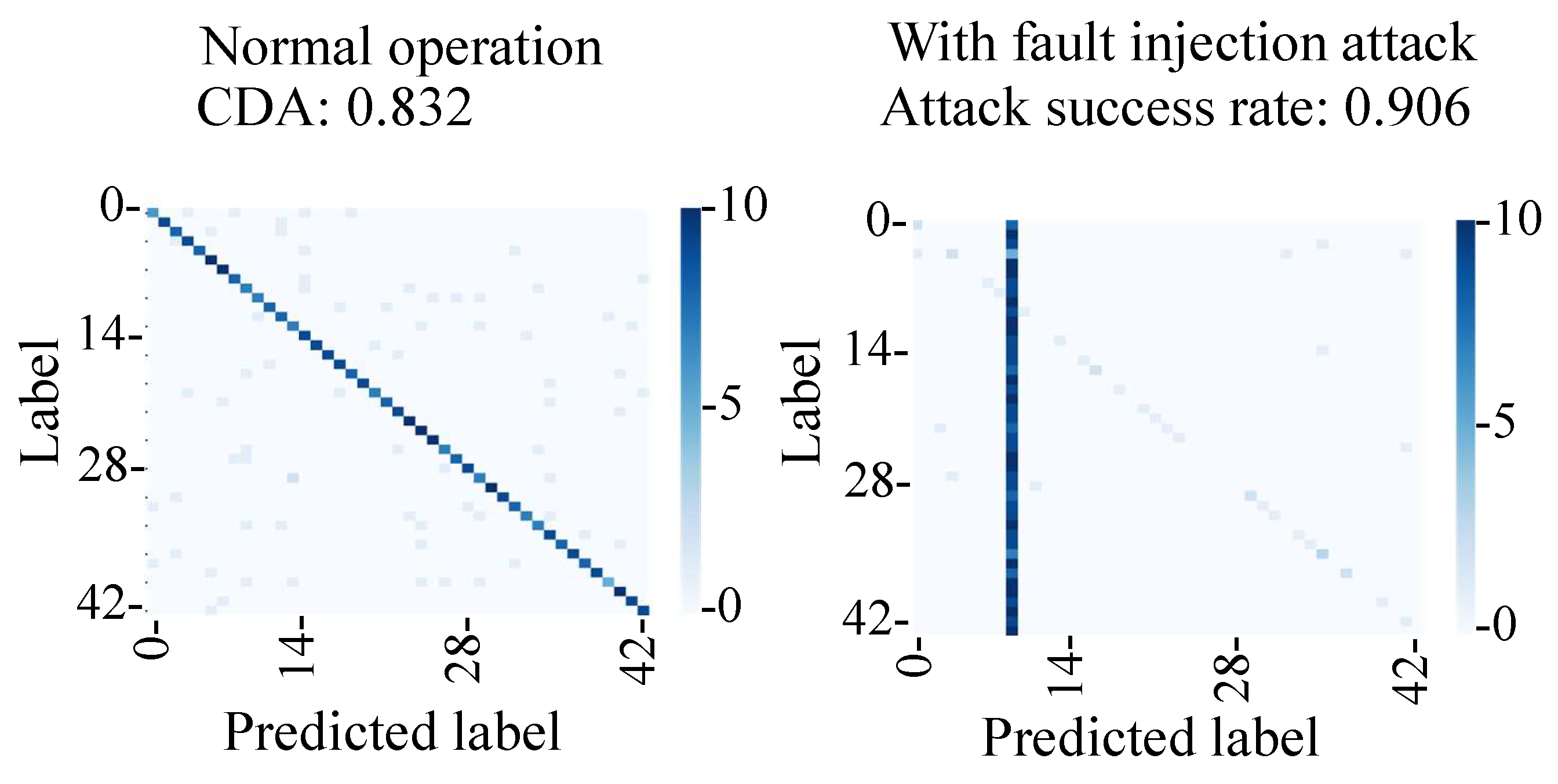
Figure 21 shows the confusion matrix of normal operation and the fault injection attack. Under normal operation, the captured images were classified into the correct classes with a CDA of 83%, which was lower than that of the simulation (95%). This was likely due to the change of the position and the brightness of the image captured in the experiment. On the other hand, the attack success rate during the fault injection attack was 91%, which is comparable to the 96% success rate in the simulation.
In the proposed fault injection attack, the position of the adversarial mark did not change even if the captured image’s position changed. Thus, the attack success rate of the proposed attack can be considered stable. As can be seen from the above results, we verified that the backdoor attack was triggered by the fault injection attack on the MIPI.
5.3. Conventional Backdoor Attacks Triggered by Taking a Picture with an Adversarial Mark
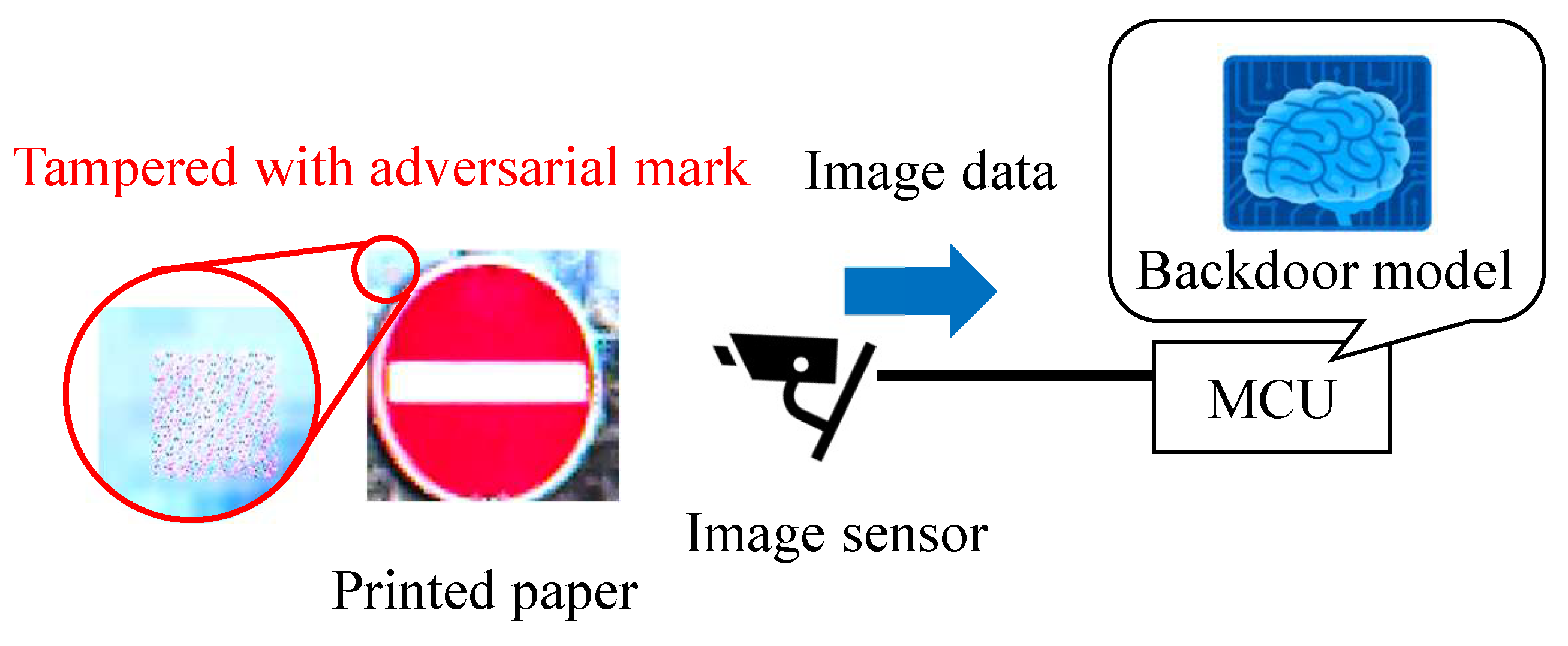
The attack success rate of the proposal backdoor attack was compared with that of the conventional backdoor attack method, in which images with an adversarial mark were used. As shown in
Figure 22, the GTSRB test images were tampered with using an adversarial mark in the digital world, and images were printed and captured with the image sensor.
The adversarial mark was generated on the image in the same way as explained in
Section 5.1, and the image was printed. Then, pictures were taken using an image sensor to evaluate the attack performance of the backdoor attack. The backdoor model was the same as the one used in
Section 5.1.
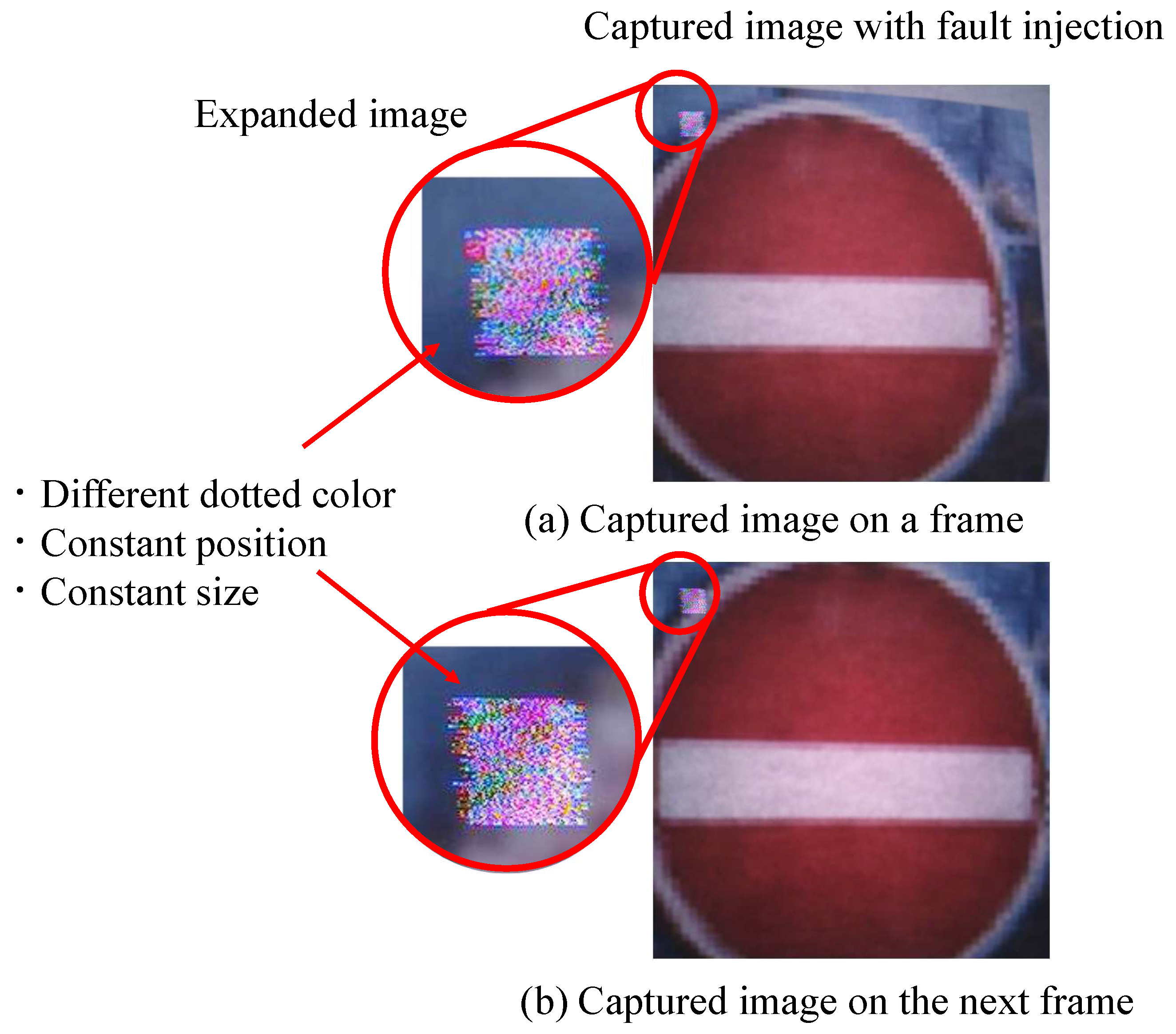
Examples of successful and unsuccessful attacks, their predicted labels, and expanded images of the tampered locations are shown in
Figure 23. The position of the adversarial mark may not have been stable in the method of inputting the mark by taking pictures, and the success rate of the attack may have changed due to the shift in the position of the adversarial mark.
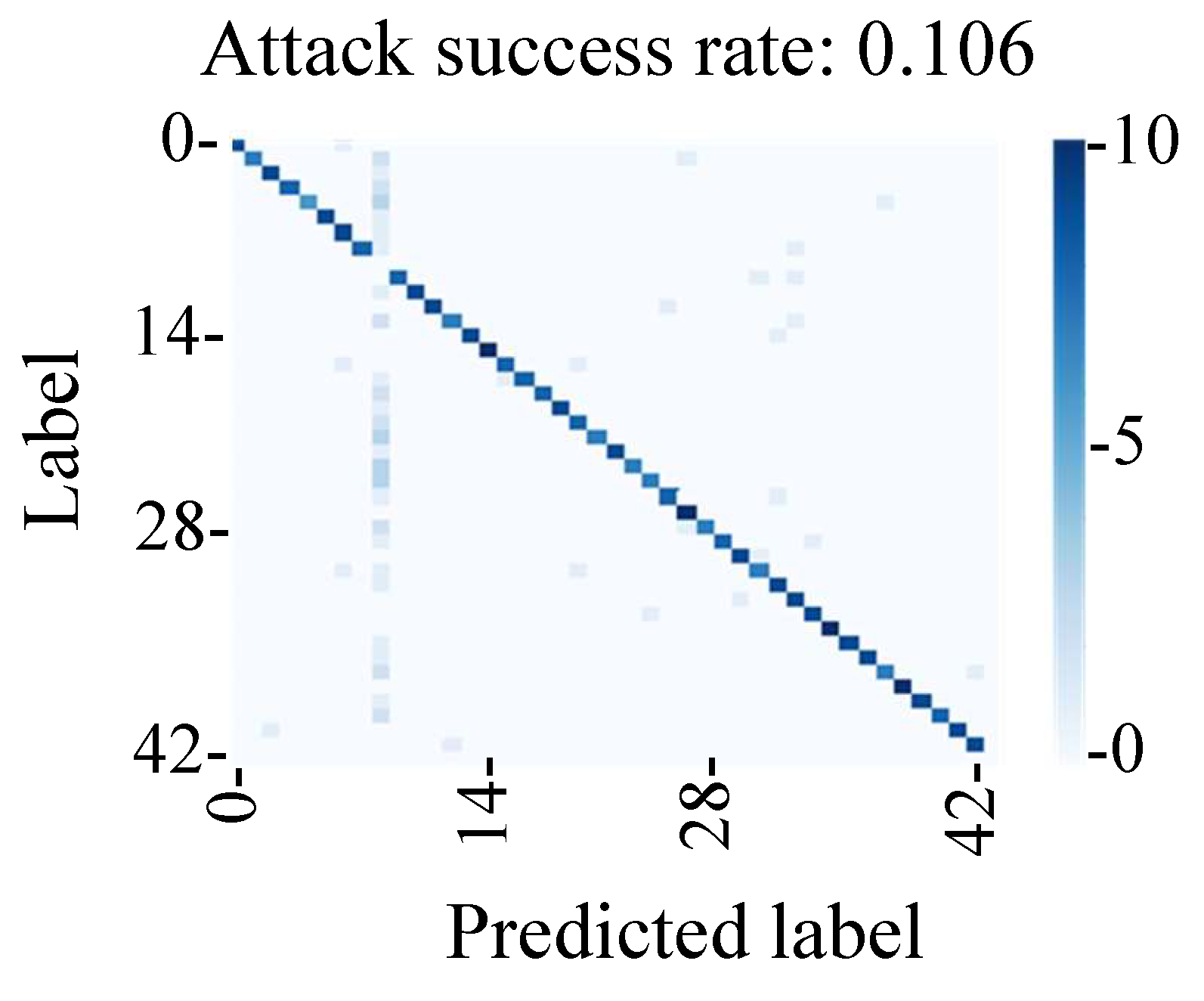
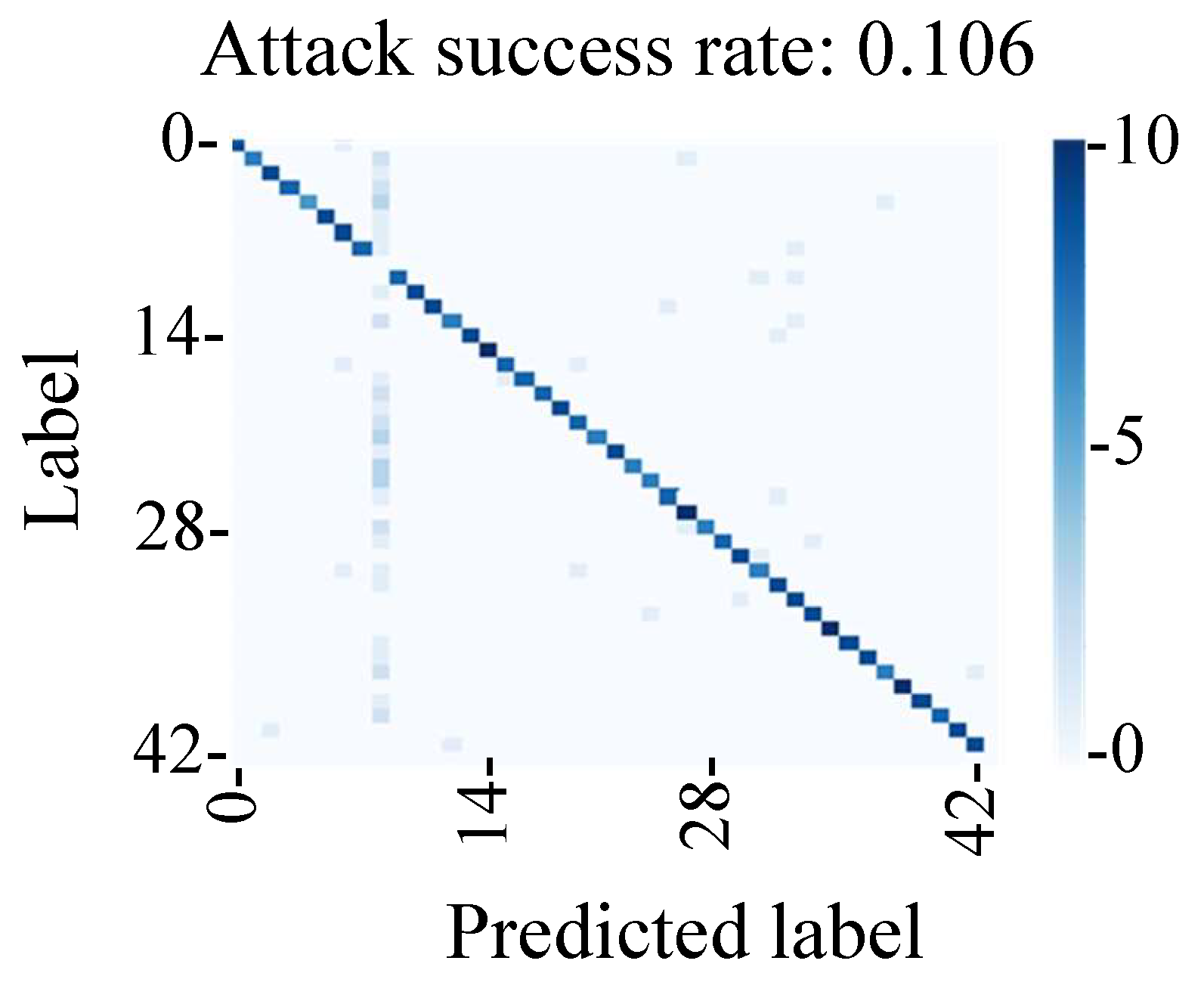
The evaluation results in
Figure 24 show that the attack success rate was 11%, which indicated that it was lower than that of the fault injection method. We found that the attack success rate of the conventional backdoor attack was affected by the shift in the adversarial mark due to the change in the shooting environment in this experimental environment. Hence, we found that the method of tampering with the MIPI data could be used to perform a stable backdoor attack by adding an adversarial mark at a stable position.
6. Summary and Conclusions
We proposed a new backdoor attack triggered by injecting a fault signal into the MIPI of an image sensor interface. The adversarial mark for triggering backdoor attacks was successfully created by superimposing the attack signal transmitted by two pairs of HS drivers on the MIPI. Almost all of the image signals were transmitted from the sensor to the processor without tampering by canceling the attack signal between the two drivers. Then, the adversarial mark was added into a target area of the image by activating the attack signal generated by the two attack drivers. Backdoor attack experiments were conducted on the GTSRB datasets using this tampering method.
We utilized the image tampering model to create the poison data. We set a model with the attack signal amplitude and the phase difference of the attack signal as parameters. By changing the amplitude of the attack signal and the phase difference between the RAW lines of the attack signal, we analyzed the kind of pattern that was generated. We compared the tampering pattern generated by the actual fault injection attack and that generated by the model in the simulation. Then, we were able to generate a pattern close to the actual pattern in the simulation by fitting these parameters.
After generating poison data using the tampering model, we conducted backdoor attack experiments. The success rate of the backdoor attack triggered by the fault injection attack was 92%. A conventional backdoor attack was also conducted as part of a comparative experiment in which the picture with the adversarial mark was used. The success rate of the conventional attack was only 11% because the position and size of the adversarial mark varied depending on the image-capturing environment. These results demonstrate that our attack on the MIPI represents a more stable backdoor attack than the conventional method.
As mentioned previously, a DNN model can be misclassified when security measures against data tampering are not implemented on the image sensor interface. As a countermeasure against this kind of attack, a message authentication code (MAC) needs to be generated for the images on the image sensor. Then, the integrity of the image data must be evaluated before using the DNN classification system.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}