1. Introduction
With the development of 5G technology and smart connected cars, cars have become equipped with stronger computing and storage capabilities, as well as information collection and communication capabilities, and many new in-vehicle applications have emerged. Although these applications can enhance the user experience and improve driving safety, such as AI-based applications, virtual reality, intelligent assisted driving, image navigation, and entertainment applications, they all have high requirements for computing and storage resources and are sensitive to latency. The computational demand for the Internet of Vehicles has thus boomed [
1,
2,
3], and the limited computational storage resources of in-vehicle terminals cannot meet the resource demand of computational tasks with high complexity, data density, and delay sensitivity [
4].
The introduction of cloud computing and Mobile Edge Computing (MEC) into the Internet of Vehicles is an effective way to solve the above problems, but the in-vehicle terminals have high requirements for task processing delay because the cloud computing uploads computing tasks to the cloud with high delay. Furthermore, the computing and storage resources of edge computing servers in MEC are limited, and more tasks will increase the task queuing delay at the server. Therefore, collaborative central cloud, edge cloud, and vehicle cloud computing provide better computing services for task vehicles. The vehicle cloud is a resource of simultaneously empty idle vehicle terminals [
5].
Initial progress has been made in the research of collaborative computing for the Internet of Vehicles scenario, where the computational offloading decision is the core research point, and the key is to find the optimal offloading decision to improve the computational efficiency and reduce the computational cost. Unfortunately, the computational offloading problem of collaborative computing in the Internet of Vehicles scenario is a mixed integer nonlinear programming (MINP) problem, which is difficult to solve directly using traditional mathematical methods. Although many scholars have studied computational offloading strategies for the Internet of Vehicles scenario, there is no popular general solution method yet. Based on the above, we study the offloading strategy of collaborative computation at the cloud-edge-end of the connected vehicle scenario with real road conditions and vehicle motion and fully adopt the intelligent swarm optimization algorithm to solve the problem and comprehensively optimize the computational delay and energy consumption. The main contributions of this work can be summarized as follows:
(1) A three-layer architecture of the central cloud, edge cloud, and vehicle cloud is proposed as a cloud-edge-end collaborative computing system model with the task offloading strategy problem in an Internet of Vehicles scenario.
(2) A Multi-strategy collaboration-Tunicate Swarm Optimization Algorithm (M-TSA) introduces a memory learning strategy, a Levy flight strategy, and an adaptive dynamic weighting strategy on the basis of the standard TSA algorithm, has stronger global optimization seeking capability, and is proposed for multi-objective optimization of offloading delay, energy consumption, and task offloading utility of cloud-edge-end collaborative computing systems.
(3) To address the offloading strategy problem presented in (1), a computational offloading strategy based on the M-TSA algorithm and combined with task prioritization and computational offloading node prediction is proposed to significantly improve the system offloading utility and reduce the computational offloading delay and energy consumption of the system by taking into account the vehicle motion characteristics and task time delay sensitivity.
3. Cloud-Edge-End Collaborative Computing System Model in the Internet of Vehicles Scenario
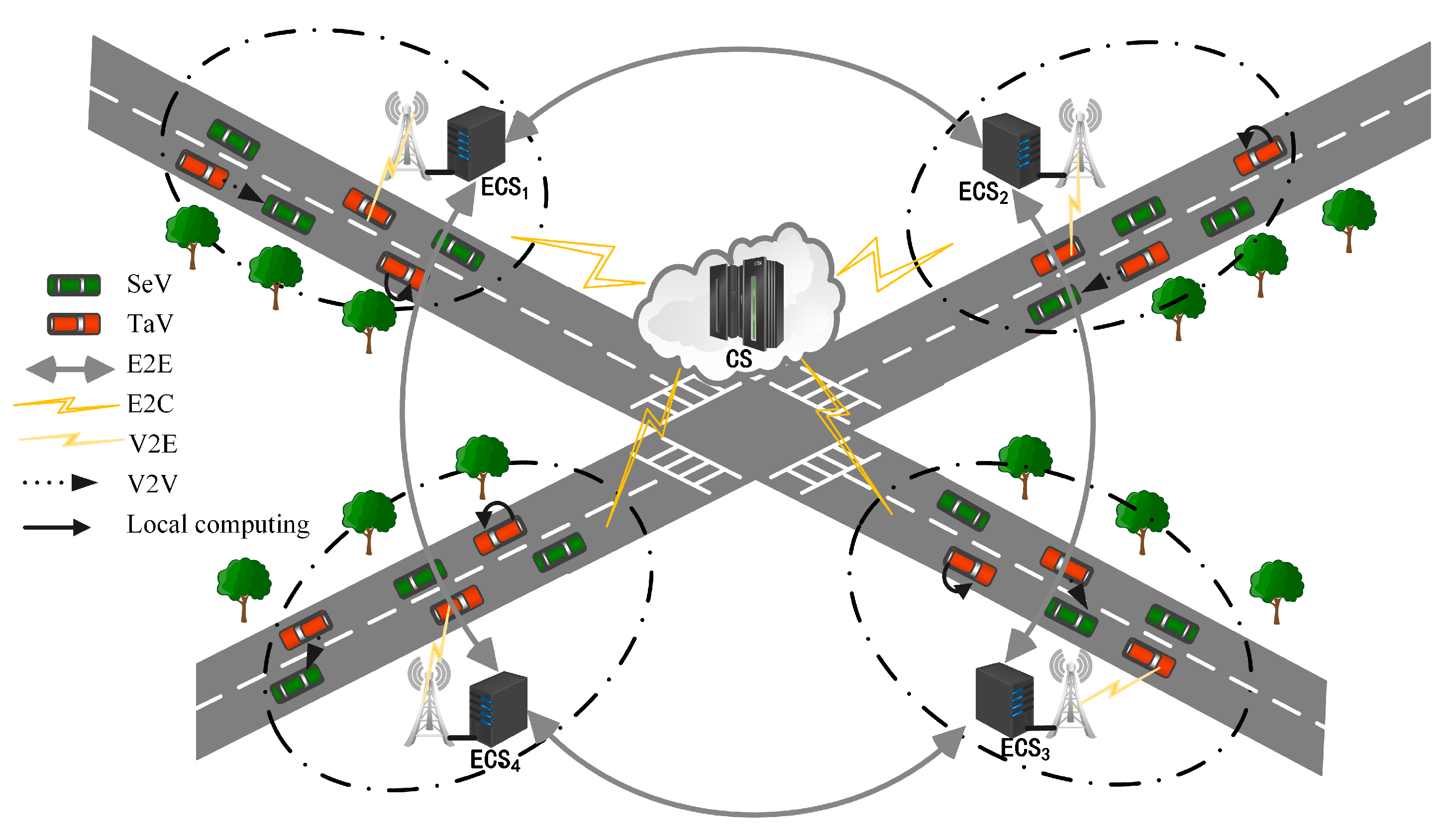
The cloud-edge-end collaborative computing network in the Internet of Vehicles scenario described in this system consists of vehicles, base stations (BS), Edge Computing Servers (ECS), and Cloud Servers (CS). As shown in
Figure 1, in a two-way straight-road scenario, many base stations equipped with edge servers are evenly deployed on the roadside, and their communication coverage radius is
L. The vehicles and ECS in the communication area of BS are called an edge computing domain. There are two types of vehicles in an edge computing domain: one is task vehicles (TaV) that generate computational tasks; the other is service vehicles (SeV) that have many available computational resources and can provide computational services to the outside world. The set of edge servers is denoted as
, and the sets of TaV and SeV in the
edge computing domain are denoted as
,
. For the convenience of the following formulation, the service vehicles SeV, edge servers, and cloud servers providing service computing are collectively referred to as service computing nodes in this system and are denoted as
. To efficiently utilize the spectrum, this system considers an OFDMA-based wireless network that connects the ECS with the task vehicle TaV and the service vehicle SeV to form a star topology, where each vehicle can communicate with the ECS in one leap point; wired connections are used between adjacent edge servers and between the ECS and the CS. In this computing network, ECS is the manager of the computing domain and is responsible for the scheduling and allocation of all tasks. At the beginning of each time slot, each vehicle in the computing domain uploads task information and computing resource information to the edge server. There are vehicles with many available computing resources, which are what we call SeV. ECS aggregates the computing tasks and the resources of service vehicles through the intelligent scheduling of tasks, which can provide higher-quality computing services to the task vehicles at the end of the network. The parameters used in this paper are listed in
Table 1.
There are mainly vertical and horizontal collaborative computing methods for the vehicles described in this system model, and there are various servers that can provide computing offload services for the task vehicles in this model, namely, cloud servers, edge servers, terminal devices of the service vehicles, and terminal devices of the task vehicles themselves. Through the intelligent scheduling of tasks, the effective utilization of global resources can be realized, and the task vehicles at the end of the network can be provided with a more high-quality computing offload service. Vertical and horizontal collaboration are differentiated as follows:
(1) Vertical collaboration: Comprised of the vehicle cloud, edge cloud, and central cloud, the three-layer Internet of Vehicles edge computing architecture provides multiple offload mode options for resource-constrained task vehicles. Thus, task vehicles can choose to process their tasks locally according to the actual situation or offload tasks to neighboring service vehicles, edge servers, and cloud servers to achieve task processing.
(2) Horizontal collaboration: The distribution of resources in the time dimension of edge servers often shows variability. Lightly loaded edge servers may cause waste due to unutilized resources, while overloaded servers may affect the normal processing of tasks due to insufficient resources. Therefore, cross-domain edge collaborative computing can be used to improve the efficiency of system resource utilization and enhance the offloading utility of tasks.
3.1. Vehicle Motion Model
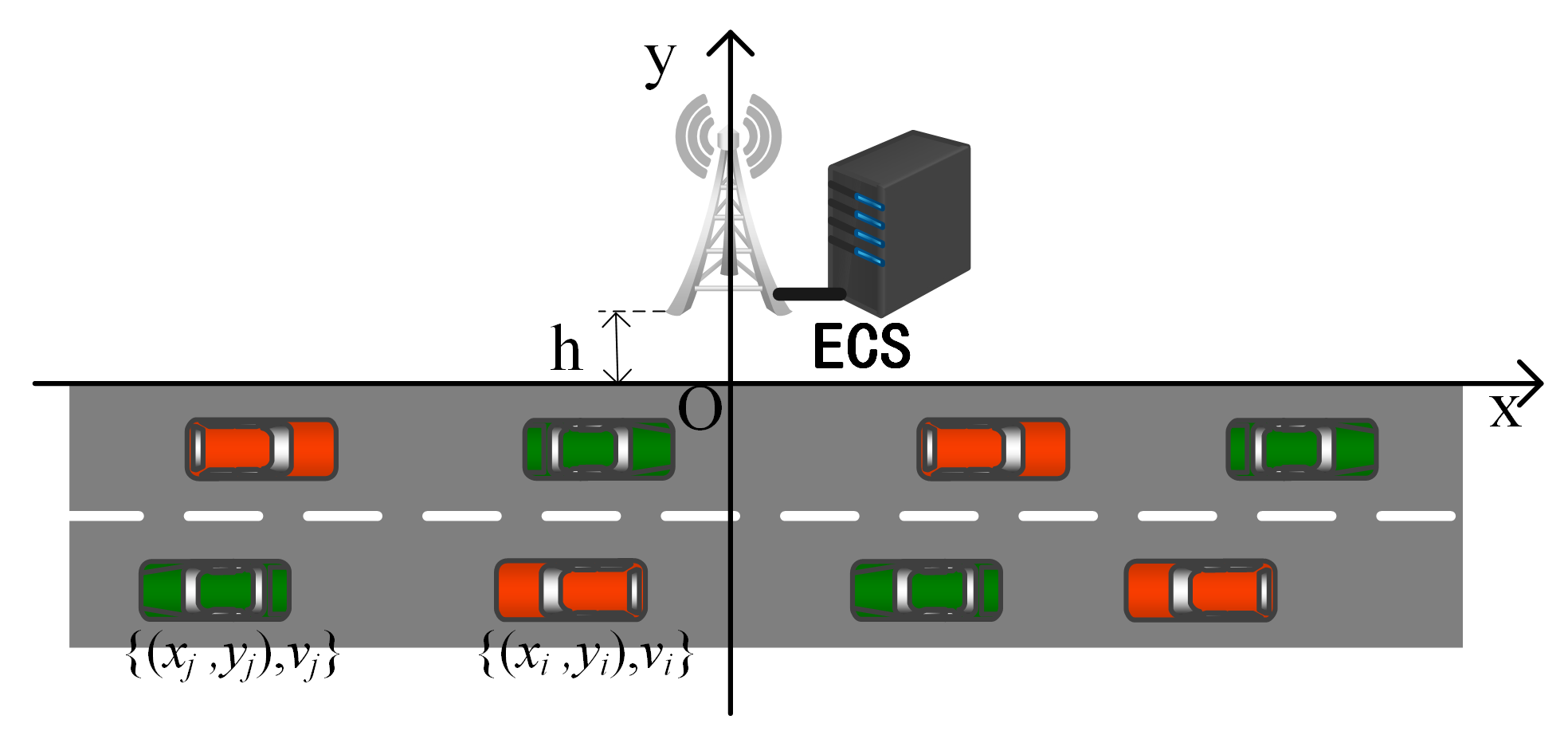
The system uses a two-dimensional coordinate system to model the motion process of the vehicle, as shown in
Figure 2, denoting the BS side of the road as the
x-axis and the vertical line of BS as the
y-axis, thus assuming that the coordinates of BS as
, where
h is the linear distance between BS and the road. The
movement pattern can be represented by a binary group as
, whereby
is
the starting position and
is the
travel speed. Assuming that the right is the positive direction, a positive sign of
indicates that
rightward travel, and the negative sign of
indicates that
travels to the left. Similarly, the
movement pattern is represented by the binary group
.The standard lane width of the road is 3 m. This system assumes that all vehicles travel in the middle of the lane, i.e., the vehicle vertical coordinate is
.
This system establishes a vehicle movement model constrained by speed and distance to simulate the real road vehicle driving environment. Since the calculated offloading time of the vehicle is very small, it is assumed that the vehicle maintains a uniform speed during the time , that is, , denotes the vehicle velocity at t moment. There are two constraints in this model:
(1) Speed constraint: Because there is a speed limit on the real road, the speed of each vehicle must be maintained in a range, i.e., .
(2) Distance constraint: Two vehicles in the same lane, at position and at position , need to satisfy . indicates the minimum distance between two vehicles driving continuously on the same lane, also known as the safety distance; if the distance between two cars is too small, it will increase the risk of traffic accidents. denotes the maximum distance between two vehicles driving continuously on the same lane; if the distance between the two vehicles is too large, it will be a waste of traffic resources. Therefore, the distance between two vehicles must be kept within a reasonable range.
3.2. Computational Model
The computational task for a single time slot of each task vehicle is considered in this system, denoted as , which is the smallest task and cannot be divided into subtasks. Each task vehicle generates a computational task , which is represented by three parameters , where (bit) is the amount of data required to complete the task, that is, the amount of input data required for the computational task execution to be transmitted from the task vehicle local device to the service computation node; (cycles) means the amount of computation to complete the task; and refers to the maximum delay limit of the computation task, determined by the task type. Each task can be executed locally in the task vehicle or offloaded to the service vehicle , the ECS, or the CS. Each service compute node has independent storage resources and compute resources . The task vehicle saves energy and task processing time by offloading the compute tasks to the service compute node; however, the amount of compute task input data sent to complete the task in the compute task offload adds additional time and energy consumption.
This section defines the task offloading variables, and the equation includes the upstream scheduling as follows:
, where
means that the task vehicle from
of the task
is offloaded to the service compute node; otherwise,
. Since each task can be executed locally or offloaded to up to one service compute node, a feasible offloading strategy must satisfy the following constraints:
The location of the calculation task
generated by the task vehicle
is as follows:
For each task vehicle
generated, due to limited computing resources, some of the computation tasks need to be transferred to the SeV, the ECS, or the CS, which then performs the computation. Since the SeV computation storage resources are limited, in this study, SeV considers single-task computation and does not create a task cache. In this system, a task queue model of the task buffer of ECS and CS is established, and
denotes the accumulated tasks at the moment
, that is,
where
is the size of the computational task that leaves the task buffer of ECS at time slot
t, i.e., the task for which ECS completes the computation, and
is the size of the computational tasks that are offloaded to the task buffer of the ECS by the task vehicle at time slot
t.
3.3. Delay Model
Once the task vehicle ’s calculation of task processing is complete, the resulting delay time includes: i. upload delay (s)—the time to transmit the input on the uplink to the service node N; ii. cache delay (s)—the queuing time in the task buffer; iii. computation delay (s)—the task computation processing time; and iv. the time to transmit the output on the downlink from the service compute node N to the task vehicle . These are described in more detail as follows:
(1) Upload delay: When the transmission rate of the communication between the computing nodes and the amount of task input data
are related, then the upload delay
of task
is
where
r denotes the transmission rate of communication between the computing nodes, and
is the amount of input data required to transmit the program execution of the computing task from the local user device to the computing node.
The upload delay of the task is divided into vehicle-to-vehicle transmission delay (V2V), vehicle-to-base station upload delay (V2E), transmission delay (E2E) between edge servers, and upload delay (E2C) from the edge server to the central cloud server.
(2) Cache delay: When the computational task
offloaded to the ECS or CS at moment
t, the task cache queuing time
is defined as
(3) Computation delay: Set
(cycles/s) denotes the CPU computing capacity of the computing node. Therefore, the task computation delay
is
Since the output data volume is usually much smaller than the input, and the data transmission rate of the downlink is much higher than that of the uplink, the transmission delay of the output is omitted in this model calculation, as also considered in [
25,
26,
27]. There are four categories of computational processing described in this system, namely, local computation, service vehicle computation, edge server computation, and cloud server computation, where the binary variable
denotes that the task vehicle
of the task
is offloaded across the domain to the collaborative edge server computation.
denotes edge computing within the edge computing domain. Then, the task
of the total computation delay computed at
is
The total time delay for this collaborative computing system is
3.4. Energy Consumption Model
The main consideration is the task vehicle’s energy consumption in this system, which is divided into local calculation energy consumption and task offloading energy consumption. The energy consumption generated by the task vehicle
while it performs task
locally, or the amount of the local computation energy consumption
, is
where
indicates the power of the vehicle terminal’s CPU.
Task vehicles
perform task offloading to service computing nodes generated by transmission energy
, denoted by
where
denotes that the vehicle terminal transmits power, and
is the power amplifier’s efficiency of the task vehicle
. In a general case, this system assumes that
, and the task vehicle
in the uplink energy consumption is calculated simply as
[
27]. The task
of the task vehicle
is executed, and its generated energy consumption is
The total energy consumption of this collaborative computing system is
3.5. Prioritization Model
To improve task offloading utility, a comprehensive evaluation of computational task
is performed based on task delay constraints and local computational urgency, and the priority of computational task
offloading is determined. The model uses a mixed weighting approach to prioritize the computational task
, where priority
is defined as
where
and satisfies
, and
and
are weighting factors.
denotes the task value of the task
.
denotes the computational task
the task urgency, and
is the local execution time of the task.
4. Computational Offloading Strategy Problem
For the cloud-edge-end collaborative computing system model in the Internet of Vehicles scenario proposed in
Section 3, this section elaborates on the problem of the system task offloading strategy. In edge computing systems, the quality of service is mainly expressed in terms of the delay and energy consumption generated by the computational task completion. In the considered Internet of Vehicles scenario, this paper, considering both delay and energy consumption improvements, defines the task offloading utility of task vehicle
is defined as
where
is the time delay weight,
denotes the energy consumption weight, and
,
, and
. For example, a task vehicle
with a small battery capacity can increase
, decreasing
and thus saving more energy at the cost of longer task delay. The task offloading utility of the system described is expressed as
.
For a given offloading strategy
X, the present collaborative computing system task offloading strategy problem is formulated as a problem of maximizing the offloading utility of the system, that is
where
denotes that
and BS can remain connected,
denotes that
and
can remain connected, and they are calculated as
where
denotes that
can move a lateral distance within the communication range of V2I at a fixed transmission power,
denotes that
can move a lateral distance within the communication range of V2V at a fixed transmission power, and
is a symbolic function, which is expressed in this equation as follows: when
,
; when
,
.
denotes that the two vehicles
and
have the same speed and that the initial position is within the communication range, whereby the two vehicles can keep communication for a long time, thus assigning
to an enormous value. In other cases, when
, this indicates that
and
are moving away from each other; when
, this indicates that
and
are moving closer to each other.
The constraints in Equation (
15) are explained as follows: constraints C1 and C2 imply that each task can be executed locally or offloaded to at most one service computing node; constraint C3 implies that each service vehicle can service at most one task vehicle; constraint C4 specifies that each task must be completed within the specified maximum time delay limit; constraint C5 specifies that the task offloaded to the service vehicle must be completed within the two-vehicle maintain-communication time, or that offloading to the ECS must be completed within the hold-communication time with the BS; constraint C6 specifies that the straight-line distance
between the task vehicle and the service vehicle for both vehicles must be no greater than the communication distance
R for the task to be offloaded.
6. Simulation Verification
To verify the effectiveness of the proposed M-TSA-based multilateral collaborative computing offloading strategy, this section presents our simulation experiments using Python, and the main parameters of the experiments are shown in
Table 2. The experiments are conducted to compare three computing systems, namely, cloud-edge-end collaborative computing, end-edge collaborative computing, and local computing. Further, the experiments are conducted to compare the offloading strategies based on the M-TSA algorithm with the TSA algorithm, PSO algorithm, Grey Wolf Optimizer algorithm (GWO), and Differential Evolution Algorithm (DE) offloading strategy comparison experiments. The algorithm parameters of this experiment are set as iteration number
, population size
, one central cloud server, four edge computing domains, and a random group of vehicles in one computational domain.
6.1. Cloud-Edge-End Architecture Verification
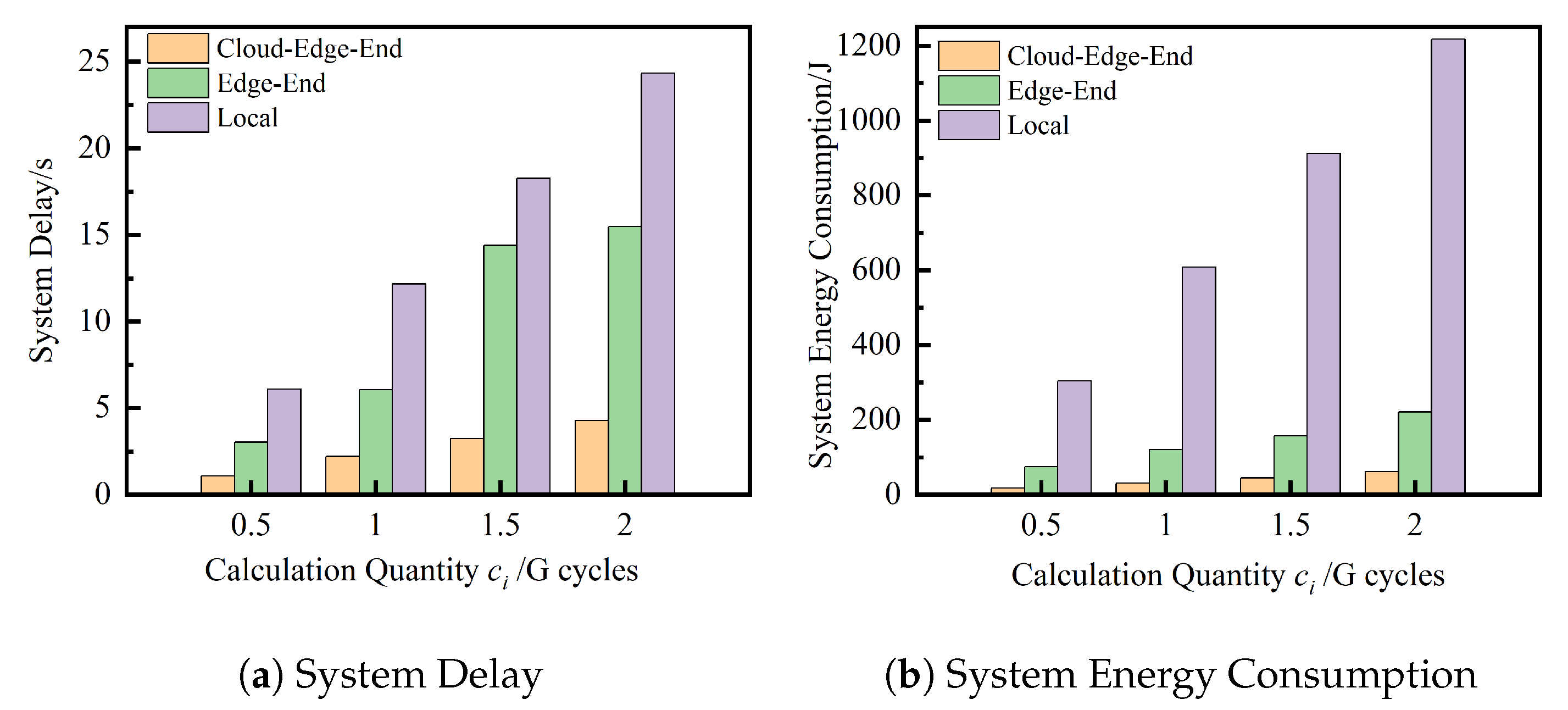
Under the same experimental environment and the same task instance, the mixed weights of delay and energy consumption () under the M-TSA algorithm are compared, and the optimization results of cloud-edge-end collaborative computing, end-edge collaborative computing, and local computing for three computing systems on delay and energy consumption are discussed. In the created task instance, the three computing systems are run 20 times independently, and the average of the optimal solutions of the results of 20 runs of each algorithm is taken.
As can be seen in
Figure 5, in the same experimental environment and with the same task instance input, the solution results of the cloud-edge-end collaborative computing system under the mixed weight evaluation are significantly better than those of the other two architectural computing systems, resulting in a smaller system delay and lower system energy consumption, and the advantage grows as the task computation volume increases. The experimental results show that the cloud-edge-end collaborative computing system is significantly better than other architectures and can realize complementary resources of cloud computing, edge nodes, and vehicle terminal devices, which can be flexibly configured according to the characteristics of the task and real-time demand to better adapt to different task scales.
6.2. Delay and Energy Mixing Weighting Optimization Comparison
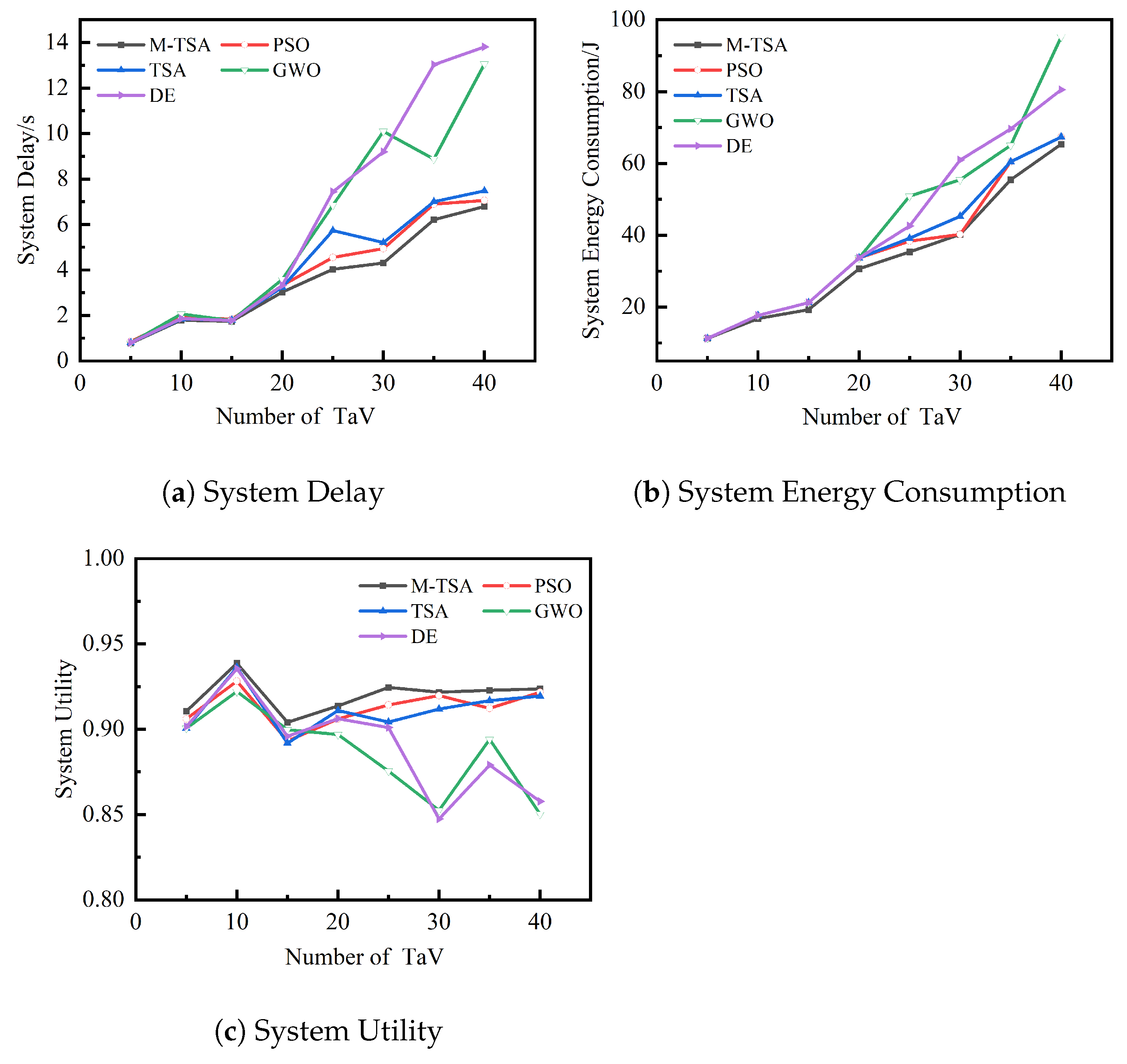
Figure 6 depicts the optimization comparison results of offloading utility, delay, and energy consumption for five algorithms to calculate offloading under mixed weights of delay and energy consumption with the same experimental environment, the same task instance, and the same initial population when the number of TaV is 20 and the number of SeV is 30. In the created task instance, the five algorithms are run 20 times independently with the same input, and the optimal solution is taken from the results of the 20 runs of each algorithm.
As can be seen in
Figure 6, the solution results of the M-TSA algorithm under the mixed weight evaluation are significantly better than the other four algorithms in the same experimental environment with the same task instances and the same initial population input, obtaining higher offloading utility, a shorter system time delay, and a lower system energy consumption, which is proof that the M-TSA algorithm has a stronger global optimization-seeking ability to derive the optimal computational offloading strategy. In addition, it can be seen in
Figure 6 that the M-TSA algorithm can obtain the optimal solution in fewer iterations compared to other algorithms, indicating that the M-TSA algorithm has a fast optimality finding capability, which enhances its application to delay-sensitive vehicular networking special scenarios to compute offloading strategies.
6.3. Delay Orientation Optimization Test
Figure 7 depicts the comparison results of offloading utility and delay for five algorithms to perform delay orientation optimization (
) experiments with the same experimental environment, the same task instances, and the same initial population when the number of TaV is 20 and the number of SeV is 30.
From
Figure 7, it can be seen that the M-TSA proposed also has better results in calculating the offloading directed optimization delay compared with the PSO, TSA, GWO, and DE algorithms. From
Figure 7a, we can see that the M-TSA algorithm has several large upward jumps relative to other algorithms, which in turn leads to better solutions. This is proof that the M-TSA algorithm has a stronger ability to jump out of the local global optimum and can continuously jump out of the local to fully search the global to arrive at the optimal computational offloading strategy.
6.4. Impact of Changes in the Number of Task Vehicles in the Computational Domain
This section is a simulation experiment in which the number of service vehicles (SeV) is 30, given
, and the optimization comparison results of offloading utility, time delay, and energy consumption for five algorithms for the different number of task vehicles in the same experimental environment and same task instance are presented. The five algorithms are run 20 times independently with the same input under a fixed number of TaV, and the average of the optimal solutions of the 20 runs of each algorithm is taken. Please refer to
Table 3,
Table 4 and
Table 5 for the data on the impact of the number of TaV.
As can be seen in
Figure 8, the solution results of the M-TSA algorithm proposed are significantly better than the other four algorithms for the different number of task vehicles. It can derive a better computational offloading strategy, which enables the vehicle cooperative system to handle all computational tasks with higher offloading utility, a minimum system time delay, and a minimum system energy consumption, indicating that this algorithm is effective.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}