1. Introduction
In classification tasks, such as face recognition and emotion recognition, multimodal information is often used to enhance classification accuracy and robustness. Multimodal classification addresses the limitations of state-of-the-art visible-camera-based classifications. These limitations include illumination and environmental variations, occlusions, background noise, and low light conditions. Multimodal classification addresses these limitations through the effective fusion of a visible camera with different sensors, such as a thermal camera [
1,
2,
3,
4,
5]. However, given a set of
K modalities,
S, the multimodal classification framework typically relies on the availability of
complete multimodal data for all modalities. Under the condition of
incomplete multimodal data, where one or more modalities are missing, the performance of multimodal classification is affected [
6,
7,
8]. This problem is referred to as the missing modality problem. Sensor failures, data corruption, and environmental noise are examples of scenarios resulting in
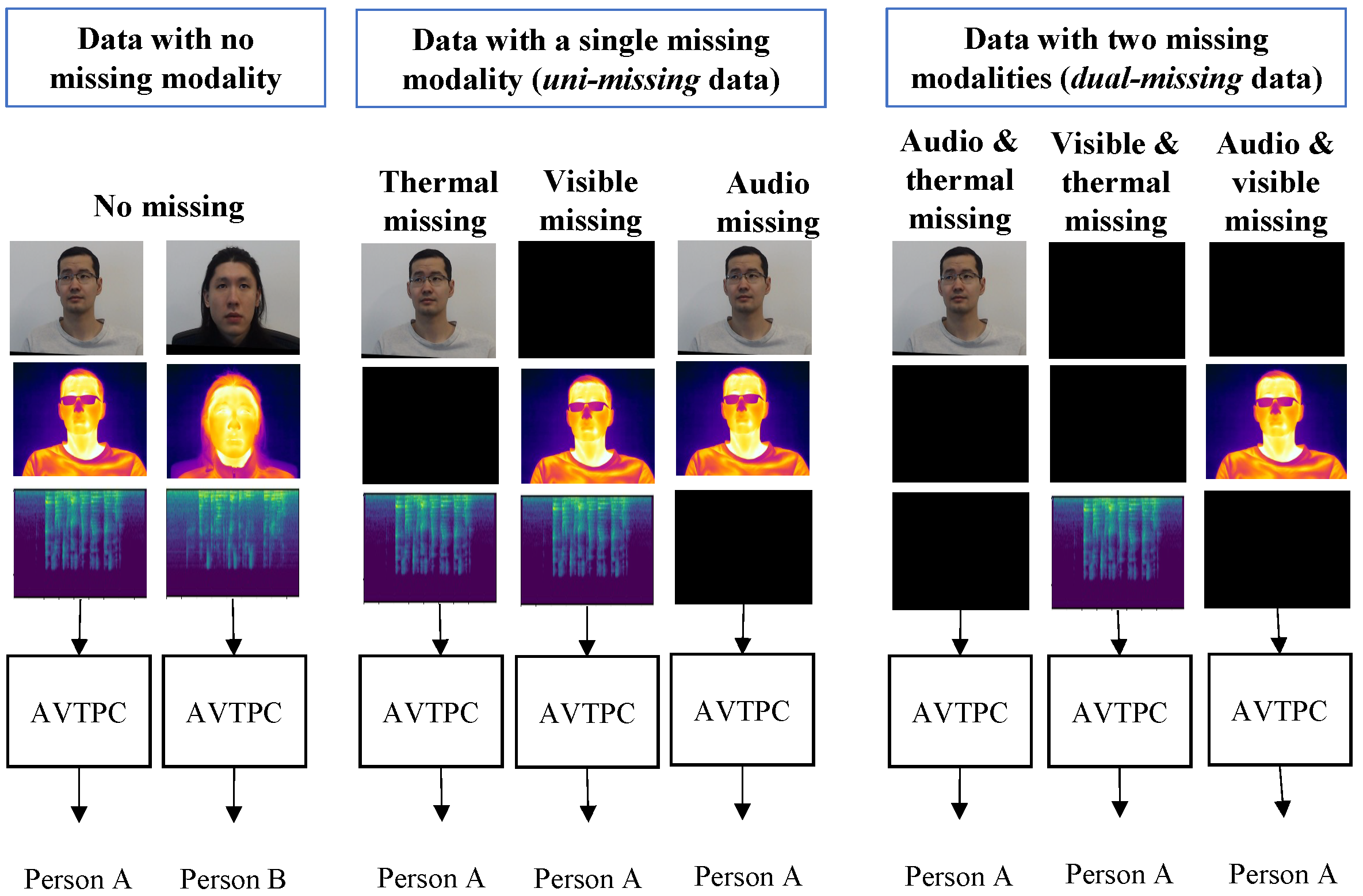
incomplete multimodal data. For example, in the audio-visible emotion recognition problem, if the query person is outside the camera’s field of view, their visible camera appearance is not available and only audio data is available for classification. Similarly, in the case of loud background noise, audio data is not available, and only visible data is available. Illustrations of the missing modality problem are presented in
Figure 1 and
Figure 2.
For a given set
S with
K modalities, power set
represents the set of all subsets of
S. We define the set of the
k-combination subsets,
, by selecting subsets of size
k as
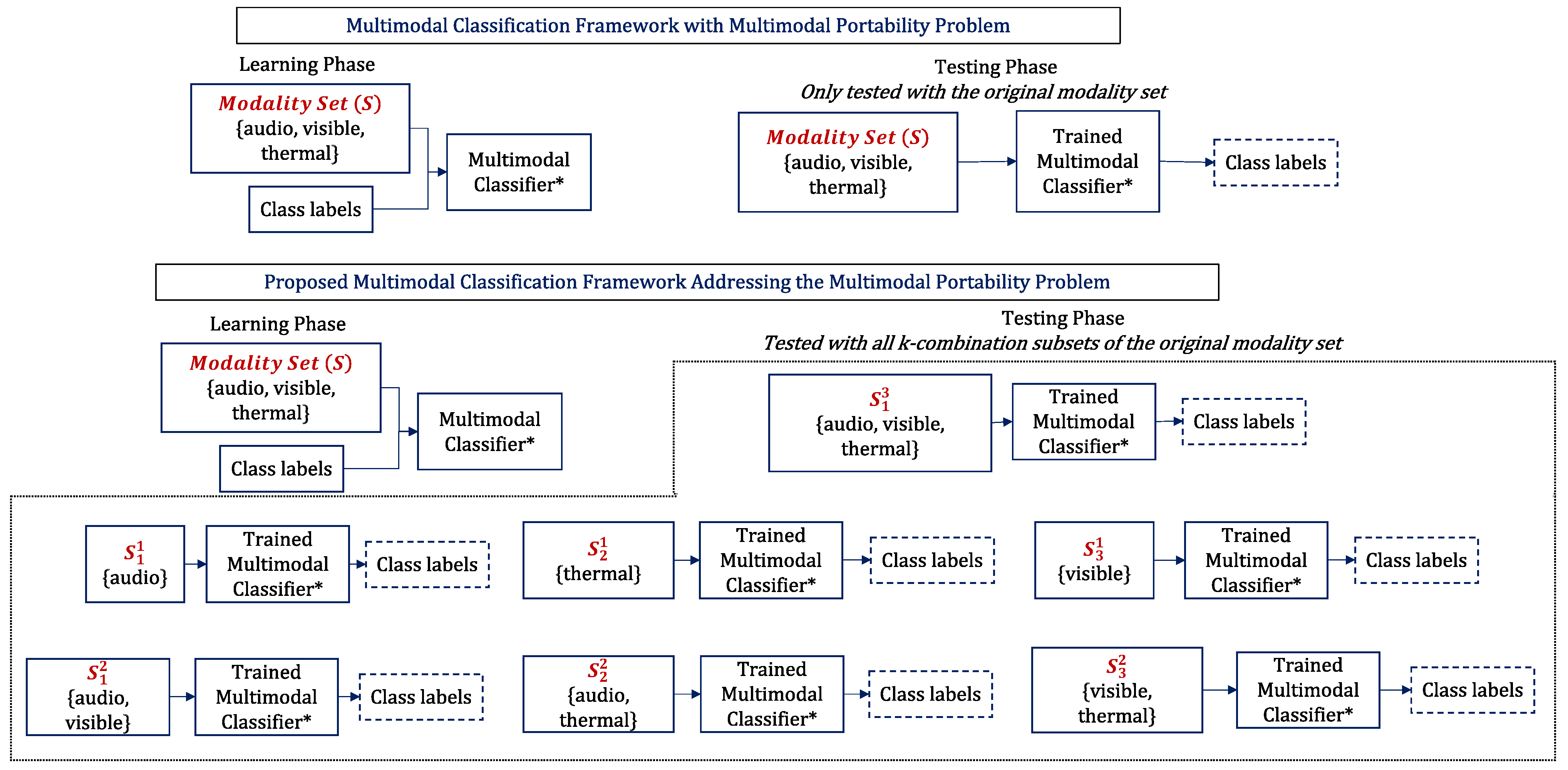
Typically, a multimodal classification framework is defined and trained using an original set of modalities. Subsequently, the trained framework is tested using the same modality set. This reduces the portability of the framework to different subsets,
. For example, given the set of
data, the 1-combination subsets
correspond to
,
, and
unimodal data. The 2-combination subsets
correspond to
,
, and
bimodal data. The 3-combination subset
corresponds to
trimodal data. In this scenario, the standard
trimodal classifier is often defined for
trimodal data, and is not directly applied to
unimodal or
bimodal classification problems. We refer to this problem as the multimodal portability problem. An illustration of the problem is presented in
Figure 3.
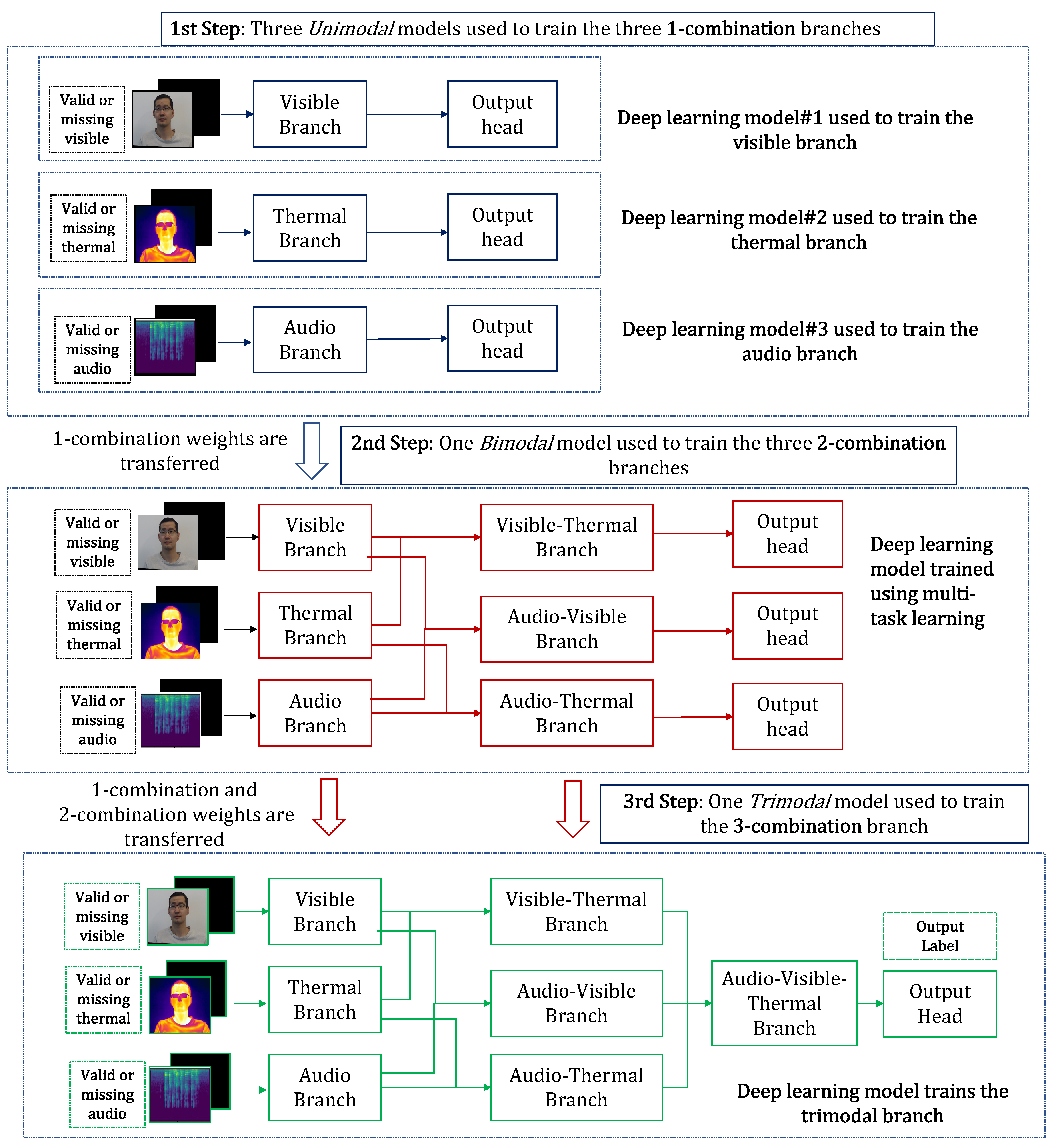
In this study, we propose a novel deep learning model, termed KModNet, which is trained with a novel progressive learning framework to simultaneously address missing modality and multimodal portability problems. KModNet is implemented with K blocks, with each k-th block containing different k-combination branches, where . KModNet is trained using a novel multi-step progressive learning framework, where each k-th step is used to train the different blocks in KModNet up to the k-th combination block. For example, the first step in the progressive learning framework is used to train the 1-combination block, and the second step is used to train the 1- and 2-combination blocks.
To enhance the robustness, in the
k-th step, the 1 to
combination blocks trained in the previous steps are further fine-tuned. For example, the 1-combination block trained in the first step is further fine-tuned in the
k-th step. To address the missing modality problem during training, multimodal data are randomly ablated to represent the missing modality data. Additionally, an “unknown” classification label is utilized to reduce the inefficient learning of certain models in the progressive learning framework. Finally, a multi-head attention transformer, which has been shown to be effective with missing modality data, is used [
9].
The proposed learning framework is applied to two different classification tasks: audio-visible-thermal person classification (AVTPC) and audio-visible emotion classification (AVEC). The frameworks are validated using the
Speaking Faces [
10],
RAVDESS [
11], and
SAVEE [
12] datasets. The results demonstrate that the progressive learning framework enhances the robustness of multimodal classification, even under conditions of missing modalities, while being portable to different modality subsets. Owing to the formulations of KModNet with different
k-combination blocks and the progressive learning strategy, the missing modality and multimodal portability problems are effectively addressed, as shown in the experimental section (
Section 5).
The main contributions of this study to the literature are as follows:
A novel multimodal classification framework termed the KModNet with 1 to k-combination blocks.
A novel multimodal progressive learning framework to train the KModNet to address the missing modality and multimodal portability problems.
The remainder of this paper is organized as follows: The related literature is reviewed in
Section 2. The proposed progressive learning framework is presented in
Section 3, and its application for two classification tasks is presented in
Section 4. The validation of the framework is performed in
Section 5. Finally, we summarize and present our conclusions in
Section 6.
2. Literature Review
Multimodal learning addresses the limitations of vision-based perception [
4,
5,
13,
14,
15,
16,
17,
18]. For example, an effective sensor fusion of the visible image with the audio and thermal image is shown to enhance the classification accuracy [
2,
3,
4,
5,
13,
19,
20,
21,
22,
23,
24]. However, the aforementioned studies are limited by the missing modality and the multimodal portability problems.
In recent years, different approaches have been proposed to address the missing modality problem [
7,
8,
25,
26]. The different approaches can be categorized as generative, latent-space, data augmentation, and optimal fusion approaches. In the generative approach, the missing modality or supplementary data predicted from the available modality are used to enhance the classification accuracy. John et al. [
27] proposed the audio-visible person classification framework, the CTNet, where the person label is estimated even when the visible image is missing. Here, person attributes, such as age, gender, and race, are predicted from the audio data. The person label is then estimated using the predicted attributes along with the audio data.
In the latent-space approach, the latent space is learned from multimodal data to address the missing modality problem [
6,
26,
28,
29]. Recently, John et al. [
6] proposed a missing modality loss function to learn the latent space even under conditions of missing data. The latent space is used within the AVTNet to estimate the person class. Similarly, Zhao et al. [
26] learned the latent representation from multimodal data using a residual autoencoder, which was subsequently used within the MMI network for emotion recognition.
In the data augmentation approach, researchers augment the training of multimodal data with ablated data, where the data corresponding to a missing modality are represented using pre-defined fixed data [
6,
30]. Finally, researchers have proposed optimal fusion frameworks using transformers to address the missing modality problem [
9,
31]. In the work by Ma et al. [
9], a dataset-dependent fusion strategy was learned to enhance perception. Alternatively, Han et al. [
31] adopted an implicit fusion strategy using multi-task learning, where the output layers were effectively shared by different modalities.
Although the aforementioned literature addresses the missing modality problem, it has not yet been solved. Moreover, the studies referred to also do not address the multimodal portability problem. In this article, compared to the literature, we propose a novel deep learning framework, the KModNet, and a novel progressive learning framework where we address the missing modality problem with multiple missing modalities in addition to the multimodal portability problem. In
Table 1, we address the differences between the proposed algorithm and the related missing modality literature.
3. Proposed Classification Framework
3.1. Overview
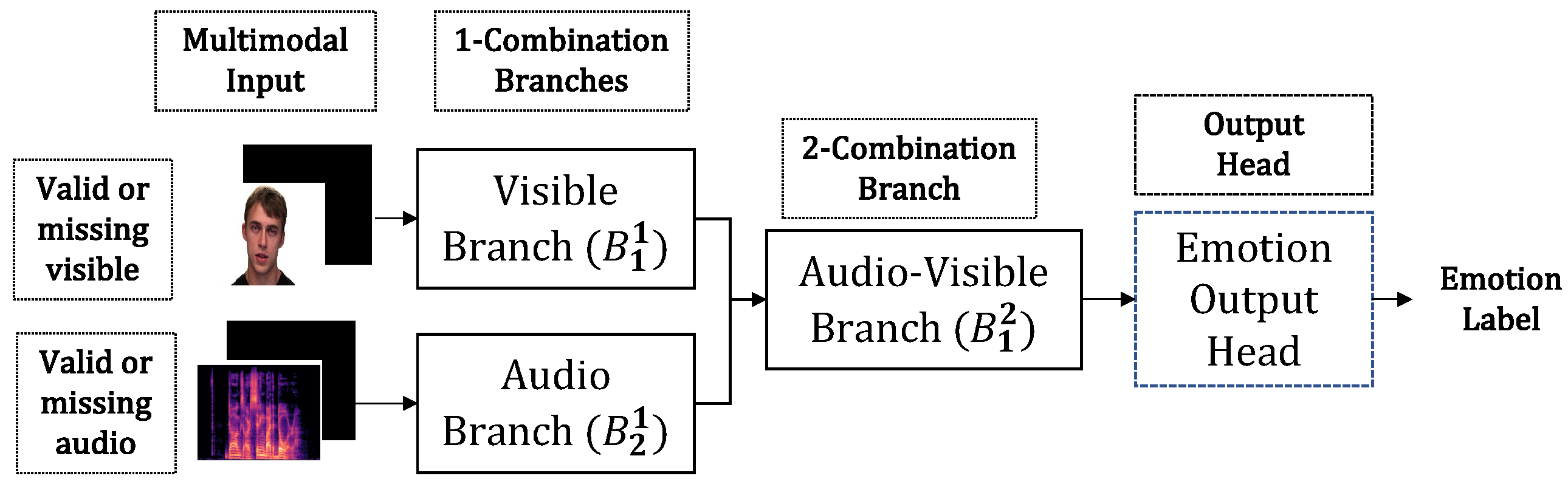
For a set S with K modalities, powerset is the set of all subsets of S. The different k-combination subsets in are represented by the set . Each contains elements that are given by =.
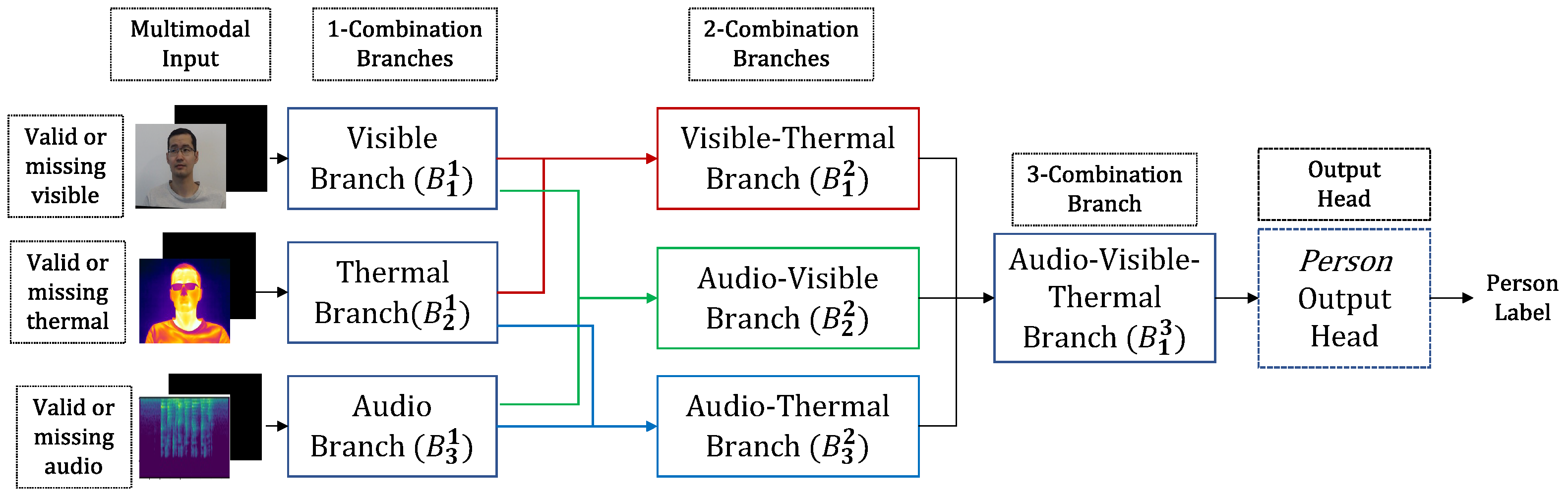
The novel KModNet is formulated with multiple blocks corresponding to different . Each k-th block contains branches corresponding to the different elements in . Each k-combination branch accepts outputs only from the -combination branches whose modalities are related to the modalities in as the input.
The KModNet is trained using a multi-step progressive learning framework. Each
k-th step in the progressive learning framework trains different blocks up to the
k-th block in KModNet. Following the training, the different branches in KModNet can be used to estimate the class label for all
k-combination subsets in
. An example of KModNet implemented for trimodal person classification is shown in
Figure 4.
To handle the missing modality problem, first, the training multimodal data is randomly ablated using pre-defined fixed data representing the missing modality data. Next, to reduce inefficient learning owing to missing modality data, an “unknown” classification label is used along with the randomly ablated data for certain models in the progressive learning phase. These are explained in detail in subsequent sections. Finally, we utilize the multi-head attention-based transformer, which has been previously studied and shown to be effective for the missing modality problem [
9].
3.2. Learning Phase
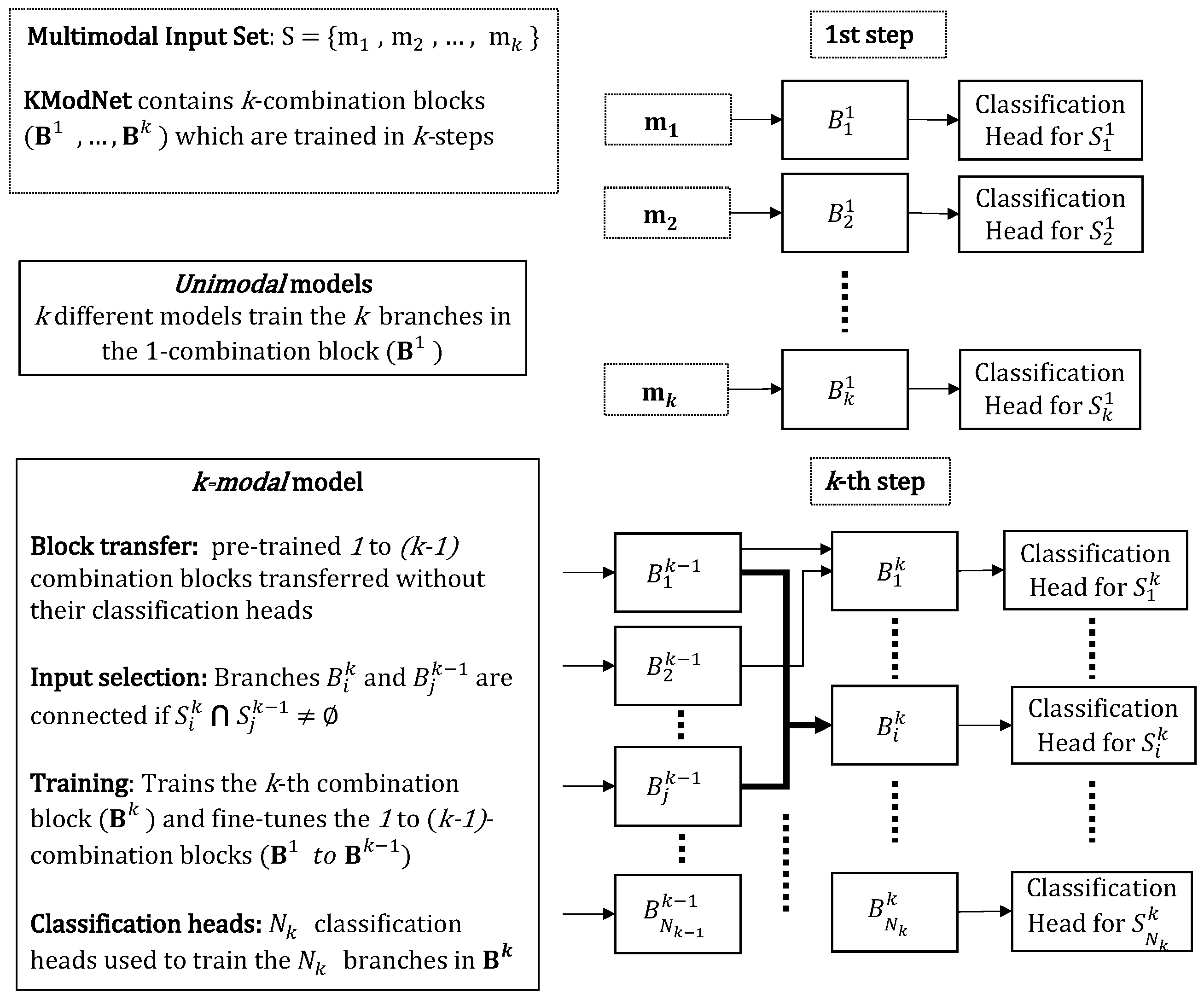
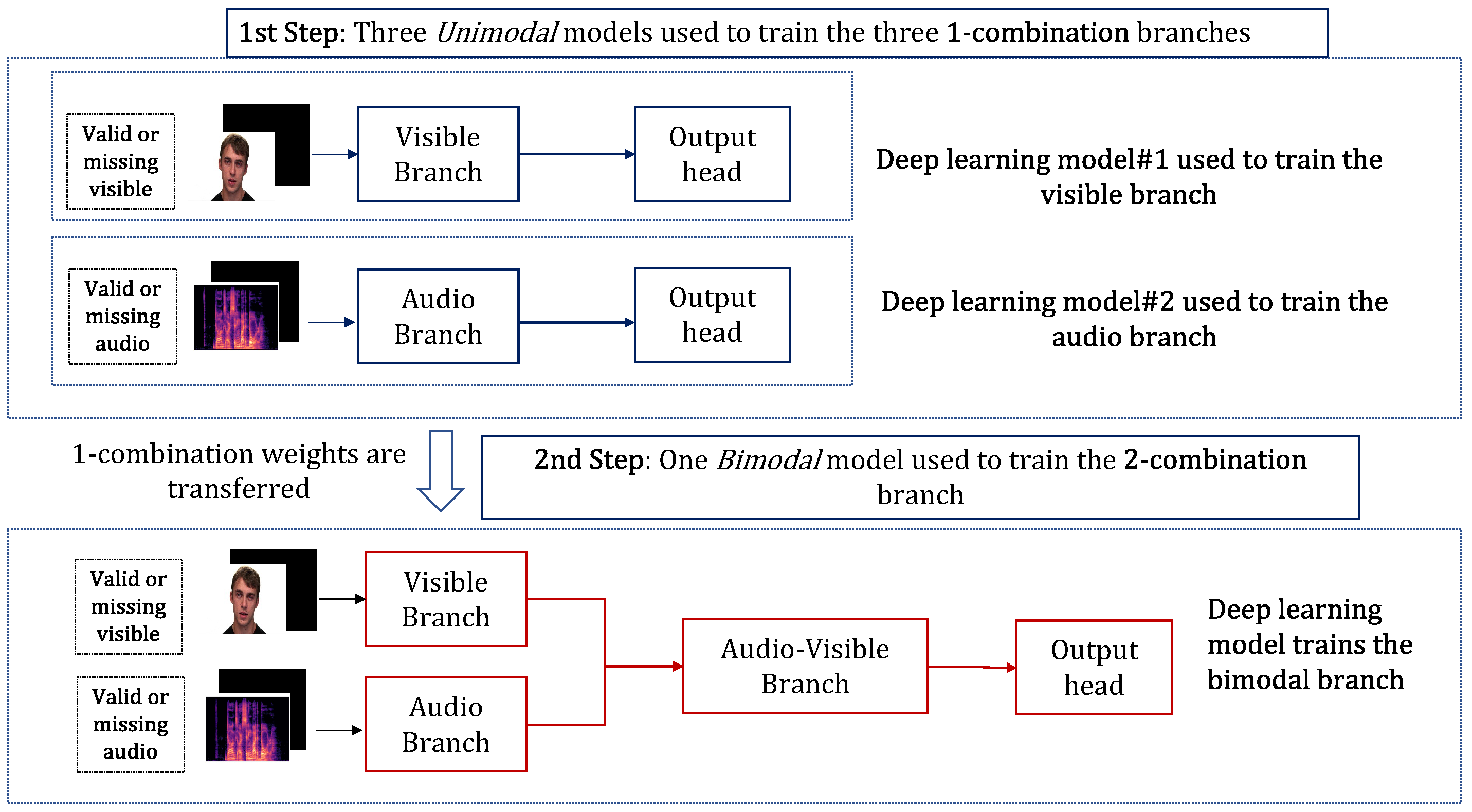
The progressive learning strategy is a multi-step learning framework where the different k-combination blocks in the KModNet are trained. Each k-th step in the learning strategy trains different blocks up to the kth-combination block in KModNet.
For each k-th step, combination blocks followed by a classification output head are used to train the network. In the first step, the 1-combination branches in the 1-combination blocks corresponding to = are trained independently. Here, the i-th deep learning model, followed by an individual classification head, is used to train the i-th 1-combination branch in block . These models are termed unimodal models.
In the subsequent k-steps, a single deep learning model called the k-modal model is used to train the k-combination branches in the k-combination block, , corresponding to = . In the k-modal model, classification heads are used to train the different k-combination branches.
In the k-modal model, first, to further enhance robustness, previously trained () models without their classification heads are transferred. Next, the i-th k-combination branch in k-th combination block outputs a fused feature from the set of modalities in . This branch selectively accepts the output of some of the branches in the previous block. The input of the i-th k-combination branch is represented by a set of outputs from the branches in the previous blocks, given as . This is referred to as the input-selection mechanism.
Following the input selection, the transferred (k–1) branches are also trained along with the k-combination branches. For example, in the case of bimodal KModNet, in the second step, the transferred unimodal models are also trained along with the 2-combination branches.
To address the missing modality data, in the learning phase, the multimodal data is randomly ablated with pre-defined fixed data. For multimodal data, if all modalities are present, the multimodal data are referred to as “complete” data. For trimodal data, if a single modality is missing, the data are referred to as “uni-missing” data. If two modalities are missing, the data are referred to as “dual-missing” data. The data corresponding to the missing modality is represented by pre-defined fixed data, the details of which are presented in
Section 5. An overview of the KModNet learning phase is shown in
Figure 5.
3.3. Testing Phase
Following progressive learning, the trained KModNet is used to estimate the classification label for the test multimodal data, even in the presence of missing modalities. Moreover, the trained unimodal, bimodal, and k-modal models in different learning steps can be used to estimate the class labels for different k-combinations of modality set S. Consequently, different branches in KModNet can be ported to any subset in . This addresses the multimodal portability problem.
As shown in
Section 5, the missing modality problem is effectively addressed because of the random ablation of the training data, use of the “unknown” classification labels for certain training steps, and integration of the transformers.
3.4. KModNet Implementation: Modal Specific
While the k-combination branches are generic, as their inputs are obtained from the preceding -combination branch, the 1-combination branches should be designed for their corresponding modality because the multimodal data is given as input directly to KModNet’s 1-combination block, which represents the 1-combination subsets . Here, we explain the modal-specific implementation of the 1-combination block.
In this article, KModNet is implemented for audio, visual, and thermal data, but not limited to them. The multimodal data for these tasks are represented by the audio spectrogram , the video with j frames of size , and thermal video with j frames of size .
For visible and thermal videos, each image in the visible or thermal video sequence is split into fixed-size patches and linearly embedded into a 128-dim projection space. Subsequently, learnable position embeddings are added to the linear embedding of each frame. The image embeddings are then concatenated to form a sequence vector. Frame embedding, which functions as a frame index, is added to the sequence vector. Frame embedding distinguishes embedded vectors among the three frames in the input video sequence. We refer to the aforementioned layers of patch extraction, position embedding, and frame embedding as standard embedding layers.
For the audio data, the audio spectrogram is given as input to three layers of Conv-1D with and 128 filters of size and 3, stride 1, and ReLU activation. We refer to this architecture as the audio convolution layers.
3.5. KModNet Implementation: Multi-Head Attention Transformer
Each branch in KModNet is implemented using a multi-head attention transformer. The layers in the transformer are termed standard transformer layers. Given the transformer input, the standard transformer layers have an initial layer normalization layer, followed by a multi-head attention layer with four heads and drop out. The output of the attention layer is added to the input to obtain the attention output vector. This vector is given as an input to two multilayer perceptron (MLP) layers with 256 and 128 units with dropout. The MLP output is then added to the attention output vector to obtain the output of the transformer branch.
For the 1-combination block, the inputs to the visible and thermal standard transformer layers in the visible and thermal-unimodal models correspond to the outputs of the standard embedding layers. For the audio standard transformer layers, the input to the audio-unimodal model is the output of the audio convolution layers.
For the k-combination blocks, the inputs to the k-modal model’s standard transformer layers are obtained by concatenating the outputs of certain branches in the -combination block. The branches in the -combination block are selected according to the previously described input selection mechanism.
5. Experiments
The proposed framework for the AVTPC problem is validated using the audio-visible-thermal Speaking Faces dataset [
10]. Similarly, the proposed framework for the AVEC problem is validated using the audio-visible RAVDESS dataset [
11] and the SAVEE dataset [
12].
5.1. AVTPC Problem
5.1.1. Dataset
In the Speaking Faces dataset, 3310 audio-visible-thermal sequences corresponding to 142 people are selected and randomly partitioned into the training and testing sequences. For the learning phase, we generate a missing dataset from the original dataset by randomly ablating of the training data. For the missing dataset, half of the sequences have ablated data corresponding to a single missing modality representing the uni-missing data, whereas the remaining half have ablated data corresponding to two missing modalities representing the dual-missing data.
The proposed framework is validated using multiple baseline algorithms. In addition, we perform a detailed validation of the progressive learning framework.
5.1.2. Baseline Algorithms
The first baseline algorithm is formulated using the convolution neural network (CNN). The audio data are provided as input to the audio convolution branch, and audio feature maps are extracted. Next, each frame in the visible and thermal videos is given as input to three layers of Conv-2D with and 32 filters of size 2, stride 2, and ReLU activation to extract the visible and thermal feature maps. The audio, visible, and thermal feature maps are then concatenated according to the classification problem and provided as input to the person output head.
The second baseline algorithm is formulated using the multi-head attention transformer [
32]. The audio features are extracted using the
audio convolution branch. Visible and thermal features are obtained using
standard embedding layers. The audio, visible, and thermal features are then concatenated according to the classification problem and given as inputs to the
standard transformer branch and the
person output head. Hereafter, this baseline will be referred to as the transformer model.
The third baseline algorithm is formulated using the
standard transformer branch and the missing modality loss proposed by John et al. [
6]. Similar to the second baseline algorithm, audio, visible, and thermal features are extracted using the
audio convolution branch and
standard embedding layers. The individual latent spaces are first learned using a metric-learning-based missing modality loss with the extracted features. Next, the extracted features are concatenated, and the joint latent space is learned using the same loss function. Finally, the individual and joint latent spaces are used within a
k-NN classifier to estimate the person label. Hereafter, we refer to this baseline as the latent model.
5.1.3. Progressive Learning Validation
In this study, we validate the progressive learning framework by comparing the accuracies of the trained
unimodal,
bimodal, and
trimodal models trained at different steps of the framework. Here, we utilize the trained models and their
person classification heads (
Section 4.1.2).
Additionally, we perform a comparative analysis of the two variants of the proposed KModNet. The first variant is an end-to-end framework (E2E-KModNet), where KModNet is trained directly in a single step without any multi-step progressive learning.
In the second variant, KModNet is trained using a multi-step learning strategy, but the unimodal, bimodal, and trimodal branches are trained only once. More specifically, following the training of the 1-combination branches in the first step, their weights are frozen and transferred to the bimodal model. In the second step, only the 2-combination branches are trained, and the 1-combination branches are not fine-tuned. In the case of the AVTPC problem, in the third step, only the 3-combination branches are trained without any fine-tuning of the other branches. Hereafter, we refer to the second variant as the DT-KModNet.
5.1.4. Training Parameters
The proposed frameworks are implemented with TensorFlow 2 using NVIDIA 3090 GPUs on an Ubuntu 20.04 desktop. The different deep learning models and baseline algorithms are trained for 50 epochs, except for the multi-tasking bimodal model and third baseline models (latent space algorithm), which are trained for 100 epochs. The deep learning models are trained at a learning rate of , = , and = . The training parameters are empirically selected and represent the best performances of the different algorithms.
5.1.5. Experimental Results
The performance of the proposed, the baseline, and the ablation study variants are reported in
Table 2 and
Table 3. In the testing phase, we report the classification accuracy for different ablations of the testing sequences. The ablations are represented by replacing the modality data with pre-defined fixed data. Apart from the original data, the test ablations include the
uni-missing and
dual-missing data.
The comparative results of classification accuracies are listed in
Table 2. The results show that both the proposed frameworks have better accuracy than the baseline algorithms.
The results of the progressive learning validation are shown in
Table 3. The results clearly demonstrate the advantage of the multi-step learning framework used within the proposed frameworks.
5.2. AVEC Problem
5.2.1. Dataset
In the SAVEE dataset, 480 audio-visible sequences from four people with seven different emotions are selected. In the RAVDESS dataset, 1440 sequences from 24 actors with eight emotions and two trials are selected. The SAVEE dataset is randomly partitioned into training and testing sequences, whereas in the RAVDESS dataset, the first trial sequences are used for training, and the second trial sequences are used for testing. In the learning phase, the missing dataset is generated from the original data by randomly ablating of the training sequences to obtain uni-missing data. The ablated visible and thermal images are represented by zero images of size and . In contrast, ablated audio is represented by a zero image of size .
5.2.2. Baseline Algorithms
For the AVEC validation, in addition to the baseline algorithms used for the AVTPC problem, the following AVEC algorithms by John et al. [
33], Ristea et al. [
34], and Mandeep et al. [
35] are also used for the comparative analysis.
For progressive learning validation, similar to the AVTPC problem, we validate the progressive learning framework by comparing the accuracy of the trained
unimodal and
bimodal models with their
emotion classification heads (
Section 4.2.2).
In addition, a comparative analysis is performed using the two variants of the proposed framework. The first variant is an end-to-end framework (E2E-KModNet), in which the bimodal model is directly trained in a single step without any pre-training. In the second variant, multi-step learning is utilized, but the unimodal branches are trained only once. More specifically, following the training of the 1-combination branches in the unimodal model, their weights are frozen and transferred to the bimodal model. Henceforth, we refer to the second variant as the DT-KModNet framework.
5.2.3. Training Parameters
The different deep learning models and baseline algorithms are trained for 50 epochs, except for the third baseline model (latent-space algorithm), which is trained for 100 epochs. The deep learning models are trained at learning rates of , = , and = . The training parameters are empirically selected and represent the best performances of the different algorithms.
5.2.4. Experimental Result
The performances of the proposed, baseline, and variants are reported in
Table 4,
Table 5,
Table 6 and
Table 7. In the testing phase, we report the classification accuracy for different ablations of the testing sequences. The ablations are represented by replacing the modality’s data with pre-defined fixed data. In addition to the original data, the test ablations include
uni-missing data.
The comparative results for emotion classification accuracy are listed in
Table 4 and
Table 5. The results show that both the proposed frameworks have better accuracy than the baseline algorithms.
The results of the progressive learning validation are shown in
Table 6 and
Table 7. The results clearly demonstrate the advantage of the multi-step learning framework used within the proposed frameworks.
5.3. Discussion
Missing Modality: The missing modality problem is observed in the results, where the performance drops with the single missing modality. The performance of the original test dataset, without any missing modality, was the best. Moreover, in
Table 3, we observe further degradation of accuracy when the two modalities are missing.
Comparison with Baseline Models: The advantages of the proposed framework are observed in
Table 2,
Table 4 and
Table 5 where the progressive framework reports a better classification accuracy than baseline algorithms while addressing the missing modality problem. In addition, unlike the different baseline algorithms, the proposed framework addresses the multimodal portability problem.
Among the different baseline methods, for the AVTPC problem (
Table 2), the transformer-based baseline models, including the transformer model, E2E, and DT, report better results than the CNN-based baseline models. In the case of the SAVEE dataset results of the AVEC problem (
Table 5), the CNN and transformer-based baseline models, on average, report similar accuracies. On the other hand, in the case of the RAVDESS dataset (
Table 4), the performance of certain CNN and transformer-based baseline models, such as the CNN, E2E, DT, and Ristea et al. [
34] are similar and higher than those of the remaining CNN and transformer-based baseline models. On average, the transformer-based models report better accuracy than the CNN-based models, which is similar to observations in the literature [
9,
32].
The latent-space-based baseline model by John et al. [
6] reports a good accuracy for the AVTPC problem and SAVEE of the AVEC problem’s SAVEE; however, in the case of the RAVDESS dataset, the latent model does not perform well. The latent-space model is only formulated for occasionally missing data in an individual modality, and not for a missing modality in multimodal data [
6]. Based on these results, we can observe that the performance of the different baseline algorithms is dataset-dependent.
Validation of the Progressive Learning Framework: In this paper, in the novel progressive learning framework, the multi-step learning and the fine-tuning of the previously trained branches are important contributions to the literature. We validate these contributions using the DT and E2E variants of the algorithms. The results in
Table 2,
Table 4 and
Table 5 show the advantages of multi-step learning, as the proposed framework yields better results than E2E-KModNet, which corresponds to the single-step trained KModNet.
The results also demonstrate the advantages of fine-tuning the previously trained branches within the progressive learning framework because the proposed framework has better accuracy than the DT-KModNet model. Unlike the proposed learning framework, in DT-ModNet, the pre-trained branches transferred from the preceding block are not fine-tuned.
The advantages of the progressive learning framework are listed in
Table 3,
Table 6 and
Table 7. Here, a layer-wise increase in classification accuracy across different models can be clearly observed. This can be attributed to the sensor fusion of the different
k-combinations and the progressive learning framework, where the previously trained branches are fine-tuned.
The results of the 1-combination or
unimodal models are obtained as averages of the different
unimodal models. In the case of AVEC, the
bimodal model yields better results than the
unimodal models (
Table 6 and
Table 7).
In the case of AVTPC, the results of the bimodal and unimodal models are obtained by averaging the accuracies of the different output heads. It can be observed that the trimodal models report better accuracy than the bimodal models, which, in turn, report better accuracy than the unimodal models. The progressive improvement in accuracy can be attributed to sensor fusion and fine-tuning of the previously trained branches.
Generalization across Varying Inputs: Compared to the baseline algorithms, the proposed algorithm reports the best results across the different types of input data, the
complete, the
uni-missing, and the
dual-missing data, as demonstrated by the average classification accuracy. For example, in
Table 5, the third baseline algorithm (Latent) [
6] provides better accuracy for
complete and
audio-missing data but does not classify
visible-missing data accurately. This result can be attributed to the latent baseline algorithm overfitting
complete and
audio-missing data during the learning phase. However, the proposed algorithm can learn across different types of missing and complete data without overfitting any missing data.
Multimodal Portability: The multimodal portability of the proposed framework is observed in the ablation study, where the
unimodal,
bimodal, and
trimodal with their
person and
emotion classification heads can be easily ported to a different
k-combination of modalities (
Section 4.1.2 and
Section 4.2.2).
Varying Modalities: In multimodal learning, a given modality can be a dominant or a weaker modality. The experimental results for the AVTPC problems show that the audio modality is weaker than the visible and thermal modalities (
Table 2). This is observed in the results of the
visible-thermal missing data, where only audio is present, indicating a low classification accuracy. However, the visible camera is shown to be the dominant modality, as observed in the
unimodal missing data, where the
visible missing data report inferior results compared to the
thermal missing and
audio missing data.
In the case of the AVEC problem, modality characteristics are dataset-dependent. In the RAVDESS dataset (
Table 4), the audio and visible modalities have similar strengths, with the audio being marginally dominant, as the
visible missing data report better accuracy than the
audio missing data. However, in the case of the SAVEE dataset (
Table 5), audio is the weaker modality because the
visible missing data are inferior to the
audio missing data.
Based on the results, we can conclude that certain modalities are either dominant or weaker depending on the situation; thus, their effective sensor fusion in progressive learning enhances the robustness of classification tasks.
Future work: In the results, we can observe that the absence of the dominant modality, the visible camera, reduces the classification accuracy (
Table 4 and
Table 5). As part of our future work, we will investigate and consider multimodal co-learning techniques [
36] to ensure that all modalities contribute equally to learning. Specifically, we will focus on the conditions under which the dominant modality is missing.
In the progressive learning framework, different k-combinations can be trained using an additional unimodal or bimodal dataset. For example, in the AVEC framework, in addition to training with the bimodal dataset, unimodal models can also be trained with an audio-only or visible camera-only emotion classification dataset. The advantages of additionally training a unimodal or bimodal model with a modality-specific dataset will be investigated in future work.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}