1. Introduction
Technological tools, such as monitoring systems, have been developed to capture, analyze and understand the parameters of bee colonies in order to reduce mortality and improve traditional apiculture; this is the aim of precision beekeeping [
1]. A parameter of particular interest for researchers is the acoustics of bee colonies; it can be effectively analyzed to understand and predict critical states of bee colonies [
2,
3]. Some examples of the acoustics patterns present in bees colonies include the process of swarming, a bee colony changes its normal activity and produces a specific buzz before the queen leaves the colony with part of the swarm [
4,
5]. On the other side, a bee colony produces a characteristic sound when the queen is absent, the queenless state causes stress in the colony members, and the usual activities become chaos. Furthermore, the high temperature inside the hive is another factor that can affect the sound of a colony [
6,
7,
8]; the bees placed at the entrance of the colony flap their wings to ventilate and reduce the temperature that can be mortal for the brood nest. Finally, when predators threaten bees, the entire colony produces a characteristic sound as a defensive behavior [
9]. To capture and analyze the bee colony acoustics, several researchers have been interested in developing monitoring systems based on low resources computers such as Raspberry Pi (RPi) [
8,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21]. The main goal is to identify colony states automatically by using these technologies and reduce invasive inspections that cause stress in colony members and reduction of the productivity.
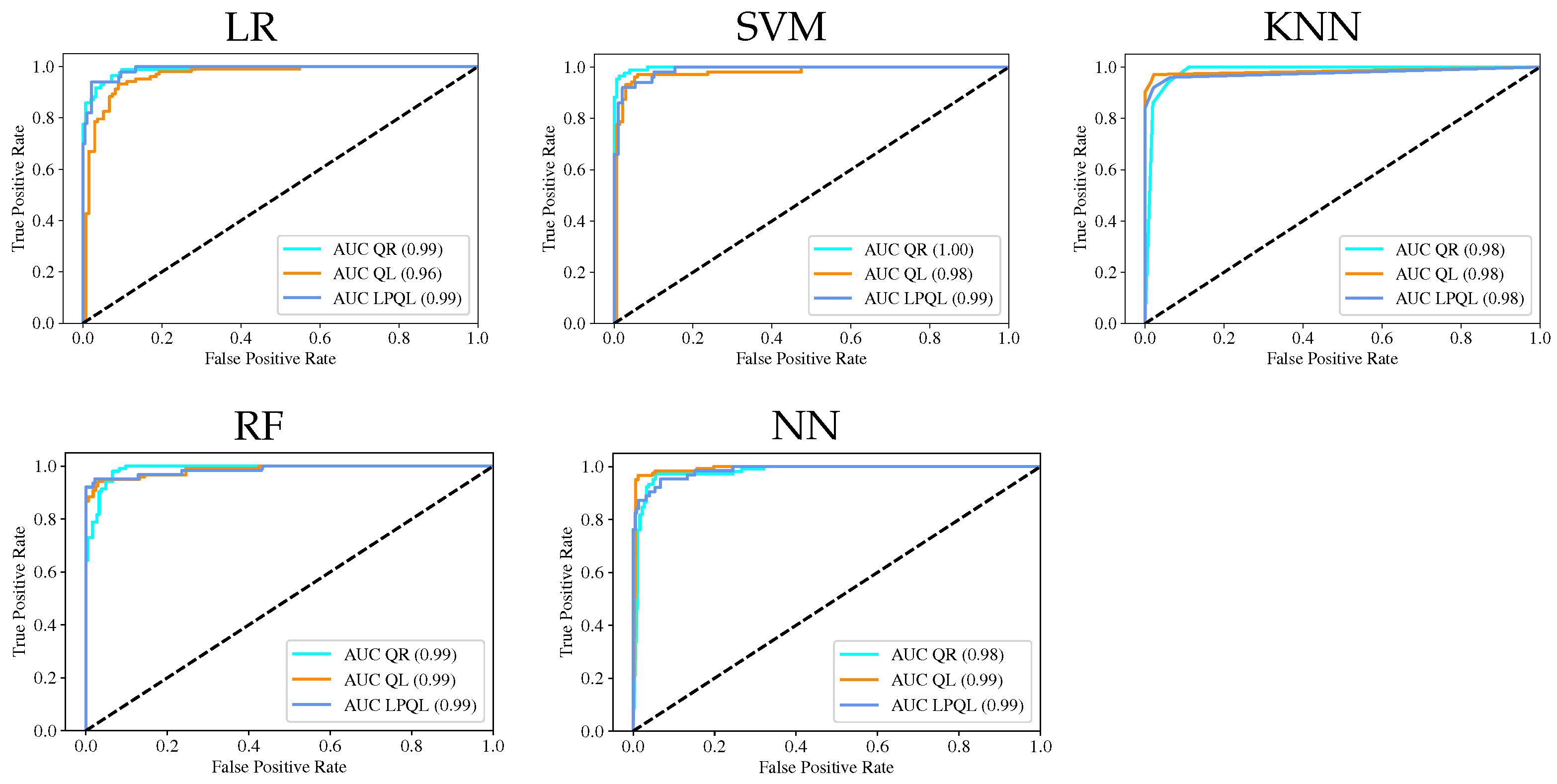
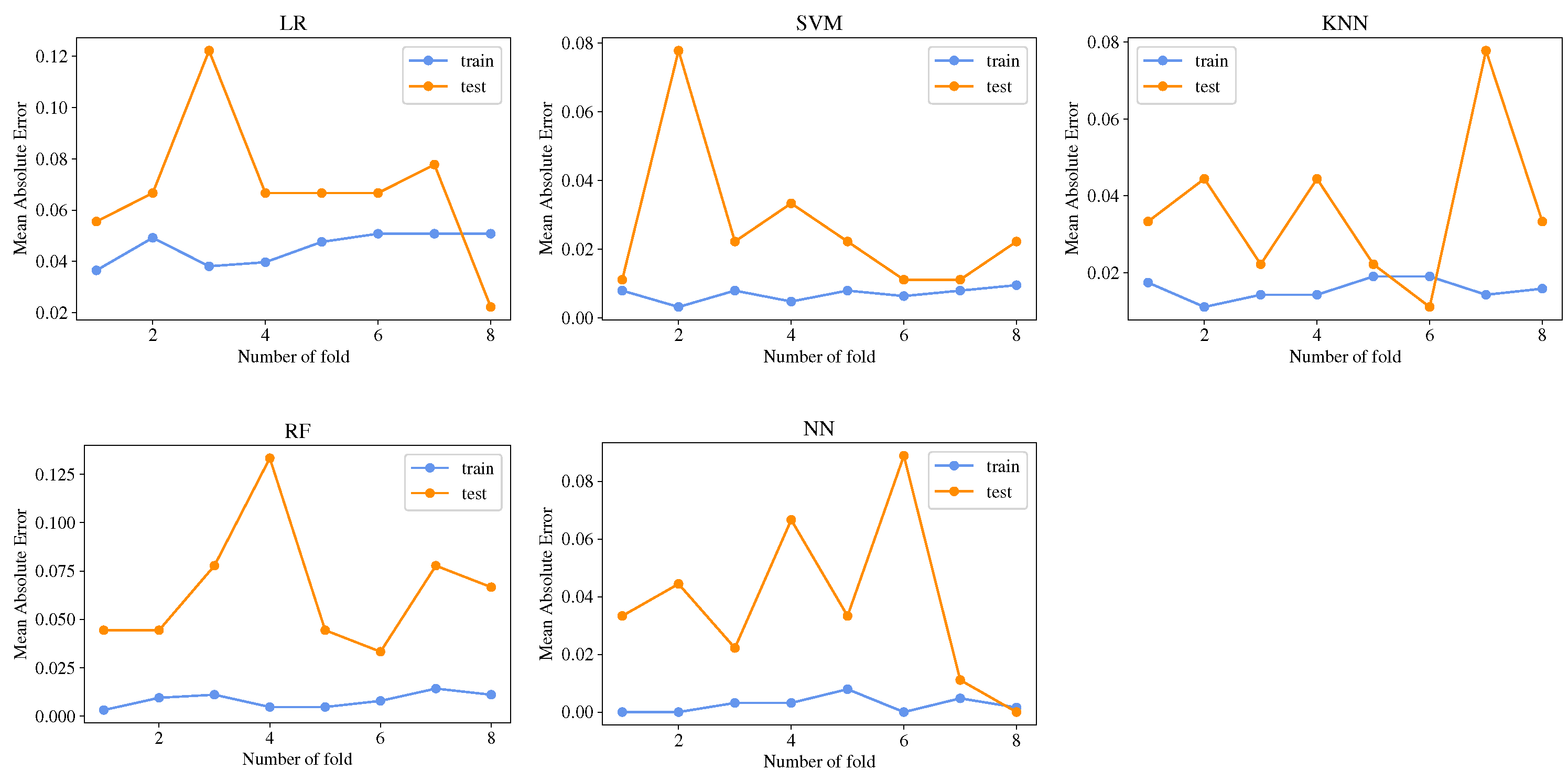
The main objective of this work is to compare the most used ML models for acoustic pattern classification in bee colonies and find a solution with a balance between performance and low consumption of computational resources. Classical ML methodologies are simple, fast, and easy to train. The main reason to implement these methodologies is that most require less computational power than deep learning techniques, which usually are more complex and time-consuming and can be limiting factors for real-time applications [
22]. Furthermore, classical ML architectures can be easily implemented in a platform with limited computational resources, such as RPi, whose principal advantage is its support and availability. Moreover, the use of Python and its open-source libraries, such as
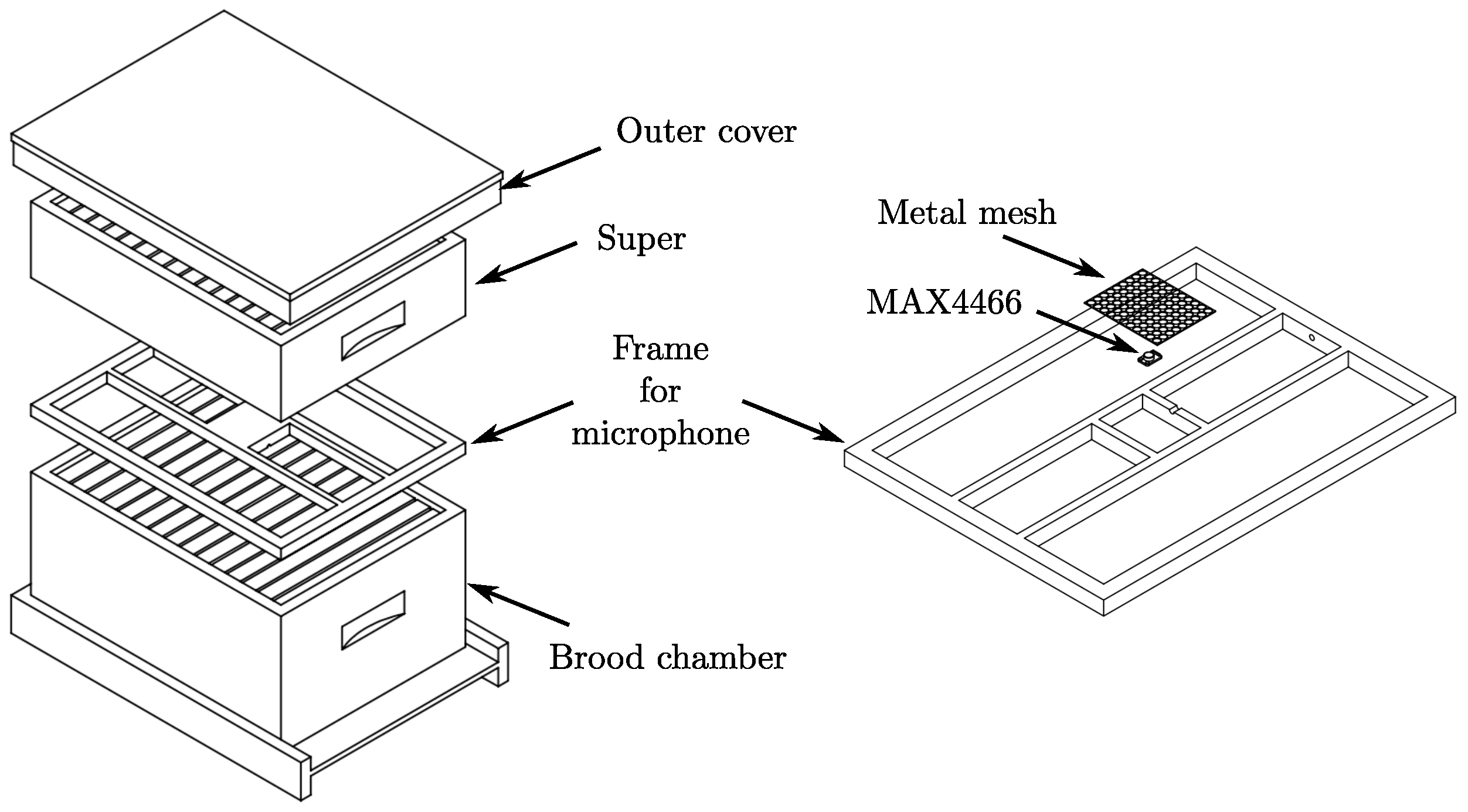
scikit-learn, allows the fast and easy development of classifiers based on ML algorithms. An important challenge in developing intelligent systems for the automatic recognition of bee colony states is the lack of computational resources and battery life. In a real-life scenario, most apiaries are in remote places where access to electric energy is not guaranteed. Therefore, a monitoring system must be powered by solar energy, and cloudy days can be a problem, even if the primary system is a single-board computer [
23]. Among the most critical tasks, a recognition system must perform include sound recording, information storage, feature extraction, and pattern classification. An alternative to reduce power consumption and increase the battery life of a monitoring system is decreasing CPU usage. The proper ML model selection can improve battery life; for that reason, five ML models were compared: Logistic Regression (LR), Support Vector Machines (SVM), Random Forest (RF), K-Nearest Neighbors (KNN), and Neural Networks (NN), the aim was to evaluate the computational requirements by comparing the execution time of the ML models on an RPi 3. Furthermore, several metrics were computed to provide a complete overview of the models’ performance: confusion matrix, accuracy, precision, recall, F1-score, and ROC (receiver operating characteristic) curves. Furthermore, a simple prepossessing step allows training the models on limited-resources hardware.
The rest of the paper is organized as follows:
Section 2 shows a literature study on monitoring systems and ML models for recognition of colony states, in
Section 3 the methodologies for sound classification, data prepossessing, and characteristics about the dataset are described. Then, results and discussion are presented in
Section 4. Finally,
Section 5 provides the conclusions and future work.
2. State of the Art
Several studies suggest that ML algorithms and classical methodologies for speech recognition can be effectively adapted for acoustic pattern classification in bee colonies; such methodologies are being implemented effectively to identify bee colony states achieving high correct classification rates. Furthermore, CNN architectures have proven effective for audio classification and have been used for bee acoustic pattern recognition. The following paragraphs review the most important research on identifying acoustics patterns in precision beekeeping.
SVM is among the most used ML techniques for the identification of the health status of bee colonies by analysis of acoustic patterns. Amro et al. [
19] implemented two ML models, an SVM model and a linear discriminant analysis, to determine the infestation level of beehives due to varroa mites. The colony’s acoustics were recorded using a credit card-sized computer and electret microphones; the prepossessing and recognition tasks took place in the monitoring system. A pattern of an infected colony is compared with a healthy colony, and both methods can successfully be used to identify differences between healthy and infected beehives.
Nolasco et al. [
24] compared two methodologies for bee sound identification, a convolutional neural network (CNN) and an SVM model. The dataset is a selection of sounds of beehives recorded in various conditions of two projects, Open Source Beehive (OSBH) and NU-Hive. The tested models have the possibility to identify bee sounds from external sounds such as traffic or birds. Mel Frequency Cepstral Coefficients (MFCCs) and Mel spectra were used for feature extraction. Furthermore, the signals were split into segments of different sizes to analyze the performances. In this study, the SVM model performed better than the CNN. However, a special issue is the possibility of generalizing on unseen colonies.
In the classification of bee sounds and external sounds, Kim et al. [
25] compared conventional ML models: RF, SVM and extreme gradient boosting with two CNN architectures: VGG-13 and Shallow CNN. The dataset consists of the sound of the OSBH project; the outputs were labeled as bee and nobee. They used Mel spectrograms, MFCCs, and constant-Q transform for feature extraction. The results show that VGG-13 has the best performance, achieving 91% of accuracy.
To discriminate swarming activity from regular activity in bee colonies, Zgank [
26] implemented a model based on Hidden Markov Models (HMM), widely used for human speech recognition, and MFCCs for feature extraction. The dataset consists of acoustic patterns of beehives from an open-source project. The model can achieve an accuracy of 80% in the classification of swarm bee activity. Zgank [
27] improved the study and compared the performance of HMM and Gaussian Mixture Models in the classification of the acoustics of bee colonies. In addition, Zgank compared MFCCs and linear predictive coding as feature extraction methods in this work. Several metrics were provided to reflect the performance, and the highest accuracy was achieved with HMM model and MFCCs features. In another work, Zgank [
28] improved previous results by using deep neural networks and MFCCs. A comparison between ML models to detect swarming and non-swarming activity was made by Dimitrios et al. [
29]. In the study, they compare the performance of KNN, SVM and U-Net CNN, they combine the acoustic samples with measures of the temperature inside the hive, and humidity and temperature outside the hive. The signals were filtered with a low pass filter. In the pre-processing step, they extract the Fast Fourier Transform (FFT) of the signals, considering the range of frequencies of 150–600 Hz. The results reveal that SVM achieves a better performance than CNN.
For the detection of queenless bee colonies, Nolasco et al. [
30] implemented a classification methodology based on previous works, SVM and a CNN models were implemented for the task. The dataset consists of the beehive sound of the NU-Hive project. They proposed MFCCs, Mel spectrograms, and the Hilbert Huang Transform (HHT) for feature extraction. According to previous results, their SVM model performs better than CNN using HHT and MFCCs. The critical point is that a better performance can be achieved when an appropriate feature extraction procedure is used. Howard et al. [
31] implemented a different approach to classify queenless states in bee colonies by using self-organizing maps; for feature extraction, they applied power spectral density and S-Transform. However, the results show that the model cannot classify the beehive state; however, the problem can be related to the dataset’s characteristics. Another study to detect queen presence was made by Cejrowski et al. [
32]. A series of experiments were conducted to reproduce the queen’s absence. This work implemented linear predictive coding as feature extraction and as learning algorithm SVM; the classification algorithm can identify the acoustic patterns of healthy and queenless colonies. To improve the detection of queenless states by CNN, Orloswska et al. [
33] propose a simple transformation to increase the classification performance. The datasets consist of audio data from the OSBH and NU-Hive projects. The transformation is applied to the spectrograms and consists of two-steps dimension reduction. The authors claim that this transformation represents a better generalization, and the CNN achieves an accuracy of 96%. Another approach to improve the identification of queenless states is presented by Peng et al. [
34]; this work proposed a Wiener filter to reduce the signal-to-noise ratio. After that, MFCCs methodology was applied for feature extraction, and the dataset was used to train a Multi-layer perceptron neural network. The authors conclude that the filter increases the classification accuracy by 12% compared with the non-filtered signal. Following the topic of queenless state identification of bee colonies, Robles et al. [
35,
36] designed a methodology for bee acoustic classification based on LR and MFCCs for feature extraction. A monitor system based on RPi 2 and omnidirectional microphones was implemented for the acoustic recording. An acoustic pattern of a healthy colony was compared with a pattern of queenless colonies. By using this methodology, the patterns were correctly identified with a high correct classification rate (above 90%).
When bees are exposed to chemicals, they respond with no natural sound. Zhao et al. [
10] recorded the sounds of bees exposed to compounds of acetone, trichloromethane, glutaric dialdehyde, and ethyl ether by using microphones and an RPi 3 model B. For feature extraction, they used the MFCCs methodology. They implemented three classification models: KNN, SVM and RF; also, they performed a principal component analysis to select the most relevant coefficients. The algorithm with the best results is SVM, and is able to identify when the bees are exposed to specific compounds of acetone. Another research to detect the acoustic response of beehives exposed to trichloromethane is presented by Sharif et al. [
37]; this study proposes a methodology known as Soundscape indices for feature extraction and it was compared with MFCCs methodology. An RF model was trained to compare the feature extraction methodologies, and the soundscape indices achieved a better performance.
A comparative of standard ML techniques (LR, KNN, SVM, and RF) and CNN for the classification of audio samples of bee colonies and ambient noise was performed by Kulyukin et al. [
15]. The audio samples were recorded by microphones and an RPi computer. The study analyzed two datasets; the first consists of 10,260 audio samples, and the second of 12,914 audio samples. For feature extraction, a methodology based on MFCCs was used. Moreover, the study performs an audio classification experiment on an RPi 3, and the results show that better performance was achieved with deep learning techniques.
SVM and MFCCs features have been used to identify circadian rhythm in bee colonies by Cejrowski et al. [
38], this work aims to classify bee sound activity in days and nights and the period when the activity is the lowest over the day. The monitor system consists of an RPi computer and an analog microphone; the sound samples were recorded at a sample rate of 3 kHz and 12-bit resolution in intervals of 15 min. The colony’s lowest activity period was found from 11 pm to 4 am.
ML models have been used to discriminate bee species by analyzing the flight sounds of bees and hornets [
39]; the sound of three species of bees and one species of hornet was recorded. They use an SVM model and MFCCs for feature extraction to classify the sound samples. The model can accurately discriminate between flight and environmental sounds (such as bird and background noise).
5. Conclusions
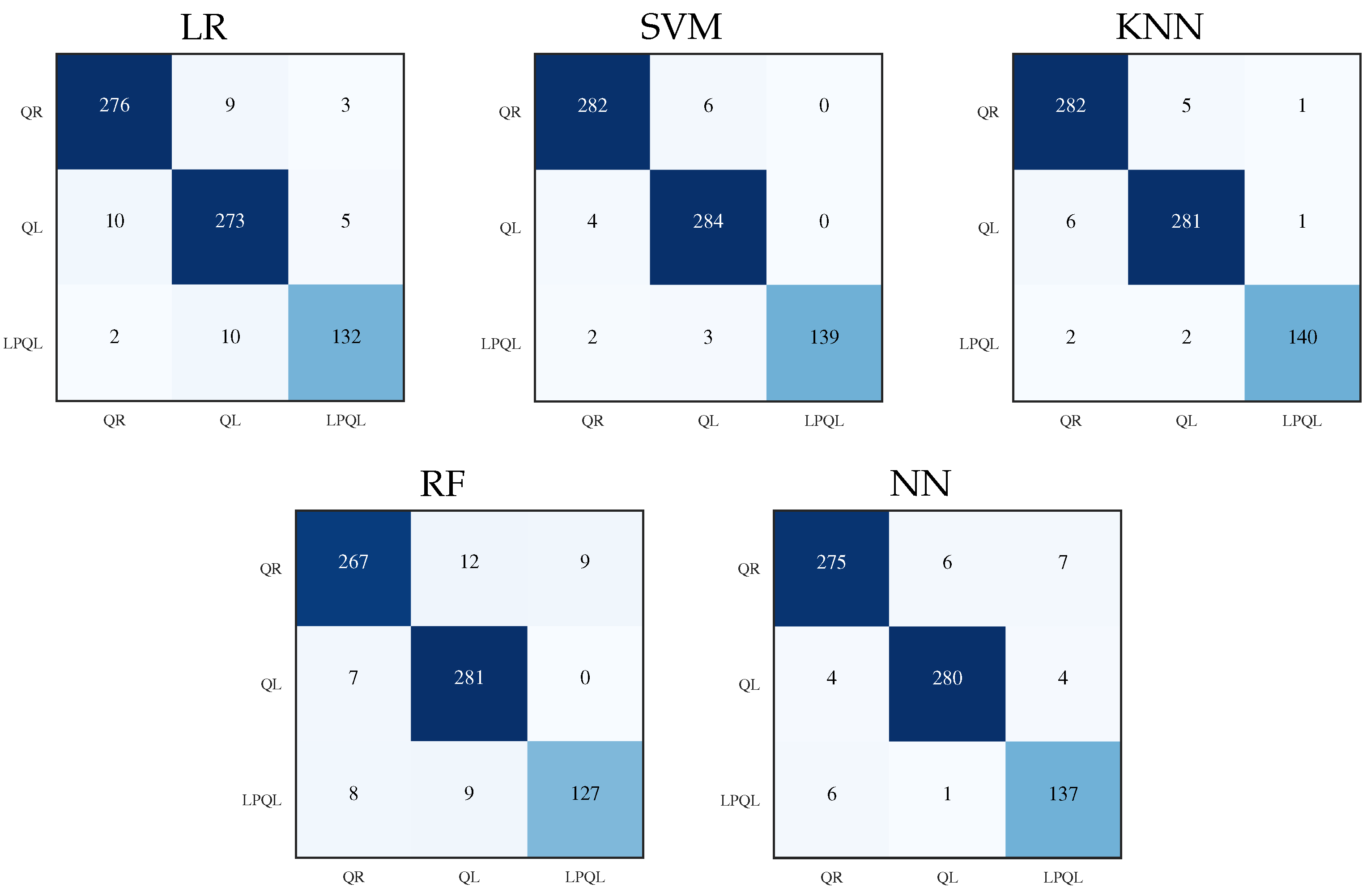
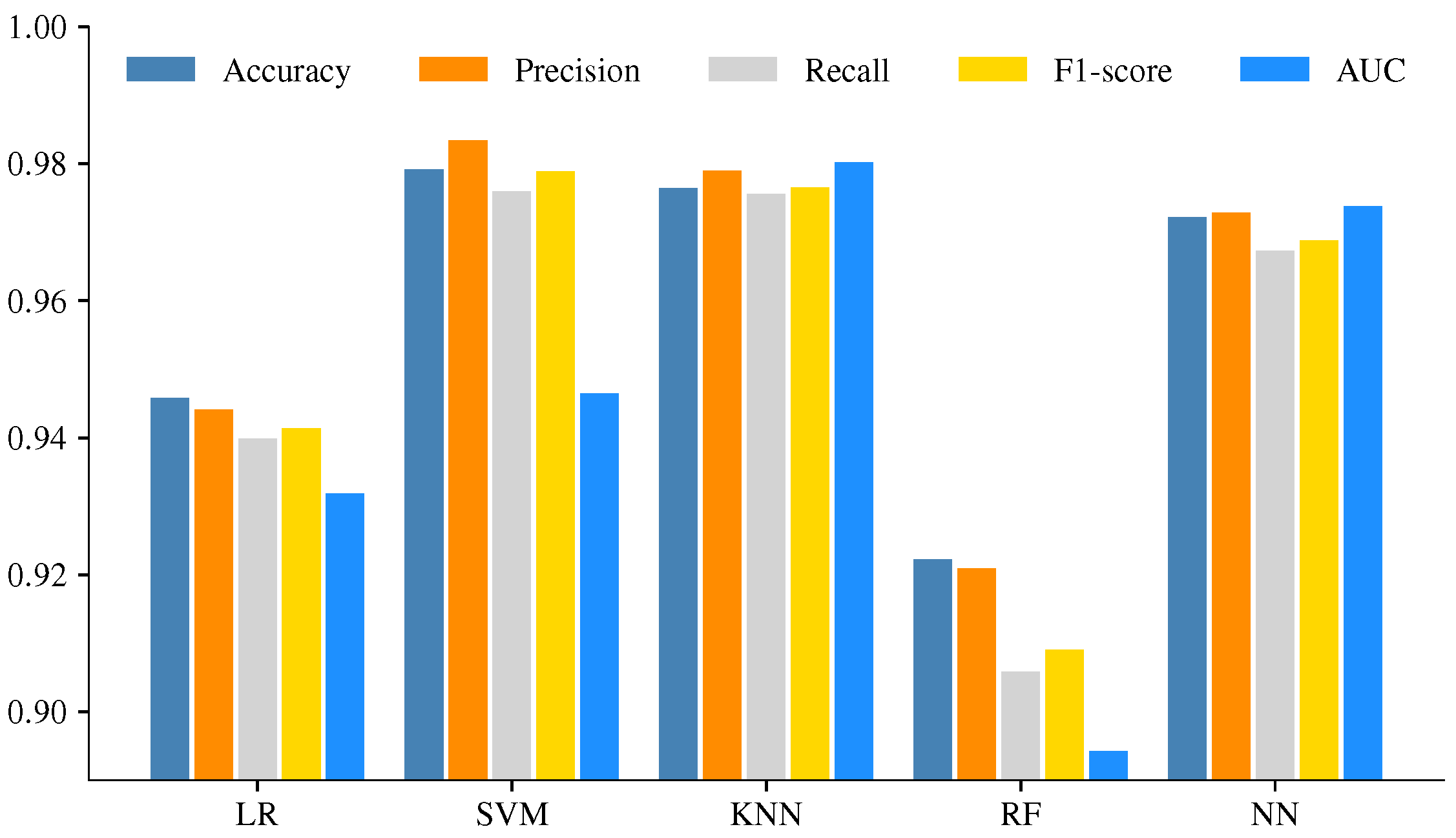
This study presents an extensive and detailed comparative analysis of the performance of five classification ML models for pattern recognition of colony states based on bee acoustics. The main goal of the analysis was to find an ML model with a balance between high performance and low computational cost. The results show the feasibility of implementing a classification task on a monitor system whose principal component is a single-board computer with low computational resources; the appropriate selection of the ML model is necessary to improve the system’s performance and extend the battery life.
The results show that all the models are efficient and produce excellent performance with a low classification error. When timing performance results are considered, the NN and SVM models highlight the faster training and classification time; therefore, NN and SVM are the most suitable for use on devices such RPi with low computational resources. Training the ML models in the device could be an interesting proposal when we are in real-life conditions; most of the apiaries are in remote places, and have the possibility to make immediate modifications and test the algorithms in the site could be an advantage. Furthermore, since the codes were written in Python, they can be easily exported and executed on any device with the python libraries. Moreover, considering the constant renovation of RPi hardware with superior characteristics, a newer RPi 4 with a superior processor can execute the codes in shorter times.
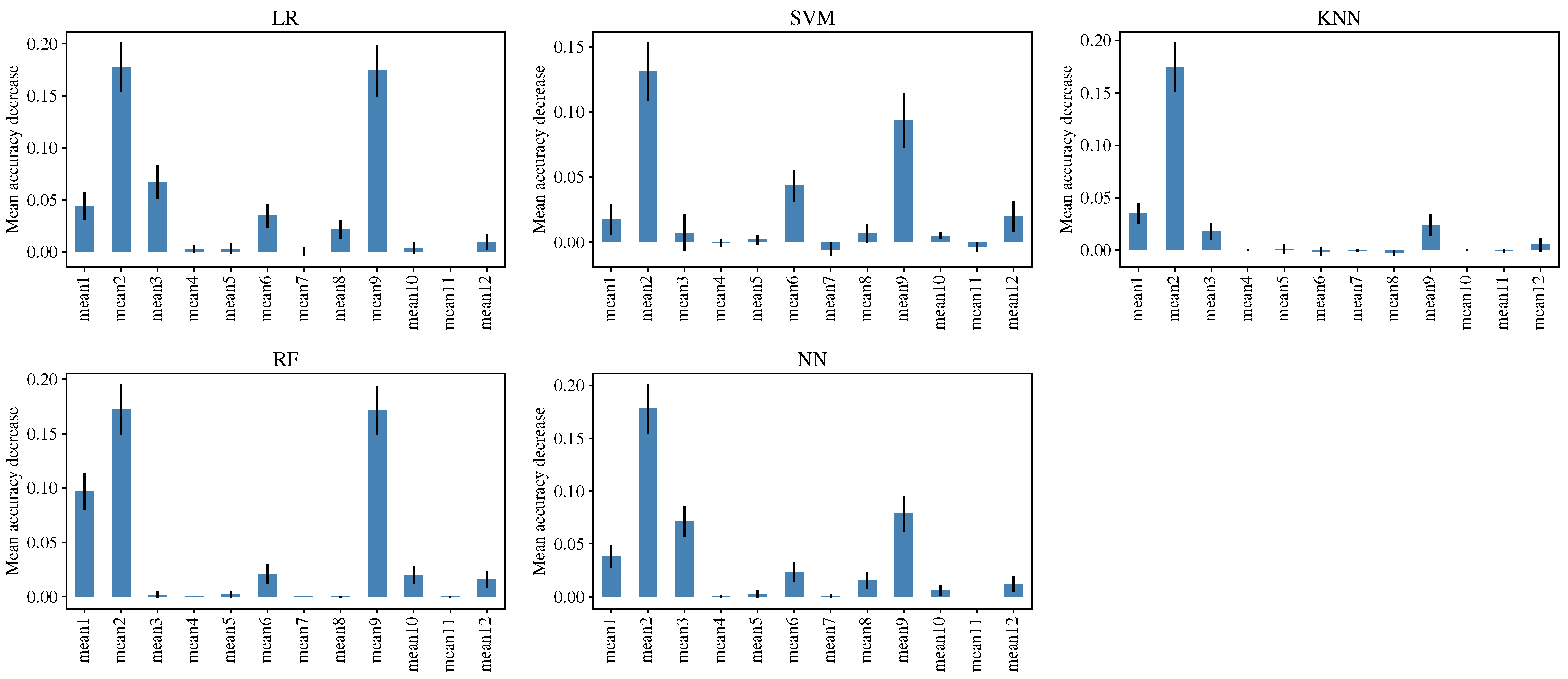
Even when the focus of this research work is not the methodology for prepossessing and feature extraction; the results show that the final dataset is compact and have enough information to discriminate the colony states; this was achieved by computing the mean value of the MFCCs, the efficiency of the classifiers evidences it. The above is one of the most critical factors and allows the possibility of implementing the complete methodology (sound recording, data preprocessing, feature extraction, and classification) in dedicated hardware.
In future work, a mandatory step that allows the generalization is to increase the dataset size and analyze more bee colonies in conditions that affect their acoustics. Furthermore, an analysis of the samples recording time will be conducted to reduce the computational complexity and space requirements and improve the prepossessing data step, which is one of the most demanding stages of the acoustic classification process. As long as the dataset size increases and the number of colony states to recognize, it could be necessary to implement more complex models, such as deep neural networks; an alternative is the Pytorch library, which offers GPU support and can take advantage of more advanced devices such as the Jetson Nano computer. Moreover, actual research trends aim to solve some inconveniences in CNN, and some proposes exist to reduce the time complexity to allow CNN for real-time applications [
22]. Finally, understanding that the results obtained to date are laboratory experiments, the effectiveness of the ML models needs to be tested in real-life conditions; further investigations will be carried out in an apiary, and this is the next step in the development of the monitor system.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
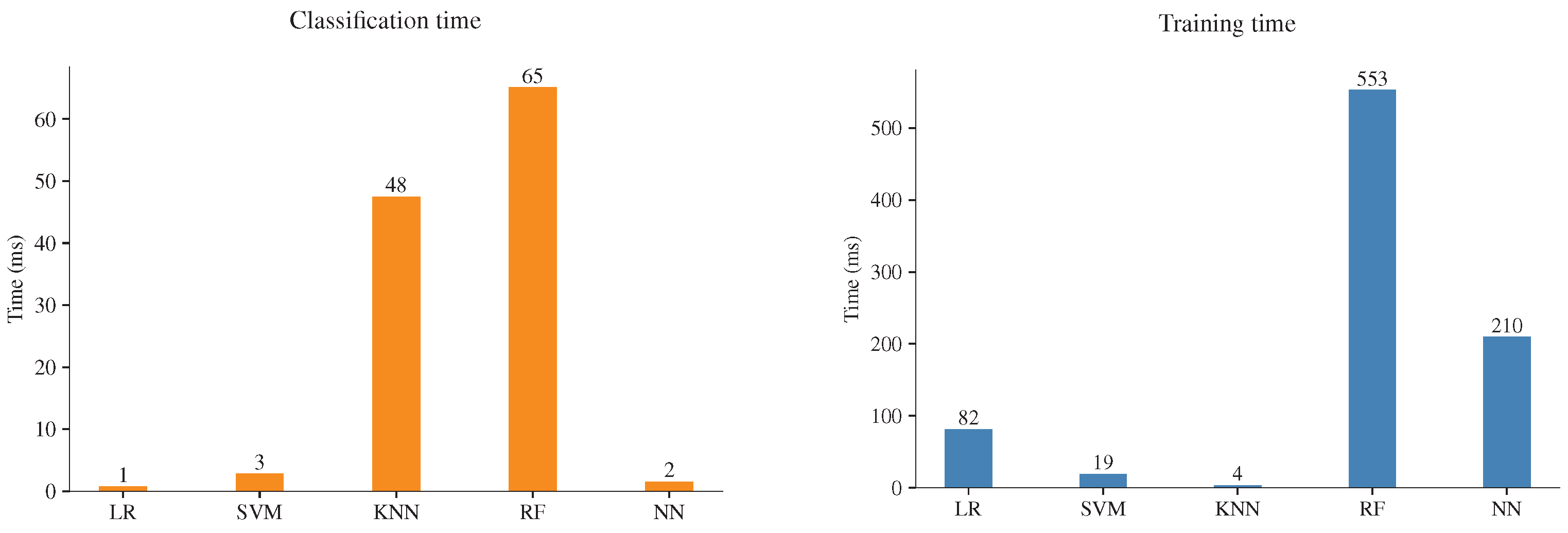{kind=link}