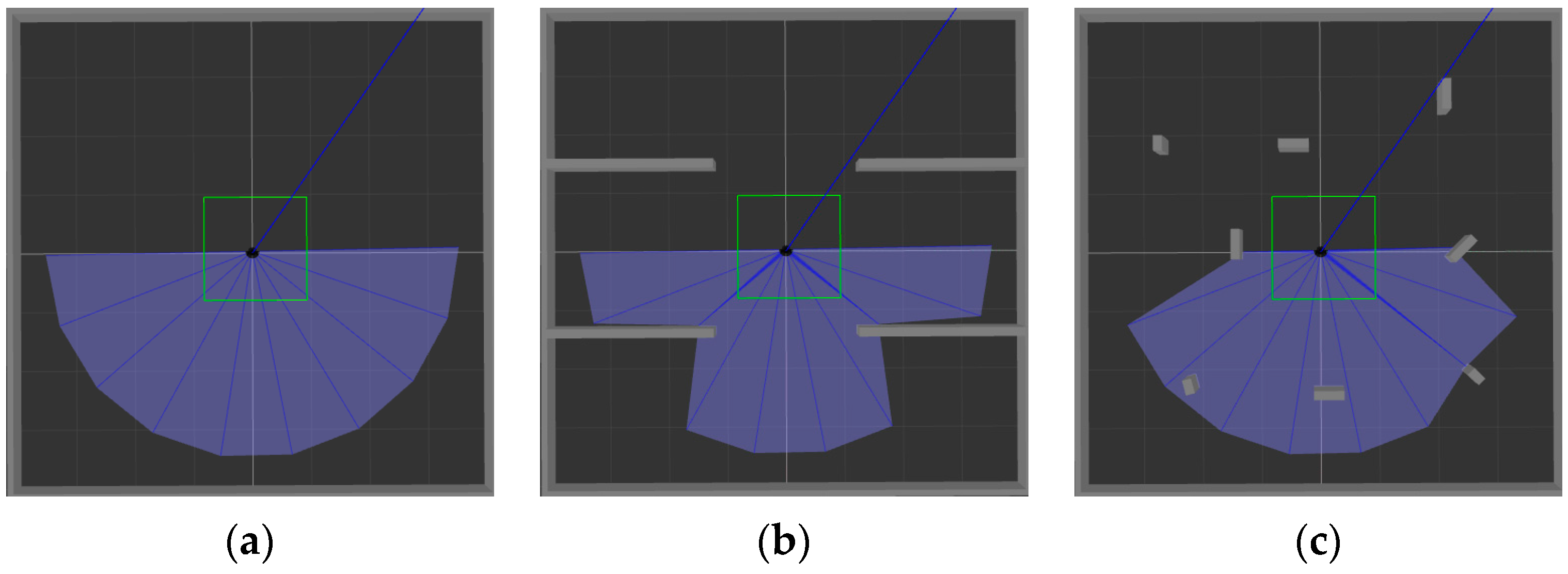
4.1. Environment Construction of Simulation Experiment
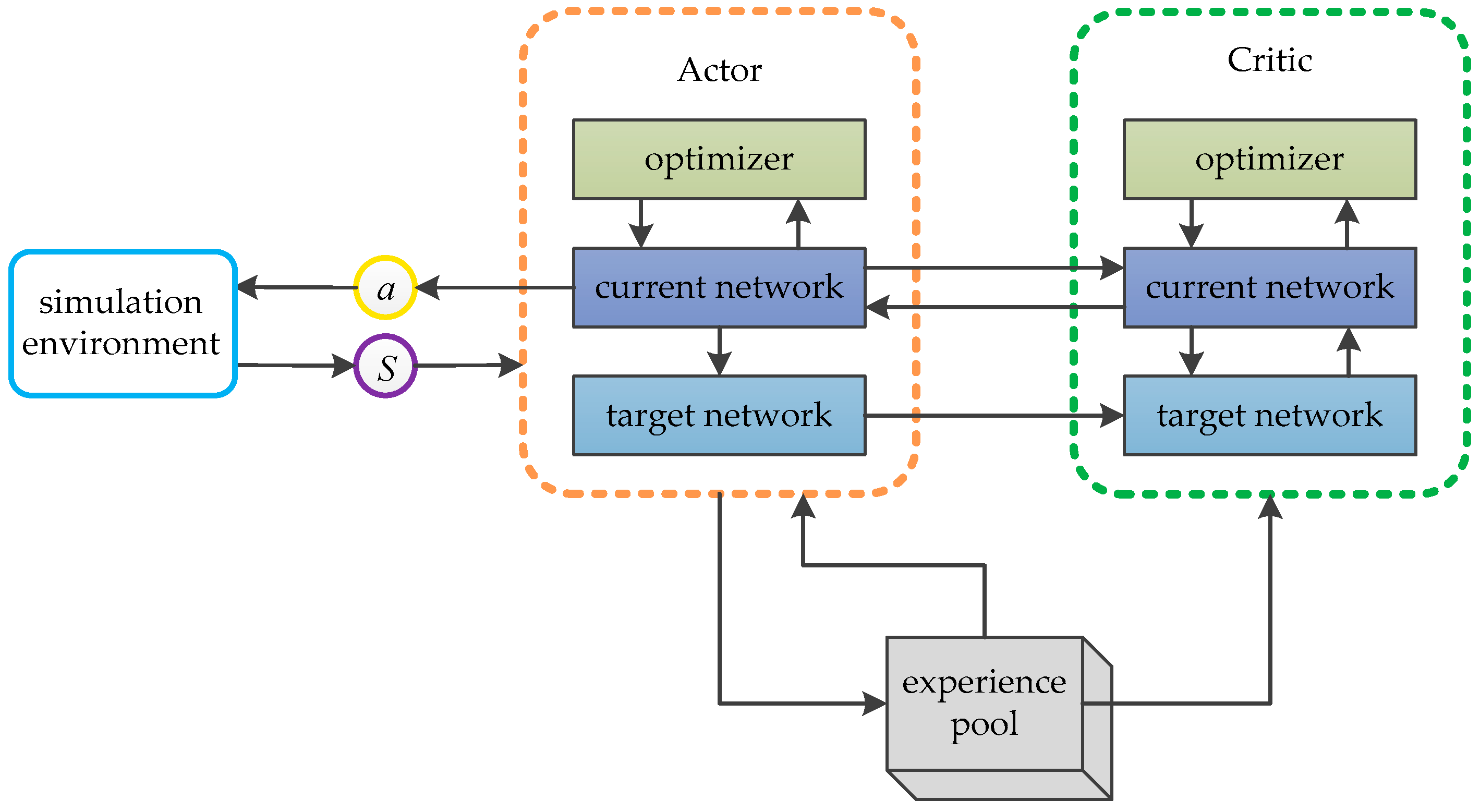
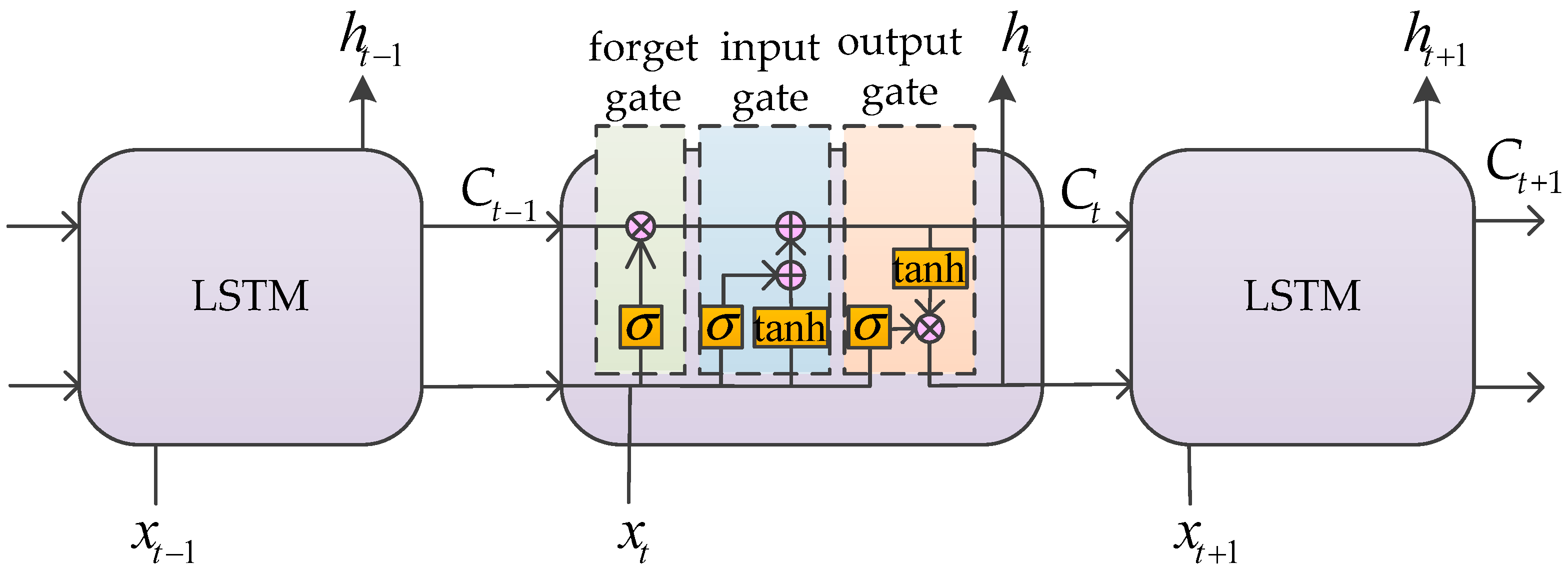
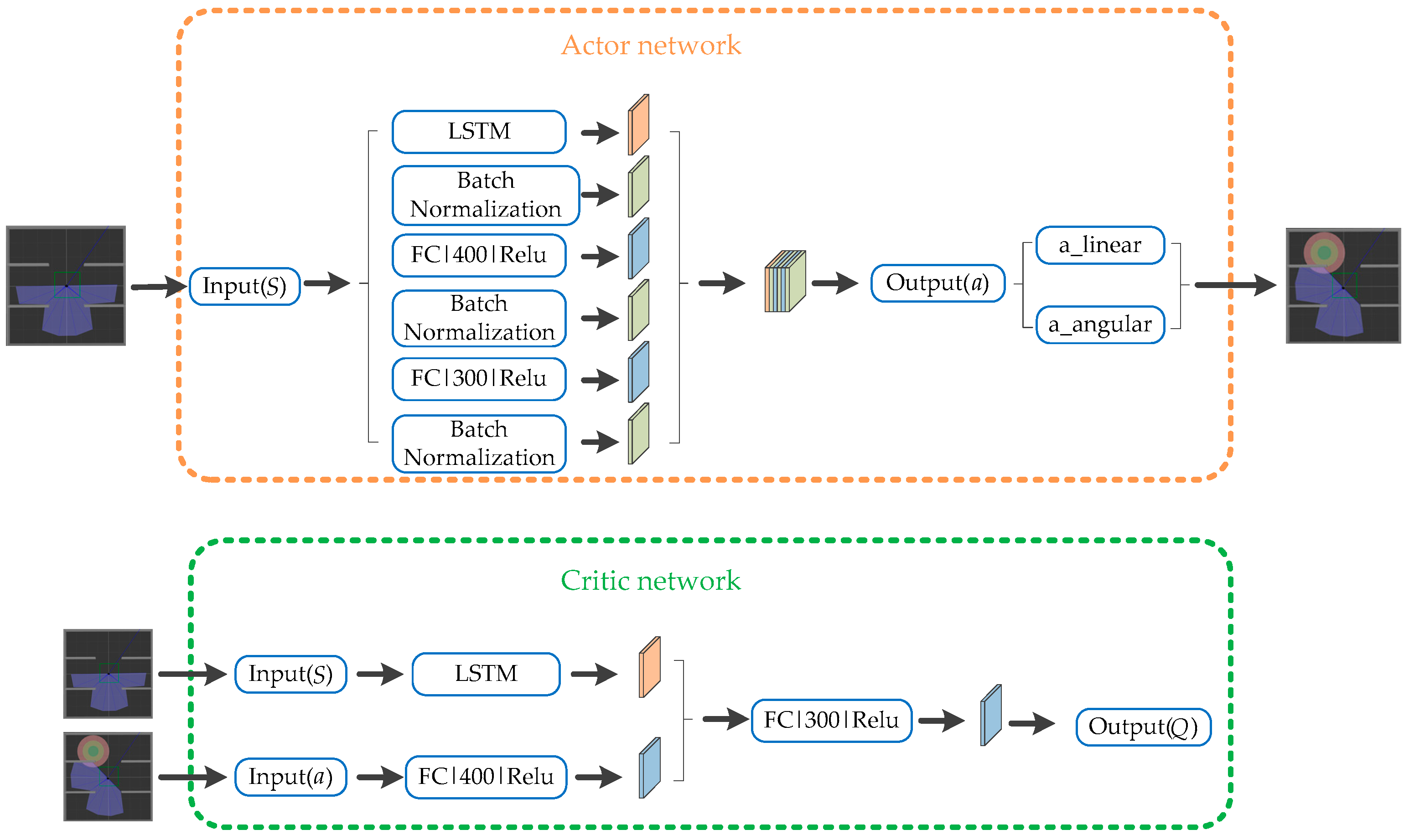
ROS is selected as the simulation experimental platform in this paper, Python and TensorFlow frameworks are used to realize the proposed algorithm, and Gazebo7 is used to establish the simulation environment, as shown in
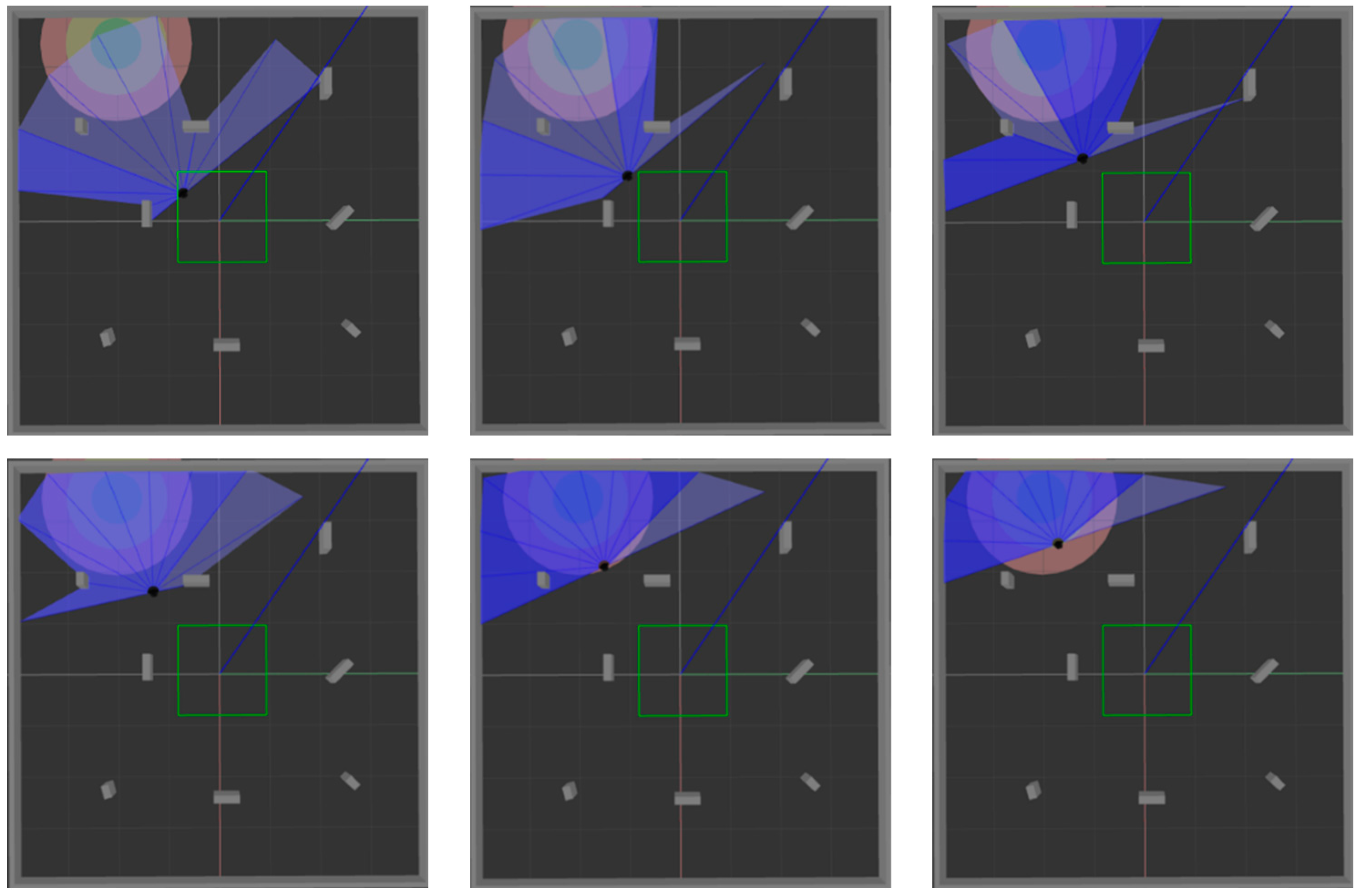
Figure 6. The black dot is the mobile robot, the blue part is the detection range of the laser sensor, and the gray part is the obstacle.
Figure 6a shows the established square-shaped simulation environment without obstacles, which is mainly used to train mobile robots to realize path planning in a limited space.
Figure 6b adds large obstacles to the environment of
Figure 6a to train the mobile robot to realize path planning in an environment with obstacles.
Figure 6c adds random small obstacles to the environment of
Figure 6a, which is mainly used to test the training effect of the mobile robot in the above two environments.
We test the proposed path planning algorithm from three aspects of convergence speed, training time and success rate and analyze the experimental results in detail. The convergence speed and training time are used as evaluation criteria of the training efficiency of the algorithm, and the success rate is used to verify the effectiveness of the algorithm. In the training process of the algorithm, the convergence speed and training time can reflect how many episodes are needed to obtain the optimal solution. The faster the convergence speed is, the shorter the training time is, which means the higher the training efficiency is. The success rate refers to the percentage of mobile robots that can successfully reach the target point from the starting point according to the path planning algorithm adopted. The higher the success rate is, the better the performance of the algorithm.
4.2. Effect Analysis of Our Algorithm
In order to verify the performance of our algorithm, the DDPG algorithm proposed in reference [
31], our algorithm with an improved network structure (LSTM-DDPG) and our algorithm after adding mixed noise further (MN-LSTM-DDPG) are all trained in the simulation environment, respectively.
Firstly, 2000 episodes of training are conducted in the simulation
Figure 6a, and the reward value of the mobile robot is recorded after each episode of training, as shown in
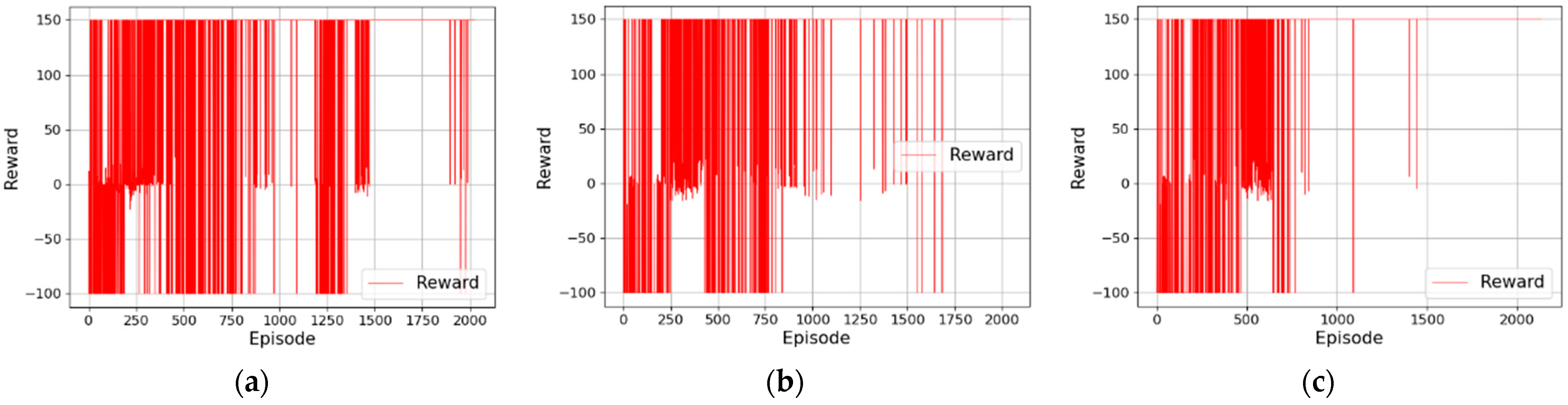
Figure 7. The results in
Figure 7a show that in an environment without obstacles, the reward value of the algorithm proposed in [
31] gradually tends to be stable with the increase in training episodes, but it still fails to converge after 2000 episodes of training. Moreover, the reward value fluctuates greatly in the first 800 episodes and is mostly negative, indicating that the mobile robot is learning how to approach the target point but fails many times. After 800 episodes, the reward value gradually tends to be positive, indicating that the mobile robot can reach the target point through training, but it still collides with obstacles.
Figure 7b is the training result after LSTM is introduced into the network of the algorithm proposed in [
31]. As can be seen, with the increase in training time, the reward value obtained by the mobile robot gradually increases from a negative value to a positive value, and finally tends to be stable, but the convergence rate is slow. After LSTM is introduced into the algorithm, the mixed noise composed of Gaussian noise and OU noise is further introduced into the output results of the network, and the reward function is optimized.
Figure 7c shows the training result of the algorithm. As can be seen, with the increase in training time, the reward value obtained by the mobile robot gradually increases and finally tends to be stable. Compared with
Figure 7b, the convergence speed is significantly faster.
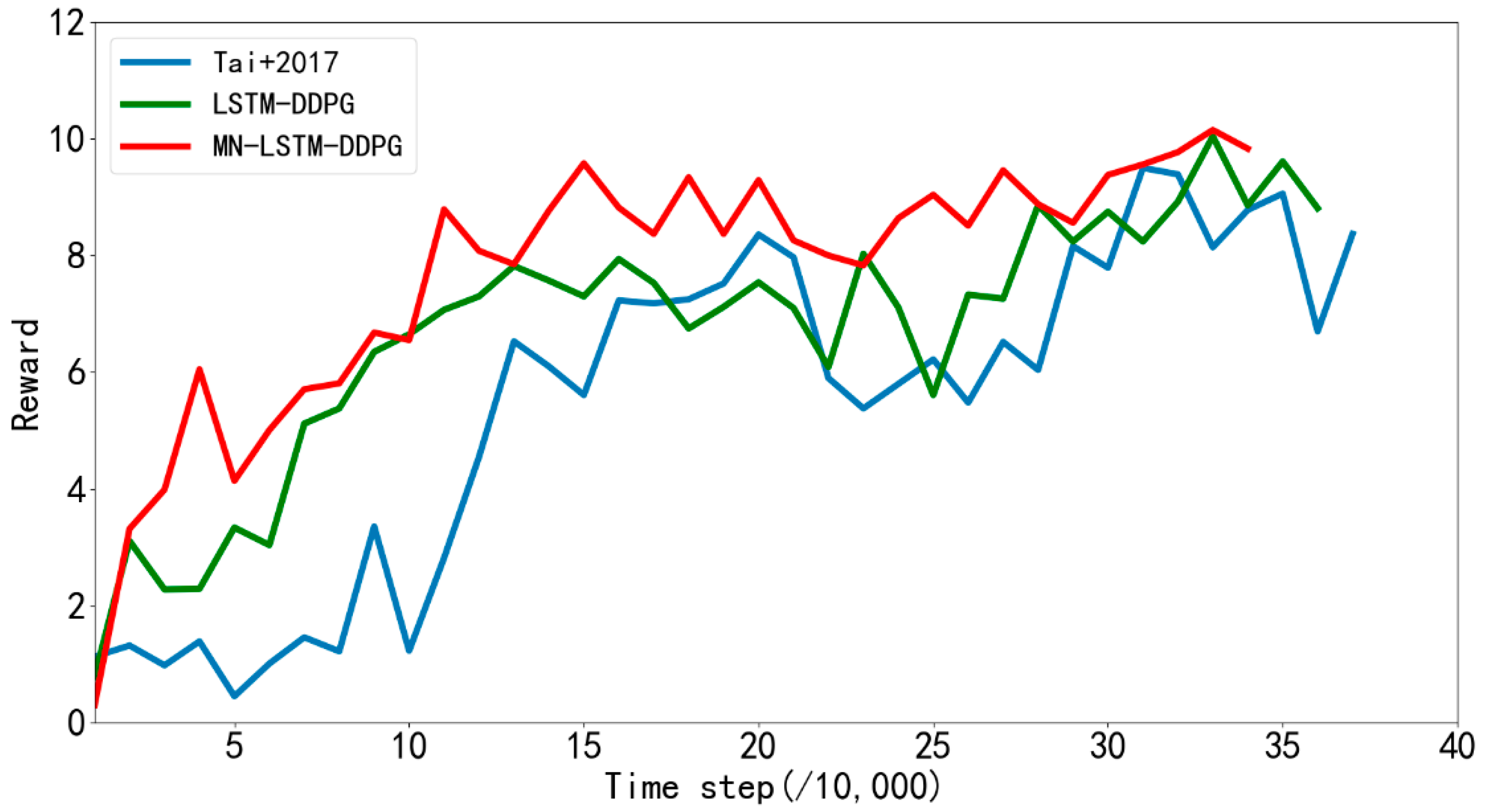
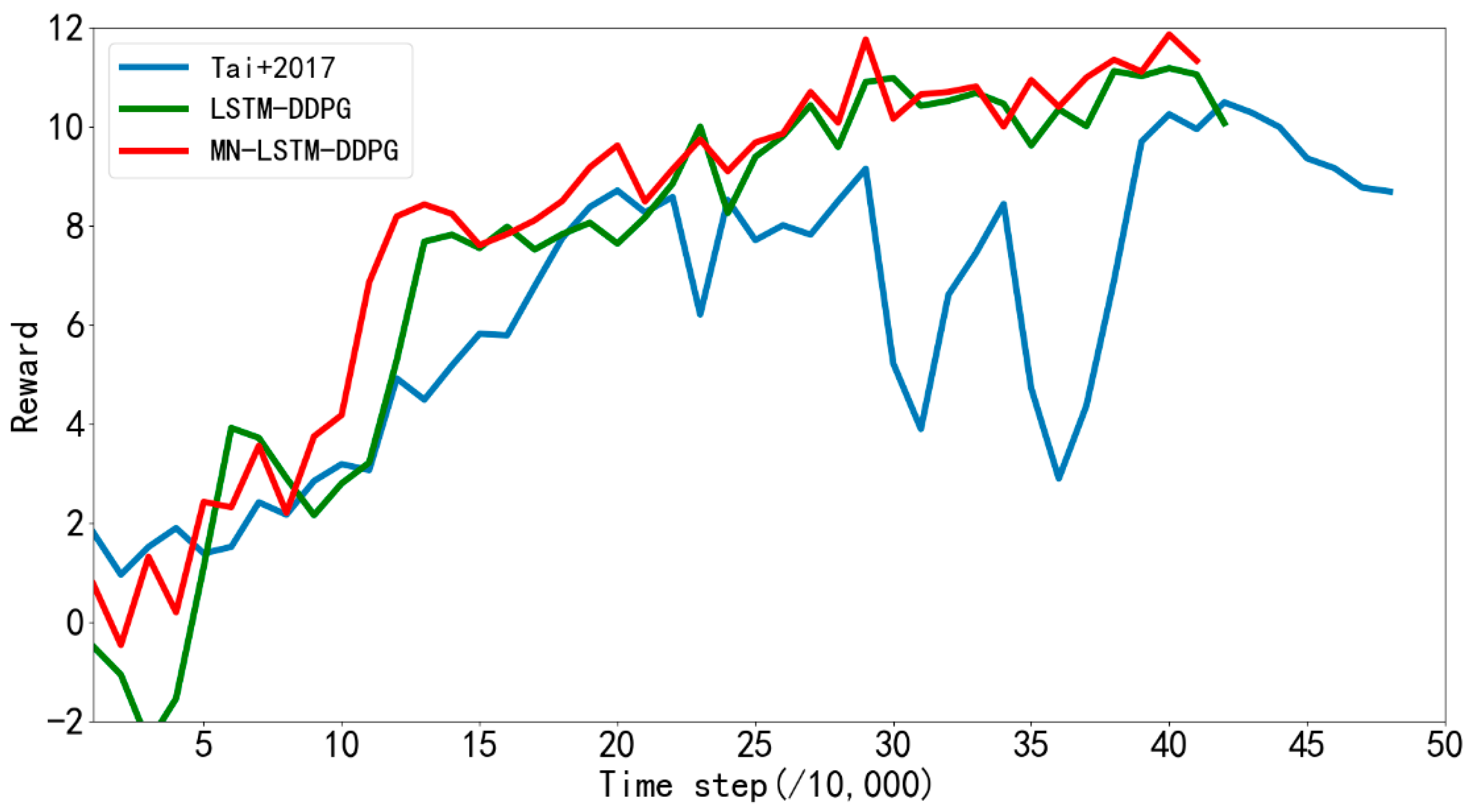
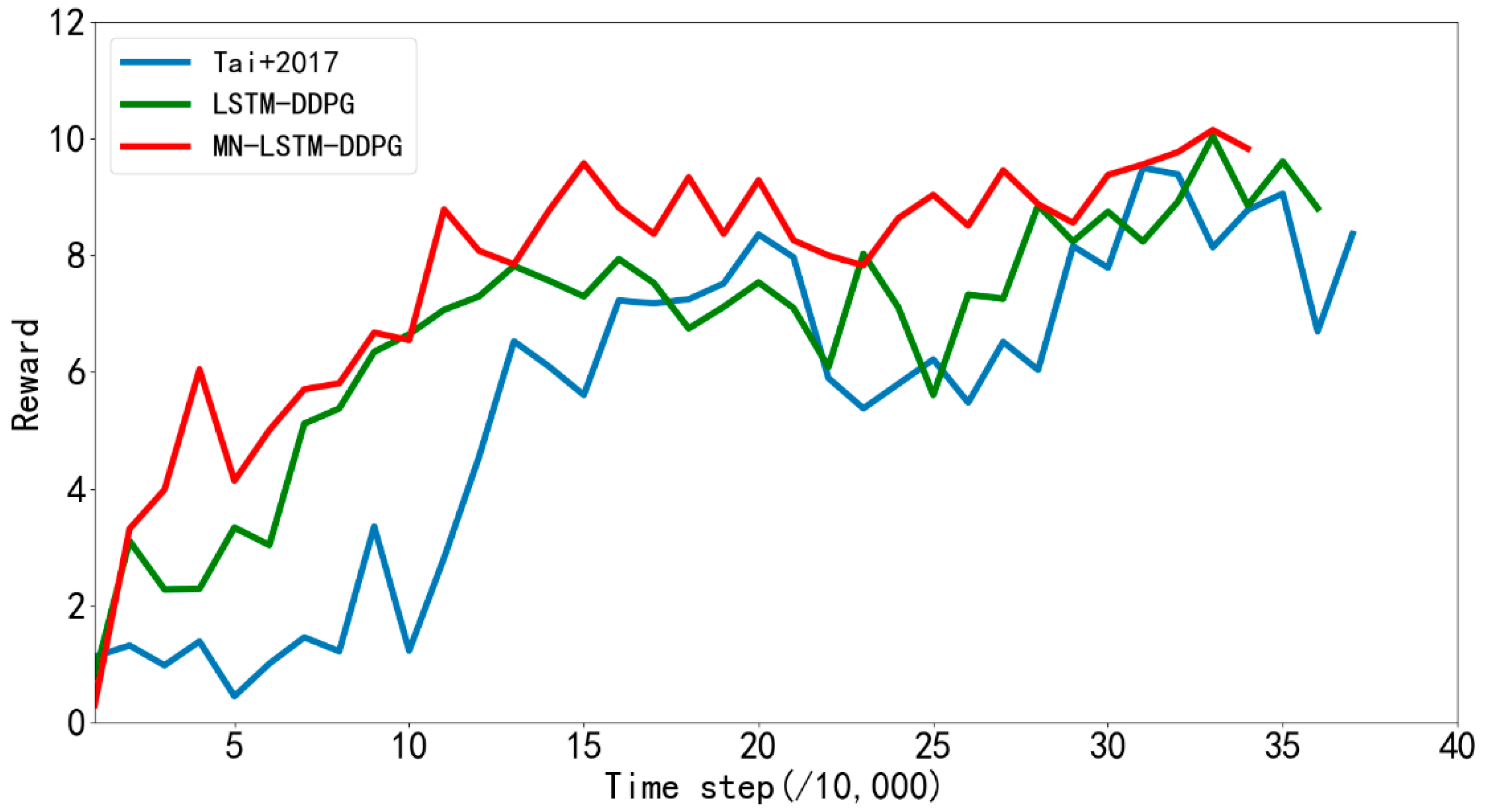
Figure 8 shows the average rewards returned every 10,000 steps by the algorithm proposed in reference [
31] and LSTM-DDPG and MN-LSTM-DDPG proposed in this paper in the path planning training in simulation
Figure 6a. The blue line represents the algorithm proposed in [
31], the green line represents the LSTM-DDPG algorithm, and the red line represents the MN-LSTM-DDPG algorithm. As can be seen, MN-LSTM-DDPG has the fastest convergence speed in the path planning of mobile robots, requiring only 120,000 steps, while the algorithm proposed in [
31] requires 200,000 steps to converge, and the convergence is not stable.
Table 1 compares the training time and the number of training steps of the three algorithms mentioned above. As can be seen from the table, the training time of the path planning of the algorithm proposed in [
31] is 28.03 h, while the training time of MN-LSTM-DDPG is only 22.75 h, which is 18.8% shorter. In terms of the number of training steps, the number of training steps of the algorithm proposed in [
31] is 484,231, while the number of training steps of MN-LSTM-DDPG is only 417,701, which significantly improves the convergence speed.
In order to verify the success rate and generalization ability of the model trained in simulation
Figure 6a, 200 tests are performed on the three algorithms in simulation
Figure 6a and simulation
Figure 6c, respectively.
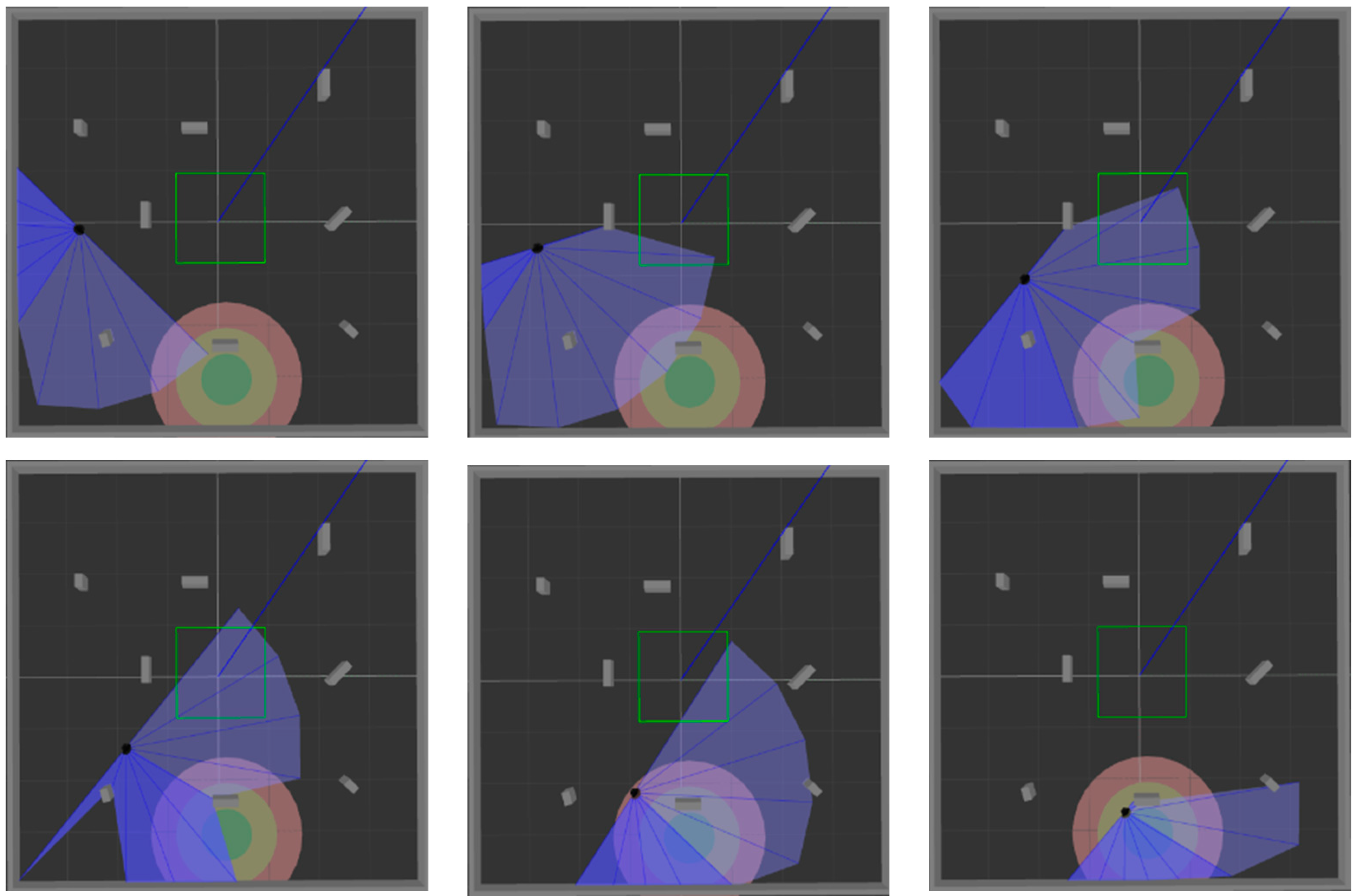
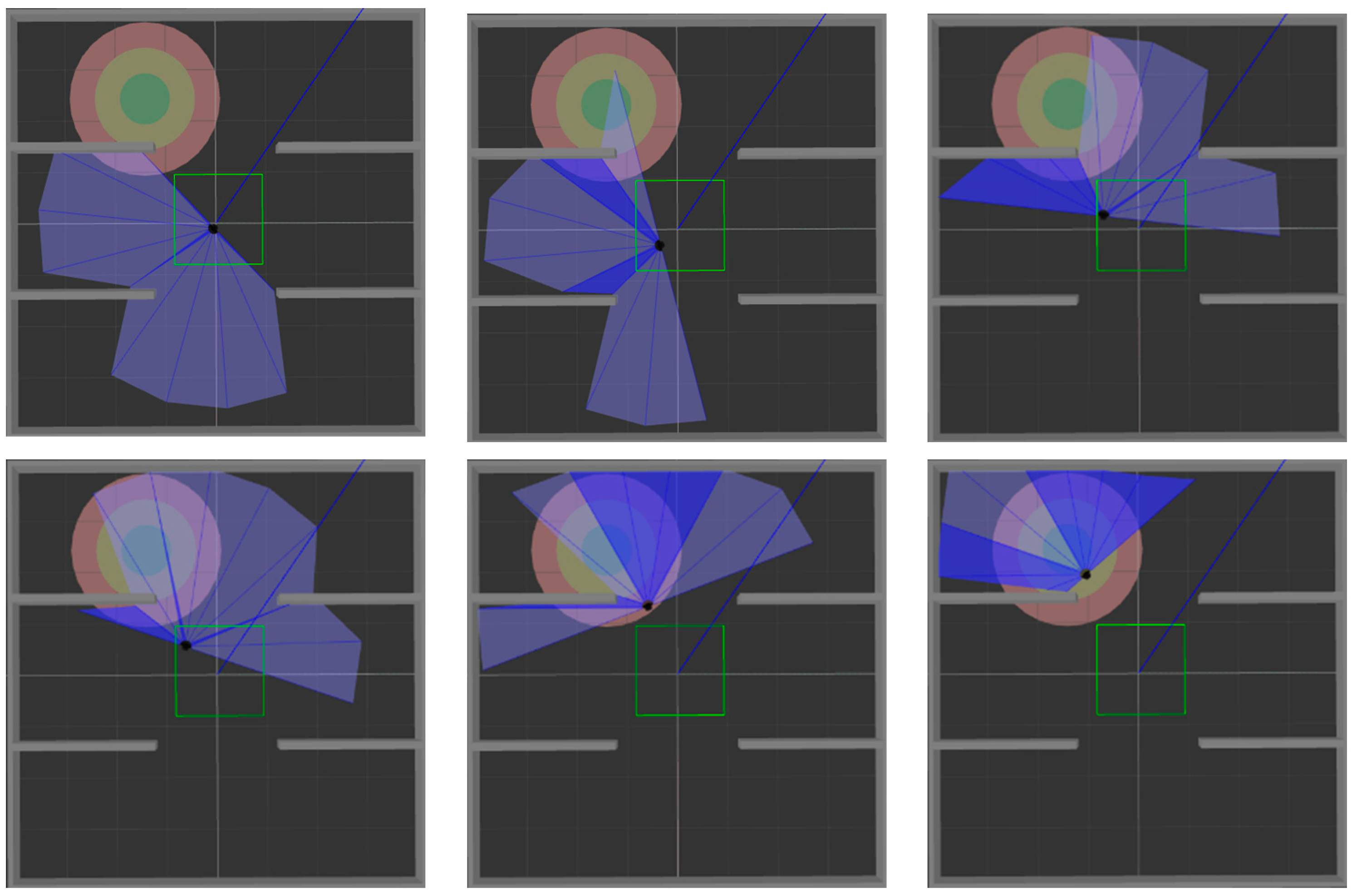
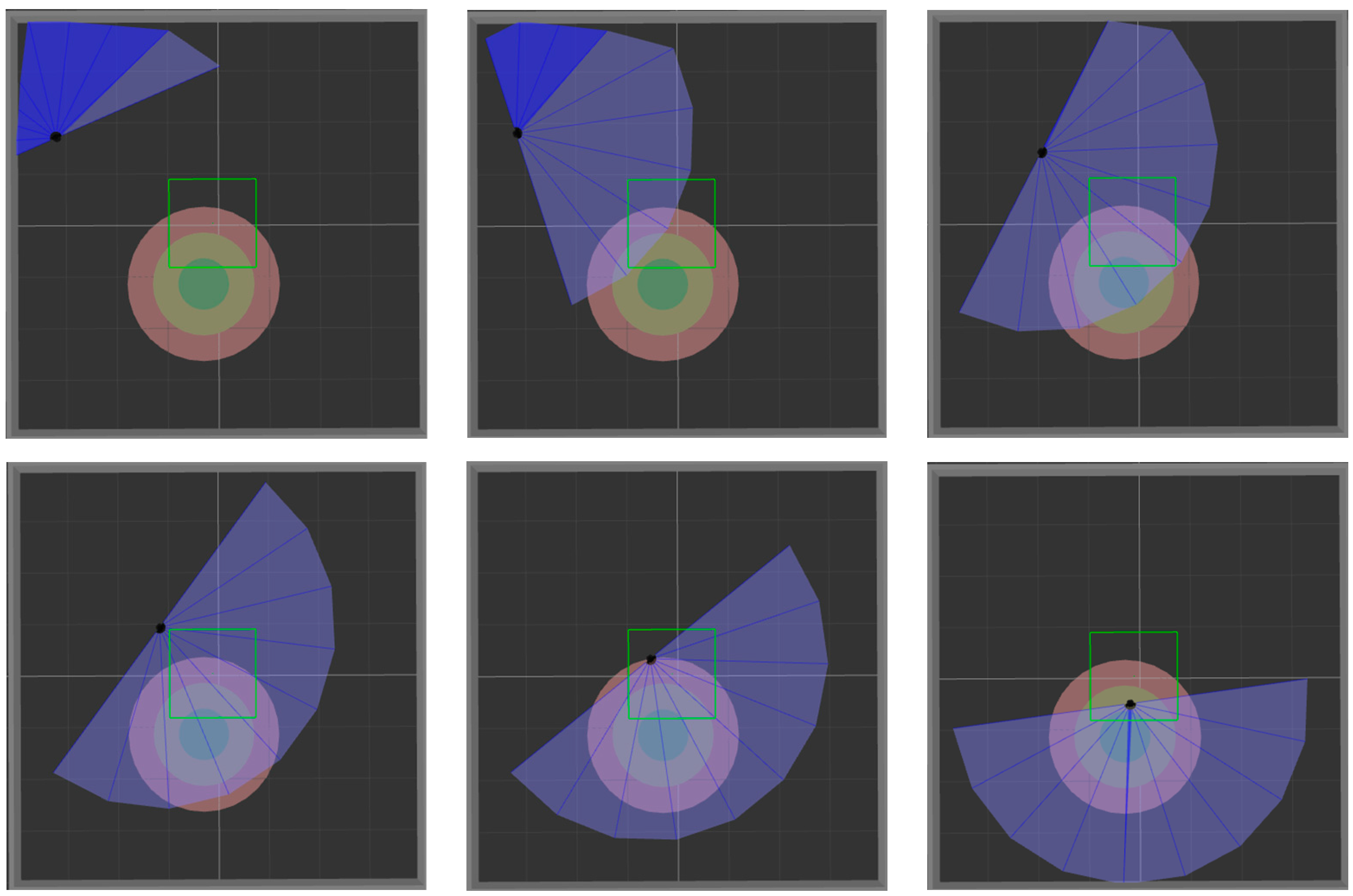
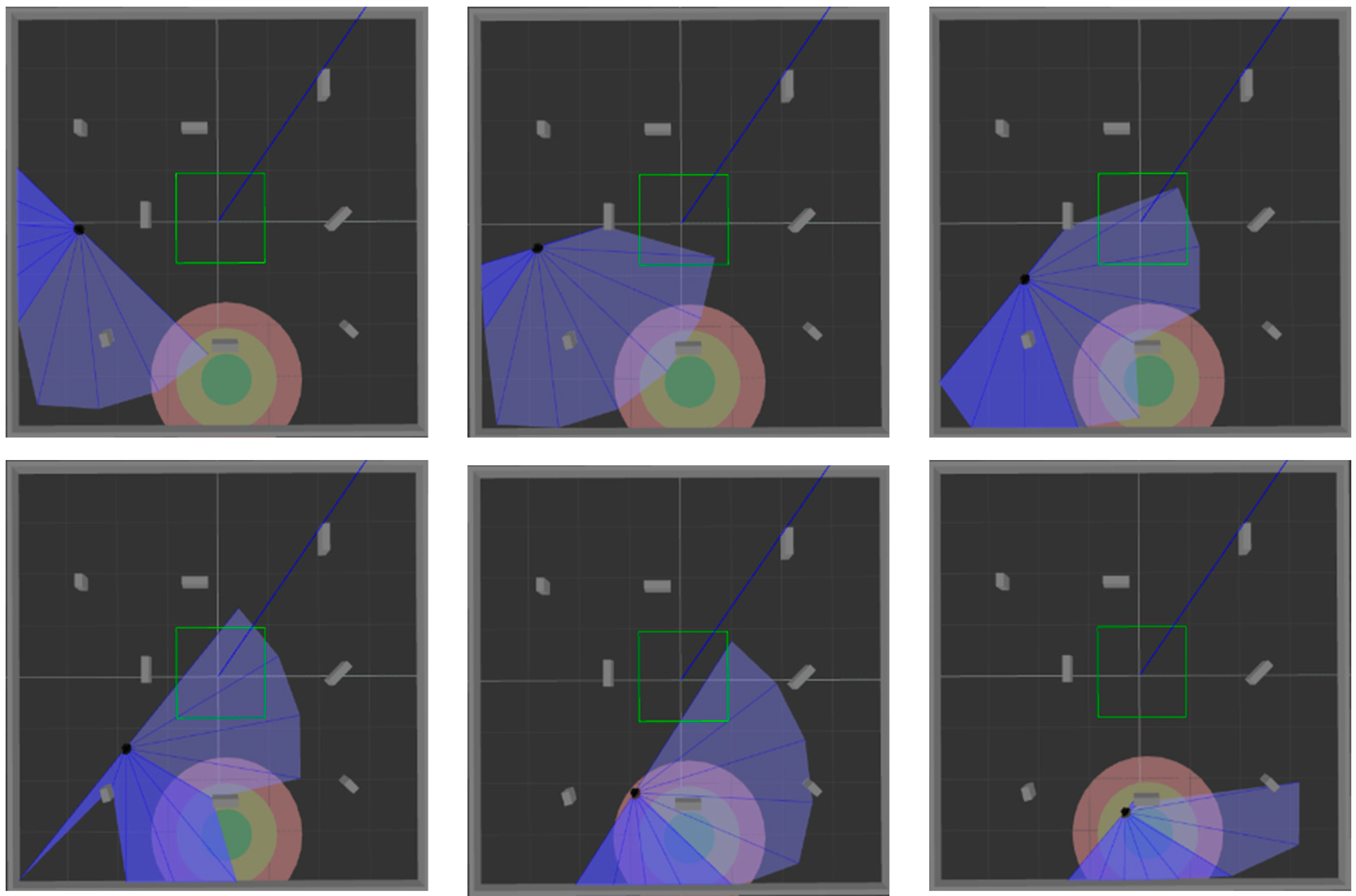
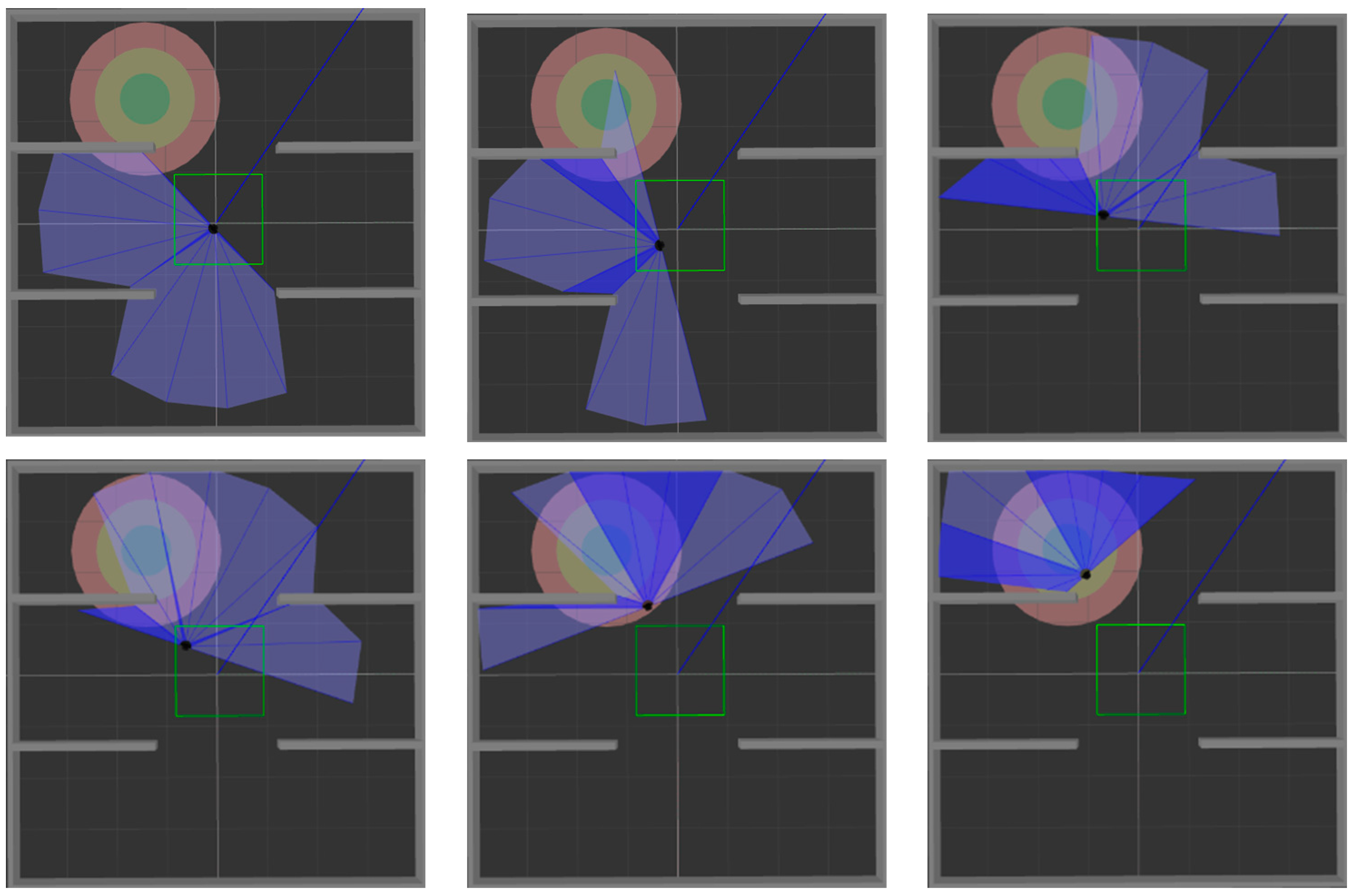
Figure 9 and
Figure 10 show the movement process of the mobile robot in these two environments when MN-LSTM-DDPG is used for path planning. The black dot is the mobile robot, the blue part is the detection range of the laser sensor, the gray part is the obstacle, and the green circle is the final target point. As can be seen, the mobile robot can avoid obstacles from the starting point and reach the target point accurately with the optimal path.
Table 2 and
Table 3 record the test results in simulation
Figure 6a and simulation
Figure 6c, respectively. It can be seen from
Table 2 that the path planning success rate of the algorithm proposed in [
31] is only 86%, while the success rate of the MN-LSTM-DDPG algorithm proposed in this paper can reach 100%. In terms of time, compared with the algorithm proposed in [
31], the path planning time of the MN-LSTM-DDPG algorithm proposed in this paper is shortened by 21.48%. However, when the model trained in simulation
Figure 6a is applied to simulation
Figure 6c, the testing effect of each algorithm is not ideal, as shown in
Table 3. Therefore, it is necessary to train the algorithm in an environment with obstacles.
In order to verify the effect of the proposed algorithm in an obstacle environment, the algorithm proposed in [
31], the LSTM-DDPG algorithm and the MN-LSTM-DDPG algorithm proposed in this paper were respectively trained for 2000 episodes in simulation
Figure 6b, and the average reward returned by the mobile robot every 10,000 steps was recorded, as shown in
Figure 11. As can be seen from the figure, the improved MN-LSTM-DDPG algorithm in this paper can achieve convergence after 110,000 steps of training in the path planning of mobile robots in the simulation
Figure 6b However, the algorithm proposed in [
31] needs 200,000 training steps to converge, and the convergence is unstable; the convergence speed is significantly slower than the algorithm proposed in this paper. Additionally, from the training results in
Table 4, it can be seen that the path planning training time of the algorithm proposed in the [
31] is 21.73 h, while the path planning training time of the improved MN-LSTM-DDPG algorithm in this paper is only 19.70 h, and the training speed shows a significant improvement. In terms of the number of training steps, the number of training steps of the algorithm proposed in [
31] is 374,316, while the number of training steps of the improved MN-LSTM-DDPG algorithm in this paper is only 346,667, which significantly improves the convergence speed of the algorithm.
After training the model in an environment with obstacles, 200 tests were performed in simulation
Figure 6b and simulation
Figure 6c, respectively, to verify the generalization ability of the model. The test process is shown in
Figure 12 and
Figure 13. The two figures respectively show the process of mobile robot avoiding obstacles from the starting point to reach the target range.
Table 5 and
Table 6 record the test results in simulation
Figure 6b and simulation
Figure 6c, respectively. As can be seen from
Table 5, in terms of success rate, the success rate of the algorithm proposed in [
31] is 76%, while the success rate of the MN-LSTM-DDPG algorithm proposed in this paper can reach 87%, which is significantly higher than that in reference [
31]. In terms of time, the test time of the algorithm in this paper is also 17.96% faster than the algorithm in [
31]. It can be seen from
Table 6 that the test effect of each algorithm in simulation
Figure 6c is better than that in simulation
Figure 6b. This is because when the obstacle is too large, the number of steps that the mobile robot needs to move increases. Since the maximum number of steps of the mobile robot is limited in the simulation environment, when the maximum number of steps has not reached the target point, it is regarded as a failure.
4.3. Comparison and Analysis with Other Algorithms
In order to fully evaluate the performance of the proposed algorithm, experiments are conducted to compare the proposed algorithm with those in references [
32,
33]. In the simulation
Figure 6a, each algorithm is trained for 2000 episodes, and the average reward returned by the mobile robot every 10,000 steps is recorded. The results are shown in
Figure 14. As can be seen from the figure, in the barrier-free environment, when the algorithm proposed in [
32] carries out path planning training, it tends to converge at about 110,000 steps, but the reward value after convergence still shows a downward trend, and the training effect is not good. The algorithm proposed in [
33] tends to stabilize after 210,000 steps of training. However, the algorithm proposed in this paper can converge and become stable after 120,000 steps of training, and the training effect is the best.
Table 7 records the comparison of training time and the number of steps of each algorithm. As can be seen from the table, in terms of training time, the training time of the algorithm proposed in [
32] is 39.63 h. The training time of the algorithm proposed in [
33] is 24.67 h. However, the training time of the algorithm proposed in this paper is only 22.75 h, which is significantly faster than the algorithm proposed in [
32] and better than the algorithm proposed in [
33]. In terms of the number of training steps, the training steps of the algorithm proposed in references [
32,
33] are 395,344 and 446,596, respectively, while the training steps of the algorithm proposed in this paper are 417,701. The algorithm proposed in [
32] will fall into local optimum during training, which leads to the mobile robot turning in place, and in this paper, the proposed algorithm can effectively avoid the phenomenon. Compared with reference [
32], this paper proposed that although the algorithm steps of training increased, the training time is significantly reduced, and the training speed is still faster than the algorithm in [
32]. However, the algorithm proposed in this paper can effectively avoid this phenomenon. Compared with the algorithm proposed in [
32], although the number of training steps is increased, the training time is significantly reduced, and the training speed is still faster than the algorithm proposed in [
32]. This indicates that the training effect of the algorithm proposed in this paper is better than the algorithm proposed in the references [
32,
33] in a barrier-free environment.
To verify the success rate and generalization ability of the model trained in simulation
Figure 6a, 200 tests were conducted each in simulation
Figure 6a and simulation
Figure 6c, and the results are shown in
Table 8 and
Table 9. It can be seen from
Table 8 that the path planning success rate of the algorithm proposed in [
32] is 87.5%, and that of the algorithm proposed in [
33] is 90%. However, the path planning success rate of the algorithm proposed in this paper can reach 100%, which is significantly higher than that in references [
32,
33]. In terms of time, the algorithm proposed in this paper takes the same time as the algorithm proposed in [
33], which is significantly shorter than that in [
32]. However, it can be seen from the test results in
Table 9 that the model trained by each algorithm in a barrier-free environment is not ideal when tested in an obstacle environment, but the algorithm proposed in this paper still performs better than the other two algorithms.
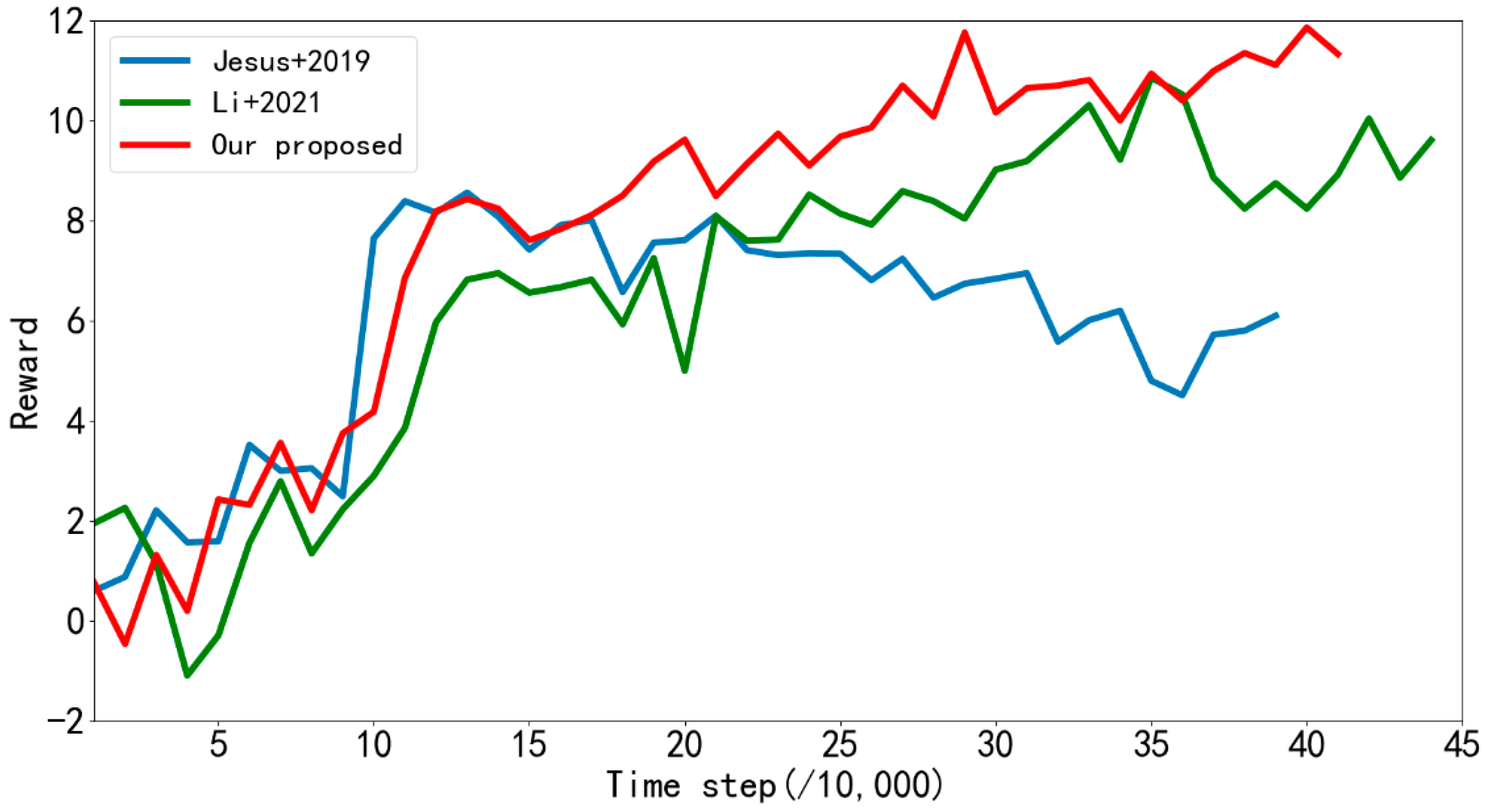
In order to verify the advantages of the algorithm in this paper in an environment with obstacles, the algorithm in this paper and the algorithm proposed in references [
32,
33] were trained for 2000 episodes in simulation
Figure 6b. The average rewards returned by the mobile robot every 10,000 steps were recorded, and the results are shown in
Figure 15. As can be seen from the figure, when the algorithm proposed in [
32] performs path planning in simulation
Figure 6b, it needs 240,000 steps of training to converge. The algorithm proposed in [
33] needs 140,000 training steps to become stable, while the algorithm proposed in this paper can achieve convergence after 110,000 training steps, and the convergence effect is obviously better than that in references [
32,
33]. It can also be seen from
Table 10 that the training time and number of training steps taken by the algorithm proposed in this paper are significantly less than those in references [
32,
33].
In order to verify the success rate of the trained model in the obstacle environment, each algorithm was tested 200 times each in simulation
Figure 6b and simulation
Figure 6c, and the results are shown in
Table 11 and
Table 12. As can be seen from the test results in
Table 11, in terms of success rate, the algorithm proposed in [
32] is 82.5%, the algorithm proposed in [
33] is 81%, and the algorithm proposed in this paper can reach 87%, which is significantly higher than the algorithm proposed in references [
32,
33]. In terms of test time, the test time of the algorithm proposed in this paper is longer than that proposed in [
33]. In the testing process, since the starting and ending points of the mobile robot are randomly selected, their relative positions will have a certain influence on the testing time. It can be seen from
Table 12, in simulation
Figure 6c, the success rate of the algorithm proposed in this paper can reach 90.5%, higher than the algorithm proposed in references [
32,
33], which indicates that the algorithm proposed in this paper has obvious advantages in path planning in an environment with obstacles.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}