
Human Activity Recognition Data Analysis: History, Evolutions, and New Trends


 , ,
, ,
Abstract
:1. Introduction
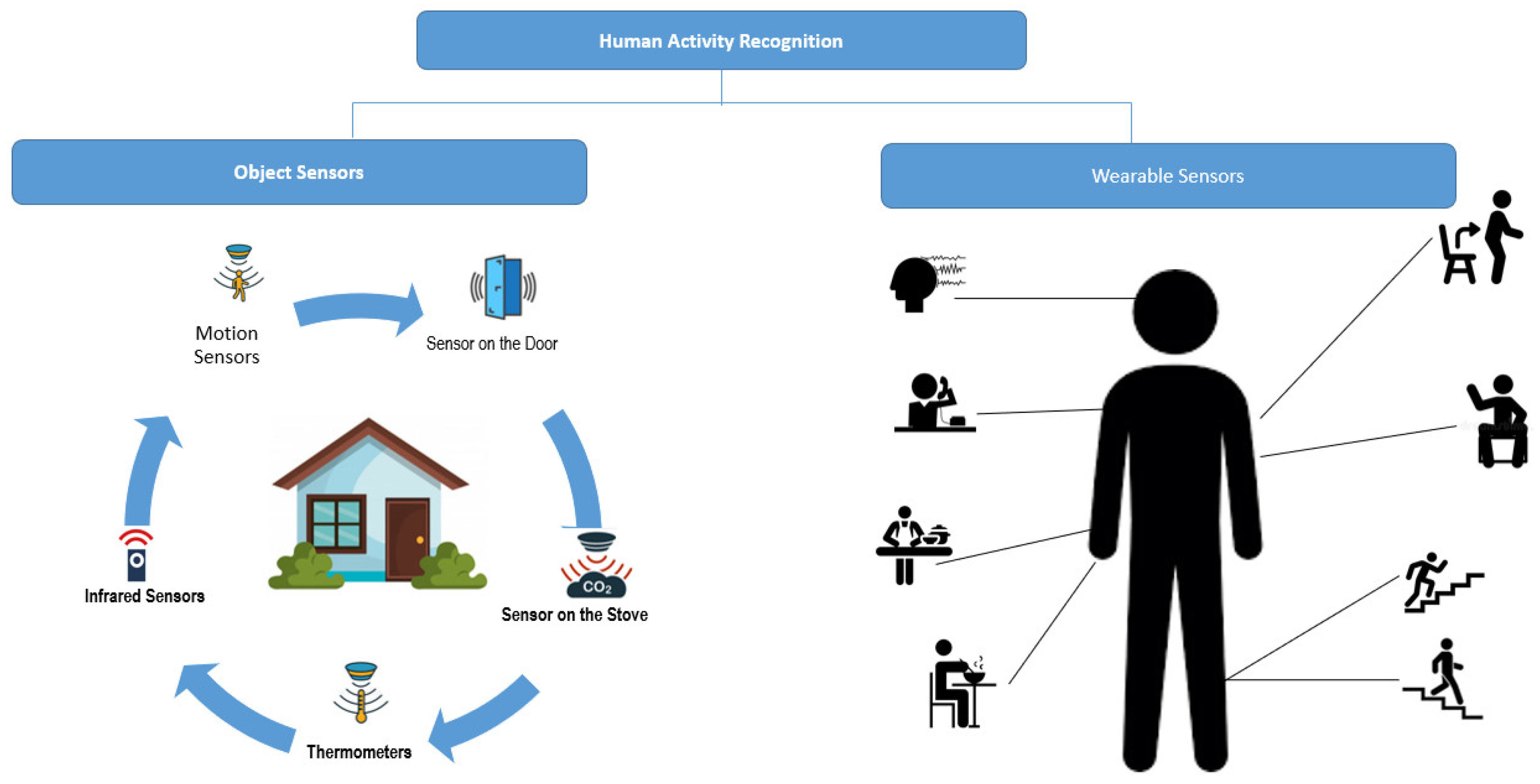
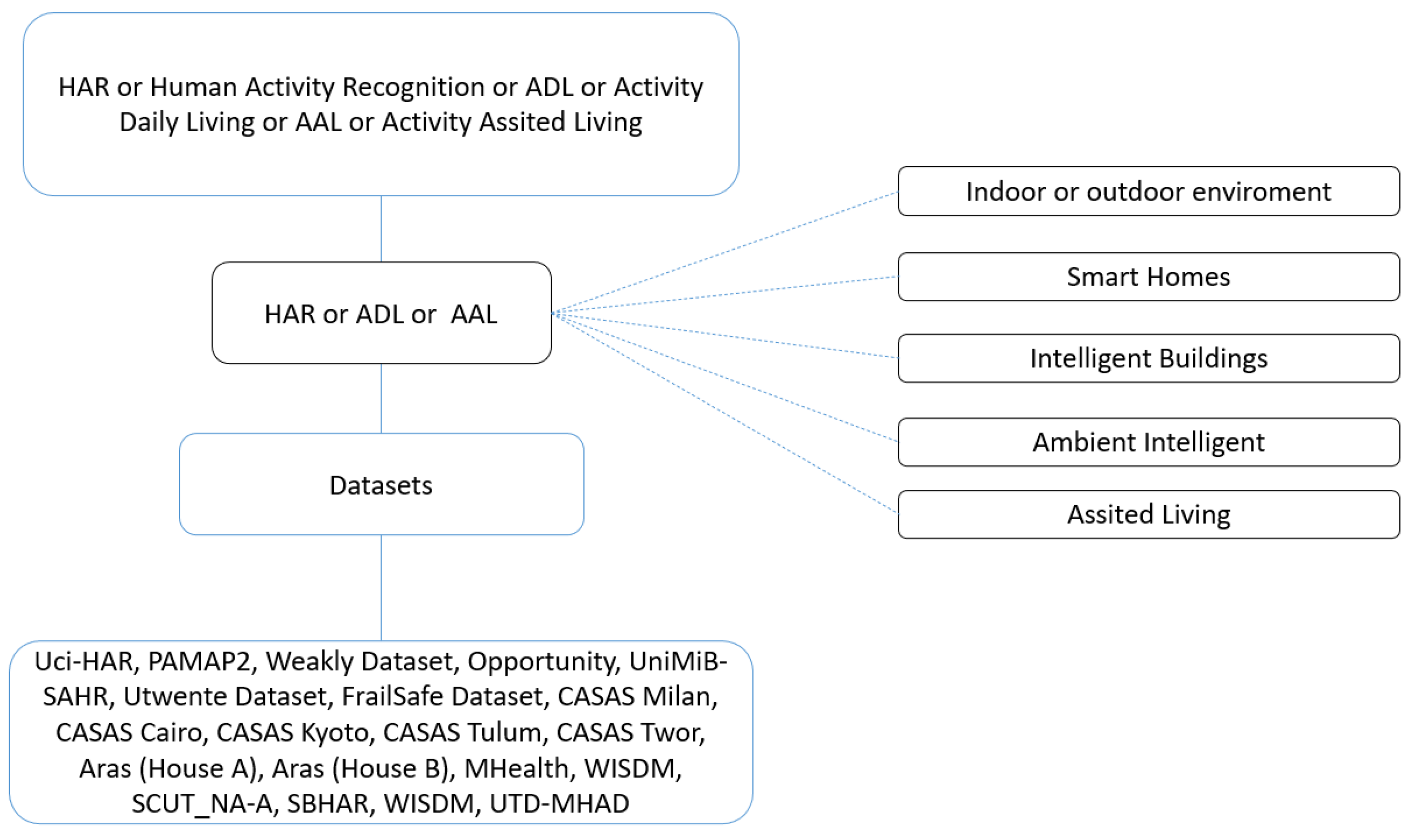
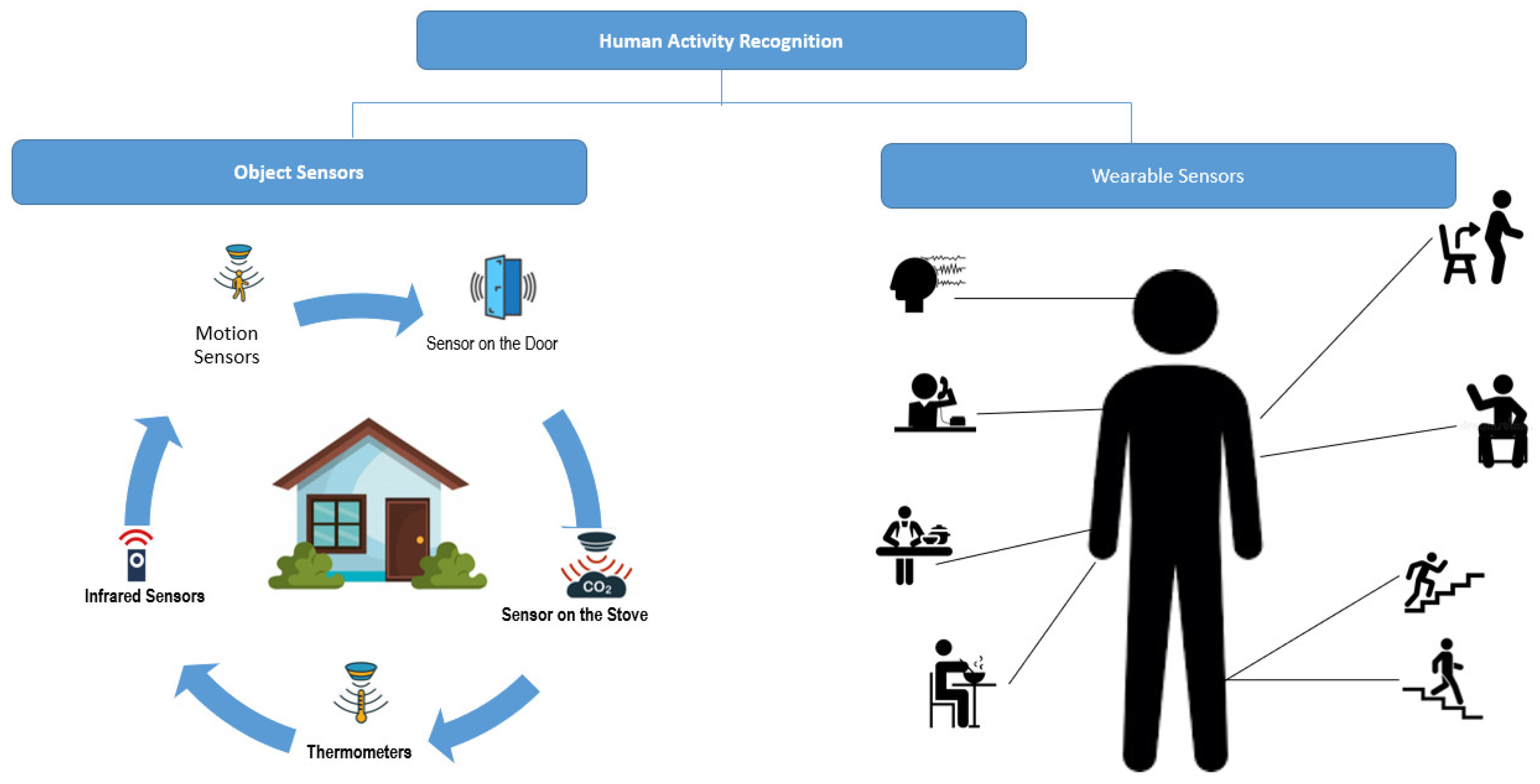
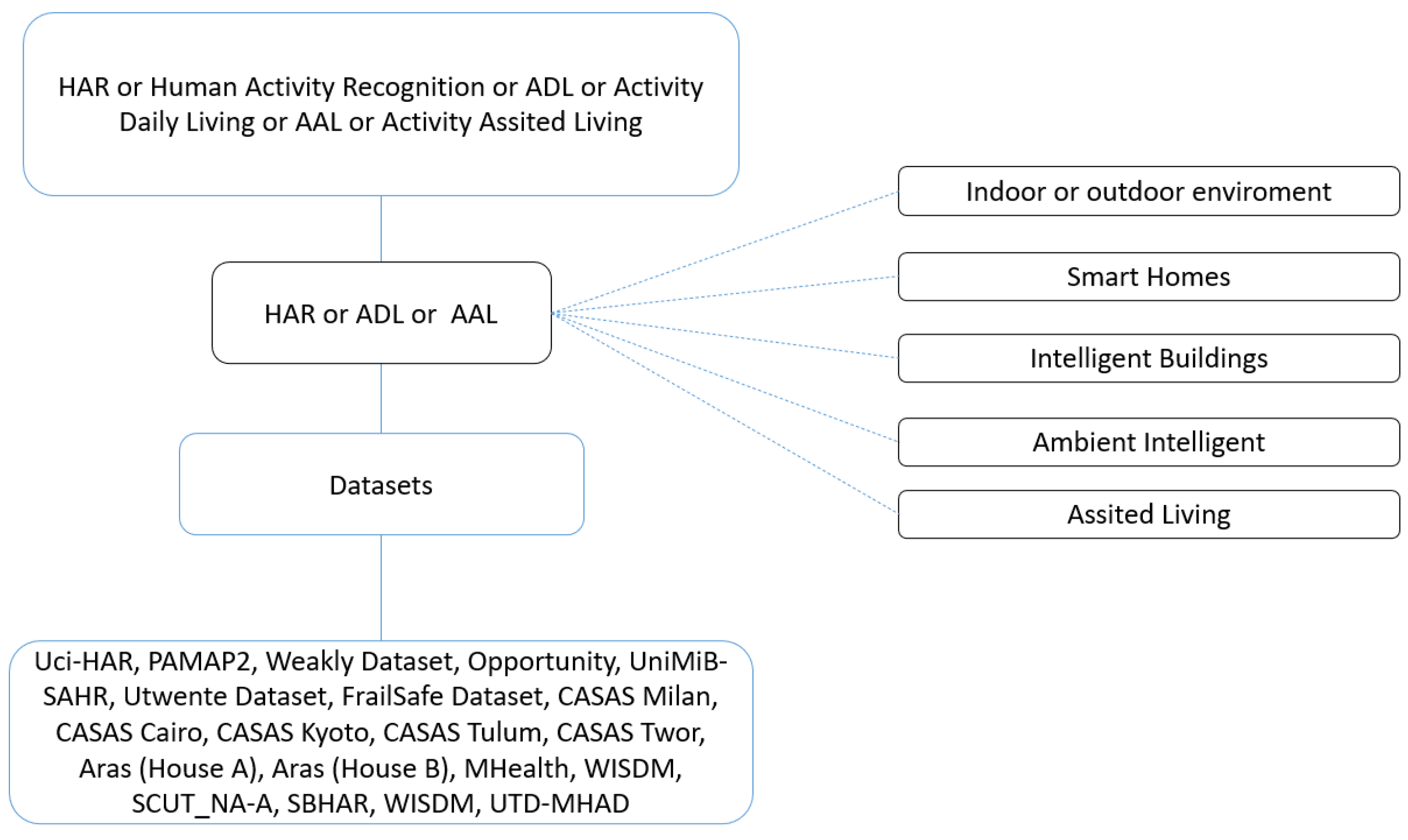
2. HAR Approach Concept Maps
3. Conceptual Information
3.1. Supervised Learning
3.1.1. Decision Tree
3.1.2. Support Vectorial Machine (SVM)
3.1.3. Naïve Bayesian Classifier
3.1.4. Artificial Neural Networks-ANN
3.1.5. Decision Tables
3.1.6. Tree-Based on the Logistic Model-LMT
3.2. Unsupervised Learning
3.2.1. Clustering Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Strategy | Applications | |
|---|---|---|---|
| Hierarchical | Agglomerative | Nearest Neighbor [43] Farthest Neighbor [44] Average Linkage Pool [45] Minimum Variance [46] Median Method [47] | |
| Divisive | |||
| Non-Hierarchical | Reassignment | Centroids | K-means [48], QuickCluster [49], Forgy Methods [50] |
| Medioid | k-medioids [51], Clara [52] | ||
| Density | Dynamic clouds [53] | ||
| Typological approximation | Modal Analysis [54], Taxmap Method [55], Fortin Method [56] | ||
| Probabilistic approximation | Wolf Methods [57] | ||
| Direct | Block Clustering [58] | ||
| Reductive | Type Q Factor Analysis [59] | ||
3.2.2. Association Rules Methods
| Based in | Algorithms |
|---|---|
| Frequent Itemsets Mining | Apriori [60] |
| Apriori-TID [61] | |
| ECLAT TID-list [62,63] | |
| FP-Growth [64] | |
| Big Data Algorithms | R-Apriori [65] |
| YAFIM [66] | |
| ParEclat [67] | |
| Par-FP (Parallel FP-Growth with Sampling) [68] | |
| HPA (Hash Partitioned Apriori) [69] | |
| Distributed algorithms | PEAR (Parallel Efficient Association Rules) [70] |
| Distributed algorithms for fuzzy association rule mining | Count Distribution algorithm [71,72] |
3.2.3. Dimensionality Reduction Methods
3.3. Ensemble Learning
3.3.1. Voting by the Majority
3.3.2. Bagging
3.3.3. Boosting
3.3.4. Stacking
3.4. Deep Learning
3.4.1. Convolutional Neural Networks (CNN)
3.4.2. Recurrent Neural Networks (RNN)
3.4.3. Generative Adversarial Networks (GAN)
3.5. Reinforcement Learning
3.5.1. SARSA
3.5.2. Q-Learning
3.5.3. Deep Reinforcement Learning
3.6. Metaheuristic Learning
3.7. Transfer Learning
3.8. Human Activity Recognition
4. Methodology for Analyzing the Information
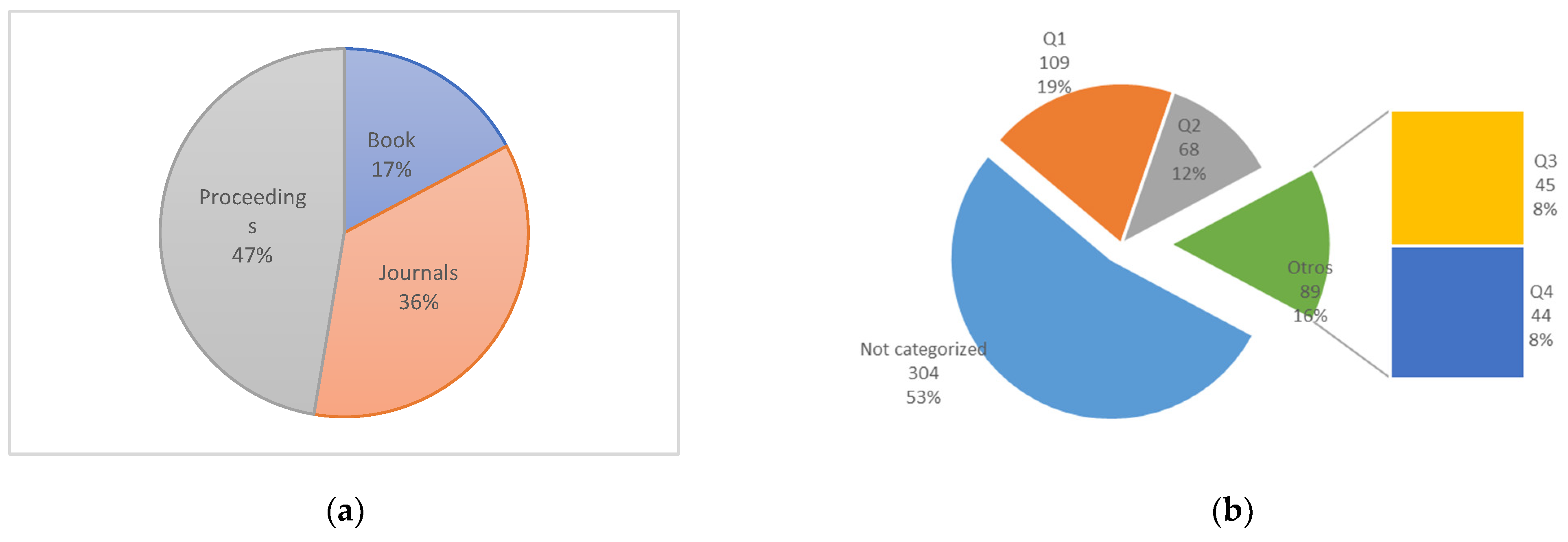
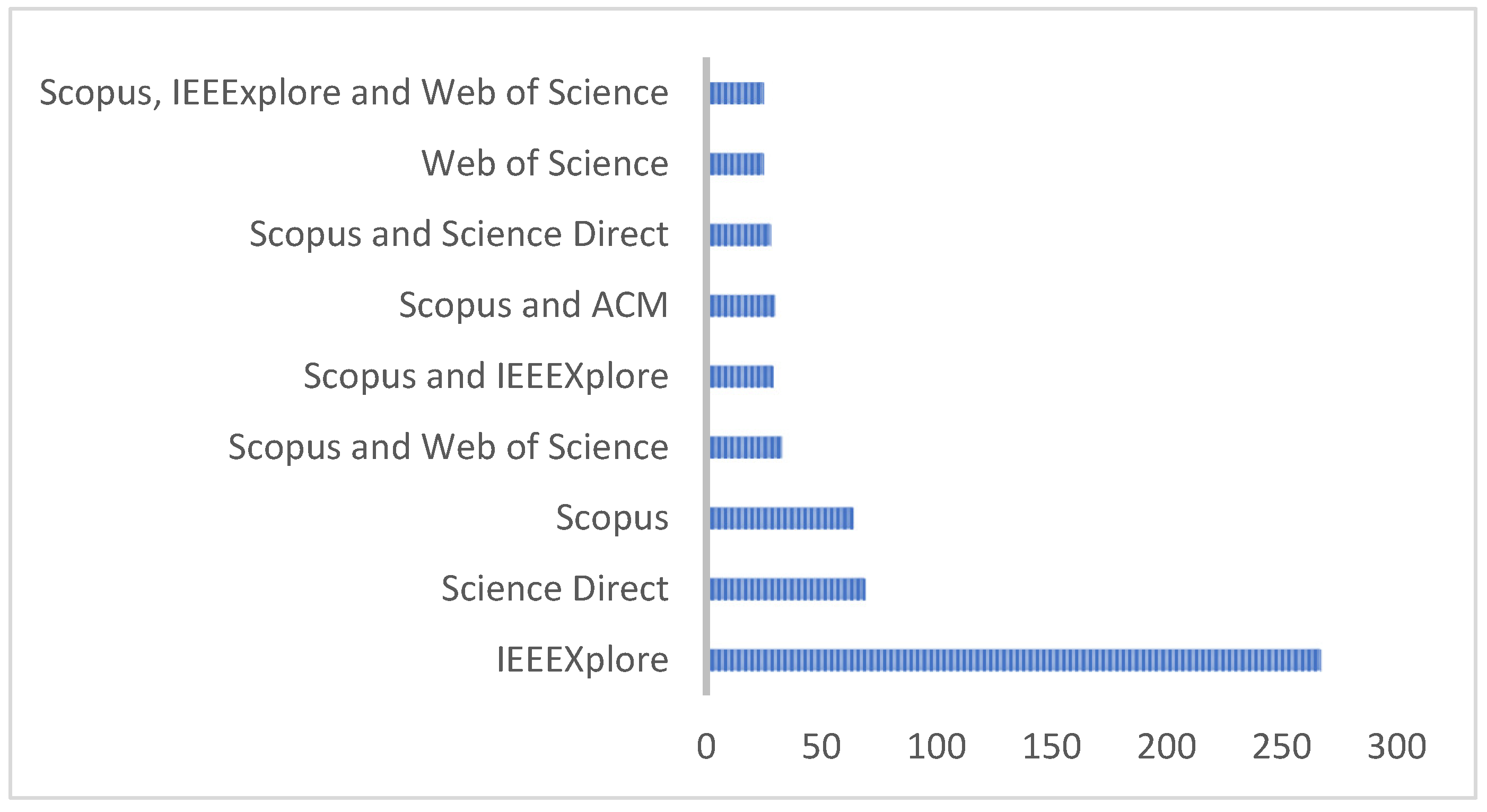
5. Scientometric Analysis
6. Technical Analysis
6.1. Supervised Learning Applied to Human Activity Recognition Dataset
| Dataset | Technique | Metrics | References | |||
|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F-Measure | |||
| UCI Machine Learning | Nearest Neighbor | 75.7 | - | - | - | [121] |
| Decision Tree | 76.3 | - | - | - | ||
| Random Forest | 75.9 | - | - | - | ||
| Naive Bayes | 76.9 | - | - | - | ||
| Aras (House A) | MSA (Margin Setting Algorithm) | 68.85 | - | - | - | [122] |
| SVM | 66.90 | - | - | - | ||
| ANN | 67.32 | - | - | - | ||
| Aras (House B) | MSA (Margin Setting Algorithm) | 96.24 | - | - | - | |
| SVM | 94.81 | - | - | - | ||
| ANN | 95.42 | - | - | - | ||
| CASAS Tulum | MSA (Margin Setting Algorithm) | 68.00 | - | - | - | |
| SVM | 66.6 | - | - | - | ||
| ANN | 67.37 | - | - | - | ||
| Mhealth | K-NN | 99.64 | - | - | 99.7 | [123] |
| ANN | 99.55 | - | - | 99.6 | ||
| SVM | 99.89 | - | - | 100 | ||
| C4.5 | 99.32 | - | - | 99.3 | ||
| CART | 99.13 | - | - | 99.7 | ||
| Random Forest | 99.89 | - | - | 99.89 | ||
| Rotation Forest | 99.79 | - | - | 99.79 | ||
| WISDM, SCUT_NA-A | Sliding window with variable size, S transform, and regularization based robust subspace (SRRS) for selection and SVM for Classification | 96.1 | - | - | - | [124] |
| SCUT NA-A | Sliding window with fixed samples, SVM like a classifier, cross-validation | 91.21 | - | - | - | |
| PAMPA2, Mhealth | Sliding windows with fixed 2s, SVM, and Cross-validation | 84.10 | - | - | - | |
| SBHAR | Sliding windows with fixed 4s, SVM, and Cross-validation | 93.4 | - | - | - | |
| WISDM | MLP based on voting techniques with nb-Tree are used | 96.35 | - | - | - | |
| UTD-MHAD | Feature level fusion approach& collaborative representation classifier | 79.1 | - | - | - | |
| Groupware | Mark Hall’s feature selection and Decision Tree | 99.4 | - | - | - | |
| Free-living | k-NN and Decision Tree | 95 | - | - | - | |
| WISDM, Skoda | Hybrid Localizing learning (k-NN-LSS-VM) | 81 | - | - | - | |
| UniMiB SHAR | LSTM and Deep Q-Learning | 95 | - | - | - | |
| Groupware | Sliding windows Gaussian Linear Filter and NB classifier | 89.5 | - | - | - | |
| Groupware | Sliding windows Gaussian Linear Filter and Decision Tree classifier | 99.99 | - | - | - | |
| CSI-data | SVM | 96 | - | - | - | [125] |
| LSTM | 89 | - | - | - | ||
| Built by the authors | IBK | 95 | - | - | - | [126] |
| Classifier based ensemble | 98 | - | - | - | ||
| Bayesian network | 63 | - | - | - | ||
| Built by the authors | Decision Tree | 91.08 | - | - | 89.75 | [127] |
| Random Forest | 91.25 | - | - | 90.02 | ||
| Gradient Boosting | 97.59 | - | - | 97.4 | ||
| KNN | 93.76 | - | - | 93.21 | ||
| Naive Bayes | 88.57 | - | - | 88.07 | ||
| SVM | 92.7 | - | - | 91.53 | ||
| XGBoost | 96.93 | - | - | 96.63 | ||
| UK-DALE | FFNN | 95.28 | - | - | - | [128] |
| SVM | 93.84 | - | - | - | ||
| LSTM | 83.07 | - | - | - | ||
| UCI Machine Learning | KNN | 90.74 | 91.15 | 90.28 | 90.45 | [129] |
| SVM | 96.27 | 96.43 | 96.14 | 96.23 | ||
| HMM+SVM | 96.57 | 96.74 | 96.49 | 96.56 | ||
| SVM+KNN | 96.71 | 96.75 | 96.69 | 96.71 | ||
| Naive Bayes | 77.03 | 79.25 | 76.91 | 76.72 | ||
| Logistic Reg | 95.93 | 96.13 | 95.84 | 95.92 | ||
| Decision Tree | 87.34 | 87.39 | 86.95 | 86.99 | ||
| Random Forest | 92.3 | 92.4 | 92.03 | 92.14 | ||
| MLP | 95.25 | 95.49 | 95.13 | 95.25 | ||
| DNN | 96.81 | 96.95 | 96.77 | 96.83 | ||
| LSTM | 91.08 | 91.38 | 91.24 | 91.13 | ||
| CNN+LSTM | 93.08 | 93.17 | 93.10 | 93.07 | ||
| CNN+BiLSTM | 95.42 | 96.58 | 95.26 | 95.36 | ||
| Inception+ResNet | 95.76 | 96.06 | 95.63 | 95.75 | ||
| UCI Machine Learning | NB-NB | 73.68 | - | - | 46.9 | [130] |
| NB-KNN | 85.58 | - | - | 61.08 | ||
| NB-DT | 89.93 | - | - | 69.75 | ||
| NB-SVM | 79.97 | - | - | 53.69 | ||
| KNN-NB | 74.93 | - | - | 45 | ||
| KNN-KNN | 79.3 | - | - | 49.82 | ||
| KNN-DT | 87.01 | - | - | 60.98 | ||
| KNN-SVM | 82.24 | - | - | 53.1 | ||
| DT-NB | 84.72 | - | - | 60.05 | ||
| DT-KNN | 91.55 | - | - | 73.11 | ||
| DT-DT | 92.73 | - | - | 75.97 | ||
| DT-SVM | 93.23 | - | - | 77.35 | ||
| SVM-NB | 30.40 | - | - | - | ||
| SVM-KNN | 25.23 | - | - | - | ||
| SVM-DT | 92.43 | - | - | 75.31 | ||
| SVM-SVM | 43.32 | - | - | - | ||
| CASAS Tulum | Back-Propagation | 88.75 | - | - | - | [131] |
| SVM | 87.42 | - | - | - | ||
| DBM | 90.23 | - | - | - | ||
| CASAS Twor | Back-Propagation | 76.9 | - | - | - | |
| SVM | 73.52 | - | - | - | ||
| DBM | 78.49 | - | - | - | ||
| WISDM | KNN | 69 | 78 | - | 78 | [132] |
| LDA | 40 | 34 | - | 34 | ||
| QDA | 65 | 58 | - | 58 | ||
| RF | 90 | 91 | - | 91 | ||
| DT | 77 | 77 | - | 77 | ||
| CNN | 66 | 62 | - | 60 | ||
| DAPHNET | KNN | 90 | 87 | - | 88 | |
| LDA | 91 | 83 | - | 83 | ||
| QDA | 91 | 82 | - | 82 | ||
| RF | 91 | 91 | - | 91 | ||
| DT | 91 | 83 | - | 83 | ||
| CNN | 90 | 87 | - | 87 | ||
| PAPAM | KNN | 65 | 66 | - | 66 | |
| LDA | 45 | 45 | - | 45 | ||
| QDA | 15 | 19 | - | 19 | ||
| RF | 80 | 83 | - | 83 | ||
| DT | 60 | 60 | - | 60 | ||
| CNN | 73 | 76 | - | 73 | ||
| HHAR(Phone) | KNN | 83 | 85 | - | 85 | |
| LDA | 43 | 45 | - | 45 | ||
| QDA | 40 | 50 | - | 50 | ||
| RF | 88 | 89 | - | 89 | ||
| DT | 67 | 66 | - | 66 | ||
| CNN | 84 | 84 | - | 84 | ||
| HHAR(watch) | KNN | 78 | 82 | - | 82 | |
| LDA | 54 | 52 | - | 52 | ||
| QDA | 26 | 27 | - | 27 | ||
| RF | 85 | 85 | - | 85 | ||
| DT | 69 | 69 | - | 69 | ||
| CNN | 83 | 83 | - | 83 | ||
| Mhealth | KNN | 76 | 81 | - | 81 | |
| LDA | 38 | 59 | - | 59 | ||
| QDA | 91 | 82 | - | 82 | ||
| RF | 85 | 85 | - | 85 | ||
| DT | 77 | 77 | - | 77 | ||
| CNN | 80 | 80 | - | 80 | ||
| RSSI | KNN | 91 | 91 | - | 91 | |
| LDA | 91 | 91 | - | 91 | ||
| QDA | 91 | 91 | - | 91 | ||
| RF | 91 | 91 | - | 91 | ||
| DT | 91 | 91 | - | 91 | ||
| CNN | 91 | 90 | - | 91 | ||
| CSI | KNN | 93 | 93 | - | 93 | |
| LDA | 93 | 93 | - | 93 | ||
| QDA | 92 | 92 | - | 92 | ||
| RF | 93 | 93 | - | 93 | ||
| DT | 93 | 93 | - | 93 | ||
| CNN | 92 | 92 | - | 92 | ||
| Casas Aruba | DT | 96.3 | 93.8 | 92.3 | 93 | [133] |
| SVM | 88.2 | 88.3 | 87.8 | 88.1 | ||
| KNN | 89.2 | 87.8 | 85.9 | 86.8 | ||
| AdaBoost | 98 | 96 | 95.9 | 95.9 | ||
| DCNN | 95.6 | 93.9 | 95.3 | 94.6 | ||
| SisFall | SVM | 97.77 | 76.17 | 75.6 | [134] | |
| Random Forest | 96.82 | 79.99 | 79.95 | |||
| KNN | 96.71 | 93.99 | 68.36 | |||
| CASAS Milan | Naive Bayes | 76.65 | [135] | |||
| HMM+SVM | 77.44 | |||||
| CRF | 61.01 | |||||
| LSTM | 93.42 | |||||
| CASAS Cairo | Naive Bayes | 82.79 | ||||
| HMM+SVM | 82.41 | |||||
| CRF | 68.07 | |||||
| LSTM | 83.75 | |||||
| CASAS Kyoto 2 | Naive Bayes | 63.98 | ||||
| HMM+SVM | 65.79 | |||||
| CRF | 66.20 | |||||
| LSTM | 69.76 | |||||
| CASAS Kyoto 3 | Naive Bayes | 77.5 | ||||
| HMM+SVM | 81.67 | |||||
| CRF | 87.33 | |||||
| LSTM | 88.71 | |||||
| CASAS Kyoto 4 | Naive Bayes | 63.27 | ||||
| HMM+SVM | 60.9 | |||||
| CRF | 58.41 | |||||
| LSTM | 85.57 | |||||
6.2. Unsupervised Learning Applied to Human Activity Recognition Dataset
| Dataset | Technique | Metrics | References | ||||
|---|---|---|---|---|---|---|---|
| ARI | Jaccard Index | Silhouette Index | Euclidean | F1 Fisher’s Discriminant Ratio | |||
| UCI HAR SmartPhone | K-means | 0.7727 | 0.3246 | 0.4416 | [130] | ||
| HAC | 0.4213 | 0.2224 | 0.5675 | ||||
| FCM | 0.8343 | 0.4052 | 0.4281 | ||||
| UCI HAR Single Chest-Mounted Accelerometer | K-means | 0.8850 | 0.6544 | 0.6935 | |||
| HAC | 0.5996 | 0.2563 | 0.6851 | ||||
| FCM | 0.9189 | 0.7230 | 0.7751 | ||||
| Nottingham Trent University | FCM | - | - | - | - | [136] | |
| Chest Sensor Dataset | PM Model | 25.8% | - | [137] | |||
| Wrist Sensor Dataset | 64.3% | - | |||||
| WISDM Dataset | 54% | - | |||||
| Smartphone Dataset | 85% | - | |||||
| DSAD | wavelet tensor fuzzy clustering scheme (WTFCS) | 0.8966 | - | - | - | [138] | |
| UCI HAR | Spectral Clustering | 0.543 | 0.583 | [139] | |||
| Single Linkage | 0.807 | 0.851 | |||||
| Ward Linkage | 0.770 | 0.810 | |||||
| Average Linkage | 0.790 | 0.871 | |||||
| K-medioids | 0.653 | 0.654 | |||||
| UCI HAR | K-means | 52.1 | [140] | ||||
| K-Means 5 | 50.7 | ||||||
| Spectral Clustering | 57.8 | ||||||
| Gaussian Mixture | 49.8 | ||||||
| DBSCAN | 16.4 | ||||||
| CADL | K-means | 50.9 | |||||
| K-Means 5 | 50.5 | ||||||
| Spectral Clustering | 61.9 | ||||||
| Gaussian Mixture | 58.9 | ||||||
| DBSCAN | 13.9 | ||||||
6.3. Ensemble Learning Applied to Human Activity Recognition Dataset
| Dataset | Technique | Metrics | References | |||
|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F-Measure | |||
| SisFall | Decision Tree | 97.48 | - | - | - | [141] |
| Ensemble | 99.51 | - | - | - | ||
| Logistic Regression | 84.87 | - | - | - | ||
| Deepnet | 99.06 | - | - | - | ||
| Cornell Activity Dataset | X-means-SVM | 98.4 | 95.0 | 95.8 | - | [142] |
| TST Dataset | 92.7 | 95.6 | 91.1 | - | ||
| HHAR | Multi-task deep clustering | 67.2 | 65.3 | 65.9 | [143] | |
| MobiAct | 68.3 | 69.1 | 66.8 | |||
| MobiSense | 72.5 | 71.2 | 70.7 | |||
| NTU-RGB + D | K-Means | 85.72 | - | - | - | [144] |
| GMM | 87.26 | - | - | - | ||
| UCI HAR | CELearning | 96.88% | - | - | - | [145] |
| UCI HAR | RF | 96.96 | 97.0 | 97.0 | 98 | [146] |
| XGB | 96.2 | 96 | 96 | 96 | ||
| AdaB | 50.5 | 61 | 51 | 51 | ||
| GB | 94.53 | 95 | 95 | 95 | ||
| ANN | 92.51 | 92 | 93 | 92 | ||
| V. RNN | 90.53 | 90 | 91 | 90 | ||
| LSTM | 91.23 | 90 | 91 | 90 | ||
| DT | 94.23 | 95 | 95 | 95 | ||
| KNN | 96.59 | 97 | 97 | 97 | ||
| NB | 80.67 | 84 | 81 | 81 | ||
| Proposed Dataset | GB | 84.1 | 84.1 | 84.2 | 84.1 | [147] |
| RFs | 83.9 | 83.9 | 84.1 | 83.9 | ||
| Bagging | 83 | 83 | 83.1 | 83 | ||
| XGB | 80.4 | 80.5 | 80.4 | 80.4 | ||
| AdaBoost | 77.2 | 77.3 | 77.3 | 77.3 | ||
| DT | 76.9 | 77 | 77 | 77 | ||
| MLP | 67.6 | 68.7 | 67.8 | 67.8 | ||
| LSVM | 65 | 65.7 | 65.1 | 64.9 | ||
| NLSVM | 63 | 63.3 | 63.2 | 62.8 | ||
| LR | 59.6 | 60.2 | 59.8 | 59.4 | ||
| KNNs | 58.9 | 60.1 | 59.2 | 58.9 | ||
| GNB | 56.1 | 59.4 | 55.4 | 45.2 | ||
| House A | Bernoulli NB | 78.7 | 64 | - | - | [148] |
| Decision Tree | 88 | 79.4 | - | - | ||
| Logistic Regression | 81.4 | 69.2 | - | - | ||
| KNN | 75.8 | 64.9 | - | |||
| House B | Bernoulli NB | 95.9 | 79.4 | - | ||
| Decision Tree | 97.2 | 86.4 | - | |||
| Logistic Regression | 96.5 | 82.7 | - | |||
| KNN | 93.1 | 79.8 | - | |||
| UCI HAR | SVM-AdaBoost | 99.9 | 99.9 | [149] | ||
| k-NN-AdaBoost | 99.43 | 99.4 | ||||
| ANN-AdaBoost | 99.33 | 99.33 | ||||
| NB-AdaBoost | 97.24 | 97.2 | ||||
| RF-AdaBoost | 99.98 | 100 | ||||
| CART-AdaBoost | 99.97 | 100 | ||||
| C4.5-AdaBoost | 99.95 | 100 | ||||
| REPTree-AdaBoost | 99.95 | 100 | ||||
| LADTree-AdaBoost | 98.84 | 98.8 | ||||
| HAR Dataset | KNN | 90.3 | [150] | |||
| CART | 84.9 | |||||
| BAYES | 77 | |||||
| RF | 92.7 | |||||
| HAPT Dataset | KNN | 89.2 | ||||
| CART | 80.2 | |||||
| BAYES | 74.7 | |||||
| RF | 91 | |||||
| ET | 91.7 | |||||
| Proposed Method | 92.6 | |||||
6.4. Deep Learning Applied to Human Activity Recognition Dataset
| Dataset | Technique | Metrics | References | |||
|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F-Measure | |||
| Uci Har | CNN | 92.71 | 93.21 | 92.82 | 92.93 | [154] |
| LSTM | 89.01 | 89.14 | 88.99 | 88.99 | ||
| BLSTM | 89.4 | 89.41 | 89.36 | 89.35 | ||
| MLP | 86.83 | 86.83 | 86.58 | 86.61 | ||
| SVM | 89.85 | 90.5 | 89.86 | 89.85 | ||
| PAMAP2 | CNN | 91.00 | 91.66 | 90.86 | 91.16 | |
| LSTM | 85.86 | 86.51 | 84.67 | 85.34 | ||
| BLSTM | 89.52 | 90.19 | 89.02 | 89.4 | ||
| MLP | 82.07 | 83.35 | 82.17 | 82.46 | ||
| SVM | 84.07 | 84.71 | 84.23 | 83.76 | ||
| Propio Infrared Images | LBP-Naive Bayes | 42.1 | - | - | - | [155] |
| HOG-Naive Bayes | 77.01 | - | - | - | ||
| LBP-KNN | 53.261 | - | - | - | ||
| HOG-KNN | 83.541 | - | - | - | ||
| LBP-SVM | 62.34 | - | - | - | ||
| HOF-SVM | 85.92 | - | - | - | ||
| Uci Har | DeepConvLSTM | 94.77 | - | - | - | [156] |
| CNN | 92.76 | - | - | - | ||
| Weakly Dataset | DeepConvLSTM | 92.31 | - | - | - | |
| CNN | 85.17 | - | - | - | ||
| Opportunity | HC | 85.69 | - | - | - | [157] |
| CBH | 84.66 | - | - | - | ||
| CBS | 85.39 | - | - | - | ||
| AE | 83.39 | - | - | - | ||
| MLP | 86.65 | - | - | - | ||
| CNN | 87.62 | - | - | - | ||
| LSTM | 86.21 | - | - | - | ||
| Hybrid | 87.67 | - | - | - | ||
| ResNet | 87.67 | - | - | - | ||
| ARN | 90.29 | - | - | - | ||
| UniMiB-SAHR | HC | 21.96 | - | - | - | |
| CBH | 64.36 | - | - | - | ||
| CBS | 67.36 | - | - | - | ||
| AE | 68.39 | - | - | - | ||
| MLP | 74.82 | - | - | - | ||
| CNN | 73.36 | - | - | - | ||
| LSTM | 68.81 | - | - | - | ||
| Hybrid | 72.26 | - | - | - | ||
| ResNet | 75.26 | - | - | - | ||
| ARN | 76.39 | - | - | - | ||
| Uci Har | KNN | 90.74 | 91.15 | 90.28 | 90.48 | [158] |
| SVM | 96.27 | 96.43 | 96.14 | 96.23 | ||
| HMM+SVM | 96.57 | 96.74 | 06.49 | 96.56 | ||
| SVM+KNN | 96.71 | 96.75 | 96.69 | 96.71 | ||
| Naive Bayes | 77.03 | 79.25 | 76.91 | 76.72 | ||
| Logistic Regression | 95.93 | 96.13 | 95.84 | 95.92 | ||
| Decision Tree | 87.34 | 87.39 | 86.95 | 86.99 | ||
| Random Forest | 92.30 | 92.4 | 92.03 | 92.14 | ||
| MLP | 95.25 | 95.49 | 95.13 | 95.25 | ||
| DNN | 96.81 | 96.95 | 96.77 | 96.83 | ||
| LSTM | 91.08 | 91.38 | 91.24 | 91.13 | ||
| CNN+LSTM | 93.08 | 93.17 | 93.10 | 93.07 | ||
| CNN+BiLSTM | 95.42 | 95.58 | 95.26 | 95.36 | ||
| Inception+ResNet | 95.76 | 96.06 | 95.63 | 95.75 | ||
| Utwente Dataset | Naive Bayes | - | - | - | 94.7 | [159] |
| SVM | - | - | - | 91.6 | ||
| Deep Stacked Autoencoder | - | - | - | 97.6 | ||
| CNN-BiGRu | - | - | - | 97.8 | ||
| PAMAP2 | DeepCOnvTCN | - | - | - | 81.8 | |
| InceptionTime | - | - | - | 81.1 | ||
| CNN-BiGRu | - | - | - | 85.5 | ||
| FrailSafe dataset | CNN | 91.84 | - | - | - | [160] |
| CASAS Milan | LSTM | 76.65 | - | - | - | [135] |
| Bi-LSTM | 77.44 | - | - | - | ||
| Casc-LSTM | 61.01 | - | - | - | ||
| ENs2-LSTM | 93.42 | - | - | - | ||
| CASAS Cairo | LSTM | 82.79 | - | - | - | |
| Bi-LSTM | 82.41 | - | - | - | ||
| Casc-LSTM | 68.07 | - | - | - | ||
| ENs2-LSTM | 83.75 | - | - | - | ||
| CASAS Kyoto 2 | LSTM | 63.98 | - | - | - | |
| Bi-LSTM | 65.79 | - | - | - | ||
| Casc-LSTM | 66.20 | - | - | - | ||
| ENs2-LSTM | 69.76 | - | - | - | ||
| CASAS Kyoto 3 | LSTM | 77.5 | - | - | - | |
| Bi-LSTM | 81.67 | - | - | - | ||
| Casc-LSTM | 87.33 | - | - | - | ||
| ENs2-LSTM | 88.71 | - | - | - | ||
| Proposal | ANN | 89.06 | - | - | - | [160] |
| SVM | 94.12 | - | - | - | ||
| DBN | 95.85 | - | - | - | ||
6.5. Reinforcement Learning Applied to Human Activity Recognition Dataset
| Dataset | Technique | Metrics | References |
|---|---|---|---|
| Accuracy | |||
| Weizmann datasets | Spiking Neural Network | 94.44 | [161] |
| KTH datasets | 92.50 | ||
| DoMSEV | Deep-Shallow | 72.9 | [162] |
| Proposal | Deep Q-Network (DQN) | 83.26 | [163] |
| S.Yousefi-2017 | Reinforcement Learning Agent Recurrent Neural Network with Long Short-Term Memory | 80 | [156] |
| FallDeFi | 83 | ||
| UCI HAR | Reinforcement Learning + DeepConvLSTM | 98.36 | [164] |
| Proposal | 79 | [165] | |
| UCF-Sports | Q-learning | 95 | [166] |
| UCF-101 | 85 | ||
| sub-JHMDB | 80 | ||
| MHEALTH | Cluster-Q learning | 94.5 | [167] |
| PAMAP2 | 83.42 | ||
| UCI HAR | 81.32 | ||
| MARS | 85.92 | ||
| DataEgo | LRCN | 88 | [168] |
| Proposal | Mask Algorithm | 96.02 | [169] |
| Proposal | LSTM-Reinforcement Learning | 90.50 | [169] |
| Proposal | Convolutional Autoencoder | 87.7 | [170] |
6.6. Metaheuristic Algorithms Applied to Human Activity Recognition Dataset
| Dataset | Technique | Metrics | References |
|---|---|---|---|
| Accuracy | |||
| Cifar-100 | L4-Banched-ActionNet + EntACS + Cub-CVM | 98.00 | [175] |
| Sbharpt | Ant-Colony, NB | 98.96 | [176] |
| Ucihar | Bee swarm optimization with a deep Q-network | 98.41 | [177] |
| Motionsense | Binary Grey Wolf Optimization | 93.95 | [178] |
| Mhealth | 96.83 | ||
| Uci Har | Genetic Algorithms-SVM | 96.43 | [171] |
| Ucf50 | Genetic Algorithms-CNN | 87.5 | [172] |
| Sbhar | GA-PCA | 95,71 | [173] |
| Mnist | GA-CNN | 99.75 | [174] |
| Cifar-100 | Genetic Algorithms-SVM | 98.00 | [175] |
| Sbharpt | Genetic Algorithms-CNN | 98.96 | [176] |
6.7. Transfer Algorithms Applied to Human Activity Recognition Dataset
| Dataset | Technique | Metrics | References | |||
|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F-Measure | |||
| CSI | KNN | 98.3 | - | - | - | [179] |
| SVM | 98.3 | - | - | - | ||
| CNN | 99.2 | - | - | - | ||
| Opportunity | KNN+PCA | 60 | - | - | - | [180] |
| GFK | 59 | - | - | - | ||
| STL | 65 | - | - | - | ||
| SA-GAN | 73 | - | - | - | ||
| USC-HAD | MMD | 80 | - | - | - | [181] |
| DANN | 77 | - | - | - | ||
| WD | 72 | - | - | - | ||
| Proposal | KNN-OS | 79.84 | 85.84 | 91.88 | 88.61 | [182] |
| KNN-SS | 89.64 | 94.41 | 94.76 | 94.52 | ||
| SVM-OS | 77.14 | 97.04 | 79.23 | 87.09 | ||
| SVM-SS | 87.5 | 94.39 | 92.61 | 93.27 | ||
| DT-OS | 87.5 | 94.61 | 92.16 | 93.14 | ||
| DT-SS | 91.79 | 95.19 | 96.26 | 95.71 | ||
| JDA | 86.79 | 92.71 | 93.07 | 92.89 | ||
| BDA | 91.43 | 95.9 | 95.18 | 95.51 | ||
| IPL-JPDA | 93.21 | 97.04 | 95.97 | 96.48 | ||
| KNN-OS | 79.84 | 85.84 | 91.88 | 88.61 | ||
| Wiezmann Dataset | VGG-16 MODEL | 96.95 | 97.00 | 97.00 | 97.00 | [183] |
| VGG-19 MODEL | 96.54 | 97.00 | 97.00 | 96.00 | ||
| Inception-v3 Model | 95.63 | 96.00 | 96.00 | 96.00 | ||
| PAMAP2 | DeepConvLSTM | - | - | - | 93.2 | [184] |
| Skoda Mini Checkpoint | - | - | - | 93 | ||
| Opportunity | PCA | 66.78 | - | - | - | [185] |
| TCA | 68.43 | - | - | - | ||
| GFK | 70.87 | - | - | - | ||
| TKL | 70.21 | - | - | - | ||
| STL | 73.22 | - | - | - | ||
| TNNAR | 78.4 | - | - | - | ||
| PAMAP2 | PCA | 42.87 | - | - | - | |
| TCA | 47.21 | - | - | - | ||
| GFK | 48.09 | - | - | - | ||
| TKL | 43.32 | - | - | - | ||
| STL | 51.22 | - | - | - | ||
| TNNAR | 55.48 | - | - | - | ||
| UCI DSADS | PCA | 71.24 | - | - | - | |
| TCA | 73.47 | - | - | - | ||
| GFK | 81.23 | - | - | - | ||
| TKL | 74.26 | - | - | - | ||
| STL | 83.76 | - | - | - | ||
| TNNAR | 87.41 | - | - | - | ||
| UCI HAR | CNN-LSTM | 90.8 | - | - | - | [186] |
| DT | 76.73 | . | - | - | [187] | |
| RF | 71.96 | - | - | - | ||
| TB | 75.65 | - | - | - | ||
| TransAct | 86.49 | - | - | - | ||
| Mhealth | DT | 48.02 | - | - | - | |
| RF | 62.25 | - | - | - | ||
| TB | 66.48 | - | - | - | ||
| TransAct | 77.43 | - | - | - | ||
| Daily Sport | DT | 66.67 | . | . | . | |
| RF | 70.38 | . | . | . | ||
| TB | 72.86 | . | - | - | ||
| TransAct | 80.83 | - | - | - | ||
| Proposal | Without SVD (Singular Value Decomposition) | 63.13% | - | - | - | [188] |
| With SVD (Singular Value Decomposition) | 43.13% | - | - | - | ||
| Transfer Accuracy | 97.5% | - | - | - | ||
| PAMAP2 | CNN | 84.89 | - | - | - | [189] |
| UCI HAR | 83.16 | - | - | - | ||
| UCI HAR | kNN | 77.28 | - | - | - | [190] |
| DT | 72.16 | - | - | - | ||
| DA | 77.46 | - | - | - | ||
| NB | 69.93 | - | - | - | ||
| Transfer Accuracy | 83.7 | - | - | - | ||
| UCF Sports Action dataset | VGGNet-19 | 97.13 | - | - | - | [191] |
| AMASS | DeepConvLSTM | 87.46 | - | - | - | [192] |
| DIP | 89.08 | - | - | - | ||
| DAR Dataset | Base CNN | 85.38 | - | - | - | [193] |
| AugToAc | 91.38 | - | - | - | ||
| HDCNN | 86.85 | - | - | - | ||
| DDC | 86.67 | - | - | - | ||
| UCI HAR | CNN_LSTM | 92.13 | - | - | - | [194] |
| CNN_LSTM_SENSE | 91.55 | - | - | - | ||
| LSTM | 91.28 | - | - | - | ||
| LSTM_DENSE | 91.40 | - | - | - | ||
| ISPL | CNN_LSTM | 99.06 | - | - | - | |
| CNN_LSTM_SENSE | 98.43 | - | - | - | ||
| LSTM | 96.23 | - | - | - | ||
| LSTM_DENSE | 98.11 | - | - | - | ||
7. Conclusions
8. Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Aracil, J.; Gordillo, F. Dinámica de Sistemas; Alianza Editorial: Madrid, Spain, 1997. [Google Scholar]
- Cramer, H.; Cansado, C. Métodos Matemáticos de Estadística; Aguilar: Madrid, Spain, 1968. [Google Scholar]
- Shapiro, S.C. Artificial intelligence. In Encyclopedia of Artificial Intelligence, 2nd ed.; Shapiro, S.C., Ed.; Wiley: New York, NY, USA, 1992; Volume 1. [Google Scholar]
- Rouse, M. Inteligencia Artificial, o AI. Available online: https://www.computerweekly.com/es/definicion/Inteligencia-artificial-o-IA (accessed on 30 October 2021).
- Duan, Y.; Edwards, J.S.; Dwivedi, Y.K. Artificial intelligence for decision making in the era of Big Data—Evolution, challenges and research agenda. Int. J. Inf. Manag. 2019, 48, 63–71. [Google Scholar] [CrossRef]
- Sekeroglu, B.; Hasan, S.S.; Abdullah, S.M. Comparison of Machine Learning Algorithms for Classification Problems. Adv. Intell. Syst. Comput. 2020, 944, 491–499. [Google Scholar]
- Jordan, M.I.; Jordan, M.T.M. Machine Learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z.; Ding, S.X.; Huang, B. Data Mining and Analytics in the Process Industry: The Role of Machine Learning. IEEE Access 2017, 5, 20590–20616. [Google Scholar] [CrossRef]
- Amiribesheli, M.; Benmansour, A.; Bouchachia, A. A review of smart homes in healthcare. J. Ambient Intell. Humaniz. Comput. 2015, 6, 495–517. [Google Scholar] [CrossRef] [Green Version]
- Cook, D.J.; Youngblood, M.; Das, S.K. Amulti-agent approach to controlling a smart environment. In Designing Smart Homes; Springer: Berlin/Heidelberg, Germany, 2006; pp. 165–182. [Google Scholar]
- Andrew McCallum, K.N. A Comparison of Event Models for Naive Bayes Text Classification. In Proceedings of the AAAI-98 Workshop on Learning for Text Categorization, Menlo Park, CA, USA, 26–27 July 1998; Volume 752, p. 307. [Google Scholar] [CrossRef] [Green Version]
- Murata, N.; Yoshizawa, S.; Amari, S. Network information criterion-determining the number of hidden units for an artificial neural network model. IEEE Trans. Neural Netw. 1994, 5, 865–872. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Du, W.S.; Hu, B.Q. Approximate distribution reducts in inconsistent interval-valued ordered decision tables. Inf. Sci. 2014, 271, 93–114. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. CATENA 2017, 151, 147–160. [Google Scholar] [CrossRef] [Green Version]
- Saxena, A.; Prasad, M.; Gupta, A.; Bharill, N.; Patel, O.P.; Tiwari, A.; Er, M.J.; Ding, W.; Lin, C.-T. A review of clustering techniques and developments. Neurocomputing 2017, 267, 664–681. [Google Scholar] [CrossRef] [Green Version]
- Jones, F.W.; McLaren, I.P.L. Rules and associations. In Proceedings of the Twenty First Annual Conference of the Cognitive Science Society, Vancouver, BC, Canada, 23 December 2020; Psychology Press: East Sussex, UK, 2020; pp. 240–245. [Google Scholar]
- Van Der Maaten, L.; Postma, E.; Van den Herik, J. Dimensionality reduction: A comparative. J. Mach. Learn. Res. 2009, 10, 13. [Google Scholar]
- Divina, F.; Gilson, A.; Goméz-Vela, F.; García Torres, M.; Torres, J.F. Stacking Ensemble Learning for Short-Term Electricity Consumption Forecasting. Energies 2018, 11, 949. [Google Scholar] [CrossRef] [Green Version]
- Sewell, M. Ensemble learning. RN 2008, 11, 1–34. [Google Scholar]
- Svetnik, V.; Wang, T.; Tong, C.; Liaw, A.; Sheridan, R.P.; Song, Q. Boosting: An ensemble learning tool for compound classification and QSAR modeling. J. Chem. Inf. Modeling 2005, 45, 786–799. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Chen, T.; Xiao, Z.; Liu, B.; Chen, Y. High-Dimensional Data Clustering with Fuzzy C-Means: Problem, Reason, and Solution. In Proceedings of the International Work-Conference on Artificial Neural Networks, Virtual Event, 16–18 June 2021; Springer: Cham, Switzerland, 2021; pp. 89–100. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Kaur, M.; Kaur, G.; Sharma, P.K.; Jolfaei, A.; Singh, D. Binary cuckoo search metaheuristic-based supercomputing framework for human behavior analysis in smart home. J. Supercomput. 2019, 76, 2479–2502. [Google Scholar] [CrossRef]
- Althöfer, I.; Koschnick, K.U. On the convergence of “Threshold Accepting”. Appl. Math. Optim. 1991, 24, 183–195. [Google Scholar] [CrossRef]
- Moscato, P.; Cotta, C.; Mendes, A. Memetic algorithms. In New Optimization Techniques in Engineering; Springer: Berlin/Heidelberg, Germany, 2004; pp. 53–85. [Google Scholar]
- Wesselkamper, J. Fail-Safe MultiBoot Reference Design; XAPP468; Xilinx: San Jose, CA, USA, 2009. [Google Scholar]
- Salcedo-Sanz, S.; Cuadra, L.; Vermeij, M. A review of Computational Intelligence techniques in coral reef-related applications. Ecol. Inform. 2016, 32, 107–123. [Google Scholar] [CrossRef]
- Krause, J.; Cordeiro, J.; Parpinelli, R.S.; Lopes, H.S. A survey of swarm algorithms applied to discrete optimization problems. In Swarm Intelligence and Bio-Inspired Computation; Elsevier: Amsterdam, The Netherlands, 2013; pp. 169–191. [Google Scholar]
- Kumar, M.; Husain, M.; Upreti, N.; Gupta, D. Genetic Algorithm: Review and Application. 2010. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3529843 (accessed on 30 October 2021).
- Glover, F.; Laguna, M.; Martí, R. Scatter search. In Advances in Evolutionary Computing; Springer: Berlin/Heidelberg, Germany, 2003; pp. 519–537. [Google Scholar]
- Hansen, P.; Mladenović, N. Variable neighborhood search. In Search Methodologies; Springer: Boston, MA, USA, 2005; pp. 211–238. [Google Scholar]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Torrey, L.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Timarán Pereira, S.R.; Hernández Arteaga, I.; Caicedo Zambrano, S.J.; Hidalgo Troya, A.; Alvarado Pérez, J.C. Descubrimiento de Patrones de Desempeño Académico con Árboles de Decisión en las Competencias Genéricas de la Formación Profesional; Ediciones Universidad Cooperativa de Colombia: Bogotá, Colombia, 2015. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Han, S.; Qubo, C.; Meng, H. Parameter selection in SVM with RBF kernel function. In Proceedings of the World Automation Congress 2012, Puerto Vallarta, Mexico, 24–28 June 2012; pp. 1–4. [Google Scholar]
- Gaikwad, N.B.; Tiwari, V.; Keskar, A.; Shivaprakash, N.C. Efficient FPGA implementation of multilayer perceptron for real-time human activity classification. IEEE Access 2019, 7, 26696–26706. [Google Scholar] [CrossRef]
- Yiyu, Y. Decision-theoretic rough set models. In Proceedings of the International Conference on Rough Sets and Knowledge Technology, Toronto, ON, Canada, 14–16 May 2007; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Springer: Berlin/Heidelberg, Germany, 2007; pp. 1–12. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. (CSUR) 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Li, J. Two-scale image retrieval with significant meta-information feedback. In Proceedings of the 13th Annual ACM International Conference on Multimedia, Singapore, 6–11 November 2005; pp. 499–502. [Google Scholar]
- Li, J.; Ray, S.; Lindsay, B.G. A Nonparametric Statistical Approach to Clustering via Mode Identification. J. Mach. Learn. Res. 2007, 8, 1687–1723. [Google Scholar]
- Xu, X. Survey of clustering algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Li, T.S.; Simon, J.D.; Drlica-Wagner, A.; Bechtol, K.; Wang, M.Y.; Garcia-Bellido, J.; Frieman, J.; Marshall, J.L.; James, D.J.; Strigari, L.; et al. Farthest Neighbor: The Distant Milky Way Satellite Eridanus II. Astrophys. J. Lett. 2017, 838, 8. [Google Scholar] [CrossRef]
- Huse, S.M.; Welch, D.M.; Morrison, H.G.; Sogin, M.L. Ironing out the wrinkles in the rare biosphere through improved OTU clustering. Environ. Microbiol. 2010, 12, 1889–1898. [Google Scholar] [CrossRef] [Green Version]
- McIntyre, R.M.; Blashfield, R.K. A Nearest-Centroid Technique for Evaluating The Minimum-Variance Clustering Procedure. Multivar. Behav. Res. 1980, 15, 225–238. [Google Scholar] [CrossRef]
- Ferrer, M.; Valveny, E.; Serratosa, F.; Bardají, I.; Bunke, H. Graph-based k-means clustering: A comparison of the set median versus the generalized median graph. In International Conference on Computer Analysis of Images and Patterns; Springer: Berlin/Heidelberg, Germany, 2009; pp. 342–350. [Google Scholar]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Kamen, J.M. Quick clustering. J. Mark. Res. 1970, 7, 199–204. [Google Scholar] [CrossRef]
- Redmond, S.; Heneghan, C. A method for initialising the K-means clustering algorithm using kd-trees. Pattern Recognit. Lett. 2007, 28, 965–973. [Google Scholar] [CrossRef]
- Park, H.-S.; Jun, C.-H. A simple and fast algorithm for K-medoids clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Gupta, T.; Panda, S.P. A comparison of k-means clustering algorithm and clara clustering algorithm on iris dataset. Int. J. Eng. Technol. 2018, 7, 4766–4768. [Google Scholar]
- Hadji, M.; Zeghlache, D. Minimum cost maximum flow algorithm for dynamic resource allocation in clouds. In Proceedings of the 2012 IEEE Fifth International Conference on Cloud Computing, Honolulu, HI, USA, 24–29 June 2012; pp. 876–882. [Google Scholar]
- Cara, F.J.; Carpio, J.; Juan, J.; Alarcón, E. An approach to operational modal analysis using the expectation maximization algorithm. Mech. Syst. Signal Processing 2012, 31, 109–129. [Google Scholar] [CrossRef] [Green Version]
- Gholami, E.; Jahromi, Y.M. Forecastingof the Value Added Tax from Tobacco Consumption Using Neural Network Method. J. Res. Econ. Model. 2015, 5, 55–72. [Google Scholar] [CrossRef] [Green Version]
- Fortin, M.; Fortin, A. A generalization of Uzawa’s algorithm for the solution of the Navier-Stokes equations. Commun. Appl. Numer. Methods 1985, 1, 205–208. [Google Scholar] [CrossRef]
- Niu, P.; Niu, S.; Liu, N.; Chang, L. The defect of the Grey Wolf optimization algorithm and its verification method. Knowl. -Based Syst. 2019, 171, 37–43. [Google Scholar] [CrossRef]
- Govaert, G.; Nadif, M. Clustering with block mixture models. Pattern Recognit. 2003, 36, 463–473. [Google Scholar] [CrossRef]
- De Roover, K. Finding Clusters of Groups with Measurement Invariance: Unraveling Intercept Non-Invariance with Mixture Multigroup Factor Analysis. Struct. Equ. Model. A Multidiscip. J. 2021, 28, 663–683. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules in large databases. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago, Chile, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Hipp, J.; Güntzer, U.; Nakhaeizadeh, G. Algorithms for association rule mining—A general survey and comparison. ACM SIGKDD Explor. Newsl. 2000, 2, 58–64. [Google Scholar] [CrossRef]
- Zaki, M. Scalable algorithms for association mining. IEEE Trans. Knowl. Data Eng. 2000, 12, 372–390. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Pei, J.; Yin, Y. Mining frequent patterns without candidate generation. In Proceedings of the ACM International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 1–12. [Google Scholar]
- Rathee, S.; Kaul, M.; Kashyap, A. R-Apriori: An efficient Apriori based algorithm on Spark. In Proceedings of the PIKM’15, ACM, Melbourne, Australia, 31 May–4 June 2015. [Google Scholar]
- Qiu, H.; Gu, R.; Yuan, C.; Huang, Y. YAFIM: A parallel frequent itemset mining algorithm with Spark. In Proceedings of the Parallel & Distributed Processing Symposium Workshops (IPDPSW), Phoenix, AZ, USA, 19–23 May 2014; pp. 1664–1671. [Google Scholar]
- Zaki, M.J.; Parthasarathy, S.; Ogihara, M.; Li, W. Parallel Algorithms for Discovery of Association Rules. Data Min. Knowl. Discov. 1997, 1, 343–373. [Google Scholar] [CrossRef]
- Cong, S.; Han, J.; Hoeflinger, J.; Padua, D. A sampling-based framework for parallel data mining. In Proceedings of the Tenth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Chicago, IL, USA, 15–17 June 2005; pp. 255–265. [Google Scholar]
- Shintani, T.; Kitsuregawa, M. Hash-based parallel algorithms for mining association rules. In Proceedings of the Fourth International Conference on Parallel and Distributed Information Systems, Miami Beach, FL, USA, 18–20 December 1996; pp. 19–30. [Google Scholar]
- Li, H.; Wang, Y.; Zhang, D.; Zhang, M.; Chang, E.Y. PFP: Parallel FP-growth for query recommendation. In Proceedings of the 2008 ACM Conference on Recommender Systems, Lausanne, Switzerland, 23–25 October 2008; pp. 107–114. [Google Scholar]
- Gabroveanu, M.; Cosulschi, M.; Slabu, F. Mining fuzzy association rules using MapReduce technique. In Proceedings of the International Symposium on INnovations in Intelligent SysTems and Applications, INISTA, Sinaia, Romania, 2–5 August 2016; pp. 1–8. [Google Scholar]
- Gabroveanu, M.; Iancu, I.; Coşulschi, M.; Constantinescu, N. Towards using grid services for mining fuzzy association rules. In Proceedings of the Ninth International Symposium on Symbolic and Numeric Algorithms for Scientific Computing, Timisoara, Romania, 26–29 September 2007; pp. 507–513. [Google Scholar]
- Palo, H.K.; Sahoo, S.; Subudhi, A.K. Dimensionality Reduction Techniques: Principles, Benefits, and Limitations. In Data Analytics in Bioinformatics: A Machine Learning Perspective; Willey: New York, NY, USA, 2021; pp. 77–107. [Google Scholar]
- Zhou, H.; Yu, K.-M.; Hsu, H.-P. Hybrid Modeling Method for Soft Sensing of Key Process Parameters in Chemical Industry. Sens. Mater. 2021, 33, 2789. [Google Scholar] [CrossRef]
- Priya, S.; Ward, C.; Locke, T.; Soni, N.; Maheshwarappa, R.P.; Monga, V.; Bathla, G. Glioblastoma and primary central nervous system lymphoma: Differentiation using MRI derived first-order texture analysis—A machine learning study. Neuroradiol. J. 2021, 34, 320–328. [Google Scholar] [CrossRef] [PubMed]
- Weerasuriya, A.U.; Zhang, X.; Lu, B.; Tse, K.T.; Liu, C.H. A Gaussian Process-Based emulator for modeling pedestrian-level wind field. Build. Environ. 2021, 188, 107500. [Google Scholar] [CrossRef]
- Uddin, M.P.; Mamun, M.A.; Afjal, M.I.; Hossain, M.A. Information-theoretic feature selection with segmentation-based folded principal component analysis (PCA) for hyperspectral image classification. Int. J. Remote Sens. 2021, 42, 286–321. [Google Scholar] [CrossRef]
- Bari, A.; Brower, W.; Davidson, C. Using Artificial Intelligence to Predict Legislative Votes in the United States Congress. In Proceedings of the 2021 IEEE 6th International Conference on Big Data Analytics (ICBDA), Xiamen, China, 5–8 March 2021; pp. 56–60. [Google Scholar]
- Nanehkaran, Y.A.; Chen, J.; Salimi, S.; Zhang, D. A pragmatic convolutional bagging ensemble learning for recognition of Farsi handwritten digits. J. Supercomput. 2021, 77, 13474–13493. [Google Scholar] [CrossRef]
- Kumari, P.; Toshniwal, D. Extreme gradient boosting and deep neural network based ensemble learning approach to forecast hourly solar irradiance. J. Clean. Prod. 2020, 279, 123285. [Google Scholar] [CrossRef]
- Cui, S.; Yin, Y.; Wang, D.; Li, Z.; Wang, Y. A stacking-based ensemble learning method for earthquake casualty prediction. Appl. Soft Comput. 2020, 101, 107038. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Kag, A.; Saligrama, V. Training Recurrent Neural Networks via Forward Propagation through Time. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 5189–5200. [Google Scholar]
- Yang, G.; Lv, J.; Chen, Y.; Huang, J.; Zhu, J. Generative Adversarial Networks (GAN) Powered Fast Magnetic Resonance Imaging—Mini Review, Comparison and Perspectives. arXiv 2021, arXiv:2105.01800. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Rummery, G.A.; Niranjan, M. On-Line q-Learning Using Connectionist Systems; University of Cambridge, Department of Engineering: Cambridge, UK, 1994. [Google Scholar]
- Watkins, C. Learning from Delayed Rewards; King’s College: Cambridge, UK, 1989. [Google Scholar]
- Watkins, C.J.C.H.; Dayan, P. Technical Note: Q-Learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M.A. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Ann, O.C.; Theng, L.B. Human activity recognition: A review. In Proceedings of the 2014 IEEE International Conference on Control System, Computing and Engineering (ICCSCE 2014), Penang, Malaysia, 28–30 November 2014; pp. 389–393. [Google Scholar]
- Glover, F. Future paths for integer programming and links to artificial intelligence. Comput. Oper. Res. 1986, 13, 533–549. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Y.; Gu, X.; Wu, C.; Han, L. Soft Computing. In Application of Soft Computing, Machine Learning, Deep Learning and Optimizations in Geoengineering and Geoscience; Springer: Singapore, 2022; pp. 7–19. [Google Scholar]
- Gavriluţ, V.; Pruski, A.; Berger, M.S. Constructive or Optimized: An Overview of Strategies to Design Networks for Time-Critical Applications. ACM Comput. Surv. 2022, 55, 1–35. [Google Scholar] [CrossRef]
- Sahoo, R.R.; Ray, M. Metaheuristic techniques for test case generation: A review. In Research Anthology on Agile Software, Software Development, and Testing; IGI Global: Hershey, PA, USA, 2022; pp. 1043–1058. [Google Scholar]
- Singh, R.M.; Awasthi, L.K.; Sikka, G. Towards Metaheuristic Scheduling Techniques in Cloud and Fog: An Extensive Taxonomic Review. ACM Comput. Surv. (CSUR) 2022, 55, 1–43. [Google Scholar] [CrossRef]
- Stevo, B.; Ante, F. The influence of pattern similarity and transfer learning upon the training of a base perceptron B2. In Proceedings of the Symposium Informatica, Gdańsk, Poland, 6–10 September 1976. [Google Scholar]
- Qi, W.; Su, H.; Yang, C.; Ferrigno, G.; De Momi, E.; Aliverti, A. A Fast and Robust Deep Convolutional Neural Networks for Complex Human Activity Recognition Using Smartphone. Sensors 2019, 19, 3731. [Google Scholar] [CrossRef] [Green Version]
- de Jesús, P.-V.R.; Palencia-Díaz, R. Teléfonos inteligentes y tabletas.¿ una herramienta o una barrera en la atención del paciente? Med. Interna De Mex. 2013, 29, 404–409. [Google Scholar]
- Organista-Sandoval, J.; McAnally-Salas, L.; Lavigne, G. El teléfono inteligente (smartphone) como herramienta pedagógica. Apertura 2013, 5, 6–19. [Google Scholar]
- Alonso, A.B.; Artime, I.F.; Rodríguez, M.Á.; Baniello, R.G. Dispositivos Móviles; EPSIG Ing. Telecomunicación Universidad de Oviedo: Oviedo, Spain, 2011. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra Perez, X.; Reyes Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition Using Smartphones. In Proceedings of the 21th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, ESANN 2013, Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Sikder, N.; Nahid, A.-A. KU-HAR: An open dataset for heterogeneous human activity recognition. Pattern Recognit. Lett. 2021, 146, 46–54. [Google Scholar] [CrossRef]
- Popescu, A.-C.; Mocanu, I.; Cramariuc, B. PRECIS HAR. 2019. Available online: https://ieee-dataport.org/open-access/precis-har (accessed on 30 October 2021).
- Martínez-Villaseñor, L.; Ponce, H.; Brieva, J.; Moya-Albor, E.; Núñez-Martínez, J.; Peñafort-Asturiano, C. UP-Fall Detection Dataset: A Multimodal Approach. Sensors 2019, 19, 1988. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Kasteren, T.; Noulas, A.; Englebienne, G.; Kröse, B. Accurate activity recognition in a home setting. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Korea, 21–24 September 2008; pp. 1–9. [Google Scholar]
- Singla, G.; Cook, D.; Schmitter-Edgecombe, M. Recognizing independent and joint activities among multiple residents in smart environments. Ambient. Intell. Humaniz. Comput. J. 2010, 1, 57–63. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weiss, G.M.; Yoneda, K.; Hayajneh, T. Smartphone and Smartwatch-Based Biometrics Using Activities of Daily Living. IEEE Access 2019, 7, 133190–133202. [Google Scholar] [CrossRef]
- Gallissot, M.; Caelen, J.; Bonnefond, N.; Meillon, B.; Pons, S. Using the Multicom Domus Dataset; Research Report RR-LIG-020; LIG: Grenoble, France, 2011. [Google Scholar]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Tröster, G.; Lukowicz, P.; Pirkl, G.; Bannach, D.; Ferscha, A.; Doppler, J.; et al. Collecting complex activity data sets in highly rich networked sensor environments. In Proceedings of the Seventh International Conference on Networked Sensing Systems (INSS’10), Kassel, Germany, 15–18 June 2010. [Google Scholar]
- Cook, D. Learning setting-generalized activity mdoels for smart spaces. IEEE Intell. Syst. 2010, 1. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Sawchuk, A.A. USC-HAD: A Daily Activity Dataset for Ubiquitous Activity Recognition Using Wearable Sensors. In Proceedings of the ACM International Conference on Ubiquitous Computing (UbiComp) Workshop on Situation, Activity and Goal Awareness (SAGAware), Pittsburgh, PA, USA, 5–8 September 2012. [Google Scholar]
- Logan, B.; Healey, B.J.; Philipose, J.M.; Tapia, E.M.; Intille, S. A long-term evaluation of sensing modalities for activity recognition. In Proceedings of the International Conference on Ubiquitous Computing, Taipei, Taiwan, 17–20 December 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 483–500. [Google Scholar]
- Nugent, C.D.; Mulvenna, M.D.; Hong, X.; Devlin, S. Experiences in the development of a Smart Lab. Int. J. Biomed. Eng. Technol. 2009, 2, 319–331. [Google Scholar] [CrossRef]
- Schmitter-Edgecombe, M.; Cook, D.J. Assessing the Quality of Activities in a Smart Environment. Methods Inf. Med. 2009, 48, 480–485. [Google Scholar] [CrossRef] [Green Version]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 16th IEEE International Symposium on Wearable Computers (ISWC), Newcastle, UK, 18–22 June 2012. [Google Scholar]
- Banos, O.; Garcia, R.; Holgado, J.A.; Damas, M.; Pomares, H.; Rojas, I.; Saez, A.; Villalonga, C. mHealthDroid: A novel framework for agile development of mobile health applications. In Proceedings of the 6th International Work-conference on Ambient Assisted Living an Active Ageing (IWAAL 2014), Belfast, UK, 2–5 December 2014. [Google Scholar]
- Barshan, B.; Yüksek, M.C. Recognizing daily and sports activities in two open source machine learning environments using body-worn sensor units. Comput. J. 2014, 57, 1649–1667. [Google Scholar] [CrossRef]
- Espinilla, M.; Martínez, L.; Medina, J.; Nugent, C. The experience of developing theUJAmI Smart lab. IEEE Access. 2018, 6, 34631–34642. [Google Scholar] [CrossRef]
- Kitchenham, B.; Brereton, O.P.; Budgen, D.; Turner, M.; Bailey, J.; Linkman, S. Systematic literature reviews in software engineering—A systematic literature review. Inf. Softw. Technol. 2009, 51, 7–15. [Google Scholar] [CrossRef]
- Tasmin, M.; Ishtiak, T.; Ruman, S.U.; Suhan, A.U.R.C.; Islam, N.S.; Jahan, S.; Rahman, R.M. Comparative Study of Classifiers on Human Activity Recognition by Different Feature Engineering Techniques. In Proceedings of the 2020 IEEE 10th International Conference on Intelligent Systems (IS), Varna, Bulgaria, 28–30 August 2020; pp. 93–101. [Google Scholar]
- Igwe, O.M.; Wang, Y.; Giakos, G.C.; Fu, J. Human activity recognition in smart environments employing margin setting algorithm. J. Ambient Intell. Humaniz. Comput. 2020, 1–13. [Google Scholar] [CrossRef]
- Subasi, A.; Radhwan, M.; Kurdi, R.; Khateeb, K. IoT based mobile healthcare system for human activity recognition. In Proceedings of the 2018 15th Learning and Technology Conference (L&T), Jeddah, Saudi Arabia, 25–26 February 2018; pp. 29–34. [Google Scholar]
- Maswadi, K.; Ghani, N.A.; Hamid, S.; Rasheed, M.B. Human activity classification using Decision Tree and Naïve Bayes classifiers. Multimed. Tools Appl. 2021, 80, 21709–21726. [Google Scholar] [CrossRef]
- Damodaran, N.; Haruni, E.; Kokhkharova, M.; Schäfer, J. Device free human activity and fall recognition using WiFi channel state information (CSI). CCF Trans. Pervasive Comput. Interact. 2020, 2, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Saha, J.; Chowdhury, C.; Biswas, S. Two phase ensemble classifier for smartphone based human activity recognition independent of hardware configuration and usage behaviour. Microsyst. Technol. 2018, 24, 2737–2752. [Google Scholar] [CrossRef]
- Das, A.; Kjærgaard, M.B. Activity Recognition using Multi-Class Classification inside an Educational Building. In Proceedings of the 2020 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Austin, TX, USA, 23–27 March 2020; pp. 1–6. [Google Scholar]
- Franco, P.; Martínez, J.M.; Kim, Y.C.; Ahmed, M.A. IoT based approach for load monitoring and activity recognition in smart homes. IEEE Access 2021, 9, 45325–45339. [Google Scholar] [CrossRef]
- Bozkurt, F. A Comparative Study on Classifying Human Activities Using Classical Machine and Deep Learning Methods. Arab. J. Sci. Eng. 2021, 47, 1507–1521. [Google Scholar] [CrossRef]
- Wang, A.; Zhao, S.; Zheng, C.; Chen, H.; Liu, L.; Chen, G. HierHAR: Sensor-Based Data-Driven Hierarchical Human Activity Recognition. IEEE Sens. J. 2020, 21, 3353–3365. [Google Scholar] [CrossRef]
- Oukrich, N. Daily Human Activity Recognition in Smart Home Based on Feature Selection, Neural Network and Load Signature of Appliances. Ph.D. Thesis, Université Mohamed V, Ecole Mohammadia d’Ingénieurs-Université Mohammed V de Rabat-Maroc, Rabat, Morocco, 2019. [Google Scholar]
- Demrozi, F.; Turetta, C.; Pravadelli, G. B-HAR: An open-source baseline framework for in depth study of human activity recognition datasets and workflows. arXiv 2021, arXiv:2101.10870. [Google Scholar]
- Xu, Z.; Wang, G.; Guo, X. Sensor-based activity recognition of solitary elderly via stigmergy and two-layer framework. Eng. Appl. Artif. Intell. 2020, 95, 10385. [Google Scholar] [CrossRef]
- Hussain, F.; Hussain, F.; Ehatisham-ul-Haq, M.; Azam, M.A. Activity-aware fall detection and recognition based on wearable sensors. IEEE Sens. J. 2019, 19, 4528–4536. [Google Scholar] [CrossRef]
- Liciotti, D.; Bernardini, M.; Romeo, L.; Frontoni, E. A sequential deep learning application for recognising human activities in smart homes. Neurocomputing 2019, 396, 501–513. [Google Scholar] [CrossRef]
- Mohmed, G.; Lotfi, A.; Langensiepen, C.; Pourabdollah, A. Clustering-based fuzzy finite state machine for human activity recognition. In UK Workshop on Computational Intelligence; Springer: Cham, Switzerland, 2018; pp. 264–275. [Google Scholar]
- Brena, R.F.; Garcia-Ceja, E. A crowdsourcing approach for personalization in human activities recognition. Intell. Data Anal. 2017, 21, 721–738. [Google Scholar] [CrossRef]
- He, H.; Tan, Y.; Zhang, W. A wavelet tensor fuzzy clustering scheme for multi-sensor human activity recognition. Eng. Appl. Artif. Intell. 2018, 70, 109–122. [Google Scholar] [CrossRef]
- Wang, X.; Lu, Y.; Wang, D.; Liu, L.; Zhou, H. Using jaccard distance measure for unsupervised activity recognition with smartphone accelerometers. In Proceedings of the Asia-Pacific Web (apweb) and Web-Age Information Management (WAIM) Joint Conference on Web and Big Data, Beijing, China, 7–9 July 2017; Springer: Cham, Switzerland, 2017; pp. 74–83. [Google Scholar]
- Bota, P.; Silva, J.; Folgado, D.; Gamboa, H. A Semi-Automatic Annotation Approach for Human Activity Recognition. Sensors 2019, 19, 501. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yacchirema, D.; de Puga, J.S.; Palau, C.; Esteve, M. Fall detection system for elderly people using IoT and ensemble machine learning algorithm. Pers. Ubiquitous Comput. 2019, 23, 801–817. [Google Scholar] [CrossRef]
- Manzi, A.; Dario, P.; Cavallo, F. A Human Activity Recognition System Based on Dynamic Clustering of Skeleton Data. Sensors 2017, 17, 1100. [Google Scholar] [CrossRef] [Green Version]
- Ma, H.; Zhang, Z.; Li, W.; Lu, S. Unsupervised Human Activity Representation Learning with Multi-task Deep Clustering. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–25. [Google Scholar] [CrossRef]
- Budisteanu, E.A.; Mocanu, I.G. Combining Supervised and Unsupervised Learning Algorithms for Human Activity Recognition. Sensors 2021, 21, 6309. [Google Scholar] [CrossRef]
- Xu, S.; Tang, Q.; Jin, L.; Pan, Z. A Cascade Ensemble Learning Model for Human Activity Recognition with Smartphones. Sensors 2019, 19, 2307. [Google Scholar] [CrossRef] [Green Version]
- Choudhury, N.A.; Moulik, S.; Roy, D.S. Physique-Based Human Activity Recognition Using Ensemble Learning and Smartphone Sensors. IEEE Sens. J. 2021, 21, 16852–16860. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, D.; Chen, J.; Ghoneim, A.; Hossain, M.A. A Triaxial Accelerometer-Based Human Activity Recognition via EEMD-Based Features and Game-Theory-Based Feature Selection. IEEE Sens. J. 2016, 16, 3198–3207. [Google Scholar] [CrossRef]
- Jethanandani, M.; Sharma, A.; Perumal, T.; Chang, J.R. Multi-label classification based ensemble learning for human activity recognition in smart home. Internet Things 2020, 12, 100324. [Google Scholar] [CrossRef]
- Subasi, A.; Dammas, D.H.; Alghamdi, R.D.; Makawi, R.A.; Albiety, E.A.; Brahimi, T.; Sarirete, A. Sensor Based Human Activity Recognition Using Adaboost Ensemble Classifier. Procedia Comput. Sci. 2018, 140, 104–111. [Google Scholar] [CrossRef]
- Padmaja, B.; Prasa, V.; Sunitha, K. A Novel Random Split Point Procedure Using Extremely Randomized (Extra) Trees Ensemble Method for Human Activity Recognition. EAI Endorsed Trans. Pervasive Health Technol. 2020, 6, e5. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Al-Garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Ma, L.; Cheng, S.; Shi, Y. Enhancing learning efficiency of brain storm optimization via orthogonal learning design. IEEE Trans. Syst. Man Cybern. Syst. 2020, 51, 6723–6742. [Google Scholar] [CrossRef]
- Wan, S.; Qi, L.; Xu, X.; Tong, C.; Gu, Z. Deep Learning Models for Real-time Human Activity Recognition with Smartphones. Mob. Netw. Appl. 2019, 25, 743–755. [Google Scholar] [CrossRef]
- Akula, A.; Shah, A.K.; Ghosh, R. Deep learning approach for human action recognition in infrared images. Cogn. Syst. Res. 2018, 50, 146–154. [Google Scholar] [CrossRef]
- He, J.; Zhang, Q.; Wang, L.; Pei, L. Weakly supervised human activity recognition from wearable sensors by recurrent attention learning. IEEE Sens. J. 2018, 19, 2287–2297. [Google Scholar] [CrossRef]
- Long, J.; Sun, W.; Yang, Z.; Raymond, O.I. Asymmetric Residual Neural Network for Accurate Human Activity Recognition. Information 2019, 10, 203. [Google Scholar] [CrossRef] [Green Version]
- Ariza-Colpas, P.; Morales-Ortega, R.; Piñeres-Melo, M.A.; Melendez-Pertuz, F.; Serrano-Torné, G.; Hernandez-Sanchez, G.; Martínez-Osorio, H. Teleagro: Iot applications for the georeferencing and detection of zeal in cattle. In Proceedings of the IFIP International Conference on Computer Information Systems and Industrial Management, Belgrade, Serbia, 19–21 September 2019; pp. 232–239. [Google Scholar]
- Mekruksavanich, S.; Jitpattanakul, A. Deep convolutional neural network with rnns for complex activity recognition using wrist-worn wearable sensor data. Electronics 2021, 10, 1685. [Google Scholar] [CrossRef]
- Papagiannaki, A.; Zacharaki, E.I.; Kalouris, G.; Kalogiannis, S.; Deltouzos, K.; Ellul, J.; Megalooikonomou, V. Recognizing Physical Activity of Older People from Wearable Sensors and Inconsistent Data. Sensors 2019, 19, 880. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hassan, M.M.; Uddin, Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Futur. Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Berlin, S.J.; John, M. R-STDP Based Spiking Neural Network for Human Action Recognition. Appl. Artif. Intell. 2020, 34, 656–673. [Google Scholar] [CrossRef]
- Lu, Y.; Li, Y.; Velipasalar, S. Efficient human activity classification from egocentric videos incorporating actor-critic reinforcement learning. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 564–568. [Google Scholar]
- Hossain, H.S.; Roy, N. Active deep learning for activity recognition with context-aware annotator selection. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1862–1870. [Google Scholar]
- Zhou, X.; Liang, W.; Wang, K.I.-K.; Wang, H.; Yang, L.T.; Jin, Q. Deep-Learning-Enhanced Human Activity Recognition for Internet of Healthcare Things. IEEE Internet Things J. 2020, 7, 6429–6438. [Google Scholar] [CrossRef]
- Xu, W.; Miao, Z.; Yu, J.; Ji, Q. Deep Reinforcement Learning for Weak Human Activity Localization. IEEE Trans. Image Process. 2019, 29, 1522–1535. [Google Scholar] [CrossRef]
- Chen, K.; Yao, L.; Zhang, D.; Wang, X.; Chang, X.; Nie, F. A Semisupervised Recurrent Convolutional Attention Model for Human Activity Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1747–1756. [Google Scholar] [CrossRef]
- Possas, R.; Caceres, S.P.; Ramos, F. Egocentric activity recognition on a budget. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5967–5976. [Google Scholar]
- Liu, G.; Ma, R.; Hao, Q. A Reinforcement Learning Based Design of Compressive Sensing Systems for Human Activity Recognition. In Proceedings of the 2018 IEEE SENSORS, New Delhi, India, 28–31 October 2018; pp. 1–4. [Google Scholar]
- Shen, X.; Guo, L.; Lu, Z.; Wen, X.; Zhou, S. WiAgent: Link Selection for CSI-Based Activity Recognition in Densely Deployed Wi-Fi Environments. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar]
- Campbell, C.; Ahmad, F. Attention-augmented convolutional autoencoder for radar-based human activity recognition. In Proceedings of the 2020 IEEE International Radar Conference (RADAR), Washington, DC, USA, 28–30 April 2020; pp. 990–995. [Google Scholar]
- Nguyen, T.D.; Huynh, T.T.; Pham, H.A. An improved human activity recognition by using genetic algorithm to optimize feature vector. In Proceedings of the 2018 10th International Conference on Knowledge and Systems Engineering (KSE), Ho Chi Minh City, Vietnam, 1–3 November 2018; pp. 123–128. [Google Scholar]
- Mocanu, I.; Axinte, D.; Cramariuc, O.; Cramariuc, B. Human activity recognition with convolution neural network using tiago robot. In Proceedings of the 2018 41st International Conference on Telecommunications and Signal Processing (TSP), Athens, Greece, 4–6 July 2018; pp. 1–4. [Google Scholar]
- El-Maaty, A.M.A.; Wassal, A.G. Hybrid GA-PCA feature selection approach for inertial human activity recognition. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1027–1032. [Google Scholar]
- Baldominos, A.; Saez, Y.; Isasi, P. Model selection in committees of evolved convolutional neural networks using genetic algorithms. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Madrid, Spain, 21–23 November 2018; Springer: Cham, Switzerland, 2018; pp. 364–373. [Google Scholar]
- Saba, T.; Rehman, A.; Latif, R.; Fati, S.M.; Raza, M.; Sharif, M. Suspicious Activity Recognition Using Proposed Deep L4-Branched-Actionnet With Entropy Coded Ant Colony System Optimization. IEEE Access 2021, 9, 89181–89197. [Google Scholar] [CrossRef]
- Li, J.; Tian, L.; Chen, L.; Wang, H.; Cao, T.; Yu, L. Optimal feature selection for activity recognition based on ant colony algorithm. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; pp. 2356–2362. [Google Scholar]
- Fan, C.; Gao, F. Enhanced human activity recognition using wearable sensors via a hybrid feature selection method. Sensors 2021, 21, 6434. [Google Scholar] [CrossRef]
- Jalal, A.; Batool, M.; Kim, K. Stochastic Recognition of Physical Activity and Healthcare Using Tri-Axial Inertial Wearable Sensors. Appl. Sci. 2020, 10, 7122. [Google Scholar] [CrossRef]
- Arshad, S.; Feng, C.; Yu, R.; Liu, Y. Leveraging transfer learning in multiple human activity recognition using wifi signal. In Proceedings of the 2019 IEEE 20th International Symposium on “A World of Wireless, Mobile and Multimedia Networks” (WoWMoM), Washington, DC, USA, 10–12 June 2019; pp. 1–10. [Google Scholar]
- Soleimani, E.; Nazerfard, E. Cross-subject transfer learning in human activity recognition systems using generative adversarial networks. Neurocomputing 2021, 426, 26–34. [Google Scholar] [CrossRef]
- Ding, R.; Li, X.; Nie, L.; Li, J.; Si, X.; Chu, D.; Zhan, D. Empirical study and improvement on deep transfer learning for human activity recognition. Sensors 2018, 19, 57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, Z.; He, X.; Wang, E.; Huo, J.; Huang, J.; Wu, D. Personalized Human Activity Recognition Based on Integrated Wearable Sensor and Transfer Learning. Sensors 2021, 21, 885. [Google Scholar] [CrossRef] [PubMed]
- Deep, S.; Zheng, X. Leveraging CNN and transfer learning for vision-based human activity recognition. In Proceedings of the 29th International Telecommunication Networks and Applications Conference (ITNAC), Auckland, New Zealand, 27–29 November 2019; pp. 1–4. [Google Scholar]
- Hoelzemann, A.; Van Laerhoven, K. Digging deeper: Towards a better understanding of transfer learning for human activity recognition. In Proceedings of the 2020 International Symposium on Wearable Computers, Virtual, 12–17 September 2020; pp. 50–54. [Google Scholar]
- Wang, J.; Zheng, V.W.; Chen, Y.; Huang, M. Deep transfer learning for cross-domain activity recognition. In Proceedings of the 3rd International Conference on Crowd Science and Engineering, Singapore, 28–31 July 2018; pp. 1–8. [Google Scholar]
- Mutegeki, R.; Han, D.S. Feature-representation transfer learning for human activity recognition. In Proceedings of the 2019 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 16–18 October 2019; pp. 18–20. [Google Scholar]
- Khan, M.A.A.H.; Roy, N. Transact: Transfer learning enabled activity recognition. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; pp. 545–550. [Google Scholar]
- Ding, X.; Jiang, T.; Li, Y.; Xue, W.; Zhong, Y. Device-free location-independent human activity recognition using transfer learning based on CNN. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Kalouris, G.; Zacharaki, E.I.; Megalooikonomou, V. Improving CNN-based activity recognition by data augmentation and transfer learning. In Proceedings of the 2019 IEEE 17th International Conference on Industrial Informatics (INDIN), Helsinki, Finland, 22–25 July 2019; Volume 1, pp. 1387–1394. [Google Scholar]
- Rokni, S.A.; Ghasemzadeh, H. Autonomous Training of Activity Recognition Algorithms in Mobile Sensors: A Transfer Learning Approach in Context-Invariant Views. IEEE Trans. Mob. Comput. 2018, 17, 1764–1777. [Google Scholar] [CrossRef]
- Verma, K.K.; Singh, B.M. Vision based Human Activity Recognition using Deep Transfer Learning and Support Vector Machine. In Proceedings of the 2021 IEEE 8th Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (UPCON), Dehradun, India, 11–13 November 2021; pp. 1–9. [Google Scholar]
- Xiao, F.; Pei, L.; Chu, L.; Zou, D.; Yu, W.; Zhu, Y.; Li, T. A deep learning method for complex human activity recognition using virtual wearable sensors. In Proceedings of the International Conference on Spatial Data and Intelligence, Virtual, 8–9 May 2020; Springer: Cham, Switzerland, 2020; pp. 261–270. [Google Scholar]
- Faridee, A.Z.M.; Khan, M.A.A.H.; Pathak, N.; Roy, N. AugToAct: Scaling complex human activity recognition with few labels. In Proceedings of the 16th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, Houston, TX, USA, 12–14 November 2019; pp. 162–171. [Google Scholar]
- Mutegeki, R.; Han, D.S. A CNN-LSTM approach to human activity recognition. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 362–366. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ariza-Colpas, P.P.; Vicario, E.; Oviedo-Carrascal, A.I.; Butt Aziz, S.; Piñeres-Melo, M.A.; Quintero-Linero, A.; Patara, F. Human Activity Recognition Data Analysis: History, Evolutions, and New Trends. Sensors 2022, 22, 3401. https://doi.org/10.3390/s22093401
Ariza-Colpas PP, Vicario E, Oviedo-Carrascal AI, Butt Aziz S, Piñeres-Melo MA, Quintero-Linero A, Patara F. Human Activity Recognition Data Analysis: History, Evolutions, and New Trends. Sensors. 2022; 22(9):3401. https://doi.org/10.3390/s22093401
Chicago/Turabian StyleAriza-Colpas, Paola Patricia, Enrico Vicario, Ana Isabel Oviedo-Carrascal, Shariq Butt Aziz, Marlon Alberto Piñeres-Melo, Alejandra Quintero-Linero, and Fulvio Patara. 2022. "Human Activity Recognition Data Analysis: History, Evolutions, and New Trends" Sensors 22, no. 9: 3401. https://doi.org/10.3390/s22093401
APA StyleAriza-Colpas, P. P., Vicario, E., Oviedo-Carrascal, A. I., Butt Aziz, S., Piñeres-Melo, M. A., Quintero-Linero, A., & Patara, F. (2022). Human Activity Recognition Data Analysis: History, Evolutions, and New Trends. Sensors, 22(9), 3401. https://doi.org/10.3390/s22093401