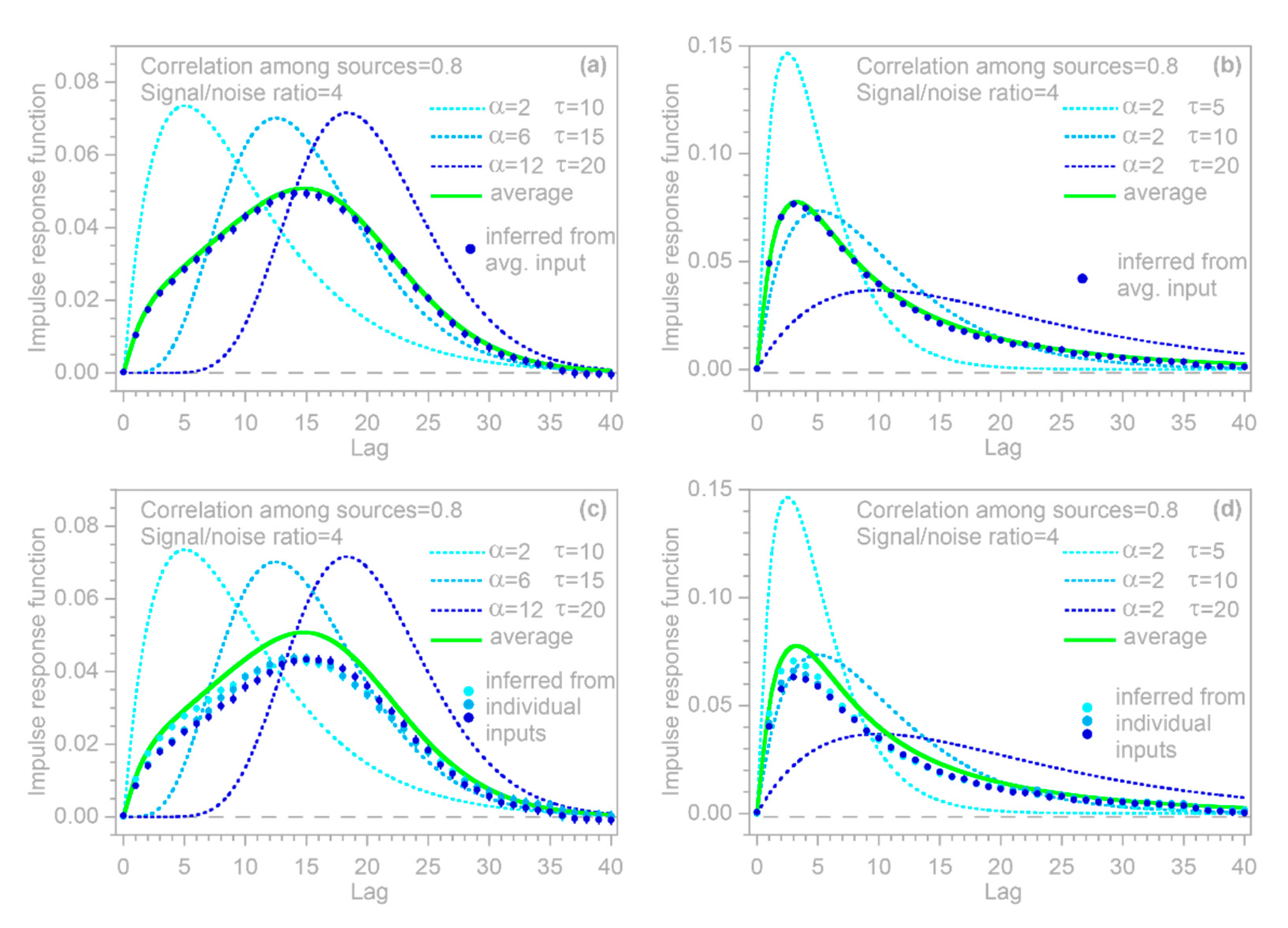
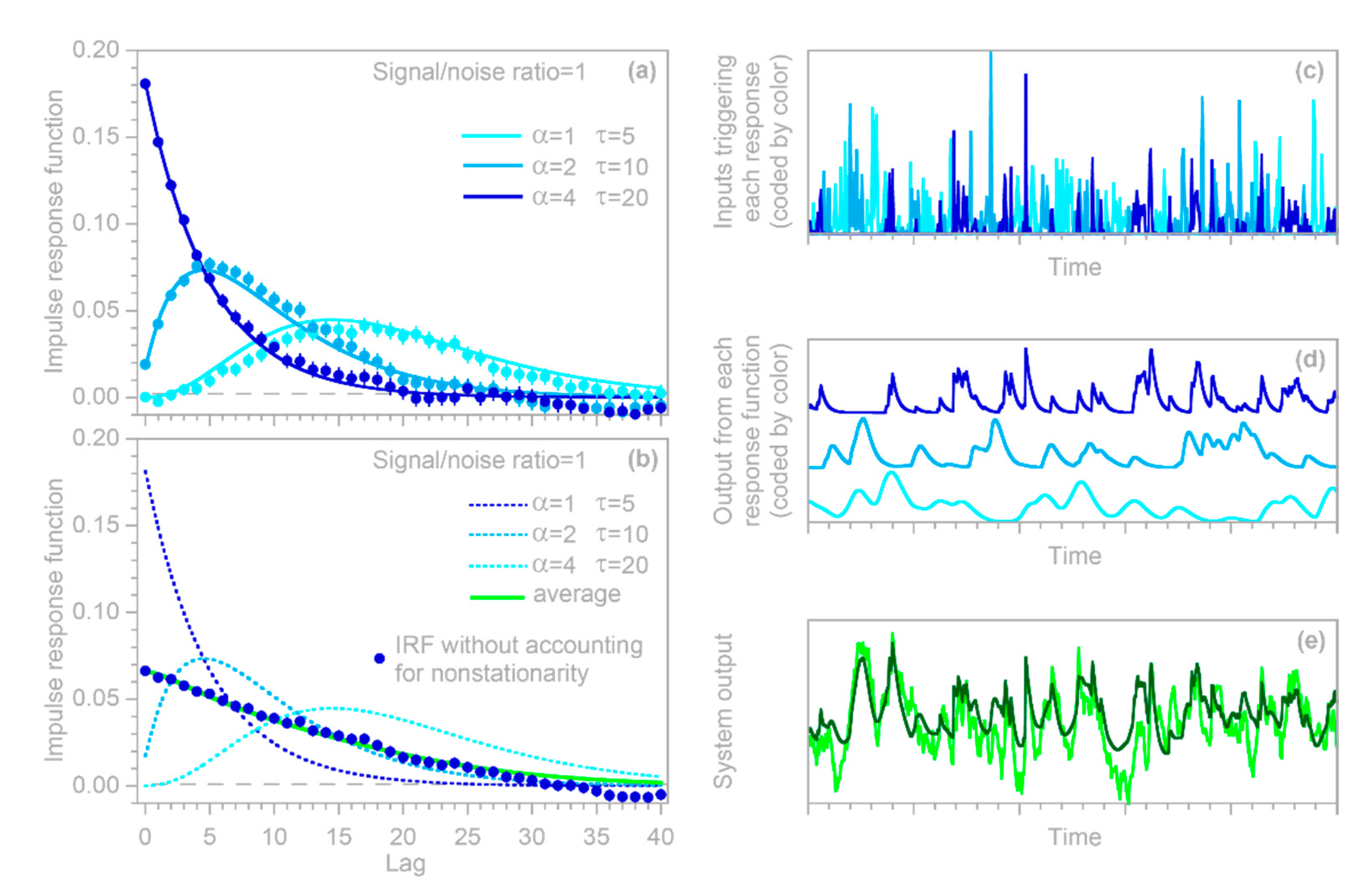
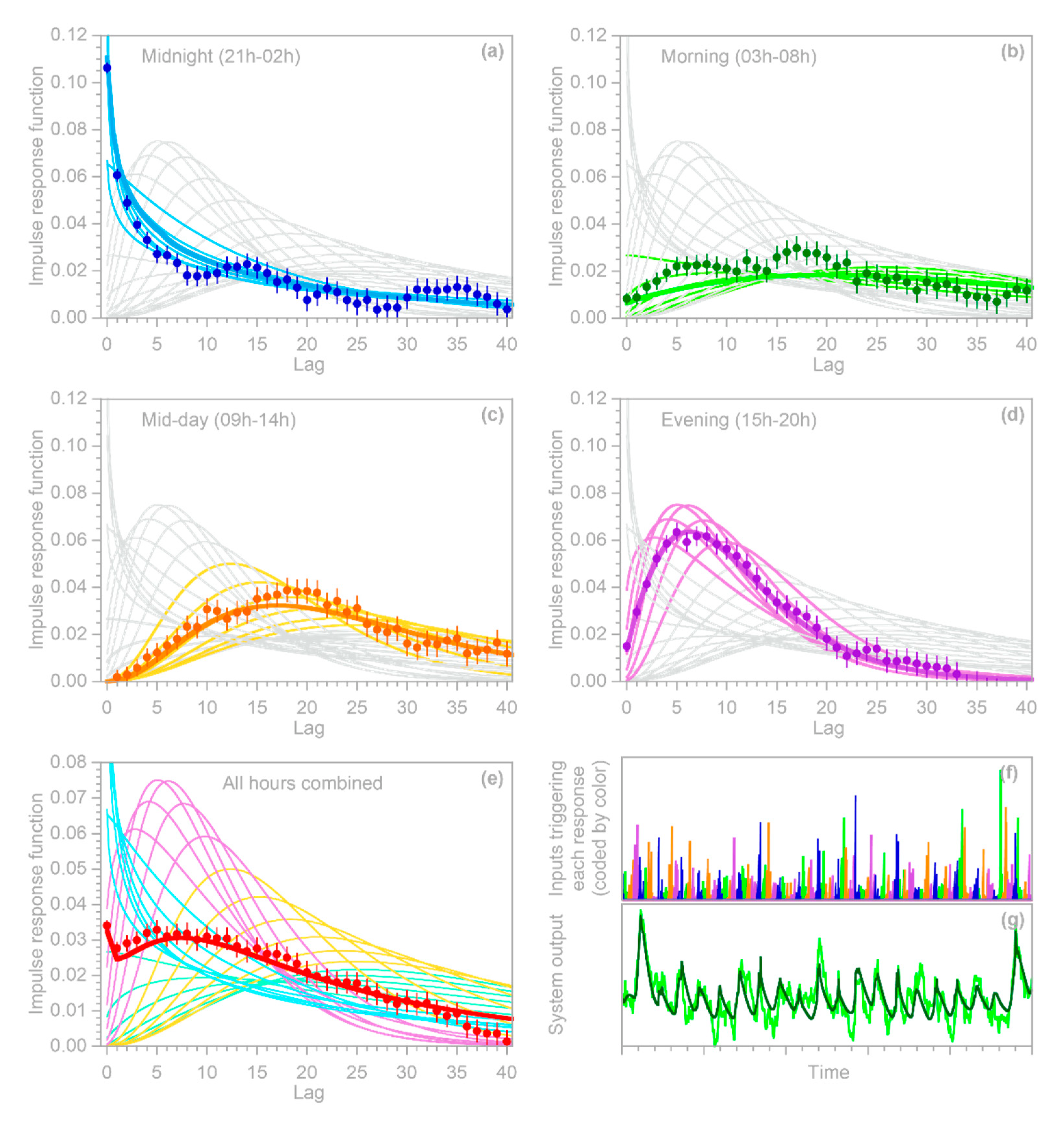
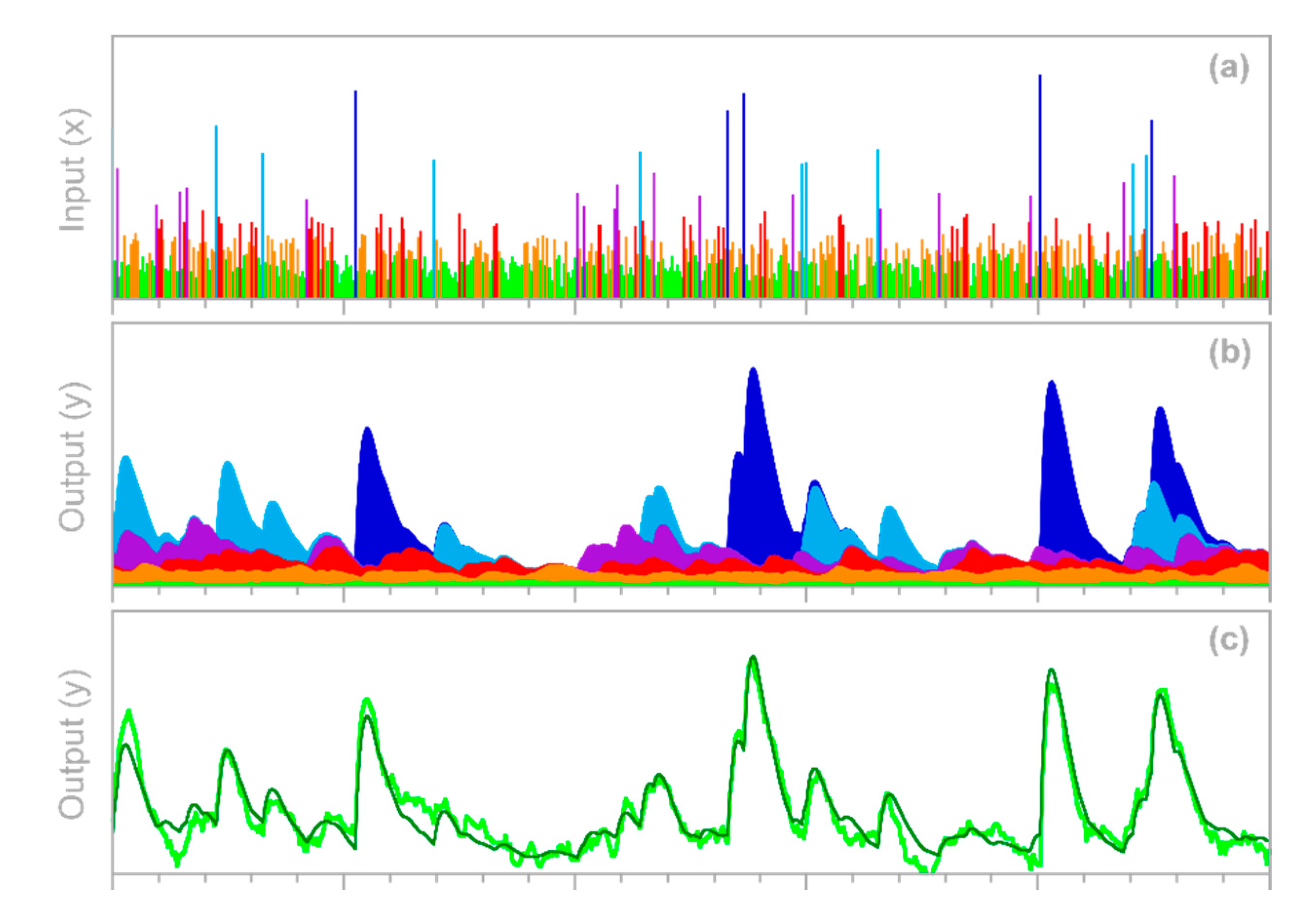
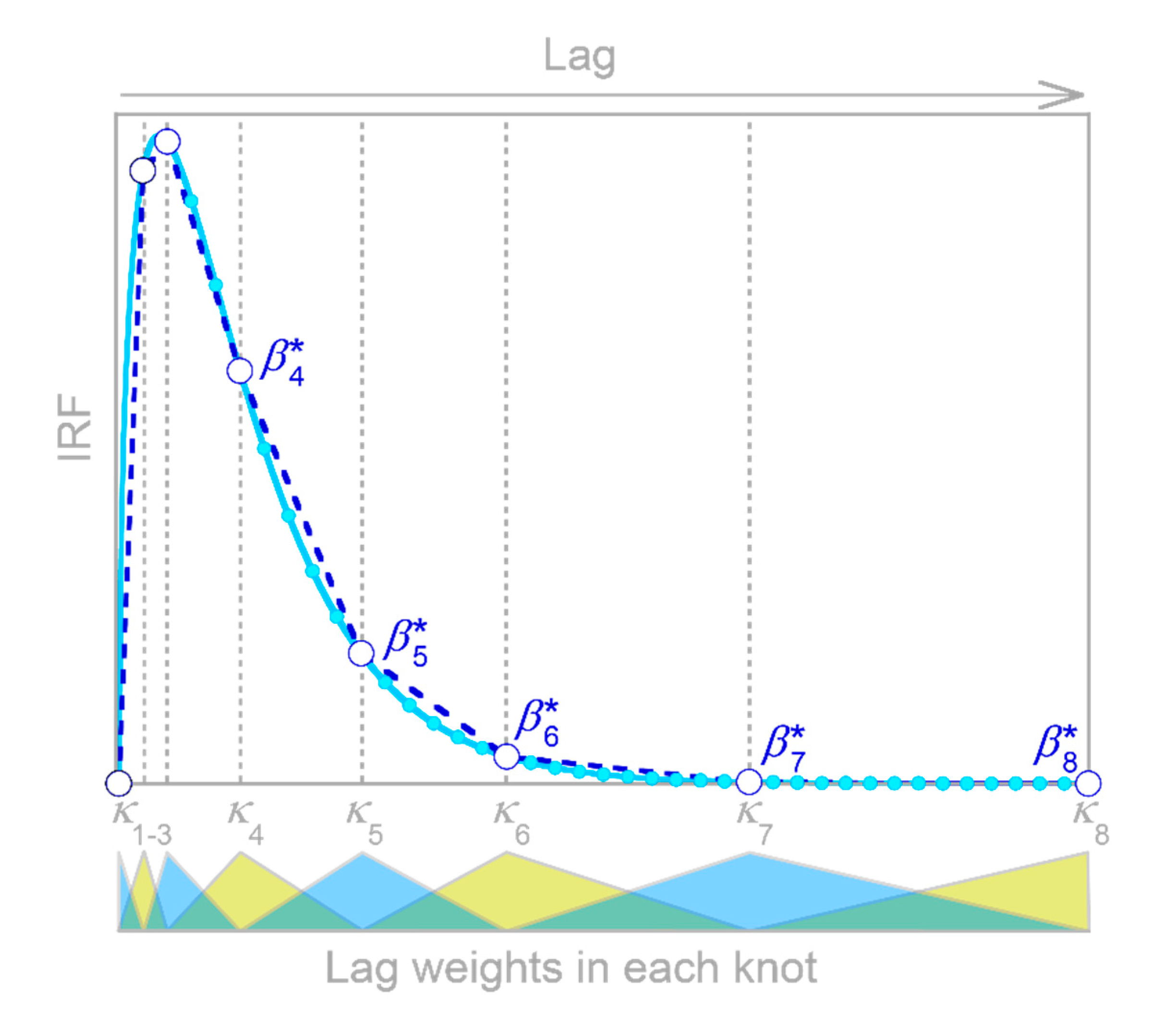
2.1. Impulse Response Functions
Many systems can be represented (at least approximately) as convolutions, in which the output
depends on an input
over a (potentially infinite) range of past lag times
, weighted by a lag function
that expresses the relative influence of the input at each lag:
The lag function
is sometimes called a
convolution kernel,
transfer function, or
Green’s function; it is also called an
impulse response function (IRF) because it shows how the system output
would respond to an input
consisting of a single Dirac delta function pulse (i.e., an infinitely high, infinitely narrow pulse that integrates to 1). A system’s impulse response can be defined more generally as the change in the time evolution of its output
when a single Dirac pulse
is added to its input
at any given time
, compared to the system’s behavior without the Dirac pulse:
The input can itself be considered as a continuous series of appropriately scaled Dirac pulses, so if the impulse response is independent of the impulse time (that is, if the impulse response is stationary), integrating Equation (2) over all will lead directly to the convolution shown in Equation (1).
In most practical cases, continuous functions such as those in Equation (1) are not directly observable, and instead are approximated by discrete time series of measurements. In such cases, Equation (1) is typically approximated by its discrete counterpart,
The discrete impulse response function in Equation (3) is sometimes termed a finite impulse response (FIR) model, because it quantifies the finite-duration system response to a finite-duration input pulse, in contrast to Equation (1), which quantifies the potentially infinite-duration system response to an infinitesimally short input pulse.
The impulse response function or is useful in characterizing the system; indeed, it is a complete description of linear time-invariant systems such as Equations (1) and (3). A linear system responds proportionally to the input , such that its response to the sum of two inputs and equals the sum of its responses to the two inputs individually; this is known as the principle of linear superposition. A time-invariant (or stationary) system responds identically to the same inputs occurring at different times (except, of course, that its response is time-shifted by the same amount as the time difference between the inputs).
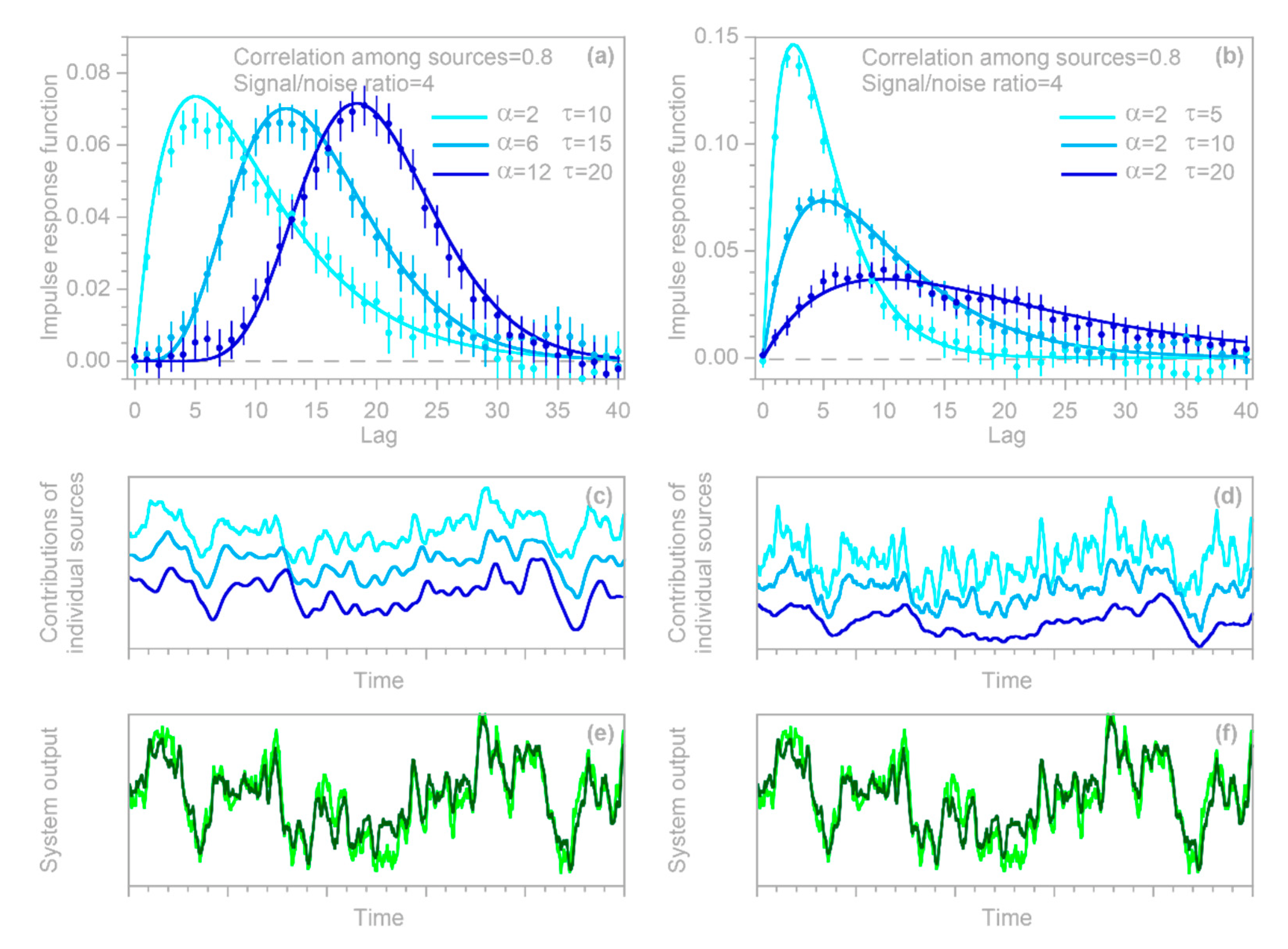
In contrast to such an idealized linear time-invariant system, many real-world systems are nonlinear, nonstationary, or both. In such cases, an impulse response function will not be a complete description of the system’s response but may still be a useful indicator of its average behavior. Precisely how the IRF averages such a system’s behavior will depend on the system characteristics and on how the IRF is estimated; this topic is explored further in
Section 3.3,
Section 3.4,
Section 3.5 and
Section 4.3 below. Furthermore, as described in
Section 4 and
Section 5 below, the simple linear time-invariant model in Equation (3) can be generalized to estimate how the IRF varies for different input intensities (thus quantitatively characterizing the nonlinearity of the system) and to estimate how the IRF varies for inputs occurring at different times (thus quantifying the system’s nonstationarity).
Convolutions such as Equations (1) and (3) scramble the input time series
and the impulse response function
together to generate the output time series
. Deconvolution methods seek to invert this process, un-scrambling
to yield estimates of
(given
) or estimates of
(given
). The term
deconvolution is often applied specifically to the inversion of Equation (1) or (3) to solve for the input time series
given the output time series
and the impulse response function
(a deconvolution of
by
). Solving instead for the impulse response function
given the input and output time series
and
is also, mathematically speaking, a deconvolution (in this case, a deconvolution of
by
), but is also often termed
system identification [
13], since
characterizes the behavior of the system linking the inputs and outputs. The classical approach to either type of deconvolution relied on Fourier transform methods, because convolution and deconvolution become simply multiplication and division in Fourier space. However, Fourier methods often yield unreliable results unless the underlying system is linear and time-invariant, and thus conforms closely to Equation (1) or (3), and unless the two “knowns” (
and
for system identification, or
and
for deconvolution of the input time series
) are virtually noise-free. These requirements are often violated by real-world systems. Instead, the system identification problem is frequently approached by considering Equation (3) as a multiple linear regression equation,
where the
kth column of the matrix
is
lagged by
time steps. Equation (4) can be straightforwardly solved for the IRF coefficients
using conventional least squares methods if the residual errors
are uncorrelated white noise.
2.2. Estimating Impulse Response Functions in the Presence of ARMA Noise
Direct application of simple approaches such as Equation (4) to many real-world systems will be complicated by the fact that the residuals
often violate the white noise assumptions underlying conventional linear regression. Instead, the residuals are often serially correlated, sometimes quite strongly, over a range of time scales, leading to biased estimates of the
coefficients and their uncertainties. The serial correlation in
can arise from many sources. Measurements of the output variable
may be subject to serially correlated, or even nonstationary, errors. The input variable
may also be subject to error (the so-called “error in variables” problem). Even if those input errors are not themselves serially correlated, they will nonetheless be reflected in serially correlated residuals
because any excess or missing
will appear to be smoothed and lagged by the same convolution process that smooths and lags the (unknown) true inputs. Equation (4) may also be a stationary approximation to a nonstationary real-world system, or may have other structural problems, such as missing variables or incorrect functional relationships, that would be reflected in serially correlated variations in the residuals
. Efficiently handling these serially correlated errors requires novel statistical methods. Although several approaches have been widely used to perform regression in the presence of serially correlated errors (e.g., [
15,
16,
17]; see also Section 9.5 of [
12]), deconvolution in the presence of such errors is potentially a more complex problem, because the output will contain serially correlated signals from both the errors and the real-world convolution process, which must somehow be distinguished from one another.
Whatever the origin of the serial correlation in the residuals, it can be simply and flexibly represented as an Autoregressive Moving Average (ARMA) process,
where the autoregressive coefficients
express how the residual
depends on its own previous values, and the moving average coefficients
express how the residual
depends on the previous values of a white noise process
. In many real-world cases, serially correlated errors can be summarized using just a few autoregressive coefficients
and moving average coefficients
. Moving-average processes that are invertible (as all real-world moving average processes should be) can be equivalently expressed as autoregressive processes (the duality principle: see Section 3.3.5 of [
12]), meaning that any real-world ARMA process can be re-expressed as a purely autoregressive (AR) process of higher order,
In theory, the autoregressive order corresponding to a moving average process can be infinite, but in practice Equation (6) will often entail only a few more AR coefficients than the corresponding ARMA process in Equation (5), with the higher-order terms dying away to practically zero.
A conventional approach to solving regression problems such as Equation (4) with autoregressive errors such as those in Equation (6) proceeds as follows. Equation (6) is first rearranged to express the uncorrelated white noise error
in terms of the AR coefficients
and the lagged values of the correlated errors
:
where
, which has a value of 1, has been included in the first term on the right-hand side to make the following equations more systematic. Writing lagged copies of the original regression equation (Equation (4)) for lags 0 through
and multiplying by the corresponding AR coefficients
yields the following stack of equations:
Readers will note that the error terms in each line of Equation (8) sum up to the right-hand side of Equation (7), so if all of these lines are added together, the combined error terms will equal the uncorrelated error
:
where the last line equals the uncorrelated error
. This conventional approach then rewrites Equation (9) by transforming each of the variables to subtract the values that they inherit from previous time steps,
yielding
Equation (11) is in the form of a linear regression equation like Equation (4), but in place of the autocorrelated error term
it instead has the white-noise error term
, and thus conforms to the assumptions underlying regression analysis. As written, however, Equation (11) is nonlinear in its parameters and thus cannot be solved by linear regression (because the AR coefficients
hidden within the
are multiplied by the regression coefficients
, as shown in the second line of Equation (9)). Historically, problems of this type were solved using the Cochrane–Orcutt procedure [
15], which alternately estimates the AR coefficients
and the regression coefficients
, iterating these two steps until convergence, or the Hildreth-Lu procedure [
16], which solves jointly for the AR coefficients
and the regression coefficients
using nonlinear search techniques [
17]. More recent approaches iteratively estimate the
’s using Generalized Least Squares and the
’s using maximum likelihood or Restricted Maximum Likelihood (REML) methods (see Section 9.5 of [
12]). Pre-programmed routines are also available, such as the R language’s
function, which estimates the
’s and
’s using nonlinear optimization methods. However, these approaches can become slow and memory-intensive for large problems, such as those that arise when long time series are used to estimate convolution kernels over many lags. The order of difficulty of the matrix operations required to solve Equation (4) or (11) scales as roughly
or
depending on the relative sizes of
and
; this is further magnified when these operations are repeatedly iterated to search for optimal values of the autoregressive coefficients
. In addition to this computational issue, the differencing procedure in Equation (10) may amplify any errors in the input variables relative to the true input values (particularly if the true inputs are less time-varying than their errors, and thus are attenuated more by Equation (10) than their errors are), thereby magnifying the “errors in variables” problem [
18,
19].
A further potentially serious concern is that the regression coefficients
estimated from Equations (9)–(11) or from R’s
function will artifactually converge toward 0 at lags approaching the largest modeled lag
, even if the real-world process linking
and
extends to lags well beyond
. Even worse, the uncertainty estimates for these
will also be artifactually driven toward 0 at lags approaching
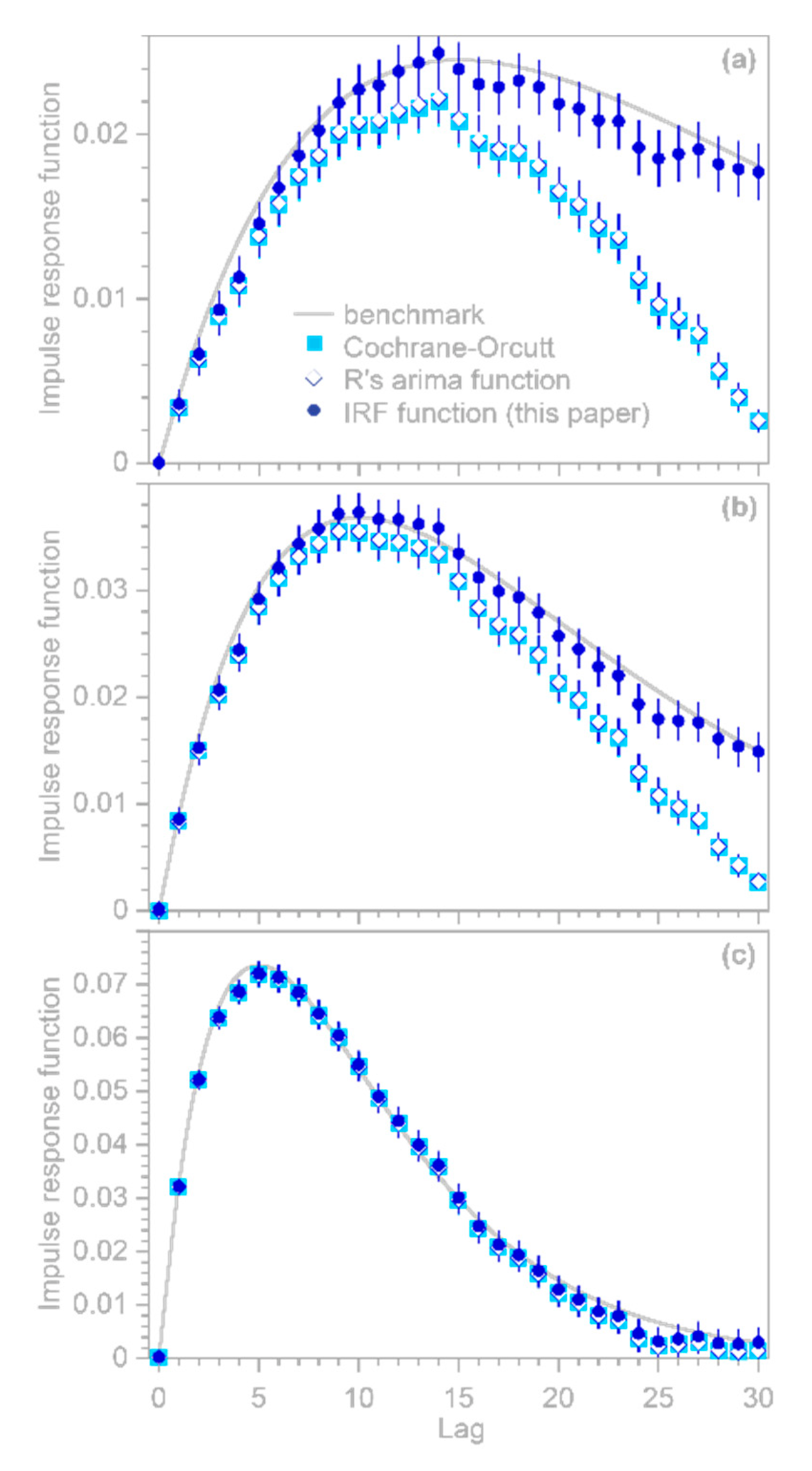
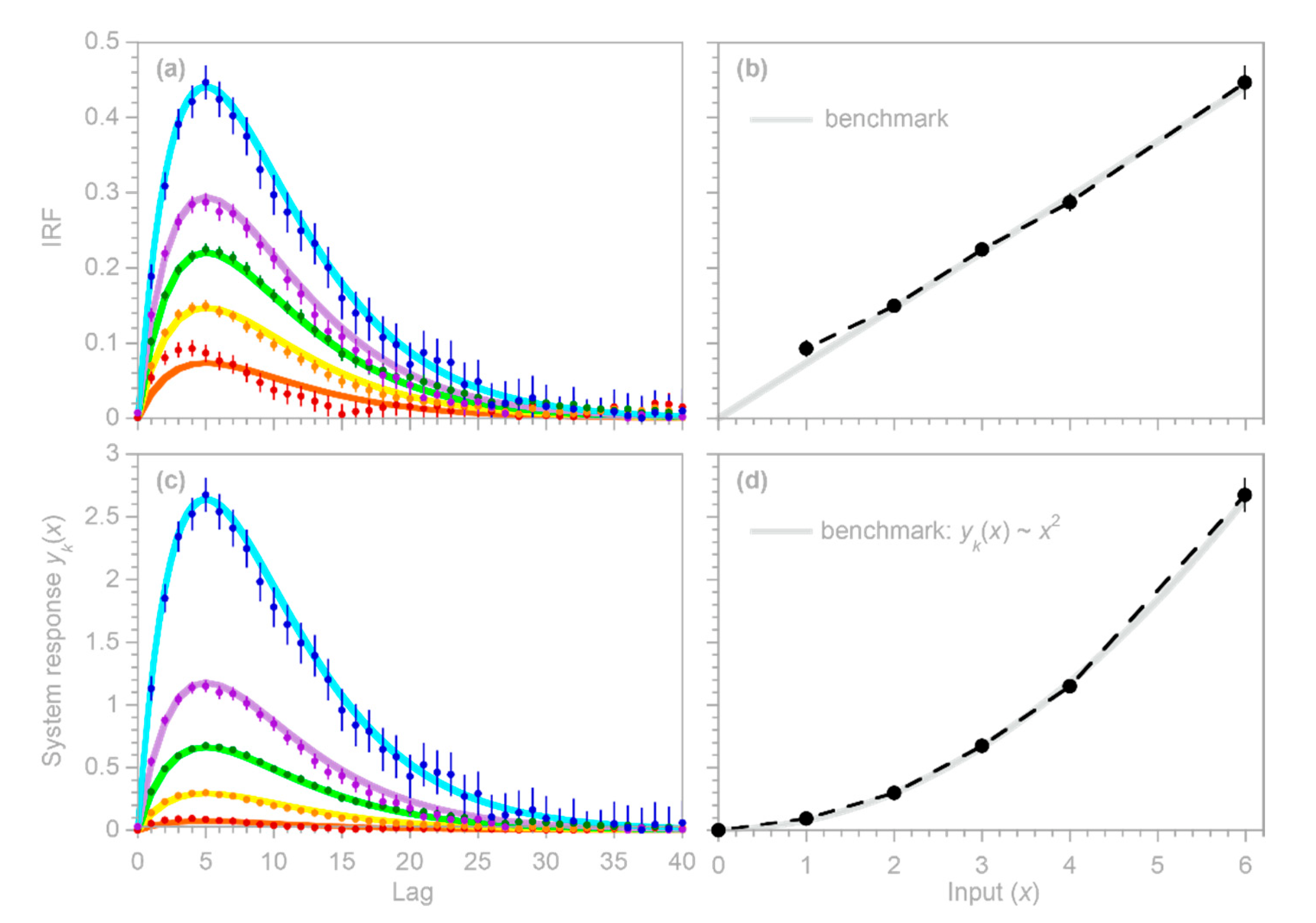
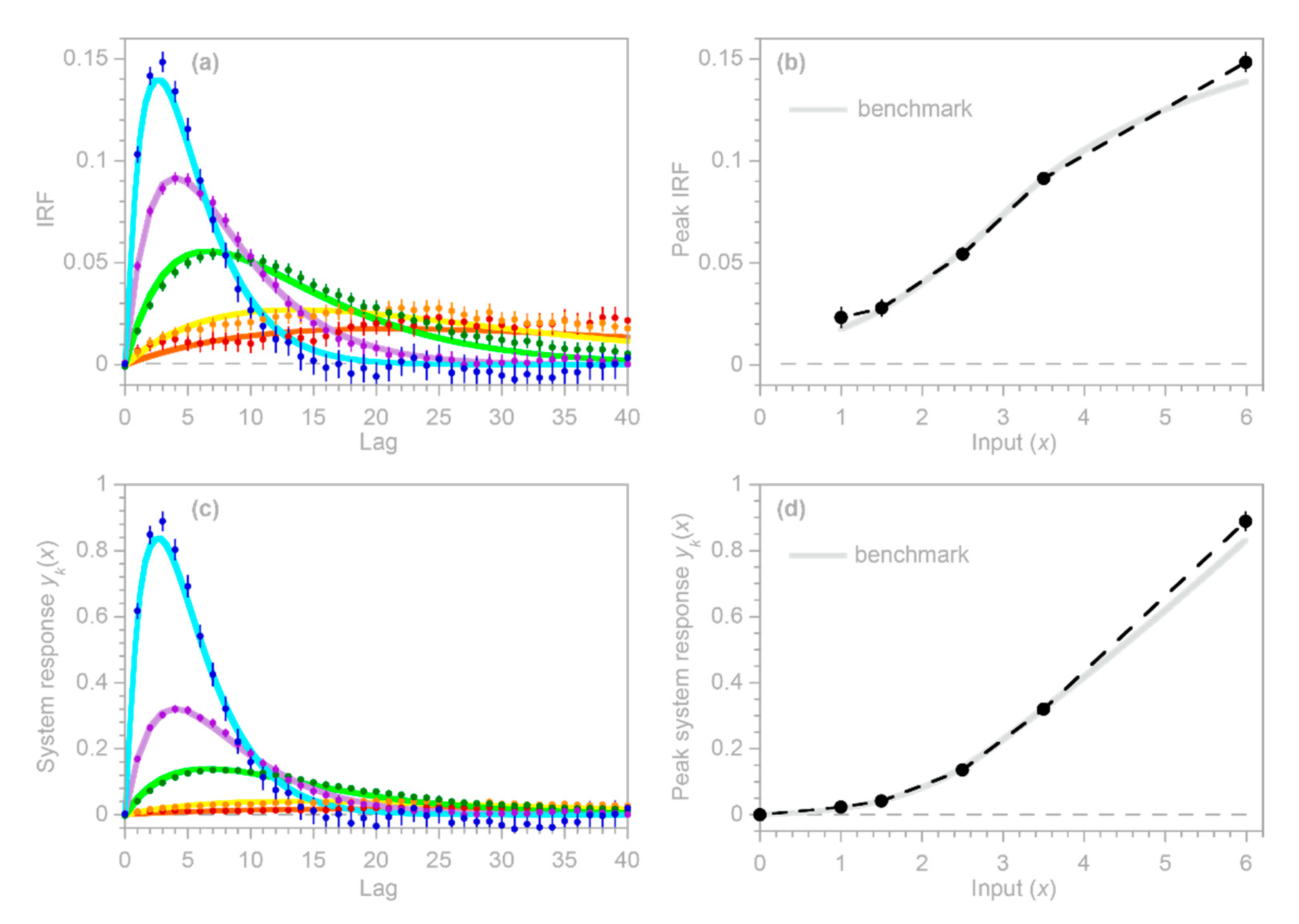
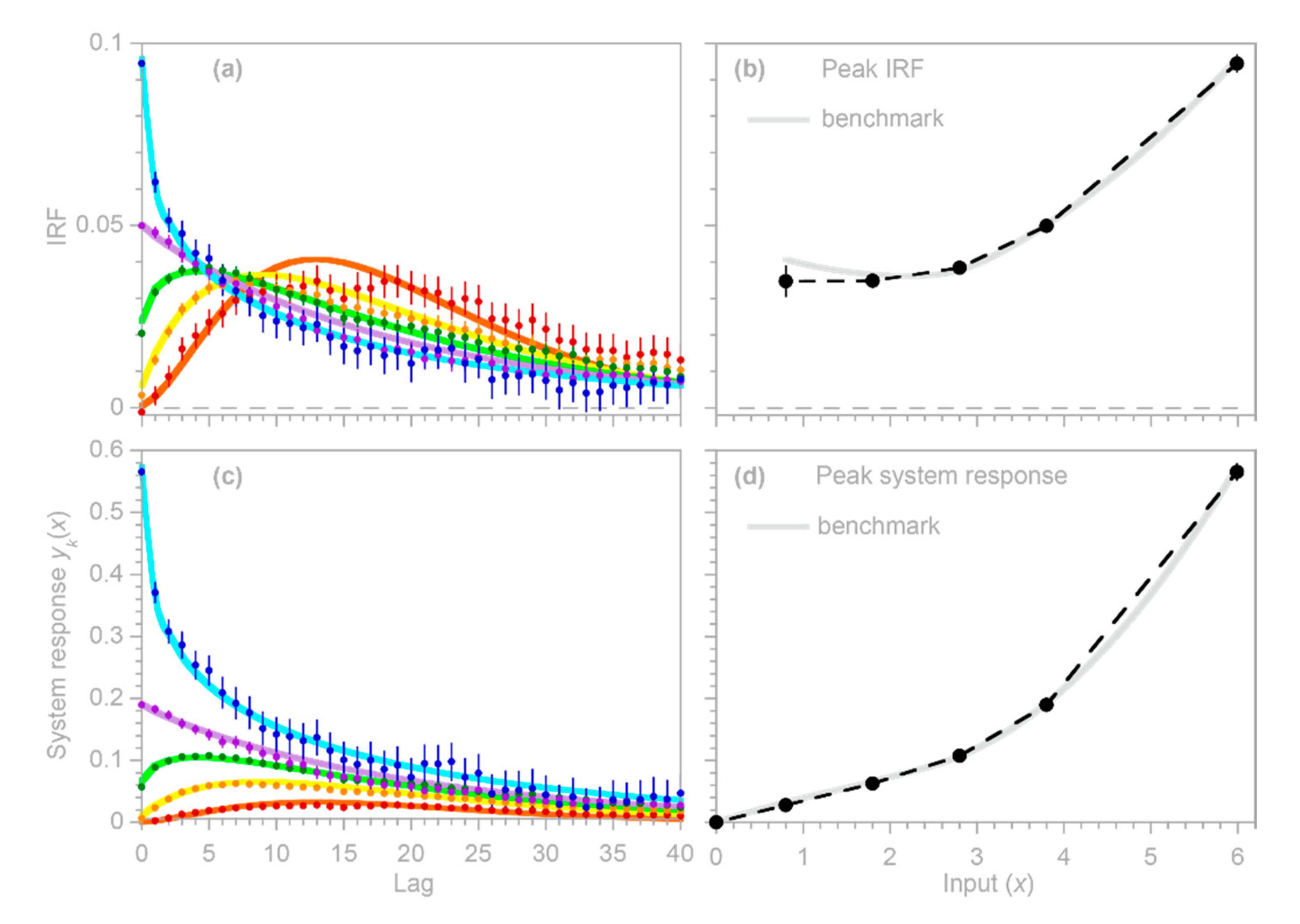
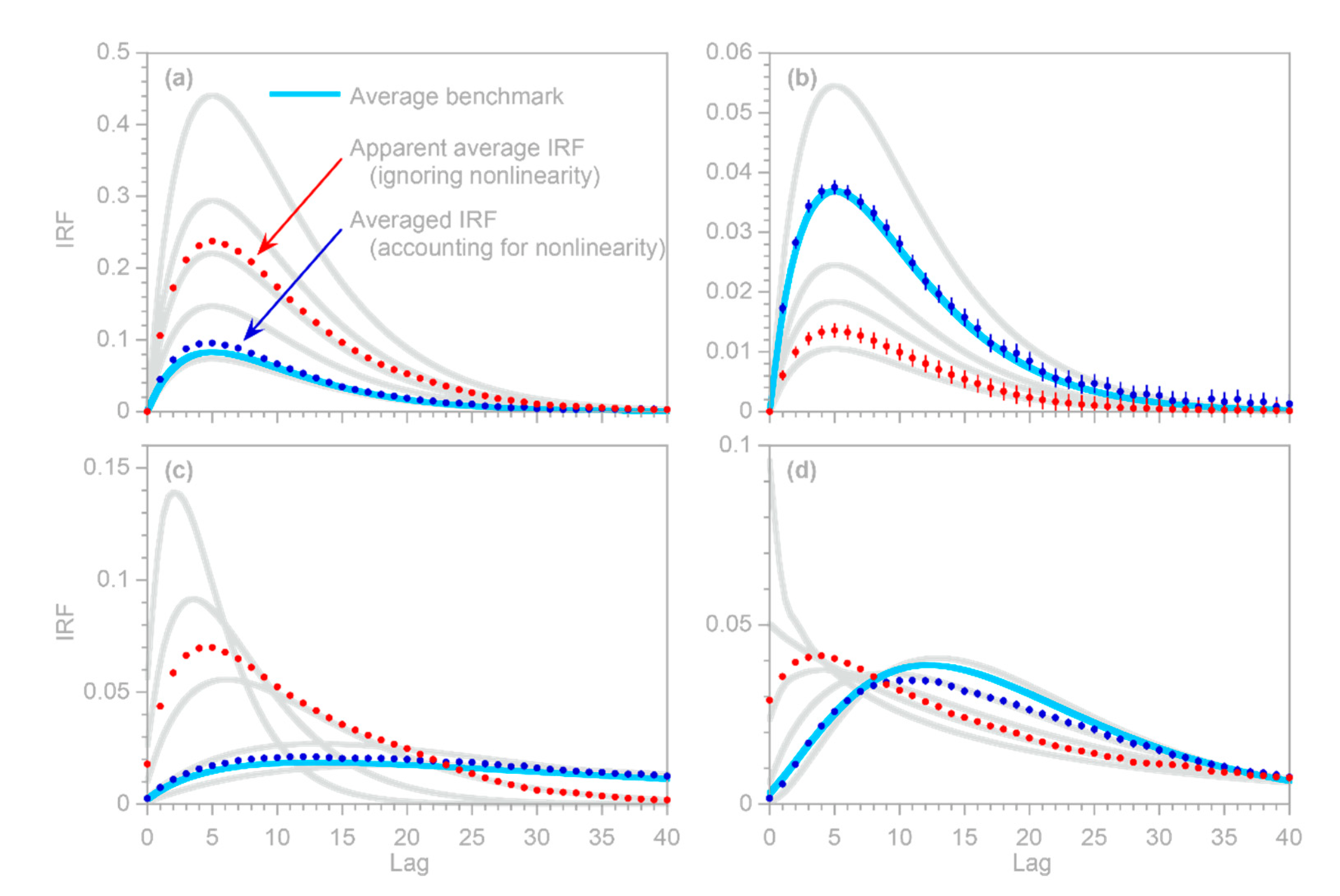
, potentially misleading users into placing exaggerated confidence in these misleading results. The benchmark tests in
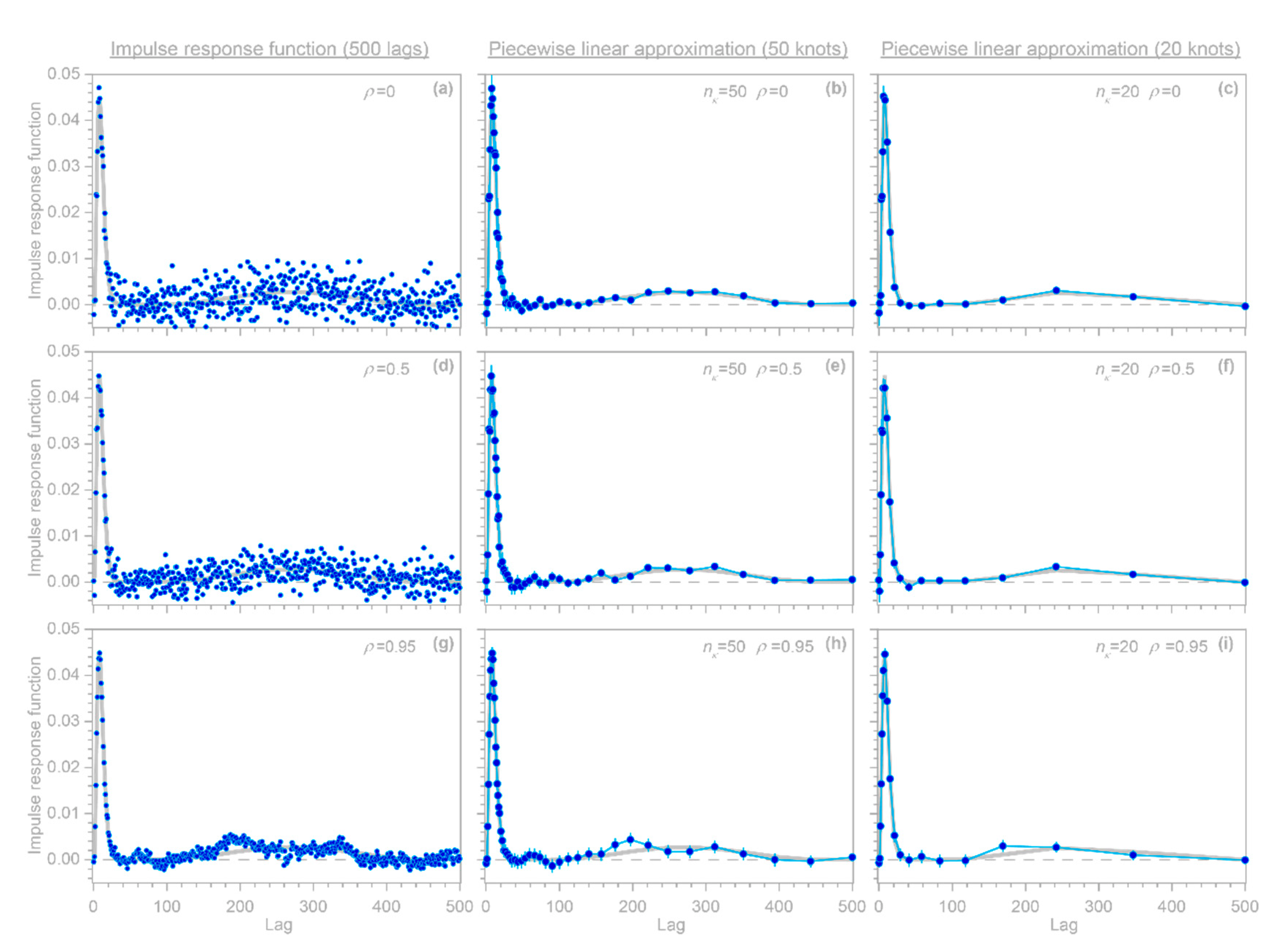
Figure 1 show that these artifacts can occur even when the correct AR coefficients
are known exactly (which of course will not be true in real-world cases).
Here I present a somewhat different approach that can efficiently handle large system identification problems in the presence of ARMA noise, and that is not vulnerable to the artifactual behavior shown in
Figure 1. This approach is based on the observation that because Equation (9) is a convolution, it can be transformed into a conventional multiple linear regression problem that can be solved for coefficients that combine both the
’s and the
’s, and these coefficients can then be back-transformed to extract the desired
values. The key is to recognize that the terms in the second line of Equation (9) can be aligned as follows (showing the first three rows as an example):
where, readers will recall,
and thus can be included or excluded without loss of generality. The vertically aligned columns in Equation (12) show that collecting terms with the same lag in
will convert Equation (9) to
which can be rearranged to create a conventional linear regression equation,
where the error term
is white noise, and the coefficients
and
. can be jointly estimated by least-squares regression, with the matrix form (here using
= 5 and
= 2 as a simple example):
or equivalently
where the matrix
includes
columns with lagged values of
and a further
columns with lagged values of
, and the parameter vector
includes both the
and
coefficients. (In practice the first
rows of the
matrix must be omitted because they have missing values, along with the corresponding rows of
; any other rows with missing values in either
or
are similarly omitted.) The least-squares estimate of the parameter vector
can be computed via the conventional matrix form of the “Normal Equation” of linear regression,
where the superscript T indicates the matrix transpose. If individual rows of Equation (15) are given different weights (for example, to exclude or down-weight uncertain or irrelevant observations), Equation (17) becomes
where
is a diagonal matrix containing the weights. The effective sample size, accounting for the uneven weights
, can be calculated straightforwardly as
; this converges to
when all rows have the same weight. The
function in IRFnnhs.R computes
using R’s
function, which in turn calls LAPACK solver routines based on LU decomposition. This is more efficient than inverting the cross-product matrix
or
followed by matrix multiplication with
. For most problems where
is much larger than, the
function’s runtime is approximately linear in and
, because the most time-consuming step is the construction of the
matrix. For larger
, runtime becomes linear in
and quadratic in
, because the most time-consuming step is the computation of the cross-product
. For very large
, the order of difficulty may approach
if the most time-consuming step becomes solving the linear system. Solution times on a 2019-vintage 1.8 GHz Intel i7-8550 CPU with four cores and 16 GB of RAM are roughly 50 ms for an
matrix with 10,000 rows and 100 columns, roughly 5 s for an
matrix with 100,000 rows and 1000 columns, and roughly 27 min for an
matrix with 1,000,000 rows and 10,000 columns. For comparison, R’s built-in
function takes roughly 2000 times longer to solve the smallest of these problems, and for larger problems the discrepancy is even greater.
Because the
coefficients estimated as part of
in Equation (17) or (18) could be noisy if the underlying time series are short or particularly noisy, the
function provides an option for Tikhonov–Phillips regularization, as described in Equations (46), (49) and (50) of [
20]. This regularization routine minimizes the mean square of the second derivatives of the
, thus penalizing
values that deviate greatly from a line connecting their adjacent neighbors. This smoothness criterion has the advantage that it does not create a downward bias in the
values, as conventional Tikhonov “ridge regression” would (see Section 4.3 of [
20] for details). The degree of regularization is controlled by a dimensionless parameter
that ranges between 0 and 1 and expresses the fractional weight given to the regularization criterion, relative to the least-squares criterion, in determining the best-fit values of
. The default value of
= 0 (no regularization) is used for all of the analyses presented here.
As with any least-squares multiple regression problem, Equations (17) and (18) are potentially vulnerable to outliers in the underlying input and output time series. Therefore, the IRFnnhs.R script includes the option for robust solution of Equations (17) and (18) via Iteratively Reweighted Least Squares (IRLS). This robust estimation method can be invoked by calling the function with the option set to TRUE. Because it is an iterative algorithm, IRLS will increase the solution time, but usually only by small multiples. A potentially greater concern is that, as with any robust estimation method, there is always a risk of excluding valid data that just happen to have unusually large influence. Therefore, it is worthwhile to investigate further, whenever robust and non-robust methods yield substantially different results. In the analyses presented here, the option is kept at its default value of FALSE, because the synthetic benchmark data sets contain no outliers (although they do contain significant noise).
The form of Equation (14) is similar to a conventional SISO (Single Input, Single Output) ARX (Autoregressive with eXogenous variables) model (e.g., [
13,
14]), but there are three essential differences. The first difference is that in ARX models, the focus is usually on the autoregressive part, and the objective is usually to be able to make one-step-ahead forecasts of the next value of
, based mostly on
’s relationship to its own prior values. By contrast, in the analysis presented here, the focus is on the exogenous variable
and its lags, and on estimating their structural relationship to
.
The second difference is that in ARX models, the autoregressive terms
,
, etc., describe autoregressive behavior in the system itself (an “equation error model”), rather than correcting for autoregressive noise in the error term (an “output error model”). (Although these two model types can be combined in so-called CARARMA models, for which iterative and hierarchical estimation algorithms have been proposed e.g., [
21], such complex models need not concern us here because in the present analysis only the noise is assumed to be autoregressive.) Because it attributes autoregressive behavior to
rather than to
, an ARX model evaluates the
coefficients only for lags from 0 to
rather than from 0 to
as shown in Equation (14). This distinction is important because without the extra coefficients
, Equation (14) would not be the same as Equation (9) and thus a solution for Equation (14) would not be a solution for the original problem as specified by Equation (4) combined with Equation (6).
The third crucial difference is that in an ARX model, the coefficients would directly measure the effects of the (lagged) external forcing . Here, by contrast, these effects are measured by the coefficients, which must be deconvolved from the coefficients as described in the next section.
2.3. Deconvolving the Impulse Response from the Fitted Coefficients
The impulse response coefficients
are not estimated by the
coefficients themselves, but rather by functions that combine the
coefficients and the AR coefficients. One can translate between the regression coefficients
and the impulse response coefficients
by recognizing from inspection of Equation (12) that the
coefficients are linear combinations of the impulse response coefficients
, weighted by the AR coefficients
,
These relationships can be represented in matrix form as (again using
= 5 and
= 2 as a simple example)
or more compactly as
where
is a unit lower triangular Toeplitz matrix whose off-diagonals are the
negatives of
. This mapping of
b to
is invertible, so the impulse response coefficients
can be retrieved from regression estimates of
and
by inverting the system of linear equations in Equation (19). This inversion can be written as a series of simple recurrence relationships (remembering that the main diagonal of the
matrix is 1):
In matrix notation, this inversion can be expressed as (here again using
= 5 as an example)
or more compactly as
where
is the inverse of the matrix
, and both
and
are truncated at lag
. Readers may recognize Equation (20) as a convolution, and Equation (23) as the corresponding deconvolution. The
matrix, like the
matrix, is a lower unit triangular Toeplitz matrix, and the individual
values can be calculated by recurrence relationships analogous to those in Equation (22) above (noting that the terms of
are
, not
, and that
and
both have 1s along the main diagonal):
The last h elements of have no effect on the calculated values (each of which depends only on values of —see Equation (22)), but they nonetheless must be present when Equation (14) is fitted by least squares, because otherwise the estimates of through can be distorted by correlations that should be absorbed by the terms through . Putting the same point differently, if Equation (14) is missing the last elements of , it will not be equivalent to Equation (9), leading to biased estimates of the resulting (unless, of course, the last elements of are all zero).
The
matrix is also the Jacobian of the system of equations that translates
into
(Equation (22)), and thus it can also be used to convert the covariance matrix
of
to the covariance matrix
of the impulse response vector
, using the matrix form of the conventional first-order, second-moment error propagation equation,
The square root of the diagonal of the covariance matrix will then yield the standard errors of the impulse response coefficients . These uncertainty estimates will be somewhat inflated if Equation (26) is applied directly to the covariance matrix obtained from Equation (14), due to interactions between the and coefficients. Statistically speaking, the coefficients are “nuisance parameters” in the sense that the goal is to determine the values of the ’s, but as part of this process the ’s must also be estimated in order to account for serial correlation in the residuals. Benchmark tests show that the standard errors of the ’s can be more accurately estimated if the ’s are treated as being fixed at their estimated values, rather than as uncertain parameters. This can be efficiently accomplished by removing the rows and columns that correspond to the lagged values of (and thus correspond to the coefficients) from the cross-product matrix after it has been used to solve Equation (14). This modified cross-product matrix is then used to calculate the covariances of the via the standard formula , where is the variance of the residuals of Equation (14). The and their covariances are then translated into estimates of the and their covariances using Equations (24) and (26).
2.4. Choosing the Number of Autoregressive Correction Terms
A practical question will inevitably arise: how should users choose the correct order
for the AR correction terms
? As noted in
Section 2.2 above, these terms should be numerous enough to capture the effects of both autoregressive and moving average noise in the measured
. One approach is to manually select the order of AR correction by trial and error, by setting the parameter
and inspecting how different values of
affect the estimates of
and the correlations in the residuals. Benchmark tests suggest that as long as
is much smaller than
m, making
too big will only slightly alter the estimates of
or their uncertainties, since the extra
coefficients will typically be very small and thus will barely affect the solution of Equation (14). (It should be clear that Equations (5) and (6) are models of the noise
, not AR or ARMA models of the underlying processes generating the system output. Thus, any additional uncertainty in the
coefficients due to overfitting is unproblematic, because the goal is to estimate the impulse response coefficients
, not the
coefficients describing the noise.)
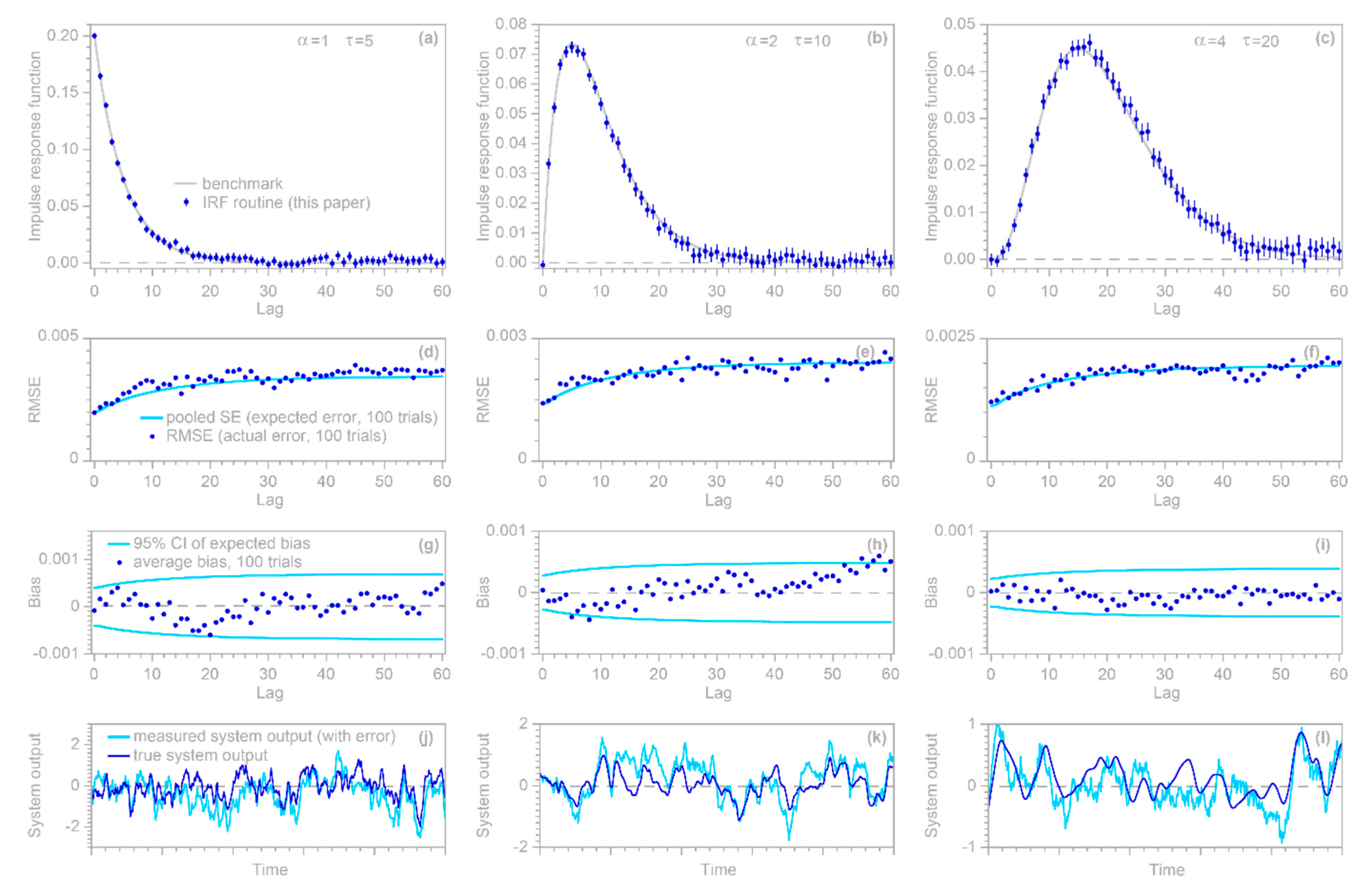
The order of autoregressive correction can also be determined automatically. One might assume that the Akaike Information Criterion (AIC) or Bayesian Information Criterion (BIC) could be used to determine an optimal value of , but AIC and BIC can only compare models that predict the same set of points , and changing alters the number of rows of Equation (15) with missing values of or (and therefore the number of values that must be excluded). A more fundamental problem is that even if AIC and BIC could be used, they would select a value of that makes Equation (14) a good predictor of rather than a good estimator of and thus of , which is the objective of this analysis. One should remember that in this analysis, the coefficients are not themselves of interest, but are necessary to whiten the residuals, that is, to convert the serially correlated residuals to nearly uncorrelated residuals . With that objective in mind, by default the algorithm will automatically find the smallest value of that sufficiently whitens the residuals, using both a practical significance test and a statistical significance test. The practical significance test examines whether the absolute values of the autocorrelation and partial autocorrelation function (ACF and PACF) coefficients of the residuals , for lags from 1 to log10(), are less than a user-specified threshold The default value of is 0.2, which corresponds to a maximum contribution of 0.22 = 4% to the variance of the residuals due to serial correlations at any individual lag. The statistical significance test examines whether the absolute values of the ACF and PACF coefficients exceed a significance threshold of (corresponding to a two-tailed significance level of < 0.05) more often than would be expected by chance according to binomial statistics, where the threshold for “by chance” is a user-specified probability (default value 0.05). The algorithm will automatically find the smallest value of that passes either of these tests. The practical significance test is needed because in large samples, even trivially small ACF and PACF coefficients may still be statistically significant, triggering a pointless effort to make them smaller than they need to be. Conversely, the statistical significance test is needed because in small samples, even true white-noise processes may yield ACF and PACF coefficients that do not meet the practical significance threshold (if is less than ), triggering a pointless effort to further whiten residuals that are already white.
A further technical detail is that if (but only if) the true impulse response function converges to 0 well before the maximum lag
, one can obtain more accurate estimates of
at lags approaching
, with correspondingly smaller uncertainties, by solving Equations (10) and (11) using the
coefficients obtained from Equation (14) rather than using the
and uncertainty estimates derived from Equation (14) itself. Users can choose between these two alternatives with the
option in the
function. If
=TRUE, then the
and their uncertainties are re-calculated via Equations (10) and (11) using the
coefficients obtained from Equation (14). This is functionally equivalent to the Cochrane–Orcutt procedure, but is much faster because it does not require iteratively solving Equations (10) and (11) to determine the
coefficients. Users should keep in mind, however, that if the true impulse response function does not converge to zero well before the maximum lag
, setting
to TRUE can lead to artifacts similar to those shown in
Figure 1; thus,
is set to FALSE by default.
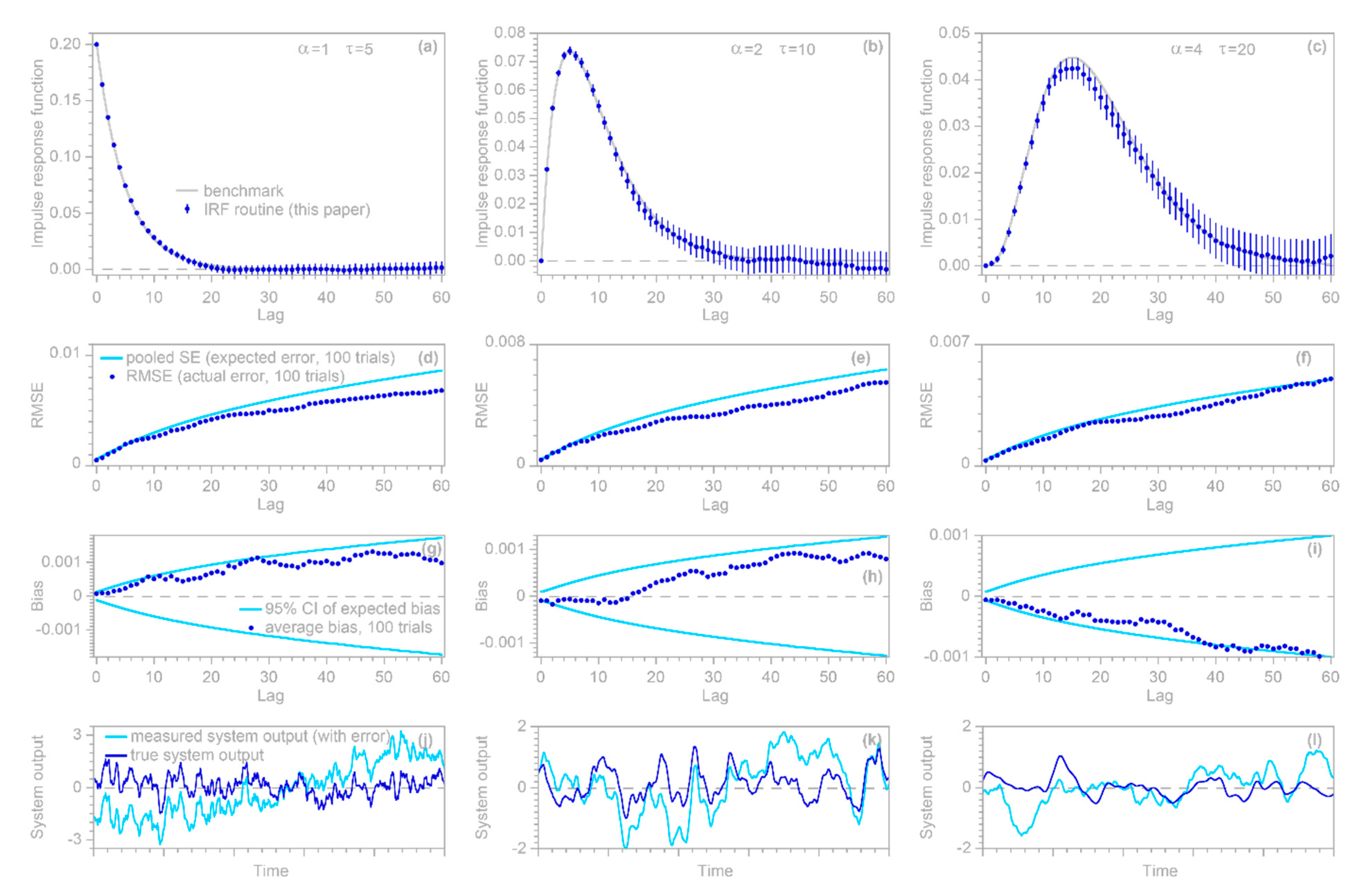
2.6. Estimating Impulse Response Functions in the Presence of Nonstationary ARIMA Noise
The error
in Equation (4) may not only be serially correlated; it may also be nonstationary, such that its true mean changes over time. Such a random error is known as ARIMA (Autoregressive Integrated Moving Average) noise instead of ARMA noise. The standard approach to handling such cases is differencing: one subtracts the prior values from each element of the time series
and
, yielding the “first differences”
and
. Then Equation (4) is conventionally re-cast in terms of these first differences:
where the intercept
is conventionally assumed to be zero, although this will often not be strictly the case, precisely because
is nonstationary so the mean of
may not equal the mean of
over a finite sample from
. The conventional approach of Equation (27) leads to
estimates that artifactually converge toward zero as
approaches
, similar to the artifact that is generated by Equation (11), as shown in
Figure 1 above. The approach of Equation (27) would also greatly complicate the analysis presented in
Section 3,
Section 4 and
Section 5 below. Therefore, a different approach will be followed here, in which first differencing is only applied to the left-hand side of Equation (4) and, similar to Equation (12) above, terms with the same lags of
are combined. This has the effect of transforming the coefficients
rather than the input time series
, yielding
where
, except when
(whereupon
) and when
(whereupon
). These transformations can be expressed in matrix form as
One advantage of this approach is that it can use the analysis already outlined in Equations (14)–(26), with the only modifications being the use of
in place of
and
in place of
. The results of that analysis will be in terms of
, which can be transformed back to
by inverting Equation (
), yielding
One can straightforwardly combine Equations (14)–(30) to eliminate the need to use
as an interim step between
and
. The resulting procedure can be summarized as follows: first, solve Equation (14), using
in place of
and
in place of
, to obtain the regression coefficients
and their covariance matrix
. Next, transform these to the IRF coefficients
and their covariance matrix
using
and
where
is the matrix in Equation (30), which is the inverse of the first difference matrix in Equation (29). In principle, this procedure can also be straightforwardly adapted to differencing of any order
, by differencing
accordingly, using
in place of
, and raising
to the power
. In practice, however, differencing beyond first order is likely to be counterproductive, because even first-differencing will magnify the high-frequency noise in the
time series, and higher-order differencing will amplify this noise further. In the
routine, setting the parameter
(default=FALSE) to TRUE will invoke the differencing procedure outlined in Equations (28)–(32) above.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}