
Fast Adaptation of Manipulator Trajectories to Task Perturbation by Differentiating through the Optimal Solution

 and
and
Abstract
:1. Introduction
1.1. Main Idea
1.2. Contribution
1.3. Related Works
| Algorithm 1 Line-Search Based Joint Trajectory Adaptation to Task Perturbation |
|
2. Proposed Approach
2.1. Symbols and Notations
2.2. Argmin Differentiation for Unconstrained Parametric Optimization
2.3. Line Search and Incremental Adaption
3. Task Constrained Joint Trajectory Optimization
3.1. Orientation Constrained Interpolation between Joint Configurations
Applications
3.2. Orientation-Constrained Trajectories through Way-Points
Application
4. Benchmarking
4.1. Implementation Details
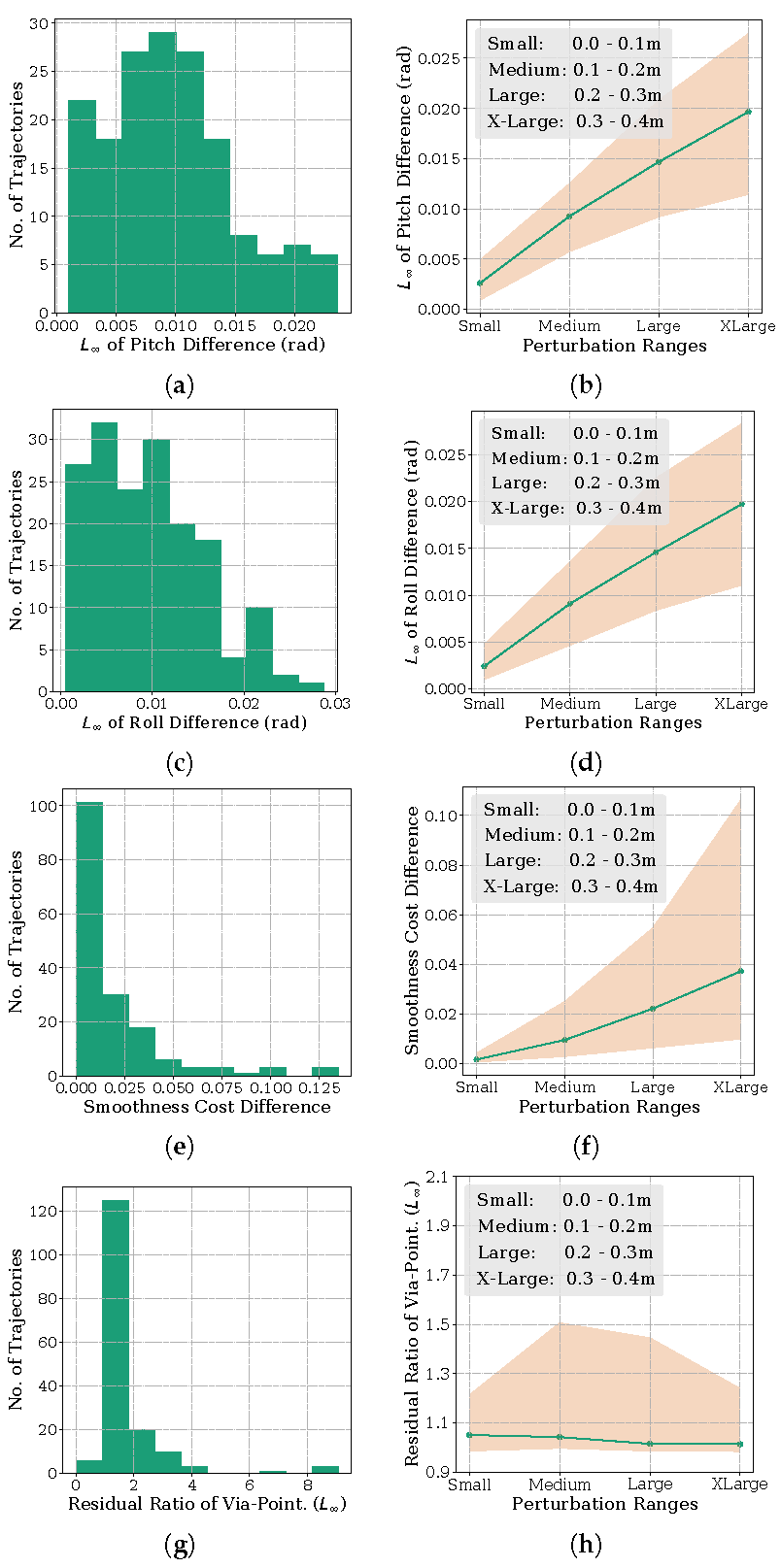
4.2. Quantitative Results
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Berenson, D.; Srinivasa, S.S.; Ferguson, D.; Kuffner, J.J. Manipulation planning on constraint manifolds. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 625–632. [Google Scholar]
- Lembono, T.S.; Paolillo, A.; Pignat, E.; Calinon, S. Memory of motion for warm-starting trajectory optimization. IEEE Robot. Autom. Lett. 2020, 5, 2594–2601. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gould, S.; Fernando, B.; Cherian, A.; Anderson, P.; Cruz, R.S.; Guo, E. On differentiating parameterized argmin and argmax problems with application to bi-level optimization. arXiv 2016, arXiv:1607.05447. [Google Scholar]
- Hauser, K. Learning the problem-optimum map: Analysis and application to global optimization in robotics. IEEE Trans. Robot. 2016, 33, 141–152. [Google Scholar] [CrossRef]
- Tang, G.; Sun, W.; Hauser, K. Time-Optimal Trajectory Generation for Dynamic Vehicles: A Bilevel Optimization Approach. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 7644–7650. [Google Scholar]
- Reiter, A.; Gattringer, H.; Müller, A. Real-time computation of inexact minimum-energy trajectories using parametric sensitivities. In Proceedings of the International Conference on Robotics in Alpe-Adria Danube Region, Torino, Italy, 21–23 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 174–182. [Google Scholar]
- Geffken, S.; Büskens, C. Feasibility refinement in sequential quadratic programming using parametric sensitivity analysis. Optim. Methods Softw. 2017, 32, 754–769. [Google Scholar] [CrossRef]
- Pirnay, H.; López-Negrete, R.; Biegler, L.T. Optimal sensitivity based on IPOPT. Math. Program. Comput. 2012, 4, 307–331. [Google Scholar] [CrossRef]
- Amos, B.; Jimenez, I.; Sacks, J.; Boots, B.; Kolter, J.Z. Differentiable MPC for end-to-end planning and control. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2018; pp. 8289–8300. [Google Scholar]
- Agrawal, A.; Barratt, S.; Boyd, S.; Stellato, B. Learning convex optimization control policies. In Proceedings of the 2nd Conference on Learning for Dynamics and Control, PMLR, Berkeley, CA, USA, 11–12 June 2020; pp. 361–373. [Google Scholar]
- Landry, B.; Lorenzetti, J.; Manchester, Z.; Pavone, M. Bilevel Optimization for Planning through Contact: A Semidirect Method. arXiv 2019, arXiv:1906.04292. [Google Scholar]
- Kalantari, H.; Mojiri, M.; Dubljevic, S.; Zamani, N. Fast l1 model predictive control based on sensitivity analysis strategy. IET Control. Theory Appl. 2020, 14, 708–716. [Google Scholar] [CrossRef]
- Pham, Q.C. A general, fast, and robust implementation of the time-optimal path parameterization algorithm. IEEE Trans. Robot. 2014, 30, 1533–1540. [Google Scholar] [CrossRef] [Green Version]
- Toussaint, M. A tutorial on Newton methods for constrained trajectory optimization and relations to SLAM, Gaussian Process smoothing, optimal control, and probabilistic inference. In Geometric and Numerical Foundations of Movements; Springer: Berlin/Heidelberg, Germany, 2017; pp. 361–392. [Google Scholar]
- Flacco, F.; Kröger, T.; De Luca, A.; Khatib, O. A depth space approach to human-robot collision avoidance. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Guangzhou, China, 11–14 December 2012; pp. 338–345. [Google Scholar]
- Bradbury, J.; Frostig, R.; Hawkins, P.; Johnson, M.J.; Leary, C.; Maclaurin, D.; Wanderman-Milne, S. JAX: Composable Transformations of Python+NumPy Programs. 2018. Available online: http://github.com/google/jax (accessed on 1 August 2020).
- Qureshi, A.H.; Dong, J.; Baig, A.; Yip, M.C. Constrained Motion Planning Networks X. arXiv 2020, arXiv:2010.08707. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SciPy-SLSQP | Our Algorithm 1 | ||
|---|---|---|---|
| Benchmarks | Wall Time (s) | Wall Time w/o Jacobian and Function Evaluation Overhead (s) | Wall Time (s) |
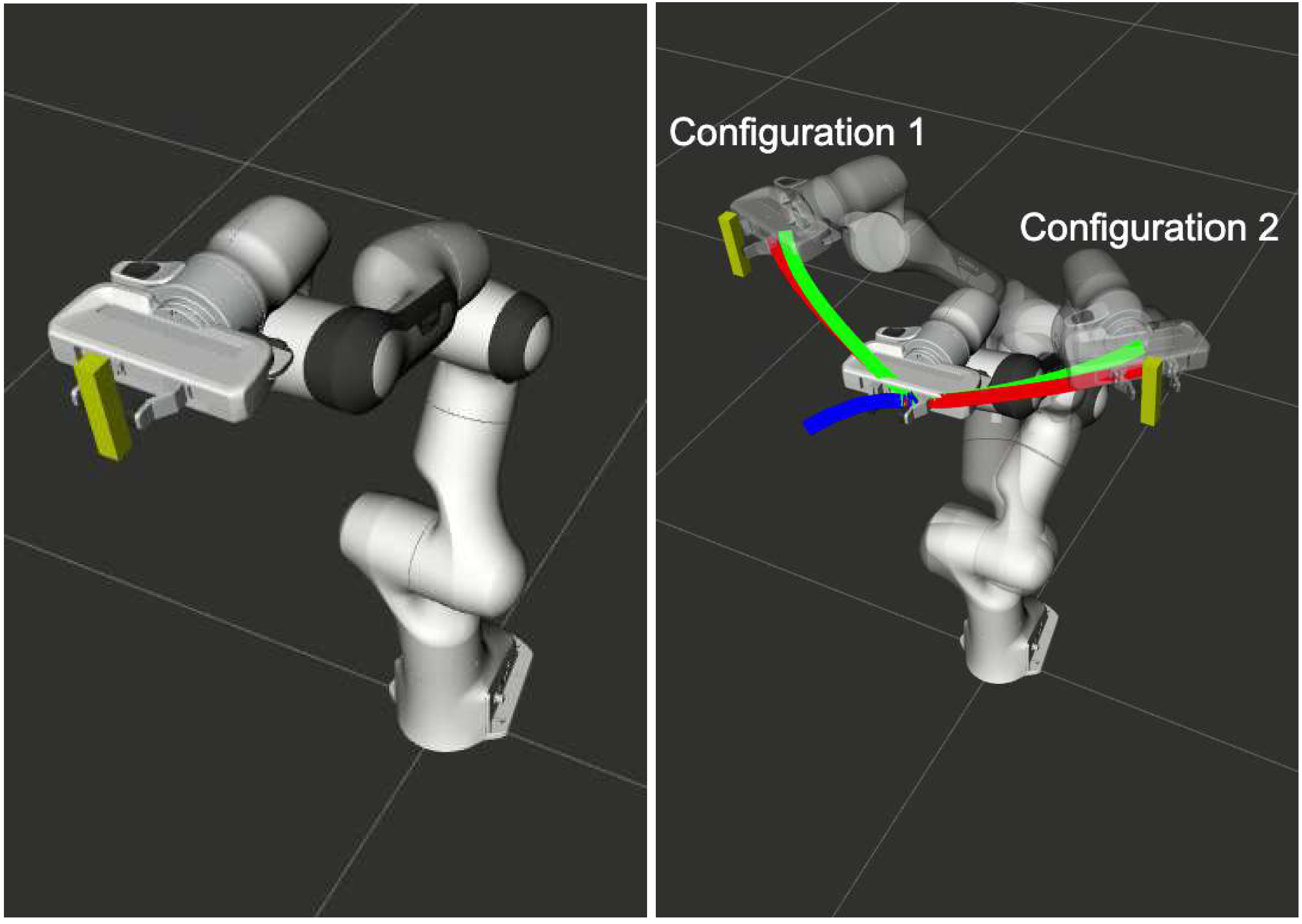
| Final Configuration Perturbation (Figure 1) | 43.91 | 41.09 | 0.039 |
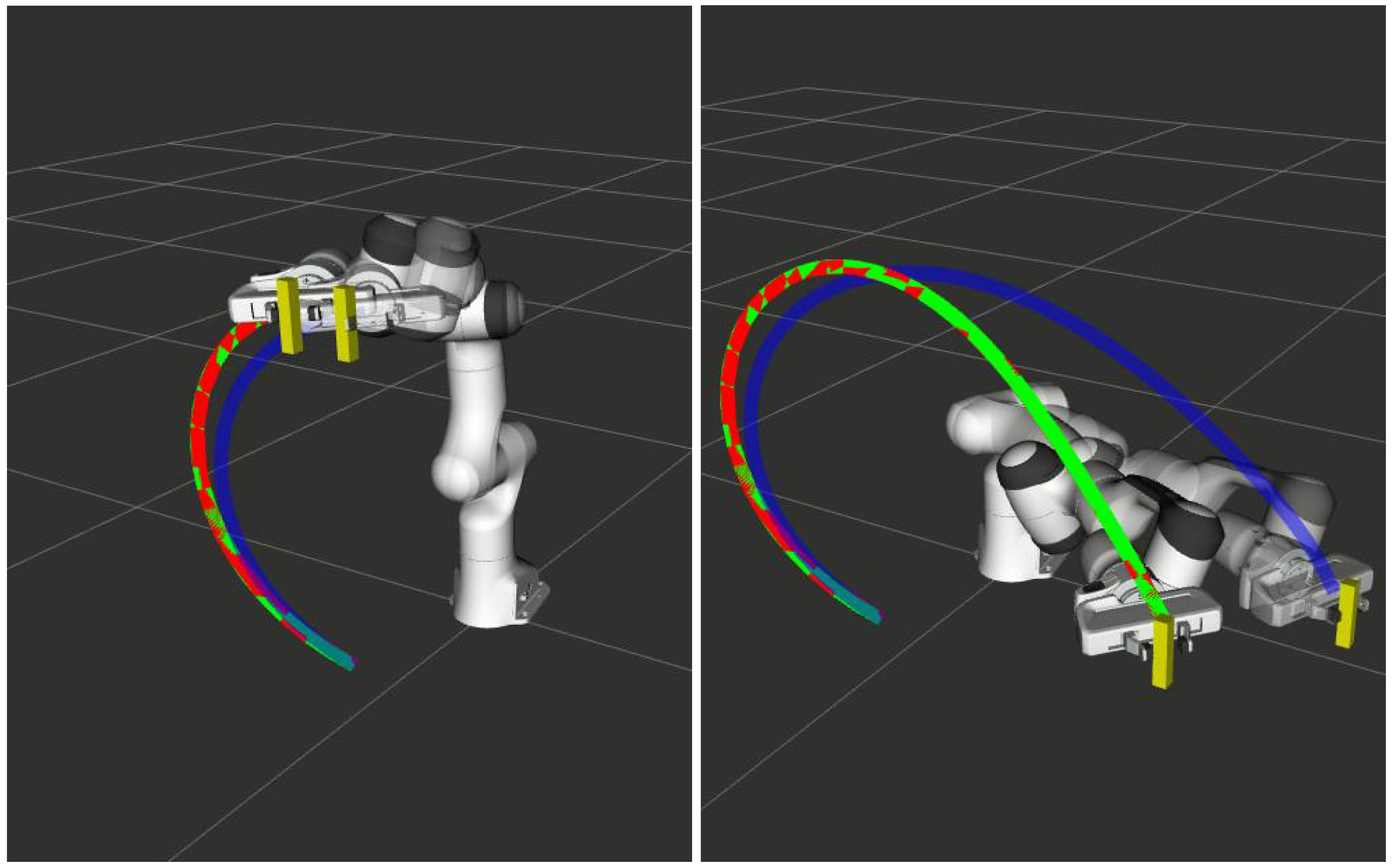
| Via Point Perturbation (Figure 2) | 53.05 | 34.74 | 0.09 |
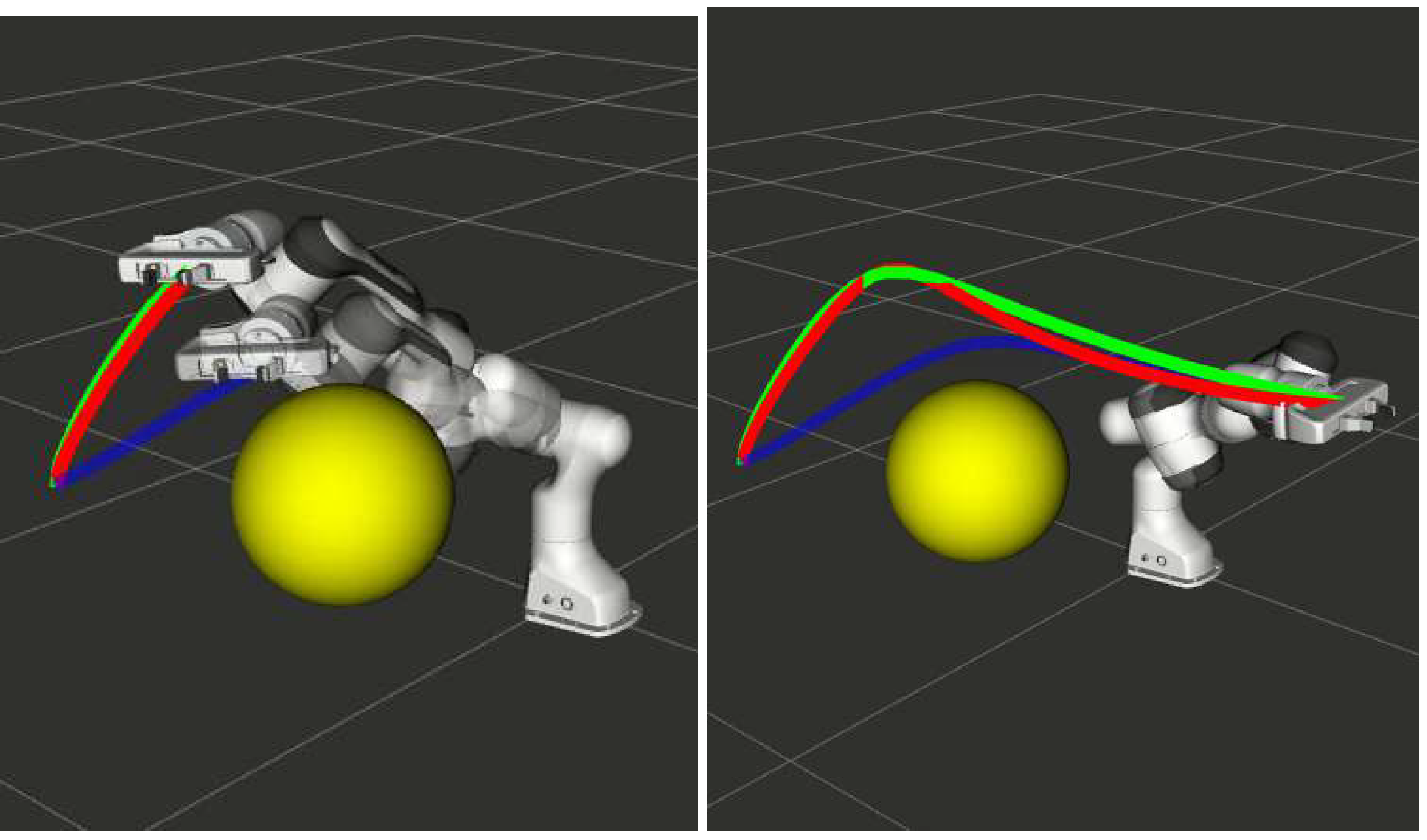
| Final Position Perturbation (Figure 3) | 35.91 | 29.09 | 0.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Srikanth, S.; Babu, M.; Masnavi, H.; Kumar Singh, A.; Kruusamäe, K.; Krishna, K.M. Fast Adaptation of Manipulator Trajectories to Task Perturbation by Differentiating through the Optimal Solution. Sensors 2022, 22, 2995. https://doi.org/10.3390/s22082995
Srikanth S, Babu M, Masnavi H, Kumar Singh A, Kruusamäe K, Krishna KM. Fast Adaptation of Manipulator Trajectories to Task Perturbation by Differentiating through the Optimal Solution. Sensors. 2022; 22(8):2995. https://doi.org/10.3390/s22082995
Chicago/Turabian StyleSrikanth, Shashank, Mithun Babu, Houman Masnavi, Arun Kumar Singh, Karl Kruusamäe, and Krishnan Madhava Krishna. 2022. "Fast Adaptation of Manipulator Trajectories to Task Perturbation by Differentiating through the Optimal Solution" Sensors 22, no. 8: 2995. https://doi.org/10.3390/s22082995
APA StyleSrikanth, S., Babu, M., Masnavi, H., Kumar Singh, A., Kruusamäe, K., & Krishna, K. M. (2022). Fast Adaptation of Manipulator Trajectories to Task Perturbation by Differentiating through the Optimal Solution. Sensors, 22(8), 2995. https://doi.org/10.3390/s22082995