
ELECTRIcity: An Efficient Transformer for Non-Intrusive Load Monitoring



Abstract
:1. Introduction
- ELECTRIcity is capable of learning long-range temporal dependencies. In seq2seq models, learning temporal dependencies is a demanding task, and often the model forgets the first part, once it completes processing the whole sequence input. ELECTRIcity utilizes attention mechanisms and identifies complex dependencies between input sequence elements regardless of their position.
- ELECTRIcity can handle imbalanced datasets. Our work demonstrates that combining the unsupervised pre-training process with downstream task fine-tuning, offers a practical solution for NILM, and handles successfully imbalanced datasets. This is a comparative advantage against the existing state-of-the-art NILM works which, in most cases, require data balancing to achieve good performance.
- ELECTRIcity is an efficient and fast transformer. ELECTRIcity introduces a computationally efficient unsupervised pre-training process through the combined use of a generator and a discriminator. This leads to a significant training time decrease without affecting model performance compared to traditional transformer architectures.
Related Work
2. Background
2.1. NILM Problem Formulation
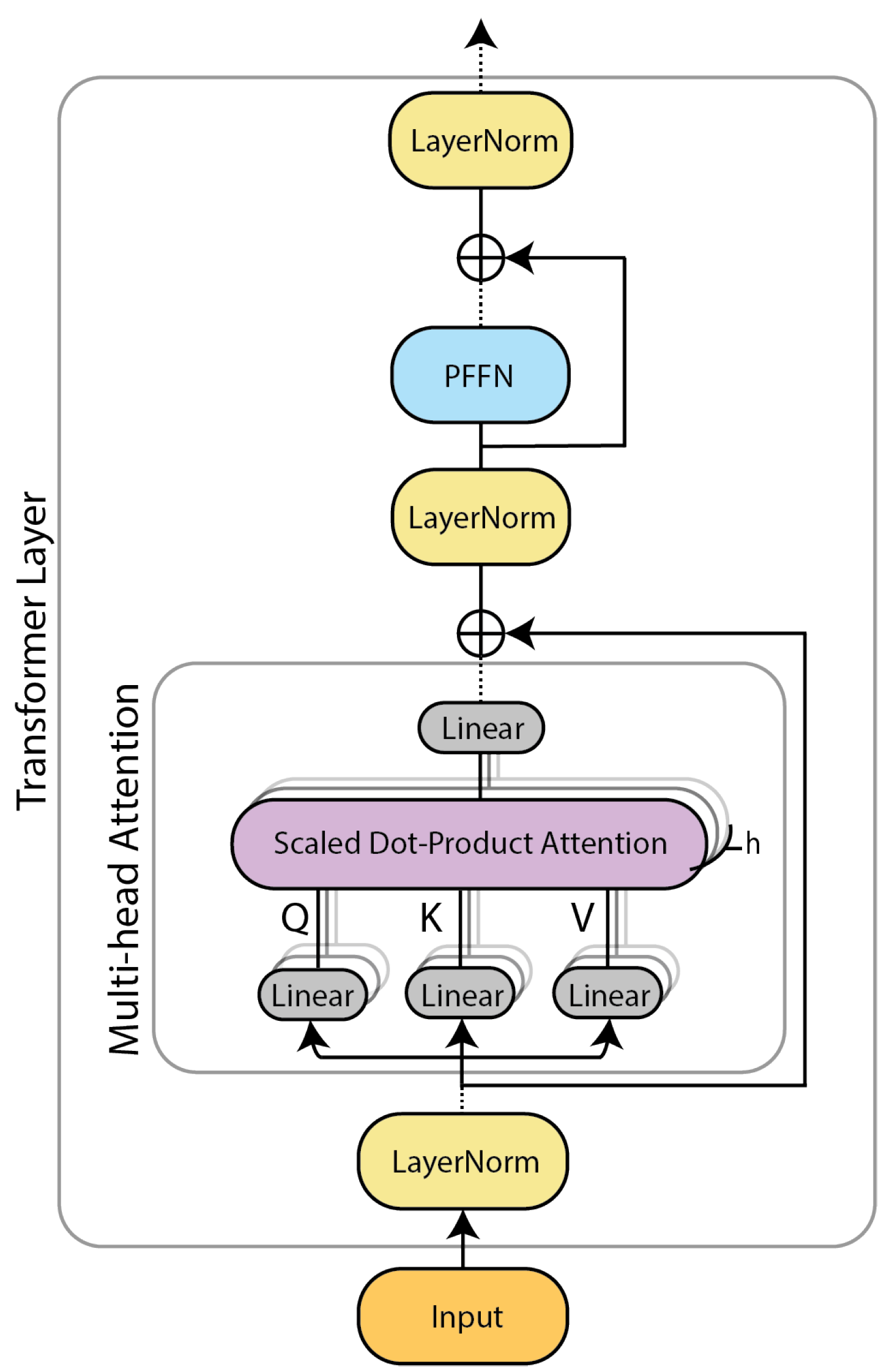
2.2. Transformer Model Fundamentals
2.2.1. Multi-Head Attention Mechanism
2.2.2. Position-Wise Feed-Forward Network
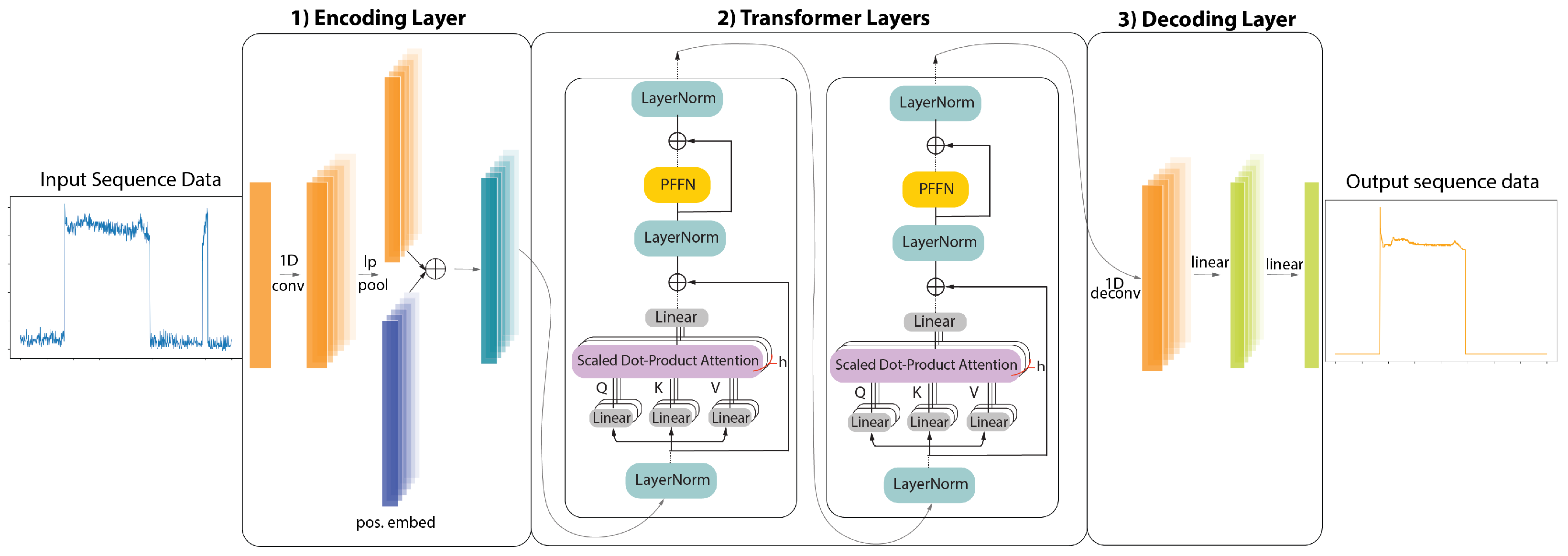
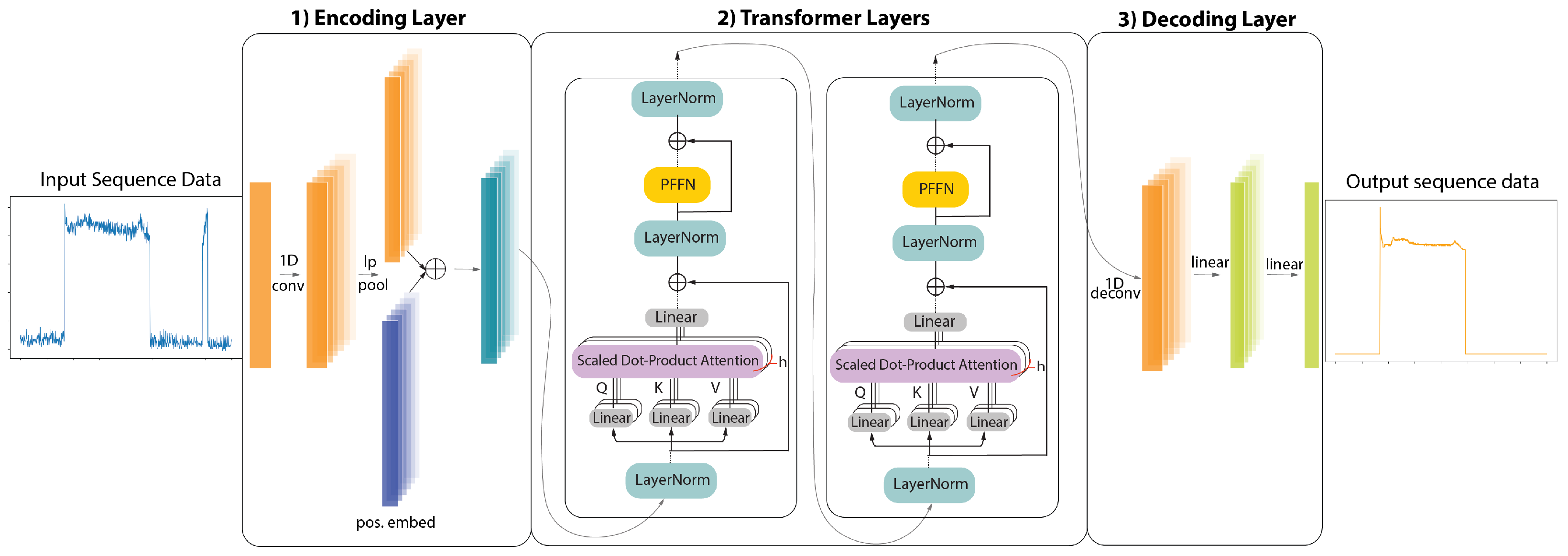
3. ELECTRIcity: An Efficient Transformer for NILM
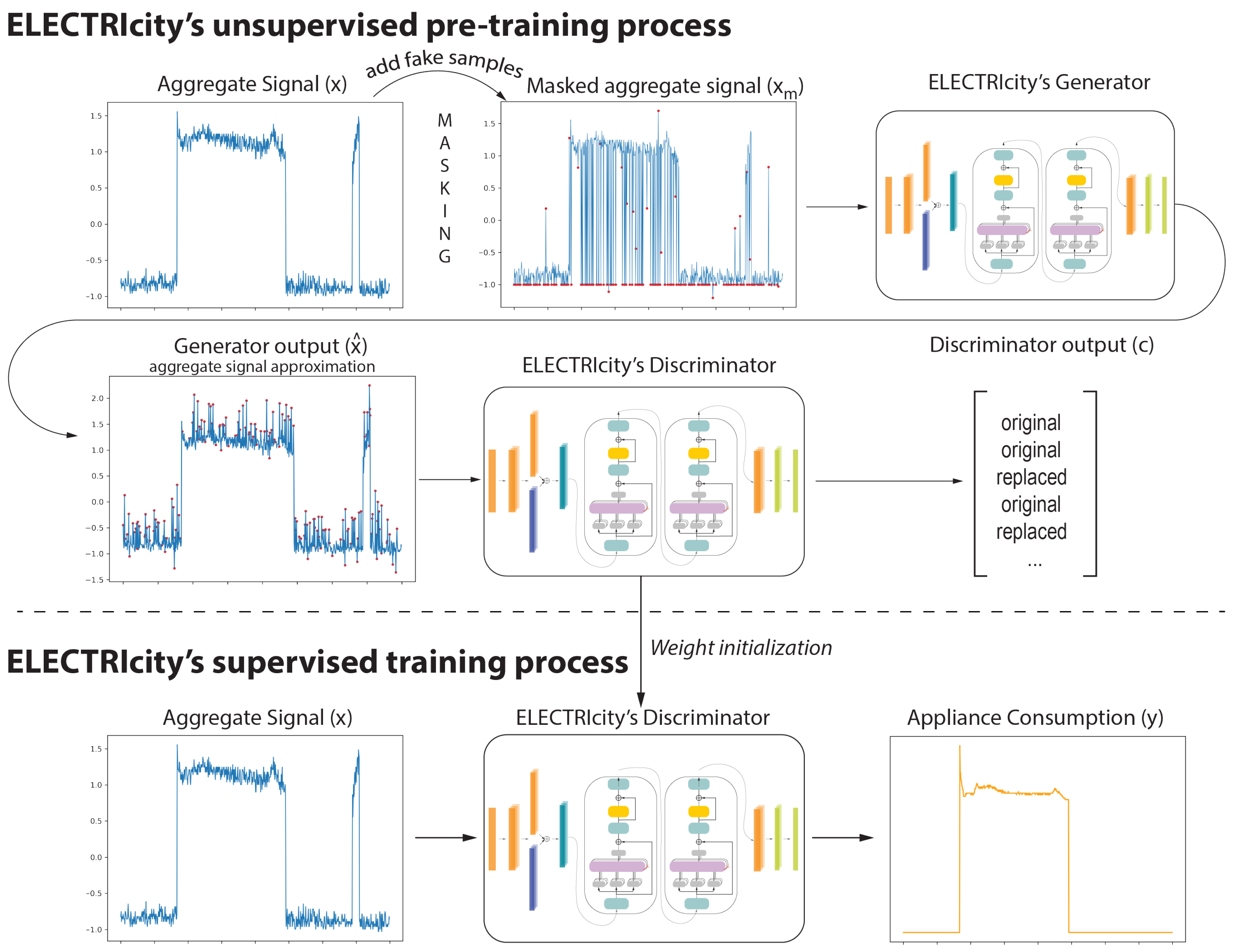
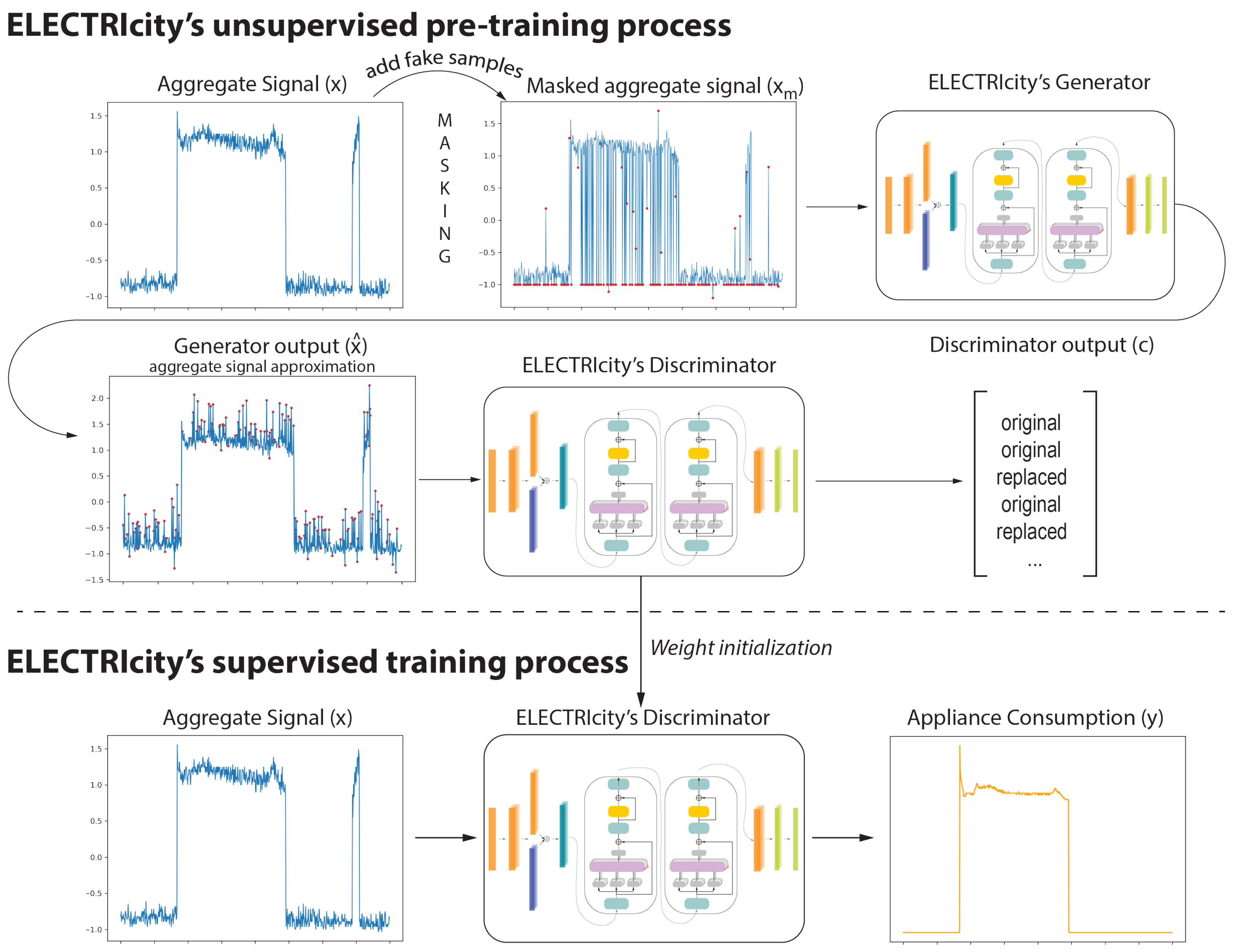
3.1. ELECTRIcity’s Unsupervised Pre-Training Process
3.2. ELECTRIcity Supervised Training Process
4. Experimental Results
4.1. Performance Metrics
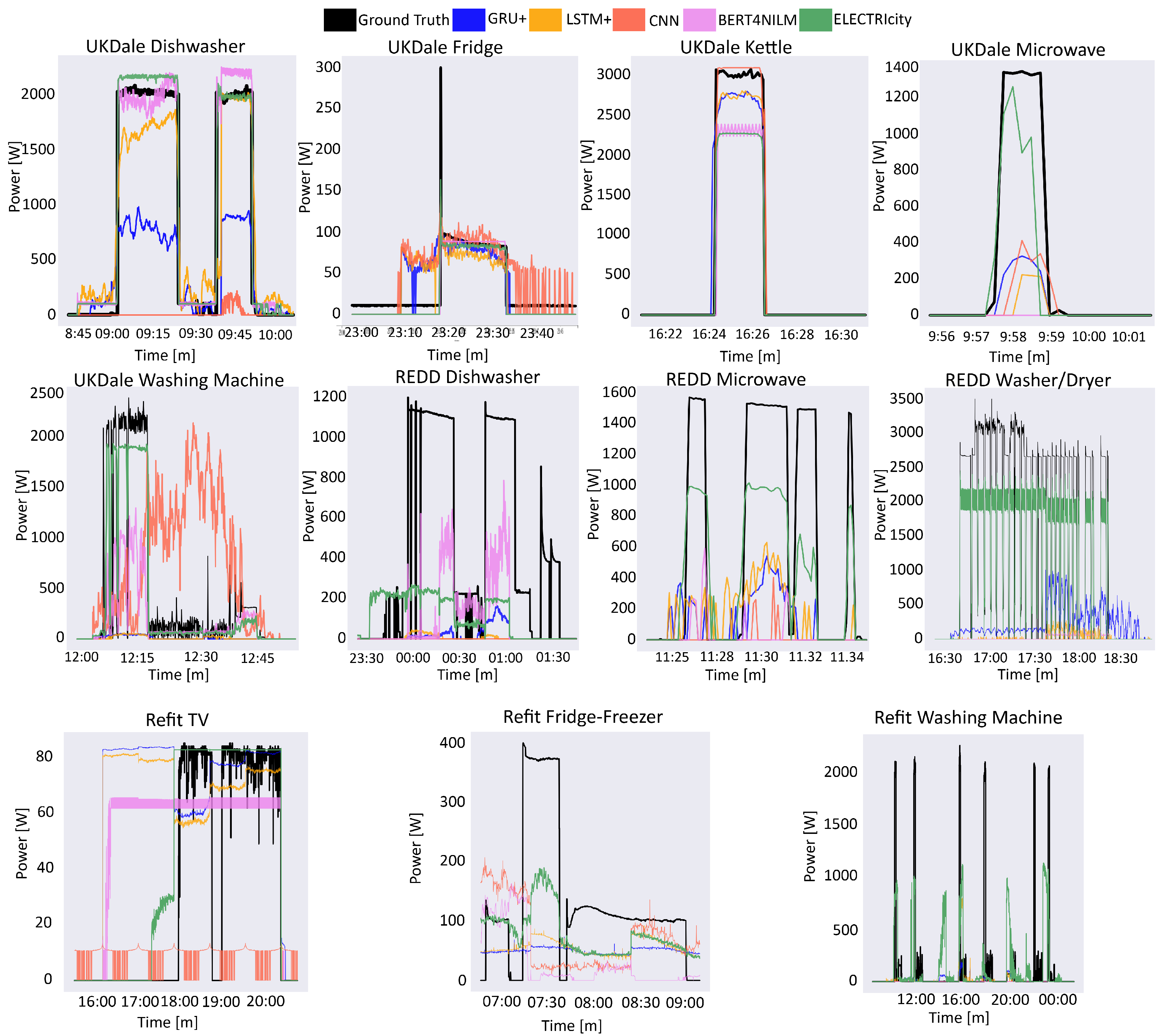
4.2. Evaluation

| Device | Model | MRE | MAE | MSE | Acc. | F1 | Training Time (min) |
|---|---|---|---|---|---|---|---|
| Washer | GRU+ [31] | 0.028 | 35.83 | 87,742.33 | 0.985 | 0.576 | 2.94 |
| LSTM+ [31] | 0.026 | 35.71 | 89,855.09 | 0.983 | 0.490 | 3.08 | |
| CNN [32,33] | 0.020 | 35.78 | 94,248.61 | 0.982 | 0.000 | 3.80 | |
| BERT4NILM [4] | 0.021 | 35.79 | 93,217.72 | 0.990 | 0.190 | 59.01 | |
| ELECTRIcity | 0.016 | 23.07 | 44,615.35 | 0.998 | 0.903 | 35.14 | |
| Microwave | GRU+ [31] | 0.061 | 18.97 | 23,352.36 | 0.983 | 0.382 | 1.89 |
| LSTM+ [31] | 0.060 | 18.91 | 24,016.75 | 0.983 | 0.336 | 1.53 | |
| CNN [32,33] | 0.056 | 18.07 | 24,653.65 | 0.987 | 0.336 | 2.22 | |
| BERT4NILM [4] | 0.055 | 16.97 | 22,761.11 | 0.989 | 0.474 | 27.72 | |
| ELECTRIcity | 0.057 | 16.41 | 17,001.33 | 0.989 | 0.610 | 16.49 | |
| Dishwasher | GRU+ [31] | 0.049 | 24.91 | 22,065.08 | 0.962 | 0.341 | 2.76 |
| LSTM+ [31] | 0.050 | 25.09 | 22,297.01 | 0.961 | 0.350 | 2.98 | |
| CNN [32,33] | 0.041 | 25.28 | 23,454.64 | 0.962 | 0.000 | 4.45 | |
| BERT4NILM [4] | 0.038 | 19.67 | 15,488.62 | 0.974 | 0.580 | 59.24 | |
| ELECTRIcity | 0.051 | 24.06 | 19,853.05 | 0.968 | 0.601 | 35.08 |
| Device | Model | MRE | MAE | MSE | Acc. | F1 | Training Time (min) |
|---|---|---|---|---|---|---|---|
| Washer | GRU+ [31] | 0.089 | 24.60 | 31,082.49 | 0.929 | 0.128 | 17.95 |
| LSTM+ [31] | 0.098 | 25.76 | 32,958.09 | 0.920 | 0.130 | 22.86 | |
| CNN [32,33] | 0.096 | 23.58 | 29,383.90 | 0.924 | 0.248 | 28.62 | |
| BERT4NILM [4] | 0.080 | 22.19 | 27,420.48 | 0.939 | 0.188 | 813.25 | |
| ELECTRIcity | 0.089 | 23.67 | 26,465.39 | 0.936 | 0.398 | 217.32 | |
| TV | GRU+ [31] | 0.619 | 38.36 | 2539.97 | 0.410 | 0.370 | 26.51 |
| LSTM+ [31] | 0.657 | 39.35 | 2467.22 | 0.374 | 0.357 | 32.59 | |
| CNN [32,33] | 0.776 | 19.52 | 980.39 | 0.352 | 0.318 | 41.17 | |
| BERT4NILM [4] | 0.593 | 32.15 | 1769.43 | 0.452 | 0.381 | 1280.10 | |
| ELECTRIcity | 0.278 | 19.29 | 1375.13 | 0.740 | 0.505 | 316.10 | |
| Fridge-Freezer | GRU+ [31] | 0.756 | 56.17 | 4773.60 | 0.552 | 0.710 | 17.95 |
| LSTM+ [31] | 0.730 | 54.92 | 4567.50 | 0.551 | 0.710 | 22.86 | |
| CNN [32,33] | 0.686 | 58.15 | 5660.37 | 0.561 | 0.713 | 28.62 | |
| BERT4NILM [4] | 0.587 | 50.16 | 5437.78 | 0.623 | 0.674 | 813.25 | |
| ELECTRIcity | 0.586 | 51.08 | 5331.71 | 0.613 | 0.668 | 217.32 |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kaselimi, M.; Doulamis, N.; Voulodimos, A.; Protopapadakis, E.; Doulamis, A. Context Aware Energy Disaggregation Using Adaptive Bidirectional LSTM Models. IEEE Trans. Smart Grid 2020, 11, 3054–3067. [Google Scholar] [CrossRef]
- Kaselimi, M.; Doulamis, N.; Doulamis, A.; Voulodimos, A.; Protopapadakis, E. Bayesian-optimized Bidirectional LSTM Regression Model for Non-intrusive Load Monitoring. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2747–2751. [Google Scholar] [CrossRef]
- Harell, A.; Makonin, S.; Bajić, I. Wavenilm: A Causal Neural Network for Power Disaggregation from the Complex Power Signal. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8335–8339. [Google Scholar]
- Yue, Z.; Witzig, C.R.; Jorde, D.; Jacobsen, H.A. BERT4NILM: A Bidirectional Transformer Model for Non-Intrusive Load Monitoring. In Proceedings of the 5th International Workshop on Non-Intrusive Load Monitoring, NILM’20, Virtual Event, Japan, 18 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 89–93. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Kelly, J.; Knottenbelt, W. Neural NILM: Deep Neural Networks Applied to Energy Disaggregation. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, Seoul, Korea, 4–5 November 2015. [Google Scholar]
- Huber, P.; Calatroni, A.; Rumsch, A.; Paice, A. Review on Deep Neural Networks Applied to Low-Frequency NILM. Energies 2021, 14, 2390. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Murray, D.; Stankovic, L.; Stankovic, V.; Lulic, S.; Sladojevic, S. Transferability of Neural Network Approaches for Low-rate Energy Disaggregation. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8330–8334. [Google Scholar] [CrossRef]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Çavdar, İ.H.; Faryad, V. New design of a supervised energy disaggregation model based on the deep neural network for a smart grid. Energies 2019, 12, 1217. [Google Scholar] [CrossRef] [Green Version]
- Kaselimi, M.; Protopapadakis, E.; Voulodimos, A.; Doulamis, N.; Doulamis, A. Multi-channel recurrent convolutional neural networks for energy disaggregation. IEEE Access 2019, 7, 81047–81056. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and Composing Robust Features with Denoising Autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 1096–1103. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, U.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sukhbaatar, S.; Szlam, A.D.; Weston, J.; Fergus, R. Weakly Supervised Memory Networks. arXiv 2015, arXiv:1503.08895. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-Attention with Relative Position Representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Liu, H.; Liu, C.; Tian, L.; Zhao, H.; Liu, J. Non-intrusive Load Disaggregation Based on Deep Learning and Multi-feature Fusion. In Proceedings of the 2021 3rd International Conference on Smart Power Internet Energy Systems (SPIES), Beijing, China, 27–30 October 2021; pp. 210–215. [Google Scholar] [CrossRef]
- Hart, G.W. Nonintrusive appliance load monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 1412–1421. [Google Scholar] [CrossRef] [Green Version]
- Hendrycks, D.; Gimpel, K. Bridging Nonlinearities and Stochastic Regularizers with Gaussian Error Linear Units. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Clark, K.; Luong, M.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Kelly, J.; Knottenbelt, W. The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes. Sci. Data 2015, 2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kolter, J.Z.; Johnson, M.J. REDD: A Public Data Set for Energy Disaggregation Research. In Workshop on Data Mining Applications in Sustainability (SIGKDD); SIGKDD: San Diego, CA, USA, 2011. [Google Scholar]
- Murray, D.; Stankovic, L.; Stankovic, V. An electrical load measurements dataset of United Kingdom households from a two-year longitudinal study. Sci. Data 2017, 4, 160122. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rafiq, H.; Zhang, H.; Li, H.; Ochani, M.K. Regularized LSTM Based Deep Learning Model: First Step towards Real-Time Non-Intrusive Load Monitoring. In Proceedings of the 2018 IEEE International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–15 August 2018; pp. 234–239. [Google Scholar]
- Zhang, C.; Zhong, M.; Wang, Z.; Goddard, N.; Sutton, C. Sequence-to-point learning with neural networks for nonintrusive load monitoring. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Batra, N.; Kelly, J.; Parson, O.; Dutta, H.; Knottenbelt, W.; Rogers, A.; Singh, A.; Srivastava, M. NILMTK: An Open Source Toolkit for Non-intrusive Load Monitoring. In Proceedings of the 5th International Conference on Future Energy Systems, Cambridge, UK, 11–13 June 2014; ACM: New York, NY, USA, 2014. [Google Scholar] [CrossRef] [Green Version]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

| Appliance | Max. Limit | On Thres. | Min. on Duration [s] | Min. off Duration [s] | |
|---|---|---|---|---|---|
| Washer | 500 | 20 | 1800 | 160 | |
| Microwave | 1 | 1800 | 200 | 12 | 30 |
| Dishwasher | 1 | 1200 | 10 | 1800 | 1800 |
| Fridge | 300 | 50 | 60 | 12 | |
| Washer | 2500 | 20 | 1800 | 160 | |
| Microwave | 1 | 3000 | 200 | 12 | 30 |
| Dishwasher | 1 | 2500 | 10 | 1800 | 1800 |
| Kettle | 1 | 3100 | 2000 | 12 | 0 |
| Washer | 2500 | 20 | 70 | 182 | |
| TV | 1.5 | 80 | 10 | 14 | 0 |
| Fridge-Freezer | 1700 | 5 | 70 | 14 |
| Device | Model | MRE | MAE | MSE | Acc. | F1 | Training Time (min) |
|---|---|---|---|---|---|---|---|
| Kettle | GRU+ [31] | 0.004 | 12.38 | 28,649.73 | 0.996 | 0.799 | 40.67 |
| LSTM+ [31] | 0.004 | 11.78 | 28,428.10 | 0.997 | 0.800 | 34.70 | |
| CNN [32,33] | 0.002 | 6.92 | 16,730.81 | 0.998 | 0.889 | 51.87 | |
| BERT4NILM [4] | 0.003 | 9.80 | 16,291.56 | 0.998 | 0.912 | 697.87 | |
| ELECTRIcity | 0.003 | 9.26 | 13,301.43 | 0.999 | 0.939 | 294.37 | |
| Fridge | GRU+ [31] | 0.797 | 31.47 | 1966.50 | 0.750 | 0.673 | 33.35 |
| LSTM+ [31] | 0.813 | 32.36 | 2058.13 | 0.748 | 0.661 | 34.67 | |
| CNN [32,33] | 0.726 | 30.46 | 1797.54 | 0.718 | 0.686 | 44.43 | |
| BERT4NILM [4] | 0.683 | 20.17 | 1087.36 | 0.859 | 0.831 | 687.12 | |
| ELECTRIcity | 0.706 | 22.61 | 1213.61 | 0.843 | 0.810 | 428.79 | |
| Washer | GRU+ [31] | 0.056 | 21.90 | 27,199.96 | 0.950 | 0.228 | 33.06 |
| LSTM+ [31] | 0.055 | 23.42 | 32,729.26 | 0.950 | 0.221 | 34.14 | |
| CNN [32,33] | 0.023 | 15.41 | 25,223.21 | 0.984 | 0.518 | 44.46 | |
| BERT4NIMLM [4] | 0.012 | 4.09 | 4369.72 | 0.994 | 0.775 | 687.74 | |
| ELECTRIcity | 0.011 | 3.65 | 2789.35 | 0.994 | 0.797 | 462.95 | |
| Microwave | GRU+ [31] | 0.015 | 7.16 | 8464.09 | 0.994 | 0.131 | 35.18 |
| LSTM+ [31] | 0.014 | 6.60 | 7917.85 | 0.995 | 0.207 | 37.05 | |
| CNN [32,33] | 0.014 | 6.44 | 7899.43 | 0.995 | 0.193 | 47.32 | |
| BERT4NILM [4] | 0.014 | 6.53 | 8148.81 | 0.995 | 0.049 | 755.58 | |
| ELECTRIcity | 0.013 | 6.28 | 7594.23 | 0.996 | 0.277 | 518.93 | |
| Dishwasher | GRU+ [31] | 0.035 | 28.60 | 43,181.30 | 0.975 | 0.722 | 44.31 |
| LSTM+ [31] | 0.036 | 28.75 | 42,333.18 | 0.975 | 0.727 | 47.48 | |
| CNN [32,33] | 0.051 | 41.44 | 80,292.31 | 0.960 | 0.087 | 56.99 | |
| BERT4NILM [4] | 0.026 | 14.11 | 14,676.17 | 0.982 | 0.804 | 859.87 | |
| ELECTRIcity | 0.028 | 18.96 | 24,152.70 | 0.984 | 0.818 | 462.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sykiotis, S.; Kaselimi, M.; Doulamis, A.; Doulamis, N. ELECTRIcity: An Efficient Transformer for Non-Intrusive Load Monitoring. Sensors 2022, 22, 2926. https://doi.org/10.3390/s22082926
Sykiotis S, Kaselimi M, Doulamis A, Doulamis N. ELECTRIcity: An Efficient Transformer for Non-Intrusive Load Monitoring. Sensors. 2022; 22(8):2926. https://doi.org/10.3390/s22082926
Chicago/Turabian StyleSykiotis, Stavros, Maria Kaselimi, Anastasios Doulamis, and Nikolaos Doulamis. 2022. "ELECTRIcity: An Efficient Transformer for Non-Intrusive Load Monitoring" Sensors 22, no. 8: 2926. https://doi.org/10.3390/s22082926
APA StyleSykiotis, S., Kaselimi, M., Doulamis, A., & Doulamis, N. (2022). ELECTRIcity: An Efficient Transformer for Non-Intrusive Load Monitoring. Sensors, 22(8), 2926. https://doi.org/10.3390/s22082926