
Recent Advances in Vision-Based On-Road Behaviors Understanding: A Critical Survey

 ,
,  , ,
, , 
Abstract
:1. Introduction
- We present the first-ever background information on our foreground topic, RBA, and do this by providing the reader with all the required information, theoretical concepts, and keywords to read the remainder of the survey and boost their attention to the approaches we are going to point out;
- We link fragmented tasks related to vision-based RBA in a coherent context so that the reader can understand the complementary relationships between all the elementary aspects and makes use of them in order to achieve a holistic RBA;
- We identify common concepts and features adopted by the milestone and the recent approaches so that we can draw fair comparisons and critics;
- We stress the contribution of deep neural networks approaches by categorizing all the reviewed papers depending on the kind of the meta-architecture used;
- We present a comprehensive comparison for all the recent publicly available datasets and we list all the metrics used in the state-of-the-art to assess the performance of RBA-related tasks;
- Critical analysis of the overall topic is finally elaborated, leading us to draw consistent future directions.
2. Related Reviews
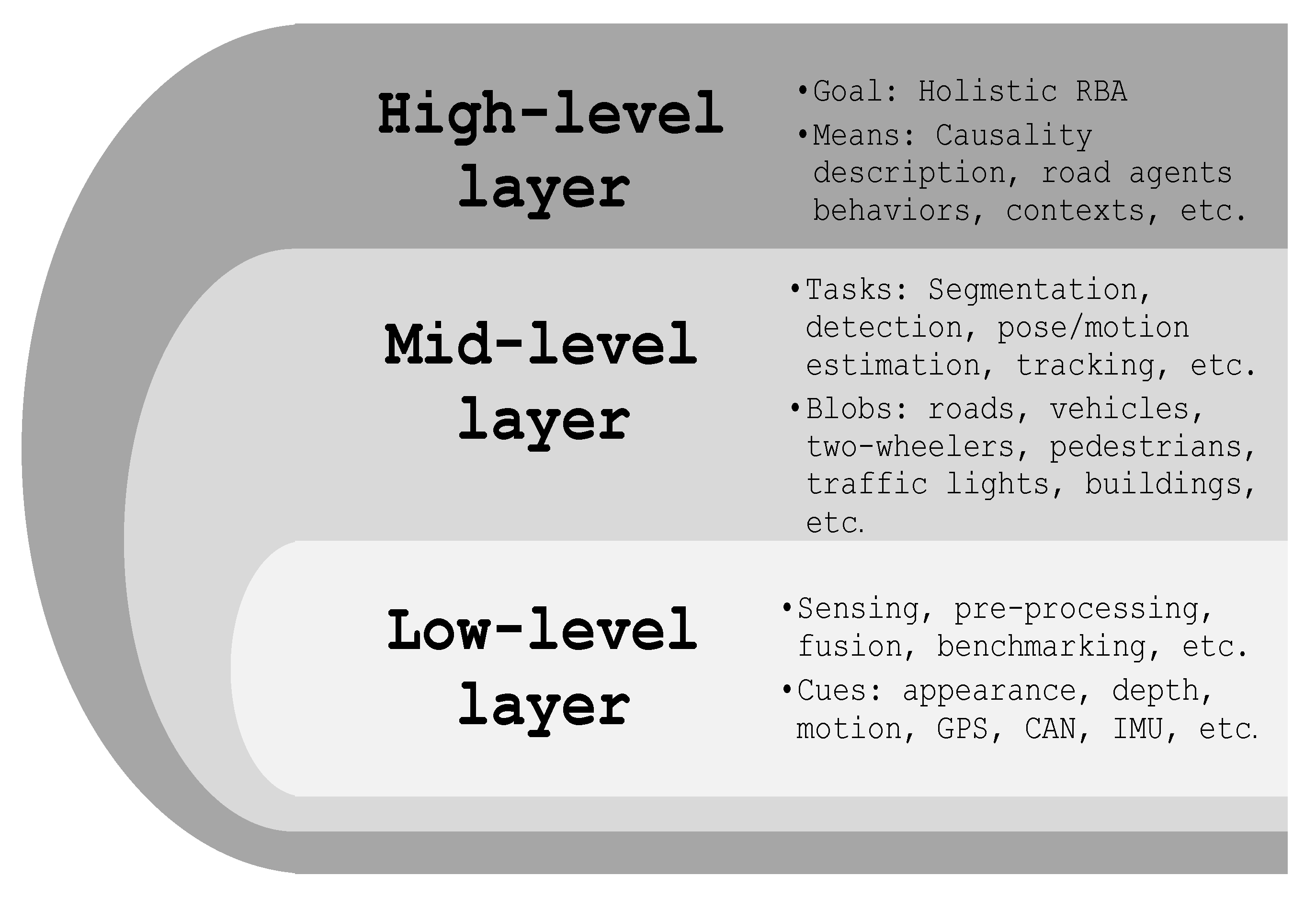
3. Importance and Challenges of On-Road Behaviors Analysis
4. RBA Components and Milestones over the Last 20 Years
4.1. Situational Awareness
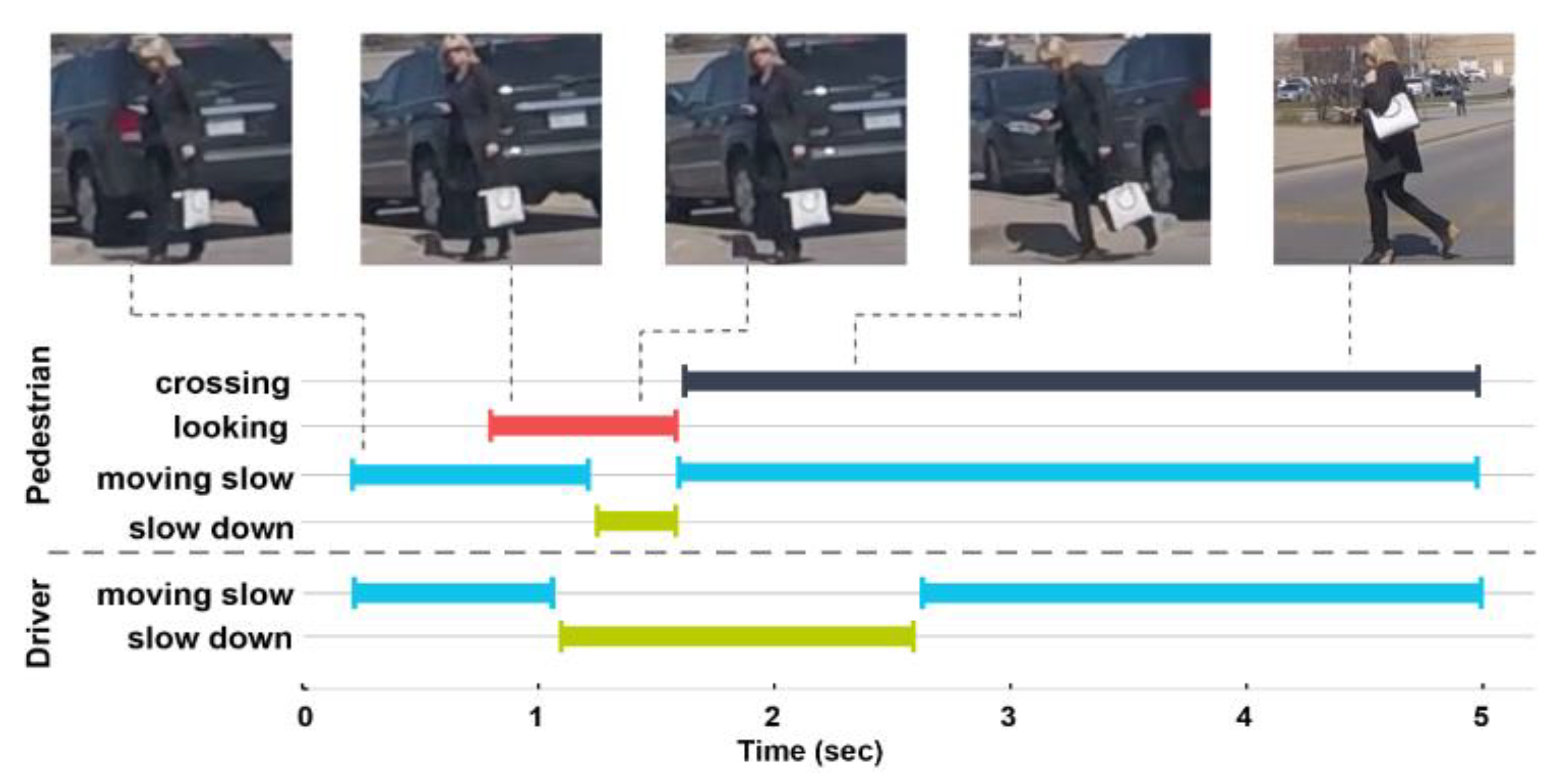
4.2. Driver-Road Interaction
4.3. Road Scene Understanding
4.4. Trajectories Forecast
4.5. Driving Activities and Status Analysis
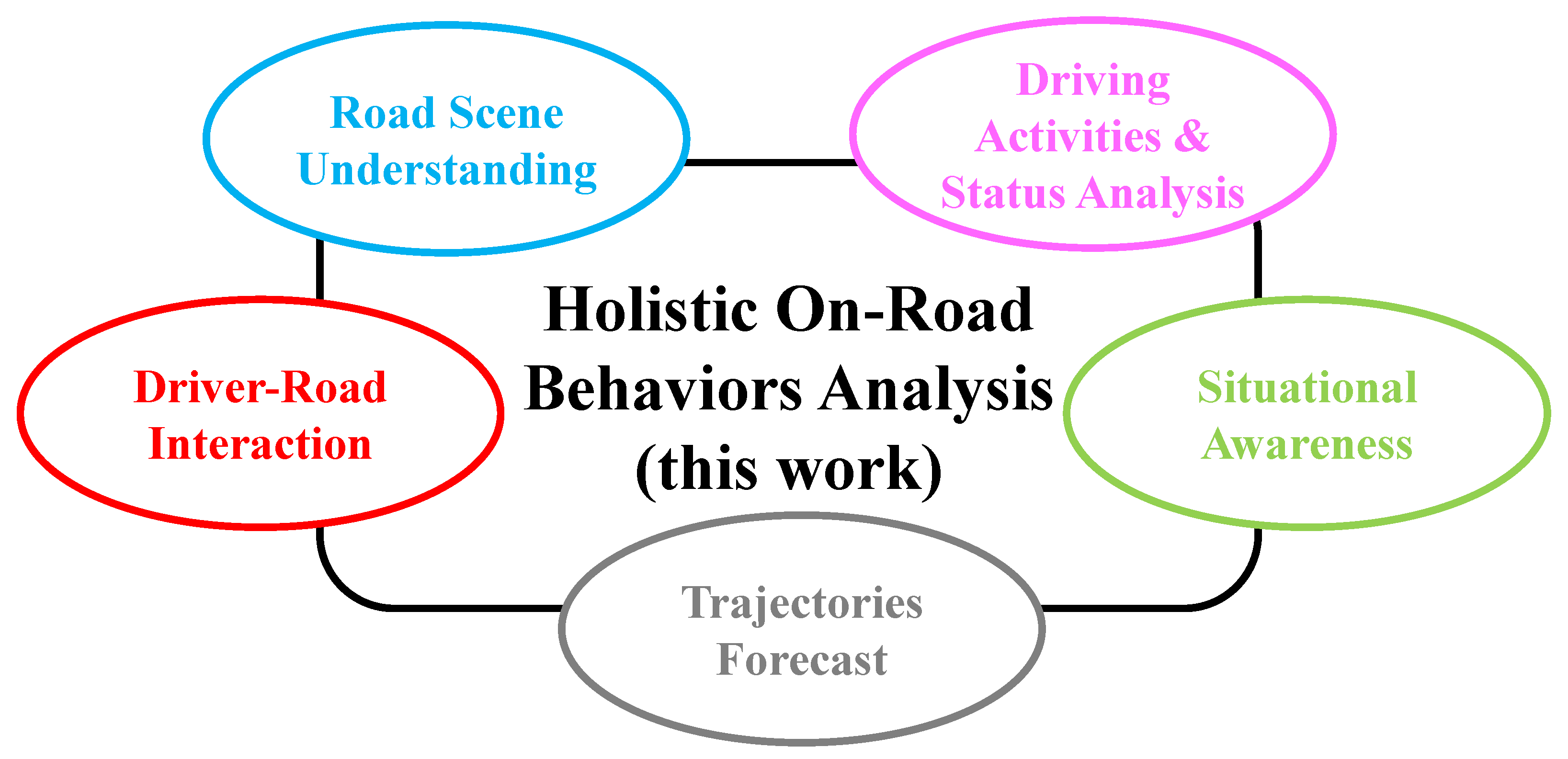
4.6. Holistic Understanding
5. Deep Learning Solutions
5.1. Deep Convolutional Neural Networks
5.2. Deep Recurrent Neural Networks
6. Benchmarks: Datasets and Metrics
6.1. Datasets
6.2. Metrics
7. Discussion and Future Directions
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADAS | Advanced Driver Assistance System |
| AV | Autonomous Vehicles |
| RBA | Road Behavior Understanding |
| ASIRT | Association for Safe International Road Travel |
| ITS | Intelligent Transportation System |
| CNN | Convolutional Neural Network |
| JAAD | Joint Attention in Autonomous Driving |
| HDD | Honda Research Institute Driving Dataset |
| GCN | Graph Convolutional Networks |
| mAP | mean Average Precision |
| RNN | Recurrent Neural Network |
| HMM | Hidden Markov Model |
| CA | Class Accuracy |
| MIoU | Mean Intersection over Union |
| OVD | Occluded Vehicle Dataset |
| ICP | Inception Conditional Probability |
| SS | Segmentation Score |
| ADE | Average Distance Error |
| FDE | Final Distance Error |
| LSTM | Long Short-Term Memory |
| DBUS | Driving Behavior Understanding System |
| ADMD | Attention-driven Driving Maneuver Detection |
| ILSVRC | ImageNet Large Scale Visual Recognition Challenge |
| GAP | Global Average Pooling |
| GCN | Graph Convolutional Networks |
| FCN | Fully Convolutional Networks |
| FC | Fully Connected |
| MLP | Multi Layer Perceptron |
| RNN | Recurrent Neural Networks |
| GRU | Gated Recurrent Units |
| GRFU | Gated Recurrent Fusion Units |
| LRS | Late Recurrent Summation |
| EGRF | Early Gated Recurrent Fusion |
| LGRG | Late Gated Recurrent State Fusion |
| BDDV | Berkeley DeepDrive Video dataset |
| DBNet | Driving Behavior Net |
| HAD | Honda Research Institute-Advice Dataset |
| nuScenes | nuTonomy scenes |
| AP | Average Precision |
| VOC | Visual Object Classes |
| IoU | Intersection over Union |
| MOTP | Multiple Object Tracking Precision |
| MOTA | Multiple Object Tracking Accuracy |
| TID | Track Initialization Duration |
| LGD | Longest Gap Duration |
| NDS | NuScenes Detection Score |
| TP | True Positive |
| SS | Segmentation Score |
| FDE | Final Distance Error |
| RMSE | Root Mean Square Error |
| DP | Driving Perplexity |
References
- Xique, I.J.; Buller, W.; Fard, Z.B.; Dennis, E.; Hart, B. Evaluating Complementary Strengths and Weaknesses of ADAS Sensors. In Proceedings of the 2018 IEEE 88th Vehicular Technology Conference (VTC-Fall), Chicago, IL, USA, 27–30 August 2018; pp. 1–5. [Google Scholar]
- Hu, H.N.; Cai, Q.Z.; Wang, D.; Lin, J.; Sun, M.; Krahenbuhl, P.; Darrell, T.; Yu, F. Joint Monocular 3D Vehicle Detection and Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5390–5399. [Google Scholar]
- Bresson, G.; Alsayed, Z.; Yu, L.; Glaser, S. Simultaneous localization and mapping: A survey of current trends in autonomous driving. IEEE Trans. Intell. Veh. 2017, 2, 194–220. [Google Scholar] [CrossRef] [Green Version]
- Santhosh, K.K.; Dogra, D.P.; Roy, P.P. Temporal unknown incremental clustering model for analysis of traffic surveillance videos. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1762–1773. [Google Scholar] [CrossRef] [Green Version]
- Luckow, A.; Cook, M.; Ashcraft, N.; Weill, E.; Djerekarov, E.; Vorster, B. Deep learning in the automotive industry: Applications and tools. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 3759–3768. [Google Scholar]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2019, 51, 92. [Google Scholar] [CrossRef]
- Talpaert, V.; Sobh, I.; Kiran, B.R.; Mannion, P.; Yogamani, S.; El-Sallab, A.; Perez, P. Exploring applications of deep reinforcement learning for real-world autonomous driving systems. arXiv 2019, arXiv:1901.01536. [Google Scholar]
- Chao, Q.; Bi, H.; Li, W.; Mao, T.; Wang, Z.; Lin, M.C.; Deng, Z. A survey on visual traffic simulation: Models, evaluations, and applications in autonomous driving. Comput. Graph. Forum 2019, 39, 287–308. [Google Scholar] [CrossRef]
- Sivaraman, S.; Trivedi, M.M. Looking at vehicles on the road: A survey of vision-based vehicle detection, tracking, and behavior analysis. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1773–1795. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Ma, L.; Zhao, J. Secure Deep Learning Engineering: A Road Towards Quality Assurance of Intelligent Systems. In Proceedings of the International Conference on Formal Engineering Methods, Shenzhen, China, 5–9 November 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 3–15. [Google Scholar]
- Kendall, A.; Hawke, J.; Janz, D.; Mazur, P.; Reda, D.; Allen, J.M.; Lam, V.D.; Bewley, A.; Shah, A. Learning to drive in a day. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8248–8254. [Google Scholar]
- Ngai, D.C.K.; Yung, N.H.C. A multiple-goal reinforcement learning method for complex vehicle overtaking maneuvers. IEEE Trans. Intell. Transp. Syst. 2011, 12, 509–522. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Chan, C.Y. Formulation of deep reinforcement learning architecture toward autonomous driving for on-ramp merge. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Samek, W.; Wiegand, T.; Müller, K.R. Explainable artificial intelligence: Understanding, visualizing and interpreting deep learning models. arXiv 2017, arXiv:1708.08296. [Google Scholar]
- Yan, X.; Wang, F.; Liu, W.; Yu, Y.; He, S.; Pan, J. Visualizing the Invisible: Occluded Vehicle Segmentation and Recovery. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7618–7627. [Google Scholar]
- Peng, X.; Zhao, A.; Wang, S.; Murphey, Y.L.; Li, Y. Attention-Driven Driving Maneuver Detection System. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Rasouli, A.; Kotseruba, I.; Tsotsos, J.K. Are they going to cross? A benchmark dataset and baseline for pedestrian crosswalk behavior. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 206–213. [Google Scholar]
- Kooij, J.F.P.; Schneider, N.; Flohr, F.; Gavrila, D.M. Context-based pedestrian path prediction. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 618–633. [Google Scholar]
- Meinecke, M.M.; Obojski, M.; Gavrila, D.; Marc, E.; Morris, R.; Tons, M.; Letellier, L. Strategies in terms of vulnerable road user protection. EU Proj. SAVE-U Deliv. D 2003, 6, 2003. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Ramanishka, V.; Chen, Y.T.; Misu, T.; Saenko, K. Toward driving scene understanding: A dataset for learning driver behavior and causal reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Istanbul, Turkey, 30–31 January 2018; pp. 7699–7707. [Google Scholar]
- Li, C.; Meng, Y.; Chan, S.H.; Chen, Y.T. Learning 3D-aware Egocentric Spatial-Temporal Interaction via Graph Convolutional Networks. arXiv 2019, arXiv:1909.09272. [Google Scholar]
- Wu, J.; Wang, L.; Wang, L.; Guo, J.; Wu, G. Learning Actor Relation Graphs for Group Activity Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 9964–9974. [Google Scholar]
- Oliver, N.; Pentland, A.P. Graphical models for driver behavior recognition in a smartcar. In Proceedings of the IEEE Intelligent Vehicles Symposium 2000 (Cat. No. 00TH8511), Dearborn, MI, USA, 5 October 2000; pp. 7–12. [Google Scholar]
- Singh, D.; Mohan, C.K. Deep spatio-temporal representation for detection of road accidents using stacked autoencoder. IEEE Trans. Intell. Transp. Syst. 2018, 20, 879–887. [Google Scholar] [CrossRef]
- Hu, X.; Xu, X.; Xiao, Y.; Chen, H.; He, S.; Qin, J.; Heng, P.A. SINet: A scale-insensitive convolutional neural network for fast vehicle detection. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1010–1019. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Gong, C.; Yang, J. Importance-aware semantic segmentation for autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2018, 20, 137–148. [Google Scholar] [CrossRef]
- Aly, M. Real time detection of lane markers in urban streets. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 7–12. [Google Scholar]
- Gong, J.; Jiang, Y.; Xiong, G.; Guan, C.; Tao, G.; Chen, H. The recognition and tracking of traffic lights based on color segmentation and camshift for intelligent vehicles. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2010; pp. 431–435. [Google Scholar]
- Gavrila, D.M.; Giebel, J.; Munder, S. Vision-based pedestrian detection: The PROTECTOR system. In Proceedings of the IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 13–18. [Google Scholar]
- Zhou, W.; Lv, S.; Jiang, Q.; Yu, L. Deep Road Scene Understanding. IEEE Signal Process. Lett. 2019, 26, 587–591. [Google Scholar] [CrossRef]
- Fauqueur, J.; Brostow, G.; Cipolla, R. Assisted video object labeling by joint tracking of regions and keypoints. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–7. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Brust, C.A.; Sickert, S.; Simon, M.; Rodner, E.; Denzler, J. Convolutional Patch Networks with Spatial Prior for Road Detection and Urban Scene Understanding. arXiv 2015, arXiv:1502.06344. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 18–20 June 2012; pp. 3354–3361. [Google Scholar]
- Frohlich, B.; Rodner, E.; Denzler, J. A fast approach for pixelwise labeling of facade images. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3029–3032. [Google Scholar]
- Choi, C.; Patil, A.; Malla, S. Drogon: A causal reasoning framework for future trajectory forecast. arXiv 2019, arXiv:1908.00024. [Google Scholar]
- Chandra, R.; Bhattacharya, U.; Bera, A.; Manocha, D. Traphic: Trajectory prediction in dense and heterogeneous traffic using weighted interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8483–8492. [Google Scholar]
- US Department of Transportation. NGSIM—Next Generation Simulation. 2007. Available online: https://ops.fhwa.dot.gov/trafficanalysistools/ngsim.htm (accessed on 1 January 2020).
- Chandra, R.; Bhattacharya, U.; Mittal, T.; Li, X.; Bera, A.; Manocha, D. GraphRQI: Classifying Driver Behaviors Using Graph Spectrums. arXiv 2019, arXiv:1910.00049. [Google Scholar]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3D Tracking and Forecasting with Rich Maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8748–8757. [Google Scholar]
- Narayanan, A.; Dwivedi, I.; Dariush, B. Dynamic Traffic Scene Classification with Space-Time Coherence. arXiv 2019, arXiv:1905.12708. [Google Scholar]
- Narayanan, A.; Siravuru, A.; Dariush, B. Temporal Multimodal Fusion for Driver Behavior Prediction Tasks using Gated Recurrent Fusion Units. arXiv 2019, arXiv:1910.00628. [Google Scholar]
- Taha, A.; Chen, Y.T.; Misu, T.; Davis, L. In Defense of the Triplet Loss for Visual Recognition. arXiv 2019, arXiv:1901.08616. [Google Scholar]
- Guangyu Li, M.; Jiang, B.; Che, Z.; Shi, X.; Liu, M.; Meng, Y.; Ye, J.; Liu, Y. DBUS: Human Driving Behavior Understanding System. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, Y.; Wang, J.; Li, J.; Lu, C.; Luo, Z.; Han, X.; Wang, C. LiDAR-Video Driving Dataset: Learning Driving Policies Effectively. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5870–5878. [Google Scholar]
- Jain, A.; Koppula, H.S.; Raghavan, B.; Soh, S.; Saxena, A. Car that knows before you do: Anticipating maneuvers via learning temporal driving models. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3182–3190. [Google Scholar]
- Bengio, Y.; Frasconi, P. An input output HMM architecture. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 November 1995; pp. 427–434. [Google Scholar]
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-to-end learning of driving models from large-scale video datasets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 2174–2182. [Google Scholar]
- Hong, J.; Sapp, B.; Philbin, J. Rules of the Road: Predicting Driving Behavior with a Convolutional Model of Semantic Interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8454–8462. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Mauri, A.; Khemmar, R.; Decoux, B.; Ragot, N.; Rossi, R.; Trabelsi, R.; Boutteau, R.; Ertaud, J.Y.; Savatier, X. Deep learning for real-time 3D multi-object detection, localisation, and tracking: Application to smart mobility. Sensors 2020, 20, 532. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–15 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Siam, M.; Gamal, M.; Abdel-Razek, M.; Yogamani, S.; Jagersand, M.; Zhang, H. A comparative study of real-time semantic segmentation for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 587–597. [Google Scholar]
- Yi, L.; Su, H.; Guo, X.; Guibas, L.J. Syncspeccnn: Synchronized spectral cnn for 3d shape segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2282–2290. [Google Scholar]
- Xu, H.; Das, A.; Saenko, K. R-c3d: Region convolutional 3d network for temporal activity detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5783–5792. [Google Scholar]
- Liu, Y.C.; Hsieh, Y.A.; Chen, M.H.; Yang, C.H.H.; Tegner, J.; Tsai, Y.C.J. Interpretable Self-Attention Temporal Reasoning for Driving Behavior Understanding. arXiv 2019, arXiv:1911.02172. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Lee, S.; Kim, J.; Oh, T.H.; Jeong, Y.; Yoo, D.; Lin, S.; Kweon, I.S. Visuomotor Understanding for Representation Learning of Driving Scenes. arXiv 2019, arXiv:1909.06979. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Zhu, X.; Sobihani, P.; Guo, H. Long short-term memory over recursive structures. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1604–1612. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Friard, O.; Gamba, M. BORIS: A free, versatile open-source event-logging software for video/audio coding and live observations. Methods Ecol. Evol. 2016, 7, 1325–1330. [Google Scholar] [CrossRef]
- Kim, J.; Misu, T.; Chen, Y.T.; Tawari, A.; Canny, J. Grounding Human-To-Vehicle Advice for Self-Driving Vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10591–10599. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3d object representations for fine-grained categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013; pp. 554–561. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. arXiv 2019, arXiv:1903.11027. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2007/workshop/index.html (accessed on 1 December 2020).
- Weng, X.; Kitani, K. A baseline for 3d multi-object tracking. arXiv 2019, arXiv:1907.03961. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 961–971. [Google Scholar]
- Ma, X.; Zhang, T.; Xu, C. Deep Multi-Modality Adversarial Networks for Unsupervised Domain Adaptation. IEEE Trans. Multimed. 2019, 21, 2419–2431. [Google Scholar] [CrossRef]
- PRESS KIT VALEO at CES 2020. Valeo Innovations at the Epicenter of Transformations in Mobility. 2020. Available online: https://www.valeo.com/wp-content/uploads/2020/01/PK_Valeo_CES_2020_ENG-1.pdf (accessed on 31 January 2020).
- Li, J.; Liu, X.; Zhang, W.; Zhang, M.; Song, J.; Sebe, N. Spatio-Temporal Attention Networks for Action Recognition and Detection. IEEE Trans. Multimed. 2020, 22, 2990–3001. [Google Scholar] [CrossRef]
- Liu, J.; Zha, Z.J.; Chen, X.; Wang, Z.; Zhang, Y. Dense 3D-convolutional neural network for person re-identification in videos. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2019, 15, 1–19. [Google Scholar] [CrossRef]
- Trabelsi, R.; Varadarajan, J.; Zhang, L.; Jabri, I.; Pei, Y.; Smach, F.; Bouallegue, A.; Moulin, P. Understanding the Dynamics of Social Interactions: A Multi-Modal Multi-View Approach. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2019, 15, 1–16. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Wittenburg, P.; Brugman, H.; Russel, A.; Klassmann, A.; Sloetjes, H. ELAN: A professional framework for multimodality research. In Proceedings of the 5th International Conference on Language Resources and Evaluation (LREC 2006), Genoa, Italy, 22–28 May 2006; pp. 1556–1559. [Google Scholar]
- Niitani, Y.; Akiba, T.; Kerola, T.; Ogawa, T.; Sano, S.; Suzuki, S. Sampling Techniques for Large-Scale Object Detection From Sparsely Annotated Objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2019; pp. 6510–6518. [Google Scholar]
- Bolte, J.A.; Bar, A.; Lipinski, D.; Fingscheidt, T. Towards corner case detection for autonomous driving. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 438–445. [Google Scholar]
- Zhang, C.; Shang, B.; Wei, P.; Li, L.; Liu, Y.; Zheng, N. Building Explainable AI Evaluation for Autonomous Perception. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 16–20 June 2019; pp. 20–23. [Google Scholar]
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 year, 1000 km: The Oxford RobotCar dataset. Int. J. Robot. Res. 2017, 36, 3–15. [Google Scholar] [CrossRef]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. Deepdriving: Learning affordance for direct perception in autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2722–2730. [Google Scholar]
- Santana, E.; Hotz, G. Learning a driving simulator. arXiv 2016, arXiv:1608.01230. [Google Scholar]
- Udacity. Public Driving Dataset. 2017. Available online: https://www.udacity.com/self-driving-car (accessed on 27 November 2019).
- Madhavan, V.; Darrell, T. The BDD-Nexar Collective: A Large-Scale, Crowsourced, Dataset of Driving Scenes. Master’s Thesis, EECS Department, University of California, Berkeley, CA, USA, 2017. [Google Scholar]
- Koschorrek, P.; Piccini, T.; Öberg, P.; Felsberg, M.; Nielsen, L.; Mester, R. A multi-sensor traffic scene dataset with omnidirectional video. Ground Truth—What is a good dataset? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 727–734. [Google Scholar]
- Pandey, G.; McBride, J.R.; Eustice, R.M. Ford campus vision and lidar data set. Int. J. Robot. Res. 2011, 30, 1543–1552. [Google Scholar] [CrossRef]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Flohr, F.; Gavrila, D. PedCut: An iterative framework for pedestrian segmentation combining shape models and multiple data cues. In Proceedings of the 24th British Machine Vision Conference, BMVC, Bristol, UK, 9–13 September 2013; pp. 66.1–66.11. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: A benchmark. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 304–311. [Google Scholar]
- Patil, A.; Malla, S.; Gang, H.; Chen, Y.T. The H3D Dataset for Full-Surround 3D Multi-Object Detection and Tracking in Crowded Urban Scenes. In Proceedings of the International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 9552–9557. [Google Scholar]
- Yao, Y.; Xu, M.; Choi, C.; Crandall, D.J.; Atkins, E.M.; Dariush, B. Egocentric Vision-based Future Vehicle Localization for Intelligent Driving Assistance Systems. In Proceedings of the International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 9711–9717. [Google Scholar]
- Xu, M.; Gao, M.; Chen, Y.T.; Davis, L.S.; Crandall, D.J. Temporal recurrent networks for online action detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5532–5541. [Google Scholar]
- Chang, W.C.; Cho, C.W. Online boosting for vehicle detection. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2009, 40, 892–902. [Google Scholar] [CrossRef]
- Sivaraman, S.; Morris, B.; Trivedi, M. Learning multi-lane trajectories using vehicle-based vision. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 2070–2076. [Google Scholar]
- Cherng, S.; Fang, C.Y.; Chen, C.P.; Chen, S.W. Critical motion detection of nearby moving vehicles in a vision-based driver-assistance system. IEEE Trans. Intell. Transp. Syst. 2009, 10, 70–82. [Google Scholar] [CrossRef] [Green Version]
- Alonso, J.D.; Vidal, E.R.; Rotter, A.; Muhlenberg, M. Lane-change decision aid system based on motion-driven vehicle tracking. IEEE Trans. Veh. Technol. 2008, 57, 2736–2746. [Google Scholar] [CrossRef]
- Zhu, Y.; Comaniciu, D.; Pellkofer, M.; Koehler, T. Reliable detection of overtaking vehicles using robust information fusion. IEEE Trans. Intell. Transp. Syst. 2006, 7, 401–414. [Google Scholar] [CrossRef]
- Wang, J.; Bebis, G.; Miller, R. Overtaking vehicle detection using dynamic and quasi-static background modeling. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05)-Workshops, San Diego, CA, USA, 20–26 June 2005; p. 64. [Google Scholar]
- Barth, A.; Franke, U. Estimating the driving state of oncoming vehicles from a moving platform using stereo vision. IEEE Trans. Intell. Transp. Syst. 2009, 10, 560–571. [Google Scholar] [CrossRef]
- Rabe, C.; Franke, U.; Gehrig, S. Fast detection of moving objects in complex scenarios. In Proceedings of the 2007 IEEE Intelligent Vehicles Symposium, Istanbul, Turkey, 13–15 June 2007; pp. 398–403. [Google Scholar]
- Barth, A.; Franke, U. Tracking oncoming and turning vehicles at intersections. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Madeira Island, Portugal, 19–22 September 2010; pp. 861–868. [Google Scholar]
- Hermes, C.; Einhaus, J.; Hahn, M.; Wöhler, C.; Kummert, F. Vehicle tracking and motion prediction in complex urban scenarios. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2010; pp. 26–33. [Google Scholar]
- Taha, A.; Chen, Y.T.; Yang, X.; Misu, T.; Davis, L. Exploring Uncertainty in Conditional Multi-Modal Retrieval Systems. arXiv 2019, arXiv:1901.07702. [Google Scholar]
- Taha, A.; Meshry, M.; Yang, X.; Chen, Y.T.; Davis, L. Two stream self-supervised learning for action recognition. arXiv 2018, arXiv:1806.07383. [Google Scholar]
- Cui, Z.; Heng, L.; Yeo, Y.C.; Geiger, A.; Pollefeys, M.; Sattler, T. Real-time dense mapping for self-driving vehicles using fisheye cameras. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6087–6093. [Google Scholar]
- Wiest, J.; Höffken, M.; Kreßel, U.; Dietmayer, K. Probabilistic trajectory prediction with Gaussian mixture models. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Alcala de Henares, Spain, 3–7 June 2012; pp. 141–146. [Google Scholar]
- Qiu, Y.; Misu, T.; Busso, C. Driving Anomaly Detection with Conditional Generative Adversarial Network using Physiological and CAN-Bus Data. In Proceedings of the 2019 International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; pp. 164–173. [Google Scholar]
- Tawari, A.; Mallela, P.; Martin, S. Learning to Attend to Salient Targets in Driving Videos Using Fully Convolutional RNN. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3225–3232. [Google Scholar]
- Taha, A.; Chen, Y.T.; Misu, T.; Shrivastava, A.; Davis, L. Unsupervised Data Uncertainty Learning in Visual Retrieval Systems. arXiv 2019, arXiv:1902.02586. [Google Scholar]
- Zhao, B.; Luo, G. A New Causal Direction Reasoning Method for Decision Making on Noisy Data. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2471–2476. [Google Scholar]
- Dua, I.; Nambi, A.U.; Jawahar, C.; Padmanabhan, V. AutoRate: How attentive is the driver? In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar]
- Fontana, V.; Singh, G.; Akrigg, S.; Di Maio, M.; Saha, S.; Cuzzolin, F. Action Detection from a Robot-Car Perspective. arXiv 2018, arXiv:1807.11332. [Google Scholar]
- Misu, T.; Chen, Y.T. Toward Reasoning of Driving Behavior. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Maui, HI, USA, 4–7 November 2018; pp. 204–209. [Google Scholar]
- Nica, A.N.; Trascau, M.; Rotaru, A.A.; Andreescu, C.; Sorici, A.; Florea, A.M.; Bacue, V. Collecting and Processing a Self-Driving Dataset in the UPB Campus. In Proceedings of the 2019 22nd International Conference on Control Systems and Computer Science (CSCS), Bucharest, Romania, 28–30 May 2019; pp. 202–209. [Google Scholar]
- Martin, M.; Roitberg, A.; Haurilet, M.; Horne, M.; Reiß, S.; Voit, M.; Stiefelhagen, R. Drive&Act: A Multi-modal Dataset for Fine-grained Driver Behavior Recognition in Autonomous Vehicles. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2801–2810. [Google Scholar]
- Li, C.; Xu, M.; Du, X.; Wang, Z. Bridge the Gap Between VQA and Human Behavior on Omnidirectional Video: A Large-Scale Dataset and a Deep Learning Model. In Proceedings of the 26th ACM International Conference on Multimedia (MM’18), Seoul, Korea, 22–26 October 2018; pp. 932–940. [Google Scholar]
- Zhan, W.; Sun, L.; Wang, D.; Shi, H.; Clausse, A.; Naumann, M.; Kummerle, J.; Konigshof, H.; Stiller, C.; de La Fortelle, A.; et al. INTERACTION Dataset: An INTERnational, Adversarial and Cooperative moTION Dataset in Interactive Driving Scenarios with Semantic Maps. arXiv 2019, arXiv:1910.03088. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar]
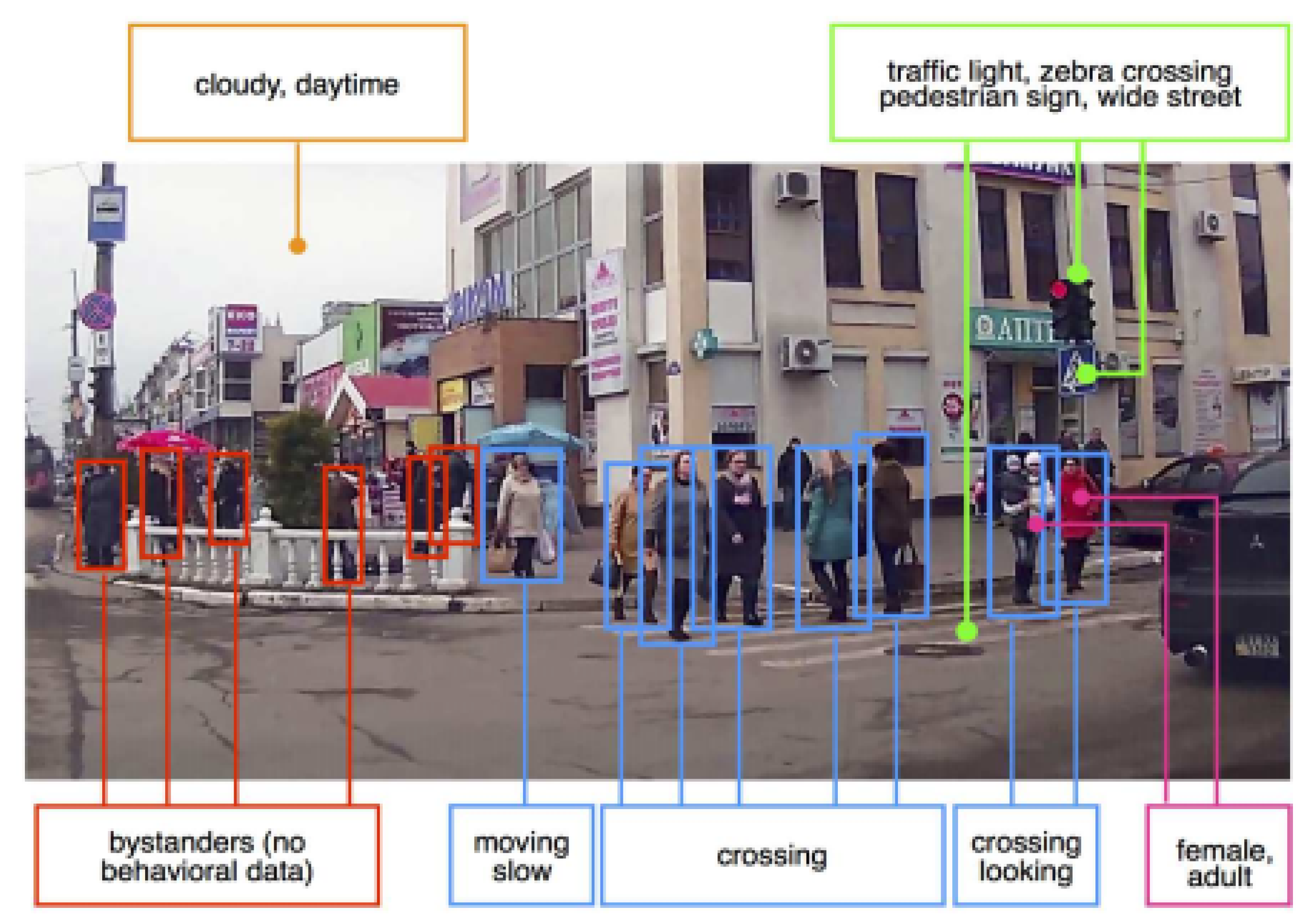



{kind=link}
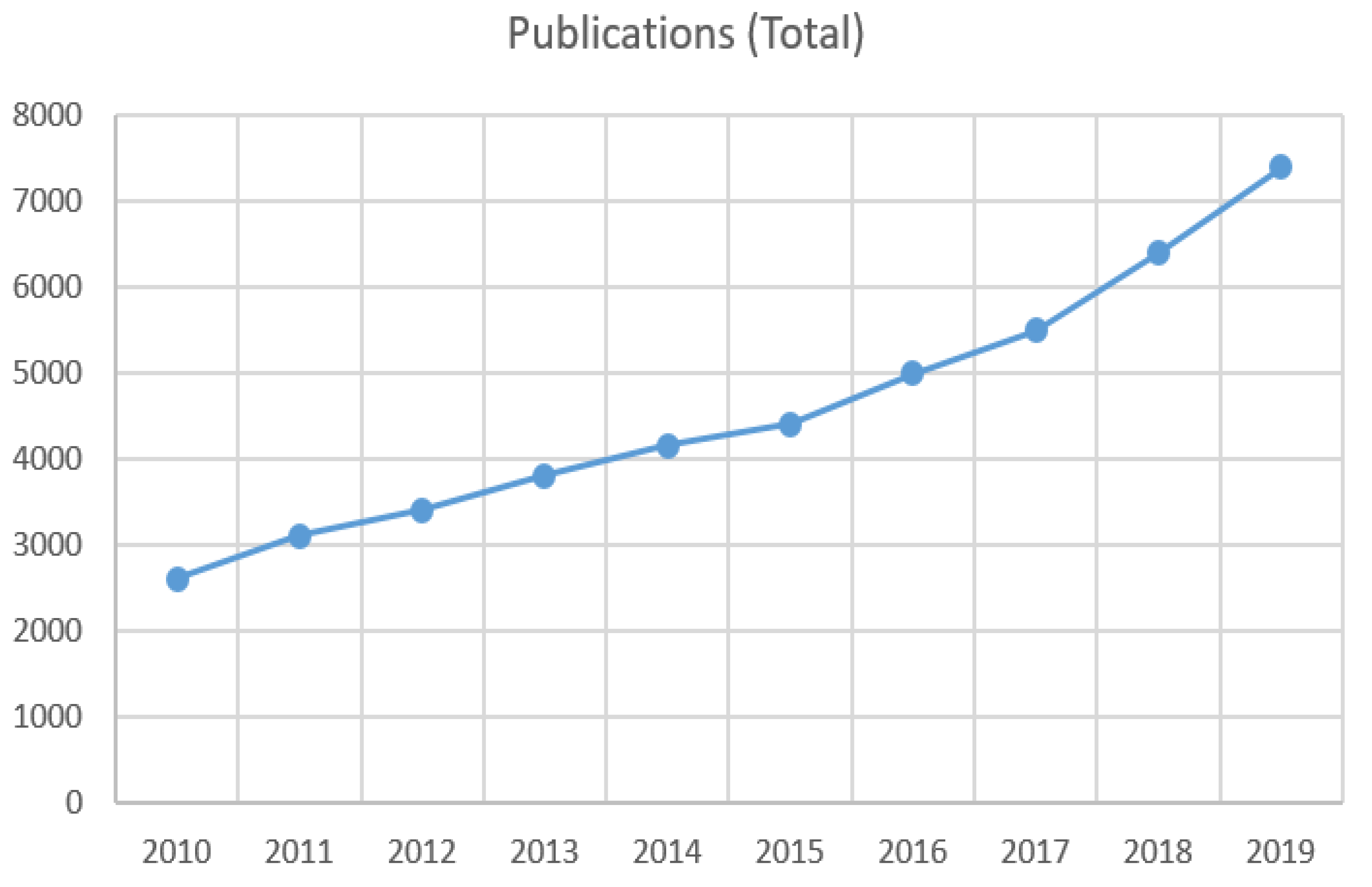
{kind=link}
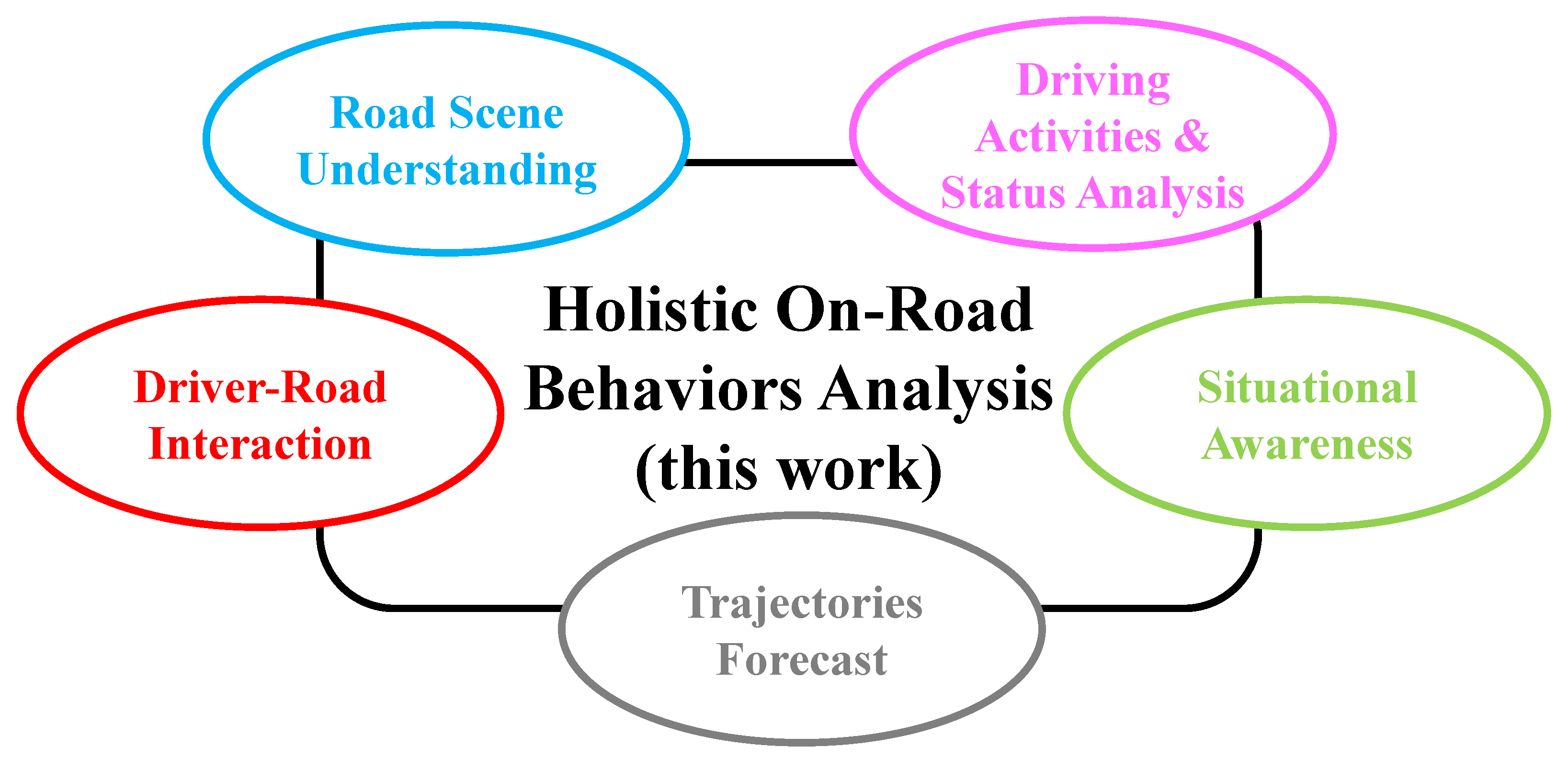
{kind=link}
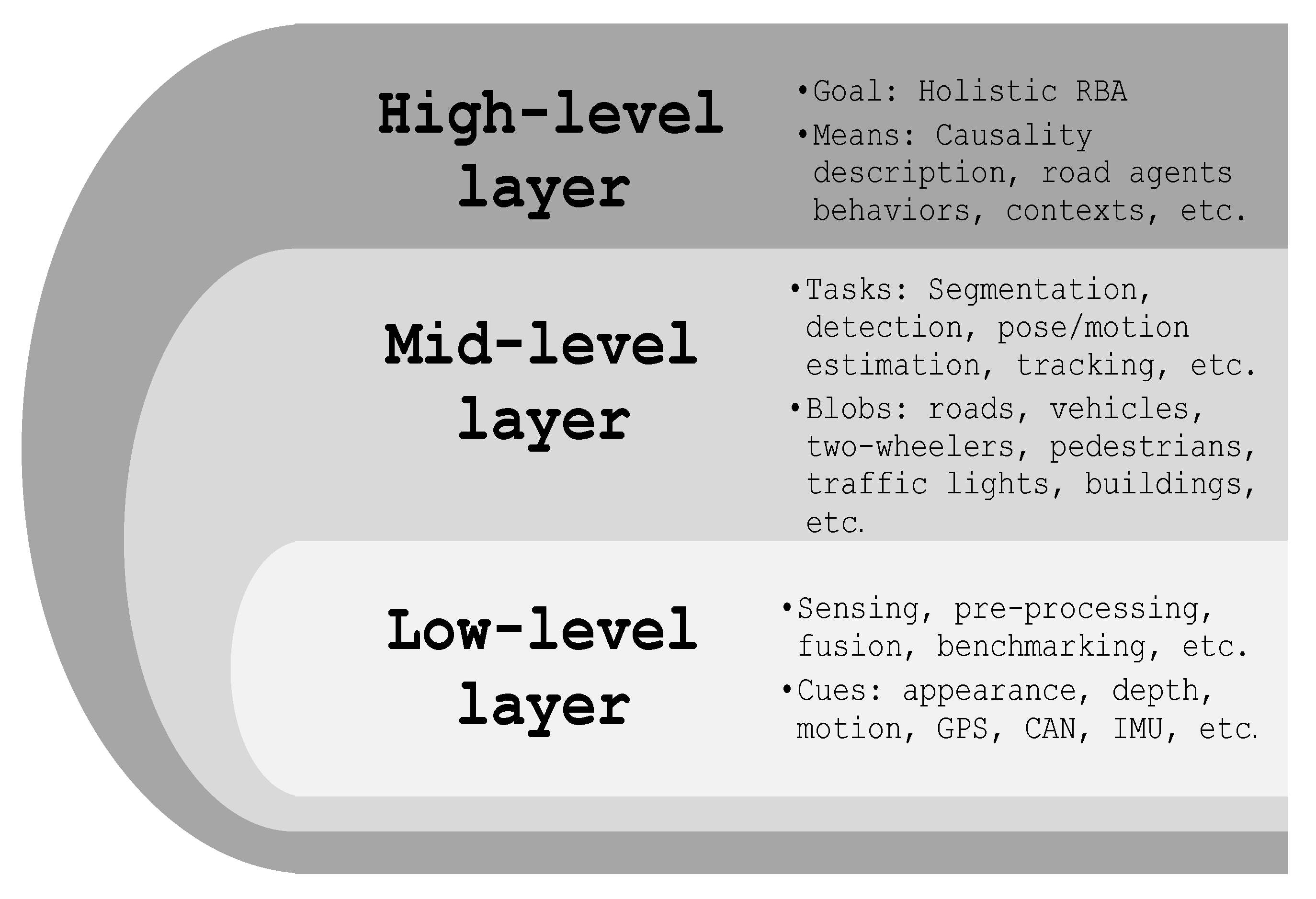
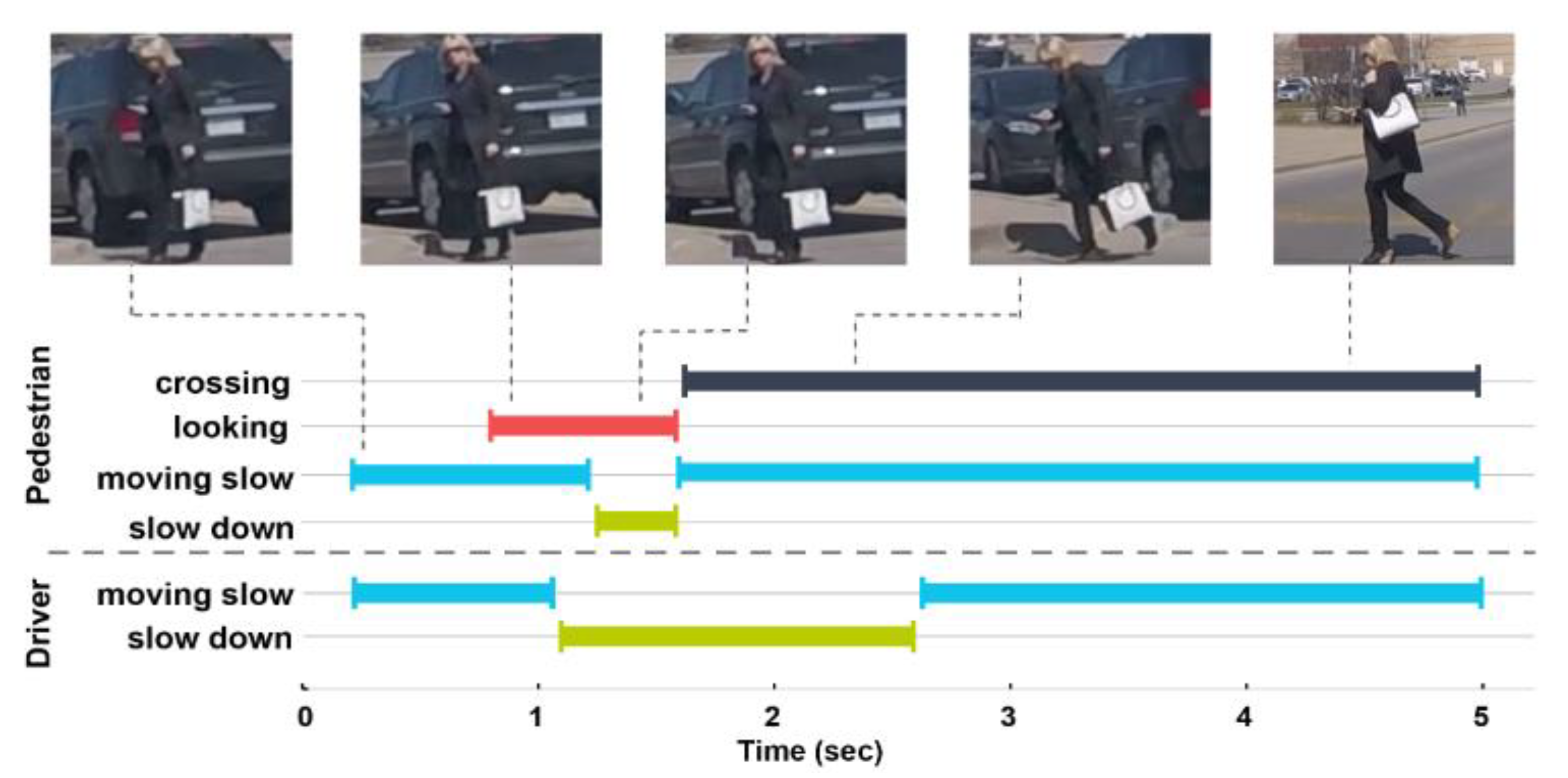{kind=link}
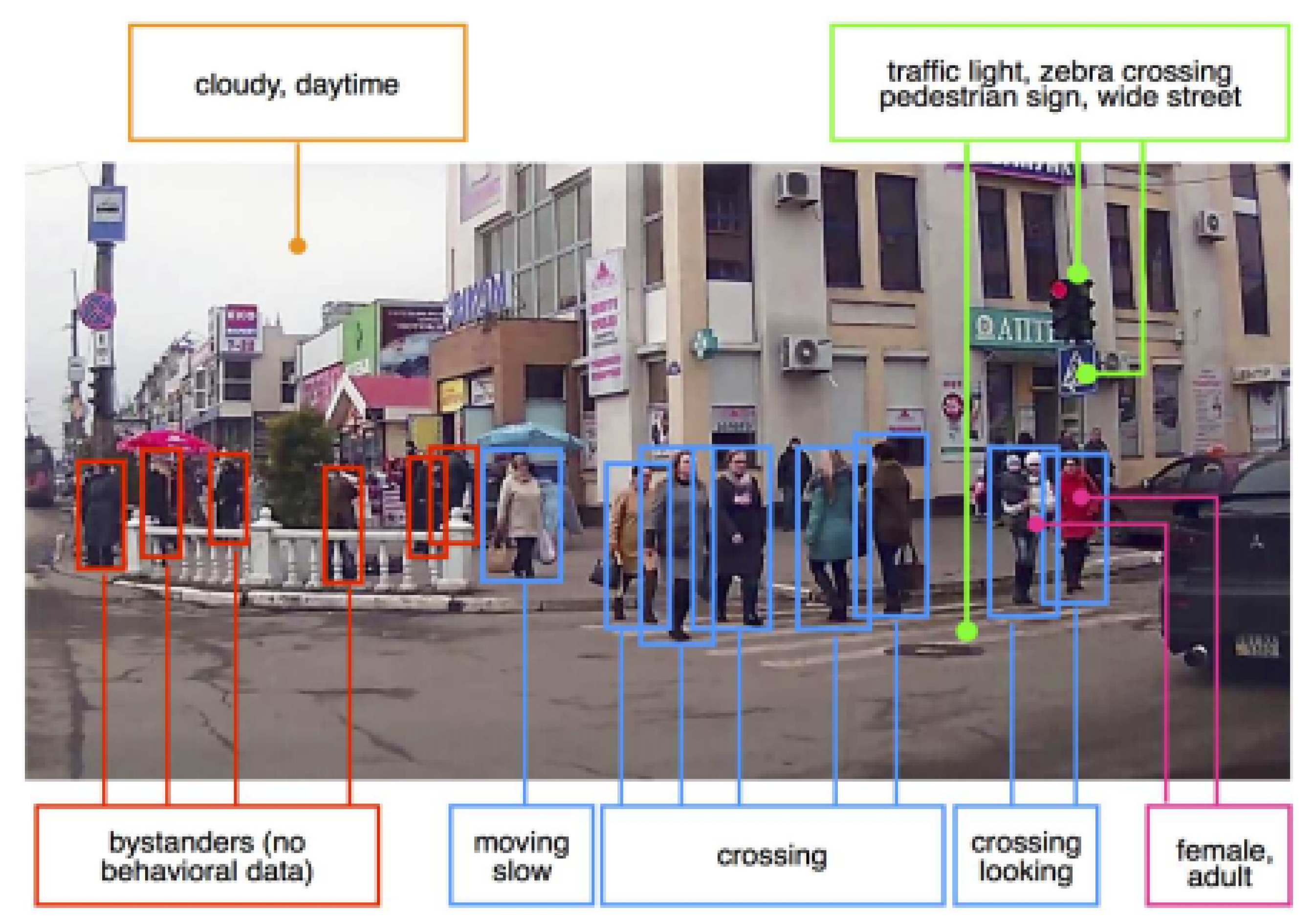{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | PS #ID | Sensor Setup | Location | Traffic Condition | Hours and/or Distance | #Sequences | #Frames |
|---|---|---|---|---|---|---|---|---|
| nuScenes [81] | 2019 | 3 | Camera RADAR LiDAR GPS IMU | Boston and Singapore | Urban | 55 h | 1 k | 1.4 M |
| Argoverse [42] | 2019 | 3 4 | Camera Stereo LiDAR IMU | Pittsburgh and Miami | Urban | 300 km | 100 | - |
| TRAF [39] | 2019 | 4 5 | Camera 3D sensor Motion- sensor | Asian cities | Urban | - | 50 | 12.4 k |
| Inter-section [38] | 2019 | 2 3 4 5 6 | Camera LiDAR GPS | San Francisco Bay Area | Urban | - | 213 | 59.4 k |
| OVD [16] | 2019 | 3 | Camera | - | - | - | 4+ | 34.1 k |
| HAD [78] | 2019 | 1 | Camera LiDAR GPS IMU CAN | San Francisco Bay Area | Suburban Urban High way | 32 h | 5.6 k | - |
| HDD [22] | 2018 | 6 | Camera LiDAR GPS IMU CAN | San Francisco Bay Area | Suburban, urban and highway | 104 h | - | - |
| DBNet [47] | 2018 | 2 5 | Camera LiDAR | - | Local route Boulevard Primary rd. Mountain roads School areas | 20 h 100 km | - | - |
| BDDV [50] | 2017 | 3 | Camera GPS IMU Gyroscope Magne- tometer | US cities | Cities Highways Rural areas | 10 k hours | - | 100 k |
| JAAD [18] | 2017 | 1 6 | Camera | North America and Europe | - | - | 346 | 82 k |
| Brain4-Cars [48] | 2015 | 5 6 | Camera GPS Speed- logger | Two US states | Suburban Urban Highway | 1899 km | 700 | 2 M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trabelsi, R.; Khemmar, R.; Decoux, B.; Ertaud, J.-Y.; Butteau, R. Recent Advances in Vision-Based On-Road Behaviors Understanding: A Critical Survey. Sensors 2022, 22, 2654. https://doi.org/10.3390/s22072654
Trabelsi R, Khemmar R, Decoux B, Ertaud J-Y, Butteau R. Recent Advances in Vision-Based On-Road Behaviors Understanding: A Critical Survey. Sensors. 2022; 22(7):2654. https://doi.org/10.3390/s22072654
Chicago/Turabian StyleTrabelsi, Rim, Redouane Khemmar, Benoit Decoux, Jean-Yves Ertaud, and Rémi Butteau. 2022. "Recent Advances in Vision-Based On-Road Behaviors Understanding: A Critical Survey" Sensors 22, no. 7: 2654. https://doi.org/10.3390/s22072654
APA StyleTrabelsi, R., Khemmar, R., Decoux, B., Ertaud, J.-Y., & Butteau, R. (2022). Recent Advances in Vision-Based On-Road Behaviors Understanding: A Critical Survey. Sensors, 22(7), 2654. https://doi.org/10.3390/s22072654