
The Emotion Probe: On the Universality of Cross-Linguistic and Cross-Gender Speech Emotion Recognition via Machine Learning




Abstract
:1. Introduction
Related Works and Datasets
2. Materials and Methods
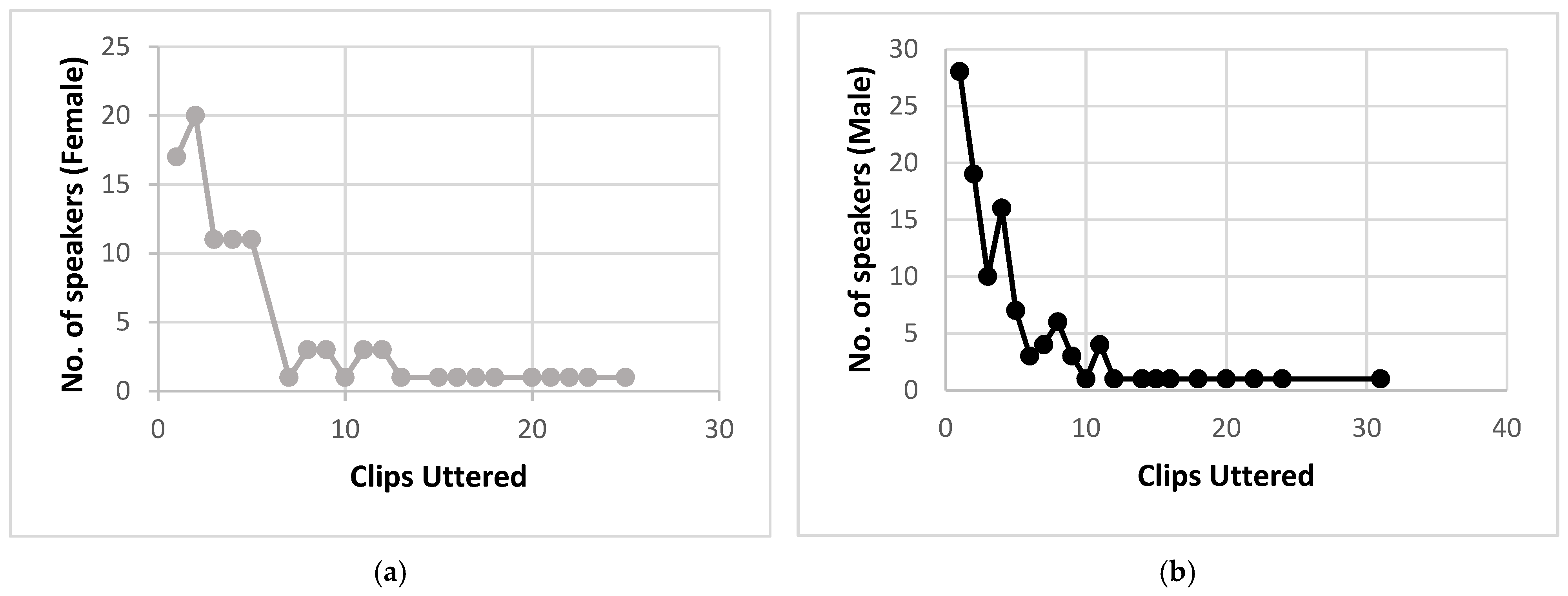
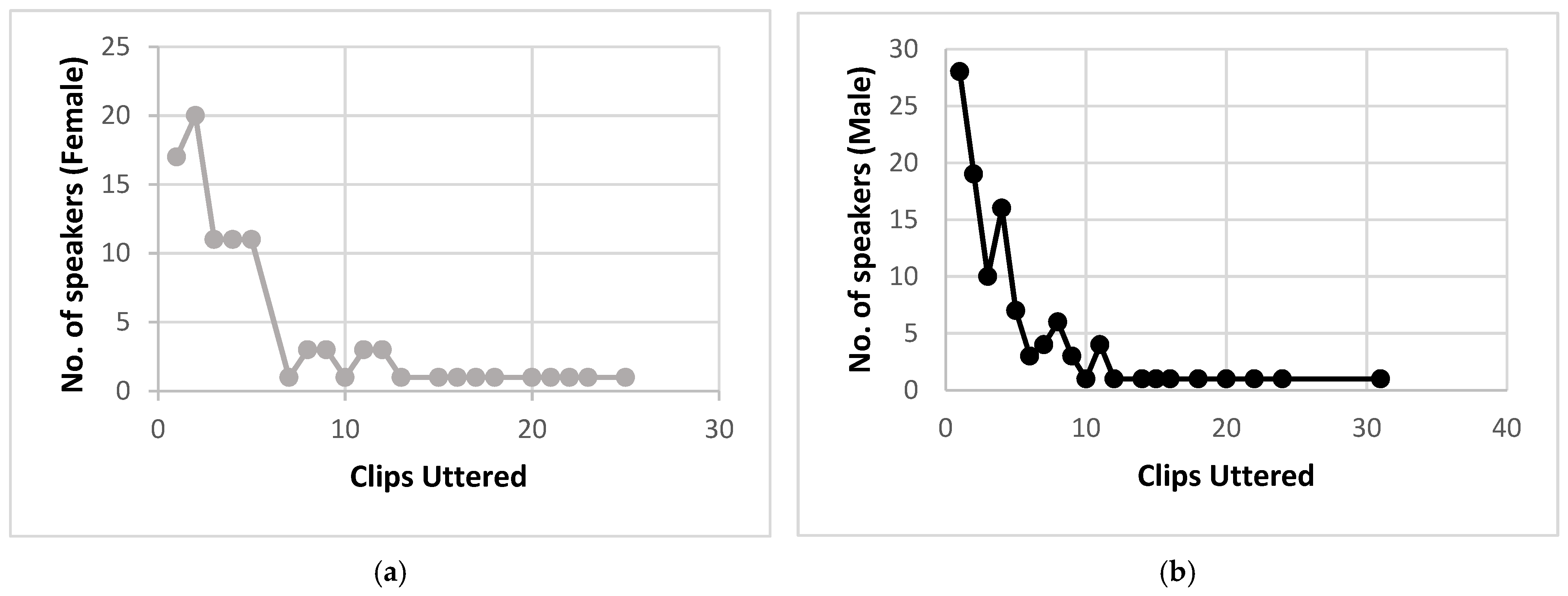
2.1. Dataset
- Emofilm contains clips made of the very same sentences uttered in three languages, and is therefore homogeneous in terms of context and acted emotions;
- The three languages encompassed by Emofilm are all of European origin and belong to Western culture;
- Actors and dubbers are trained professionals, ensuring the best possible performance on acted emotions;
- The voice is professionally recorded and processed.
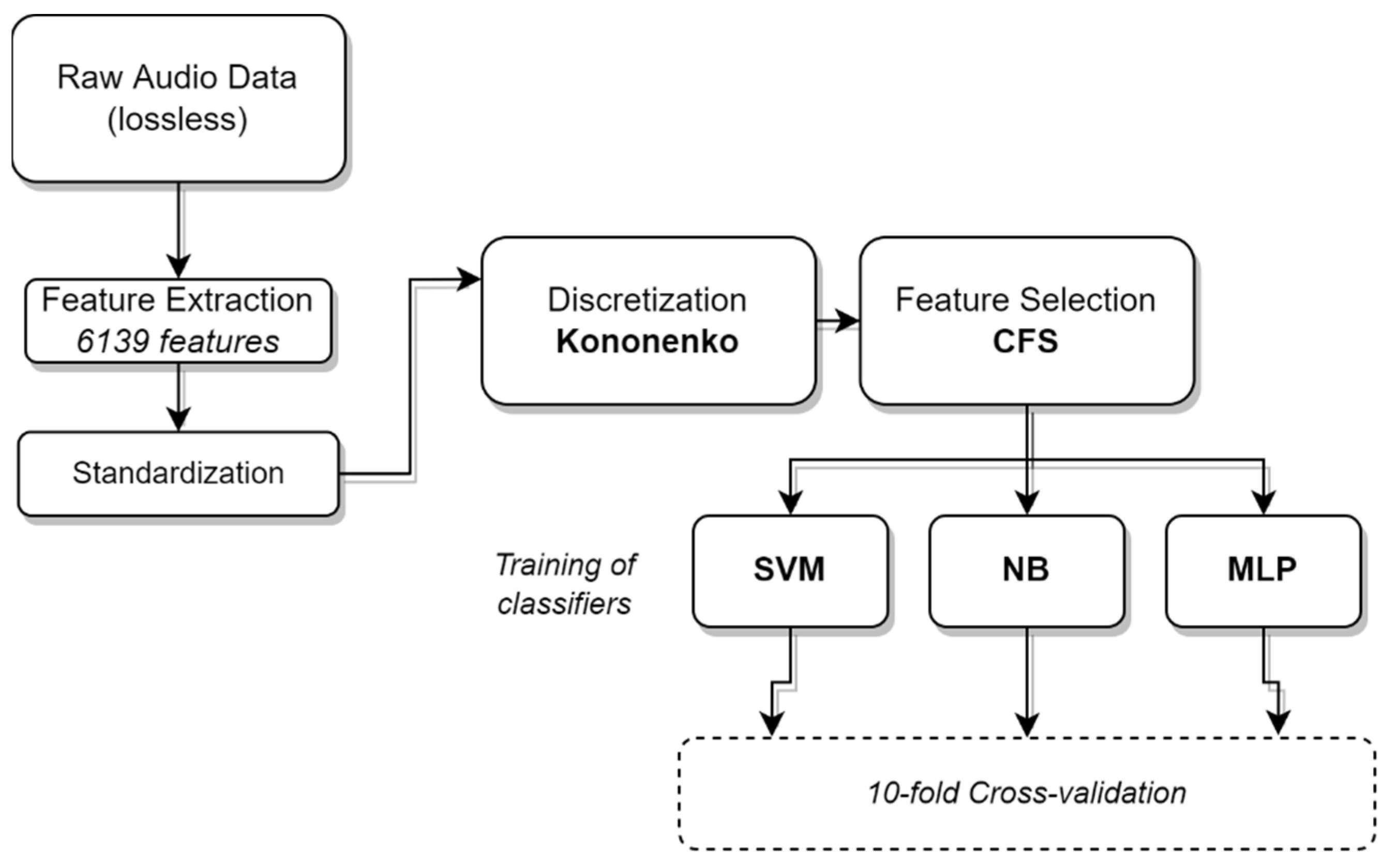
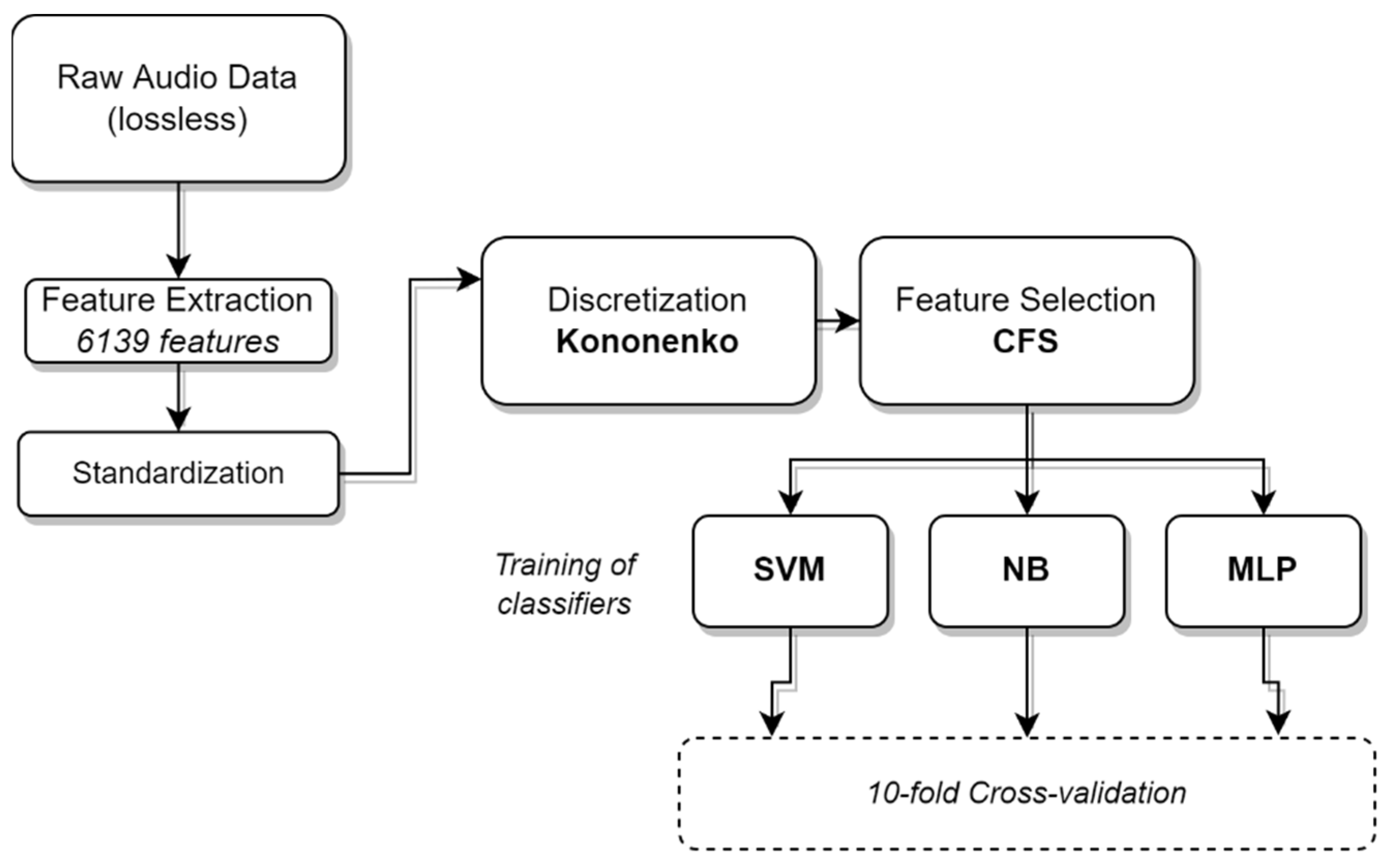
2.2. Machine Learning Framework
- Feature Extraction followed by a standardization procedure;
- Discretization, using Kononenko’s criterion [49];
- Feature Selection, using a Correlation-based Feature Selector (CFS);
- Training of Classifiers, namely SVM, Naïve Bayes (NB) and Multi-layer Perceptron (MLP). The three classifiers are independently trained on the same feature sets;
- Emotion Output, which in our specific case comes out of a 10-fold cross-validation;
- Statistical analysis of the obtained results.
2.3. Feature Extraction
2.4. Kononenko’s Discretization
2.5. CFS: Correlation-Based Feature Selection
2.6. Classification
2.6.1. SVM (Support Vector Machine)
2.6.2. NB (Naïve Bayes)
2.6.3. MLP (Multi-Layer Perceptron)
3. Results
3.1. Classification Tasks
- Monolingual with gender variations: a single language (It, Sp, En) with males only (M), females only (F), or both (M + F).
- Bilingual without gender variations: two languages (It + Sp, It + En, Sp + En) with both genders (M + F); these couplings aim to explore whether there were more poignant similarities between any two out of three languages; for this reason, no cross gender comparison has been considered for these tasks.
- Multilingual (All) with gender variation: all languages (It + Sp + En) with only M, only F, or M + F; this aims to obtain a single SER tool.
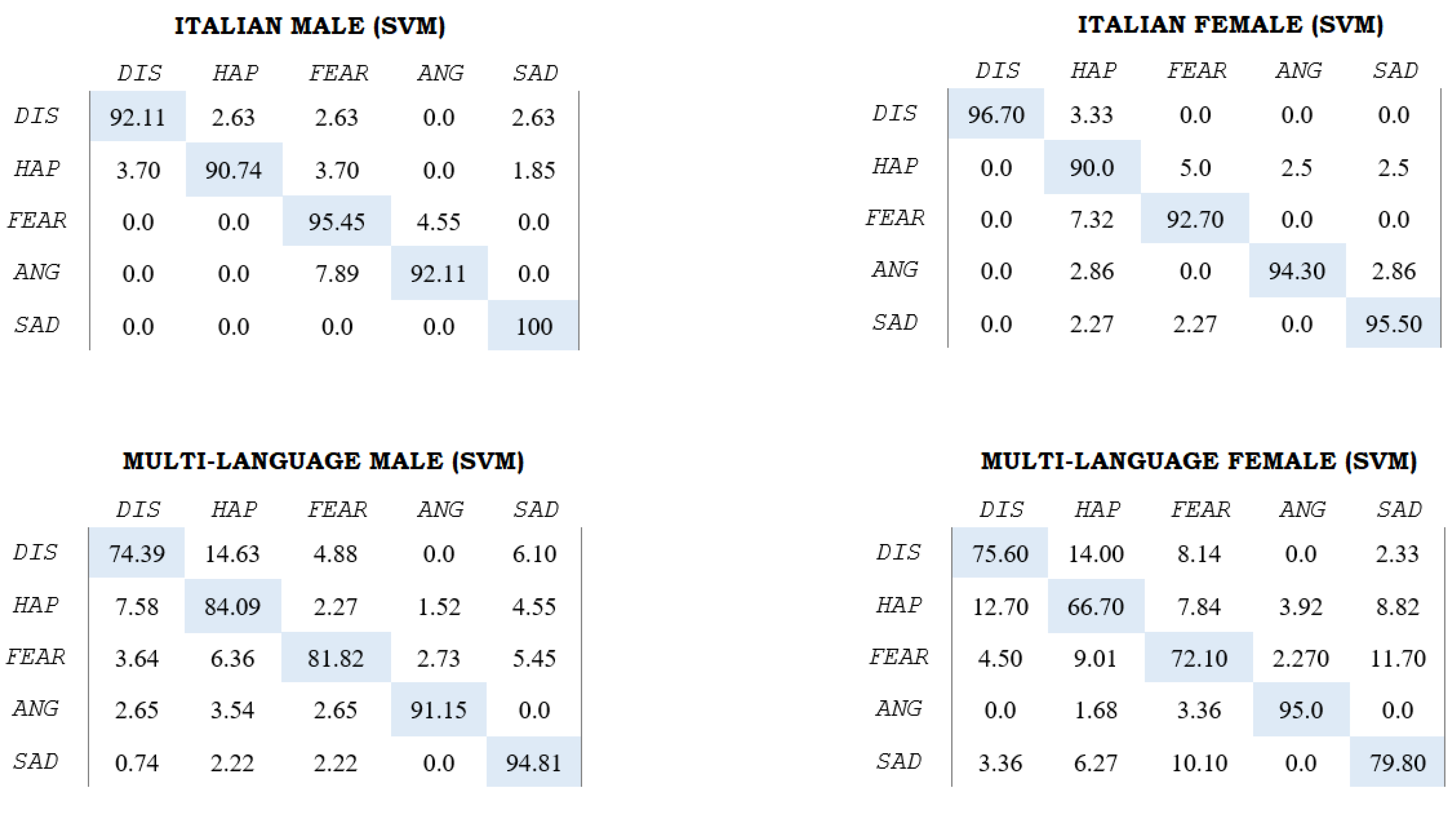
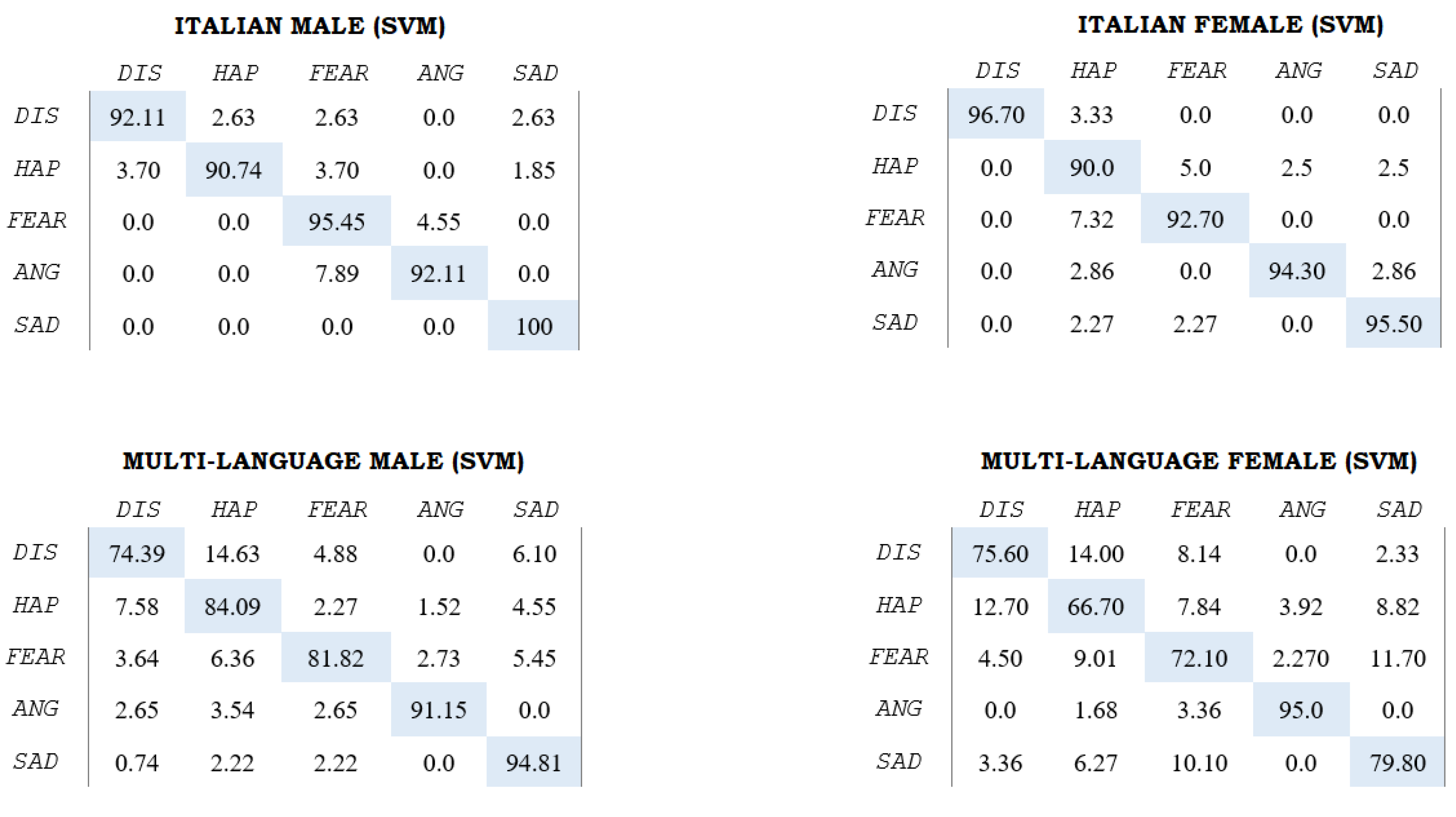
3.2. Experimental Results
3.3. Statistical Analysis
- NB vs. SVM: p = 0.001609
- NB vs. MLP: p = 0.0001964
- MLP vs. SVM: p = 0.001474
- Single-gender vs. cross-gender: p = 1.092 × 10−13
- Single-language vs. double-language: p = 1.285 × 10−8
4. Discussion
4.1. Acoustic Features Analysis
4.2. Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| It M—Feature List |
|---|
| audSpec_Rfilt_sma[7]_leftctime |
| audSpec_Rfilt_sma[8]_quartile1 |
| audSpec_Rfilt_sma[10]_quartile1 |
| audSpec_Rfilt_sma[10]_lpc4 |
| audSpec_Rfilt_sma[11]_leftctime |
| audSpec_Rfilt_sma[12]_lpc4 |
| audSpec_Rfilt_sma[15]_lpc3 |
| audSpec_Rfilt_sma[16]_maxPos |
| audSpec_Rfilt_sma[20]_risetime |
| audSpec_Rfilt_sma[21]_minPos |
| audSpec_Rfilt_sma[22]_percentile1.0 |
| audSpec_Rfilt_sma[25]_percentile1.0 |
| pcm_Mag_fband250-650_sma_lpgain |
| pcm_Mag_fband250-650_sma_lpc0 |
| pcm_Mag_fband250-650_sma_lpc2 |
| pcm_Mag_fband1000-22000_sma_iqr2-3 |
| pcm_Mag_fband1000-22000_sma_lpc3 |
| pcm_Mag_spectralRollOff50.0_sma_quartile2 |
| pcm_Mag_spectralRollOff75.0_sma_quartile1 |
| pcm_Mag_spectralRollOff75.0_sma_risetime |
| pcm_Mag_spectralRollOff90.0_sma_risetime |
| pcm_Mag_spectralFlux_sma_lpc0 |
| pcm_Mag_spectralCentroid_sma_quartile1 |
| pcm_Mag_spectralCentroid_sma_lpc1 |
| pcm_Mag_spectralEntropy_sma_lpc0 |
| pcm_Mag_spectralVariance_sma_quartile3 |
| pcm_Mag_spectralVariance_sma_iqr1-3 |
| pcm_Mag_spectralKurtosis_sma_quartile1 |
| pcm_Mag_harmonicity_sma_quartile2 |
| mfcc_sma[1]_quartile1 |
| mfcc_sma[1]_quartile3 |
| mfcc_sma[1]_pctlrange0-1 |
| mfcc_sma[1]_skewness |
| mfcc_sma[1]_leftctime |
| mfcc_sma[2]_percentile1.0 |
| mfcc_sma[2]_lpc0 |
| mfcc_sma[3]_quartile1 |
| mfcc_sma[4]_skewness |
| mfcc_sma[6]_maxPos |
| mfcc_sma[6]_percentile1.0 |
| mfcc_sma[6]_upleveltime75 |
| mfcc_sma[6]_lpc1 |
| mfcc_sma[8]_lpgain |
| mfcc_sma[10]_maxPos |
| mfcc_sma[10]_quartile2 |
| mfcc_sma[10]_stddev |
| mfcc_sma[11]_quartile3 |
| mfcc_sma[11]_percentile1.0 |
| mfcc_sma[12]_quartile3 |
| mfcc_sma[13]_percentile99.0 |
| mfcc_sma[13]_upleveltime75 |
| mfcc_sma[14]_percentile1.0 |
| mfcc_sma[14]_skewness |
| mfcc_sma[14]_upleveltime50 |
| audSpec_Rfilt_sma_de[2]_leftctime |
| audSpec_Rfilt_sma_de[8]_iqr1-3 |
| audSpec_Rfilt_sma_de[13]_lpc0 |
| audSpec_Rfilt_sma_de[21]_quartile2 |
| audSpec_Rfilt_sma_de[23]_quartile2 |
| audspec_lengthL1norm_sma_iqr2-3 |
| pcm_zcr_sma_skewness |
| audspec_lengthL1norm_sma_de_range |
| audspec_lengthL1norm_sma_de_stddev |
| audspec_lengthL1norm_sma_de_lpc4 |
| audspecRasta_lengthL1norm_sma_de_iqr2-3 |
| pcm_Mag_fband250-650_sma_de_iqr1-3 |
| pcm_Mag_fband1000-22000_sma_de_iqr1-3 |
| pcm_Mag_spectralRollOff25.0_sma_de_minPos |
| pcm_Mag_spectralRollOff25.0_sma_de_percentile1.0 |
| pcm_Mag_spectralRollOff50.0_sma_de_leftctime |
| pcm_Mag_spectralFlux_sma_de_iqr1-3 |
| pcm_Mag_spectralFlux_sma_de_lpgain |
| pcm_Mag_spectralCentroid_sma_de_quartile2 |
| pcm_Mag_spectralCentroid_sma_de_percentile1.0 |
| pcm_Mag_spectralSkewness_sma_de_iqr2-3 |
| pcm_Mag_spectralSlope_sma_de_lpc2 |
| pcm_Mag_harmonicity_sma_de_upleveltime50 |
| mfcc_sma_de[2]_iqr1-3 |
| mfcc_sma_de[2]_percentile1.0 |
| mfcc_sma_de[3]_lpgain |
| mfcc_sma_de[3]_lpc1 |
| mfcc_sma_de[4]_minPos |
| mfcc_sma_de[4]_lpc3 |
| mfcc_sma_de[5]_percentile1.0 |
| mfcc_sma_de[5]_lpgain |
| mfcc_sma_de[6]_iqr1-2 |
| mfcc_sma_de[6]_lpc0 |
| mfcc_sma_de[7]_quartile2 |
| mfcc_sma_de[11]_percentile99.0 |
| mfcc_sma_de[13]_skewness |
| mfcc_sma_de[14]_leftctime |
| F0final_sma_rqmean |
| F0final_sma_quartile1 |
| F0final_sma_quartile2 |
| F0final_sma_quartile3 |
| F0final_sma_skewness |
| F0final_sma_upleveltime25 |
| jitterLocal_sma_linregc1 |
| jitterLocal_sma_iqr1-2 |
| jitterLocal_sma_iqr1-3 |
| shimmerLocal_sma_iqr2-3 |
| shimmerLocal_sma_iqr1-3 |
| shimmerLocal_sma_lpc0 |
| F0final_sma_de_qregc1 |
| F0final_sma_de_risetime |
| jitterLocal_sma_de_posamean |
| jitterLocal_sma_de_iqr1-2 |
| audspec_lengthL1norm_sma_qregc3 |
| audSpec_Rfilt_sma[0]_flatness |
| audSpec_Rfilt_sma[5]_minRangeRel |
| audSpec_Rfilt_sma[6]_peakMeanAbs |
| audSpec_Rfilt_sma[6]_peakMeanRel |
| audSpec_Rfilt_sma[11]_minRangeRel |
| pcm_Mag_fband250-650_sma_linregc1 |
| pcm_Mag_fband250-650_sma_qregc1 |
| pcm_Mag_fband1000-22000_sma_peakRangeAbs |
| pcm_Mag_fband1000-22000_sma_qregc3 |
| pcm_Mag_spectralRollOff25.0_sma_qregc2 |
| pcm_Mag_spectralRollOff90.0_sma_flatness |
| pcm_Mag_spectralFlux_sma_stddevFallingSlope |
| pcm_Mag_spectralEntropy_sma_qregc3 |
| pcm_Mag_spectralVariance_sma_meanFallingSlope |
| pcm_Mag_spectralSkewness_sma_peakMeanMeanDist |
| pcm_Mag_spectralSlope_sma_peakRangeRel |
| pcm_Mag_harmonicity_sma_rqmean |
| pcm_Mag_harmonicity_sma_peakRangeRel |
| pcm_Mag_harmonicity_sma_peakMeanAbs |
| mfcc_sma[1]_peakDistStddev |
| mfcc_sma[1]_peakMeanAbs |
| mfcc_sma[1]_meanFallingSlope |
| mfcc_sma[1]_qregc3 |
| mfcc_sma[2]_linregerrQ |
| mfcc_sma[4]_rqmean |
| mfcc_sma[5]_meanFallingSlope |
| mfcc_sma[8]_peakMeanRel |
| mfcc_sma[9]_peakMeanAbs |
| mfcc_sma[9]_peakMeanMeanDist |
| mfcc_sma[10]_peakMeanRel |
| mfcc_sma[11]_peakMeanAbs |
| mfcc_sma[12]_peakDistStddev |
| mfcc_sma[12]_peakMeanRel |
| mfcc_sma[13]_stddevRisingSlope |
| mfcc_sma[13]_qregc2 |
| mfcc_sma[14]_stddevFallingSlope |
| audspec_lengthL1norm_sma_de_posamean |
| audspec_lengthL1norm_sma_de_peakMeanMeanDist |
| audspec_lengthL1norm_sma_de_meanFallingSlope |
| audSpec_Rfilt_sma_de[18]_minRangeRel |
| audSpec_Rfilt_sma_de[24]_peakMeanRel |
| audSpec_Rfilt_sma_de[25]_peakRangeRel |
| pcm_Mag_fband1000-22000_sma_de_peakMeanAbs |
| pcm_Mag_spectralRollOff75.0_sma_de_meanPeakDist |
| pcm_Mag_spectralSkewness_sma_de_minRangeRel |
| pcm_Mag_spectralSlope_sma_de_peakMeanAbs |
| pcm_Mag_harmonicity_sma_de_peakRangeAbs |
| mfcc_sma_de[2]_meanRisingSlope |
| mfcc_sma_de[7]_meanPeakDist |
| mfcc_sma_de[7]_meanRisingSlope |
| mfcc_sma_de[9]_peakDistStddev |
| mfcc_sma_de[14]_peakRangeAbs |
References
- Seibert, P.S.; Ellis, H.C. Irrelevant thoughts, emotional mood states, and cognitive task performance. Mem. Cognit. 1991, 19, 507–513. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frijda, N.H. Moods, emotion episodes, and emotions. In Handbook of Emotions; The Guilford Press: New York, NY, USA, 1993; pp. 381–403. ISBN 978-0-89862-988-0. [Google Scholar]
- Ellis, H.; Seibert, P.; Varner, L. Emotion and memory: Effect of mood states on immediate and unexpected delayed recall. Psychol. J. Soc. Behav. Personal. 1995, 10, 349. [Google Scholar]
- Kwon, O.-W.; Chan, K.; Hao, J.; Lee, T.-W. Emotion recognition by speech signals. In Proceedings of the 8th European Conference on Speech Communication and Technology, Eurospeech 2003—Interspeech 2003, Geneva, Switzerland, 1–4 September 2003. [Google Scholar]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Nwe, T.L.; Foo, S.W.; De Silva, L.C. Speech emotion recognition using hidden Markov models. Speech Commun. 2003, 41, 603–623. [Google Scholar] [CrossRef]
- Nicholson, J.; Takahashi, K.; Nakatsu, R. Emotion Recognition in Speech Using Neural Networks. Neural Comput. Appl. 2000. [Google Scholar] [CrossRef]
- Cullen, C.; Vaughan, B.; Kousidis, S.; Wang, Y.; McDonnell, C.; Campbell, D. Generation of High Quality Audio Natural Emotional Speech Corpus using Task Based Mood Induction. In Proceedings of the International Conference on Multidisciplinary Information Sciences and Technologies Extremadura (InSciT), Merida, Spain, 25–28 October 2006. [Google Scholar]
- Kenealy, P.M. The velten mood induction procedure: A methodological review. Motiv. Emot. 1986, 10, 315–335. [Google Scholar] [CrossRef]
- Seibert, P.S.; Ellis, H.C. A convenient self-referencing mood induction procedure. Bull. Psychon. Soc. 1991, 29, 121–124. [Google Scholar] [CrossRef] [Green Version]
- Larsen, R.J.; Sinnett, L.M. Meta-Analysis of Experimental Manipulations: Some Factors Affecting the Velten Mood Induction Procedure. Pers. Soc. Psychol. Bull. 1991, 17, 323–334. [Google Scholar] [CrossRef]
- Petrides, K.; Furnham, A. Trait Emotional Intelligence: Behavioural Validation in Two Studies of Emotion Recognition and Reactivity to Mood Induction. Eur. J. Personal. 2003, 17, 39–57. [Google Scholar] [CrossRef]
- Parada-Cabaleiro, E.; Costantini, G.; Batliner, A.; Schmitt, M.; Schuller, B. DEMoS: An Italian emotional speech corpus: Elicitation methods, machine learning, and perception. Lang. Resour. Eval. 2019, 54, 341–383. [Google Scholar] [CrossRef]
- Russell, J. A Circumplex Model of Affect. J. Pers. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Giovannella, C.; Floris, D.; Paoloni, A. An exploration on possible correlations among perception and physical characteristics of EMOVO emotional portrayals. IxD&A 2012, 15, 102–111. [Google Scholar]
- Swethashrree, A. Speech Emotion Recognition. Int. J. Res. Appl. Sci. Eng. Technol. 2021, 9, 2637–2640. [Google Scholar] [CrossRef]
- Xiao, Z.; Wu, D.; Zhang, X.; Tao, Z. Speech emotion recognition cross language families: Mandarin vs. western languages. In Proceedings of the 2016 International Conference on Progress in Informatics and Computing (PIC), Shanghai, China, 23–25 December 2016; pp. 253–257. [Google Scholar] [CrossRef]
- Jawad, M.; Dujaili, A.; Ebrahimi-Moghadam, A.; Fatlawi, A. Speech emotion recognition based on SVM and KNN classifications fusion. Int. J. Electr. Comput. Eng. 2021, 11, 1259–1264. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Costantini, G.; Cesarini, V.; Casali, D. A Subset of Acoustic Features for Machine Learning-Based and Statistical Approaches in Speech Emotion Recognition. In Proceedings of the BIOSIGNALS 2022: 15th International Conference on Bio-Inspired Systems and Signal Processing, Online Streaming, 9–11 February 2022. [Google Scholar]
- Alonso, J.; Cabrera, J.; Medina-Molina, M.; Travieso, C. New approach in quantification of emotional intensity from the speech signal: Emotional temperature. Expert Syst. Appl. 2015, 42, 9554–9564. [Google Scholar] [CrossRef]
- Wen, G.; Li, H.; Huang, J.; Li, D.; Xun, E. Random Deep Belief Networks for Recognizing Emotions from Speech Signals. Comput. Intell. Neurosci. 2017, 2017, 1945630. [Google Scholar] [CrossRef]
- Sun, L.; Fu, S.; Wang, F. Decision tree SVM model with Fisher feature selection for speech emotion recognition. EURASIP J. Audio Speech Music Process. 2019, 2019, 2. [Google Scholar] [CrossRef] [Green Version]
- Kaur, J.; Kumar, A. Speech Emotion Recognition Using CNN, k-NN, MLP and Random Forest. In Computer Networks and Inventive Communication Technologies; Springer: Singapore, 2021; pp. 499–509. ISBN 9789811596469. [Google Scholar]
- Lech, M.; Stolar, M.; Best, C.; Bolia, R. Real-Time Speech Emotion Recognition Using a Pre-trained Image Classification Network: Effects of Bandwidth Reduction and Companding. Front. Comput. Sci. 2020, 2, 14. [Google Scholar] [CrossRef]
- Aftab, A.; Morsali, A.; Ghaemmaghami, S.; Champagne, B. Light-SERNet: A lightweight fully convolutional neural network for speech emotion recognition. arXiv 2021, arXiv:2110.03435. [Google Scholar]
- Gat, I.; Aronowitz, H.; Zhu, W.; Morais, E.; Hoory, R. Speaker Normalization for Self-supervised Speech Emotion Recognition. arXiv 2022, arXiv:2202.01252. [Google Scholar]
- Shukla, S.; Dandapat, S.; Prasanna, S. A Subspace Projection Approach for Analysis of Speech Under Stressed Condition. Circuits Syst. Signal Process. 2016, 35, 4486–4500. [Google Scholar] [CrossRef]
- Suppa, A.; Asci, F.; Saggio, G.; Di Leo, P.; Zarezadeh, Z.; Ferrazzano, G.; Ruoppolo, G.; Berardelli, A.; Costantini, G. Voice Analysis with Machine Learning: One Step Closer to an Objective Diagnosis of Essential Tremor. Mov. Disord. 2021, 36, 1401–1410. [Google Scholar] [CrossRef] [PubMed]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.; Weiss, B. A database of German emotional speech. In Proceedings of the Interspeech 2005, Lisbon, Portugal, 4–8 September 2005; ISCA: Singapore, 2005; pp. 1517–1520. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.-C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335. [Google Scholar] [CrossRef]
- Haq, S.; Jackson, P.J.B. Machine Audition: Principles, Algorithms and Systems; Wang, W., Ed.; IGI Global: Hershey, PA, USA, 2010; pp. 398–423. [Google Scholar]
- Williams, C.E.; Stevens, K.N. Emotions and speech: Some acoustical correlates. J. Acoust. Soc. Am. 1972, 52, 1238–1250. [Google Scholar] [CrossRef] [PubMed]
- Costantini, G.; Iaderola, I.; Paoloni, A.; Todisco, M. EMOVO Corpus: An Italian Emotional Speech Database. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; pp. 3501–3504. [Google Scholar]
- James, W. II.—What Is an Emotion? Mind 1884, os-IX, 188–205. [Google Scholar] [CrossRef]
- Banse, R.; Scherer, K. Acoustic Profiles in Vocal Emotion Expression. J. Pers. Soc. Psychol. 1996, 70, 614–636. [Google Scholar] [CrossRef]
- Rajoo, R.; Aun, C. Influences of languages in speech emotion recognition: A comparative study using Malay, English and Mandarin languages. In Proceedings of the IEEE Symposium on Computer Applications & Industrial Electronics (ISCAIE), Penang, Malaysia, 30–31 May 2016; p. 39. [Google Scholar] [CrossRef]
- Fu, C.; Dissanayake, T.; Hosoda, K.; Maekawa, T.; Ishiguro, H. Similarity of Speech Emotion in Different Languages Revealed by A Neural Network with Attention. In Proceedings of the IEEE 14th International Conference on Semantic Computing (ICSC), San Diego, CA, USA, 3–5 February 2020. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Akagi, M. Improving multilingual speech emotion recognition by combining acoustic features in a three-layer model. Speech Commun. 2019, 110, 1–12. [Google Scholar] [CrossRef]
- Tamulevičius, G.; Korvel, G.; Yayak, A.B.; Treigys, P.; Bernatavičienė, J.; Kostek, B. A Study of Cross-Linguistic Speech Emotion Recognition Based on 2D Feature Spaces. Electronics 2020, 9, 1725. [Google Scholar] [CrossRef]
- Wani, T.M.; Gunawan, T.S.; Qadri, S.A.A.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition Systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Suppa, A.; Asci, F.; Saggio, G.; Marsili, L.; Casali, D.; Zarezadeh, Z.; Costantini, G. Voice analysis in adductor spasmodic dysphonia: Objective diagnosis and response to botulinum toxin. In Parkinsonism & Related Disorders; Elsevier: Amsterdam, The Netherlands, 2020; Volume 73, pp. 23–30. [Google Scholar] [CrossRef]
- Parada-Cabaleiro, E.; Costantini, G.; Batliner, A.; Baird, A.; Schuller, B. Categorical vs. Dimensional Perception of Italian Emotional Speech. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; ISCA: Singapore, 2018; pp. 3638–3642. [Google Scholar] [CrossRef] [Green Version]
- Hansen, J.H.L.; Bou-Ghazale, S.E. Getting started with SUSAS: A speech under simulated and actual stress database. In Proceedings of the 5th European Conference on Speech Communication and Technology (EUROSPEECH 1997), Rhodes, Greece, 22–25 September 1997; ISCA: Singapore, 1997; pp. 1743–1746. [Google Scholar]
- Kerkeni, L.; Serrestou, Y.; Mbarki, M.; Raoof, K.; Mahjoub, M.A.; Cleder, C. Automatic Speech Emotion Recognition Using Machine Learning. In Social Media and Machine Learning; IntechOpen: London, UK, 2019; ISBN 978-1-78984-028-5. [Google Scholar]
- Zehra, W.; Javed, A.R.; Jalil, Z.; Khan, H.U.; Gadekallu, T.R. Cross corpus multi-lingual speech emotion recognition using ensemble learning. Complex Intell. Syst. 2021, 7, 1845–1854. [Google Scholar] [CrossRef]
- Shih, J. The Rise of the Italian Dubbing Industry; JBI Localization: Los Angeles, CA, USA, 18 March 2020; Available online: https://jbilocalization.com/italian-dubbing-growing-industry/ (accessed on 20 February 2022).
- Benavides, L. Dubbing Movies Into Spanish Is Big Business for Spain’s Voice Actors, npr.org. 2018. Available online: https://www.npr.org/2018/11/27/671090473/dubbing-movies-into-spanish-is-big-business-for-spains-voice-actors (accessed on 19 February 2022).
- Kononenko, I. On biases in estimating multi-valued attributes. In Proceedings of the 14th International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; pp. 1034–1040. [Google Scholar]
- Eibe, F.; Hall, M.A.; Witten, I.H. The WEKA Workbench. Online Appendix for “Data Mining: Practical Machine Learning Tools and Techniques”, 4th ed.; Morgan Kauffman: Burlington, MA, USA, 2016. [Google Scholar]
- Kacur, J.; Puterka, B.; Pavlovicova, J.; Oravec, M. On the Speech Properties and Feature Extraction Methods in Speech Emotion Recognition. Sensors 2021, 21, 1888. [Google Scholar] [CrossRef] [PubMed]
- Bimbot, F.; Cerisara, C.; Cecile, F.; Gravier, G.; Lamel, L.; Pellegrino, F.; Perrier, P. In Proceedings of the Interspeech 2013, 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013.
- Eyben, F.; Schuller, B. openSMILE:): The Munich open-source large-scale multimedia feature extractor. ACM SIGMultimedia Rec. 2015, 6, 4–13. [Google Scholar] [CrossRef]
- Grünwald, P.D. The Minimum Description Length Principle. In Adaptive Computation and Machine Learning Series; MIT Press: Cambridge, MA, USA, 2007; ISBN 978-0-262-07281-6. [Google Scholar]
- Grünwald, P.; Roos, T. Minimum Description Length Revisited. Int. J. Math. Ind. 2019, 11, 1930001. [Google Scholar] [CrossRef] [Green Version]
- Kira, K.; Rendell, L.A. The Feature Selection Problem: Traditional Methods and a New Algorithm. In Proceedings of the 10th National Conference on Artificial Intelligence, San Jose, CA, USA, 12–16 July 1992; AAAI Press: Atlanta, GA, USA, 1992; pp. 129–134. [Google Scholar]
- Cestnik, B. Informativity-Based Splitting of Numerical Attributes into Intervals. In Proceedings of the IASTED International Conference on Expert Systems, Theory and Applications, Zurich, Switzerland, 26–28 June 1989; pp. 59–62. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning; University of Waikato: Hamilton, New Zealand, 1999. [Google Scholar]
- Webb, G.I. Naïve Bayes. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; pp. 713–714. ISBN 978-0-387-30164-8. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.; Franklin, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Math. Intell. 2004, 27, 83–85. [Google Scholar] [CrossRef]
- Wilcoxon, F. Individual Comparisons by Ranking Methods. Biom. Bull. 1945, 1, 80. [Google Scholar] [CrossRef]
- McDonald, J.H. Wilcoxon Signed-Rank Test—Handbook of Biological Statistics. Available online: http://www.biostathandbook.com/wilcoxonsignedrank.html (accessed on 12 March 2022).
- Student. The probable error of a mean. Biometrika 1908, 4, 1–25. [Google Scholar]
- Dair, Z.; Donovan, R.; O’Reilly, R. Linguistic and Gender Variation in Speech Emotion Recognition using Spectral Features. arXiv 2021, arXiv:2112.09596. [Google Scholar]
- Bogert, B.P. The quefrency alanysis of time series for echoes; Cepstrum, pseudo-autocovariance, cross-cepstrum and saphe cracking. In Proceedings of the Symposium on Time Series Analysis, New York, NY, USA, 11–14 June 1963; pp. 209–243. [Google Scholar]
- Saggio, G.; Costantini, G. Worldwide Healthy Adult Voice Baseline Parameters: A Comprehensive Review. J. Voice 2020. [Google Scholar] [CrossRef]
- Hermansky, H.; Morgan, N. RASTA processing of speech. IEEE Trans. Speech Audio Process. 1994, 2, 578–589. [Google Scholar] [CrossRef] [Green Version]
- Hermes, D. Measurement of pitch by subharmonic summation. J. Acoust. Soc. Am. 1988, 83, 257–264. [Google Scholar] [CrossRef] [PubMed]
- Kamińska, D.; Sapiński, T.; Anbarjafari, G. Efficiency of chosen speech descriptors in relation to emotion recognition. EURASIP J. Audio Speech Music Process. 2017, 2017, 3. [Google Scholar] [CrossRef] [Green Version]
- Cesarini, V.; Casiddu, N.; Porfirione, C.; Massazza, G.; Saggio, G.; Costantini, G. A Machine Learning-Based Voice Analysis for the Detection of Dysphagia Biomarkers. In Proceedings of the 2021 IEEE International Workshop on Metrology for Industry 4.0 IoT (MetroInd4.0 IoT), Roma, Italy, 7–9 June 2021; pp. 407–411. [Google Scholar] [CrossRef]
- Robotti, C.; Costantini, G.; Saggio, G.; Cesarini, V.; Calastri, A.; Maiorano, E.; Piloni, D.; Perrone, T.; Sabatini, U.; Ferretti, V.V.; et al. Machine Learning-based Voice Assessment for the Detection of Positive and Recovered COVID-19 Patients. J. Voice 2021. [Google Scholar] [CrossRef] [PubMed]
- Gupta, K.; Gupta, D. An analysis on LPC, RASTA and MFCC techniques in Automatic Speech recognition system. In Proceedings of the 6th International Conference—Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016. [Google Scholar] [CrossRef]
| Study | Year | Database | Emotions | Features | Classifier | Reported Results |
|---|---|---|---|---|---|---|
| Alonso et al. [21] | 2015 | EMO-DB [30], others | Happy, Angry, Sad, Bored. | Spectral, Prosody, Pitch | SVM | 94.9% (EMO-DB) |
| Shukla et al. [28] | 2016 | SUSAS [44] | Neutral, Angry, Sad, Lombard, others. | MFCC | HMM | 93.9% |
| Wen et al. [22] | 2017 | EMO-DB, SAVEE [32], CASIA | Neutral, Happy, Angry, Sad, Fear, Disgust, Surprise. | Spectral, Prosody, Hu Moments | DBN, SVM | 82.3% (EMO-DB) 53.6% (SAVEE) 48.5% (CASIA) |
| Sun et al. [23] | 2019 | EMO-DB, CASIA | Neutral, Happy, Angry, Sad, Bored, Fear, Disgust. | Spectral, Prosody, MFCC, Voice Quality | SVM | 86.7% (EMO-DB) 83.7% (CASIA) |
| Kerkeni et al. [45] | 2019 | EMO-DB, Spanish | Neutral, Happy, Angry, Sad, Bored, Fear, Disgust. | MFCC, Spectral | SVM, RNN | 83% (EMO-DB) 94% (Spanish) |
| Aftab et al. [26] | 2021 | EMO-DB, IEMOCAP [31] | Neutral, Happy, Angry, Sad, Bored, Fear, Disgust. | - | CNN | 94.2% (EMO-DB) 79.9% (IEMOCAP) |
| Zehra et al. [46] | 2021 | EMO-DB, SAVEE, EMOVO [34] | Neutral, Happy, Angry, Sad, Fear, Disgust, Surprise. | MFCC, Spectral, Prosody | SVM | Many (single and cross-corpora) |
| Gat et al. [27] | 2022 | IEMOCAP | Neutral, Happy, Sad, Angry | - | Gradient-base Adversary Learning | 81% |
| Task | Dis | Hap | Fea | Ang | Sad | Total |
|---|---|---|---|---|---|---|
| It M | 37 | 23 | 33 | 41 | 31 | 165 |
| It F | 35 | 27 | 37 | 36 | 43 | 178 |
| Sp M | 33 | 33 | 29 | 43 | 44 | 182 |
| Sp F | 31 | 17 | 47 | 39 | 43 | 177 |
| En M | 41 | 30 | 40 | 35 | 44 | 190 |
| En F | 44 | 38 | 54 | 38 | 49 | 223 |
| Total | 221 | 168 | 240 | 232 | 254 |
| Classification: Language(s) | Classification: Gender(s) | No. of Features | WA (%): SVM | WA (%): NB | WA (%): MLP | Best Emotion | Worst Emotion |
|---|---|---|---|---|---|---|---|
| It | M | 160 | 94.2 | 89.7 | 96.0 | sad | dis |
| It | F | 177 | 93.7 | 89.5 | 94.2 | sad | hap |
| It | M + F | 176 | 80.4 | 77.0 | 83.3 | ang | fea |
| Sp | M | 158 | 97.2 | 95.5 | 97.7 | sad | dis |
| Sp | F | 163 | 91.8 | 91.2 | 91.8 | ang | hap |
| Sp | M + F | 167 | 82.5 | 82.5 | 85.0 | sad | dis |
| En | M | 166 | 97.2 | 95.5 | 97.2 | sad | fea |
| En | F | 173 | 94.6 | 94.6 | 95.8 | sad | hap |
| En | M + F | 149 | 81.9 | 78.4 | 82.5 | ang | hap |
| It + Sp | M | 196 | 89.8 | 84.3 | 91.0 | ang | dis |
| It + Sp | F | 202 | 85.2 | 84.0 | 88.4 | ang | fea |
| Sp + En | M | 199 | 89.0 | 85.1 | 89.9 | ang | dis |
| Sp + En | F | 176 | 84.4 | 85.1 | 89.9 | ang | hap |
| It + En | M | 215 | 85.8 | 80.6 | 85.8 | sad | dis |
| It + En | F | 185 | 79.7 | 81.4 | 82.5 | ang | hap |
| All | M | 215 | 85.3 | 77.7 | 85.3 | sad | fea |
| All | F | 195 | 78.4 | 76.4 | 80.3 | sad | hap |
| All | M + F | 204 | 67.3 | 60.6 | 67.3 | ang | fea |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Costantini, G.; Parada-Cabaleiro, E.; Casali, D.; Cesarini, V. The Emotion Probe: On the Universality of Cross-Linguistic and Cross-Gender Speech Emotion Recognition via Machine Learning. Sensors 2022, 22, 2461. https://doi.org/10.3390/s22072461
Costantini G, Parada-Cabaleiro E, Casali D, Cesarini V. The Emotion Probe: On the Universality of Cross-Linguistic and Cross-Gender Speech Emotion Recognition via Machine Learning. Sensors. 2022; 22(7):2461. https://doi.org/10.3390/s22072461
Chicago/Turabian StyleCostantini, Giovanni, Emilia Parada-Cabaleiro, Daniele Casali, and Valerio Cesarini. 2022. "The Emotion Probe: On the Universality of Cross-Linguistic and Cross-Gender Speech Emotion Recognition via Machine Learning" Sensors 22, no. 7: 2461. https://doi.org/10.3390/s22072461
APA StyleCostantini, G., Parada-Cabaleiro, E., Casali, D., & Cesarini, V. (2022). The Emotion Probe: On the Universality of Cross-Linguistic and Cross-Gender Speech Emotion Recognition via Machine Learning. Sensors, 22(7), 2461. https://doi.org/10.3390/s22072461