
Smart Contract Vulnerability Detection Model Based on Multi-Task Learning


Abstract
:1. Introduction
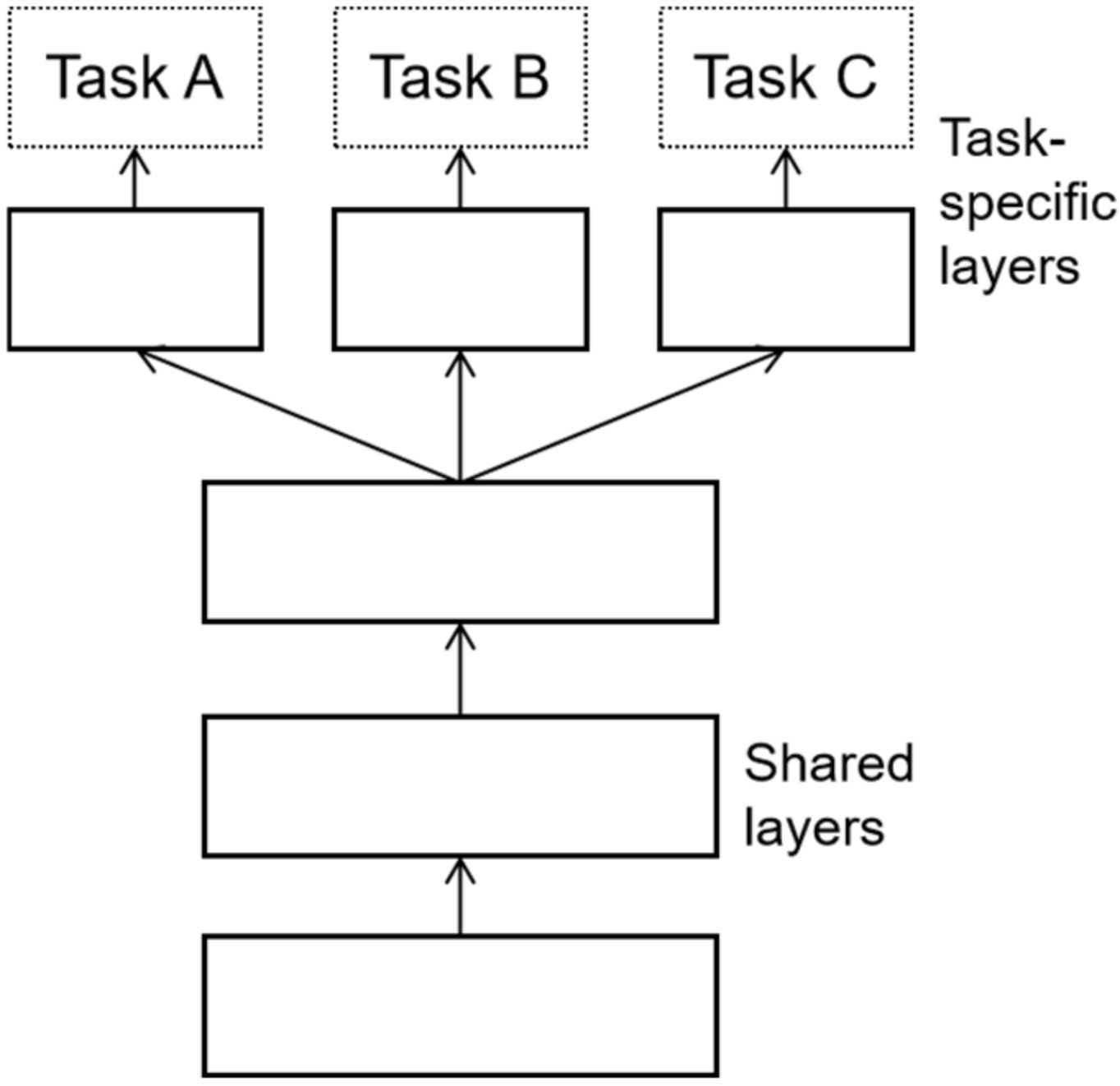
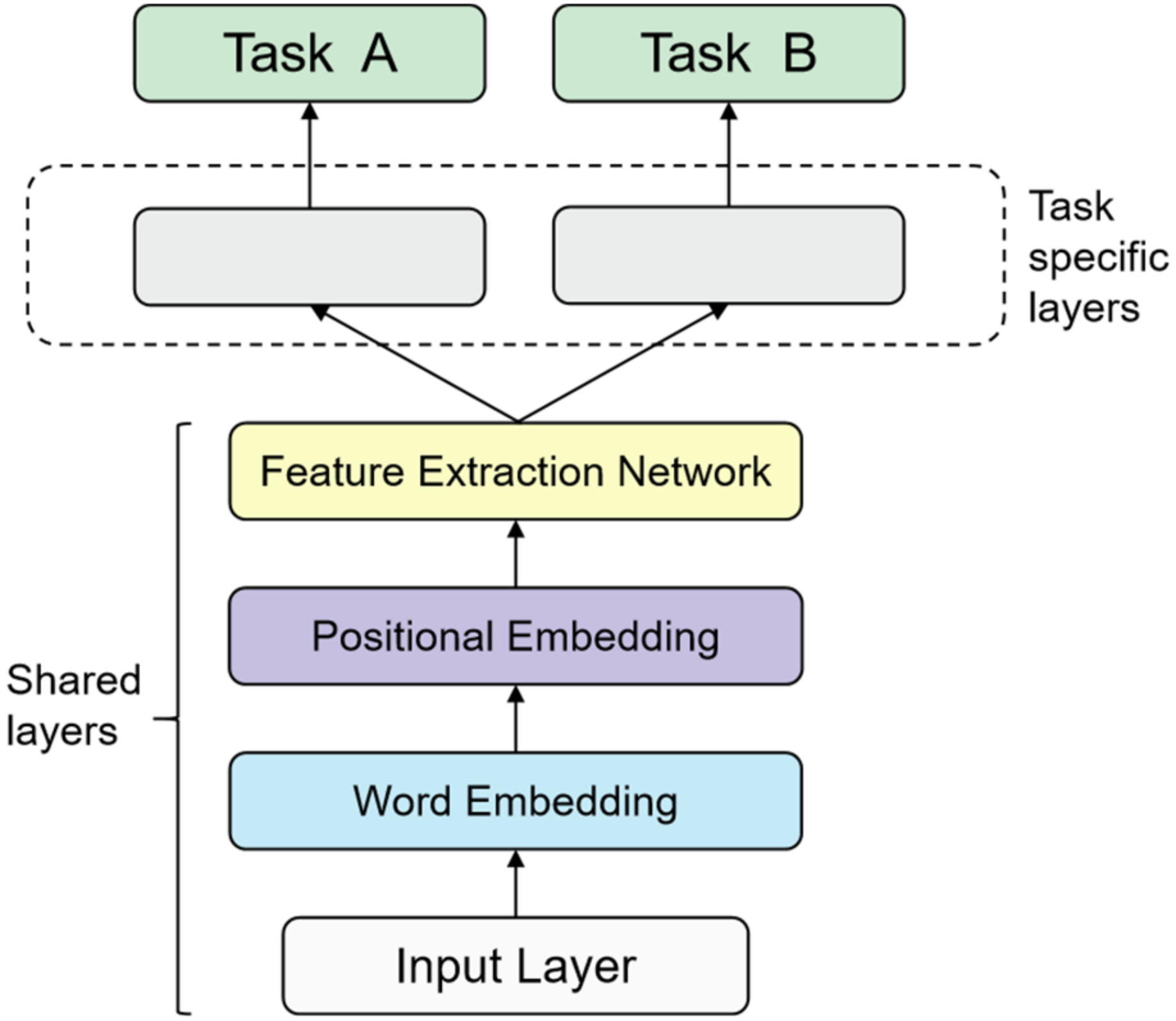
- This paper proposes a smart contract vulnerability detection model and introduces multi-task learning into security detection. The model consists of two parts—(1) the bottom sharing layer, which uses neural networks based on the attention mechanism to learn the semantic information of input contracts and extract feature vectors; (2) the specific task layer, which uses the classical convolutional neural network (CNN) [41] to establish a classification network for each task branch. The captured features are learned from the sharing layer for detection and recognition to realize the detection of various vulnerabilities;
- The proposed multi-task learning model can effectively improve the precision of vulnerability detection in comparison with other methods. Compared to the single-task model, the multi-task model can complete multiple tasks at the same time, thereby saving costs in terms of time, computation, and storage. At the same time, this model can be extended to support the learning and detection of new vulnerabilities;
- In this study, we collected and downloaded 149,363 smart contracts running on real-world Ethereum from the XBlock platform [42] and used the existing detection tools to detect and label them and construct an open-source dataset containing the labeling information. This dataset provides key attributes, including the address, bytecode, and source code, and can be employed for smart contract vulnerability detection research.
2. Background and Related Work
2.1. Smart Contracts and Vulnerability
- (1)
- Arithmetic vulnerability: This type of vulnerability is also known as integer overflow or underflow, arithmetic problems, and so forth. It is very common because programming languages have a length limit for integer types of storage, and it occurs when the results run outside of this range. For example, if a number is stored in the uint8 type, it means that the number is stored in an 8-bit unsigned number ranging from 0 to 255, and an arithmetic vulnerability occurs when an arithmetic operation tries to create a number outside of that range. Arithmetic vulnerability is also one of the most common vulnerabilities in smart contracts, and malicious attackers use this vulnerability to steal a large number of tokens, resulting in considerable economic losses.
- (2)
- Reentrancy: The ability to call external contract codes is one of the features of smart contracts, and contracts can send digital currency to external user addresses for transactions. Such calls to external contracts may cause reentrancy. The attacker uses reentrancy vulnerability to perform the recursive callback of the main function and continuously carries out the “withdrawal” operation in the contract until the account balance in the contract is cleared or the gas upper limit is reached. In 2016, the DAO attack [8] took place, wherein a malicious attacker applied to the DAO contract for funds several times before the contract balance was updated. The vulnerability was caused by a code error in which the developer failed to consider recursive calls. Although Ethereum resolved the attack with a blockchain hard fork, it still caused significant economic losses.
- (3)
- Contract contains unknown address: Smart contracts are P2P computer transaction protocols. Thus, when a contract contains an unknown address, this address is likely to be used for some malicious activities. When this vulnerability occurs, it is required to check the address. In addition, it is required to check the code of the called contract for vulnerabilities.
2.2. Methods for Smart Contract Vulnerability Detection
- (1)
- Symbolic execution: Oyente [11] was one of the earliest works to use symbolic execution for detecting vulnerabilities in the source code or bytecode of smart contracts. It constructs the control flow graph and uses it to crease inputs and provides a symbolic execution engine for other tools. Osiris [12] has been improved based on Oyente, using symbolic execution and taint analysis to detect vulnerabilities. Similarly, Manticore [15] analyzes contracts by executing symbolic transactions against the bytecode, tracking the contracts’ states, and verifying the contracts. Maian [14] and Mythril [13] are also based on symbolic execution.
- (2)
- Formal Verification: Hirai et al. [46] used Isabelle/HOL to formalize contracts to prove their security. In addition, many methods have been developed to formalize smart contracts, such as ZEUS [18], which translates source codes into LLVM intermediate language, uses XACML to write validation rules, and then uses SeaHorn [47] to formalize validation. Securify [22] and VerX [23] are two other mainstream formal verification tools.
- (3)
- Fuzzy Testing: Fuzzy testing has been widely used in the vulnerability mining of traditional programs, and it attempts to expose vulnerabilities by executing the program with inputs. Echidna [24], published by Trail of Bits, is a complete fuzzy testing framework for analyzing smart contracts and simulation testing. ContractFuzzer [25] is also a kind of fuzzy testing scheme that performs vulnerability detection by recording the instruction log during the execution of smart contracts. ILF [26] is a fuzzy testing scheme based on neural networks that are used to generate better test cases in fuzzy testing.
- (4)
- Other technologies: Program analysis and taint analysis are also commonly used in vulnerability detection, and program analysis involves determining the safety of a program by analyzing it to obtain its characteristics, while taint analysis involves marking key data and tracking its flow in the process of program execution to achieve program analysis. SASC [28] is a smart contract vulnerability detection based on static program analysis methods that searches for control flow characteristics to detect vulnerabilities through automatic analysis of the source code. Similarly, SmartCheck [29] and Slither [30] are also detection tools based on program analysis. Sereum [31] uses taint analysis to trace data streams to detect vulnerabilities.
- (5)
- ML-based methods: As mentioned above, the security of smart contracts has garnered public attention, and some achievements have been made in the research of contract vulnerability detection methods using ML. TonTon Hsien-De Huang [35] proposed a method for the in-depth analysis of potential vulnerabilities that involves converting bytecode into an RGB image and then training a CNN for automatic feature extraction and learning. Sun et al. [48] added an attention mechanism [49] to CNN to further improve its accuracy in detecting vulnerabilities. Wesley et al. [36] used a long short-term memory (LSTM) neural network to learn vulnerabilities by a sequential learning method and realized a relatively fast detection of vulnerability contracts. However, these methods can only be used to distinguish whether there are vulnerabilities, which are essentially binary classification models, and they cannot identify the types of vulnerabilities or detect multiple vulnerabilities. To realize the detection of multiple vulnerabilities, Moment et al. [50] and ContractWard [37] used various ML algorithms (support vector machine, decision tree, random forest, XGBoost, AdaBoost, k-nearest neighbor, etc.) to establish an independent classification model for each vulnerability; the main difference is that the former used an abstract syntax tree to construct the vulnerability features of a smart contract, while the latter used an N-Gram language model [51] to extract binary syntax features from the simplified opcodes of smart contracts. Although these two methods have realized various vulnerability detection, they are still dichotomous and not separate models. In addition, ESCORT [52] proposed a multi-output architecture that connected each vulnerability classification branch to the feature extractor based on a deep neural network (DNN) and established a separate output for each vulnerability type, thus realizing the detection of multiple vulnerabilities. This provided the preliminary idea for our model design, and in this work, we propose a multi-task learning-based model for smart contract detection, which not only detects the presence of vulnerabilities in the contract but also recognizes the types of contract vulnerabilities, that is, it includes multi-vulnerability detection.
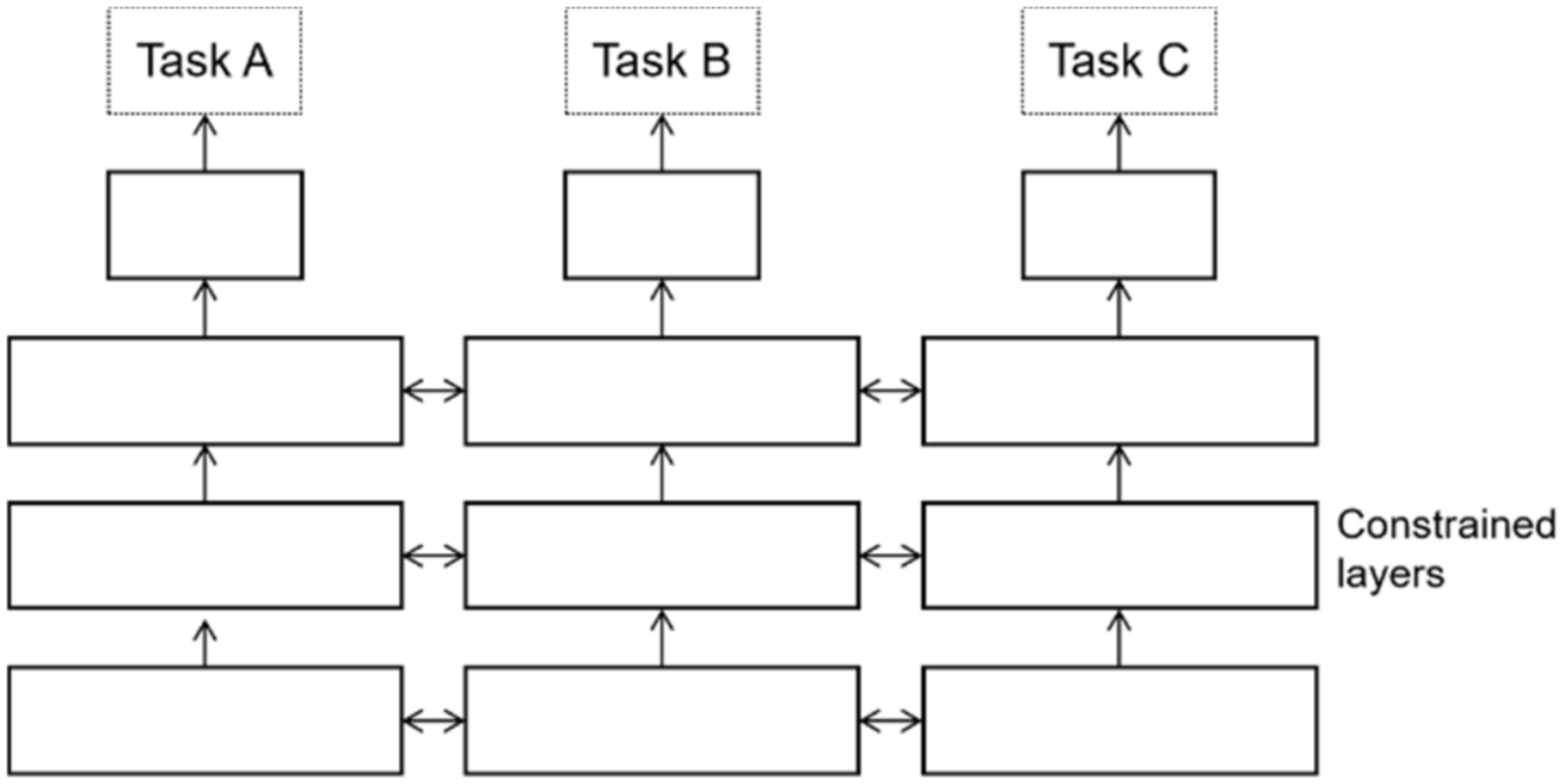
2.3. Multi-Task Learning
3. The Proposed Smart Contract Vulnerability Detection Model
3.1. Data Collection and Preprocessing
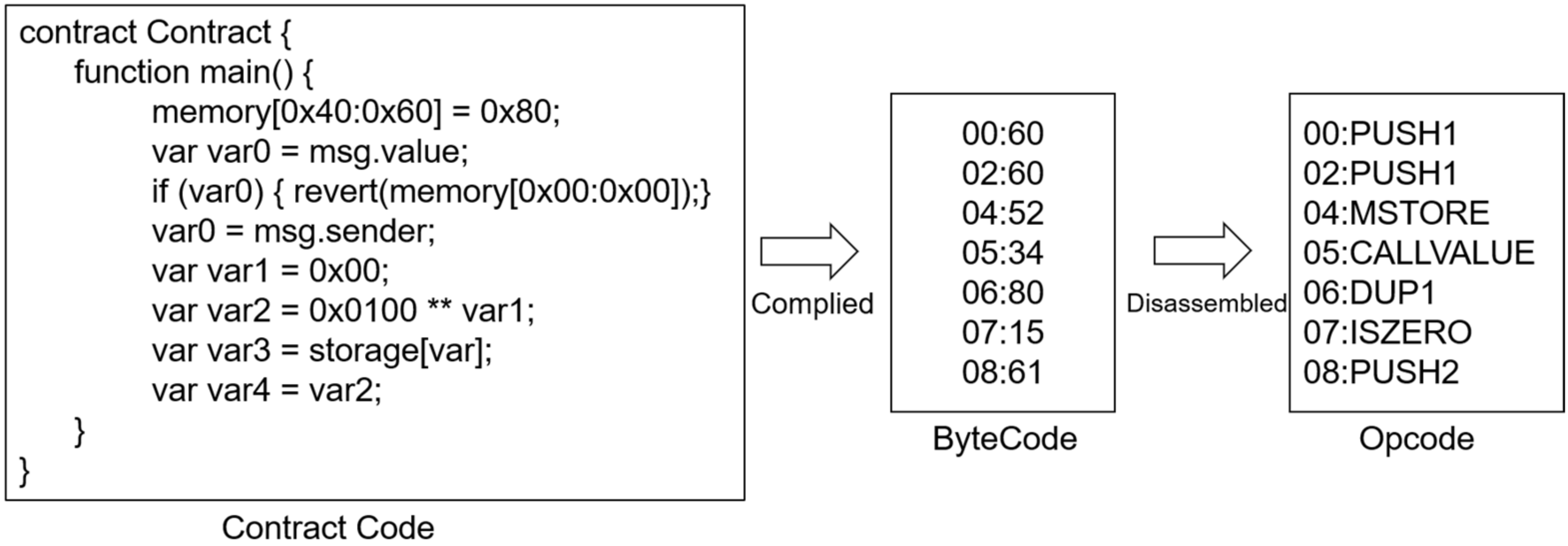
3.1.1. The Source Codes, Bytecodes, and Operation Codes of Smart Contracts
3.1.2. Data Acquisition
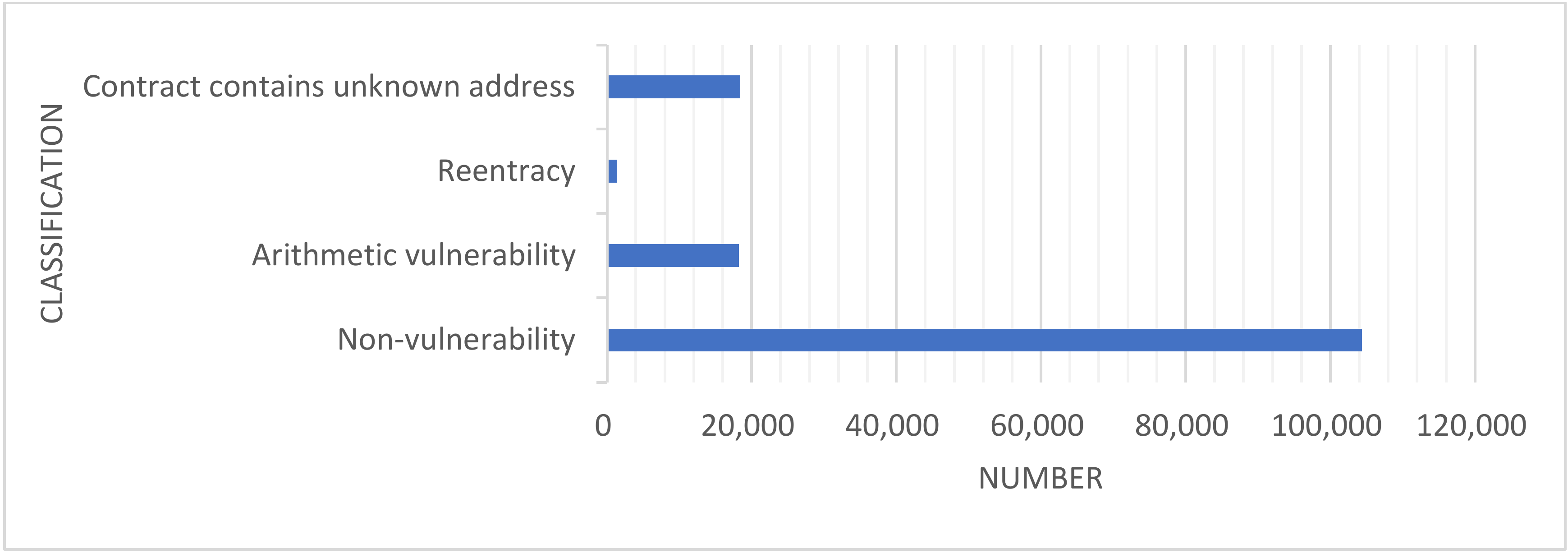
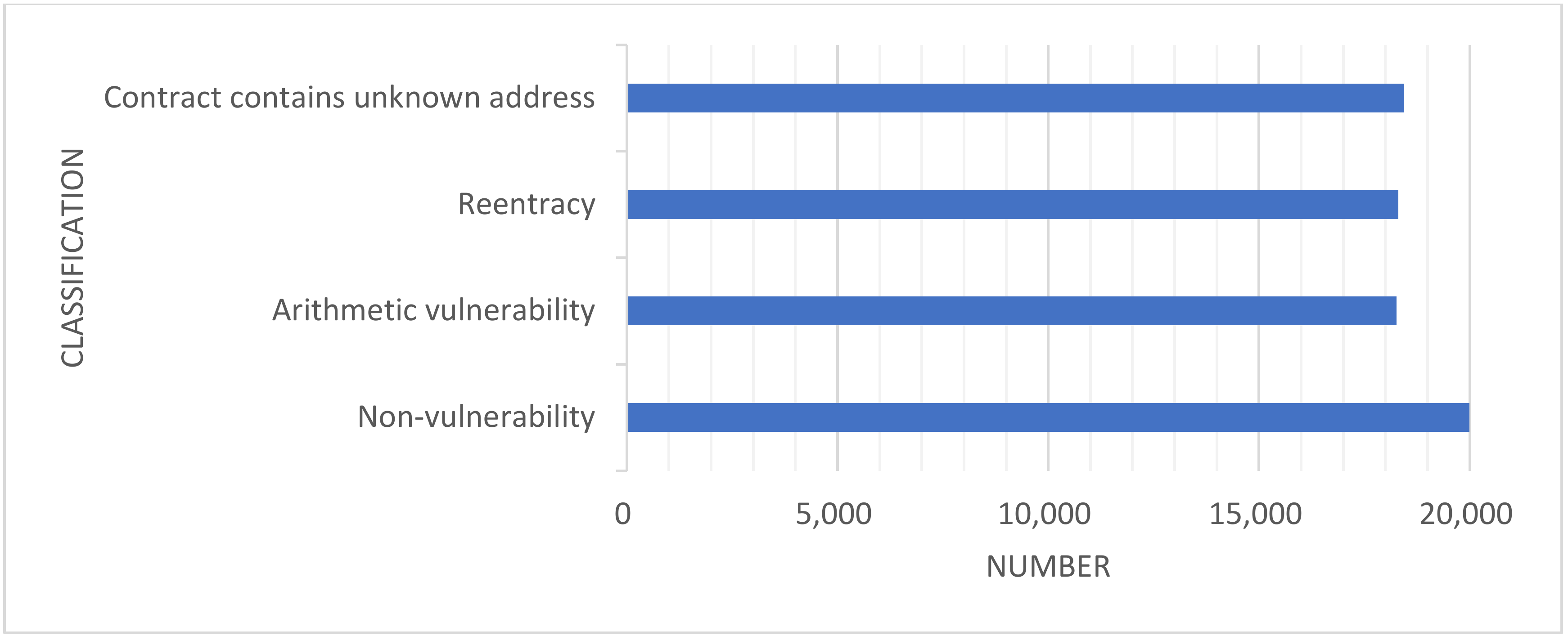
3.1.3. Data Imbalance
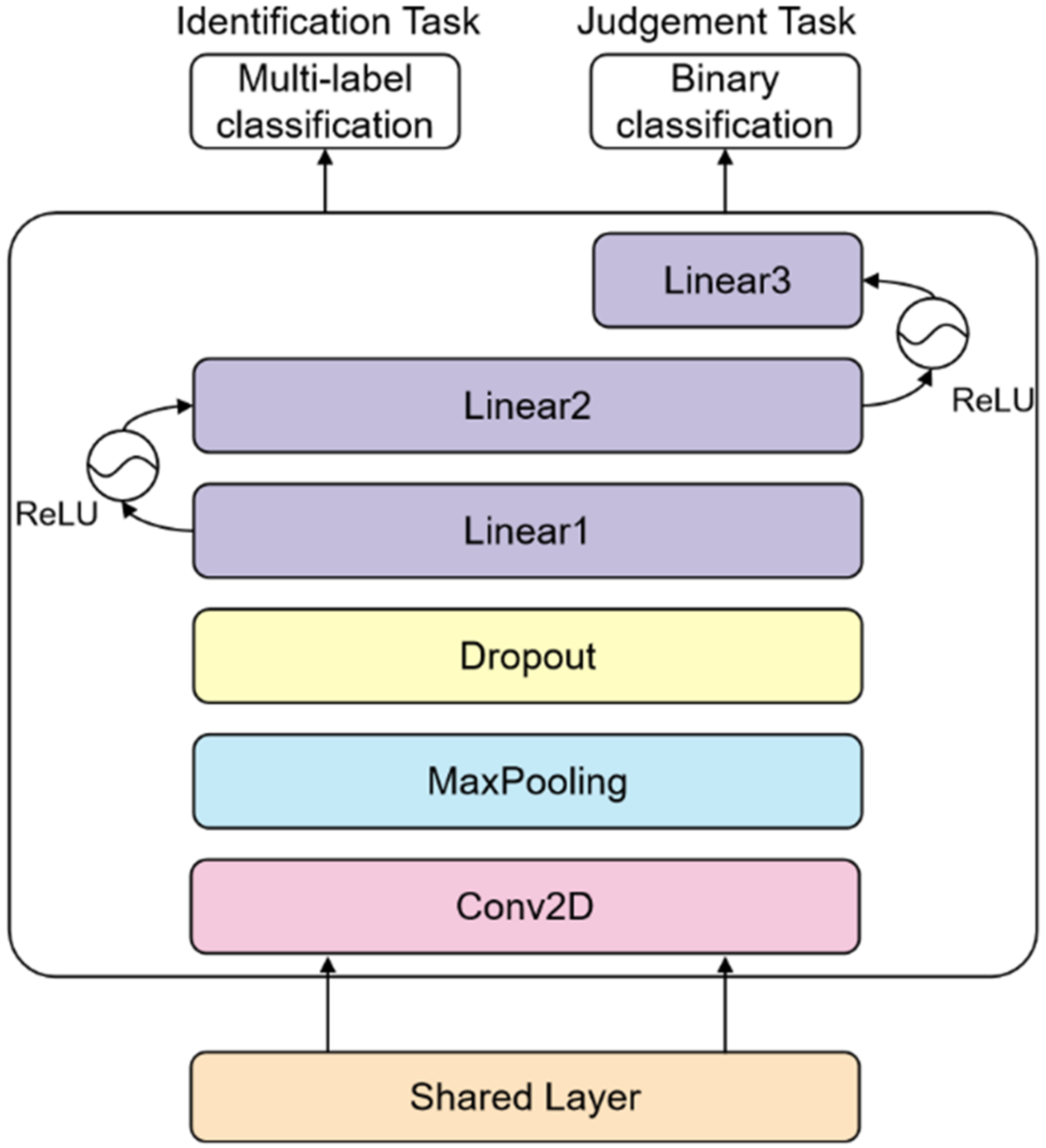
3.2. Model Design
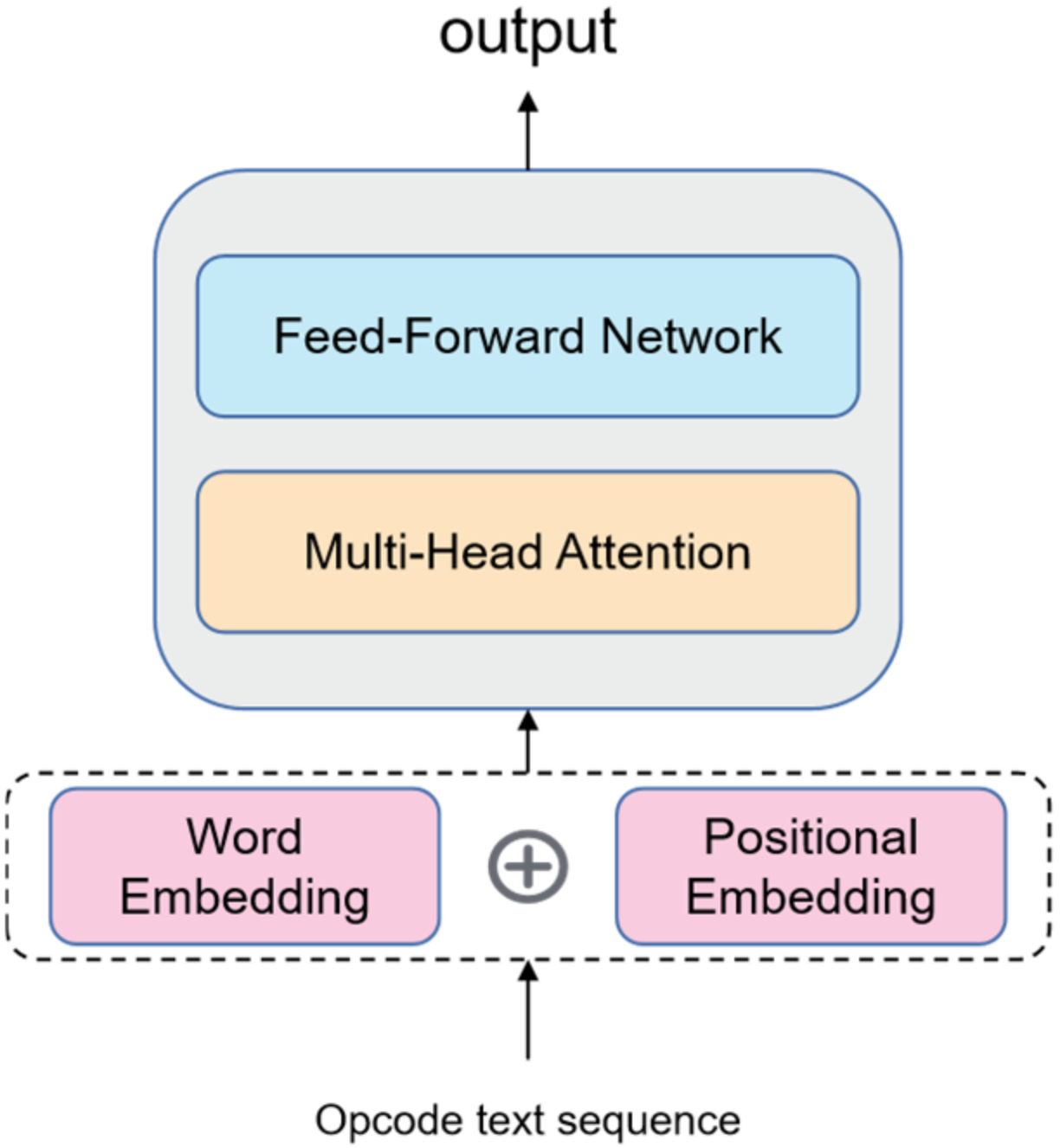
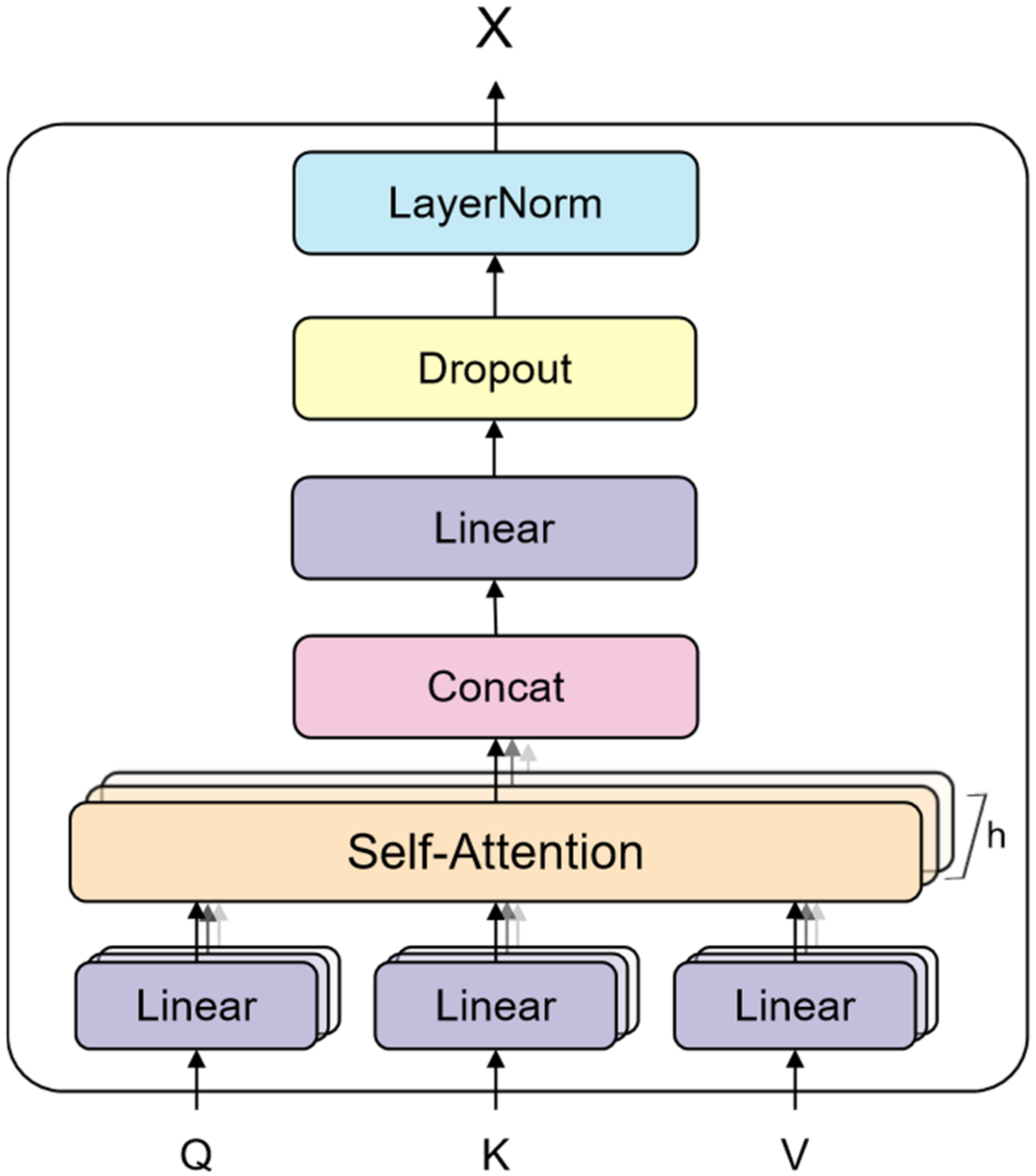
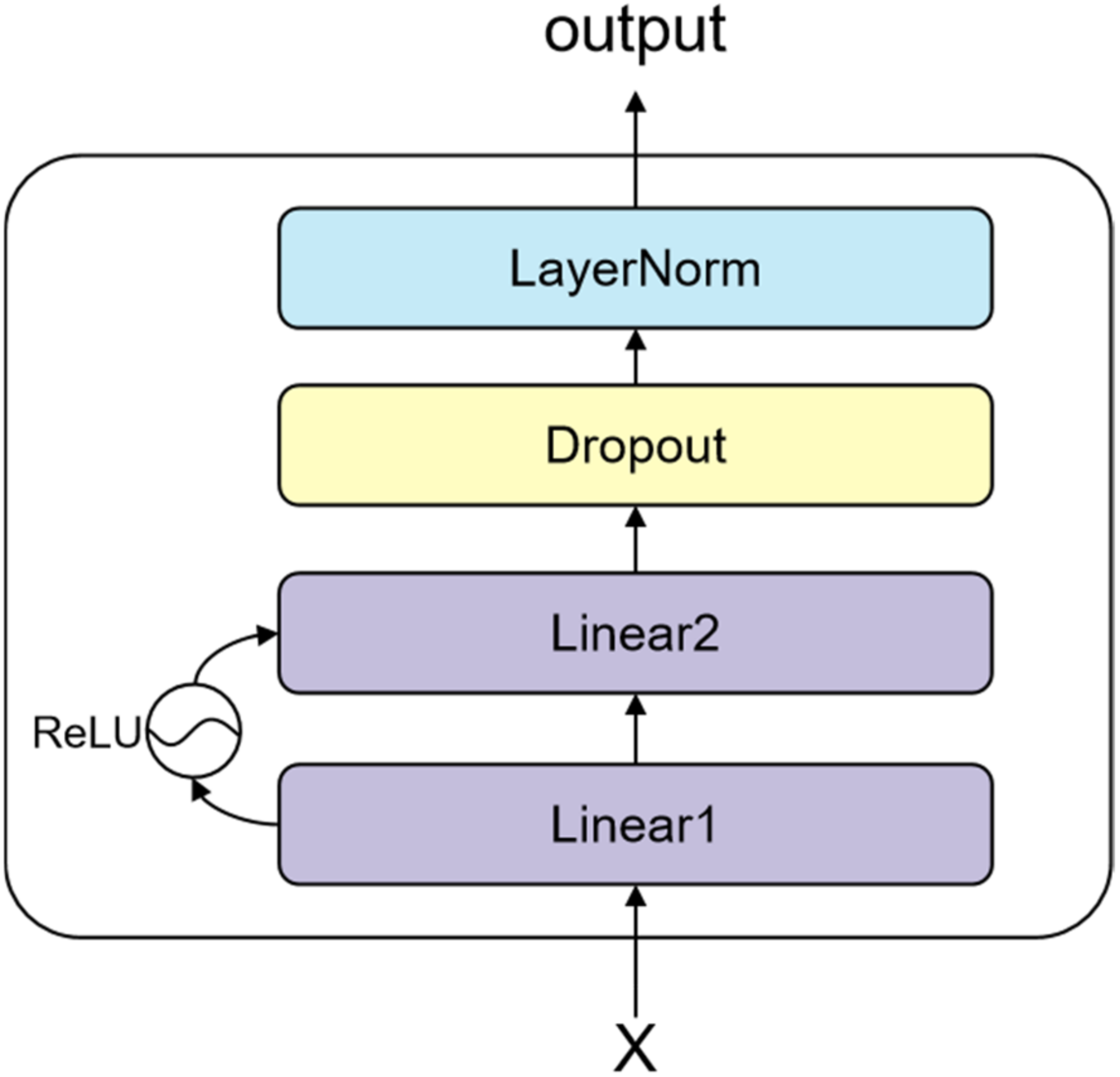
3.2.1. The Bottom Sharing Layer
3.2.2. The Top Specific Tasks Layer
| Algorithm 1. Training model. |
| 1: Initialize model parameters randomly 2: Pre-train the shared layers 3: Set the max number of epoch: 4: for t in 1, 2, …, T do 5: Pack the dataset t into mini-batch: 6: End 7: for epoch in 1, 2, … , do 8: 1. Merge all the datasets: 9: D = 10: 2. Shuffle D 11: for in D do // is a mini-batch of task t 12: 3. Compute loss: 13: = Equation (7) for judgment task 14: = Equation (8) for identification task 15: = Equation (9) for multi-task learning model 16: 4. Compute gradient: 17: 5. Update model: 18: End 19: End |
4. Experiment and Analysis
4.1. Experimental Setup
4.2. Evaluation Metrics
4.3. Experiments
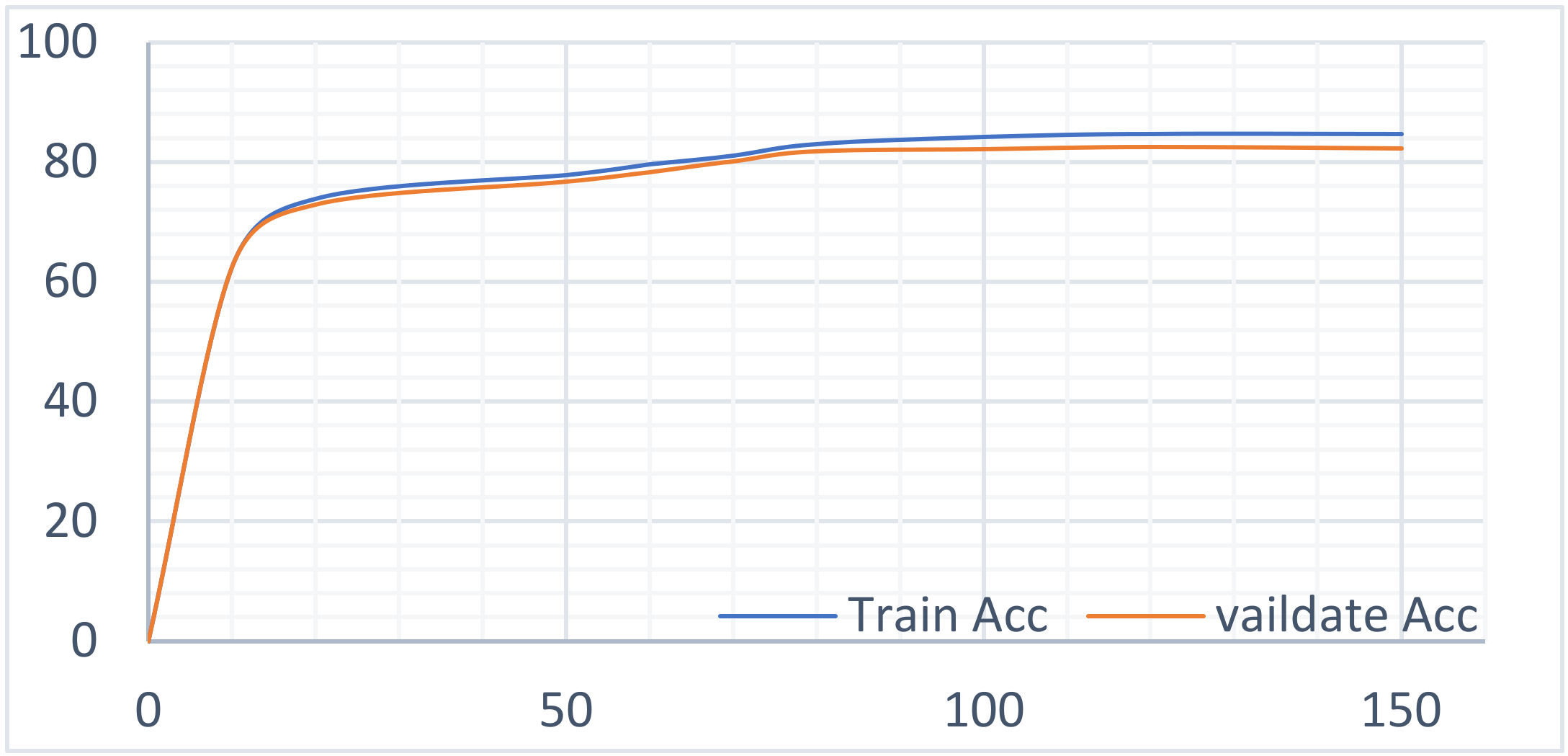
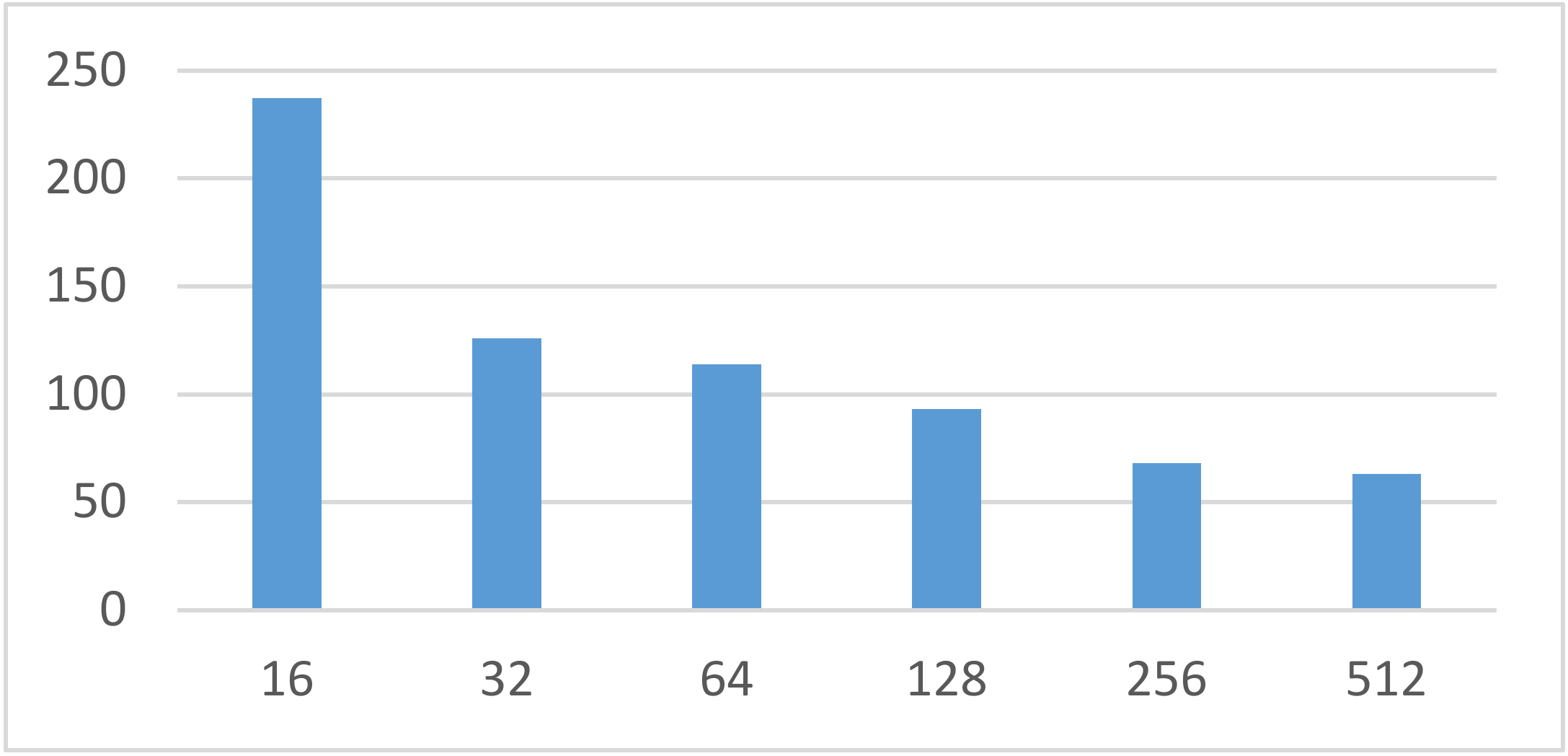
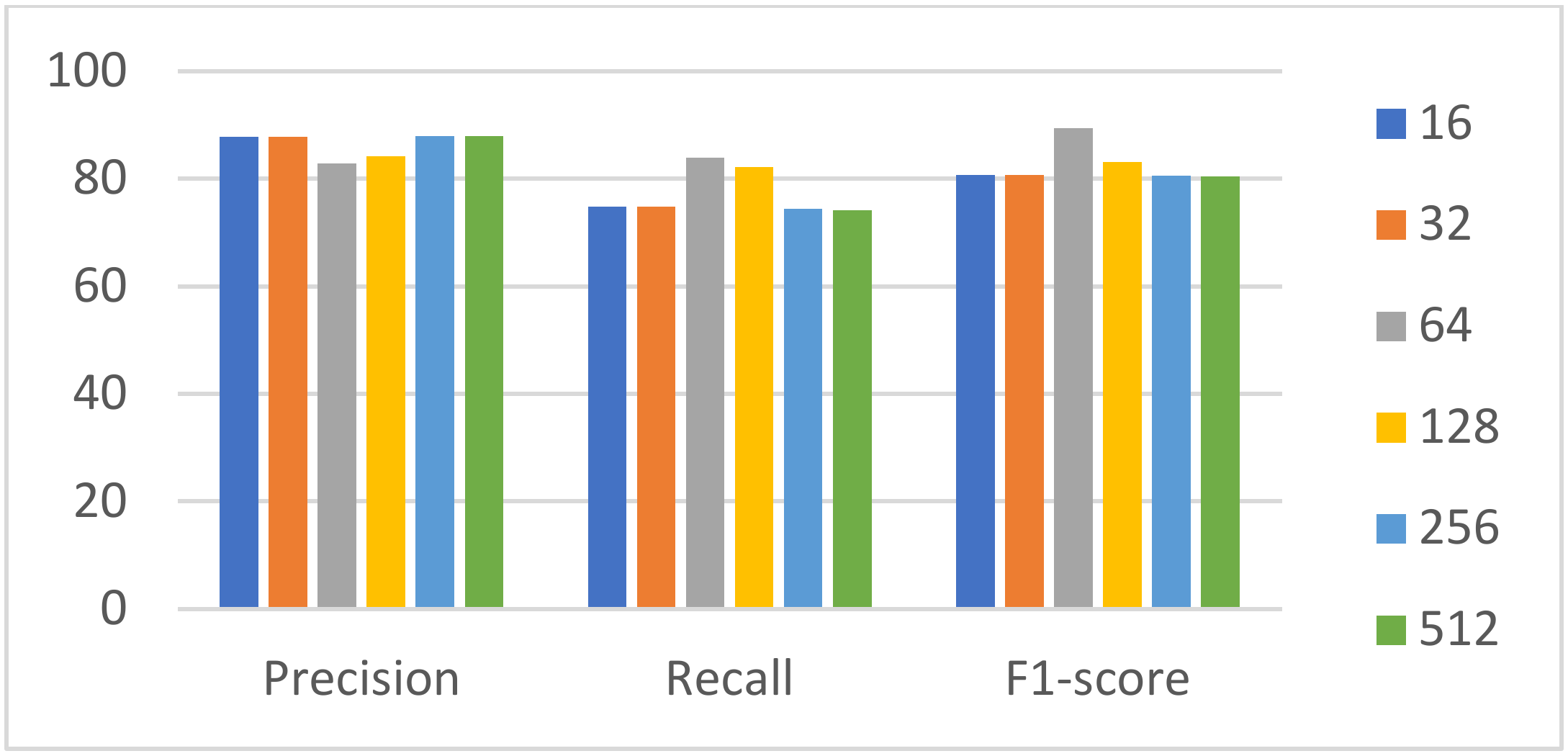
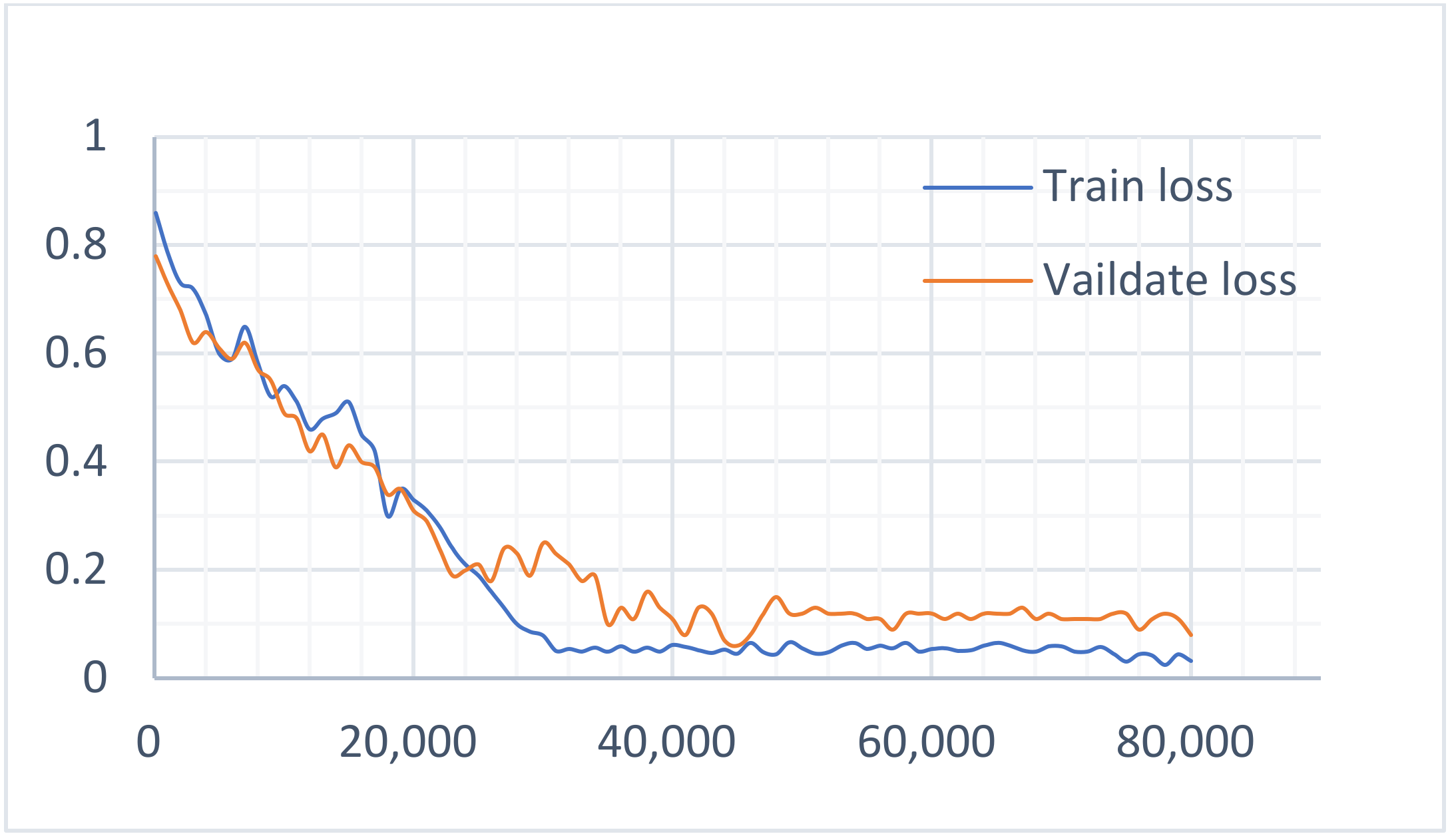
4.3.1. Experiment 1: Multi-Task Learning Model Experiments
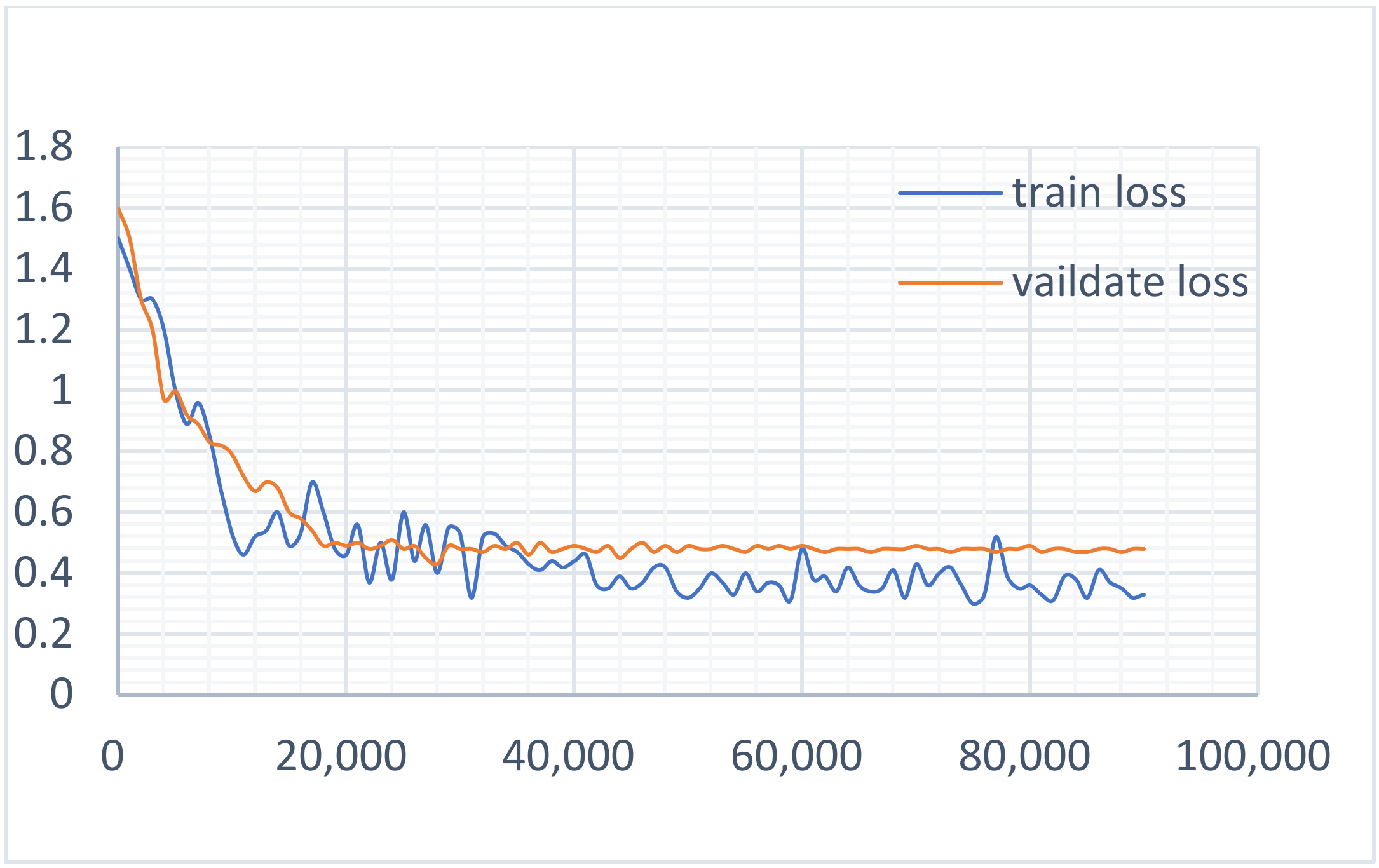
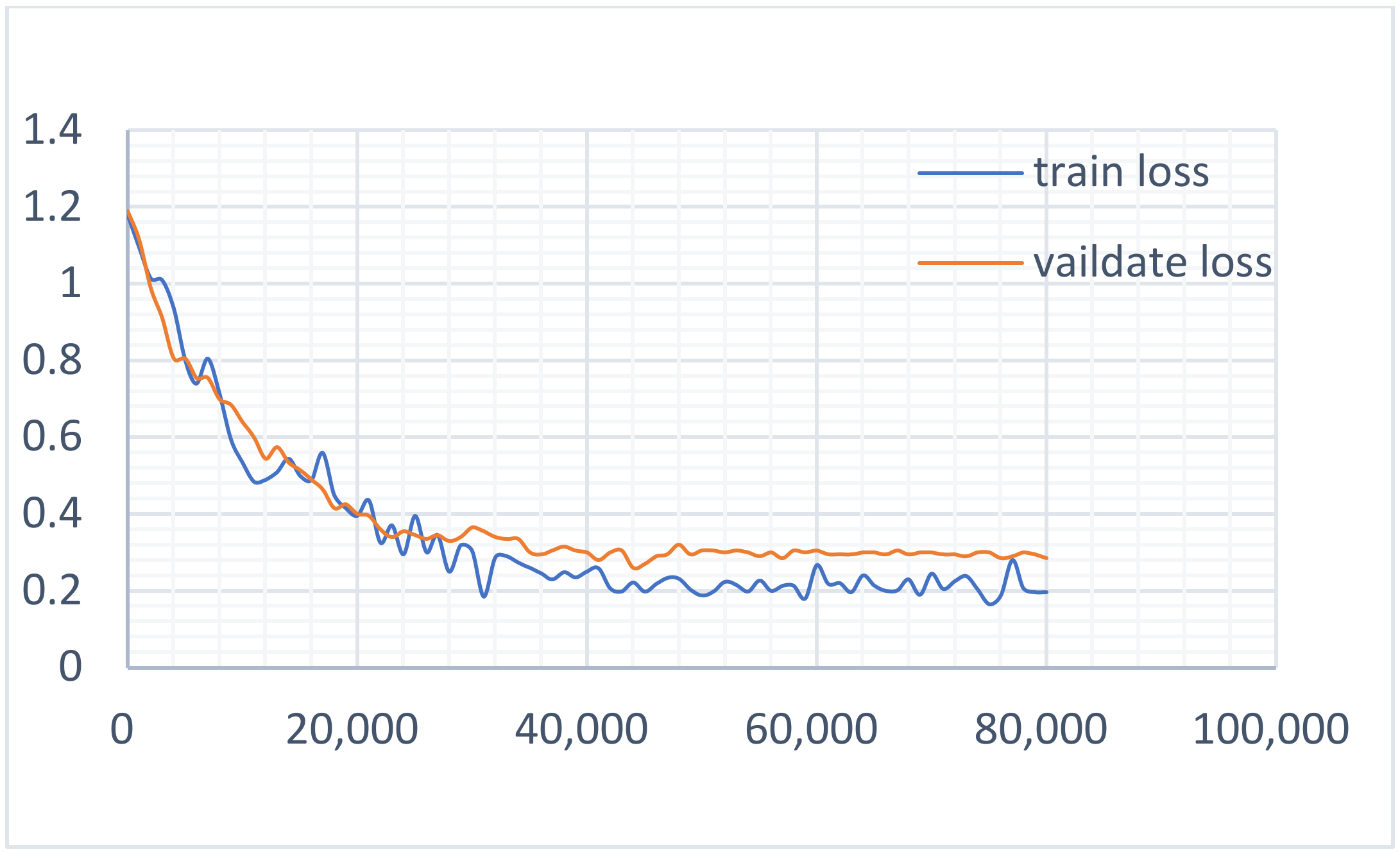
4.3.2. Experiment 2: Baseline Model Experiment
4.3.3. Experiment 3: Comparison with ML Methods
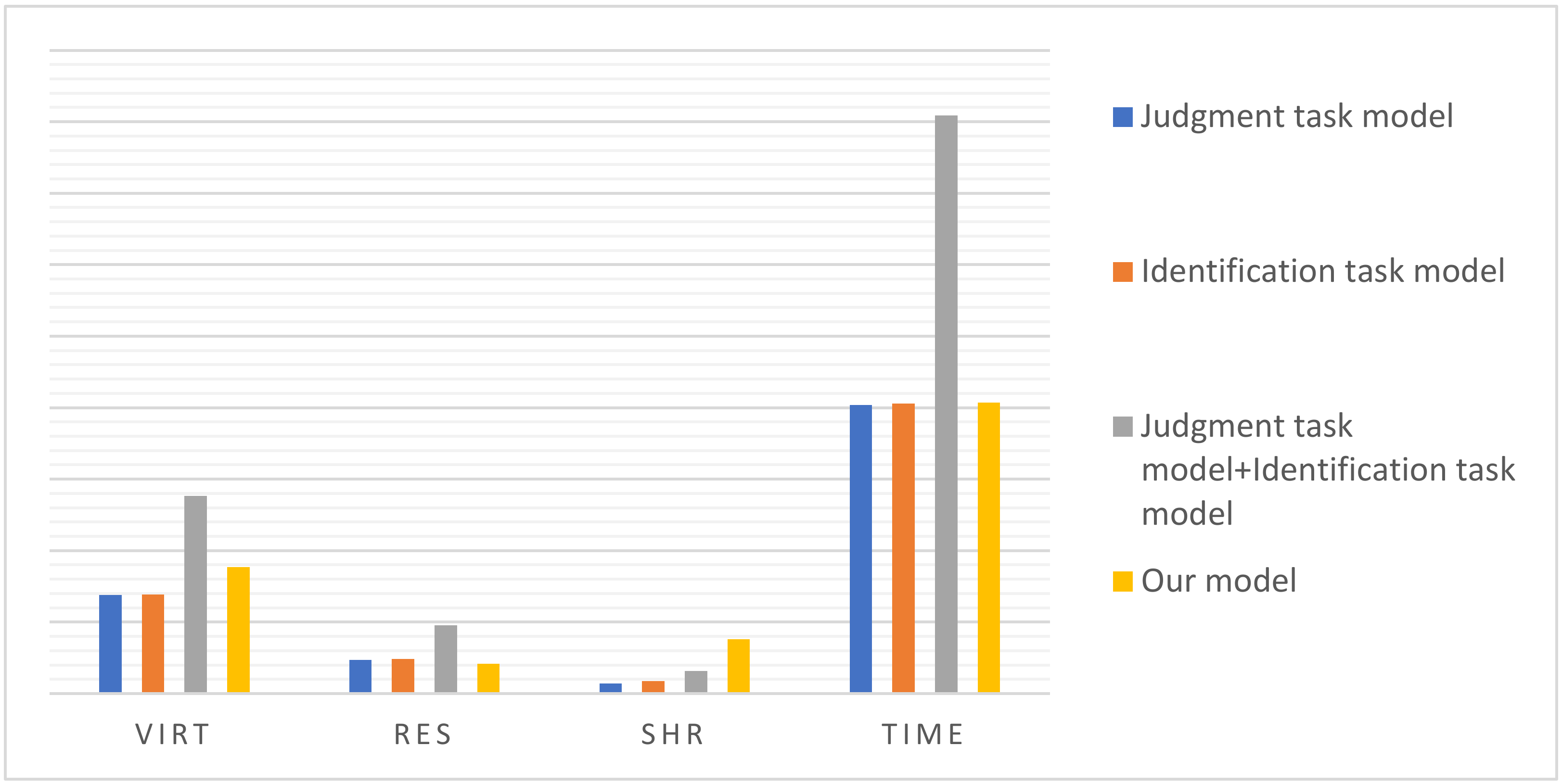
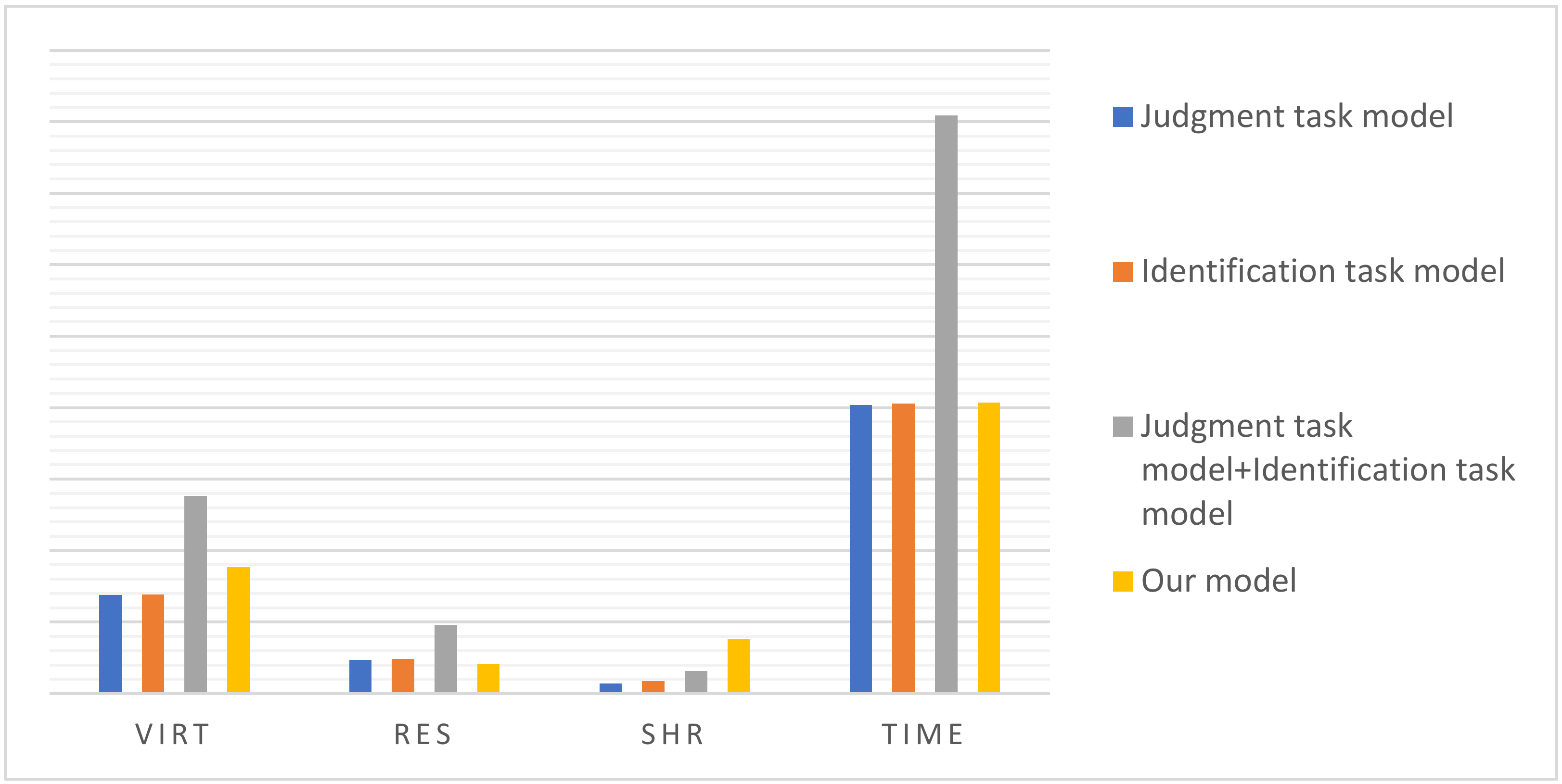
4.3.4. Experiment 4: Ablation Experiments
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Szabo, N. Smart contracts: Building blocks for digital markets. EXTROPY J. Transhumanist Thought 1996, 16, 18. [Google Scholar]
- Nakamoto, S. Bitcoin: A peer-to-peer electronic cash system. Decentralized Bus. Rev. 2008, 21260. [Google Scholar]
- Dannen, C. Introducing Ethereum and Solidity; Apress: Berkeley, CA, USA, 2017. [Google Scholar]
- Hyperledger Project. Available online: https://www.hyperledger.org/ (accessed on 28 October 2021).
- Lin, I.C.; Liao, T.C. A survey of blockchain security issues and challenges. Int. J. Netw. Secur. 2017, 19, 653–659. [Google Scholar]
- The Solidity Contract-Oriented Programming Language. Available online: https://github.com/ethereum/solidity (accessed on 28 October 2021).
- Atzei, N.; Bartoletti, M.; Cimoli, T. A survey of attacks on ethereum smart contracts (sok). In Proceedings of the International Conference on Principles of Security and Trust, Uppsala, Sweden, 24–25 April 2017; pp. 164–186. [Google Scholar]
- Mehar, M.I.; Shier, C.L.; Giambattista, A.; Gong, E.; Fletcher, G.; Sanayhie, R.; Kim, H.M.; Laskowski, M. Understanding a Revolutionary and Flawed Grand Experiment in Blockchain. J. Cases Inf. Technol. 2019, 21, 19–32. [Google Scholar] [CrossRef] [Green Version]
- The Parity Wallet Hack Explained. Available online: https://blog.openzeppelin.com/on-the-parity-wallet-multisig-hack-405a8c12e8f7/ (accessed on 28 October 2021).
- Batch Overflow Bug on Ethereum ERC20 Token Contracts and SafeMath. Available online: https://blog.matryx.ai/batch-overflow-bug-on-ethereum-erc20-token-contracts-and-safemath-f9ebcc137434 (accessed on 28 October 2021).
- Luu, L.; Chu, D.H.; Olickel, H.; Saxena, P.; Hobor, A. Making smart contracts smarter. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 254–269. [Google Scholar]
- Torres, C.F.; Schütte, J.; State, R. Osiris: Hunting for integer bugs in ethereum smart contracts. In Proceedings of the 34th Annual Computer Security Applications Conference, New York, NY, USA, 3–7 December 2018; pp. 664–676. [Google Scholar]
- Mythril-Reversing and Bug Hunting Framework for the Ethereum Blockchain. Available online: https://pypi.org/project/mythril/0.8.2/ (accessed on 28 October 2021).
- Nikolić, I.; Kolluri, A.; Sergey, I.; Saxena, P.; Hpbpr, A. Finding the greedy, prodigal, and suicidal contracts at scale. In Proceedings of the 34th Annual Computer Security Applications Conference, New York, NY, USA, 3–7 December 2018; pp. 653–663. [Google Scholar]
- Mossberg, M.; Manzano, F.; Hennenfent, E.; Groce, A.; Grieco, G.; Feist, J.; Brunson, T.; Dinaburg, A. Manticore: A user-friendly symbolic execution framework for binaries and smart contracts. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), San Diego, CA, USA, 11–15 November 2019; pp. 1186–1189. [Google Scholar]
- Wood, G. Ethereum: A secure decentralised generalised transaction ledger. Ethereum Proj. Yellow Pap. 2014, 151, 1–32. [Google Scholar]
- Formal Verification of Deed Contract in Ethereum Name Service. Available online: https://yoichihirai.com/deed.pdf (accessed on 28 October 2021).
- Kalra, S.; Goel, S.; Dhawan, M.; Sharma, S. Zeus: Analyzing safety of smart contracts. In Proceedings of the Network and Distributed System Symposium (NDSS), San Diego, CA, USA, 18–21 February 2018; pp. 1–12. [Google Scholar]
- Hildenbrandt, E.; Saxena, M.; Rodrigues, N.; Zhu, X.; Daian, P.; Guth, D.; Moore, B.; Park, D.; Zhang, Y.; Stefanescu, A.; et al. KEVM: A complete formal semantics of the ethereum virtual machine. In Proceedings of the 2018 IEEE 31st Computer Security Foundations Symposium (CSF), Oxford, UK, 9–12 July 2018; pp. 204–217. [Google Scholar]
- Bhargavan, K.; Delignat-Lavaud, A.; Fournet, C.; Gollamudi, A.; Gonthier, G.; Kobeissi, N.; Kulatova, N.; Rastogi, A.; Sibut-Pinote, T.; Swamy, N.; et al. Formal verification of smart contracts: Short paper. In Proceedings of the 2016 ACM Workshop on Programming Languages and Analysis for Security, Vienna, Austria, 20–24 October 2016; pp. 91–96. [Google Scholar]
- Grishchenko, I.; Maffei, M.; Schneidewind, C. A semantic framework for the security analysis of ethereum smart contracts. Proceeding of the International Conference on Principles of Security and Trust, Thessaloniki, Greece, 16–19 April 2018; pp. 243–269. [Google Scholar]
- Tsankov, P.; Dan, A.; Drachsler-Cohen, D.; Gervais, A.; Bünzli, F.; Vechev, M. Securify: Practical security analysis of smart contracts. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 67–82. [Google Scholar]
- Permenev, A.; Dimitrov, D.; Tsankov, P.; Drachsler-Cohen, D.; Vechev, M. Verx: Safety verification of smart contracts. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 17–21 May 2020; pp. 1661–1677. [Google Scholar]
- Grieco, G.; Song, W.; Cygan, A.; Feist, J.; Groce, A. Echidna: Effective, usable, and fast fuzzing for smart contracts. In Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, New York, NY, USA, 18–22 July 2020; pp. 557–560. [Google Scholar]
- Jiang, B.; Liu, Y.; Chan, W.K. ContractFuzzer: Fuzzing Smart Contracts for Vulnerability Detection. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, New York, NY, USA, 3–7 September 2018; pp. 259–269. [Google Scholar]
- He, J.; Balunović, M.; Ambroladze, N.; Tsankov, P.; Vechev, M. Learning to fuzz from symbolic execution with application to smart contracts. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 531–548. [Google Scholar]
- Wüstholz, V.; Christakis, M. Harvey: A greybox fuzzer for smart contracts. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Rome, Italy, 6–8 November 2020; pp. 1398–1409. [Google Scholar]
- Zhou, E.; Hua, S.; Pi, B.; Sun, J.; Nomura, Y.; Yamashita, K.; Kurihara, H. Security assurance for smart contract. In Proceedings of the 2018 9th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 26–28 February 2018; pp. 1–5. [Google Scholar]
- Tikhomirov, S.; Voskresenskaya, E.; Ivanitskiy, I.; Takhaview, R.; Marchenko, E.; Alexandrov, Y. Smartcheck: Static analysis of ethereum smart contracts. In Proceedings of the 1st International Workshop on Emerging Trends in Software Engineering for Blockchain, Gothenburg, Sweden, 27 May 2018; pp. 9–16. [Google Scholar]
- Slither. Available online: https://github.com/crytic/slither (accessed on 28 October 2021).
- Rodler, M.; Li, W.; Karame, G.O.; Davi, L. Sereum: Protecting existing smart contracts against re-entrancy attacks. In Proceedings of the 2019 Network and Distributed System Security Symposium, San Diego, CA, USA, 24–27 February 2019; pp. 12–19. [Google Scholar]
- Wu, S.Z.; Guo, T.; Dong, G.W. Software Vulnerability Analysis Technology. Sci. Press 2012, 52, 215–269, 1309–1319. [Google Scholar]
- Fey, G. Assessing system vulnerability using formal verification techniques. In Proceedings of the International Doctoral Workshop on Mathematical and Engineering Methods in Computer Science, Berlin/Heidelberg, Germany, 14–16 October 2011; pp. 47–56. [Google Scholar]
- Li, J.; Zhao, B.; Zhang, C. Fuzzing: A survey. Cybersecurity 2018, 1, 1–13. [Google Scholar] [CrossRef]
- Huang, T.T.H.D. Hunting the ethereum smart contract: Color-inspired inspection of potential attacks. arXiv 2018, arXiv:1807.01868. [Google Scholar]
- Tann, W.J.W.; Han, X.J.; Gupta, S.S.; Ong, Y.-S. Towards safer smart contracts: A sequence learning approach to detecting security threats. arXiv 2018, arXiv:1811.06632. [Google Scholar]
- Wang, W.; Song, J.; Xu, G.; Li, Y.; Wang, H.; Su, C. Contractward: Automated vulnerability detection models for ethereum smart contracts. IEEE Trans. Netw. Sci. Eng. 2020, 8, 1133–1144. [Google Scholar] [CrossRef] [Green Version]
- Merity, S.; Keskar, N.S.; Socher, R. Regularizing and optimizing LSTM language models. arXiv 2017, arXiv:1708.02182. [Google Scholar]
- Zhuang, Y.; Liu, Z.; Qian, P.; Liu, Q.; Wang, X.; He, Q. Smart Contract Vulnerability Detection using Graph Neural Network. In Proceedings of the International Joint Conferences on Artificial Intelligence (IJCAI), Online, 11–13 January 2020; pp. 3283–3290. [Google Scholar]
- Zhang, Y.; Yang, Q. A survey on multi-task learning. IEEE Trans. Knowl. Data Eng. 2021, 1. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Huang, Y.; Kong, Q.; Jia, N.; Chen, X.; Zheng, Z. Recommending differentiated code to support smart contract update. In Proceedings of the 2019 IEEE/ACM 27th International Conference on Program Comprehension (ICPC), Montreal, QC, Canada, 25–26 May 2019; pp. 260–270. [Google Scholar]
- Buterin, V. A next-generation smart contract and decentralized application platform. White Pap. 2014, 3. [Google Scholar]
- Nabilou, H. How to regulate bitcoin? Decentralized regulation for a decentralized cryptocurrency. Int. J. Law Inf. Technol. 2019, 27, 266–291. [Google Scholar] [CrossRef]
- Smart Contract Weakness Classification and Test Cases. Available online: http://swcregistry.io (accessed on 28 October 2021).
- Hirai, Y. Formal verification of Deed contract in Ethereum name service. In Proceedings of the 10th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Canary Islands, Spain, 24–26 June 2019; pp. 1–6. [Google Scholar]
- SeaHorn. Verification Framework. Available online: https://seahorn.github.io/ (accessed on 13 February 2022).
- Sun, Y.; Gu, L. Attention-based Machine Learning Model for Smart Contract Vulnerability Detection. J. Phys. Conf. Ser. 2021, 1820, 012004. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), San Diego, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Momeni, P.; Wang, Y.; Samavi, R. Machine learning model for smart contracts security analysis. In Proceedings of the 2019 17th International Conference on Privacy, Security and Trust (PST), Fredericton, NB, Canada, 26–28 August 2019; pp. 1–6. [Google Scholar]
- Cavnar, W.B.; Trenkle, J.M. N-gram-based text categorization. In Proceedings of the SDAIR-94, 3rd Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, NV, USA, 11–13 April 1994; pp. 161–175. [Google Scholar]
- Lutz, O.; Chen, H.; Fereidooni, H.; Sender, C.; Dmitrienko, A.; Sadeghi, A.R.; Koushanfar, F. ESCORT: Ethereum Smart Contracts Vulnerability Detection using Deep Neural Network and Transfer Learning. arXiv 2021, arXiv:2103.12607. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Niu, J.; Yang, Y.; Zhang, S.; Sun, Z.; Zhang, W. Multi-task character-level attentional networks for medical concept normalization. Neural Processing Lett. 2019, 49, 1239–1256. [Google Scholar] [CrossRef]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. arXiv 2016, arXiv:1605.05101. [Google Scholar]
- Yang, J.; Liu, Y.; Qian, M.; Guan, C.; Yuan, X. Information Extraction from Electronic Medical Records Using Multitask Recurrent Neural Network with Contextual Word Embedding. Appl. Sci. 2019, 9, 3658. [Google Scholar] [CrossRef] [Green Version]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Duong, L.; Cohn, T.; Bird, S.; Cook, P. Low resource dependency parsing: Cross-lingual parameter sharing in a neural network parser. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 2, pp. 845–850, short papers. [Google Scholar]
- Barandela, R.; Sánchez, J.S.; García, V.; Ferri, F.J. Learning from imbalanced sets through resampling and weighting. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Puerto de Andratx, Spain, 4–6 June 2003; pp. 80–88. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Google Machine Learning Glossary. Available online: https://developers.google.com/machine-learning/glossary (accessed on 28 October 2021).
- Powers, D.M.W. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Xpath Cover Page—W3C. Available online: https://www.w3.org/TR/xpath/all/ (accessed on 28 October 2021).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Boston, MA, USA, 2016; pp. 367–415. [Google Scholar]
- Ma, J.; Zhao, Z.; Yi, X.; Hong, L.; Chi, E.H. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1930–1939. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack | Types of Vulnerability | Economic Loss | Time |
|---|---|---|---|
| The DAO attack [8] | Reentrancy | Direct costs USD 60 million | June 2016 |
| The Parity Wallet hack [9] | Code injection | Over USD 280 million were frozen | July 2017 |
| The ERC-20 campaign [10] | Integer overflow | Indirect losses run into billions of dollars (USD) | April 2018 |
| Bytecode | Flag | Arithmetic Vulnerability | Reentrancy | Contract Contains Unknown Address |
|---|---|---|---|---|
| 0x6080604052600436100da5763fffffff7c010000… | 0 | 0 | 0 | 0 |
| 0x606060405236156100c25763ffffffff7c0100000… | 1 | 0 | 1 | 0 |
| … | … | … | … | … |
| 0x6080604052600436106101c157363fffffffc0100… | 1 | 1 | 0 | 1 |
| Substituted Opcodes | Original Opcodes |
|---|---|
| ARIT | ADD,MUL,SUB,DIV,SDIV,SMOD,MOD,ADDMOD,MULMOD,EXP,SIGNEXTEND |
| COMP | LT,GT,SLT,SGT |
| CONS1 | BLOCKHASH,TIMESTAMP,NUMBER,DIFFICULTY,GASLIMIT,COINBASE |
| CONS2 | ADDRESS,ORIGIN,CALLER |
| CONS3 | GASPRICE,BALANCE,CALLVALUE,GAS |
| LOGIC | AND,OR,XOR,NOT |
| MEMORY | MLOAD,MSTORE,SLOAD,SSTORE,MSIZE |
| RETURN | RETURN,REVERT,RETURNDATASIZE,RETURNDATACOPY |
| PUSH | PUSH1-PUSH32 |
| DUP | DUP1-DUP16 |
| SWAP | SWAP1-SWAP16 |
| LOG | LOG0-LOG4 |
| Opcode | Flag | Arithmetic Vulnerability | Reentrancy | Contract Contains Unknown Address |
|---|---|---|---|---|
| PUSH MSTORE PUSH MEMORY COMP… | 0 | 0 | 0 | 0 |
| PUSH MSTORE MEMORY ISZERO PUSH… | 1 | 0 | 1 | 0 |
| … | … | … | … | … |
| PUSH MSTORE MEMORY PUSH JUMPI… | 1 | 1 | 0 | 1 |
| Type | Number | ||
|---|---|---|---|
| Before | After | Total | |
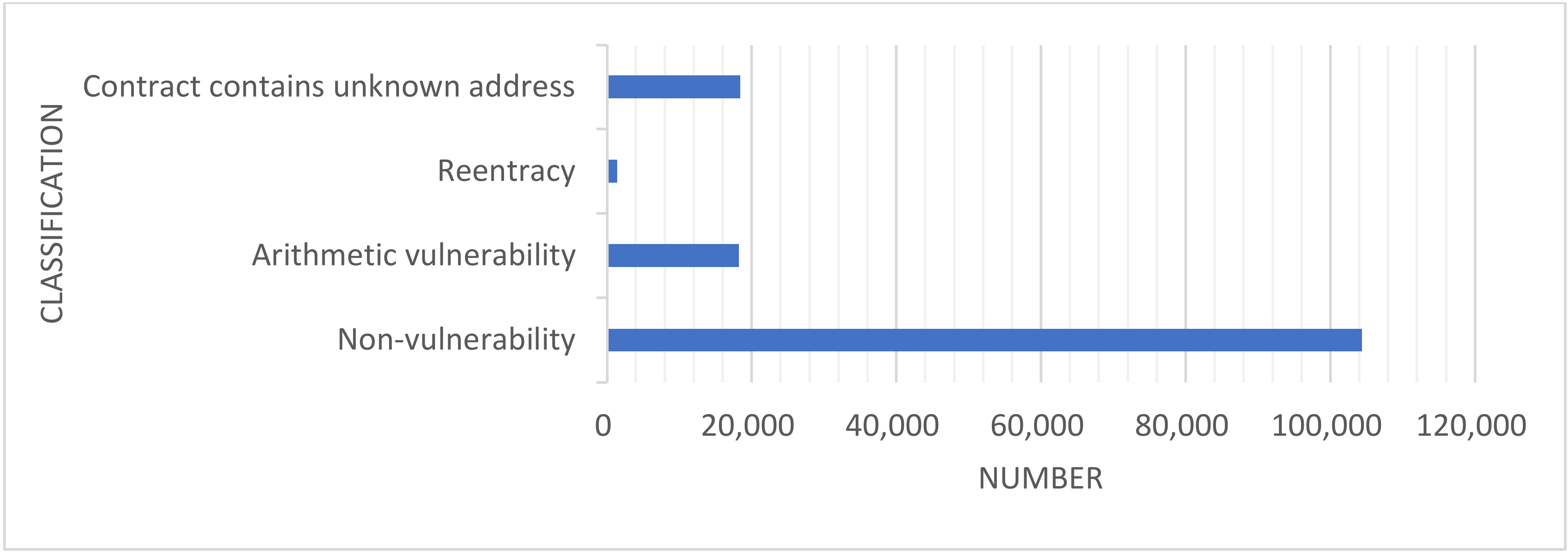
| Arithmetic vulnerability | 18,263 | 18,263 | 75,000 |
| Reentrancy | 1422 | 18,304 | 75,000 |
| Contract contains unknown address | 18,433 | 18,433 | 75,000 |
| Non-vulnerability | 104,369 | 20,000 | 75,000 |
| Software and Hardware | Configuration |
|---|---|
| Server model | Dell Precision T7920 |
| Operating system | Ubuntu 18.04 LTS |
| CPU | Intel Xeon Silver 4210 |
| GPU | NVIDIA GeForce RTX 3080 |
| Memory size | 64 GB |
| Disk capacity | 2 T |
| CUDA | 11.1 |
| cuDNN | 8.1.0 |
| Python | 3.7.10 |
| PyTorch | 1.14 |
| Model Parameters | Configuration |
|---|---|
| Number of heads in multi-head attention layer | 5 |
| Number of convolution kernel windows | 3 |
| Epoch | 100 |
| Batch size | 64 |
| Learning rate | 0.0001 |
| Dropout | 0.4 |
| Optimizer | Adam |
| Method | Arithmetic Vulnerability | Reentrancy | Contract Contains Unknown Address | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1score (%) | Precision (%) | Recall (%) | F1score (%) | Precision (%) | Recall (%) | F1score (%) | |
| SmartCheck | - | - | - | 41.63 | 43.06 | 42.18 | - | - | - |
| Securify | - | - | - | 50.85 | 56.60 | 53.57 | - | - | - |
| Mythril | 59.65 | 52.63 | 55.92 | 49.58 | 51.69 | 50.61 | - | - | - |
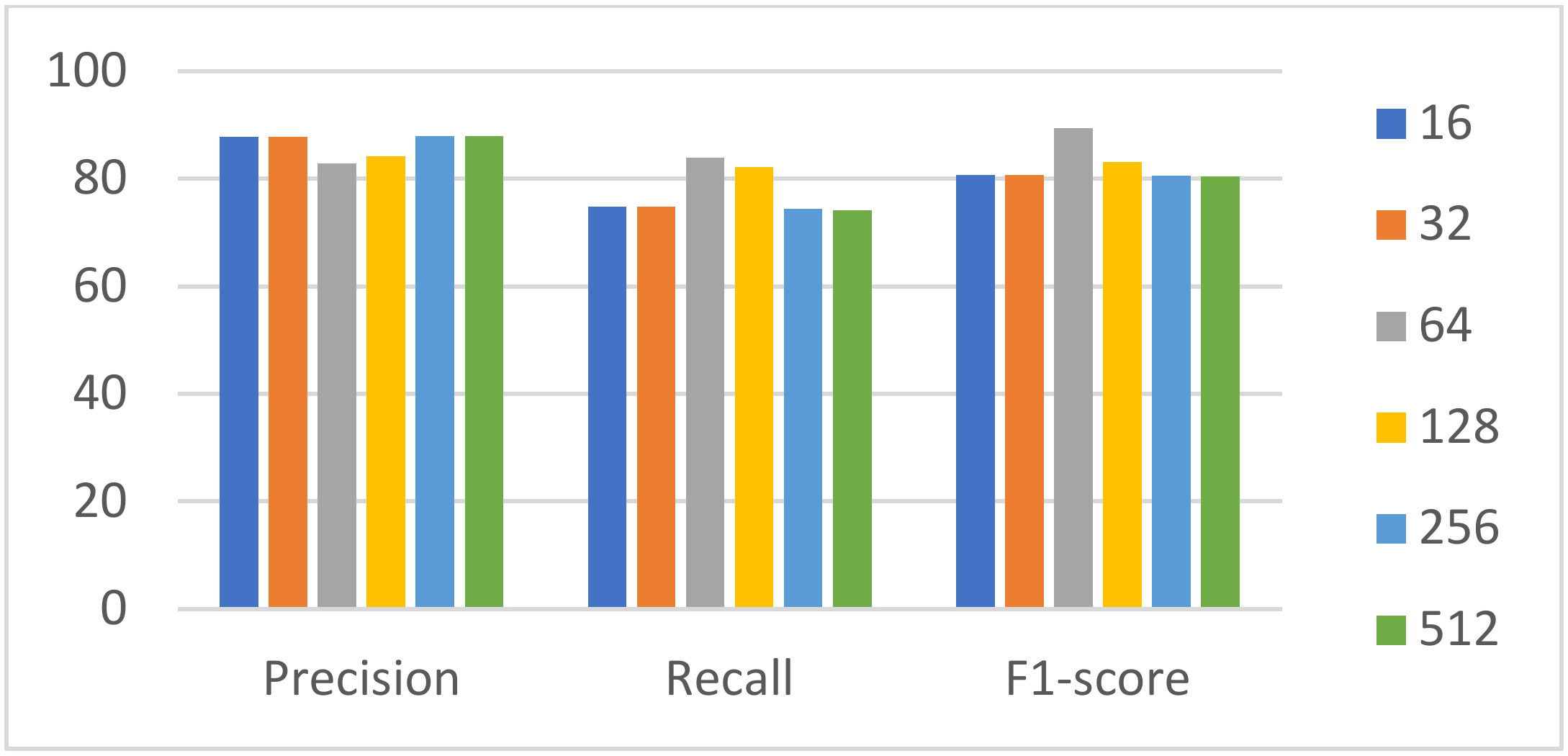
| Our model | 77.50 | 84.46 | 80.83 | 70.31 | 77.83 | 73.87 | 78.85 | 87.94 | 83.14 |
| Method | Arithmetic Vulnerability | Reentrancy | Contract Contains Unknown Address | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1score (%) | Precision (%) | Recall (%) | F1score (%) | Precision (%) | Recall (%) | F1score (%) | |
| RNN | 42.10 | 45.86 | 43.90 | 51.82 | 56.78 | 54.19 | 48.22 | 57.80 | 52.57 |
| LSTM | 44.07 | 57.26 | 49.80 | 51.65 | 67.82 | 58.64 | 52.60 | 57.94 | 55.14 |
| ABCNN | 73.87 | 74.46 | 74.16 | 59.56 | 63.76 | 61.58 | 73.41 | 80.65 | 76.85 |
| Our model | 77.50 | 84.46 | 80.83 | 70.31 | 77.83 | 73.87 | 78.85 | 87.94 | 83.14 |
| Method | Precision (%) | Recall (%) | F1score (%) |
|---|---|---|---|
| Detection task model | 78.02 | 78.77 | 78.39 |
| Our model | 82.17 | 84.11 | 83.13 |
| Method | Arithmetic Vulnerability | Reentrancy | Contract Contains Unknown Address | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1score (%) | Precision (%) | Recall (%) | F1score (%) | Precision (%) | Recall (%) | F1score (%) | |
| Recognition task model | 62.09 | 80.48 | 70.10 | 32.92 | 55.38 | 41.29 | 64.69 | 78.61 | 70.97 |
| Our model | 77.50 | 84.46 | 80.83 | 70.31 | 77.83 | 73.87 | 78.85 | 87.94 | 83.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.; Zhou, K.; Xiong, A.; Li, D. Smart Contract Vulnerability Detection Model Based on Multi-Task Learning. Sensors 2022, 22, 1829. https://doi.org/10.3390/s22051829
Huang J, Zhou K, Xiong A, Li D. Smart Contract Vulnerability Detection Model Based on Multi-Task Learning. Sensors. 2022; 22(5):1829. https://doi.org/10.3390/s22051829
Chicago/Turabian StyleHuang, Jing, Kuo Zhou, Ao Xiong, and Dongmeng Li. 2022. "Smart Contract Vulnerability Detection Model Based on Multi-Task Learning" Sensors 22, no. 5: 1829. https://doi.org/10.3390/s22051829
APA StyleHuang, J., Zhou, K., Xiong, A., & Li, D. (2022). Smart Contract Vulnerability Detection Model Based on Multi-Task Learning. Sensors, 22(5), 1829. https://doi.org/10.3390/s22051829