1. Introduction
Forensic science has largely relied upon face and fingerprint modalities when it comes to identifying the perpetrators of serious crimes. However, it is not always feasible to obtain any sample of these traits with acceptable quality, or at all. In fact, there are instances when images of the hand were the only available evidence to compare against the identity of the perpetrator [
1,
2]. The texture and creases of the finger-knuckles, which are visible on the dorsal view of the hand, can prove vital in human identification [
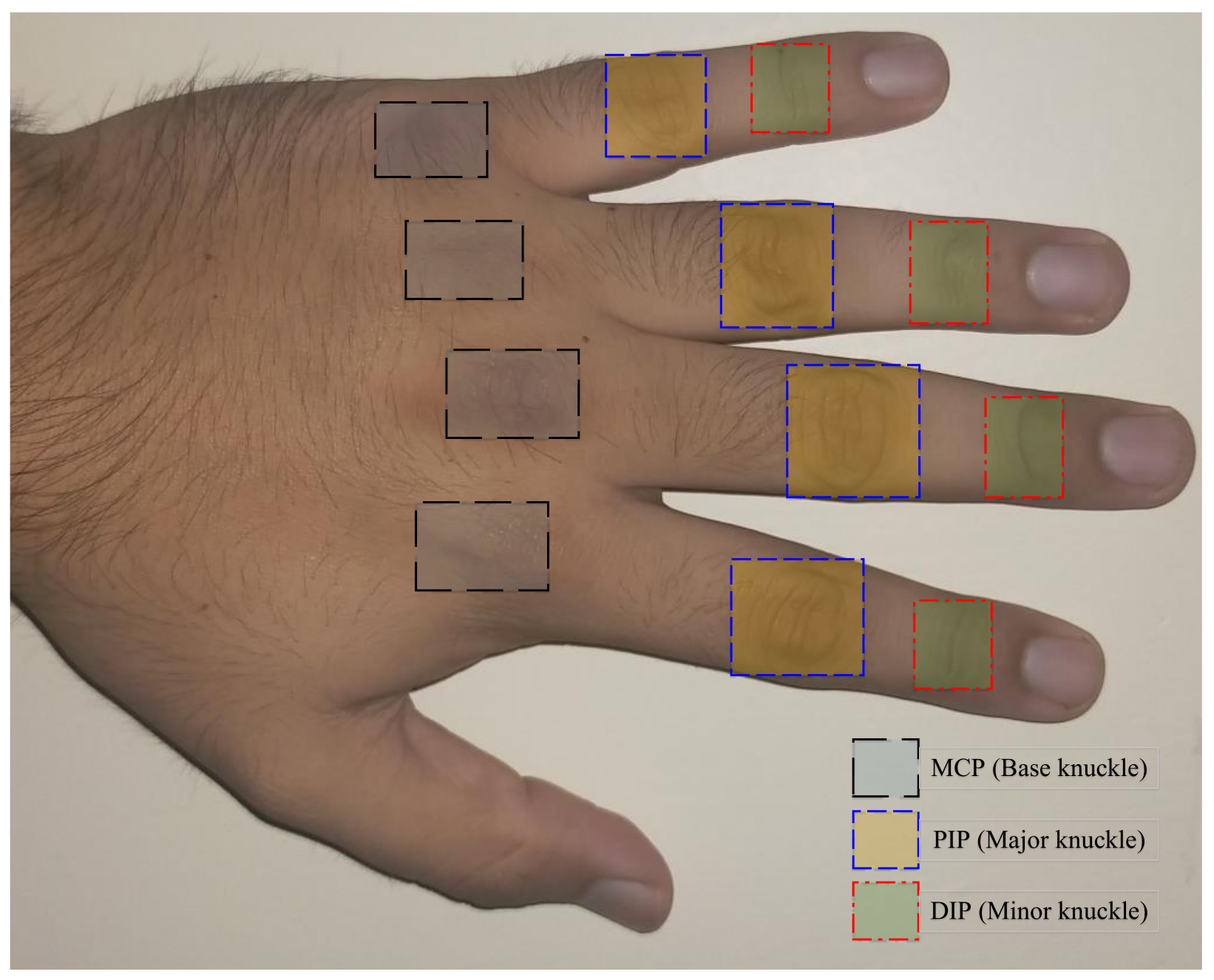
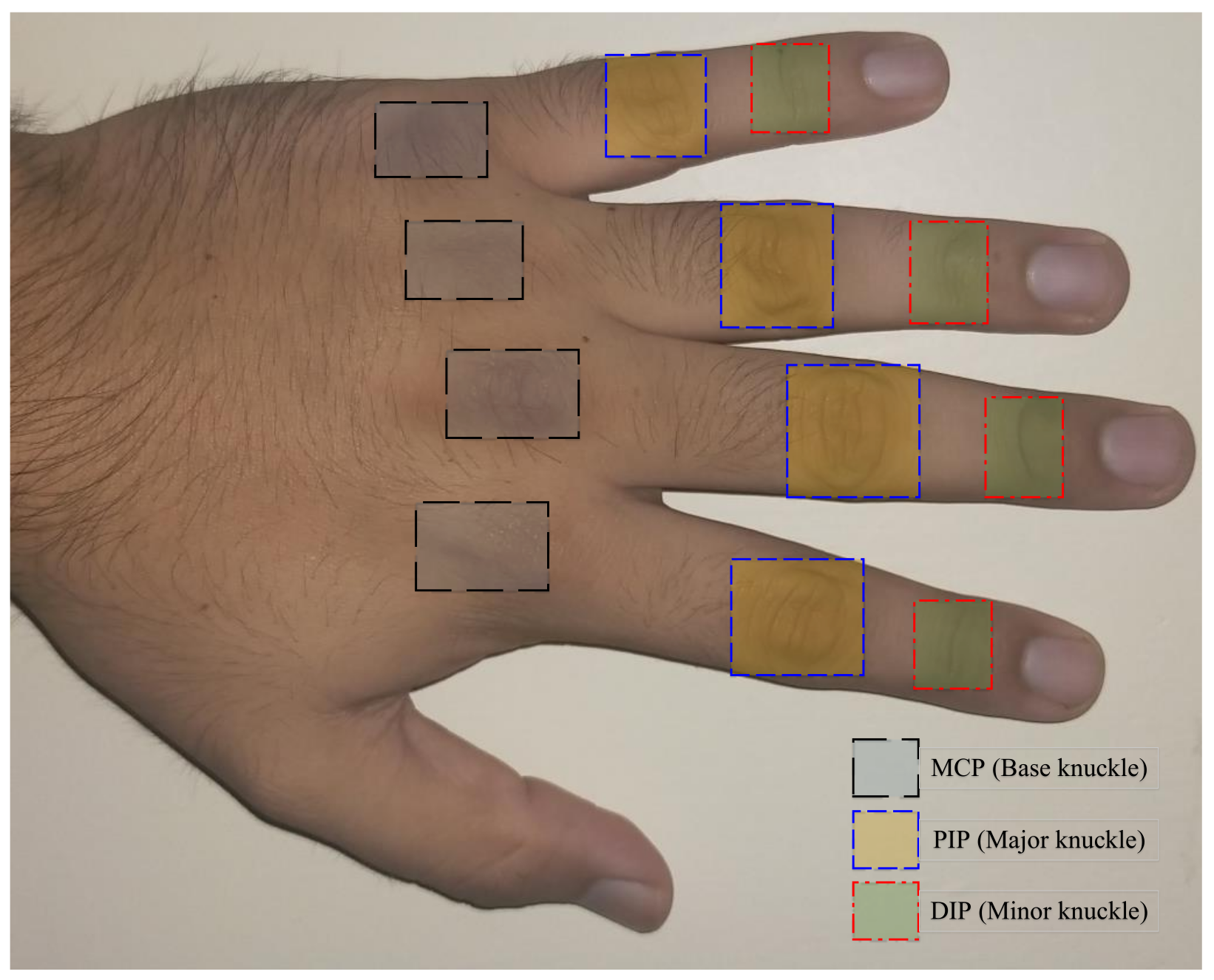
3]. The knuckles are formed on three types of finger joints which are termed as the metacarpophalangeal (MCP), proximal interphalangeal (PIP), and distal interphalangeal (DIP) joints, which in the biometrics terminology are also known as the base, major, and minor knuckles, respectively [
4]. The knuckle nomenclature is depicted in
Figure 1. It is also pertinent to specify here that the current work only considers the knuckles from the four fingers, and not from the thumb (which only has MCP and interphalangeal (IP) joints).
The knuckle patterns have been extensively used for biometrics applications in the last decade [
3,
5,
6,
7,
8,
9,
10,
11,
12]. The initial attempts of knuckle recognition employed only the PIP joints (or major knuckles), as they tend to possess relatively larger area comprising knuckle creases and corresponding texture [
3]. The state-of-the-art methods to extract the knuckle features included tools such as Gabor [
8] and log-Gabor filters [
13], Radon transforms [
3,
6], and phase-only correlation [
14]. With the progression of technology, efficient methods had been derived to recognize the humans by virtue of their DIP (minor) [
9] and MCP (base) [
4] knuckles as well.
Notably, there are very limited works in the literature that elaborate on the automated localization of knuckle regions [
8,
15,
16]. On one hand, the work by Zhang et al. [
8] utilized a contact-based acquisition setup which comprised of a finger bracket and a CCD camera to capture the knuckle region of the index and middle fingers of human hands. The acquisition was followed by extraction of the region of interest (ROI) in an automated way, using the edge detection and convex direction coding scheme. The other works [
15,
16], on the other hand, employed automatic localization of key points from the hand-contour images by finding the finger-valleys. These valley keypoints were then used to localize various knuckle regions (MCP, PIP, and DIP). However, the keypoint localization approach suffers from an inherent limitation that arises due to its demand to have wide-opened fingers. Furthermore, forensic applications require expert anthropologists for adept localization of knuckle creases, leading to the issues related to long annotating time and the subjectivity involved. These factors also act as a bottleneck for evaluation of large datasets.
Simon et al. [
17] proposed Openpose as a state-of-the-art real-time hand keypoint detector, which used multiview bootstrapping process to detect 21 keypoints from the input hand image. The Openpose detector utilized the modified architecture of convolutional pose machines (CPMs) which in turn was used to predict the confidence map for each keypoint of the hand. The Openpose keypoint detector worked with an input hand image of dimensions 368 × 368, assuming a bounding box around the right hand. The trained model for Openpose hand keypoint detector is made publicly available (URL:
https://github.com/CMU-Perceptual-Computing-Lab/openpose/releases, accessed on 21 December 2021) and can readily be used to compare relevant works.
Deep learning (DL) based approaches of object detection are capable of detecting the objects irrespective of their shape, scale, background, and orientation [
18]. The tremendous competence of these DL based approaches can be utilized for the task of knuckle localization with high accuracy, despite the challenges such as variations in sizes of the (MCP/PIP/DIP) knuckles, the backgrounds, the orientations (arbitrary angles due to rotation of hands), and the poses (opened/closed fingers). Moreover, the availability of high computing power can facilitate the deployment of DL based knuckle region detectors for larger datasets. However, evidence suggests that such DL based approaches suffer from data scarcity (which is quite common in the biometrics applications) and inabilities of the single detector model, but usage of data augmentation schemes and ensemble of multiple object detectors could solve these issues to a large extent. Among these two solutions, the data augmentation can be an ingenious step, whereas performing ensemble of various detectors can be a complex and sophisticated task. In this paper, we present an ensemble approach for automated localization of the knuckle regions, which leverage from the capabilities of individual object detectors. In order to make the investigations more comprehensive, we choose the individual detectors from both the single-stage and two-stage detector classes (YOLO and Faster R-CNN, respectively [
19]).
The major contributions of our work can be listed as follows:
- 1.
The ground truth bounding boxes (GTBBs) for the MCP, PIP, and DIP knuckles from a subset of one thousand images each from two public-domain datasets are created and are being released (
http://wp.lancs.ac.uk/icvl/research/datasets/, accessed on 21 December 2021) with this paper. We believe that this ground truth will serve as an aid to the researchers willing to reproduce/advance our results.
- 2.
An improved way of automated knuckle localization is presented, which utilizes the region predictions from multiple object detector models and combine those predictions through an ensemble approach. This ensemble approach is tested on two large-scale public hand dorsal databases (HD and 11k) and one unconstrained hand dorsal database (H-Unique).
- 3.
A capacious evaluation is employed to demonstrate the potential of the proposed approach for both localization and identification.
The evaluation of localization is performed through box-form and point-form analyses using metrics such as “suitable for identification”, “mean-IOUs”, and “inscribing accuracy values” (for full, half, and quarter ground truth boxes, respectively).
The proposed approach is compared against state-of-the-art Openpose hand keypoint detector, where it has demonstrated its outperforming nature for the problem at hand.
The potential of improvements in matching (or identification) evaluation is also demonstrated through a standard metric equal error rate (EER).
- 4.
The generalization of the proposed approach is demonstrated through several cross-dataset or external evaluation experiments.
2. Proposed Methodology
This paper employs convolutional neural network (CNN) based object detection models for the task of knuckle localization. As stated in the introduction section, traditional ways of knuckle localization require certain hand-poses and illumination/background, whereas the hand images obtained as real evidence are not supposed to possess uniform backgrounds and/or specific hand poses. Hence, the deep learning based object detectors can serve the purpose of knuckle localization in a more robust and generalized way.
There are multiple object detectors, which could be employed for the said task. The popular CNN-based object detectors can be categorized as single-stage and two-stage detectors. On one hand, single-stage detectors such as You Only Look Once (YOLO) [
20] can be deployed as a true end-to-end approach. On the other hand, there are two-stage detectors such as region-based convolutional neural network (R-CNN) [
21], which generates the region of interest (through the region proposal networks) in the first stage followed by classification and bounding box regression in the second.
In this section, we first summarize the individual object detectors used in this work and then will demonstrate the employed ensemble approach. The proposed framework considers four individual detectors named as YOLO-v2, YOLO-v3, and Faster R-CNN with background models as ResNet50 and ResNet101. Among these four detectors, first two belong to the single-stage object detectors, whereas the last two models belong to the two-stage detectors category. Both category models are chosen to add generalizability to the proposed knuckle localization framework, facilitating an appropriate blend of speed (from the single-stage detectors) and accuracy (from the two-stage detectors), hence making the proposed ensemble framework more effective.
2.1. YOLO Detectors
You Only Look Once (YOLO) is a single-stage object detector where the bounding box predictions are made directly from the input image [
20]. YOLO was originally proposed for real-time object detection with the capability to generate 100 bounding boxes per image. The YOLO pipeline works as a regression problem, where the class probabilities and bounding boxes are predicted from the small patches generated from the input image [
18]. For the current work, we have chosen two improved versions of YOLO, which are YOLO-v2 and YOLO-v3, known for their certain advancements over the baseline YOLO methods.
The YOLO-v2 model improves the network’s convergence by adding the batch-normalization layer ahead of each convolutional layer. This add-on would also regularize the base model. Another improvement in the YOLO-v2 model was achieved by removing the fully-connected layer from the basic YOLO network and incorporating the mechanism of using anchor-boxes as reference to generate the box-predictions [
22]. The other notable improvements which YOLO-v2 incorporated included dimension clusters, fine-grained features, and multi-scale training [
18]. On the other hand, YOLO-v3 further improves over YOLO-v2 through the inclusion of objectness score of each prediction (obtained through logistic regression) in addition to the class probability and the bounding-box coordinates [
23]. In addition to that, the bounding boxes are predicted in YOLO-v3 at three different scales through a deeper and robust feature extractor.
2.2. Faster R-CNN Detectors
The region-based convolutional neural networks (R-CNN) are the two-stage object detectors that exhibit high performance in the object detection tasks [
21]. In addition to the baseline R-CNN, there exist two other variants, which are named as Fast R-CNN [
24] and Faster R-CNN [
25]. The basic modules of an R-CNN model are the category-independent region proposals, convolutional-network-based feature extractor, class-specific support vector machines (SVMs), and bounding box regressor [
18]. For higher detail, R-CNN uses the selective search algorithm [
26] for generating the region proposals, followed by extraction of fixed-dimension features and SVM classification.
In R-CNN, a forward pass of ConvNet is performed for each region proposal without sharing the computation, hence making the detection slow. To avoid this, the Fast R-CNN model was proposed, which used an RoI pooling layer to extract a fixed-length feature vector from the feature map of the whole image followed by inputting the feature vector to two sibling output branches softmax and bounding box regressor [
24]. Apart from these improvements of R-CNN, Fast R-CNN still used selective search to generate the region proposals, which limited the overall training and testing speed. Hence, another improved version, called Faster R-CNN, was proposed, which replaced the selective search by a novel region proposal network (RPN) which could predict the regions with varying scales and aspect ratios. This RPN used to share the features with the detection network. Owing to its overall advantages, we employ Faster R-CNN for our knuckle-localization experiments. Another important aspect for the Faster R-CNN model is the backbone network, which acts as the feature extractor and generates the feature maps for the input images. The backbone networks are generally the classification networks with their last fully connected layer removed [
18]. Moreover, deeper and densely connected backbone networks can be employed to achieve more competitive object detecting accuracy with Faster R-CNN [
25]. The better features, which may be extracted from deeper backbone networks, could help in improved region proposals and eventually in higher detecting accuracy. It is for this reason we have considered two deeper backbone networks, named ResNet50 and ResNet101 [
27], to explore their accuracy for the specific task of knuckle localization.
2.3. Weighted Box Fusion
Both the single-stage and two-stage object detectors work considerably for the knuckle localization problem. However, they both possess certain limitations in terms of detecting accuracy and the generalizability. Hence, in this paper, we present an ensemble approach, which can leverage from the individual advantages of the single- and two-stage detectors and generate the knuckle localizations in a more generalized and accurate way. For this purpose, we incorporate the weighted box fusion (WBF) scheme, which is meant for fusing the bounding-box predictions from individual detectors and producing the fused boxes and their final confidence scores [
28]. The WBF approach is claimed to perform better than other popular approaches such as non-maximal suppression (NMS).
The WBF scheme works to combine the bounding box coordinates of various single object detectors (such as YOLO and Faster R-CNN), weighted with their corresponding confidence values, and produce the coordinates for the fused bounding box, which tends to be more indicative and inclusive when compared against the original predictions [
28]. The scheme initiates with tracing down all the available prediction boxes from multiple detectors and forms the clusters of matching boxes (i.e., boxes which have higher intersection over union (IoU) values). The boxes from all such clusters are then fused together using the following equations [
28]:
where
B denotes the number of matching boxes (i.e., the number of boxes available for fusion) and
is the confidence value for
box. The bounding box coordinates are represented by their top-left (
) and bottom-right (
) corner points which, when fused through the WBF Equation (
1), yield the corresponding coordinates (
and
) for the fused box. After obtaining the fused confidence value (
), it is rescaled by the ratio of the number of boxes in a cluster to the number of models. This is essential, because sometimes the number of boxes in the cluster is small, indicating that only a few models have predicted it and hence there is a need to decrease the confidence [
28].
3. Experimental Setup and Performance Metrics
The proposed framework of knuckle localization is tested with two large and public hand databases, known as PolyU hand-dorsal (HD) dataset [
16] and the 11k dataset [
29]. Both these datasets provide hand dorsal images with different backgrounds and poses. In addition to the public datasets, this paper presents evaluation with a third hand dataset, known as the H-Unique dataset (HUQ), which provides hand dorsal images with random backgrounds, illuminations, and orientations. More details about the datasets are furnished in the subsequent subsections.
3.1. HD Dataset
The HD dataset provides 4650 hand-dorsal images from right hands of 501 different subjects. All images in this dataset have a resolution of and possess the same hand pose with all fingers wide open.
3.2. 11k Dataset
The 11k dataset provides 11,076 hand images in total, out of which 5680 images have dorsal view of hands. Further, these hand dorsal images belong to both left (2788 images) and right (2892 images) hands of 190 subjects. The resolution of images from 11k is identical to that of images from HD dataset. However, images from 11k possess varying hand poses such as opened/closed fingers and arbitrary orientations. Additionally, the hand dorsal images from both these datasets offer certain challenges in the form of accessories such as rings.
3.3. HUQ Dataset
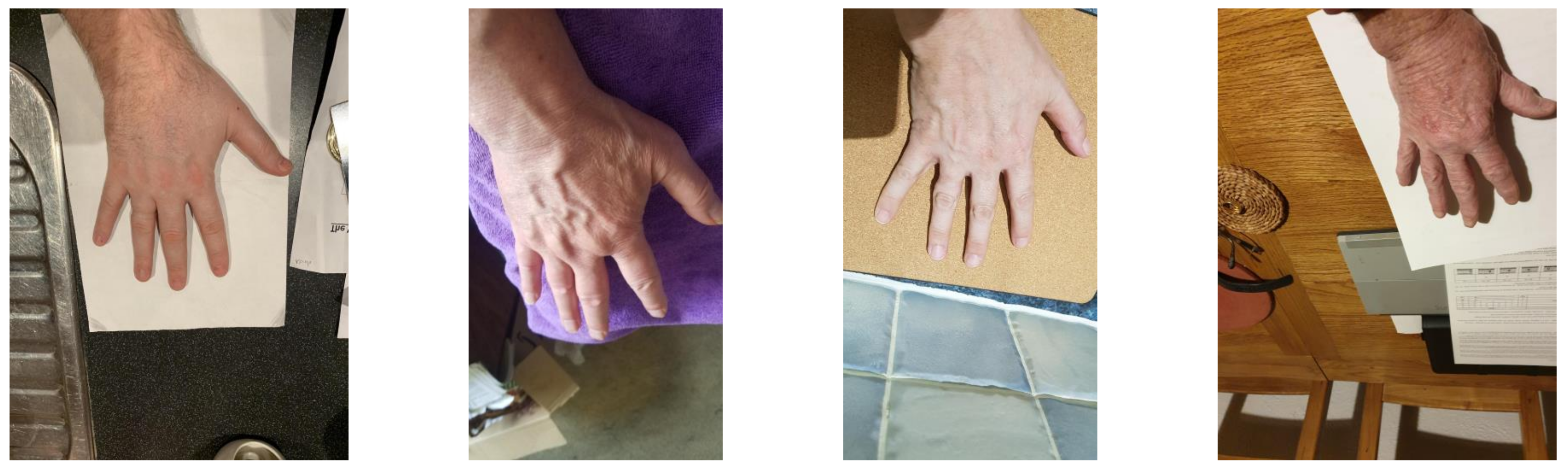
This is an ambitious dataset being collected under the aegis of the H-Unique project (More details at
https://h-unique.lancaster.ac.uk/, accessed on 21 December 2021). The dataset has more than 3000 hand dorsal images from people of various ethnic backgrounds. This dataset has the most challenging settings among all the three employed datasets in this paper as it is an unconstrained dataset where there is no control over the attributes such as backgrounds, orientations, scaling and illumination. A few sample images from the HUQ dataset are illustrated in
Figure 2, which shows the lack of constraints and huge variations in the capturing conditions. Hence, we believe this dataset to be the best one to closely mimic the real-life scenarios of an actual crime scene.
In order to train the object detector models efficiently and perform the first-of-its-kind numerical evaluation of knuckle localization, we create a ground truth of a small subset of images from both the employed datasets. This ground truth comprises of 1000 images from each of the three employed databases. In order to make the ground truth representative of the entire dataset, random images from each class of the 11k and HD datasets are carefully included in it. Subsequently, manual annotations from experienced human annotators are acquired to complete the ground truth, wherein twelve annotations are made for each hand; labeling three knuckle regions (MCP, PIP, and DIP) for each of the four fingers. We look forward to releasing the ground truth data in the public domain through an accessible URL (will be provided on acceptance of the article), so that interested researchers could compare their results and/or advance the topic. Notably, the first 500 images from the ground truth are used to train the detector models, whereas the remaining ground truth images are utilized for testing and evaluation.
The proposed knuckle localization scheme is evaluated through several meaningful and readily applicable performance metrics. The evaluation is mainly performed with two types of analysis, namely box-form analysis and point-form analysis. Both these analyses are meant to measure the appropriateness of the detected knuckle regions with respect to the ground truth. The box-form analysis is targeted towards measuring the intersection over union (IoU) value of each predicted knuckle region with their corresponding ground truth box. Subsequently, these IoU values are then utilized to infer whether the predicted knuckle boxes are “acceptable for identification” or not. Another important measure in the box-form analysis is the “mean-IoU” which indicates the overall box-fitting ability for any object detector. On the other hand, the point-form analysis is meant for measuring the placements in terms of the centroids of the bounding boxes. In other words, we use gradual measures to indicate the preciseness of the centroids with respect to the full, half, and quarter ground truth bounding boxes, where quarter box measurement is apparently the most strict measurement and is expected to be the lowest in value. Another important advantage of the point-form analysis is that it enables us to compare our approach with an off-the-shelf hand keypoint detector called Openpose. More details about the definition and effectiveness of these metrics are provided in the following sections.
4. Results and Discussion
This section elucidates the various analysis performed to evaluate the results of the proposed knuckle localization. To the best of our knowledge, this is the first attempt to present the knuckle localization results in numerical form. These numerical results are obtained from the test subset of the ground truth formed from the employed hand datasets. In addition to the numerical results,
Figure 3 demonstrates the localization results in pictorial form. This figure shows sample images from HD, 11k, and HUQ datasets, along with the bounding box predictions made from various individual object detectors and the proposed ensemble approach. For each prediction image, the predicted boxes are presented through bounding boxes with different colored boundaries. The colors are used to better illustrate the knuckle region predictions in the three categories, i.e., acceptable, borderline, and unacceptable, on the basis of their corresponding proportion of overlap with the ground truth boxes. It can be noticed from the figure that the box predictions made from the ensemble approach are more appropriate and cover the corresponding knuckle creases to a larger extent (which is also reflected from the IoU results shown later in this section).
4.1. Box-Form Analysis
As stated earlier, the box-form analysis of the knuckle localization results deals with the corresponding IoU values of the predicted boxes. It also defines whether the predicted knuckle can be used for biometric/forensic identification (a first-of-its kind dedicated evaluation metric). Hence, for finding the “suitable for identification” knuckle regions, there is a need of an appropriate threshold which should be chosen in an empirical way. For the current work, this threshold is chosen through visual observation of random images from the test set of both the employed datasets. Firstly, the identifiable knuckles were observed visually and then the correlation was obtained between the acceptability of the regions and their corresponding IoUs. Following this visual inspection, the IoU thresholds for both the hand datasets are fixed as 0.5 for the PIP (or major) knuckles and 0.3 for both the DIP and MCP (or minor and base, respectively) knuckles. Keeping these threshold values in view, the proportion of “suitable for identification” knuckle regions is calculated for the ground truth test subset.
Table 1 presents the values of these proportions for all three datasets for various object detectors along with the proposed ensemble approach of knuckle localization. It can be observed from the table that the proposed ensemble approach yields the highest proportion of knuckle regions which are “
suitable for identification”, with more than 99% PIP and DIP (major and minor) suitable knuckle regions for the HD and 11k hand datasets, whereas the proportions of suitable PIP and DIP knuckles for the challenging HUQ dataset are 96.39% and 97.82%, respectively. These high values for the HUQ dataset highlight the effectiveness of the proposed knuckle localization approach with unconstrained hand dorsal images (i.e., images with less user cooperation). Furthermore, the proportions of suitable MCP (or base) knuckles for HD, 11k and HUQ datasets are 98.75%, 94.07% and 89.28%, respectively, which outperforms the other object detectors with reasonable margins. Nonetheless, the proportion of suitable knuckles for the MCP knuckles is relatively lower than their counterparts for PIP and DIP knuckles. This can be attributed to little prominence of creases in the MCP knuckles.
On the other hand,
Table 2 furnishes the mean-IoU values for all individual detectors and the proposed ensemble approach. It is evident from the table that the proposed approach outperforms all other detector models and provides more relevant predictions with the highest
mean-IoUs for all knuckle types and all three datasets. Higher values of mean IoU for a specific knuckle type would mean that the knuckles of that type are localized with increased assuredness.
4.2. Point-Form Analysis
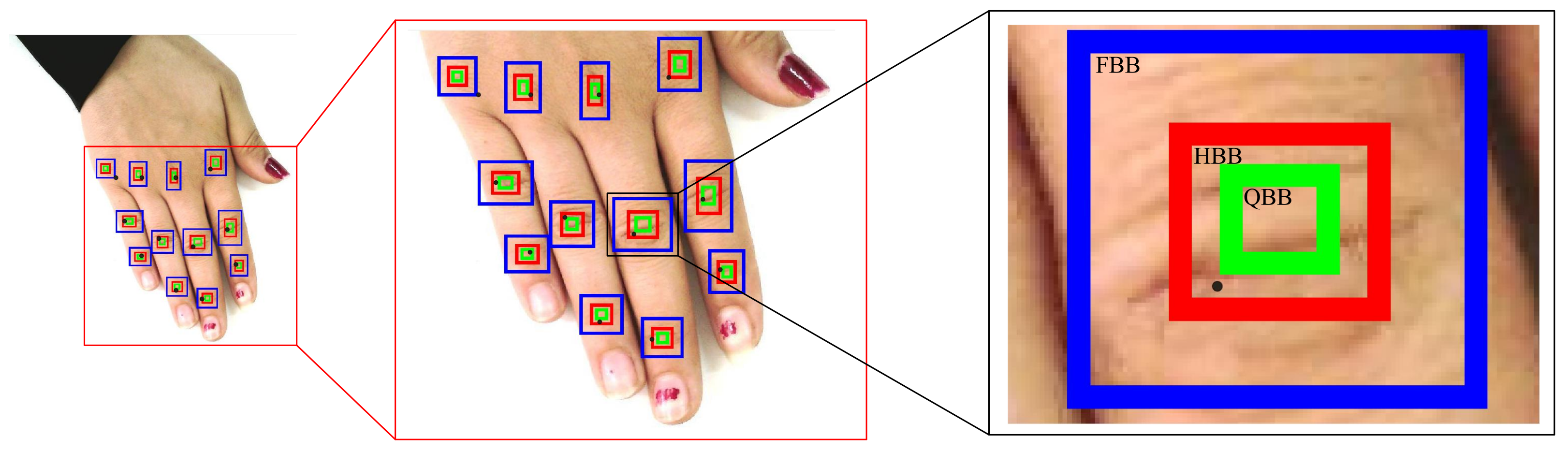
The point-form analysis is performed to evaluate the correctness of the centroids of the bounding boxes predicted from various object detectors. It is to ensure whether the centroid falls within the full bounding boxes (FBB), half bounding box (HBB), or quarter bounding box (QBB) of the ground truth boxes in increasing order of the strict sense of inclusiveness, respectively. The idea of FBB, HBB, and QBB is depicted more clearly in
Figure 4. Any keypoint or centroid that falls within the respective box counts towards the calculation of FBB, HBB, or QBB accuracy. This analysis facilitates the comparison of the proposed approach with the state-of-the-art hand keypoint detector, called Openpose [
17]. Moreover, it also offers to evaluate the appropriateness of the predicted boxes by checking their centroids, which cannot be otherwise checked through the box-form analysis.
For the numerical evaluation of the point form analysis, we define following important evaluation metrics, which would measure the preciseness of the detected keypoint to varying degrees.
- 1.
Full bounding box (FBB) accuracy: This metric measures the accuracy of keypoints by just referring to their placements inside the full GTBB, i.e., any keypoint lying inside the GTBB is treated as correct.
- 2.
Half bounding box (HBB) accuracy: This metric calculates the accuracy of the hand keypoints in terms of their placement inside the half-sized GTBB placed at the center, i.e., any keypoint lying inside the half-size GTBB is treated as correct.
- 3.
Quarter bounding box (QBB) accuracy: This metric calculates the accuracy of the hand keypoints in terms of their placement inside the quarter-sized GTBB placed at the center, i.e., any keypoint lying inside the quarter-size GTBB is treated as correct.
In other words, the three evaluation metrics defined above provide the degree of preciseness of the detected keypoints in the increasing order.
Figure 4 illustrates an instance where one of the detected keypoints (the PIP of middle finger) counts towards the FBB and HBB accuracy (as it falls within the respective boxes), but does not count towards the QBB accuracy (as it is outside the QBB box). Hence, it can be stated that the QBB accuracy is the most competitive among all metrics of the point-form analysis.
The comparison of point-form metrics for various object detectors, Openpose, and the proposed ensemble approach is presented in
Table 3. It is not difficult to observe that the QBB accuracy has the least values for all types of detectors. Despite this, the proposed ensemble approach yields the best values for all three metrics and for all the datasets. The FBB accuracy values yielded by the proposed approach for the PIP (major) knuckles are 99.59%, 99.90%, and 98.53% for the 11k, HD, and HUQ datasets, respectively. These values are on par in comparison to their counterpart values for all other detectors. It is also apparent from the table that Openpose generates reasonable accuracy for knuckle localization with 11k and HUQ datasets (especially for the 11k dataset, where it is close to the second best value after the proposed approach). It is also worth specifying that the left hand images from 11k were horizontally flipped before executing the Openpose algorithm on them. This is to comply with the requirement of Openpose, where the input hand image is always considered to come from the right hand [
17]. However, it was also observed that Openpose performs very poorly with the HD dataset which may be due to various reasons such as absence of discernible wrist, dark skin color, and brighter background. Furthermore, the proposed ensemble approach furnishes outperforming values for the QBB accuracy, which happens to be the toughest accuracy value. Notably, the state-of-the-art hand keypoint detector Openpose detects the knuckle keypoints with reasonable FBB accuracy. However, those keypoints seem to be off the quarter bounding boxes, as indicated by the consistent low values of QBB accuracy with Openpose for all three datasets. This is a rationale for the inference that the keypoints detected by the state-of-the-art Openpose tool are more likely to be away from the center of the ground truth boxes, which limits its applicability for knuckle localization in forensics applications.
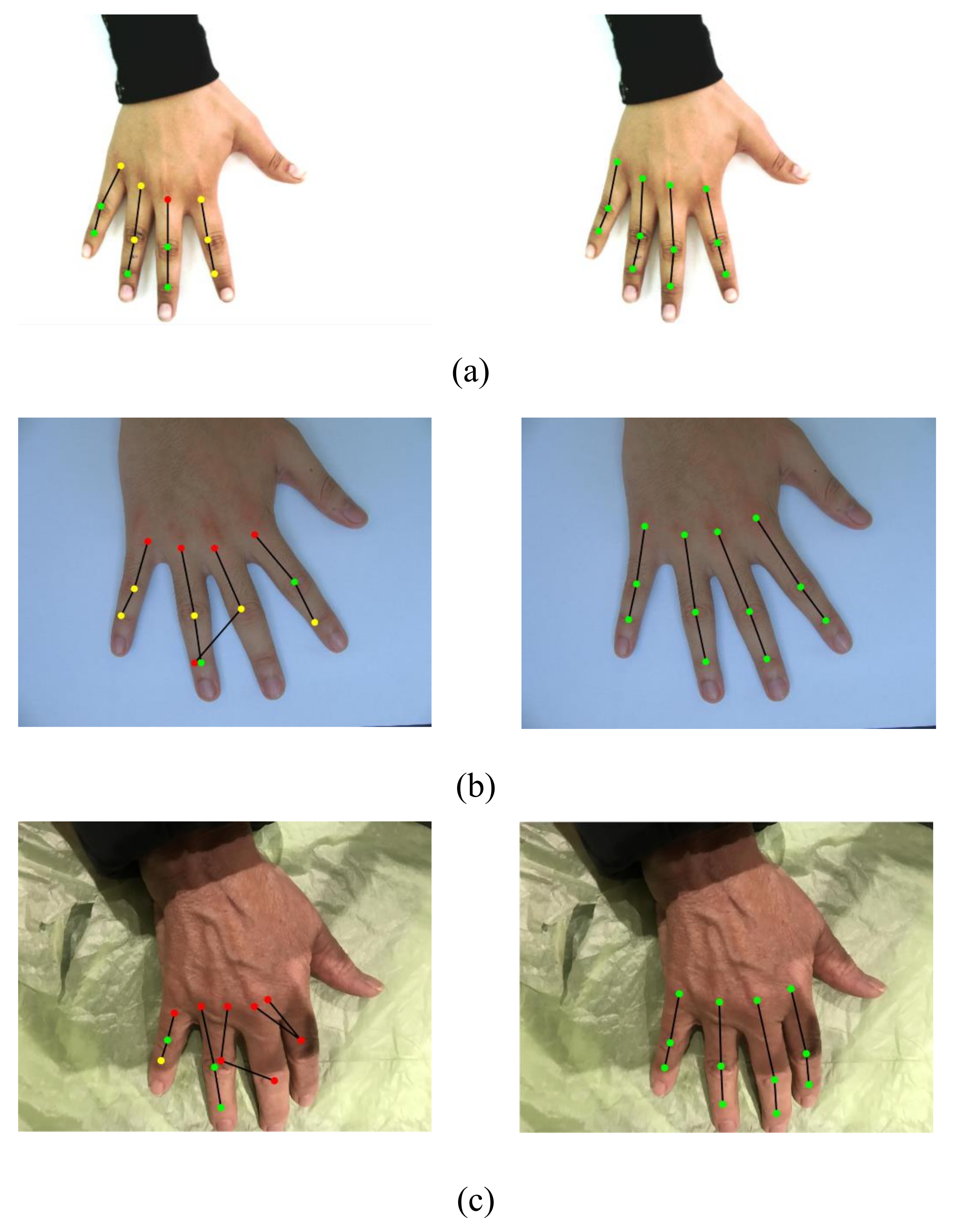
The comparison of skeletonization achieved by the state-of-the-art Openpose hand keypoint detector and the proposed WBF approach is presented in
Figure 5. The figure demonstrates that Openpose works nicely with 11k and HUQ datasets, though the placement of keypoints detected by Openpose is not aligned with the knuckle crease region. This is the reason for the poor results of Openpose, especially the QBB accuracy. Additionally, performance of Openpose with the HD dataset is very poor. Openpose does not provide adequate skeletonization for the majority of the images from the HD dataset. The same is reflected from low values of point-form accuracy of Openpose with the HD dataset. On the other hand, the proposed knuckle localization framework performs strongly with all the three datasets, as is depicted in
Figure 5. It also outperforms the Openpose algorithm for HD and the challenging HUQ datasets. Furthermore, the skeletonization achieved by the proposed approach indicates that the centroids of the predicted bounding boxes are placed nicely at or near to the centers of the knuckle crease region. This precisely supports the high values of point-form accuracy metrics of the proposed approach presented in
Table 3.
4.3. Cross-Dataset Evaluation
In order to evaluate the generalizability of the proposed knuckle localization approach, we further perform the cross-dataset evaluation, were models trained on hand images from one database are tested with hand images from another database. This evaluation facilitates the generalizability study of the proposed approach and a more meaningful comparison against the state-of-the-art Openpose algorithm because both these testing environments constitute exclusive test data which are completely unknown for the concerned model. To make this comparison appropriate and fair, we test the models trained on the multi-ethnic HUQ database against the images of HD and 11k databases. For the better understanding of the readers, we adopt following nomenclature for the models for cross-dataset testing:
Model : Trained on original right and left hand images from HUQ dataset.
Model : Trained on original right and flipped left hand images from HUQ dataset (the flipping of left hand images is performed to ascertain the procedure fall in line with the procedure of state-of-the-art hand keypoint detector Openpose).
The results for cross-dataset evaluation of HD and 11k datasets using Model
are presented in
Table 4 and
Table 5, respectively. Results for the state-of-the-art Openpose hand keypoint detector are also included in these tables. It can be observed from
Table 4 that the proposed ensemble based approach outperforms all individual detectors and Openpose in all possible cases. The poor performance of Openpose can be related with the imaging properties of the HD dataset, where wrist region is absent in the majority of the images, leading to misinterpretation of the hand keypoints. On the other hand, if we refer to
Table 5, performance of the proposed approach is either superior or comparable to the individual detectors and Openpose. There is only one case (FBB accuracy for minor knuckles) where Openpose has outperformed the proposed approach significantly. This substantial performance of the proposed approach validates its generalizability to work across multiple datasets.
However, in order to align the cross-dataset experimentation more with the setup of Openpose, we consider another scenario of testing where all the left hand images are flipped in advance to appear as right hand images (named as Model
). In this scenario, the training and testing tasks are performed with original right and flipped left hand images, similar to the Openpose algorithm [
17]. This scenario of testing images reduces the complexity of the training task and allows comprehensive learning of the individual object detectors (though at the cost of one additional step of identifying left hand images and flipping them). The cross-dataset results for model
are presented in
Table 6 and
Table 7, respectively. It can be observed from these tables that model
aids in the overall results. Notably, it also improves the result for the proposed approach over Openpose in the specific case of FBB accuracy of minor knuckles from the 11k dataset, from 91.77% to 98.53%.
4.4. Matching Comparison
In order to establish the superiority of the proposed ensemble based knuckle localization approach, the matching experiment is performed with the knuckle regions extracted from all the detectors. All the knuckle localizations made in the manuscript are completed in the form of bounding box regression, and each bounding box is represented by the x- and y-coordinates of the top-left position and the associated width and height. Hence, all the predicted knuckle regions are extracted from the original hand image through rectangular crops, and these extracted knuckle regions are stored in order of the knuckle type and finger label they belong to. The transfer learning [
30] is employed for the task of extracting distinguishing features. The pretrained DenseNet201 [
31] model is employed for the transfer learning task, and to learn the fine-details of the extracted knuckle regions. The matching between feature vectors is performed through the Cosine distance and an “all-to-all” matching protocol. More details about the matching experiment can be found in [
32]. Notably, the matching results are obtained by using the knuckle regions extracted from the WBF model trained on the HUQ dataset in “all-right hand” scenario. The mean equal error rates (mean-EERs) for various knuckle types of the two public databases are presented in
Table 8.
The mean-EERs and mean-AUCs presented in
Table 8 and
Table 9 are calculated by taking average of the individual EERs and AUCs of all the fingers for each knuckle type.
Table 8 demonstrates that the proposed ensemble based approach outperforms the individual detectors for each knuckle type for 11k datasets. Notably, the proposed approach yields a relative improvement of 16.20%, 5.07%, and 8.01%, respectively, for major, minor, and base knuckle types of 11k dataset with respect to the second best performing detector. On the other hand, mean-EERs for the HD dataset are also improved through the proposed ensemble approach of knuckle localization. In particular, mean-EERs for the major and base knuckle types of HD dataset improve by 19.16% and 8.73%, respectively, which is a significant improvement for real-world knuckle-matching scenario. However, the performance of WBF stands comparable to FRCNN101 for the minor knuckle types of HD dataset (with a marginal difference of 0.22%). The overall performance of the proposed approach shows a substantial improvement in the recognition capabilities of the system, which is validated through the mean-EER values for the whole hand for both the datasets. The best EER values considering the knuckle regions of the entire hand are reported to be 5.26% and 8.07% for HD and 11k datasets, respectively. The large values of percentage relative improvement turn out to be 7.88% and 18.41% for the HD and 11k datasets. The table once again highlights the need of the ensemble approach of localization, especially looking at the fact that the second best mean-EERs for HD and 11k datasets are not reported by any single object detector, hence accrediting the hypothesis of comprehensive localization through ensemble of multiple knuckle detectors algorithms.
On the other hand,
Table 9 presents another important performance metric for biometrics matching, i.e., AUC. This table clearly demonstrates that the mean-AUC values for the proposed approach are the best among all detectors and for both the public datasets. The mean-AUC values for the HD dataset consistently fall in the range of 98.30–99.04%, which is a high AUC range, whereas the mean-AUC values for the 11k dataset is marginally lower than their counterparts for HD, especially with the base knuckles. Nevertheless, the proposed approach yields outperforming AUC values for 11k dataset. This is another evidence of how the matching performance can be improved by employing a more appropriate knuckle localization scheme, such as ours.
5. Discussion
It has been demonstrated that the performance of our approach can outperform the competing approaches for localizing the MCP, PIP, and DIP finger knuckle regions. Notably, there has been no work in the literature that report numerical evaluation of knuckle localization. However, certain studies established the automatic localization of knuckle regions [
8,
15,
16]. The approaches in [
8,
15] were designed to handle the knuckle images from images of a single finger or half dorsal view (without clear base knuckles) of the hands, as depicted in
Figure 6 (left) and (right), respectively. Therefore, these approaches were designed to work in a much more limited scenario without considering the full hand image or hand pose with touching fingers. Hence, they do not offer a direct comparison with the proposed approach.
On the other hand, the approach in [
16] focused on localising the finger-valley keypoints for isolation of fingers and then used the finger geometry for knuckle localization. Therefore, these approaches cannot export comparable regions without further work. It also becomes cumbersome to detect the finger valley keypoints for the hand images having fingers closed. Moreover, all these known approaches which present automated knuckle localization do not perform any quantitative evaluation of the same, hence making it impossible to report any accuracy for the said problem of knuckle localization.
Additionally, the proposed approach can localize the knuckle centroid keypoints and knuckle regions for extraction and work with data having large variations. The results include evaluations from both the region localization (box-form) and center-point detection (point-form) framework. The proposed approach has excelled in both these frameworks hence establishing a single best approach to be employed with diverse datasets. This work has demonstrated that accurate localization of knuckle regions can lead to improvements in the performance of biometric matching experiments, which is illustrated through apposite performance metrics EER and AUC.
Beyond CNN, graph convolutional networks (GCNs) apply convolutions on graph structured data, which are usually more sparse, unlike unstructured data, and have been used to assist object detection [
33,
34]. GCN has been employed for applications such as action recognition, aerial images, and scene text recognition, but there is no reported work on knuckle localization. It may be worth considering the potential for GCN refinement for the current application. Transformers have also observed increasing utility in computer vision applications, including object detection [
35,
36]. However, they usually need costly pre-training on large datasets because they provide the convolutional inductive bias by performing self-attention across the patches of images, unlike CNN which leverages from the hard inductive bias in presence of low data. This requirement is a particular disadvantage for knuckle detection, because such large datasets do not yet exist.
6. Conclusions
This paper proposes an ensemble approach of knuckle localization, which leverages from multiple single-stage and two-stage state-of-the-art object detectors to perform classification and bounding box regression for various knuckle types available on the hand-dorsum. The ensemble approach is developed with the idea to have improved and more accurate localization of the knuckle regions, which can in turn make the whole recognition process inclusive and comprehensive without the need to refer a considerable portion of images. The proposed ensemble approach of knuckle localization builds over the capabilities of individual detectors and provide more apt bounding boxes for all three knuckle types (MCP, PIP, and DIP). The superior performance of the proposed approach is ascertained through exhaustive set of experiments on two large-scale public hand databases (11k and HD) and one realistic and challenging dataset (HUQ). The outperforming nature of the proposed approach is established through various suitable metrics which are evolved by keeping the two-fold requirement of the problem at hand. In view of this, the predicted knuckle regions are assessed through both the point- and box-form analysis to ensure the quality of overall bounding boxes and preciseness of their centroids, respectively. The paper is also furnished with the first-of-its-kind numerical evaluation of the knuckle localization, facilitating a justified comparison of various detectors and inviting more investigations in the said domain. Furthermore, the comparison of EER for various knuckle regions of the employed datasets reveal that the proposed approach generates outperforming results in the matching experiment too, leading to the development of an overall improved hand-biometric system. In the future, we will investigate the knuckle localization procedure for hand images in the 3D domain. Moreover, we would like to extend the investigation of the current approach to a greater number of unconstrained images having large variations in illumination, orientation, and background.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}