
Identifying Voice Individuality Unaffected by Age-Related Voice Changes during Adolescence

Abstract
1. Introduction
2. Related Work
3. Methodology
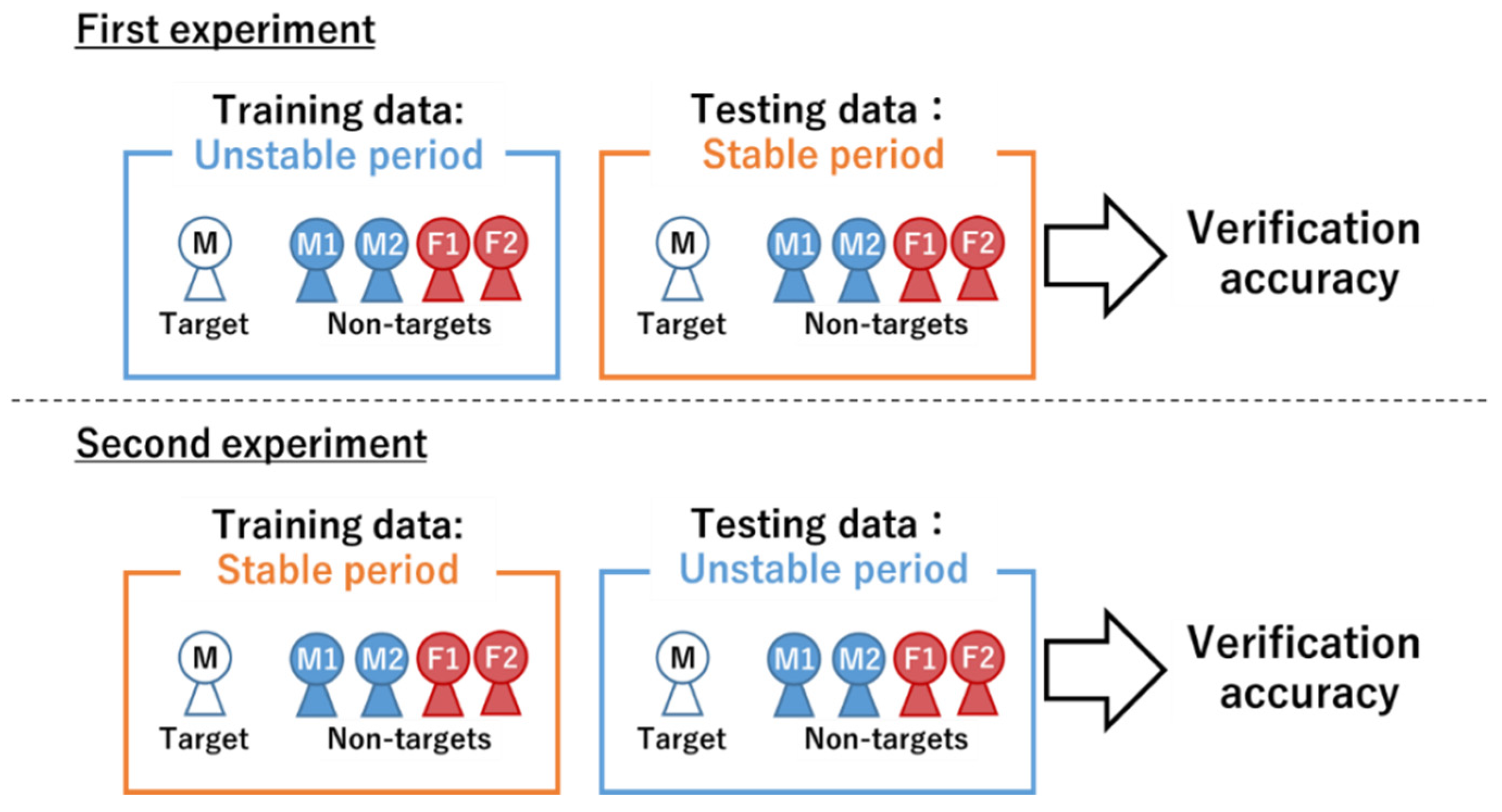
3.1. Definition of the Unstable Period and the Stable Period
3.2. Data Preparation
3.2.1. Collection of Audio Data
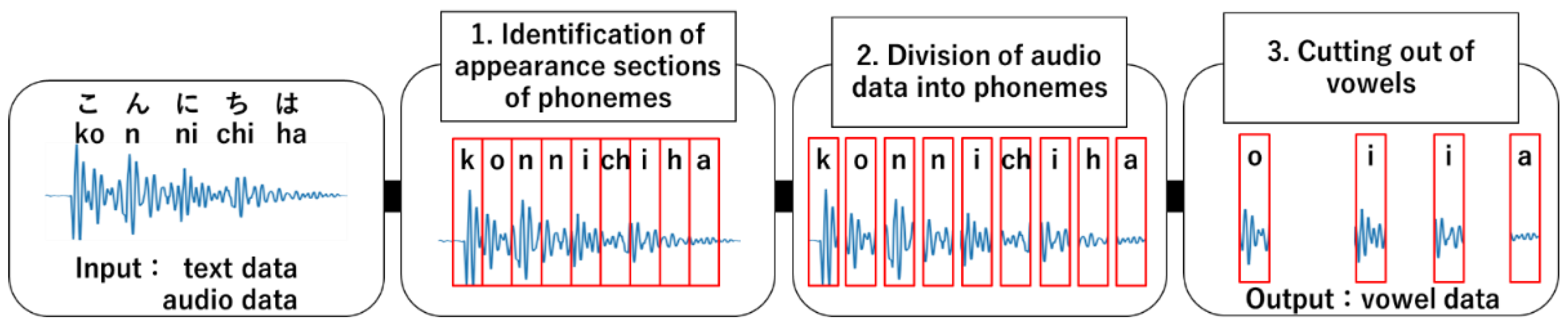
3.2.2. Extraction of Vowel Data
3.2.3. Preparation of Voice Samples
3.3. Experimental Setup
3.3.1. Extraction of Voice Feature
3.3.2. Construction of Verification Model
3.3.3. Evaluation Index in Verification Test
3.4. Experimental Method
3.4.1. Speaker Verification Test
3.4.2. Evaluation of Voice Individuality
4. Results
4.1. Results of Verification Tests
4.1.1. Verification Results Obtained with Phrase Samples
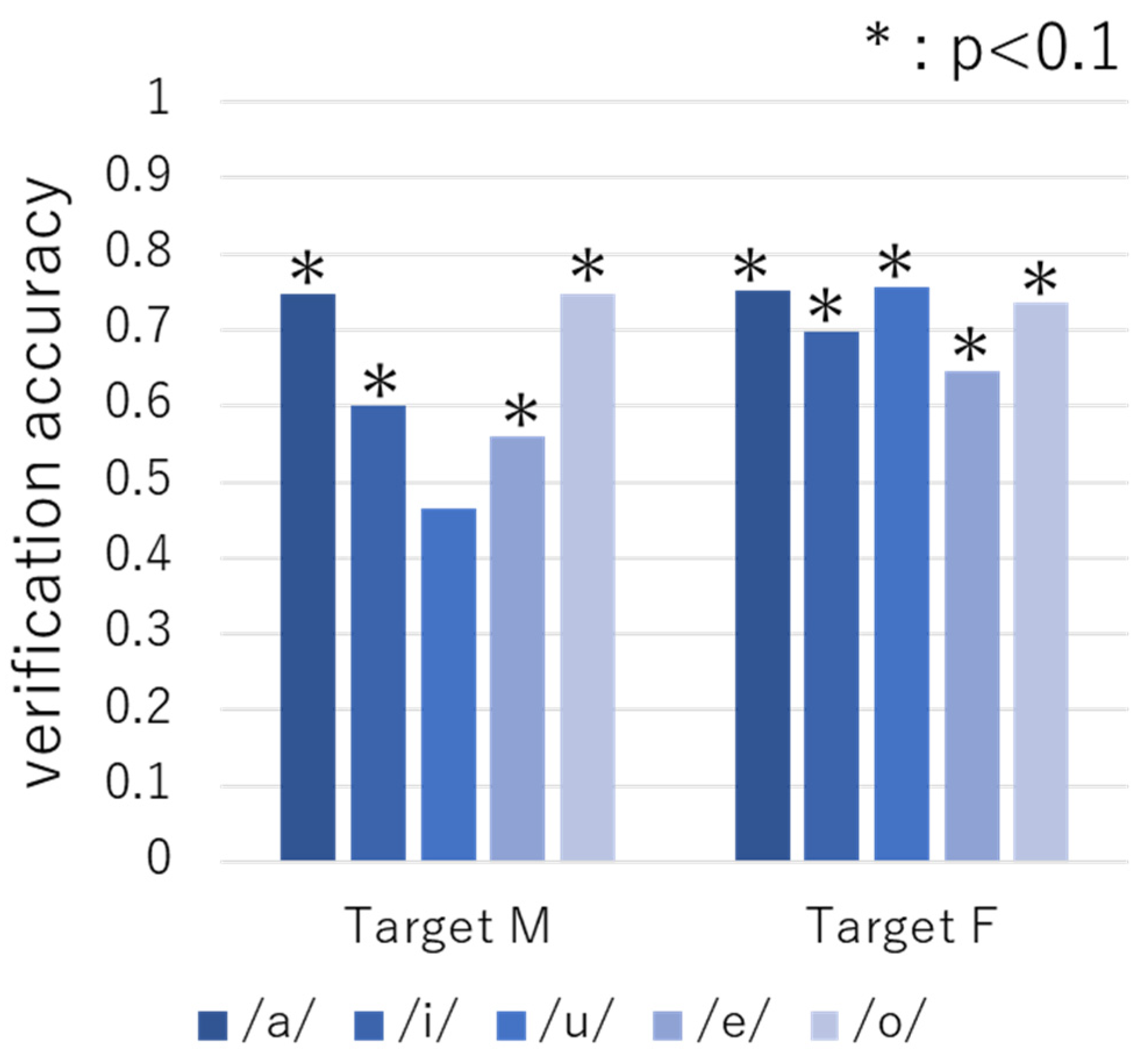
4.1.2. Verification Results Obtained with Vowel Samples
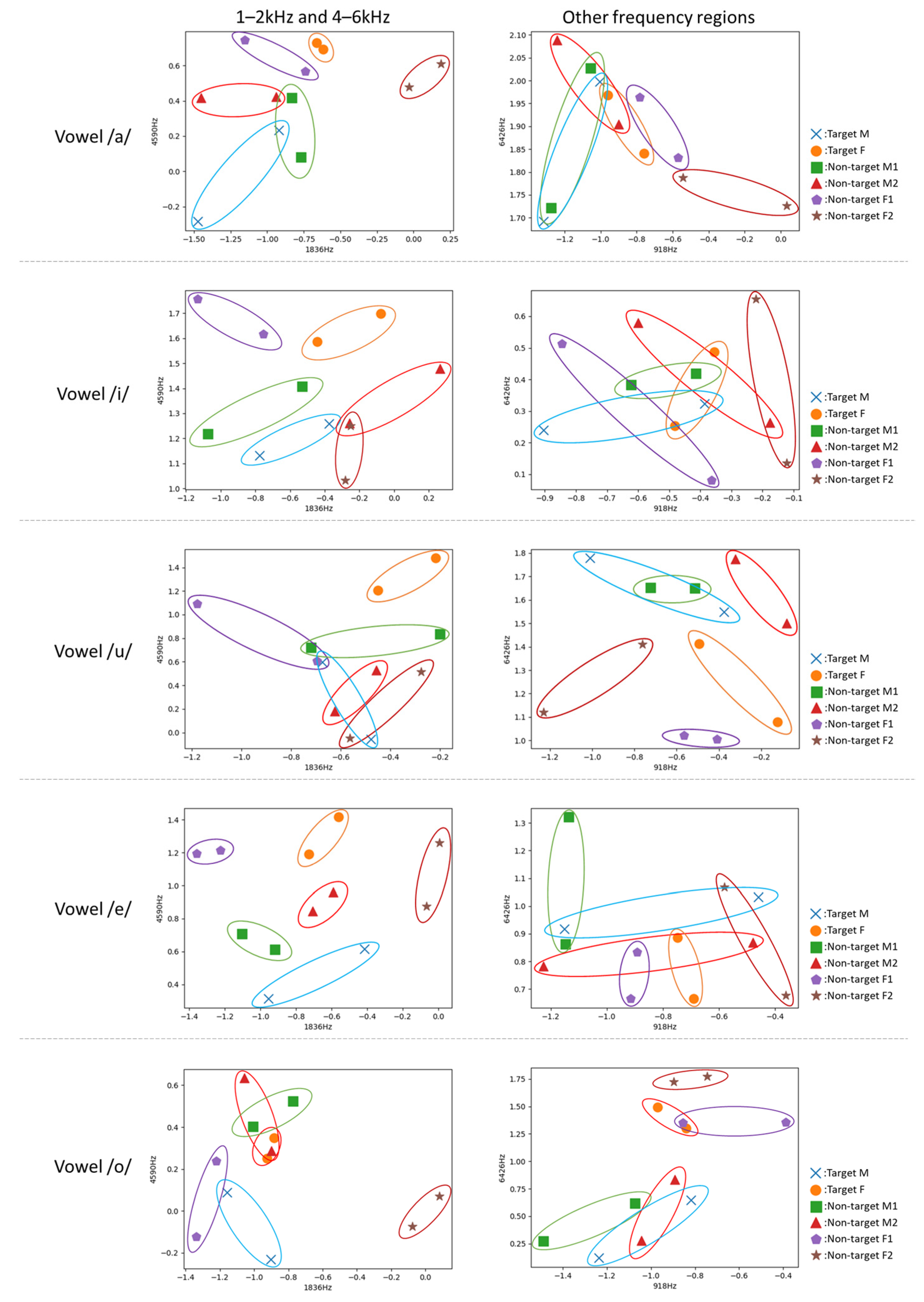
4.2. Frequency Bands Involved in Voice Individuality
4.2.1. Evaluation Results of Voice Individuality with Phrase Samples
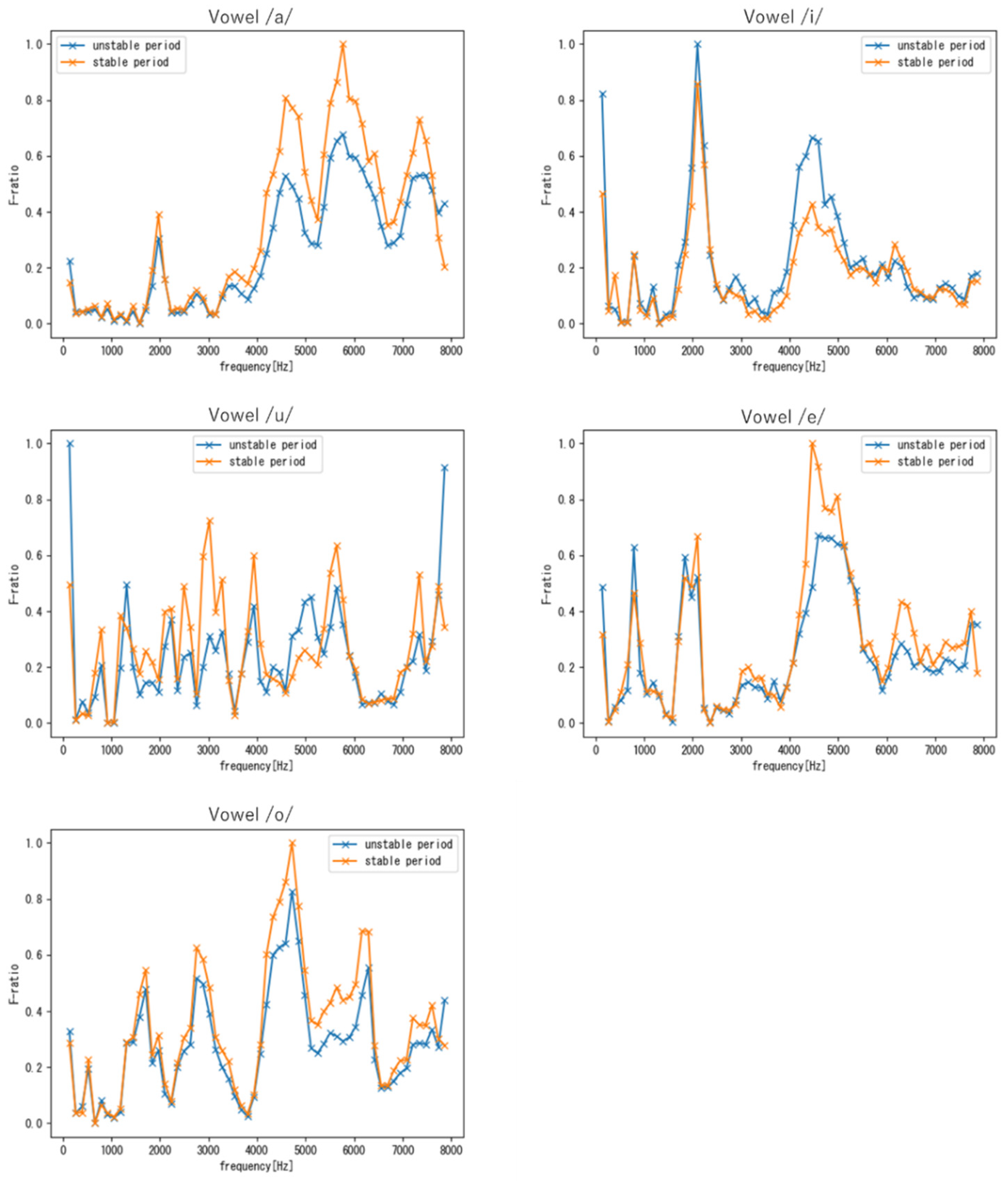
4.2.2. Evaluation Results of Voice Individuality Obtain with Vowel Samples
4.3. Evaluation of the Robustness of the Frequency Regions Related to Voice Individuality
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Taskiran, M.; Kahraman, N.; Erdem, C.E. Face recognition: Past, present and future (a review). Digit. Signal Process. 2020, 106, 102809. [Google Scholar] [CrossRef]
- Jahangir, R.; Teh, Y.W.; Nweke, H.F.; Mujtaba, G.; Al-Garadi, M.A.; Ali, I. Speaker identification through artificial intelligence techniques: A comprehensive review and research challenges. Expert Syst. Appl. 2021, 171, 114591. [Google Scholar] [CrossRef]
- Mohanty, M.N.; Sikka, R. oReview on fingerprint-based identification system. Mater. Today Proc. 2021; in press. [Google Scholar] [CrossRef]
- Latman, N.S.; Herb, E. A field study of the accuracy and reliability of a biometric iris recognition system. Sci. Justice 2013, 53, 98–102. [Google Scholar] [CrossRef] [PubMed]
- Rida, I.; Almaadeed, N.; Almaadeed, S. Robust gait recognition: A comprehensive survey. IET Biom. 2019, 8, 14–28. [Google Scholar] [CrossRef]
- Rida, I. Feature Extraction for Temporal Signal Recognition: An Overview. arXiv 2018, arXiv:1812.01780. [Google Scholar]
- Rida, I.; Maadeed, N.A.; Maadeed, S.A. A Novel Efficient Classwise Sparse and Collaborative Representation for Holistic Palmprint Recognition. In Proceedings of the 2018 NASA/ESA Conference on Adaptive Hardware and Systems, Edinburgh, UK, 6–9 August 2018; pp. 156–161. [Google Scholar]
- Rida, I.; Hérault, R.; Gasso, G. An efficient supervised dictionary learning method for audio signal recognition. arXiv 2018, arXiv:1812.04748. [Google Scholar]
- Hanifa, R.M.; Isa, K.; Mohamad, S. A review on speaker recognition: Technology and challenges. Comput. Electr. Eng. 2021, 90, 107005. [Google Scholar] [CrossRef]
- Saxena, N.; Varshney, D. Smart Home Security Solutions using Facial Authentication and Speaker Recognition through Artificial Neural Networks. Int. J. Cogn. Comput. Eng. 2021, 2, 154–164. [Google Scholar] [CrossRef]
- Morrison, G.S.; Sahito, F.H.; Jardine, G.; Djokic, D.; Clavet, S.; Berghs, S.; Dorny, C.G. INTERPOL survey of the use of speaker identification by law enforcement agencies. Forensic Sci. Int. 2016, 263, 92–100. [Google Scholar] [CrossRef]
- Jokinen, E.; Saeidi, R.; Kinnunen, T.; Alku, P. Vocal effort compensation for MFCC feature extraction in a shouted versus normal speaker recognition task. Comput. Speech Lang. 2019, 53, 1–11. [Google Scholar] [CrossRef]
- Amino, K.; Arai, T. Speaker-dependent characteristics of the nasals. Forensic Sci. Int. 2009, 185, 21–28. [Google Scholar] [CrossRef] [PubMed]
- Leemann, A.; Kolly, M.-J.; Dellwo, V. Speaker-individuality in suprasegmental temporal features: Implications for forensic voice comparison. Forensic Sci. Int. 2014, 238, 59–67. [Google Scholar] [CrossRef] [PubMed]
- Akagi, M.; Ienaga, T. Speaker individuality in fundamental frequency contours and its control. J. Acoust. Soc. Jpn. 1997, 18, 73–80. [Google Scholar] [CrossRef][Green Version]
- Zhu, Z.; Nishino, Y.; Miyauchi, R.; Unoki, M. Study on linguistic information and speaker individuality contained in temporal envelope of speech. Acoust. Sci. Technol. 2016, 37, 258–261. [Google Scholar] [CrossRef]
- Lu, X.; Dang, J. An investigation of dependencies between frequency components and speaker characteristics for text-independent speaker identification. Speech Commun. 2008, 50, 312–322. [Google Scholar] [CrossRef]
- Kitamura, T.; Akagi, M. Speaker individualities in speech spectral envelopes. J. Acoust. Soc. Jpn. (E) 1995, 16, 283–289. [Google Scholar] [CrossRef][Green Version]
- Kitamura, T.; Honda, K.; Takemoto, H. Individual variation of the hypopharyingeal cavities and its acoustic effects. Acoust. Sci. Technol. 2005, 26, 16–26. [Google Scholar] [CrossRef]
- Xue, S.A.; Cheng, R.W.C.; Ng, M.L. Vocal tract dimensional development of adolescents: An acoustic reflection study. Int. J. Pediatric Otorhinolaryngol. 2010, 74, 907–912. [Google Scholar] [CrossRef]
- Adolescent Health. Available online: https://www.who.int/health-topics/adolescent-health#tab=tab_1 (accessed on 26 December 2021).
- Sundberg, J. The Science of the Singing Voice; Northern Illinois University Press: New York, NY, USA, 1987. [Google Scholar]
- Beigi, H. Effects of time lapse on Speaker Recognition results. In Proceedings of the 16th international conference on Digital Signal Processing, Santorini, Greece, 5–7 July 2009. [Google Scholar]
- Kelly, F.; Drygajlo, A.; Harte, N. Speaker verification with long-term ageing data. In Proceedings of the 5th IAPR International Conference on Biometrics, New Delhi, India, 29 March–1 April 2012. [Google Scholar]
- Kelly, F.; Drygajlo, A.; Harte, N. Speaker verification in score-ageing-quality classification space. Comput. Speech Lang. 2013, 27, 1068–1084. [Google Scholar] [CrossRef][Green Version]
- Wang, L.; Wang, J.; Li, L.; Zheng, T.F.; Soong, F.K. Improving speaker verification performance against long-term speaker variability. Speech Commun. 2016, 79, 14–29. [Google Scholar] [CrossRef]
- Spiegel, J.R.; Sataloff, R.T.; Kate, A.; Emerich, K.A. The young adult voice. J. Voice 1997, 11, 138–143. [Google Scholar] [CrossRef]
- Hirano, M.; Kurita, S.; Toh, Y. Growth, development and aging of the vocal fold. Pract. Oto-Rhino-Laryngol. 1981, 74, 1791–1802. (In Japanese) [Google Scholar] [CrossRef]
- Julius now on GitHub. Available online: http://julius.osdn.jp/ (accessed on 6 November 2021).
- Tirumala, S.S.; Shahamiri, S.R.; Garhwal, A.S.; Wang, R. Speaker identification features extraction methods: A systematic review. Expert Syst. Appl. 2017, 90, 250–271. [Google Scholar] [CrossRef]
- Lei, H.; Gonzalo, E.L. Mel, linear, and antimel frequency cepstral coefficients in broad phonetic regions for telephone speaker recognition. INTERSPEECH 2009. In Proceedings of the 10th Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009. [Google Scholar]
- Zhou, X.; Garcia-Romero, D.; Duraiswami, R.; Espy-Wilson, C.; Shamma, S. Linear versus mel frequency cepstral coefficients for speaker recognition. In Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition & Understanding, Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167v3. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Teh, P.S.; Zhang, N.; Teoh, A.B.J.; Chen, K. A survey on touch dynamics authentication in mobile devices. Comput. Secur. 2016, 59, 210–235. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Voice Actor | Gender | Unstable Period (Age) | Stable Period (Age) |
|---|---|---|---|
| Target M | Male | 12, 13, 15, 16, 18 | 21, 22 |
| Target F | Female | 13, 14, 16, 17, 19 | 21, 22, 23 |
| Non-target M1 | Male | 13, 14, 16, 17, 19 | 22, 23 |
| Non-target M2 | Male | 12, 13, 15, 16, 18 | 22 |
| Non-target F1 | Female | 14, 17, 19 | 21, 22, 23 |
| Non-target F2 | Female | 17, 19 | 21 |
| Unstable Period | Stable Period | Total | |
|---|---|---|---|
| Phrase | 47,041 | 22,709 | 69,750 |
| Vowel /a/ | 4223 | 1535 | 5758 |
| Vowel /i/ | 1277 | 591 | 1868 |
| Vowel /u/ | 360 | 189 | 549 |
| Vowel /e/ | 1266 | 613 | 1879 |
| Vowel /o/ | 3254 | 1343 | 4597 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suzuki, N.; Ishimaru, M.; Toyoshima, I.; Okada, Y. Identifying Voice Individuality Unaffected by Age-Related Voice Changes during Adolescence. Sensors 2022, 22, 1542. https://doi.org/10.3390/s22041542
Suzuki N, Ishimaru M, Toyoshima I, Okada Y. Identifying Voice Individuality Unaffected by Age-Related Voice Changes during Adolescence. Sensors. 2022; 22(4):1542. https://doi.org/10.3390/s22041542
Chicago/Turabian StyleSuzuki, Natsumi, Momoko Ishimaru, Itsuki Toyoshima, and Yoshifumi Okada. 2022. "Identifying Voice Individuality Unaffected by Age-Related Voice Changes during Adolescence" Sensors 22, no. 4: 1542. https://doi.org/10.3390/s22041542
APA StyleSuzuki, N., Ishimaru, M., Toyoshima, I., & Okada, Y. (2022). Identifying Voice Individuality Unaffected by Age-Related Voice Changes during Adolescence. Sensors, 22(4), 1542. https://doi.org/10.3390/s22041542