
Application of Thermography and Adversarial Reconstruction Anomaly Detection in Power Cast-Resin Transformer



Abstract
:1. Introduction
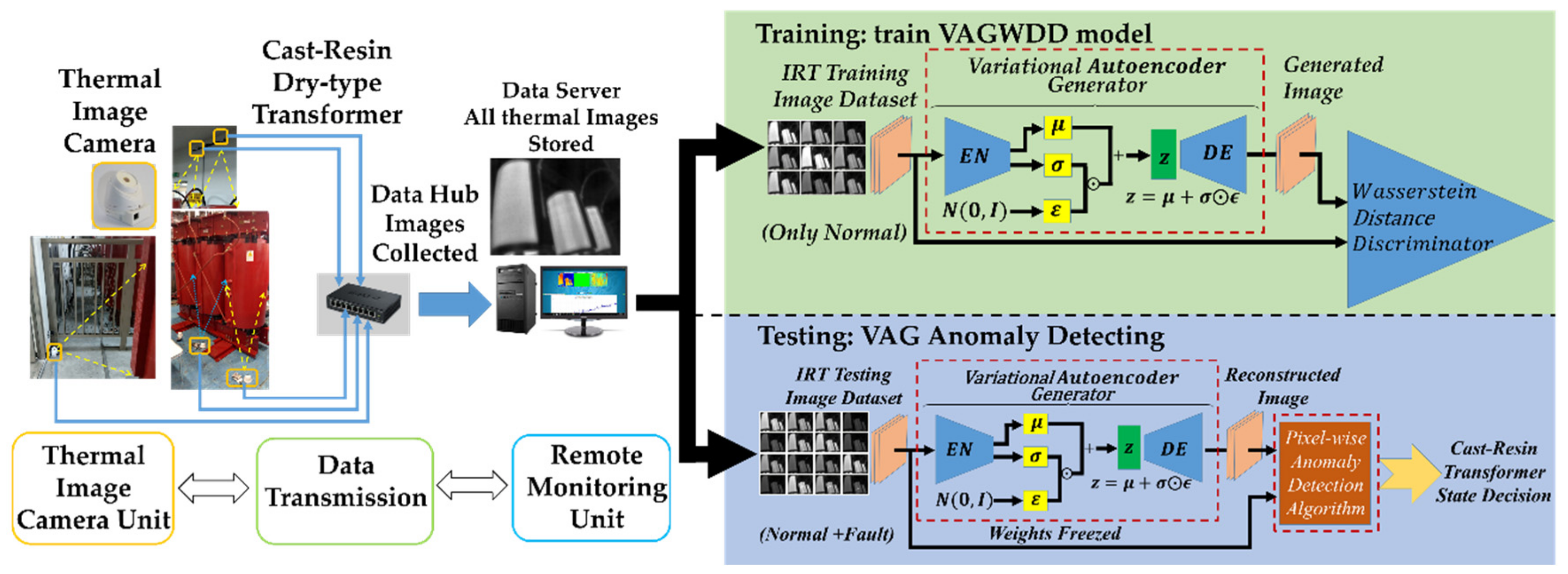
- We propose an unsupervised anomaly detection method system based on IRT image recognition. Without a large number of labeled defect images, the system can monitor the operation of the transformer online and find the outlier situation early.
- Compared with other existing methods, the proposed method leads to significantly finer reconstructed images and achieves good results in terms of anomaly accuracy, AUROC, F1-scores and average precision.
- The proposed method also has the advantages of fewer weights and less storage space. In addition, ablation studies are conducted to verify the effectiveness of the combination of the loss function.
2. Theoretical Background
2.1. Variational Autoencoder Generator
2.2. Generative Adversarial Networks
3. The Proposed Anomaly Detection Approach
3.1. Image Acquisition
3.2. Offline Training Model
3.3. Online Anomaly Detecting
4. Experiments
4.1. Experiments Setup
4.1.1. Dataset Establishment
4.1.2. Defect Description
4.1.3. Baselines
- AE-L2 [27] and AE-SSIM [27]: We try to compare the convolutional autoencoder model in terms of the capability of anomaly detection. We train an autoencoder on only normal datasets. So, when input data that have different features from the normal dataset are fed to the model, the corresponding pixel-wise reconstruction error will increase via L2 distance and SSIM, respectively. The network architecture is composed of nine convolutional layers for the encoder and nine deconvolutional layers for the decoder. Leaky rectified linear units (ReLUs) [41] with slope 0.2 are implemented as activation functions after each layer, except for the output layers. The output size is 128 × 128 × 3.
- f-AnoGAN [29]: f-AnoGAN is a model based on GAN for anomaly detection. This method needs to train two components: the WGAN [39] and the encoder, and it tries to generate the nearest normal image for the test image with the WGAN generator trained only on the normal data. A characteristic of this model is that two adversarial networks (Generator and Discriminator) and the encoder are trained separately. Besides, an anomaly score is calculated by both a discriminator features residual error and an image reconstruction error. The output size is 64 × 64 × 3.
- GANomaly [30]: GANomaly is an encoder–decoder structured GAN which utilizes adversarial, contextual and encoder losses. The method trains only on normal data. In inference time, it re-generates normal images that contain the features of the input image whether the input image is a normal or abnormal sample. GANomaly predicts whether the new image from test data is normal or not by the following formula which is the L1 distance between the encoded original image by the first encoder and the encoded generated image by the second encoder.
- ADAE [31]: Vu et al. has advanced the semi-supervised methods, called the Adversarial Dual Autoencoders (ADAE) model, which has two autoencoders as generators and discriminators to stabilize during the process of training. The method uses the reconstruction error and conventional adversarial loss of an autoencoder-based model for anomaly detection. The output size is 64 × 64 × 3.
- RSRAE [32]: Lai et al. designed a special regularizer into the embedding of the encoder to enforce an anomaly subspace recovery layer with the energy-based penalty, which is called the Robust Subspace Recovery Autoencoder (RSRAE). RSRAE trains a model using the normal data and is applied to detect outliers at the testing. The anomaly score is computed by cosine similarity metrics, which means the higher reconstruction errors are viewed as outliers.
4.1.4. Network Setup
4.1.5. Training Details
4.2. Evaluation Metrics
4.3. Comparison Results
4.3.1. Comparison against Other Methods
4.3.2. Comparison against Other Distance Metric
- The Euclidean distance (Euclidean): the L2-norm of the difference, a special case of the Minkowski distance with p = 2. It is the natural distance in a geometric interpretation.
- The squared Euclidean distance (Sqeuclidean): like the Euclidean distance metric but does not take the square root. As a result, classification with the Euclidean squared distance metric is faster than classification with the regular Euclidean distance.
- The Manhattan distance (Manhattan): the L1-norm of the difference, a special case of the Minkowski distance with p = 1 and equivalent to the sum of absolute difference.
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Y.; Li, X.; Li, H.; Fan, X. Global Temperature Sensing for an Operating Power Transformer Based on Raman Scattering. Sensors 2020, 20, 4903. [Google Scholar] [CrossRef] [PubMed]
- Sen, P. Application guidelines for dry-type distribution power transformers. In Proceedings of the IEEE Technical Conference on Industrial and Commercial Power Systems, St. Louis, MO, USA, 4–8 May 2003. [Google Scholar] [CrossRef]
- Rajpurohit, B.S.; Savla, G.; Ali, N.; Panda, P.K.; Kaul, S.K.; Mishra, H. A case study of moisture and dust induced failure of dry type transformer in power supply distribution. Water Energy Int. 2017, 60, 43–47. [Google Scholar]
- Cremasco, A.; Wu, W.; Blaszczyk, A.; Cranganu-Cretu, B. Network modelling of dry-type transformer cooling systems. COMPEL Int. J. Comput. Math. Electr. Electron. Eng. 2018, 37, 1039–1053. [Google Scholar] [CrossRef]
- Chen, P.; Huang, Y.; Zeng, F.; Jin, Y.; Zhao, X.; Wang, J. Review on Insulation and Reliability of Dry-Type Transformer. In Proceedings of the 2019 IEEE Sustainable Power and Energy Conference (iSPEC), Beijing, China, 21–23 November 2019. [Google Scholar]
- Islam, M.; Lee, G.; Hettiwatte, S.N. A review of condition monitoring techniques and diagnostic tests for lifetime estimation of power transformers. Electr. Eng. 2018, 100, 581–605. [Google Scholar] [CrossRef]
- Athikessavan, S.C.; Jeyasankar, E.; Manohar, S.S.; Panda, S.K. Inter-Turn Fault Detection of Dry-Type Transformers Using Core-Leakage Fluxes. IEEE Trans. Power Deliv. 2019, 34, 1230–1241. [Google Scholar] [CrossRef]
- Alonso, P.E.B.; Meana-Fernández, A.; Oro, J.M.F. Thermal response and failure mode evaluation of a dry-type transformer. Appl. Therm. Eng. 2017, 120, 763–771. [Google Scholar] [CrossRef]
- Liu, Y.; Yin, J.; Tian, Y.; Fan, X. Design and Performance Test of Transformer Winding Optical Fibre Composite Wire Based on Raman Scattering. Sensors 2019, 19, 2171. [Google Scholar] [CrossRef] [Green Version]
- Khalili Senobari, R.; Sadeh, J.; Borsi, H. Frequency response analysis (FRA) of transformers as a tool for fault detection and location: A review. Electr. Power Syst. Res. 2018, 155, 172–183. [Google Scholar] [CrossRef]
- Zhang, X.; Gockenbach, E. Asset-Management of Transformers Based on Condition Monitoring and Standard Diagnosis. IEEE Electr. Insul. Mag. 2008, 24, 26–40. [Google Scholar] [CrossRef]
- Ward, S.; El-Faraskoury, A.; Badawi, M.; Ibrahim, S.; Mahmoud, K.; Lehtonen, M.; Darwish, M. Towards Precise Interpretation of Oil Transformers via Novel Combined Techniques Based on DGA and Partial Discharge Sensors. Sensors 2021, 21, 2223. [Google Scholar] [CrossRef]
- He, Y.; Zhou, Q.; Lin, S.; Zhao, L. Validity Evaluation Method Based on Data Driving for On-Line Monitoring Data of Transformer under DC-Bias. Sensors 2020, 20, 4321. [Google Scholar] [CrossRef]
- Zhang, C.; He, Y.; Du, B.; Yuan, L.; Li, B.; Jiang, S. Transformer fault diagnosis method using IoT based monitoring system and ensemble machine learning. Futur. Gener. Comput. Syst. 2020, 108, 533–545. [Google Scholar] [CrossRef]
- Muttillo, M.; Nardi, I.; Stornelli, V.; De Rubeis, T.; Pasqualoni, G.; Ambrosini, D. On Field Infrared Thermography Sensing for PV System Efficiency Assessment: Results and Comparison with Electrical Models. Sensors 2020, 20, 1055. [Google Scholar] [CrossRef] [Green Version]
- Laib dit Leksir, Y.; Mansour, M.; Moussaoui, A. Localization of thermal anomalies in electrical equipment using Infrared Thermography and support vector machine. Infrared Phys. Technol. 2018, 89, 120–128. [Google Scholar] [CrossRef]
- Duan, L.; Yao, M.; Wang, J.; Bai, T.; Zhang, L. Segmented infrared image analysis for rotating machinery fault diagnosis. Infrared Phys. Technol. 2016, 77, 267–276. [Google Scholar] [CrossRef] [Green Version]
- Ioannidou, A.; Chatzilari, E.; Nikolopoulos, S.; Kompatsiaris, I. Deep Learning Advances in Computer Vision with 3D Data: A Survey. ACM Comput. Surv. 2018, 50, 1–38. [Google Scholar] [CrossRef]
- Yang, J.; Xu, R.; Qi, Z.; Shi, Y. Visual Anomaly Detection for Images: A Survey. arXiv 2021, arXiv:2109.13157. [Google Scholar]
- Nomura, Y. A Review on Anomaly Detection Techniques Using Deep Learning. J. Soc. Mater. Sci. Jpn. 2020, 69, 650–656. [Google Scholar] [CrossRef]
- Thudumu, S.; Branch, P.; Jin, J.; Singh, J. A comprehensive survey of anomaly detection techniques for high dimensional big data. J. Big Data 2020, 7, 42. [Google Scholar] [CrossRef]
- Alloqmani, A.; Abushark, Y.B.; Irshad, A.; Alsolami, F. Deep Learning based Anomaly Detection in Images: Insights, Challenges and Recommendations. Int. J. Adv. Comput. Sci. Appl. 2021, 12. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep Learning for Anomaly Detection: A Review. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Mitiche, I.; McGrail, T.; Boreham, P.; Nesbitt, A.; Morison, G. Data-Driven Anomaly Detection in High-Voltage Transformer Bushings with LSTM Auto-Encoder. Sensors 2021, 21, 7426. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.; Wang, Y.; Li, H.; He, Y.; Zhao, Y. Power Transformer Abnormal State Recognition Model Based on Improved K-Means Clustering. In Proceedings of the 2018 IEEE Electrical Insulation Conference (EIC), San Antonio, TX, USA, 17–20 June 2018; pp. 327–330. [Google Scholar]
- Tang, K.; Liu, T.; Xi, X.; Lin, Y.; Zhao, J. Power Transformer Anomaly Detection Based on Adaptive Kernel Fuzzy C-Means Clustering and Kernel Principal Component Analysis. In Proceedings of the 2018 Australian & New Zealand Control Conference (ANZCC), Melbourne, VIC, Australia, 7–8 December 2018. [Google Scholar] [CrossRef]
- Bergmann, P.; Löwe, S.; Fauser, M.; Sattlegger, D.; Steger, C. Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders. In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Scitepress, VISAPP, Prague, Czech Republic, 25–27 February 2019; Volume 5, pp. 372–380. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In Proceedings of the International Conference on Information Processing in Medical Imaging, Boone, NC, USA, 25–30 June 2017; pp. 146–157. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training. In Computer Vision–ACCV 2018; Springer International Publishing: Cham, Switzerland, 2019; pp. 622–637. [Google Scholar]
- Vu, H.S.; Ueta, D.; Hashimoto, K.; Maeno, K.; Pranata, S.; Shen, S.M. Anomaly Detection with Adversarial Dual Autoencoders. arXiv 2019, arXiv:1902.06924. [Google Scholar]
- Lai, C.-H.; Zou, D.; Lerman, G. Robust Subspace Recovery Layer for Unsupervised Anomaly Detection. arXiv 2019, arXiv:1904.00152v2. [Google Scholar]
- Wang, L.; Zhang, D.; Guo, J.; Han, Y. Image Anomaly Detection Using Normal Data Only by Latent Space Resampling. Appl. Sci. 2020, 10, 8660. [Google Scholar] [CrossRef]
- Tang, T.-W.; Kuo, W.-H.; Lan, J.-H.; Ding, C.-F.; Hsu, H.; Young, H.-T. Anomaly Detection Neural Network with Dual Auto-Encoders GAN and Its Industrial Inspection Applications. Sensors 2020, 20, 3336. [Google Scholar] [CrossRef]
- Fanchiang, K.-H.; Huang, Y.-C.; Kuo, C.-C. Power Electric Transformer Fault Diagnosis Based on Infrared Thermal Images Using Wasserstein Generative Adversarial Networks and Deep Learning Classifier. Electronics 2021, 10, 1161. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.-A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114v10. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 214–223. [Google Scholar]
- Yuan, X.; Liu, Q.; Long, J.; Hu, L.; Wang, Y. Deep Image Similarity Measurement Based on the Improved Triplet Network with Spatial Pyramid Pooling. Information 2019, 10, 129. [Google Scholar] [CrossRef] [Green Version]
- Schmidt-Hieber, J. Nonparametric regression using deep neural networks with ReLU activation function. Ann. Stat. 2020, 48, 1875–1897. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Hoi, S.C.H. Deep Learning for Image Super-Resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3365–3387. [Google Scholar] [CrossRef] [Green Version]
- Weller-Fahy, D.J.; Borghetti, B.J.; Sodemann, A.A. A Survey of Distance and Similarity Measures Used Within Network Intrusion Anomaly Detection. IEEE Commun. Surv. Tutorials 2014, 17, 70–91. [Google Scholar] [CrossRef]
- Mercioni, M.A.; Holban, S. A Survey of Distance Metrics in Clustering Data Mining Techniques. In Proceedings of the 2019 3rd International Conference on Graphics and Signal Processing, New York, NY, USA, 1–3 June 2019. [Google Scholar] [CrossRef]
- Borji, A. Pros and cons of GAN evaluation measures: New developments. Comput. Vis. Image Underst. 2021, 215, 103329. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Training Dataset | Testing Dataset |
|---|---|---|
| F0 | 300 | 109 |
| F1 | 0 | 126 |
| F2 | 0 | 119 |
| F3 | 0 | 115 |
| F4 | 0 | 124 |
| F5 | 0 | 102 |
| F6 | 0 | 106 |
| F7 | 0 | 117 |
| F8 | 0 | 104 |
| Ranking | @Epoch | Mean_SSIM | Mean_PSNR |
|---|---|---|---|
| 1 | 7240 | 0.99993577 | 77.668 |
| 2 | 7540 | 0.99991863 | 77.291 |
| 3 | 6920 | 0.99992996 | 77.679 |
| 4 | 6240 | 0.99994356 | 77.328 |
| 5 | 6040 | 0.99994149 | 77.570 |
| 6 | 8760 | 0.99993628 | 77.812 |
| 7 | 8780 | 0.99994446 | 77.998 |
| 8 | 6700 | 0.99993794 | 77.684 |
| 9 | 5960 | 0.99994363 | 77.647 |
| 10 | 9880 | 0.99995971 | 78.807 |
| Category | AE-ssim | GANomaly | RSRAE | ADAE | Proposed | |
|---|---|---|---|---|---|---|
| Only F0 | 0.743 | 0.990 | 0.844 | 0.596 | 0.697 | 0.991 |
| F1 + F0 | 0.778 | 0.640 | 0.278 | 0.484 | 0.921 | 0.960 |
| F2 + F0 | 0.857 | 0.695 | 0.218 | 0.387 | 0.891 | 0.975 |
| F3 + F0 | 0.513 | 0.465 | 0.217 | 0.383 | 0.661 | 0.948 |
| F4 + F0 | 0.742 | 0.455 | 0.218 | 0.306 | 0.629 | 0.944 |
| F5 + F0 | 0.412 | 0.535 | 0.225 | 0.422 | 0.559 | 0.882 |
| F6 + F0 | 0.406 | 0.676 | 0.264 | 0.377 | 0.443 | 0.642 |
| F7 + F0 | 0.675 | 0.759 | 0.197 | 0.359 | 0.658 | 0.940 |
| F8 + F0 | 0.462 | 0.573 | 0.260 | 0.452 | 0.567 | 0.904 |
| mean | 0.621 | 0.643 | 0.302 | 0.418 | 0.670 | 0.910 |
| Category | AE-ssim | GANomaly | RSRAE | ADAE | f-anoGAN | Proposed | |
|---|---|---|---|---|---|---|---|
| F1 + F0 | 0.819 | 0.817 | 0.532 | 0.507 | 0.848 | 0.468 | 0.976 |
| F2 + F0 | 0.834 | 0.844 | 0.446 | 0.428 | 0.828 | 0.533 | 0.983 |
| F3 + F0 | 0.759 | 0.730 | 0.426 | 0.427 | 0.716 | 0.537 | 0.969 |
| F4 + F0 | 0.812 | 0.725 | 0.452 | 0.374 | 0.708 | 0.591 | 0.967 |
| F5 + F0 | 0.727 | 0.760 | 0.460 | 0.466 | 0.687 | 0.476 | 0.937 |
| F6 + F0 | 0.729 | 0.835 | 0.430 | 0.414 | 0.594 | 0.562 | 0.816 |
| F7 + F0 | 0.793 | 0.876 | 0.455 | 0.423 | 0.718 | 0.553 | 0.965 |
| F8 + F0 | 0.741 | 0.784 | 0.479 | 0.465 | 0.665 | 0.523 | 0.947 |
| mean | 0.777 | 0.796 | 0.460 | 0.438 | 0.720 | 0.530 | 0.945 |
| Category | AE-ssim | GANomaly | RSRAE | ADAE | Proposed | |
|---|---|---|---|---|---|---|
| F1 + F0 | 0.875 | 0.802 | 0.217 | 0.326 | 0.959 | 0.974 |
| F2 + F0 | 0.923 | 0.836 | 0.179 | 0.279 | 0.942 | 0.982 |
| F3 + F0 | 0.678 | 0.706 | 0.179 | 0.277 | 0.796 | 0.969 |
| F4 + F0 | 0.852 | 0.693 | 0.179 | 0.235 | 0.772 | 0.966 |
| F5 + F0 | 0.583 | 0.751 | 0.184 | 0.296 | 0.717 | 0.938 |
| F6 + F0 | 0.577 | 0.833 | 0.209 | 0.274 | 0.614 | 0.812 |
| F7 + F0 | 0.806 | 0.871 | 0.164 | 0.264 | 0.794 | 0.965 |
| F8 + F0 | 0.632 | 0.777 | 0.206 | 0.311 | 0.724 | 0.948 |
| mean | 0.741 | 0.784 | 0.190 | 0.283 | 0.790 | 0.944 |
| Category | AE-ssim | GANomaly | RSRAE | ADAE | f-anoGAN | Proposed | |
|---|---|---|---|---|---|---|---|
| F1 + F0 | 0.823 | 0.827 | 0.570 | 0.533 | 0.800 | 0.522 | 0.974 |
| F2 + F0 | 0.821 | 0.847 | 0.498 | 0.476 | 0.743 | 0.569 | 0.980 |
| F3 + F0 | 0.736 | 0.733 | 0.464 | 0.480 | 0.621 | 0.591 | 0.966 |
| F4 + F0 | 0.807 | 0.739 | 0.498 | 0.464 | 0.665 | 0.646 | 0.966 |
| F5 + F0 | 0.692 | 0.747 | 0.462 | 0.462 | 0.586 | 0.514 | 0.930 |
| F6 + F0 | 0.681 | 0.828 | 0.458 | 0.444 | 0.526 | 0.587 | 0.809 |
| F7 + F0 | 0.754 | 0.876 | 0.481 | 0.474 | 0.628 | 0.604 | 0.963 |
| F8 + F0 | 0.684 | 0.774 | 0.473 | 0.478 | 0.567 | 0.563 | 0.941 |
| mean | 0.750 | 0.796 | 0.488 | 0.476 | 0.642 | 0.575 | 0.941 |
| Method | Parameter | Storage Size |
|---|---|---|
| f-anoGAN | 24.57 M | 18 MB |
| AE-ssim | 1.2 M | 8.63 MB |
| AE-L2 | 1.2 M | 8.63 MB |
| GANomaly | 5.43 M | 21.8 MB |
| ADAE | 0.101 M | 0.258 MB |
| Proposed | 0.12 M | 0.550 MB |
| Evaluation Metric | Dataset | Sqeuclidean | Euclidean | Manhattan | Cosine (Proposed) |
|---|---|---|---|---|---|
| Accuracy | 109 testing normal images | 0.982 | 0.982 | 0.991 | 0.991 |
| Accuracy | 1022 testing images | 0.840 | 0.823 | 0.843 | 0.908 |
| AUROC | 0.902 | 0.893 | 0.908 | 0.940 | |
| F1 scores | 0.902 | 0.890 | 0.904 | 0.946 | |
| AP | 0.979 | 0.977 | 0.980 | 0.987 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fanchiang, K.-H.; Kuo, C.-C. Application of Thermography and Adversarial Reconstruction Anomaly Detection in Power Cast-Resin Transformer. Sensors 2022, 22, 1565. https://doi.org/10.3390/s22041565
Fanchiang K-H, Kuo C-C. Application of Thermography and Adversarial Reconstruction Anomaly Detection in Power Cast-Resin Transformer. Sensors. 2022; 22(4):1565. https://doi.org/10.3390/s22041565
Chicago/Turabian StyleFanchiang, Kuo-Hao, and Cheng-Chien Kuo. 2022. "Application of Thermography and Adversarial Reconstruction Anomaly Detection in Power Cast-Resin Transformer" Sensors 22, no. 4: 1565. https://doi.org/10.3390/s22041565
APA StyleFanchiang, K.-H., & Kuo, C.-C. (2022). Application of Thermography and Adversarial Reconstruction Anomaly Detection in Power Cast-Resin Transformer. Sensors, 22(4), 1565. https://doi.org/10.3390/s22041565