
Improving Radar Human Activity Classification Using Synthetic Data with Image Transformation

 , ,
, ,
Abstract
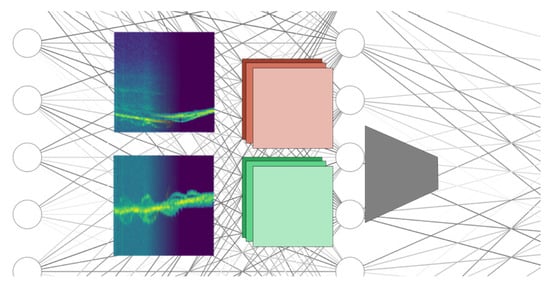
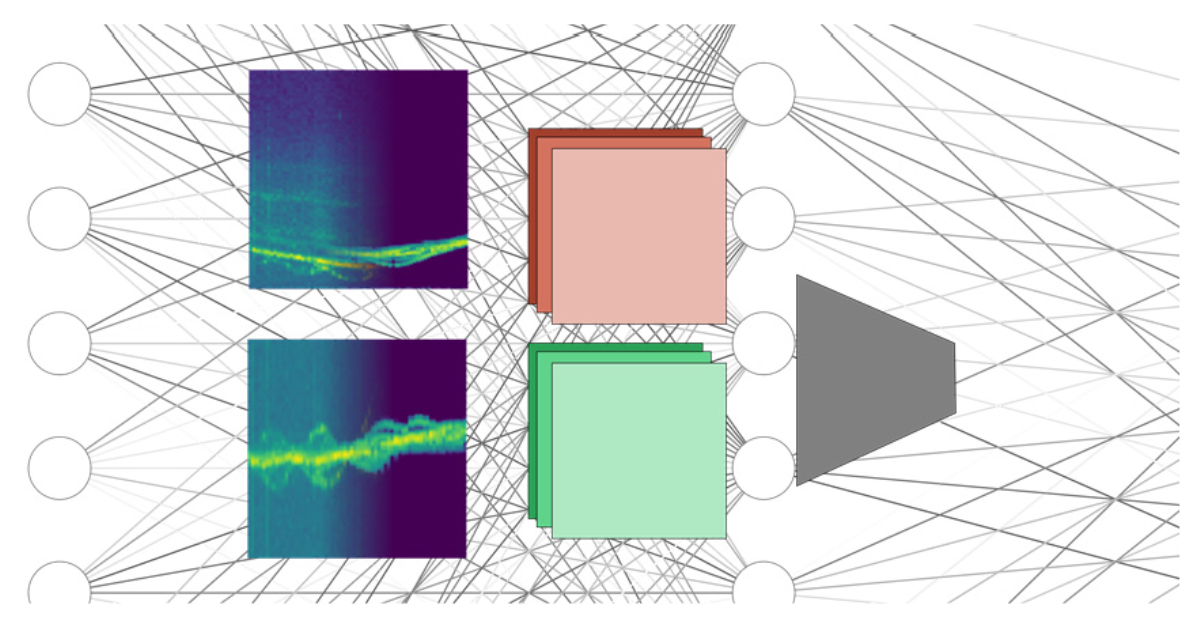
:
1. Introduction
1.1. Motivation
- Incomplete dataset, meaning that a limited number of subjects executed the activities.
- Insufficient measurement time, meaning that just a short time frame of the activity for each person is captured for the dataset.
- Different radar sensor settings or parameters, e.g., bandwidth, measurement time, repetition time, etc.
- Inconsistent measurement times, meaning the same person performing a specific activity task executes the activity differently at different times, e.g., after a coffee break or at a different distance to the sensor, etc.
- We first show that data from a source time and a target time interval in our dataset differ significantly.
- As a baseline, we train a Convolutional Neural Network (CNN) with only real data from one source time interval and test the trained CNN with data from a target time interval.
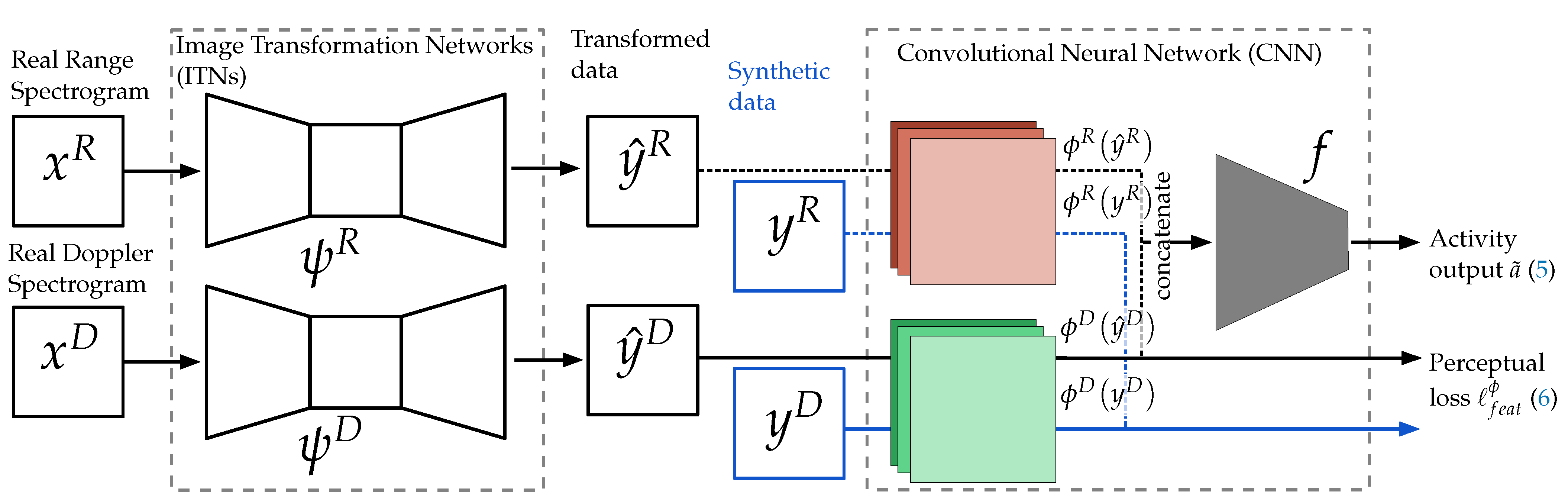
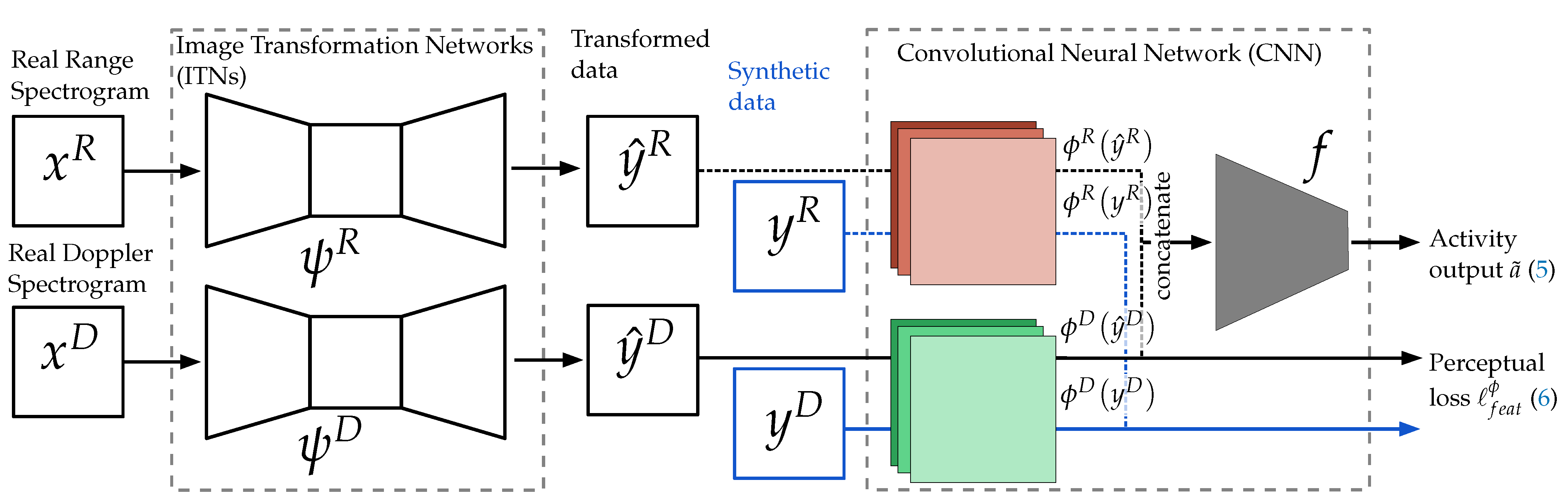
- We demonstrate the approach of perceptual loss with Image Transformation Networks [11] to show that we can increase classification accuracy by only using synthetic radar data from the target time (generated by taking the human motion data from the target time and using it as input for the human radar reflection model from Chen [10]).
- We propose improvements of this method for future research.
1.2. Related Work
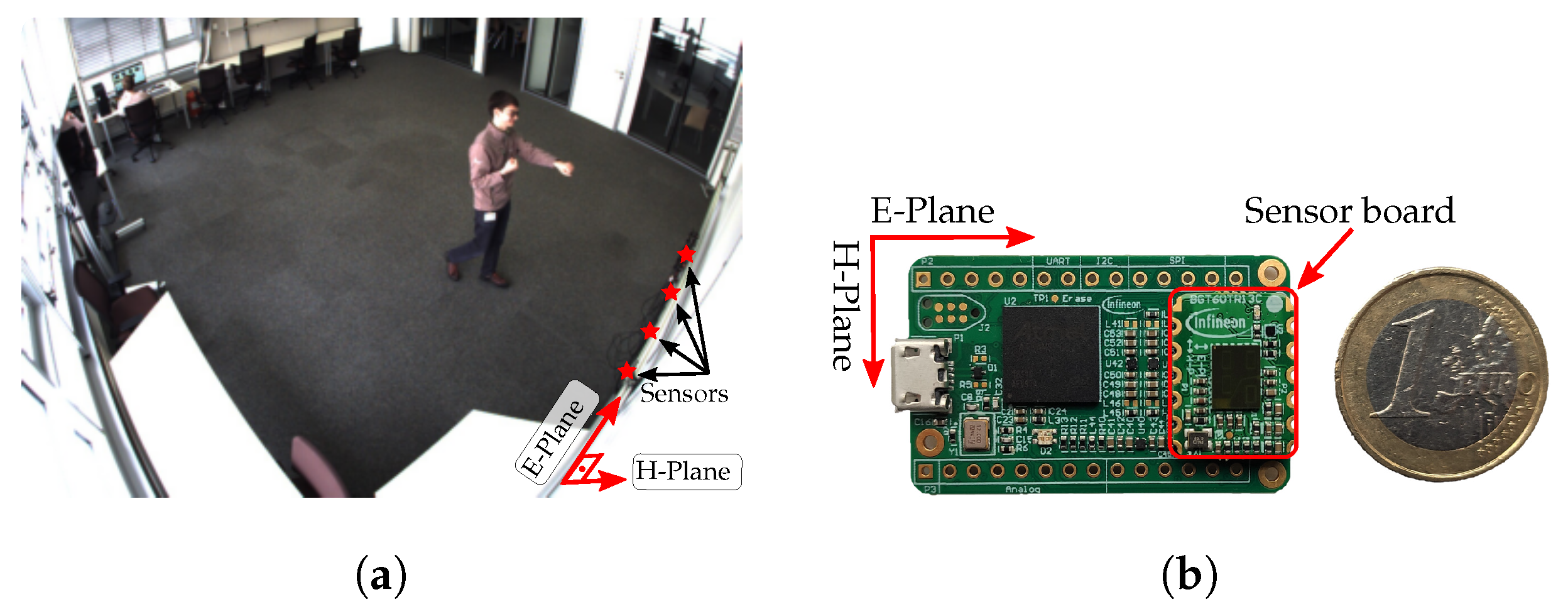
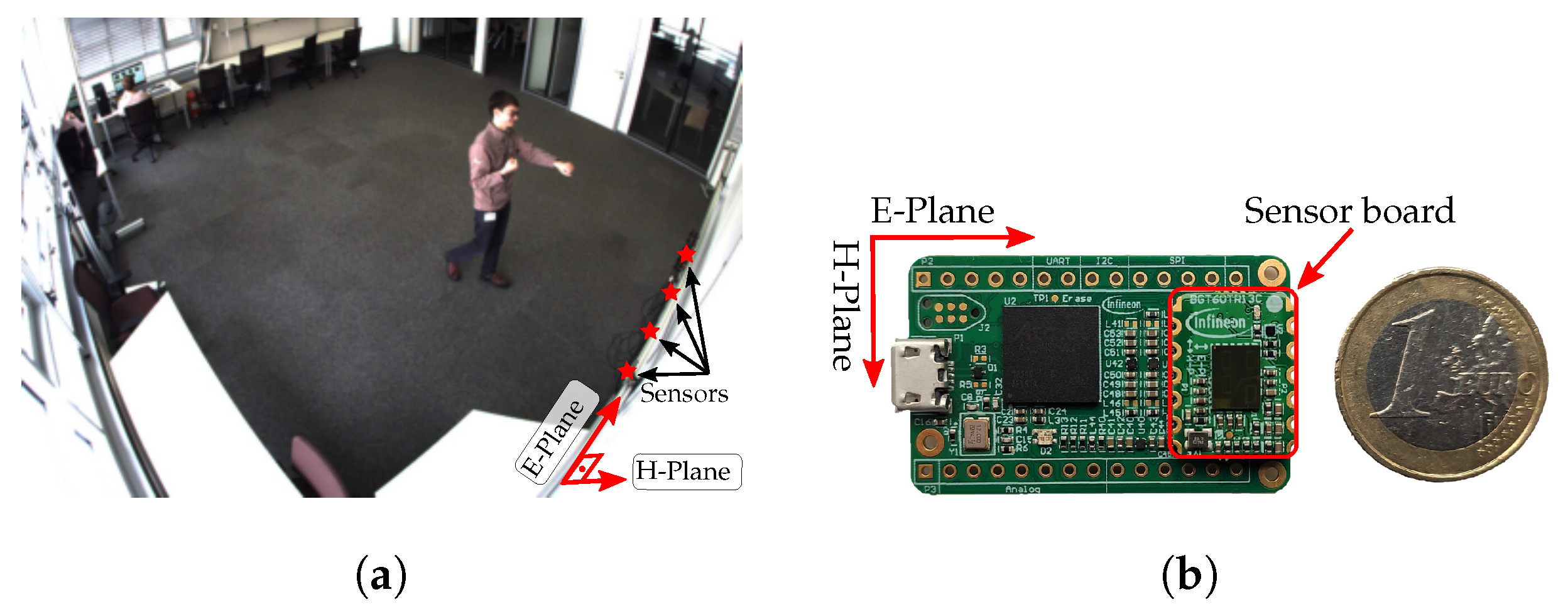
2. Radar Sensor and Dataset
- (a)
- Standing in front of the sensor.
- (b)
- Waving with the hand at the sensor.
- (c)
- Walking back and forth to the sensor.
- (d)
- Boxing while standing still.
- (e)
- Boxing while walking towards the sensor.
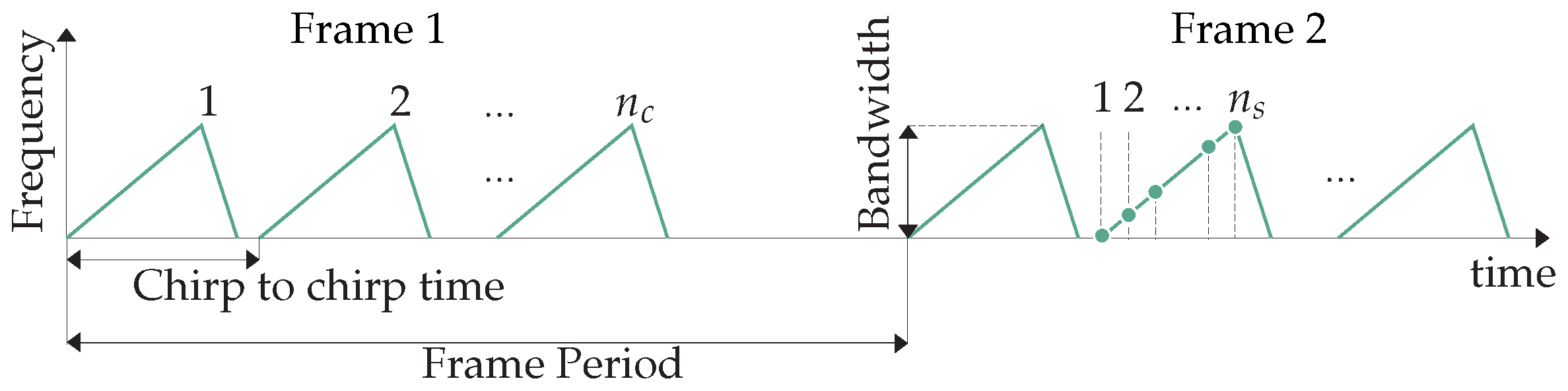
- Moving Target Indication (MTI): In order to filter out the clutter from static objects, we calculate the mean across the slow time to obtain an -long vector that we subtract from every column of the frame [22].
- Doppler FFT: We also perform an FFT across the slow time, turning the range profiles into a Range-Doppler Map (RDM) that conveys information on the returned power across range and Doppler, i.e., distance and velocity (c.f. Figure 3c). Here we use a Chebyshev window with 60 sidelobe attenuation [23] and the same zero-padding strategy as for the range FFT. As a result, the dimensions of the RDMs are for all configurations.
- Slicing and normalization: As the last step, we slice each long recording into 64-frame long spectrograms with an overlap such that the last 56 frames of one spectrogram coincide with the first 56 frames of the next sliced spectrogram. Furthermore, we shift the decibel values of each sliced spectrogram so that the maximum value equals 0 and we subsequently clip out all values below .
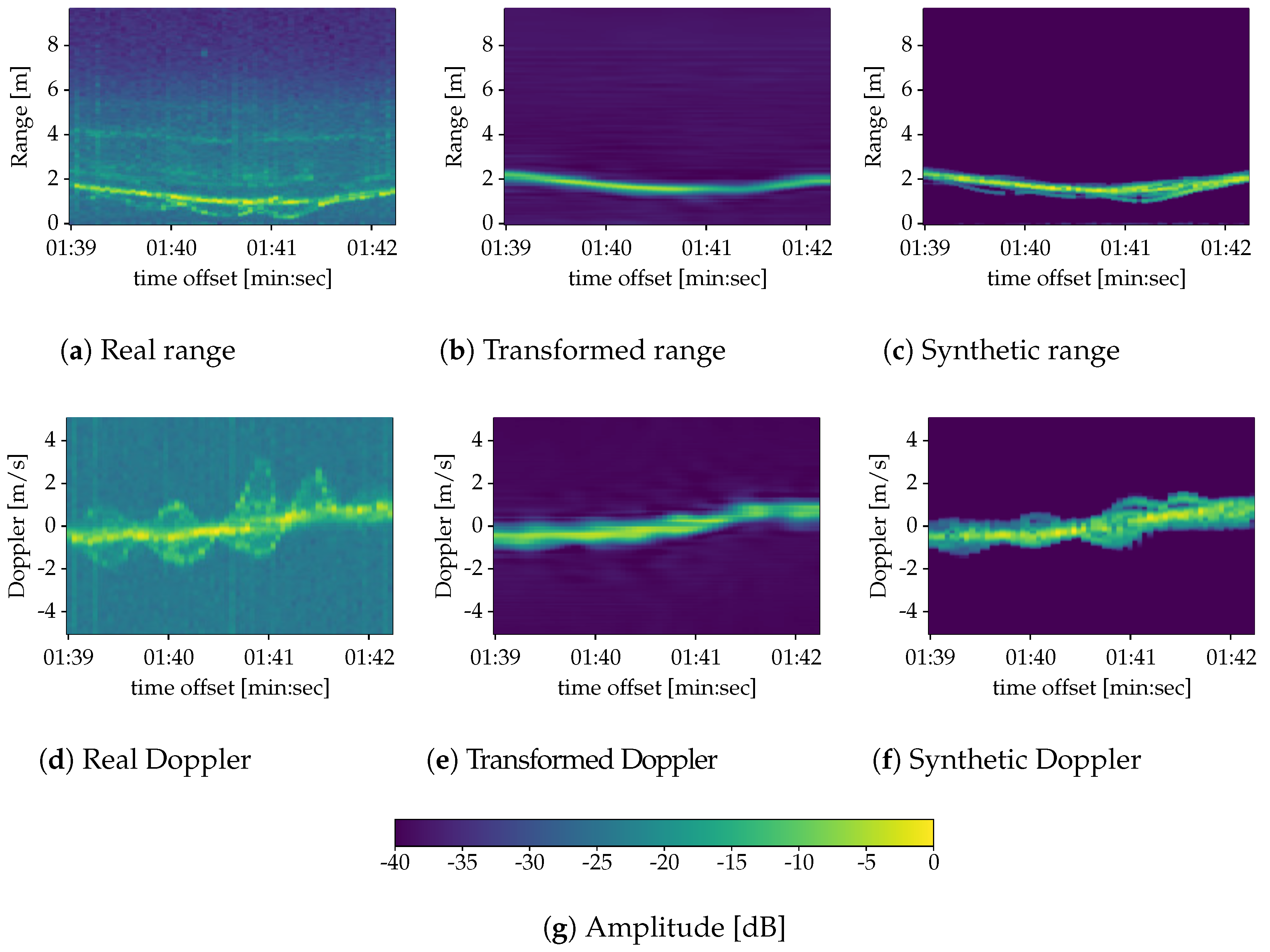
Data Synthesis
3. Method
Implementation and Training
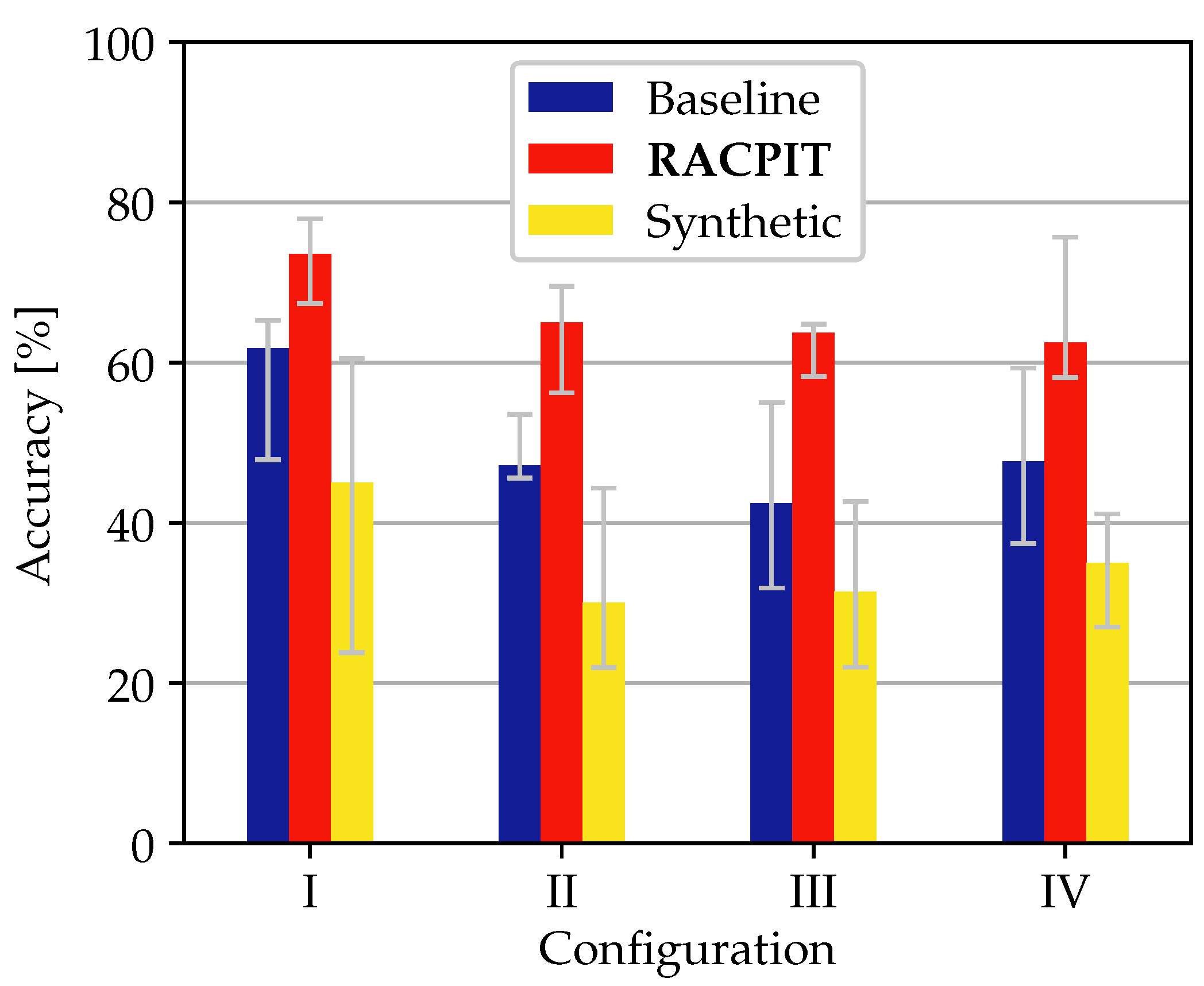
4. Results
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| CV | Computer Vision |
| GAN | Generative Adversarial Network |
| IF | Intermediate Frequency |
| ITN | Image Transformation Network |
| FMCW | Frequency-Modulated Continuous-Wave |
| FFT | Fast Fourier Transform |
| ML | Machine Learning |
| MOCAP | MOtion CAPture |
| MTI | Moving Target Indication |
| RACPIT | Radar Activity Classification with Perceptual Image Transformation |
| RCS | Radar Cross Section |
| RDM | Range-Doppler Map |
| SBR | Shooting and Bouncing Rays |
| UWB | Ultra-wideband |
References
- Hazra, S.; Santra, A. Robust Gesture Recognition Using Millimetric-Wave Radar System. IEEE Sens. Lett. 2018, 2, 7001804. [Google Scholar] [CrossRef]
- Stephan, M.; Santra, A. Radar-Based Human Target Detection using Deep Residual U-Net for Smart Home Applications. In Proceedings of the 2019 18th IEEE International Conference on Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 175–182. [Google Scholar] [CrossRef]
- Stephan, M.; Stadelmayer, T.; Santra, A.; Fischer, G.; Weigel, R.; Lurz, F. Radar Image Reconstruction from Raw ADC Data using Parametric Variational Autoencoder with Domain Adaptation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 9529–9536. [Google Scholar] [CrossRef]
- Redko, I.; Morvant, E.; Habrard, A.; Sebban, M.; Bennani, Y. Advances in Domain Adaptation Theory; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar] [CrossRef]
- Kim, Y.; Moon, T. Human Detection and Activity Classification Based on Micro-Doppler Signatures Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 8–12. [Google Scholar] [CrossRef]
- Shah, S.A.; Fioranelli, F. Human Activity Recognition: Preliminary Results for Dataset Portability using FMCW Radar. In Proceedings of the 2019 International Radar Conference (RADAR), Toulon, France, 23–27 September 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Du, H.; Jin, T.; Song, Y.; Dai, Y. Unsupervised Adversarial Domain Adaptation for Micro-Doppler Based Human Activity Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 62–66. [Google Scholar] [CrossRef]
- Li, X.; Jing, X.; He, Y. Unsupervised Domain Adaptation for Human Activity Recognition in Radar. In Proceedings of the 2020 IEEE Radar Conference (RadarConf20), Florence, Italy, 21–25 September 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Khodabakhshandeh, H.; Visentin, T.; Hernangómez, R.; Pütz, M. Domain Adaptation Across Configurations of FMCW Radar for Deep Learning Based Human Activity Classification. In Proceedings of the 2021 21st International Radar Symposium (IRS), Berlin, Germany, 21–22 June 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Chen, V.C. The Micro-Doppler Effect in Radar; Artech House: Norwood, MA, USA, 2011. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. arXiv 2016, arXiv:1603.08155. [Google Scholar]
- Hernangómez, R.; Santra, A.; Stańczak, S. Human Activity Classification with Frequency Modulated Continuous Wave Radar Using Deep Convolutional Neural Networks. In Proceedings of the 2019 International Radar Conference (RADAR), Toulon, France, 23–27 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Hernangómez, R.; Santra, A.; Stańczak, S. A Study on Feature Processing Schemes for Deep-Learning-Based Human Activity Classification Using Frequency-Modulated Continuous-Wave Radar. IET Radar Sonar Navig. 2020, 15, 932–944. [Google Scholar] [CrossRef]
- Gurbuz, S.Z.; Rahman, M.M.; Kurtoglu, E.; Macks, T.; Fioranelli, F. Cross-frequency training with adversarial learning for radar micro-Doppler signature classification (Rising Researcher). In Radar Sensor Technology XXIV; International Society for Optics and Photonics: Bellingham, WA, USA, 2020; Volume 11408. [Google Scholar] [CrossRef]
- Gusland, D.; Christiansen, J.M.; Torvik, B.; Fioranelli, F.; Gurbuz, S.Z.; Ritchie, M. Open Radar Initiative: Large Scale Dataset for Benchmarking of micro-Doppler Recognition Algorithms. In Proceedings of the 2021 IEEE Radar Conference (RadarConf21), Atlanta, GA, USA, 7–14 May 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Yeo, H.S.; Minami, R.; Rodriguez, K.; Shaker, G.; Quigley, A. Exploring Tangible Interactions with Radar Sensing. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Zhang, A.; Nowruzi, F.E.; Laganiere, R. RADDet: Range-Azimuth-Doppler based Radar Object Detection for Dynamic Road Users. In Proceedings of the 2021 18th Conference on Robots and Vision (CRV), Burnaby, BC, Canada, 26–28 May 2021. [Google Scholar]
- Stolz, M.; Schubert, E.; Meinl, F.; Kunert, M.; Menzel, W. Multi-target reflection point model of cyclists for automotive radar. In Proceedings of the 2017 European Radar Conference (EURAD), Nuremberg, Germany, 11–13 October 2017; pp. 94–97. [Google Scholar] [CrossRef]
- De la Torre, F.; Hodgins, J.; Montano, J.; Valcarcel, S.; Forcada, R.; Macey, J. Guide to the Carnegie Mellon University Multimodal Activity (CMU-MMAC) Database; Robotics Institute, Carnegie Mellon University: Pittsburgh, PA, USA, 2009; Volume 5. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Richards, M.A.; Scheer, J.; Holm, W.A.; Melvin, W.L. Principles of Modern Radar; Citeseer: Princeton, NJ, USA, 2010. [Google Scholar]
- Manolakis, D.G.; Ingle, V.K.; Kogon, S.M. Statistical and Adaptive Signal Processing: Spectral Estimation, Signal Modeling, Adaptive Filtering and Array Processing; Artech House Signal Processing Library, Artech House: Boston, MA, USA, 2005. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. Available online: https://github.com/facebookresearch/detectron2 (accessed on 14 February 2022).
- Boulic, R.; Thalmann, N.M.; Thalmann, D. A global human walking model with real-time kinematic personification. Vis. Comput. 1990, 6, 344–358. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Wu, X.Z.; Zhou, Z.H. A unified view of multi-label performance measures. In Proceedings of the 34th International Conference on Machine Learning (ICML’17), Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 3780–3788. [Google Scholar]
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The Balanced Accuracy and Its Posterior Distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3121–3124. [Google Scholar] [CrossRef]
- Guler, R.A.; Neverova, N.; Kokkinos, I. DensePose: Dense Human Pose Estimation in the Wild. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7297–7306. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration Name | I | II | III | IV | |
|---|---|---|---|---|---|
| Chirps per frame | 64 | 64 | 64 | 128 | |
| Samples per chirp | 256 | 256 | 256 | 256 | |
| Chirp to chirp time | [] | 250 | 250 | 250 | 250 |
| Bandwidth | [] | 2 | 4 | 4 | 4 |
| Frame period | [] | 50 | 32 | 50 | 50 |
| Range resolution | [] | 7.5 | 3.8 | 3.8 | 3.8 |
| Max. range | [] | 9.6 | 4.8 | 4.8 | 4.8 |
| Max. speed | [] | 5.0 | 5.0 | 5.0 | 5.0 |
| Speed resolution | [] | 0.15 | 0.15 | 0.15 | 0.08 |
| Configuration | I | II | III | IV |
|---|---|---|---|---|
| Baseline | 0.49 | 0.41 | 0.37 | 0.47 |
| RACPIT | 0.65 | 0.55 | 0.56 | 0.55 |
| Configuration | I | II | III | IV |
|---|---|---|---|---|
| Baseline | 0.53 | 0.44 | 0.40 | 0.48 |
| RACPIT | 0.67 | 0.57 | 0.57 | 0.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernangómez, R.; Visentin, T.; Servadei, L.; Khodabakhshandeh, H.; Stańczak, S. Improving Radar Human Activity Classification Using Synthetic Data with Image Transformation. Sensors 2022, 22, 1519. https://doi.org/10.3390/s22041519
Hernangómez R, Visentin T, Servadei L, Khodabakhshandeh H, Stańczak S. Improving Radar Human Activity Classification Using Synthetic Data with Image Transformation. Sensors. 2022; 22(4):1519. https://doi.org/10.3390/s22041519
Chicago/Turabian StyleHernangómez, Rodrigo, Tristan Visentin, Lorenzo Servadei, Hamid Khodabakhshandeh, and Sławomir Stańczak. 2022. "Improving Radar Human Activity Classification Using Synthetic Data with Image Transformation" Sensors 22, no. 4: 1519. https://doi.org/10.3390/s22041519
APA StyleHernangómez, R., Visentin, T., Servadei, L., Khodabakhshandeh, H., & Stańczak, S. (2022). Improving Radar Human Activity Classification Using Synthetic Data with Image Transformation. Sensors, 22(4), 1519. https://doi.org/10.3390/s22041519