
Improved Spoken Language Representation for Intent Understanding in a Task-Oriented Dialogue System


Abstract
:1. Introduction
2. Related Work
2.1. Text-Based Intent Classification
2.2. ASR-SLU-Based Intent Classification
3. Observations and Analyses of Intent Understanding Performance Regarding ASR Errors
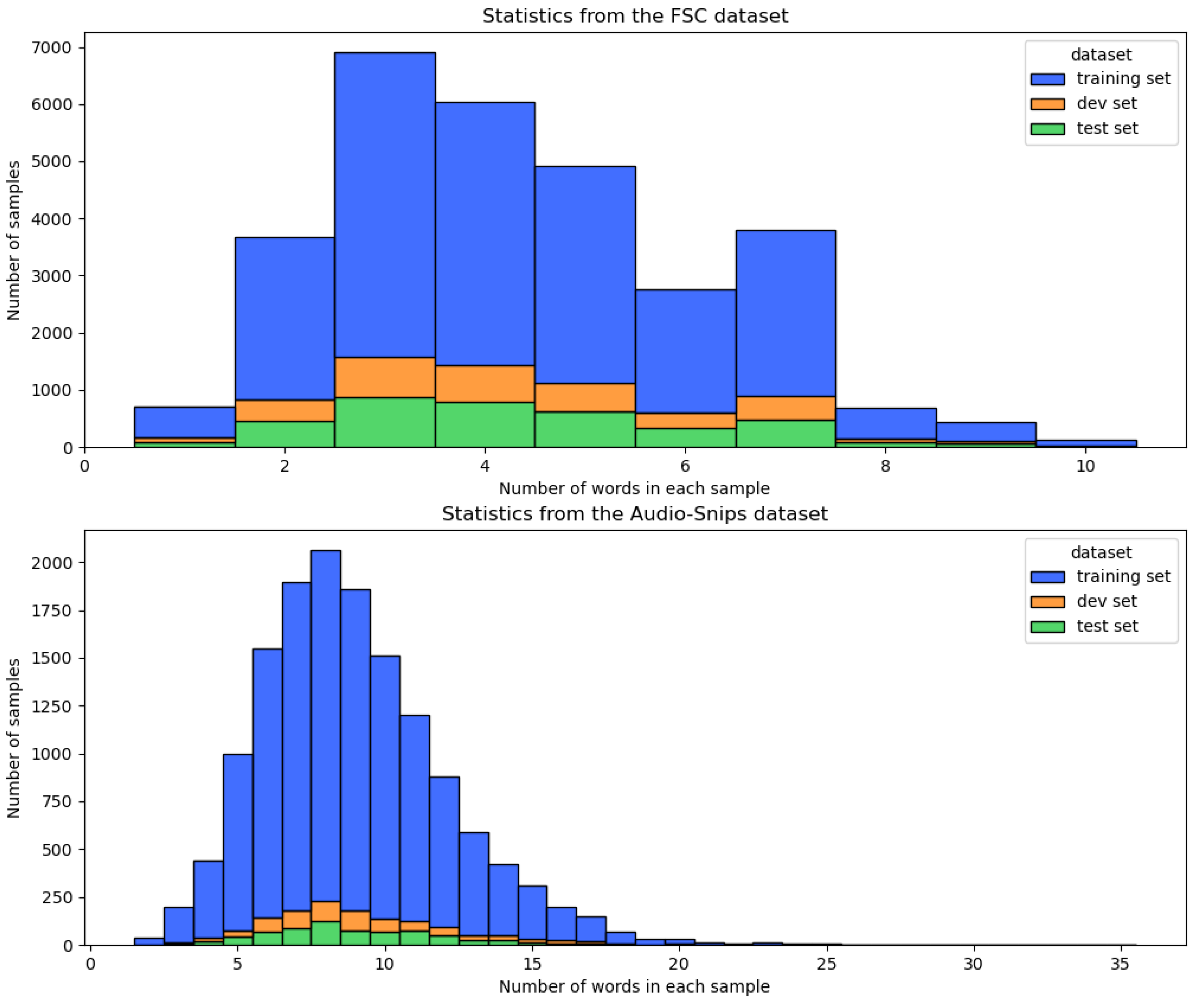
3.1. Dataset
3.2. Dataset Statistics
3.3. Analyses on ASR Errors of Two Datasets
3.4. Correlation between ASR Errors and Intent Classification
3.5. Need for Language Representation Using Recognized Text
4. Methodology
4.1. Reasons for Utilizing the Pre-Trained Language Model
4.2. Training Phase
4.3. Evaluation Phase
5. Experiment and Result Analysis
5.1. Experiment Setting
5.2. Results
5.3. Comparisons to Other Studies
5.4. Analysis
5.5. Ablation Studies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, B.; Lane, I. Attention-based recurrent neural network models for joint intent detection and slot filling. arXiv 2016, arXiv:1609.01454. [Google Scholar]
- Goo, C.W.; Gao, G.; Hsu, Y.K.; Huo, C.L.; Chen, T.C.; Hsu, K.W.; Chen, Y.N. Slot-gated modeling for joint slot filling and intent prediction. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Short Papers), New Orleans, LA, USA, 1–6 June 2018; Volume 2, pp. 753–757. [Google Scholar]
- Zhang, C.; Li, Y.; Du, N.; Fan, W.; Yu, P.S. Joint slot filling and intent detection via capsule neural networks. arXiv 2018, arXiv:1812.09471. [Google Scholar]
- Qin, L.; Che, W.; Li, Y.; Wen, H.; Liu, T. A stack-propagation framework with token-level intent detection for spoken language understanding. arXiv 2019, arXiv:1909.02188. [Google Scholar]
- Chen, Q.; Zhuo, Z.; Wang, W. Bert for joint intent classification and slot filling. arXiv 2019, arXiv:1902.10909. [Google Scholar]
- Niu, P.; Chen, Z.; Song, M. A novel bi-directional interrelated model for joint intent detection and slot filling. arXiv 2019, arXiv:1907.00390. [Google Scholar]
- Lugosch, L.; Ravanelli, M.; Ignoto, P.; Tomar, V.S.; Bengio, Y. Speech model pre-training for end-to-end spoken language understanding. arXiv 2019, arXiv:1904.03670. [Google Scholar]
- Wang, P.; Wei, L.; Cao, Y.; Xie, J.; Nie, Z. Large-scale unsupervised pre-training for end-to-end spoken language understanding. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7999–8003. [Google Scholar]
- Huang, C.W.; Chen, Y.N. Learning asr-robust contextualized embeddings for spoken language understanding. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 8009–8013. [Google Scholar]
- Cao, J.; Wang, J.; Hamza, W.; Vanee, K.; Li, S.W. Style attuned pre-training and parameter efficient fine-tuning for spoken language understanding. arXiv 2020, arXiv:2010.04355. [Google Scholar]
- Kim, S.; Kim, G.; Shin, S.; Lee, S. Two-stage textual knowledge distillation to speech encoder for spoken language understanding. arXiv 2020, arXiv:2010.13105. [Google Scholar]
- Kim, M.; Kim, G.; Lee, S.W.; Ha, J.W. ST-BERT: Cross-modal Language Model Pre-training For End-to-end Spoken Language Understanding. arXiv 2020, arXiv:2010.12283. [Google Scholar]
- Lai, C.I.; Cao, J.; Bodapati, S.; Li, S.W. Towards Semi-Supervised Semantics Understanding from Speech. arXiv 2020, arXiv:2011.06195. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5753–5763. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. 2001. Available online: https://repository.upenn.edu/cis_papers/159/?ref=https://githubhelp.com (accessed on 31 December 2021).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Chen, Y.P.; Price, R.; Bangalore, S. Spoken language understanding without speech recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6189–6193. [Google Scholar]
- Haghani, P.; Narayanan, A.; Bacchiani, M.; Chuang, G.; Gaur, N.; Moreno, P.; Prabhavalkar, R.; Qu, Z.; Waters, A. From audio to semantics: Approaches to end-to-end spoken language understanding. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 720–726. [Google Scholar]
- Chung, Y.A.; Zhu, C.; Zeng, M. SPLAT: Speech-Language Joint Pre-Training for Spoken Language Understanding. arXiv 2020, arXiv:2010.02295. [Google Scholar]
- Qian, Y.; Bianv, X.; Shi, Y.; Kanda, N.; Shen, L.; Xiao, Z.; Zeng, M. Speech-language pre-training for end-to-end spoken language understanding. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7458–7462. [Google Scholar]
- Coucke, A.; Saade, A.; Ball, A.; Bluche, T.; Caulier, A.; Leroy, D.; Doumouro, C.; Gisselbrecht, T.; Caltagirone, F.; Lavril, T.; et al. Snips voice platform: An embedded spoken language understanding system for private-by-design voice interfaces. arXiv 2018, arXiv:1805.10190. [Google Scholar]
- Wolf, T.; Chaumond, J.; Debut, L.; Sanh, V.; Delangue, C.; Moi, A.; Cistac, P.; Funtowicz, M.; Davison, J.; Shleifer, S.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Guo, H.; Mao, Y.; Zhang, R. Augmenting data with mixup for sentence classification: An empirical study. arXiv 2019, arXiv:1905.08941. [Google Scholar]
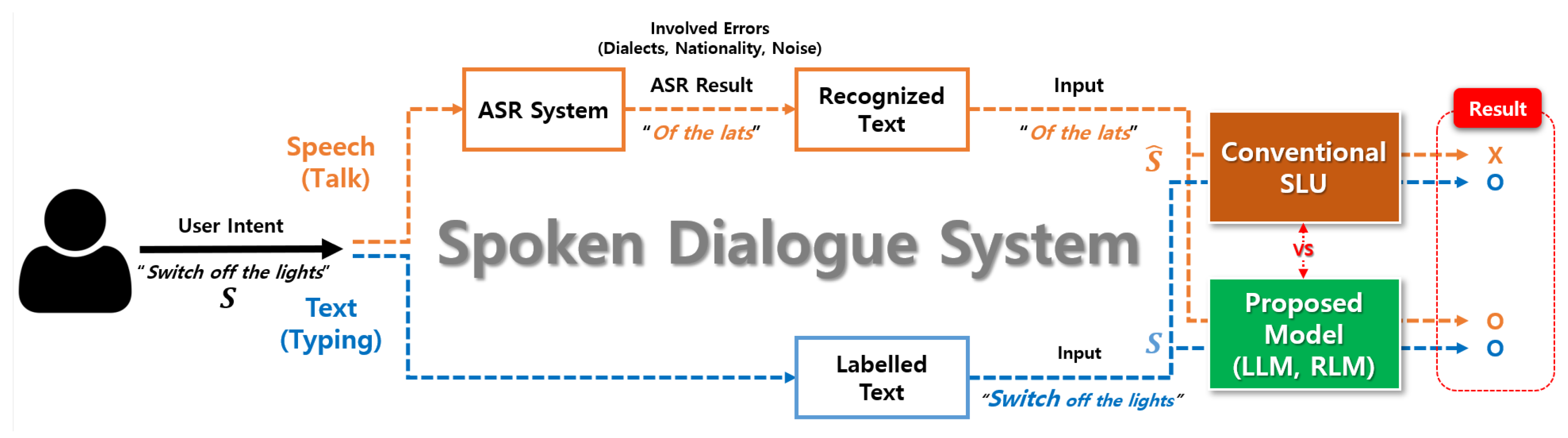



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Speaker | Language | Gender | Training Set | Test Set | ||
|---|---|---|---|---|---|---|---|
| CER (%) | WER (%) | CER (%) | WER (%) | ||||
| Audio-Snips | Aditi | Hindi | Female | 18.04 | 41.71 | 17.60 | 40.92 |
| Amy | English (British) | Female | 15.25 | 35.55 | 14.66 | 34.72 | |
| Brain | English (British) | Male | 25.22 | 52.94 | 24.44 | 50.72 | |
| Emma | English (British) | Female | 14.89 | 34.84 | 14.16 | 33.76 | |
| Geraint | English (Welsh) | Male | 21.81 | 48.37 | 21.04 | 45.93 | |
| Ivy | English (US) | Female (child) | 14.85 | 35.30 | 14.48 | 34.95 | |
| Joanna | English (US) | Female | 14.15 | 33.06 | 13.41 | 32.03 | |
| Joey | English (US) | Male | 19.83 | 43.39 | 19.16 | 42.28 | |
| Justin | English (US) | Male (child) | 19.44 | 44.06 | 18.38 | 42.17 | |
| Kendra | English (US) | Female | 13.78 | 33.06 | 13.11 | 32.18 | |
| Kimberly | English (US) | Female | 13.49 | 32.89 | 12.85 | 31.90 | |
| Matthew | English (US) | Male | 20.96 | 45.62 | 20.12 | 43.87 | |
| Nicole | English (Australian) | Female | 19.69 | 43.99 | 19.00 | 42.02 | |
| Raveena | English (Indian) | Female | 18.24 | 41.69 | 17.93 | 41.42 | |
| Russell | English (Australian) | Male | 24.00 | 51.17 | 22.57 | 48.40 | |
| Salli | English (US) | Female | 14.19 | 33.87 | 13.54 | 32.68 | |
| En-US (average) | 16.34 | 37.66 | 15.63 | 36.51 | |||
| Non En-US (average) | 19.64 | 43.78 | 18.93 | 42.24 | |||
| All (average) | 17.99 | 40.72 | 17.28 | 39.37 | |||
| FSC | All | 12.75 | 27.20 | 5.58 | 14.26 | ||
| Dataset | # | Labeled Text | Recognized Text | Intent |
|---|---|---|---|---|
| Audio-Snips | 1 | Rate this album a 1 | Great thi salbumawan | RateBook |
| 2 | Can you tell me the weather forecast for six am in grenada | Can ye tell me the wether folcasfa seek samin grenado | GetWeather | |
| 3 | Book a spot for oneat the wolseley at elevenses | Bokust spot for one at the wosli atalevanses | BookRestaurant | |
| 4 | Book a table for doris and i in new tulsa | Bucetabu fidarus and iin neutalsa | BookRestaurant | |
| 5 | Use groove shark to play the today and tomorrow album | Ese grieve shock to play the to day and to morrow album | PlayMusic | |
| FSC | 1 | Decrease the heating in the bathroom | Bigly then heaping in the budroom | Decrease-heat-washroom |
| 2 | Kitchen heat up | Internal heed of | Increase-heat-kitchen | |
| 3 | Volume up | Vilum a | Increase-volume-none | |
| 4 | Bedroom heat down | By blon heap don | Decrease-heat-bedroom | |
| 5 | Switch off the lights | Of the lats | Deactivate-lights-none |
| Dataset | Speaker | WER (%) | Intent Acc of the BERT Trained with Labeled Text (%) | ||
|---|---|---|---|---|---|
| Training Set | Test Set | Test with Labeled Set | Test with Recognized Set | ||
| Audio-Snips | Aditi | 41.71 | 40.92 | 98.43 | 84.71 |
| Amy | 35.55 | 34.72 | 90.86 | ||
| Brian | 52.94 | 50.72 | 75.86 | ||
| Emma | 34.84 | 33.76 | 90.43 | ||
| Geraint | 48.37 | 45.93 | 82.29 | ||
| Ivy | 35.30 | 34.95 | 93.85 | ||
| Joanna | 33.06 | 32.03 | 92.29 | ||
| Joey | 43.39 | 42.28 | 87.42 | ||
| Justin | 44.06 | 42.17 | 85.29 | ||
| Kendra | 33.06 | 32.18 | 93.86 | ||
| Kimberly | 32.89 | 31.90 | 94.57 | ||
| Matthew | 45.62 | 43.87 | 84.57 | ||
| Nicole | 43.99 | 42.02 | 85.43 | ||
| Raveena | 41.69 | 41.42 | 83.57 | ||
| Russell | 51.17 | 48.40 | 80.71 | ||
| Salli | 33.87 | 32.68 | 94.86 | ||
| En-US | 37.66 | 36.51 | 90.84 | ||
| Non En-US | 43.78 | 42.24 | 84.23 | ||
| Average | 40.72 | 39.37 | 87.54 | ||
| FSC | All | 27.20 | 14.26 | 100 | 89.63 |
| Intent Classification Acc (%) | |||||||
|---|---|---|---|---|---|---|---|
| Dataset | Used Model | ||||||
| Audio-Snips | BERT | 98.29 | 89.77 | 98.29 | 96.96 | 99.43 | 98.62 |
| ALBERT | 97.86 | 87.29 | 97.71 | 96.84 | 98.29 | 97.97 | |
| XLNet | 98.14 | 89.41 | 97.57 | 97.31 | 99.29 | 98.43 | |
| ELECTRA | 98.57 | 89.58 | 98.14 | 97.21 | 99.14 | 98.52 | |
| RoBERTa | 97.71 | 85.15 | 97.31 | 96.44 | 98.57 | 97.76 | |
| Average | 98.11 | 88.24 | 97.80 | 96.95 | 98.94 | 98.26 | |
| FSC | BERT | 100 | 88.81 | 98.50 | 96.23 | 100 | 98.63 |
| ALBERT | 100 | 85.65 | 98.39 | 95.86 | 100 | 98.68 | |
| XLNet | 100 | 88.16 | 99.14 | 96.97 | 100 | 98.66 | |
| ELECTRA | 100 | 85.73 | 96.94 | 93.38 | 100 | 98.63 | |
| RoBERTa | 100 | 89.40 | 97.68 | 94.99 | 100 | 98.60 | |
| Average | 100 | 87.55 | 98.13 | 95.49 | 100 | 98.64 | |
| Model | Intent Acc (%) | Input |
|---|---|---|
| Huang et al. [9] | 89.55 | Recognized text |
| Cao et al. [10] | 98.60 | Recognized text |
| Lai et al. [13] | 98.65 | Speech |
| Ours (BERT) | ||
| 99.43 | Labeled text | |
| 98.62 | Recognized text | |
| Average | 99.03 | Labeled & Recognized text |
| Dataset | Speaker | # | Labeled Text | Recognized Text | Label | Prediction | |
|---|---|---|---|---|---|---|---|
| Audio-Snips | Brian | 1 | Book a reservation at tavern for noodle | Bork te resurvation of tavernfemoodl | BookRestaurant | PlayMusic | BookRestaurant |
| 2 | Add brazilian flag anthem to top 100 alternative tracks on spotify | Ad brazilian flagamthum to top 100 alternative tracks on spotify | AddToPlaylist | PlayMusic | AddToPlaylist | ||
| 3 | Tell me the weather forecast for gibsland | Tell me the worther forecast for gibsland | GetWeather | SearchCreativeWork | GetWeather | ||
| 4 | Rate this current album 0 starts | Break this caran talbon’s ero stars | RateBook | PlayMusic | RateBook | ||
| 5 | Add abacab to beryl’s party on fridays playlist | A dabicabto party on friday’s playlist | AddToPlaylist | PlayMusic | AddToPlaylist | ||
| Russell | 1 | Let’s hear good mohammad mamle on vimeo | Lets heer good mahammed mammelon venier | PlayMusic | AddToPlaylist | PlayMusic | |
| 2 | What is the weather forecast for burundi | Orders the wore forme cost or branby | GetWeather | BookRestaurant | GetWeather | ||
| 3 | Where can i find the movie schedules | Where can i find the murvy schedules | SearchScreeningEvent | SearchCreativeWork | SearchScreeningEvent | ||
| 4 | Add farhad darya song in virales de siempre | Out far hou die your songs in the rowls to see em prey | AddToPlaylist | SearchScreeningEvent | SearchScreeningEvent | ||
| 5 | Add we have a theme song to my house afterwork | Ad we have a theme song to my house off to wor | AddToPlaylist | SearchScreeningEvent | AddToPlaylist | ||
| FSC | All | 1 | Turn down the heat in the washroom | Turn down we heet in the wateroom | decrease-heat -washroom | decrease-volume -none | decrease-heat -washroom |
| 2 | Heat down | Keep down | decrease-heat -none | decrease-volume -none | decrease-heat -none | ||
| 3 | Volume up | Fall him up | increase-volume -none | deactivate-lights -none | increase-volume -none | ||
| 4 | Washroom lights off | Washed him lights off | deactivate-lights -washroom | deactivate-lights -none | deactivate-lights -washroom | ||
| 5 | I need to practice my korean switch the language | I need to practice my careean which the language | change language -Korean-none | change language -English-none | change language -Korean-none | ||
| Dataset | Performance (%) | ||||||
|---|---|---|---|---|---|---|---|
| BERT [15] | ALBERT [16] | XLNet [17] | ELECTRA [18] | RoBERTa [19] | |||
| Audio-Snips | 0.85 | 0.15 | 98.62 | 97.72 | 98.10 | 98.52 | 97.76 |
| 0.55 | 0.45 | 98.08 | 97.97 | 98.43 | 98.34 | 93.34 | |
| 0.50 | 0.50 | 98.07 | 97.77 | 98.13 | 98.17 | 96.63 | |
| 0.45 | 0.55 | 98.19 | 97.83 | 97.74 | 98.33 | 96.98 | |
| 0.15 | 0.85 | 98.29 | 97.75 | 97.72 | 98.14 | 96.38 | |
| FSC | 0.85 | 0.15 | 98.60 | 98.44 | 98.66 | 98.55 | 98.55 |
| 0.55 | 0.45 | 98.63 | 98.68 | 98.66 | 98.63 | 98.60 | |
| 0.50 | 0.50 | 98.43 | 98.44 | 98.58 | 98.52 | 98.52 | |
| 0.45 | 0.55 | 98.52 | 98.37 | 98.47 | 98.52 | 98.47 | |
| 0.15 | 0.85 | 98.49 | 98.18 | 98.47 | 98.39 | 98.52 | |
| Method (BERT) | Acc (%) | |
|---|---|---|
| Audio-Snips | FSC | |
| 89.77 | 88.81 | |
| 93.78 | 93.06 | |
| 94.28 | 92.51 | |
| 93.81 | 93.01 | |
| 77.92 | 89.61 | |
| 98.26 | 98.63 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-W.; Yoon, H.; Jung, H.-Y. Improved Spoken Language Representation for Intent Understanding in a Task-Oriented Dialogue System. Sensors 2022, 22, 1509. https://doi.org/10.3390/s22041509
Kim J-W, Yoon H, Jung H-Y. Improved Spoken Language Representation for Intent Understanding in a Task-Oriented Dialogue System. Sensors. 2022; 22(4):1509. https://doi.org/10.3390/s22041509
Chicago/Turabian StyleKim, June-Woo, Hyekyung Yoon, and Ho-Young Jung. 2022. "Improved Spoken Language Representation for Intent Understanding in a Task-Oriented Dialogue System" Sensors 22, no. 4: 1509. https://doi.org/10.3390/s22041509
APA StyleKim, J.-W., Yoon, H., & Jung, H.-Y. (2022). Improved Spoken Language Representation for Intent Understanding in a Task-Oriented Dialogue System. Sensors, 22(4), 1509. https://doi.org/10.3390/s22041509