
gRDF: An Efficient Compressor with Reduced Structural Regularities That Utilizes gRePair


Abstract
:1. Introduction
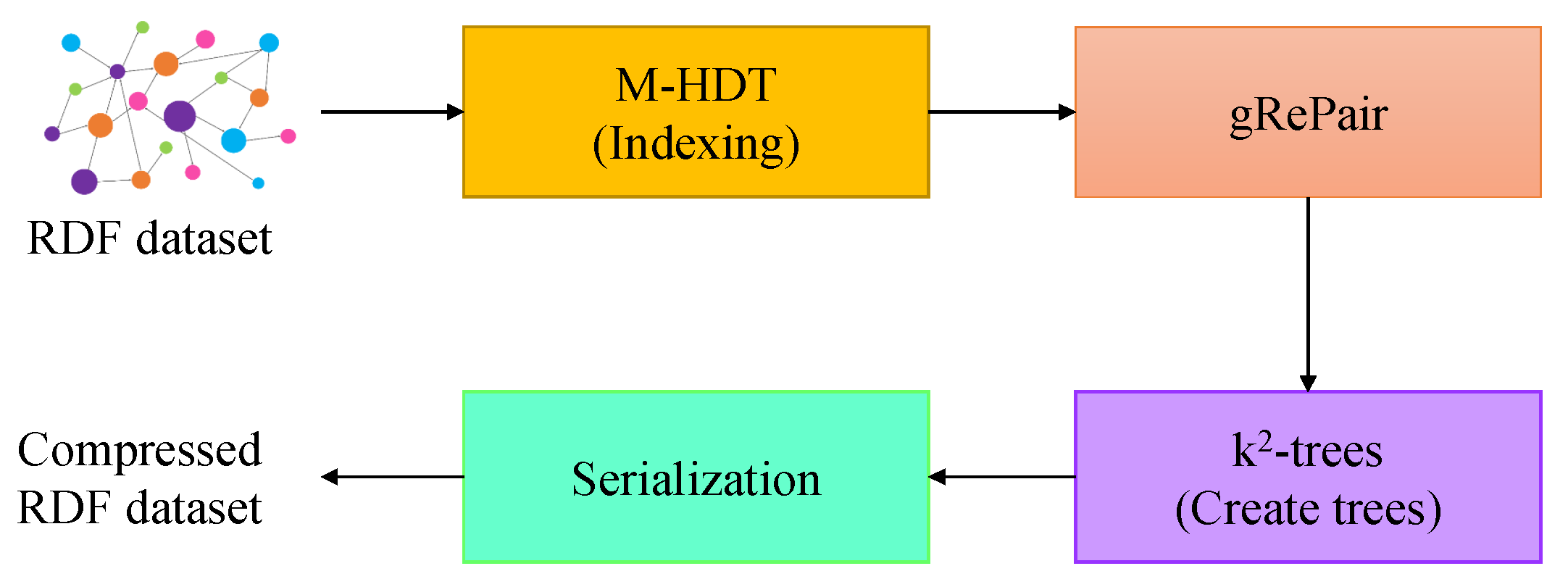
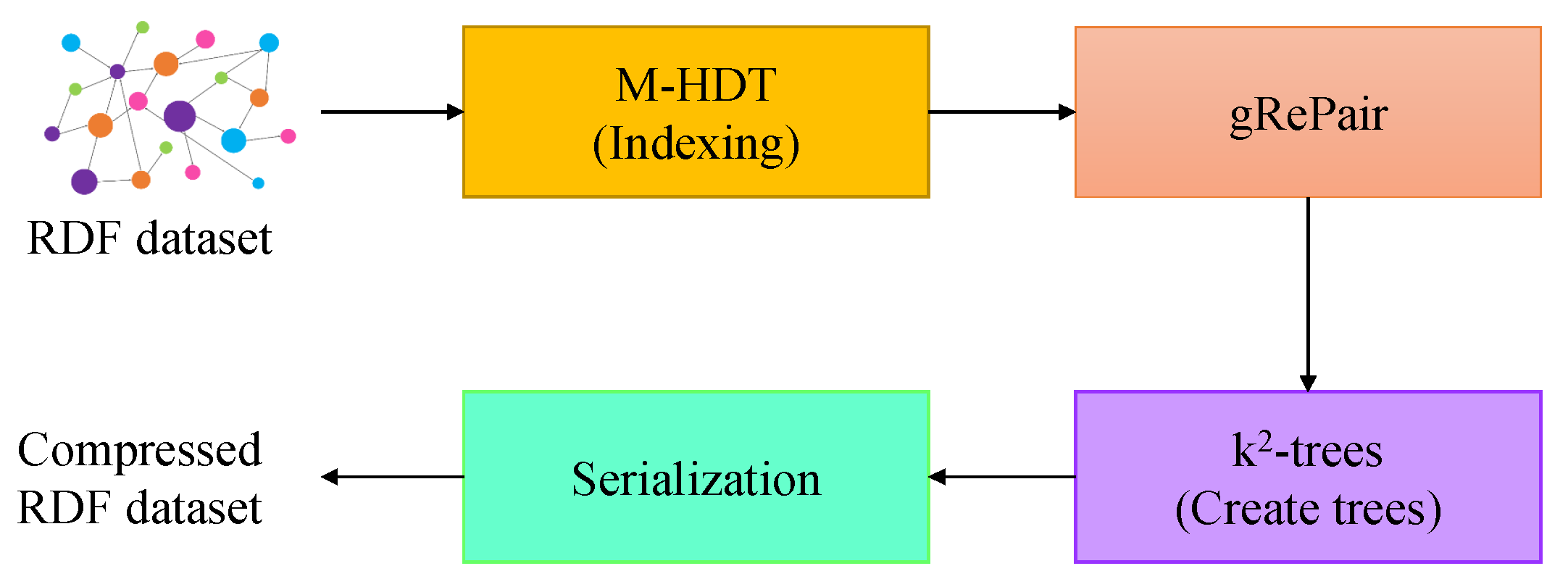
- We improve the performance of HDT by introducing modified HDT (M-HDT) to identify and hold predicates and graph patterns. It compresses the RDF dataset by considering the redundancy of the data. Therefore, our proposed scheme can optimize the use of memory space and reduce the loss of the data by employing a single-pass operation in the RDF dataset.
- We employ the gRePair algorithm, which is one of the best graph compression schemes, to the RDF dataset after indexing it by using our proposed M-HDT scheme in our proposed gRDF scheme.
- We store the remaining graph in the -trees. In our proposed scheme, we develop an efficient algorithm for -trees to achieve a more compressed RDF dataset with reduced run time.
- Extensive experiments were carried out to validate the performance in terms of compactness and processing efficiency.
2. Related Work
3. Materials and Methods
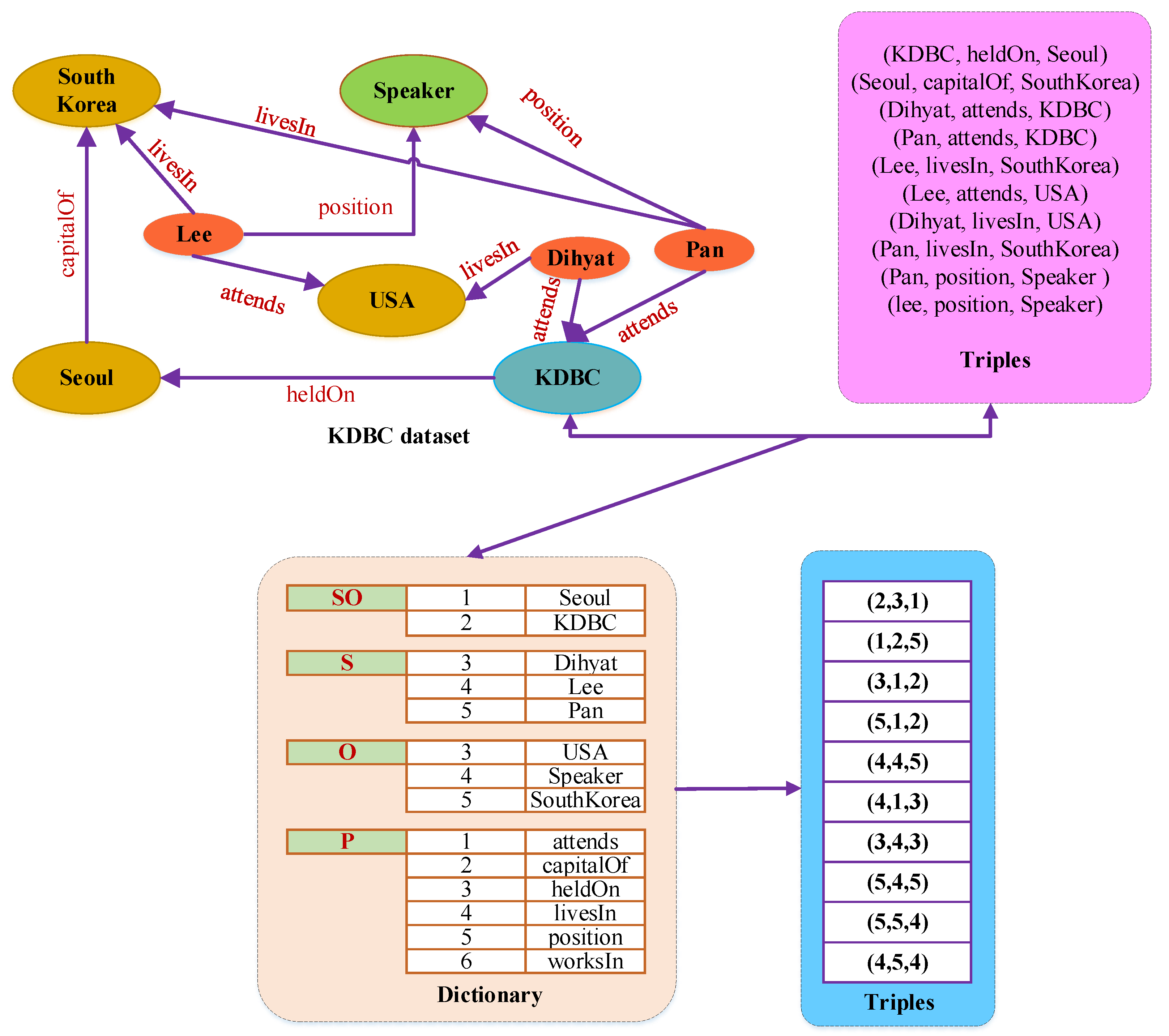
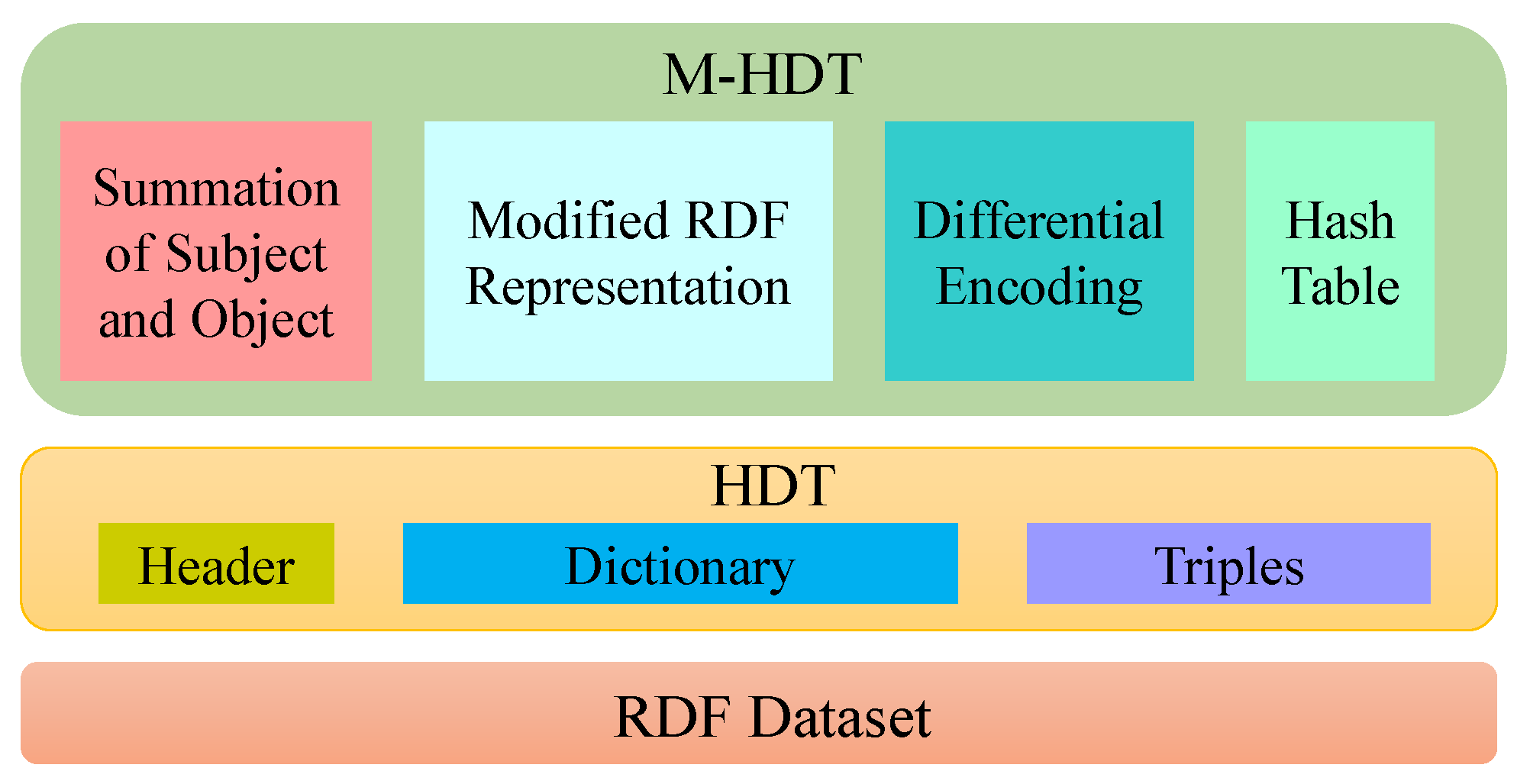
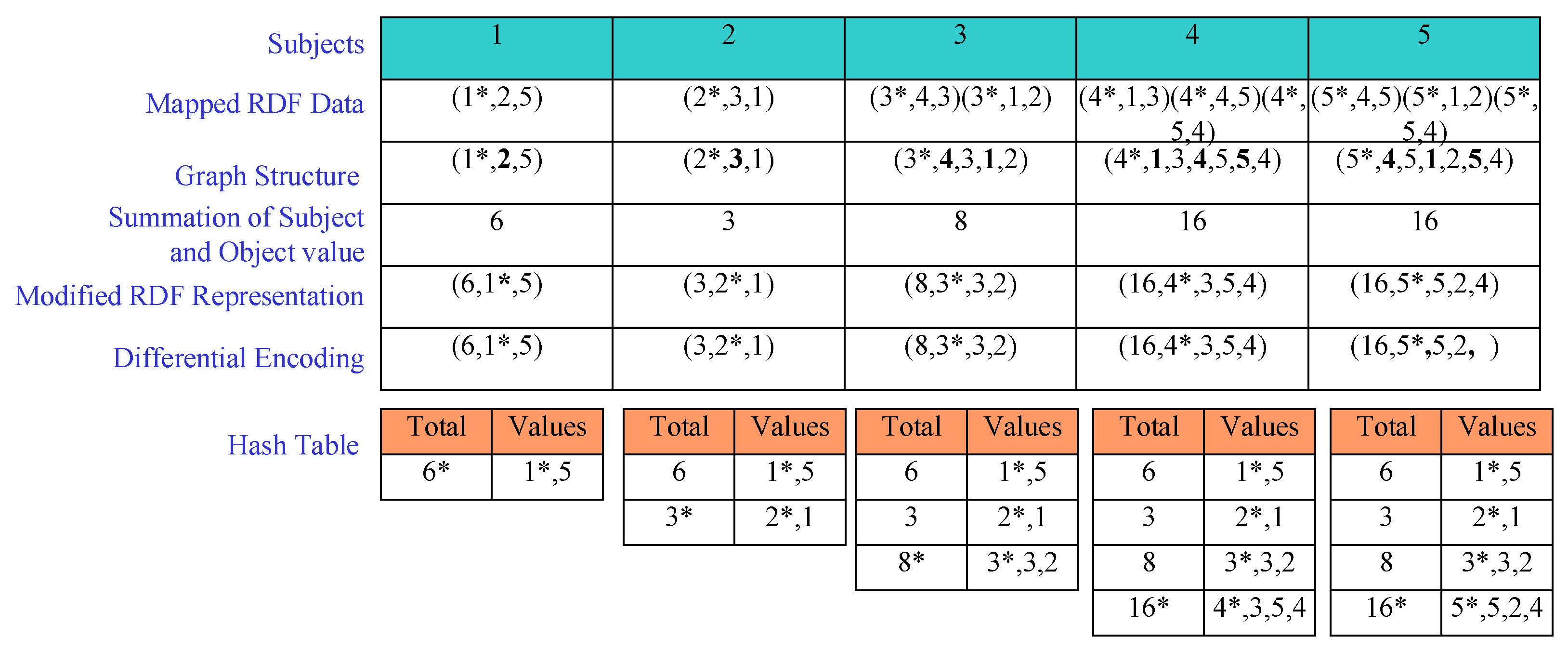
3.1. M-HDT
- Negative differential operation. It keeps the elements of A by replacing the elements that are similar to B. These similar elements are represented by the empty string by using the following equation:whereThus, if and then .
- Positive differential operation. It keeps the elements of A that are not empty. In other cases, it returns the elements having similar indexes to A from B. The mathematical representation of the positive differential operation is depicted as follows:whereFor example, and then .
| Algorithm 1: M-HDT algorithm |
| Input: RDFTriple(T) Output: CompressedHashTable(CHT) 1: CHT (graphPattern(GP), Objectlist) 2: foreach Graph ∈ T 3: GP. construct 4: GraphN ← GBV + Graph. subject + Graph. objects 5: if GP ∈ CHT then 6: PreviuosGraph ← CHT. get (GP) 7: CHT. put (GP, GraphN) 8: GraphN ← GraphN-PreviousGraph 9: else 10: HT. put (GP, GraphN) 11: end if 12: return GraphN |
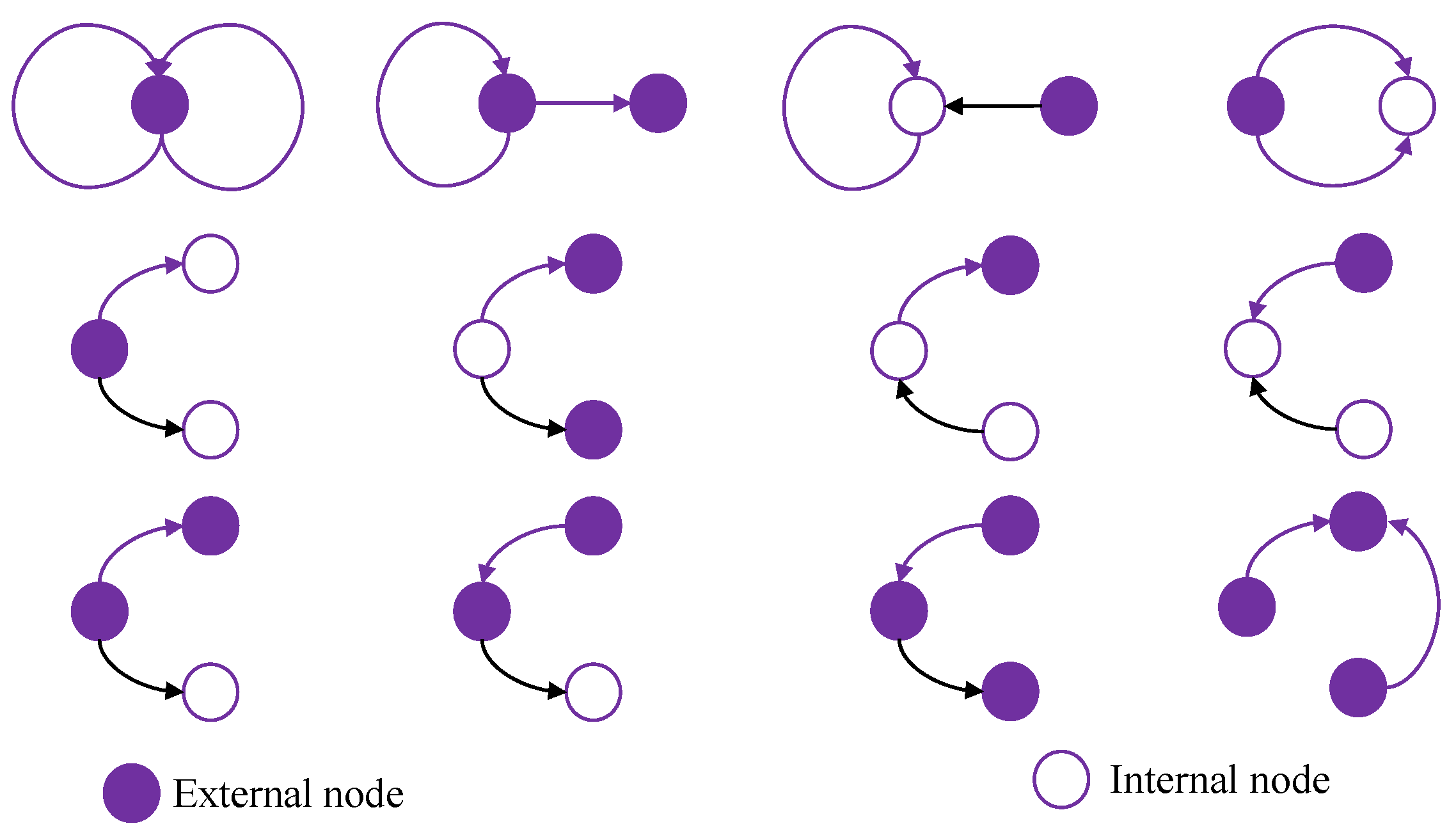
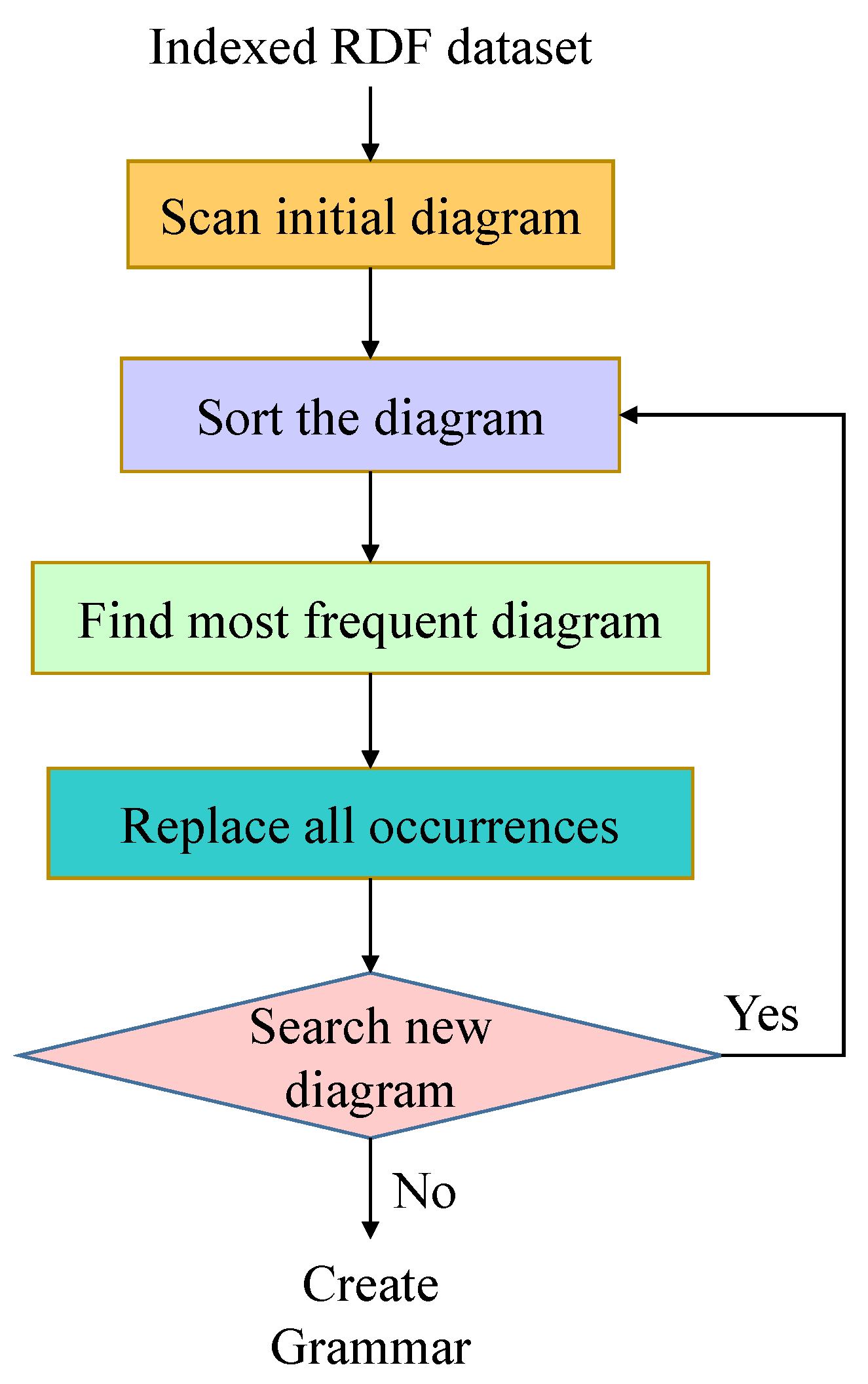
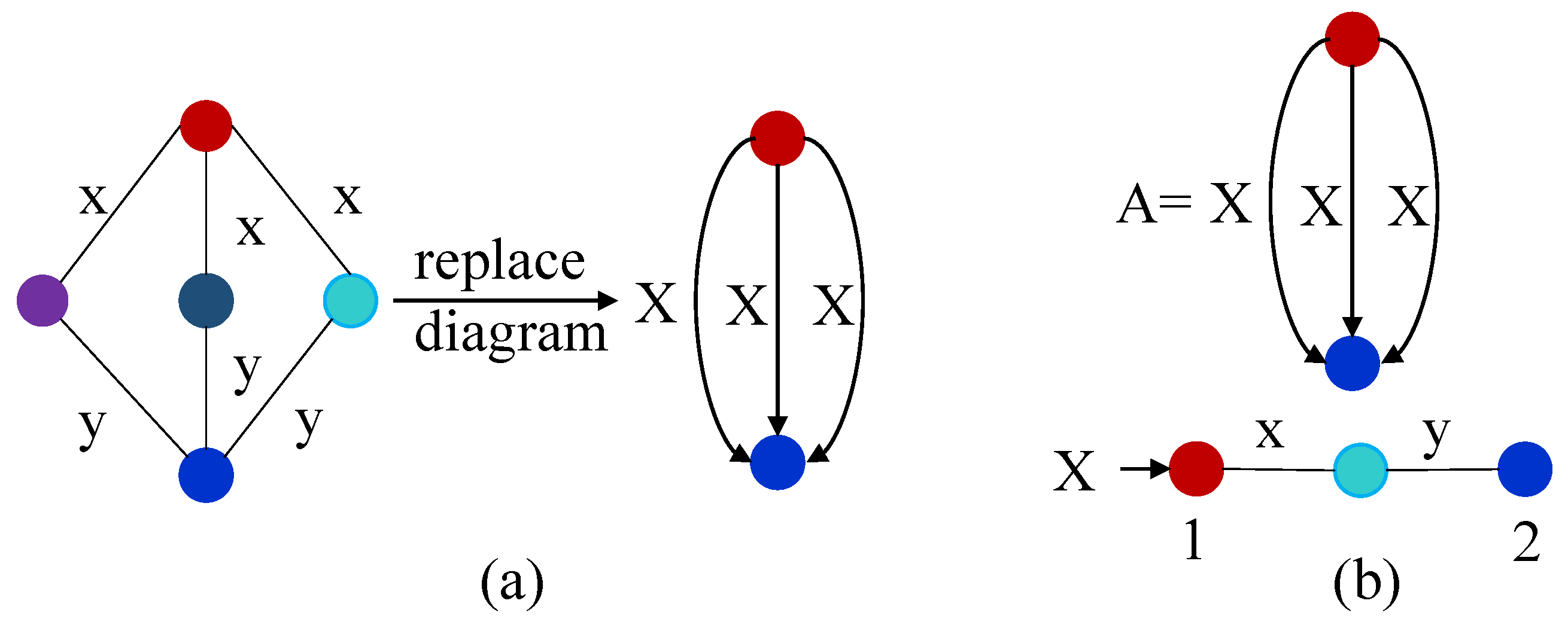
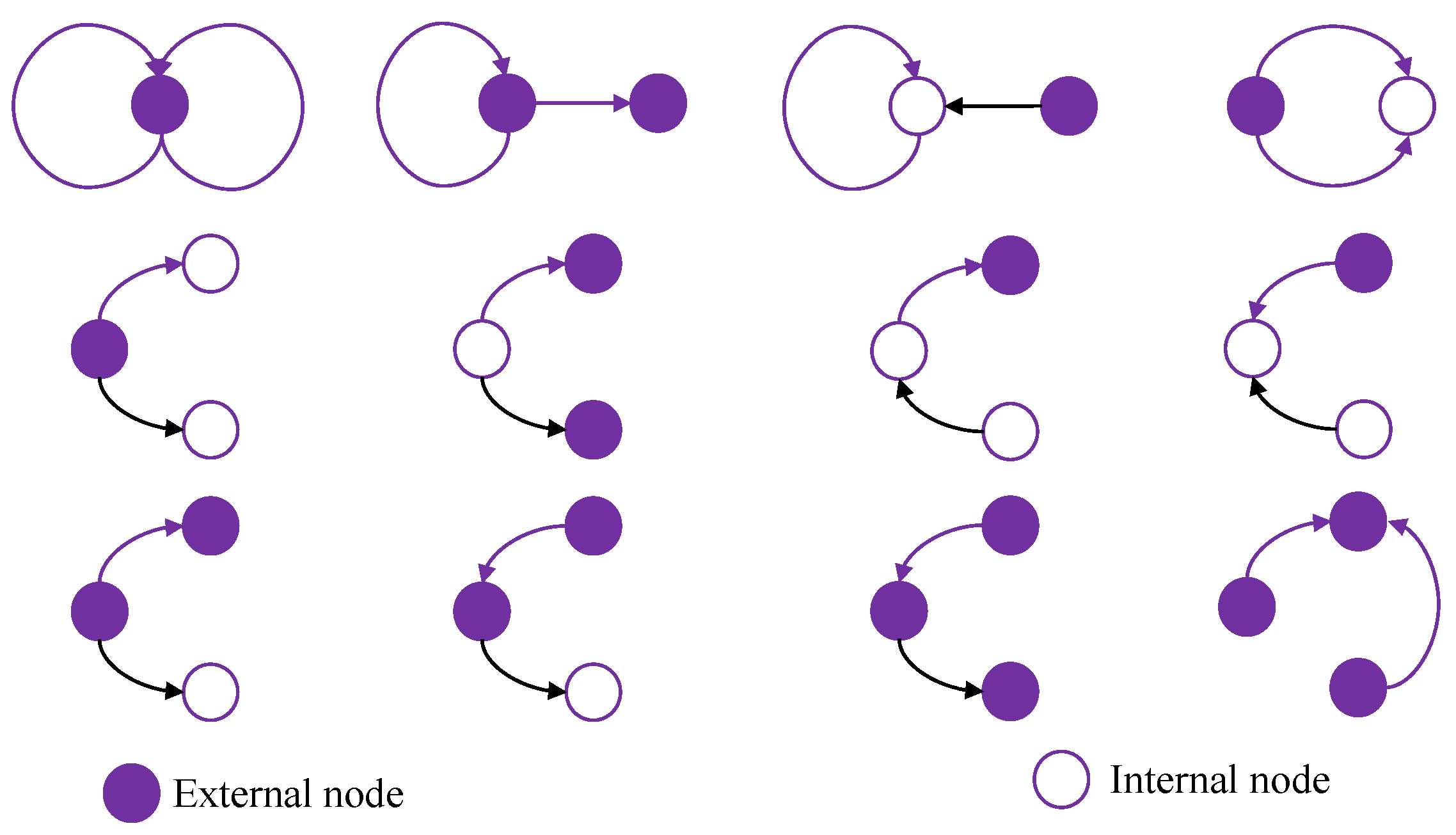
3.2. gRePair
| Algorithm 2: Replacement of the occurrences in the gRePair algorithm |
| Input: Output: 1: Index of all the occurrences that are not overlapped for each diagram, in 2: while do 3: Select a diagram that is most frequent, 4: Replace each occurrence at by a new edge in 5: Occurrence list update 6: end while 7: return |
3.3. -Trees
- First quadrant: to .
- Second quadrant: to .
- Third quadrant: to .
- Fourth quadrant: to .
| Algorithm 3: Path creation and merging algorithm of -trees |
| Input: Matrix N, int m, k Output: list of paths 1: a1 = 0, b1 = 0, a2 = , b2 = 2: root = new () 3: presentNode = root 4: for Point x: N.getPoints() do 5: Q = getQuadrant(x, a1, b1, a2, b2) 6: C = new () 7: presentNode.set(Q,C) 8: presentNode = C 9: shrinkBoundaries(a1, b1, a2, b2, Q) 10: Map(int,) = map 11: if m == k OR == null then 12: return 13: for C:.getC() do 14: map.get(k).add(C) 15: for C:.getC() do 16: merge(C, map, k + 1, m) 17: return map |
3.4. Serialization
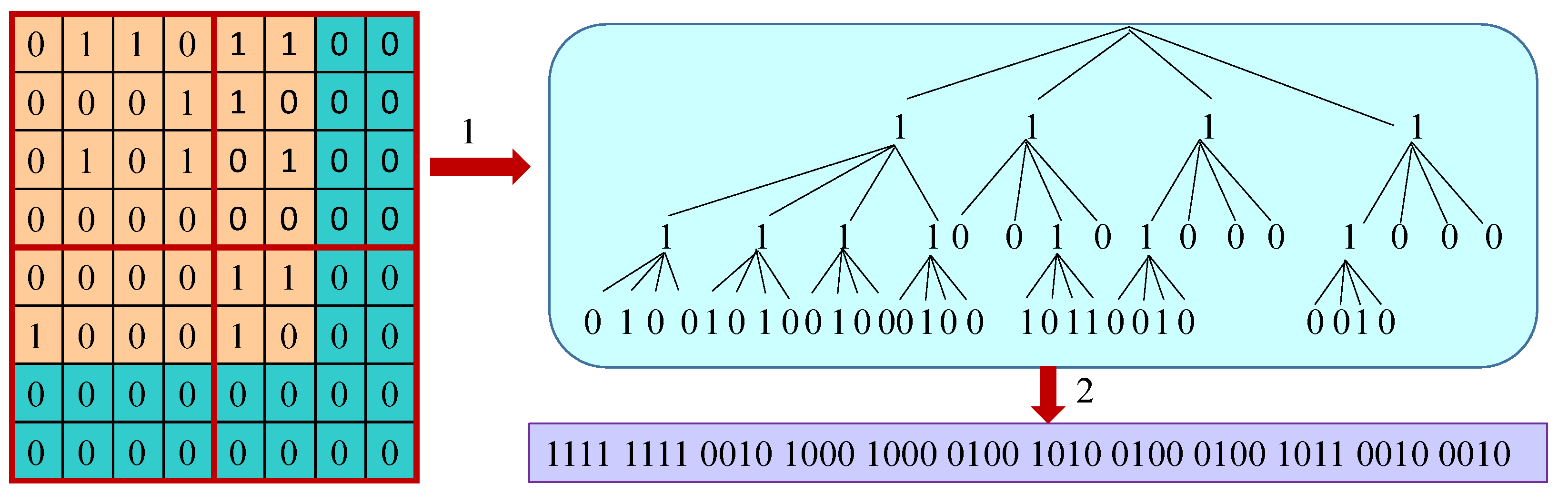
- Start graph. Our system serializes the start graph according to the sequence of -trees. Every tree is preceded by its edge label ID (4 bytes). One bit is used to represent each tree node. Therefore, the system serializes the tree from the root to the leaf according to the sequence of bits denoted by its nodes. If there is an uneven number of nodes present in the tree, the system uses zero to pad the last byte. An example of serialization is shown in Figure 8, where we can use only 6 bytes to store the whole tree.
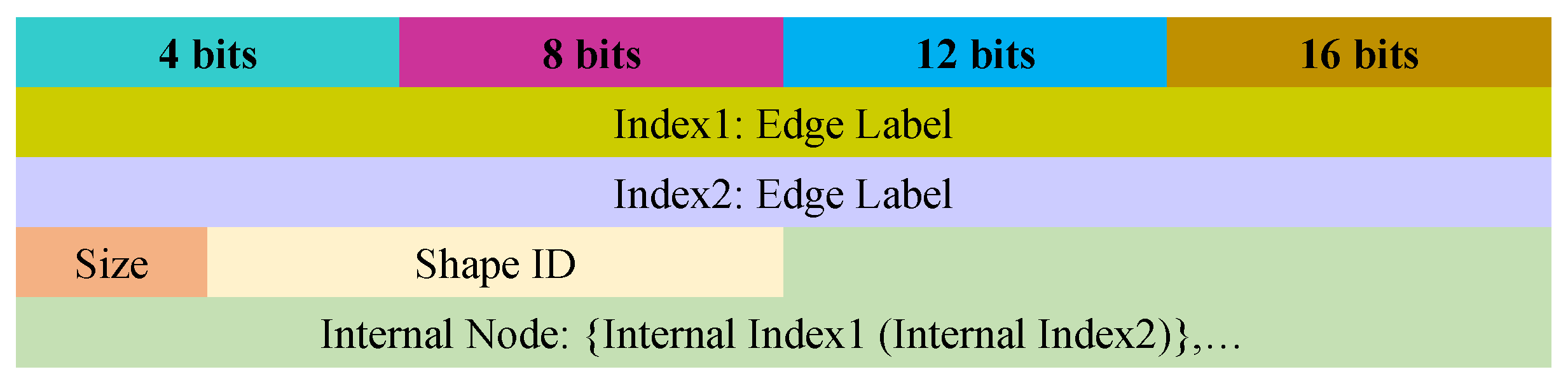
- Diagram. Our system serializes the diagram to reduce the size of the graph according to Figure 9. It consists of two indexes of edge labels. The IDs of the edge label denote the diagrams or properties ID that correspond to that edge label. For employing in the single internal node IDs and decoding the bytes number, our system uses two bits for the size flag. However, the diagrams shape ID is stored into the shape ID which consists of 6 bits. The diagrams shape can be one of the shapes among 33 different shapes. Moreover, the IDs of the internal nodes that occur in the diagram are stored in the internal node of Figure 9. The diagrams’ occurrence IDs are sorted according to the external node IDs. In addition to that, the mapping of the individual occurrences of the diagram and the internal nodes are implicitly sorted without occupying further space.
3.5. Decompression
4. Discussion
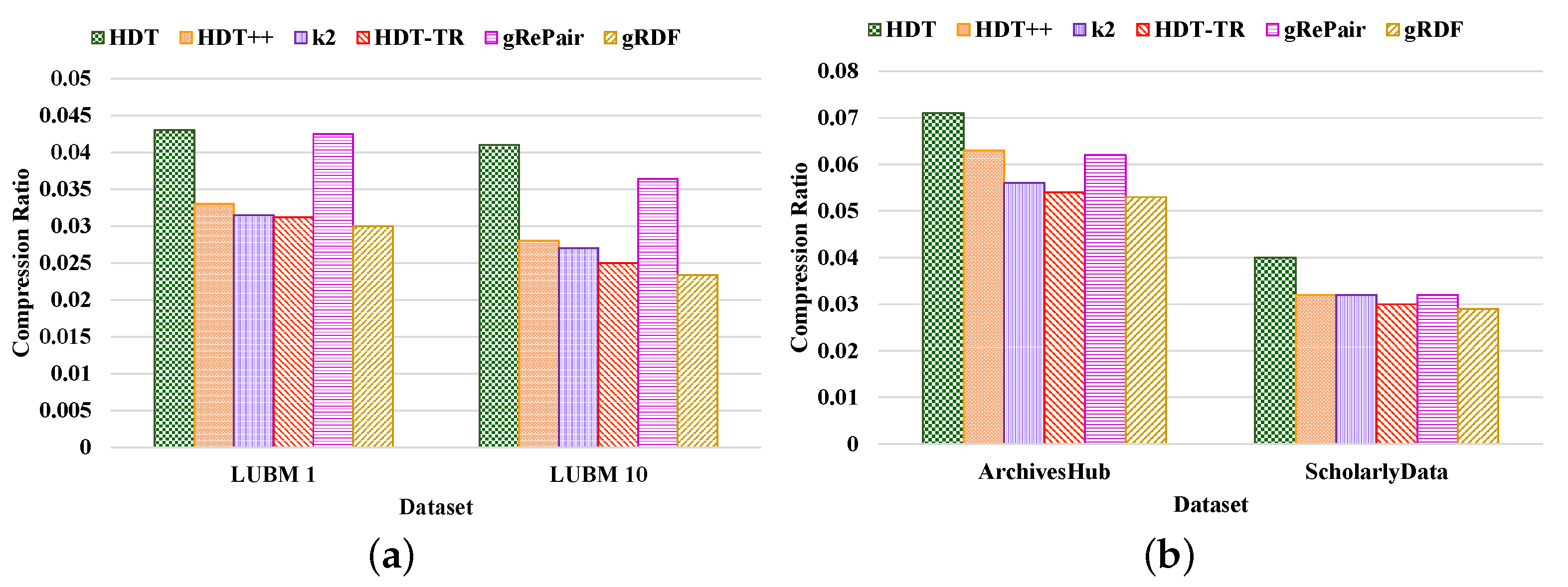
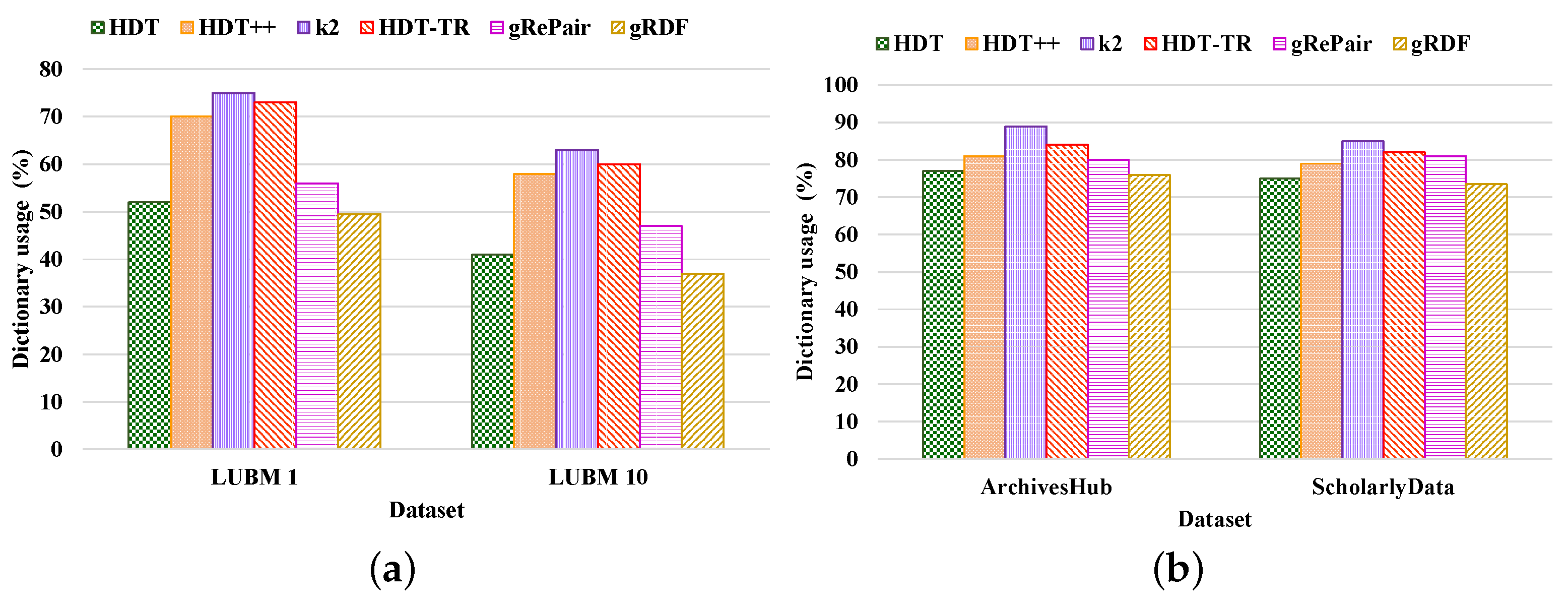
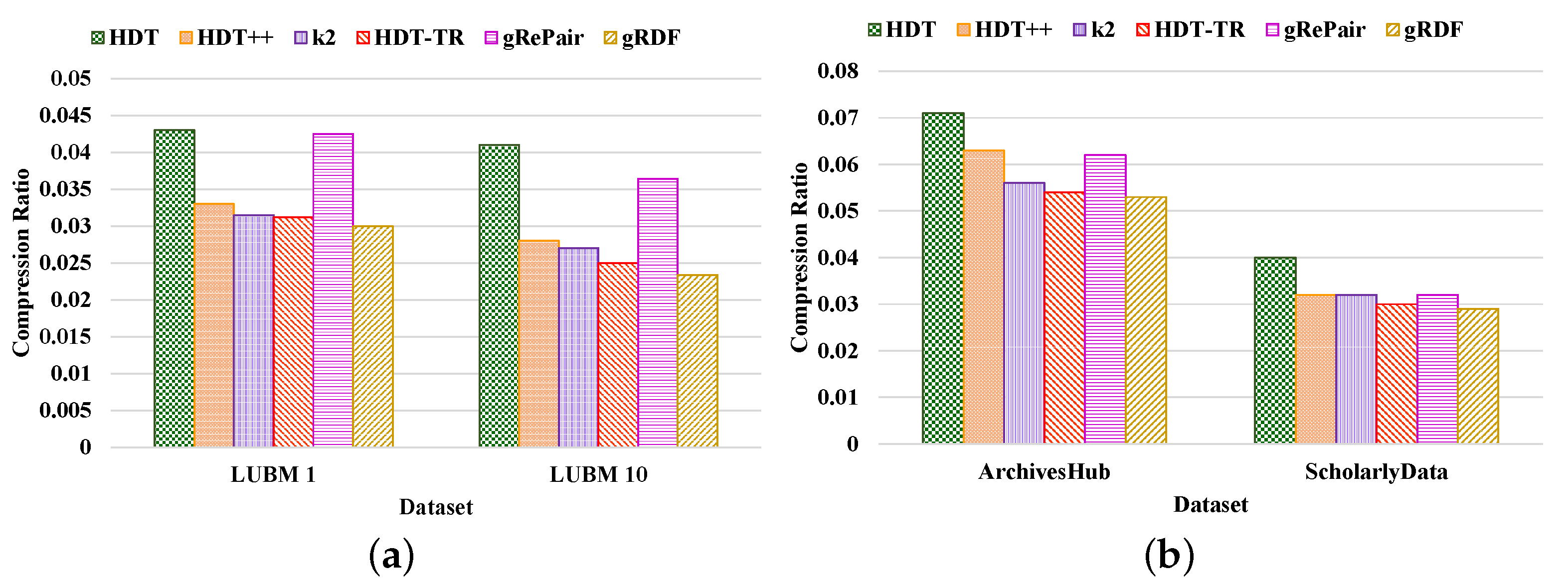
- Compactness Results. We compared the performance of our proposed system with the existing HDT [7], HDT++ [18], -trees [9], RDF-TR [8], and gRePair [21] techniques for compact RDF serialization to analyze the efficiency of our proposed system. Figure 10 shows the compression ratio for different datasets compressed by the existing state-of-the-art techniques and our proposed system. The compression ratio measures the ratio of the number of triples that remain in the dataset after compression to the total number of triples. Therefore, a lower compression ratio indicates better performance. The figure proves that our proposed system achieves a better compression ratio than the other techniques. For example, our proposed system has achieved approximately 36.42%, 12.45%, 8.71%, 4.98%, and 32.31%; and 26.12%, 13.68%, 6.81%, 2.38%, and 12.76% better compression ratio than the existing HDT, HDT++, -trees, RDF-TR, and gRePair schemes in the case of LUBM datasets and real-world datasets, respectively (Figure 10a). On the other hand, our system has approximately 30.23%, 9.09%, 4.76%, 3.84%, and 29.41% better compression ratio when using LUBM 1 dataset and 42.92%, 16.42%, 13.33%, 6.4%, and 35.71% better compression ratio when using LUBM 10 dataset than the existing HDT, HDT++, -trees, RDF-TR, and gRePair schemes (Figure 10a). In addition to that, our system also has approximately 25.35%, 15.87%, 5.35%, 1.85%, and 14.51% better compression ratio when using ArchivesHub dataset and 27.5%, 9.37%, 8.98%, 3.33%, and 9.12% better compression ratio when using ScholarlyData dataset than the existing HDT, HDT++, -trees, RDF-TR, and gRePair schemes (Figure 10b). This is because our proposed system can discover and remove the structural redundancies of the datasets before compressing the dataset efficiently. In addition to that, the hash table in the M-HDT can detect, hold predicates, and graph patterns to optimize the memory space usages. On the other hand, we have received the same dataset size after decompression by using our proposed scheme; this means that our proposed gRDF scheme does not lose any data during compression. Furthermore, we have also analyzed the percentage of gain in the compression ratios provided by our proposed gRDF scheme with respect to the best performing exiting scheme for various datasets [37]. From Figure 10, we have come to know that the RDF-TR scheme performs better among the existing schemes for all the experimented datasets. Therefore, our proposed gRDF scheme outperforms RDF-TR. After analyzing Figure 10a, we can conclude that for LUBM 1 and LUBM 10 datasets, our proposed scheme has achieved 3.84% and 6.4% gain. On the other hand, our proposed gRDF scheme has achieved 1.85% and 3.33% gain for ArchivesHub and ScholarlyData datasets, which is evaluated from Figure 10b.Then, we measured the space required to store the compressed dictionary in terms of the total size of the compressed dataset, which is shown in Figure 11. The dictionary replaces long terms of the RDF triples to the short IDs along with their references. It enormously compresses the RDF datasets as well as elevates the issues of scalability. From this figure, we can observe that most of the space used by the compared state-of-the-art techniques and our proposed scheme is consumed by the dictionary. The less the space used by the dictionary leads, the better the compression ratio. From this figure, we can observe that our proposed system can use the dictionary much better than others. For example, the average size of the dictionary of our proposed scheme in terms of all the real-world datasets is at approximately 75%, which is much better than other schemes (Figure 11b). Moreover, the average dictionary size of our system is approximately 1.29%, 6.17%, 14.60%, 9.52%, and 5.00%; 2.00%, 6.96%, 13.52%, 10.36%, and 9.25% better than the existing HDT, HDT++, -trees, RDF-TR, and gRePair schemes in terms of ArchivesHub and ScholarlyData dataset (Figure 11b). In addition to that, the average dictionary size of our proposed system is approximately 4.80%, 29.28%, 34.00%, 32.19%, and 11.60%; 9.75%, 36.20%, 41.26%, 38.33%, and 21.27% better than the existing HDT, HDT++, -trees, RDF-TR, and gRePair schemes in terms of LUBM 1 and LUBM 10 dataset (Figure 11a). This is because our proposed M-HDT can store the hash table in a compressed form by removing the frequent patterns of the RDF dataset. Moreover, the triples in the RDF can be represented in the star pattern and trees which are compressed well by using gRePair because during the replacement of the occurrences, it reduces the edge number in half. This saves processing resources and enables larger size dictionaries to be managed in a fixed main memory. However, we have also analyzed the percentage of gain in the dictionary size achieved by the proposed gRDF scheme in terms of best performing existing scheme among various datasets. Therefore, after analyzing Figure 11, we have come to know that the dictionary of HDT uses much less space among other existing schemes. However, the gain of our proposed scheme is 4.80% and 9.75% for LUBM 1 and LUBM 10; and 1.29% and 2% for ArchivesHub and ScholarlyData datasets (Figure 11a,b).
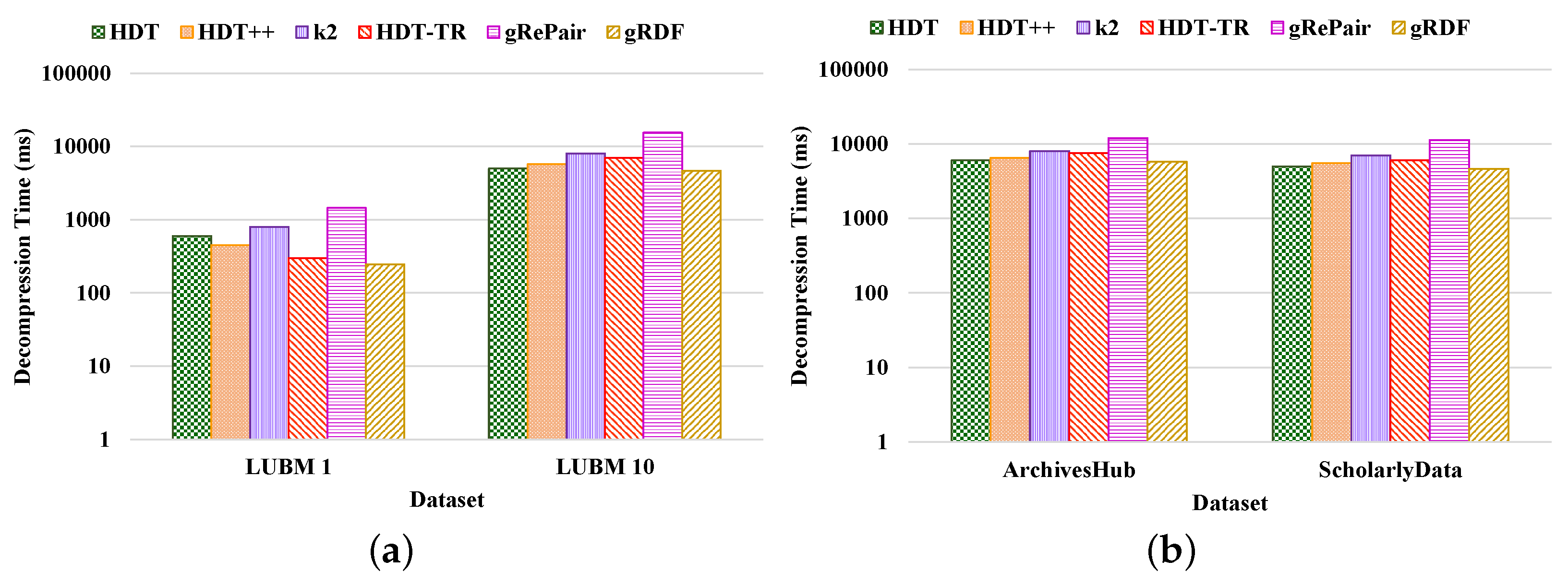
- Processing efficiency. We have analyzed the compression and decompression time of our proposed scheme in terms of the various datasets and compared the performance with respect to the state-of-the-art techniques. From Figure 12 and Figure 13, we can observe that our proposed gRDF scheme has better compression and decompression time than the other state-of-the-art schemes. This is because of the better dealing capacity for the redundant structure of the dataset as well as the use of simple data structure for identifying and building graph patterns. Moreover, gRePair has the capability to execute the finite automata without prior decompression in one pass by using a speed-up algorithm [21]. For example, our proposed gRDF scheme compressed the real-world datasets at approximately 4.51%, 17.77%, 51.31%, 37.02%, and 57.83% times faster than the existing HDT, HDT++, -trees, RDF-TR, and gRePair schemes, respectively (Figure 12b). Moreover, it decompressed the real-world datasets at approximately 5.68%, 13.54%, 30.83%, 23.14%, and 55.28% times faster than the existing HDT, HDT++, -trees, RDF-TR, and gRePair schemes, respectively (Figure 13b). On the other hand, after observing Figure 12 and Figure 13, we can observe that the difference between the compression and decompression time of our proposed scheme is larger than the other existing schemes when using the LUBM 1 dataset. In future work, we will try to resolve this issue.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, H.; Balakrishnan, A.; Eric, M.; Liang, P. Learning symmetric collaborative dialogue agents with dynamic knowledge graph embeddings. arXiv 2017, arXiv:1704.07130. [Google Scholar]
- Young, T.; Cambria, E.; Chaturvedi, I.; Zhou, H.; Biswas, S.; Huang, M. Augmenting end-to-end dialogue systems with commonsense knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Berant, J.; Chou, A.; Frostig, R.; Liang, P. Semantic parsing on freebase from question-answer pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1533–1544. [Google Scholar]
- Lopez, V.; Unger, C.; Cimiano, P.; Motta, E. Evaluating question answering over linked data. J. Web Semant. 2013, 21, 3–13. [Google Scholar] [CrossRef] [Green Version]
- Singhal, A. Introducing the Knowledge Graph: Things, Not Strings. Official Google Blog. 16 May 2012. Available online: https://blog.google/products/search/introducing-knowledge-graph-things-not/ (accessed on 16 February 2022).
- Fernández, J.D.; Gutierrez, C.; Martínez-Prieto, M.A. RDF compression: Basic approaches. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 1091–1092. [Google Scholar]
- Fernández, J.D.; Martínez-Prieto, M.A.; Gutierrez, C. Compact representation of large RDF data sets for publishing and exchange. In The Semantic Web—ISWC 2010, Proceedings of the International Semantic Web Conference, Shanghai, China, 7–11 November 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 193–208. [Google Scholar]
- Hernández-Illera, A.; Martínez-Prieto, M.A.; Fernández, J.D. RDF-TR: Exploiting structural redundancies to boost RDF compression. Inf. Sci. 2020, 508, 234–259. [Google Scholar] [CrossRef]
- Álvarez-García, S.; Brisaboa, N.R.; Fernández, J.D.; Martínez-Prieto, M.A. Compressed k2-triples for full-in-memory RDF engines. arXiv 2011, arXiv:1105.4004. [Google Scholar]
- Iannone, L.; Palmisano, I.; Redavid, D. Optimizing RDF storage removing redundancies: An Algorithm. In Innovations in Applied Artificial Intelligence, Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Bari, Italy, 22–24 June 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 732–742. [Google Scholar]
- Joshi, A.K.; Hitzler, P.; Dong, G. Logical linked data compression. In The Semantic Web: Semantics and Big Data, Proceedings of the Extended Semantic Web Conference, Montpellier, France, 26–30 May 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 170–184. [Google Scholar]
- Sultana, T.; Lee, Y.K. Expressive Rule Pattern Based Compression with Ranking in Horn Rules on RDF Style KB. In Proceedings of the 2021 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Korea, 17–20 January 2021; pp. 13–19. [Google Scholar]
- Grimm, S.; Wissmann, J. Elimination of redundancy in ontologies. In The Semantic Web: Research and Applications, Proceedings of the Extended Semantic Web Conference, Crete, Greece, 29 May–2 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 260–274. [Google Scholar]
- Beckett, D.; McBride, B. RDF/XML syntax specification (revised). W3C Recomm. 2004, 10, 1–56. Available online: https://www.w3.org/TR/2003/WD-rdf-syntax-grammar-20031010/ (accessed on 16 February 2022).
- Yuan, P.; Liu, P.; Wu, B.; Jin, H.; Zhang, W.; Liu, L. TripleBit: A fast and compact system for large scale RDF data. Proc. Vldb Endow. 2013, 6, 517–528. [Google Scholar] [CrossRef]
- Martínez-Prieto, M.A.; Fernández, J.D.; Cánovas, R. Querying RDF dictionaries in compressed space. ACM SIGAPP Appl. Comput. Rev. 2012, 12, 64–77. [Google Scholar] [CrossRef]
- Fernández, J.D.; Martínez-Prieto, M.A.; Gutiérrez, C.; Polleres, A.; Arias, M. Binary RDF representation for publication and exchange (HDT). J. Web Semant. 2013, 19, 22–41. [Google Scholar] [CrossRef]
- Hernández-Illera, A.; Martínez-Prieto, M.A.; Fernández, J.D. Serializing RDF in compressed space. In Proceedings of the 2015 Data Compression Conference, Snowbird, UT, USA, 7–9 April 2015; pp. 363–372. [Google Scholar]
- Sultana, T.; Qudus, U.; Umair, M.; Kim, T.; Morshed, M.G.; Lee, Y.K. Efficient Frequent Pattern Management and Compression System in Multiple Named Graphs. In Proceedings of the KIISE Korea Computer Congress 2020 (KCC 2020), Busan, Korea, 2–4 July 2021; pp. 38–40. [Google Scholar]
- Brisaboa, N.R.; Ladra, S.; Navarro, G. k2-trees for compact web graph representation. In String Processing and Information Retrieval, Proceedings of the International Symposium on String Processing and Information Retrieval, Saariselkä, Finland, 25–27 August 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 18–30. [Google Scholar]
- Maneth, S.; Peternek, F. Grammar-based graph compression. Inf. Syst. 2018, 76, 19–45. [Google Scholar] [CrossRef] [Green Version]
- Sultana, T.; Lee, Y.K. Employing Graph Compression Technique for Efficiently Compressing RDF Knowledge Graphs. In Proceedings of the Korean Database Conference 2021 (KDBC 2021), Daejeon, Korea, 12–13 November 2021; pp. 21–24. [Google Scholar]
- Álvarez-García, S.; Brisaboa, N.; Fernández, J.D.; Martínez-Prieto, M.A.; Navarro, G. Compressed vertical partitioning for efficient RDF management. Knowl. Inf. Syst. 2015, 44, 439–474. [Google Scholar] [CrossRef]
- Martínez-Prieto, M.A.; Fernández, J.D.; Cánovas, R. Compression of RDF dictionaries. In Proceedings of the 27th Annual ACM Symposium on Applied Computing, Trento, Italy, 26–30 March 2012; pp. 340–347. [Google Scholar]
- Brisaboa, N.R.; Ladra, S.; Navarro, G. Compact representation of web graphs with extended functionality. Inf. Syst. 2014, 39, 152–174. [Google Scholar] [CrossRef] [Green Version]
- Brisaboa, N.R.; Cerdeira-Pena, A.; Farina, A.; Navarro, G. A compact RDF store using suffix arrays. In String Processing and Information Retrieval, Proceedings of the International Symposium on String Processing and Information Retrieval, London, UK, 1–4 September 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 103–115. [Google Scholar]
- Swacha, J.; Grabowski, S. OFR: An Efficient Representation of RDF Datasets. International Symposium on Languages, Applications and Technologies; Springer: Berlin/Heidelberg, Germany, 2015; pp. 224–235. [Google Scholar]
- Sadakane, K. New text indexing functionalities of the compressed suffix arrays. J. Algorithms 2003, 48, 294–313. [Google Scholar] [CrossRef]
- Salomon, D. Data Compression: The complete Reference; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Meier, M. Towards rule-based minimization of RDF graphs under constraints. In Web Reasoning and Rule Systems, Proceedings of the International Conference on Web Reasoning and Rule Systems, Karlsruhe, Germany, 31 October 31–1 November 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 89–103. [Google Scholar]
- Pichler, R.; Polleres, A.; Skritek, S.; Woltran, S. Redundancy elimination on RDF graphs in the presence of rules, constraints, and queries. In Web Reasoning and Rule Systems, Proceedings of the International Conference on Web Reasoning and Rule Systems, Bressanone/Brixen, Italy, 22–24 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 133–148. [Google Scholar]
- Pan, J.Z.; Pérez, J.M.G.; Ren, Y.; Wu, H.; Wang, H.; Zhu, M. Graph pattern based RDF data compression. In Semantic Technology, Proceedings of the Joint International Semantic Technology Conference, Chiang Mai, Thailand, 9–11 November 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 239–256. [Google Scholar]
- Gayathri, V.; Kumar, P.S. Horn-rule based compression technique for RDF data. In Proceedings of the 30th Annual ACM Symposium on Applied Computing, Salamanca, Spain, 13–17 April 2015; pp. 396–401. [Google Scholar]
- Guang, T.; Gu, J.; Huang, L. Detect redundant rdf data by rules. In Database Systems for Advanced Applications, Proceedings of the International Conference on Database Systems for Advanced Applications, Dallas, TX, USA, 16–19 April 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 362–368. [Google Scholar]
- Ding, L.; Finin, T. Characterizing the semantic web on the web. In The Semantic Web—ISWC 2006, Proceedings of the International Semantic Web Conference, Athens, GA, USA, 5–9 November 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 242–257. [Google Scholar]
- Theoharis, Y.; Tzitzikas, Y.; Kotzinos, D.; Christophides, V. On graph features of semantic web schemas. IEEE Trans. Knowl. Data Eng. 2008, 20, 692–702. [Google Scholar] [CrossRef]
- Fernández, N.; Arias, J.; Sánchez, L.; Fuentes-Lorenzo, D.; Corcho, Ó. RDSZ: An approach for lossless RDF stream compression. In The Semantic Web: Trends and Challenges, Proceedings of the European Semantic Web Conference, Crete, Greece, 25–29 May 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 52–67. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Triples | Resources | Classes |
|---|---|---|---|
| LUBM 1 | 100545 | 17209 | 15 |
| LUBM 10 | 1272577 | 207461 | 15 |
| ArchivesHub | 1361815 | 135643 | 46 |
| ScholarlyData | 859840 | 95016 | 46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sultana, T.; Lee, Y.-K. gRDF: An Efficient Compressor with Reduced Structural Regularities That Utilizes gRePair. Sensors 2022, 22, 2545. https://doi.org/10.3390/s22072545
Sultana T, Lee Y-K. gRDF: An Efficient Compressor with Reduced Structural Regularities That Utilizes gRePair. Sensors. 2022; 22(7):2545. https://doi.org/10.3390/s22072545
Chicago/Turabian StyleSultana, Tangina, and Young-Koo Lee. 2022. "gRDF: An Efficient Compressor with Reduced Structural Regularities That Utilizes gRePair" Sensors 22, no. 7: 2545. https://doi.org/10.3390/s22072545
APA StyleSultana, T., & Lee, Y.-K. (2022). gRDF: An Efficient Compressor with Reduced Structural Regularities That Utilizes gRePair. Sensors, 22(7), 2545. https://doi.org/10.3390/s22072545