1. Introduction
Due to their simple mechanical structure and flexible control, skid steering distributed drive vehicles are widely applied in various scenarios, including the construction industry, wheeled robots, agricultural vehicles, military vehicles, and so on. Generally, a skid steering vehicle has four independent driving wheels, forming a redundant actuator system, which delivers remarkable maneuverability and more options for control methods [
1]. With the development of artificial intelligence (AI) technology, some recent research has applied the RL algorithm to the torque distribution of skid steering vehicles, providing new insights into vehicle control mechanisms. In real-world applications, more actuators in a system increases the probability of actuator faults. Therefore, a reasonable FTC method is very important for skid steering vehicles with redundant drive systems.
The types of actuator faults in driving wheels are complex and may include additive faults, stuck-at-fixed-level faults, loss-of-effectiveness, and so on. In addition to the large number of possible faults, certain faults never seen before may occur during operation [
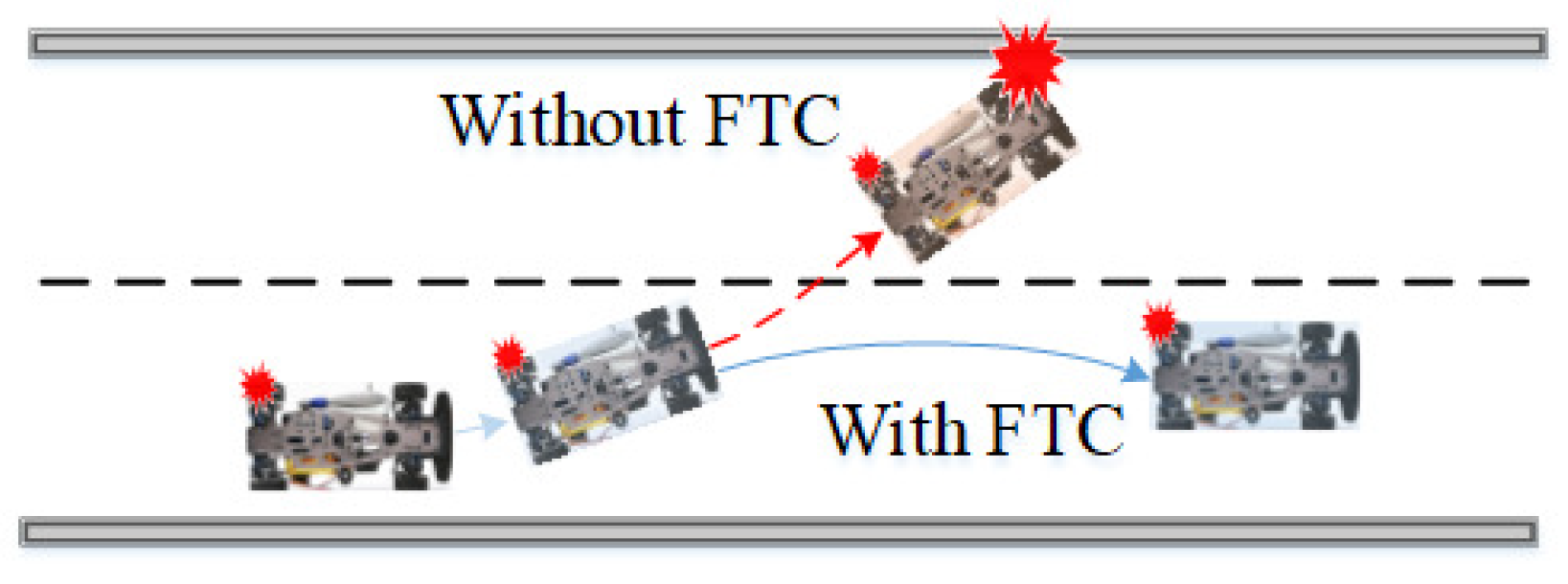
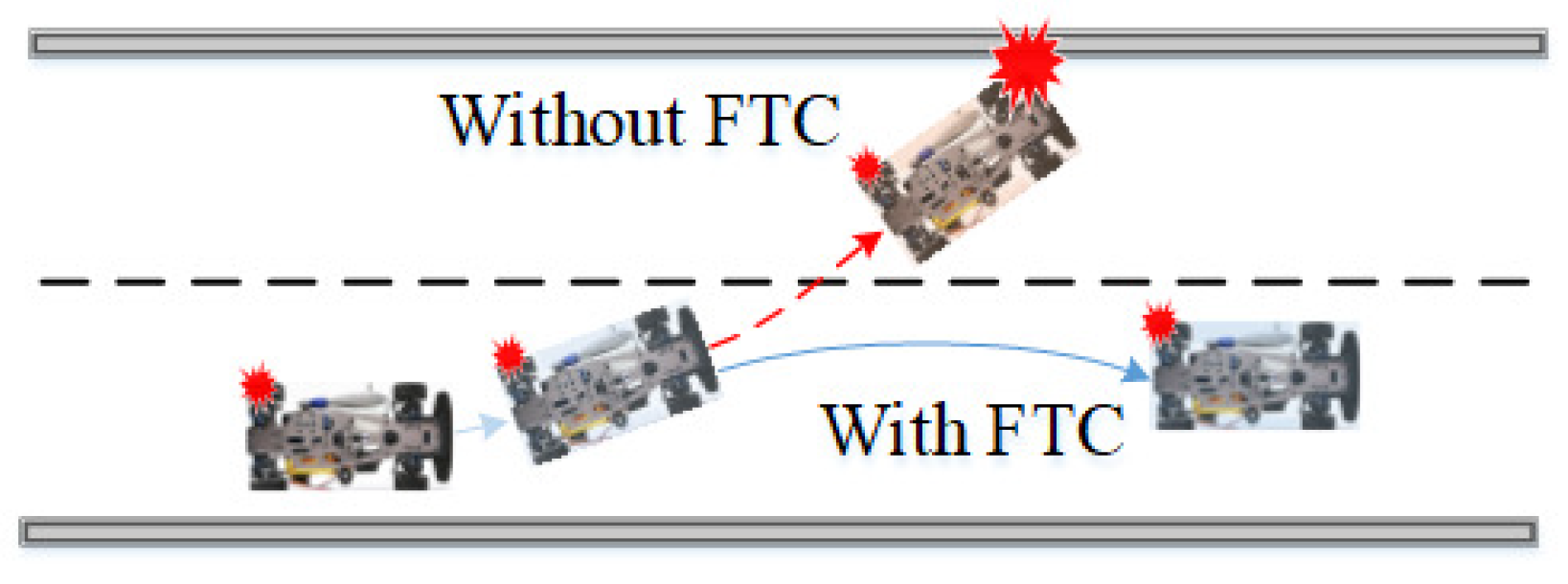
2], causing vehicles to operate in an unstable state or even leading to catastrophic events. For example, assume a skid steering vehicle is operating on the road, as depicted in
Figure 1, when an unexpected fault on the rear left wheel compromises the stability of the vehicle. Without FTC, the vehicle would operate under an instability condition and collide with nearby facilities; conversely, with FTC, the vehicle’s collision risk may be avoided [
3].
To deal with such unforeseen and undesired faults, the controller must quickly learn their models under new runtime conditions and adapt proper torque distribution accordingly. A large variety of conventional methods are applied to guarantee the stability of the faulty vehicle in fault conditions, such as sliding mode control [
4], robust control method [
5], multi-agent control [
6], and so on. These methods require however the explicit knowledge of specific failures and how these changes affect the system’s dynamical model in order to design resilient controllers. Traditional RL models can learn torque distribution policies based on feedback from the environment and have shown better performance than traditional methods [
7]. However, the training mechanism of RL follows a trial-and-error manner; thus, the agent requires a large number of training episodes to learn an efficient strategy. The cost of computational resources and learning time is unacceptable when addressing the FTC problem with skid steering vehicles.
Metalearning is a recent method developed to “learn to learn” by leveraging optimization techniques [
8]. Different from traditional RL, metalearning involves learning an initial parametrized control strategy from multiple relevant tasks, then relies on the obtained strategy to improve its performance on target tasks without training from scratch. Combining metalearning and RL, meta-RL has been widely studied for online FTC of systems [
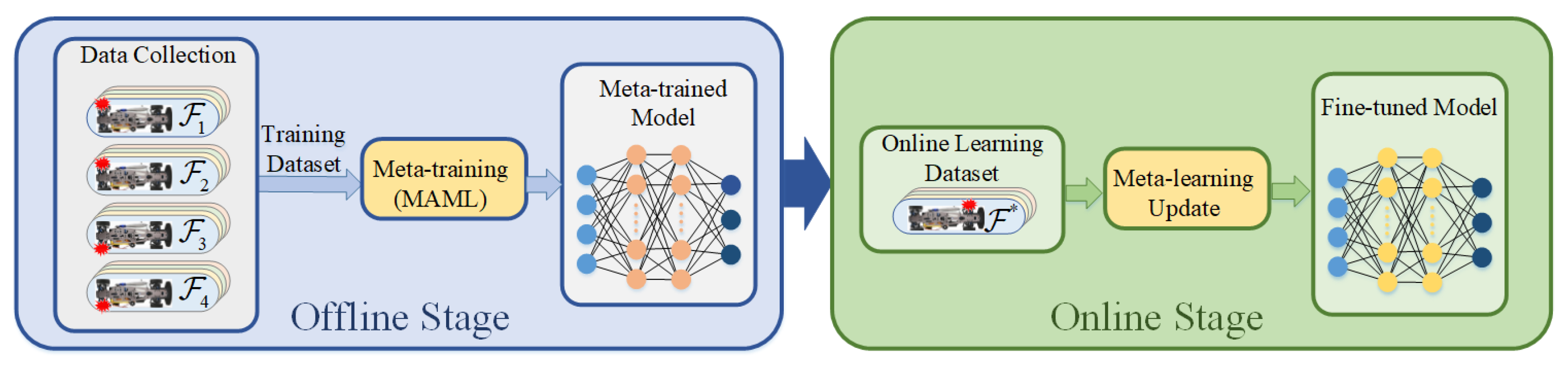
9]. This study, in combination with the DDPG-based torque distribution method, proposes a meta-DDPG-based FTC method for skid steering vehicles so as to improve the tracking performance when an actuator fault occurs. We first design an agent for torque distribution based on the DDPG algorithm; then, we construct an experience replay buffer with various actuator faults and train a metatrained model in the offline stage. Based on the metatrained model, the agent can quickly adapt to the faulty vehicle’s model through a small number of online iterations.
The main contributions of this study are as follows: (1) We develop a driving torque distribution method based on DDPG, which can perform dual-channel control over longitudinal speed and yaw rate. (2) We construct an offline actuator fault dataset—based on this, the meta-DDPG-based FTC method is proposed to quickly adapt to the vehicle’s model with actuator faults and to improve the desired value of tracking performance in the degraded conditions. To the best of our knowledge, this is the first work to deploy the meta-RL paradigm in the FTC of skid steering vehicles.
The remainder of this paper is as follows.
Section 2 introduces related works concerning meta-RL and DDPG. The problem formulation is described in
Section 3.
Section 4 introduces the FTC method based on meta-DDPG, including the agent design of torque distribution and the meta-DDPG training approach.
Section 5 presents the simulation environment and setting. We validate the proposed method with diverse simulation scenarios in
Section 6. Conclusions are provided in
Section 7.
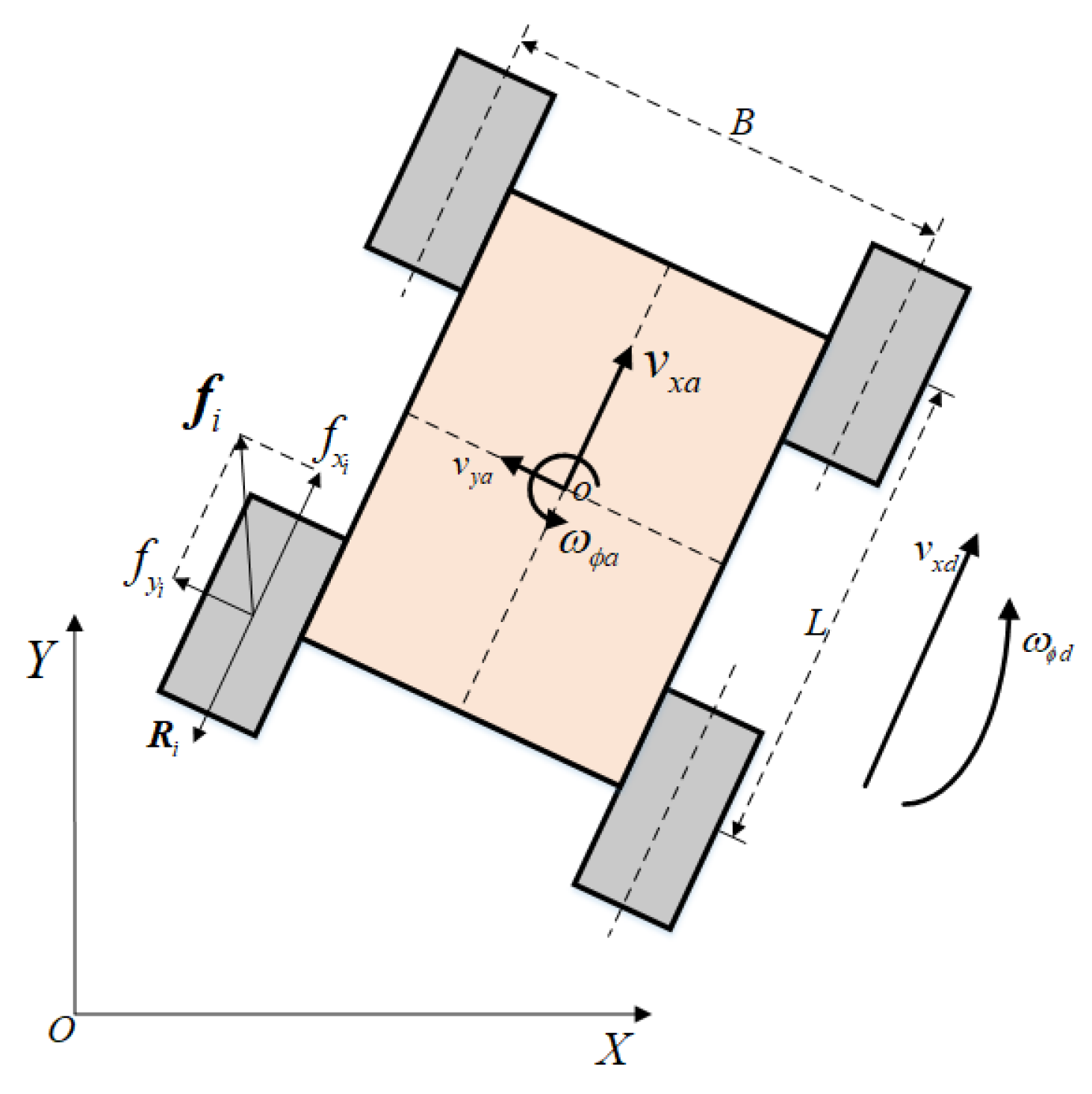
3. Problem Formulation: Meta-RL-Based FTC
In this work, we use MAML as the metalearning approach, which is one of the representative gradient-based meta-RL algorithms. We consider a metalearning model represented by a parameterized function
with parameters
. During metatraining, the model’s parameters
are initialized randomly and updated to
while adapting to fault
:
Metaoptimization is conducted across the faults; then, model parameters are updated according to Equation (
2):
where
and
are hyperparameters for optimization step size.
Our approach mirrors MAML, and the whole procedure of metalearning can be split as two steps: metatraining and metatesting. In MAML, the metatraining samples are randomly selected from a population defining the MDP. These samples are applied to derive intermediate parameters. In this work, we forego the sampling process, but instead, exploit the experience with different actuator faults. In other words, MAML evaluates multiple processes on a single set of parameters. We propose to evaluate a single process on multiple sets of parameters.
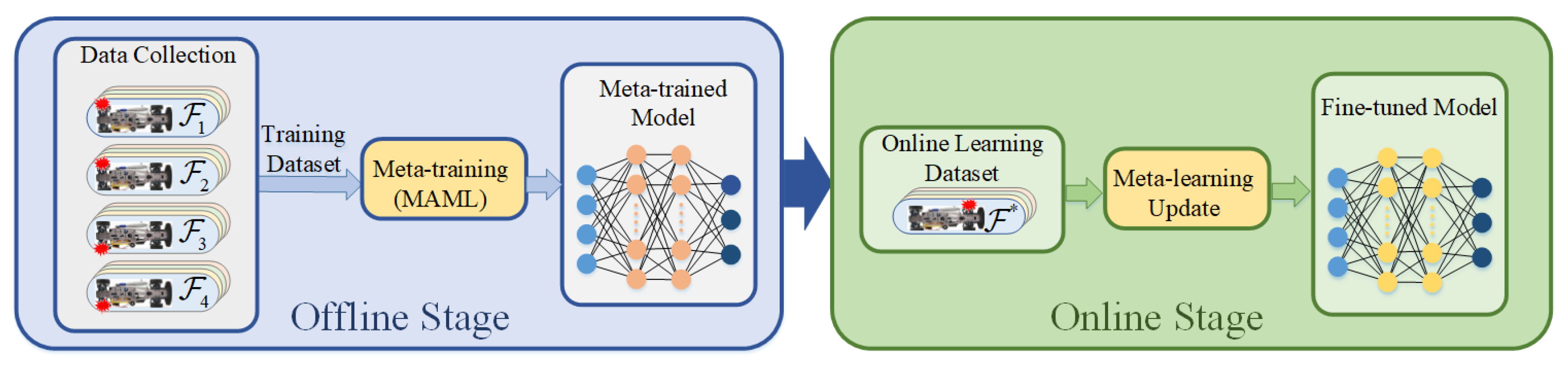
The process of FTC is described as follows: FTC step begins with an abrupt fault, causing a discontinuous change in the process dynamics
. In the aftermath of the fault, the agent continues to interact with
and records the states, actions, and rewards in an online memory buffer
by using its current policy parameters
. Once sufficient interactions are buffered, the offline metatrained model is adapted, obtaining a fine-tuned model with updated parameters
. This fine-tuned model is then used to distribute the driving torque under the actuator fault condition. The proposed FTC method operates under the flowchart depicted in
Figure 2.
6. Results
In this section, we simulate three different conditions and compare the simulation results. The conditions are as follows: (1) no fault; (2) fault without FTC; (3) fault with the proposed FTC method. The simulation is conducted in two scenarios: straight scenario and constant steering scenario. In each scenario, the actuator faults are assigned as in
Table 3, and the vehicle behaviors under the corresponding faults are discussed. The study cases are listed in
Table 5.
As a commonly used evaluation method, the vehicles’ tracking performance are evaluated for their stability. Two functions are utilized to evaluate the longitudinal speed tracking performance and yaw rate tracking performance of vehicles. The integrals of the quadratic function of the deviations of both the longitudinal speed and the yaw rate from the desired value are used to evaluate the vehicle tracking control performance. The two integrals are denoted as
and
, respectively [
43].
6.1. Simulations in the Straight Scenario
Simulations in the straight scenario are performed with a constant zero steering angle, so as to identify the drifts of the faulty vehicle. Two different actuator faults,
and
, are employed in the simulations; the simulation results in the straight scenario are shown in
Figure 6 and
Figure 7, respectively.
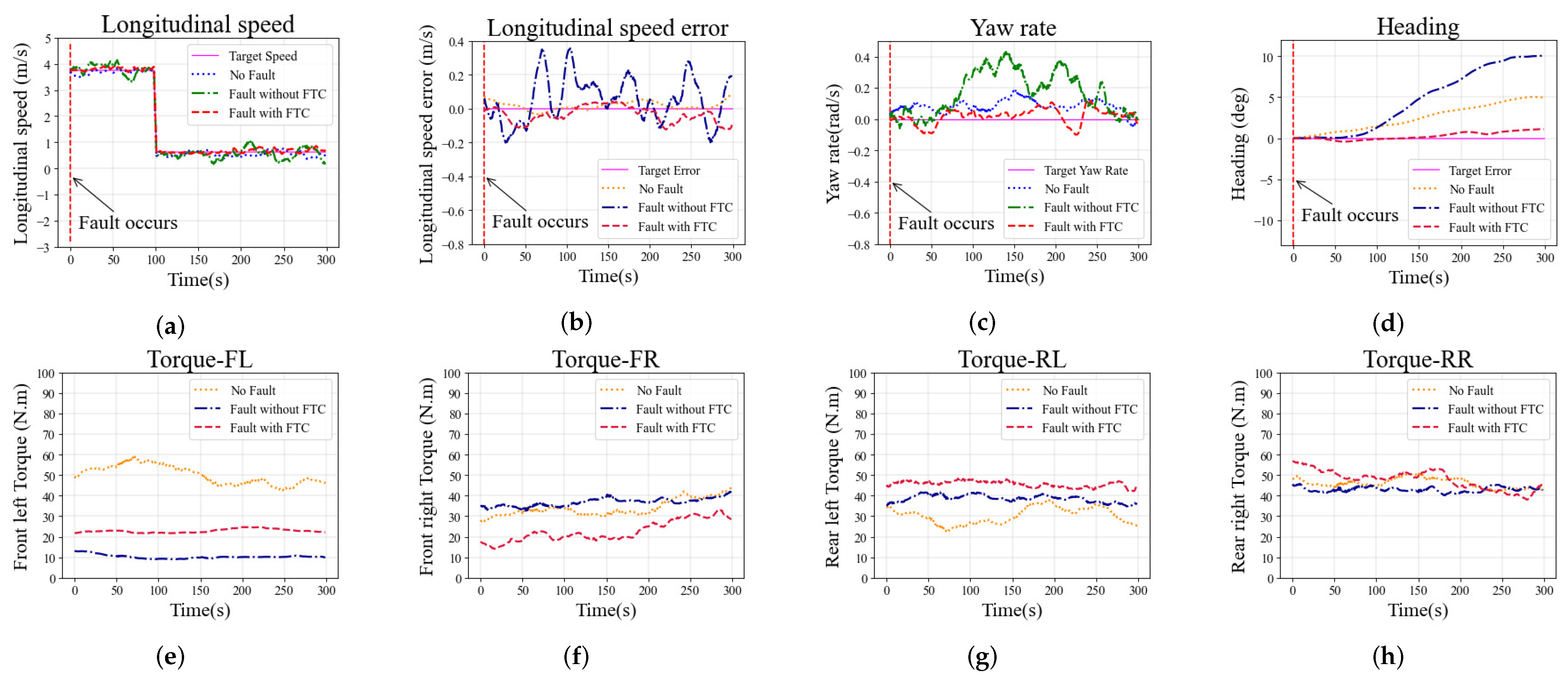
The longitudinal speed is set to
m/s at the beginning, and
m/s at 100 s, while the yaw rate is set to 0 rad/s and kept constant. The longitudinal speed at different moments in the simulation is shown in
Figure 6a. As observed in
Figure 6b, fluctuations in the longitudinal speed in the case without FTC are significantly greater than in other cases. The errors with the longitudinal speed in cases with FTC and with no-fault demonstrate no significant difference, and the results in both cases are smaller than in the case without FTC. The yaw rates in different cases are shown in
Figure 6c. The desired yaw rate is a constant zero in the straight scenario. The cases with FTC and no-fault show that errors with the yaw rate can be kept within
rad/s. However, without FTC, the errors exceeded
rad/s. As shown in
Figure 6d, the heading of the vehicle without FTC has a larger errors than in other cases, indicating that the vehicle suffers a greater drift. The driving torques on each wheel are shown in
Figure 6e–h. The case with FTC generates an additional torque on the rear left wheel to compensate for the front left wheel fault, while the torque on the front right wheel is reduced to balance the yaw of the vehicle. The above analysis shows that the vehicle’s tracking performance in the case of FTC is not much different from that in the case of no-fault, and it is significantly better than in the case without FTC, indicating that the proposed FTC method can improve the tracking performance of the vehicle when it encounters a fault within the training bounds.
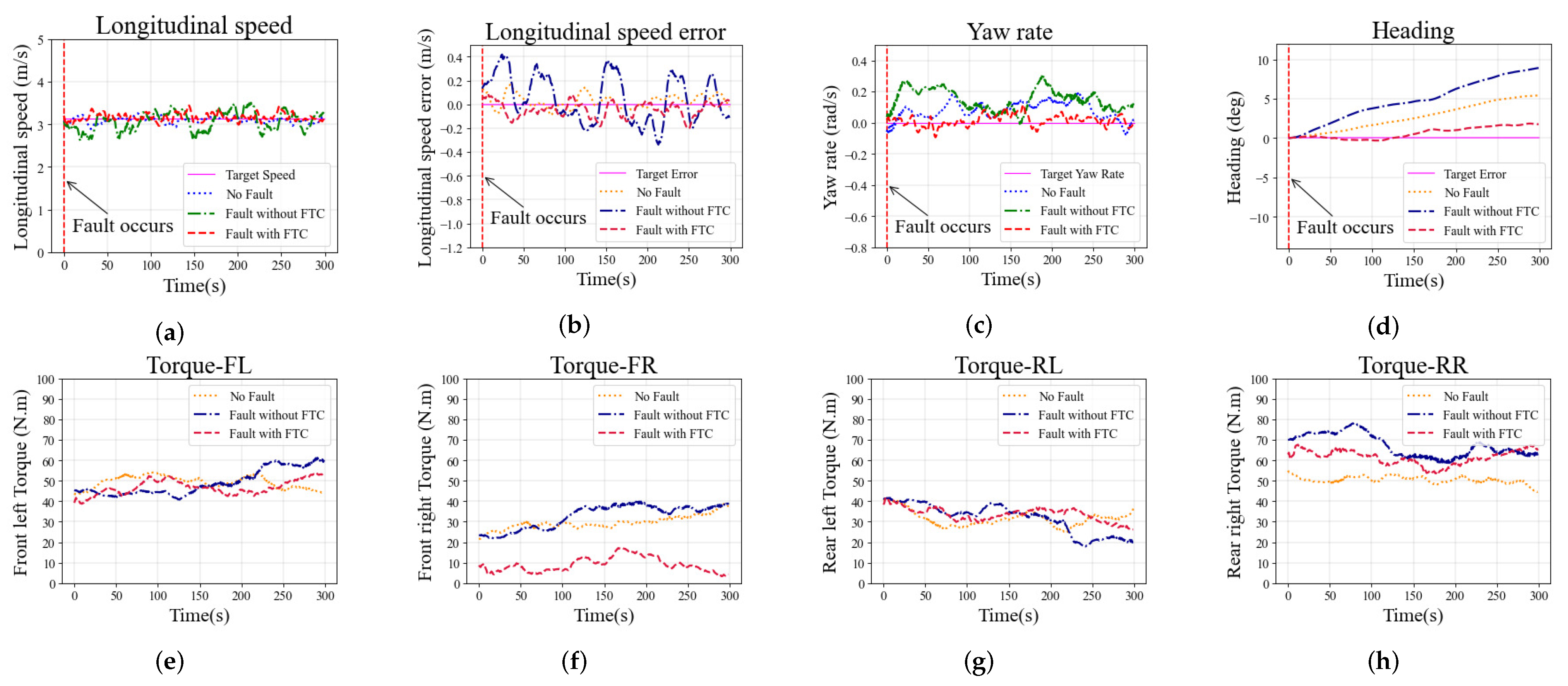
The second simulation in the straight scenario is conducted with fault
on the rear right wheel. The additive fault of the driving wheel is outside the offline training bounds, which is used to simulate the vehicle encountering a novel fault. Simulation results are shown in
Figure 7 and have the same trend as the case with fault
. The longitudinal speed of the case without FTC fluctuates greatly, and the maximum error exceeds
m/s, as shown in
Figure 7a,b. The longitudinal speed tracking performance shows no significant difference between the cases with FTC and no-fault, and the results of both of the cases are better than in the cases without FTC. The yaw rate tracking performance also shows the same trend, as shown in
Figure 7c. The yaw rate error in the cases with FTC and no-fault is kept within
rad/s; without FTC, the error exceeds
rad/s. As shown in
Figure 7d, the heading of the vehicle without FTC shows a larger error than in other cases, indicating that the vehicle has a greater drift. The driving torques on each wheel are shown in
Figure 7e–h. The torque on the front right wheel is reduced to compensate for the rear right wheel’s additive fault. The above analysis is sufficient to demonstrate that the proposed FTC method can also improve the stability of vehicles when they encounter a fault outside of the training bounds.
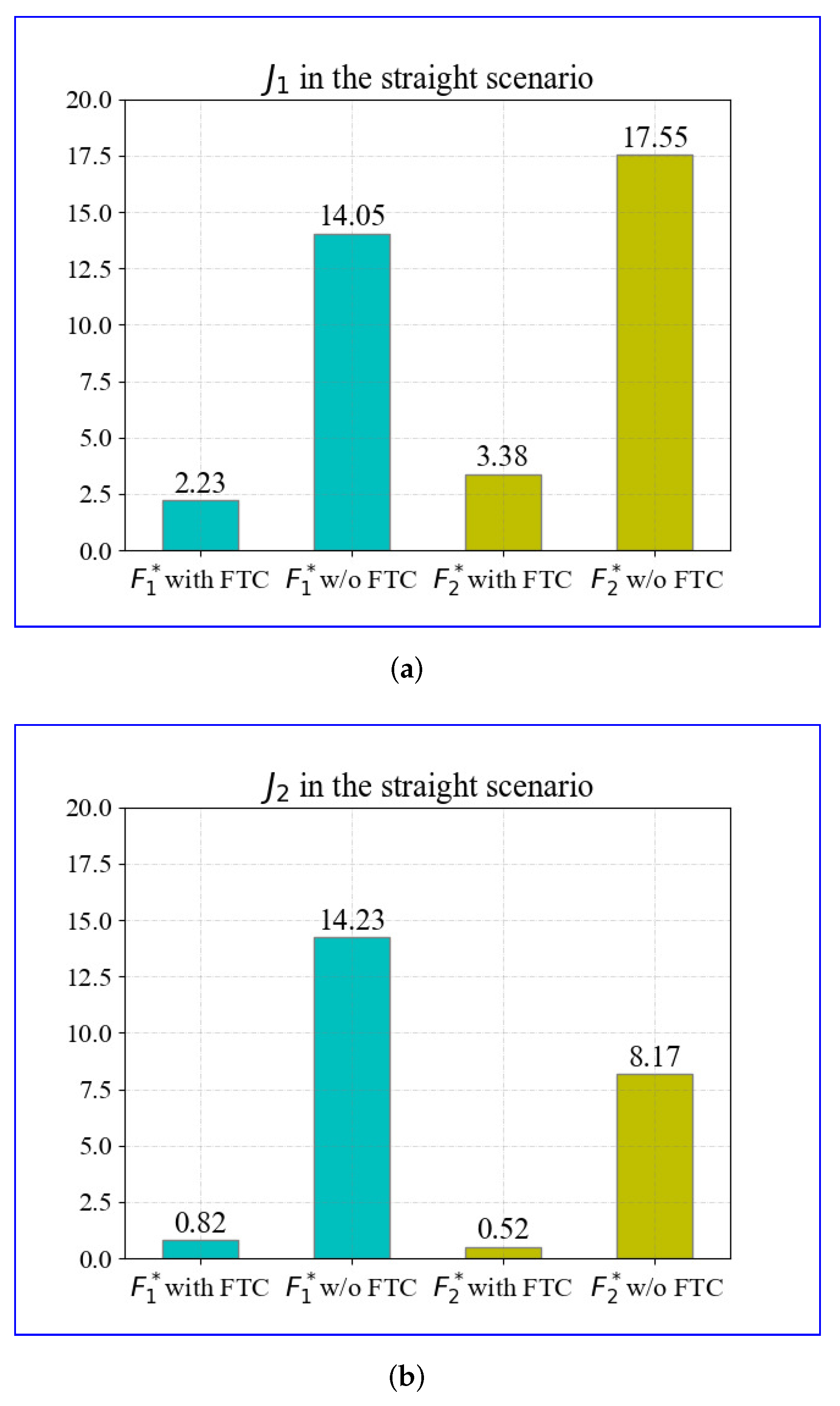
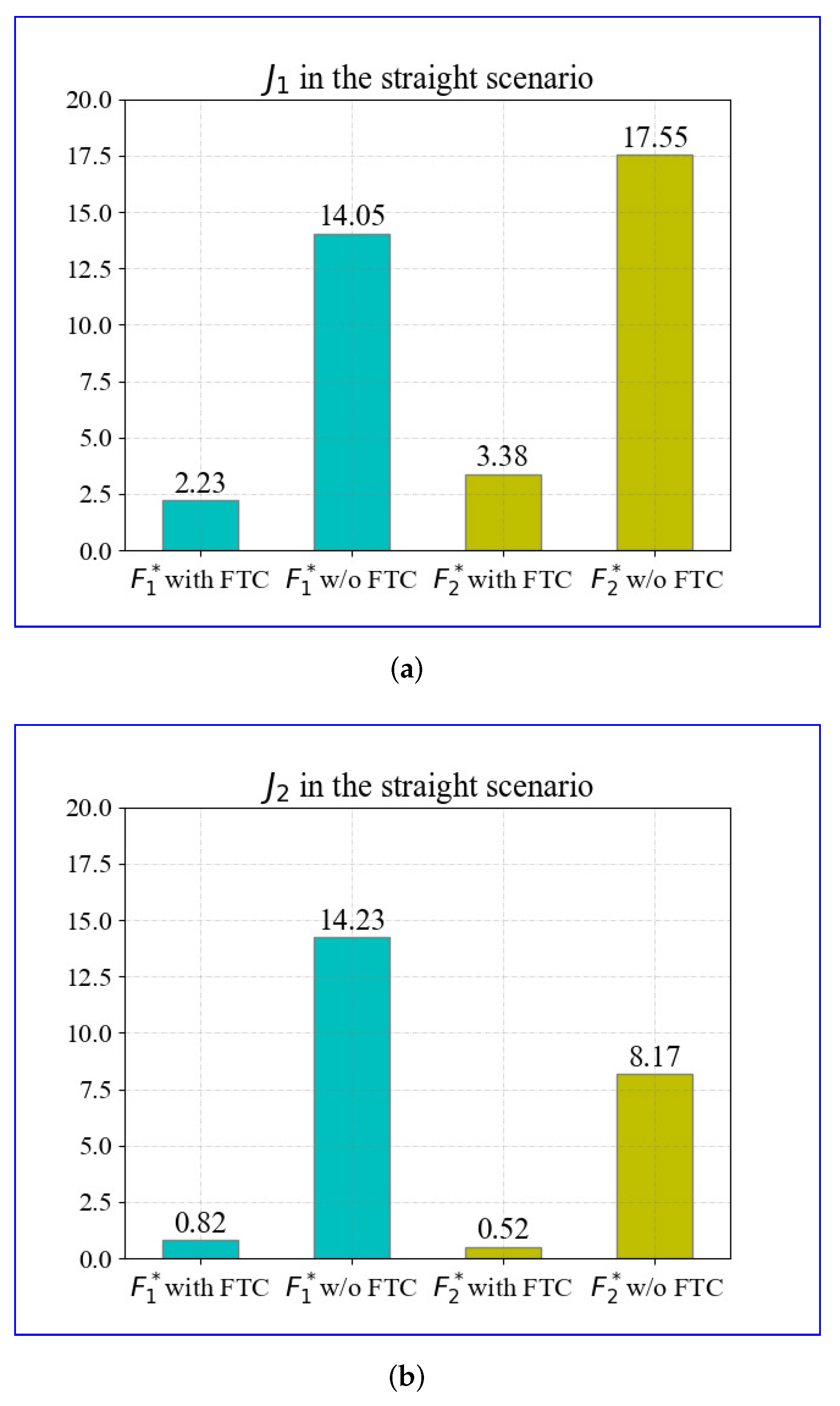
To quantitatively illustrate the improvement of the proposed FTC control strategy more specifically, Equation (
18) is used to evaluate the performance of the longitudinal speed tracking and yaw rate tracking. The results of
and
in the straight scenario are displayed in
Figure 8.
The evaluation results are obtained based on the aforementioned simulations. Comparisons of
in cases with and without the FTC under 300 s of driving are displayed in
Figure 8a. The FTC method reduces
of the fault
by
and the fault
by
. The results of
are shown in
Figure 8b; the FTC method reduces
of the fault
by
and the fault
by
. The evaluation results in the straight scenario demonstrate that the proposed FTC can effectively reduce the severity of actuator faults, including those outside of the training bounds, that is, those that had never occurred before.
6.2. Simulations in the Constant Steering Scenario
The second simulation study is conducted with constant steering of the vehicle to identify the vehicle’s cornering ability under actuator fault conditions. The simulation is performed at a constant
m/s longitudinal speed and a constant
rad/s yaw rate with two different fault conditions, and the fault types are consistent with those discussed in
Section 6.1. The simulation results of constant steering with the faults
and
are shown in
Figure 9 and
Figure 10, respectively.
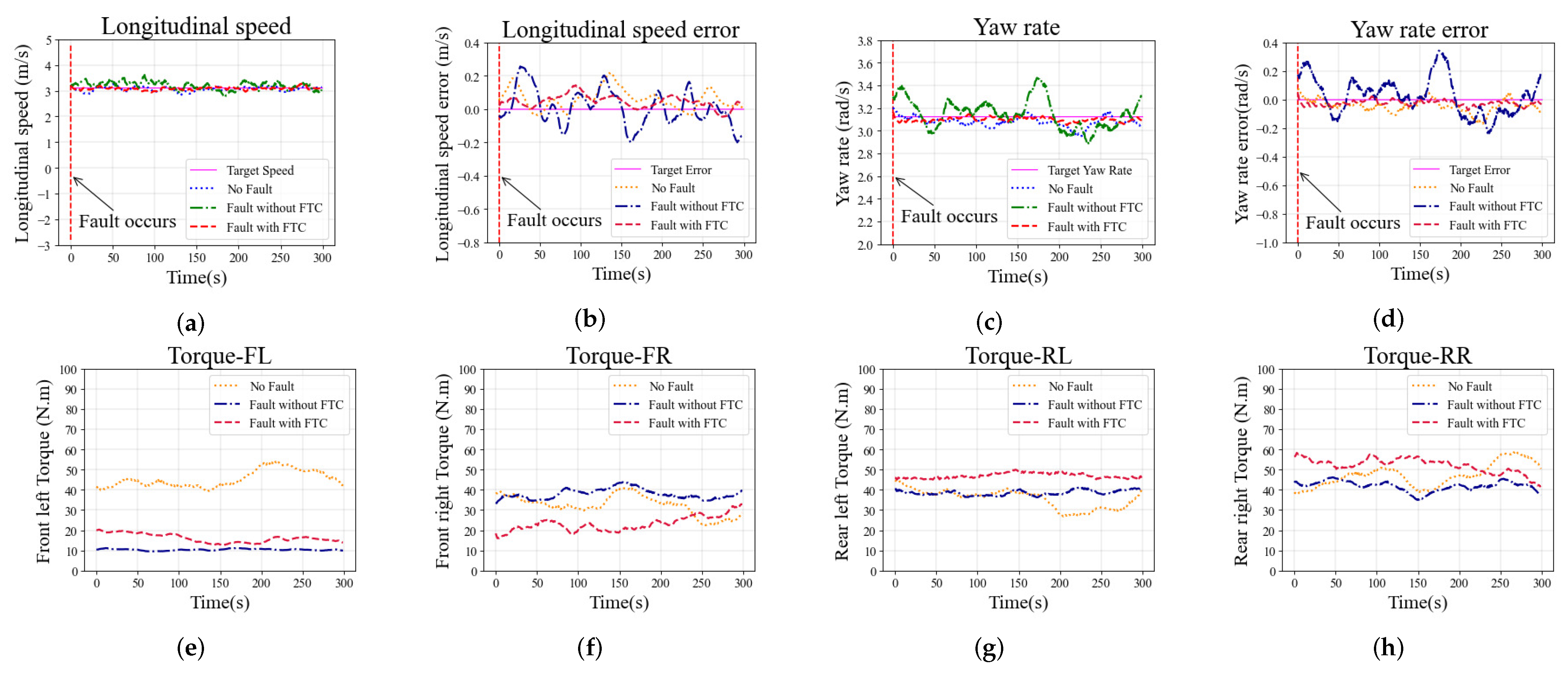
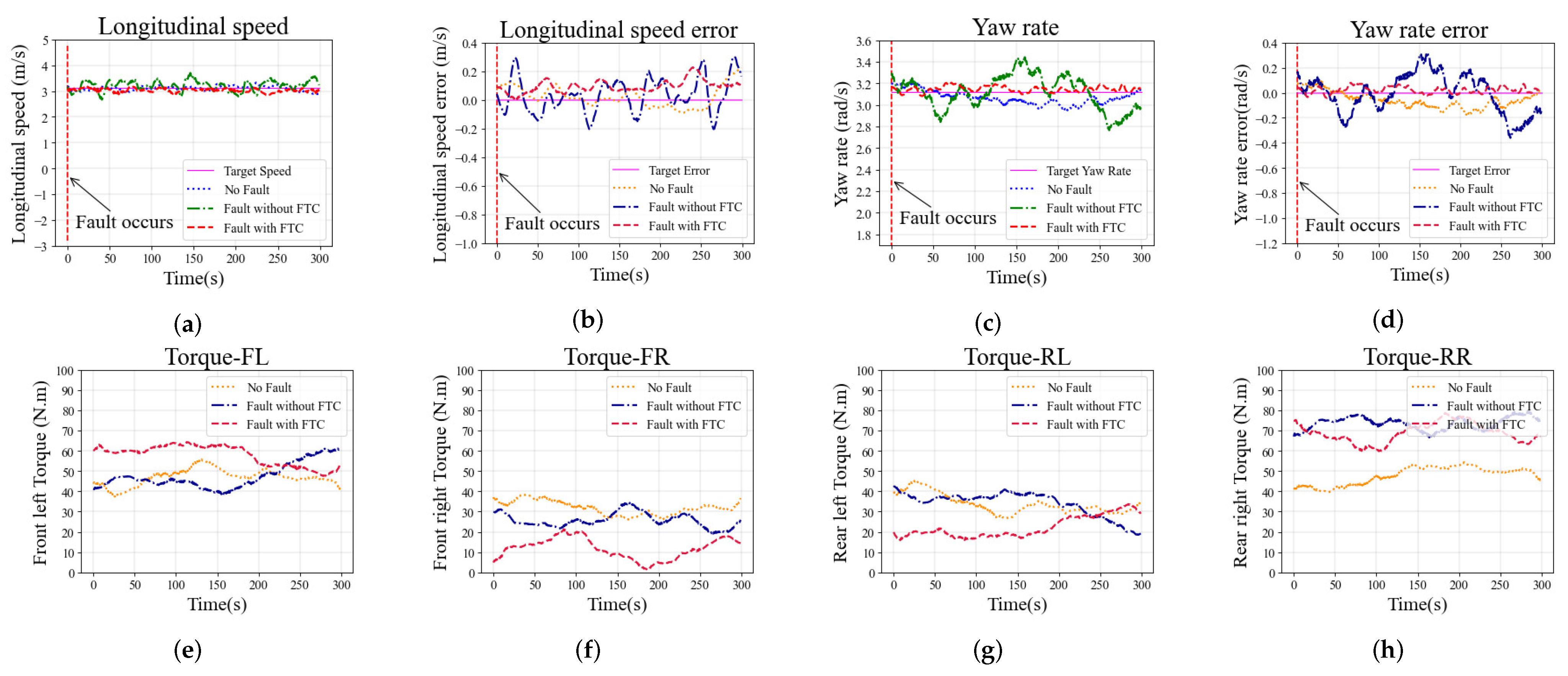
The longitudinal speed tracking and longitudinal speed error of the vehicle with fault
during the simulation are shown in
Figure 9a,b, respectively. The maximum longitudinal speed error of the case without FTC exceeds
m/s, the longitudinal speed fluctuates sharply, and the longitudinal speed tracking performance is worse than in the other two cases. For the cases with FTC and with no-fault, the longitudinal speed tracking error performance is not remarkably different, and both are better than in the case without FTC. The yaw rate tracking and the yaw rate error are shown in
Figure 9c,d, respectively. The case with FTC shows that the yaw rate error is close to zero. However, without the FTC algorithm, the yaw rate fluctuates sharply and the yaw rate tracking error increases significantly. The driving torque on each wheel are shown in
Figure 9e,h. Due to the fault
, the torque on the faulty front left wheel is significantly reduced. The case with FTC algorithm generates additional torque on the rear left wheel to compensate for the fault
, and the front right torque is reduced to balance the yaw of the vehicle. The comparison of torque distribution shows that the proposed FTC method can adapt to the impact of fault
on the vehicle.
The same trend is observed in the case with fault
in the constant steering scenario, as shown in
Figure 10. The longitudinal speed and yaw rate fluctuations in the case without FTC are more severe than in the other two cases, and the tracking error performance is worse as well. Compared with the no-fault case, the longitudinal speed and yaw rate tracking performance of the case with FTC is similar or even better. Driving wheel torques with fault
in the constant steering scenario are shown in
Figure 10e–h. The torque on the rear right wheel with fault
is significantly increased due to additive fault, and the front right torque is reduced to balance the yaw of the vehicle.
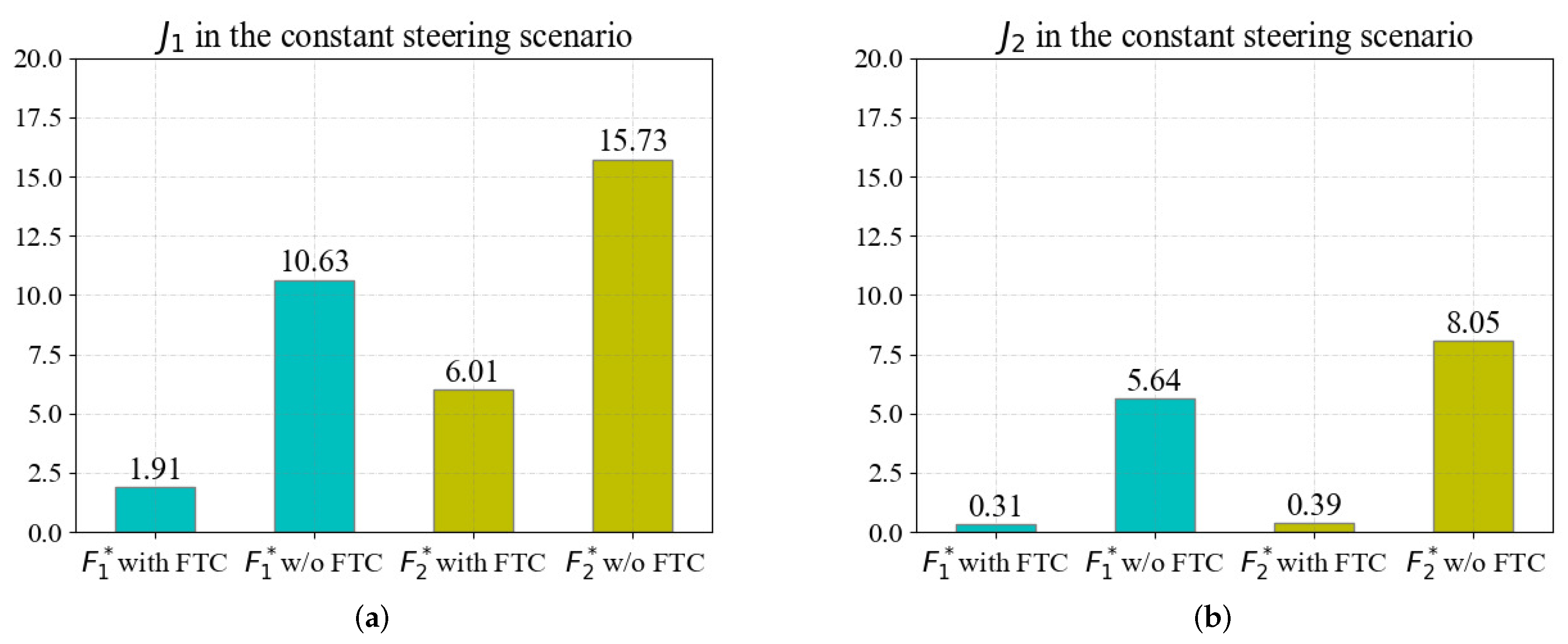
The quantitative evaluation results in the constant steering scenario are shown in
Figure 11, which are similar to those in the straight scenario. The results of
are shown in
Figure 11a; the FTC method reduces
of the fault
by
and the fault
by
. As shown in
Figure 11b, the FTC method reduces
of the fault
by
and the fault
by
. The evaluation results demonstrate that the proposed FTC can effectively reduce the impact of actuator faults in the constant steering scenario, indicating that the proposed FTC method can effectively improve the tracking performance of the vehicle with faults in the constant steering scenario.
Based on all the simulation results illustrated above, the effect of the meta-DDPG-based FTC method on the skid steering vehicles’ longitudinal speed and yaw rate tracking have been investigated. In such vehicles, a single wheel fault can impose a serious impact on longitudinal speed and yaw rate tracking. However, such an impact can be overcome with the implementation of the FTC method proposed in this study.
7. Conclusions
In this work, we propose a meta-DDPG-based FTC method for skid steering vehicles moving under actuator faults. We have leveraged metalearning, which can quickly adapt the vehicle’s model at runtime using a small number of online data to maintain tracking performance. Based on the DDPG algorithm, we developed an agent that can perform dual-channel control over the longitudinal speed and yaw rate of skid steering vehicles. Considering the diversity of actuator faults, we designed the method to learn more general tracking policy by metalearning from a variety of actuator faults. We constructed an experience replay buffer with various actuator faults to provide data for multi-faults learning of RL algorithm. A metalearned model is trained from the data provided by the experience replay buffer in the offline stage. Based on the meta-learned model, the agent can quickly online adapt to the vehicle’s model with an actuator fault using a few gradient steps. Four types of testing scenarios were explored. The simulation results demonstrate that actuator faults can have a serious impact on tracking performance and the proposed FTC can effectively overcome this impact.
This work creates an exciting path towards using metalearning approaches for the FTC method of skid steering vehicles. A redundant driving system can provide a hardware platform to address the actuator FTC problems, making the novel FTC algorithm possible. Currently, we are exploring ways to extend this work by incorporating fault detection techniques. Time delays are critical in systems such as skid steering vehicles, and the study of actuator delays in vehicles will also be considered in future work. We also plan to apply the proposed method to different vehicle systems, such as independent driving electric vehicles as they are also prone to actuator faults.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}