
Evaluation of Random Forests (RF) for Regional and Local-Scale Wheat Yield Prediction in Southeast Australia


Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Region Paddocks
2.2. PlanetTM Satellite Imagery
2.3. Weather Data
2.4. RF Model Development
2.5. Feature Importance Analysis
3. Results
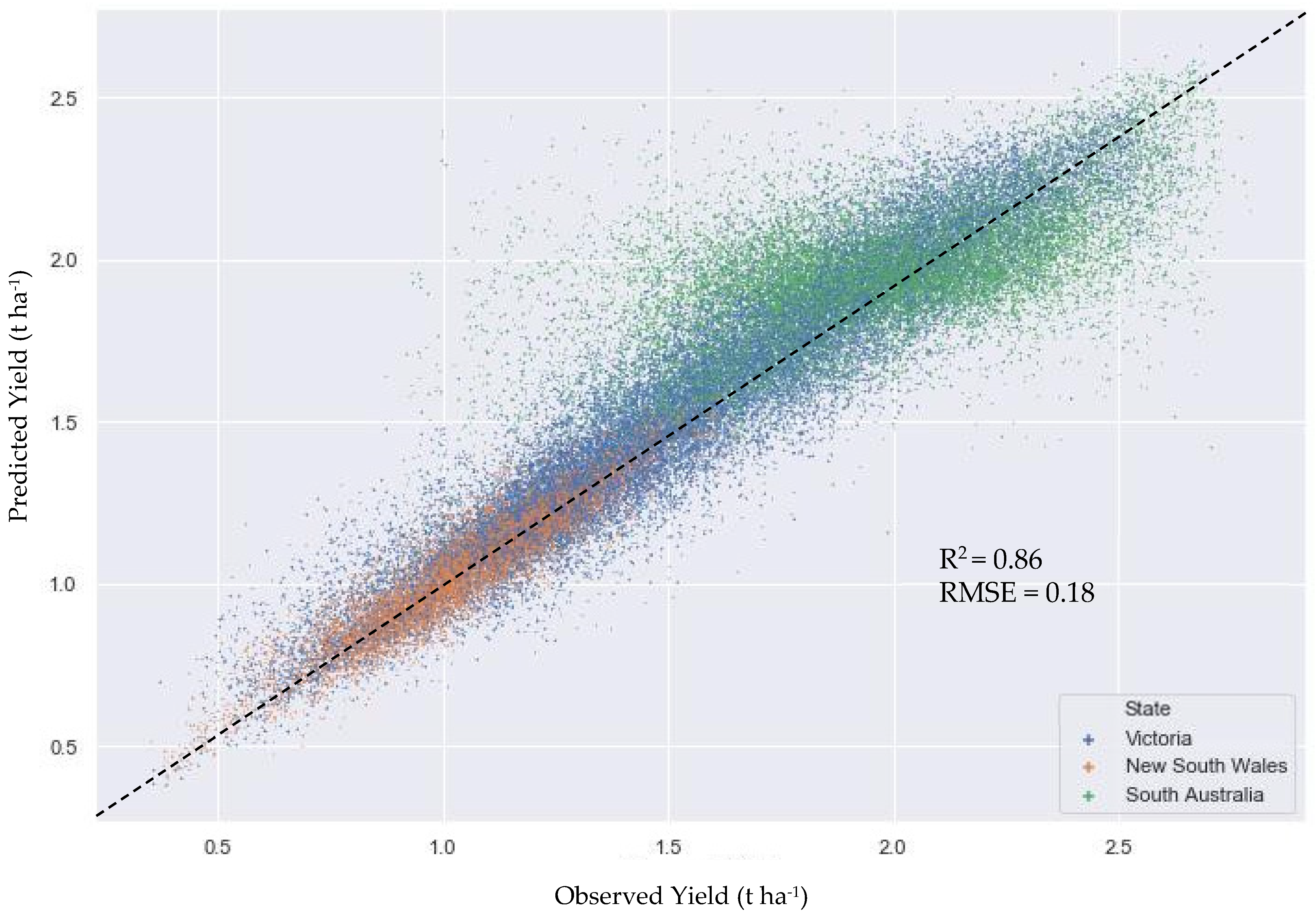
3.1. Regional (Composite) Yield Prediction
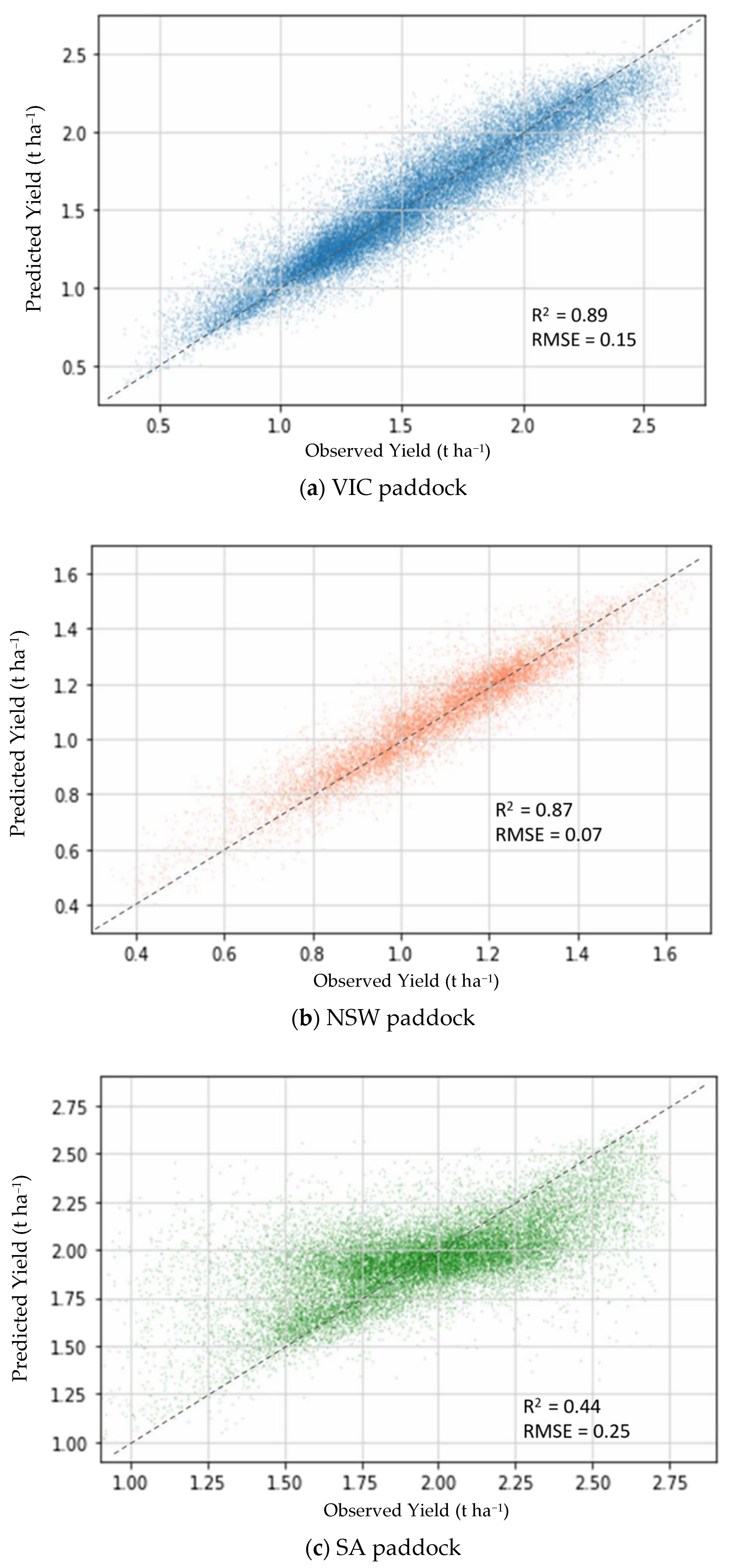
3.2. Individual Paddock Yield Prediction Models
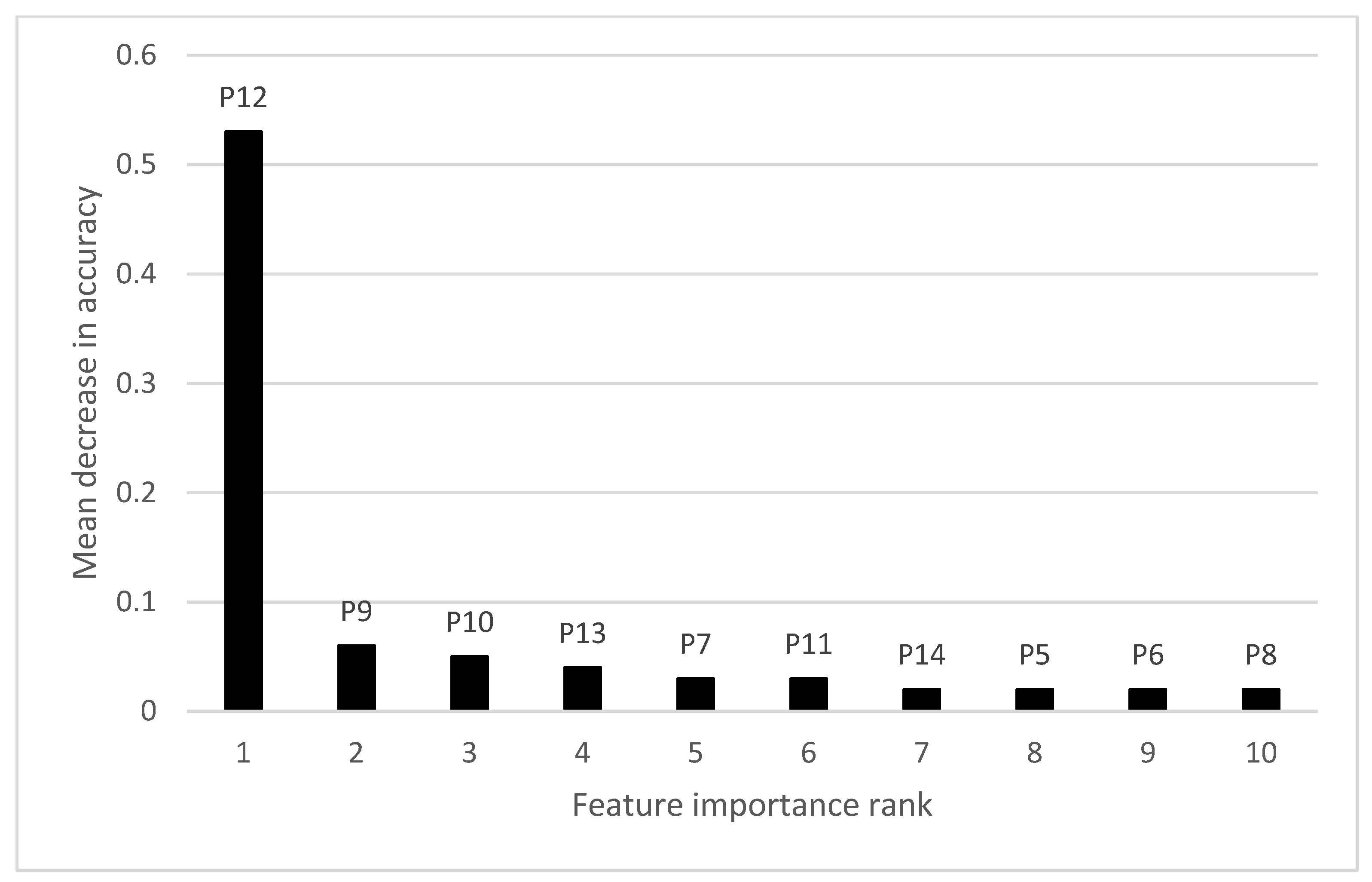
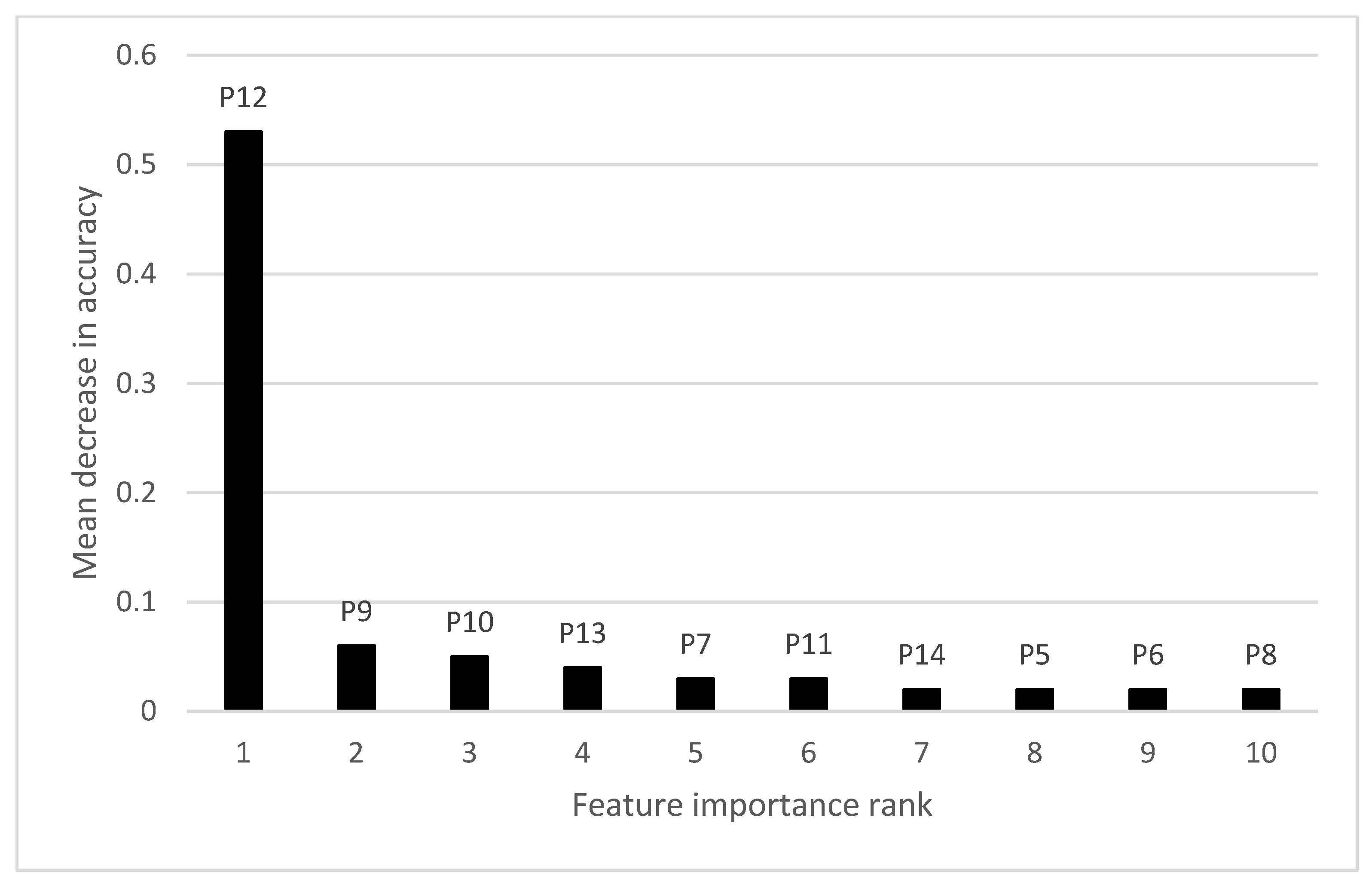
3.3. Feature Importance Analysis for Individual Paddocks
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nordblom, T.L.; Hutchings, T.R.; Godfrey, S.S.; Schefe, C.R. Precision variable rate nitrogen for dryland farming on waterlogging riverine plains of southeast Australia? Agric. Syst. 2021, 186, 102962. [Google Scholar] [CrossRef]
- Kath, J.; Mushtaq, S.; Henry, R.; Adeyinka, A.A.; Stone, R.; Marcussen, T.; Kouadio, L. Spatial variability in regional scale drought index insurance viability across Australia’s wheat growing regions. Clim. Risk Manag. 2019, 24, 13–29. [Google Scholar] [CrossRef]
- Feng, P.; Liu, D.L.; Wang, B.; Waters, C.; Zhang, M.; Yu, Q. Projected changes in drought across the wheat belt of southeastern Australia using a downscaled climate ensemble. Int. J. Climatol. 2019, 39, 1041–1053. [Google Scholar] [CrossRef]
- Ray, D.K.; Gerber, J.S.; MacDonald, G.K.; West, P.C. Climate variation explains a third of global crop yield variability. Nat. Commun. 2015, 6, 5989. [Google Scholar] [CrossRef] [Green Version]
- Van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Hao, S.; Ryu, D.; Western, A.; Perry, E.; Bogena, H.; Franssen, H.J.H. Performance of a wheat yield prediction model and factors influencing the performance: A review and meta-analysis. Agric. Syst. 2021, 194, 103278. [Google Scholar] [CrossRef]
- Aasen, H.; Honkavaara, E.; Lucieer, A.; Zarco-Tejada, P.J. Quantitative remote sensing at ultra-high resolution with UAV spectroscopy: A review of sensor technology, measurement procedures, and data correction workflows. Remote Sens. 2018, 10, 1091. [Google Scholar] [CrossRef] [Green Version]
- Whitcraft, A.K.; Vermote, E.F.; Becker-Reshef, I.; Justice, C.O. Cloud cover throughout the agricultural growing season: Impacts on passive optical earth observations. Remote Sens. Environ. 2015, 156, 438–447. [Google Scholar] [CrossRef]
- Planet Team. Planet Application Program Interface: In Space for Life on Earth. San Francisco, CA. Available online: https://api.planet.com (accessed on 17 July 2019).
- Houborg, R.; McCabe, M.F. High-resolution NDVI from planet’s constellation of earth observing nano-satellites: A new data source for precision agriculture. Remote Sens. 2016, 8, 768. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Cai, F.; Tian, J.; Williams, T.K.-A. Spatiotemporal fusion of multisource remote sensing data: Literature survey, taxonomy, principles, applications, and future directions. Remote Sens. 2018, 10, 527. [Google Scholar] [CrossRef] [Green Version]
- Gao, F.; Hilker, T.; Zhu, X.; Anderson, M.; Masek, J.; Wang, P.; Yang, Y. Fusing Landsat and MODIS data for vegetation monitoring. IEEE Geosci. Remote Sens. Mag. 2015, 3, 47–60. [Google Scholar] [CrossRef]
- Liao, C.; Wang, J.; Dong, T.; Shang, J.; Liu, J.; Song, Y. Using spatio-temporal fusion of Landsat-8 and MODIS data to derive phenology, biomass and yield estimates for corn and soybean. Sci. Total Environ. 2019, 650, 1707–1721. [Google Scholar] [CrossRef] [PubMed]
- Ali, I.; Greifeneder, F.; Stamenkovic, J.; Neumann, M.; Notarnicola, C. Review of machine learning approaches for biomass and soil moisture retrievals from remote sensing data. Remote Sens. 2015, 7, 16398–16421. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Mutanga, O.; Adam, E.; Cho, M.A. High density biomass estimation for wetland vegetation using Worldview-2 imagery and random forest regression algorithm. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 399–406. [Google Scholar] [CrossRef]
- Wolanin, A.; Camps-Valls, G.; Gómez-Chova, L.; Mateo-García, G.; van der Tol, C.; Zhang, Y.; Guanter, L. Estimating crop primary productivity with Sentinel-2 and Landsat 8 using machine learning methods trained with radiative transfer simulations. Remote Sens. Environ. 2019, 225, 441–457. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cravero, A.; Sepúlveda, S. Use and adaptations of machine learning in big data—Applications in real cases in agriculture. Electronics 2021, 10, 552. [Google Scholar] [CrossRef]
- Everingham, Y.; Sexton, J.; Robson, A. In A statistical approach for identifying important climatic influences on sugarcane yields. In Proceedings of the 37th Annual Conference of the Australian Society of Sugar Cane Technologists, Bundaberg, Australia, 28–30 April 2015; pp. 8–15. [Google Scholar]
- Everingham, Y.; Sexton, J.; Skocaj, D.; Inman-Bamber, G. Accurate prediction of sugarcane yield using a random forest algorithm. Agron. Sustain. Dev. 2016, 36, 27. [Google Scholar] [CrossRef] [Green Version]
- Stephens, D.; Lyons, T.; Lamond, M. A simple model to forecast wheat yield in Western Australia. J. R. Soc. West. Aust. 1989, 71, 77–81. [Google Scholar]
- Marletto, V.; Ventura, F.; Fontana, G.; Tomei, F. Wheat growth simulation and yield prediction with seasonal forecasts and a numerical model. Agric. Forest Meteorol. 2007, 147, 71–79. [Google Scholar] [CrossRef]
- Ahmed, M.; Akram, M.N.; Asim, M.; Aslam, M.; Hassan, F.-U.; Higgins, S.; Stöckle, C.O.; Hoogenboom, G. Calibration and validation of APSIM-Wheat and CERES-Wheat for spring wheat under rainfed conditions: Models evaluation and application. Comput. Electron. Agric. 2016, 123, 384–401. [Google Scholar] [CrossRef]
- Mehrabi, F.; Sepaskhah, A.R. Winter wheat yield and DSSAT model evaluation in a diverse semi-arid climate and agronomic practices. Int. J. Plant Prod. 2020, 14, 221–243. [Google Scholar] [CrossRef]
- Feng, P.; Wang, B.; Liu, D.L.; Waters, C.; Xiao, D.; Shi, L.; Yu, Q. Dynamic wheat yield forecasts are improved by a hybrid approach using a biophysical model and machine learning technique. Agric. Forest Meteorol. 2020, 285–286, 107922. [Google Scholar] [CrossRef]
- Jeong, J.H.; Resop, J.P.; Mueller, N.D.; Fleisher, D.H.; Yun, K.; Butler, E.E.; Timlin, D.J.; Shim, K.-M.; Gerber, J.S.; Reddy, V.R.; et al. Random forests for global and regional crop yield predictions. PLoS ONE 2016, 11, e0156571. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Zhou, X.; Zhu, X.; Dong, Z.; Guo, W. Estimation of biomass in wheat using random forest regression algorithm and remote sensing data. Crop J. 2016, 4, 212–219. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Zhang, Z.; Cao, J.; Luo, Y.; Zhang, L.; Li, Z.; Zhang, J. Prediction of winter wheat yield based on multi-source data and machine learning in China. Remote Sens. 2020, 12, 236. [Google Scholar] [CrossRef] [Green Version]
- Fajardo, M.; Whelan, B.M. Within-farm wheat yield forecasting incorporating off-farm information. Precis. Agric. 2021, 22, 569–585. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Bramley, R.G.V.; Ouzman, J. Farmer attitudes to the use of sensors and automation in fertilizer decision-making: Nitrogen fertilization in the Australian grains sector. Precis. Agric. 2019, 20, 157–175. [Google Scholar] [CrossRef]
- Guerrero, A.; Mouazen, A.M. Evaluation of variable rate nitrogen fertilization scenarios in cereal crops from economic, environmental and technical perspective. Soil Tillage Res. 2021, 213, 105110. [Google Scholar] [CrossRef]
- Maleki, M.R.; Mouazen, A.M.; De Ketelaere, B.; Ramon, H.; De Baerdemaeker, J. On-the-go variable-rate phosphorus fertilisation based on a visible and near-infrared soil sensor. Biosyst. Eng. 2008, 99, 35–46. [Google Scholar] [CrossRef]
- Gobbett, D.; Ouzman, J.; Ratcliff, C.; Bramley, R. Yield map workflow for precision agriculture: Challenges of real-world data. In Proceedings of the Collaborative Conference on Computational and Data Intensive Science (C3DIS), Online, 6–8 July 2021; Available online: http://www.c3dis.com/wp-content/uploads/2020/05/A-Precision-Agriculture-workflow-v1g.pdf (accessed on 10 December 2021).
- Angus, J.F.; Kirkegaard, J.A.; Hunt, J.R.; Ryan, M.H.; Ohlander, L.; Peoples, M.B. Break crops and rotations for wheat. Crop Pasture Sci. 2015, 66, 523–552. [Google Scholar] [CrossRef]
- GRDC. Grdc Grownotes—Wheat, Southern; Grains Research and Development Corporation: Canberra, Australia, 2018. [Google Scholar]
- Bureau of Meteorology Australia. Annual Climate Statement 2018. Available online: http://www.bom.gov.au/climate/current/annual/aus/2018/ (accessed on 1 November 2021).
- Fan, X.; Liu, Y.; Wu, G.; Zhao, X. Compositing the minimum NDVI for daily water surface mapping. Remote Sens. 2020, 12, 700. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Donohue, R.J.; McVicar, T.R.; Waldner, F.; Mata, G.; Ota, N.; Houshmandfar, A.; Dayal, K.; Lawes, R.A. Nationwide crop yield estimation based on photosynthesis and meteorological stress indices. Agric. For. Meteorol. 2020, 284, 107872. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with Erts; Freden, S.C., Mercanti, E.P., Becker, M., Eds.; NASA: Washington, DC, USA, 1974; Volume I, pp. 309–317.
- Houborg, R.; McCabe, M.F. Daily retrieval of NDVI and LAI at 3 m resolution via the fusion of CubeSat, Landsat, and MODIS data. Remote Sens. 2018, 10, 890. [Google Scholar] [CrossRef] [Green Version]
- Guilherme Teixeira Crusiol, L.; Sun, L.; Chen, R.; Sun, Z.; Zhang, D.; Chen, Z.; Wuyun, D.; Rafael Nanni, M.; Lima Nepomuceno, A.; Bouças Farias, J.R. Assessing the potential of using high spatial resolution daily NDVI-time-series from Planet CubeSat images for crop monitoring. Int. J. Remote Sens. 2021, 42, 7114–7142. [Google Scholar] [CrossRef]
- QGIS Development Team. QGIS Geographic Information System. Open Source Geospatial Foundation Project. Available online: http://qgis.osgeo.org (accessed on 1 November 2021).
- Queensland Department of Environment and Science. Scientific Information for Land Owners (SILO), Queensland Government. Available online: https://www.longpaddock.qld.gov.au/silo/ (accessed on 20 June 2019).
- Barlow, K.M.; Christy, B.P.; O’Leary, G.J.; Riffkin, P.A.; Nuttall, J.G. Simulating the impact of extreme heat and frost events on wheat crop production: A review. Field Crops Res. 2015, 171, 109–119. [Google Scholar] [CrossRef] [Green Version]
- Figueiredo, B.; Dhillon, J.; Eickhoff, E.; Nambi, E.; Raun, W. Value of composite Normalized Difference Vegetative Index and growing degree days data in Oklahoma, 1999 to 2018. Agrosystems Geosci. Environ. 2020, 3, e20013. [Google Scholar] [CrossRef] [Green Version]
- McKinney, W. Python for Data analysis: Data Wrangling with Pandas, Numpy, and Ipython; O’Reilly Media, Inc.: Newton, MA, USA, 2012. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Fawagreh, K.; Gaber, M.M.; Elyan, E. Random forests: From early developments to recent advancements. Syst. Sci. Control Eng. 2014, 2, 602–609. [Google Scholar] [CrossRef] [Green Version]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence—Volume 2; Morgan Kaufmann Publishers Inc.: Montreal, QC, Canada, 1995; pp. 1137–1143. [Google Scholar]
- Rogers, J.; Gunn, S. Identifying Feature Relevance Using a Random Forest; Springer: Berlin/Heidelberg, Germany, 2006; pp. 173–184. [Google Scholar]
- Menze, B.H.; Kelm, B.M.; Masuch, R.; Himmelreich, U.; Bachert, P.; Petrich, W.; Hamprecht, F.A. A comparison of random forest and its Gini importance with standard chemometric methods for the feature selection and classification of spectral data. BMC Bioinform. 2009, 10, 213. [Google Scholar] [CrossRef] [Green Version]
- Abdel-Rahman, E.M.; Ahmed, F.B.; Ismail, R. Random forest regression and spectral band selection for estimating sugarcane leaf nitrogen concentration using EO-1 Hyperion hyperspectral data. Int. J. Remote Sens. 2013, 34, 712–728. [Google Scholar] [CrossRef]
- Hassan, M.A.; Yang, M.; Rasheed, A.; Yang, G.; Reynolds, M.; Xia, X.; Xiao, Y.; He, Z. A rapid monitoring of NDVI across the wheat growth cycle for grain yield prediction using a multi-spectral UAV platform. Plant Sci. 2019, 282, 95–103. [Google Scholar] [CrossRef] [PubMed]
- Lai, Y.R.; Pringle, M.J.; Kopittke, P.M.; Menzies, N.W.; Orton, T.G.; Dang, Y.P. An empirical model for prediction of wheat yield, using time-integrated Landsat NDVI. Int. J. Appl. Earth Obs. Geoinf. 2018, 72, 99–108. [Google Scholar] [CrossRef]
- Nagy, A.; Fehér, J.; Tamás, J. Wheat and maize yield forecasting for the Tisza river catchment using MODIS NDVI time series and reported crop statistics. Comput. Electron. Agric. 2018, 151, 41–49. [Google Scholar] [CrossRef]
- Xiao, D.; Moiwo, J.P.; Tao, F.; Yang, Y.; Shen, Y.; Xu, Q.; Liu, J.; Zhang, H.; Liu, F. Spatiotemporal variability of winter wheat phenology in response to weather and climate variability in China. Mitig. Adapt. Strateg. Glob. Change 2015, 20, 1191–1202. [Google Scholar] [CrossRef]
- Johnson, D.M. An assessment of pre- and within-season remotely sensed variables for forecasting corn and soybean yields in the united states. Remote Sens. Environ. 2014, 141, 116–128. [Google Scholar] [CrossRef]
- French, R.; Schultz, J. Water use efficiency of wheat in a Mediterranean-type environment. I. The relation between yield, water use and climate. Aust. J. Agric. Res. 1984, 35, 743–764. [Google Scholar] [CrossRef]
- Saeed, U.; Dempewolf, J.; Becker-Reshef, I.; Khan, A.; Ahmad, A.; Wajid, S.A. Forecasting wheat yield from weather data and MODIS NDVI using random forests for Punjab province, Pakistan. Int. J. Remote Sens. 2017, 38, 4831–4854. [Google Scholar] [CrossRef]
- Li, C.; Li, H.; Li, J.; Lei, Y.; Li, C.; Manevski, K.; Shen, Y. Using NDVI percentiles to monitor real-time crop growth. Comput. Electron. Agric. 2019, 162, 357–363. [Google Scholar] [CrossRef]
- Fu, Y.; Yang, G.; Wang, J.; Song, X.; Feng, H. Winter wheat biomass estimation based on spectral indices, band depth analysis and partial least squares regression using hyperspectral measurements. Comput. Electron. Agric. 2014, 100, 51–59. [Google Scholar] [CrossRef]
- Tan, C.-W.; Zhang, P.-P.; Zhou, X.-X.; Wang, Z.-X.; Xu, Z.-Q.; Mao, W.; Li, W.-X.; Huo, Z.-Y.; Guo, W.-S.; Yun, F. Quantitative monitoring of leaf area index in wheat of different plant types by integrating NDVI and Beer-Lambert law. Sci. Rep. 2020, 10, 929. [Google Scholar] [CrossRef] [PubMed]
- Prabhakara, K.; Hively, W.D.; McCarty, G.W. Evaluating the relationship between biomass, percent groundcover and remote sensing indices across six winter cover crop fields in Maryland, United States. Int. J. Appl. Earth Obs. Geoinf. 2015, 39, 88–102. [Google Scholar] [CrossRef] [Green Version]
- Fukuda, S.; Spreer, W.; Yasunaga, E.; Yuge, K.; Sardsud, V.; Müller, J. Random forests modelling for the estimation of mango (Mangifera indica L. cv. Chok Anan) fruit yields under different irrigation regimes. Agric. Water Manag. 2013, 116, 142–150. [Google Scholar] [CrossRef]
- Khanal, S.; Fulton, J.; Klopfenstein, A.; Douridas, N.; Shearer, S. Integration of high resolution remotely sensed data and machine learning techniques for spatial prediction of soil properties and corn yield. Comput. Electron. Agric. 2018, 153, 213–225. [Google Scholar] [CrossRef]
- Vannoppen, A.; Gobin, A. Estimating farm wheat yields from NDVI and meteorological data. Agronomy 2021, 11, 946. [Google Scholar] [CrossRef]
- Muschietti-Piana, P.; McBeath, T.M.; McNeill, A.M.; Cipriotti, P.A.; Gupta, V.V.S.R. Combined nitrogen input from legume residues and fertilizer improves early nitrogen supply and uptake by wheat. J. Plant Nutr. Soil Sci. 2020, 183, 355–366. [Google Scholar] [CrossRef]
- Thilakarathna, M.S.; Raizada, M.N. Challenges in using precision agriculture to optimize symbiotic nitrogen fixation in legumes: Progress, limitations, and future improvements needed in diagnostic testing. Agronomy 2018, 8, 78. [Google Scholar] [CrossRef] [Green Version]
- Wheeler, R.; Grains Research and Development Corporation (GRDC). Wheat and Barley Variety Update 2018. Available online: https://grdc.com.au/resources-and-publications/grdc-update-papers/tab-content/grdc-update-papers/2019/02/wheat-and-barley-variety-update-2018 (accessed on 12 November 2021).
- Drăguţ, L.; Schauppenlehner, T.; Muhar, A.; Strobl, J.; Blaschke, T. Optimization of scale and parametrization for terrain segmentation: An application to soil-landscape modeling. Comput. Geosci. 2009, 35, 1875–1883. [Google Scholar] [CrossRef]
- Nuttall, J.G.; O’Leary, G.J.; Khimashia, N.; Asseng, S.; Fitzgerald, G.; Norton, R. ‘Haying-off’ in wheat is predicted to increase under a future climate in south-eastern Australia. Crop Pasture Sci. 2012, 63, 593–605. [Google Scholar] [CrossRef]
- Filippi, P.; Jones, E.J.; Wimalathunge, N.S.; Somarathna, P.D.S.N.; Pozza, L.E.; Ugbaje, S.U.; Jephcott, T.G.; Paterson, S.E.; Whelan, B.M.; Bishop, T.F.A. An approach to forecast grain crop yield using multi-layered, multi-farm data sets and machine learning. Precis. Agric. 2019, 20, 1015–1029. [Google Scholar] [CrossRef]
- Patel, M.K.; Ryu, D.; Western, A.W.; Suter, H.; Young, I.M. Which multispectral indices robustly measure canopy nitrogen across seasons: Lessons from an irrigated pasture crop. Comput. Electron. Agric. 2021, 182, 106000. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent advances of hyperspectral imaging technology and applications in agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Dang, C.; Liu, Y.; Yue, H.; Qian, J.; Zhu, R. Autumn crop yield prediction using data-driven approaches:- support vector machines, random forest, and deep neural network methods. Can. J. Remote Sens. 2021, 47, 162–181. [Google Scholar] [CrossRef]
- Liu, Y.-N.; Li, Y.-C.; Peng, Z.-P.; Wang, Y.-Q.; Ma, S.-Y.; Guo, L.-P.; Lin, E.-D.; Han, X. Effects of different nitrogen fertilizer management practices on wheat yields and N2O emissions from wheat fields in north China. J. Integr. Agric. 2015, 14, 1184–1191. [Google Scholar] [CrossRef] [Green Version]
- Shafiee, S.; Lied, L.M.; Burud, I.; Dieseth, J.A.; Alsheikh, M.; Lillemo, M. Sequential forward selection and support vector regression in comparison to lasso regression for spring wheat yield prediction based on UAV imagery. Comput. Electron. Agric. 2021, 183, 106036. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location | 2018 Wheat Crop Information | Paddock Area & Cropping Sequence 2015–2016–2017 | Climate | Soil Description |
|---|---|---|---|---|
| Ouyen, VIC 142.37 E 35.12 S | Variety: Kord Sowing: 15 May Harvest: 30 Nov Growing days: 199 Mean yield: 1.53 t ha−1 | 181.2 ha Barley–Wheat–Fallow | Mean Max Temp: 23.8 °C Mean Min Temp: 9.8 °C Mean Annual Rainfall: 331.2 mm | Calcarosol (dune systems with series of alkaline sandy/loamy duplex, and sandy clay soils). |
| Barmedman, NSW 147.46 E 34.15 S | Variety: Lancer Sowing: 4 April Harvest: 27 Jan Growing days: 298 Mean yield: 1.06 t ha−1 | 67.6 ha Canola–Wheat–Canola | Mean Max Temp: 24.0 °C Mean Min Temp: 9.9 °C Mean Annual Rainfall: 470.9 mm | Brown Vertosol (heavy clay soil, alkaline with strongly sodic subsoil). |
| Pinery, SA 138.46 E 34.32 S | Variety: Scepter Sowing: 9 May Harvest: 11 Dec Growing days: 216 Mean yield: 1.95 t ha−1 | 120.1 ha Wheat–Wheat–Lentils | Mean Max Temp: 23.6 °C Mean Min Temp: 9.7 °C Mean Annual Rainfall: 408.9 mm | Calcarosol (alkaline silty clay loam to medium-heavy clay) variable soil profiles on dune systems. |
| Location | Ouyen, VIC | Barmedman, NSW | Pinery, SA | |||
|---|---|---|---|---|---|---|
| Period | 2018 Date | DAS | 2018 Date | DAS | 2018 Date | DAS |
| 1 | - | - | 19 April | 15 | - | - |
| 2 | - | - | 30 April | 26 | - | - |
| 3 | 25 May | 10 | 14 May | 40 | 16 May | 7 |
| 4 | 31 May | 16 | 29 May | 55 | 31 May | 22 |
| 5 | 14 June | 30 | 22 June | 79 | 13 June | 35 |
| 6 | 30 June | 46 | 30 June | 87 | 29 June | 51 |
| 7 | 14 July | 60 | 14 July | 101 | 14 July | 66 |
| 8 | 29 July | 75 | 12 August | 130 | 29 July | 81 |
| 9 | 13 August | 90 | 27 August | 145 | 26 August | 109 |
| 10 | 7 September | 115 | 4 September | 153 | 4 September | 118 |
| 11 | 20 September | 128 | 21 September | 170 | 17 September | 131 |
| 12 | 4 October | 142 | 30 September | 179 | 1 October | 145 |
| 13 | 19 October | 157 | 18 October | 197 | 19 October | 163 |
| 14 | 4 November | 173 | 11 November | 221 | 2 November | 177 |
| 15 | 18 November | 187 | 26 November | 236 | 17 November | 192 |
| 16 | - | - | 12 December | 252 | - | - |
| Observed Yield | Predicted Yield | |
|---|---|---|
| sample size, n | 75,495 | 75,495 |
| minimum (t ha−1) | 0.35 | 0.38 |
| maximum (t ha−1) | 2.79 | 2.67 |
| mean (t ha−1) | 1.60 | 1.60 |
| standard deviation (t ha−1) | 0.47 | 0.44 |
| Metric | Test Dataset | Validation Dataset |
|---|---|---|
| R Squared (R2) | 0.858 | 0.860 |
| Adjusted R Squared (R2) | 0.858 | 0.860 |
| Mean Absolute Error (MAE) | 0.126 | 0.126 |
| Mean Squared Error (MSE) | 0.032 | 0.031 |
| Root Mean Squared Error (RMSE) (t ha−1) | 0.179 | 0.177 |
| VIC (n = 37,773) | NSW (n = 13,566) | SA (n = 24,156) | ||||
|---|---|---|---|---|---|---|
| Yield Statistic (t ha−1) | Observed | Predicted | Observed | Predicted | Observed | Predicted |
| mean | 1.55 | 1.56 | 1.08 | 1.08 | 1.95 | 1.94 |
| standard deviation | 0.44 | 0.41 | 0.20 | 0.19 | 0.33 | 0.22 |
| minimum | 0.36 | 0.38 | 0.34 | 0.40 | 0.91 | 0.96 |
| maximum | 2.72 | 2.66 | 1.67 | 1.59 | 2.80 | 2.66 |
| VIC | NSW | SA | ||||
|---|---|---|---|---|---|---|
| Metric | Test Dataset | Validation Dataset | Test Dataset | Validation Dataset | Test Dataset | Validation Dataset |
| R2 | 0.890 | 0.887 | 0.870 | 0.878 | 0.447 | 0.443 |
| Adjusted R2 | 0.890 | 0.887 | 0.869 | 0.877 | 0.445 | 0.441 |
| Mean Absolute Error (MAE) | 0.110 | 0.111 | 0.056 | 0.054 | 0.186 | 0.185 |
| Mean Squared Error (MSE) | 0.021 | 0.022 | 0.005 | 0.005 | 0.061 | 0.060 |
| Root Mean Squared Error (RMSE) (t ha−1) | 0.146 | 0.147 | 0.073 | 0.071 | 0.246 | 0.246 |
| Feature Importance Rank | VIC | NSW | SA | |||
|---|---|---|---|---|---|---|
| NDVI Period | MDA | NDVI Period | MDA | NDVI Period | MDA | |
| 1 | 18 | 0.68 | 16 | 0.68 | 13 | 0.22 |
| 2 | 17 | 0.11 | 17 | 0.14 | 16 | 0.12 |
| 3 | 20 | 0.04 | 7 | 0.02 | 18 | 0.09 |
| 4 | 13 | 0.03 | 21 | 0.02 | 15 | 0.08 |
| 5 | 12 | 0.03 | 18 | 0.02 | 14 | 0.07 |
| 6 | 16 | 0.02 | 19 | 0.02 | 17 | 0.06 |
| 7 | 15 | 0.02 | 20 | 0.02 | 12 | 0.06 |
| 8 | 19 | 0.02 | 13 | 0.02 | 22 | 0.06 |
| 9 | 14 | 0.02 | 14 | 0.01 | 19 | 0.04 |
| 10 | 11 | 0.01 | 9 | 0.01 | 11 | 0.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, A.; Chang, M.W.L.; Chen, Y. Evaluation of Random Forests (RF) for Regional and Local-Scale Wheat Yield Prediction in Southeast Australia. Sensors 2022, 22, 717. https://doi.org/10.3390/s22030717
Pang A, Chang MWL, Chen Y. Evaluation of Random Forests (RF) for Regional and Local-Scale Wheat Yield Prediction in Southeast Australia. Sensors. 2022; 22(3):717. https://doi.org/10.3390/s22030717
Chicago/Turabian StylePang, Alexis, Melissa W L Chang, and Yang Chen. 2022. "Evaluation of Random Forests (RF) for Regional and Local-Scale Wheat Yield Prediction in Southeast Australia" Sensors 22, no. 3: 717. https://doi.org/10.3390/s22030717
APA StylePang, A., Chang, M. W. L., & Chen, Y. (2022). Evaluation of Random Forests (RF) for Regional and Local-Scale Wheat Yield Prediction in Southeast Australia. Sensors, 22(3), 717. https://doi.org/10.3390/s22030717