Abstract
Taxonomy illustrates that natural creatures can be classified with a hierarchy. The connections between species are explicit and objective and can be organized into a knowledge graph (KG). It is a challenging task to mine features of known categories from KG and to reason on unknown categories. Graph Convolutional Network (GCN) has recently been viewed as a potential approach to zero-shot learning. GCN enables knowledge transfer by sharing the statistical strength of nodes in the graph. More layers of graph convolution are stacked in order to aggregate the hierarchical information in the KG. However, the Laplacian over-smoothing problem will be severe as the number of GCN layers deepens, which leads the features between nodes toward a tendency to be similar and degrade the performance of zero-shot image classification tasks. We consider two parts to mitigate the Laplacian over-smoothing problem, namely reducing the invalid node aggregation and improving the discriminability among nodes in the deep graph network. We propose a top-k graph pooling method based on the self-attention mechanism to control specific node aggregation, and we introduce a dual structural symmetric knowledge graph additionally to enhance the representation of nodes in the latent space. Finally, we apply these new concepts to the recently widely used contrastive learning framework and propose a novel Contrastive Graph U-Net with two Attention-based graph pooling (Att-gPool) layers, CGUN-2A, which explicitly alleviates the Laplacian over-smoothing problem. To evaluate the performance of the method on complex real-world scenes, we test it on the large-scale zero-shot image classification dataset. Extensive experiments show the positive effect of allowing nodes to perform specific aggregation, as well as homogeneous graph comparison, in our deep graph network. We show how it significantly boosts zero-shot image classification performance. The Hit@1 accuracy is 17.5% relatively higher than the baseline model on the ImageNet21K dataset.
1. Introduction
Automatic species classification is a problem of great concern in computer vision and pattern recognition. Visual phenomena in practical scenarios generally follow a long-tail distribution [1,2], which leads to a different margin of difficulty in obtaining samples for each category, and some categories do not even have samples. Thus, it is impossible to perform supervised learning on all visual phenomena. Several recent approaches have performed zero-shot learning on some species-specific datasets [3,4]. Reference [3] introduces fusion prototype and hierarchical prototype loss to optimize a network for zero-shot learning on zoological illustrations. Reference [4] proposes a dual autoencoder model for phytoplankton. These existing methods generally use attributes or word vectors, ignoring the explicit hierarchical connections that exist between species. Furthermore, in some emergencies, such as COVID-19 [5,6,7], the ZSL-based model can respond quickly, which improves the accuracy of disease intelligent diagnosis.
In recent years, GCN-based zero-shot learning (ZSL) has shown great potential. Similar to the operation of traditional convolution on Euclidean space, graph convolution enables convolutional operations on the data of non-Euclidean structure by introducing Laplacian matrices as convolutional kernels for weight sharing. This approach allows nodes in the graph to share statistical strength, providing ways for knowledge transfer from the known categories to the unknown in ZSL. Specifically, the GCN-based method is accomplished with both the implicit node feature and explicit hierarchical information. Graph convolution transfers the semantic and structural priors of unlabeled data from source domains, and trains a classifier for classifying unlabeled data in the target domain.
Existing works have pointed out the limitations of graph convolutional neural networks [8,9,10,11]. Multi-layer stacked graph convolutional layers normally raise the Laplacian over-smoothing problem [12,13], which eventually leads the node features in the graph to be similar, thereby reducing the performance of the model. Due to these limitations, most advanced graph convolutional models limit graph convolutional layers to within four layers [11]. Reference [8] gives an insight that a graph convolution is a special form of Laplacian smoothing that aggregates the features of a node and its neighbors to improve the performance on clustering tasks. However, zero-shot classification tasks need to pass messages from known nodes to the unknown in a more fine-grained manner, and the depth of GCN reflects the distance that implicit knowledge can be passed in the graph. Hence, deeper graph convolutional networks enable aggregating features from remote nodes, taking advantage of the global information. Nevertheless, deep graph convolution will exacerbate the effect of smoothing, bringing indistinguishable features between neighboring nodes, which results in a smoothing filter.
To balance the insufficient message passing of shallow graph networks and the severe over-smoothing of deep graph networks, we propose GUN-2A and CGUN-2A. We first propose GUN-2A, a graph convolutional network with five graph convolutional layers. Our intuition is that some nodes after shallow GCN aggregation are analogous to their neighbors and should be discarded before deeper aggregation. We design a novel U-Net-like graph convolutional framework adapted to zero-shot learning. In this method, a new top-k graph pooling scheme based on the self-attention mechanism, Att-gPool, is proposed to highlight under-aggregated nodes. The proposed framework introduces additional implicit knowledge to enhance the representation power of the model without destroying the original topological structure of the knowledge graph. Second, we consider that contrastive learning effectively encourages the intra-class compactness for positive sample pairs and inter-class separability for negative sample pairs. This paradigm seems naturally suitable for node-wise representation in a hybrid knowledge graph and, to some extent, resists the over-smoothing problem. In this case, we propose CGUN-2A. We seamlessly integrate the mentioned graph encoder GUN-2A into a novel graph contrastive learning framework, which utilizes a dual knowledge graph—Hierarchy Knowledge Graph (HKG) and Structural Symmetric Knowledge Graph (SSKG)—to generate visual classifiers for unknown categories via a contrastive loss. The proposed method incorporates various priors for global structural information and fine-grained semantic representation. Experimental results show that our proposed method consistently outperforms existing multi-layer GCN models, which validates the effectiveness of the proposed GUN-2A and contrastive learning modules. Our contributions are as follows:
- We propose a novel graph encoder, GUN-2A, for performing zero-shot image classification individually or applied as an effective graph encoder in the graph contrastive learning module.
- We introduce a Structural Symmetric Knowledge Graph for zero-shot image classification. The additional knowledge graph enhances the representative power of the nodes in the embedding space.
- We propose a graph contrastive learning framework, CGUN-2A. We test it on the most challenging zero-shot image classification dataset, ImageNet-21K, and the result shows that our method significantly outperforms the baseline methods.
2. Related Works
2.1. ZSL in Ecological Monitoring
With the availability of image sensors, ecologists can easily get access to a large number of ecological pictures or videos based on monitors. However, processing data from surveys remains a major bottleneck in ecology. Deep learning (DL) algorithms have been increasingly used in ecological monitoring. The success of traditional supervised learning methods often depends on a training dataset with a large number of examples. Reference [14] discussed the shortcomings of DL algorithms in ecological monitoring: training bias brought by long-tailed data and misclassification caused by absent data. For the former problem, [15] considered a few-shot learning method based on the feature fusion model and center neighborhood loss for phytoplankton recognition. For the limitation of absent data, [4] proposed a model with a dual-encoder structure for the phytoplankton dataset to perform zero-shot learning. Furthermore, [16] used a ZSL classification framework based on embedding space projection for land cover recognition.
2.2. Graph Representation Learning for ZSL and Over-Smoothing Problem
Knowledge transfer is the key to ZSL, which is used to establish relationships between seen and unseen classes. The relationship can be established through implicit semantic information or explicit hierarchical structure. Early works used semantic information, such as manually defined attributes [17,18], word vectors [19,20,21] and textual descriptions [22,23], as source domain. References [24,25,26,27,28,29] attempted to introduce object class hierarchy to constrain the expression of semantic information. Reference [27] developed GCN to encode graph structure and node features according to a first-order approximation of spectral convolutions on graphs. Reference [28] explicitly proposed to learn logistic regression classifiers for unseen classes via GCN. Reference [29] considered the over-smoothing problem of deep GCNs and proposed two shallow networks, SGCN and DGP. DGP exploits the hierarchical structure of knowledge graphs by adding a weighted dense connection scheme.
The over-smoothing problem has been extensively discussed in previous works, mainly concentrating on node classification tasks. DropEdge [30] randomly deletes a certain proportion of edges in the input graph. This method can be regarded as an attenuator for information propagation, generating a sparse variant from the original graph, which avoids the over-smoothing of the deep GCN to a certain extent. Moreover, an important idea to solve the over-smoothing is to expand the range of neighborhood aggregation as much as possible without increasing the depth of the model, such as JK-Net [31], MixHop [32], GDC [33] and APPNP [34]. JK-Net considers the influence of the aggregation radius on information averaging and proposes skip connection, which directly maps the output in the iterative aggregation process to the final output. Similar to dilated convolution, MixHop directly expands the receptive field of the GCN layer by performing mixed feature representations with different hops in the graph, avoiding the use of deep graph networks. GDC uses generalized graph diffusion to eliminate the limitation that the single-layer convolution can only be extended to first-order neighbors. AAPNP separates the neural network that generates predictions from the propagation scheme. In its initial version PPNP, the node attribute is first transformed to obtain an initial node state, and then the personalized PageRank is used to update this state until convergence. However, multiple non-linear operations on the feature matrix in APPNP lead to overfitting. Therefore, APPNP applies a linear combination between different layers; thus, APPNP is still a shallow model, which shows that residual connections are not enough to extend GCN to deep layers [35].
2.3. Contrastive Learning for ZSL
Recently, contrastive learning has renewed a surge of interest [36,37,38] in zero-shot learning, including tasks at both the node and graph levels. Several works [39,40] have noted the ability of contrastive learning to mine supervised signals from the data itself, which can be used to address the problem of sparse supervised signals that exist in zero-shot learning. Recent works have successfully applied contrastive learning to zero-shot learning tasks [41,42,43,44]. Reference [41] propose a Transferable Contrastive Network (TCN), which automatically compares images with class semantics to ensure their consistency. Reference [42] aligns triples (state, text, image), in a contrastive manner, in a common embedding space, motivating the model to learn efficient embeddings by exploiting the information in multiple modalities simultaneously. Reference [43] considered the entanglement between state and object, capturing their prototypes in the Siamese contrast embedding space and mitigating the interaction between them. Furthermore, contrastive learning can improve the discriminability between adjacent nodes in the latent embedding space [13,44]. Reference [44] proposed a dual-level contrastive learning network (DCLN) by seamlessly integrating intra-domain and cross-domain contrast learning modules to generate more discriminative features and to ensure explicit knowledge transfer across both domains. The work of [13], which explicitly incorporates a contrastive learning module in a GCN model, is most similar to our research as it also effectively improves the intra-class representation consistency.
3. Materials and Methods
3.1. Problem Definition
In zero-shot learning settings, assume that set contains the whole classes, which can be split into the seen classes set and the unseen classes set . Note that the training set and test set are disjoint, , and for each , there is a -dimensional semantic representation vector corresponding to . We denote a set of training data point , where denotes the -th training image set labeled by and denotes the total number of categories in . From then, the common zero-shot learning classification task aims to predict a held-out classifier to categorize images of unseen classes based on the training data point, where contains the number of all categories in both and .
3.2. Preliminary Works
In this section, we summarize some preliminary works, mainly including three parts: Graph Convolutional Learning, Graph U-Nets and Graph Contrastive Learning.
3.2.1. Graph Convolutional Network
Graph convolutional layers are the basis for extensive aggregation in graph networks. We employ the random walk regularization Laplacian matrix [27] as a graph convolution kernel for message propagation and aggregation in the knowledge graph. Specifically, given a knowledge graph containing nodes, our graph convolution propagation rule is as follows:
where is the output feature representation of the -th GCN layer, and represents the trainable weight matrix of the -th layer. is the number of learned convolution kernels. denotes the input features matrix in the knowledge graph. denotes the nonlinear activation function LeakyReLU. refers to the degree matrix after row regularization to ensure global stability when nodes are aggregated. represents a degree matrix with self-loops, and is the identity matrix.
3.2.2. Graph U-Nets
We observed the application of the Graph U-Nets (GUN) proposed in [12], which aims to handle node classification tasks in a semi-supervised way. Consider the great success of U-Nets in pixel-wise prediction tasks that are somewhat similar to zero-shot classification, both of which aim to classify each element in the input. Thus, the U-Net-like structure seems to be well-suited for zero-shot classification tasks. However, it is unnatural to apply this approach to data with graph structure due to the different connectivity between nodes. To bridge the gap, [12], for the first time, presents a novel graph pooling (gPool) and a graph unpooling (gUnpool) operation for top-k selection by linear projection scores. The graph pooling is similar to convolutional pooling, which plays an important role in convolutional neural networks with grid-like data. They can reduce the size of the feature map and enlarge the receptive field, thus improving the generalization performance [45]. Based on these two operations, they propose a U-Net-like architecture for processing graph data.
3.2.3. Graph Contrastive Learning
Most of the previous GCN methods accomplish the aggregation of node features with a single knowledge graph, usually a Hierarchy Knowledge Graph (HKG). HKG is constructed by concepts and hierarchical relationships in WordNet, where concepts are transformed into semantic embeddings by a GloVe text model train on the Wikipedia dataset. Recent developments in contrastive learning have shown the great potential of this approach to regularize consistent representations of different inputs. In particular, this method usually works in a self-supervised manner. The work of [13] introduces contrastive learning into graph representation learning for the first time, aiming at optimizing representations generated by the graph encoder during the feature aggregation phase. The proposed method has illustrated the benefits of hybrid knowledge graphs by additionally constructing explicit semantic relation knowledge graphs for contrastive learning. The contrastive learning module can maximize the agreement of the same nodes in different knowledge graphs whilst expanding the discriminability between different nodes via a contrastive loss in the latent space. This work constructs a heterogeneous K-nearest neighbor graph, Semantic Correlation Knowledge Graph (SCKG), by the top-k sampling of nodes in the original graph. Two simple SGCNs are used to obtain node embeddings on SCKG and HKG, respectively. Note that, here, they perform an end-to-end contrastive learning paradigm, which is different from ours and will be discussed later in Section 3.4.
3.3. GUN-2A Architecture
In this section, we will start by describing the framework of GUN-2A, as the improved GUN model fitting for ZSL tasks and the fundamental graph encoder utilized throughout the CGUN-2A in our experiments. Then, we explain the attention-based graph pooling (Att-gPool) layer in detail. Last, the improvement of GUN-2A on GUN will be discussed.
3.3.1. Overview of GUN-2A
The complete architecture of the proposed encoder, GUN-2A, is shown in Figure 1, which is a key component to accomplishing the transfer of knowledge from semantic space to embedding space. Considering that zero-shot classification on graph data is more sensitive to fine-grained features between nodes, we retain the gUnpool operation in [12] and design a new graph pooling layer based on the self-attention mechanism. We use a Graph U-Net with two attention-based gPool and gUnpool layers as the graph encoder during the training. The encoder aims to output more qualitative representations. We measure the performance of both methods on the ZSL task directly, and the experimental result in Section 4.3 supports this view.
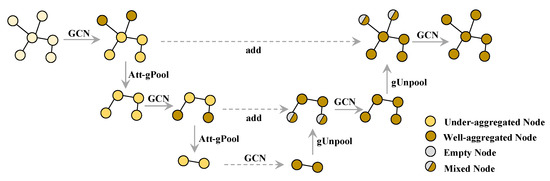
Figure 1.
Overview of Graph U-Net with two attention-based graph pooling layers. In this example, the GCN layers aggregate adjacent node features and convert them into a high-dimensional representation. The Att-gPools choose nodes with high attention scores through top-k selection and send them to the next GCN for further aggregation. The gUnpools reconstruct the original graph structure by using position information and empty feature vectors of unselected nodes.
3.3.2. Attention-Based gPool
In this section, we explain our attention-based graph pooling (Att-gPool) layer on graph data. The layer closely follows the work of [12], but the framework adopts a simple projection as its way to calculate the top k score of nodes. We adaptively select a subset of nodes based on the self-attention coefficient to form a new but smaller graph.
Suppose a graph has nodes, each with -dimension features, and the relationships between nodes are constructed by experts. Specifically, the graph contains a feature matrix and an adjacency matrix . Each non-zero element in the adjacency matrix represents an edge between two nodes. Each row vector in the feature matrix refers to the feature vector of a node .
We take the graph data as input. Given nodes and their feature vector , we compute the attention coefficient on adjacent nodes before the top-k node selection stage.
where the weight matrix is a learnable linear transformation that transforms the input features into higher-level features. represents the importance of the feature of node to node , and is a certain neighborhood of node . In our experiments, we basically follow the setting of [46].
By calculating the attention coefficients of all nodes, we build the attention coefficient matrix . Then, we use a convolutional layer to build node-wise attention dependencies and perform dimensionality reduction on channels to obtain the top-k score vector . By top-k sampling the graph, we want to retain as much information as possible from the original graph to fight against over-smoothing. To achieve this, we select the nodes with the largest attention scores to form a new subgraph. The propagation rule of the Att-gPool layer is shown in Figure 2 and defined as:
where is the feature matrix as input. Attention coefficient matrix is defined by element . represents the column blocks of . denotes the operation of performing convolution on . The attention score measures how much information nodes can retain. is returned by , which returns indices of the k-largest scores in vector . and are the row/column extraction to form the adjacency matrix and the feature matrix for the subgraph. are the network embeddings of the layer, which is used as the input of the next layer. means element-wise matrix multiplication.
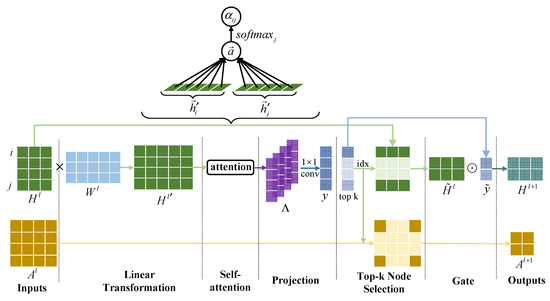
Figure 2.
Overview of the proposed attention-based graph pooling layer with k = 2. We take a graph with adjacency matrix and feature matrix as input to form a smaller subgraph with and . In the linear transformation stage, we use a learnable weight matrix to increase the dimension of features and obtain hidden features . Then, a shared attentional mechanism is performed to compute attention coefficients. Note that a single-head attention is applied here. are the column blocks from the coefficient matrix. The scalar is the projection of the vector concatenated by node on the trainable weight vector . We use a conv to fuse the attention coefficients in node-level and obtain attention score . Two nodes in and , respectively, with the highest scores are selected in the top-k node selection stage. At the gate stage, we perform element-wise multiplication between and the selected node scores vector , resulting in .
Differences between GUN-2A and GUN: Compared with the semi-supervised node classification task, the zero-shot learning classification task is more like a regression that needs to output real-valued weights for each node in a fine-grained manner. In this case, the previous GUN may not have enough potential to classify every node in the knowledge graph. Our practice in Section 4.4 illustrates this phenomenon; our re-implementation of GUN has significantly lower performance. We believe that the simple gPool layer in GUN based on computing projection scores does not have sufficient discriminative power to identify similar nodes. Therefore, we reconstruct the whole GUN using the proposed Att-gPool based on self-attention scores. Our goal is to match a model with a U-Net-like structure to the zero-shot learning classification task. The GUN-2A samples the subset of important nodes to make sure that highly abstract features are encoded and the receptive field is enlarged. In addition, to transfer such a model to ZSL, we have to make some compromises, such as the graph power being removed and the feature dimension increasing from 300 to 2049. More details of re-implementation are described in Section 4.2.
3.4. CGUN-2A Architecture
In this section, to begin with, we present the overall framework of CGUN-2A. Next in importance, the Structural Symmetric Knowledge Graph is described for maintaining the dual semantic knowledge for contrastive learning. Once again, we explain how the CGUN-2A is used for ZSL. In the end, differences between DKG [13] and CGUN-2A are also discussed.
3.4.1. Overview of CGUN-2A
Besides the widely used GolVe-encoded knowledge graph , we additionally use the semantic encoder in CLIP Transformer [47] with the WordNet hierarchy [48] to build a dual homogeneous knowledge graph, , in another semantic space. This dual graph is taken as the input of the model. The model consists of three parts: graph encoder, contrastive learning module and classifier learning module, as shown in Figure 3. The graph encoder contains a GUN-2A and an MLP component. During encoder updating, we map the dual graph to the embedding space with two invariant spread GUN-2A, respectively. Then, we use two MLPs to output the embeddings separately to the latent common space . In the contrastive learning phase, we define the proxy task in a common space and maximize the gap between positive and negative samples by contrastive loss. Finally, the model is trained to predict the classifier weights for the unseen classes by optimizing the classifier loss between the last layer weights of a pre-trained visual feature extractor and the seen node embeddings in common space.

Figure 3.
The overall framework of the proposed zero-shot classification model CGUN-2A. The model is constructed by (a) graph encoder, (b) contrastive learning module and (c) classifier learning module.
3.4.2. Structural Symmetric Knowledge Graph
In addition to the widely spread hierarchy knowledge graph, we further explore the potential of CLIP [47] used in the construction knowledge graph. CLIP has now become a de facto general-purpose framework for visual-semantic tasks because it establishes a strong connection between visual and semantic signals, and is also very convenient for downstream tasks. For this purpose, we use the CLIP Transformer text encoder to obtain a class representation for each concept. We first pick up the WordNet id (wnid) of each concept and get all the words in the synset of the wnid. Note that about half of the class concepts in ImageNet21K contain more than one synonym. Then, prompt engineering is used to create a prompt template for each word, and we take it as input for the CLIP text encoder. Finally, we perform mean pooling on all synonym semantic vectors and obtain the final class representation of the concept. A specific example is shown in Figure 4.
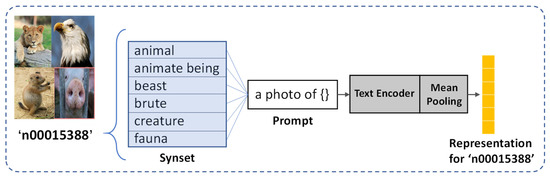
Figure 4.
An illustration for generating the representation of class ‘n00015338′ in ImageNet21K, which is a wnid concept consisting of 6 synonyms.
3.4.3. CGUN-2A for ZSL
In the graph contrastive learning module, the inputs of our module are two topological correlation knowledge graphs, and , as shown in Figure 3b, which are encoded by the pre-trained semantic encoders Glove and CLIP Transformer, respectively. Note that the dual knowledge graph has a consistent topology, built by the WordNet hierarchy. We take the feature of node in the knowledge graph as the input of the encoder . The feature of the corresponding node and its neighbor nodes in the knowledge graph is used as the input of the encoder . Encoders q and k are two invariant spread GUNs. We define the proxy task as a pair of positive samples formed by the feature of the adjoint node in , respectively, and the feature of node as a negative sample of . In our experiments, we randomly sample nodes from the second-order neighborhood of node as negative samples. In addition, following the observation of [49], we introduce a learnable nonlinear transformation before the contrastive loss to obtain sufficient expressive power. To that end, we use an MLP with one hidden layer to map the representation to the space of contrast loss effects, , where is the ReLU nonlinear activation function. For the output encoded query , there exists a set of encoded samples . Note that there is a single key (denoted as ) in the dictionary that matches. Our goal at this stage is to use a contrastive loss to maximize the difference between positive samples and negative samples by sampling in different signal spaces to alleviate Laplacian over-smoothing. With similarity measured by dot product, the loss function of contrastive learning [50] is formulated as
where τ is a temperature hyper-parameter [51] that controls the shape of the logits’ distribution.
Our model builds upon the Contrastive Graph U-Net. Inspired by [28,29], the purpose is to output a classifier for each unseen class. In the inference stage, we use this classifier directly as head for visual features to preform zero-shot classification, as shown in Figure 3. As an initial step, we use the semantic hidden states output by CGUN-2A to initialize the predicted classifier weights . The final predicted visual classifier is obtained by optimizing masked L2 Loss [29]:
where denotes the ground truth weights for seen categories obtained by extracting the last layer weights of a pre-trained CNN. Note that we mask the last unseen categories in , and only use the first seen categories. Finally, our total loss includes the loss from the contrastive learning and classifier learning stages and is defined as:
where is the weight parameter.
During the inference phase, we use the obtained classifier to replace the last layer of the pretrained CNN model for prediction.
Differences between CGUN-2A and DKG: The main distinctions are summarized in three aspects: knowledge graphs as input, graph encoder and loss function. First, we apparently use different dual knowledge graphs. DKG seems to use an HKG and a skip-connected HKG, which can be thought of as a contrast between SGCN and DGP. In our dual knowledge graph, we preserve the original structure of the graph while introducing additional semantic information in a loose coupling manner. Second, based on the proposed graph aggregator GUN-2A, we construct a graph encoder with higher efficiency, which makes full use of the hierarchical information in the knowledge graph. Last, in our task, we want to generate stronger intra-class compactness and inter-class separability for the node representations of the two outputs, q and k. We take the InfoNCE loss, which is designed to have a low value when the query is similar to its positive key and dissimilar to all other keys. We draw a simple comparison of the two modules we mentioned in Figure 5.
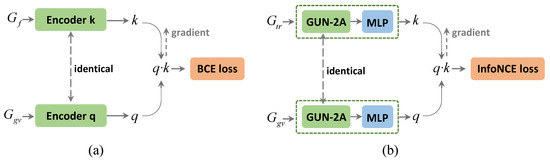
Figure 5.
A paradigm comparison of the contrastive learning module in DKG (a) and CGUN-2A (b) with different inputs, graph encoders and loss function.
4. Discussion of Results
4.1. Experimental Settings
We performed a comparative evaluation of our experiments on ImageNet [52], currently the large-scale and most widely used dataset for zero-shot learning. The categories in ImageNet are constructed based on the WordNet hierarchy, based on which we can organize the categories in the form of a knowledge graph. Reference [19] proposed to use the ImageNet 21K dataset for zero-shot learning. Our work follows the splitting setting of the training/test set of the previous work [13,19,28,29,53]. Specifically, we take the 1000 categories in the ISLVRC 2012 dataset with WordNet hierarchy as the seen classes, and the 20842 categories in the ImageNet 21K dataset as the unseen class set. Note that images in the unseen dataset are completely invisible during the training. ImageNet 21K is divided into three benchmark datasets of increasing difficulty: “2-hops”, “3-hops” and “all”. Furthermore, we use the same metric, Hit@k, which represents the percentage of the top-k predictions that hit ground truth labels. We compare our CGUN-2A to the following methods, EXEM [19], GCNZ [28], SGCN [29], DGP [29], DKG [13] and ZSL-KG [53].
4.2. Implementation Details
Consistent with previous works [13,28,29], we adopt the ResNet-50 [54] model pretrained on the ISLVRC 2012 dataset as the visual feature extractor. In the contrastive learning phase, we use two text feature extractors, CLIP Transformer [47] and GloVe [55] trained on the Wikipedia dataset. CGUN-2A uses two attention-based graph pooling layers and two graph unpooling layers. The downsampling rates of the encoder GUN-2A are set to 0.7 and 0.5. The number of randomly sampled nodes in the contrastive learning module is , and the shortages are supplemented by orthogonal vectors of the sampled node if the node does not have enough neighbors. Similarly, we perform Dropout with a dropout rate of 0.5 in each layer. Our model is trained with 300 epochs, using Adam with a learning rate of 0.001 and a weight decay of 0.0005. The proposed CGUN-2A model is trained on a GTX 3090 GPU.
4.3. Performance Comparison
The results of our comparative evaluation experiments on three datasets are summarized in Table 1. The proposed method CGUN-2A significantly outperforms previous works on three benchmark datasets, including EXEM [19], GCNZ [28], SGCN [29], DGP [29], DKG [13] and ZSL-KG [53]. Furthermore, we implement Transformer-encoded knowledge graphs in SGCN and DGP on the “2-hops” dataset and achieve some performance improvements. Specifically, compared to the “2-hops” and “3-hops” datasets, our method outperforms the previous models on the “All” task with a considerable margin, achieving a relative improvement of 17.5% in Top-1 accuracy, illustrating that the proposed method works at the global level of the graph and effectively resists over-smoothing. We also test the performance of the encoder GUN-2A in our model separately on the zero-shot classification task, and the results outperform the shallow SGCN and GCNZ with one and four layers on all three datasets. In particular, GUN-2A outperforms DGP on the “3-hops” and “all” datasets, illustrating the effectiveness of our encoder in aggregating global knowledge.

Table 1.
Hit@k performance for different methods on three datasets. Only testing on the unseen classes.
In the test involving seen classes, namely generalized zero-shot learning (GZSL), we add the weights of both seen and unseen classes to the final predictive classifier, and the results are shown in Table 2. Compared with Table 1, we observe that the accuracy is considerably lower, but the CGCN-2A has a relative improvement of 40% in top-1 accuracy in the “all” dataset compared to previous methods. Compared with the relative improvement of 17.5% in Table 1, we believe that although the smoothing exists, its impact is greatly reduced. Moreover, CGUN-2A still outperforms the previous state-of-the-art method DKG by a large margin on all tasks for low k in the Top-k accuracy measure. We confirm that the proposed encoder structure and the introduced structural symmetric knowledge graph make more efficient use of implicit knowledge.
Table 2.
Hit@k performance for different methods on three datasets. Testing on both the seen and unseen classes.
4.4. Analysis of Smoothness
We quantify our two proposed frameworks based on the mean average distance (MAD) [9] metric. MAD measures the smoothness (cosine distance) of output representations by computing the mean average distance among the predicted weights of the visual classifier. We performed calculations using both GZSL and CZSL settings on the “2-hops”, “3-hops, and “all” benchmark datasets, and the results are shown in Table 3. We observe the effectiveness of our method in promoting the inter-class separability of prediction weights. Note that our method is a model with five GCN layers, while both SGCN and DGP are shallow models. From the observation in [9], as the number of model layers increases, the smoothness of the graph representation also rises significantly. Additionally, in the GZSL settings, we can observe an overall increase in the smoothness of the output results, which verifies that the mentioned over-smoothing is the real problem where the GCN-based methods are difficult to work in the GZSL settings.
Table 3.
The MAD values of some GCN-based methods on the ‘2-hops’, ‘3-hops’ and ‘all’ datasets with both CZSL and GZSL settings.
4.5. Analysis of Ablation
We conduct ablation studies to verify the effectiveness of each component in our proposed method. As is shown in Table 3, we implement some variants of the proposed model and report the comparison results. From Table 4, we note the following. (1) the model using the Transformer-encoded knowledge graphs performs better than GloVe-encoded knowledge graph models. (2) The model that integrates both and achieves better performance than the model with either or only. This shows that combining both and can capture more complete correlation information among categories. (3) The performance of our model is better than other variants. This demonstrates the capability of our graph contrastive learning module to generate discriminative and effective classifiers.
Table 4.
Results for the ablation study for 2-hops. and represent graphs encoded by the encoders Glove and Transformer, respectively.
4.6. Analysis of the Number of Layers
We perform an empirical evaluation to verify that our intuition is correct and that additional hidden layers in GUN-2A indeed aggregate more information from the global structure in the knowledge graph. Table 5 reports the model performance of previous similar works [28,29] using GCN with a different number of layers and illustrates the performance when adding additional layers to the GUN for 2-hops task. We observe a steady decline in the performance of previous methods as the number of layers increases. In our experiments, the performance of our model increases with more GCN layers. Compared to the 4-layers GCNZ, we believe that our GUN structure effectively aggregates valid features from remote nodes without modifying the origin topology. However, this aggregation also brings potential concerns of gradients vanishing as the number of GCN layers continues to increase.
Table 5.
Results for 2-hops for the model with different depths.
5. Conclusions
In this paper, we propose a new zero-shot image classification method in ecological monitoring. The proposed method explicitly exploits the hierarchy among natural creatures and explores multiple relations between different classes for learning the weight of a visual classifier. The proposed encoder GUN-2A achieves broad cross-node knowledge propagation. The introduced structural, symmetric knowledge graph and graph contrastive learning module substantially alleviate the Laplacian over-smoothing problem in a single knowledge graph and enhances the distinguishability of the predicted classifier. To validate the potential of our method in real-world environments, we tested it on several large-scale benchmark datasets. Our experimental results demonstrate the effectiveness of the proposed zero-shot learning framework.
Author Contributions
Investigation, L.L. (Lin Liu) and X.D.; resources, P.Z.; data curation, Z.Z.; methodology, L.L. (Liangwei Li); writing—original draft preparation, L.L. (Liangwei Li); writing—review and editing, X.W.; project administration, J.L.; funding acquisition, J.Z. and J.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported partly by the National Natural Science Foundation of China (No. 61405028) and the Fundamental Research Funds for the Central Universities (University of Electronic Science and Technology of China) (No. ZYGX2019J053 and ZYGX2021YGCX020).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The algorithm codes and our dataset will be released online at www.github.com/lil-wayne-0319/CGUN-2A (accessed on 14 December 2022).
Acknowledgments
We would like to express our thanks to Yu-Tang Ye and the staff at the MOEMIL laboratory, who collected and counted the samples used in this study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Salakhutdinov, R.; Torralba, A.; Tenenbaum, J. Learning to Share Visual Appearance for Multiclass Object Detection. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1481–1488. [Google Scholar]
- Wang, Y.-X.; Ramanan, D.; Hebert, M. Learning to Model the Tail. Adv. Neural. Inf. Process Syst. 2017, 30, 7032–7042. [Google Scholar]
- Stork, L.; Weber, A.; van den Herik, J.; Plaat, A.; Verbeek, F.; Wolstencroft, K. Large-Scale Zero-Shot Learning in the Wild: Classifying Zoological Illustrations. Ecol. Inform. 2021, 62, 101222. [Google Scholar] [CrossRef]
- Li, Q.; Rigall, E.; Sun, X.; Lam, K.M.; Dong, J. Dual Autoencoder Based Zero Shot Learning in Special Domain. Pattern Anal. Appl. 2022, 1–12. [Google Scholar] [CrossRef]
- Rasheed, J. Analyzing the Effect of Filtering and Feature-Extraction Techniques in a Machine Learning Model for Identification of Infectious Disease Using Radiography Imaging. Symmetry 2022, 14, 1398. [Google Scholar] [CrossRef]
- Rasheed, J.; Waziry, S.; Alsubai, S.; Abu-Mahfouz, A.M. An Intelligent Gender Classification System in the Era of Pandemic Chaos with Veiled Faces. Processes 2022, 10, 1427. [Google Scholar] [CrossRef]
- Rasheed, J.; Shubair, R.M. Screening Lung Diseases Using Cascaded Feature Generation and Selection Strategies. Healthcare 2022, 10, 1313. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Han, Z.; Wu, X.-M. Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Chen, D.; Lin, Y.; Li, W.; Li, P.; Zhou, J.; Sun, X. Measuring and Relieving the Over-Smoothing Problem for Graph Neural Networks from the Topological View. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3438–3445. [Google Scholar]
- Zhao, L.; Akoglu, L. Pairnorm: Tackling Oversmoothing in Gnns. arXiv 2019, arXiv:1909.12223. [Google Scholar]
- Li, G.; Muller, M.; Thabet, A.; Ghanem, B. Deepgcns: Can Gcns Go as Deep as Cnns? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9267–9276. [Google Scholar]
- Gao, H.; Ji, S. Graph U-Nets. In Proceedings of the International Conference on Machine Learning, PMLR; 2019; pp. 2083–2092. [Google Scholar]
- Wang, J.; Jiang, B. Zero-Shot Learning via Contrastive Learning on Dual Knowledge Graphs. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 885–892. [Google Scholar]
- Villon, S.; Iovan, C.; Mangeas, M.; Vigliola, L. Confronting Deep-Learning and Biodiversity Challenges for Automatic Video-Monitoring of Marine Ecosystems. Sensors 2022, 22, 497. [Google Scholar] [CrossRef]
- Sun, X.; Xv, H.; Dong, J.; Zhou, H.; Chen, C.; Li, Q. Few-Shot Learning for Domain-Specific Fine-Grained Image Classification. IEEE Trans. Ind. Electron. 2020, 68, 3588–3598. [Google Scholar] [CrossRef]
- Pradhan, B.; Al-Najjar, H.A.H.; Sameen, M.I.; Tsang, I.; Alamri, A.M. Unseen Land Cover Classification from High-Resolution Orthophotos Using Integration of Zero-Shot Learning and Convolutional Neural Networks. Remote Sens. 2020, 12, 1676. [Google Scholar] [CrossRef]
- Lampert, C.H.; Nickisch, H.; Harmeling, S. Learning to Detect Unseen Object Classes by Between-Class Attribute Transfer. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 951–958. [Google Scholar]
- Misra, I.; Gupta, A.; Hebert, M. From Red Wine to Red Tomato: Composition with Context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1792–1801. [Google Scholar]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. Devise: A Deep Visual-Semantic Embedding Model. Adv. Neural. Inf. Process Syst. 2013, 26, 2121–2129. [Google Scholar]
- Socher, R.; Ganjoo, M.; Manning, C.D.; Ng, A. Zero-Shot Learning through Cross-Modal Transfer. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, USA, 2-8 December 2012; pp. 935–943. [Google Scholar]
- Norouzi, M.; Mikolov, T.; Bengio, S.; Singer, Y.; Shlens, J.; Frome, A.; Corrado, G.S.; Dean, J. Zero-Shot Learning by Convex Combination of Semantic Embeddings. arXiv 2013, arXiv:1312.5650. [Google Scholar]
- Elhoseiny, M.; Saleh, B.; Elgammal, A. Write a Classifier: Zero-Shot Learning Using Purely Textual Descriptions. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2584–2591. [Google Scholar]
- Changpinyo, S.; Chao, W.-L.; Sha, F. Predicting Visual Exemplars of Unseen Classes for Zero-Shot Learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3476–3485. [Google Scholar]
- Palatucci, M.; Pomerleau, D.; Hinton, G.E.; Mitchell, T.M. Zero-Shot Learning with Semantic Output Codes. In Proceedings of the 22nd International Conference on Neural Information Processing Systems, Vancouver, Canada, 8–13 December 2008; pp. 1410–1418. [Google Scholar]
- Rohrbach, M.; Stark, M.; Schiele, B. Evaluating Knowledge Transfer and Zero-Shot Learning in a Large-Scale Setting. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1641–1648. [Google Scholar]
- Deng, J.; Ding, N.; Jia, Y.; Frome, A.; Murphy, K.; Bengio, S.; Li, Y.; Neven, H.; Adam, H. Large-Scale Object Classification Using Label Relation Graphs. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 48–64. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Wang, X.; Ye, Y.; Gupta, A. Zero-Shot Recognition via Semantic Embeddings and Knowledge Graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6857–6866. [Google Scholar]
- Kampffmeyer, M.; Chen, Y.; Liang, X.; Wang, H.; Zhang, Y.; Xing, E.P. Rethinking Knowledge Graph Propagation for Zero-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11487–11496. [Google Scholar]
- Rong, Y.; Huang, W.; Xu, T.; Huang, J. Dropedge: Towards Deep Graph Convolutional Networks on Node Classification. arXiv 2019, arXiv:1907.10903. [Google Scholar]
- Xu, K.; Li, C.; Tian, Y.; Sonobe, T.; Kawarabayashi, K.; Jegelka, S. Representation Learning on Graphs with Jumping Knowledge Networks. In Proceedings of the International Conference on Machine Learning, Macau, China, 26–28 February 2018; pp. 5453–5462. [Google Scholar]
- Abu-El-Haija, S.; Perozzi, B.; Kapoor, A.; Alipourfard, N.; Lerman, K.; Harutyunyan, H.; ver Steeg, G.; Galstyan, A. Mixhop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 21–29. [Google Scholar]
- Klicpera, J.; Weißenberger, S.; Günnemann, S. Diffusion Improves Graph Learning. arXiv 2019, arXiv:1911.05485 2019. [Google Scholar]
- Klicpera, J.; Bojchevski, A.; Günnemann, S. Predict Then Propagate: Graph Neural Networks Meet Personalized Pagerank. arXiv 2018, arXiv:1810.05997. [Google Scholar]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and Deep Graph Convolutional Networks. In Proceedings of the International Conference on Machine Learning, Shenzhen, China, 13–18 July 2020; pp. 1725–1735. [Google Scholar]
- Zhu, Y.; Xu, Y.; Yu, F.; Liu, Q.; Wu, S.; Wang, L. Graph Contrastive Learning with Adaptive Augmentation. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 2069–2080. [Google Scholar]
- Velickovic, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. ICLR (Poster) 2019, 2, 4. [Google Scholar]
- You, Y.; Chen, T.; Sui, Y.; Chen, T.; Wang, Z.; Shen, Y. Graph Contrastive Learning with Augmentations. Adv. Neural. Inf. Process Syst. 2020, 33, 5812–5823. [Google Scholar]
- Hassani, K.; Khasahmadi, A.H. Contrastive Multi-View Representation Learning on Graphs. In Proceedings of the International Conference on Machine Learning, Shenzhen, China, 15–17 February 2020; pp. 4116–4126. [Google Scholar]
- Zou, D.; Wei, W.; Mao, X.-L.; Wang, Z.; Qiu, M.; Zhu, F.; Cao, X. Multi-Level Cross-View Contrastive Learning for Knowledge-Aware Recommender System. arXiv 2022, arXiv:2204.08807. [Google Scholar]
- Jiang, H.; Wang, R.; Shan, S.; Chen, X. Transferable Contrastive Network for Generalized Zero-Shot Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9765–9774. [Google Scholar]
- Anwaar, M.U.; Khan, R.A.; Pan, Z.; Kleinsteuber, M. A Contrastive Learning Approach for Compositional Zero-Shot Learning. In Proceedings of the 2021 International Conference on Multimodal Interaction, Montreal, QC, Canada, 18–22 October 2021; pp. 34–42. [Google Scholar]
- Li, X.; Yang, X.; Wei, K.; Deng, C.; Yang, M. Siamese Contrastive Embedding Network for Compositional Zero-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 9326–9335. [Google Scholar]
- Guan, J.; Meng, M.; Liang, T.; Liu, J.; Wu, J. Dual-Level Contrastive Learning Network for Generalized Zero-Shot Learning. Vis. Comput. 2022, 38, 3087–3095. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Miller, G.A. WordNet: A Lexical Database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning, online, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised Feature Learning via Non-Parametric Instance Discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3733–3742. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R. Resnest: Split-Attention Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 2736–2746. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26–28 October 2014; pp. 1532–1543. [Google Scholar]
- Nayak, N.V.; Bach, S.H. Zero-Shot Learning with Common Sense Knowledge Graphs. arXiv 2020, arXiv:2006.10713. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).