

Structure and Base Analysis of Receptive Field Neural Networks in a Character Recognition Task


Abstract
1. Introduction
1.1. Simplification of Convolutional Neural Networks
1.2. Path towards Receptive Field Neural Networks
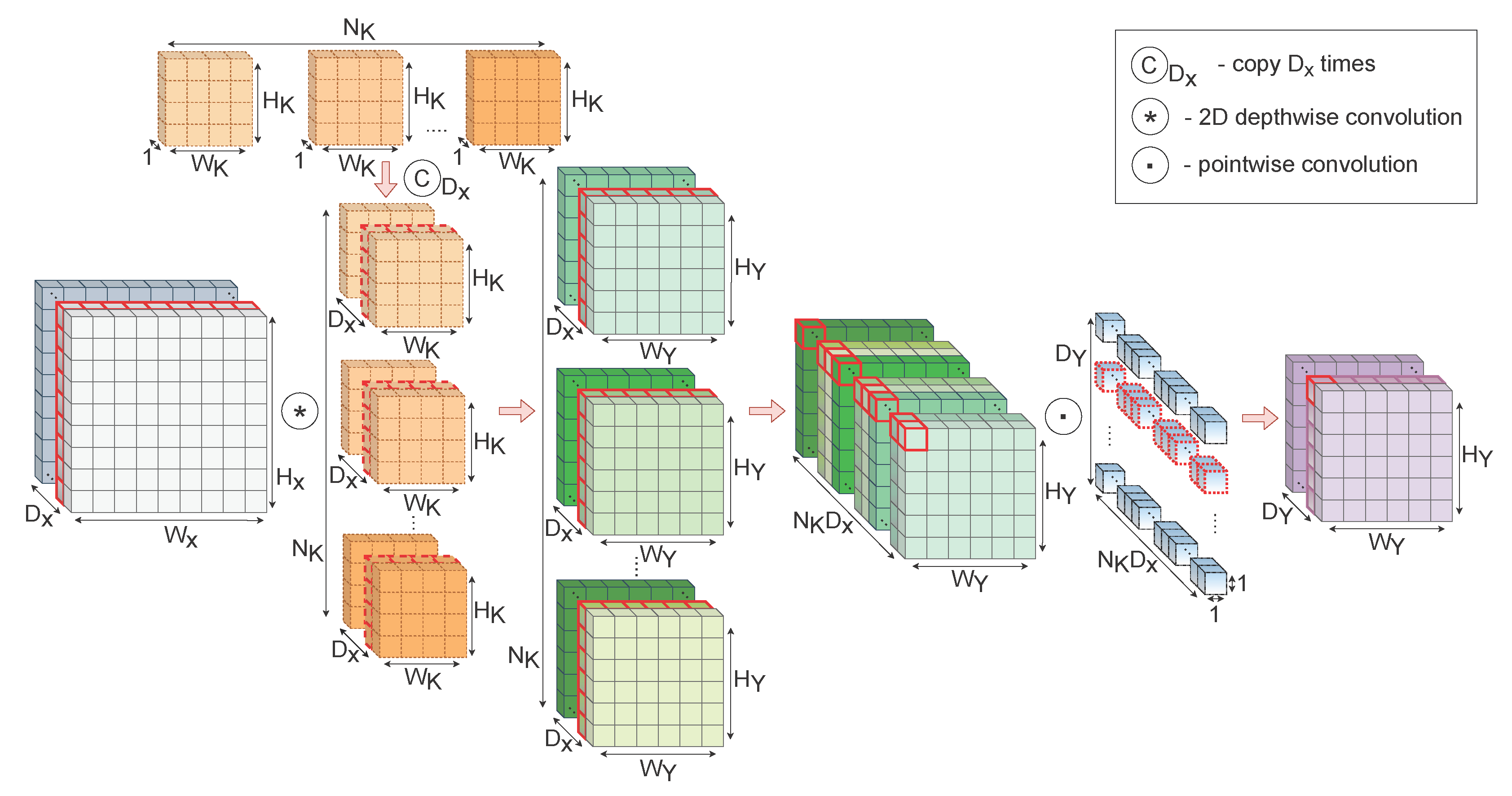
2. Receptive Field Neural Layer
- A set of fixed two-dimensional kernels (—number of kernels; , —width and height of kernels);
- The convolution parameters used for feature extraction (padding, stride, and possibly other additional parameters);
- The number of output feature maps (—depth dimension of the output tensor).
3. Choice of Reference Architecture
4. Proposed Changes
- All used frameworks were set to deterministic mode;
- All parameters were initialised based on one chosen experimental seed;
- To ensure variability, the selected experimental seed was used to generate a seed vector for all runs of the experiment.
5. Experiments and Results
5.1. Experiment 1—Reference Architecture Evaluation
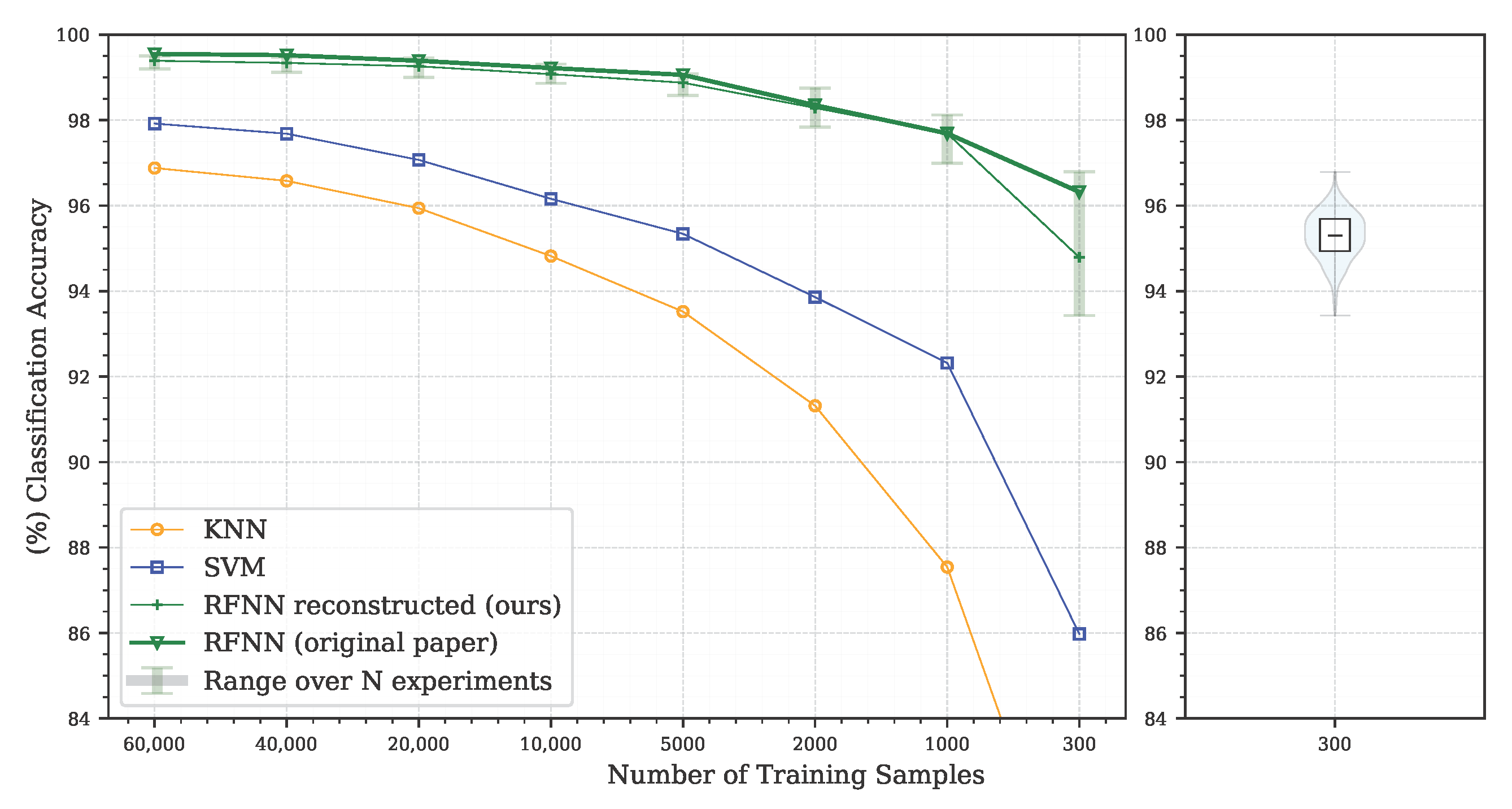
5.2. Experiment 2—Reference Architecture and Limited Number of Training Samples
5.2.1. Stratified Sampling

5.2.2. Early Stopping
5.2.3. Optimizer Modification

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methodology | Mean Accuracy | Min Accuracy | Max Accuracy | Variance |
|---|---|---|---|---|
| Adadelta + lr decay (orig) | 95.26 | 93.70 | 96.63 | 0.3033 |
| (orig) + Stratification | 95.30 | 93.64 | 96.54 | 0.2684 |
| (orig) + Early Stopping (20) | 92.39 | 84.78 | 95.03 | 2.7026 |
| (orig) + Early Stopping (100) | 93.28 | 84.78 | 95.76 | 2.3816 |
| AdamW | 94.64 | 93.08 | 96.39 | 0.3854 |
| Nadam | 94.88 | 92.93 | 96.18 | 0.3993 |
| Adam | 94.65 | 92.67 | 96.17 | 0.3889 |
| Adadelta | 94.08 | 91.15 | 95.78 | 0.5439 |
| AdaBound | 92.94 | 90.59 | 94.76 | 0.6310 |
| AdamW + lr decay | 95.67 | 94.08 | 96.92 | 0.2204 |
5.3. Experiment—Simplification of RFNN Architecture
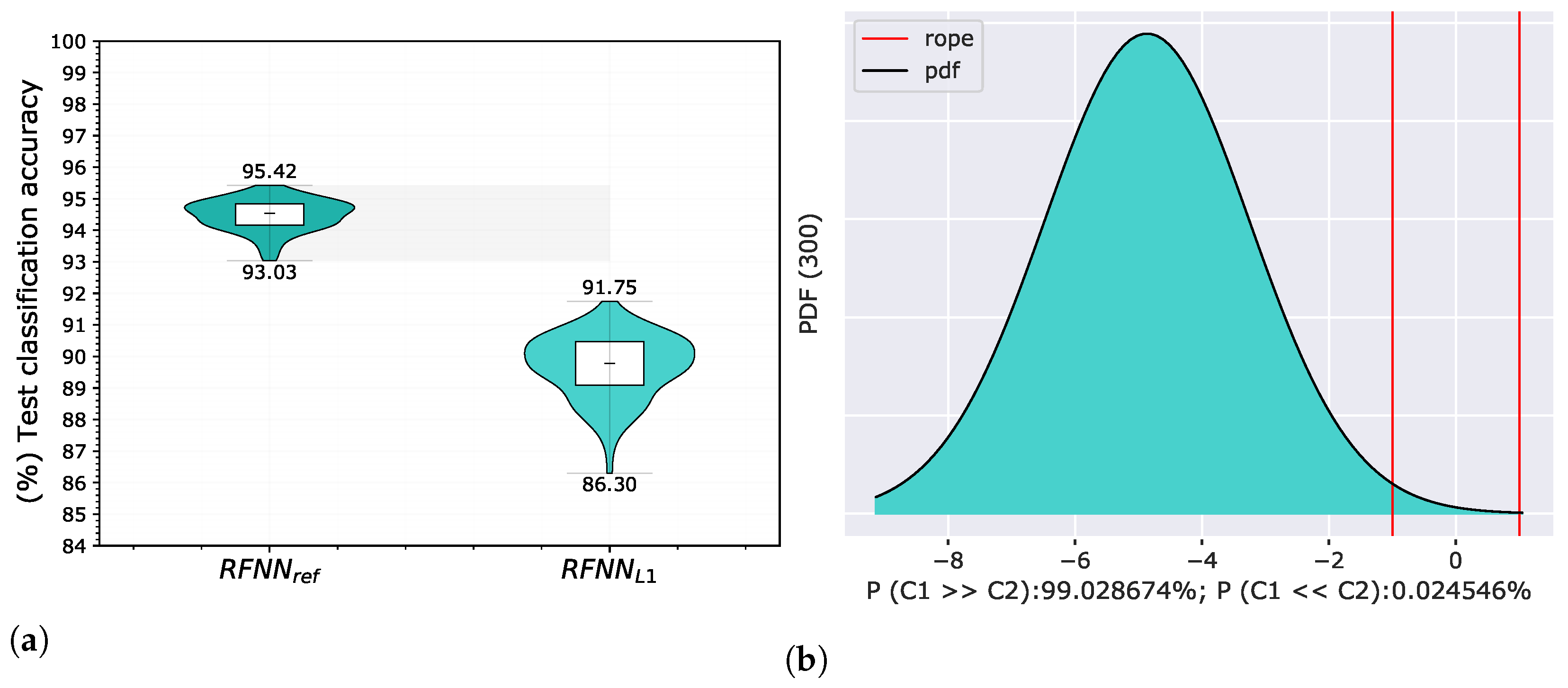
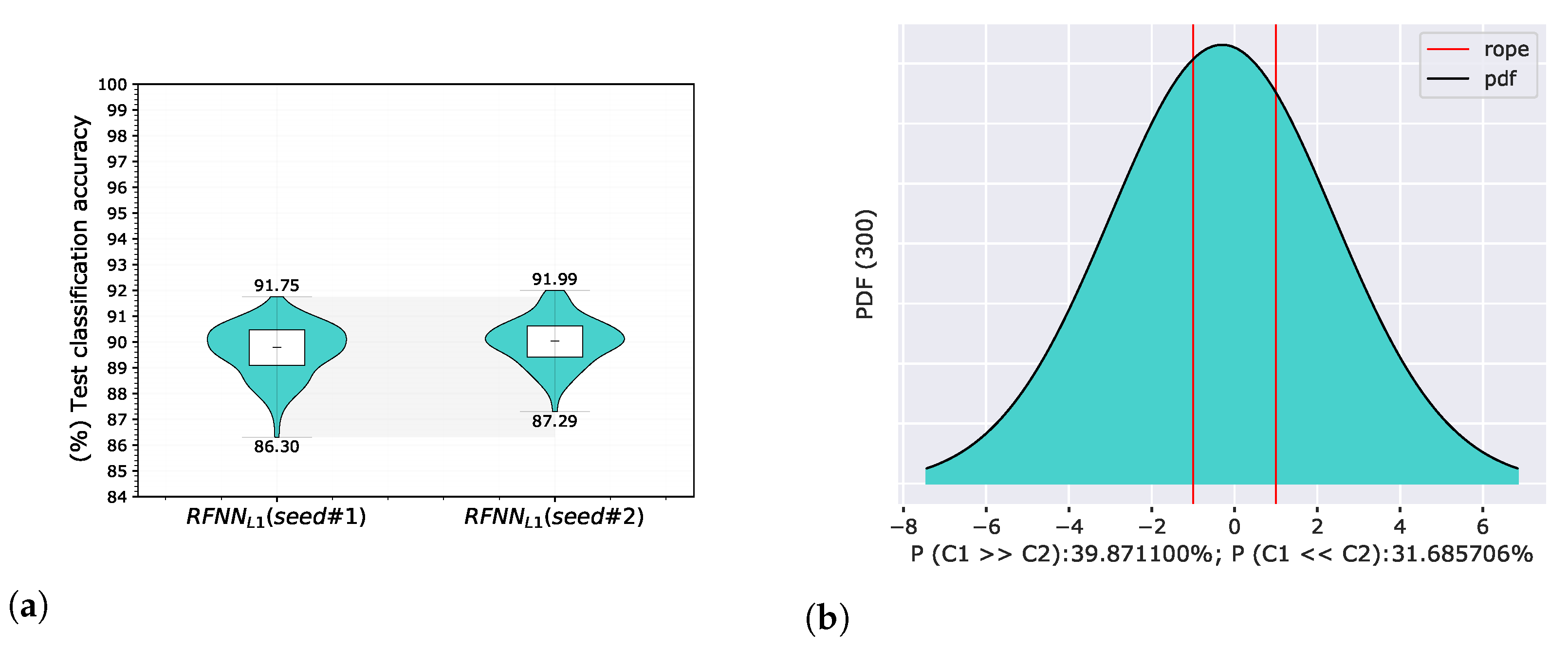
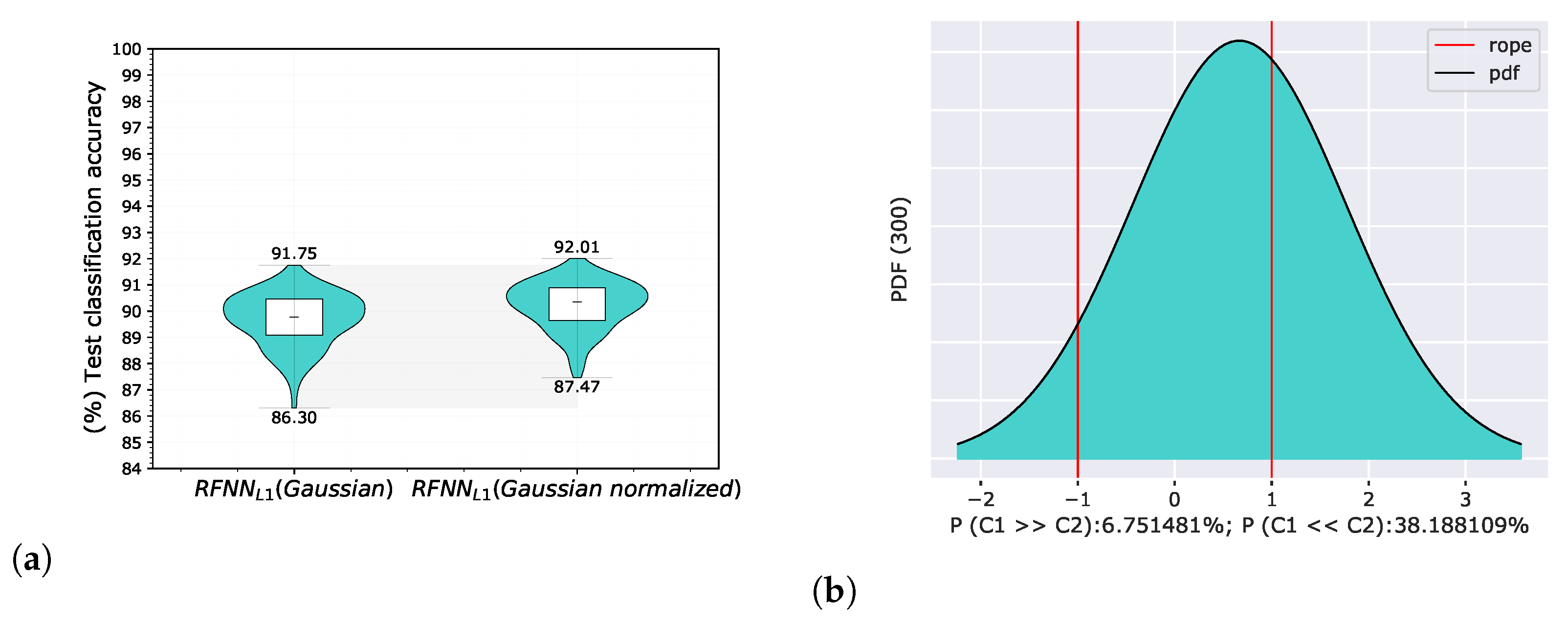
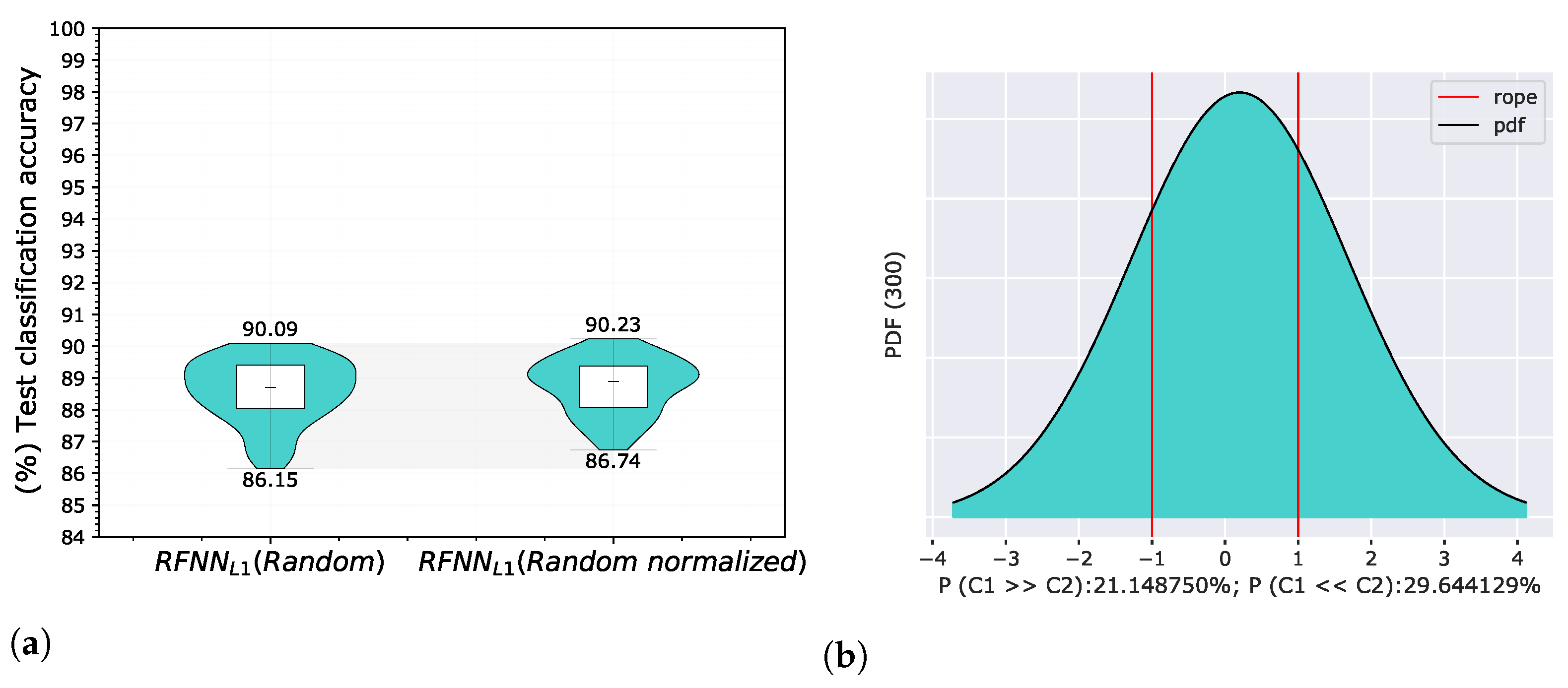
5.4. Experiment 4—Sample Selection and Energy Normalization
5.4.1. Sample Selection
5.4.2. Basis Energy Normalization
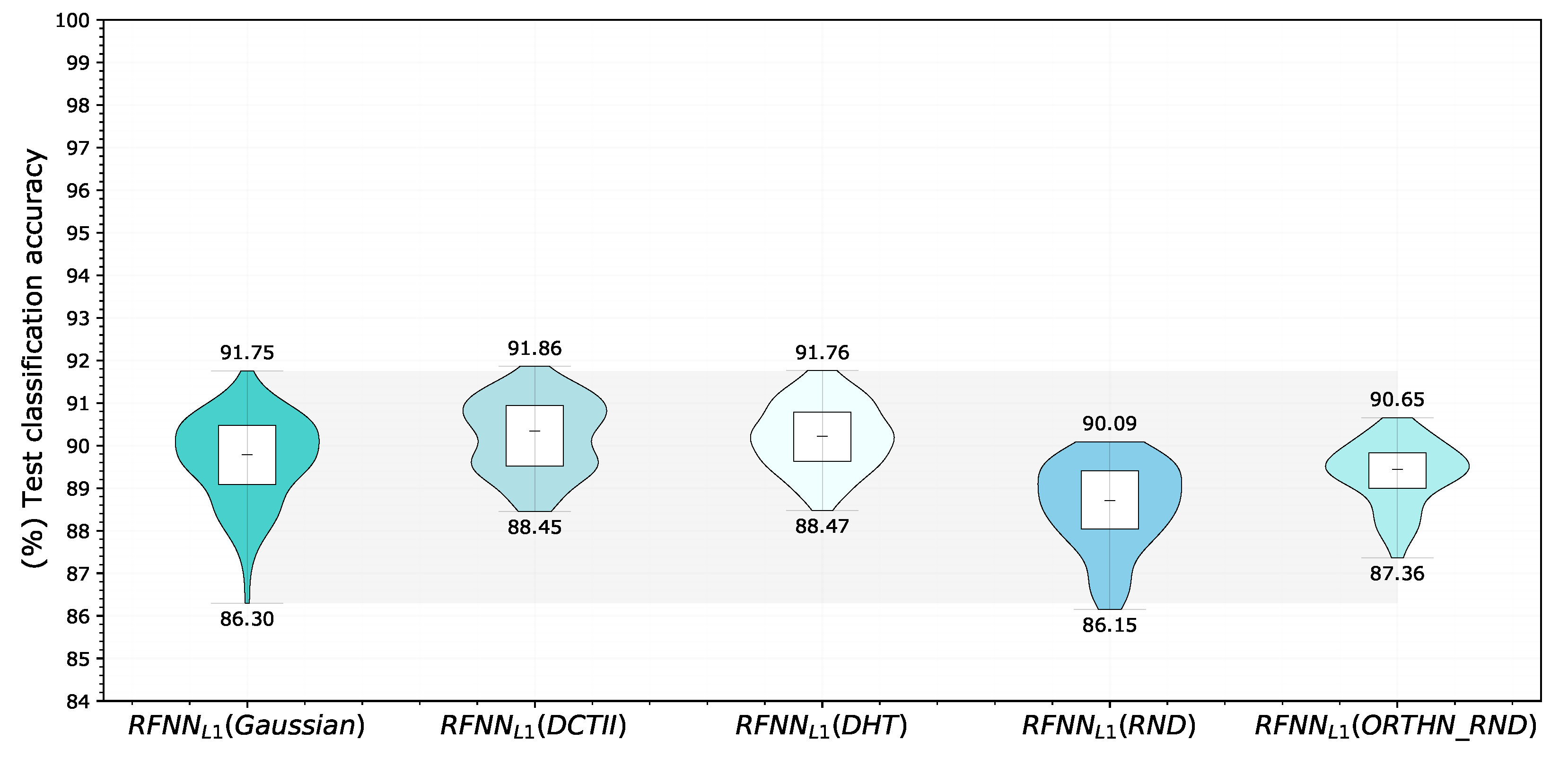
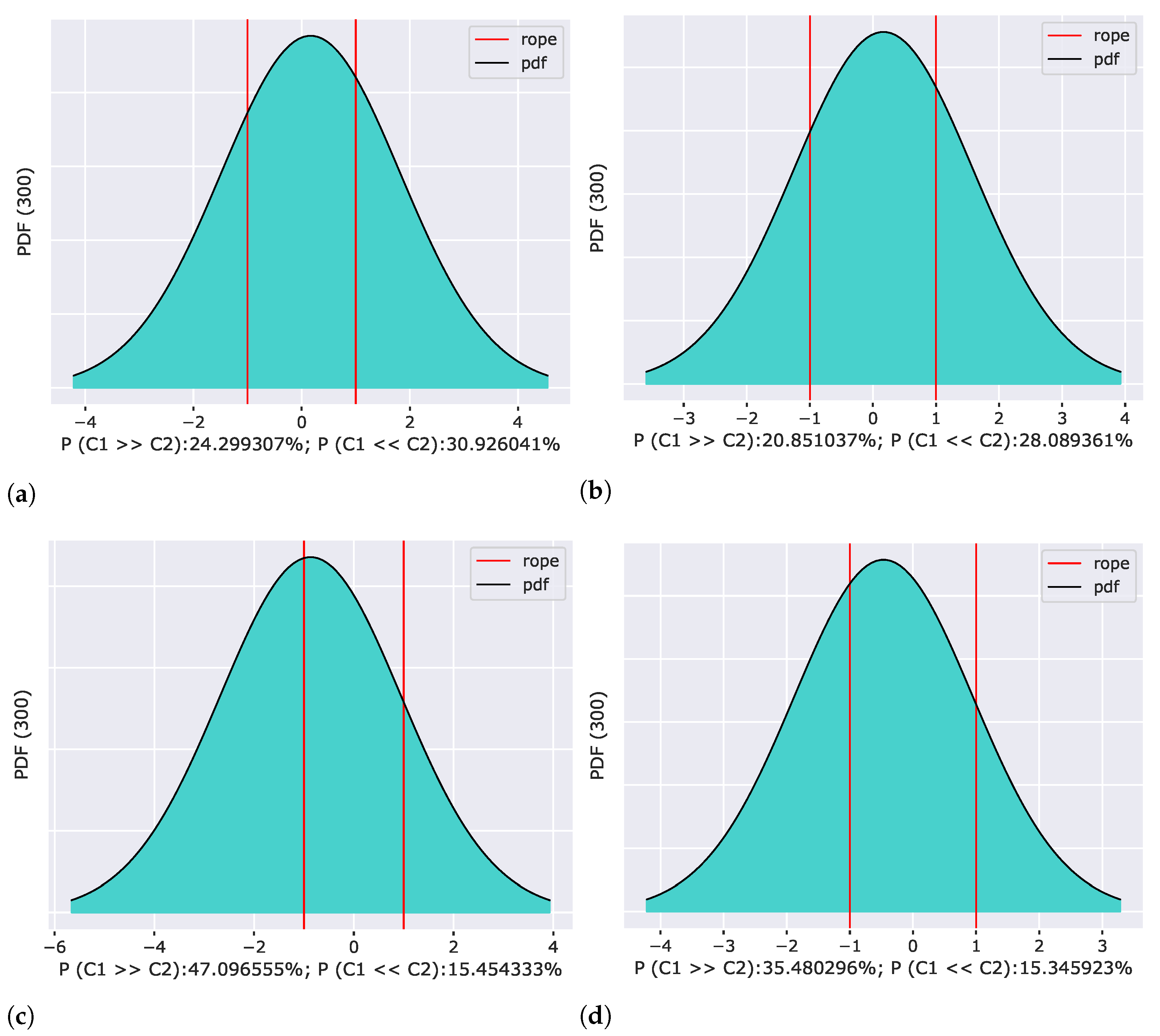
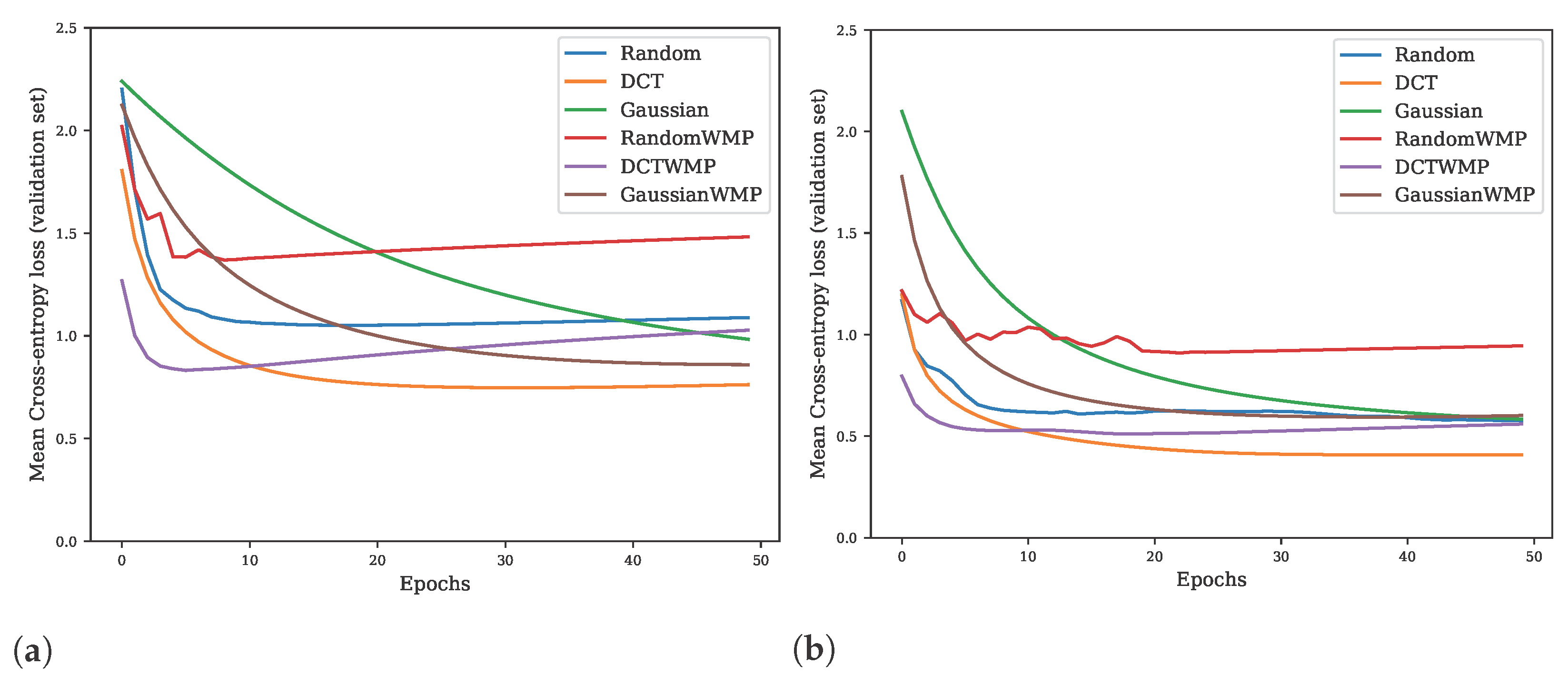
5.5. Experiment 5—Basis-Related Experiments
5.6. Experiment 6—Learning Curve Analysis and Max-Pooling Removal
6. Discussion
7. Conclusions, Limitations, and Future Research Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mishkin, D.; Sergievskiy, N.; Matas, J. Systematic Evaluation of Convolution Neural Network Advances on the Imagenet. Comput. Vis. Image Underst. 2017, 161, 11–19. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ozturk, S.; Ozkaya, U.; Akdemir, B.; Seyfi, L. Convolution Kernel Size Effect on Convolutional Neural Network in Histopathological Image Processing Applications. In Proceedings of the 2018 International Symposium on Fundamentals of Electrical Engineering, ISFEE 2018, Bucharest, Romania, 1–3 November 2018. [Google Scholar]
- Karatzoglou, A.; Schnell, N.; Beigl, M. Applying Depthwise Separable and Multi-Channel Convolutional Neural Networks of Varied Kernel Size on Semantic Trajectories. Neural Comput. Appl. 2020, 32, 6685–6698. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python; Manning: Shelter Island, NY, USA, 2017; p. 384. ISBN 9781617294433. [Google Scholar]
- Yao, H.; Chuyi, L.; Dan, H.; Weiyu, Y. Gabor Feature Based Convolutional Neural Network for Object Recognition in Natural Scene. In Proceedings of the Proceedings—2016 3rd International Conference on Information Science and Control Engineering, ICISCE 2016, Beijing, China, 8–10 July 2016. [Google Scholar]
- Rudin, C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A Survey of Transfer Learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Hussain, Z.; Gimenez, F.; Yi, D.; Rubin, D. Differential Data Augmentation Techniques for Medical Imaging Classification Tasks. AMIA Annu. Symp. Proc. 2017, 2017, 979. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv 2016. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. Conference Track Proceedings. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sifre, L.; Mallat, S. Rotation, Scaling and Deformation Invariant Scattering for Texture Discrimination. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Chang, S.Y.; Morgan, N. Robust CNN-Based Speech Recognition with Gabor Filter Kernels. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Singapore, 14–18 September 2014. [Google Scholar]
- Li, J.; Wang, T.; Zhou, Y.; Wang, Z.; Snoussi, H. Using Gabor Filter in 3D Convolutional Neural Networks for Human Action Recognition. In Proceedings of the Chinese Control Conference, CCC, Dalian, China, 26–28 July 2017. [Google Scholar]
- Sarwar, S.S.; Panda, P.; Roy, K. Gabor Filter Assisted Energy Efficient Fast Learning Convolutional Neural Networks. In Proceedings of the International Symposium on Low Power Electronics and Design, Taipei, Taiwan, 24–26 July 2017. [Google Scholar]
- Shelhamer, E.; Wang, D.; Darrell, T. Efficient Receptive Field Learning by Dynamic Gaussian Structure. In Proceedings of the ICLR 2019 Workshop, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Luan, S.; Chen, C.; Zhang, B.; Han, J.; Liu, J. Gabor Convolutional Networks. IEEE Trans. Image Process. 2018, 27, 4357–4366. [Google Scholar] [CrossRef] [PubMed]
- Tabernik, D.; Kristan, M.; Leonardis, A. Spatially-Adaptive Filter Units for Deep Neural Networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Tabernik, D.; Kristan, M.; Leonardis, A. Spatially-Adaptive Filter Units for Compact and Efficient Deep Neural Networks. Int. J. Comput. Vis. 2020, 128, 2049–2067. [Google Scholar] [CrossRef]
- Li, J.Y.; Zhao, Y.K.; Xue, Z.E.; Cai, Z.; Li, Q. A Survey of Model Compression for Deep Neural Networks. Gongcheng Kexue Xuebao/Chinese J. Eng. 2019, 41, 1229–1239. [Google Scholar]
- Blalock, D.; Gonzalez Ortiz, J.J.; Frankle, J.; Guttag, J. What is the state of neural network pruning? In Proceedings of the 3rd MLSys Conference, Austin, TX, USA, 2–4 March 2020.
- Jacobsen, J.H.; Van Gemert, J.; Lou, Z.; Smeulders, A.W.M. Structured Receptive Fields in CNNs. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; Volume 2016. [Google Scholar]
- Schlimbach, R.J. Investigating Scale in Receptive Fields Neural Networks. Bachelor’s Thesis, University of Amsterdam, Amsterdam, The Netherlands, 2018. [Google Scholar]
- Pintea, S.L.; Tomen, N.; Goes, S.F.; Loog, M.; Van Gemert, J.C. Resolution Learning in Deep Convolutional Networks Using Scale-Space Theory. IEEE Trans. Image Process. 2021, 30, 8342–8353. [Google Scholar] [CrossRef]
- Hilbert, A.; Veeling, B.S.; Marquering, H.A. Data-Efficient Convolutional Neural Networks for Treatment Decision Support in Acute Ischemic Stroke 2018. In Proceedings of the 1st Conference on Medical Imaging with Deep Learning (MIDL 2018), Amsterdam, The Netherlands, 4–6 July 2018. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the Proceedings—30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; Volume 2017. [Google Scholar]
- Verkes, G. Receptive Fields Neural Networks Using the Gabor Kernel Family. Bachelor’s Thesis, University of Amsterdam, Amsterdam, The Netherlands, 2017. [Google Scholar]
- Labate, D.; Safaripoorfatide, M.; Karantzas, N.; Prasad, S.; Foroozandeh Shahraki, F. Structured Receptive Field Networks and Applications to Hyperspectral Image Classification. In Proceedings of the Wavelets Sparsity XVIII, San Diego, CA, USA, 11–15 August 2019; Volume 11138, pp. 218–226. [Google Scholar] [CrossRef]
- Karantzas, N.; Safari, K.; Haque, M.; Sarmadi, S.; Papadakis, M. Compactly Supported Frame Wavelets and Applications in Convolutional Neural Networks. In Proceedings of the Wavelets Sparsity XVIII, San Diego, CA, USA, 11–15 August 2019; Volume 11138, pp. 152–164. [Google Scholar] [CrossRef]
- Ulicny, M.; Krylov, V.A.; Dahyot, R. Harmonic Convolutional Networks Based on Discrete Cosine Transform. Pattern Recognit. Pattern Recognit. 2022, 129, 108707. [Google Scholar] [CrossRef]
- Ulicny, M.; Krylov, V.A.; Dahyot, R. Harmonic Networks for Image Classification. In Proceedings of the British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Ulicny, M.; Krylov, V.A.; Dahyot, R. Harmonic Networks with Limited Training Samples; In Proceedings of the 27th European Signal Processing Conference, EUSIPCO, Coruña, Spain, 2–6 September 2019.
- Kumawat, S.; Raman, S. Depthwise-STFT Based Separable Convolutional Neural Networks. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3337–3341. [Google Scholar] [CrossRef]
- Tomen, N.; Pintea, S.-L.; Gemert, J. Van Deep Continuous Networks. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event. 18–24 July 2021. PMLR 139:10324-110335. [Google Scholar]
- Saldanha, N.; Pintea, S.L.; Van Gemert, J.C.; Tomen, N. Frequency Learning for Structured CNN Filters with Gaussian Fractional Derivatives. arXiv 2021, arXiv:2111.06660. [Google Scholar]
- Lindeberg, T. Scale-Covariant and Scale-Invariant Gaussian Derivative Networks. J. Math. Imaging Vis. 2022, 64, 223–242. [Google Scholar] [CrossRef]
- Elmoataz, A.; Fadili, J.; Quéau, Y.; Rabin, J.; Simon, L. (Eds.) Scale Space and Variational Methods in Computer Vision: 8th International Conference, SSVM 2021, Virtual Event, May 16–20, 2021, Proceedings; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2021; Volume 12679, pp. 3–14. [Google Scholar] [CrossRef]
- Fukuzaki, S.; Ikehara, M. Principal Components of Neural Convolution Filters. IEEE Access 2022, 10, 104328–104336. [Google Scholar] [CrossRef]
- Penaud–Polge, V.; Velasco-Forero, S.; Angulo, J. Fully Trainable Gaussian Derivative Convolutional Layer. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 2421–2425. [Google Scholar] [CrossRef]
- Wei, H.; Wang, Z.; Hua, G. Dynamically Mixed Group Convolution to Lighten Convolution Operation. In Proceedings of the 2021 4th International Conference on Artificial Intelligence and Big Data, ICAIBD 2021, Chengdu, China, 28–31 May 2021. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the Proceedings—30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury Google, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the 33rd Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar] [CrossRef]
- Yann, L.; Corinna, C. Burges Christopher THE MNIST DATABASE of Handwritten Digits. Courant Inst. Math. Sci. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 1 October 2022).
- Benavoli, A.; Corani, G.; Demšar, J.; Zaffalon, M. Time for a Change: A Tutorial for Comparing Multiple Classifiers through Bayesian Analysis. J. Mach. Learn. Res. 2017, 18, 2653–2688. [Google Scholar]
- Corani, G.; Benavoli, A.; Demšar, J.; Mangili, F.; Zaffalon, M. Statistical Comparison of Classifiers through Bayesian Hierarchical Modelling. Mach. Learn. 2017, 106, 1817–1837. [Google Scholar] [CrossRef]
- Nilsson, A.; Smith, S.; Ulm, G.; Gustavsson, E.; Jirstrand, M. A Performance Evaluation of Federated Learning Algorithms. In Proceedings of the DIDL 2018—Proceedings of the 2nd Workshop on Distributed Infrastructures for Deep Learning, Part of Middleware 201, Rennes, France, 10 December 2018. [Google Scholar]
- Crane, M. Questionable Answers in Question Answering Research: Reproducibility and Variability of Published Results. Trans. Assoc. Comput. Linguist. 2018, 6, 241–252. [Google Scholar] [CrossRef]
- Hintze, J.L.; Nelson, R.D. Violin Plots: A Box Plot-Density Trace Synergism Statistical Computing and Graphics Violin Plots: A Box Plot-Density Trace Synergism. Source Am. Stat. 1998, 52, 181–184. [Google Scholar]
- Prechelt, L. Early Stopping—But When? Lect. Notes Comput. Sci. 2012, 7700, 55–69. [Google Scholar] [CrossRef]
- Choi, D.; Shallue, C.J.; Nado, Z.; Lee, J.; Maddison, C.J.; Dahl, G.E. On Empirical Comparisons of Optimizers for Deep Learning. arXiv 2019. [Google Scholar] [CrossRef]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive Gradient Methods with Dynamic Bound of Learning Rate. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Dozat, T. Incorporating Nesterov Momentum into Adam. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016 —Conference Track Proceedings, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Shao, J.; Hu, K.; Wang, C.; Xue, X.; Raj, B. Is Normalization Indispensable for Training Deep Neural Networks? In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 2020. [Google Scholar]
- Huang, L.; Qin, J.; Zhou, Y.; Zhu, F.; Liu, L.; Shao, L. Normalization Techniques in Training DNNs: Methodology, Analysis and Application. arXiv 2020. [Google Scholar] [CrossRef]
- Clanuwat, T.; Bober-Irizar, M.; Kitamoto, A.; Lamb, A.; Yamamoto, K.; Ha, D. Deep Learning for Classical Japanese Literature. arXiv 1998. Available online: https://github.com/rois-codh/kmnist (accessed on 1 December 2022).
- Li, L.; Wang, K.; Li, S.; Feng, X.; Zhang, L. LST-Net: Learning a Convolutional Neural Network with a Learnable Sparse Transform. Lect. Notes Comput. Sci. 2020, 12355, 562–579. [Google Scholar] [CrossRef]










| Authors | Proposed Network | Reference Architecture | Fixed Kernels |
|---|---|---|---|
| Jacobsen et al. (2016) [26] | Receptive Field Neural Network | multi-layer CNN, Network in Network | Gaussian derivative basis |
| Verkes (2017) [31] | Gabor RFNN | multi-layer CNN | Gabor kernel family |
| Schlimbach (2018) [27] | Gaussian RFNN | multi-layer CNN | Gaussian derivative basis |
| Hilbert et al. (2018) [29] | Multi-Scale and -Orientation RFNN | DenseNet | Gaussian derivative basis |
| Karantzas et al. (2019) [33] | ResnetRF | ResNet18, ResNet34, ResNet50 | directional Parseval frames with compact support |
| Labate et al. (2019) [32] | Geometric-Biased CNN | multi-layer CNN | directional Parseval frames with compact support |
| Ulicny et al. (2019, 2019, 2022) [34,35,36] | Harmonic Network | multi-layer CNN, Wide residual network, SE-ResNeXt, Resnet-50, Resnet-101 | DCT basis (various) |
| Kumawat et al. (2020) [37] | Depthwise-STFT Based Separable Convolutional Neural Network | MobileNet, ShuffleNet, ReLPU | Short-Term Fourier Transform kernels |
| Pintea et al. (2021) [28] | N-JetNet | Network in Network, ALLCNN, Resnet-32, Resnet-110, EfficientNet | Gaussian derivative basis (dynamic size) |
| Tomen et al. (2021) [38] | Deep Continuous Network | ResNet-34, ODE-Net | Gaussian derivative basis (dynamic size) |
| Saldanha et al. (2021) [39] | FracSRF Network | Network in Network, Resnet-32, EfficientNet-b0 | Gaussian derivative basis (dynamic size) |
| Lindeberg (2021, 2022) [40,41] | Scale-covariant and Scale-invariant Gaussian Derivative Network | multi-layer CNN | scale-normalized Gaussian derivative basis (various) |
| Fukuzaki et al. (2022) [42] | OtX | VGG-16,
DenseNet-121, EfficientNetV2-S, NFNet- F0 | Principal Component Analysis of well-trained filter weights |
| Penaud–Polge et al. (2022) [43] | Fully Trainable Gaussian Derivative Network | VGG-16, U-Net | oriented and shifted Gaussian derivative kernels (various) |
| Layer Number and Type | Inner Computational Layers | Hyperparameters | Output Shape | Learnable Parameters |
|---|---|---|---|---|
| #0 Input | - | - | 0 | |
| #1 RFConv | Depthwise convolution | fixed Gaussian kernels of shape , stride = 1, padding = 5 | 0 | |
| Pointwise convolution | number of kernels = 64, stride = 1, padding = 0 | 640 | ||
| Max pooling | kernel size = , stride = 2 | 0 | ||
| ReLu | - | 0 | ||
| Local response normalization | size = 9, , , | 0 | ||
| Dropout | p = | 0 | ||
| #2 RFConv | Depthwise convolution | fixed Gaussian kernels of shape , stride = 1, padding = 6 | 0 | |
| Pointwise convolution | number of kernels = 64, stride = 1, padding = 0 | 24,576 | ||
| Max pooling | kernel size = , stride = 2 | 0 | ||
| ReLu | - | 0 | ||
| Local response normalization | size = 9, , , | 0 | ||
| Dropout | p = | 0 | ||
| #3 RFConv | Depthwise convolution | fixed Gaussian kernels of shape , stride = 1, padding = 6 | 0 | |
| Pointwise convolution | number of kernels = 64, stride = 1, padding = 0 | 24,576 | ||
| Max pooling | kernel size = , stride = 2 | 0 | ||
| ReLu | - | 0 | ||
| Local response normalization | size = 9, , , | 0 | ||
| Dropout | p = | 0 | ||
| #4 Flatten | Reshape | - | 0 | |
| #5 Linear | Fully-connected | - | 31,360 | |
| #6 Output | Softmax | - | 0 |
| Number of samples | 60,000 | 40,000 | 20,000 | 10,000 | 5000 | 2000 | 1000 | 300 |
| Number of epochs | 100 | 100 | 100 | 100 | 150 | 200 | 300 | 1000 |
| Layer Number and Type | Inner Computational Layers | Hyperparameters | Output Shape | Learnable Parameters |
|---|---|---|---|---|
| #0 Input | - | - | 0 | |
| #1 RFConv | Depthwise convolution | fixed Gaussian kernels of shape , stride = 1, padding = same | 0 | |
| Pointwise convolution | number of kernels = 64, stride = 1, padding = 0 | 640 | ||
| Max pooling | kernel size = , stride = 2 | 0 | ||
| ReLu | - | 0 | ||
| #4 Flatten | Reshape | - | 0 | |
| #5 Linear | Fully connected | - | 108,160 | |
| #6 Output | Softmax | - | 0 |
| Base | Mean Accuracy | Min Accuracy | Max Accuracy | Variance |
|---|---|---|---|---|
| Gaussian | 89.67 | 86.30 | 91.75 | 1.0131 |
| Discrete Cosine (DCTII) | 90.21 | 88.45 | 91.86 | 0.7268 |
| Discrete Hartley (DHT) | 90.20 | 88.47 | 91.76 | 0.5958 |
| Random (RND) | 88.48 | 86.15 | 90.09 | 0.9813 |
|
Orthonormal random (ORTHN_RND) | 89.32 | 87.36 | 90.65 | 0.5528 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goga, J.; Vargic, R.; Pavlovicova, J.; Kajan, S.; Oravec, M. Structure and Base Analysis of Receptive Field Neural Networks in a Character Recognition Task. Sensors 2022, 22, 9743. https://doi.org/10.3390/s22249743
Goga J, Vargic R, Pavlovicova J, Kajan S, Oravec M. Structure and Base Analysis of Receptive Field Neural Networks in a Character Recognition Task. Sensors. 2022; 22(24):9743. https://doi.org/10.3390/s22249743
Chicago/Turabian StyleGoga, Jozef, Radoslav Vargic, Jarmila Pavlovicova, Slavomir Kajan, and Milos Oravec. 2022. "Structure and Base Analysis of Receptive Field Neural Networks in a Character Recognition Task" Sensors 22, no. 24: 9743. https://doi.org/10.3390/s22249743
APA StyleGoga, J., Vargic, R., Pavlovicova, J., Kajan, S., & Oravec, M. (2022). Structure and Base Analysis of Receptive Field Neural Networks in a Character Recognition Task. Sensors, 22(24), 9743. https://doi.org/10.3390/s22249743