2.1. The YOLOv5 Model
YOLOv5 is divided into four versions according to the size of the model, namely YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x, and the width and depth of each version increases in order. The YOLOv5 model is divided into four layers of structure: Input, Backbone, Neck, and Detect. The input contains three parts: Mosaic data enhancement, adaptive computation of the anchor frame, and adaptive scaling of the image. During training, the input side enriches the dataset by image stitching or overlaying random scaling, in which the interaction ratio is obtained by adaptively computing the anchor frame, and finally the dimensionally consistent image is obtained by adaptive scaling.
The Backbone layer extracts the main feature information. YOLOv5 version 6.0 uses convolutional operations instead of Focus module in previous versions. The backbone layer is mainly divided into Conv module, C3 module, and SPPF module. Conv module in YOLOv5 version 6.0 contains Conv2d, Batch Normalization, and SiLU activation function. C3 module contains 3. The C3 module contains 3 Conv modules and several Bottleneck modules. The Spatial Pyramid Pooling—Fast (SPPF) module replaces the original Spatial Pyramid Pooling (SPP) module in YOLOv5 6.0 and is much faster.
The Neck layer uses Path Aggregation Network (PANet) and Feature Pyramid Networks for feature fusion, fusing features from different layers to detect small and large targets, and is responsible for passing image features to the Detect layer. Among them, Path Aggregation Network (PANet) serves to solve the problem of arbitrary size of input data and increase the perceptual field of the network, and Feature Pyramid Networks improve the detection of small targets.
YOLOv5 makes a prediction for each grid of the feature map, uses the predicted information to compare with the true information, and then decides the next convergence. The loss function is the evaluation criterion for predicted information and the real information, the smaller the loss function is, the closer the predicted information is to the real information. The loss of YOLOv5 mainly contains bbox_loss (Rectangular frame loss), cls_loss (Classification loss), and obj_loss (Confidence loss).
IoU (Interaction Over Union), also known as interaction ratio, is an indication of the degree of overlap between the prediction bounding box and the object bounding box. It is used to determine whether the result has been predicted successfully. A threshold value can be set for IoU, and if the interaction ratio is greater than this threshold, the prediction is considered successful; otherwise, the prediction fails. If the IoU threshold is set too low, it is difficult to guarantee the quality for the detection samples. In order to achieve high quality positive samples, the IoU threshold can be manually adjusted upward, but too high an IoU threshold will lose the small-scale target frame. Therefore, the threshold was generally set to 0.5. IoU is defined in Equation (1).
When the prediction frame does not intersect with the real frame, the IoU loss is 0, and IoU will affect the model convergence process. As such, YOLOv5 uses CIoU (Complete-IoU) to calculate bbox_loss by default. The loss calculation formula of CIoU is shown in Equation (2).
where b and
denote the centroids of the prediction frame and the real frame, respectively,
denotes the Euclidean distance between the two centroids, and c denotes the diagonal distance between the minimum closure region of the prediction frame and the real frame. α is the weight parameter as shown in Equation (3). v is used to measure the consistency of the aspect ratio, as shown in Equation (4).
YOLOv5 uses the binary cross-entropy function to calculate cls_loss and obj_loss by default. The binary cross-entropy function is shown in Equation (5).
where
is the label corresponding to the input sample (1 for positive samples and 0 for negative samples) and
is the probability that the model predicts this input sample to be positive.
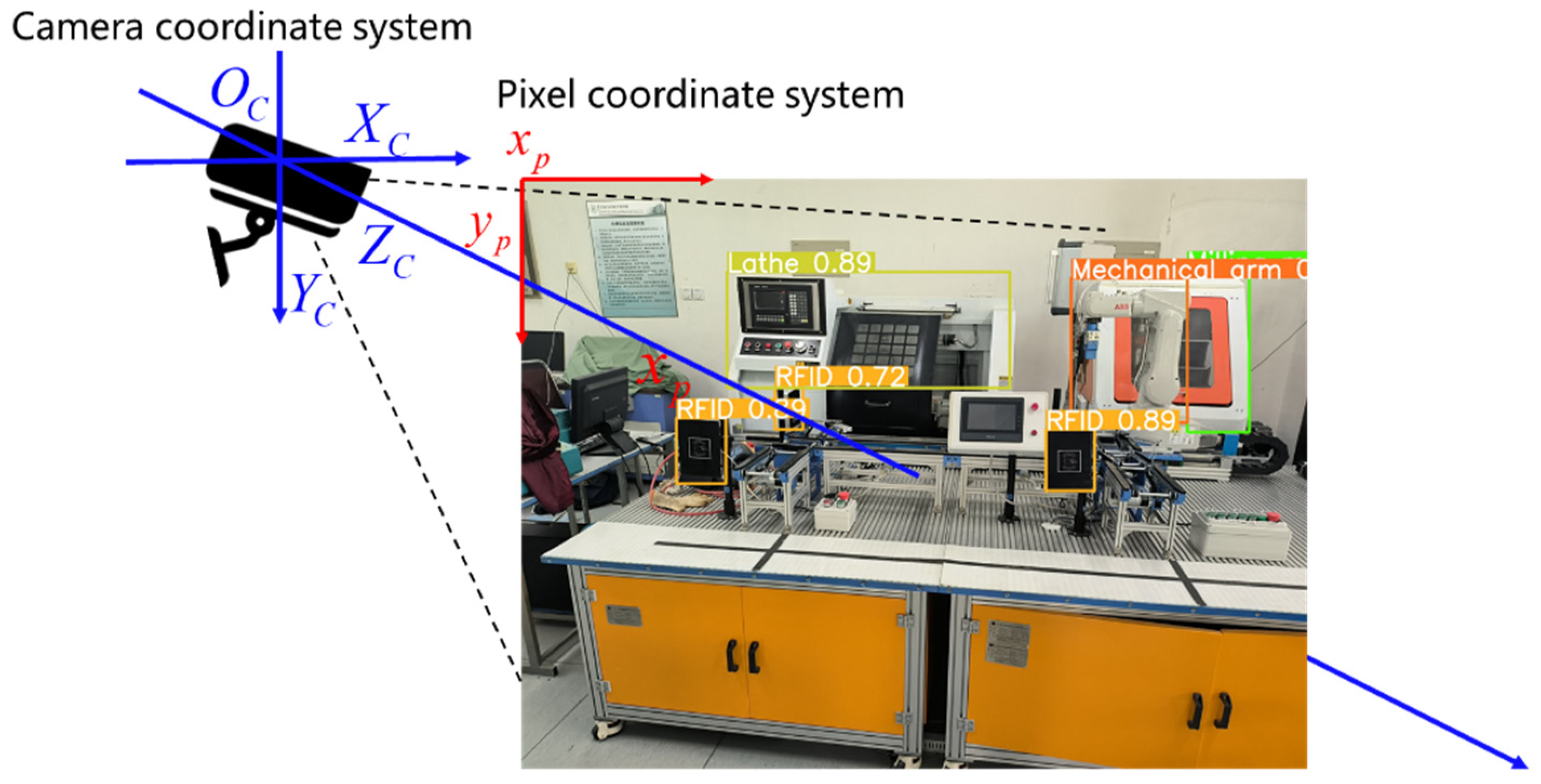
The YOLOv5 model is able to output the position information of the detected target while recognizing the target. The color image and depth image are generated when using RGB-D camera for detection, and the position coordinates are obtained by converting the pixel coordinate system to the camera coordinate system to obtain the 3D position coordinates of the detection target. In order to obtain more reliable depth information, the RGB-D camera is usually calibrated for depth before detection [
34,
35]. The pixel coordinate system and the camera coordinate system are shown in
Figure 1. Usually, the upper-left pixel point of the image is used as the origin position of the pixel coordinate system, and the pixel coordinate system axes are shown as the red arrows in
Figure 1. The center coordinate point of the detected target is obtained and projected into the pixel coordinate system of the depth image, so the pixel value of the center coordinate point of the detected target in the depth image is the distance of the detected target to the RGB-D camera. Taking the RGB-D camera as the origin of the camera coordinate system, the camera coordinate system axes are shown as the blue arrows in
Figure 1.
YOLOv5 has been widely used in the field of pedestrian detection and has achieved good results. For the detection of production line equipment that changes dynamically in real time in a complex background, we cite YOLOv5, which has a more concise network structure and faster processing speed, as a baseline network model for production line equipment identification and localization improvement.
2.3. A Framework of Production Line Equipment Identification and Localization Method Based on Improved YOLOv5s Model
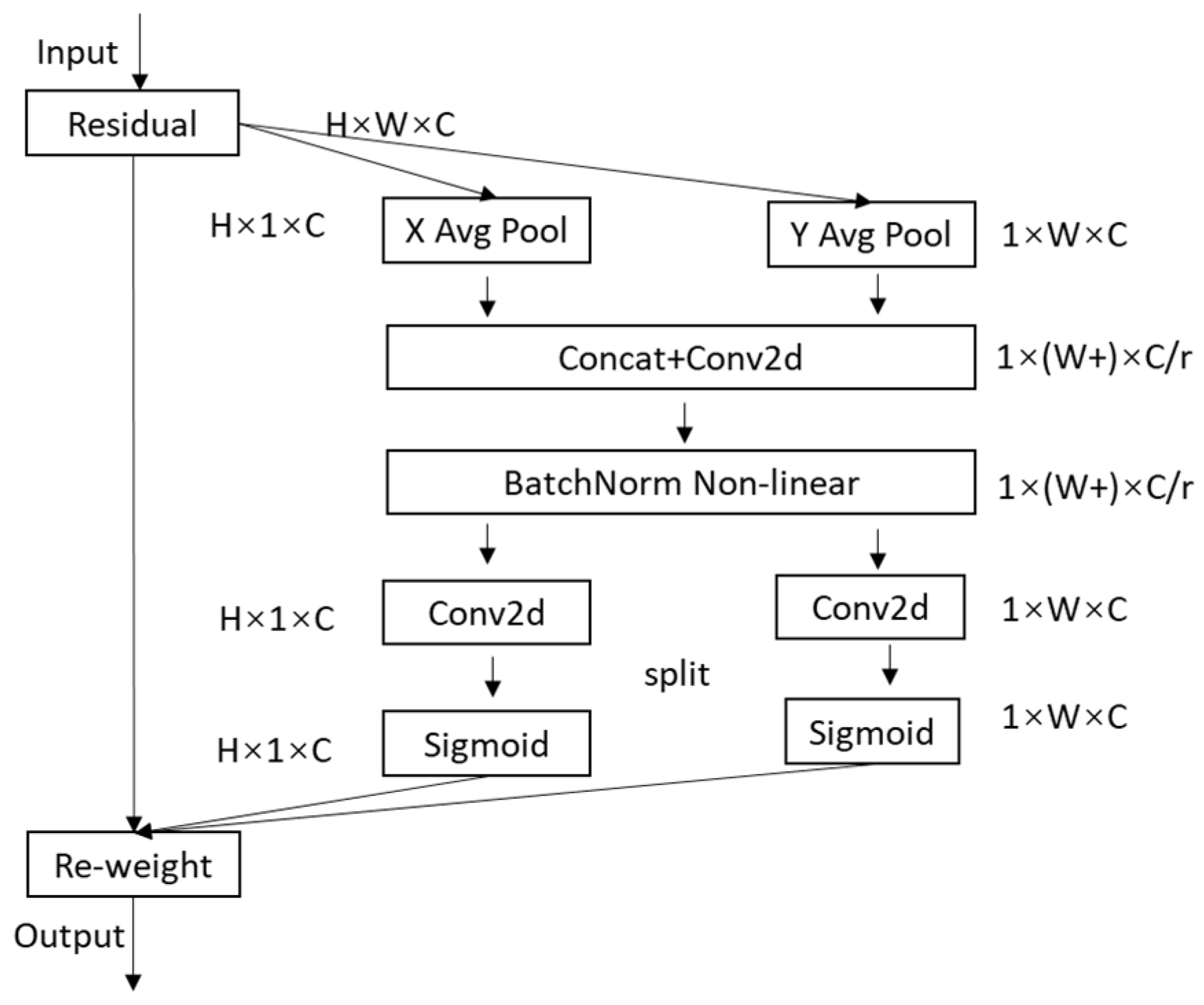
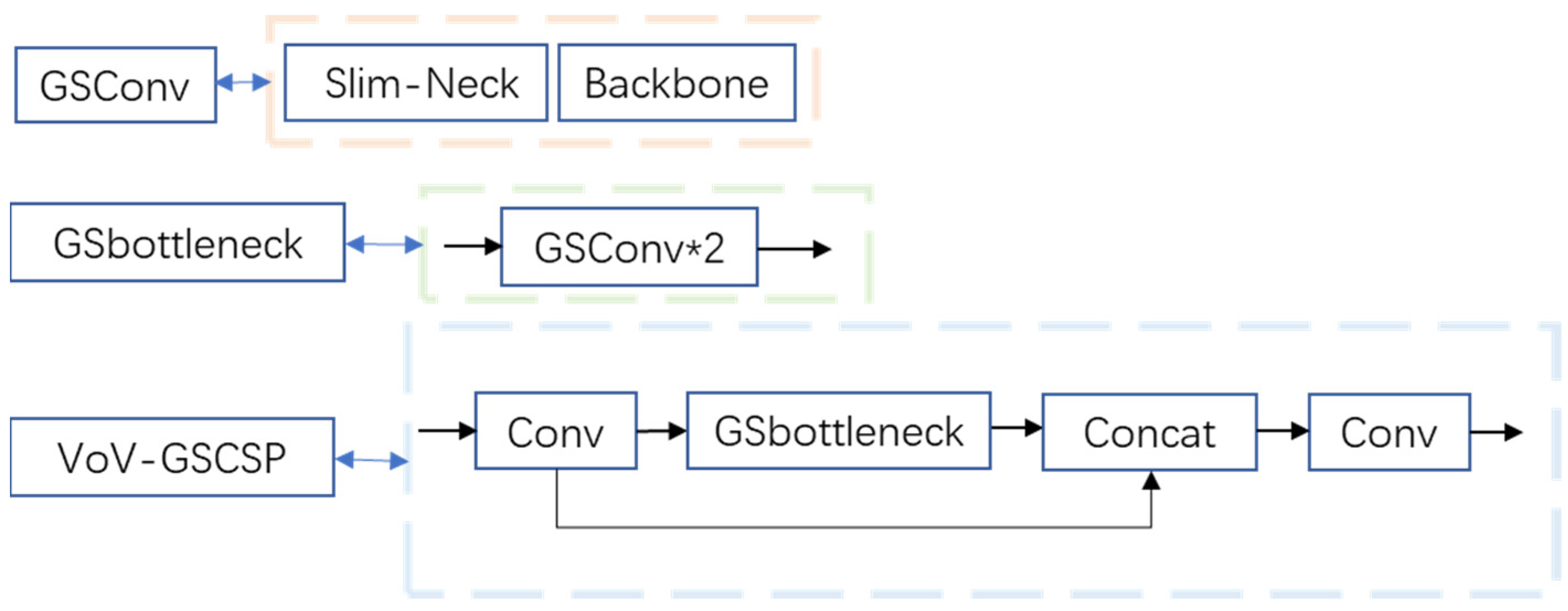
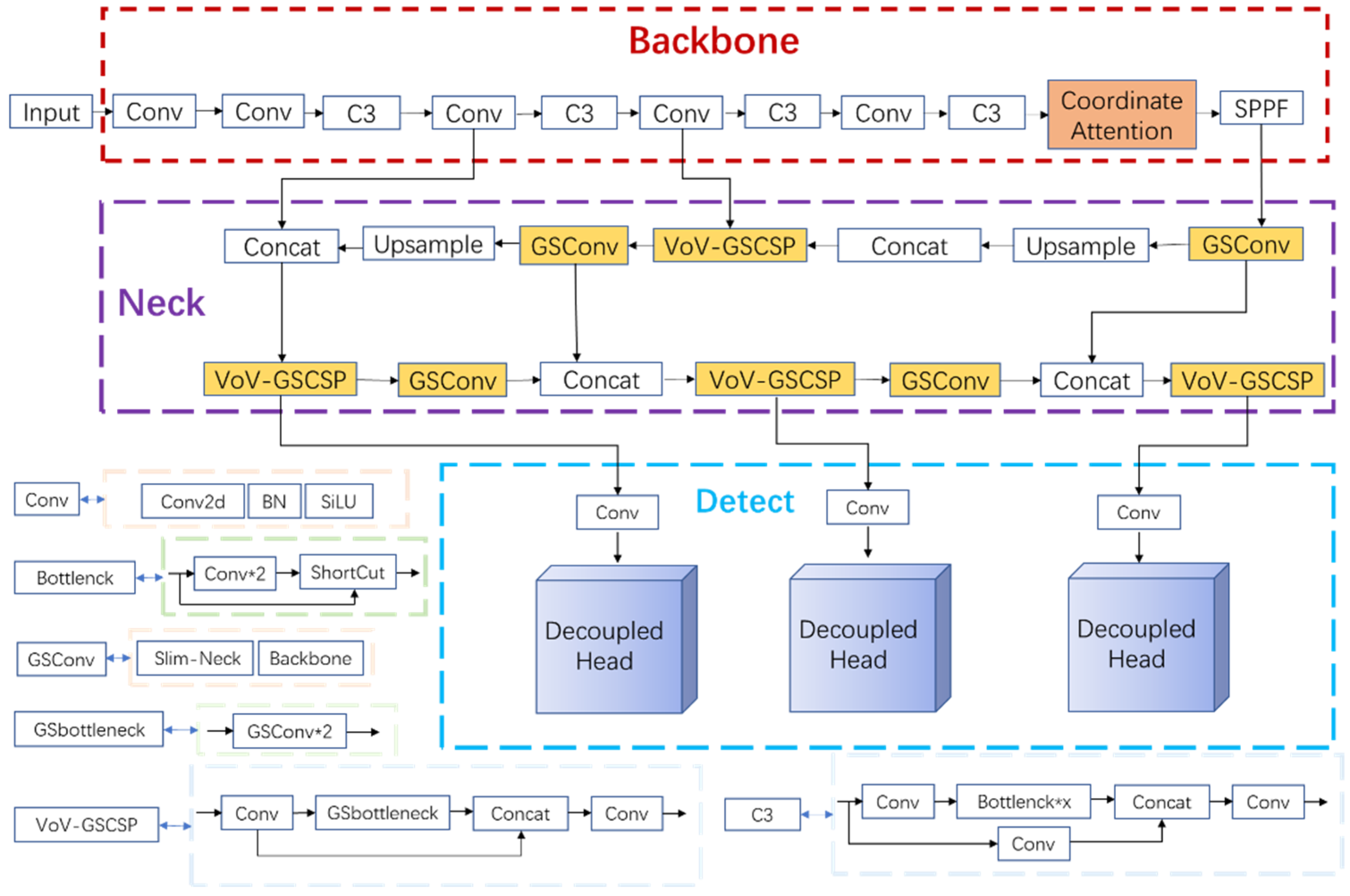
In order to achieve accurate recognition and classification, this paper proposes a production line equipment recognition and localization method based on an improved YOLOv5s model. Aiming at the problems that the model is not accurate enough for object localization and the weak expression ability of model learning features, the CA attention module was introduced into the YOLOv5s network model architecture. To address the problems of easy overfitting, slow training speed, and excessive parameters in the training process, we replaced Conv in the Neck layer with the lightweight convolution method GSConv and introduced the Slim-Neck method. To improve the performance index of the model for the inspection of production line equipment, we used the Decoupled Head in the Detect layer of the YOLOv5 model.
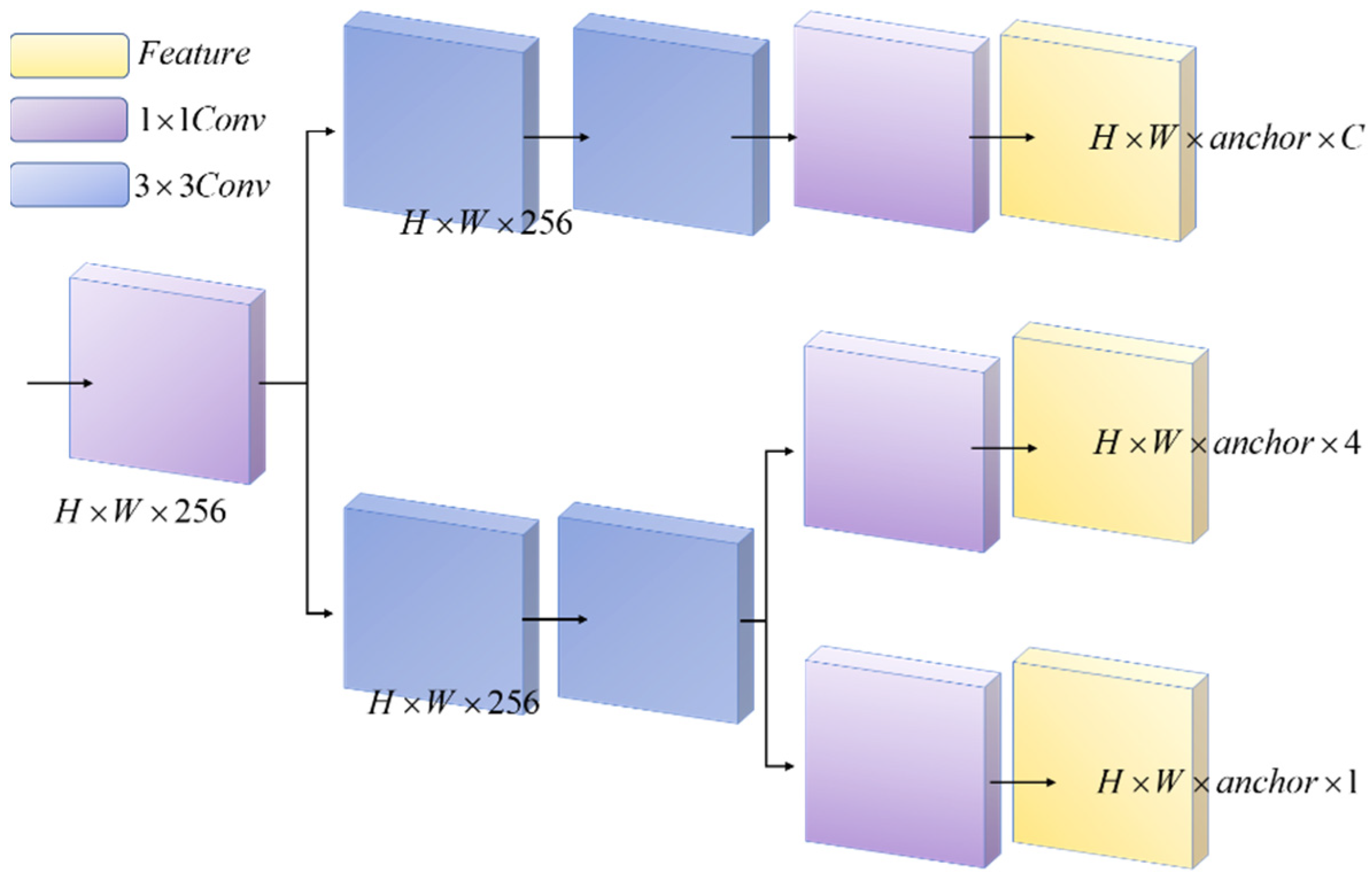
The model of this method consists of Input, Backbone, Neck, and Detect. The Backbone layer mainly performs feature extraction, which extracts the object information from the image through the convolutional network for later target detection. The Neck layer blends and combines the features to enhance the robustness of the network and strengthen the object detection ability and passes these features to the Head layer for prediction. To improve training speed, YOLOv5s version 6.0 replaces the Focus module with a convolution operation of size 6 × 6, step size 2, and padding 2. The Bottleneck module is based on the residual structure of ResNet, which can effectively reduce the training time. The C3 module contains three standard convolutional layers and multiple Bottleneck modules. This way, remote dependencies can be captured along one spatial direction, while accurate location information can be preserved along the other spatial direction. The generated feature maps are then encoded as a pair of orientation-aware and position-sensitive attention maps, respectively, which can be applied complementarily to the input feature maps to enhance the representation of objects of interest. Version 6.0 of YOLOv5s uses the SPPF module instead of the SPP (Spatial Pyramid Pooling) module. The SPPF module uses multiple small-sized pooling kernels in cascade instead of a single large-sized pooling kernel in the SPP module. GSConv and Slim-Neck methods are introduced in Neck layer. On the one hand, it replaces the Conv module with the lightweight convolution method GSConv, and on the other hand, it replaces the previous C3 module with the VOV-GSCSP module, which consists of the GSbottleneck module and Conv module, which are set up by GSConv. Finally, the three higher resolution features from the fused features are input to the decoupling head to complete the task of identifying the target class (classification problem), determining the target location (regression problem) and the confidence level. The improved network model and structure are shown in
Figure 5.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
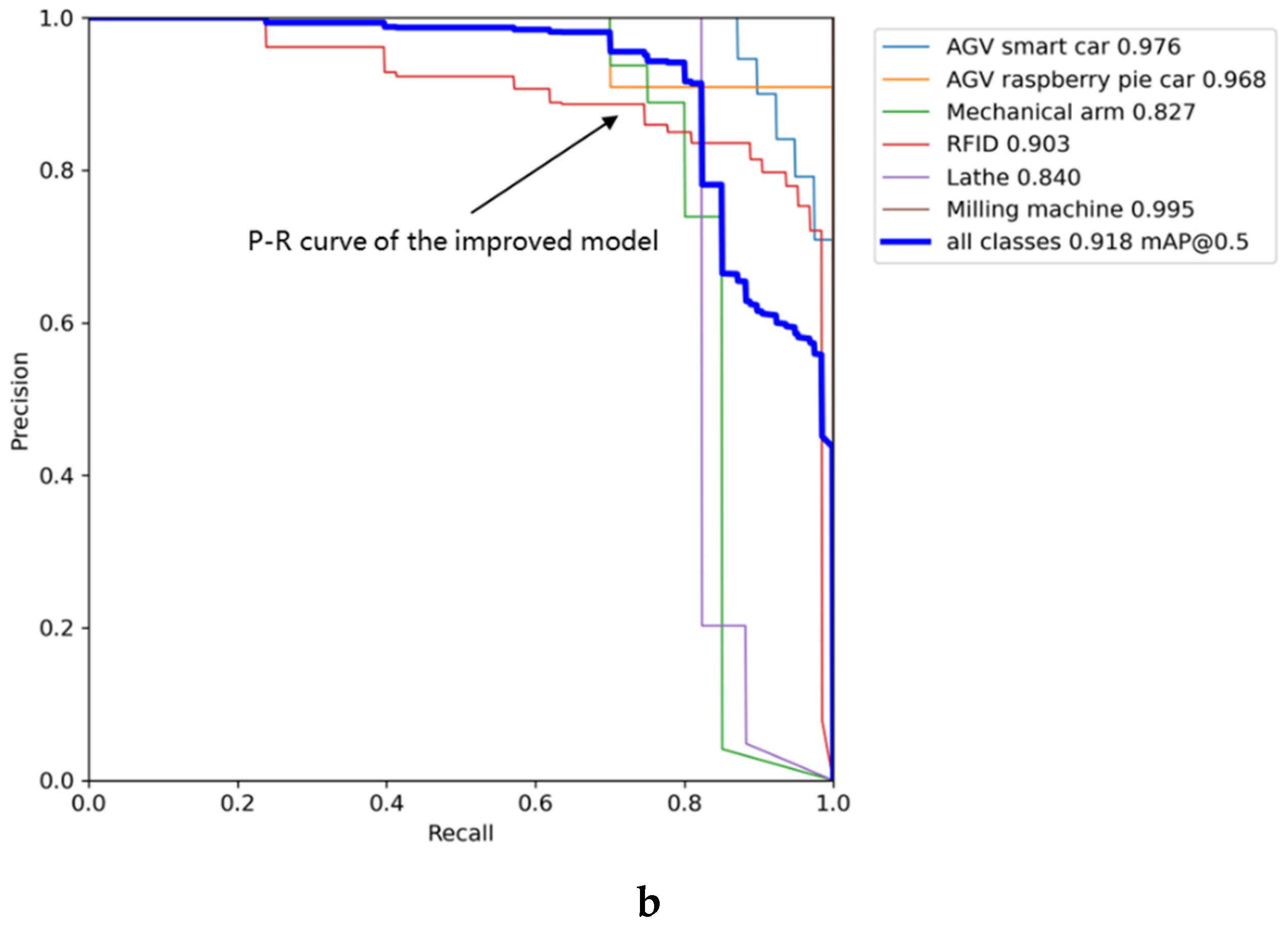{kind=link}
{kind=link}
{kind=link}
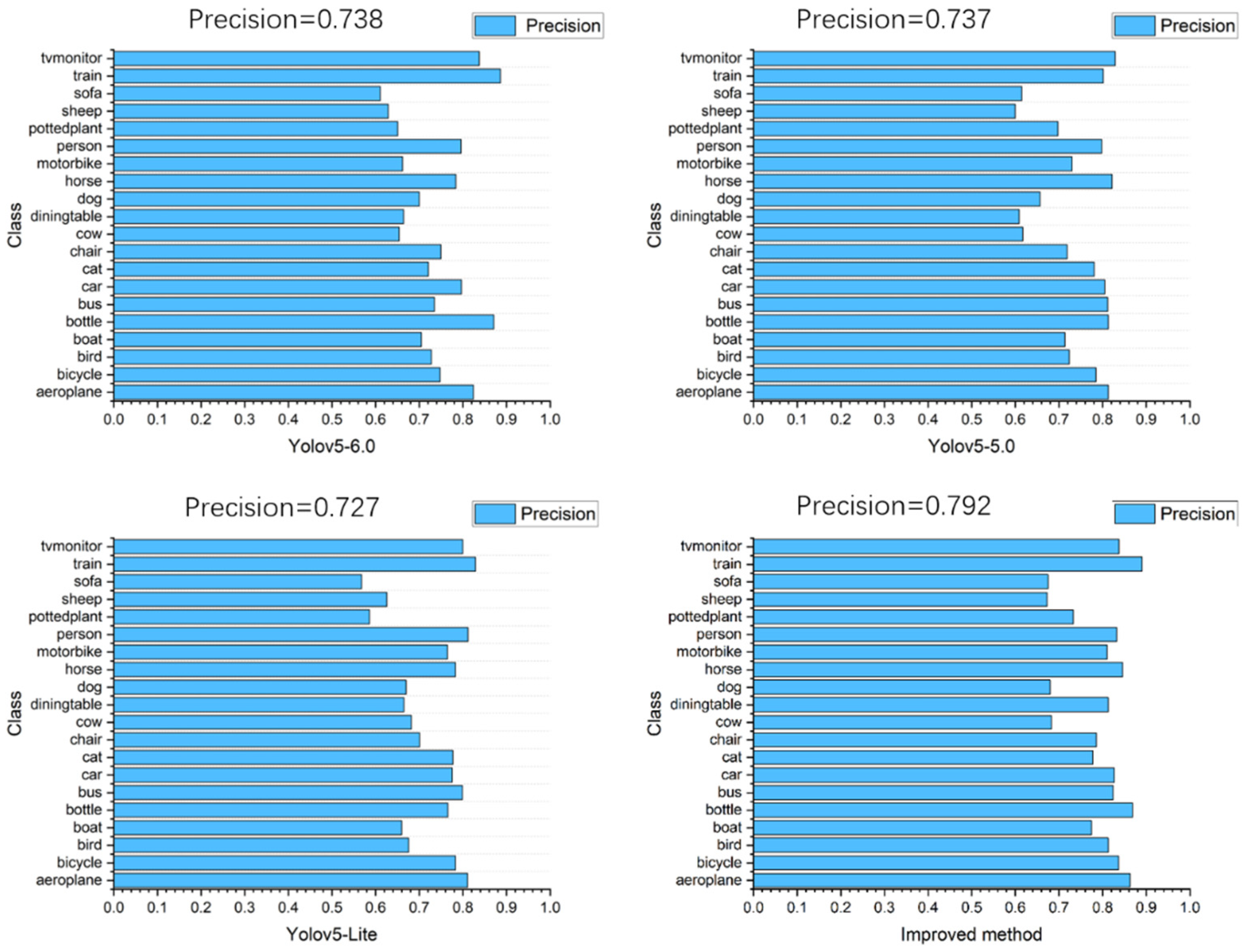{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
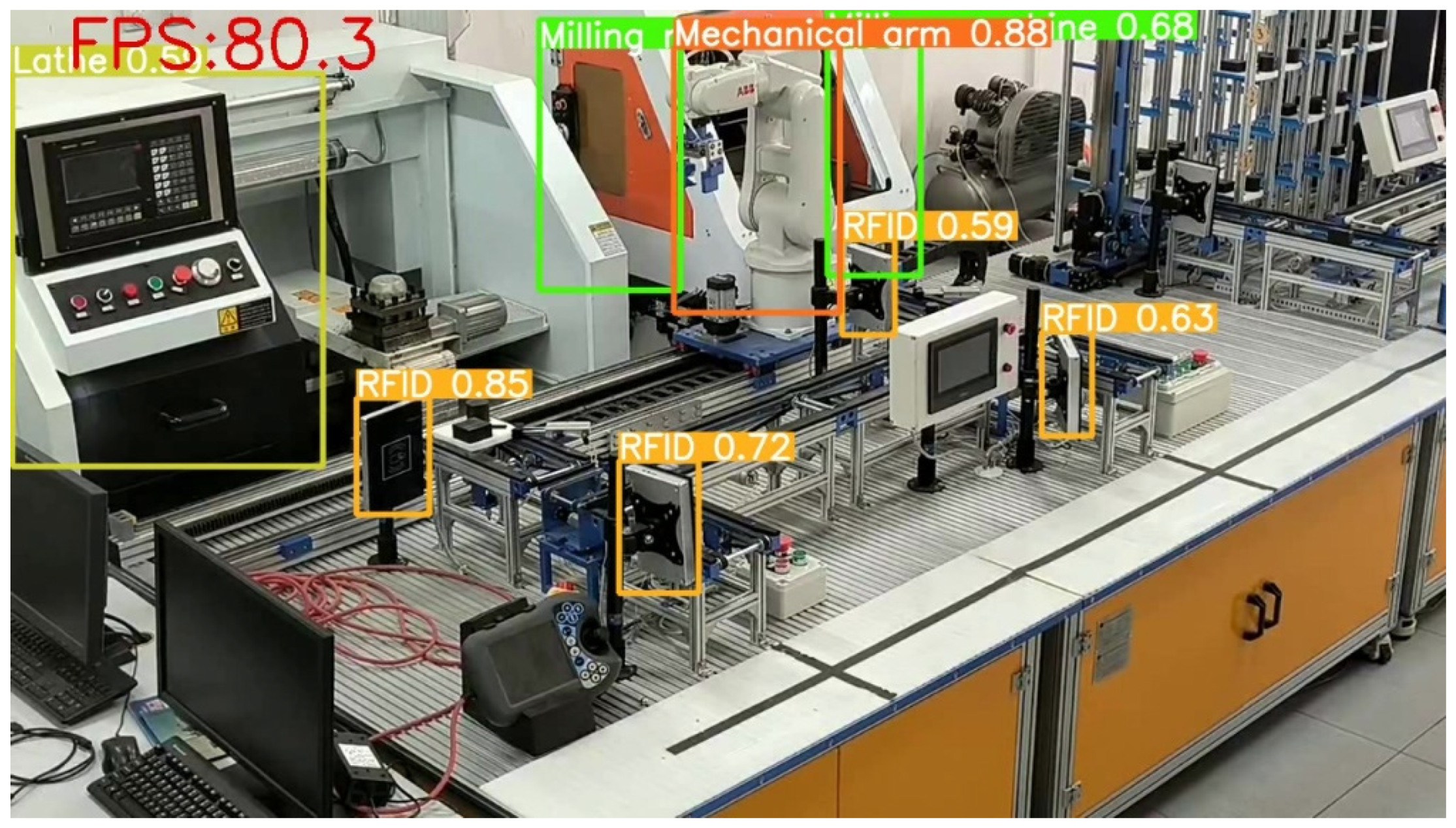{kind=link}