3.4. Experimental Results and Analysis
To verify the effectiveness of the improved method proposed in this paper, we performed comparative experiments on the setting of super-parameters of the anchor box, the selection of the loss function, and the selection of attention mechanisms. The baseline of each experiment is the YOLOv7 model. Because this paper’s primary goal is to improve detection accuracy, our experiment here mainly uses recall, precision, and mAP to evaluate the effect.
First, we determined the nine parameter values of the anchor box. For the generation of the anchor box, we used the K-means algorithm to cluster the anchor box of the COCO dataset and K-means++ clustering to compare the parameters. It can be seen from the results (shown in
Table 4) that all the evaluation indexes have increased significantly when using the nine anchor frame parameters obtained after K-means++ clustering, which verifies the idea of selecting the initial center of the anchor box with appropriate methods.
Then, we made a comparison of different loss functions. YOLOv7 uses CIoU as its loss function. We compared the performances of three methods: GIoU, CIoU, and SIoU (ours); the results are shown in
Table 5.
As seen from
Table 5, using SIoU can improve precision and recall by about 1.4% and 1.1%, compared with other methods. These experimental results show that the SIoU loss function can obtain good performance in insulator-defect detection.
In order to add appropriate attention mechanisms to the network, this paper added SE, CBAM, and CoordAtt attention mechanisms to the backbone layer and feature fusion layer of the model for training and comparison. The results are shown in
Table 6.
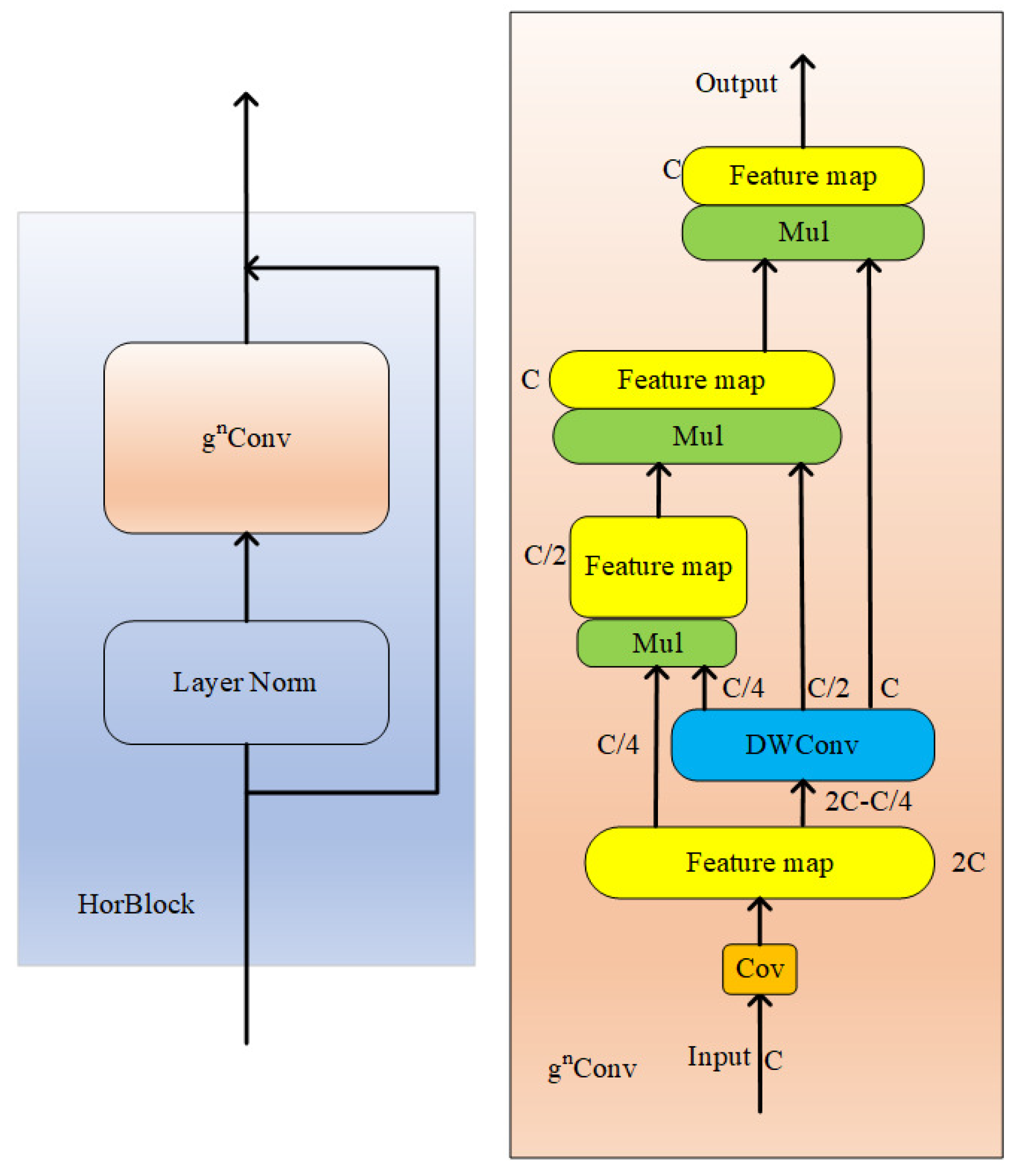
The effect on model detection caused by different attention mechanisms added to the backbone is different. Not every kind of attention will improve the model’s performance after joining the network. Although SE attention ignores location information, it also considers channel attention. From the results, the performance effect of the model is reduced after SE attention is added to the backbone. CBAM tries to use location information by reducing the channel dimensions of the input tensor and then calculating spatial attention by convolution. However, convolution can only capture local relationships; it cannot model long-term dependencies crucial to visual tasks. After CBAM attention is added to the backbone, the performance effect of the model is improved, but it is not apparent. The CoordAtt attention mechanism embeds location information into channel attention, capturing remote dependencies in one spatial direction and keeping accurate location information in another. According to the results, the mAP increased by 1% after adding CoordAtt to the backbone. This proves that using the CoordAtt attention mechanism can make the network model notice the target in a broader range and improve the detection ability of the network.
Ablation experiments were carried out to verify the positive impact on the network of the improved strategy proposed in this paper. The improved strategy proposed in this paper was trained on the insulator dataset. The experimental ablation results are shown in
Table 7 below. “✓” indicates that the corresponding improvement method is used, and “✕” indicates that the improvement method is not used.
The first row in the table is the detection result of the original YOLOv7 network. It can be seen from the above table that when the HorBlock module and CoordAtt module are added to the original network, mAP@0.5 and accuracy are increased by 1.3% and 1.1%, respectively, compared with the original YOLOv7 without any improvement strategy. When YOLOv7 uses the K-means++ algorithm to cluster anchor boxes generated by insulator datasets, the positioning accuracy is improved to 3.6% higher than the original YOLOv7 algorithm. In addition, because the K-means++ algorithm does not increase the number of layers and parameters of the network, it will not reduce the model’s speed. Moreover, K-means++ does not have the problem of significantly affecting the initial value selection, which can improve the speed of model border regression. Using the improved strategy of SIoU+NMS, precision increased by 2.4% and mAP@0.5 increased by 1%.
Combining the above three groups of improved methods, it can be found that the combined improved algorithm has the best effect; the detection accuracy can reach 94.9% and mAP@0.5 can reach 93.8%, which can meet the requirements for detection accuracy on insulator images.
Table 8 shows the detection of this model in each category. The insulator has high precision and low leakage rates. However, because complex environments and tiny targets characterize the defects of pollution flashover and damaged insulators, the precision and recall rates are not as good as those of insulators.
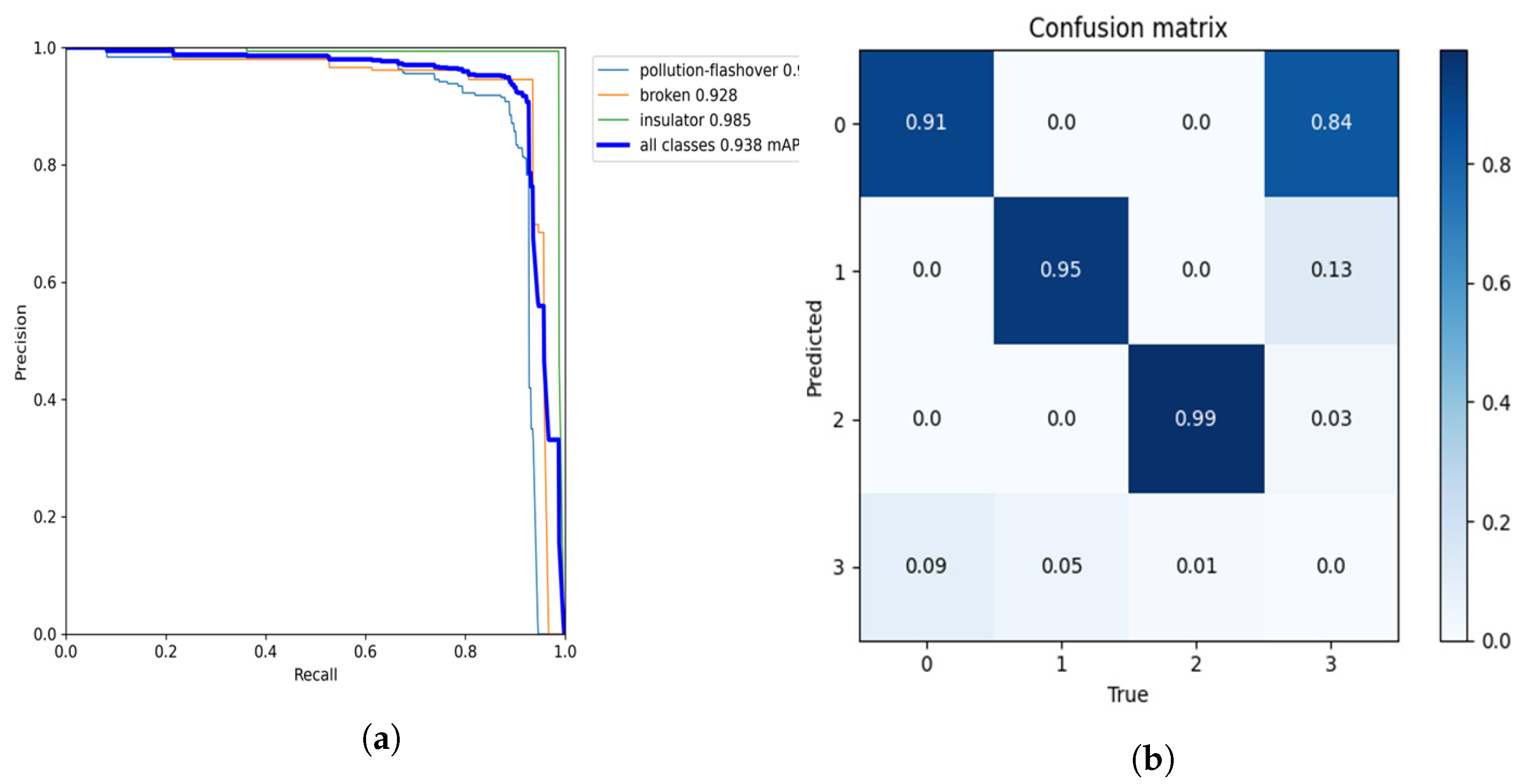
Precision and recall cannot be used as the only indicators to measure the model’s performance, as they may lead us to misunderstand the model’s performance. Therefore, we further use a PR curve to measure the model’s performance. The PR curve comprehensively considers the precision and recall rate of each category detected by the model.
The PR curve of this model is shown in
Figure 12a. The horizontal axis of the PR curve is recall and the vertical axis is precision. You can intuitively see the change rate of precision as recall increases. If the curve in the figure is close to the upper right corner, it means that with the increase in recall, the fall in precision is not obvious, and the overall performance of the model is better.
Figure 12b is a confusion matrix diagram; 0 represents the defect of pollution flashover; 1 represents the defect of damage; 2 represents the insulator; 3 represents the background. The row direction in the figure represents the real label and the column direction represents the predicted category. From the values in each line, the correct detection rates of damage and pollution flashover are 95% and 91%. The confusion matrix is a summary of the prediction results of classification problems. It can be seen that the classification of insulator defects is accurate.
The ablation experiments can only prove that the improved strategy in this paper is effective compared with the original algorithm, but whether it can reach an advanced level needs to be proved. Therefore, under the same experimental conditions, a series of comparative experiments were carried out on insulator datasets between the improved method and the current mainstream target detection method.
The comparison of the training results of different models is shown in
Figure 13. From the figure, it can be seen that the mAP@0.5 and recall of the improved algorithm in this paper are significantly higher than those of the other three models.
Figure 14 shows the comparison of training loss curves of different models. After 20 iterations, the loss curves of different models are stable and the training results can converge. It can be seen that YOLOv5s is far less effective than YOLOv7 in terms of regression loss and classification loss. Since the network structure is added to the improved model in this paper, the convergence speed of the improved model in the figure is slightly lower than that of YOLOv7. However, in about 20 iterations, the model in this paper shows a better decline rate and convergence ability than YOLOv7. It is proven that the loss function’s adjustment improves the network’s convergence ability.
Compare the loss function curves during model training;
Figure 15 shows the loss on the test set. The loss is the sum of model regression, confidence, and classification loss. The figure shows that the effect of our model is better than other models.
Finally,
Table 9 lists the comparison results of evaluation indicators of different models. It can be seen from the table that the recall of this model was greater by 6.3% and mAP@0.5 by 3.7% compared with YOLOv7. Although the model’s speed has decreased, the speed is still 95 FPS, much faster than the speed of the two-phase model.
Based on the comparison and analysis of the above series of experiments, it can be concluded that the improved YOLOv7 algorithm proposed in this paper has obvious advantages in detection accuracy. Although the speed is decreased to a certain extent, it can still meet the real-time requirements of insulator-defect detection in practical engineering.
To better verify the generalization ability and robustness of the model in this paper, we specifically selected small targets and targets in complex environments in the test set for testing. In the contrast-detection experiment, to verify that the model in this paper is more suitable for insulator-defect detection, we also purposely add the comparison of detection results of the YOLOX model. The detection results are shown in
Figure 16,
Figure 17 and
Figure 18. Through comparative analysis, the improved algorithm can better identify micro-defects of insulators and can accurately identify some insulator targets in complex environments.
In conclusion, the results of ablation and comparison tests show that the strategy in this paper has significantly improved the accuracy of insulator-defect detection.
Dian et al. [
39] previously proposed a Faster R-Transformer algorithm for aerial insulator detection. The algorithm also combines self-attention mechanism, with an average accuracy of 97.31%. However, the FPS is only 12, which does not meet the actual application requirements of the project. The research results in this paper can improve the accuracy, while the FPS is still 95. Ding et al. [
40] detected insulator defects by improving the classic YOLOv5 model. This model also improves the regression loss function, anchor frame generation method, and NMS method, which improves the model detection accuracy. However, the recall rate is only 90.4%, while the recall rate in this paper is 93.4%.
The improved strategy proposed in this paper provides more possibilities for small-target detection such as insulator defects. In the future, this model can also be applied to various small-target detection scenarios in agriculture and industry. Finally, the improvement of this paper is mainly in the backbone of the network. The detection head is also important for model fusion features. We plan to expand our research in the future to understand the network model more fully.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}