
Detecting Enclosed Board Channel of Data Acquisition System Using Probabilistic Neural Network with Null Matrix




Abstract
:1. Introduction
- (1)
- Multiple input signals are proposed to activate the working state of the board tunnel, which extends the scope of exploration for the dispersivity of a healthy board concerning the working environment and internal parameters.
- (2)
- The critical faulty data are successfully constructed by using the null matrix based on the health data, which overcomes the difficulty of lacking faulty data.
- (3)
- The PNN is used to adapt to the law of probability hidden in the time series, and case studies verify the effectiveness.
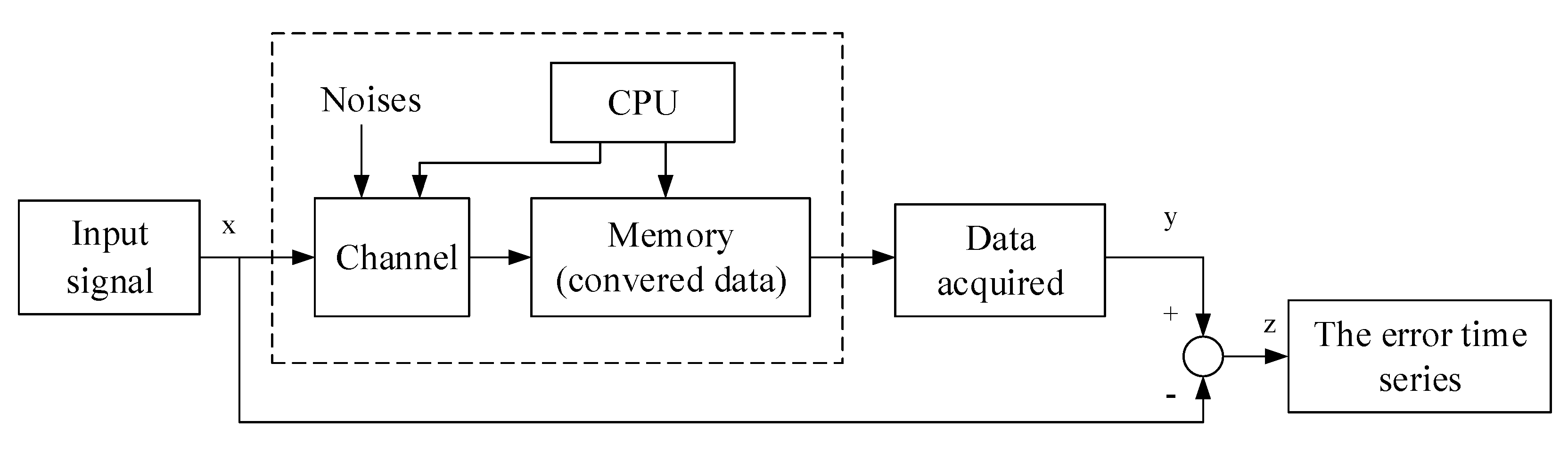
2. The Error Time Series of Board Tunnel
3. The Proposed Approach
3.1. Probability Neural Network
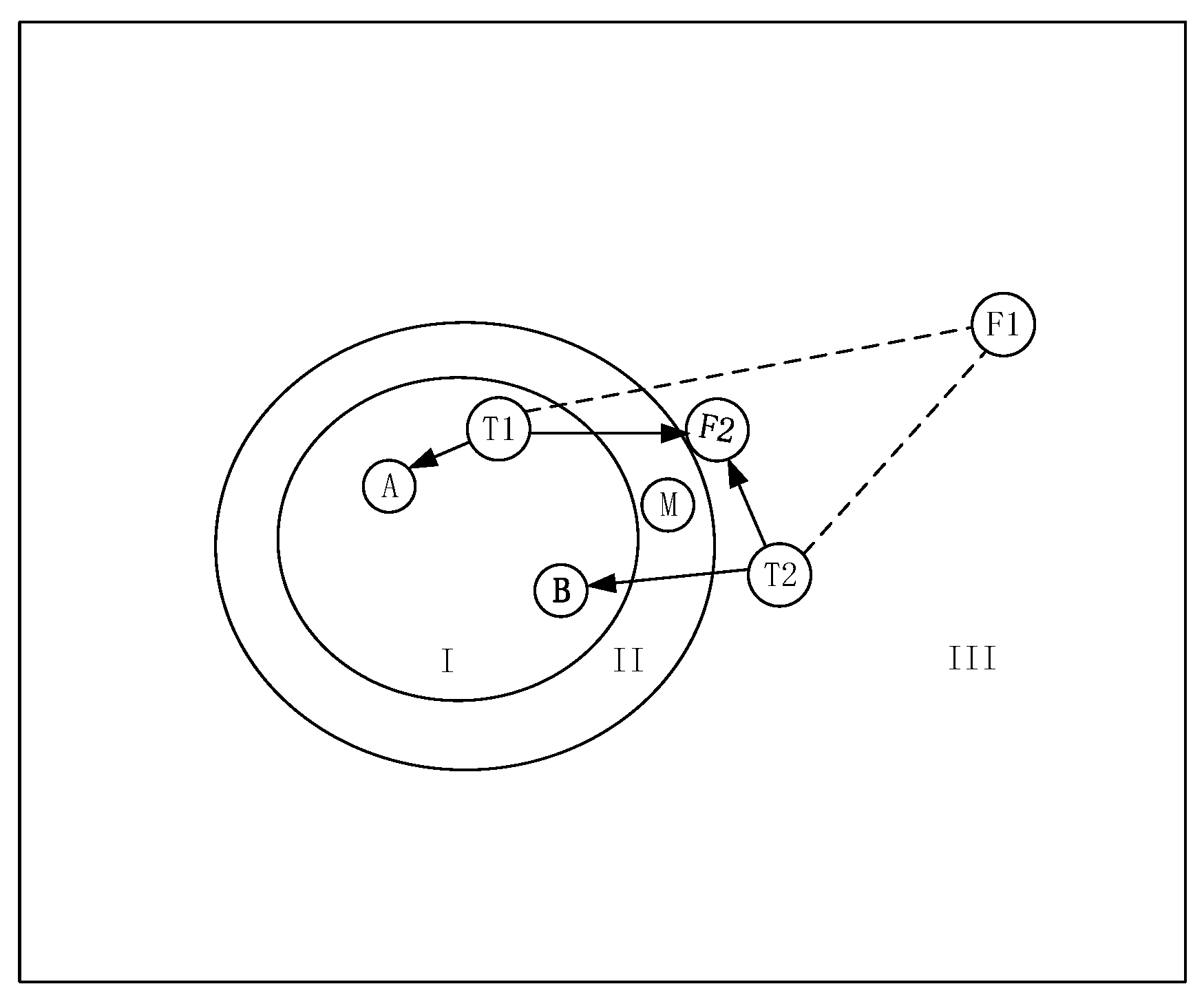
3.2. The Construction of Critical Faulty Data
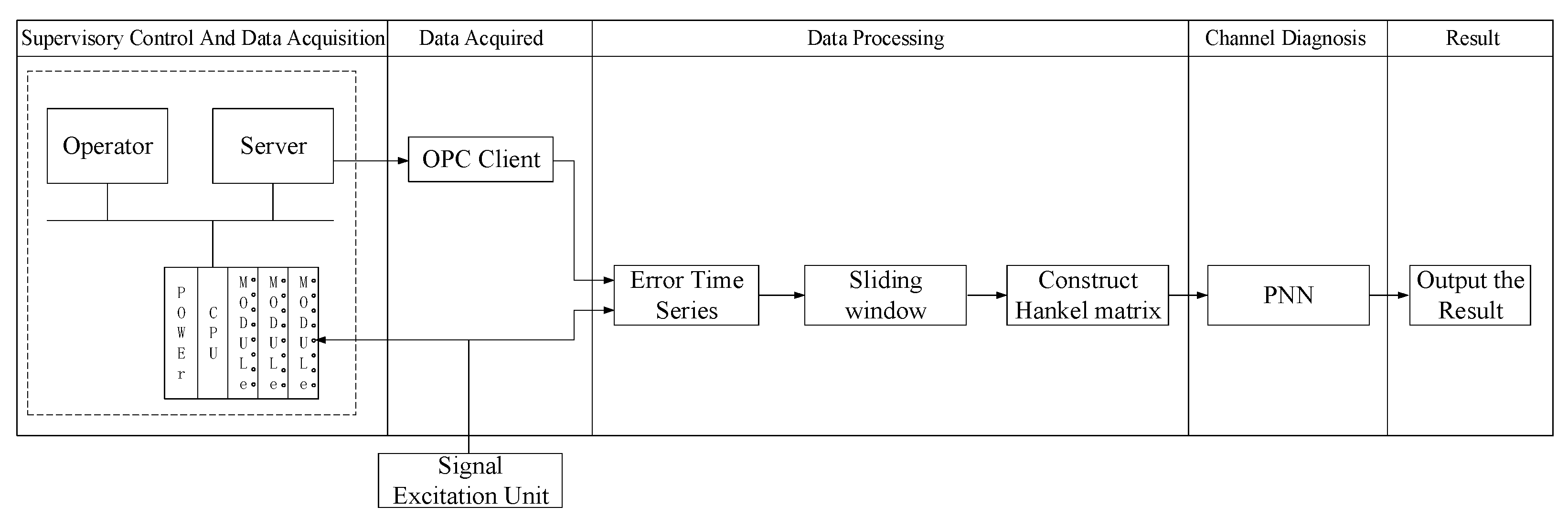
3.3. The Structure and Workflow of Proposed Approach
4. Case Studies
4.1. Change the Number of Intermediate Layers of PNN
4.2. Effects of Different Groups of Health Data Combination as Sample Input
4.3. Comparison with LDM
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Roh, Y.; Heo, G.; Whang, S.E. A Survey on Data Collection for Machine Learning: A Big Data—AI Integration Perspective. IEEE Trans. Knowl. Data Eng. 2019, 33, 1328–1347. [Google Scholar] [CrossRef] [Green Version]
- Binu, D.; Kariyappa, B. A survey on fault diagnosis of analog circuits: Taxonomy and state of the art. AEU Int. J. Electron. Commun. 2017, 73, 68–83. [Google Scholar] [CrossRef]
- Industrial Automation Systems SIMATIC. Available online: https://new.siemens.com/global/en/products/automation/systems/industrial.html (accessed on 20 May 2022).
- Honeywell. Available online: https://hps.honeywell.com.cn/product-and-service/control-monitoring-safety-sytems/integrated-control-and-safety-systems/experion-pks/ (accessed on 20 May 2022).
- ABB. Available online: http://www.cechina.cn/Company/46258_138835/messagedetail.aspx (accessed on 20 May 2022).
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques—Part I: Fault diagnosis with model-Based and signal-based approaches. IEEE T Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef] [Green Version]
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques—Part II: Fault diagnosis with knowledge-based and hybrid/active approaches. IEEE T Ind. Electron. 2015, 62, 3768–3774. [Google Scholar] [CrossRef] [Green Version]
- Liang, J.; Du, R. Model-based Fault Detection and Diagnosis of HVAC systems using Support Vector Machine method. Int. J. Refrig. 2007, 30, 1104–1114. [Google Scholar] [CrossRef]
- Gagnol, V.; Le, T.-P.; Ray, P. Modal identification of spindle-tool unit in high-speed machining. Mech. Syst. Signal Process. 2011, 25, 2388–2398. [Google Scholar] [CrossRef]
- Zhang, D.; Lin, Z.; Gao, Z. A Novel Fault Detection with Minimizing the Noise-Signal Ratio Using Reinforcement Learning. Sensors 2018, 18, 3087. [Google Scholar] [CrossRef] [Green Version]
- Suzuki, A.; Ohnishi, K. Frequency-Domain Damping Design for Time-Delayed Bilateral Teleoperation System Based on Modal Space Analysis. IEEE Trans. Ind. Electron. 2012, 60, 177–190. [Google Scholar] [CrossRef]
- He, X.; Wang, Z.; Liu, Y.; Zhou, D.H. Least-Squares Fault Detection and Diagnosis for Networked Sensing Systems Using A Direct State Estimation Approach. IEEE Trans. Ind. Inform. 2013, 9, 1670–1679. [Google Scholar] [CrossRef]
- Han, H.; Cui, X.; Fan, Y.; Qing, H. Least squares support vector machine (LS-SVM)-based chiller fault diagnosis using fault indicative features. Appl. Therm. Eng. 2019, 154, 540–547. [Google Scholar] [CrossRef]
- Jiang, Z.; Molisch, A.F.; Caire, G.; Niu, Z. Achievable Rates of FDD Massive MIMO Systems With Spatial Channel Correlation. IEEE Trans. Wirel. Commun. 2015, 14, 2868–2882. [Google Scholar] [CrossRef] [Green Version]
- Gao, Z.; Liu, X. An Overview on Fault Diagnosis, Prognosis and Resilient Control for Wind Turbine Systems. Processes 2021, 9, 300. [Google Scholar] [CrossRef]
- Alauddin, M.; Khan, F.; Imtiaz, S.A.; Ahmed, S. A Bibliometric Review and Analysis of Data-Driven Fault Detection and Diagnosis Methods for Process Systems. Ind. Eng. Chem. Res. 2018, 57, 10719–10735. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, B.; Chen, W.; Yi, H. Data-driven Detection and Diagnosis of Incipient Faults in Electrical Drives of High-Speed Trains. IEEE Trans. Ind. Electron. 2019, 66, 4716–4725. [Google Scholar] [CrossRef]
- Wu, H.; Zhao, J. Deep convolutional neural network model based chemical process fault diagnosis. Comput. Chem. Eng. 2018, 115, 185–197. [Google Scholar] [CrossRef]
- Wang, Y.; Pan, Z.; Yuan, X.; Yang, C.; Gui, W. A novel deep learning based fault diagnosis approach for chemical process with extended deep belief network. ISA Trans. 2019, 96, 457–467. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z.; Saxen, H.; Gao, C. Data-driven approaches for complex industrial systems. IEEE T Ind. Inform. 2013, 9, 2210–2212. [Google Scholar] [CrossRef]
- Guo, L.; Zhang, Y.-M.; Wang, H.; Fang, J.-C. Observer-Based Optimal Fault Detection and Diagnosis Using Conditional Probability Distributions. IEEE Trans. Signal Process. 2006, 54, 3712–3719. [Google Scholar] [CrossRef]
- Amin, T.; Khan, F.; Imtiaz, S. Fault detection and pathway analysis using a dynamic Bayesian network. Chem. Eng. Sci. 2018, 195, 777–790. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, S.; Li, H.; Gao, F.; Jin, S. Sparse Bayesian Learning for the Time-Varying Massive MIMO Channels: Acquisition and Tracking. IEEE Trans. Commun. 2018, 67, 1925–1938. [Google Scholar] [CrossRef]
- Specht, D.F. Probabilistic Neural Networks. Neural Netw. 1990, 3, 109–118. [Google Scholar] [CrossRef]
- MathWorks. Available online: https://www.mathworks.com/help/matlab/ref/null.html (accessed on 20 May 2022).
- OPC. Available online: https://opcfoundation.org/forum/opc-ua-standard/ (accessed on 20 May 2022).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Symbols | Description |
|---|---|---|
| 1 | Case1 | Input signal with additional pulse voltage of duty cycle 50% and frequency 20 Hz |
| 2 | Case2 | Input signal with additional piecewise linear voltage of slope 0.5; amplitude: 0 to −2 V |
| 3 | Case3 | Input signal with additional exponential voltage from 0 to 2 V in 5 s |
| 4 | Case4 | Input signal with additional thermal noise of 1 MHz bandwidth |
| 5 | Case5 | Input signal with additional chirp signal: initial frequency—0 Hz; final frequency—500 Hz; amplitude—1 V; delay—0.05 s |
| 6 | Case6 | The reference signal with additional random noise (Fault1) |
| 7 | Case7 | The reference signal with periodic voltage signal (Fault2) |
| No. | Length of Sliding Window | Case5 | Case6 | Case7 | |||
|---|---|---|---|---|---|---|---|
| Correct/Wrong (Times) | Accuracy | Correct/Wrong (Times) | Accuracy | Correct/Wrong (Times) | Accuracy | ||
| 1 | 100 | 1000/0 | 100% | 0/1000 | 0% | 0/1000 | 0% |
| 2 | 150 | 1000/0 | 100% | 0/1000 | 0% | 0/1000 | 0% |
| 3 | 200 | 896/104 | 89.6% | 999/1 | 99.9% | 992/8 | 99.2% |
| 4 | 500 | 897/103 | 89.7% | 998/2 | 99.8% | 971/29 | 97.1% |
| 5 | 1000 | 922/78 | 92.2% | 1000/0 | 100% | 1000/0 | 100% |
| 6 | 1500 | 905/95 | 90.5% | 1000/0 | 100% | 1000/0 | 100% |
| 7 | 2000 | 1000/0 | 100% | 1000/0 | 100% | 1000/0 | 100% |
| 8 | 20,000 | 1000/0 | 100% | 0/1000 | 0% | 0/1000 | 0% |
| No. | Training Examples | Test | Correct (Times) | Wrong (Times) | Accuracy |
|---|---|---|---|---|---|
| 1 | Case1/Case2/Case3/Case4 | Case5 | 1000 | 0 | 100% |
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 2 | Case1/Case2/Case3/Case5 | Case4 | 1000 | 0 | 100% |
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 3 | Case1/Case2/Case4/Case5 | Case3 | 1000 | 0 | 100% |
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 4 | Case1/Case3/Case4/Case5 | Case2 | 1000 | 0 | 100% |
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 5 | Case2/Case3/Case4/Case5 | Case1 | 1000 | 0 | 100% |
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% |
| No. | Training Examples | Test | Correct (Times) | Wrong (Times) | Accuracy |
|---|---|---|---|---|---|
| 1 | Case1/Case2/Case3 | Case4 | 1000 | 0 | 100% |
| Case5 | 1000 | 0 | 100% | ||
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 2 | Case1/Case2/Case4 | Case3 | 1000 | 0 | 100% |
| Case5 | 1000 | 0 | 100% | ||
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 3 | Case1/Case2/Case5 | Case3 | 1000 | 0 | 100% |
| Case4 | 1000 | 0 | 100% | ||
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 4 | Case1/Case3/Case4 | Case2 | 687 | 314 | 68.7% |
| Case5 | 1000 | 0 | 100% | ||
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 5 | Case1/Case3/Case5 | Case2 | 680 | 320 | 68% |
| Case4 | 1000 | 0 | 100% | ||
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 6 | Case1/Case4/Case5 | Case2 | 667 | 333 | 66.7% |
| Case3 | 1000 | 0 | 100% | ||
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 7 | Case2/Case3/Case4 | Case1 | 879 | 121 | 87.9% |
| Case5 | 1000 | 0 | 100% | ||
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 8 | Case2/Case3/Case5 | Case1 | 792 | 208 | 79.2% |
| Case4 | 1000 | 0 | 100% | ||
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 9 | Case2/Case4/Case5 | Case1 | 811 | 189 | 81.1% |
| Case3 | 1000 | 0 | 100% | ||
| Case6 | 1000 | 0 | 100% | ||
| Case7 | 1000 | 0 | 100% | ||
| 10 | Case3/Case4/Case5 | Case1 | 184 | 816 | 18.4% |
| Case2 | 762 | 238 | 76.2% | ||
| Case6 | 998 | 2 | 99.8% | ||
| Case7 | 1000 | 0 | 100% |
| Case1 | Case2 | Case3 | Case4 | Case5 | Case6 | |
|---|---|---|---|---|---|---|
| Correct | 993 | 1000 | 1000 | 1000 | 997 | 1000 |
| Incorrect | 7 | 0 | 0 | 0 | 13 | 0 |
| Accuracy | 99.3% | 100% | 100% | 100% | 99.7% | 100% |
| Health | Fault | |||||
|---|---|---|---|---|---|---|
| Case1 | Case2 | Case3 | Case4 | Case5 | Case6 | |
| Case7 | 164 | 133 | 0 | 0 | 0 | 703 |
| Total: 297 | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, D.; Lin, Z.; Gao, Z. Detecting Enclosed Board Channel of Data Acquisition System Using Probabilistic Neural Network with Null Matrix. Sensors 2022, 22, 5559. https://doi.org/10.3390/s22155559
Zhang D, Lin Z, Gao Z. Detecting Enclosed Board Channel of Data Acquisition System Using Probabilistic Neural Network with Null Matrix. Sensors. 2022; 22(15):5559. https://doi.org/10.3390/s22155559
Chicago/Turabian StyleZhang, Dapeng, Zhiling Lin, and Zhiwei Gao. 2022. "Detecting Enclosed Board Channel of Data Acquisition System Using Probabilistic Neural Network with Null Matrix" Sensors 22, no. 15: 5559. https://doi.org/10.3390/s22155559
APA StyleZhang, D., Lin, Z., & Gao, Z. (2022). Detecting Enclosed Board Channel of Data Acquisition System Using Probabilistic Neural Network with Null Matrix. Sensors, 22(15), 5559. https://doi.org/10.3390/s22155559