
A Collision Relationship-Based Driving Behavior Decision-Making Method for an Intelligent Land Vehicle at a Disorderly Intersection via DRQN


Abstract
:1. Introduction
- A collision relationship-based driving behavior decision-making method for intelligent land vehicles is put forward. The collision relationship between an intelligent land vehicle and surrounding vehicles is utilized as the state input, rather than the positions and velocities of all the vehicles. This effectively avoids dimension explosion of the network’s input with the increase in surrounding vehicles. Therefore, this design helps to make right decisions quickly.
- By using long short-term memory (LSTM) to train the time-series input, the proposed method effectively weakens the adverse effects of reduced perception confidence. Further, this method ensures the safety of driving behavior decision-making.
- A series of comparative simulations are carried out for a scene of disorderly intersection. The experiments verify that the proposed algorithm is superior to traditional DQN and its variants in the safety and comfort of decision-making.
2. Related Work
3. Foundation of Deep Reinforcement Learning
3.1. Partially Observable Markov Decision Process under Sensor Noise
3.2. Deep Reinforcement Learning
4. Collision Relationship-Based Driving Behavior Decision-Making via DRQN
4.1. Design of the Driving Behavior Decision-Making Model
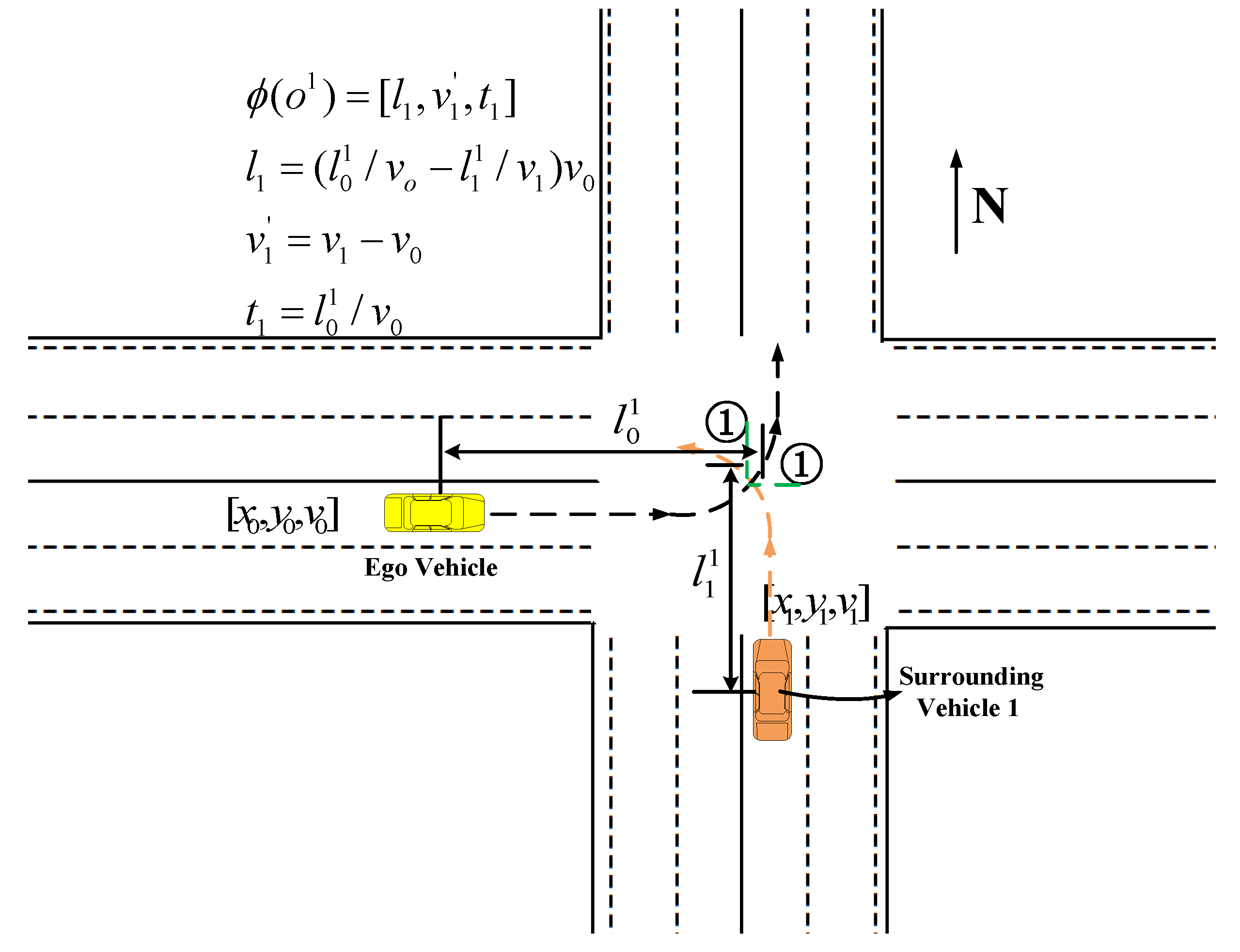
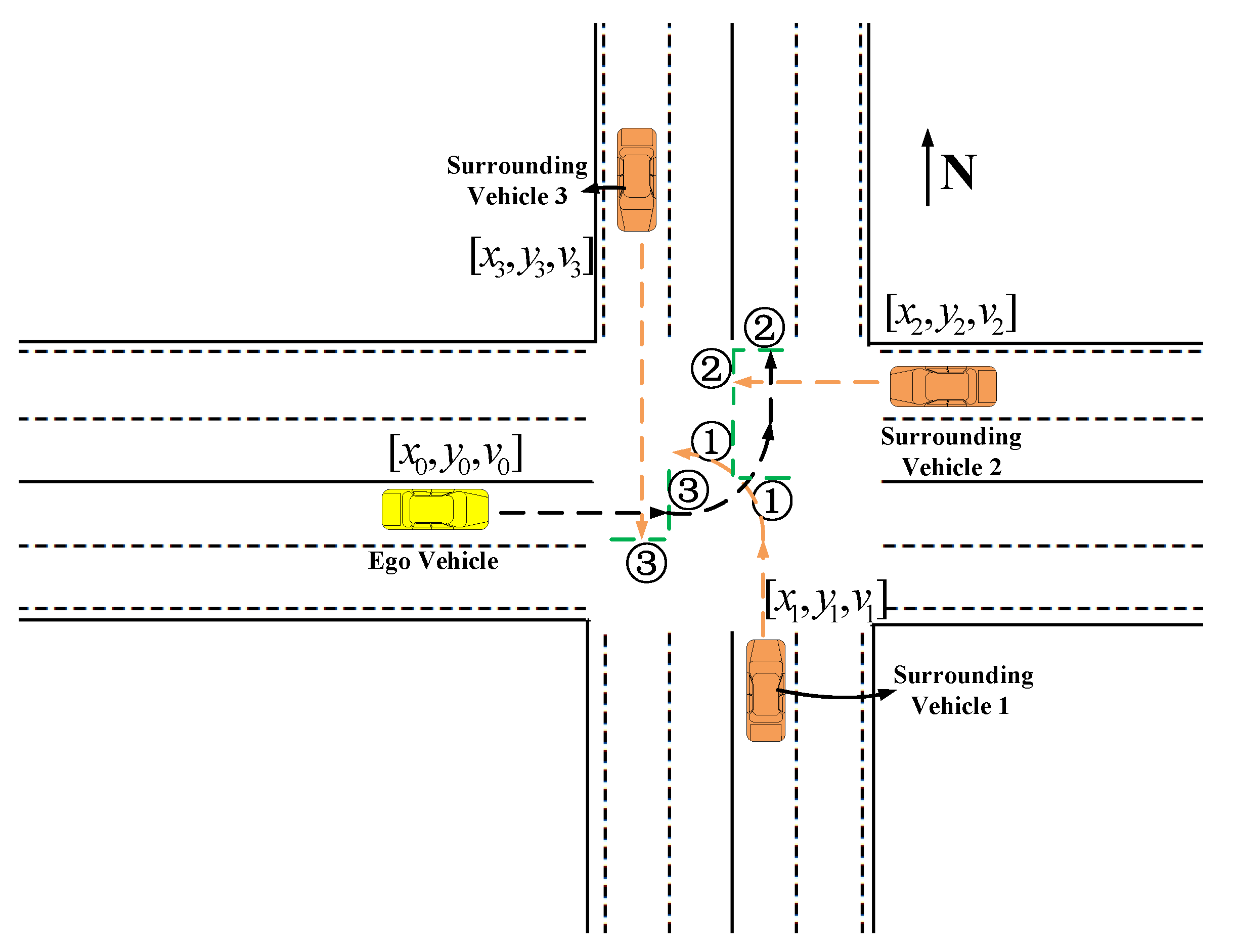
4.1.1. State Space
4.1.2. Action Space
4.1.3. Reward Function
4.2. Driving Behavior Decision-Making Method Based on CR-DRQN
| Algorithm 1: CR-DRQN pseudocode |
|
5. Simulation Results and Discussions
5.1. Experiment Settings
- If the ego vehicle takes the accelerate slowly action, acceleration a is +1 m/s2.
- If the ego vehicle takes the accelerate fast action, acceleration a is +3 m/s2.
- If the ego vehicle takes the decelerate slowly action, acceleration a chooses −2 m/s2.
- If the ego vehicle takes the brake action, acceleration a is set to −4 m/s2.
- If the ego vehicle takes the maintain action, acceleration a is 0.
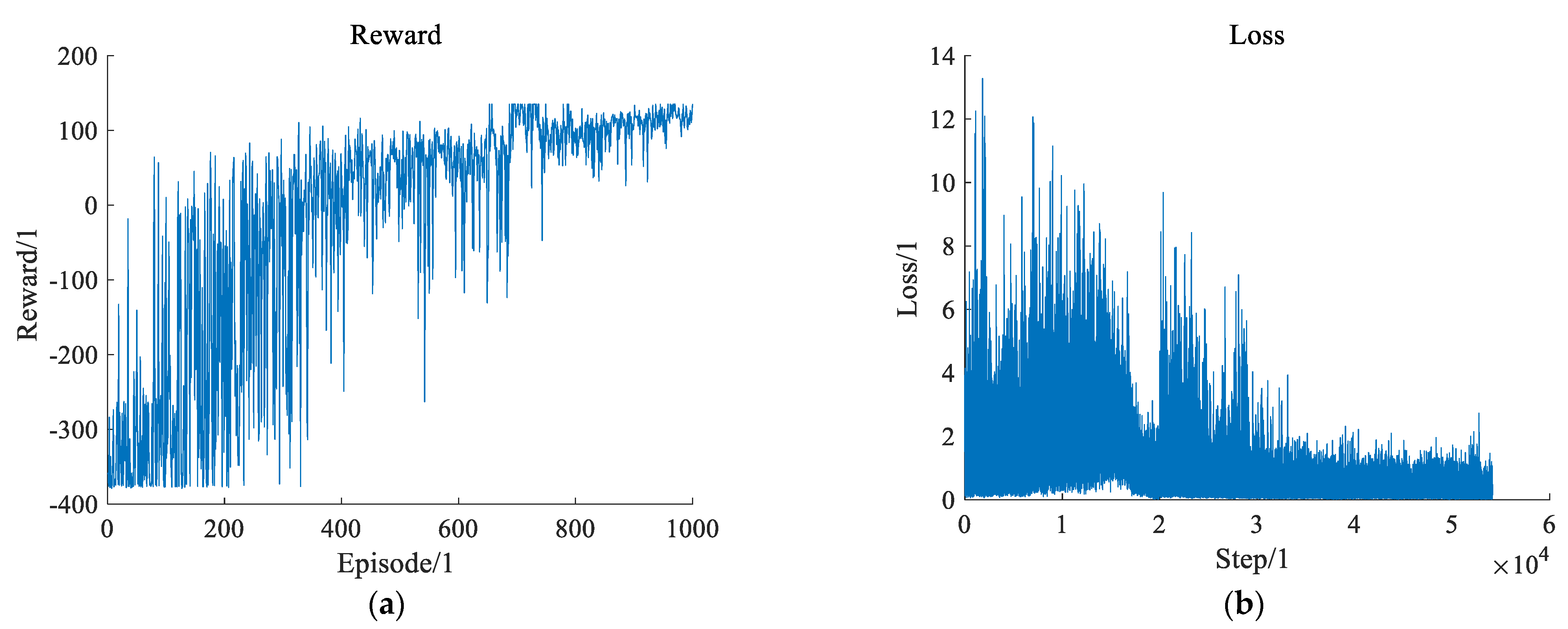
5.2. Settings of CR-DRQN’s Network Layers and Neurons
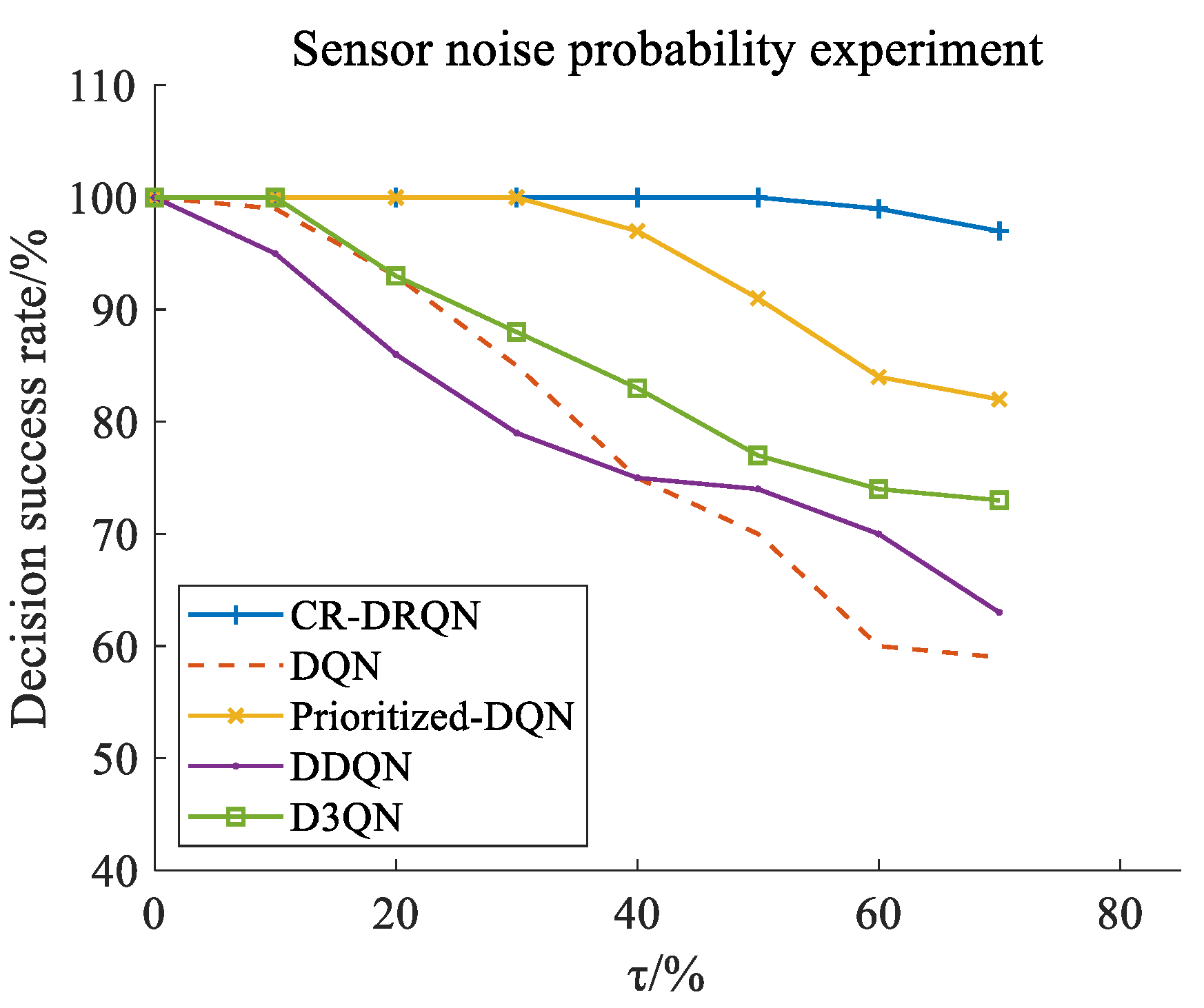
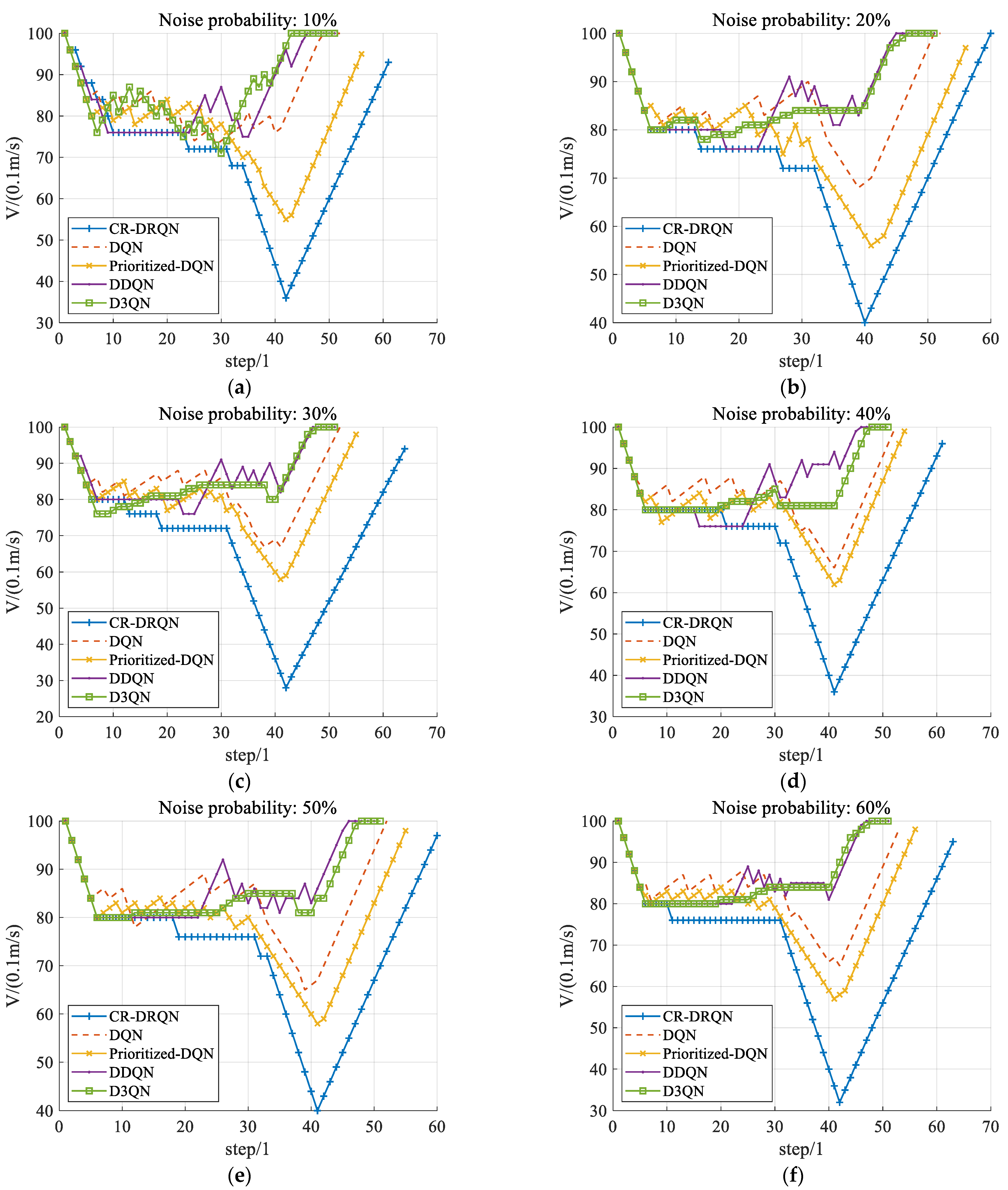
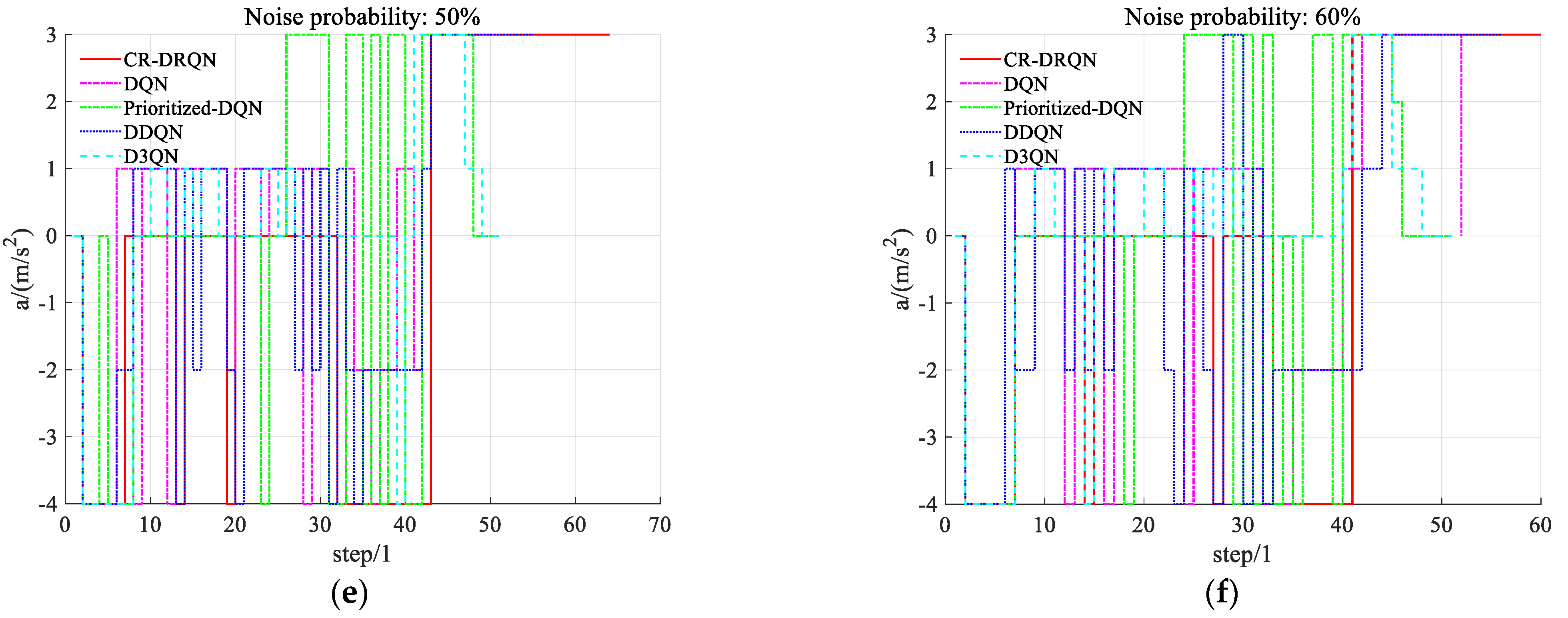
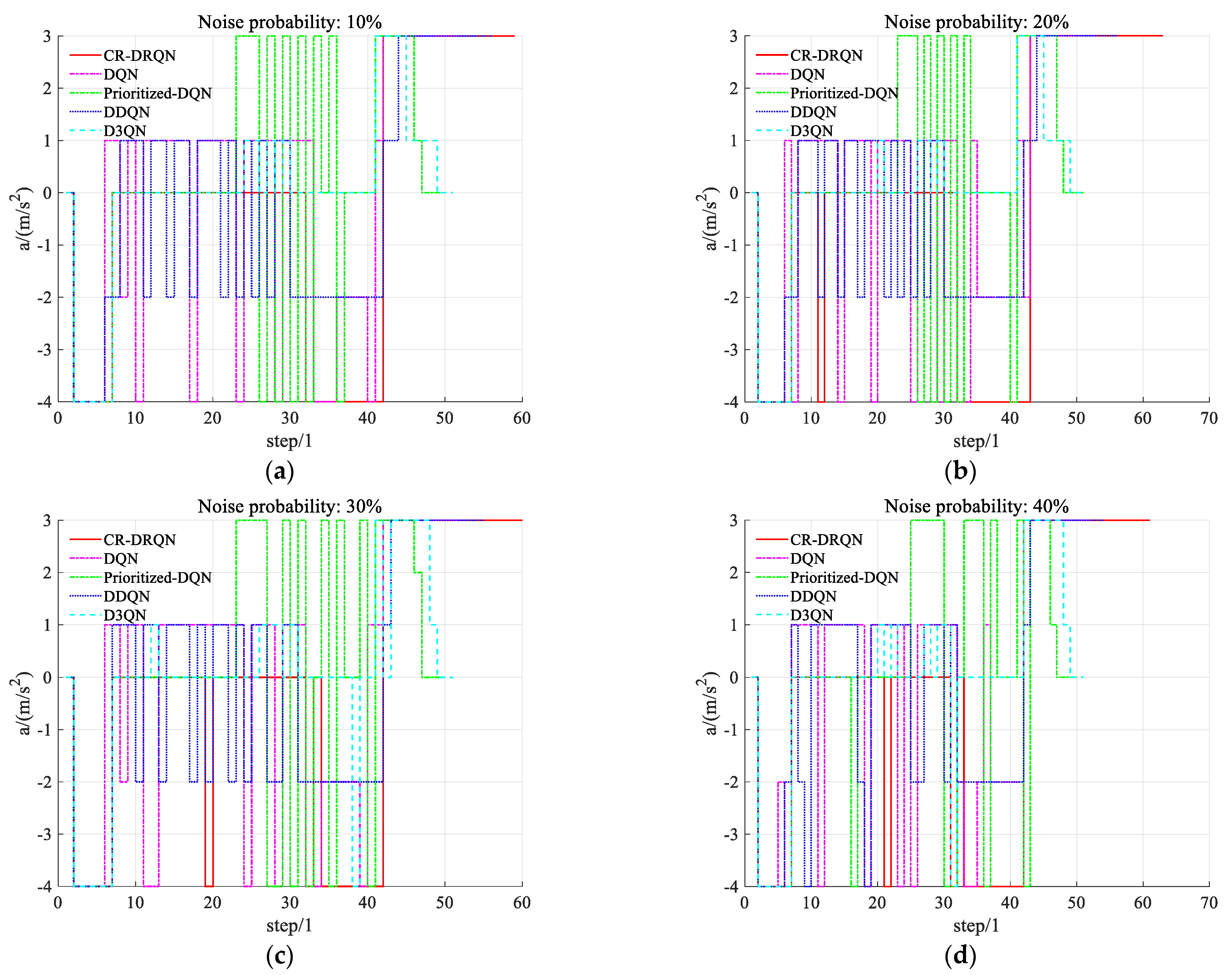
5.3. Performance of Comparative Experiments with Different Sensor Noise
5.3.1. Safety Evaluation
5.3.2. The Ability of Collision Risk Prediction
5.3.3. Comfort Evaluation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bijelic, M.; Muench, C.; Ritter, W.; Kalnishkan, Y.; Dietmayer, K. Robustness Against Unknown Noise for Raw Data Fusing Neural Networks. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2177–2184. [Google Scholar]
- Fayyad, J.; Jaradat, M.A.; Gruyer, D.; Najjaran, H. Deep Learning Sensor Fusion for Autonomous Vehicle Perception and Localization: A review. Sensors 2020, 20, 4220. [Google Scholar] [CrossRef]
- Pan, X.; Lin, X. Research on the Behavior Decision of Connected and Autonomous Vehicle at the Unsignalized Intersection. In Proceedings of the 2021 IEEE International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI), Fuzhou, China, 24–26 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 440–444. [Google Scholar]
- Badue, C.; Guidolini, R.; Carneiro, R.V.; Azevedo, P.; Cardoso, V.B.; Forechi, A.; De Souza, A.F. Self-driving cars: A survey. Expert Syst. Appl. 2021, 165, 113816. [Google Scholar] [CrossRef]
- Hang, P.; Lv, C.; Xing, Y.; Huang, C.; Hu, Z. Human-Like Decision Making for Autonomous Driving: A Noncooperative Game Theoretic Approach. IEEE Trans. Intell. Transp. Syst. 2020, 22, 2076–2087. [Google Scholar] [CrossRef]
- Li, S.; Shu, K.; Chen, C.; Cao, D. Planning and Decision-making for Connected Autonomous Vehicles at Road Intersections: A Review. Chin. J. Mech. Eng. 2021, 34, 133. [Google Scholar] [CrossRef]
- Smirnov, N.; Liu, Y.Z.; Validi, A.; Morales-Alvarez, W.; Olaverri-Monreal, C. A Game Theory-Based Approach for Modeling Autonomous Vehicle Behavior in Congested, Urban Lane-Changing Scenarios. Sensors 2021, 21, 1523. [Google Scholar] [CrossRef]
- Chen, X.M.; Sun, Y.F.; Ou, Y.J.X. A Conflict Decision Model Based on Game Theory for Intelligent Vehicles at Urban Unsignalized Intersections. IEEE Access 2020, 8, 189546–189555. [Google Scholar] [CrossRef]
- Zhu, H.M.; Feng, S.Z.; Yu, F.Q. Parking Detection Method Based on Finite-State Machine and Collaborative Decision-Making. IEEE Sens. J. 2018, 18, 9829–9839. [Google Scholar] [CrossRef]
- Cueva, F.G.; Pascual, E.J.; Garcia, D.V. Fuzzy decision method to improve the information exchange in a vehicle sensor tracking system. Appl. Soft Comput. 2015, 35, 708–716. [Google Scholar] [CrossRef]
- Balal, E.; Cheu, R.L.; Sarkodie, G.T. A binary decision model for discretionary lane changing move based on fuzzy inference system. Transp. Res. Part C-Emerg. Technol. 2016, 67, 47–61. [Google Scholar] [CrossRef]
- Silva, I.; Naranjo, J.E. A Systematic Methodology to Evaluate Prediction Models for Driving Style Classification. Sensors 2020, 20, 1692. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Delport, J.; Wang, Y. Lateral Motion Prediction of On-Road Preceding Vehicles: A Data-Driven Approach. Sensors 2019, 19, 2111. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Li, S.; Li, S.; Qin, Y.; Cao, D.; Qu, X.; Cheng, B. Deep Reinforcement Learning Enabled Decision-Making for Autonomous Driving at Intersections. Automot. Innov. 2020, 3, 374–385. [Google Scholar] [CrossRef]
- Alizadeh, A.; Moghadam, M.; Bicer, Y.; Ure, N.K.; Yavas, U.; Kurtulus, C. Automated Lane Change Decision Making using Deep Reinforcement Learning in Dynamic and Uncertain Highway Environment. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1399–1404. [Google Scholar]
- Sallab, A.E.L.; Abdou, M.; Perot, E. Deep Reinforcement Learning Framework for Autonomous Driving. Electron. Imaging 2017, 70–76. [Google Scholar] [CrossRef] [Green Version]
- Jeong, Y.; Kim, S.; Yi, K. Surround Vehicle Motion Prediction Using LSTM-RNN for Motion Planning of Autonomous Vehicles at Multi-Lane Turn Intersections. IEEE Open J. Intell. Transp. Syst. 2020, 1, 2–14. [Google Scholar] [CrossRef]
- Zeng, J.H.; Hu, J.M.; Zhang, Y. Adaptive Traffic Signal Control with Deep Recurrent Q-learning. In Proceedings of the IEEE Intelligent Vehicles Symposium, Changshu, China, 26–30 June 2018. [Google Scholar]
- Choe, C.J.; Baek, S.; Woon, B.; Kong, S.H. Deep Q Learning with LSTM for Traffic Light Control. In Proceedings of the 2018 24th Asia-Pacific Conference on Communications, Ningbo, China, 12–14 November 2018. [Google Scholar]
- Jozefowicz, R.; Zaremba, W.; Sutskever, I. An Empirical Exploration of Recurrent Network Architectures. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2342–2350. [Google Scholar]
- Iberraken, D.; Adouane, L.; Denis, D. Multi-Level Bayesian Decision-Making for Safe and Flexible Autonomous Navigation in Highway Environment. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Noh, S. Probabilistic Collision Threat Assessment for Autonomous Driving at Road Intersections Inclusive of Vehicles in Violation of Traffic Rules. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Li, L.H.; Gan, J.; Yi, Z.W.; Qu, X.; Ran, B. Risk perception and the warning strategy based on safety potential field theory. Accid. Anal. Prev. 2020, 148, 105805–105822. [Google Scholar] [CrossRef]
- Galceran, E.; Cunningham, A.G.; Eustice, R.M.; Olson, E. Multipolicy decision-making for autonomous driving via changepoint-based behavior prediction: Theory and experiment. Auton. Robot. 2017, 41, 1367–1382. [Google Scholar] [CrossRef]
- Hsu, T.M.; Chen, Y.R.; Wang, C.H. Decision Making Process of Autonomous Vehicle with Intention-Aware Prediction at Unsignalized Intersections. In Proceedings of the 2020 International Automatic Control Conference (CACS), Hsinchu, Taiwan, 4–7 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Huang, Z.Q.; Zhang, J.; Tian, R.; Zhang, Y.X. End-to-end autonomous driving decision based on deep reinforcement learning. In Proceedings of the 5th International Conference on Control, Automation and Robotics, Beijing, China, 19–22 April 2019. [Google Scholar]
- Chen, J.; Xue, Z.; Fan, D. Deep Reinforcement Learning Based Left-Turn Connected and Automated Vehicle Control at Signalized Intersection in Vehicle-to-Infrastructure Environment. Information 2020, 11, 77. [Google Scholar] [CrossRef] [Green Version]
- Fu, Y.C.; Li, C.L.; Yu, F.R.; Luan, T.H.; Zhang, Y. A decision-making strategy for vehicle autonomous braking in emergency via deep reinforcement learning. IEEE Trans. Veh. Technol. 2020, 69, 5876–5888. [Google Scholar] [CrossRef]
- Qian, L.L.; Xu, X.; Zeng, Y.J. Deep consistent behavioral decision making with planning features for autonomous vehicles. Electronics 2019, 8, 1492. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Kai, S.; Wang, B.; Chen, D.; Hao, J.; Zhang, H.; Liu, W. A Multi-Task Reinforcement Learning Approach for Navigating Unsignalized Intersections. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1583–1588. [Google Scholar]
- Chen, L.; Hu, X.; Tang, B.; Cheng, Y. Conditional DQN-Based Motion Planning with Fuzzy Logic for Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2020, 1–12. [Google Scholar] [CrossRef]
- Kamran, D.; Lopez, C.F.; Lauer, M.; Stiller, C. Risk-Aware High-level Decisions for Automated Driving at Occluded Intersections with Reinforcement Learning. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1205–1212. [Google Scholar]
- Zhang, S.; Wu, Y.; Ogai, H.; Inujima, H.; Tateno, S. Tactical Decision-Making for Autonomous Driving Using Dueling Double Deep Q Network With Double Attention. IEEE Access 2021, 9, 151983–151992. [Google Scholar] [CrossRef]
- Mokhtari, K.; Wagner, A.R. Safe Deep Q-Network for Autonomous Vehicles at Unsignalized Intersection. arXiv 2021, arXiv:2106.04561. [Google Scholar]
- Graesser, L.; Keng, W.L. Foundations of Deep Reinforcement Learning: Theory and Practice in Python, 1st ed.; Addison-Wesley Professional: Boston, MA, USA, 2019; pp. 32–36. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018; pp. 6–7. [Google Scholar]
- Chollet, F. Deep Learning with Python, 6th ed.; Manning Publications Co.: Shelter Island, NY, USA, 2017; pp. 55–58. [Google Scholar]
- Yu, L.; Shao, X.; Wei, Y.; Zhou, K. Intelligent Land-Vehicle Model Transfer Trajectory Planning Method Based on Deep Reinforcement Learning. Sensors 2018, 18, 2905. [Google Scholar]
- Farebrother, J.; Machado, M.C.; Bowling, M.H. Generalization and Regularization in DQN. arXiv 2018, arXiv:1810.00123. [Google Scholar]
- Hausknecht, M.J.; Stone, P. Deep Reinforcement Learning in Parameterized Action Space. arXiv 2015, arXiv:1511.04143. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Reference | Application | |
|---|---|---|---|
| Game theory-based | [7] | Lane changing at congested, urban scenarios | |
| [8] | Decision-making at an urban unsignalized intersection | ||
| Generative decision-making | [9] | Parking | |
| Fuzzy decision-making | [10] | Decision-making in a vehicle sensor tracking system | |
| [11] | Lane changing | ||
| Partially observable Markov decision-making | Machine learning | [12] | Driving style classification |
| [13] | Lateral motion prediction | ||
| Deep reinforcement learning | [14] | Decision-making at intersections | |
| [15] | Lane changing in dynamic and uncertain highways | ||
| SerialNumber | Network Layers | Network Parameters | Rsafe | Rcomfort | Refficient | Q-Value |
|---|---|---|---|---|---|---|
| 1 | 4 | 64/32/16/5 | −5 | −0.2 | 442.7 | 83.34 |
| 2 | 128/64/32/5 | 9 | −1.6 | 466.4 | 100.68 | |
| 3 | 256/128/64/5 | 12 | −1.4 | 447.8 | 100.26 | |
| 4 | 5 | 64/32/16/8/5 | 3 | −0.4 | 448.3 | 92.26 |
| 5 | 128/64/32/16/5 | −4 | −0.6 | 446.6 | 84.72 | |
| 6 | 256/128/64/32/5 | 3 | −6.4 | 444.8 | 85.56 | |
| 7 | 6 | 128/64/32/16/8/5 | 3 | −0.4 | 448.3 | 92.26 |
| 8 | 160/80/40/20/10/5 | 3 | −0.4 | 448.3 | 92.26 | |
| 9 | 256/128/64/32/16/5 | 30 | −0.8 | 485.5 | 126.3 | |
| 10 | 320/160/80/40/20/5 | 30 | −1 | 485.5 | 126.1 | |
| 11 | 7 | 256/128/64/32/16/8/5 | −15 | −11.6 | 439 | 61.2 |
| 12 | 320/160/80/40/20/10/5 | 15 | −4.3 | 554.9 | 121.68 | |
| 13 | 512/256/128/64/32/16/5 | 26 | −0.5 | 474.7 | 120.44 | |
| 14 | 640/320/160/80/40/20/5 | 6 | −0.4 | 443.4 | 94.26 | |
| 15 | 8 | 512/256/128/64/32/16/8/5 | −3 | −8.2 | 437 | 76.2 |
| 16 | 640/320/160/80/40/20/10/5 | −9 | −0.7 | 434.4 | 77.18 |
| Noise Probability | 10% | 20% | 30% | 40% | 50% | 60% |
|---|---|---|---|---|---|---|
| DQN | 33 | 36 | 28 | 36 | 40 | 25 |
| Prioritized-DQN | 40 | 37 | 40 | 33 | 41 | 44 |
| DDQN | 38 | 32 | 35 | 32 | 32 | 38 |
| D3QN | 22 | 23 | 32 | 29 | 32 | 40 |
| CR-DRQN | 9 | 12 | 15 | 16 | 16 | 16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, L.; Huo, S.; Li, K.; Wei, Y. A Collision Relationship-Based Driving Behavior Decision-Making Method for an Intelligent Land Vehicle at a Disorderly Intersection via DRQN. Sensors 2022, 22, 636. https://doi.org/10.3390/s22020636
Yu L, Huo S, Li K, Wei Y. A Collision Relationship-Based Driving Behavior Decision-Making Method for an Intelligent Land Vehicle at a Disorderly Intersection via DRQN. Sensors. 2022; 22(2):636. https://doi.org/10.3390/s22020636
Chicago/Turabian StyleYu, Lingli, Shuxin Huo, Keyi Li, and Yadong Wei. 2022. "A Collision Relationship-Based Driving Behavior Decision-Making Method for an Intelligent Land Vehicle at a Disorderly Intersection via DRQN" Sensors 22, no. 2: 636. https://doi.org/10.3390/s22020636
APA StyleYu, L., Huo, S., Li, K., & Wei, Y. (2022). A Collision Relationship-Based Driving Behavior Decision-Making Method for an Intelligent Land Vehicle at a Disorderly Intersection via DRQN. Sensors, 22(2), 636. https://doi.org/10.3390/s22020636