1. Introduction
The inspections of structures that are necessary after earthquakes are laborious, high-risk, and subject to human error. Describing the nature of inspections in a post-disaster scenario, the ATC-20 field manual [
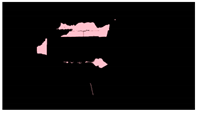
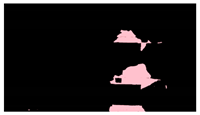
1] states that post-earthquake safety evaluations of buildings are “grueling work,” resulting in a high level of stress on the volunteer inspectors that may lead to “burn-out.” Entry into damaged structures for inspections poses a serious safety risk due to the unknown nature of their structural integrity. Additionally, the time-consuming nature of these inspections can exacerbate the social and economic impacts of the disaster on affected communities. For example, immediately after the 2017 Central Mexico Earthquake, hundreds of thousands of citizens had to exit damaged buildings (
Figure 1a) and were left with uncertainty about the state of their homes and offices [
2]. The initial evaluations conducted by the Civil Engineering Association took three weeks from the occurrence of the earthquake [
3]; at that time, 1210 buildings showed signs of damage (e.g.,
Figure 1a), but were safe to occupy, 327 buildings were severely damaged and unsafe to occupy, and 427 buildings needed detailed evaluation [
4]. Nearly 17,000 people were being housed in camps for weeks [
5] while waiting for detailed inspections [
6], and hundreds could still be seen still camping out in tents after six months (
Figure 1b). Similar scenarios may be observed anytime a large earthquake hits a densely populated region [
7,
8,
9]. To help communities recover swiftly after a disaster and get people back in their homes and businesses as soon as possible, more efficient inspections are required.
Data acquisition with unmanned aerial vehicles (UAVs) and data processing using deep learning algorithms have shown tremendous potential in advancing the level of autonomy in post-earthquake inspections. A frequently studied problem is the application of machine learning algorithms, with a specific focus on the use of deep convolutional neural networks (CNNs) for damage identification after earthquakes. Yeum et al. [
10] proposed the use of region-based R-CNN for spalling detection in earthquake-damaged buildings. Mondal et al. [
11], implemented the Faster R-CNN [
12] algorithm to compare different network architectures for multi-class detection of damage in earthquake-affected buildings. Xu et al. [
13] utilized Faster R-CNN for damage identification of cracks, spalling, and exposed rebar in concrete columns. Researchers have also sought to incorporate the context of the damage and information from the entire structure to contribute to a structural assessment using deep learning methods. For example, Hoskere, et al. [
14,
15] proposed the use of deep-learning based semantic segmentation for multiple types of damage and materials. The proposed methodology was extended to the semantic segmentation of scenes, components, and damage in reinforced concrete (RC) buildings in [
16]. Narazaki et al. [
17,
18] proposed the use of fully convolutional neural networks to identify bridge components for post-earthquake inspections. Narazaki et al. [
19] employed recurrent neural networks with video data to help better understand the structural component context of close up videos during bridge inspections. Gao et al. [
20] developed the PEER-Hub dataset incorporating multiple classification challenges for the post-earthquake assessment of buildings. Liang et al. [
21] proposed a three–level image–based approach for post–disaster inspection reinforced concrete bridges using deep learning. Dizaji et al. [
22] conducted preliminary research on using 3D data to train a network for defect identification of cracks and spalling on concrete columns. Pan et al. [
23] presented a framework to combine performance assessment with repair cost evaluation using deep learning, extending the types of information that can be extracted from image data to aid decision-makers. A detailed review of advances in vision-based inspection and monitoring can be found in Spencer et al. [
24].
The significant progress in computer graphics software over the past decade has allowed the creation of photo-realistic images and videos from 3D synthetic environments that have spurred advances in computer vision. The data generated from these graphics models, termed synthetic data, provides the ability to rapidly generate a large amount of diverse data (e.g., representing different geometries, colors, lighting, viewpoints, etc.) that may be impossible to otherwise acquire in the real world. Synthetic data has been used to validate applications like robotic simulation (e.g., Gazebo [
25]) and for reinforcement learning in autonomous vehicles (e.g., AirSim [
26]). Such synthetic data has also been used for semantic segmentation of urban scenes that have shown promising performance on field-collected data (Ros et al. [
27]). Moreover, improving diversity and photorealism of the simulated worlds has helped improve the performance of methods trained on synthetic data and subsequently applied on field data, as demonstrated by recent results in self-driving [
28,
29,
30].
Researchers have recently begun utilizing 3D synthetic environments for applications in vision-based inspection and monitoring. Hoskere et al. [
31,
32,
33] proposed ideas on physics- and heuristics-based damage models as inspection testbeds and demonstrated them for inland navigation infrastructure. For structural monitoring applications, Narazaki et al. [
34,
35] also developed physics-based graphics models for displacement and strain measurement of inland navigation infrastructure and laboratory bridge structures. Zdziebko et al. [
36] developed a physics-based graphics model of a laboratory beam structure for the development of vision-based displacement measurement algorithms. For post-earthquake inspections of RC viaducts, Narazki et al. [
37] proposed heuristics-based models in a 3D synthetic environment to obtain a dataset of images and train a deep neural network for damage detection. While the efficacy of deep learning methods has been demonstrated for autonomous inspection subtasks (such as data acquisition, damage identification, and decision making), for robust real-world applicability, these subtasks need to be addressed in an integrated manner, incorporating diverse scenarios including variations in structure properties (e.g., geometry, color, material properties, damage amount), loading (intensity, frequency content, etc.), camera properties (distance, viewpoint, etc.), and environment (lighting, surrounding objects).
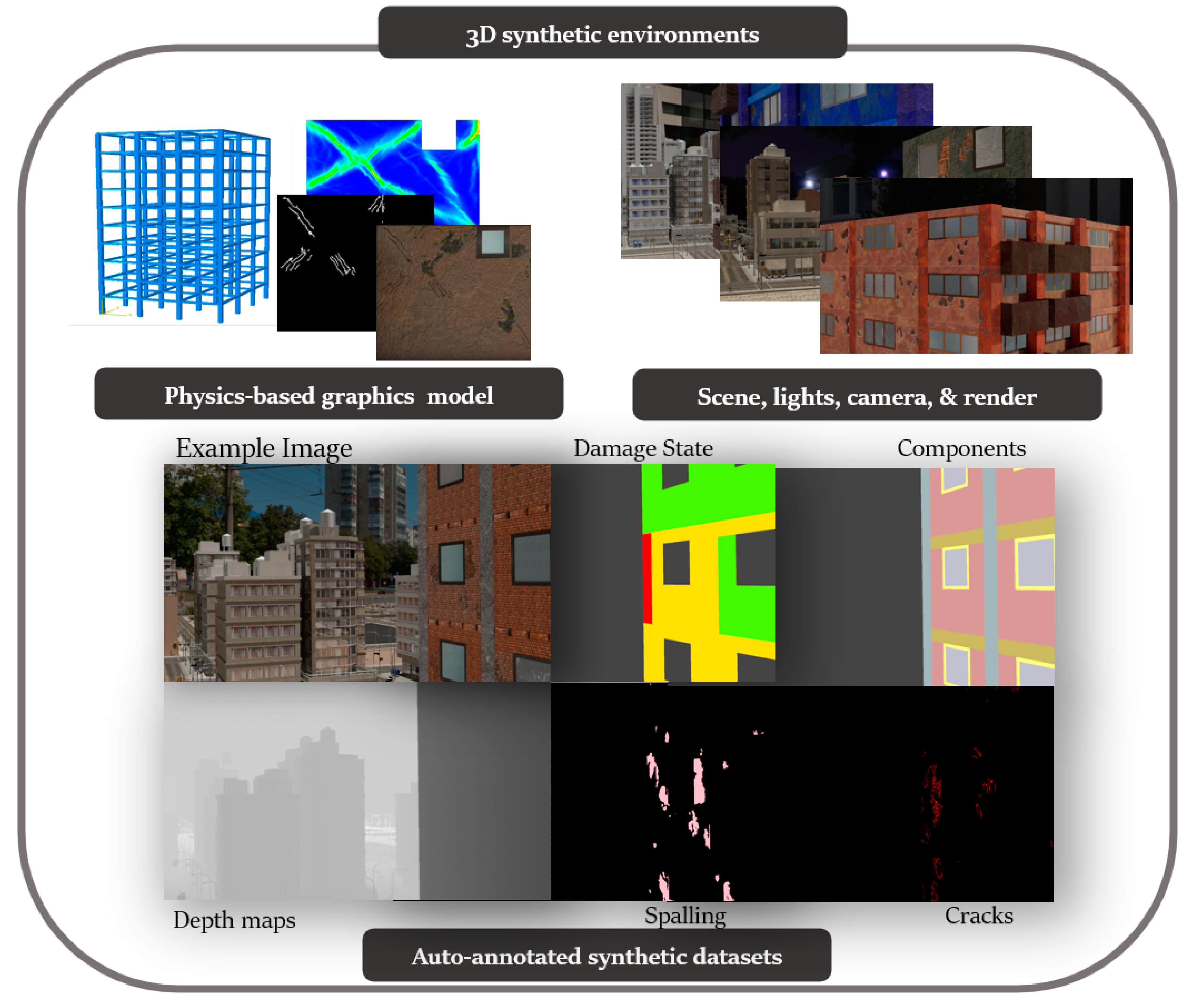
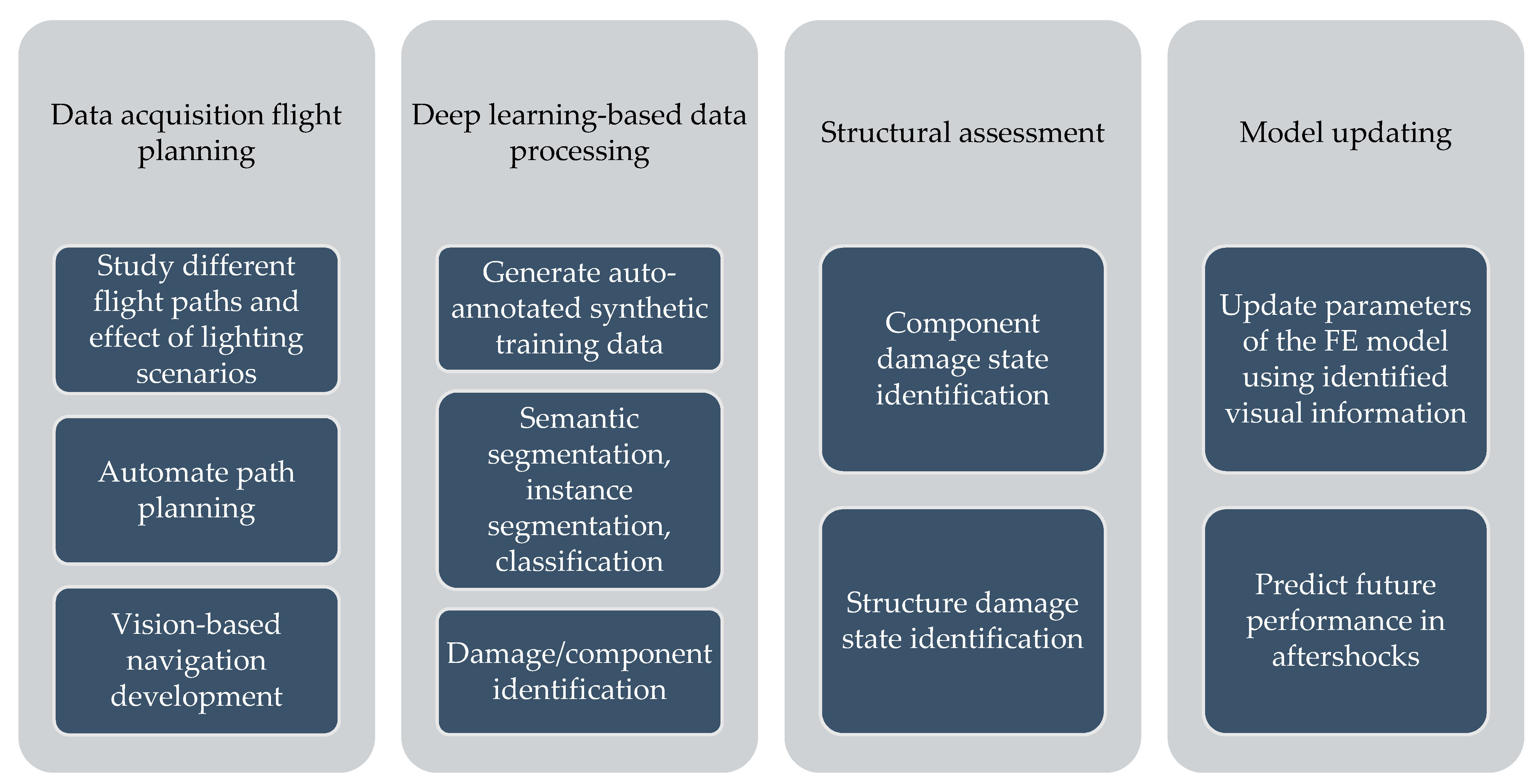
This paper proposes a novel framework for automatically generating 3D synthetic environments spanning diverse scenarios in structure properties, loading, camera properties, and environment necessary for a robust inspection testbed. In particular, we propose a procedure to generate physics-based graphics models (PBGMs) that incorporate a finite element model with non-linear time history analysis for modeling the response of a structure, and novel graphics algorithms to render physically consistent damage. Another significant contribution of our research is the demonstration of the utility of the proposed testbed through experiments with reinforced concrete RC buildings subject to earthquake excitation. First, we implement the proposed framework to generate a new large-scale annotated benchmark dataset for post-earthquake inspections of buildings termed QuakeCity. Second, we demonstrate the improved performance of deep learning models trained using the QuakeCity dataset for inference on real data. Finally, a comparison of deep learning-based damage state estimation for different data acquisition strategies is carried out. A general flowchart of the testbed process is provided in
Figure 2. The manuscript is organized into the following sections, (i) 3D synthetic environments for inspections, (ii) implementation of the proposed framework for RC buildings, (iii) applications and experiments, (iv) results, and (v) conclusions followed by references.
2. Physics-Based Graphics Models in 3D Synthetic Environments
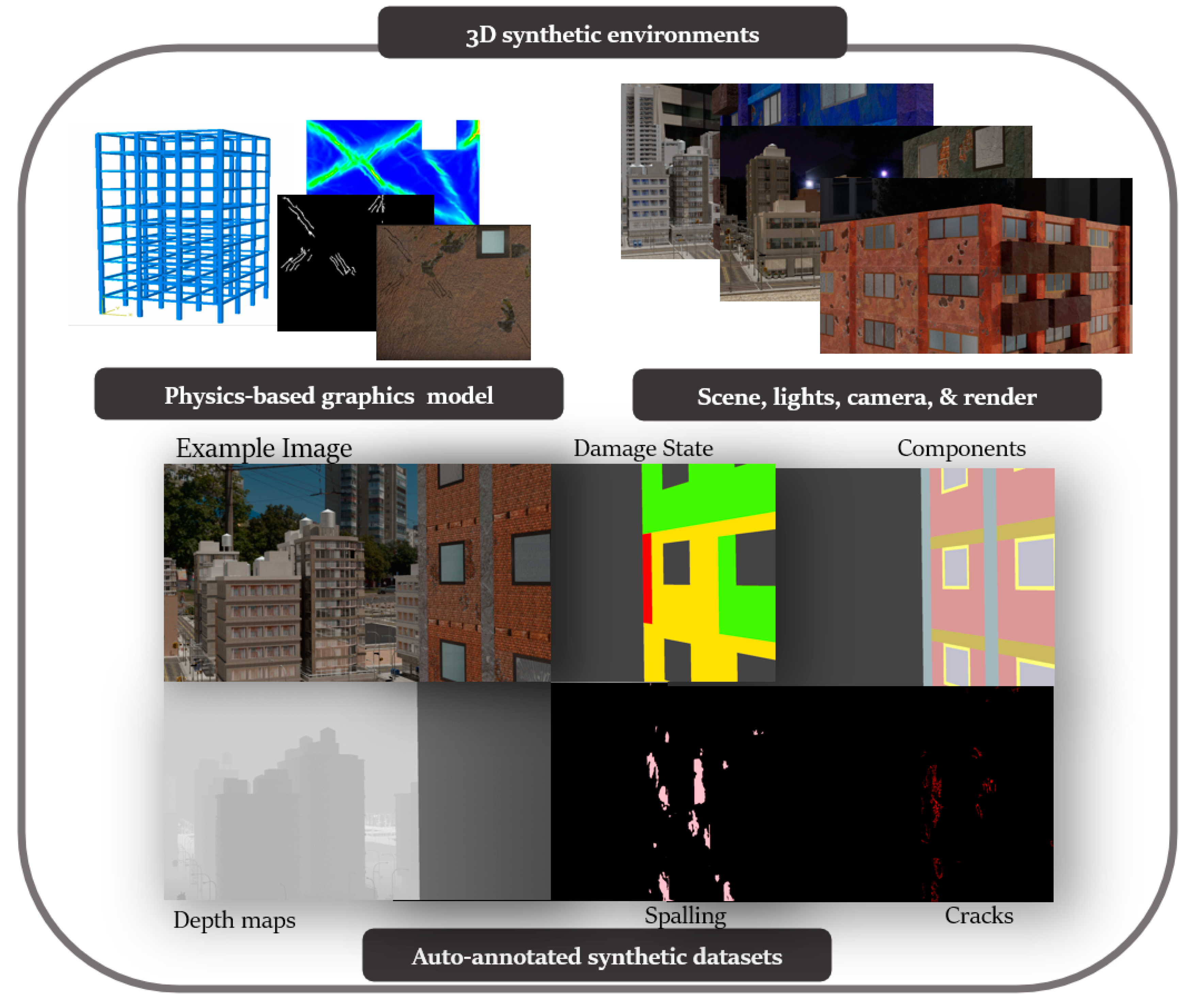
3D synthetic environments (
Figure 3) are defined as modeling software with the ability to simulate object geometries and textures, lighting sources, and cameras. Using synthetic environments, image capture from UAV during an inspection is simulated by rendering images from camera locations following planned flight trajectories. Different flight paths and data acquisition schemes can be evaluated in the synthetic environment for identification of flight parameters like distance from the structure for optimal identification accuracy of both damage and components, flight path for complete coverage, etc. Before such tests can be carried out, a key challenge is to model the structure and environment of interest. In this study, PBGMs are proposed as an effective tool for modeling the structures of interest in 3D synthetic environments. Generation of synthetic data using PBGMs allows for the creation of useful annotated datasets of damaged structures, as any data from algorithmically generated graphics models will be automatically labeled, both at the pixel and image-level using damage locations and states implicit in the PBGM. Different conditions, such as ground excitation, lighting, paint colors, dirt, etc. can be simulated, to generate a wider variety of training data robustly representing different realistic environments (
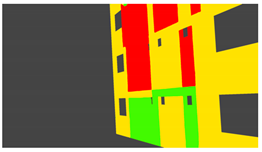
Figure 4). The generated data can be used to train a deep network for semantic segmentation, facilitating the automation of multiple tasks. As the damage is informed by a finite-element model, the generated data can be used to conduct overall assessments using the ground truth of the structure condition is available. Finally, as the visual representations are linked to the results of the finite element model, they provide one means of developing finite element model updating strategies.
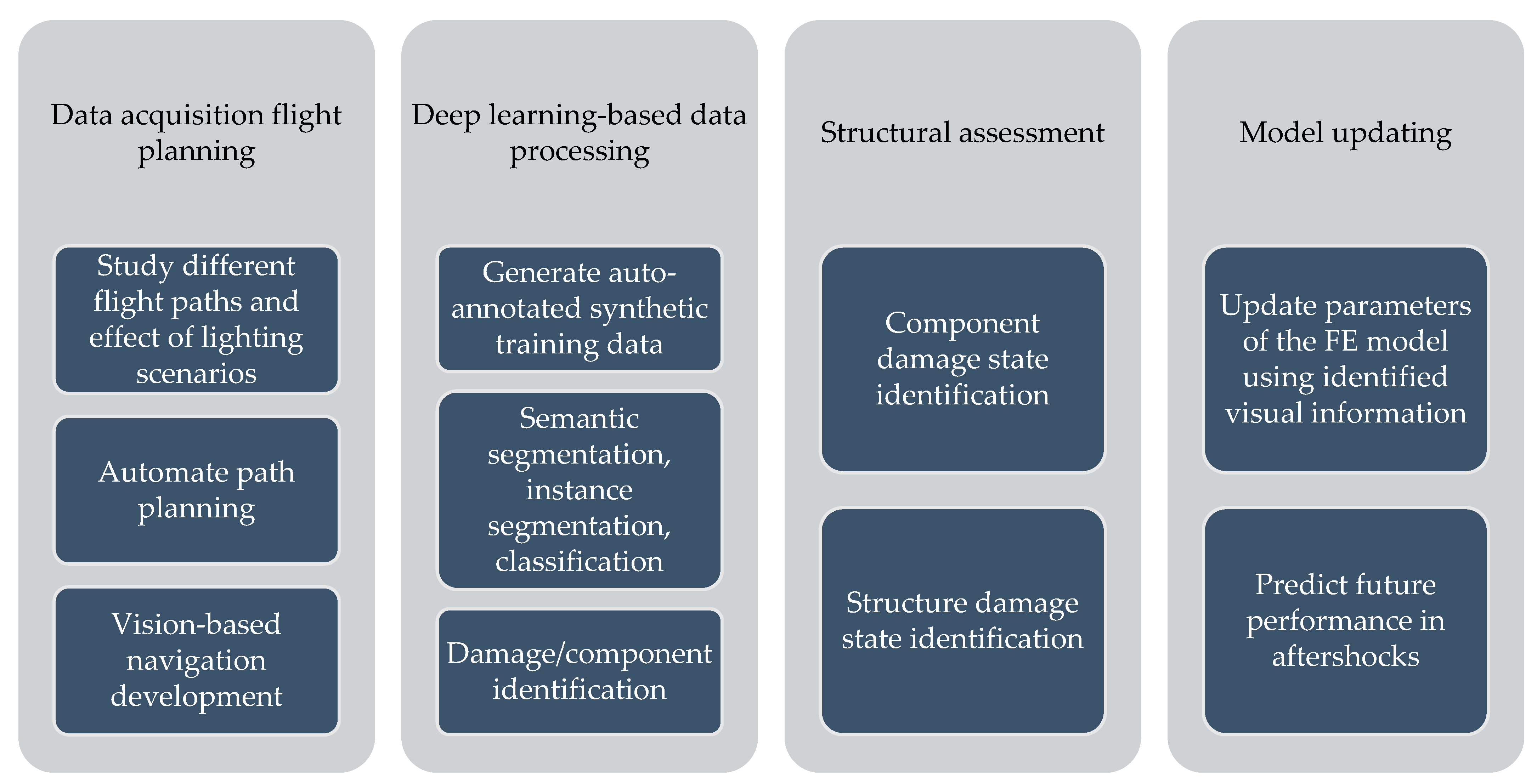
Figure 5 lists applications of PBGMs in synthetic environments for various visual inspection tasks. PBGMs and synthetic environments will provide a testbed for vision-algorithms with readily repeatable conditions. Algorithms that are effective in these virtual testbeds will be more likely to work well on field-collected datasets. The developed datasets using can also be used to augment field datasets to enhance accuracy.
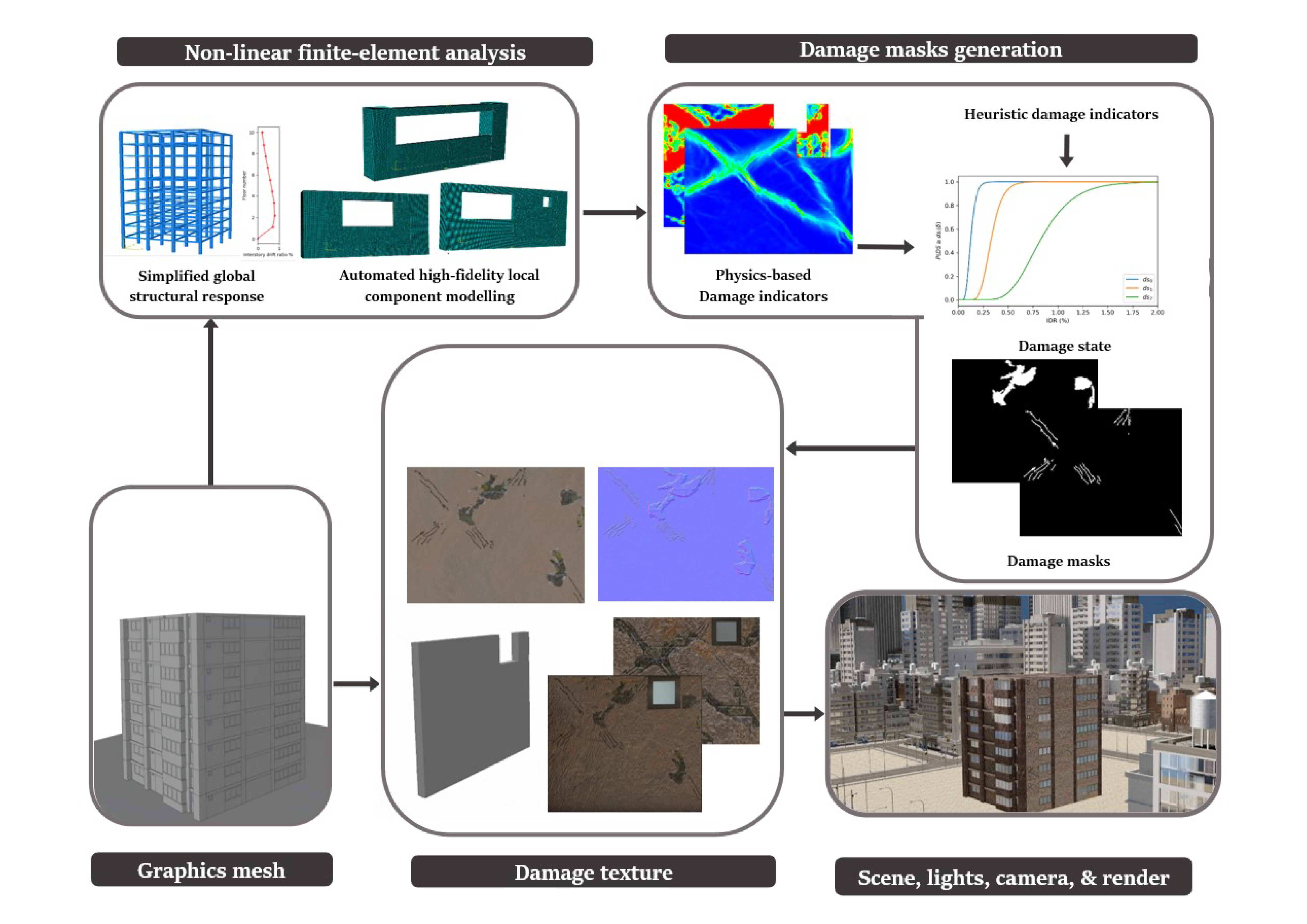
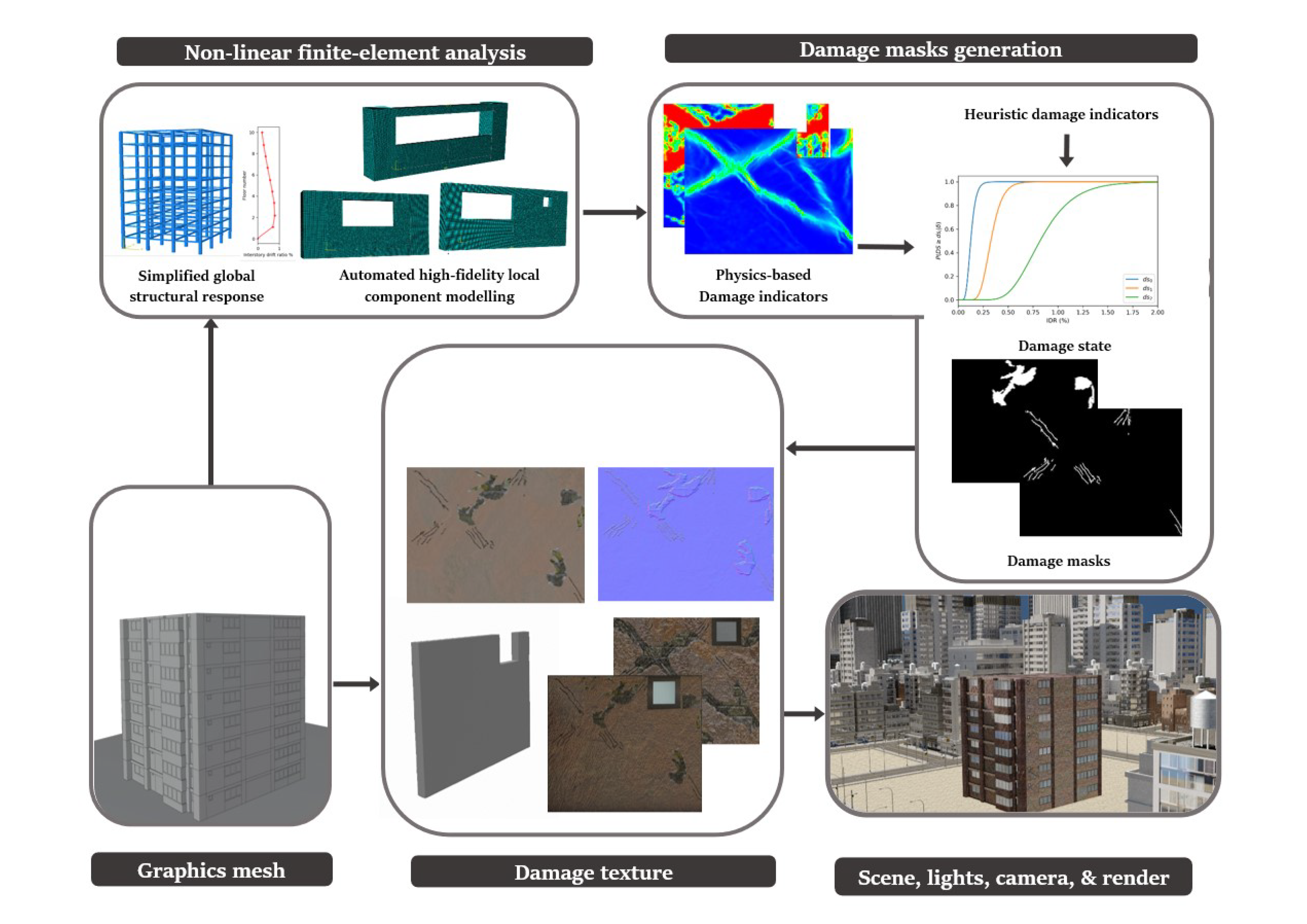
A framework for the generation of physics-based graphics models (PBGMs) for inspections is now presented. For clarity, the framework is illustrated in a schematic presented in
Figure 6 with reinforced concrete buildings with masonry infill walls as the structure type. However, the same procedures may be followed for other structures where the physics can be simulated through finite element models. The framework consists of five steps including, (i) graphics mesh, (ii) non-linear finite element analysis, (iii) damage masks generation (iv) damage texture, and (v) scene, lights, camera, and render.
2.1. Graphics Mesh
The geometry of the structure of interest in the PBGM is represented by a 3D mesh. The mesh may be created in any 3D creator software. The features of buildings incorporated in the 3D mesh will enable networks trained on synthetic data to learn representations for those features in real images. For structural inspections of buildings, structural components like beams, columns, and shear walls, and non-structural components like infill walls, doors, windows, and balconies, are highly relevant as damage to these components provides visual indicators of structural health. Similar lists can be made for other types of structures to be inspected. All these components should be created programmatically through parameterization, or, as referred to in the field of computer graphics, created “procedurally”. Procedural generation of the mesh will allow programmatic implementation of subsequent steps, thus enabling randomization of both geometry and textures. Randomization has been shown to improve the performance for related tasks like robotic perception when learning from synthetic data by Tobin et al. [
38] and is regarded as an effective way to learn generalizable representations [
29].
2.2. Non-Linear Finite Element Analysis
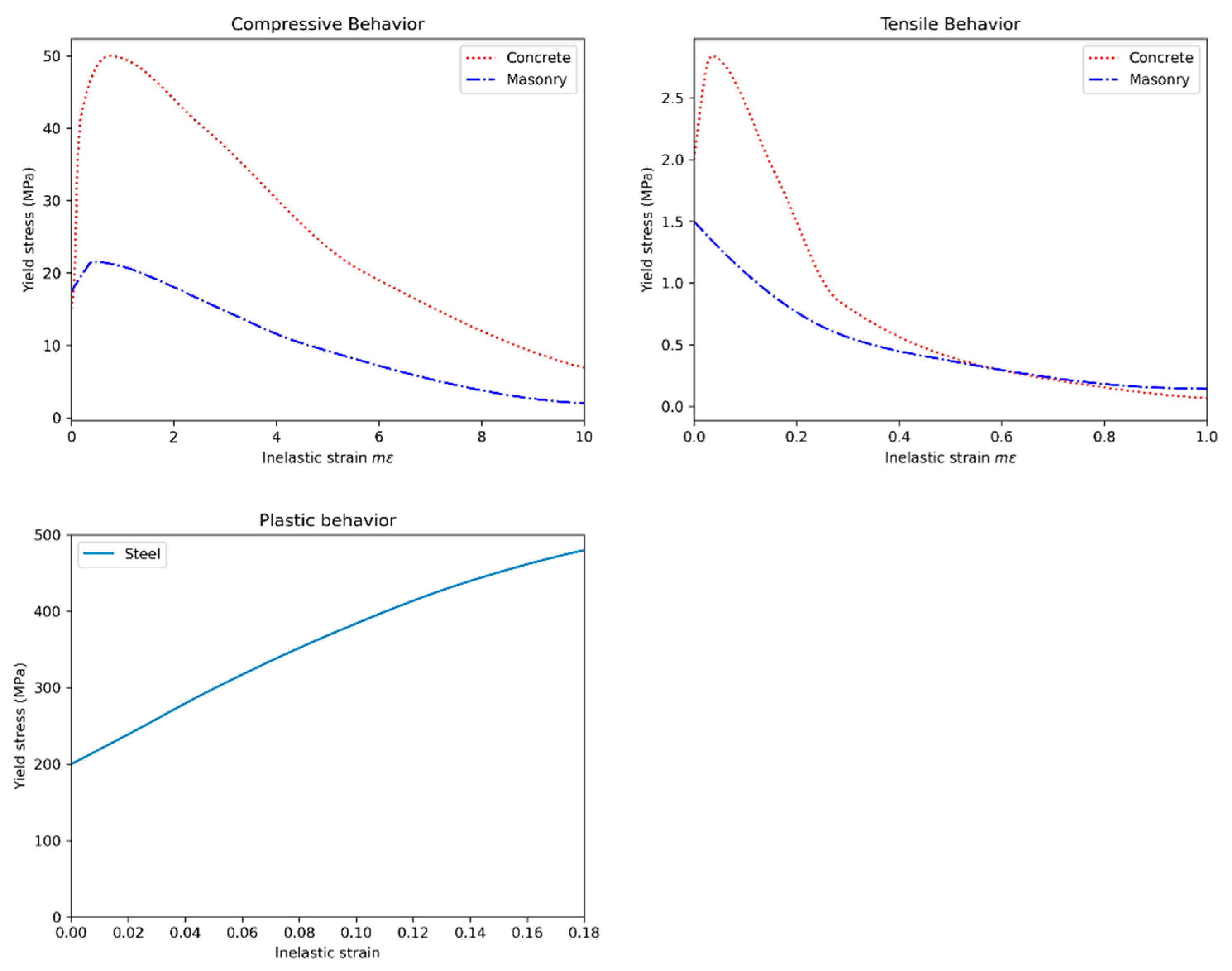
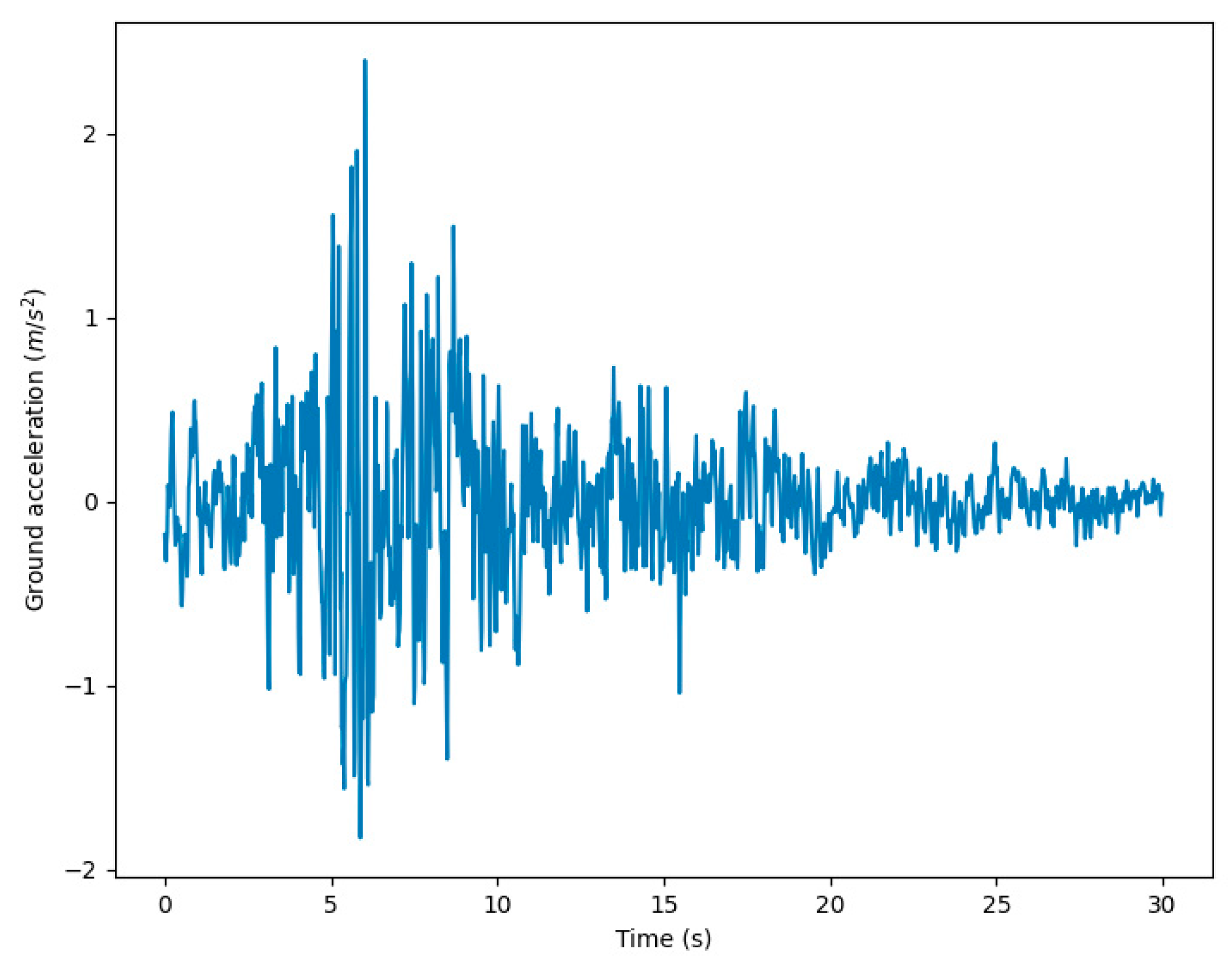
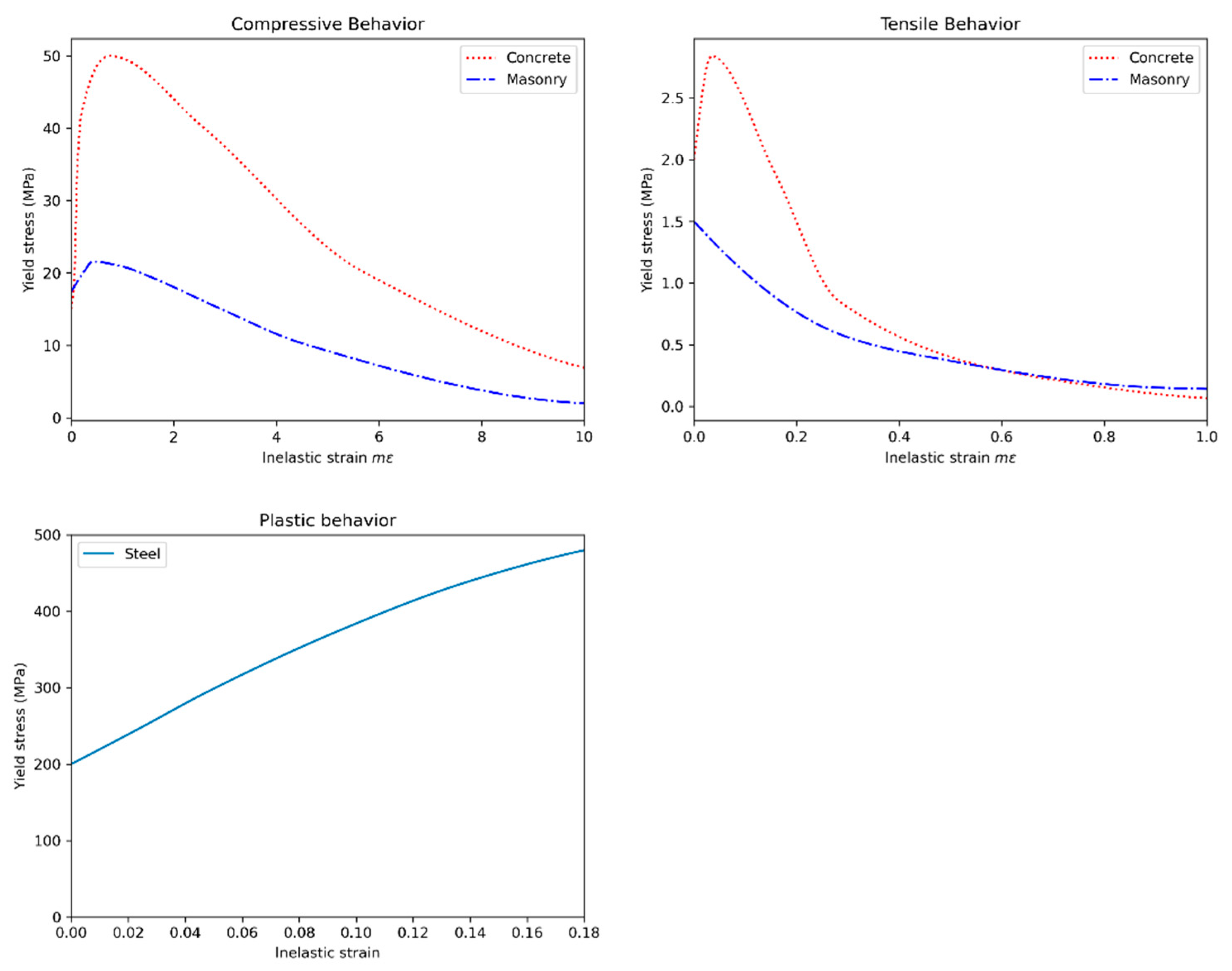
From the perspective of PBGM generation, non-linear finite element analyses provide valuable insight into the regions in a structure where damage is most likely to occur. The same parameters used to construct the mesh procedurally are used to generate finite element models as well. In the particular case of post-earthquake inspections, a two-step analysis approach is proposed, first obtaining a simplified global response of the structure and then conducting a high-fidelity analysis for the visible components to generate accurate damage patterns. The main pieces of information derived from these analyses are the plastic strain contours, and other damage indicators such as the compression damage index from a concrete damaged plasticity model, which provides direct indicators for cracking and spalling of members–two of the main visual indicators of structural health after an earthquake. As the distribution of plastic strain is not likely to change for small changes in the loading, the number of analyses can be further reduced for large structures with little effect on the final result (i.e., the rendered PBGM) by taking advantage of the fact that components often repeat in a structure (e.g., across floors in a building). The next subsection describes the proposed methodology to identify physics-based damage hotspots using non-linear analysis.
2.3. Damage Masks Generation
Damage masks are 2D binary images that indicate the presence of damage on component surfaces. Several damage parameters need to be determined before these masks can be generated using the conducted analysis. These parameters relate to the number, size, shape, and location of the damage. Each of the relevant parameters may be determined through, (i) physics-based response, or (ii) defined heuristics. Both these modes come with their own set of merits and demerits. Heuristic methods are the only viable option for many damage cases that are difficult to model (e.g., due to lack of suitable material models or load representations) or for which no empirical data is available. Methods stemming from empirical data are reliable because they are based directly on observations but identifying good heuristics is challenging. When realizable, physics-based damage masks provide a rigorous approach that links the visual representation to results of finite element analyses, leveraging efforts by researchers in developing state-of-the-art constitutive models. Incorporating the physics enables applications such as estimating structural response (e.g., interstory drift, damage state, etc.), failure mechanisms, and model updating. We first propose a general framework to determine damage parameters and then demonstrate generating masks for common damage types of cracks and spalling using the structural response.
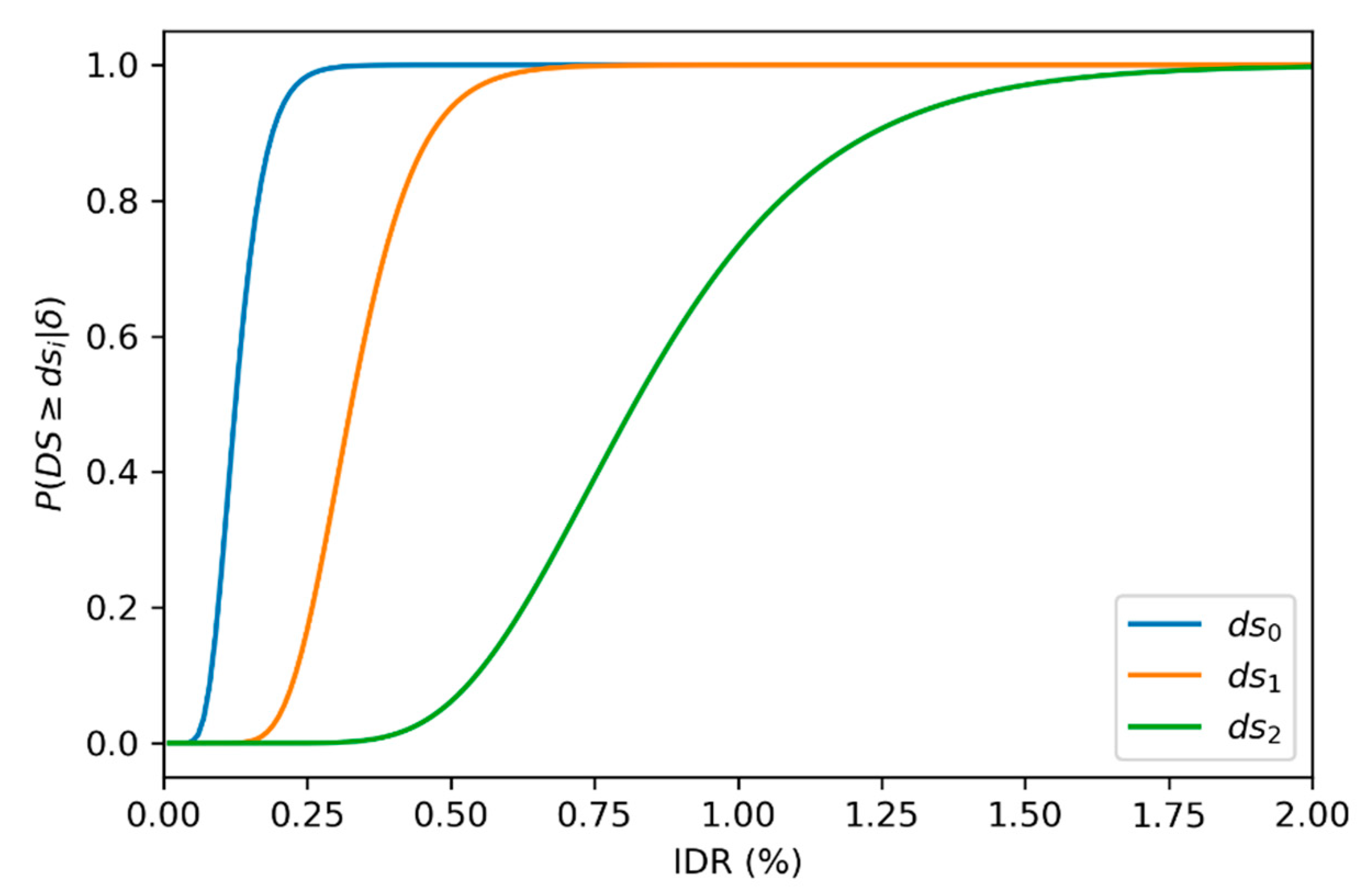
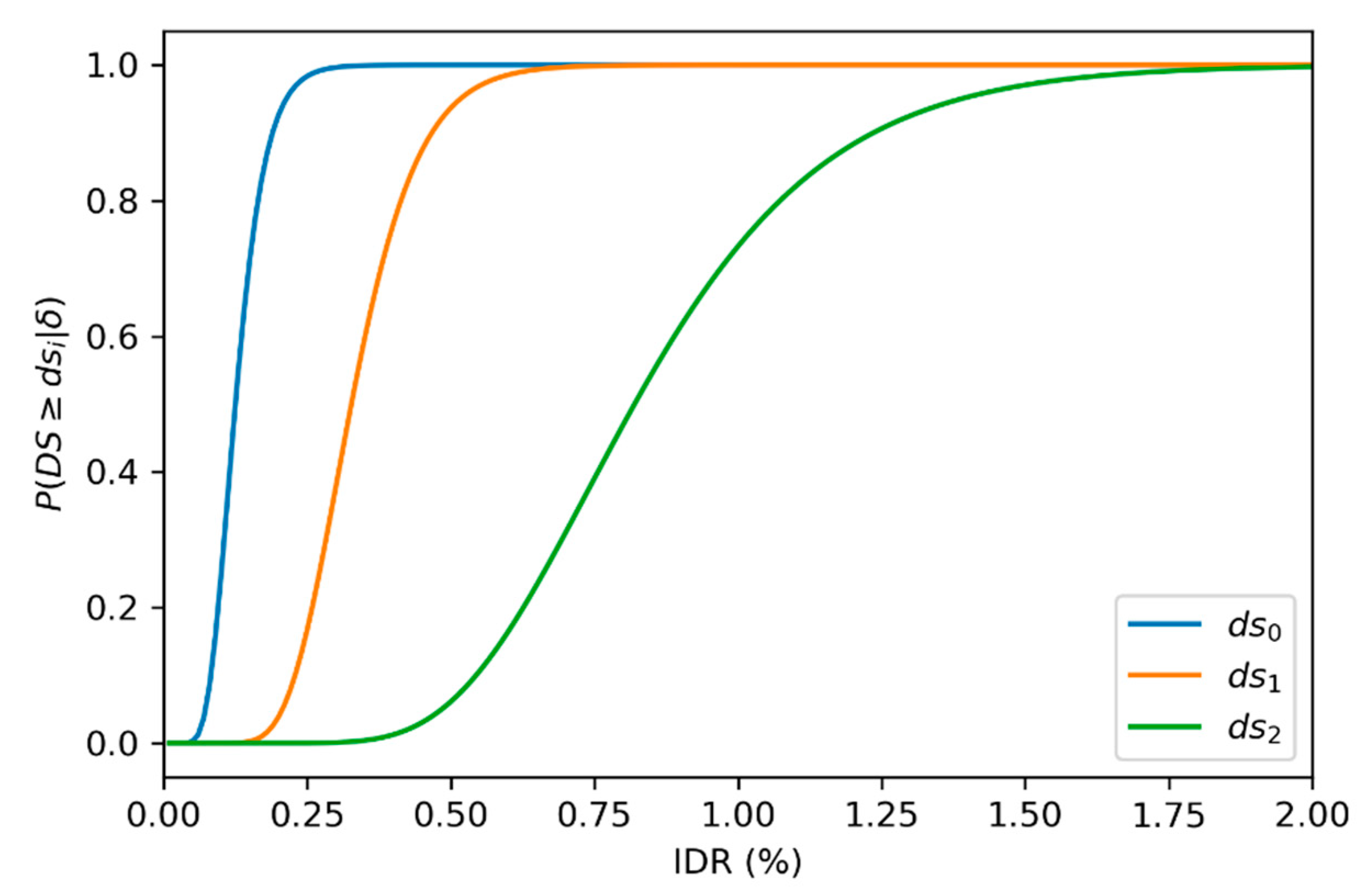
The damage parameters are obtained by Monte Carlo sampling from empirical or heuristic distributions. The first step is to determine the damage state (
DS) of the component based on some structural response measure
. The response measure used may be anything that is sensitive to visual damage. For example, for reinforced concrete buildings with masonry infill, a commonly used damage indicator, the interstory drift may be used as the response measure. The relationship between
DS and
is then modeled through a probability distribution (1). This distribution represents uncertainties in the geometry, method of construction, and material properties. The component damage state
is determined by sampling from the distribution given by
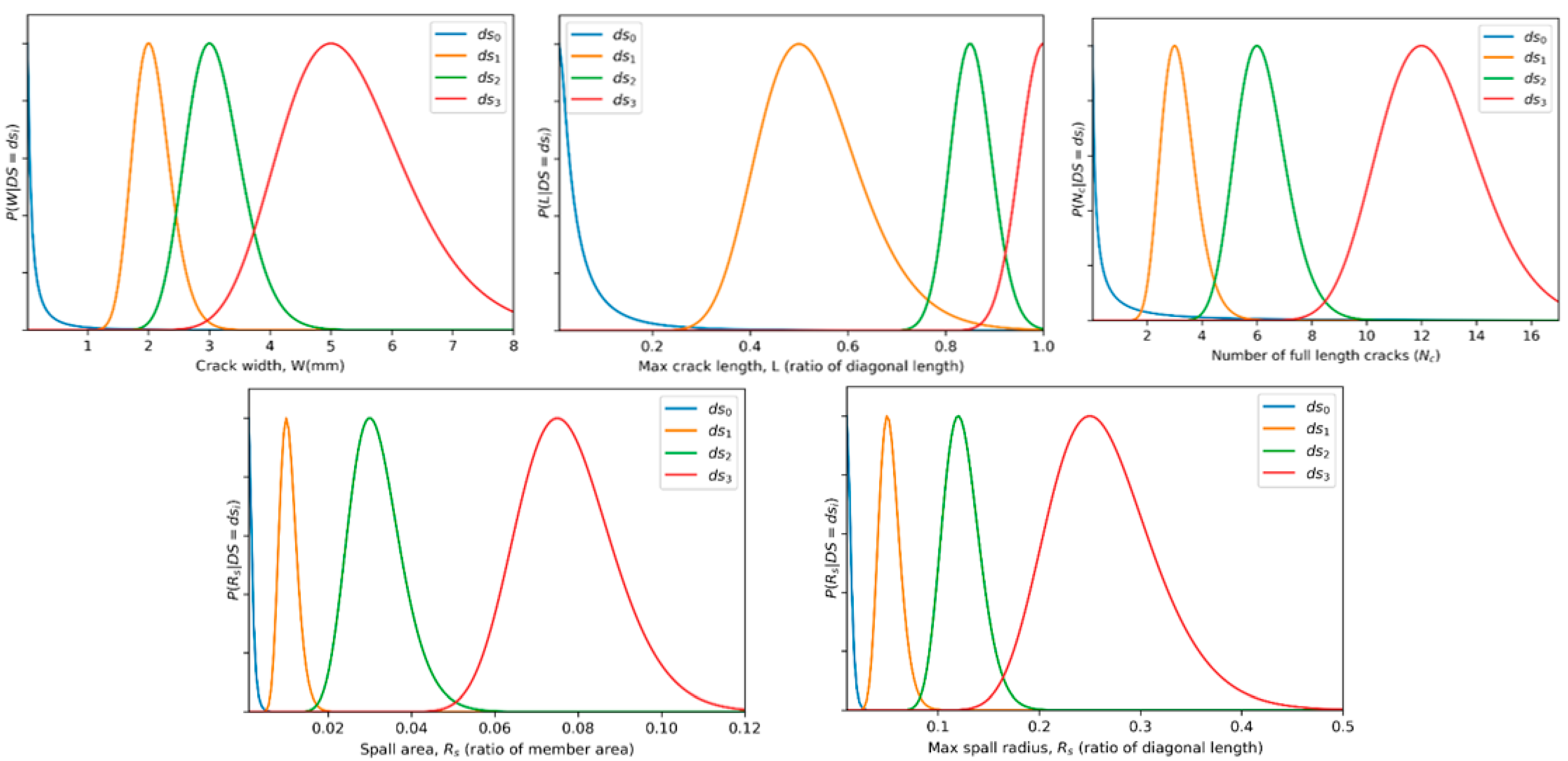
Various parameters
(e.g., number of cracks, crack width, crack length, etc.) are then calculated by sampling from their corresponding distributions representing variation in damage observed given a particular damage state shown in Equation (2).
While it may be possible to estimate the parameters
directly from
this two-step approach allows for a more intuitive method facilitating the construction of the distributions
and
based on empirical data. For parameters whose value will vary depending on the location in the member, parameters are further modified by a multiplicative factor derived from the structural response as shown in Equation (3).
where
is a function of some structural response parameter (e.g., plastic strain) varying in the component. Examples for selecting each of
,
, and
for RC buildings with masonry infill are provided in
Section 3. The next subsections discuss the generation of masks for cracks and spalls–two common types of defects once the damage parameters have been determined.
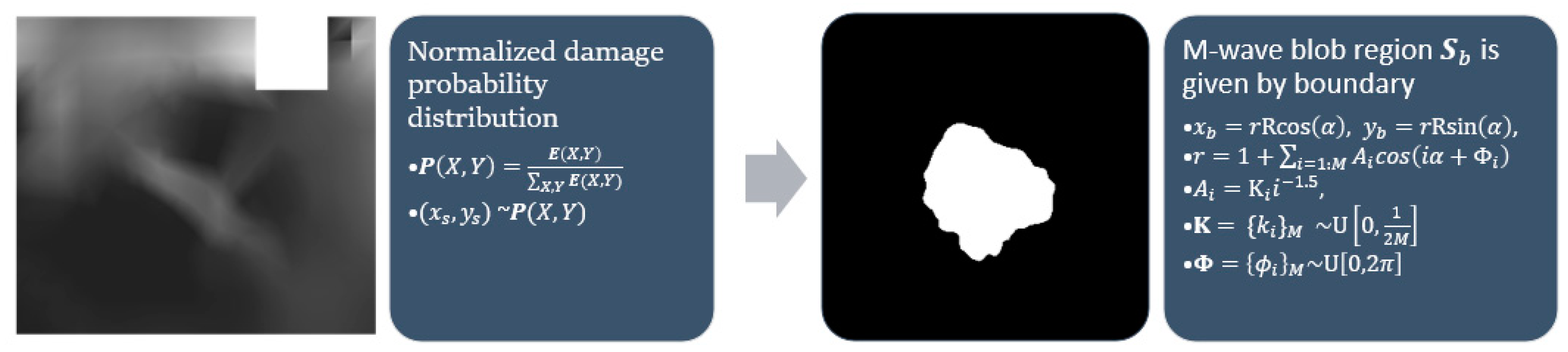
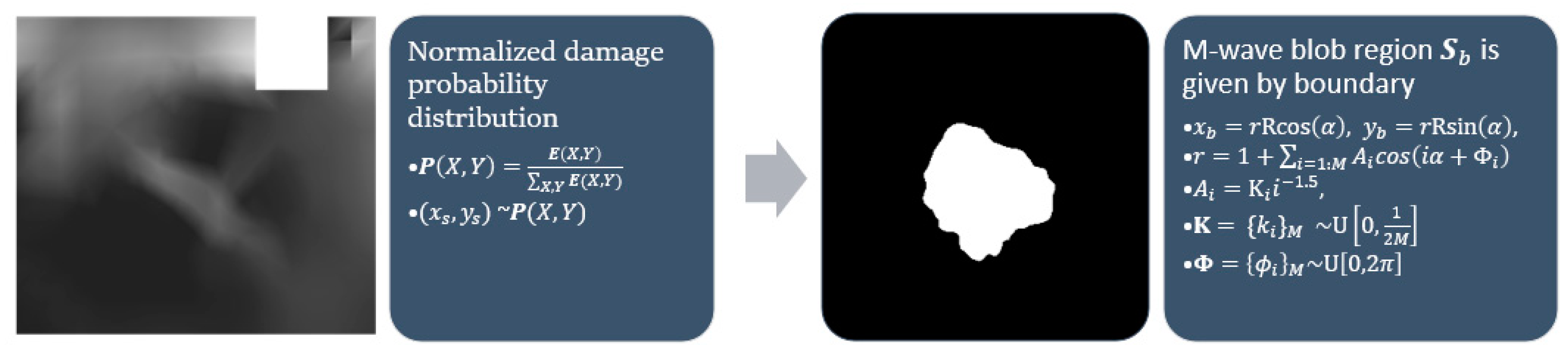
Stochastic blobs are amorphous shapes generated to select subregions of generated masks. The plastic strain map
is normalized to take the form of a probability distribution
. A center point
is obtained by sampling from the distribution. An amorphous blob-shaped region
is marked around the center point using a stochastic radius defined as the cumulative sum of a periodic function with random amplitude and phase. The blob generating function takes as input the number of waves along the circumference,
. The precise equations proposed can be found in
Figure 7 where
represents sampling from a uniform distribution between
and
.
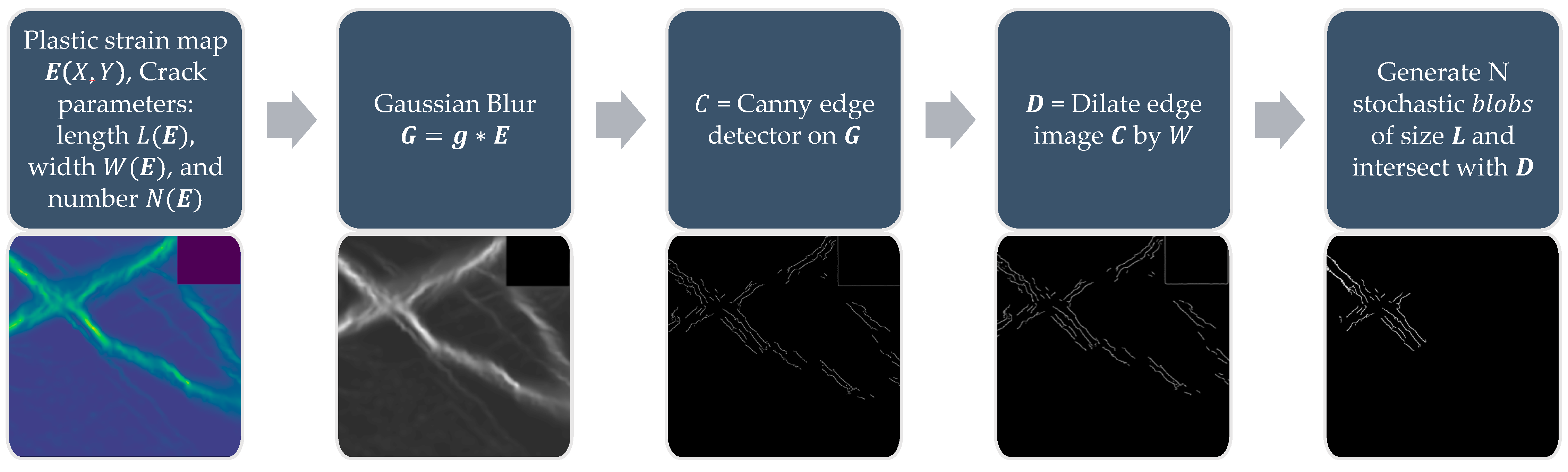
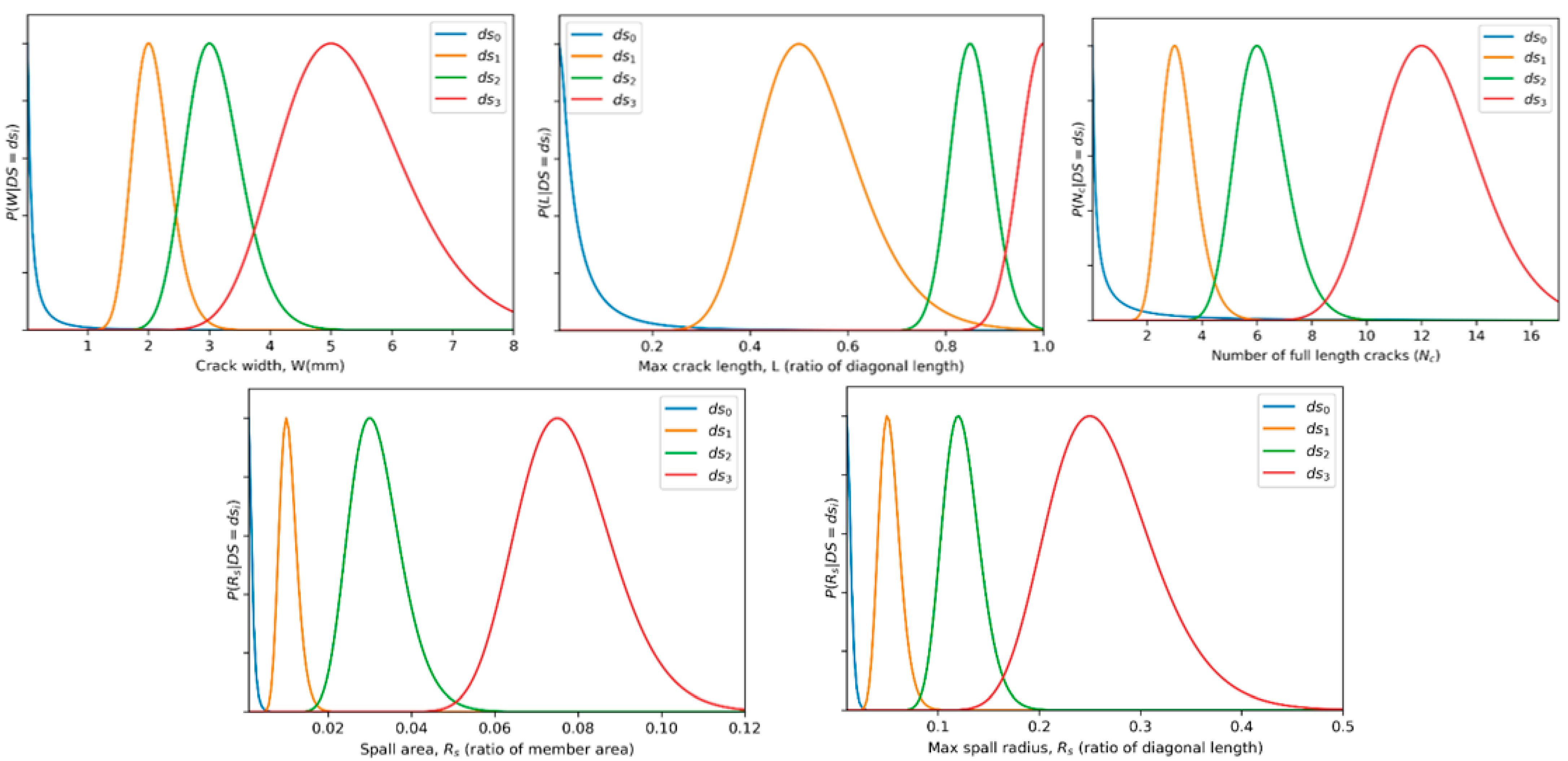
For each component, the set of crack parameters are
where
is the number of cracks,
is the length of cracks in pixels,
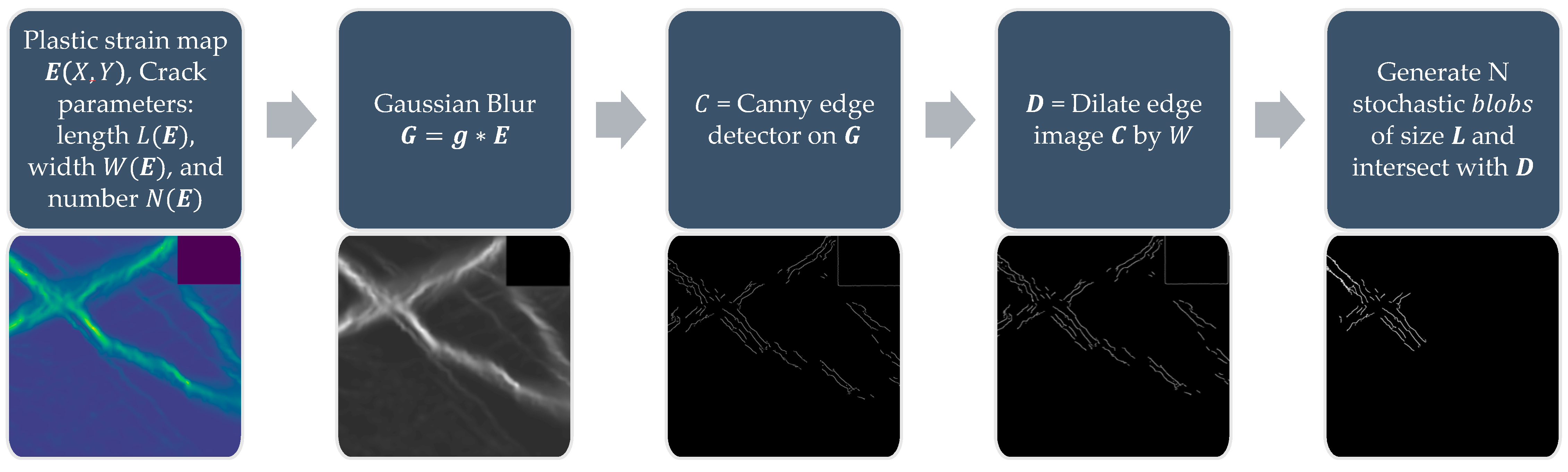
is the crack widths in pixels. Once these parameters are determined, the following pipeline for the generation of crack masks from the plastic strain map provided in
Figure 8 can be applied. A gaussian blur, with a kernel
is applied, followed by a Canny edge detector [
39] to obtain an edge image. The edges are dilated by a factor of
. Finally, to add randomness to each component, a stochastic blob is generated and the intersection of the blob with the dilated edge image is included in the crack mask. This process is repeated
times.
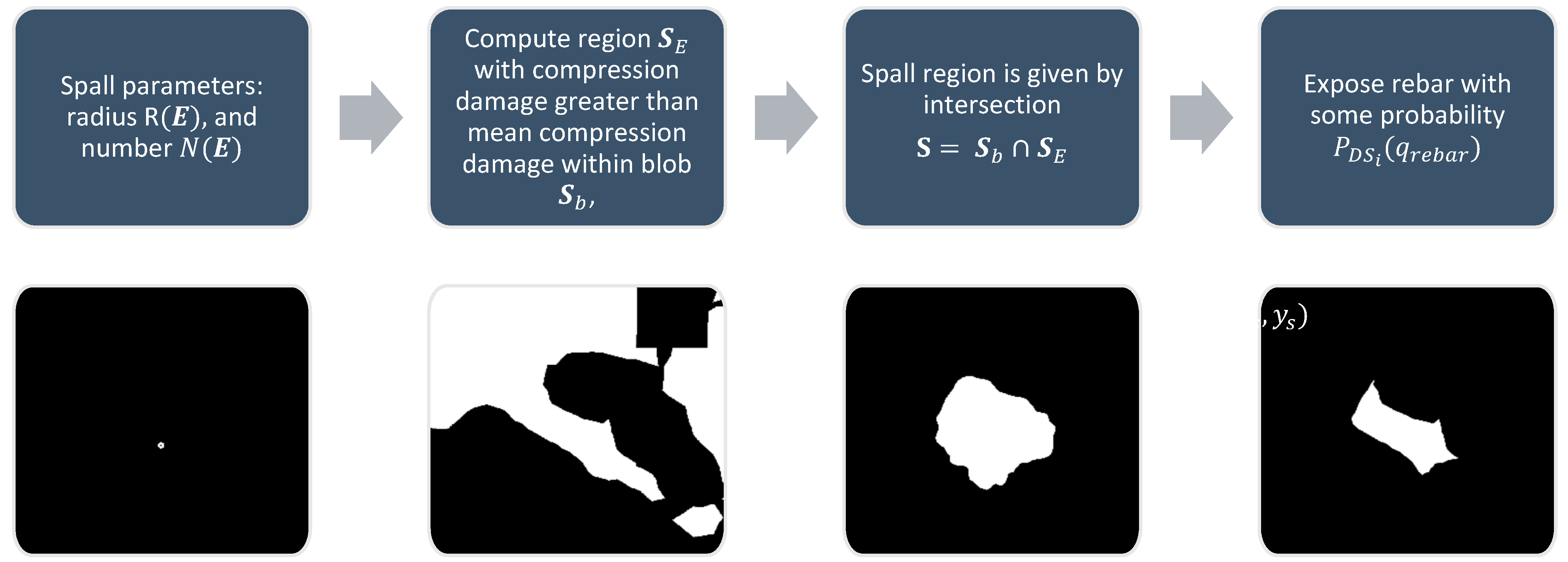
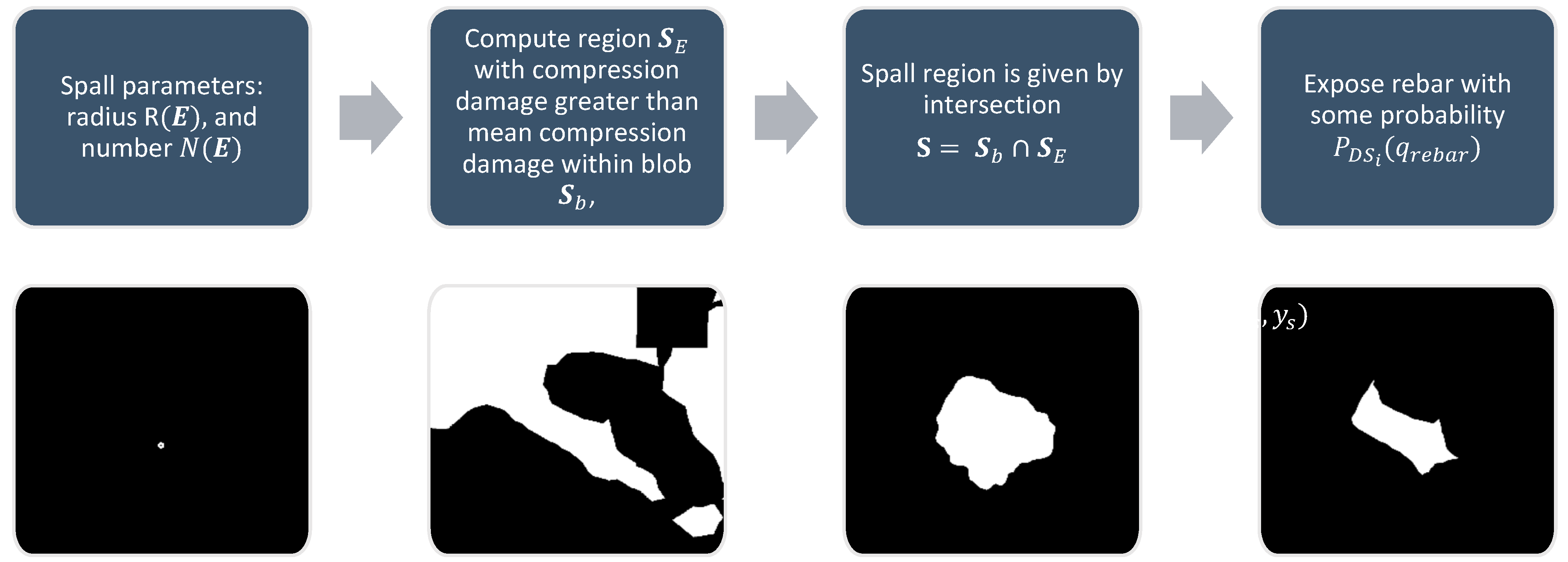
Spalling is another common damage type for reinforced concrete and masonry structures affecting the integrity of components. The damage parameters to be determined here are
where
is the number of spalled regions, and
is the nominal spall radius. To generate spall masks with these parameters, an area of pixels corresponding to the spall must first be defined. A stochastic blob
is generated following the process outlined in
Figure 7. In addition to the blob, another region
is constructed corresponding to pixels with compression damage greater than the mean compression within the blob. The spall region
is then set as the intersection of
and
. Rebar is made visible under spalled regions with some probability
. The process is illustrated in
Figure 9.
2.4. Damage Textures
Damage textures are image textures of damaged components. Damage textures need to be generated so as to provide a realistic visual representation of the damaged structure. The following points are discussed to illustrate the process followed in generating damage textures: (i) Bidirectional scattering distribution functions, (ii) material textures, (iii) damage textures, and (iv) annotation textures.
Bidirectional scattering distribution functions: The visual appearance of an object is dependent on how light incident on its surfaces is scattered, transmitted, or reflected. In computer graphics, the behavior of light incident on a given material is represented by a bidirectional scattering distribution function or BSDF [
40]. BSDFs can be measured through optical experiments with structured light sources. Based on experiments, researchers have proposed different methods to model BSDFs. A widely implemented model available in many 3D creator software known as the Principled BSDF was proposed by Burely et al. [
41] and is a physically-based rendering (PBR) model but with artistically intuitive parameters. Apart from the base color, BSDFs have 10 parameters to describe each pixel including properties of roughness, metallic, specularity, anisotropy, etc. Depending on the type of material, several of these may not be applicable, for example, a concrete surface may have negligible metallic scattering properties. In addition to these values defining the scattering, the incorporation of surface normal directions at every point plays a significant role in accurate renderings. If the surface is modeled at a very small-scale incorporating undulations, then the values of the surface normal can be computed directly from the geometry. However, such detailed surface modeling is seldom feasible and an alternative way to retrieve the same effect is to use a predefined surface normal map.
Material textures: PBR textures encompassing maps with BSDF parameters for the base color, roughness, metallicity, etc., and surface normals can be used to adequately represent materials for the purpose of structural inspection simulation. PBR textures for common construction materials incorporating BSDF parameters created through height field photogrammetry are available on websites like CC0textures [
42]. A sample image texture of a brick wall rendered from [
42] using Blender [
43], an open-source 3D model creation software is shown in
Figure 10. The example incorporates three maps: the base color, a roughness map, and the normal map. The roughness changes how the light is reflected, especially near the edges of the bricks and the normal map helps visualize the fine surface undulations and the protrusion of the bricks from the mortar plane. In addition to photogrammetry-based textures, textures can also be procedurally generated in material authoring programs like Substance [
44] and provide the ability to create multiple textures with different random seeds. As noted in [
29,
38] randomization is a crucial means of enforcing generalization. We utilize both types of PBR maps (photogrammetric and procedural) in the construction of the PBGMs. When multiple layers of materials are present, (e.g., cement plaster over masonry, paint over concrete, etc.) maps are selected for each material layer, and the displayed layer is selected based on the presence of damage at any given pixel.
Damage textures: The damage textures for the PBGM are obtained using the material textures as the base and modifying the region within the generated physics-based damage masks using opencv-Python [
45]. The crack is textured by modifying the corresponding surface normal through a bump map. The depth is set as a heuristic function of the plastic strain similar to the width and length and the crack. The spall region is defined by applying a Musgrave [
46] texture to create a bump map controlling the variation of depth within the spall region. For reinforced concrete components, rebar is exposed depending on the damage state of the material with some probability
. The rebars are modeled as cylinders with surface variation and a metallic map.
Annotation textures: For deep learning methods, the ground truth synthetic data is rendered by using an emission BSDF. As opposed to the principled BSDF with 10 parameters, an emission BSDF has a single color parameter and acts as a light source. The emission shader is useful for rendering homogenous colors, which is what is required as ground truth for tasks like semantic segmentation. Depending on whether image data or annotation data is being rendered, the appropriate texture types are selected during the rendering process.
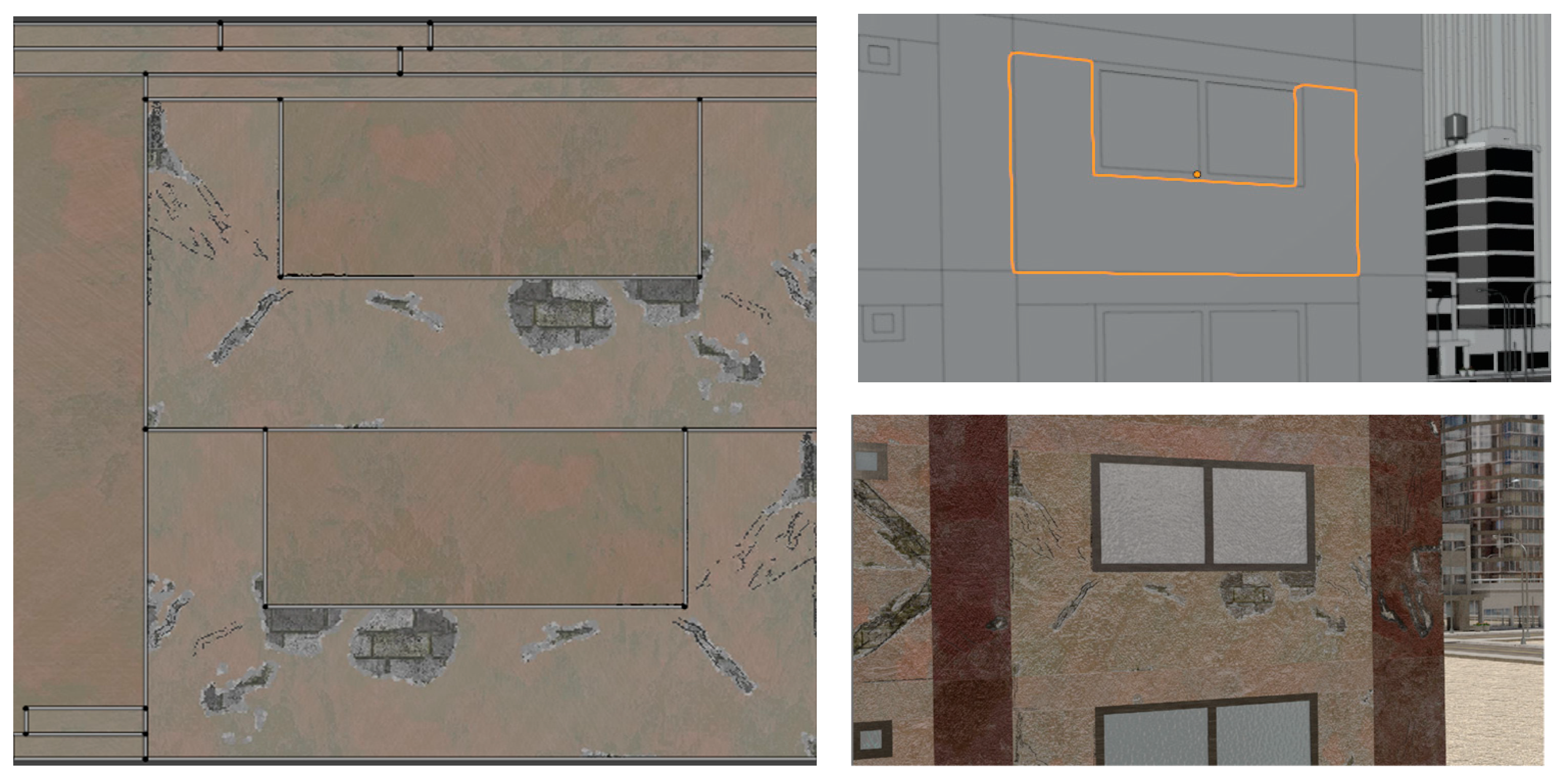
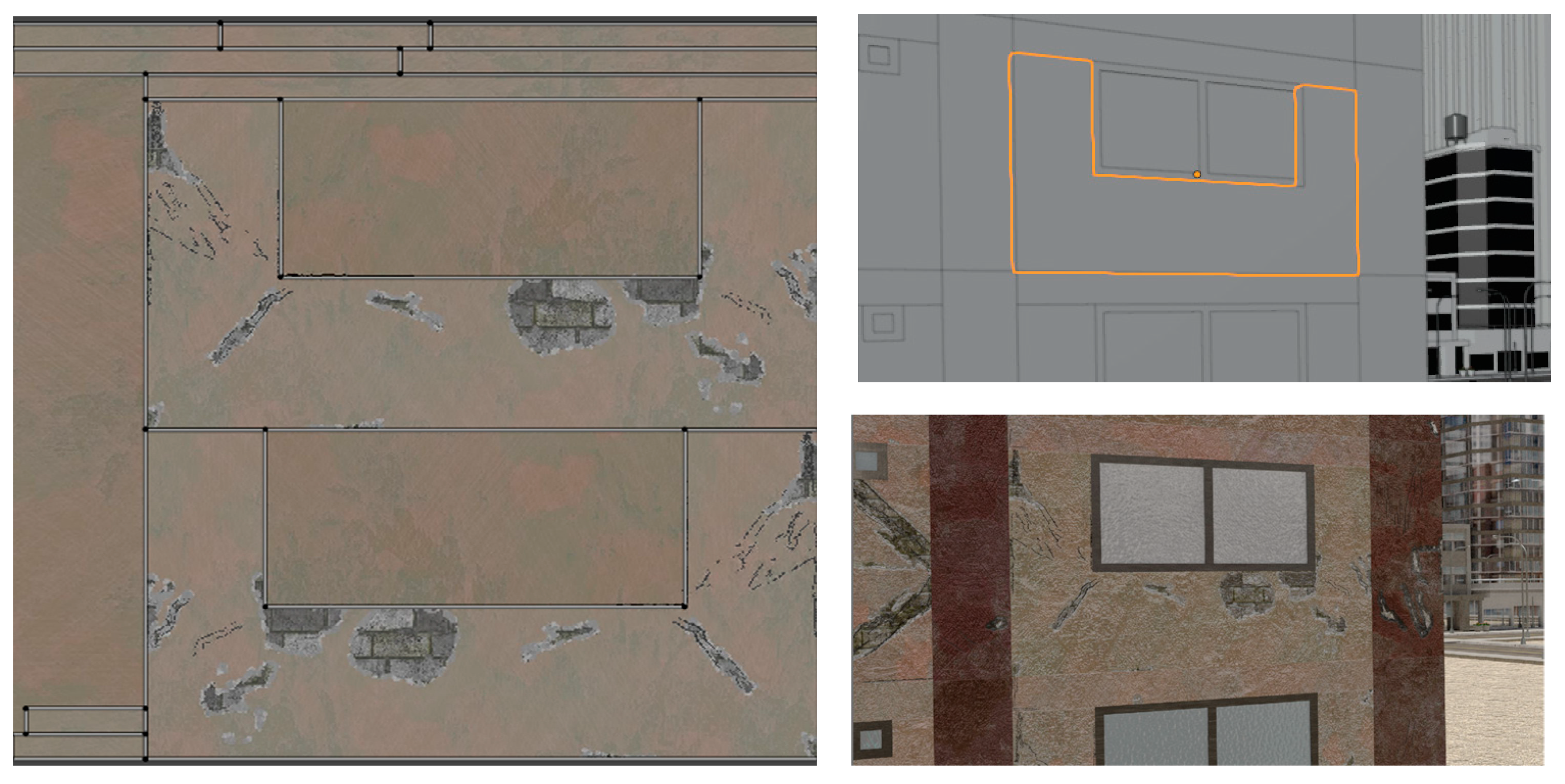
The generated textures are applied to the components after UV unwrapping the components. For 3D models application of 2D textures requires a correspondence to be created such that 2D surfaces can map to corresponding locations on the 3D surface. This process of “unwrapping” the 3D model is termed UV unwrapping. UV unwrapping is conducted by selecting the edges that are to serve as seams to break up the 3D model. In most programs, once the seams are selected, the resulting 2D surfaces are then arranged to fit within a square surface. The obtained damage masks are also assembled in the same arrangement to create a direct correspondence to the UV map and thus to the 3D model. Other masks like the rebar mask are also arranged in the same way. Here, depending on the aspect ratio of the component, the arrangement can take on a handful of configurations that are hard coded along with the dimensions of the corresponding component so that the rest of the process can be automated. An example of a UV unwrapped image is provided in
Figure 11.
2.5. Scene, Lights, Camera & Rendering
The steps discussed thus far describe the construction of a single PBGM. To obtain photo-realistic images, the background scene also needs to be populated. For post-earthquake building inspections, which include multiple buildings, roads, sidewalks, light poles, electric cables, trees, etc. Randomization of geometry and textures is important towards the ultimate goal of the generalizability of deep learning models trained in the synthetic environment. Thus procedural methods are adopted even in the scene assembly for the generation of these items.
The final step is to render the images. There are two modes of rendering commonly available in 3D creator software, namely path tracing and rasterization. Path tracing involves simulating the path of light in the scene and is more computationally expensive than rasterization but is preferred as it produces more photorealistic representations. To render images, a light source and the camera locations and orientations are to be set in the synthetic environment. To simulate realistic outdoor lighting, HDRI maps are used to light the scene [
47].
4. Experiments and Results
The developed procedure for PBGMs is used to generate synthetic images that can be used for automated visual inspection studies. Three applications and examples are illustrated, (i) QuakeCity Dataset: Large-scale synthetic dataset of earthquake-damaged buildings, (ii) Augmenting real data with synthetic data, and (iii) Comparing post-disaster UAV data acquisition with ground camera data acquisition.
4.1. QuakeCity Dataset: Large-Scale Synthetic Dataset of Earthquake Damaged Buildings
Images are rendered from multiple simulated UAV surveys of 11 damaged buildings in a city environment to create a new dataset called QuakeCity. Each survey replicates a field scenario where a UAV circles the building at different altitudes to cover the entire height, width, and length of the building. Each image captured by the simulated UAV is associated with six different sets of annotations, including three damage masks (cracks, spalling, exposed rebar), components, component damage states, and a depth map. In total, 4688 images and six annotations per image of size 1920 × 1080 are included in the dataset, with 3684 for training, and 1004 for testing.
Example images of the generated dataset are shown in
Figure 19. The images demonstrate the diversity of damaged buildings in the dataset in terms of layout, color, damage level. Images in the scenes are taken from different viewpoints and with different lighting conditions. Each image in the dataset has six annotations and the color key for annotations are provided in
Figure 20.
Figure 21 shows three example annotations including component damage state, depth map, and component annotations.
Figure 22 shows another image generated with spalling, cracks, and rebar annotations for each pixel.
4.2. Augmenting Real Data with Synthetic Data
To reliably train an autonomous visual inspection system, a large amount of training data with damaged structures would be required. Frequently, however, the amount of such training data available is limited. Additionally, careful annotation of available images is also a challenge. In this experiment, we are interested in studying whether the incorporation of synthetic data in cases with limited availability of real data with annotations can help boost the accuracy of networks on unseen real data.
4.2.1. Real Image Dataset
A dataset for semantic segmentation of real earthquake-damaged buildings was developed for the purpose of this study. The images were acquired by the authors after the 2017 Mexico City Earthquake using a DJI Phantom 3, and a Nikon D3300. The images were annotated for the presence of spalling using InstaDam [
59]. In total, 150 images of resolution 1920 × 1080 were annotated as part of the dataset.
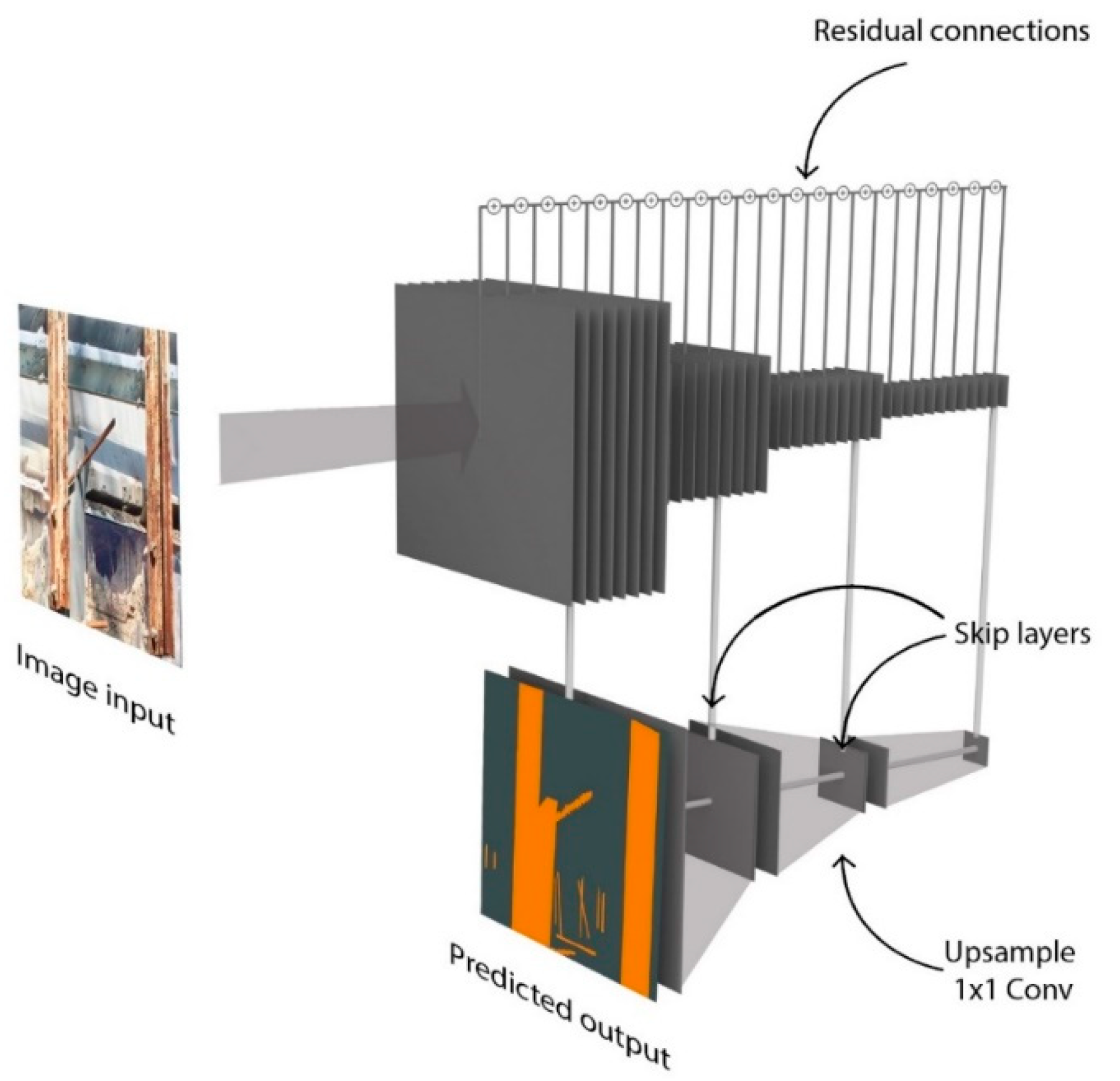
4.2.2. Network Architecture
A deep network is constructed for semantic segmentation using a ResNet [
60] architecture with 45 layers. The details of the encoder part of the architecture are provided in
Figure 23. Residual connections involve the summation of the output of prior layers to enforce learning of new information in subsequent layers. These residual connections are used between alternate layers (e.g., Conv0 to Conv2, Conv2 to Conv4, etc.). A rectified linear unit is used as the non-linearity for all layers of the network. The details of the decoder part of the architecture are provided in Model training. The skip connections with 1 × 1 convolutions described in the previous subsection are taken after the Conv8, Conv20, and Conv32 layers. The network parameters were trained by minimizing the cross-entropy loss function between the predicted softmax probabilities and the corresponding one-hot labels with an L2-regularization weight decay [
53]. The incorporation of the weight decay term gives preference to smaller weights and helps tackle overfitting. Batch normalization was applied to address the covariate shift that occurs during training [
24], where each feature dimension is shifted by a weighted mean and standard deviation that was learned during training. The percentage of pixels in each of the classes varies significantly. For example, some classes such as cracks have much fewer pixels than spalling or corrosion due to the nature of the damage. To balance the frequencies of different classes in the data set and prioritize all classes equally, median class balancing [
26] was applied by reweighting each class in the cross-entropy loss. Data augmentation by resizing and cropping was incorporated in order to increase the efficacy and efficiency of training and prevent issues such as overfitting. The training was conducted using the Adam optimizer [
54] implemented in Pytorch [
61].
4.2.3. Model Training
Eight different models were trained to evaluate the potential role of synthetic data in enhancing the overall performance of the models on real data. The eight models included four pairs of training schemes listed in
Table 5, where each scheme had one model trained purely on real data and another trained on real plus synthetic data. In each pair, the train/test split of real data was varied, starting from 0.2 train + 0.8 test, to 0.8 train + 0.2 test, in increments of 0.2. The same amount of synthetic training data was used in all four schemas, and this included the training images from the QuakeCity dataset (i.e., 3684 images).
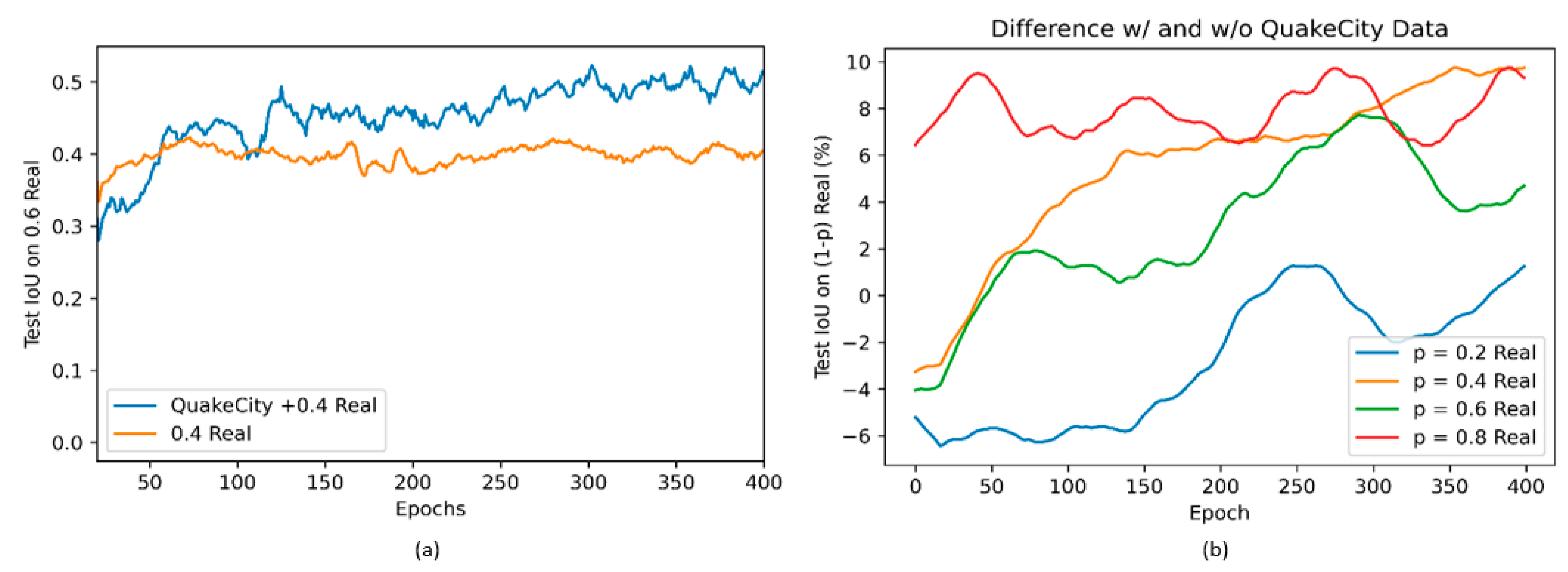
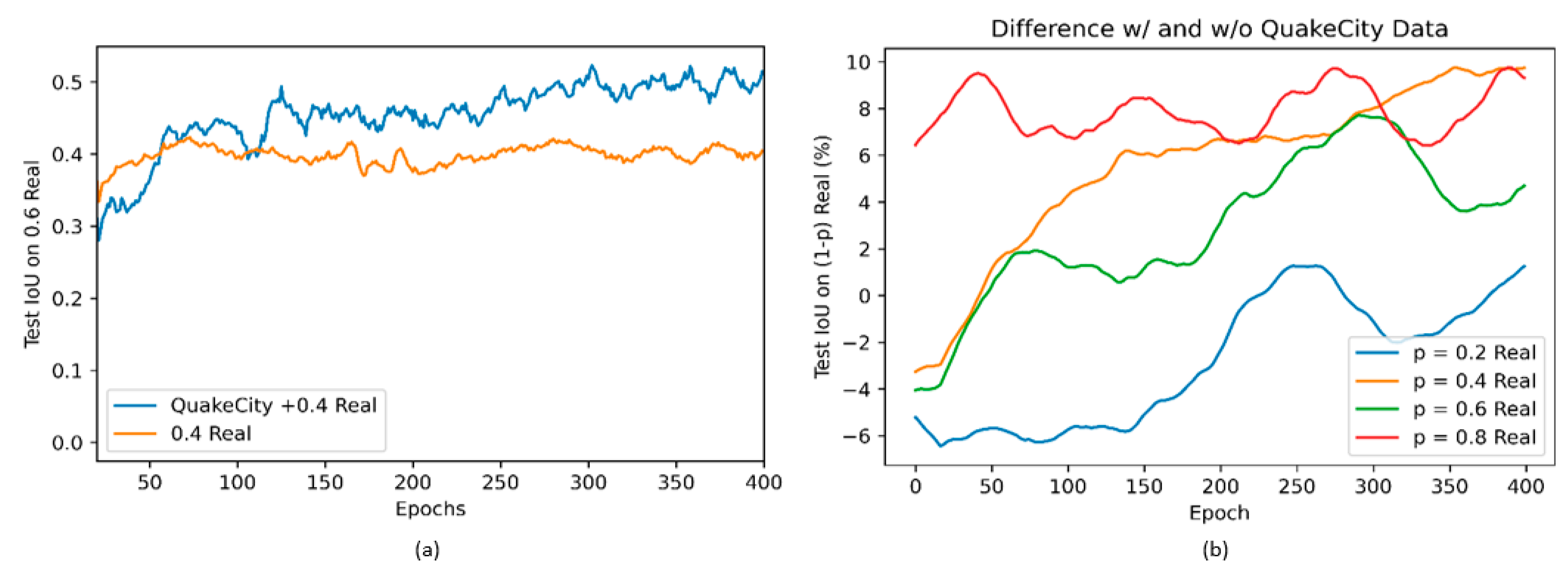
The results from the different models trained are shown in
Figure 24a,b.
Figure 24a shows the comparison of test Intersection-over-Union (IoU) [
62] on 60% of real data while training on 40% of the real images with and without QuakeCity data. While the initial accuracy with only real data is higher than with QuakeCity, after about 75 epochs, it was noticed that there was a significant increase in the performance of the model trained with QuakeCity data. The performance of the model clearly highlights the benefits of using synthetic data to improve the performance of deep learning models on unseen real data.
The addition of synthetic data was also shown to improve the performance of the deep neural network even for varying splits of training and testing data.
Figure 24b shows the difference between the two values plotted in
Figure 24a, for all four models trained. The performance of all models trained with the QuakeCity dataset is better than the model without the QuakeCity data after 400 epochs. The improvement in IoU is seen to be as much as 10%.
Table 6 shows examples of images where the 0.4 Real model with QuakeCity data performs better than the model without. The quality of the predictions is clearly improved, and the border of the predictions can be seen to be more accurate.
4.3. Comparing Damage State Estimation Using UAV and Ground-Based Images
While implementing autonomous visual inspection systems after disasters, a trained model using a dataset conducted prior to the disaster would be used to process new data acquired after the disaster. The quality of the predictions on new data may however vary widely depending on the image acquisition distance. For example, it may not always be possible to have consistent data acquisition modes or distances for various structures of interest. This is especially so in crowded cities where many obstacles are present. To better study the robustness of the trained models, practitioners may want to evaluate the model’s performance for different camera distances to see where data gaps are present in the model, or to inform their field acquisition strategies. In such a scenario, using a PBGM would prove very useful, as images could be acquired with different camera paths, and the accuracy of predictions of a fixed trained model can be studied.
In this experiment, we train two different ResNet 45 models to predict component damage states. One model is using only the QuakeCity training dataset and is tested on images from another building. Two test sets are prepared, one simulating a UAV camera for data acquisition (UAV-B12), and another simulating a person on the ground collecting images of the structure by pointing the camera forward and upward (Ground-B12). Together, the datasets are referred to as B12. Another model is trained with the QuakeCity training dataset plus 25% of the images from B12 (QuakeCity + 0.25 B12) and evaluated on 75% of the B12 data (0.75 B12). The results of performance on the ground data are reported separately for the UAV and Ground parts of B12.
Table 7 shows the test IoU for different damage states for the various models trained. The model trained on the QuakeCity dataset only, which is limited to UAV views performs poorly on Ground B12 images. As a comparison, the performance of the model on 75% of UAV B12 is also shown. With the addition of 25% of B12 to the training dataset, the model performs much better on the remaining 75% of the data and is much closer to the performance on 75% of the UAV B12 set. While the results are along expected lines, the study nonetheless highlights the benefits of using a PBGM for tasks where the value and type of additional information to be incorporated into the network needs to be quantified. Given that there will be some cost associated with incorporating new data into the training dataset, a performance-based approach for data inclusion can be set-up using a PBGM as a reference.
Table 8 and
Table 9 show examples of predictions for the Ground and UAV B12 test datasets, respectively.
5. Discussion
5.1. PBGM Parameters
An important aspect of generating effective PBGMs is the selection of various parameters in the five different steps of the proposed framework. The choice of these parameters will most certainly have an influence on the realism of the resulting simulations. In the absence of any data about the structure’s properties, several arbitrary assumptions were made in relation to the structure geometry, material properties, paint color, ground shaking intensity, etc., based on published literature. However, for autonomous inspection studies, the key requirement is the ability to generate large amounts of diverse data, and thus such assumptions, while not perfectly realistic, were reasonable for this research.
5.2. Computational Cost
The proposed framework for data generation has several components that contribute to the relatively high computational cost of generating the data. Running non-linear time history analysis for each component of the structure is very computationally expensive. Leveraging the regularity of the plan in the buildings, and the fact that the same material model will produce similar responses at different floors for identically shaped components, the analysis was run for just one story with different intensities and re-purposed for use with other stories. This simplification greatly reduced the overall computational time. The 3D synthetic environment for one damaged building can be created in about 8 h of total time on a PC with 2 Nvidia RTX 2080 Ti, Intel i7-8700K, and 16 GB of RAM. The rendering of each image then takes about 1.5 min, and each annotation takes about 0.05 min using Blender Cycles. The distribution of time taken for each component of the framework is provided in
Table 10.
5.3. Autonomous Inspection Experiments
The experiments conducted demonstrate the efficacy of the proposed framework as a testbed for end-to-end validation of autonomous inspections.
The first experiment involved implementing the proposed framework to generate the QuakeCity dataset. The quantity and diversity of data generated in the QuakeCity dataset underscore the benefits of using 3D synthetic environments to generate data to study algorithms for autonomous inspections. While such studies were out of the scope of this manuscript, the dataset has been released as part of the International Competition on Structural Health Monitoring; over 150 teams of researchers are participating to study the performance of different algorithms with the dataset.
The second experiment was conducted to study the utility of synthetic data generated from the proposed framework to directly augment deep networks trained for inference on real data for autonomous inspections. The results demonstrated that the use of synthetic data allowed the deep networks to learn better features that resulted in better performance on real data. The transferability of features learned on synthetic data to real data makes the use of the synthetic environment even more attractive.
The third experiment illustrates another use case of the proposed framework to study the ability of already trained networks to perform on new scenarios. In the experiment, a deep network trained on UAV acquired data for physics-based damage state estimation is applied to data collected from the ground. The poor results, in this case, indicate that additional data would be required from a ground viewpoint to have an effective network. The addition of about 25% of the data from a single survey was found to increase significantly the performance of the network. Given the cost associated with acquiring data in the real world, such studies are crucial in efficiently developing inspection systems for use in field applications.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}